

Intelligent Waste-Volume Management Method in the Smart City Concept

 ,
,  , and
, and
Abstract
:1. Introduction
2. Literature Review
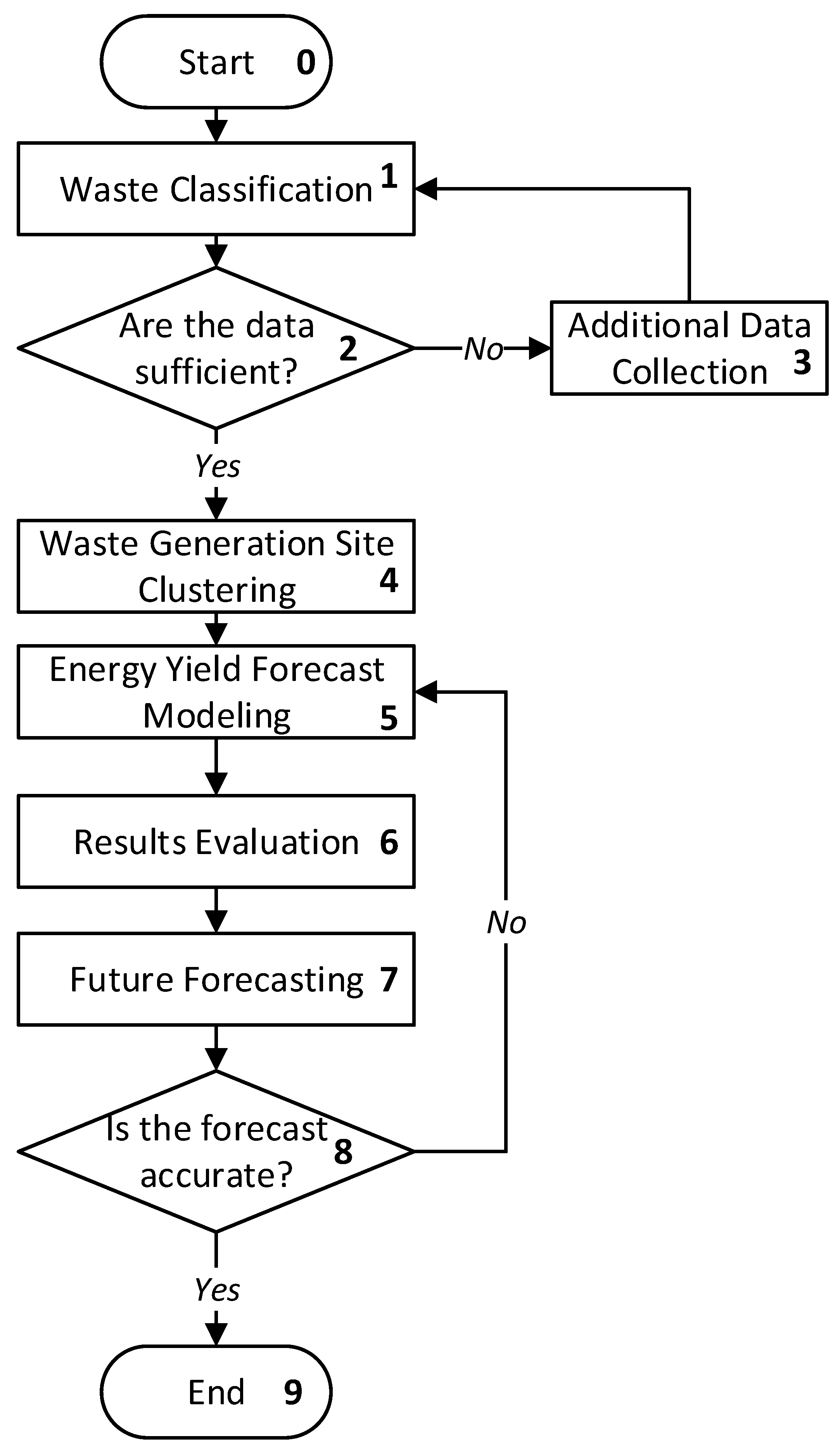
3. Proposed Method
- Step 1.
- Classification of waste [16,29,30] (Figure 1, Block 1): Using data [31] on the composition and quantity of waste, it is classified by type. Various parameters can be used to classify waste, such as composition, quantity, size, shape, etc. However, for a more accurate classification, machine learning methods can be used [32,33,34,35]. To classify waste, it necessary (Figure 1, Blocks 2,3) to have sufficient data about, for example, its composition, and other parameters that impact its classification. After model training, it can be used to classify new kinds waste.
- Step 2.
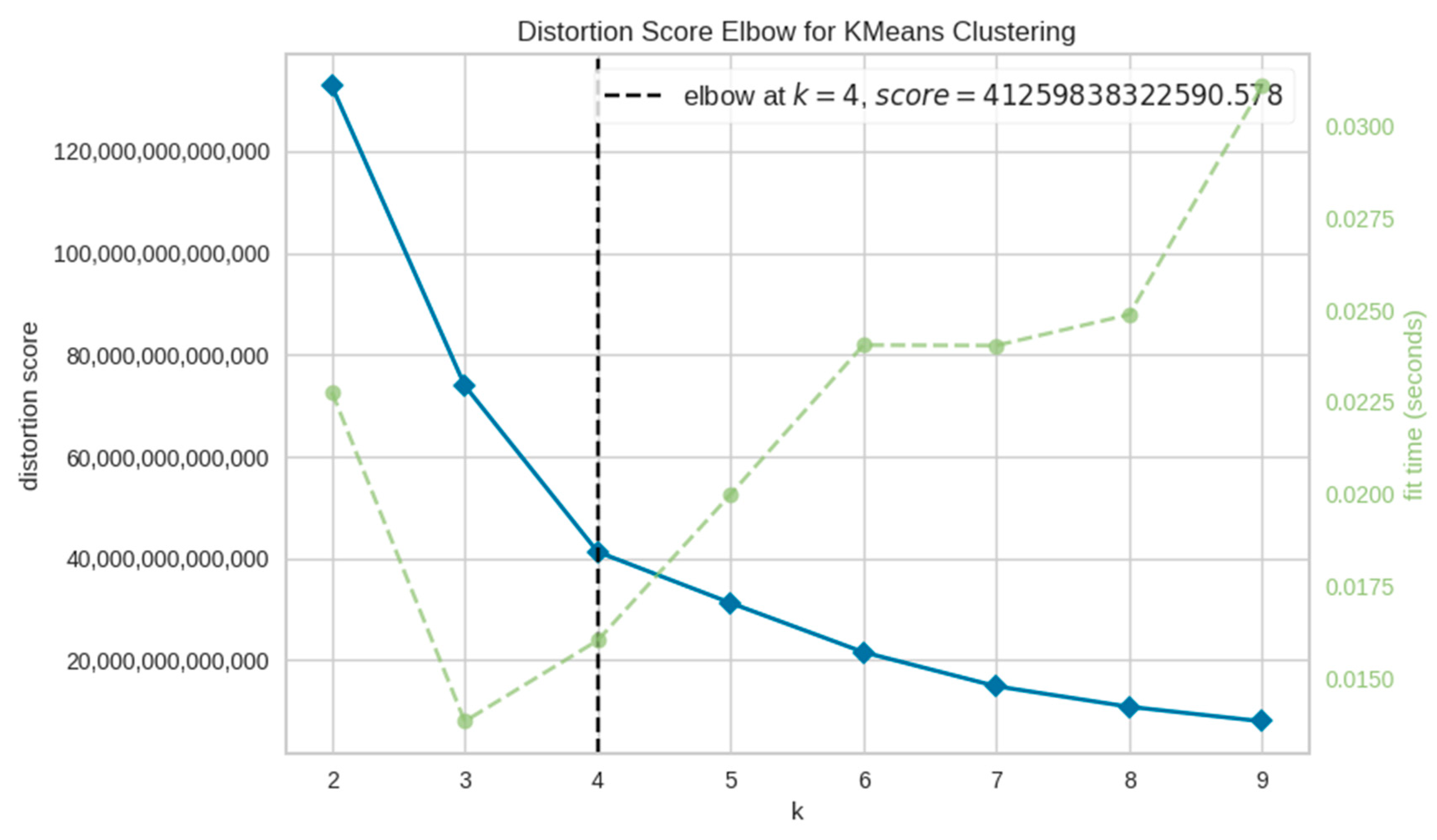
- Clustering (Figure 1, Block 4), according to A.E. Ezugwu and Ahmad A. [36,37], of waste generation locations: Using data on the place and time of waste generation, the clustering of waste generation sites is performed using clustering algorithms such as K-Means, agglomerative clustering, DBSCAN, birch, OPTICS, and spectral clustering.
