On the Road: Route Proposal from Radar Self-Supervised by Fuzzy LiDAR Traversability



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
Simple Summary
Abstract
1. Introduction
- The requirement for robust exteroceptive sensing which enables autonomy of mobile platforms in previously unvisited environments, and
- The difficulty of labelling in the radar domain, even by human experts.
- A rules-based system for encoding LiDAR measurements as traversable for an autonomous vehicle (AV),
- An automatic labelling procedure for the radar domain,
- Several learned models which effectively model traversability directly from radar, and
- A joint model which is trained considering traversabile routes which have also been demonstrated by the survey platform.
2. Related Work
2.1. Navigation and Scene Understanding from Radar
2.2. Traversability Analysis
2.3. Route Prediction
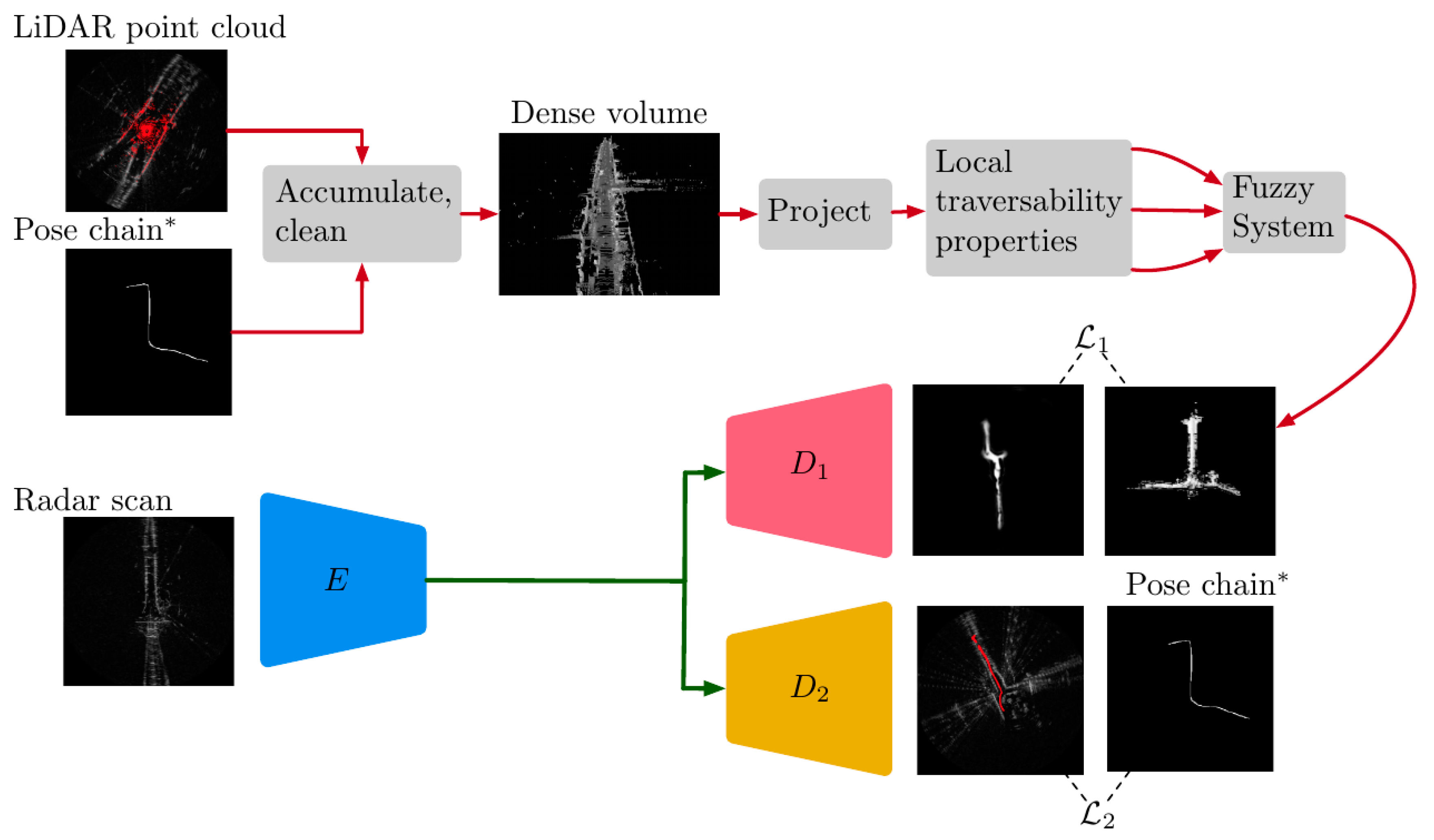
3. Learned Traversability From Radar
3.1. Training Data Generation
3.1.1. Pose-Chain Accumulation of a Dense Point Cloud
3.1.2. Spatial Downsampling of the Accumulated Dense Point Cloud
3.1.3. Selectively Pruning the Dense Accumulated Point Cloud
3.1.4. Segmentation-Based ICP for Registering Multiple Traversals
3.1.5. Removal Of Duplicate Dynamic Obstacles
- Ground plane fitting and Ground vs. obstacle segmentation using three point random sample consensus (RANSAC). An outlier ratio is determined experimentally as 0.46—taking an average over 10 randomly selected point clouds and a conservative number of 50 trials is used to ensure convergence.
- Voxelisation of obstacle point clouds. Each point cloud in the obstacle point cloud set is voxelised with a fine voxel side length of .
- Static vs. Dynamic segmentation. An occupancy grid representing the number of points in each voxel is constructed. The contents of all static voxels are combined with those points in the ground plane to yield a point cloud containing only static obstacles.
