Carrot Yield Mapping: A Precision Agriculture Approach Based on Machine Learning

 , ,
, , 
Abstract
1. Introduction
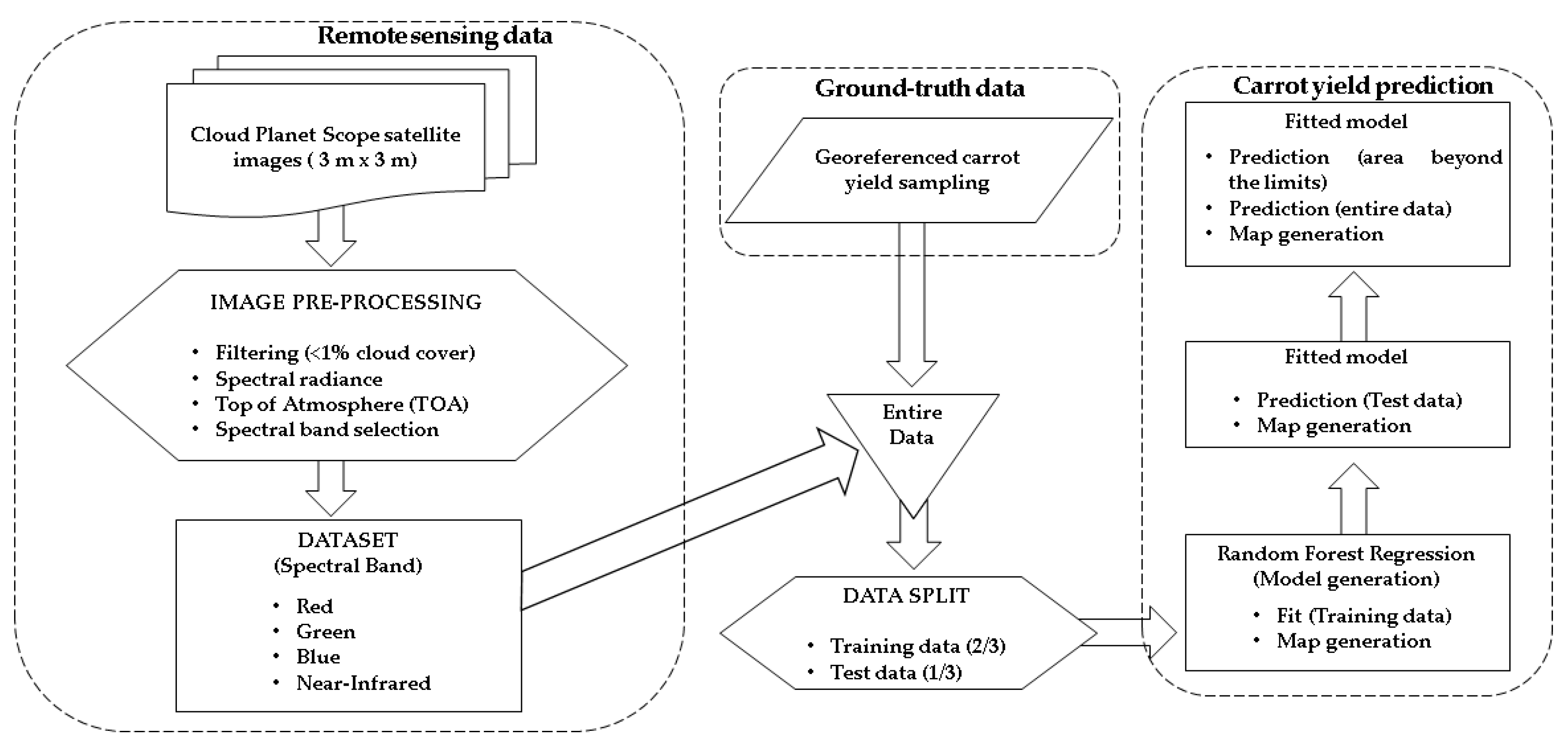
2. Materials and Methods
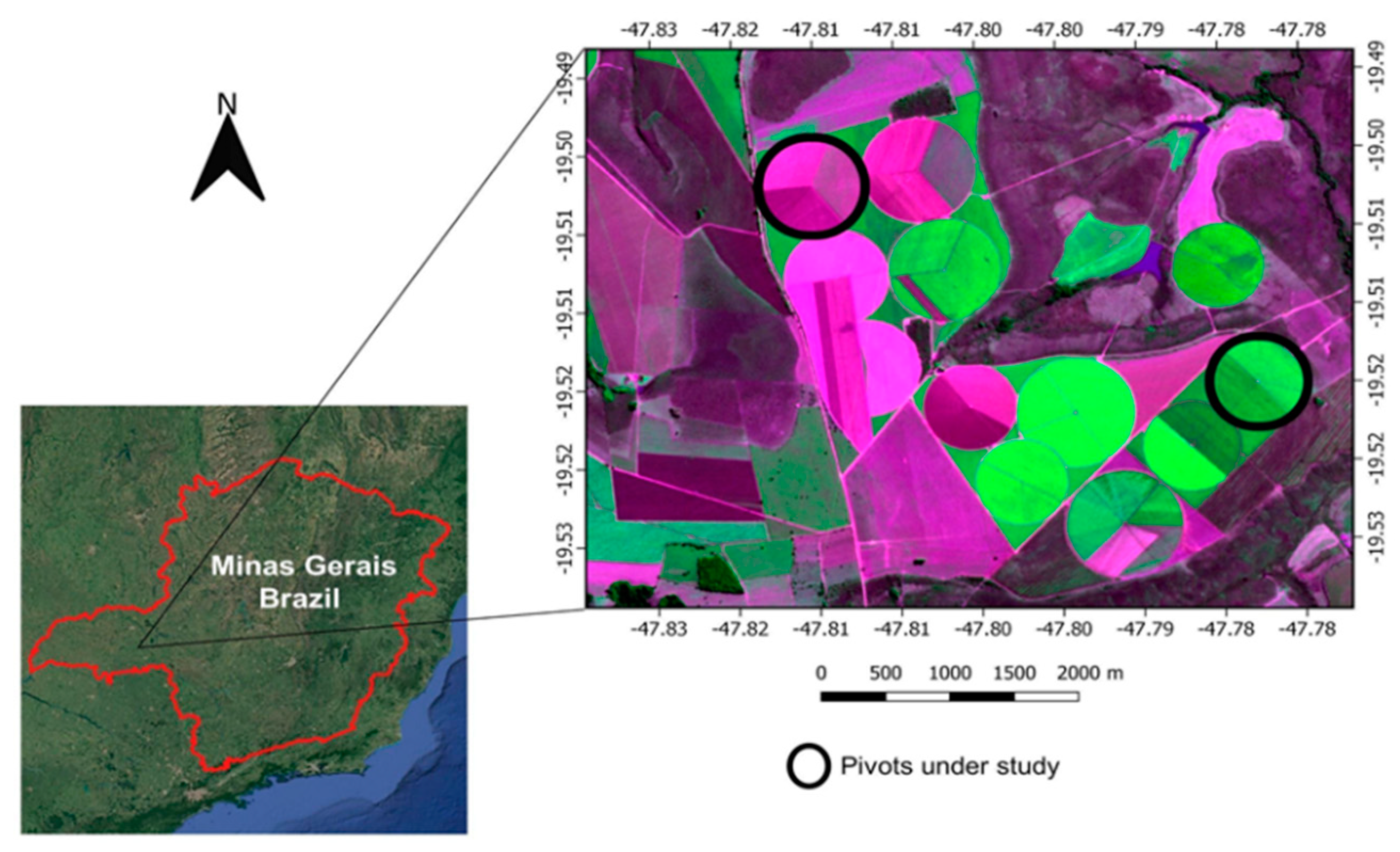
