Predicting Venue Popularity Using Crowd-Sourced and Passive Sensor Data



Abstract
1. Introduction
2. Methodology
2.1. Research Area
2.2. Data Sources
2.3. Data Structure
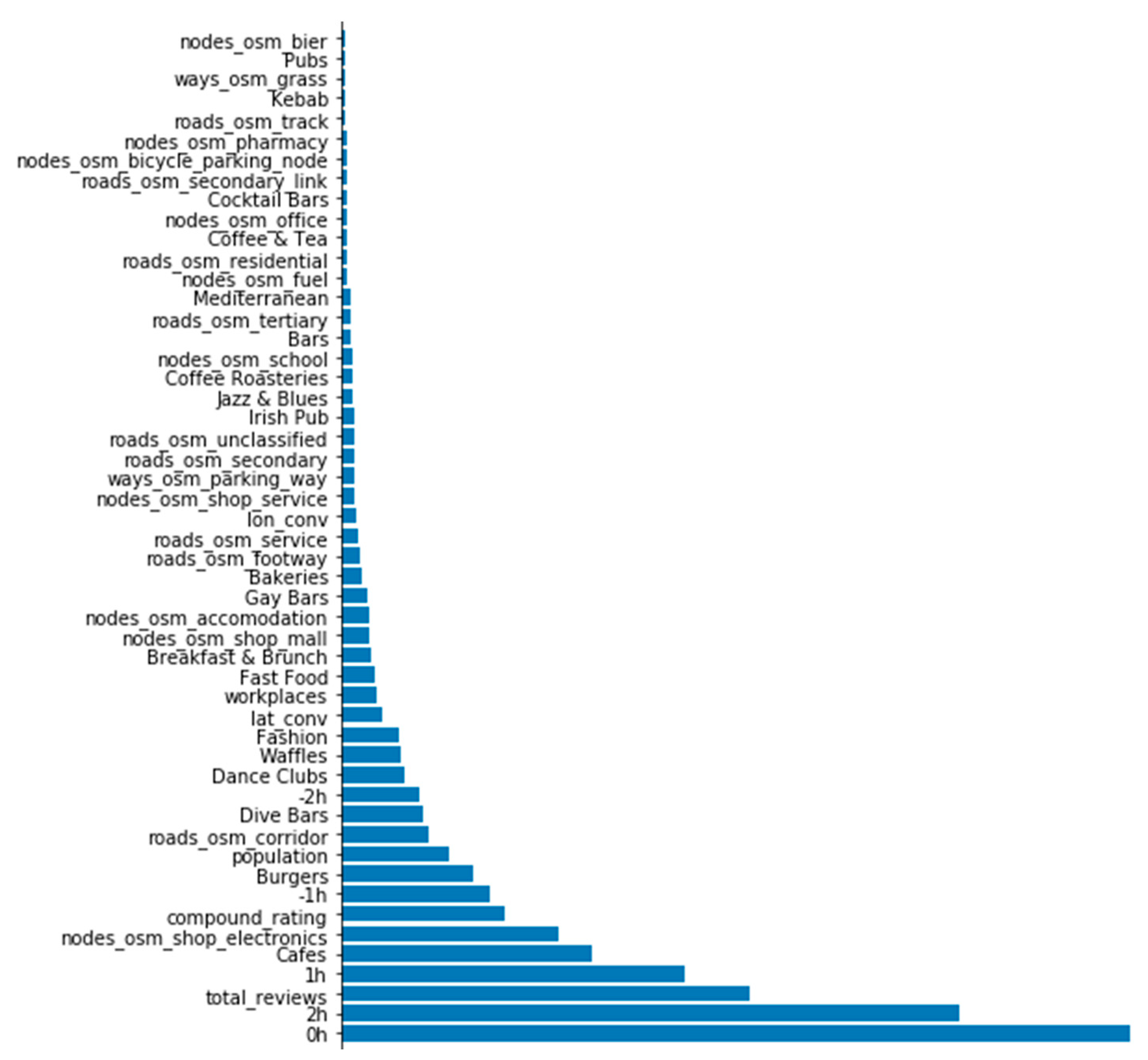
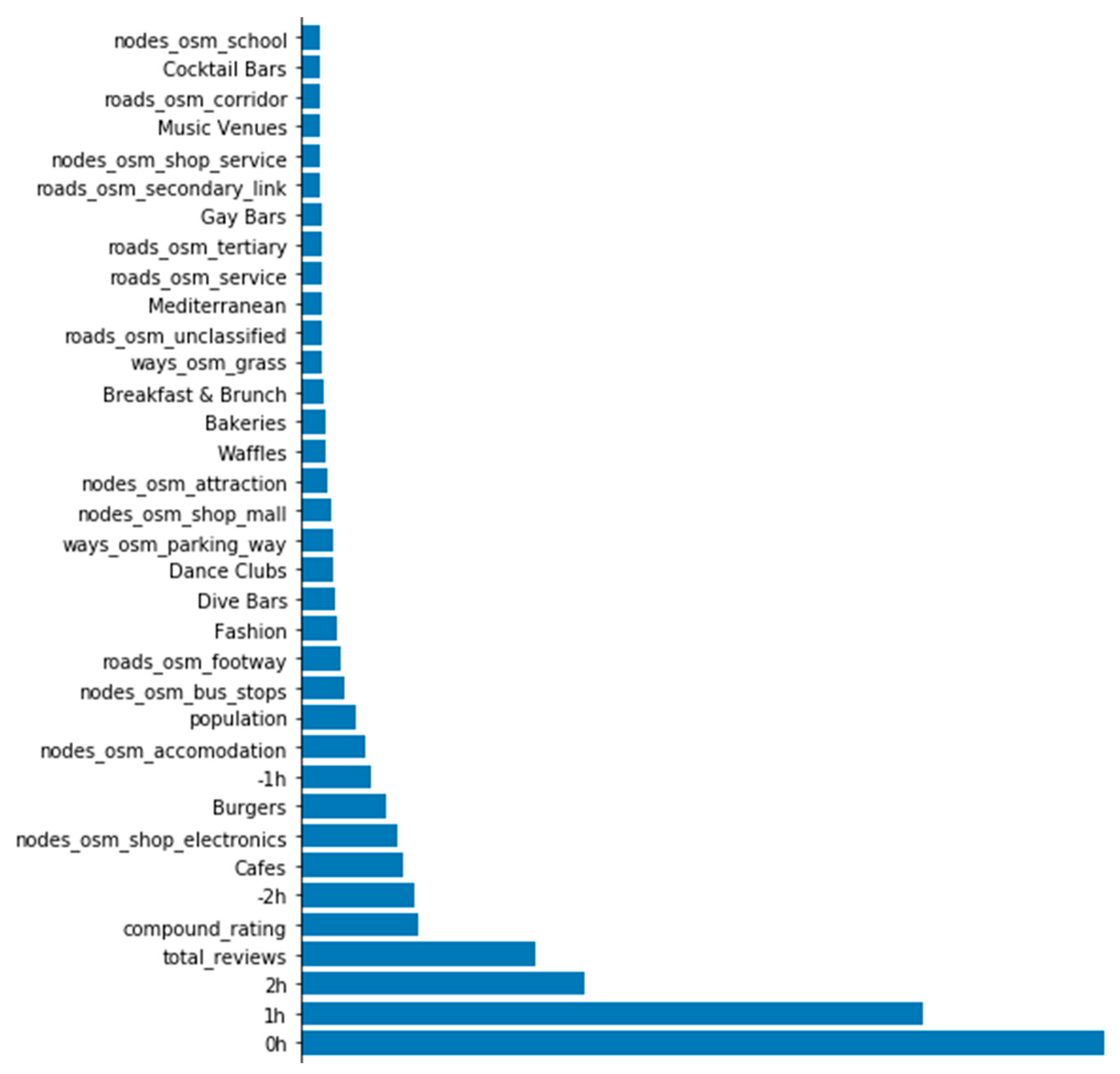
3. Modeling
4. Discussion of Venue Popularity Measuring
4.1. Setup Description
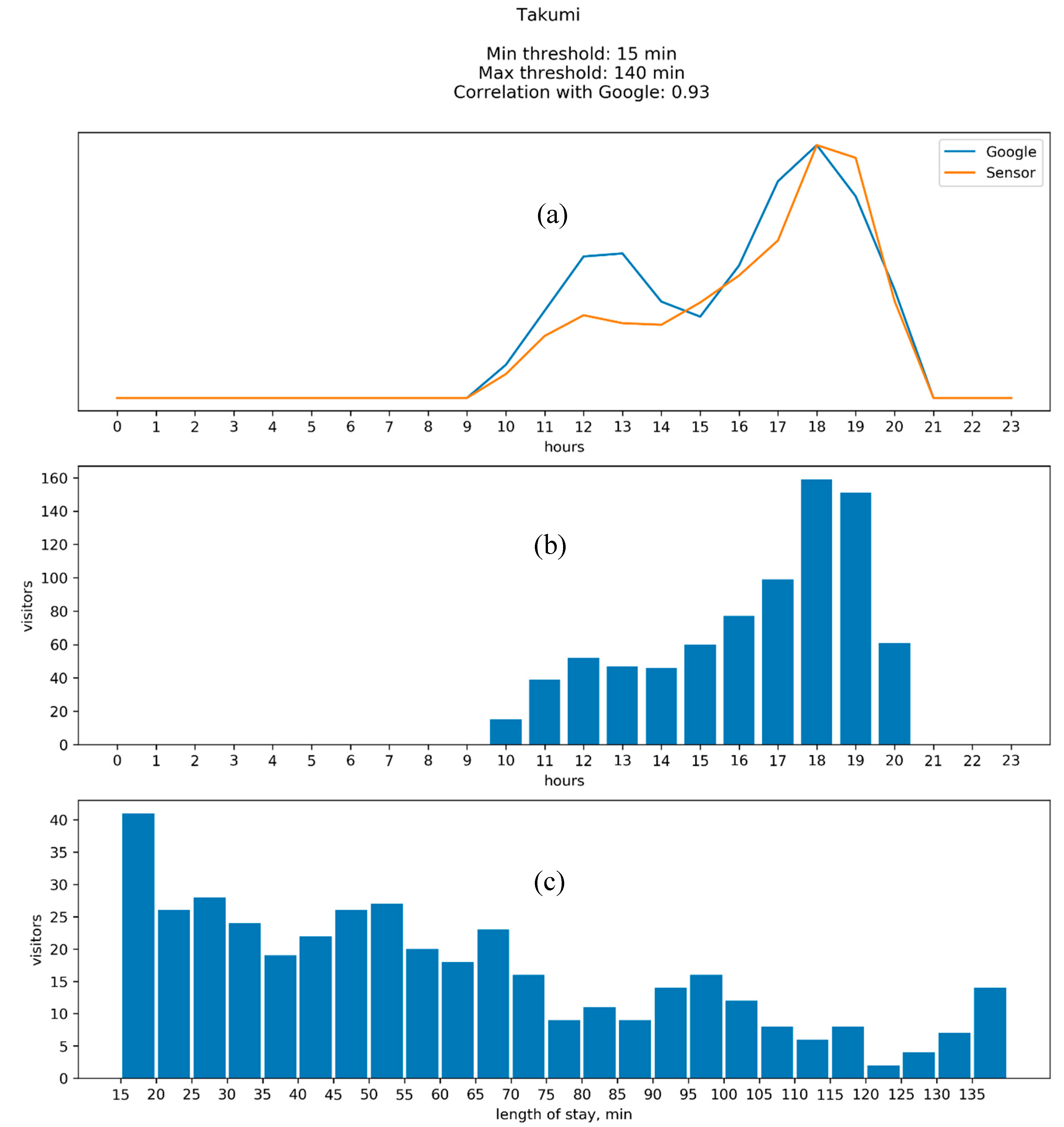
