Stochastic Static Analysis of Planar Elastic Structures with Multiple Spatially Uncertain Material Parameters


Abstract
:1. Introduction
2. Navier’s Equations of Elasticity
2.1. Weak Formulation
2.2. Stochastic Formulation
3. Galerkin Method
3.1. Deterministic Part: hp-Version
3.2. Probability Preliminaries
3.3. Karhunen–Loève Expansion
3.4. Legendre Chaos
3.5. Discretized System
3.6. Response Statistics
4. Selection of Chaos Polynomials
4.1. Standard Truncation Schemes
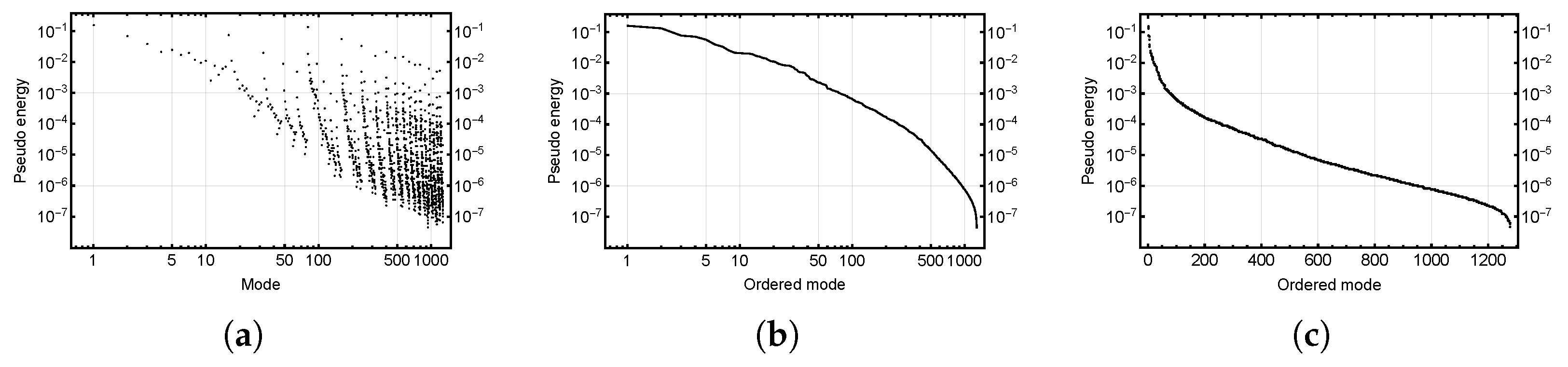
4.2. Andreev’s Selection Algorithm
| Algorithm 1 Andreev’s Selection [18]. |
Given , , set .
|
5. Iterative Solver Formulation
| Algorithm 2 Preconditioner: . |
Given Matrix , vector b,
|
| Algorithm 3 Matrix-Vector Multiply: . |
Given matrices , , , and vector x. is assumed to be an identity matrix.
|
| Algorithm 4 Conjugate Gradient Method [36]. |
Given matrix-vector multiply: , and preconditioner: .
|
6. Numerical Experiments
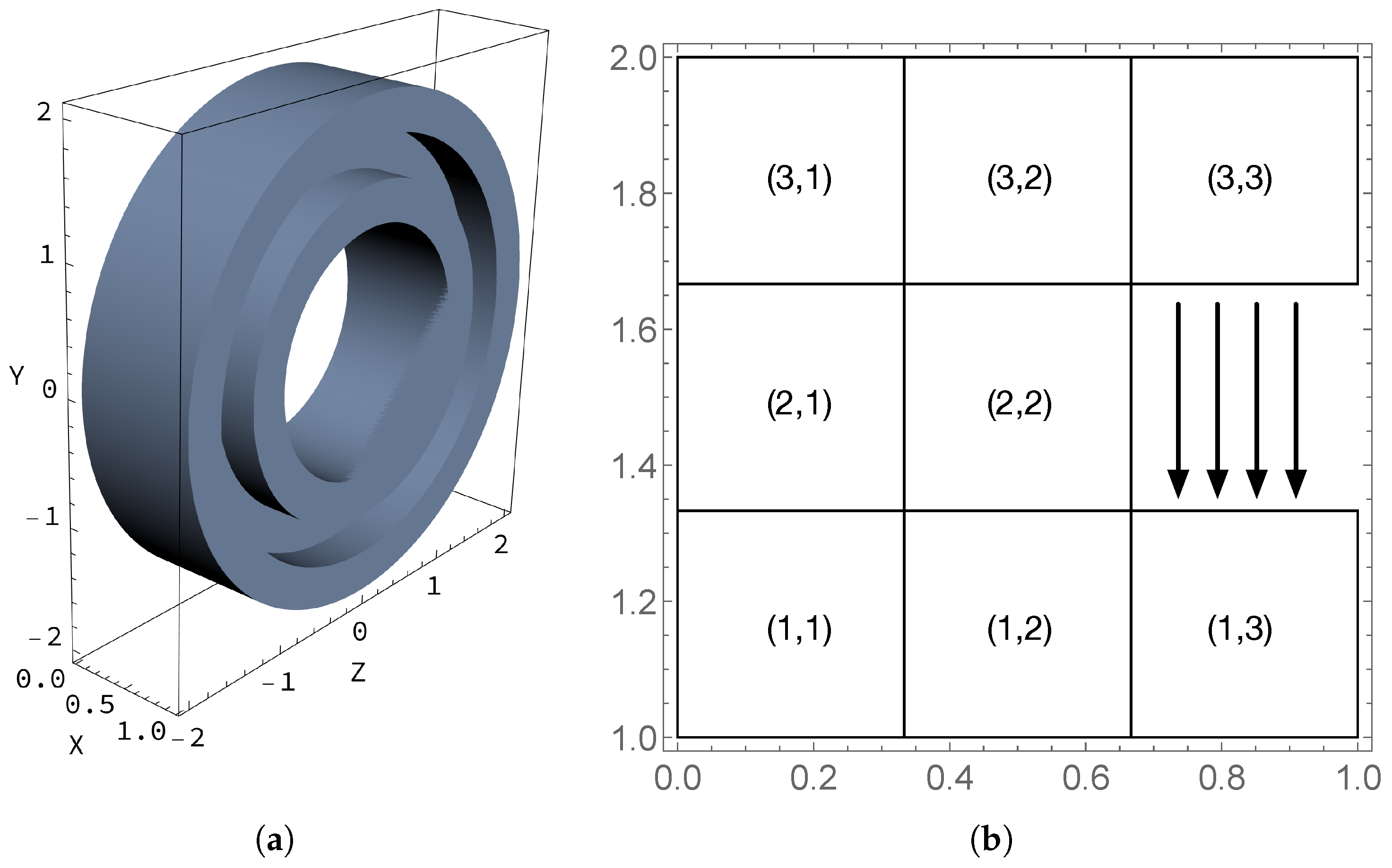
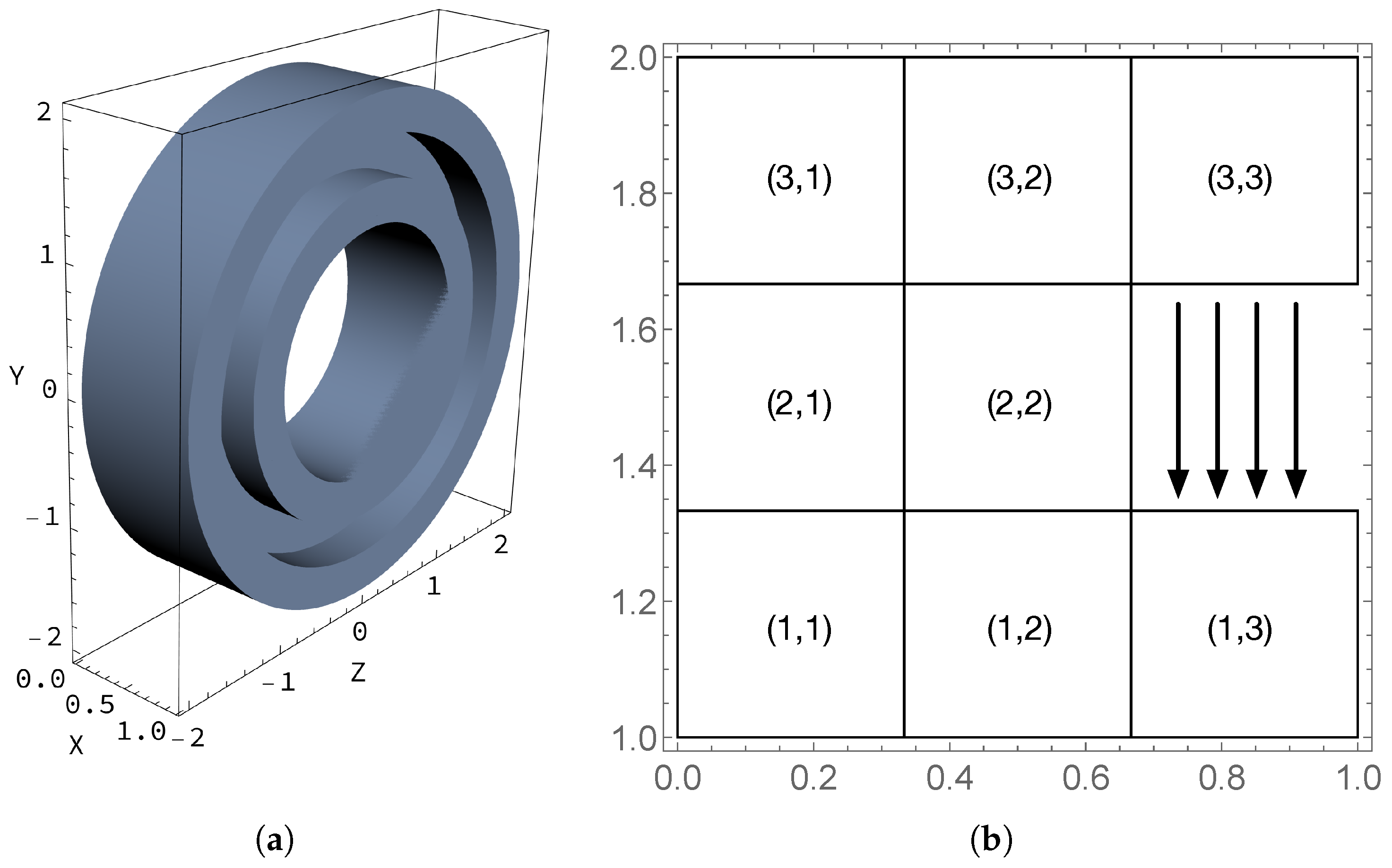
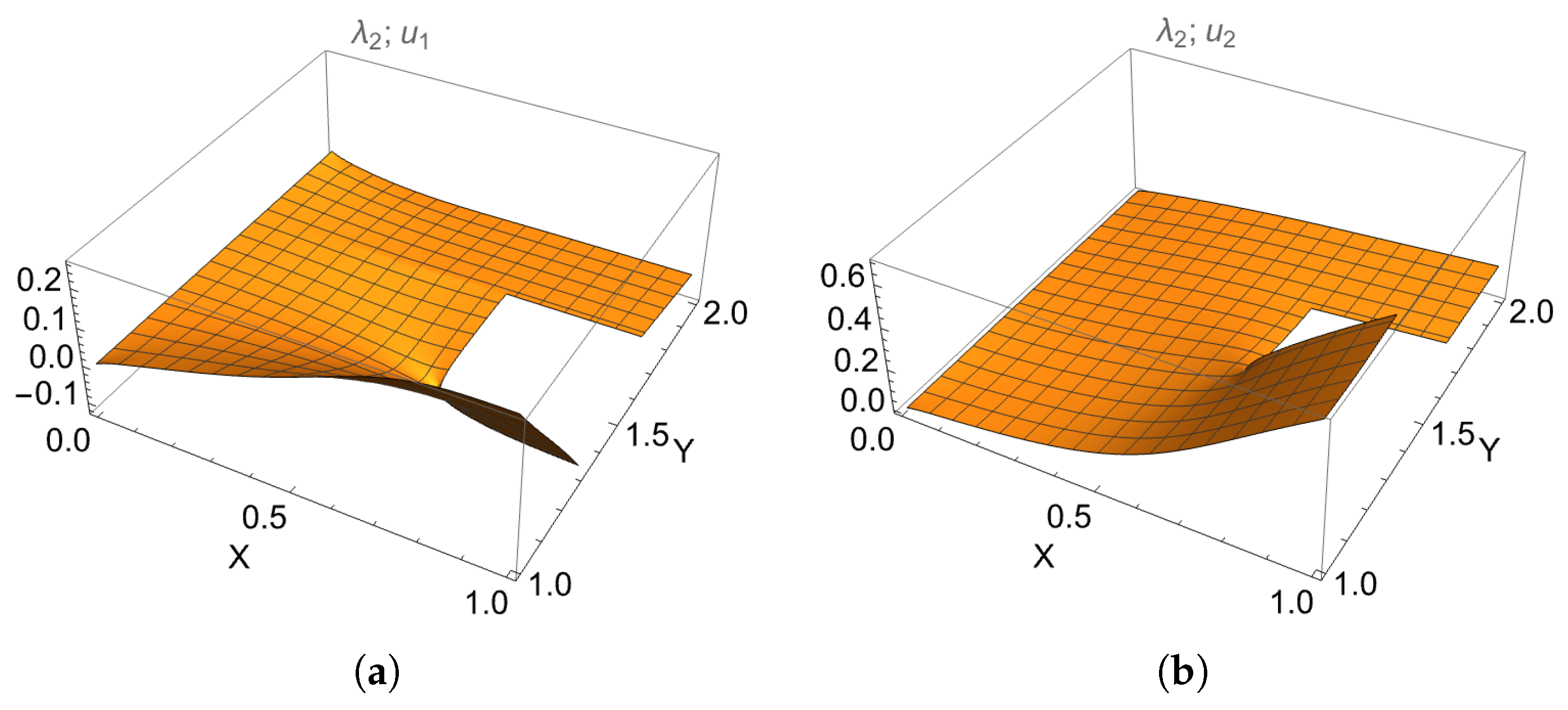
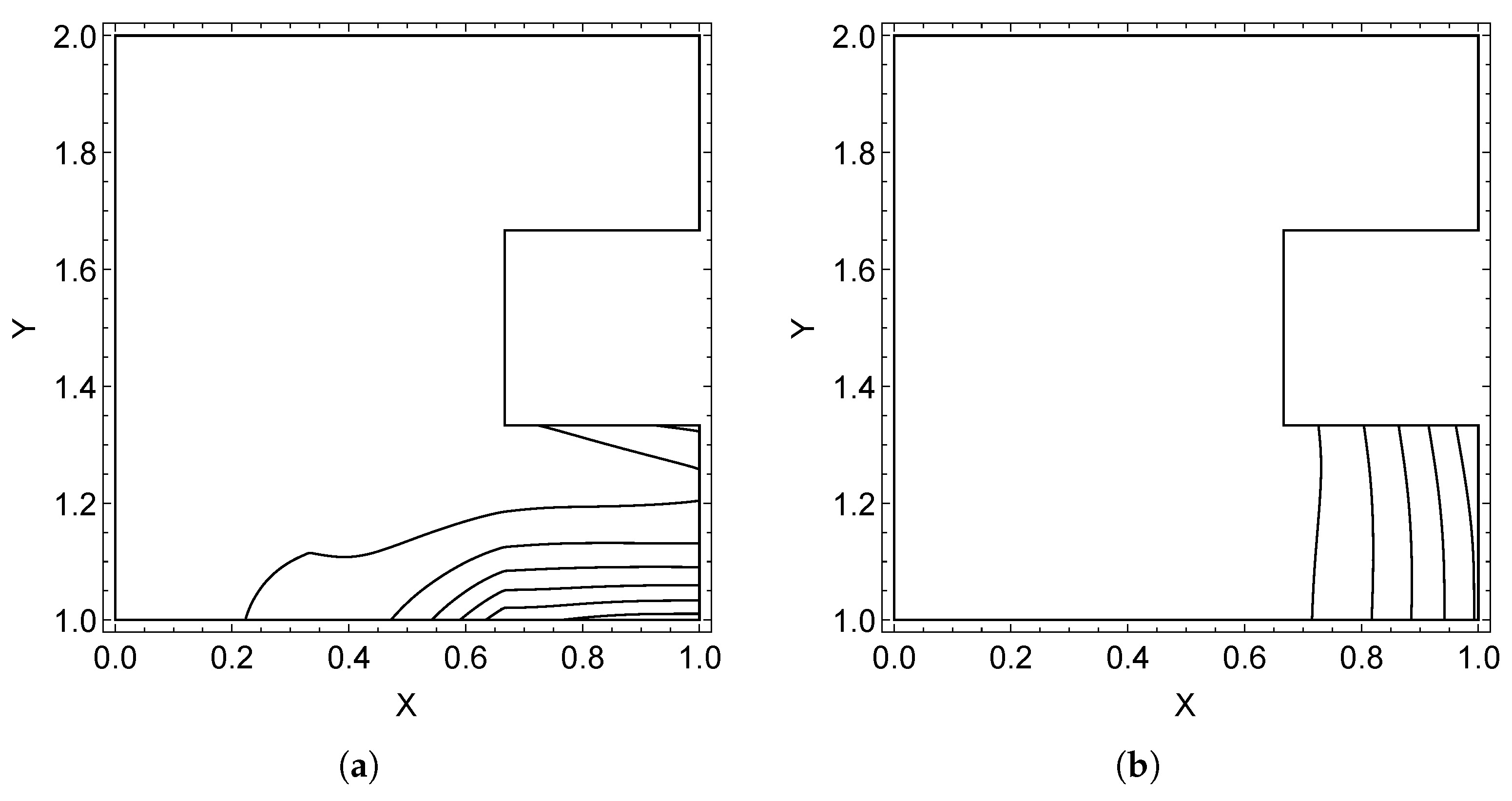
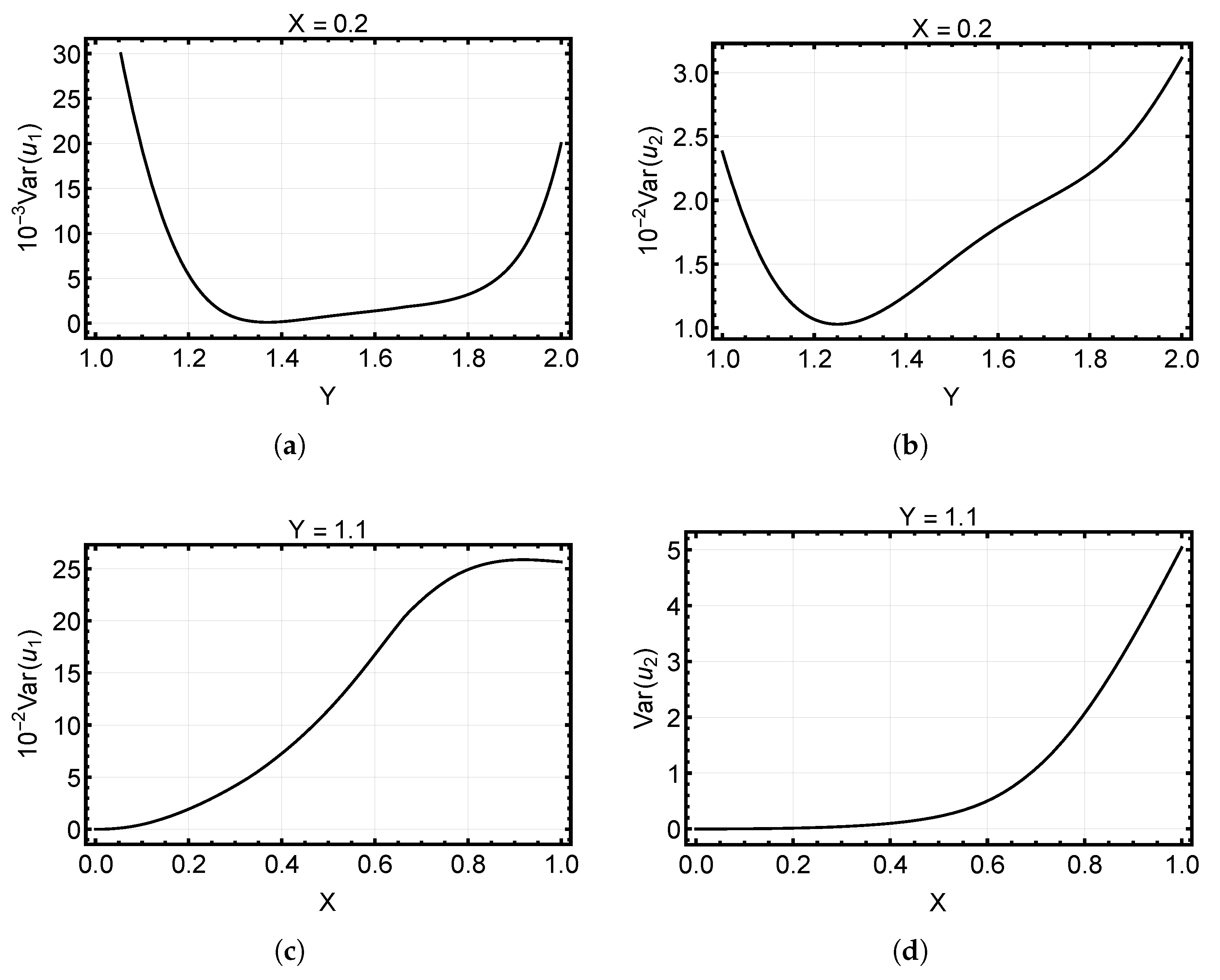
6.1. Case 1: Three Regions
6.2. Case 2: Eight Regions
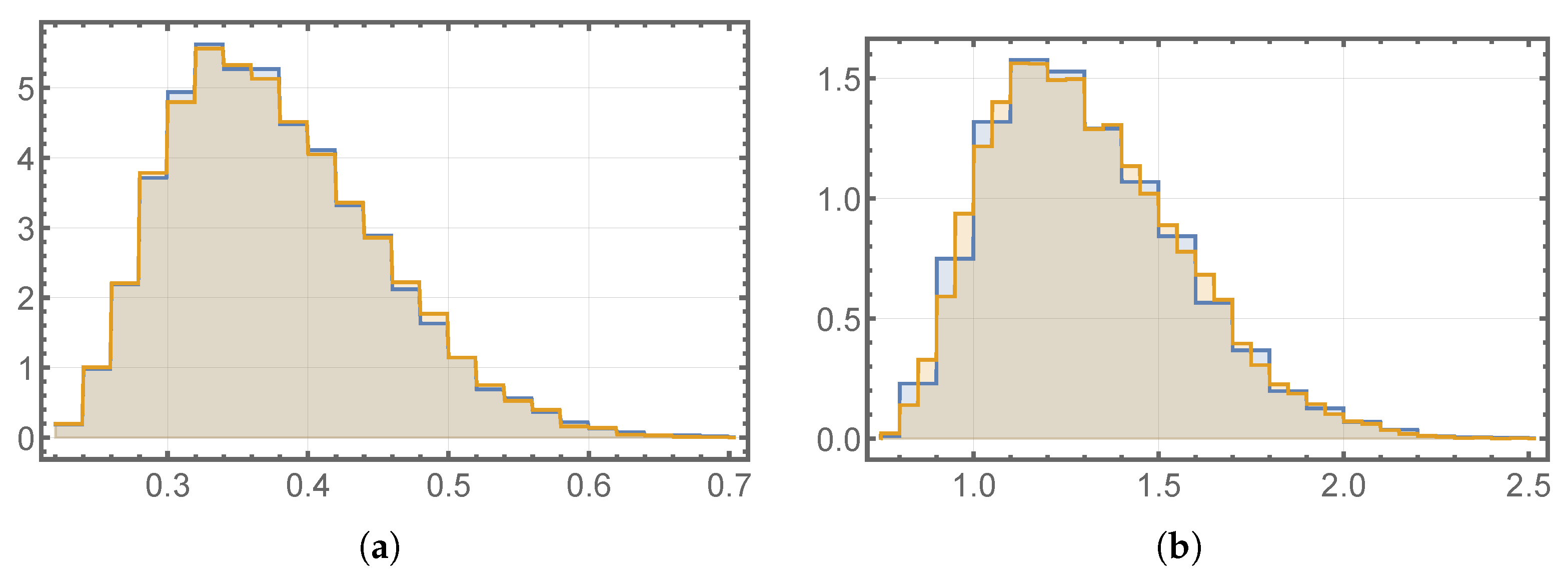
