




A Hybrid Deep Learning Model for Aromatic and Medicinal Plant Species Classification Using a Curated Leaf Image Dataset



Abstract
1. Introduction
2. Related Work
3. Rationale and Research Objectives
- Morphological Diversity in Leaf Shape and Size: The 39 plant species selected exhibit diverse leaf morphologies, including lanceolate, cordate, and elliptical forms. These shapes serve as essential visual identifiers in plant taxonomy. CNNs excel at capturing such geometric patterns through convolutional filters, reducing the need for manual annotation or segmentation, which is often required in classical techniques.
- Species-Specific Venation Patterns: Venation patterns, such as parallel, reticulate, and palmate types, are taxonomically significant but challenging to quantify using traditional image processing methods. CNNs are capable of learning these intricate structures at multiple levels of abstraction, enabling more reliable classification by focusing on both global and local vein arrangements.
- Distinct Leaf Margins, Tips, and Bases: Features such as serrated versus entire leaf margins and apex types, including acuminate or mucronate, are subtle yet crucial for species differentiation. CNNs can effectively learn and recognize these nuanced features from high-resolution imagery, allowing for precise classification that would otherwise be challenging to encode algorithmically.
- Texture and Color Variations: Variability in surface texture (e.g., succulent vs. waxy leaves), trichome presence, and subtle color gradients serve as additional distinguishing factors. Deep learning models are particularly adept at capturing these features, even under variable lighting conditions or environmental noise, thereby improving generalization across real-world data.