3.2. Traversability Labelling
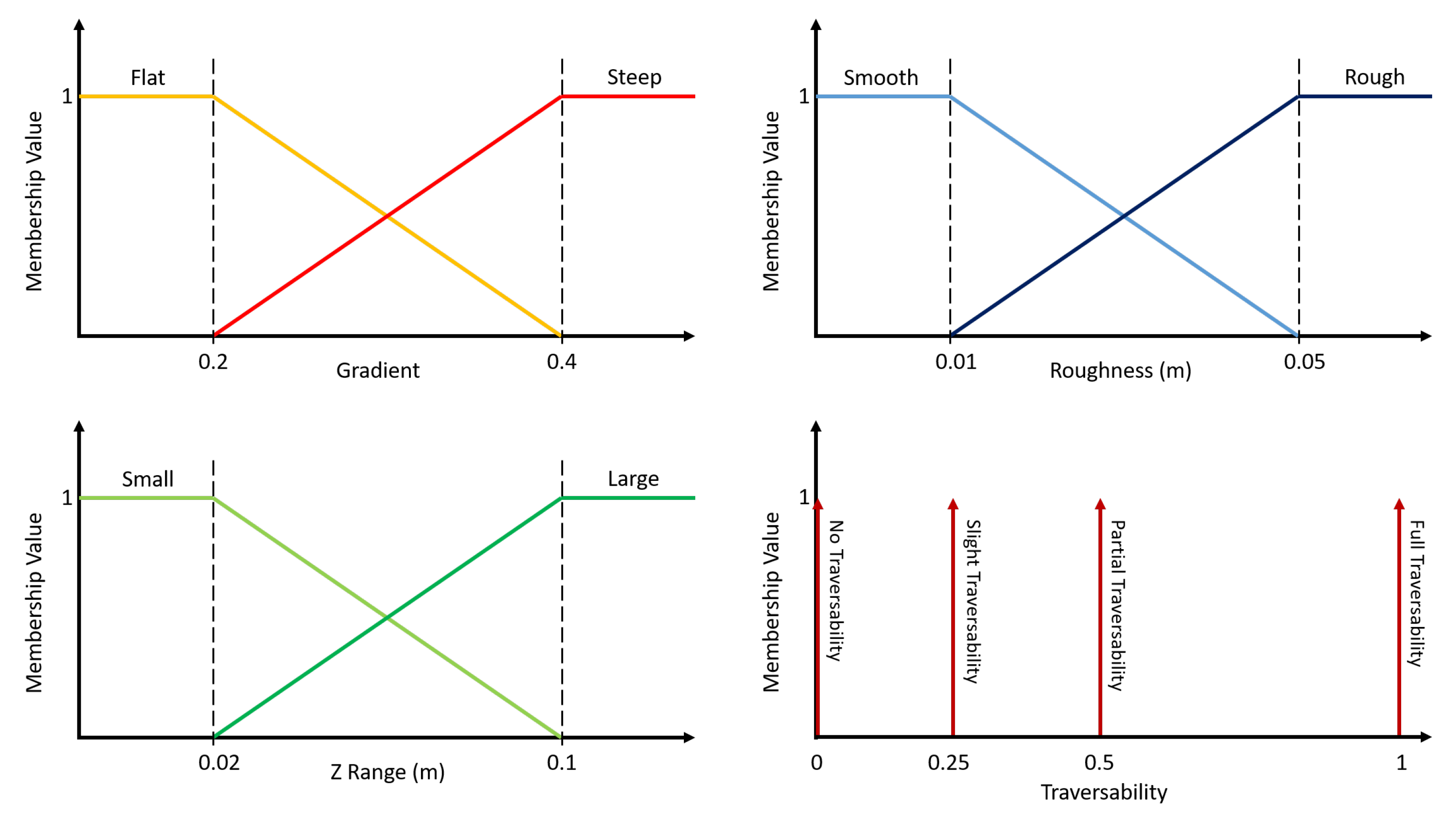
3.2.1. Geometric Traversability Quantities
- gradient,
- roughness, and
- maximum height variation.
Local Gradient
Local Roughness
Local Maximum Height Variation
3.2.2. Fuzzy Logic Data Fusion
Fuzzy Sets
Membership Value
3.2.3. Traversability Labels
Voxelisation
Data Fusion
Examples
3.3. Single-Task Traversability Network
3.3.1. Neural Network Architecture
3.3.2. Learned Objective
3.3.3. Data Augmentation
3.3.4. Training Configuration
4. Learned Route Proposals From Radar
4.1. Training Data Generation
4.1.1. Pose Chain Construction
4.1.2. Spline Interpolation
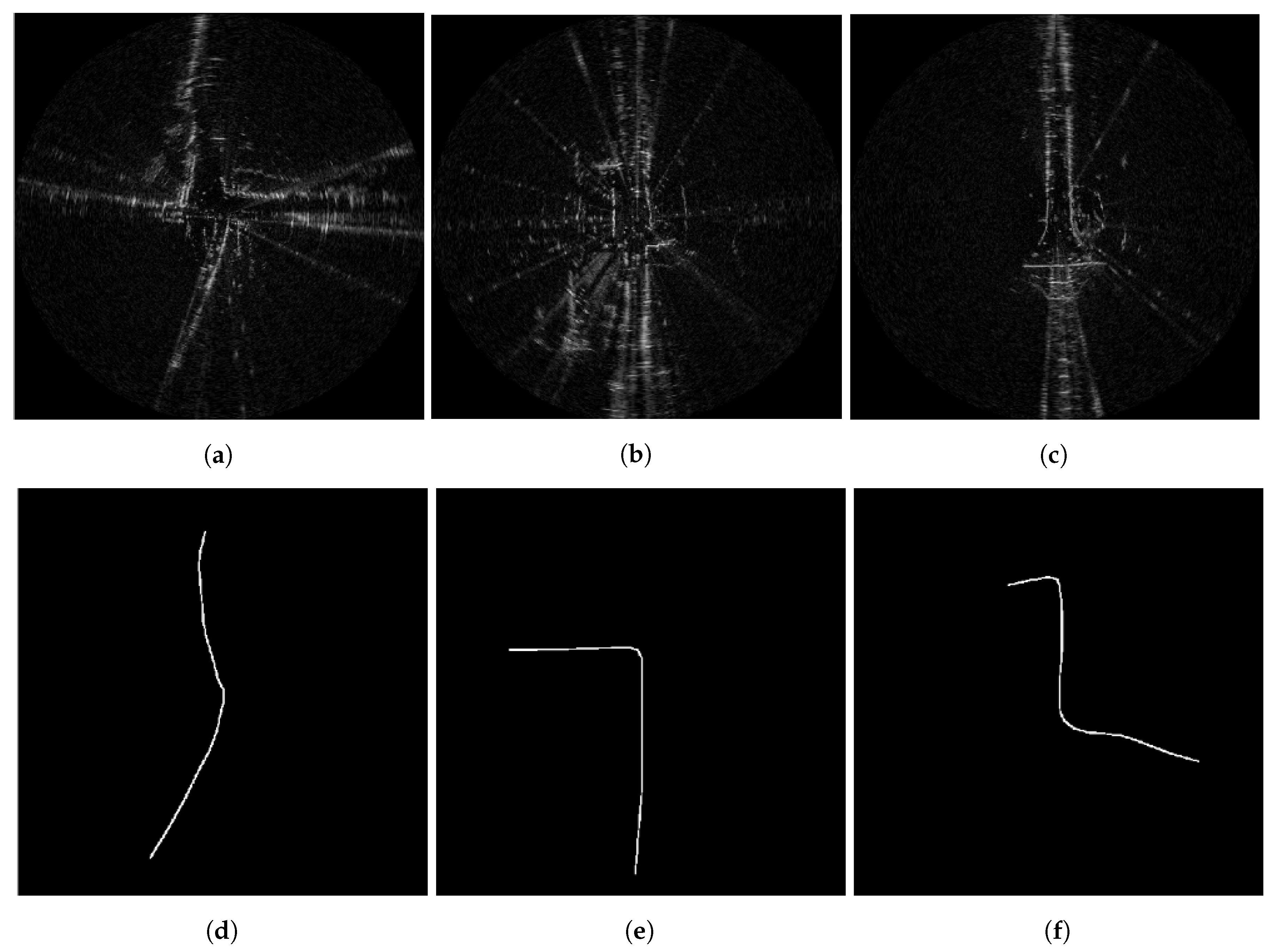
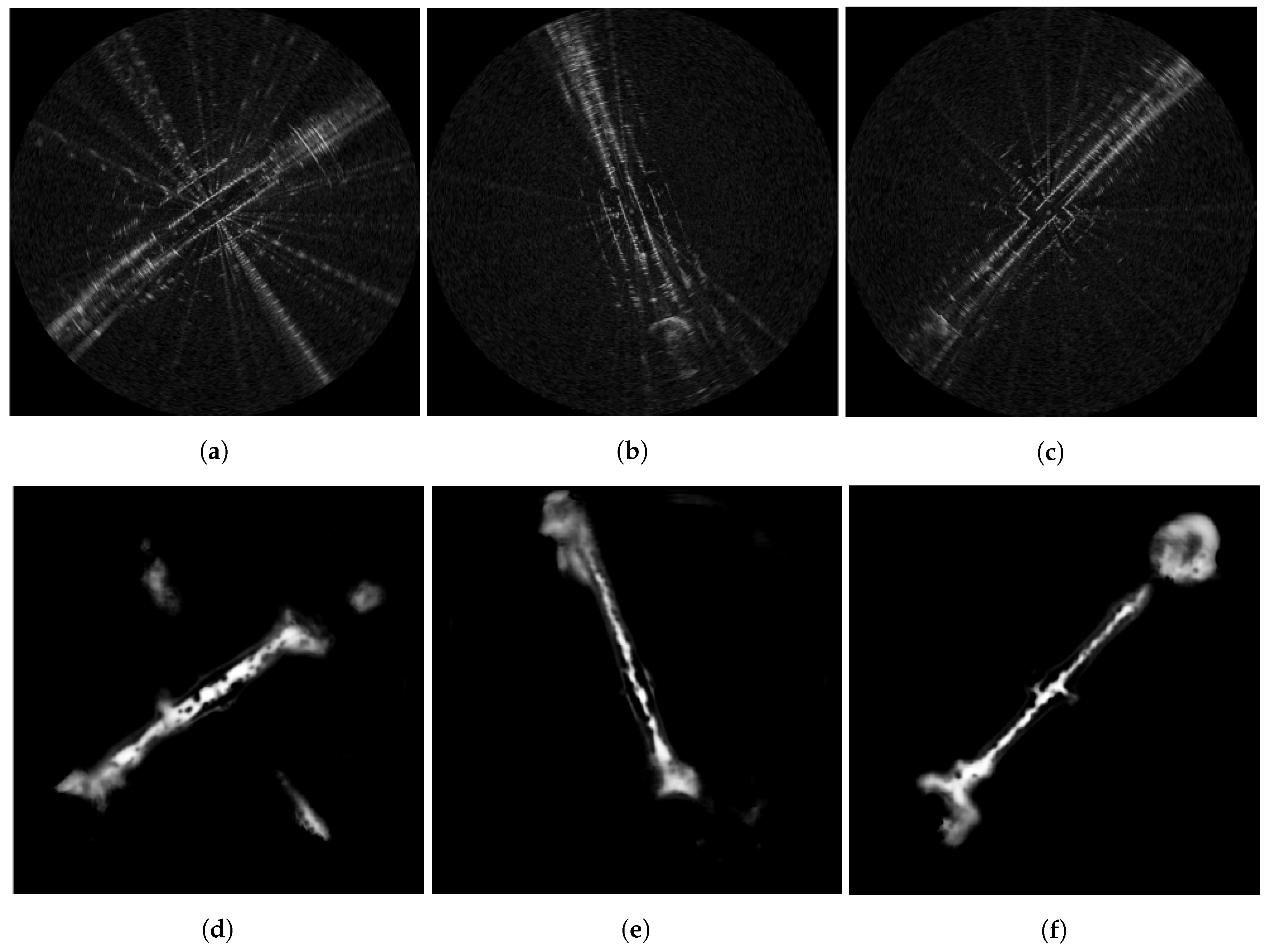
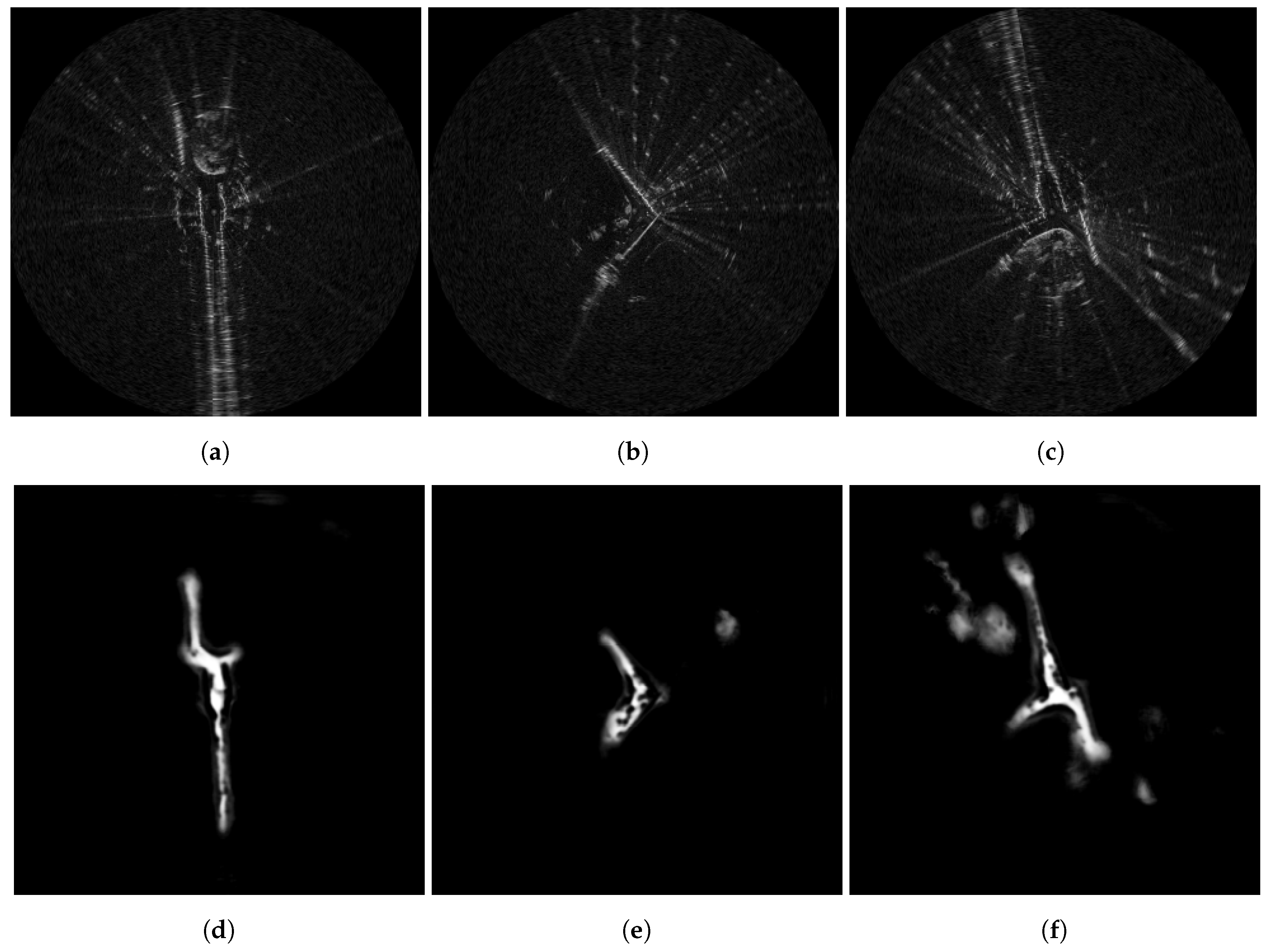
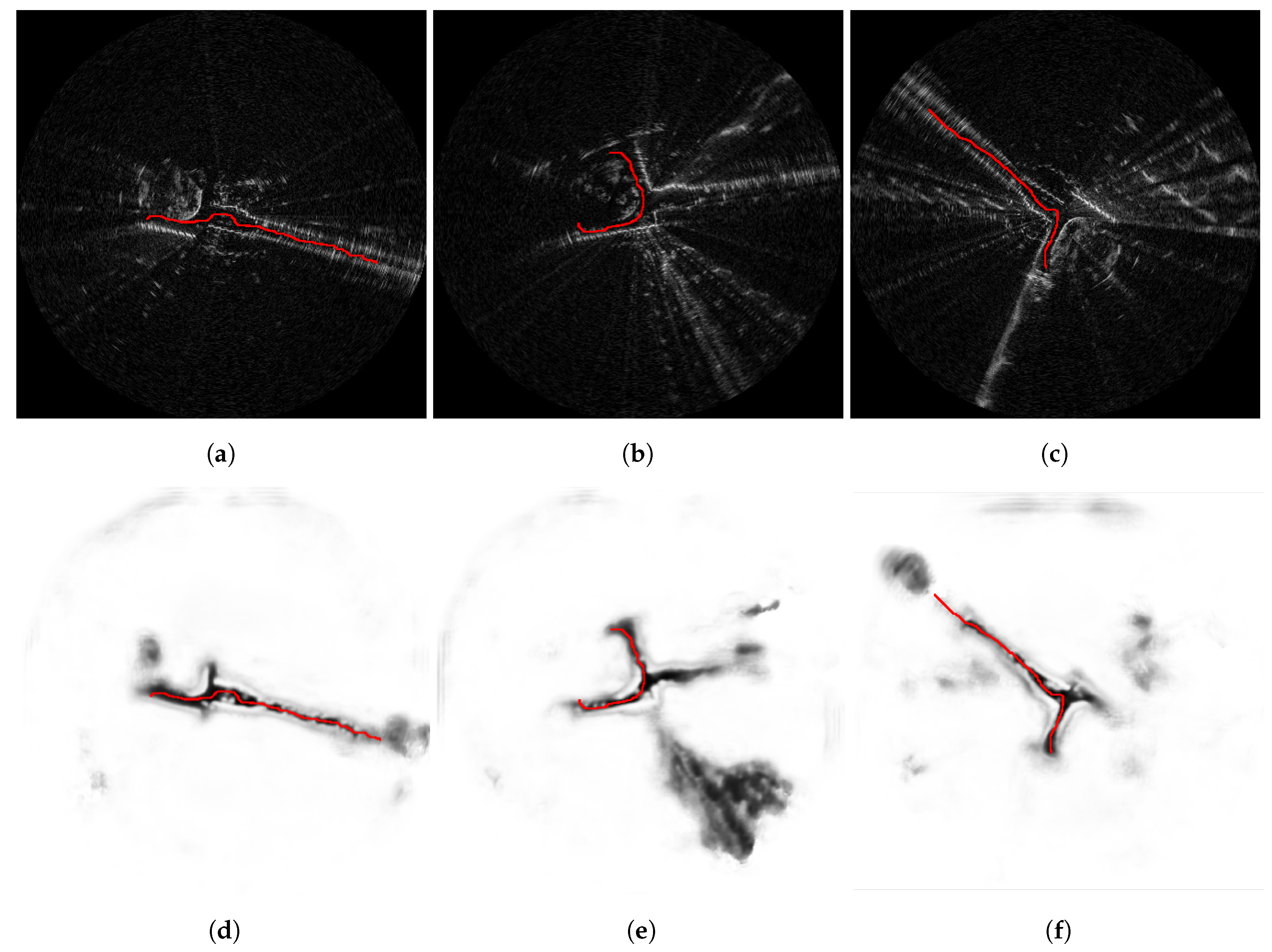
4.1.3. Pixelwise Segmentation of the Moving Vehicle Wheelbase
4.1.4. Route Labels
4.2. Multi-Task Traversable Route Prediction Network
4.2.1. Neural Network Architecture
4.2.2. Learned Objective
4.2.3. Data Augmentation
4.2.4. Training Configuration
5. Experimental Setup
5.1. Sensor Suite
5.2. Dataset
5.2.1. Ground Truth Odometry
5.2.2. Dataset Splits
5.3. Model Selection
5.3.1. Traversability Model
5.3.2. Traversable Route Prediction Model
5.4. Compute Hardware
6. Results and Discussion
6.1. Traversability Predictions
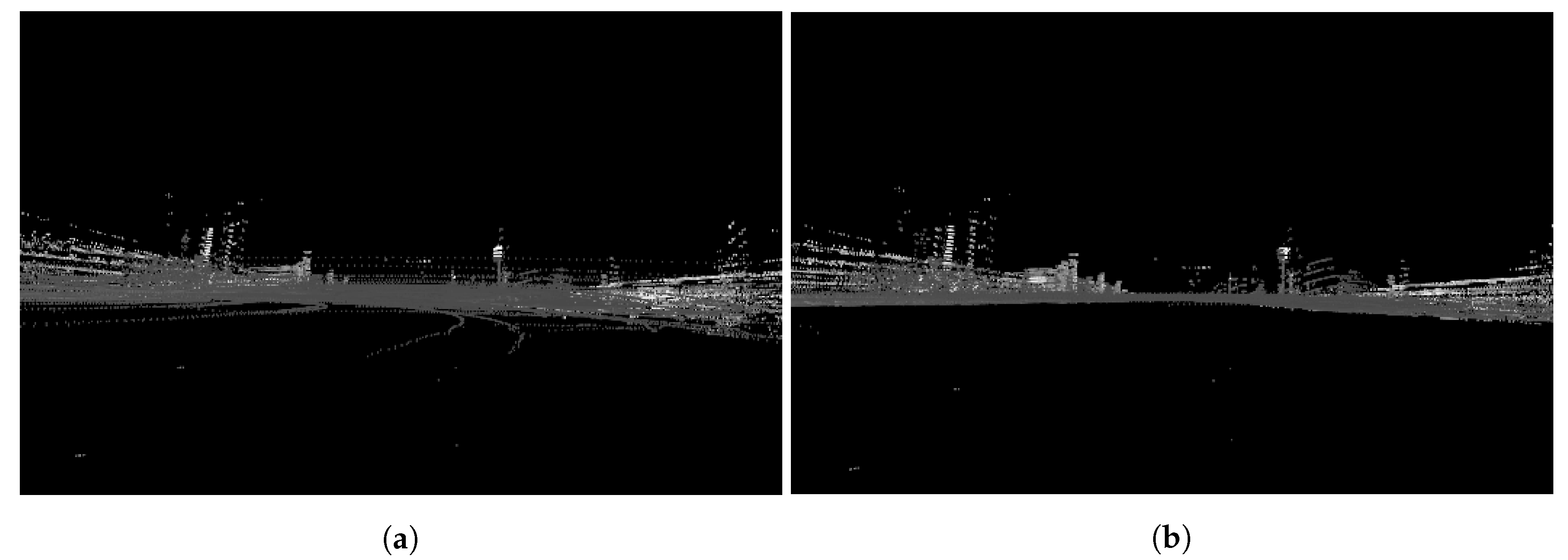
6.1.1. Sensor Artefacts
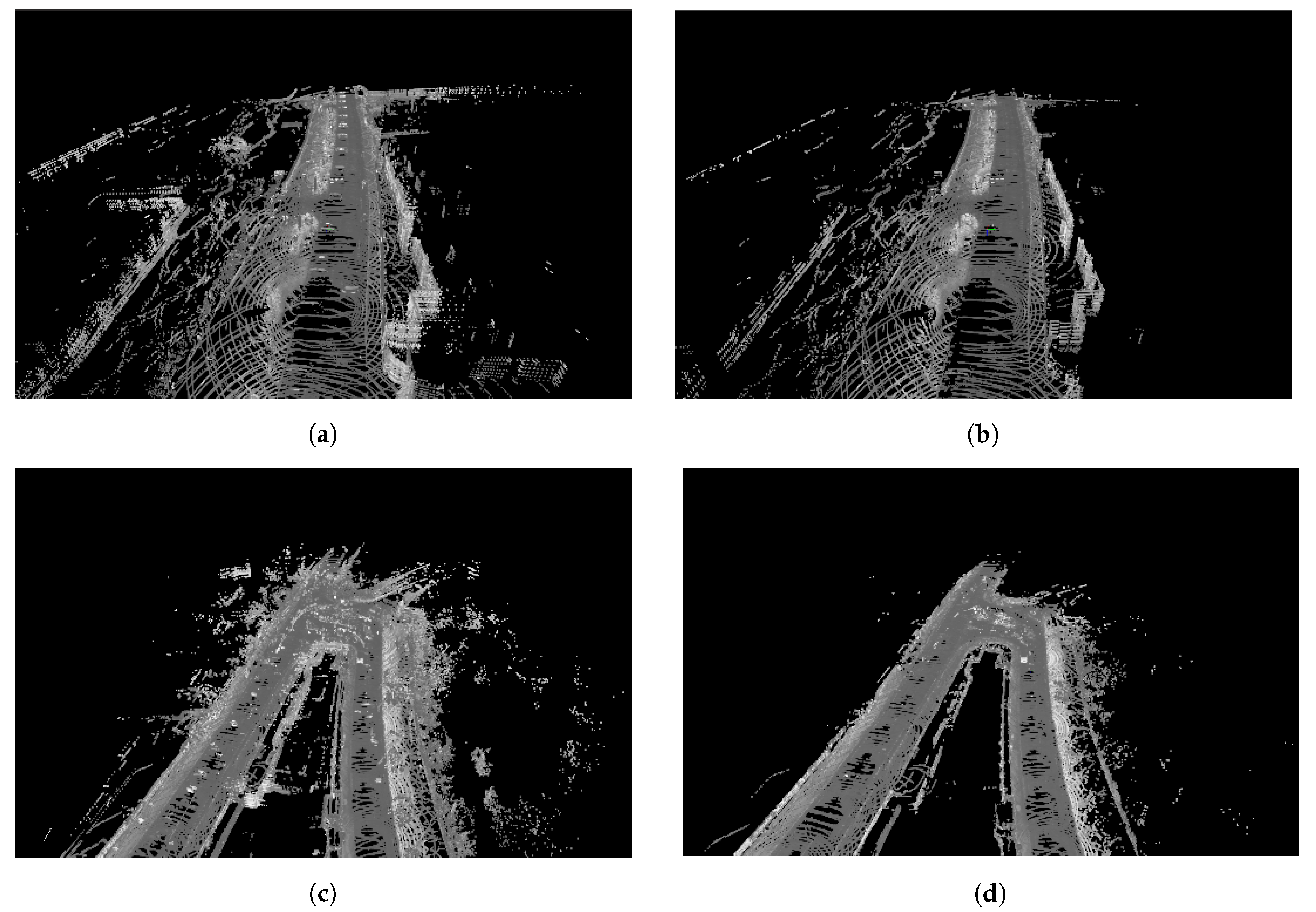
6.1.2. Unusual Road Layout
6.1.3. Traversability Planning
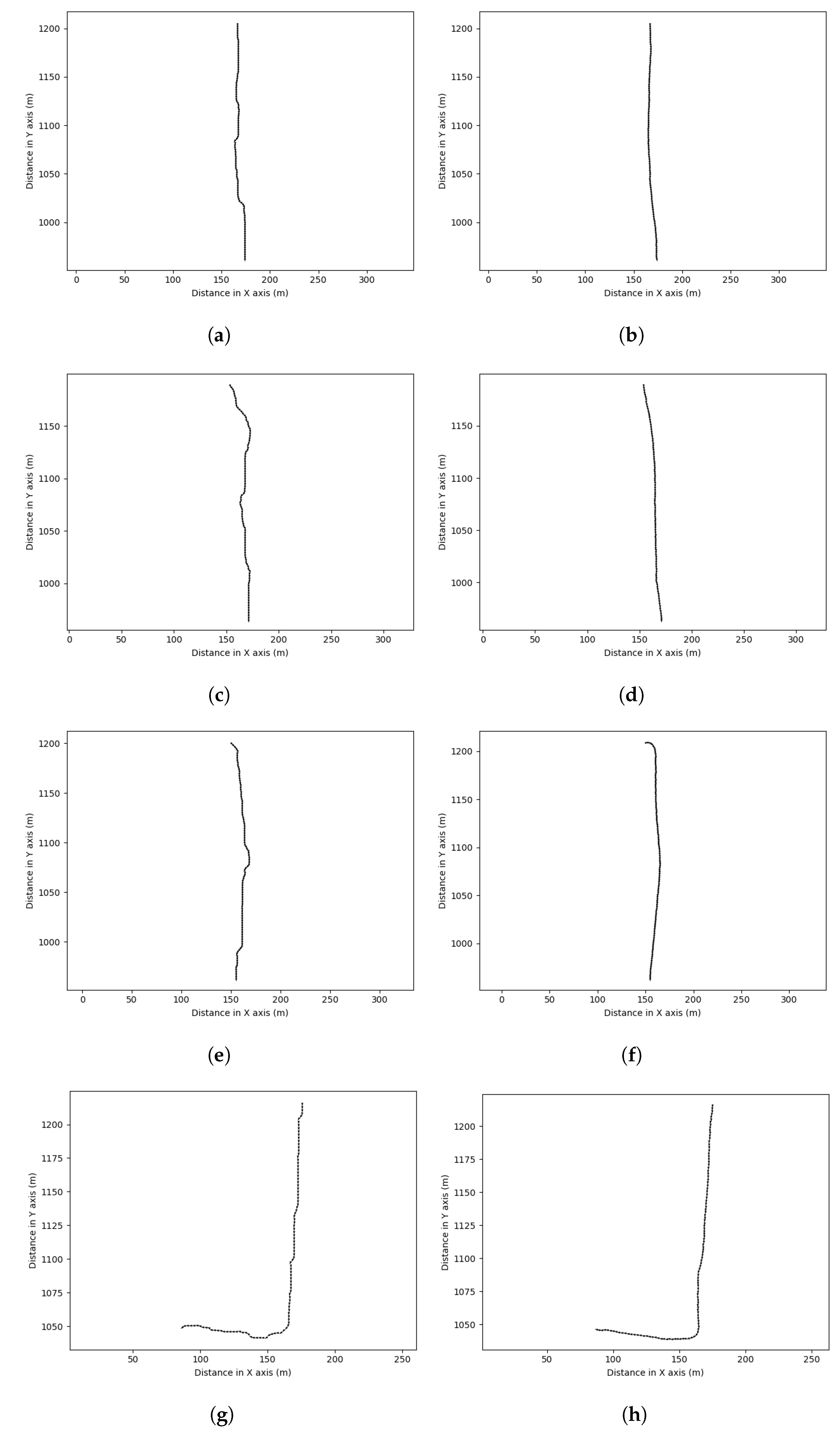
6.2. Traversable Route Prediction
7. Conclusions
8. Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Piotrowsky, L.; Jaeschke, T.; Kueppers, S.; Siska, J.; Pohl, N. Enabling high accuracy distance measurements with FMCW radar sensors. IEEE Trans. Microw. Theory Tech. 2019, 67, 5360–5371. [Google Scholar] [CrossRef]
- Brooker, G.; Hennessey, R.; Bishop, M.; Lobsey, C.; Durrant-Whyte, H.; Birch, D. High-resolution millimeter- wave radar systems for visualization of unstructured outdoor environments. J. Field Robot. 2006, 23, 891–912. [Google Scholar] [CrossRef]
- Barnes, D.; Maddern, W.; Posner, I. Find Your Own Way: Weakly-Supervised Segmentation of Path Proposals for Urban Autonomy. arXiv 2016, arXiv:cs.RO/1610.01238. [Google Scholar]
- Sun, Y.; Zuo, W.; Liu, M. See the Future: A Semantic Segmentation Network Predicting Ego-Vehicle Trajectory With a Single Monocular Camera. IEEE Robot. Autom. Lett. 2020, 5, 3066–3073. [Google Scholar] [CrossRef]
- Williams, D.; De Martini, D.; Gadd, M.; Marchegiani, L.; Newman, P. Keep off the Grass: Permissible Driving Routes from Radar with Weak Audio Supervision. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Rhodes, Greece, 20–23 September 2020. [Google Scholar]
- Cen, S.H.; Newman, P. Precise ego-motion estimation with millimeter-wave radar under diverse and challenging conditions. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Barnes, D.; Weston, R.; Posner, I. Masking by moving: Learning distraction-free radar odometry from pose information. arXiv 2019, arXiv:1909.03752. [Google Scholar]
- Barnes, D.; Posner, I. Under the radar: Learning to predict robust keypoints for odometry estimation and metric localisation in radar. arXiv 2020, arXiv:2001.10789. [Google Scholar]