2.1. Study Site
2.2. Harvesting and Yield Mapping
2.3. Satellite Imagery Data
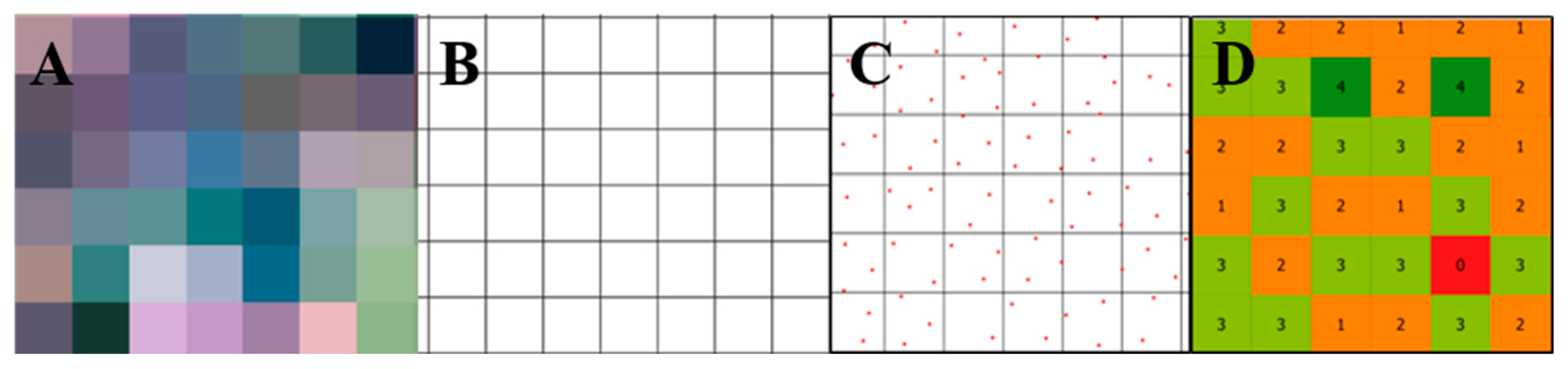
2.4. Dataset
2.5. Random Forest Regression Prediction
3. Results and Discussion
3.1. Harvesting and Yield Mapping