- Agglomerative clustering (AC) [40] uses a hierarchical approach, combining the closest clusters by different distance metrics: single linkage, complete linkage, average linkage, etc.;
- DBSCAN [40] groups points based on density (minPts) and radius (eps): if the distance between and is less than eps, and the number of points in the neighborhood of is greater than minPts, and belong to the same cluster;
- Birch [40] is based on a CF-tree that stores cluster statistics (sum, number, and squares sum of points) for efficient clustering;
- OPTICS [41] is similar to DBSCAN but uses reachability and density order to define clusters, which allows distinguishing between clusters with different densities;
- Spectral clustering [42] uses the eigenvectors of the Laplace matrix of the adjacency graph to separate clusters that are related but not globally similar.
- Step 3.
3.1. ARIMA [46] (p, d, q)
3.2. DNN (Deep Neural Networks) [47]
3.3. XGBoost [48]
- Step 4.
- Step 5.
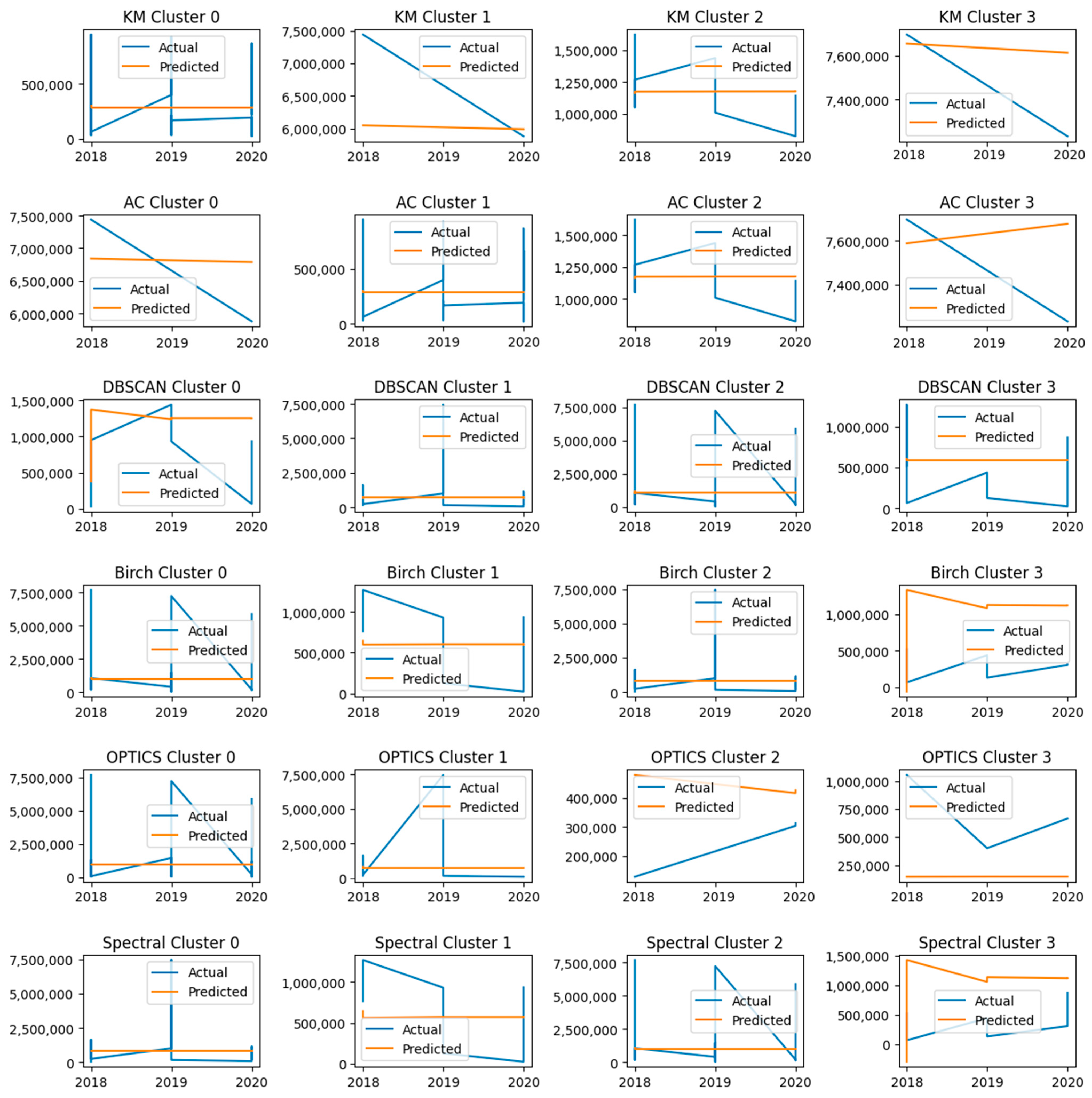
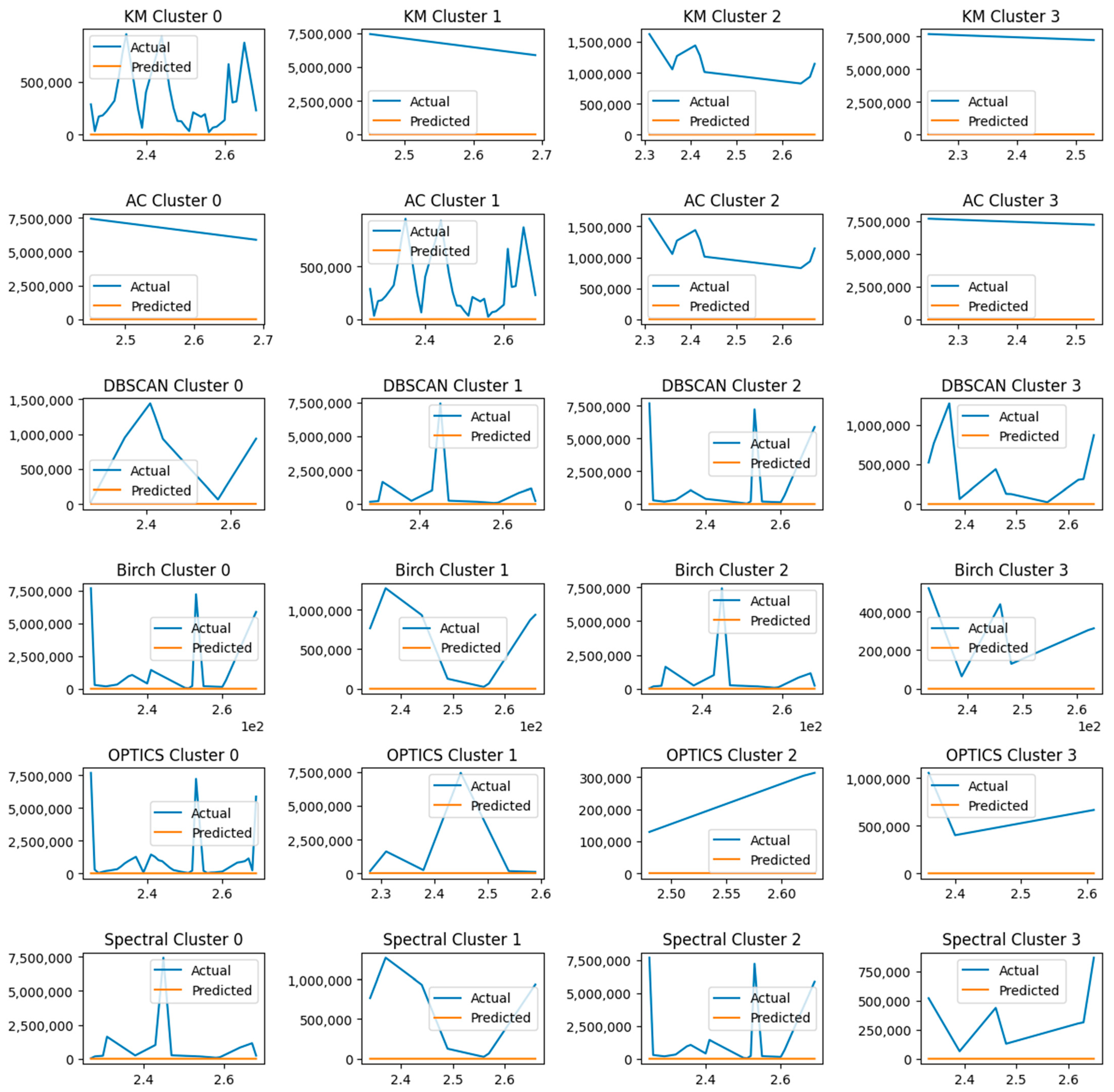
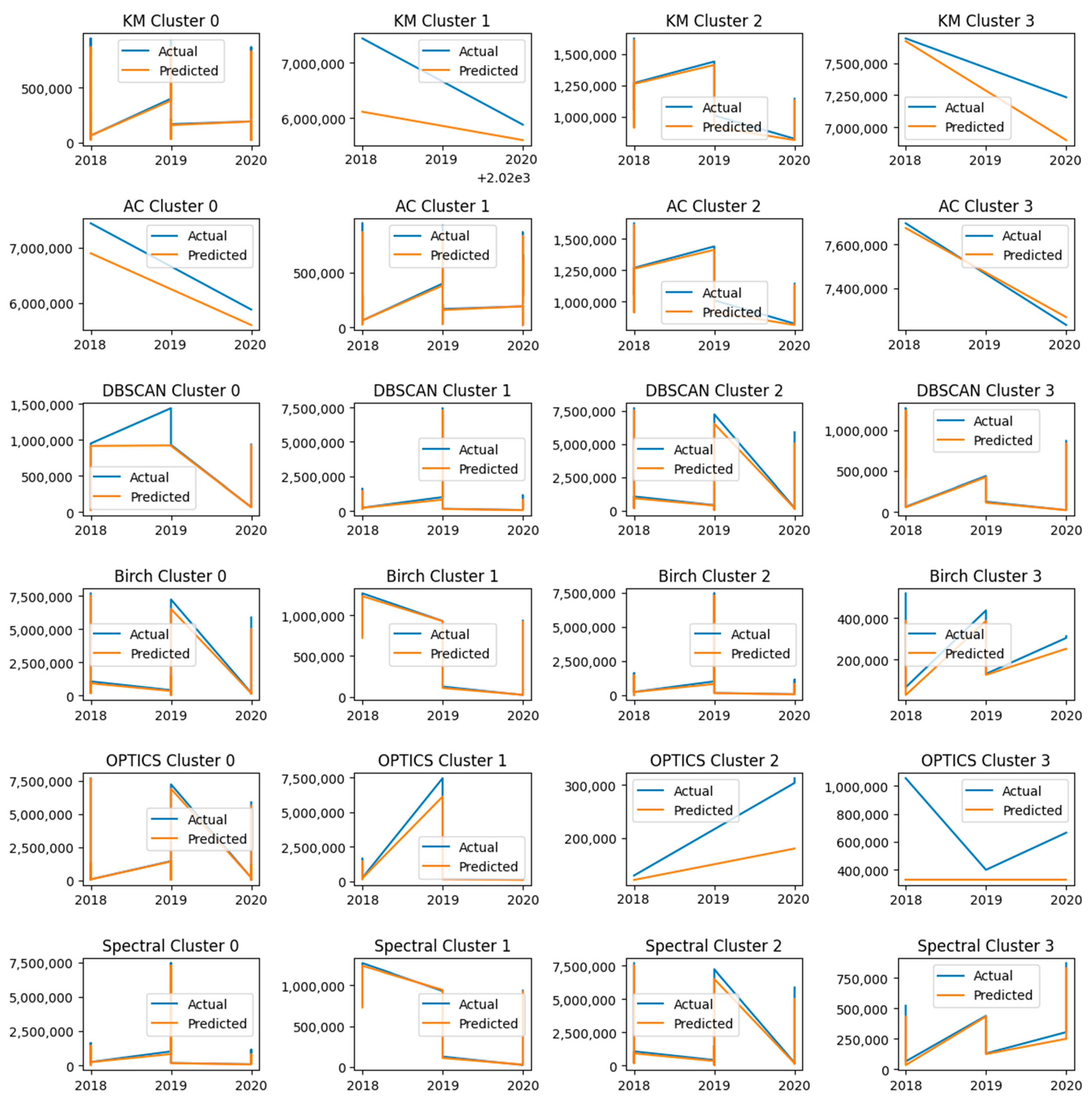
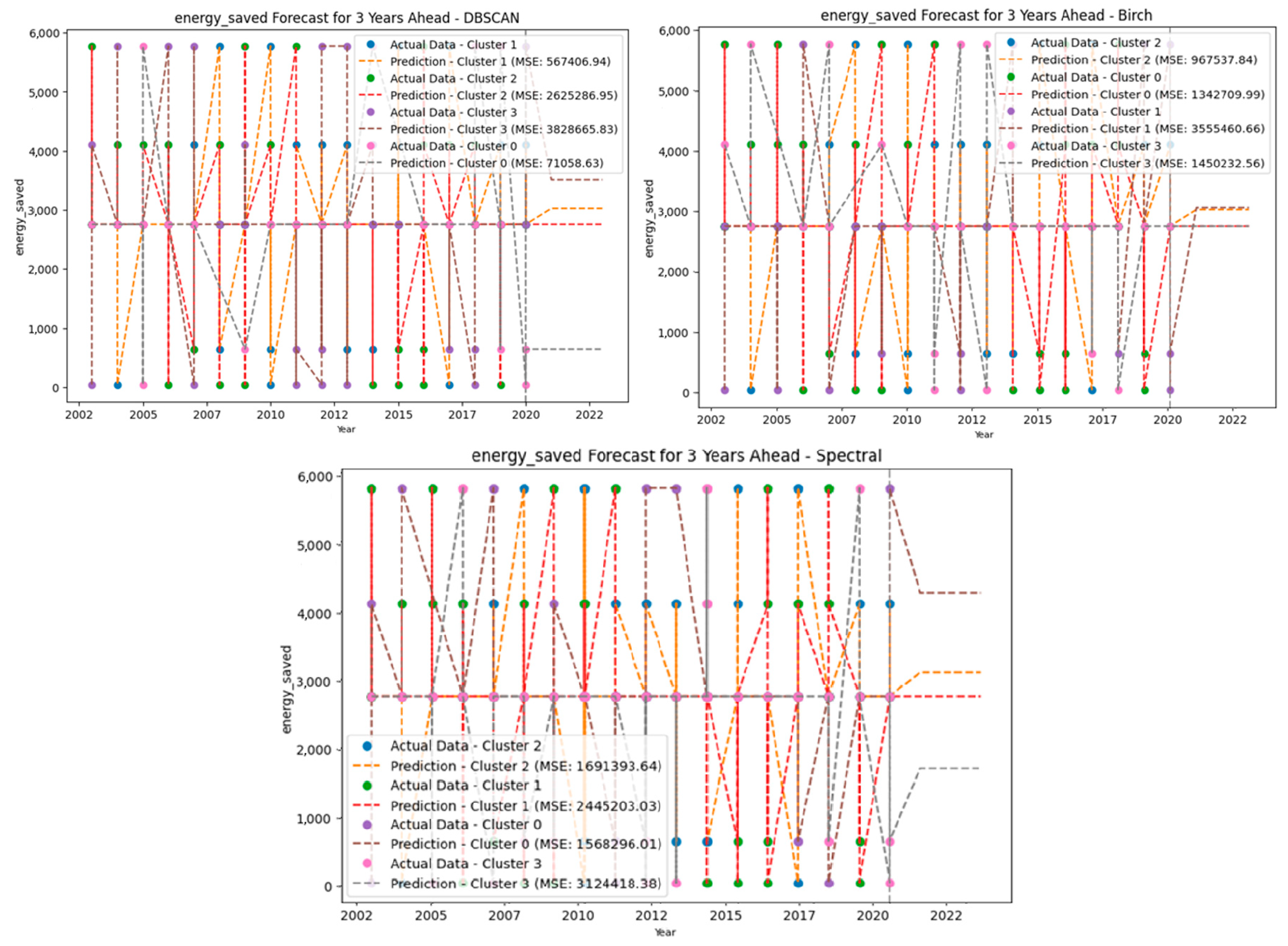
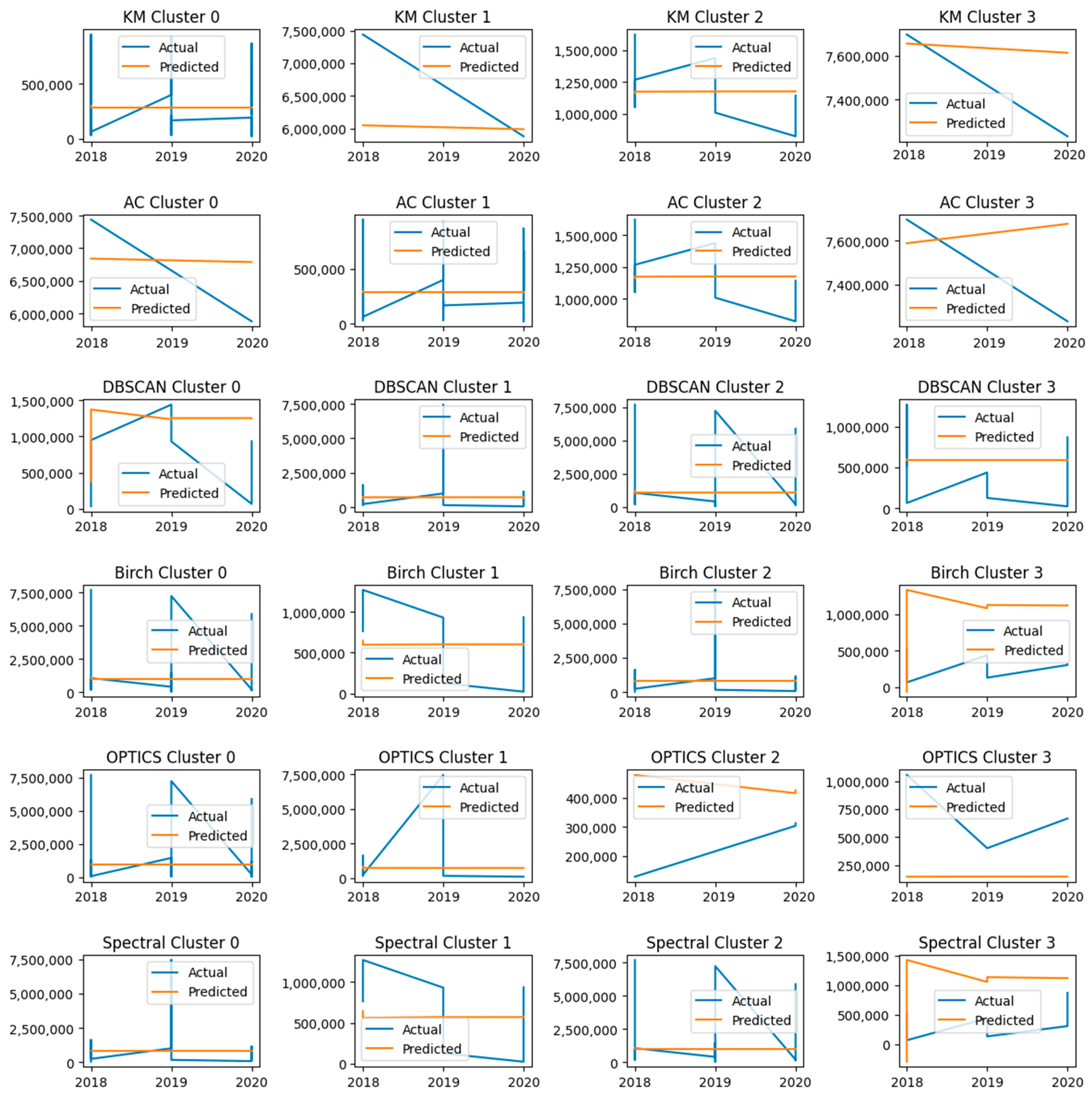
4. Results
- -
- MAE—708,051;
- -
- MSE—8.83075 × 1011;
- -
- RMSE—939,720.9474.
