Image Collection Summarization Method Based on Semantic Hierarchies

Abstract
1. Introduction
- An image summarization technique was proposed that was based on a semantic hierarchical image classification approach.
- A set of hierarchical features was introduced, and it was shown that semantic hierarchies are an important factor not only in the classification but also in the summarization step.
- It was shown that a trade-off point existed between the degree of freedom of the classification technique and the goodness of the summarization method.
2. Related Works
2.1. Visual Image Summarization Systems
2.2. Multi-Modal Image Summarization System
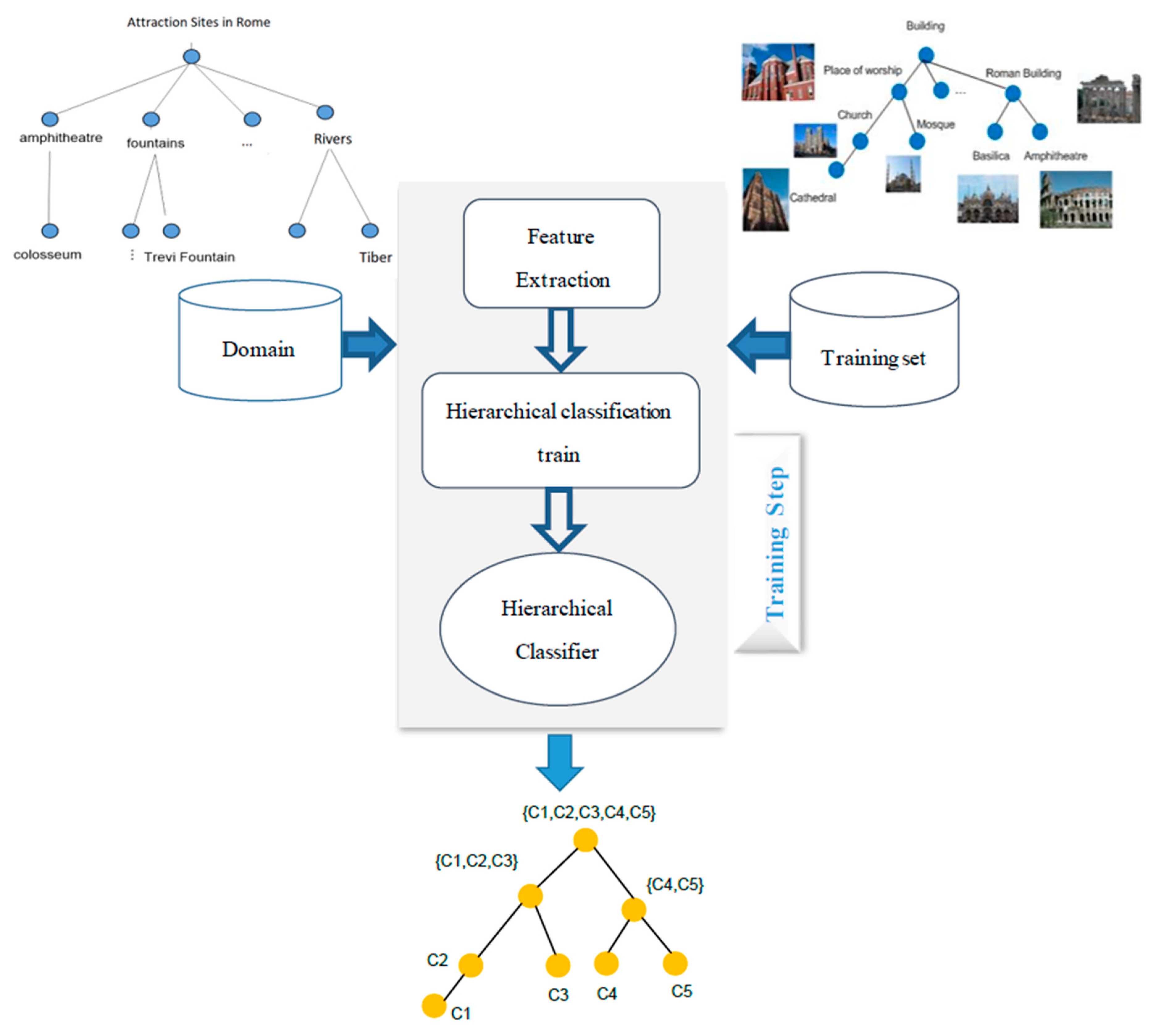
3. Proposed Method
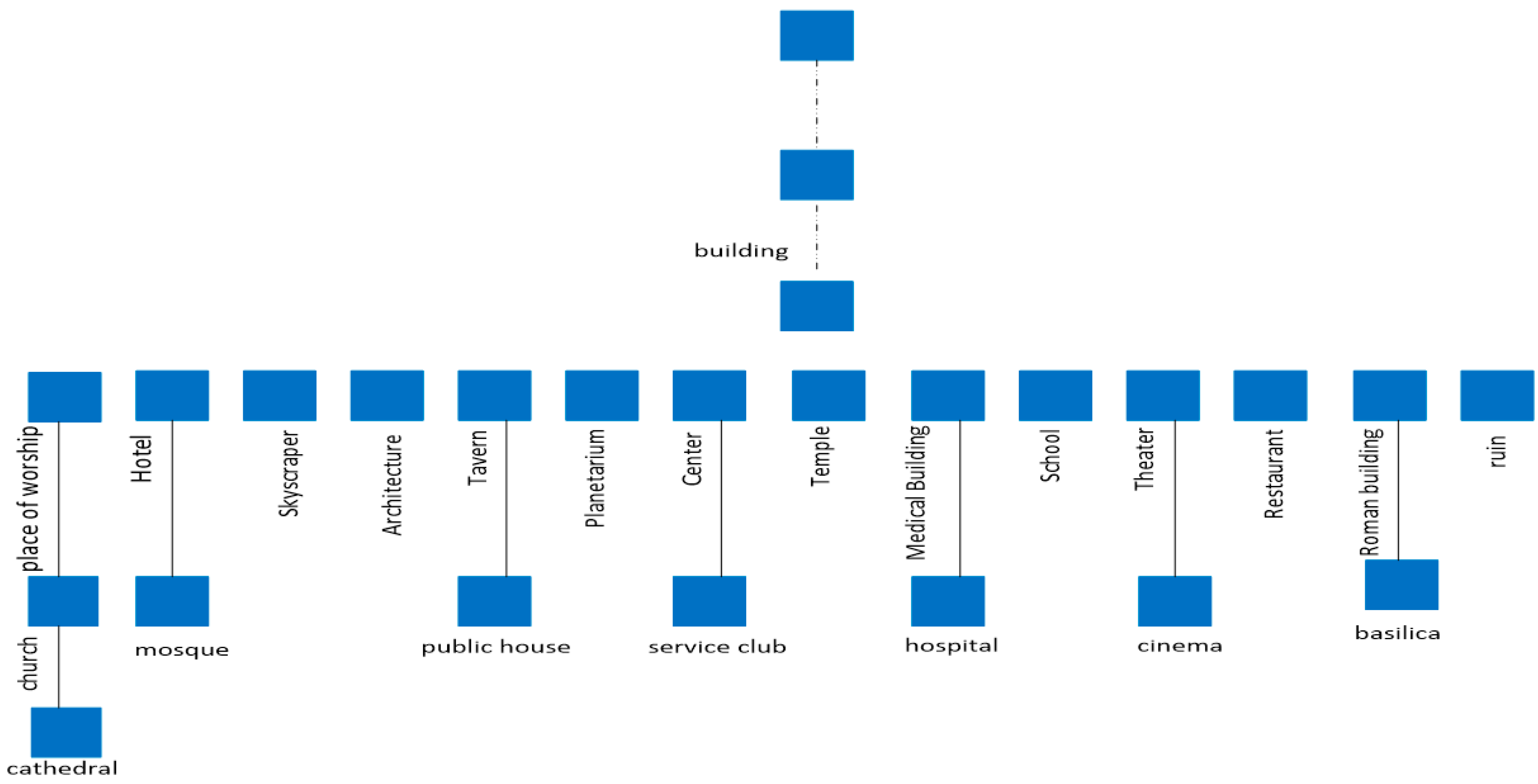
3.1. Hierarchical Classification
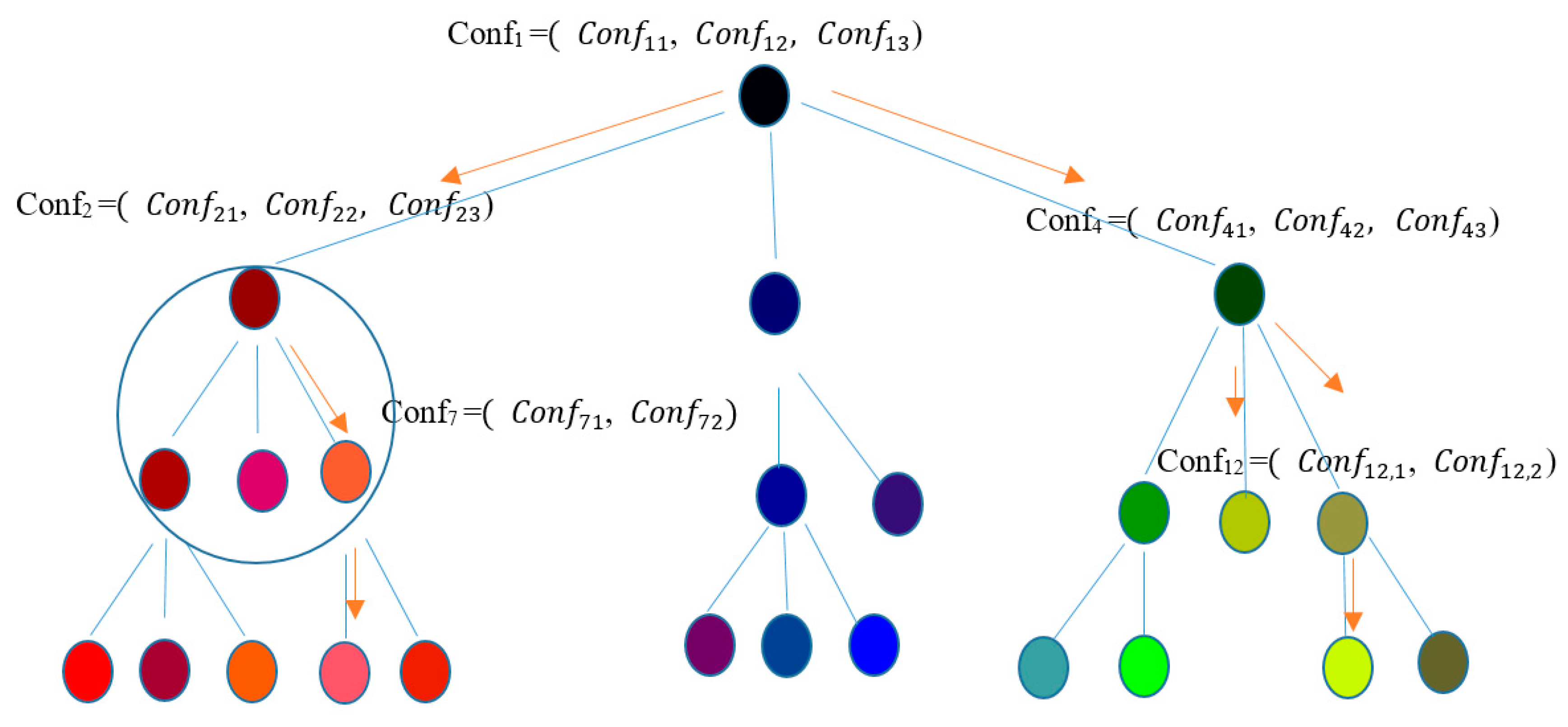
3.2. Summarization
| Algorithm 1 Summarization algorithm |
| 1: function Sim: Similarity Vector C: Original Collection 2: 3: for selected numbers of do 4: 5: Update 6: end for 7: Update 8: 9: end function |
4. Experimental Results
- Datasets and implementation details
- Methods for comparison
- Evaluation metric for the proposed approach
- The goodness of the summary created by the proposed method
- The effect of the hierarchical classifier on the result of the summarization approach
- The effect of ontology features on the result of the summarization method
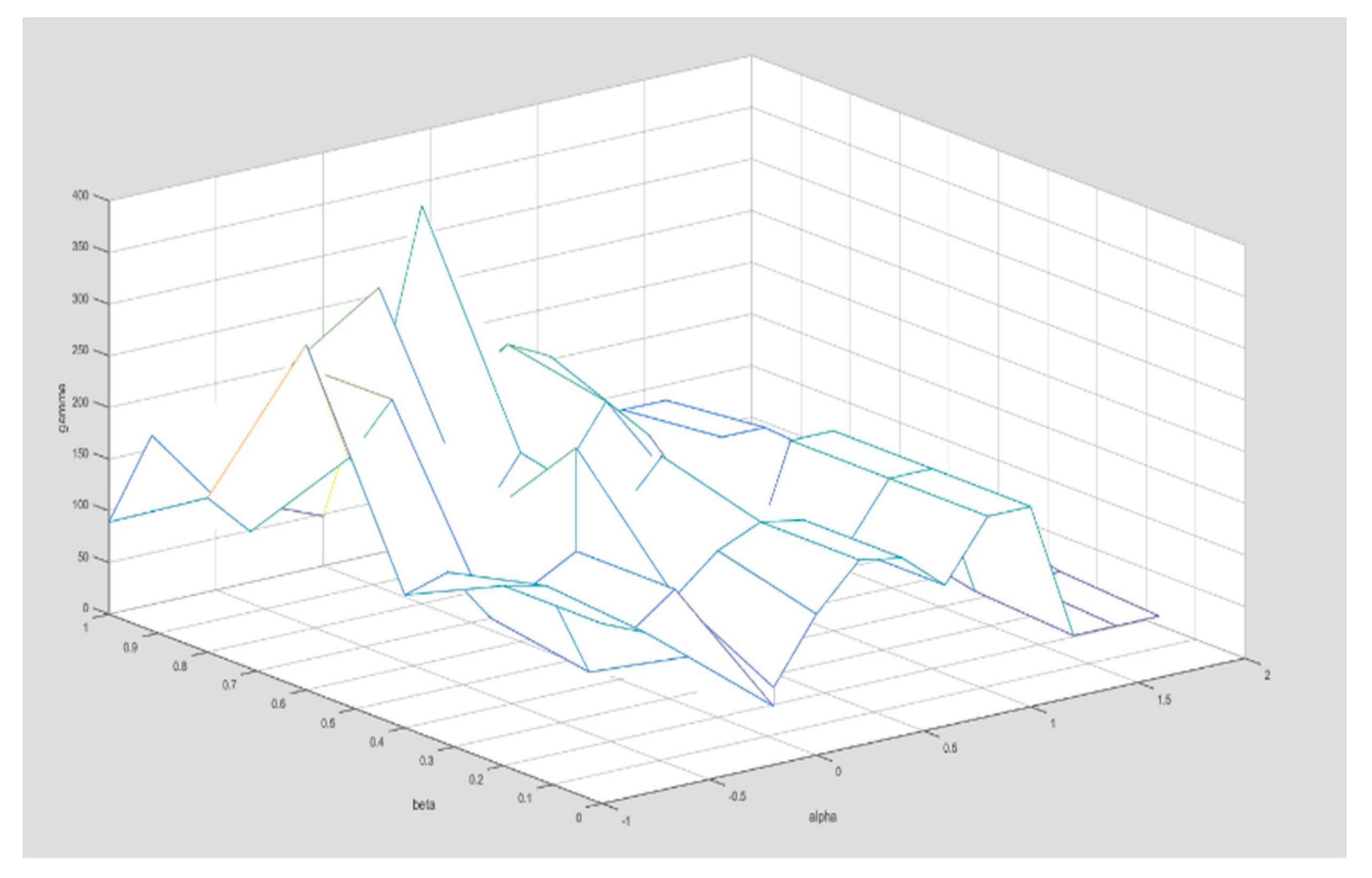
- The effect of alpha and beta parameters on the result of the proposed summarization method
- Computational complexity of the proposed method
- Limitation
4.1. Datasets and Implementation Details
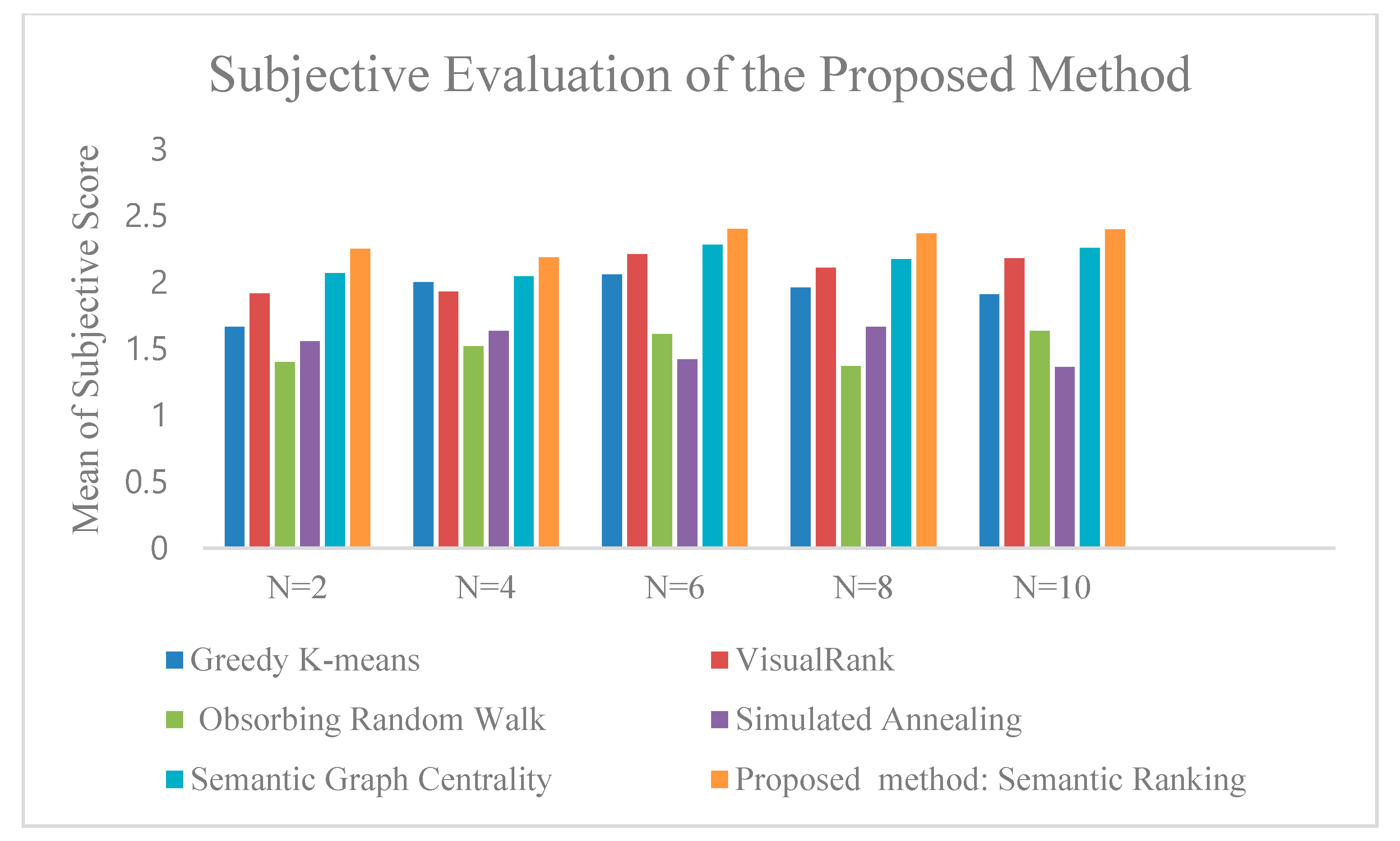
4.2. Comparative Methods
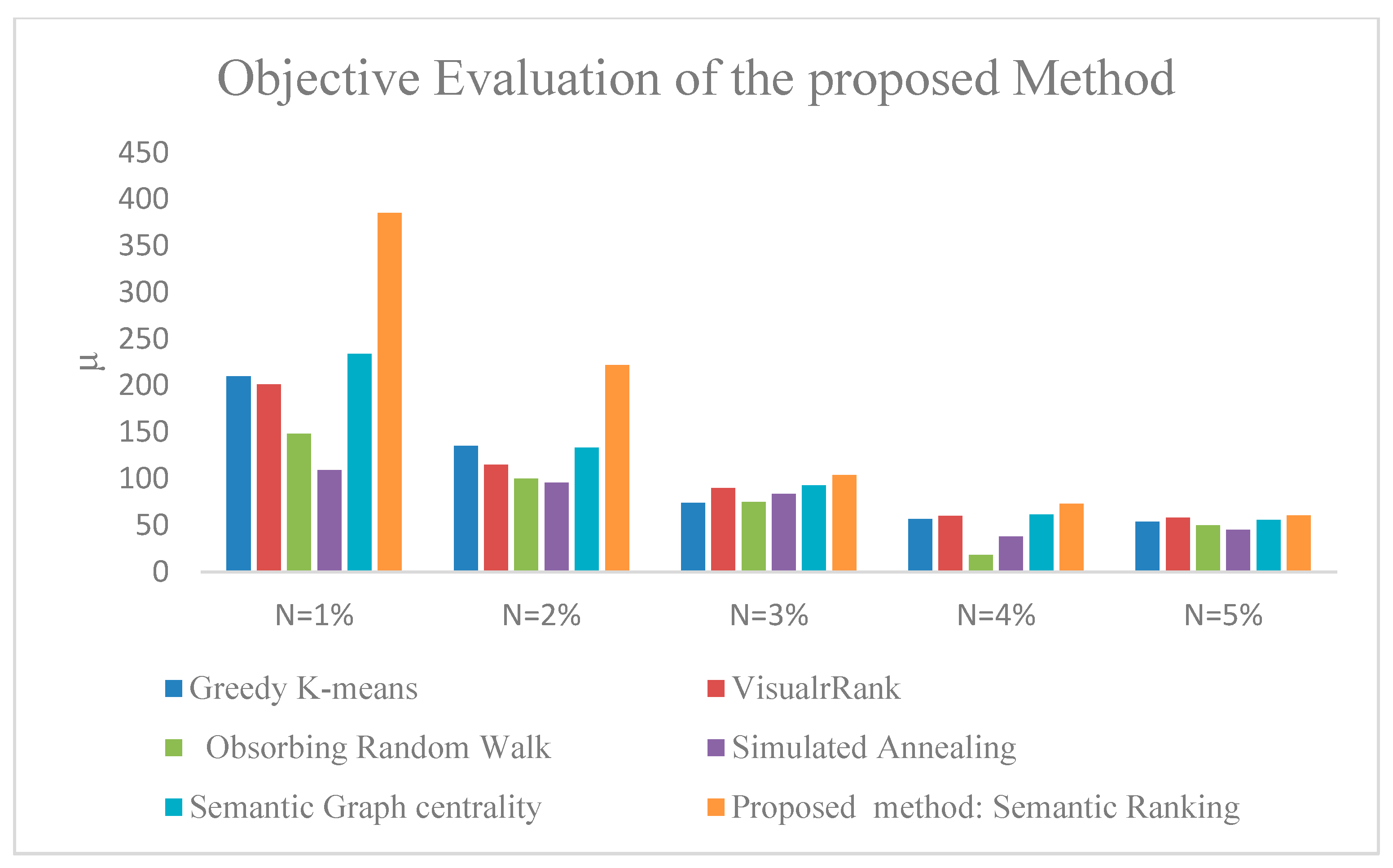
- Greedy-K means: This technique is a greedy version of the k-means algorithm that was introduced in [14]. The algorithm was designed to meet an optimization objective function that is defined as the similarity maximization of the summary set to the original image set and the similarity minimization of the summary set to itself.
- VisualRank: This technique was introduced in [19]. They employed the PageRank algorithm on a graph that represents the images’ similarities, where images are represented as nodes of the graph, and edges correspond to the visual similarity.
