
Probabilistic Estimation of Parameters for Lubrication Application with Neural Networks



Abstract
1. Introduction
Problem Description
2. Materials and Methods
2.1. Test Stand and Methodology
- Robot picks up specimen from buffer storage.
- Robot places specimen on scale to measure empty weight.
- Robot moves specimen to pulsing valve position.
- a.
- Pulsing valve shoots 15 single grease points onto the specimen.
- b.
- Robot moves after every shot to prevent overlapping.
- Robot places specimen on scale to measure full weight.
- Robot moves specimen to camera station.
- a.
- Picture from front view is taken.
- b.
- Picture from side view is taken.
- Robot places specimen on exit station.
- Back to nr. 1.
2.2. Grease Application Process
- Pressure set point on the pressure controller.
- Temperature set point on the temperature controller.
- Pin tension.
- Valve pin release time (opening time of valve).
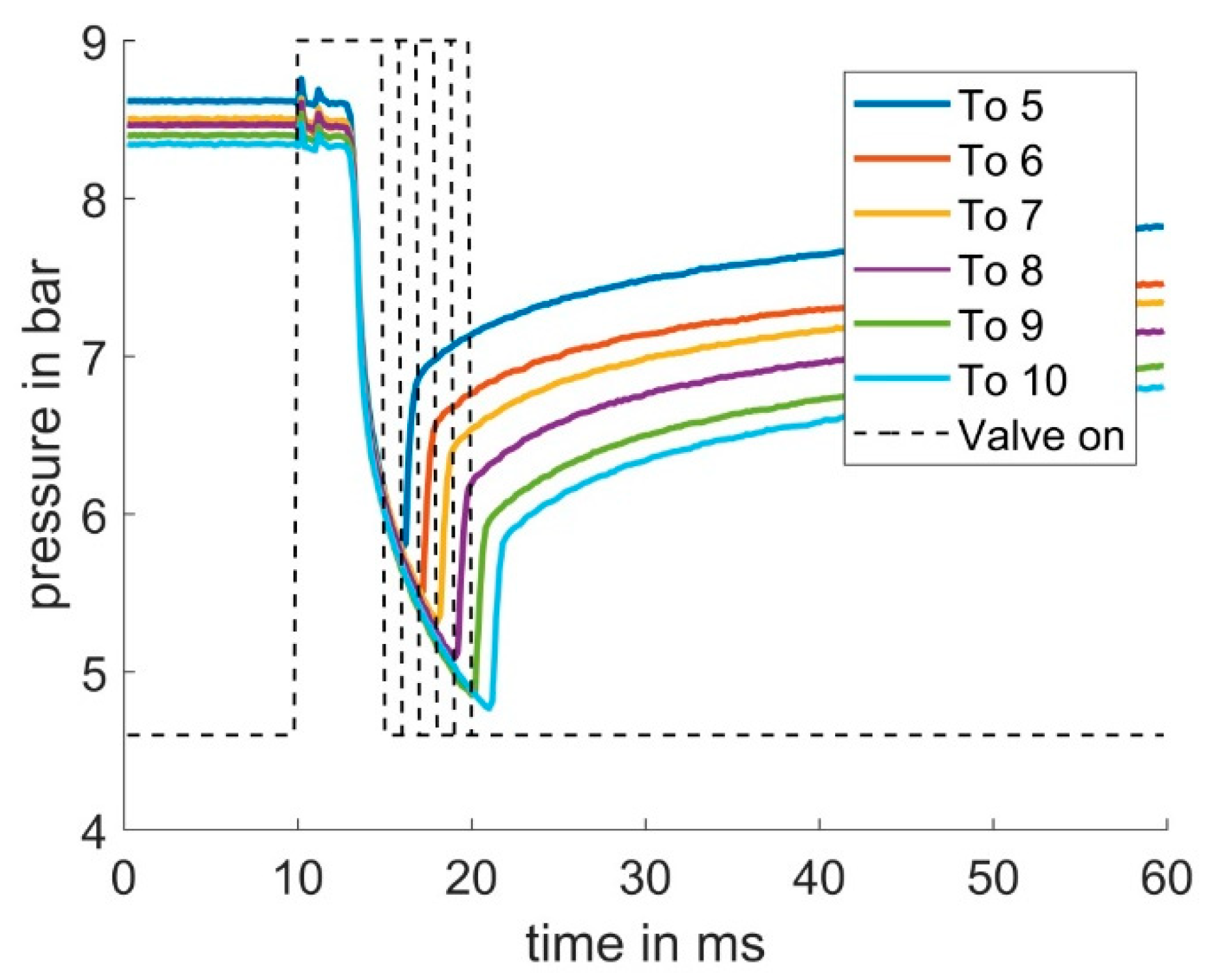
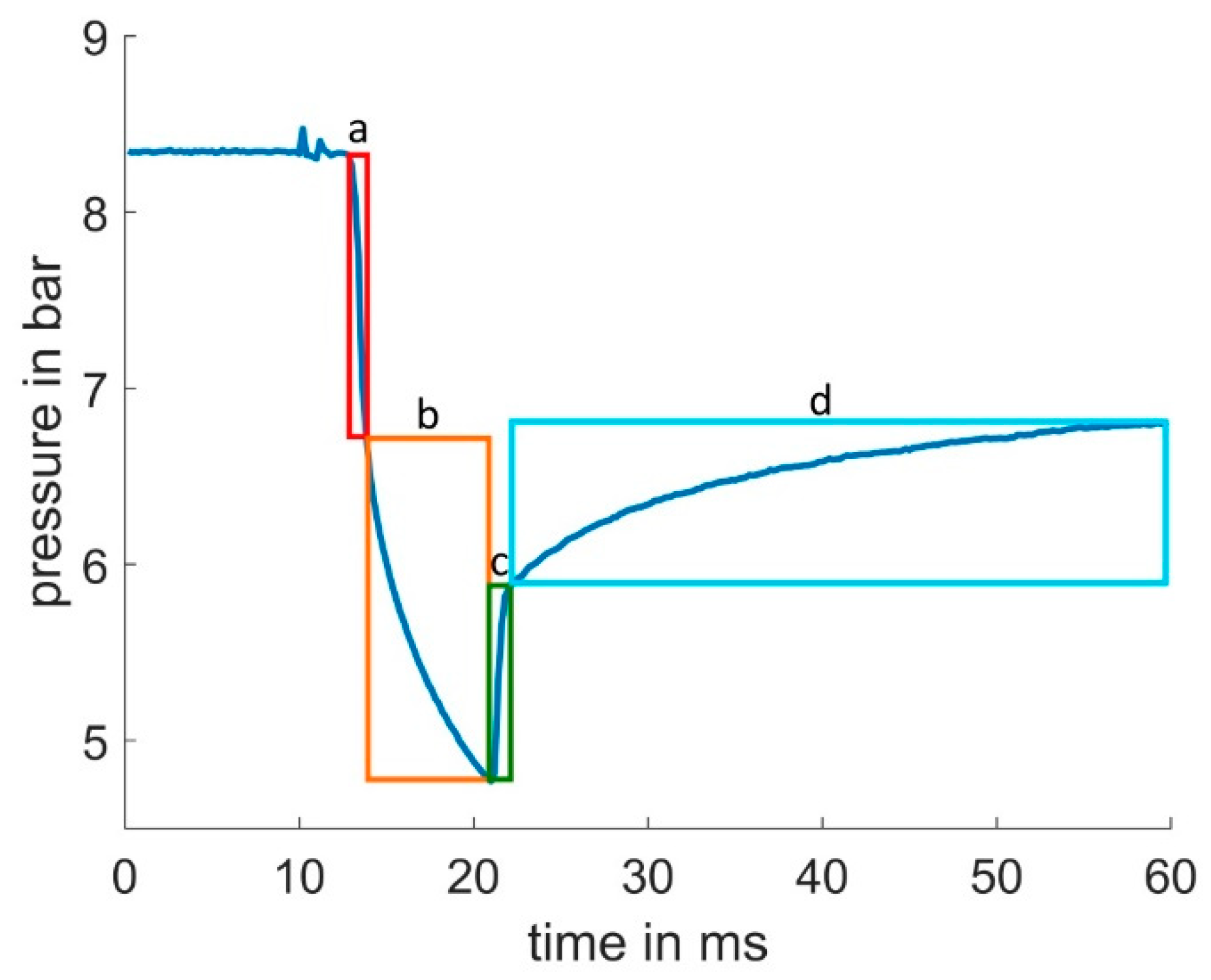
2.3. Pressure Curve
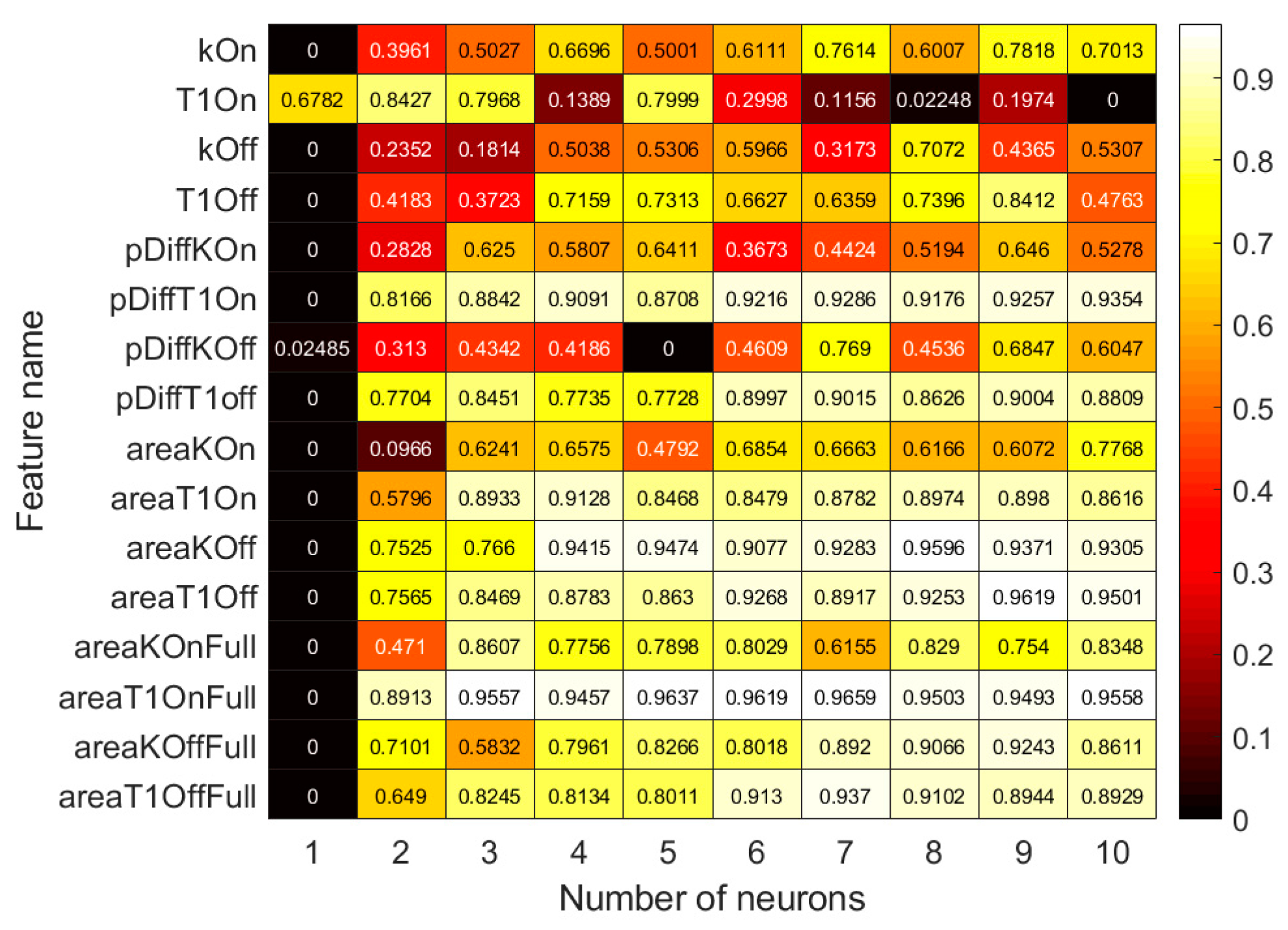
2.4. Feature Selection
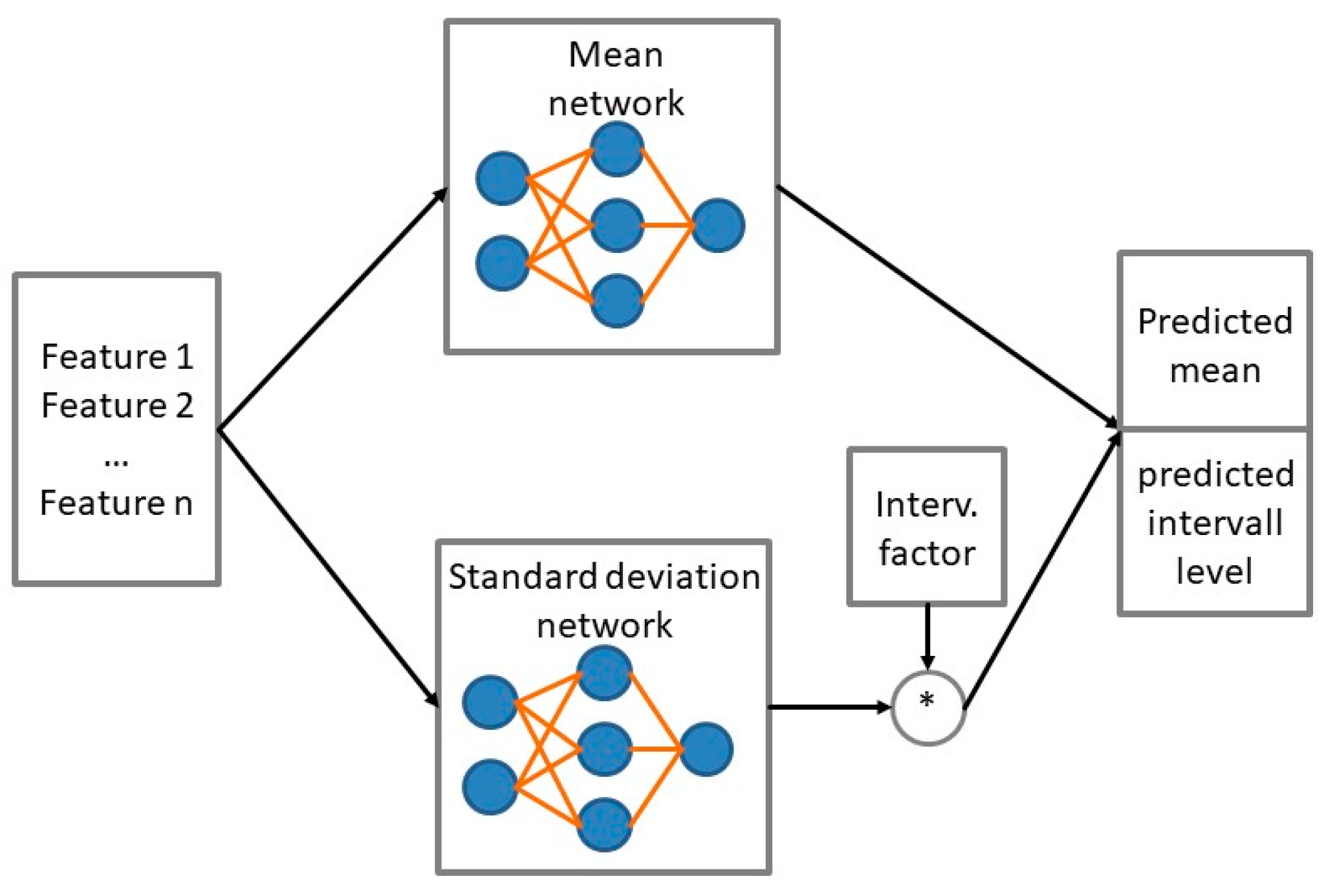
2.5. Predictive Neural Networks and Probability