6.3. Comparative Analysis
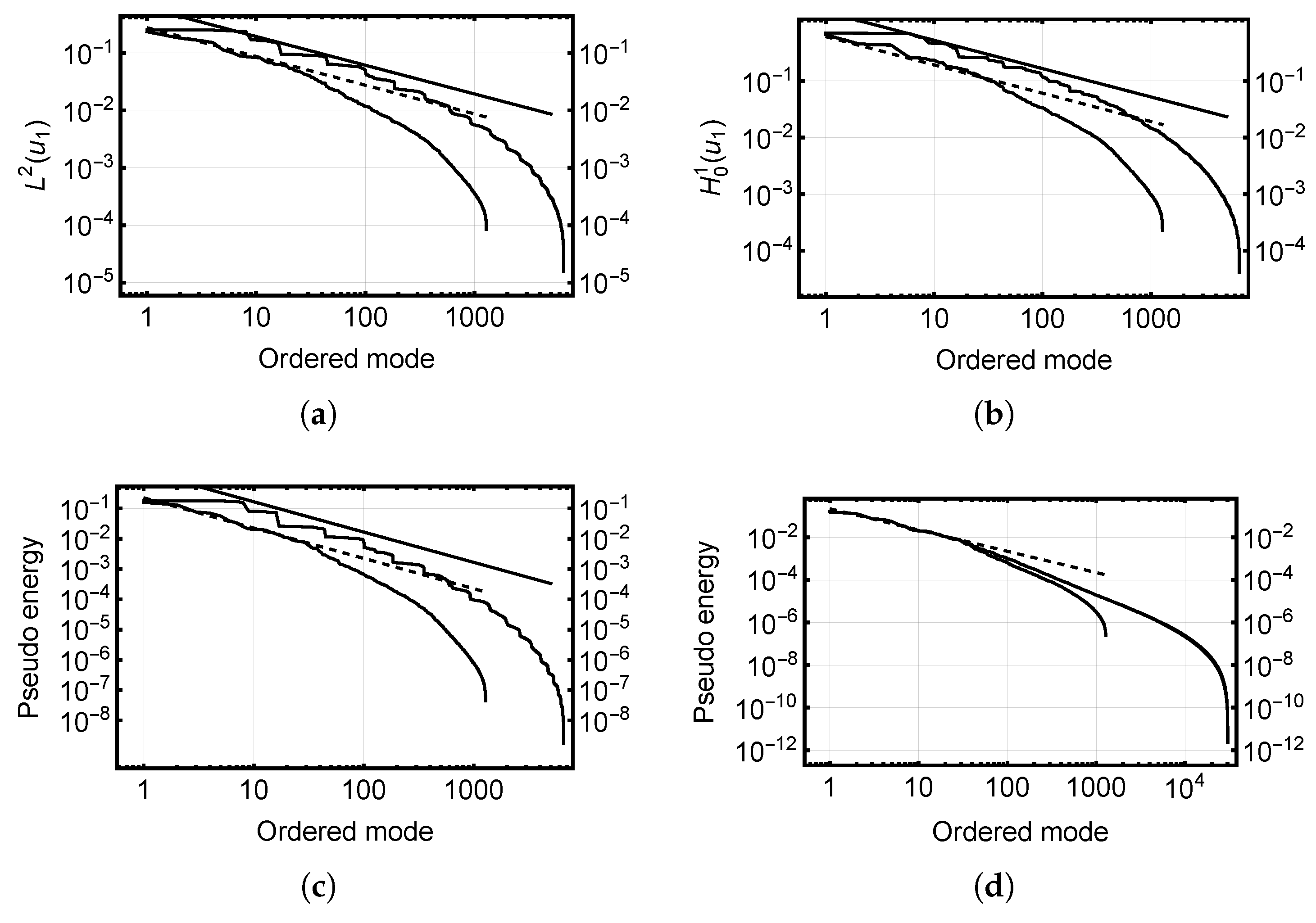
6.3.1. Verification Study of Case 1
6.3.2. Time and Space Complexity
7. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ghanem, R.; Spanos, P. Stochastic Finite Elements: A Spectral Approach; Dover Publications, Inc.: Mineola, NY, USA, 2003. [Google Scholar]
- Schenk, C.A.; Schuëller, G.I. Uncertainty Assessment of Large Finite Element Systems; Lecture Notes in Applied and Computational Mathematics; Springer: Berlin/Heidelberg, Germany, 2005; Volume 24. [Google Scholar]
- Babuška, I.; Nobile, F.; Tempone, R. A stochastic collocation method for elliptic partial differential equations with random input data. SIAM J. Numer. Anal. 2007, 45, 1005–1034. [Google Scholar] [CrossRef]
- Schwab, C.; Gittelson, C.J. Sparse Tensor Discretizations of High-Dimensional Parametric and Stochastic PDEs. Acta Numer. 2011, 20, 291–467. [Google Scholar] [CrossRef] [Green Version]
- Xiu, D. Numerical Methods for Stochastic Computations: A Spectral Method Approach; Princeton University Press: Princeton, NJ, USA, 2010. [Google Scholar]
- Sullivan, T.J. Introduction to Uncertainty Quantification; Texts in Applied Mathematics; Springer: Berlin/Heidelberg, Germany, 2015; Volume 63. [Google Scholar]