- -
- MAE—17,512.4694;
- -
- MSE—1,160,221,158.
5. Discussion
6. Conclusions
- -
- Cluster 0: best MAE 36,854.49 (birch);
- -
- Cluster 1: best MAE 7791.988 (agglomerative clustering);
- -
- Cluster 2: best MAE 28,470.26 (birch);
- -
- Cluster 3: best MAE 13,827.25 (spectral clustering).
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kaza, S.; Yao, L.C.; Bhada-Tata, P.; Van Woerden, F. What a Waste 2.0: A Global Snapshot of Solid Waste Management to 2050; World Bank: Washington, DC, USA, 2018. [Google Scholar] [CrossRef]
- Mensah, A. People and their waste in an emergency context: The case of Monrovia, Liberia. Habitat Int. 2006, 30, 754–768. [Google Scholar] [CrossRef]
- Internet of Things (IoT) Architecture: Layers Explained. Dgtl Infra. Available online: https://dgtlinfra.com/internet-of-things-iot-architecture/ (accessed on 26 September 2023).
- Kirimtat, A.; Krejcar, O.; Kertesz, A.; Tasgetiren, M.F. Future Trends and Current State of Smart City Concepts: A Survey. IEEE Access. 2020, 8, 86448–86467. [Google Scholar] [CrossRef]
- Adekola, P.O.; Iyalomhe, F.O.; Paczoski, A.; Abebe, S.T.; Pawłowska, B.; Bąk, M.; Cirella, G.T. Public perception and awareness of waste management from Benin City. Sci. Rep. 2021, 11, 306. [Google Scholar] [CrossRef] [PubMed]
- Gutberlet, J. Waste in the city: Challenges and opportunities for urban agglomerations. Urban Agglom. 2018, 21, 191. [Google Scholar]
- Raab, K.; Tolotti, G.; Wagner, R. Challenges in solid waste management: Insights into the disposal behavior of suburban consumers in Guatemala City. Front. Sustain. Cities 2021, 3, 683576. [Google Scholar] [CrossRef]
- Gardiner, R.; Hajek, P. Municipal waste generation, R&D intensity, and economic growth nexus—A case of EU regions. Waste Manag. 2020, 114, 124–135. [Google Scholar] [PubMed]
- Kebaili, F.K.; Baziz-Berkani, A.; Aouissi, H.A.; Mihai, F.-C.; Houda, M.; Ababsa, M.; Azab, M.; Petrisor, A.-I.; Fürst, C. Characterization and planning of household waste management: A case study from the MENA region. Sustainability 2022, 14, 5461. [Google Scholar] [CrossRef]
- Lee-Geiller, S.; Kütting, G. From management to stewardship: A comparative case study of waste governance in New York City and Seoul metropolitan city. Resour. Conserv. Recycl. 2021, 164, 105110. [Google Scholar] [CrossRef]
- Iqbal, A.; Liu, X.; Chen, G.H. Municipal solid waste: Review of best practices in application of life cycle assessment and sustainable management techniques. Sci. Total Environ. 2020, 729, 138622. [Google Scholar] [CrossRef]
- Lu, D.; Iqbal, A.; Zan, F.; Liu, X.; Dong, Z.; Jiang, C.; Chen, G. Integrated life cycle assessment with data envelopment analysis for enhancing medical waste management during a public health crisis. J. Clean. Prod. 2023, 426, 139074. [Google Scholar] [CrossRef]
- Iqbal, A.; Zan, F.; Liu, X.; Chen, G.H. Integrated municipal solid waste management scheme of Hong Kong: A comprehensive analysis in terms of global warming potential and energy use. J. Clean. Prod. 2019, 225, 1079–1088. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, X.; Mu, X.; Wang, Z.; Tian, R.; Wang, X.; Liu, X. Recyclable waste image recognition based on deep learning. Resour. Conserv. Recycl. 2021, 171, 105636. [Google Scholar] [CrossRef]
- Andeobu, L.; Wibowo, S.; Grandhi, S. Artificial intelligence applications for sustainable solid waste management practices in Australia: A systematic review. Sci. Total Environ. 2022, 834, 155389. [Google Scholar] [CrossRef] [PubMed]
- Lin, K.; Zhao, Y.; Kuo, J.-H.; Deng, H.; Cui, F.; Zhang, Z.; Zhang, M.; Zhao, C.; Gao, X.; Zhou, T.; et al. Toward smarter management and recovery of municipal solid waste: A critical review on deep learning approaches. J. Clean. Prod. 2022, 346, 130943. [Google Scholar] [CrossRef]
- Filho, R.H.; de Sousa, D.C.B.; de Brito, W.A.; Chaves, J.L.M.d.S.; Sá, E.L.; Ribeiro, V.P.d.A. Increasing Data Availability for Solid Waste Collection Using an IoT Platform based on LoRaWAN and Blockchain. Procedia Comput. Sci. 2023, 220, 119–126. [Google Scholar] [CrossRef]
- Castiglione, A.; Cimmino, L.; Di Nardo, M.; Murino, T. A framework for achieving a circular economy us-ing the blockchain technology in a sustainable waste management system. Comput. Ind. Eng. 2023, 180, 109263. [Google Scholar] [CrossRef]
- Hidalgo-Crespo, J.; Álvarez-Mendoza, C.I.; Soto, M.; Amaya-Rivas, J. Quantification and mapping of domestic plastic waste using GIS/GPS approach at the city of Guayaquil. Procedia CIRP 2022, 105, 86–91. [Google Scholar] [CrossRef]