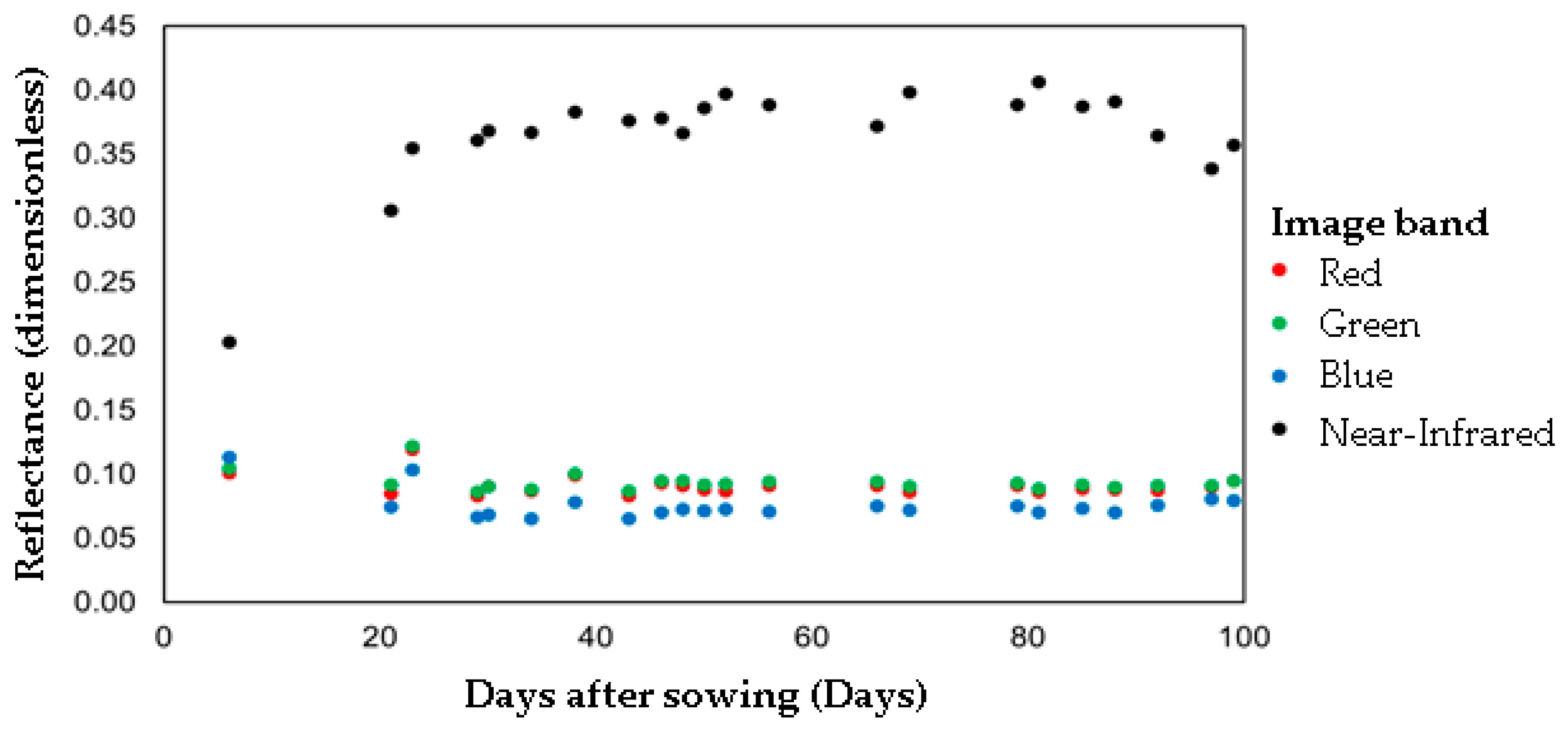
3.2. Satellite Imagery Data
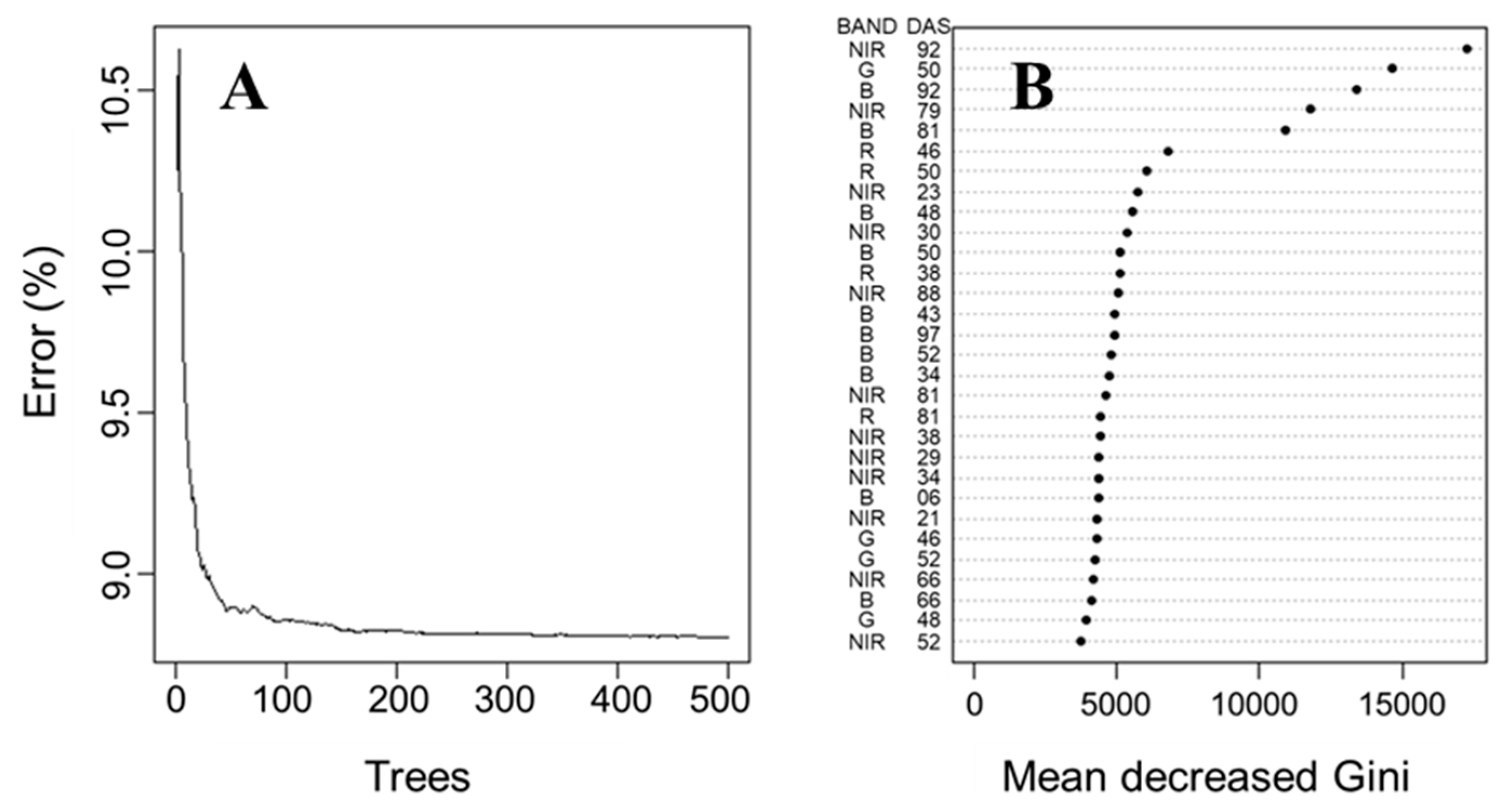
3.3. Random Forest Regression Prediction
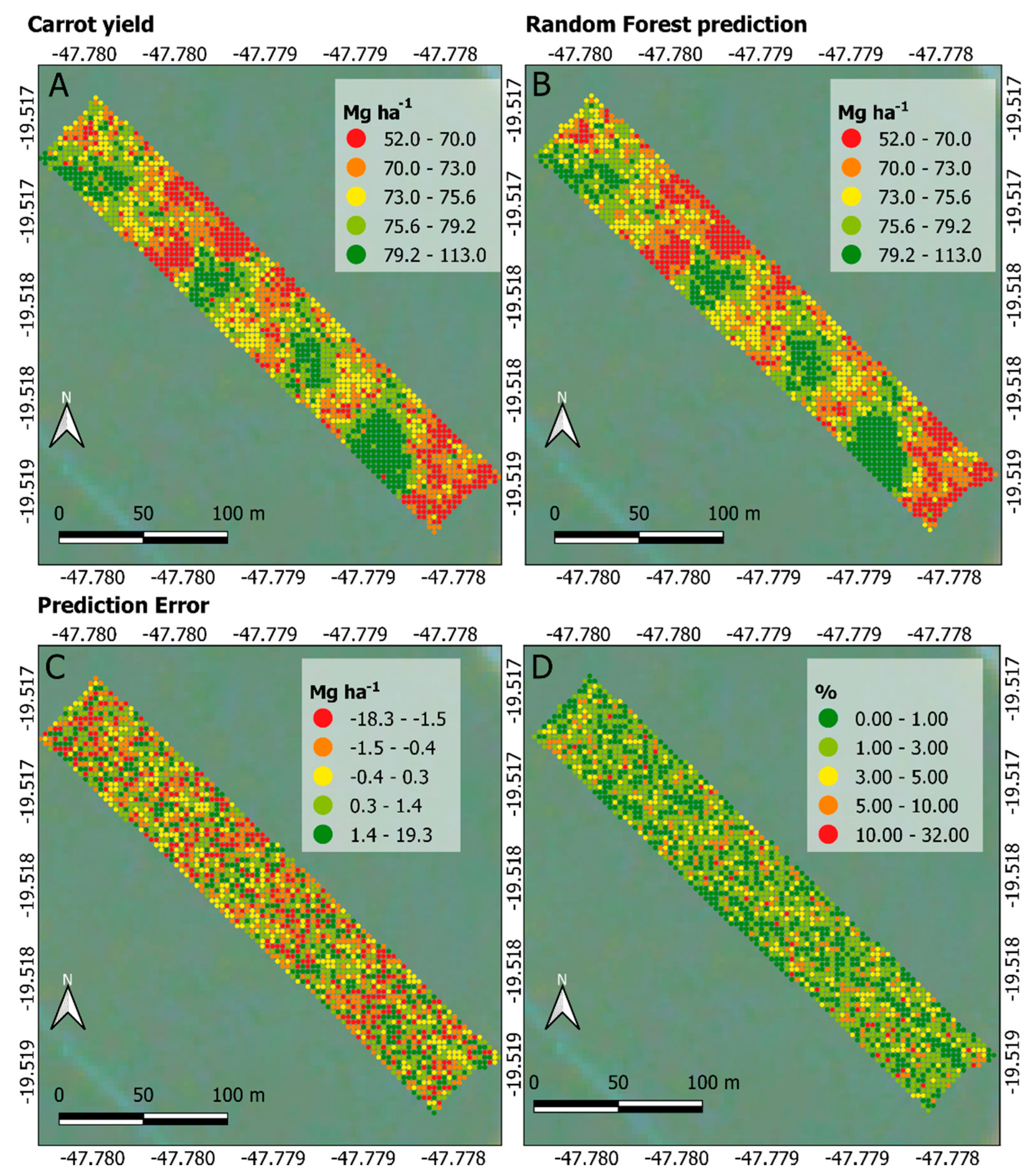