- Handling Inter-Class Similarity and Intra-Class Variability: Morphologically similar species often lead to inter-class similarity, while environmental factors, seasonal changes, or developmental stages introduce intra-class variability. CNNs are inherently capable of learning robust and discriminative representations that generalize well across these variations, outperforming feature-specific or rule-based models in such complex classification scenarios
- Environmental Robustness and Scalability: By utilizing data augmentation techniques, CNNs exhibit resilience to common field-related challenges, including image rotation, scale variation, lighting changes, and background clutter. Additionally, these models are scalable and can be trained on large datasets to support classification across hundreds of plant species, making them ideal for real-world, large-scale deployment.
4. Materials and Methods
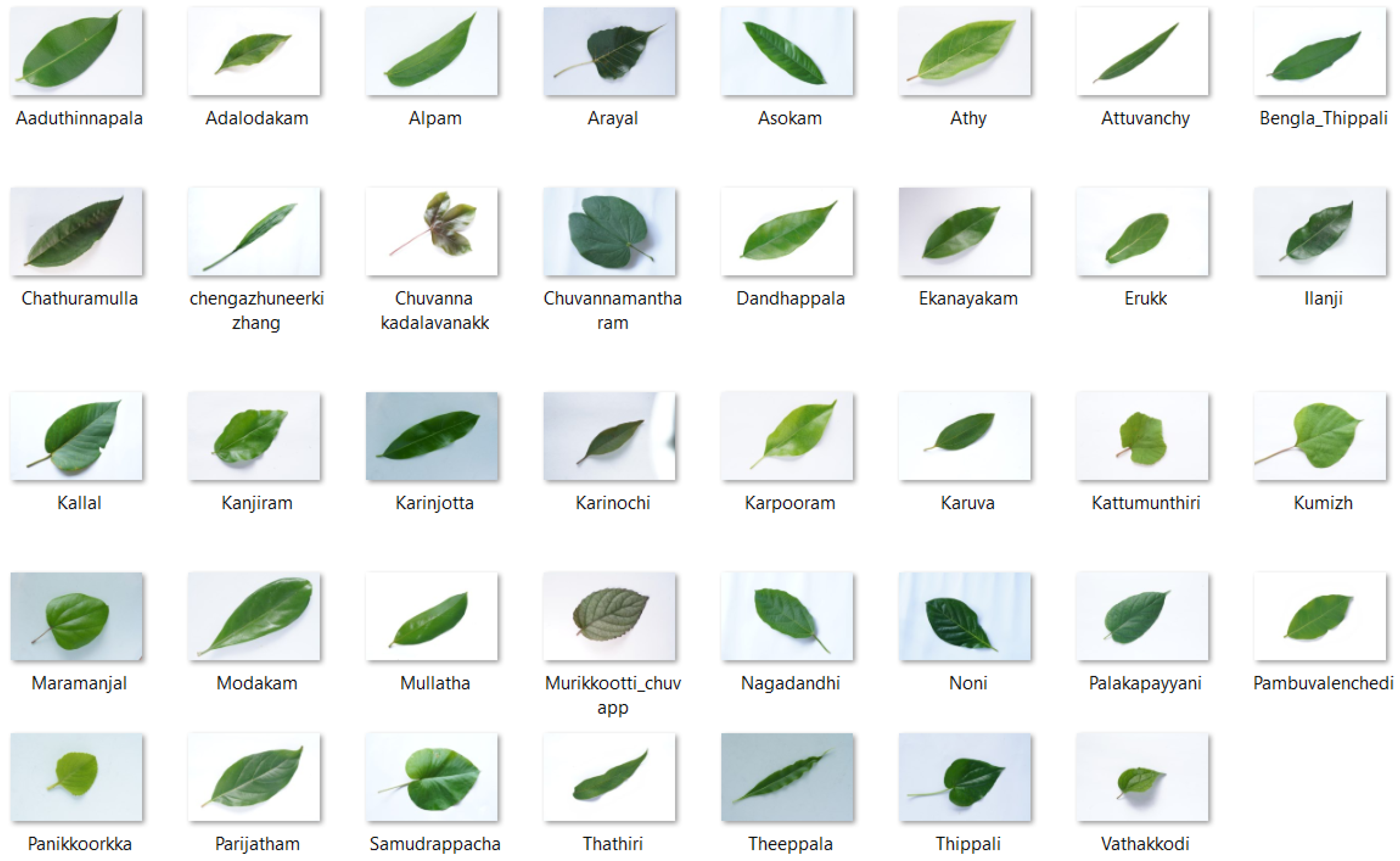
4.1. Dataset Collection
4.2. Preprocessing and Data Augmentation
4.3. Model Architectures and Experimental Setup
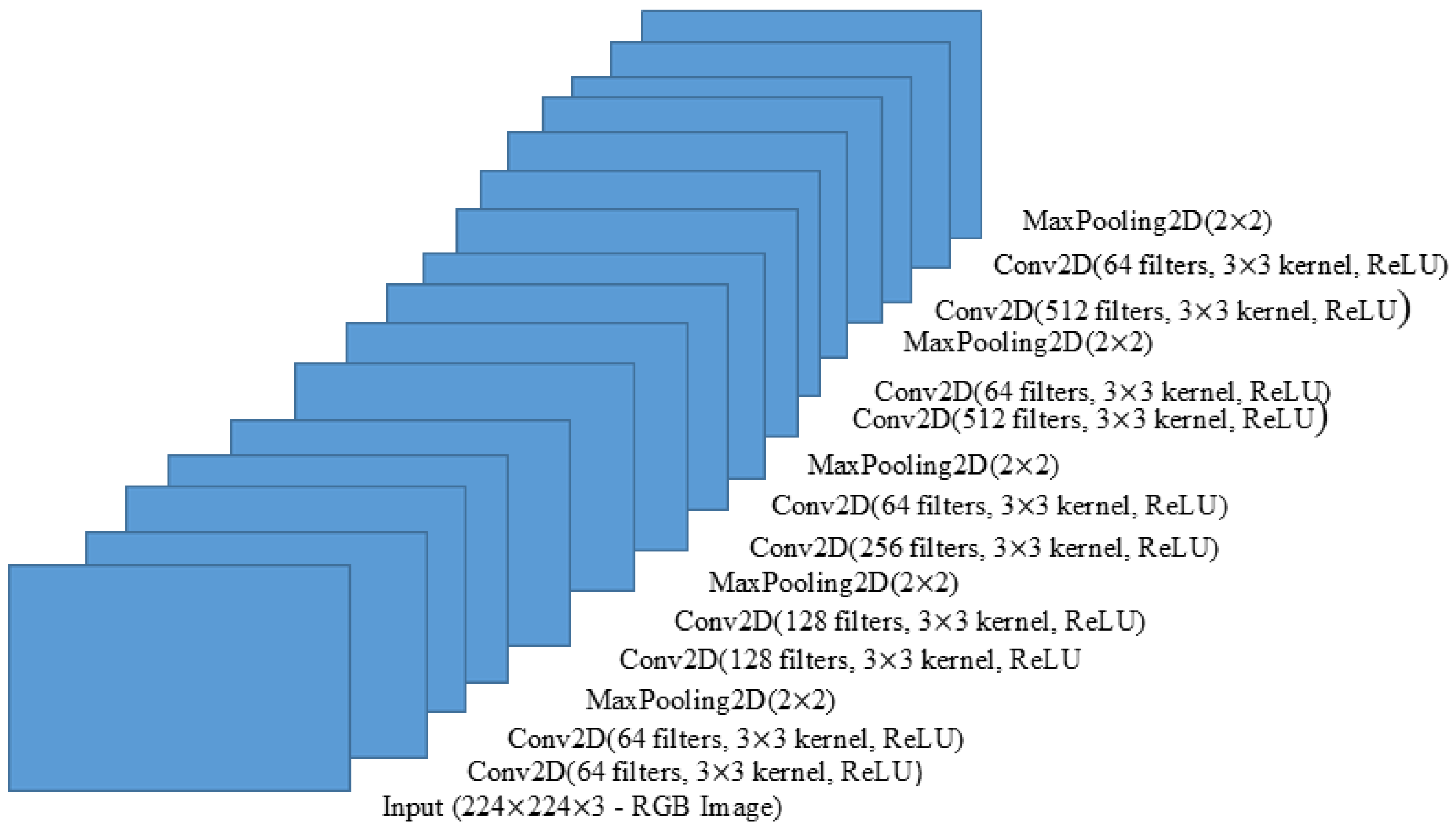
4.3.1. Custom CNN Architecture
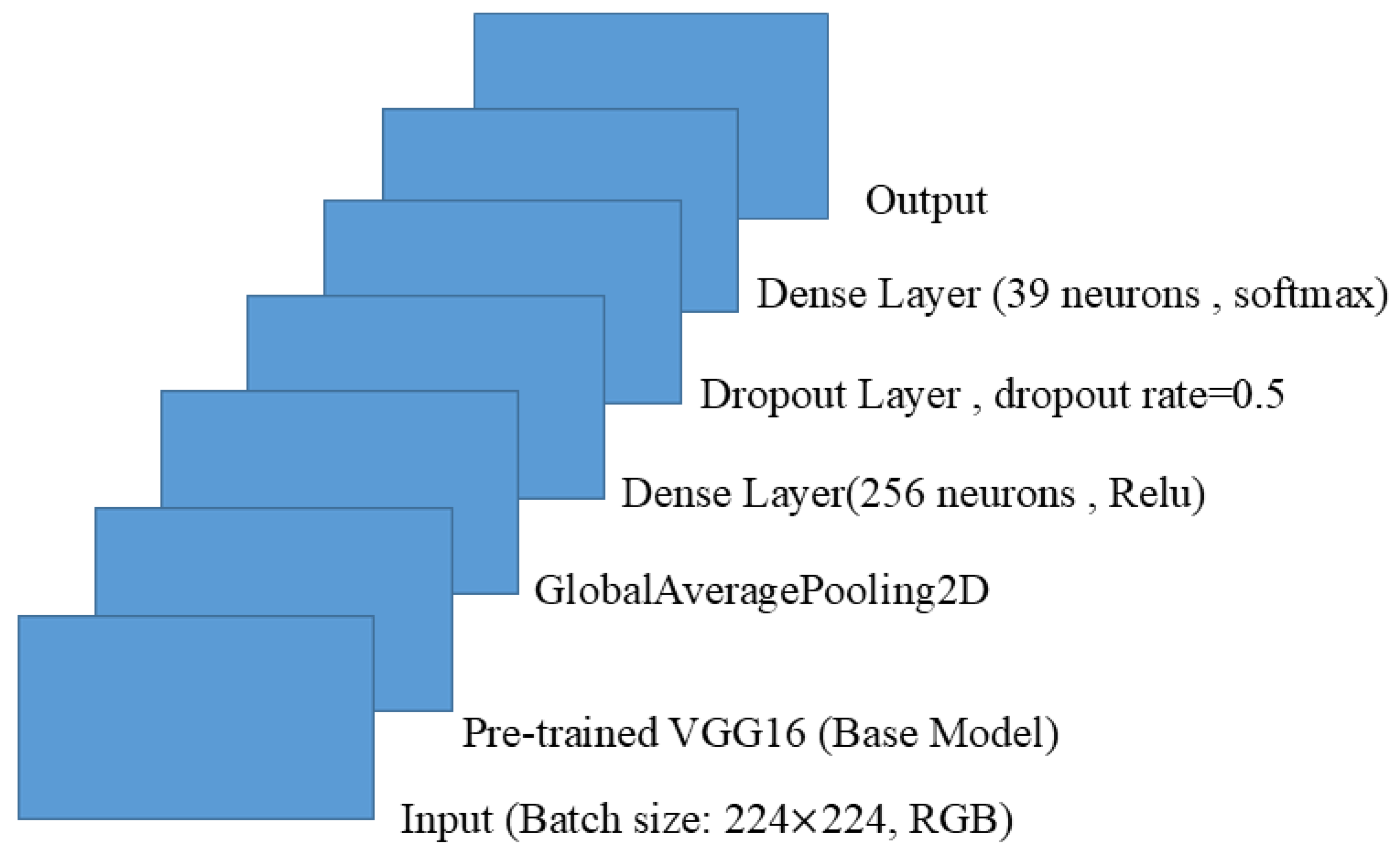
4.3.2. Transfer Learning with VGG16
4.3.3. Fine-Tuned VGG16
4.3.4. VGG16 with Squeeze-and-Excitation (SE) Blocks
- Squeeze: This operation compresses the spatial dimensions of the feature map to a channel descriptor using Global Average Pooling (GAP). For a feature map , where H and W are the spatial dimensions and C is the number of channels, GAP is applied independently on each channel to produce a vector :
- Excitation: This step models channel-wise dependencies and learns which channels are more informative. The vector z is passed through two fully connected layers with ReLU and sigmoid activations:where and are the learned weight matrices, is the ReLU activation function, is the sigmoid activation function, and r is the channel reduction ratio (typically ).
