Highlights
What are the main findings?
- A new type of lightweight model has been designed, which enhances real-time urban monitoring by improving the detection accuracy of unmanned aerial vehicles and significantly reducing the computational load.
- This system integrates a parallel dual-attention mechanism and a lightweight feature module, enabling the robust detection of small and dense targets in complex urban scenarios.
What is the implication of the main finding?
- This work provides a framework that successfully balances accuracy and efficiency, enabling the practical deployment of advanced deep learning on edge devices for large-scale smart city applications.
Abstract
The effective management of smart cities relies on real-time data from urban environments, where Unmanned Aerial Vehicles (UAVs) are critical sensing platforms. However, deploying high-performance detection models on resource-constrained UAVs presents a major challenge, particularly for identifying small, dense targets like pedestrians and vehicles from high altitudes. This study aims to develop a lightweight yet accurate detection algorithm to bridge this gap. We propose YOLOv10-DSNet, an improved architecture based on YOLOv10. The model integrates three key innovations: a parallel dual attention mechanism (CBAM-P) to enhance focus on small-target features; a novel lightweight feature extraction module (C2f-LW) to reduce model complexity; and an additional 160 × 160 detection layer to improve sensitivity to fine-grained details. Experimental results demonstrate that YOLOv10-DSNet significantly outperforms the baseline, increasing mAP50-95 by 4.1% while concurrently decreasing computational costs by 1.6 G FLOPs and model size by 0.7 M parameters. The proposed model provides a practical and powerful solution that balances high accuracy with efficiency, advancing the capability of UAVs for critical smart city applications such as real-time traffic monitoring and public safety surveillance.
1. Introduction
The global trend towards urbanization has spurred the development of smart cities, which leverage advanced information and communication technologies to enhance urban management, sustainability, and the quality of life for citizens [1]. A cornerstone of this paradigm is the ability to acquire real-time, fine-grained data on urban dynamics, such as traffic flow, crowd density, and environmental conditions [2]. Unmanned Aerial Vehicles, with their high mobility, broad field of view, and flexible deployment, have emerged as indispensable tools for this purpose, finding critical applications in intelligent transportation systems (ITS), public safety surveillance, and disaster response [3]. By providing a bird’s-eye perspective, UAVs can capture data that is inaccessible to fixed ground-level sensors, enabling a more comprehensive understanding of the urban landscape. Despite their potential, the practical deployment of UAVs for intelligent urban monitoring faces a significant technological bottleneck: the accurate and efficient detection of small targets from high-altitude imagery. As UAVs operate at considerable heights, objects of interest—such as pedestrians, vehicles, or infrastructure defects—often occupy only a few pixels in the captured video stream [4]. This results in sparse feature information, low contrast against complex urban backgrounds (e.g., roads, buildings, foliage), and frequent occlusions, posing a severe challenge to conventional object detection algorithms [5]. Furthermore, the limited payload and battery capacity of most UAVs impose strict constraints on the computational resources and model size of onboard deep learning models, making it infeasible to deploy large, computationally expensive algorithms that are common in server-based applications. Therefore, a critical research gap exists for a detection model that is both lightweight enough for real-time onboard processing and accurate enough to handle the unique difficulties of small target detection in UAV imagery.
According to the number of detection stages, the target detection algorithm can be divided into two-stage detection and single-stage detection. The classic two-stage algorithm is R-CNN [6], SPP-Net [7], Fast R-CNN [8] and Mask R-CNN [9]. The detection process is divided into two stages, the first stage is to generate candidate regions, and the second stage is to classify and fine tune the candidate regions, while the mainstream single-stage algorithm is SDD [10], YOLO (You Only Look Once) series [11,12,13] and FCOS [14] and so on, the checking process directly completes the end-to-end prediction on the input data without intermediate candidate generation. Therefore, the single-stage method usually has faster processing speed than the two-stage method, and shows better performance in application scenarios with high real-time requirements. Wang et al. put for-ward [15] YOLOv10. The previous YOLO model relied on NMS (Non-Maximum Sup-pression) in the reasoning process, and its loop steps led to low computational efficiency. Secondly, when the classification confidence is taken as the priority measure index, the box with high confidence is not necessarily accurate, which affects the positioning accuracy of the model, and by raising the threshold to forcibly remove the borders with low scores, the borders of dense objects may be wrongly suppressed, thus reducing the recall rate, and the threshold setting is completely dependent on experience and lacks universality. This not only affects the inference speed, but also makes it im-possible to handle some complex environments, such as scenarios with dense targets. YOLOv10 improves on this basis. The NMS dependence is eliminated by applying the double allocation strategy, namely one-to-many allocation and one-to-one allocation.
However, even state-of-the-art models like YOLOv10 are not inherently optimized for the specific challenges of UAV-based small target detection. Their feature pyramid networks can still lead to the loss of fine-grained spatial details crucial for identifying small targets, and their standard backbones may not be sufficiently lightweight for deployment on all UAV platforms. While some studies have attempted to improve small target detection by integrating attention mechanisms or modifying network architectures, they often do so at the cost of increased computational complexity, failing to simultaneously address the dual requirements of accuracy and efficiency for edge deployment [16].
Therefore, this paper proposes a new Network structure DSNet [17] (Dual attention and Scale-aware Network) based on YOLOv10. This model adds a multi-scale feature fusion strategy of 160 × 160 detection layer, which improves the recognition accuracy of small targets, as well as the lightweight design and real-time balance of the model. To solve the problem of feature loss in the sampling process and improve the weight of small targets, this model introduces attention mechanism into the target detection algorithm [18]. And an improved Module CBAM-P based on the CBAM (Convolutional Block Attention Module) attention mechanism [19] was proposed. This attention module improves the serial structure of CBAM to a parallel structure, enabling it not only to connect the context and capture long-distance dependencies, but also to complement and enhance the feature information and avoid interference between channels. To reduce the model calculation cost, this paper also proposes a lightweight feature extraction model C2f-LW to replace some C2f modules in YOLOv10 network. The main improvements are as follows:
- Add a small target detection layer to the neck network of YOLOv10 model to enhance its small target detection performance.
- A new attention module CBAM-P (Parallel CBAM) is introduced to improve the weight of the detection target in the whole image and enhance the ability of feature expression.