- Park, Y.S.; Shin, Y.S.; Kim, A. PhaRaO: Direct Radar Odometry using Phase Correlation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar]
- Sheeny, M.; Wallace, A.; Wang, S. 300 GHz Radar Object Recognition based on Deep Neural Networks and Transfer Learning. arXiv 2019, arXiv:1912.03157. [Google Scholar] [CrossRef]
- Kaul, P.; De Martini, D.; Gadd, M.; Newman, P. RSS-Net: Weakly-Supervised Multi-Class Semantic Segmentation with FMCW Radar. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 23–26 June 2020. [Google Scholar]
- Barnes, D.; Gadd, M.; Murcutt, P.; Newman, P.; Posner, I. The Oxford Radar RobotCar Dataset: A Radar Extension to the Oxford RobotCar Dataset. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar]
- Kim, G.; Park, Y.S.; Cho, Y.; Jeong, J.; Kim, A. Mulran: Multimodal range dataset for urban place recognition. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020. [Google Scholar]
- Iannucci, P.A.; Narula, L.; Humphreys, T.E. Cross-Modal Localization: Using automotive radar for absolute geolocation within a map produced with visible-light imagery. In Proceedings of the 2020 IEEE/ION Position, Location and Navigation Symposium (PLANS), Portland, OR, USA, 20–23 April 2020; pp. 285–296. [Google Scholar]
- Narula, L.; Iannucci, P.A.; Humphreys, T.E. All-Weather sub-50-cm Radar-Inertial Positioning. arXiv 2020, arXiv:2009.04814. [Google Scholar]
- Tang, T.Y.; De Martini, D.; Barnes, D.; Newman, P. RSL-Net: Localising in Satellite Images From a Radar on the Ground. IEEE Robot. Autom. Lett. 2020, 5, 1087–1094. [Google Scholar] [CrossRef]