- Scaling: The original feature map U is scaled (recalibrated) by channel-wise multiplication with the learned attention weights S to produce the refined output :
4.3.5. Hybrid Model with VGG16, Batch Normalization, GRUs, Transformers, and Dilated Convolutions
Backbone: VGG16
Batch Normalization
Dilated Convolutions
GRU Layer for Spatial Dependencies
Transformer Encoder for Global Context
Classification Layers
Justification of Complexity
- VGG16 provides robust local and hierarchical features.
- Batch Normalization accelerates convergence and reduces overfitting.
- Dilated Convolutions enable multi-scale feature extraction without loss of resolution.
- GRUs capture spatial dependencies in sequential form for elongated patterns.
- Transformer Encoder models global context and long-range feature interactions.
Mathematical Formulations
5. Results and Discussion
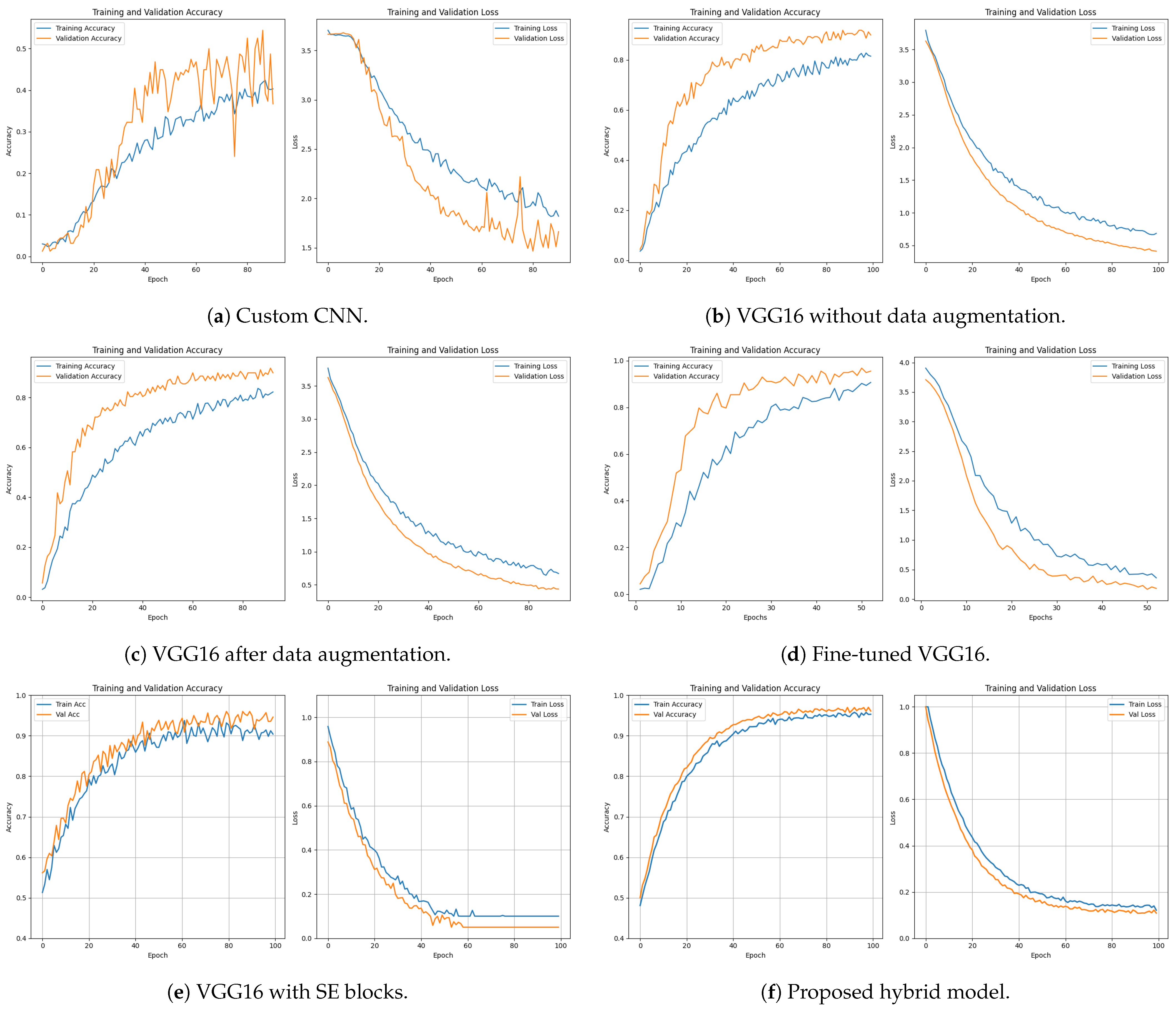
5.1. Model Performance Analysis
5.2. Baseline Deep Learning Model Comparison
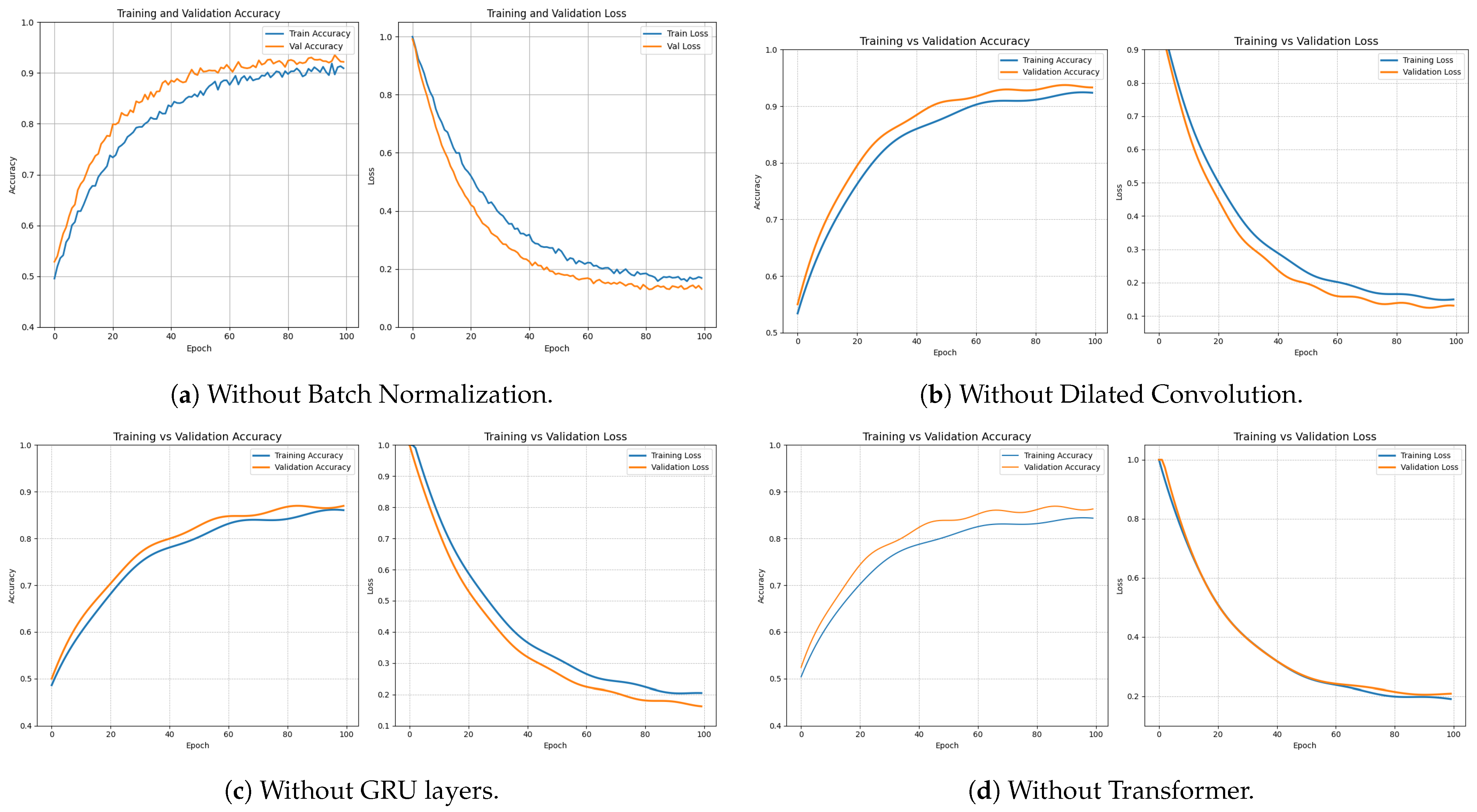
5.3. Ablation Study
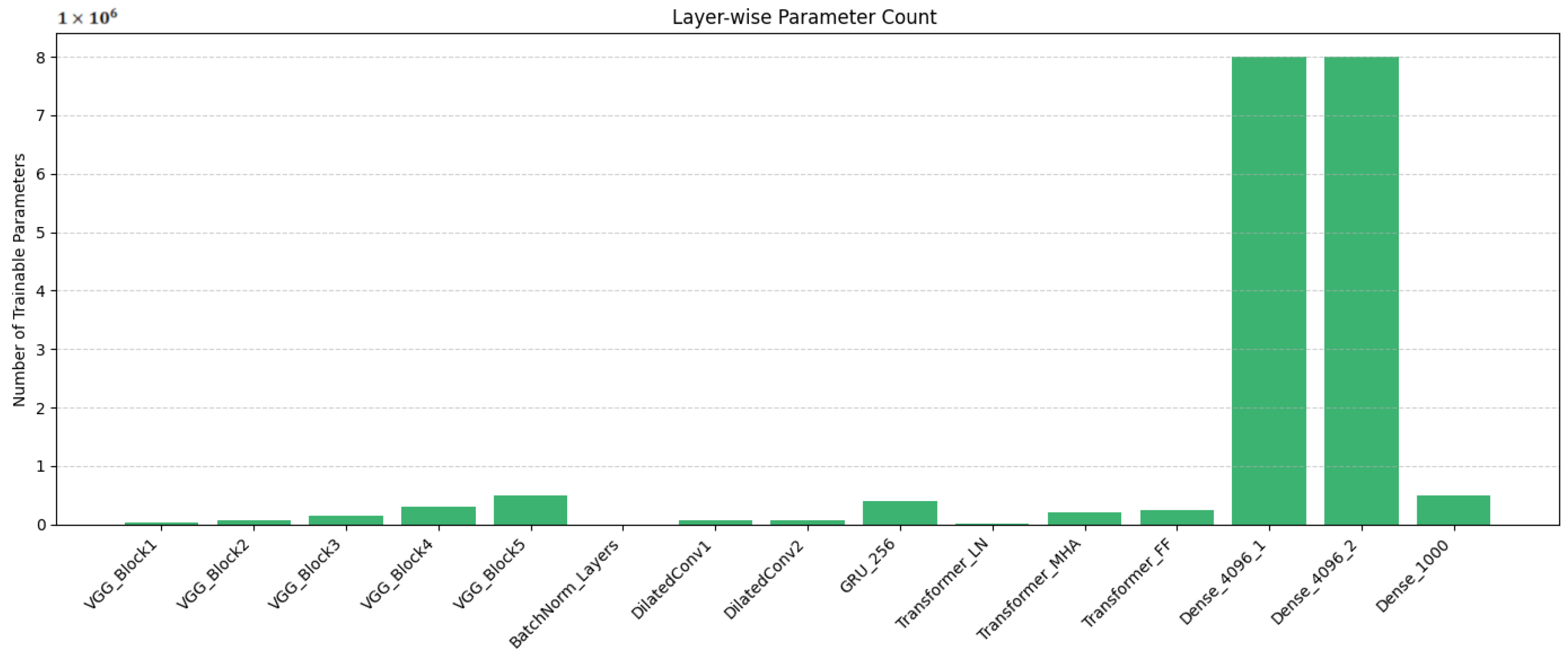
5.4. Computational Complexity and Parameter Analysis
5.5. State-of-the-Art Comparison
5.6. Limitations
- Dataset Specificity: The dataset used in this work comprises high-resolution images of 39 aromatic and medicinal plant species collected under controlled conditions at a single research station (AMPRS, Odakkali, Kerala). While this ensures data quality and consistency, the model’s limited geographic scope may restrict its generalizability to other regions, environments, or species not included in the dataset.
- Controlled Image Capture Conditions: All images were acquired using a SONY ALPHA 7R III camera with uniform lighting and a white background or consistent natural field conditions. In real-world deployment scenarios, factors such as occlusion, variable lighting, background clutter, and different device cameras may degrade classification performance.
- Computational Complexity: The proposed model combines multiple architectural modules, including VGG16, Batch Normalization, Dilated Convolutions, GRU layers, and a Transformer Encoder, which, while effective, introduce a high level of computational complexity. This could pose challenges for deployment on edge devices or mobile applications where resources are constrained.
- Data-Hungry Architecture: Deep learning models with GRUs and Transformer layers typically require large datasets to generalize effectively. Although our dataset is balanced with 100 samples per class, its overall size (3900 images) remains relatively small compared to large-scale image recognition benchmarks. Further scaling or augmentation may be necessary to utilize the model’s capacity fully.