- The lightweight feature extraction module C2f-LW (Light Weight) is introduced into the neck network, in which the bottleneck block is replaced by the Group Fusion module, which can reduce the calculation of the model and simplify the model.
- The depth-based separable convolution is introduced into C2f-LW module [20]. The improved module aims to improve the feature extraction ability of the model for small targets.
The remaining part of this article is organized into four additional sections. Section 2 introduces the existing attention mechanisms and the small target detection algorithm based on YOLO. This section is mainly used to summarize the advantages and disadvantages of the existing methods and introduce the improvement directions of this research. Section 3 provides a detailed introduction to the YOLOv10-DSNet framework we proposed, elaborating on the architecture of its core components: the CBAM-P attention mechanism, the C2f-LW lightweight module, and the small target detection layer. Section 4 conducts a comprehensive empirical evaluation of the model. It includes ablation studies to verify the effectiveness of each proposed component, comparative analyses with the most advanced methods, and qualitative results to demonstrate the model’s superior performance in real urban scenarios. Finally, Section 5 summarizes the main findings of this paper, discusses their impact on the development of smart cities, and proposes future research directions.
2. Related Work
2.1. Attention Mechanism
In recent years, the attention mechanism has developed into an important methodological framework in the field of deep learning and has demonstrated significant performance advantages in computer vision tasks. This mechanism constructs a dynamic weight allocation system through an adaptive feature selection strategy, which can achieve fine-grained information focusing and feature enhancement. Its global context modeling ability effectively breaks through the limitations of traditional RNN sequence processing, and avoids the gradient dispersion problem in long-range dependencies by parallelizing the global modeling feature. This paradigm breakthrough not only reconstructs the learning method of feature representation, but also gives rise to the general model paradigm represented by the Transformer architecture, demonstrating powerful generalization capabilities in cross-modal tasks such as image understanding and natural language processing [21].
Hu et al. proposed the SE (Squeeze and Excitation) module [22]. The spatial information is compressed by global average pooling to generate channel descriptors. Then, the channel weights are dynamically adjusted through the fully connected layer to enhance the responses of important channels. The ECA (Efficient Channel Attention) module proposed by Wang et al. [23] avoids the fully connected layer in the SE module and instead uses local one-dimensional convolution to generate channel weights, reducing the number of parameters and computational complexity. By dynamically adjusting the kernel size of one-dimensional convolution, the dependency relationships between channels of different spans can be flexibly captured. The BAM (Bottleneck Attention Module) proposed by Park et al. [24] adopts parallel channels and spatial attention branches, compresses the feature dimensions through the bottleneck structure, and reduces computational redundancy. The SKNet (Selective Kernel Network) proposed by Li et al. [25] generates feature maps of different scales through a multi-branch structure, dynamically selects the optimal kernel size, and enhances the adaptability of the model to complex textures and scale changes. The DAN (Dual Attention Network) proposed by Fu et al. [26] captures long-distance dependencies through the non-local self-attention mechanism in the channel and spatial dimensions, significantly improving the accuracy of the image segmentation task. And the autocorrelation matrix is directly utilized to achieve attention calculation, enhancing the expressive ability of the model. Chen et al. proposed SCA-CNN (Spatial and Channel-wise Attention-based Convolutional Neural Network) [27], which adaptively generates spatial attention maps based on input features to enhance the positioning ability of complex scenes. Through the collaborative optimization of spatial-channel attention, the relevance and details of the generated results are improved.
Target detection algorithms often enhance the detection ability of targets by introducing attention mechanism. Zhang et al. [28] fused the attention mechanism with convolution-based object detection features to enhance the influence of salient features and reduce background interference. Wang et al. proposed a pooling and global feature fusion self-attention mechanism (PGFSM), aiming to capture the multi-level correlations among different features and effectively cascade and aggregate them to enhance the feature representation ability [29]. Zhu et al. combined deformable convolution with Transformer’s attention mechanism to optimize long-distance dependence modeling, which has outstanding performance in occlusion and small target detection [30]. Therefore, in this paper, CBAM-P, an improved module of CBAM, is introduced into YOLO v10, and parallel channels are adopted, so that our network can not only capture the global features of images, but also avoid the interference between channels in the conventional CBAM structure.
2.2. Small Target Detection in UAV Imagery
The detection of small targets in unmanned aerial vehicle (UAV) images is a major challenge currently faced in the field of object detection. This difficulty stems from several inherent characteristics: Firstly, the target usually occupies very few pixels, resulting in sparse feature information and being easily overwhelmed by background noise. Secondly, the contrast between the target and its surrounding environment is often low, increasing the possibility of interference and resulting in a low signal-to-noise ratio. In addition, the scenes captured by drones vary greatly in terms of target position and scale, and issues such as occlusion and motion blur can blur object boundaries, further complicating detection. To overcome these multi-faceted challenges, researchers have proposed various strategies, enhancing multi-scale feature representation, designing lightweight and efficient network architectures, and developing dedicated modules tailored to the unique complexity of aviation data [31].
