4.3. Visual Map Evaluation
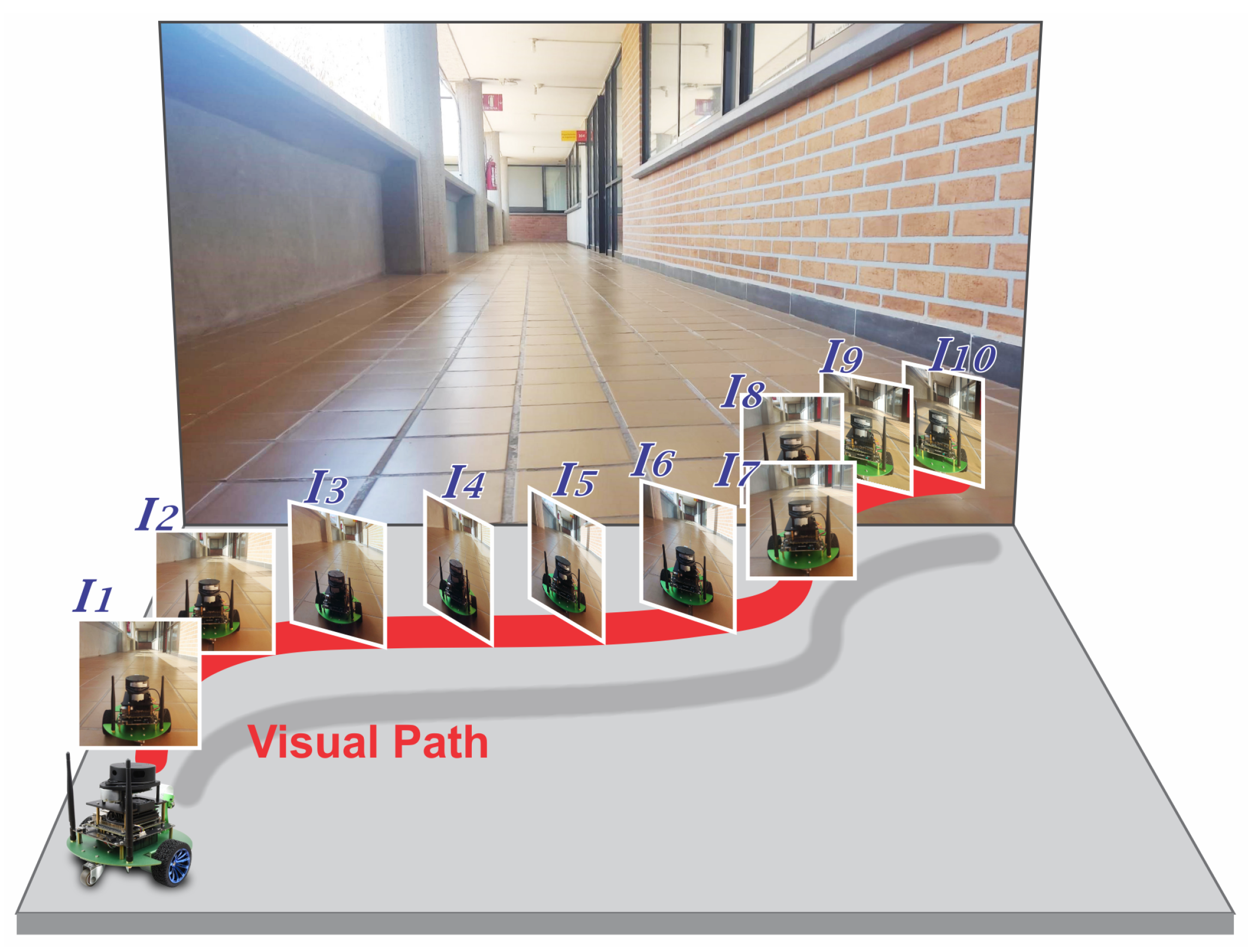
After completing the human-guided navigation to capture images of each environment, we proceeded to the learning stage for building the visual map. In this stage, we compare the visual map generation using hand-crafted feature extraction and matching using ORB and the deep learning approach within LoFTR. Since this first exploratory navigation and the learning stage were not performed simultaneously, the experiments were implemented in Python using Kornia [
26], an Open Source Computer Vision Library for PyTorch, and executed in Google Colaboratory [
27]. Geometric validation utilized the fundamental matrix with RANSAC and MAGSAC as feature-matching refinement (outlier detection). Moreover, we used different similarity threshold values from
to
to study the effect of the feature matching ratio between the last key image and a current frame. Thus, the lower the similarity, the fewer key images are selected; on the other hand, the higher the thresholds, the greater the number of key images.