- Limited Cross-Domain Evaluation: The model is trained and evaluated solely on the collected dataset, without using cross-validation on external datasets or unseen species. As such, its robustness and transferability across different domains remain to be evaluated in future work.
6. Conclusions and Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shasany, A.K.; Shukla, A.K.; Khanuja, S.P. Medicinal and aromatic plants. In Technical Crops; Springer: Berlin/Heidelberg, Germany, 2007; pp. 175–196. [Google Scholar]
- Pandey, A.K.; Kumar, P.; Saxena, M.; Maurya, P. Distribution of aromatic plants in the world and their properties. In Feed Additives; Elsevier: Amsterdam, The Netherlands, 2020; pp. 89–114. [Google Scholar]
- Stuessy, T.F. Plant Taxonomy: The Systematic Evaluation of Comparative Data; Columbia University Press: New York, NY, USA, 2009. [Google Scholar]
- Ereshefsky, M. Species, taxonomy, and systematics. In Philosophy of Biology; Elsevier: Amsterdam, The Netherlands, 2007; pp. 403–427. [Google Scholar]
- Aptoula, E.; Yanikoglu, B. Morphological features for leaf based plant recognition. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 1496–1499. [Google Scholar]
- Singhal, P.; Maheshwari, A.; Semwal, P. Medicinal and aromatic plants: Healthcare and industrial applications—A book review. Ethnobot. Res. Appl. 2025, 30, 1–5. [Google Scholar] [CrossRef]
- Paulson, A.; Ravishankar, S. AI based indigenous medicinal plant identification. In Proceedings of the 2020 Advanced Computing and Communication Technologies for High Performance Applications (ACCTHPA), Cochin, India, 2–4 January 2020; pp. 57–63. [Google Scholar]
- Balick, M.J.; Cox, P.A. Plants, People, and Culture: The Science of Ethnobotany; Garland Science: New York, NY, USA, 2020. [Google Scholar]
- Wang, M.; Lin, H.; Lin, H.; Du, P.; Zhang, S. From species to varieties: How modern sequencing technologies are shaping Medicinal Plant Identification. Genes 2024, 16, 16. [Google Scholar] [CrossRef] [PubMed]
- Mosa, K.A.; Gairola, S.; Jamdade, R.; El-Keblawy, A.; Al Shaer, K.I.; Al Harthi, E.K.; Shabana, H.A.; Mahmoud, T. The promise of molecular and genomic techniques for biodiversity research and DNA barcoding of the Arabian Peninsula flora. Front. Plant Sci. 2019, 9, 1929. [Google Scholar] [CrossRef] [PubMed]
- Pacifico, L.D.; Britto, L.F.; Oliveira, E.G.; Ludermir, T.B. Automatic classification of medicinal plant species based on color and texture features. In Proceedings of the 2019 8th Brazilian Conference on Intelligent Systems (BRACIS), Salvador, Brazil, 15–18 October 2019; pp. 741–746. [Google Scholar]
- Jiang, Y.; Li, C. Convolutional neural networks for image-based high-throughput plant phenotyping: A review. Plant Phenomics 2020, 2020, 4152816. [Google Scholar] [CrossRef] [PubMed]
- Mahadevan, K.; Punitha, A.; Suresh, J. A novel rice plant leaf diseases detection using deep spectral generative adversarial neural network. Int. J. Cogn. Comput. Eng. 2024, 5, 237–249. [Google Scholar] [CrossRef]
- Lokesh, G.H.; Chandregowda, S.B.; Vishwanath, J.; Ravi, V.; Ravi, P.; Al Mazroa, A. Intelligent Plant Leaf Disease Detection Using Generative Adversarial Networks: A Case-study of Cassava Leaves. Open Agric. J. 2024, 18, e18743315288623. [Google Scholar] [CrossRef]
- Gu, J.; Yu, P.; Lu, X.; Ding, W. Leaf species recognition based on VGG16 networks and transfer learning. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; Volume 5, pp. 2189–2193. [Google Scholar]
- Sambasivam, G.; Prabu Kanna, G.; Chauhan, M.S.; Raja, P.; Kumar, Y. A hybrid deep learning model approach for automated detection and classification of cassava leaf diseases. Sci. Rep. 2025, 15, 7009. [Google Scholar] [CrossRef]
- Barhate, D.; Pathak, S.; Dubey, A.K. Hyperparameter-tuned batch-updated stochastic gradient descent: Plant species identification by using hybrid deep learning. Ecol. Inform. 2023, 75, 102094. [Google Scholar] [CrossRef]
- Rashid, J.; Khan, I.; Abbasi, I.A.; Saeed, M.R.; Saddique, M.; Abbas, M. A hybrid deep learning approach to classify the plant leaf species. Comput. Mater. Contin. 2023, 76, 3897–3920. [Google Scholar] [CrossRef]
- Mulugeta, A.K.; Sharma, D.P.; Mesfin, A.H. Deep learning for medicinal plant species classification and recognition: A systematic review. Front. Plant Sci. 2024, 14, 1286088. [Google Scholar] [CrossRef]
- Dey, B.; Ferdous, J.; Ahmed, R.; Hossain, J. Assessing deep convolutional neural network models and their comparative performance for automated medicinal plant identification from leaf images. Heliyon 2024, 10, e23655. [Google Scholar] [CrossRef]
- Ibrahim, Z.; Sabri, N.; Isa, D. Multi-maxpooling convolutional neural network for medicinal herb leaf recognition. In Proceedings of the 6th IIAE International Conference on Intelligent Systems and Image Processing, Kitakyushu, Japan, 27–30 September 2018; pp. 327–331. [Google Scholar]
- Kadiwal, S.M.; Hegde, V.; Shrivathsa, N.; Gowrishankar, S.; Srinivasa, A.; Veena, A. Deep Learning based Recognition of the Indian Medicinal Plant Species. In Proceedings of the 2022 4th International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 21–22 July 2022; pp. 762–767. [Google Scholar]
- Malik, O.A.; Ismail, N.; Hussein, B.R.; Yahya, U. Automated real-time identification of medicinal plants species in natural environment using deep learning models—A case study from Borneo Region. Plants 2022, 11, 1952. [Google Scholar] [CrossRef] [PubMed]
- Van Hieu, N.; Hien, N.L.H. Recognition of plant species using deep convolutional feature extraction. Int. J. Emerg. Technol. 2020, 11, 904–910. [Google Scholar]
- Sharrab, Y.; Al-Fraihat, D.; Tarawneh, M.; Sharieh, A. Medicinal plants recognition using deep learning. In Proceedings of the 2023 International Conference on Multimedia Computing, Networking and Applications (MCNA), San Diego, CA, USA, 13–15 December 2023; pp. 116–122. [Google Scholar]