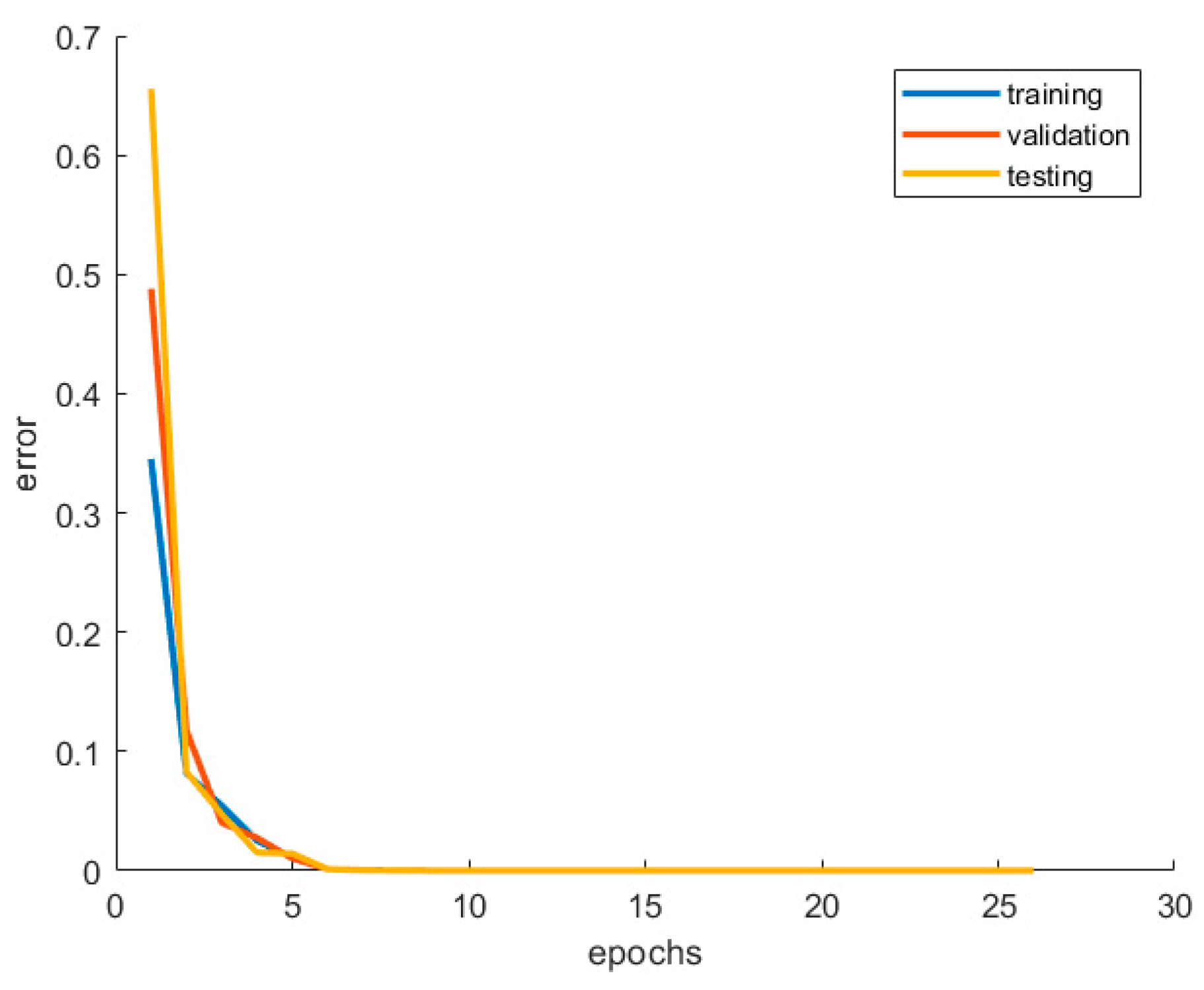
2.6. Training Process
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Opening time | To |
| Temperature set point | Temp |
| Pressure set point | Preg |
| Pressure in valve | Vu |
| Starting pressure | maxP |
| Lowest pressure reached | minP |
| Initial slope during fast pressure drop | KOn |
| Time constant during pressure drop | T1On |
| Initial slope during fast pressure regeneration | KOff |
| Time constant during pressure regeneration | T1Off |
| Pressure–time area during KOn | areaKOn |
| Pressure–time area during T1On | areaT1On |
| Pressure–time area during KOff | areaKOff |
| Pressure–time area during T1Off | areaT1Off |
| Pressure difference–time area during KOn | areaKOnFull |
| Pressure difference–time area during T1On | areaT1OnFull |
| Pressure difference–time area during KOff | areaKOffFull |
| Pressure difference–time area during T1Off | areaT1OffFull |
| Pressure difference for KOn | pDiffKOn |
| Pressure difference for T1On | pDiffT1On |
| Pressure difference for KOff | pDiffKOff |
| Pressure difference for T1Off | pDiffT1Off |
References