Zhu et al. [32] proposed an improved algorithm for object detection based on YOLOv5, which enhances the performance of small target detection by introducing the Transformer Prediction Heads (TPH) to replace the original prediction heads and the CBAM attention module. However, when dealing with small targets, the Transformer enhances the perception of local features through its self-attention mechanism, but this also brings a huge computational burden. Especially on large-scale datasets, the computing cost is relatively high, and the training and inference time is long, which is not suitable for real-time applications with limited resources. Zhao et al. [33] proposed an architecture combining Swin Transformer units to solve the problem of high-density object detection, and introduced multiple detection heads and the CBAM convolutional attention module in the YOLOv7 network to extract features of different scales. Liu et al. [34] introduced partial deep convolution (PDWConv) to construct the PDWFasterNet module, replacing the C2f module of the original YOLOv8. They used depth wise separable convolution (DWSConv) to replace conventional convolution for down sampling, reducing model complexity while maintaining high accuracy. Benjumea et al. [35] replaced the Backbone with DenseNet or ResNet50 in YOLOv5 to enhance the feature extraction ability for small targets, and replaced PANet with Bi-FPN to optimize multi-scale feature fusion. Liu et al. [36] used Lite-HRNet as the Backbone in YOLOv5 one, generate high-resolution feature maps. Fusing visible light and infrared images to enhance detection performance in low-light scenarios. Peng et al. [37] proposed an efficient local-global feature fusion module to optimize the multi-scale feature expression of UAV images, achieving a balance between real-time performance and detection accuracy, and is applicable to UAV images in complex backgrounds. Wang et al. [38] proposed a module based on the YOLOv8 architecture Lightweight dense pedestrian detection algorithm. Adopting MobileViT as the backbone network has enhanced the overall ability of the model in feature extraction in pedestrian aggregation areas. The EMA attention mechanism module was introduced for global information encoding, and the aggregation of pixel-level features was further enhanced through dimensional interaction. Combined with a detection head of 160 × 160 scale, the detection performance of small targets has been optimized. Use the Repulsion loss as the bounding box loss function significantly reduces the missed detection and false detection of small target pedestrians in crowded situations. Pan et al. [39] replaced the spatial pyramid pooling (SPP) in the backbone network to optimize the gradient calculation, implemented multi-level bidirectional fusion with differentiated feature levels for the network neck, and added an adaptive feature fusion (AFF) model to the output head Block to achieve multi-level feature enhancement. Guan et al. [40] introduces innovative techniques like edge deformable convolution and point set representations to achieve highly accurate oriented ship detection in SAR imagery. Such methods allow the model to learn the geometric properties of targets more effectively, which is particularly advantageous for tasks requiring precise heading estimation or shape analysis. Li et al. [41] introduced the Multi-azimuth Scattering Feature Fusion Network (MASFF-Net), which enhances target recognition in SAR images by fusing features captured from different azimuth angles. This method enables the model to construct a more comprehensive and view-invariant representation of target features, which is particularly beneficial for improving the robustness of transient occlusion and blurred viewing angles that are common in dynamic unmanned aerial vehicle video streams.
3. Proposed Methodology
3.1. Overall Framework
The overall framework of YOLOv10-DSNet is shown in Figure 1. The network mainly consists of five parts (input, backbone, neck, head and output). Based on the original structure of YOLOv10, additional algorithms are added and the existing structure is improved, which improves the detection effect and performance of small targets. The unmanned aerial vehicle uploads real-time images through the camera and outputs the target detection result map after passing through the network.
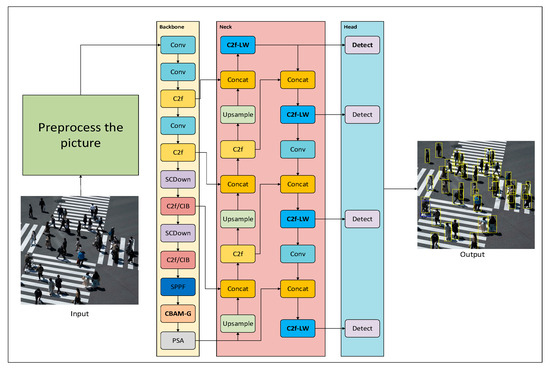
Figure 1.
YOLOv10-DSNet overall framework.
Below are the specifics of the CBAM-P attention mechanism, C2f-LW lightweight feature extraction module, and small target detection layer.
3.2. Design of the Attention Mechanism
3.2.1. CBAM Attention Mechanism
CBAM is an attention module integrated in convolutional neural network, which aims to enhance the feature expression ability of the model. By emphasizing important features and suppressing unimportant features, CBAM works through two main parts: channel attention module and spatial attention module. For the input feature map, the channel attention module compresses it through average pooling and maximum pooling, respectively. To obtain more detailed feature weights, input the pooled image into the shared network, and reduce its dimension first and then increase it in order to reduce the amount of calculation parameters. Finally, sum the two weight matrices to merge the feature vectors and obtain the weight vectors through sigmoid function. This weight vector is multiplied by the original input feature map to obtain a new feature map, and then the spatial attention module averages and maximizes it. The two obtained matrices are spliced on the channel, and the number of channels is changed to 1 again through a convolution layer, so that all the obtained feature information is distributed on one channel. Then, the weight vector is generated through the sigmoid function through the output of the convolution layer, and the spatial attention weight is multiplied by the feature map obtained through the channel attention mechanism, and the final output result is obtained. Figure 2 shows the specific structure of CBAM.
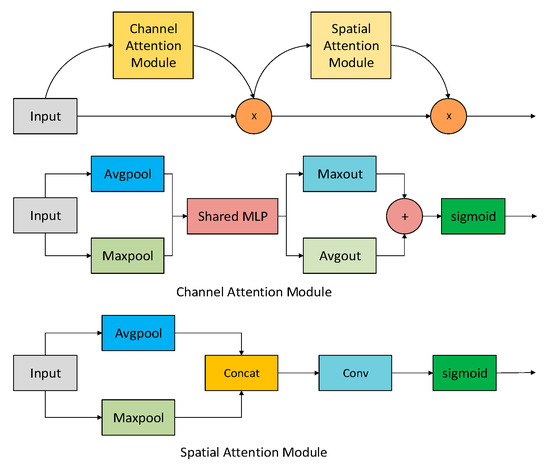
Figure 2.
CBAM structure.
3.2.2. CBAM-P Attention Mechanism
Based on the CBAM attention mechanism, we represent the input feature map with , and the weighted result of channel attention is . The spatial attention weighting yields the output feature map . According to the above structure, the process formula of CBAM can be obtained as:
Among them, and respectively, represent a feature weight obtained after the channel attention and spatial attention are input into the feature map. By multiplying them with the original feature map, the information of important channels is emphasized and the important spatial regions are highlighted.