- Lee, S.H.; Chan, C.S.; Wilkin, P.; Remagnino, P. Deep-plant: Plant identification with convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 452–456. [Google Scholar]
- Roslan, N.A.M.; Diah, N.M.; Ibrahim, Z.; Munarko, Y.; Minarno, A.E. Automatic plant recognition using convolutional neural network on malaysian medicinal herbs: The value of data augmentation. Int. J. Adv. Intell. Inform. 2023, 9, 136–147. [Google Scholar] [CrossRef]
- Gopal, A.; Reddy, S.P.; Gayatri, V. Classification of selected medicinal plants leaf using image processing. In Proceedings of the 2012 International Conference on Machine Vision and Image Processing (MVIP), Taipei, Taiwan, 7–8 December 2012; pp. 5–8. [Google Scholar]
- Gao, L.; Lin, X. Fully automatic segmentation method for medicinal plant leaf images in complex background. Comput. Electron. Agric. 2019, 164, 104924. [Google Scholar] [CrossRef]
- Maulana, O.; Herdiyeni, Y. Combining image and text features for medicinal plants image retrieval. In Proceedings of the 2013 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Jakarta, Indonesia, 28–29 September 2013; pp. 273–277. [Google Scholar]
- Zin, I.A.M.; Ibrahim, Z.; Isa, D.; Aliman, S.; Sabri, N.; Mangshor, N.N.A. Herbal plant recognition using deep convolutional neural network. Bull. Electr. Eng. Inform. 2020, 9, 2198–2205. [Google Scholar] [CrossRef]
- Taslim, A.; Saon, S.; Mahamad, A.K.; Muladi, M.; Hidayat, W.N. Plant leaf identification system using convolutional neural network. Bull. Electr. Eng. Inform. 2021, 10, 3341–3352. [Google Scholar] [CrossRef]
- Mardiana, B.D.; Utomo, W.B.; Oktaviana, U.N.; Wicaksono, G.W.; Minarno, A.E. Herbal leaves classification based on leaf image using cnn architecture model vgg16. J. RESTI (Rekayasa Sist. Dan Teknol. Inf.) 2023, 7, 20–26. [Google Scholar] [CrossRef]
- Javanmardi, S.; Ashtiani, S.H.M. AI-driven deep learning framework for shelf life prediction of edible mushrooms. Postharvest Biol. Technol. 2025, 222, 113396. [Google Scholar] [CrossRef]
- Akter, R.; Hosen, M.I. CNN-based leaf image classification for Bangladeshi medicinal plant recognition. In Proceedings of the 2020 Emerging Technology in Computing, Communication and Electronics (ETCCE), Dhaka, Bangladesh, 21–22 December 2020; pp. 1–6. [Google Scholar]
- Rakib, A.F.; Rahman, R.; Razi, A.A.; Hasan, A.T. A lightweight quantized CNN model for plant disease recognition. Arab. J. Sci. Eng. 2024, 49, 4097–4108. [Google Scholar] [CrossRef]
- Anubha Pearline, S.; Sathiesh Kumar, V.; Harini, S. A study on plant recognition using conventional image processing and deep learning approaches. J. Intell. Fuzzy Syst. 2019, 36, 1997–2004. [Google Scholar] [CrossRef]
- Borugadda, P.; Lakshmi, R.; Sahoo, S. Transfer Learning VGG16 Model for Classification of Tomato Plant Leaf Diseases: A Novel Approach for Multi-Level Dimensional Reduction. Pertanika J. Sci. Technol. 2023, 31, 813–841. [Google Scholar] [CrossRef]
- Paymode, A.S.; Malode, V.B. Transfer learning for multi-crop leaf disease image classification using convolutional neural network VGG. Artif. Intell. Agric. 2022, 6, 23–33. [Google Scholar] [CrossRef]
- Mousavi, S.; Farahani, G. A novel enhanced VGG16 model to tackle grapevine leaves diseases with automatic method. IEEE Access 2022, 10, 111564–111578. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Jin, X.; Xie, Y.; Wei, X.S.; Zhao, B.R.; Chen, Z.M.; Tan, X. Delving deep into spatial pooling for squeeze-and-excitation networks. Pattern Recognit. 2022, 121, 108159. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Bjorck, N.; Gomes, C.P.; Selman, B.; Weinberger, K.Q. Understanding batch normalization. Adv. Neural Inf. Process. Syst. 2018, 31, 7694–7705. [Google Scholar]
- Lagnaoui, S.; En-Naimani, Z.; Haddouch, K. The Effect of Normalization and Batch Normalization Layers in CNNs Models: Application to Plant Disease Classifications. In Proceedings of the International Conference On Big Data and Internet of Things, Virtual, 22–24 December 2022; pp. 250–262. [Google Scholar]
- Ramya, R.; Kumar, P. High-performance deep transfer learning model with batch normalization based on multiscale feature fusion for tomato plant disease identification and categorization. Environ. Res. Commun. 2023, 5, 125015. [Google Scholar] [CrossRef]
- Lee, S.H.; Chang, Y.L.; Chan, C.S.; Alexis, J.; Bonnet, P.; Goeau, H. Plant classification based on gated recurrent unit. In Experimental IR Meets Multilinguality, Multimodality, and Interaction, Proceedings of the 9th International Conference of the CLEF Association, CLEF 2018, Avignon, France, 10–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 169–180. [Google Scholar]
- Rani, N.S.; Bhavya, K.; Pushpa, B.; Devadas, R.M. HerbSimNet: Deep Learning-Based Classification of Indian Medicinal Plants with High Inter-Class Similarities. Procedia Comput. Sci. 2025, 258, 765–774. [Google Scholar] [CrossRef]
- Pushpa, B.; Rani, N.S.; Chandrajith, M.; Manohar, N.; Nair, S.S.K. On the importance of integrating convolution features for Indian medicinal plant species classification using hierarchical machine learning approach. Ecol. Inform. 2024, 81, 102611. [Google Scholar] [CrossRef]
- Rana, T.; Sinha, S.; Roy, R. A Novel Cascade Classifier Framework for Open-World Medicinal Plant Classification. In Proceedings of the 2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC), Osaka, Japan, 1–4 July 2024; pp. 902–907. [Google Scholar]
- Kumar, G.; Kumar, V.; Hrithik, A.K. Herbal plants leaf image classification using machine learning approach. In Intelligent Systems and Smart Infrastructure; CRC Press: Boca Raton, FL, USA, 2023; pp. 549–558. [Google Scholar]
- Amuthalingeswaran, C.; Sivakumar, M.; Renuga, P.; Alexpandi, S.; Elamathi, J.; Hari, S.S. Identification of medicinal plant’s and their usage by using deep learning. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 886–890. [Google Scholar]