- Rahmadiawan, D.; Abral, H.; Shi, S.-C.; Huang, T.-T.; Zainul, R.; Ambiyar, A.; Nurdin, H. Tribological Properties of Polyvinyl Alcohol/Uncaria Gambir Extract Composite as Potential Green Protective Film. Tribol. Ind. 2023, 45, 367–374. [Google Scholar] [CrossRef]
- Abral, H.; Ikhsan, M.; Rahmadiawan, D.; Handayani, D.; Sandrawati, N.; Sugiarti, E.; Muslimin, A.N. Anti-UV, antibacterial, strong, and high thermal resistant polyvinyl alcohol/Uncaria gambir extract biocomposite film. J. Mater. Res. Technol. 2022, 17, 2193–2202. [Google Scholar] [CrossRef]
- Rudnick, L.R. Synthetics, Mineral Oils, and Bio-Based Lubricants: Chemistry and Technology (Chemical Industries); CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Specht, D.F. Probabilistic Neural Networks for Classification, mapping, or associative memory. In Proceedings of the IEEE International Conference on Neural Networks, San Diego, CA, USA, 24–27 July 1988; IEEE Press: New York, NY, USA, 1988; Volume 1, pp. 525–532. [Google Scholar]
- Malone, C.; Fennell, L.; Folliard, T.; Kelly, C. Using a neural network to predict deviations in mean heart dose during the treatment of left-sided deep inspiration breath hold patients. Phys. Med. 2019, 65, 137–142. [Google Scholar] [CrossRef]