- Absorbing random walk: This method was proposed in [20]. They used the idea of a random walk on a similarity graph and nodes, with the largest stationary probability chosen as representative nodes. They proposed the absorbing random walk with the absorbing states dragging down the stationary probabilities of the nodes close to them, hence encouraging the diversity.
- Simulated annealing: It is a technique that was introduced in [15]. They treated the image summarization problem the same as dictionary learning for sparse representation problem (the initial image collection is constructed sparsely with a dictionary of summary images). They proposed an objective function similar to greedy-k means [14] and applied a simulated annealing approach for the optimization process.
- Semantic graph centrality: This method was proposed in [5]. They used a domain ontology to establish a graph for similarity based on image semantic similarities. Graph centrality is applied to the similarity graph to find summary images.
4.3. Image Summarization Evaluation
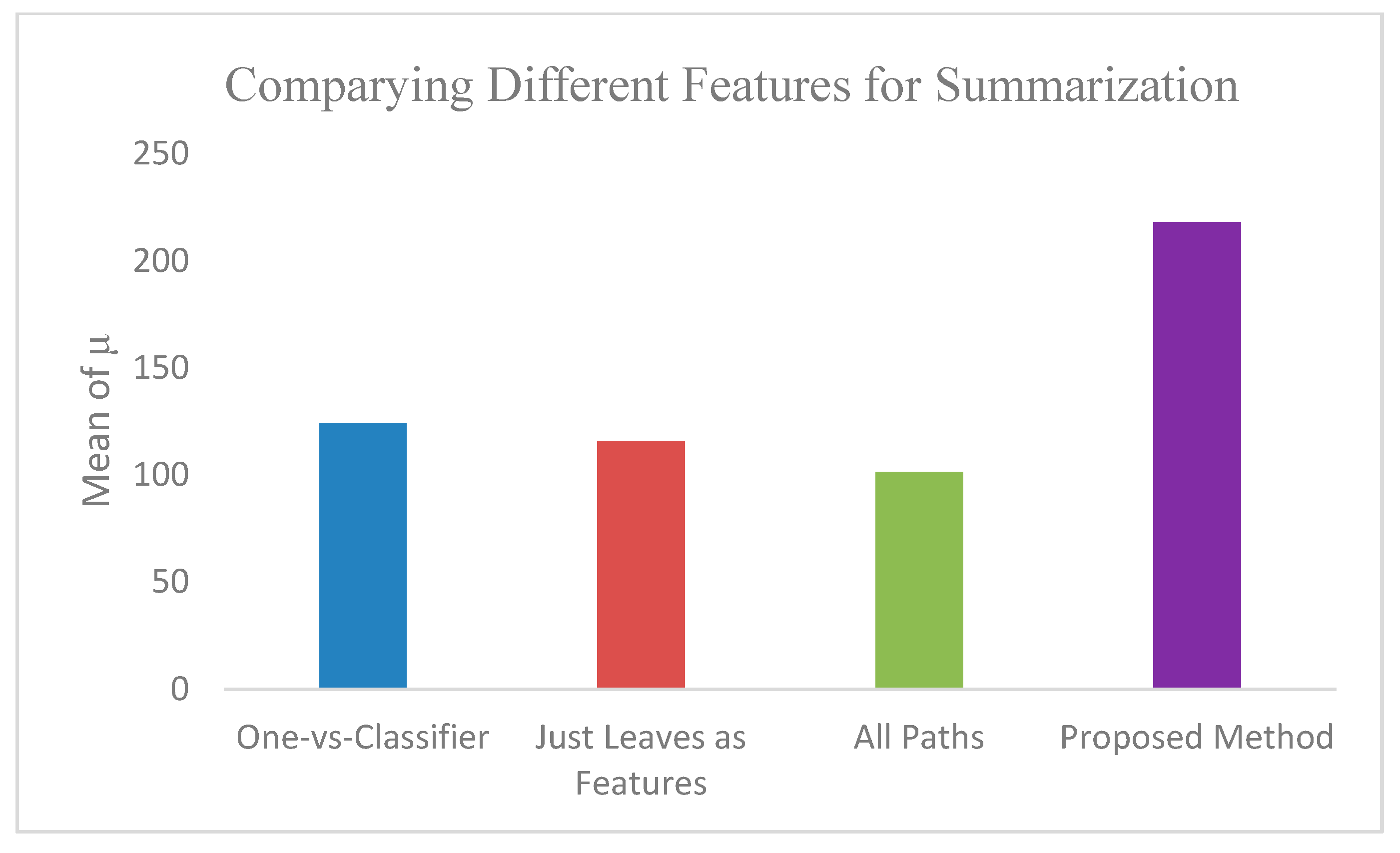
4.4. Hierarchical Classification and Ontology Feature Evaluation
4.5. Computational Complexity
4.6. Limitation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Samani, Z.R.; Guntuku, S.C.; Moghaddam, M.E.; Preoţiuc-Pietro, D.; Ungar, L.H. Cross-platform and cross-interaction study of user personality based on images on Twitter and Flickr. PLoS ONE 2018, 13, e0198660. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Virmani, L.; Subramanyam, A. Image Corpus Representative Summarization. In Proceedings of the 2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM), Singapore, 11–13 September 2019; pp. 21–29. [Google Scholar]
- Ozkose, Y.E.; Celikkale, B.; Erdem, E.; Erdem, A. Diverse Neural Photo Album Summarization. In Proceedings of the 2019 Ninth International Conference on Image Processing Theory, Tools and Applications (IPTA), Istanbul, Turkey, 6–9 November 2019; pp. 1–6. [Google Scholar]
- Chen, J.; Zhuge, H. Extractive summarization of documents with images based on multi-modal RNN. Futur. Gener. Comput. Syst. 2019, 99, 186–196. [Google Scholar] [CrossRef]