- Li, N.; Chen, Y. Municipal solid waste classification and real-time detection using deep learning methods. Urban Clim. 2023, 49, 101462. [Google Scholar] [CrossRef]
- Saha, S.; Chaki, R. IoT based smart waste management system in aspect of COVID-19. J. Open Innov. Technol. Mark. Complex. 2023, 9, 100048. [Google Scholar] [CrossRef]
- Gue, I.H.V.; Lopez, N.S.A.; Chiu, A.S.; Ubando, A.T.; Tan, R.R. Predicting waste management system performance from city and country attributes. J. Clean. Prod. 2022, 366, 132951. [Google Scholar] [CrossRef]
- Zhang, C.; Dong, H.; Geng, Y.; Liang, H.; Liu, X. Machine learning based prediction for China’s municipal solid waste under the shared socioeconomic pathways. J. Environ. Manag. 2022, 312, 114918. [Google Scholar] [CrossRef] [PubMed]
- Kutty, A.A.; Wakjira, T.G.; Kucukvar, M.; Abdella, G.M.; Onat, N.C. Urban resilience and livability performance of European smart cities: A novel machine learning approach. J. Clean. Prod. 2022, 378, 134203. [Google Scholar] [CrossRef]
- Izquierdo-Horna, L.; Damazo, M.; Yanayaco, D. Identification of urban sectors prone to solid waste accumulation: A machine learning approach based on social indicators. Computers. Environ. Urban Syst. 2022, 96, 101834. [Google Scholar] [CrossRef]
- El Ouadi, J.; Malhene, N.; Benhadou, S.; Medromi, H. Towards a machine-learning based approach for split-ting cities in freight logistics context: Benchmarks of clustering and prediction models. Comput. Ind. Eng. 2022, 166, 107975. [Google Scholar] [CrossRef]
- El Ouadi, J.; Malhene, N.; Benhadou, S.; Medromi, H. Strategic zoning approach for urban areas: Towards a shared transportation system. Procedia Comput. Sci. 2020, 170, 211–218. [Google Scholar] [CrossRef]
- El Ouadi, J.; Errousso, H.; Benhadou, S.; Medromi, H.; Malhene, N. A machine-learning based approach for zoning urban area in consolidation schemes context. In Proceedings of the 2020 IEEE 13th International Colloquium of Logistics and Supply Chain Management (LOGISTIQUA), IEEE, Fez, Morocco, 2–4 December 2020; pp. 1–7. [Google Scholar]
- Gramyak, R.; Lipyanina-Goncharenko, H.; Sachenko, A.; Lendyuk, T.; Zahorodnia, D. Intelligent Method of a Competitive Product Choosing based on the Emotional Feedbacks Coloring. IntelITSIS 2021, 2853, 246–257. [Google Scholar]
- Lipyanina, H.; Maksymovych, V.; Sachenko, A.; Lendyuk, T.; Fomenko, A.; Kit, I. Assessing the investment risk of virtual IT company based on machine learning. In International Conference on Data Stream Mining and Processing; Springer International Publishing: Cham, Switzerland, 2020; pp. 167–187. [Google Scholar]
- Singapore Waste Management. Kaggle: Your Machine Learning and Data Science Community. Available online: https://www.kaggle.com/datasets/kingabzpro/singapore-waste-management?select=waste_energy_stat.csv (accessed on 28 September 2023).
- Lipyanina, H.; Sachenko, S.; Lendyuk, T.; Brych, V.; Yatskiv, V.; Osolinskiy, O. Method of detecting a fictitious company on the machine learning base. In Advances in Computer Science for Engineering and Education IV; Springer International Publishing: Cham, Switzerland, 2021; pp. 138–146. [Google Scholar] [CrossRef]
- Wang, C.; Shakhovska, N.; Sachenko, A.; Komar, M. A New Approach for Missing Data Imputation in Big Data Interface. Inf. Technol. Control. 2020, 49, 541–555. [Google Scholar] [CrossRef]
- Golovko, V.; Kroshchanka, A.; Bezobrazov, S.; Sachenko, A.; Komar, M.; Novosad, O. Development of solar panels detector. In Proceedings of the 2018 International Scientific-Practical Conference Problems of Infocommunications, Science and Technology (PIC S&T), IEEE, Kharkiv, Ukraine, 9–12 October 2018; pp. 761–764. [Google Scholar] [CrossRef]
- Komar, M.; Dorosh, V.; Hladiy, G.; Sachenko, A. Deep neural network for detection of cyber attacks. In Proceedings of the 2018 IEEE First International Conference on System Analysis & Intelligent Computing (SAIC), IEEE, Kyiv, Ukraine, 8–12 October 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Ezugwu, A.E.; Ikotun, A.M.; Oyelade, O.O.; Abualigah, L.; Agushaka, J.O.; Eke, C.I.; Akinyelu, A.A. A comprehensive survey of clustering algorithms: State-of-the-art machine learning applications, taxonomy, challenges, and future research prospects. Eng. Appl. Artif. Intell. 2022, 110, 104743. [Google Scholar] [CrossRef]
- Ahmad, A.; Khan, S.S. Survey of State-of-the-Art Mixed Data Clustering Algorithms. IEEE Access. 2019, 7, 31883–31902. [Google Scholar] [CrossRef]