We conducted extensive experiments using six datasets, combining ORB and LoFRT algorithms with varying similarity thresholds, for both ORB and LoFTR detectors.
Table 3 presents the results for ORB with MAGSAC, specifically for dataset D1. It can be seen that for thresholds 0.1 to 0.5, the algorithm yields 1303 key images, that is, 33% of the total images, with similar average match values. For the threshold of 0.9, there are more key images, maintaining 66% of the images; hence, there are more matched points (an average of 244), as expected. The maximum quality was obtained with a threshold of 0.8; thus, 1434 key images were selected, which is 39% of the images. A mean of 43 matches was computed between consecutive key images.
We evaluated the ORB and LoFTR descriptors.
Figure 7 illustrates examples of only 50 matches between consecutive key images for the best quality visual map. The LoFTR+MAGSAC has more and better-distributed points than ORB+MAGSAC.
Table 4 exhibits the experiment conducted using LoFTR and MAGSAC for dataset D1. This table shows a better distribution of the key images selected by the algorithm. Specifically, at a threshold of 0.7, the algorithm identifies the best-quality visual map, with 269 key images, that is, 7% of the total images. This threshold gives a mean of matched points of 2180 instead of 19 achieved with ORB. Thus, a reliable fundamental matrix can be estimated.
Figure 8 shows three consecutive key images obtained with LoFTR+MAGSAC.
Now, we evaluate our framework using the RANSAC algorithm as an outlier detector.
Table 5 presents the results of ORB with RANSAC for Dataset D1. This combination yielded the best quality at the threshold of 0.7, where 1533 key images were obtained. The execution time of the algorithms was faster with MAGSAC.
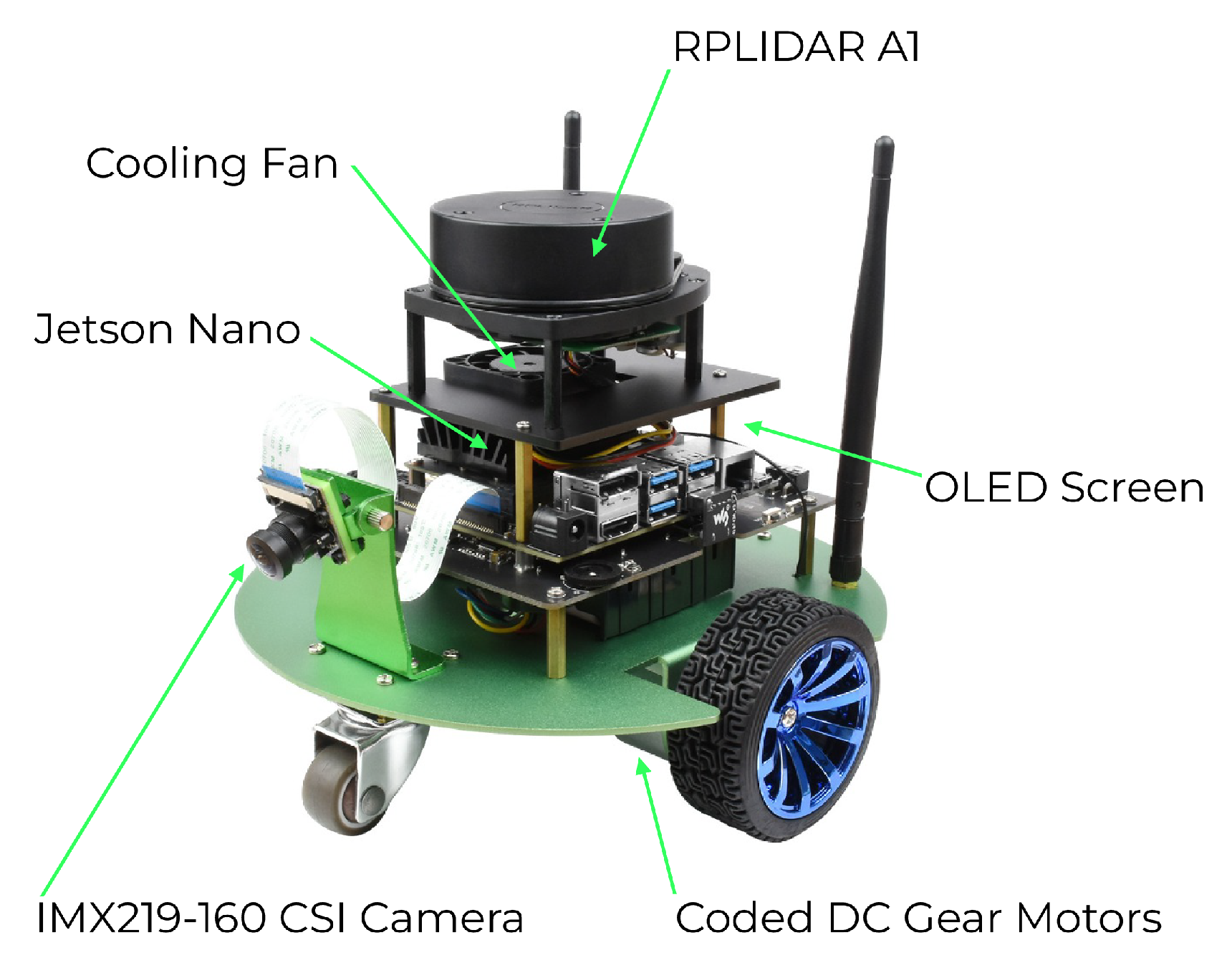
Executing the algorithms using Jetbot’s GPU and RAM yields similar results. Tests were conducted within a virtual environment using Python 3.10, along with Jupyter Notebook. Dataset D1 was employed to obtain the average execution time per video frame. To keep the Google Colaboraty time factors consistent, we kept the original Notebook in the web server and established a local runtime WebSocket connection to use the available resources of the robot. An average time of 1.62 min per frame was obtained for MAGSAC, with a slightly slower time of 1.72 min per frame for RANSAC.On the other hand, executing our algorithm in the Cloud GPU resulted in an average time of 1.4 s per frame for the LoFTR and 0.05 s for ORB. Thus, all experiments were conducted in the offline mode.