- Samani, Z.R.; Moghaddam, M.E. A knowledge-based semantic approach for image collection summarization. Multimed. Tools Appl. 2017, 76, 11917–11939. [Google Scholar] [CrossRef]
- Fergus, R.; Bernal, H.; Weiss, Y.; Torralba, A. Semantic label sharing for learning with many categories. In Computer Vision–ECCV 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 762–775. [Google Scholar]
- Kramer, G.; Bouma, G.; Hendriksen, D.; Homminga, M. Classifying image galleries into a taxonomy using metadata and wikipedia. In Natural Language Processing and Information Systems; Springer: Berlin/Heidelberg, Germany, 2012; pp. 191–196. [Google Scholar]
- Seo, Y.; Shin, K.-S. Hierarchical convolutional neural networks for fashion image classification. Expert Syst. Appl. 2019, 116, 328–339. [Google Scholar] [CrossRef]
- Li, H.; Wang, T.; Zhang, M.; Zhu, A.; Shan, G.; Snoussi, H. Hierarchical Attention Networks for Image Classification of Remote Sensing Images Based on Visual Q&A Methods. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 23 November 2019; pp. 4712–4717. [Google Scholar]
- Samani, Z.R.; Moghaddam, M.E. A multi-criteria context-sensitive approach for social image collection summarization. Sādhanā 2018, 43, 143. [Google Scholar] [CrossRef]
- Pan, X.; Tang, F.; Dong, W.; Ma, C.; Meng, Y.; Huang, F.; Lee, T.-Y.; Xu, C. Content-Based Visual Summarization for Image Collections. IEEE Trans. Vis. Comput. Graph. 2019. [Google Scholar] [CrossRef]
- Raguram, R.; Lazebnik, S. Computing iconic summaries of general visual concepts. In Proceedings of the Computer Vision and Pattern Recognition Workshops, CVPRW’08, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Rudinac, S.; Larson, M.; Hanjalic, A. Learning crowdsourced user preferences for visual summarization of image collections. IEEE Trans. Multimed. 2013, 15, 1231–1243. [Google Scholar] [CrossRef]
- Simon, I.; Snavely, N.; Seitz, S.M. Scene summarization for online image collections. In Proceedings of the IEEE 11th International Conference on Computer Vision (ICCV 2007), Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Yang, C.; Shen, J.; Peng, J.; Fan, J. Image collection summarization via dictionary learning for sparse representation. Pattern Recognit. 2013, 46, 948–961. [Google Scholar] [CrossRef]