- Lipianina-Honcharenko, K.; Wolff, C.; Chyzhovska, Z.; Sachenko, A.; Lendiuk, T.; Grodskyi, S. Intelligent Method for Forming the Consumer Basket. In International Conference on Information and Software Technologies; Springer International Publishing: Cham, Switzerland, 2022; pp. 221–231. [Google Scholar]
- Asri, H. Big Data and IoT for real-time miscarriage prediction A clustering comparative study. In Procedia Computer Science; Elsevier: Amsterdam, The Netherlands, 2021; Volume 191, pp. 200–206. [Google Scholar] [CrossRef]
- Tokuda, E.K.; Comin, C.H.; Costa, L.d.F. Revisiting agglomerative clustering. Phys. A Stat. Mech. Its Appl. 2022, 585, 126433. [Google Scholar] [CrossRef]
- Wu, C.; Chen, Y.; Dong, Y.; Zhou, F.; Zhao, Y.; Liang, C.J. VizOPTICS: Getting insights into OPTICS via interactive visual analysis. Comput. Electr. Eng. 2023, 107, 108624. [Google Scholar] [CrossRef]
- Hu, Z.; Nie, F.; Wang, R.; Li, X. Multi-view spectral clustering via integrating nonnegative embedding and spectral embedding. Inf. Fusion 2020, 55, 251–259. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Stavroyiannis, S.; Pintelas, P. Ensemble Deep Learning Models for Forecasting Cryptocurrency Time-Series. Algorithms 2020, 13, 121. [Google Scholar] [CrossRef]
- Hajirahimi, Z.; Khashei, M. Hybrid structures in time series modeling and forecasting: A review. Eng. Appl. Artif. Intell. 2019, 86, 83–106. [Google Scholar] [CrossRef]
- Anfilets, S.; Bezobrazov, S.; Golovko, V.; Sachenko, A.; Komar, M.; Dolny, R.; Kasyanik, V.; Bykovyy, P.; Mikhno, E.; Osolinskyi, O. Deep multilayer neural network for predicting the winner of football matches. Int. J. Comput. 2020, 19, 70–77. [Google Scholar] [CrossRef]
- Krylov, V.; Sachenko, A.; Strubytskyi, P.; Lendiuk, D.; Lipyanina, H.; Zahorodnia, D.; Lendyuk, T. Multiple regression method for analyzing the tourist demand considering the influence factors. In Proceedings of the 2019 10th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Metz, France, 18–21 September 2019; Volume 2, pp. 974–979. [Google Scholar] [CrossRef]
- Howlader, A.M.; Patel, D.; Gammariello, R. Data-driven approach for instantaneous vehicle emission predicting using integrated deep neural network. Transp. Res. Part D Transp. Environ. 2023, 116, 103654. [Google Scholar] [CrossRef]
- Yan, Z.; Chen, H.; Dong, X.; Zhou, K.; Xu, Z. Research on prediction of multi-class theft crimes by an optimized decomposition and fusion method based on XGBoost. Expert Syst. Appl. 2022, 207, 117943. [Google Scholar] [CrossRef]
- Kolassa, S. Do we want coherent hierarchical forecasts, or minimal MAPEs or MAEs?(We won’t get both!). Int. J. Forecast. 2023, 39, 1512–1517. [Google Scholar] [CrossRef]
- Daubechies, I.; DeVore, R.; Foucart, S.; Hanin, B.; Petrova, G. Nonlinear approximation and (deep) ReLU networks. Constr. Approx. 2022, 55, 127–172. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Description | Results |
|---|---|---|
| Qiang Zhang et al. [14] | Improving the accuracy of waste sorting using deep learning methods. A model for classifying waste images based on deep learning was proposed. A self-supervision module was added to the residual block network model. Tested on the TrashNet dataset. | Waste image classification accuracy: 95.87%. |
| Kunsen Lin et al. [16] | An overview of the application of deep learning methods in municipal solid waste management and recovery. Different algorithms and their applications were considered. | CNNs are widely used for waste sorting (89.61%), the next most popular are ANNs (6.49%), areLSTMs (2.56%), and GANs (1.34%). |
| Ninghui Li et al. [20] | Using deep learning to detect and classify waste. CNN and Graph-LSTM were used to recognize waste on a belt conveyor. | System accuracy on real objects: 97.5%. |
| Gue et al. [22] | Use of interpreted machine learning models to link city attributes and waste management system performance. A rule-based machine learning model for city attributes and waste management performance was developed. | Classification accuracy: 89–91%. |
| Zhang et al. [23] | Forecasting the volume of municipal solid waste in China using machine learning (XGBoost). | Increase in municipal solid waste in China, volume forecast for 2060. |
| Kutty et al. [24] | Assessing the sustainability and livability of cities using machine learning methods. | A model was developed to assess the sustainability and suitability of different cities. |
| Izquierdo-Horna et al. [25] | Using machine learning to identify areas with solid waste accumulation in cities. | The RF algorithm detects classes with waste accumulation. Accuracy: 63–64%. |