- Stella, K.; Thamizhazhakan, K.; Ruthika, S.; Sriharini, M. Precise Recognition of Medicinal Plants using Xception Architecture. In Proceedings of the 2024 5th International Conference on Data Intelligence and Cognitive Informatics (ICDICI), Tirunelveli, India, 18–20 November 2024; pp. 1397–1402. [Google Scholar]
- Anami, B.S.; Nandyal, S.S.; Govardhan, A. A combined color, texture and edge features based approach for identification and classification of indian medicinal plants. Int. J. Comput. Appl. 2010, 6, 45–51. [Google Scholar] [CrossRef]
- Kyalkond, S.A.; Aithal, S.S.; Sanjay, V.M.; Kumar, P.S. A novel approach to classification of Ayurvedic medicinal plants using neural networks. Int. J. Eng. Res. Technol. (IJERT) 2022, 11, 6. [Google Scholar]
- Begue, A.; Kowlessur, V.; Singh, U.; Mahomoodally, F.; Pudaruth, S. Automatic recognition of medicinal plants using machine learning techniques. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 166–175. [Google Scholar] [CrossRef]
- Khan, S.; Siddiqui, F.; Ahad, M.A. Deep Learning for Classification and Efficacy of Medicinal Plants for Managing Respiratory Disorders. Procedia Comput. Sci. 2025, 258, 1640–1650. [Google Scholar] [CrossRef]
- Rao, R.U.; Lahari, M.S.; Sri, K.P.; Srujana, K.Y.; Yaswanth, D. Identification of medicinal plants using deep learning. Int. J. Res. Appl. Sci. Eng. Technol 2022, 10, 306–322. [Google Scholar] [CrossRef]
- Widneh, M.A.; Workneh, A.T.; Alemu, A.A. Medicinal Plant Parts identification and classification using deep learning based on multi label categories. Ethiop. J. Sci. Sustain. Dev. 2021, 8, 96–108. [Google Scholar]
- Roy, R.; Roy, R.; Chatterjee, D. AI-Driven Recognition of Indian Medicinal Flora using Convolutional Neural Networks. In Computational Intelligence and Machine Learning; SCRS: Delhi, India, 2025. [Google Scholar]
- Kalaiselvi, P.; Esther, C.; Aburoobha, A.; Nishanth, J.; Gopika, S.; Kabilan, M. Deep Learning Technique for Medicinal Plant Leaf Identification: Using Fine-Tuning of Transfer Learning Model. In Proceedings of the 2024 International Conference on Power, Energy, Control and Transmission Systems (ICPECTS), Chennai, India, 8–9 October 2024; pp. 1–6. [Google Scholar]
- Sivappriya, K.; Kar, M.K. Classification of Indian Medicinal Plant Species Using Attention Module with Transfer Learning. In Proceedings of the 2024 IEEE International Conference on Signal Processing, Informatics, Communication and Energy Systems (SPICES), Kottayam, India, 20–22 September 2024; pp. 1–8. [Google Scholar]
- Pushpa, B.; Rani, N.S. Ayur-PlantNet: An unbiased light weight deep convolutional neural network for Indian Ayurvedic plant species classification. J. Appl. Res. Med. Aromat. Plants 2023, 34, 100459. [Google Scholar] [CrossRef]
- Custodio, E.F. Classifying Philippine Medicinal Plants Based on Their Leaves Using Deep Learning. In Proceedings of the 2023 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 7–10 June 2023; pp. 0029–0035. [Google Scholar]
- Pallavi, K.; Hegde, D.; Parimelazhagan, R.; Sanjay, S.; Acharya, S.P. Enhanced Medicinal Plant Leaf Classification via Transfer Learning: A VGG16-Driven Approach for Precise Feature Extraction. In Proceedings of the 2024 4th International Conference on Mobile Networks and Wireless Communications (ICMNWC), Tumkuru, India, 4–5 December 2024; pp. 1–6. [Google Scholar]
- Bandla, R.; Priyanka, J.S.; Dumpali, Y.C.; Hattaraki, S.K.M. Plant Identification and Analysis of Medicinal Properties Using Image Processing and CNN with MobileNetV2 and AlexNet. In Proceedings of the 2024 International Conference on Innovation and Novelty in Engineering and Technology (INNOVA), Vijayapura, India, 20–21 December 2024; Volume 1, pp. 1–5. [Google Scholar]
- Kan, H.; Jin, L.; Zhou, F. Classification of medicinal plant leaf image based on multi-feature extraction. Pattern Recognit. Image Anal. 2017, 27, 581–587. [Google Scholar] [CrossRef]
- Lasya, S.; S, J.; Pushpa, B. Optimized Plant Species Classification through MobileNet-Enhanced Hybrid Models. In Proceedings of the 2024 5th International Conference for Emerging Technology (INCET), Belgaum, India, 24–26 May 2024; pp. 1–6. [Google Scholar]
- Pushpa, B.; Jyothsna, S.; Lasya, S. HybNet: A hybrid deep models for medicinal plant species identification. MethodsX 2025, 14, 103126. [Google Scholar] [CrossRef]
- Janani, R.; Gopal, A. Identification of selected medicinal plant leaves using image features and ANN. In Proceedings of the 2013 international Conference on Advanced Electronic Systems (ICAES), Pilani, India, 21–23 September 2013; pp. 238–242. [Google Scholar]
- Girinath, S.; Neeraja, P.; Kumar, M.S.; Kalyani, S.; Mamatha, B.L.; GruhaLakshmi, N. Real-Time Identification of Medicinal Plants Using Deep Learning Techniques. In Proceedings of the 2024 International Conference on Trends in Quantum Computing and Emerging Business Technologies, Bhimdatta, Nepal, 18–20 February 2024; pp. 1–5. [Google Scholar]
- Thendral, R.; Mohamed Imthiyas, M.; Aswin, R. Enhanced Medicinal Plant Identification and Classification Using Vision Transformer Model. In Proceedings of the 2024 International Conference on Emerging Research in Computational Science (ICERCS), Coimbatore, India, 12–14 December 2024; pp. 1–7. [Google Scholar]
- Kavitha, K.; Sharma, P.; Gupta, S.; Lalitha, R. Medicinal Plant Species Detection using Deep Learning. In Proceedings of the 2022 First International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT), Trichy, India, 16–18 February 2022; pp. 1–6. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameter | Description |
|---|---|
| Base Architecture | VGG16 pre-trained on ImageNet |
| SE Block Insertion | After each of the five max-pooling layers |
| SE Reduction Ratio | 16 |
| Activation Function | ReLU + Sigmoid |
| Optimizer | Adam |
| Learning Rate | 0.0001 |
| Batch Size | 32 |
| Dropout Rate | 0.5 in fully connected layers |
| Dense Layers | 2 × 4096 (ReLU) followed by Softmax |
| Loss Function | Categorical Cross-Entropy |
| Hyper-Parameter | Description |
|---|---|