However, this structure has some flaws in practical applications. Regardless of the order of channel attention and spatial attention, the feature map input by the attention mechanism located later is modified by the previous attention mechanism, rather than the original feature map . Such a situation will inevitably lead to the previous attention mechanism having an impact on the subsequent attention mechanism to a certain extent. Such an impact cannot be determined as positive or negative, and thus will cause the effect of the entire attention module to become unstable. To solve the interference problem between channels, in this paper, the original serial structure is changed to a parallel structure, and a new attention mechanism, CBAM-P. The specific structure is shown in Figure 3. In this structure, the channel attention and spatial attention can directly learn the original feature map and obtain the feature weights based on the original feature map. The final weight M is obtained by fusing the weights, and the final output feature map is obtained by weighting with . Since both and output values in [0, 1] through the Sigmoid activation function, after addition, ∈ [0, 2]. To avoid the situation of over-enhancement of features caused by superposition, we introduce the attention control parameter α, where α ∈ [0, 1]. The specific calculation formula is as follows:
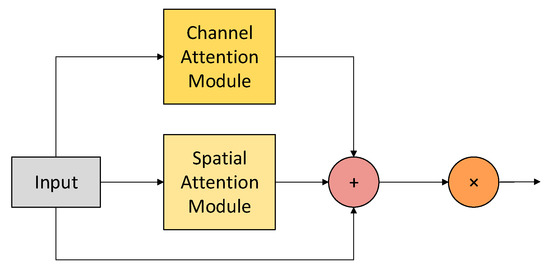
Figure 3.
CBAM-P structure.
In the above formula, both and are output as values in [0, α] and [0, (1 − α)], respectively, through the Sigmoid activation function. After addition, ∈ [0, 1]. Moreover, the value of α can be independently adjusted according to the task situation to control the weight proportion of channel attention and spatial attention in the entire attention mechanism, making the use of the module more flexible (the default value of α is 0.5).
In YOLOv10-DSNet network, the placement of attention mechanism has a significant impact on the performance of the whole network [42]. Structurally, CBAM-P consists of spatial attention and channel attention. Both abstract feature mapping into a series of point attention weights through global average pooling, and then establish the relationship between these weights and attach them to the original spatial features or channel features. When extracting CBAM attention in the initial stage of the network, the channel attention weights obtained are only based on RGB three channels. Spatial attention is based on the characteristics of the whole image. This design is not reasonable in logic, because the feature map extracted at this stage is usually large and the number of channels is small, which leads to the generalization of the extracted channel weights and fails to capture the specific features effectively. Spatial attention may lack sufficient generalization due to the lack of channels, and its learning process is sensitive and easy to introduce negative effects. However, when the extraction position of CBAM-P moves to the back layer of the network, too many channels will easily lead to over-fitting, while too small the size of the feature map will introduce a lot of non-pixel information in the convolution operation. Especially when the feature map is reduced to 1 × 1, the attention mechanism turns into a fully connected layer, and the effectiveness of this structure is questioned. When it is close to the classification layer, the attention mechanism has a more significant impact on the classification results and easily interferes with the decision-making process of the classification layer. The attention mechanism of CBAM-P is usually suitable for the middle layer of the network with moderate channel and spatial characteristics.
To sum up, the initial layers of the network extract low-level features like edges and textures, where attention may not be as effective. Conversely, the final layers have high-level semantic information but suffer from low spatial resolution. The middle layers of the network, particularly after a feature fusion module like SPPF, represent a ‘sweet spot’ where the feature maps contain rich semantic context while retaining sufficient spatial detail. Placing the attention mechanism at this stage allows it to most effectively weigh ‘what’ is important (channel attention) and ‘where it is located (spatial attention), leading to optimal performance gains. Therefore, in this paper, CBAM-P is placed after the pool layer and the SPPF module.
3.3. 2f-LW: Lightweight Feature Extraction Module
3.3.1. Group Fusion Module
In the ordinary convolution operation, the input feature map and each convolution kernel are convolved in a fully connected way to generate the output feature map. Assuming that the size of the input feature map is C × H × W and the number of convolution kernels in the convolution layer is N, then the number of channels of the output feature map is also N. The size of each convolution kernel is C × K × K, so the total number of parameters of the convolution kernel is N × C × K × K, where K represents the spatial size of the convolution kernel. By Group Conv [43], the number of channels of the input feature map is divided into multiple groups, and each group is convolved separately, to reduce the parameter quantity. It is assumed that the number of channels of each group of input characteristic graphs is C/G, while the number of channels of each group of output characteristic graphs is N/G, and the shape of convolution kernel is (C/G) × K × K. In this case, the number of convolution kernels is N/G in each group, and each convolution kernel only convolves with the input of the corresponding group. Although the number of convolution kernels is the same as that of the original convolution layer, that is N, the parameter quantity of each convolution kernel is only 1/G, so the total parameter quantity is N × (C/G) × K × K, which is G times lower than the traditional convolution operation. Where G represents the number of packets for packet convolution.
Although in theory, compared with ordinary convolution, the number of parameters is obviously reduced with the increase in the number of groups G, but block convolution divides the input channel into several independent groups, and convolution operation is carried out in each group, which leads to the direct interaction between the features of different groups. This will lead to the blocking of information flow between groups and the weakening of model expression ability. To solve this problem, Channel Shuffle is proposed in ShuffleNet [44]. By shuffling the channels of the feature graph, that is, rearranging the channel order instead of simply arranging or stacking them in order, the problem of blocking the packet convolution channels is effectively improved, and the network can learn the feature representation more effectively, thus improving the performance of the network.
In this paper, by retaining the advantages of the original bottleneck block, residual connection is introduced to realize the fusion of shallow features and deep features, and the ability of multi-scale feature expression is enhanced. The structure of Group Fusion is shown in Figure 4.

Figure 4.
Group Fusion structure.
When outputting 1 × 1 packet convolution, the parameters can be reduced while maintaining the packet calculation, and then the characteristic channels output by packet convolution are reorganized through Channel Shuffle to prevent the feature isolation caused by packet convolution and provide a richer fusion foundation for subsequent layers. Then, 3 × 3 depth separable convolution efficiently extracts spatial features in a channel-by-channel manner, avoiding redundant point convolution operations in traditional depth separable convolution, and further reducing computational overhead. Depth separable convolution contains point convolution, to global integration of all the channel information, eliminate grouping calculation of the residual deviation in the group, and restoring the channel dimension to be consistent with the input, ensuring that the residual connection can be directly added and avoiding the extra calculation of dimension matching.