- Soize, C. Uncertainty Quantification; Interdisciplinary Applied Mathematics; Springer: Berlin/Heidelberg, Germany, 2017; Volume 47. [Google Scholar]
- Wu, L.; Nguyen, V.D.; Adam, L.; Noels, L. An inverse micro-mechanical analysis toward the stochastic homogenization of nonlinear random composites. Comput. Methods Appl. Mech. Eng. 2019, 348, 97–138. [Google Scholar] [CrossRef] [Green Version]
- Kumar, D.; Koutsawa, Y.; Rauchs, G.; Marchi, M.; Kavka, C.; Belouettar, S. Efficient uncertainty quantification and management in the early stage design of composite applications. Compos. Struct. 2020, 251, 112538. [Google Scholar] [CrossRef]
- Mathew, T.V.; Pramod, A.; Ooi, E.T.; Natarajan, S. An efficient forward propagation of multiple random fields using a stochastic Galerkin scaled boundary finite element method. Comput. Methods Appl. Mech. Eng. 2020, 367, 112994. [Google Scholar] [CrossRef]
- Ostoja-Starzewski, M. Material spatial randomness: From statistical to representative volume element. Probabilistic Eng. Mech. 2006, 21, 112–132. [Google Scholar] [CrossRef]
- Charrier, J.; Scheichl, R.; Teckentrup, A.L. Finite element error analysis of elliptic PDEs with random coefficients and its application to multilevel Monte Carlo methods. SIAM J. Numer. Anal. 2013, 51, 322–352. [Google Scholar] [CrossRef] [Green Version]