| El Ouadi et al. [26] | Application of machine learning to divide cities into sectors in the context of freight logistics. | The SVM algorithm showed the best result, about 95%. |
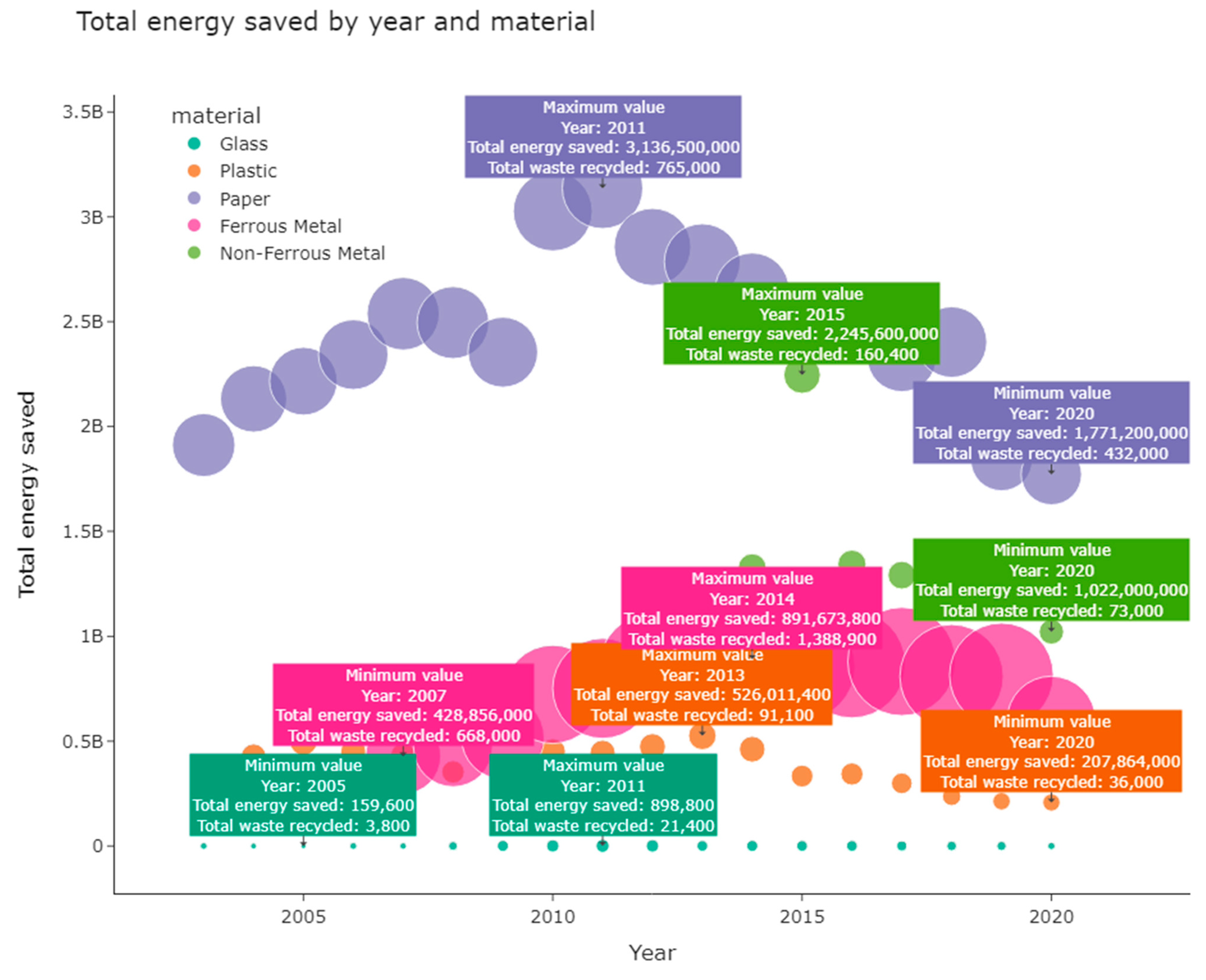
| Waste_Type | Recycling_Rate |
|---|---|
| Ferrous metal | 0.900714 |
| Glass | 0.166667 |
| Non-ferrous metal | 0.942857 |
| Paper | 0.498333 |
| Plastic | 0.086667 |
| Cluster | MAE_KM | MSE_KM | MAE_AC | MSE_AC | MAE_DBSCAN | MSE_DBSCAN |
| 0 | 88,026.97 | 1.15 × 1010 | 2,789,141 | 9.57 × 1012 | 880,265.1 | 2.07 × 1012 |
| 1 | 184,962.7 | 4.01 × 1010 | 88,026.97 | 1.15 × 1010 | 460,953 | 2.59 × 1011 |
| 2 | 480,856.5 | 3.04 × 1011 | 480,856.5 | 3.04 × 1011 | 1,040,098 | 2.17 × 1012 |
| 3 | 2,210,423 | 6.7 × 1012 | 208,962.4 | 4.98 × 1010 | 309,976.9 | 2.18 × 1011 |
| Cluster | MAE_Birch | MSE_Birch | MAE_OPTICS | MSE_OPTICS | MAE_Spectral | MSE_Spectral |
| 0 | 950,825.9 | 1.78 × 1012 | 825,342.1 | 1.46 × 1012 | 2,508,444 | 6.92 × 1012 |
| 1 | 382,085.7 | 2.52 × 1011 | 482,378.7 | 3.17 × 1011 | 957,179.1 | 1.78 × 1012 |
| 2 | 483,847.3 | 2.76 × 1011 | 54,969.14 | 4.84 × 109 | 485,186.4 | 2.77 × 1011 |
| 3 | 2,467,320 | 6.75 × 1012 | 228,094.7 | 8.71 × 1010 | 221,838.9 | 7.93 × 1010 |
| Cluster | MAE_KM | MSE_KM | MAE_AC | MSE_AC | MAE_DBSCAN | MSE_DBSCAN |
| 0 | 295,809.4 | 1.56 × 1011 | 6,659,999 | 4.5 × 1013 | 804,137.2 | 9.07 × 1011 |
| 1 | 7,464,499 | 5.58 × 1013 | 296,076.6 | 1.57 × 1011 | 1,038,752 | 4.72 × 1012 |
| 2 | 1,175,435 | 1.44 × 1012 | 1,175,427 | 1.44 × 1012 | 1,740,194 | 1.06 × 1013 |
| 3 | 6,659,996 | 4.5 × 1013 | 7,464,499 | 5.58 × 1013 | 437,984.4 | 3.31 × 1011 |
| Cluster | MAE_Birch | MSE_Birch | MAE_OPTICS | MSE_OPTICS | MAE_Spectral | MSE_Spectral |
| 0 | 1,648,788 | 8.99 × 1012 | 1,081,495 | 4.83 × 1012 | 376,712 | 2.04 × 1011 |
| 1 | 622,368.5 | 5.88 × 1011 | 1,624,832 | 9.69 × 1012 | 1,648,786 | 8.99 × 1012 |
| 2 | 966,808.8 | 4.38 × 1012 | 248,666.3 | 6.9 × 1010 | 966,818.8 | 4.38 × 1012 |
| 3 | 294,831.3 | 1.12 × 1011 | 706,327.3 | 5.71 × 1011 | 587,280.1 | 5.64 × 1011 |
| Cluster | MAE_KM | MSE_KM | MAE_AC | MSE_AC | MAE_DBSCAN | MSE_DBSCAN |
| 0 | 7791.988 | 2.58 × 108 | 315,950.5 | 1.51 × 1011 | 217,556.1 | 1.46 × 1011 |
| 1 | 31,274.75 | 1.02 × 109 | 7791.988 | 2.58 × 108 | 29,536.66 | 3.69 × 109 |
| 2 | 31,683.96 | 2.04 × 109 | 31,683.96 | 2.04 × 109 | 43,658.28 | 6.86 × 109 |
| 3 | 708,051 | 8.83 × 1011 | 31,274.63 | 1.02 × 109 | 21,710.09 | 3.18 × 109 |
| Cluster | MAE_Birch | MSE_Birch | MAE_OPTICS | MSE_OPTICS | MAE_Spectral | MSE_Spectral |
| 0 | 36,854.49 | 5.21 × 109 | 17,512.47 | 1.16 × 109 | 60,089.5 | 1.04 × 1010 |
| 1 | 36,116.84 | 5.15 × 109 | 206,123.7 | 2.24 × 1011 | 42,911.9 | 5.95 × 109 |
| 2 | 28,470.26 | 3.51 × 109 | 29,513.58 | 1.37 × 109 | 28,951.16 | 3.53 × 109 |
| 3 | 46,568.81 | 4.49 × 109 | 258,016.7 | 1.53 × 1011 | 13,827.25 | 4.79 × 108 |
| Authors | Forecast Accuracy | Approaches Used |
|---|---|---|
| Gue et al. [22] | 89–91% | A machine learning model based on rough sets |
| Zhang et al. [23] | ~95% (XGBoost) | Machine learning methods and common socioeconomic paths |
| Izquierdo-Horna et al. [25] | 63–64% (RF) | Machine learning approach based on social metrics |
| El Ouadi et al. [26,27,28] | ~95% (SVM) | Machine learning for city separation in the context of logistics |
| Proposed method | ~98% (XGBoost) | Machine learning methods: clustering, XGBoost, and forecasting methods |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lipianina-Honcharenko, K.; Komar, M.; Osolinskyi, O.; Shymanskyi, V.; Havryliuk, M.; Semaniuk, V. Intelligent Waste-Volume Management Method in the Smart City Concept. Smart Cities 2024, 7, 78-98. https://doi.org/10.3390/smartcities7010004
Lipianina-Honcharenko K, Komar M, Osolinskyi O, Shymanskyi V, Havryliuk M, Semaniuk V. Intelligent Waste-Volume Management Method in the Smart City Concept. Smart Cities. 2024; 7(1):78-98. https://doi.org/10.3390/smartcities7010004
Chicago/Turabian StyleLipianina-Honcharenko, Khrystyna, Myroslav Komar, Oleksandr Osolinskyi, Volodymyr Shymanskyi, Myroslav Havryliuk, and Vita Semaniuk. 2024. "Intelligent Waste-Volume Management Method in the Smart City Concept" Smart Cities 7, no. 1: 78-98. https://doi.org/10.3390/smartcities7010004
APA StyleLipianina-Honcharenko, K., Komar, M., Osolinskyi, O., Shymanskyi, V., Havryliuk, M., & Semaniuk, V. (2024). Intelligent Waste-Volume Management Method in the Smart City Concept. Smart Cities, 7(1), 78-98. https://doi.org/10.3390/smartcities7010004