- Specht, D.F. Probabilistic Neural Networks. Neural Netw. 1990, 3, 109–118. [Google Scholar] [CrossRef]
- Othman, M.F.; Basri, M.A.M. Probabilistic Neural Network for Brain Tumor Classification. In Proceedings of the 2011 Second International Conference on Intelligent Systems, Modelling and Simulation, Kuala Lumpur, Malaysia, 25–27 January 2011; pp. 136–138. [Google Scholar]
- Camousseigt, L.; Galfré, A.; Couenne, F.; Oumahi, C.; Muller, S.; Tayakout-Fayolle, M. Oil-bleeding dynamic model to predict permeability characteristics of lubricating grease. Tribol. Int. 2023, 183, 108418. [Google Scholar] [CrossRef]
- Akchurin, A.; Van den Ende, D.; Lugt, P.M. Modeling impact of grease mechanical ageing on bleed and permeability in rolling bearings. Tribol. Int. 2022, 170, 107507. [Google Scholar] [CrossRef]
- Lu, W.; Zhang, Z.; Qin, F.; Zhang, W.; Lu, Y.; Liu, Y.; Zheng, Y. Analysis on the inherent noise tolerance of feedforward network and one noise-resilient structure. Neural Netw. 2023, 165, 786–798. [Google Scholar] [CrossRef] [PubMed]
- Geman, S.; Bienenstock, E.; Doursat, R. Neural networks and the bias/variance dilemma. Neural Comput. 1992, 4, 1–58. [Google Scholar] [CrossRef]