- Kuo, F.Y.; Schwab, C.; Sloan, I.H. Quasi-Monte Carlo Finite Element Methods for a Class of Elliptic Partial Differential Equations with Random Coefficients. SIAM J. Numer. Anal. 2012, 50, 3351–3374. [Google Scholar] [CrossRef]
- Kuo, F.Y.; Nuyens, D. Application of Quasi-Monte Carlo Methods to Elliptic PDEs with Random Diffusion Coefficients: A Survey of Analysis and Implementation. Found. Comput. Math. 2016, 16, 1631–1696. [Google Scholar] [CrossRef] [Green Version]
- Kuo, F.Y.; Nuyens, D. Application of Quasi-Monte Carlo Methods to PDEs with Random Coefficients—An Overview and Tutorial. In Monte Carlo and Quasi-Monte Carlo Methods; Owen, A.B., Glynn, P.W., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 53–71. [Google Scholar]
- Bungartz, H.J.; Griebel, M. Sparse grids. Acta Numer. 2004, 13, 1–123. [Google Scholar] [CrossRef]
- Lang, J.; Scheichl, R.; Silvester, D. A fully adaptive multilevel stochastic collocation strategy for solving elliptic PDEs with random data. J. Comput. Phys. 2020, 419, 109692. [Google Scholar] [CrossRef]
- Bieri, M.; Andreev, R.; Schwab, C. Sparse Tensor Discretization of Elliptic SPDEs. SIAM J. Sci. Comput. 2009, 31, 4281–4304. [Google Scholar] [CrossRef]