3.4. Carrot Yield Map Visualization
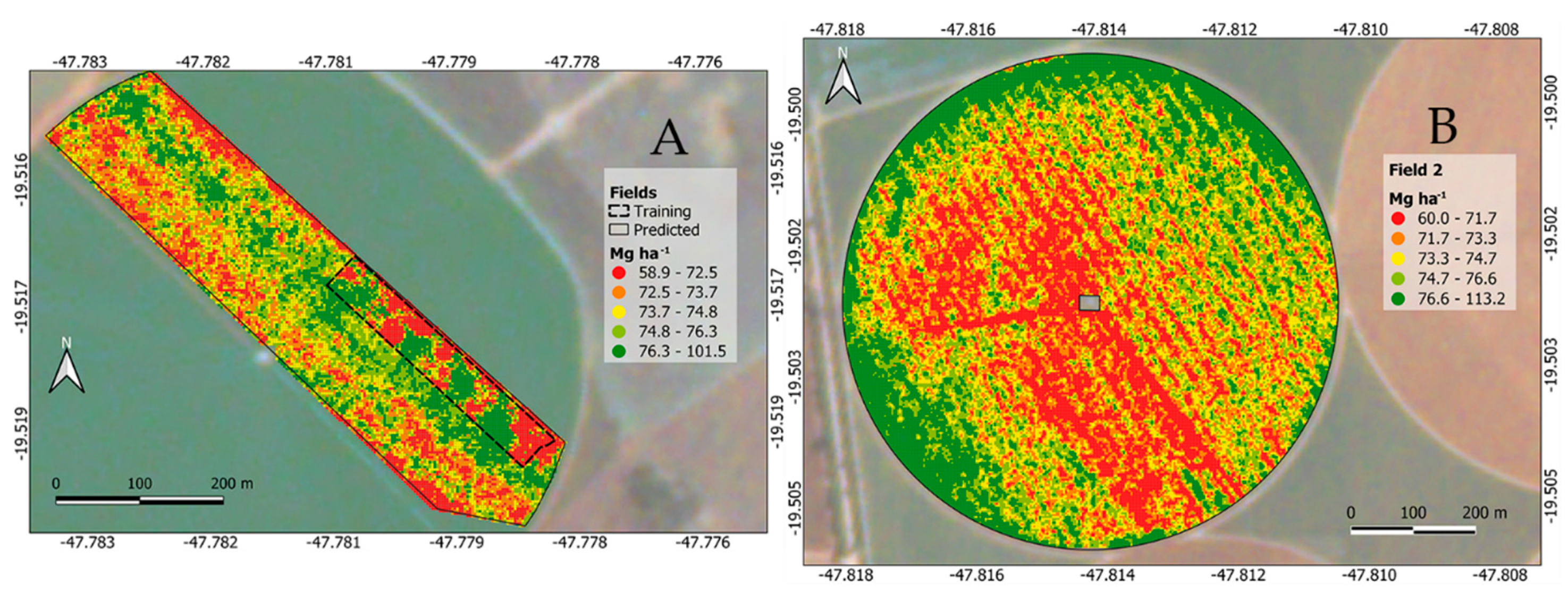
3.5. Future Perspectives
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Vega, A.; Córdoba, M.; Castro-Franco, M.; Balzarini, M. Protocol for automating error removal from yield maps. Precis. Agric. 2019, 20, 1030–1044. [Google Scholar] [CrossRef]
- International Society of Precision Agriculture (ISPA). Available online: https://www.ispag.org (accessed on 24 March 2020).