- Popescu, M.C.; Balas, V.E.; Perescu-Popescu, L.; Mastorakis, N. Multilayer perceptron and neural networks. WSEAS Trans. Circuits Syst. 2009, 8, 579–588. [Google Scholar]
- Shanker, M.; Hu, M.Y.; Hung, M.S. Effect of data standardization on neural network training. Omega 1996, 24, 385–397. [Google Scholar] [CrossRef]
- Hagan, M.T.; Menhaj, M.B. Training Feedforward Networks with the Marquardt Algorithm. IEEE Trans. Neural Netw. 1994, 5, 989–993. [Google Scholar] [CrossRef] [PubMed]
- Lv, C.; Xing, Y. Levenberg-Marquardt Backpropagation Training of Multilayer Neural Networks for State Estimation of A Safety Critical Cyber-Physical System. IEEE Trans. Ind. Inform. 2018, 14, 3436–3446. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Table | |||||
|---|---|---|---|---|---|
| Optical | Scale | System Input | Pressure Curve | ||
| Pressure Difference | Areas | Constants | |||
| width | mass | To | pDiffKOn | areaKOn | kOn |
| height | Temp | pDiffKOff | areaT1On | kOff | |
| Vu | PDiffT1On | areakOff | T1On | ||
| Preg | PDiffT1Off | areaT1Off | T1Off | ||
| maxP | Area-KOnFull | ||||
| minP | Area-KT1OnFull | ||||
| Area-KOffFull | |||||
| Area-KOnFull | |||||
| Coefficient of Determination | ||||||||