- Klawonn, A.; Pavarino, L.F.; Rheinbach, O. Spectral element FETI-DP and BDDC preconditioners with multi-element subdomains. Comput. Methods Appl. Mech. Eng. 2008, 198, 511–523. [Google Scholar] [CrossRef]
- Eigel, M.; Gruhlke, R. A local hybrid surrogate-based finite element tearing interconnecting dual-primal method for nonsmooth random partial differential equations. Int. J. Numer. Methods Eng. 2021, 122, 1001–1030. [Google Scholar] [CrossRef]
- Khan, A.; Powell, C.E.; Silvester, D.J. Robust Preconditioning for Stochastic Galerkin Formulations of Parameter-Dependent Nearly Incompressible Elasticity Equations. SIAM J. Sci. Comput. 2019, 41, A402–A421. [Google Scholar] [CrossRef]
- Bespalov, A.; Praetorius, D.; Ruggeri, M. Convergence and rate optimality of adaptive multilevel stochastic Galerkin FEM. IMA J. Numer. Anal. 2021, 42, 2190–2213. [Google Scholar] [CrossRef]
- Heinlein, A.; Klawonn, A.; Lanser, M. Adaptive Nonlinear Domain Decomposition Methods; Technical Report for Center for Data and Simulation Science: Cologne, Germany, 2021. [Google Scholar]
- Slaughter, W.S. The Linearized Theory of Elasticity; Birkhäuser: Basel, Switzerland, 2002. [Google Scholar]