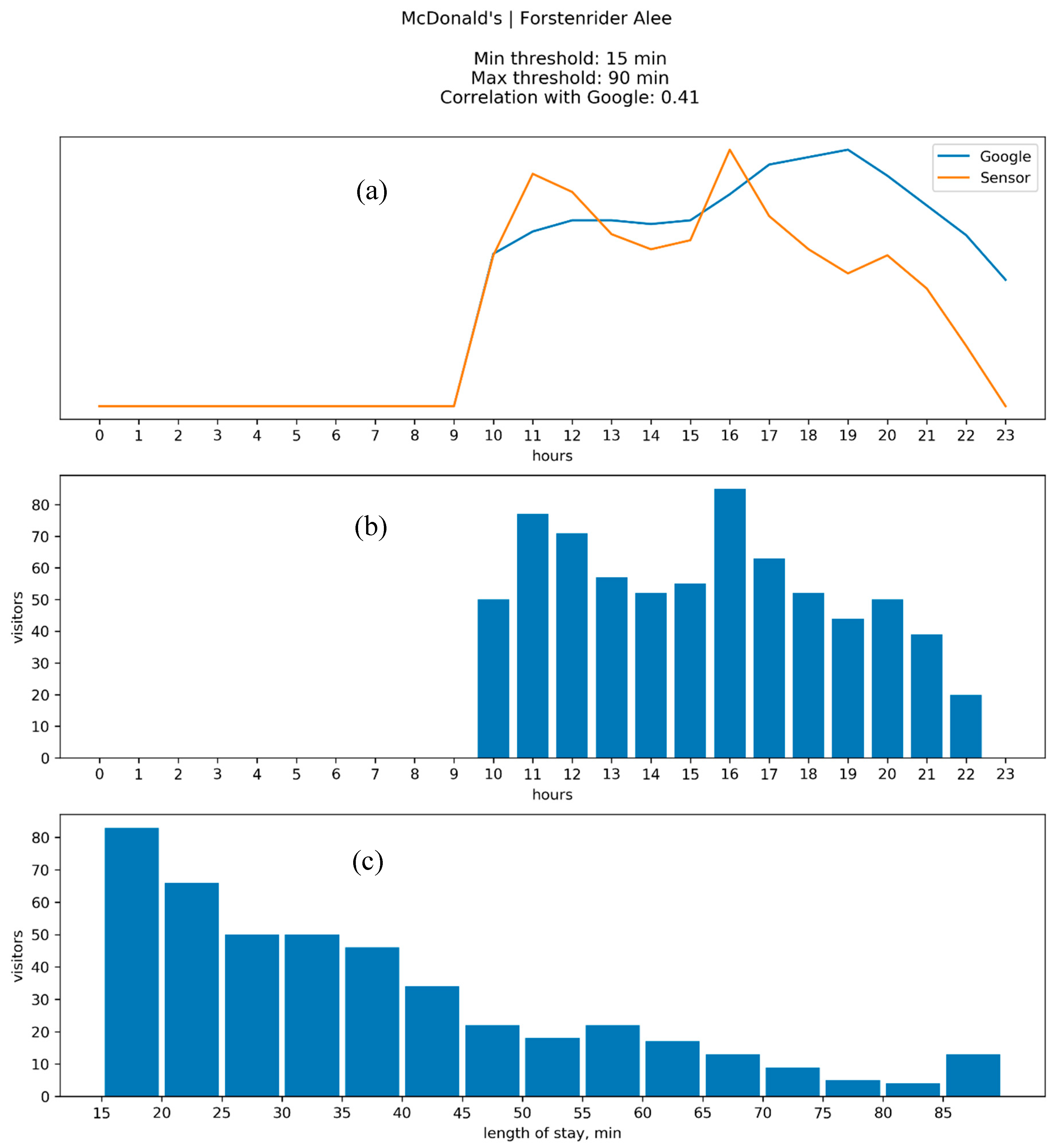
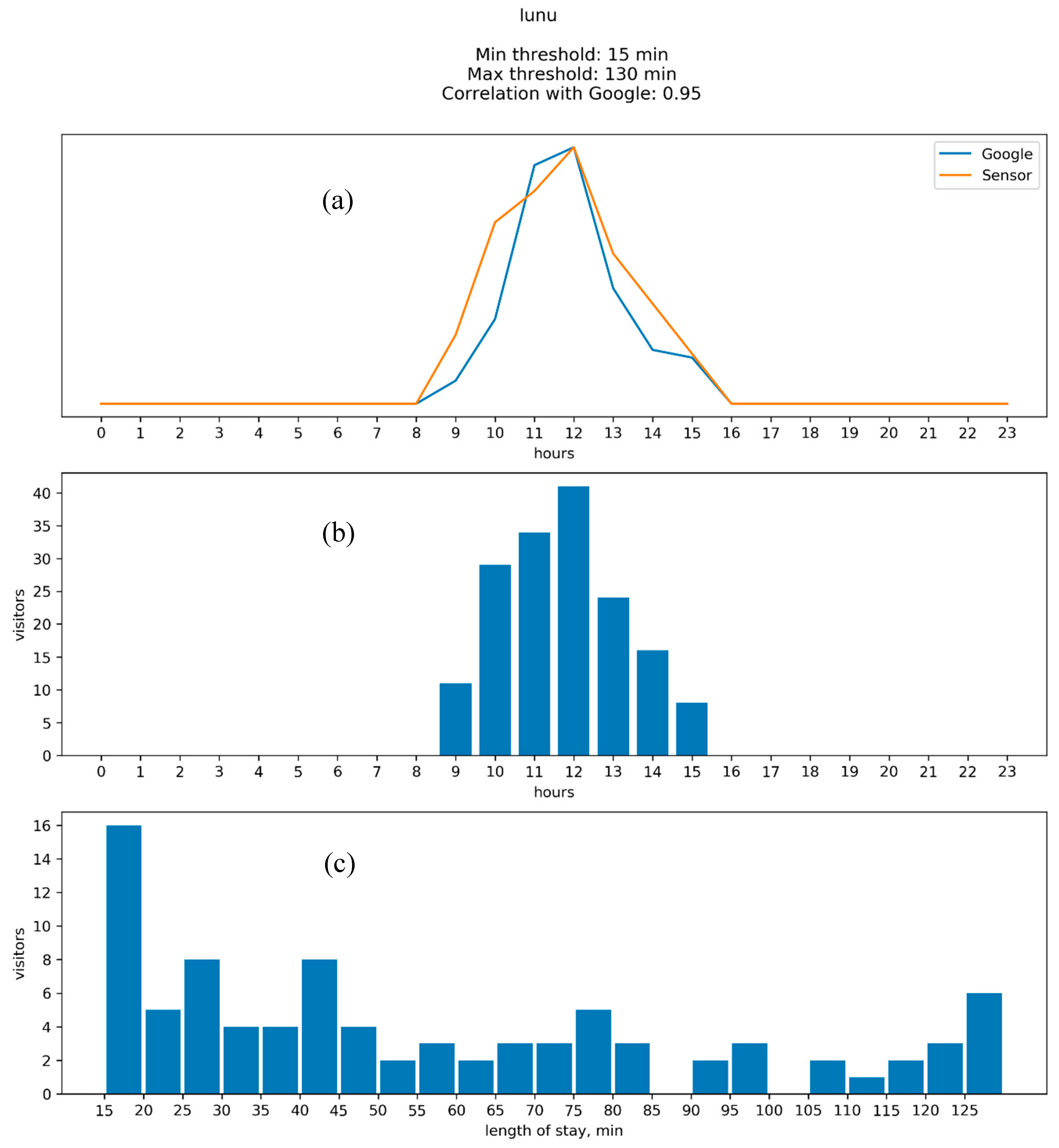
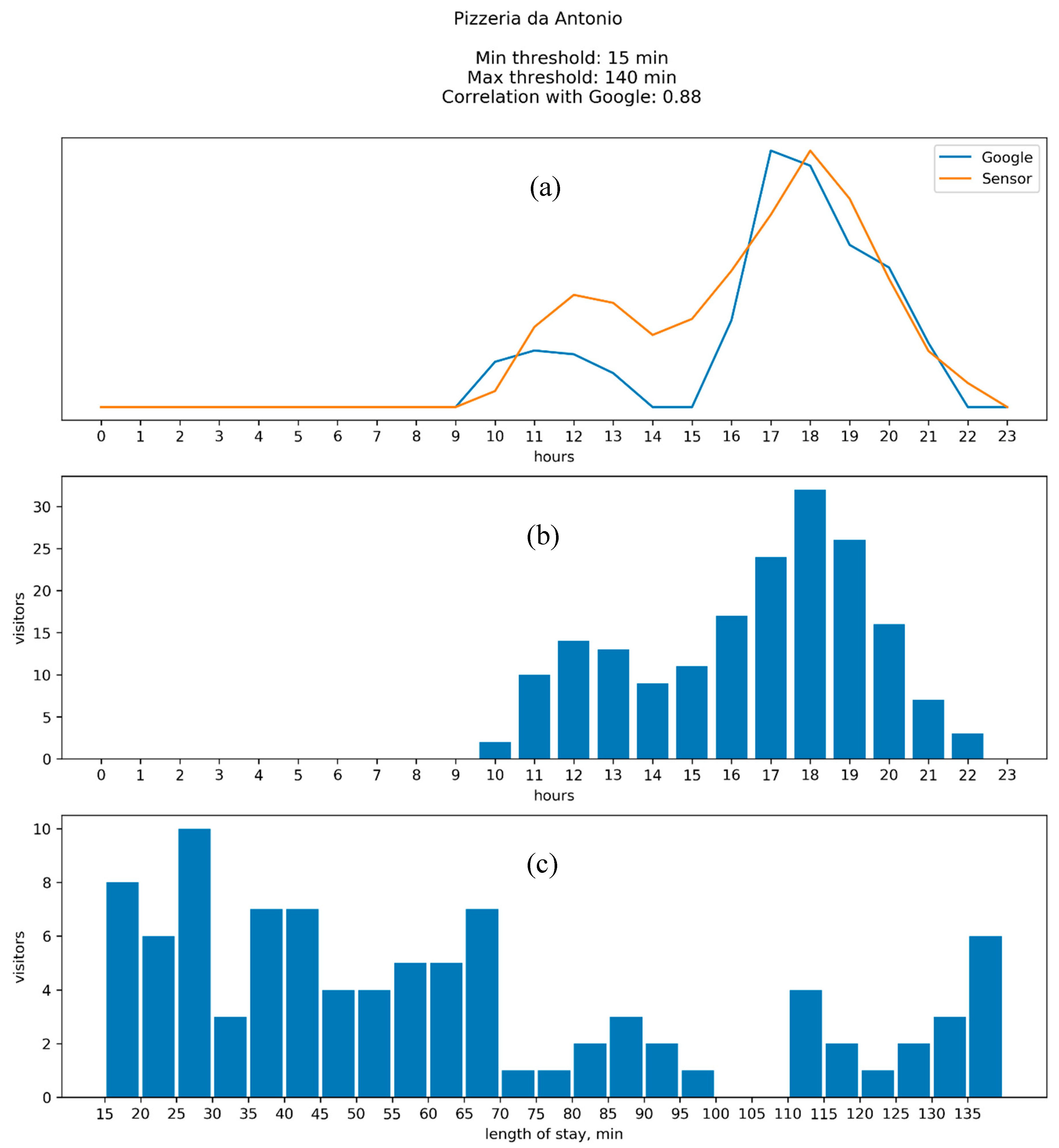
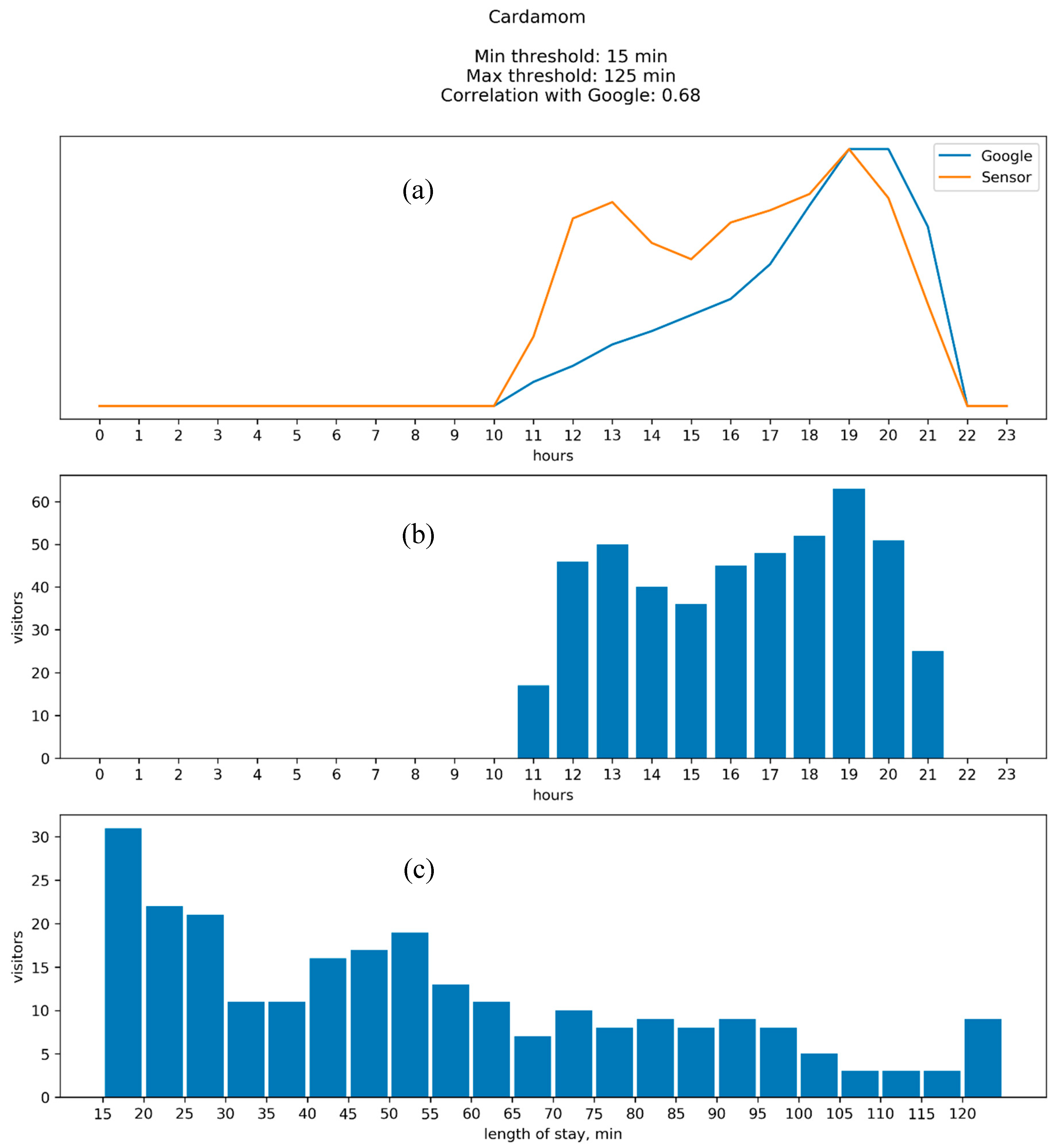