- Ko, E.; Kim, E.Y.; Yu, Y. Summarizing Social Image Search Results using Human Affects. In Proceedings of the 22nd International Conference on Intelligent User Interfaces Companion, Limassol, Cyprus, 13–16 March 2017; pp. 101–104. [Google Scholar]
- Zhao, Y.; Hong, R.; Jiang, J. Visual summarization of image collections by fast RANSAC. Neurocomputing 2016, 172, 48–52. [Google Scholar] [CrossRef]
- Alguliyev, R.M.; Aliguliyev, R.M.; Isazade, N.R.; Abdi, A.; Idris, N. COSUM: Text summarization based on clustering and optimization. Expert Syst. 2018, 36, e12340. [Google Scholar] [CrossRef]
- Jing, Y.; Baluja, S. Visualrank: Applying pagerank to large-scale image search. Pattern Anal. Mach. Intell. IEEE Trans. 2008, 30, 1877–1890. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Jia, L.; Hua, X.-S. Interactive browsing via diversified visual summarization for image search results. Multimed. Syst. 2011, 17, 379–391. [Google Scholar] [CrossRef]
- Yang, L.; Adviser-Johnstone, J.K. Mining Canonical Views from Internet Image Collections; University of Alabama at Birmingham: Birmingham, AL, USA, 2011. [Google Scholar]
- Zhang, H.; Gong, Y.; Yan, Y.; Duan, N.; Xu, J.; Wang, J.; Gong, M.; Zhou, M. Pretraining-based natural language generation for text summarization. arXiv 2019, arXiv:1902.09243. [Google Scholar]
- Rekabdar, B.; Mousas, C.; Gupta, B. Generative adversarial network with policy gradient for text summarization. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; pp. 204–207. [Google Scholar]
- Zhao, B.; Li, X.; Lu, X. TTH-RNN: Tensor-Train hierarchical recurrent neural network for video summarization. IEEE Trans. Ind. Electron. 2020. [Google Scholar] [CrossRef]
- Goularte, F.B.; Nassar, S.M.; Fileto, R.; Saggion, H. A text summarization method based on fuzzy rules and applicable to automated assessment. Expert Syst. Appl. 2019, 115, 264–275. [Google Scholar] [CrossRef]
- Song, S.; Huang, H.; Ruan, T. Abstractive text summarization using LSTM-CNN based deep learning. Multimed. Tools Appl. 2019, 78, 857–875. [Google Scholar] [CrossRef]
- Singh, A.; Sharma, D.K. Image Collection Summarization: Past, Present and Future. In Data Visualization and Knowledge Engineering; Springer: Berlin/Heidelberg, Germany, 2020; pp. 49–78. [Google Scholar]