- Colaço, A.F.; Trevisan, R.G.; Karp, F.H.S.; Molin, J.P. Yield mapping methods for manually harvested crops. In Precision Agriculture’15; Stafford, J.V., Ed.; Wageningen Academic Publishers: Wageningen, The Netherlands, 2015; pp. 39–44. [Google Scholar]
- Simbahan, G.C.; Dobermann, A.; Ping, J.L. Screening yield monitor data improves grain yield maps. Agron. J. 2004, 96, 1091–1102. [Google Scholar] [CrossRef]
- Erkan, M.; Dogan, A. Harvesting of horticultural commodities. In Postharvest Technology of Perishable Horticultural Commodities; Yahia, E.M., Ed.; Woodhead Publishing: Cambridge, UK, 2019; pp. 129–159. [Google Scholar]
- Fulton, J.; Hawkins, E.; Taylor, R.; Franzen, A. Yield Monitoring and Mapping. In Precision Agriculture Basics; Shannon, D.K., Clay, D.E., Kitchen, N.R., Eds.; ASA, CSSA, and SSSA: Madison, WI, USA, 2018; pp. 63–78. [Google Scholar]
- Liu, J.; Li, J.; Li, W.; Wu, J. Rethinking big data: A review on the data quality and usage issues. ISPRS J. Photogramm. 2015, 115, 134–142. [Google Scholar] [CrossRef]
- Wolfert, S.; Ge, L.; Verdouw, C.; Bogaardt, M.J. Big data in smart farming—A review. Agric. Syst. 2017, 153, 69–80. [Google Scholar] [CrossRef]
- Hochachka, W.M.; Caruana, R.; Fink, D.; Munson, A.; Riedewald, D.; Sorokina, D.; Kelling, S. Data-mining discovery of pattern and process in ecological systems. J. Wildlife Manage. 2007, 71, 2427–2437. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Li, G.; Wan, S.; Zhou, J.; Yang, Z.; Qin, P. Leaf chlorophyll fluorescence, hyperspectral reflectance, pigments content, malondialdehyde, and proline accumulation responses of castor bean (Ricinus communis L.) seedlings to salt stress levels. Ind. Crops Prod. 2010, 31, 13–19. [Google Scholar] [CrossRef]
- Usha, K.; Singh, B. Potential applications of remote sensing in horticulture—A review. Sci. Hortic. 2013, 153, 71–83. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, Z.X.; Tao, Y.U.; Huang, X.Z.; Gu, X.F. Agricultural remote sensing big data: Management and applications. J. Integr. Agric. 2018, 17, 1915–1931. [Google Scholar] [CrossRef]
- Shanahan, J.F.; Schepers, J.S.; Francis, D.D.; Varvel, G.E.; Wilhelm, W.W.; Tringe, J.S.; Schlemmer, M.R.; Major, D.J. Use of remote sensing imagery to estimate corn yield. Agron. J. 2001, 93, 583–589. [Google Scholar] [CrossRef]
- Marino, S.; Aria, M.; Basso, B.; Leone, A.P.; Alvino, A. Use of soil and vegetation spectroradiometry to investigate crop water use efficiency of a drip-irrigated tomato. Eur. J. Agron. 2014, 59, 67–77. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Farid, H.U.; Bakhsh, A.; Ahmad, N.; Ahmad, A.; Mahmood-Khan, Z. Delineating site-specific management zones for precision agriculture. J. Agric. Sci. 2016, 154, 273–286. [Google Scholar] [CrossRef]
- Peralta, N.R.; Assefa, Y.; Du, J.; Barden, C.J.; Ciampitti, I.A. Mid-Season High-Resolution Satellite Imagery for Forecasting Site-Specific Corn Yield. Remote Sens. 2016, 8, 848. [Google Scholar] [CrossRef]
- Al-Gaadi, K.A.; Hassaballa, A.A.; Tola, E.; Kayad, A.G.; Madugundu, R.; Alblewi, B.; Assiri, F. Prediction of potato crop yield using precision agriculture techniques. PLoS ONE 2016, 11, 9. [Google Scholar] [CrossRef]
- Skakun, S.; Franch, B.; Vermote, E.; Roger, J.-C.; Justice, C.; Masek, J.; Murphy, E. Winter wheat yield assessment using Landsat 8 and Sentinel-2 data. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 5964–5967. [Google Scholar] [CrossRef]
- Gaso, D.V.; Berger, A.G.; Ciganda, V.S. Predicting wheat grain yield and spatial variability at field scale using a simple regression or a crop model in conjunction with Landsat images. Comput. Electron. Agric. 2019, 159, 75–83. [Google Scholar] [CrossRef]
- Fieuzal, R.; Bustillo, V.; Collado, D.; Dedieu, G. Estimation of Sunflower Yields at a Decametric Spatial Scale—A Statistical Approach Based on Multi-Temporal Satellite Images. Proceedings 2019, 18, 7. [Google Scholar] [CrossRef]
- Everingham, Y.; Sexton, J.; Skocaj, D.; Inman-Bamber, G. Accurate prediction of sugarcane yield using a random forest algorithm. Agron. Sustain. Dev. 2016, 36, 27. [Google Scholar] [CrossRef]
- Narasimhamurthy, V.; Kumar, P. Rice Crop Yield Forecasting Using Random Forest Algorithm. Int. J. Res. Appl. Sci. Eng. Technol. 2017, 5, 1220–1225. [Google Scholar] [CrossRef]
- Ngie, A.; Ahmed, F. Estimation of Maize grain yield using multispectral satellite data sets (SPOT 5) and the random forest algorithm. S. Afr. J. Geomat. 2018, 7, 11–30. [Google Scholar] [CrossRef]
- Molin, J.P.; Mascarin, L.S. Colheita de citros e obtenção de dados para mapeamento da produtividade. Eng. Agric. Jaboticabal 2007, 27, 259–266. (In Portuguese) [Google Scholar] [CrossRef]
- Centro de Abastecimento do Estado de São Paulo (CEAGESP). Available online: http://www.ceagesp.gov.br/wp-content/uploads/2015/07/cenoura.pdf (accessed on 24 March 2020). (In Portuguese)
- Spekken, M.; Anselmi, A.A.; Molin, J.P. A simple method for filtering spatial data. In Proceedings of the European Conference of Precision Agriculture, Lleida, Spain, 7–11 July 2013. [Google Scholar]
- Planet. Daily Satellite Imagery and Insights. Available online: https://www.planet.com (accessed on 24 March 2020).