Given an input , the input feature map first undergoes a grouped convolution with a convolution kernel size of 1 × 1, where the feature map of each channel is Fg , and its calculation formula is as follows:
The obtained feature map is input into the Channel Shuffle. A new feature map is obtained by reorganizing and integrating the original channels, where N represents the batch dimension and G represents the number of groups. The specific calculation is as follows:
The feature map undergoes a deep convolution with a convolution kernel size of 3 × 3 again, F convolves each channel C with the convolution kernel W one by one, and a new feature map is obtained:
Convolve with a kernel size of 1 × 1 point by point:
Finally, perform residual connection between the obtained feature map and the original feature map to obtain the final output :
Assuming that the input size and output size of feature mapping to Group Fusion module and bottleneck block are the same, the residual differential branch is excluded, and its parameter calculation formula is deduced for the main part.
For Group Fusion, the convolution kernel size of each group is 1 × 1 × (Cin/G) × (Cmid/G), and its parameters are as follows:
3 × 3 deep convolution is equivalent to 3×3 group convolution with group number g, and its parameters are:
Point-by-point convolution is 1 × 1 convolution, and its parameters are:
where Cin = Cout = 2Cmid = C, the total number of participants is:
For the bottleneck block, it consists of two ordinary convolutions of 3 × 3, and its parameters are:
Let the number of groups G = 2, and the number of channels of the input feature map C = 64. The parameters obtained by Formulas (12) and (13) are 2848 and 36,864, respectively, and it is obvious that the parameters are greatly reduced. Theoretically, it is proved that the module has excellent performance in reducing parameters and making the model lightweight.
3.3.2. LSKA Module
Guo et al. proposed a novel attention mechanism for visual recognition—Large Kernel Attention (LKA) [45]. Lau et al. proposed the attention mechanism of large Separable Kernel Attention (LSKA) [46] on this basis. The LSKA module innovatively decomposes the large kernel convolution operation. It optimizes efficiency by reducing the spatial positions that need to be calculated and the convolution window or kernel size for calculation, thereby reducing the computational load. This module is also capable of capturing a wide range of spatial information, improving performance in tasks that capture large-scale or long-distance dependencies.
The structure of the LSKA module is shown in Figure 5. When the input feature map enters, a deep convolution with a convolution kernel size of 1 × (2d − 1) is performed first to extract the features in the horizontal or vertical direction of the feature map. Then, a deep convolution with a convolution kernel of (2d − 1) × 1 is used again to extract the features in the other direction, while reducing the number of parameters. Immediately after, the features extracted in the first two parts are fully extracted through depth-expanding convolution with a convolution kernel of (k/d) × (k/d). Finally, the number of channels is restored through 1 × 1 convolution and multiplied element by element in the initial feature map to obtain the output result.

Figure 5.
LSKA structure.
3.3.3. C2f-LW Structure
The C2f-LW module is mainly composed of LSKA, Split, Group Fusion and Concat. The specific network structure is shown in Figure 6.

Figure 6.
C2f-LW structure.
The C2f-LW module replaces the bottleneck block with the improved Group Fusion module and introduces the LSKA module to replace the 1 × 1 convolution module, aiming to improve the feature expression performance. This module can integrate local context information, providing a larger perception range, and thereby enhancing the representational ability of features. The C2f-LW module also reduces the parameter number of the overall algorithm, which not only improves the computational efficiency, reduces the demand for memory and computing resources, but also lowers the training and inference costs. Through these features, the C2f-LW module effectively improves the overall performance of the YOLOv10-DSNet model in the detection of small targets in UAVs.
3.4. Small Target Detection Layer
After a series of feature fusions in the traditional YOLOv10 model, the backbone part will output three feature maps of sizes 20 × 20, 40 × 40 and 80 × 80, respectively, to the head part for detection. The larger the feature map is, the more it can highlight the features of small targets. Since the largest feature map is only 80 × 80, the scale of the feature map is relatively small and it is not suitable for detecting small targets. To improve the accuracy of small target detection and avoid losing too many detailed features due to down sampling at the same time, a small target detection layer was added to the original network structure of YOLOv10. The upper layer of the neck part in the figure is the newly added 160 × 160 small target detection layer. YOLOv10-DSNet extracts features from the upper part of the backbone and utilizes Concat concatenation fuses the shallow features extracted from the neck with C2f-LW capture and extensive spatial information, and finally outputs the fourth detection head. By strengthening the extraction of feature details of small targets and using it as the small target detection head, the detection ability of YOLOv10-DSNet for small targets is enhanced. After adding the small target detection layer, the network can focus on local details more precisely and enhance the recognition ability of small targets. The additional detection layer can provide more information for the low-level feature map, thereby reducing missed detections and false detections. Moreover, the network can conduct more reasoning models at different feature scales and perform positioning and classification in more feature Spaces, thereby reducing the problem of incorrect classification caused by blurred target boundaries or complex backgrounds.
4. Experiments and Results
4.1. Experimental Setup
To ensure a rigorous and reproducible evaluation of our proposed model, we established a comprehensive experimental setup covering the dataset, evaluation metrics, and implementation environment.
4.1.1. Dataset for Urban Scene Analysis
To evaluate the performance of YOLOv10-DSNet in realistic urban environments, we have curated a custom dataset designed to simulate the challenging scenarios frequently encountered in smart city monitoring. Compared to well-known public UAV datasets such as VisDrone and UAVDT, our dataset places a specific emphasis on these urban monitoring scenarios, featuring a meticulous balance of peak-hour traffic, dense crowds, and diverse lighting conditions. This makes it particularly well-suited for validating the real-world applicability of our proposed framework.
The targeted curation process ensures that the dataset effectively tests the model’s robustness against common interferences such as occlusion, low contrast, and multi-scale, examples of which are shown in Figure 7.

Figure 7.
Examples of challenging cases from our curated dataset. (a) heavy occlusion in dense traffic, (b) low contrast and poor illumination during nighttime, (c) significant multi-scale variations among targets.
The final dataset comprises 2000 images, annotated with three critical urban object classes: ‘person’ (pedestrians), ‘motor’ (motor vehicles), and ‘non-motor’ (non-motorized vehicles), with a distribution ratio of approximately 4:4:1. A key challenge inherent in such high-altitude drone images is the prevalence of small targets. To quantitatively characterize this aspect, we analyzed the distribution of object sizes based on the standard COCO evaluation index. As shown in Figure 8, most of the labeled objects belong to the “Small” category (area < 322 pixels). The high proportion of small targets confirms the applicability of the dataset to the strict evaluation of small target detection algorithms.