- Weston, R.; Cen, S.; Newman, P.; Posner, I. Probably unknown: Deep inverse sensor modelling radar. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5446–5452. [Google Scholar]
- Bekhti, M.A.; Kobayashi, Y. Regressed Terrain Traversability Cost for Autonomous Navigation Based on Image Textures. Appl. Sci. 2020, 10, 1195. [Google Scholar] [CrossRef]
- Zhang, K.; Yang, Y.; Fu, M.; Wang, M. Traversability assessment and trajectory planning of unmanned ground vehicles with suspension systems on rough terrain. Sensors 2019, 19, 4372. [Google Scholar] [CrossRef]
- Martínez, J.L.; Morán, M.; Morales, J.; Robles, A.; Sánchez, M. Supervised Learning of Natural-Terrain Traversability with Synthetic 3D Laser Scans. Appl. Sci. 2020, 10, 1140. [Google Scholar] [CrossRef]
- Yang, K.; Wang, K.; Cheng, R.; Hu, W.; Huang, X.; Bai, J. Detecting traversable area and water hazards for the visually impaired with a pRGB-D sensor. Sensors 2017, 17, 1890. [Google Scholar] [CrossRef]
- Langer, D.; Rosenblatt, J.K.; Hebert, M. A behavior-based system for off-road navigation. IEEE Trans. Robot. Autom. 1994, 10, 776–783. [Google Scholar] [CrossRef]
- Gennery, D.B. Traversability Analysis and Path Planning for a Planetary Rover. Auton. Robot. 1999, 6, 131–146. [Google Scholar] [CrossRef]
- Ye, C. Navigating a Mobile Robot by a Traversability Field Histogram. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2007, 37, 361–372. [Google Scholar] [CrossRef]
- Angelova, A.; Matthies, L.; Helmick, D.; Perona, P. Learning and Prediction of Slip from Visual Information: Research Articles. J. Field Robot. 2007, 24, 205–231. [Google Scholar] [CrossRef]