| Base Architecture | VGG-16 (5 convolution blocks) |
| Convolutional Kernel Size | |
| Activation Function | ReLU (after convolution and dense layers) |
| Batch Normalization | After each convolution layer |
| GRU Units | 256 |
| Dilated Convolution Layer | 2 layers, kernels, dilation rate = 2 |
| Transformer Encoder | 1 layer |
| GRU Direction | Uni-directional (spatial row-wise modeling) |
| Feed-Forward Network | 2 layers |
| Multi-Head Attention | 8 heads |
| Normalization | Layer normalization in Transformer |
| Residual Connections | Applied in Transformer Encoder |
| Fully Connected Layers | 2 × Dense (4096 units, ReLU), 1 × Dense (1000 units, softmax) |
| Dropout Rate | 0.3 (after attention and fully connected layers) |
| Learning Rate | 0.0001 |
| Optimizer | Adam |
| Loss Function | Categorical cross-entropy |
| Batch Size | 32 |
| Gradient Clipping | 1 |
| Validation Split | 0.2 |
| Model | Training Accuracy (%) | Validation Accuracy (%) | Training Loss | Validation Loss |
|---|---|---|---|---|
| Custom CNN | 43.14 | 52.53 | 1.76 | 1.71 |
| VGG-16 before data augmentation | 78.93 | 89.87 | 0.76 | 0.74 |
| VGG-16 after data augmentation | 91.14 | 92.10 | 0.44 | 0.43 |
| VGG-16 after fine-tuning | 92.90 | 93.21 | 0.24 | 0.19 |
| VGG-16 and SE | 93.80 | 94.30 | 0.14 | 0.12 |
| Proposed Hybrid Model | 95.60 | 96.70 | 0.13 | 0.11 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| Custom CNN | 44.94 | 45.79 | 45.92 | 41.00 |
| VGG-19 | 59.49 | 64.47 | 59.49 | 58.20 |
| VGG-16 (before data augmentation) | 71.52 | 75.44 | 71.52 | 69.61 |
| Xception | 85.44 | 90.65 | 85.44 | 84.84 |
| Inception v3 | 87.97 | 88.81 | 87.97 | 87.31 |
| VGG-16 (after data augmentation) | 89.24 | 92.03 | 89.24 | 88.94 |
| VGG-16 (after fine-tuning) | 90.51 | 92.40 | 90.51 | 90.19 |
| MobileNetV2 | 93.67 | 94.99 | 93.67 | 93.65 |
| VGG-16 + SE block | 94.94 | 96.01 | 94.94 | 95.00 |
| Proposed Model (VGG-16 + GRU + Transformer) | 95.24 | 96.13 | 95.24 | 95.05 |
| Model Variant | BN | DC | GRU | Trans. | Val. Accuracy (%) | Observations |
|---|---|---|---|---|---|---|
| No Batch Normalization | ✗ | ✓ | ✓ | ✓ | 92.19 | Training is slow and generalization performance diminished |
| No Dilated Convolution | ✓ | ✗ | ✓ | ✓ | 93.31 | Limited receptive field and fine details get lost |
| No GRU | ✓ | ✓ | ✗ | ✓ | 86.97 | Poor learning of spatial relationship and modeling of leaf margin is failed |
| No Transformers | ✓ | ✓ | ✓ | ✗ | 86.30 | Fail to model spatial interactions and fine details |
| Proposed model combining all | ✓ | ✓ | ✓ | ✓ | 96.70 | Combining all components, overall performance is excellent |
| Ref. | Dataset | No. of Classes | Model | Architecture Summary | Val. Accuracy (%) |
|---|---|---|---|---|---|
| [48] | Self-built | 12 | HerbSimNet | Custom shallow CNN | 60.00 |
| [35] | Self-built | 10 | CNN | Basic convolutional layers | 71.30 |
| [49] | RTP40 | 40 | Hierarchical Classifier | Multi-stage classification model | 75.46 |
| [50] | Self-built | 10 | VGG-16 + Cascade | Deep CNN + cascaded classifier | 81.66 |
| [51] | Self-built | 25 | MLP | Multi-layer perceptron | 82.51 |
| [52] | Self-built | 4 | DNN | Fully connected dense network | 85.00 |
| [53] | Self-built | 30 | Xception | Depthwise separable CNN | 88.00 |
| [54] | Self-built | 3 | Texture + SVM | Texture features + SVM | 90.00 |
| [55] | Self-built | 100 | CNN | Deep CNN on large class count | 90.00 |
| [56] | Self-built | 24 | RF Classifier | Texture + Random Forest | 90.10 |
| [57] | DIMPSAR | 80 | EfficientNet B4 | EfficientNet scaled CNN | 91.37 |
| [58] | Self-built | 50 | CNN | Conventional deep CNN | 91.80 |
| [59] | Self-built | 5 | MobileNet | Lightweight CNN model | 92.00 |
| [60] | Self-built | 98 | Xception | Residual separable convolution | 92.00 |
| [61] | PlantVillage | 38 | ResNet-18 | Deep residual learning | 92.00 |
| [62] | DIMPSAR | 40 | Attn-CNN | CNN with attention layers | 92.10 |
| [63] | Self-built | 40 | Ayur-PlantNet | Hybrid CNN architecture | 92.27 |
| [64] | Self-built | 40 | VGG19 | Deep CNN via transfer learning | 92.67 |
| [65] | Self-built | 35 | VGG16 | Fine-tuned deep CNN | 93.00 |
| [66] | Indian Med. Plants | 40 | MobileNetV2 | Compact CNN for mobile vision | 93.00 |
| [67] | Self-built | 12 | SF + TF + SVM | Shape + Texture + SVM | 93.30 |
| [68] | Self-built | 13 | AlexNet + MobileNet | Optimized hybrid CNN | 93.86 |
| [69] | Self-built | 13 | MobileNetV2 + SE | MobileNet with SE block | 94.24 |
| [70] | Self-built | 6 | ANN | Feedforward ANN | 94.40 |
| [71] | DFCU 2020 | 20 | MobileNetV3 | Optimized lightweight CNN | 95.00 |
| [72] | Self-built | 3 | Vision Transformer | Pure attention mechanism | 95.00 |
| [73] | Medicinal Leaf | 30 | Inception v3 | Inception-based deep CNN | 95.16 |
| Ours | Self-built | 39 | VGG-16 + GRU + Transformer | CNN + temporal + attention fusion | 96.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
E. M., S.; Chandy, D.A.; P. M., S.; Poulose, A. A Hybrid Deep Learning Model for Aromatic and Medicinal Plant Species Classification Using a Curated Leaf Image Dataset. AgriEngineering 2025, 7, 243. https://doi.org/10.3390/agriengineering7080243
E. M. S, Chandy DA, P. M. S, Poulose A. A Hybrid Deep Learning Model for Aromatic and Medicinal Plant Species Classification Using a Curated Leaf Image Dataset. AgriEngineering. 2025; 7(8):243. https://doi.org/10.3390/agriengineering7080243
Chicago/Turabian StyleE. M., Shareena, D. Abraham Chandy, Shemi P. M., and Alwin Poulose. 2025. "A Hybrid Deep Learning Model for Aromatic and Medicinal Plant Species Classification Using a Curated Leaf Image Dataset" AgriEngineering 7, no. 8: 243. https://doi.org/10.3390/agriengineering7080243
APA StyleE. M., S., Chandy, D. A., P. M., S., & Poulose, A. (2025). A Hybrid Deep Learning Model for Aromatic and Medicinal Plant Species Classification Using a Curated Leaf Image Dataset. AgriEngineering, 7(8), 243. https://doi.org/10.3390/agriengineering7080243