- Planet Labs. Developer Resource Center. 2020. Available online: https://developers.planet.com/tutorials/convert-planetscope-imagery-from-radiance-to-reflectance/ (accessed on 5 May 2020).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Planet. Planet Imagery Product Specification: PlanetScope & RapidEye. 2016. Available online: https://www.planet.com/products/satellite-imagery/files/1610.06_Spec%20Sheet_Combined_Imagery_Product_Letter_ENGv1.pdf (accessed on 5 May 2020).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Blanco, C.M.G.; Gomez, V.M.B.; Crespo, P.; Ließ, M. Spatial prediction of soil water retention in a Páramo landscape: Methodological insight into machine learning using random forest. Geoderma 2018, 316, 100–114. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. Random Forests. In The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin, Germany, 2009; pp. 587–603. [Google Scholar]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using random forests. Remote Sens. Environ. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Rahmati, O.; Pourghasemi, H.R.; Melesse, A. Application of GIS based data driven random forest and maximum entropy models for groundwater potential mapping: A case study at Mehran Region, Iran. Catena 2016, 137, 360–372. [Google Scholar] [CrossRef]
- Quantum Geographic Information System (QGIS). Available online: https://qgis.org/en/site/forusers/download.html (accessed on 24 March 2020).
- Thompson, R. Some factors affecting carrot root shape and size. Euphytica 1969, 18, 277–285. [Google Scholar]
- Sri Agung, I.G.A.M.; Blair, G.J. Effects of soil bulk density and water regime on carrot yield harvested at different growth stages. J. Hortic. Sci. Biotech. 1989, 64, 17–25. [Google Scholar] [CrossRef]
- Dawuda, M.M.; Boateng, P.Y.; Hemeng, O.B.; Nyarko, G. Growth and yield response of carrot (Daucus carota L.) to different rates of soil amendments and spacing. J. Sci. Technol. 2011, 31, 11–22. [Google Scholar] [CrossRef]
- Guermazi, E.; Bouaziz, M.; Zairi, M. Water irrigation management using remote sensing techniques: A case study in Central Tunisia. Environ. Earth Sci. 2016, 75, 202. [Google Scholar] [CrossRef]
- Madugundu, R.; Al-Gaadi, K.A.; Tola, E.; Hassaballa, A.A.; Kayad, A.G. Utilization of Landsat-8 data for the estimation of carrot and maize crop water footprint under the arid climate of Saudi Arabia. PLoS ONE 2018, 13, 2. [Google Scholar] [CrossRef] [PubMed]
- Bernard, S.; Heutte, L.; Adam, S. Influence of hyperparameters on random forest accuracy. In Multiple Classifier System; Benediktsson, J.A., Kittler, J., Roli, F., Eds.; Springer: Heilderberg, Germany, 2009; Volume 5519, pp. 171–180. [Google Scholar]
- Xu, Z.; Lian, J.; Bin, L.; Hua, K.; Xu, K.; Chan, H.Y. 2019. Water Price Prediction for Increasing Market Efficiency Using Random Forest Regression: A Case Study in the Western United States. Water 2019, 11, 228. [Google Scholar] [CrossRef]
- Tracy, T.; Fu, Y.; Roy, I.; Jonas, E.; Glendenning, P. Towards Machine Learning on the Automata Processor. In High Performance Computing; Kunkel, J., Balaji, P., Dongarra, J., Eds.; Springer: Cham, Switzerland, 2016; Volume 9697, pp. 200–218. [Google Scholar]
- Fox, E.W.; Hill, R.A.; Leibowitz, S.G.; Olsen, A.R.; Thornbrugh, D.J.; Weber, M.H. Assessing the accuracy and stability of variable selection methods for random forest modeling in ecology. Environ. Monit. Assess. 2017, 189, 316. [Google Scholar] [CrossRef] [PubMed]
- Bushong, J.T.; Mullock, J.L.; Miller, E.C.; Raun, W.R.; Klatt, A.R.; Arnall, D.B. Development of an in-season estimate of yield potential utilizing optical crop sensors and soil moisture data for winter wheat. Precis. Agric. 2016, 17, 451–469. [Google Scholar] [CrossRef]