- Ghanem, R.G.; Doostan, A. On the construction and analysis of stochastic models: Characterization and propagation of the errors associated with limited data. J. Comput. Phys. 2006, 217, 63–81. [Google Scholar] [CrossRef]
- Das, S.; Ghanem, R.; Finette, S. Polynomial chaos representation of spatio-temporal random fields from experimental measurements. J. Comput. Phys. 2009, 228, 8726–8751. [Google Scholar] [CrossRef]
- Szabo, B.; Babuska, I. Finite Element Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1991. [Google Scholar]
- Schwab, C. p- and hp-Finite Element Methods; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Soize, C.; Ghanem, R. Physical Systems with Random Uncertainties: Chaos Representations with Arbitrary Probability Measure. SIAM J. Sci. Comput. 2004, 26, 395–410. [Google Scholar] [CrossRef] [Green Version]
- Xiu, D.; Karniadakis, G.E. The Wiener-Askey Polynomial Chaos for Stochastic Differential Equations. SIAM J. Sci. Comput. 2002, 24, 619–644. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remarks on multivariate transformation. Ann. Math. Stat. 1952, 23, 470–472. [Google Scholar] [CrossRef]
- Bieri, M. Sparse Tensor Discretizations of Elliptic PDEs with Random Input Data. Ph.D. Thesis, ETH Zürich, Zürich, Switzerland, 2009. [Google Scholar]