Table 6 shows the results of LoFTR with RANSAC, which select more key images than LoFTR with MAGSAC. For instance, the optimal threshold is 0.5, at which we retrieved 152 key images; thus, 4% of the images were selected against the 7% selected with MAGSAC. Additionally, the mean matches were reduced with RANSAC, with 1356 vs. 2180 with the MAGSAC configuration.
It is worth noting that MAGSAC is more restrictive than RANSAC with higher thresholds, making it more convenient to create a visual map, in which fewer key images are selected but with higher similarity ratios. Based on these results, MAGSAC was chosen for subsequent experiments.
In the case of Dataset D2,
Table 7 and
Table 8 show the comparative study between ORB and LoFTR, respectively. With the ORB+MAGSAC combination, the number of key images remains constant at 454 for similarity thresholds ranging from 0.1 to 0.7. The average number of matches is around 20. The best memory quality, with a score of 0.86, was achieved using a threshold of 0.9. In this case, the memory map comprises 796 key images with a mean of 441 matches. When using LoFTR+MAGSAC, the number of key images increases as the threshold value grows. For instance, for the threshold of 0.6 that maximizes the quality, 45 key images were selected with 1122 mean matches, three times more matches than the best mean matches obtained with ORB. This corresponds to approximately only 1.2% of the total images comprising the visual map.
Figure 9 displays four examples of the first 50 matched points in consecutive key images employing the best visual map obtained with LoFTR+MAGSAC, and
Figure 10 presents three examples of three consecutive key images from Dataset D2.
Evaluating our approach for Dataset D3, we observe a similar behavior to the previous datasets, where the ORB+MAGSAC was only available to match around 30 features. Meanwhile, the LoFTR+MAGSAC matches more than 500 features for threshold values higher than 0.5. This can be seen in
Table 9 and
Table 10, respectively. Additionally, the number of key images in the LoFTR+MAGSAC is lower than in the ORB+MAGSAC. Particularly, the best-quality memory of 0.53 for ORB+MAGSAC was obtained with a threshold of 0.9, obtaining 3000 key images. In total, 86% of the images were selected. On the other hand, LoFTR+MAGSAC with a similarity threshold of 0.2 obtained a quality of 0.77, around 49 mean matches, and only 32 key images (0.9% of the total images).