- Pantazi, X.E.; Moshou, D.; Alexandridis, T.; Whetton, R.L.; Mouzaen, A.M. Wheat yield prediction using machine learning and advanced sensing techniques. Comput. Electron. Agric. 2016, 121, 57–65. [Google Scholar] [CrossRef]
- Sun, J.; Rutkoski, J.E.; Poland, J.A.; Crossa, J.; Jannink, J.; Sorrells, M.E. Multigrain, random regression, or simple repeatability model in high-throughput phenotyping data improve genomic prediction for wheat grain yield. Plant Genome 2017, 10, 1–12. [Google Scholar] [CrossRef]
- Sharma, L.K.; Franzen, D.W. Use of corn height to improve the relationship between active optical sensor readings and yield estimates. Precis. Agric. 2014, 15, 331–345. [Google Scholar] [CrossRef]
- Sharma, L.K.; Bu, H.; Denton, A.; Franzen, D.W. Active-optical sensors using RED NDVI compared to red edge NDVI for prediction of corn grain yield in North Dakota, USA. Sensors 2015, 15, 27832–27853. [Google Scholar] [CrossRef]
- Maresma, A.; Ariza, M.; Martínez, E.; Lloveras, J.; Martínez-Casasnovas, J.A. Analysis of Vegetation Indices to determine nitrogen application and yield prediction in maize (Zea mays L.) from a standard UAV service. Remote Sens. 2016, 8, 973. [Google Scholar] [CrossRef]
- Tagarakis, A.C.; Ketterings, Q.M. In-season estimation of corn yield potential using proximal sensing. Agron. J. 2017, 109, 1323–1330. [Google Scholar] [CrossRef]
- Noorhosseini, S.A.; Soltani, A.; Ajamnoroozi, H. Simulating peanut (Arachis hypogaea L.) growth and yield with the use of the simple simulation model (SSM). Comput. Electron. Agric. 2018, 145, 63–75. [Google Scholar] [CrossRef]
- Gong, A.; Yu, J.; He, Y.; Qiu, Z. Citrus yield estimation based on images processed by an Android mobile phone. Biosyst. Eng. 2013, 115, 162–170. [Google Scholar] [CrossRef]
- Mulla, D.J.; Schepers, J.S. Key process and properties for site-specific soil and crop management. In The State of Site-specific Management for Agriculture; Pierce, F.J., Sadler, E.J., Eds.; ACSESS: Madison, WI, USA, 1997; pp. 1–18. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Min 1 | Median | Mean a | Max 2 | Standard Deviation b | CV 3,c |
|---|---|---|---|---|---|
| kg box−1 | % | ||||
| 27.20 | 28.68 | 28.59 | 30.09 | 0.62 | 2.15 |
| P a | Seed | Mtry b | Dataset | Number of Observations | Ntree c | RMSE d | R 2,e | MAE f |
|---|---|---|---|---|---|---|---|---|
| 88 | 123 | 29 | Training | 9961 | 500 | 2.98 | 0.80 | 1.97 |
| 100 | 2.97 | 0.80 | 1.96 | |||||
| Test | 5132 | 500 | 2.99 | 0.78 | 1.97 | |||
| 100 | 2.99 | 0.78 | 1.97 | |||||
| Entire | 15093 | 500 | 2.64 | 0.82 | 1.74 | |||
| 100 | 2.64 | 0.82 | 1.74 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, M.C.F.; Maldaner, L.F.; Ottoni, P.M.N.; Molin, J.P. Carrot Yield Mapping: A Precision Agriculture Approach Based on Machine Learning. AI 2020, 1, 229-241. https://doi.org/10.3390/ai1020015
Wei MCF, Maldaner LF, Ottoni PMN, Molin JP. Carrot Yield Mapping: A Precision Agriculture Approach Based on Machine Learning. AI. 2020; 1(2):229-241. https://doi.org/10.3390/ai1020015
Chicago/Turabian StyleWei, Marcelo Chan Fu, Leonardo Felipe Maldaner, Pedro Medeiros Netto Ottoni, and José Paulo Molin. 2020. "Carrot Yield Mapping: A Precision Agriculture Approach Based on Machine Learning" AI 1, no. 2: 229-241. https://doi.org/10.3390/ai1020015
APA StyleWei, M. C. F., Maldaner, L. F., Ottoni, P. M. N., & Molin, J. P. (2020). Carrot Yield Mapping: A Precision Agriculture Approach Based on Machine Learning. AI, 1(2), 229-241. https://doi.org/10.3390/ai1020015