|---|---|---|---|---|---|---|---|---|
| Feature | F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 |
| Full net | 0.402 | 0.131 | 0.895 | 0.760 | 0.481 | 0.643 | 0.888 | 0.983 |
| Mean net | 0.335 | 0.179 | 0.883 | 0.716 | 0.420 | 0.631 | 0.873 | 0.918 |
| Feature | F9 | F10 | F11 | F12 | F13 | F14 | F15 | F16 |
| Full net | 0.371 | 0.998 | 0.960 | 0.986 | 0.995 | 1.000 | 0.996 | 1.000 |
| Mean net | 0.305 | 0.987 | 0.919 | 0.634 | 0.995 | 0.997 | 0.994 | 0.998 |
| Percentage of Test Points in Boundary | ||||||||
|---|---|---|---|---|---|---|---|---|
| Feature | F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 |
| Full Isig | 72% | 51% | 76% | 76% | 69% | 74% | 75% | 68% |
| Full 2sig | 96% | 74% | 94% | 94% | 96% | 96% | 93% | 93% |
| Full 3sig | 98% | 85% | 96% | 97% | 99% | 98% | 96% | 98% |
| Mean lsig | 70% | 44% | 75% | 71% | 68% | 72% | 74% | 51% |
| Mean 2sig | 95% | 64% | 93% | 92% | 95% | 95% | 93% | 79% |
| Mean 3sig | 98% | 77% | 97% | 96% | 98% | 99% | 96% | 91% |
| Feature | F9 | F10 | F11 | F12 | F13 | F14 | F15 | F16 |
| Full Isig | 74% | 84% | 72% | 87% | 90% | 89% | 86% | 92% |
| Full 2sig | 96% | 97% | 97% | 97% | 98% | 97% | 97% | 98% |