- Helmick, D.; Angelova, A.; Matthies, L. Terrain Adaptive Navigation for Planetary Rovers. J. Field Robot. 2009, 26, 391–410. [Google Scholar] [CrossRef]
- Howard, A.; Turmon, M.; Matthies, L.; Tang, B.; Angelova, A.; Mjolsness, E. Towards learned traversability for robot navigation: From underfoot to the far field. J. Field Robot. 2006, 23, 1005–1017. [Google Scholar] [CrossRef]
- Papadakis, P. Terrain traversability analysis methods for unmanned ground vehicles: A survey. Eng. Appl. Artif. Intell. 2013, 26, 1373–1385. [Google Scholar] [CrossRef]
- Sock, J.; Kim, J.; Min, J.; Kwak, K. Probabilistic traversability map generation using 3D-LIDAR and camera. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5631–5637. [Google Scholar]
- Lu, L.; Ordonez, C.; Collins, E.G.; DuPont, E.M. Terrain surface classification for autonomous ground vehicles using a 2D laser stripe-based structured light sensor. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 2174–2181. [Google Scholar]
- Schilling, F.; Chen, X.; Folkesson, J.; Jensfelt, P. Geometric and visual terrain classification for autonomous mobile navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 2678–2684. [Google Scholar]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. In Proceedings of the 1985 IEEE International Conference on Robotics and Automation, St. Louis, MO, USA, 25–28 March 1985; Volume 2, pp. 500–505. [Google Scholar]
- Lavalle, S. Rapidly-Exploring Random Trees: A New Tool for Path Planning. Research Report 9811. 1998. Available online: http://msl.cs.illinois.edu/~lavalle/papers/Lav98c.pdf (accessed on 2 December 2020).