- Beck, J.; Tempone, R.F.; Nobile, F.; Tamellini, L. On the optimal polynomial approximation of stochastic PDEs by Galerkin and collocation methods. Math. Models Methods Appl. Sci. 2012, 22, 1250023. [Google Scholar] [CrossRef] [Green Version]
- Bäck, J.; Nobile, F.; Tamellini, L.; Tempone, R.F. Stochastic Spectral Galerkin and Collocation Methods for PDEs with Random Coefficients: A Numerical Comparison. In Spectral and High Order Methods for Partial Differential Equations; Lecture Notes in Computational Science and, Engineering; Hesthaven, J.S., Ronquist, E.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 76, pp. 43–62. [Google Scholar] [CrossRef]
- Powell, C.E.; Elman, H.C. Block-diagonal preconditioning for spectral stochastic finite-element systems. IMA J. Numer. Anal. 2008, 29, 350–375. [Google Scholar] [CrossRef] [Green Version]
- Golub, G.H.; van Loan, C.F. Matrix Computations, 4th ed.; JHU Press: Baltimore, MD, USA, 2013. [Google Scholar]
- Wolfram Research. Mathematica, Version 13.0.1; Wolfram Research: Champaign, IL, USA, 2021. [Google Scholar]
- Hakula, H.; Tuominen, T. Mathematica implementation of the high order finite element method applied to eigenproblems. Computing 2013, 95, 277–301. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Component | |||