| Full 3sig | 99% | 99% | 99% | 98% | 99% | 99% | 98% | 98% |
| Mean Isig | 73% | 62% | 62% | 75% | 88% | 73% | 81% | 81% |
| Mean 2sig | 95% | 84% | 90% | 91% | 98% | 92% | 96% | 93% |
| Mean 3sig | 98% | 92% | 95% | 94% | 99% | 95% | 97% | 96% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paschek, S.; Förster, F.; Kipfmüller, M.; Heizmann, M. Probabilistic Estimation of Parameters for Lubrication Application with Neural Networks. Eng 2024, 5, 2428-2440. https://doi.org/10.3390/eng5040127
Paschek S, Förster F, Kipfmüller M, Heizmann M. Probabilistic Estimation of Parameters for Lubrication Application with Neural Networks. Eng. 2024; 5(4):2428-2440. https://doi.org/10.3390/eng5040127
Chicago/Turabian StylePaschek, Stefan, Frederic Förster, Martin Kipfmüller, and Michael Heizmann. 2024. "Probabilistic Estimation of Parameters for Lubrication Application with Neural Networks" Eng 5, no. 4: 2428-2440. https://doi.org/10.3390/eng5040127
APA StylePaschek, S., Förster, F., Kipfmüller, M., & Heizmann, M. (2024). Probabilistic Estimation of Parameters for Lubrication Application with Neural Networks. Eng, 5(4), 2428-2440. https://doi.org/10.3390/eng5040127