- Jaffe, A.; Naaman, M.; Tassa, T.; Davis, M. Generating summaries and visualization for large collections of geo-referenced photographs. In Proceedings of the 8th ACM International Workshop on Multimedia Information Retrieval, Santa Barbara, CA, USA, 26–27 October 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 89–98. [Google Scholar]
- Qian, X.; Lu, D.; Wang, Y.; Zhu, L.; Tang, Y.Y.; Wang, M. Image re-ranking based on topic diversity. IEEE Trans. Image Process. 2017, 26, 3734–3747. [Google Scholar] [CrossRef]
- Pang, Y.; Hao, Q.; Yuan, Y.; Hu, T.; Cai, R.; Zhang, L. Summarizing tourist destinations by mining user-generated travelogues and photos. Comput. Vis. Image Underst. 2011, 115, 352–363. [Google Scholar] [CrossRef]
- Camargo, J.E.; González, F.A. Multimodal latent topic analysis for image collection summarization. Inf. Sci. 2016, 328, 270–287. [Google Scholar] [CrossRef]
- Zhang, W.; Fu, K.; Sun, X.; Zhang, Y.; Sun, H.; Wang, H. Joint optimisation convex-negative matrix factorisation for multi-modal image collection summarisation based on images and tags. IET Comput. Vis. 2018, 13, 125–130. [Google Scholar] [CrossRef]
- Jeong, J.-W.; Hong, H.-K.; Heu, J.-U.; Qasim, I.; Lee, D.-H. Visual Summarization of the Social Image Collection Using Image Attractiveness Learned from Social Behaviors. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, Australia, 9–13 July 2012; pp. 538–543. [Google Scholar]
- Shen, X.; Tian, X. Multi-modal and multi-scale photo collection summarization. Multimed. Tools Appl. 2016, 75, 2527–2541. [Google Scholar] [CrossRef]
- Tschiatschek, S.; Iyer, R.K.; Wei, H.; Bilmes, J.A. Learning Mixtures of Submodular Functions for Image Collection Summarization. In Advances in Neural Information Processing Systems 27; NeurIPS: Montreal, QC, Canada, 2014; pp. 1413–1421. [Google Scholar]
- Fang, H.; Lu, W.; Wu, F.; Zhang, Y.; Shang, X.; Shao, J.; Zhuang, Y. Topic aspect-oriented summarization via group selection. Neurocomputing 2015, 149, 1613–1619. [Google Scholar] [CrossRef]
- Jacobs, A.M.; Kinder, A. Computing the affective-aesthetic potential of literary texts. AI 2020, 1, 11–27. [Google Scholar] [CrossRef]