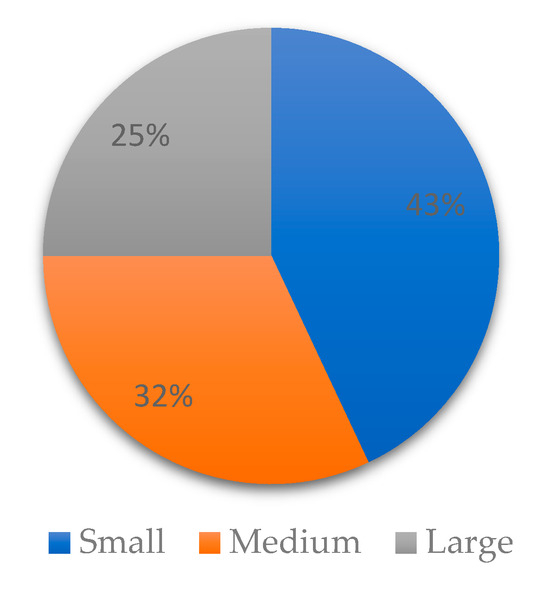
Figure 8.
The proportion of each goal.
To enhance model generalization and mitigate overfitting, a comprehensive set of data augmentation techniques were applied during the training phase. We carefully selected the parameters to enrich the training data without excessively distorting or removing small targets. The specific augmentations and their corresponding hyperparameters are detailed in Table 1.

Table 1.
Data augmentation methods and hyperparameters.
This paper sets up comparative experiments and ablation experiments to comprehensively evaluate the performance of the model. To ensure the accuracy and rigor of the experimental results, all models were trained, verified and tested on the same hardware platform and software environment.
4.1.2. Evaluation Metrics
The performance evaluation indicators cover four aspects: accuracy (P), recall rate (R), average accuracy (mAP), computing power (FLOPs), and parameter count (Para). The higher the accuracy, the more accurate the model is in positive class prediction and the fewer the false detection phenomena. The higher the recall rate is, the stronger the model’s recognition ability for positive class targets is and the fewer the missed detections are. In multi-object detection tasks, average precision (mAP) is used as a more comprehensive metric, which can simultaneously evaluate the accuracy of classification and positioning. The smaller the computing power and model size are, the more lightweight the model is, and the lower the demand for hardware resources, making it suitable for deployment in resource-constrained environments.
4.1.3. Implementation Detail
All experiments, including model training, validation, and testing, were conducted on a consistent hardware and software platform to ensure fair and reproducible comparisons. The models were implemented using the PyTorch 2.8.0 deep learning framework with CUDA 12.9 and trained on a workstation equipped with an NVIDIA GeForce RTX 4060 GPU. Key training hyperparameters included a batch size of 16, an initial learning rate of 0.001 with a cosine annealing scheduler, and training for 300 epochs using the AdamW optimizer.
4.2. Results and Analysis
4.2.1. Evaluations on Tiny Object Detection Layer
To verify the effectiveness of the small target detection layer, this structure was added to the YOLOV10 neck network. The experimental results are shown in Table 2. This improvement has increased the accuracy by 2.1%, the recall by 1.8%, and mAP0.50 and mAP0.5-0.95 by 1.9% and 2.4%, respectively. Because additional convolution operations were performed in the neck network, higher computations and parameters were generated.
Table 2.
Evaluation of the small target detection layer.
To provide a more quantitative analysis of the model’s focus, we utilized Grad-CAM to visualize the class activation maps. It can be seen from Figure 9 that the tiny detection layer is more sensitive to small targets and has more outstanding performance.
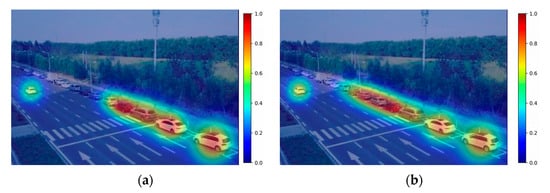
Figure 9.
Grad-CAM visualization. (a) YOLOv10n, (b) YOLOv10n-tiny. In the heatmaps, red indicates regions of high model attention, while blue represents regions of low attention.
4.2.2. Analysis on the Effectiveness of CBAM-P in Improving Attention Mechanism
In this paper, we compare CBAM-P attention mechanism with CBAM and six other mainstream attention mechanisms (including CA [47], SE, ECA, BAM, SENet and SKNet) in the same network, because this model adds an attention mechanism to enhance the recognition ability of small targets, so only the average accuracy is taken as the index here. Figure 10 shows that CBAM-P is obviously superior to CA, SE, ECA, BAM, SENet and SKNet in the average accuracy index.
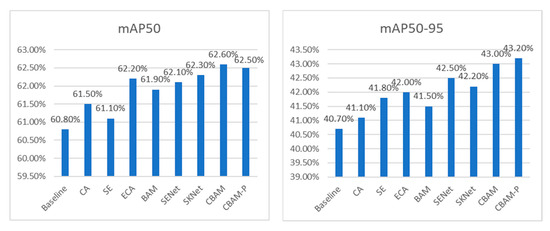
Figure 10.
Comparative experiment of attention mechanism.
In the comparison with CBAM in Figure 10, it is found that the mAP50 of the improved module CBAM-P even decreases slightly, which may be related to the value of the attention control parameter α. Therefore, we set up an experiment, and bring it into the model with an increase of 0.02 based on the default value of the parameter α of 0.5, and compare the results, and the results are shown in Figure 11. It can be seen from Figure 11 that the attention mechanism can be used more flexibly by fine-tuning the value of parameter α. For this experiment, the best mAP50 is obtained when α is 0.46, and the mAP50-95 currently is also higher than the original module, so α is 0.46 in the following.
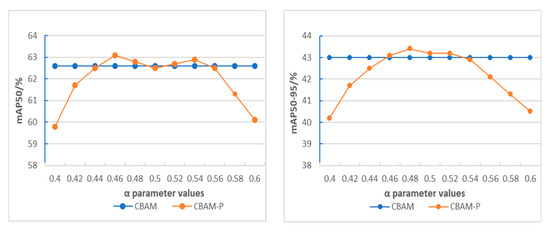
Figure 11.
Comparison chart of broken line of attention mechanism.