- Zhan, Q.; Huang, S.; Wu, J. Automatic Navigation for A Mobile Robot with Monocular Vision. In Proceedings of the 2008 IEEE Conference on Robotics, Automation and Mechatronics, Chengdu, China, 21–24 September 2008; pp. 1005–1010. [Google Scholar]
- Álvarez, J.M.; López, A.M.; Baldrich, R. Shadow resistant road segmentation from a mobile monocular system. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Girona, Spain, 6–8 June 2007; pp. 9–16. [Google Scholar]
- Yamaguchi, K.; Watanabe, A.; Naito, T.; Ninomiya, Y. Road region estimation using a sequence of monocular images. In Proceedings of the 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Asvadi, A.; Premebida, C.; Peixoto, P.; Nunes, U. 3D Lidar-based Static and Moving Obstacle Detection in Driving Environments: An approach based on voxels and multi-region ground planes. Robot. Auton. Syst. 2016, 83. [Google Scholar] [CrossRef]
- Joho, D.; Stachniss, C.; Pfaff, P.; Burgard, W. Autonomous Exploration for 3D Map Learning. In Autonome Mobile Systeme 2007; Berns, K., Luksch, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 22–28. [Google Scholar]
- Lee, C.C. Fuzzy logic in control systems: Fuzzy logic controller. I. IEEE Trans. Syst. Man Cybern. 1990, 20, 404–418. [Google Scholar] [CrossRef]
- Iakovidis, D.K.; Papageorgiou, E. Intuitionistic Fuzzy Cognitive Maps for Medical Decision Making. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 100–107. [Google Scholar] [CrossRef]