|---|---|---|---|---|
| 1 | 0.0155271 | 0.377051 | 2.92399 | |
| 0.161968 | 1.30773 | 3.50161 | ||
| 1 (TD) | 0.0156688 | 0.377103 | 2.92443 | |
| 0.163275 | 1.30790 | 3.50212 | ||
| 2 | 0.102814 | 0.433761 | 3.3545 | |
| 1.00627 | 1.49574 | 4.0166 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hakula, H. Stochastic Static Analysis of Planar Elastic Structures with Multiple Spatially Uncertain Material Parameters. Appl. Mech. 2022, 3, 974-994. https://doi.org/10.3390/applmech3030055
Hakula H. Stochastic Static Analysis of Planar Elastic Structures with Multiple Spatially Uncertain Material Parameters. Applied Mechanics. 2022; 3(3):974-994. https://doi.org/10.3390/applmech3030055
Chicago/Turabian StyleHakula, Harri. 2022. "Stochastic Static Analysis of Planar Elastic Structures with Multiple Spatially Uncertain Material Parameters" Applied Mechanics 3, no. 3: 974-994. https://doi.org/10.3390/applmech3030055
APA StyleHakula, H. (2022). Stochastic Static Analysis of Planar Elastic Structures with Multiple Spatially Uncertain Material Parameters. Applied Mechanics, 3(3), 974-994. https://doi.org/10.3390/applmech3030055