As discussed above, the placement of attention mechanism will also affect the accuracy and recall rate of the model. To verify the rationality of the placement of CBAM-P module in this paper, a comparative experiment is set up, and the experimental results are shown in Table 3. YOLOv10-DSNet-F stands for CBAM-P pre-placement, and YOLOv10-DSNet-B stands for CBAM-P post-placement. As can be seen from Table 3, the incorrect placement of attention mechanism may even lead to the overall performance of the model being worse than the original algorithm.
Table 3.
Placement experiment of CBAM-P.
4.2.3. Ablation Experiment
To verify the superiority and effectiveness of two modules in C2f-LW module, the ablation experiment of C2f-LW module was carried out separately, and the experimental results are shown in Table 4. When LSKA and Group Fusion modules are added separately in C2f module, LSKA slightly improves in accuracy, recall rate and mAP50, but does not change obviously in lightweight. The Group Fusion module presents the opposite situation. When the two modules are combined, the model accuracy increases by 1.1%, the recall rate increases by 0.9%, mAP50 and mAP50-95 increase by 1.1% and 1.5%, respectively, FLOPs decrease by 2.2 G, and the parameter quantity decreases by 0.7 M This shows that the two modules complement each other, which makes C2f-LW module not only improve the extraction ability of small targets, but also make the model lightweight.
Table 4.
Ablation experiment of c2f-lw module.
Table 5 presents the overall ablation study of YOLOv10-DSNet, in which the parameters and positions of each module remain unchanged, confirming that the proposed module improves the performance of the algorithm under a consistent experimental setup. Due to the increase in the number of network layers in the small target detection layer, it has slightly increased the FLOPs and parameters, but its detection performance for small targets is the best, and its accuracy is improved by 2.1%, 1.9% and 2.4% compared with YOLOv10. The CBAM-P module improves the feature extraction ability of the module for small targets without introducing too many parameters. The FLOPs and parameters of C2f-LW module are significantly reduced by 3.2 G and 0.8 M compared with YOLOv10, which can reduce the influence of introducing parameters in the above modules.
Table 5.
Ablation experiment of YOLOv10-DSNet improved module.
4.2.4. Model Comparison Test
To comprehensively evaluate the performance of YOLOv10-DSNet, we conducted a comparative analysis of various state-of-the-art target detectors, including several classic and the latest YOLO variants. The results are summarized in Table 6.
Table 6.
Model comparison experiment.
Table 6 shows that the accuracy, recall rate, mAP, FLOPs and parameter count of YOLOv10-DSNet are all superior to those of YOLOv8, YOLO-Z, Faker-YOLO-AP, TPH-YOLOv5, OW-YOLO [48] and CSF-YOLO [49]. Although the FLOPs and parameter count of YOLOv10-DSNet are slightly larger than those of YOLOv5-lite, its accuracy and recall rate are significantly higher than those of YOLOv5-lite. Compared with the initial version of YOLOv10, YOLOv10-DSNet has improved by 3.2% in accuracy and 2.8% in recall rate, respectively. It rose by 3.7% and 4.1% on mAP50 and MAP50-95, respectively. Furthermore, the FLOPs of YOLOv10-DSNet is 1.6 G less than that of YOLOv10, and the number of parameters is 0.7 M less. It indicates that the algorithm proposed in this paper shows obvious performance advantages in multiple evaluation indicators.
4.2.5. Algorithm Effect Test
To evaluate the detection performance of each algorithm in different scenes, this experiment selects three representative scenes: peak traffic, crowd gathering and poor light, and uses five target detection algorithms, YOLOv8n, YOLOv5-Lite, YOLOv10, TPH-YOLOv5 and YOLOv10-DSNet, to detect the above scenes. The detection results are shown in Figure 12 (from left to right according to the above algorithm sequence, where the yellow box corresponds to person, the red box corresponds to motor, and the basket corresponds to non-motor), which can more intuitively compare the detection effects of different algorithms in these typical scenes.

Figure 12.
Comparison chart of detection accuracy.
It can be clearly observed from the figure that YOLOv10-DSNet shows significant performance advantages in three typical scenarios. During peak traffic hours, YOLOv10-DSNet can accurately identify individual motor vehicles with significant differences, and it can also effectively identify smaller-sized non-motor vehicles. In scenarios where people gather, even when facing the challenge of unclear pedestrian Outlines, YOLOv10-DSNet can still efficiently identify all targets. For night scenes in low-light environments, YOLOv10-DSNet can not only successfully identify motor vehicles but also accurately detect pedestrians on the roadside in a relatively blurry background, truly achieving the detection of small targets in complex environments.
5. Conclusions
This study verified the effectiveness of YOLOv10-DSNet, a lightweight deep learning architecture specifically designed for the real-time small target detection of unmanned aerial vehicles to enhance urban surveillance within smart cities. By combining advanced attention mechanisms with model optimization techniques, this system can accurately identify small-scale objects such as pedestrians and vehicles in complex high-altitude scenes, thereby providing key data for applications in intelligent traffic control and public safety. Although adding a new detection layer would lead to a slight increase in parameters, the impact was effectively offset by introducing an improved lightweight module, ultimately reducing the overall model size. This synergy significantly enhances detection accuracy, especially for small targets, demonstrating a very favorable performance-cost trade-off. It is worth noting that the research results show that by adjusting the attention control parameter α of a specific urban dataset, the performance of the model can be further improved. The dual advantages of efficiency and accuracy make YOLOv10-DSNet particularly suitable for deployment on resource-constrained UAV hardware without compromising real-time capabilities. As urban environments become increasingly complex, the integration of this unmanned aerial vehicle-based intelligent sensing solution brings great hope for building more efficient, resilient and safe cities. Future work will focus on improving the balance of multiple types of detection, exploring the fusion of multimodal data, and further optimizing the architecture of ultra-low power edge devices, thereby providing an overall approach for smart city governance.
Author Contributions
Conceptualization, J.C.; Data curation, Y.Y. and J.C.; Formal analysis, L.X.; Investigation, Z.P., Y.Y. and D.Z.; Methodology, X.Q.; Project administration, X.Q.; Resources, D.Z.; Supervision, L.X.; Validation, G.G. and Z.P.; Writing—review and editing, X.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Defense Technology Foundation Research Project under Grant JCKY2023xxxx007, and in part by the Jiangsu Province Industry University Research Cooperation Project, under Grant BY20240019.