- Stover, J.A.; Hall, D.L.; Gibson, R.E. A fuzzy-logic architecture for autonomous multisensor data fusion. IEEE Trans. Ind. Electron. 1996, 43, 403–410. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:cs.CV/1505.04597. [Google Scholar]
- Bertels, J.; Robben, D.; Vandermeulen, D.; Suetens, P. Optimization with soft Dice can lead to a volumetric bias. In Proceedings of the International MICCAI Brainlesion Workshop, Shenzhen, China, 17 October 2019. [Google Scholar]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 Year, 1000km: The Oxford RobotCar Dataset. Int. J. Robot. Res. (IJRR) 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Lam, L.; Lee, S.W.; Suen, C.Y. Thinning methodologies-a comprehensive survey. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 869–885. [Google Scholar] [CrossRef]



















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Broome, M.; Gadd, M.; De Martini, D.; Newman, P. On the Road: Route Proposal from Radar Self-Supervised by Fuzzy LiDAR Traversability. AI 2020, 1, 558-585. https://doi.org/10.3390/ai1040033
Broome M, Gadd M, De Martini D, Newman P. On the Road: Route Proposal from Radar Self-Supervised by Fuzzy LiDAR Traversability. AI. 2020; 1(4):558-585. https://doi.org/10.3390/ai1040033
Chicago/Turabian StyleBroome, Michael, Matthew Gadd, Daniele De Martini, and Paul Newman. 2020. "On the Road: Route Proposal from Radar Self-Supervised by Fuzzy LiDAR Traversability" AI 1, no. 4: 558-585. https://doi.org/10.3390/ai1040033
APA StyleBroome, M., Gadd, M., De Martini, D., & Newman, P. (2020). On the Road: Route Proposal from Radar Self-Supervised by Fuzzy LiDAR Traversability. AI, 1(4), 558-585. https://doi.org/10.3390/ai1040033