- Hao, W.; Menglin, J.; Guohui, T.; Qing, M.; Guoliang, L. R-KG: A novel method for implementing a robot intelligent service. AI 2020, 1, 117–140. [Google Scholar] [CrossRef]
- Ma, M.; Mei, S.; Wan, S.; Hou, J.; Wang, Z.; Feng, D.D. Video summarization via block sparse dictionary selection. Neurocomputing 2020, 378, 197–209. [Google Scholar] [CrossRef]
- Hennig, L.; Umbrath, W.; Wetzker, R. An ontology-based approach to text summarization. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, WI-IAT’08, Sydney, Australia, 9–12 December 2008; pp. 291–294. [Google Scholar]
- Samani, Z.; Shamsfard, M. A fuzzy ontology model for qualitative spatial reasoning. In Proceedings of the 2011 6th International Conference on Computer Sciences and Convergence Information Technology (ICCIT), Seogwipo, Korea, 29 November–1 December 2011; pp. 1–6. [Google Scholar]
- Samani, Z.R.; Shamsfard, M. On the application of fuzzy ontology for qualitative spatial reasoning. JNIT 2012, 3, 9–18. [Google Scholar]
- Nister, D.; Stewenius, H. Scalable recognition with a vocabulary tree. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2161–2168. [Google Scholar]
- Zhao, B.; Li, F.; Xing, E.P. Large-scale category structure aware image categorization. In Advances in Neural Information Processing Systems 24; NeurIPS: Granada, Spain, 2011; pp. 1251–1259. [Google Scholar]
- Li, L.; Jiang, S.; Huang, Q. Learning hierarchical semantic description via mixed-norm regularization for image understanding. IEEE Trans. Multimed. 2012, 14, 1401–1413. [Google Scholar]
- Abdollahpour, Z.; Samani, Z.R.; Moghaddam, M.E. Image classification using ontology based improved visual words. In Proceedings of the 2015 23rd Iranian Conference on Electrical Engineering (ICEE), Tehran, Iran, 10–14 May 2015; pp. 694–698. [Google Scholar]
- Verma, N.; Mahajan, D.; Sellamanickam, S.; Nair, V. Learning Hierarchical Similarity Metrics. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2280–2287. [Google Scholar]
- Gao, T.; Koller, D. Discriminative Learning of Relaxed Hierarchy for Large-scale Visual Recognition. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2072–2079. [Google Scholar]
- Samani, Z.R.; Alappatt, J.A.; Parker, D.; Ismail, A.A.O.; Verma, R. QC-Automator: Deep learning-based automated quality control for diffusion mr images. Front. Neurosci. 2020, 13, 1456. [Google Scholar] [CrossRef]