Figure 11 shows four examples of matched points in key images from the best-quality visual maps, and
Figure 12 presents three examples of consecutive key images from the D3 dataset.
Table 11 shows the experiment results with LoFTR and MAGSAC with Dataset D4. This table shows a better distribution of the key images selected by the algorithm. At the threshold of 0.5, the best quality was obtained; it returned 63 key images. This threshold gives a mean of matched points of 1030 compared to ORB, whose mean of matched points is 28 with a threshold range of 0.1 to 0.5. At these thresholds, the number of key images was 2372, that is, 37 times more key images than LoFTR (see
Table 12).
Figure 13 shows examples of matches between consecutive key images for the best threshold for both detectors. Additionally,
Figure 14 shows three consecutive key images obtained with LoFTR+MAGSAC.
Table 13 shows the experiment results with LoFTR and MAGSAC with Dataset D5. A top quality of 0.77 was obtained with the 0.5 threshold value, selecting 54 key images with a mean matches of 640. The number of key images represents the 1.6% of the total images. On the scheme that used ORB (see
Table 14, the best achieved quality was 0.96 but with only 20 matches in the 39 key images selected.
Figure 15 shows some images with the matches between consecutive key images for the optimal threshold of 0.7 and 0.5 for ORB and LoFTR, respectively. Additionally,
Figure 16 depicts three successive key images obtained with LoFTR+MAGSAC.
Table 15 shows the experiment results with LoFTR and MAGSAC with Dataset D6. In particular, using a threshold of 0.4, it achieved the best memory quality (0.75) and returned 32 key images, a mean of matched points of 319. For ORB, in comparison, whose results can be seen in
Table 16, the optimal threshold of 0.7 obtained a mean of matched points of 18 and 3023 key images from 3330. Only seven images were discarded.
Figure 17 shows the images with the matches between consecutive key images for the best ORB and LoFTR detectors.
Figure 18 presents an example of three key images obtained with LoFTR+MAGSAC.
4.4. Discussion
First, an ablation study was presented in the indoor Dataset D1 to select the best outlier algorithm between RANSAC and MAGSAC. We observed that MAGSAC was more restrictive with higher similarity thresholds, allowing us to create the visual map with fewer key images and higher similarity ratios. In general, with the datasets presented for indoor environments (D1, D3, and D4) and outdoor environments (D2, D5, and D6), we present extensive visual memory comparisons for ORB+MAGSAC and LoFTR+MAGSAC. The LoFTR+MAGSAC scheme presents the best results for the visual map quality. Additionally, LoFTR+MAGSAC reached the visual memory aim to obtain fewer key images with more matches between consecutive key images.
The LoFTR descriptors perform better under various conditions, such as lighting changes, viewpoint changes, and weather conditions. ORB uses variants of FAST as a detector, i.e., they detect key points by comparing gray levels along a circle of radius 3 to the gray level of the circle center. ORB uses oriented FAST key points, an improved version of FAST, including an adequate orientation component. The ORB descriptor is a binary vector of user-choice length. Each bit results from an intensity comparison between some pixels within a patch around the detected key points. The patches are previously smoothed with a Gaussian kernel to reduce noise. ORB computes a dominant orientation between the center of the key point and the intensity centroid of its patch to be robust to orientation changes. The key points are not robust to lighting changes present in the outdoor scenarios. On the other hand, LoFTR was trained with a large dataset, including images under different lighting conditions, view changes, stopovers, and hours of the day. For such a reason, LoFTR is more robust than ORB in these scenarios.
It is possible to extend the framework to any type of robot, for this is necessary to adapt the design of movement controllers to move the robot from an initial configuration to the final configuration keeping the key points on the images of the visual map. According to the kinematics model of the robot and the controller design, it is necessary to change the camera position on different parts of the robot to maintain specific parts of the environment in the camera field of view (fov) or avoid singularities with the controller. We planned to use an MPC; with this scheme, the camera location is not relevant. Using other sensors can help to deal with obstacles that lie out of the fov or the visual map generated and problems related to circumstances of the environment, such as the lighting or reflective or transparent surfaces.


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}