Data Availability Statement
All data are available within this article.
Acknowledgments
This article has only undergone text editing on the Aichatos platform using the GPT-4o model, and some grammar issues have been corrected.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Javed, A.R.; Shahzad, F.; ur Rehman, S.U.; Zikria, Y.B.; Razzak, I.; Jalil, Z.; Xu, G. Future smart cities: Requirements, emerging technologies, applications, challenges, and future aspects. Cities 2022, 129, 103794. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Unal, M. Applications of ML/DL in the management of smart cities and societies based on new trends in information technologies: A systematic literature review. Sustain. Cities Soc. 2022, 85, 104089. [Google Scholar] [CrossRef]
- Abbas, N.; Abbas, Z.; Liu, X.; Khan, S.S.; Foster, E.D.; Larkin, S. A survey: Future smart cities based on advance control of Unmanned Aerial Vehicles (UAVs). Appl. Sci. 2023, 13, 9881. [Google Scholar] [CrossRef]
- Xu, H.; Wang, L.; Han, W.; Yang, Y.; Li, J.; Lu, Y.; Li, J. A survey on UAV applications in smart city management: Challenges, advances, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 8982–9010. [Google Scholar] [CrossRef]
- Zuo, G.; Zhou, K.; Wang, Q. UAV-to-UAV small target detection method based on deep learning in complex scenes. IEEE Sens. J. 2024, 25, 3806–3820. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th Eur-Opean Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Jocher, G. Ultralytics YOLOv5. GitHub Repository. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 18 February 2025).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Ultralytics. Ultralytics YOLOv8. GitHub Repository. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 18 February 2025).
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. arXiv 2019, arXiv:1904.01355. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Taye, M.M. Theoretical understanding of convolutional neural network: Concepts, architectures, applications, future directions. Computation 2023, 11, 52. [Google Scholar] [CrossRef]
- Wang, W.; Wang, S.; Li, Y.; Jin, Y. Adaptive multi-scale dual attention network for semantic segmentation. Neurocomputing 2021, 460, 39–49. [Google Scholar] [CrossRef]
- Soydaner, D. Attention mechanism in neural networks: Where it comes and where it goes. Neural Comput. Appl. 2022, 34, 13371–13385. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Howard, A.G. Mobilenets: Efficient convolute-onal neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. BAM: Bottleneck attention module. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 565–578. [Google Scholar]
- Zhang, Y.; Chen, Y.; Huang, C.; Gao, M. Object detection network based on feature fusion and attention mechanism. Future Internet 2019, 11, 9. [Google Scholar] [CrossRef]
- Wang, C.; Wang, H. Cascaded feature fusion with multi-level self-attention mechanism for object detection. Pattern Recognit. 2023, 138, 109377. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Chen, G.; Wang, H.; Chen, K.; Li, Z.; Song, Z.; Liu, Y.; Chen, W.; Knoll, A. A Survey of the Four Pillars for Small Object Detection: Multiscale Representation, Contextual Information, Super-Resolution, and Region Proposal. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 936–953. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Zhao, L.; Zhu, M. MS-YOLOv7: YOLOv7 based on multi-scale for object detection on UAV aerial photography. Drones 2023, 7, 188. [Google Scholar] [CrossRef]
- Liu, Z.; Abeyrathna, R.R.D.; Sampurno, R.M.; Nakaguchi, V.M.; Ahamed, T. Faster-YOLO-AP: A lightweight apple detection algorithm based on improved YOLOv8 with a new efficient PDWConv in orchard. Comput. Electron. Agric. 2024, 223, 109118. [Google Scholar] [CrossRef]
- Benjumea, A.; Teeti, I.; Cuzzolin, F.; Bradley, A. YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles. arXiv 2021, arXiv:2112.11798. [Google Scholar]
- Liu, Z.L.; Shen, X.F. A fusion of Lite-HRNet with YOLO v5 for small target detection in autonomous driving. Automot. Eng. 2022, 44, 1511–1520. [Google Scholar]
- Peng, H.; Xie, H.; Liu, H.; Guan, X. LGFF-YOLO: Small object detection method of UAV images based on efficient local–global feature fusion. J. Real-Time Image Process. 2024, 21, 167. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, H.; Zhu, X.; Li, C.; Liu, Z.; Wang, Z.Y. An improved dense pedestrian detection algorithm based on YOLOv8: MER-YOLO. Comput. Eng. Sci. 2024, 46, 1050. [Google Scholar]
- Pan, Y.; Yang, Z. Optimization model for small object detection based on multi-level feature bidirectional fusion. J. Comput. Appl. 2023, 43, 1985–1992. [Google Scholar]
- Guan, T.; Chang, S.; Deng, Y.; Xue, F.; Wang, C.; Jia, X. Oriented SAR Ship Detection Based on Edge Deformable Convolution and Point Set Representation. Remote Sens. 2025, 17, 1612. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, W.; Deng, J.; Guo, Y.; Liu, S.; Zhang, J. MASFF-Net: Multi-azimuth scattering feature fusion network for SAR target recognition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 19425–19440. [Google Scholar] [CrossRef]
- Chen, E.; Lusi, A.; Gao, Q.; Bian, S.; Li, B.; Guo, J.; Zhang, D.; Yang, C.; Hu, W.; Huang, F. CB−YOLO: Dense object detection of YOLO for crowded wheat head identification and localization. J. Circuits Syst. Comput. 2024, 34, 2550079. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual attention network. Comput. Vis. Media 2023, 9, 733–752. [Google Scholar] [CrossRef]
- Lau, K.W.; Po, L.M.; Rehman, Y.A.U. Large separable kernel attention: Rethinking the large kernel attention design in CNN. Expert Syst. Appl. 2024, 236, 121352. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wang, H.; Yun, L.; Yang, C.; Wu, M.; Wang, Y.; Chen, Z. Ow-yolo: An improved yolov8s lightweight detection method for obstructed walnuts. Agriculture 2025, 15, 159. [Google Scholar] [CrossRef]
- Wang, C.; Wang, L.; Ma, G.; Zhu, L. CSF-YOLO: A Lightweight Model for Detecting Grape Leafhopper Damage Levels. Agronomy 2025, 15, 741. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).