- Kennedy, L.S.; Naaman, M. Generating diverse and representative image search results for landmarks. In Proceedings of the 17th international conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 297–306. [Google Scholar]
- Yang, Y.; Chen, S.-C. Disaster Image Filtering and Summarization Based on Multi-layered Affinity Propagation. In Proceedings of the IEEE International Symposium on Multimedia (ISM), Irvine, CA, USA, 10–12 December 2012; pp. 100–103. [Google Scholar]
- Fan, J.; Gao, Y.; Luo, H.; Keim, D.A.; Li, Z. A novel approach to enable semantic and visual image summarization for exploratory image search. In Proceedings of the 1st ACM International Conference on Multimedia Information Retrieval, Vancouver, BC, Canada, 30–31 October 2008; pp. 358–365. [Google Scholar]
- Van Leuken, R.H.; Garcia, L.; Olivares, X.; van Zwol, R. Visual diversification of image search results. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; pp. 341–350. [Google Scholar]
- Xu, H.; Wang, J.; Hua, X.-S.; Li, S. Hybrid image summarization. In Proceedings of the 19th ACM International Conference on Multimedia, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 1217–1220. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. DBpedia–A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web 2014, 6, 167–195. [Google Scholar] [CrossRef]
- Mousas, C.; Anagnostopoulos, C.-N. Learning motion features for example-based finger motion estimation for virtual characters. 3D Res. 2017, 8, 25. [Google Scholar] [CrossRef]
- Lee, J.; Kong, T.; Lee, K. Ensemble patch sparse coding: A feature learning method for classification of images with ambiguous edges. Expert Syst. Appl. 2019, 124, 1–12. [Google Scholar] [CrossRef]
- Sohn, K.; Jung, D.Y.; Lee, H.; Hero, A.O. Efficient learning of sparse, distributed, convolutional feature representations for object recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2643–2650. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition CVPR 2009, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Li, M.; Zhao, C.; Tang, J. Hybrid image summarization by hypergraph partition. Neurocomputing 2013, 119, 41–48. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2005, 60, 91–110. [Google Scholar] [CrossRef]
- Samani, Z.R.; Shamsfard, M. The state of the art in developing fuzzy ontologies: A survey. arXiv 2018, arXiv:1805.02290. [Google Scholar]
- Guermah, H.; Fissaa, T.; Guermah, B.; Hafiddi, H.; Nassar, M.; Kriouile, A. How can reasoning improve ontology-based context-aware system? Int. J. Adv. Intell. Paradig. 2020, 15, 300–316. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Modality | Supervision | Criteria | Approach |
|---|---|---|---|---|
| Visual Rank [5] | Image | Unsupervised | Single Criteria | Semantic Graph Centrality |
| Ozkose [3] | Images | Supervised | Multi-Criteria | Recurrent Neural Network (RNN) |
| Tschiatscheket [35] | Images | Supervised | Single Criteria | Learning Sub Modular Function |
| Singh [2] | Images | UnSupervised | Single Criteria | Generative Adversarial Network (GAN) |
| MCCS [10] | Image + Social Activities | Unsupervised | Multi-Criteria | Semantic and Attractiveness Ranking |
| Proposed Approach | Images | Unsupervised | Single Criteria | Joint Optimization of Hierarchical Classification |
| Rekabdar et al. [23] | Text | Supervised | Single | Generative Adversarial Network (GAN) |
| Ma et al. [39] | Video | Supervised | Single | Sparse Dictionary Selection |
| Images | Features | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | N10 | N11 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
 | I1 | |||||||||||
 | I2 |
| Low | Medium | High | Very High |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Riahi Samani, Z.; Ebrahimi Moghaddam, M. Image Collection Summarization Method Based on Semantic Hierarchies. AI 2020, 1, 209-228. https://doi.org/10.3390/ai1020014
Riahi Samani Z, Ebrahimi Moghaddam M. Image Collection Summarization Method Based on Semantic Hierarchies. AI. 2020; 1(2):209-228. https://doi.org/10.3390/ai1020014
Chicago/Turabian StyleRiahi Samani, Zahra, and Mohsen Ebrahimi Moghaddam. 2020. "Image Collection Summarization Method Based on Semantic Hierarchies" AI 1, no. 2: 209-228. https://doi.org/10.3390/ai1020014
APA StyleRiahi Samani, Z., & Ebrahimi Moghaddam, M. (2020). Image Collection Summarization Method Based on Semantic Hierarchies. AI, 1(2), 209-228. https://doi.org/10.3390/ai1020014