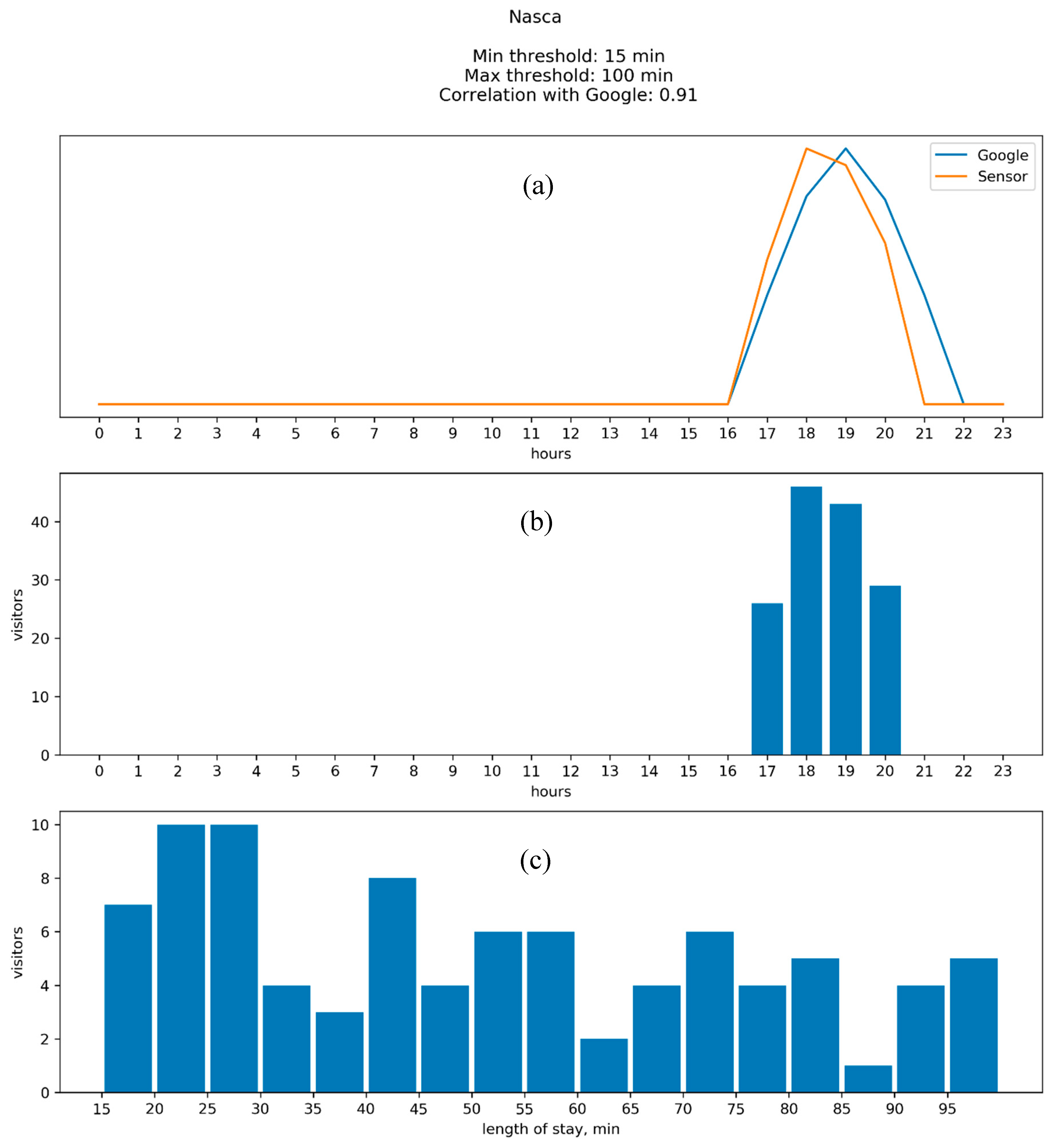
4.2. Results: Google vs. WiFi
5. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
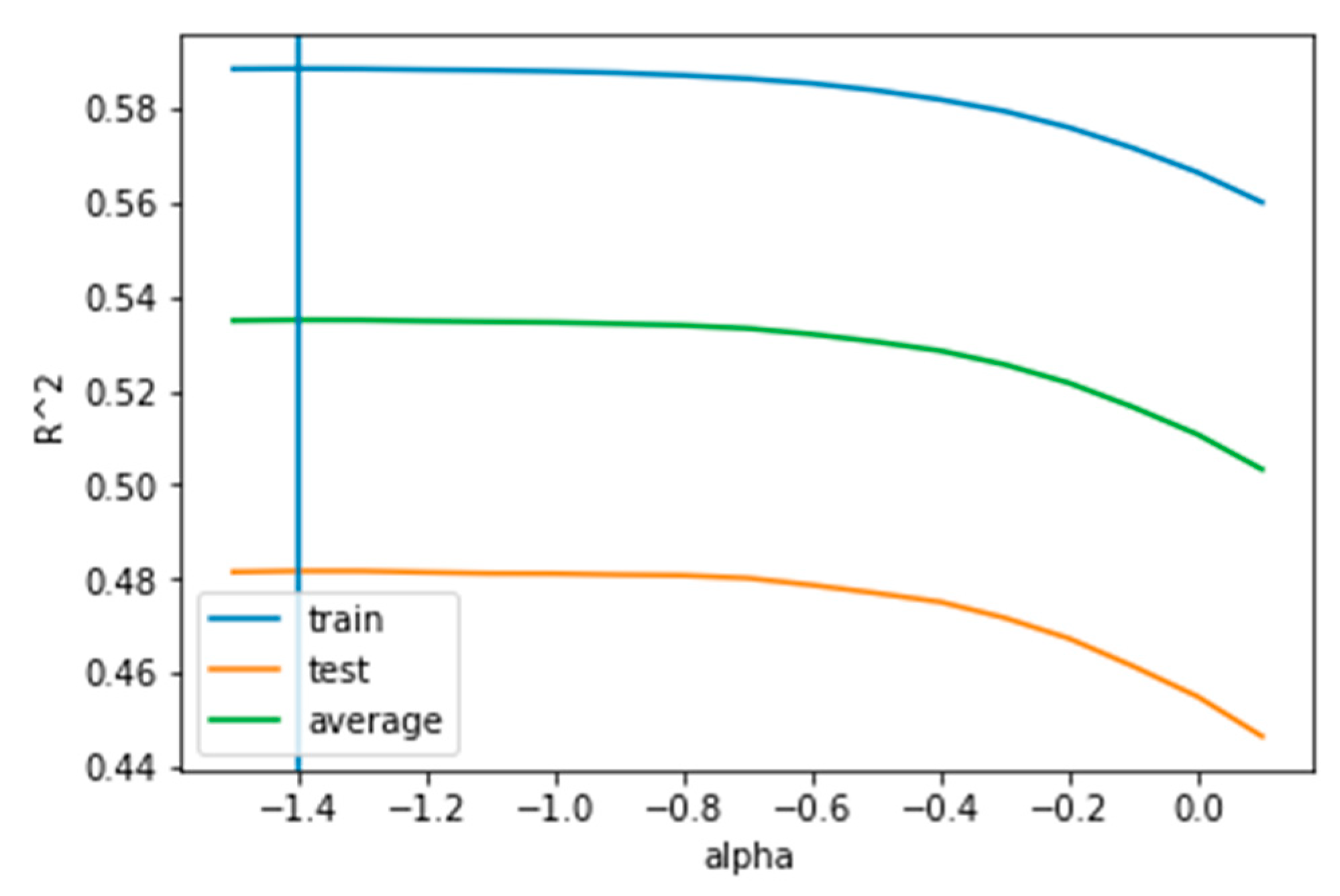
Appendix A. Cross-Validation Method


Appendix B. Comparison between the Results of WiFi Data Collection and Google “Popular Times”





References
- Hu, W.; Jin, P.J. An adaptive hawkes process formulation for estimating time-of-day zonal trip arrivals with location-based social networking check-in data. Transp. Res. Part C Emerg. Technol. 2017, 79, 136–155. [Google Scholar] [CrossRef]
- Chaniotakis, E.; Antoniou, C.; Grau, J.M.S.; Dimitriou, L. Can Social Media data augment travel demand survey data? In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1642–1647. [Google Scholar]
- Chaniotakis, E.; Antoniou, C.; Aifadopoulou, G.; Dimitriou, L. Inferring activities from social media data. Transp. Res. Rec. J. Transp. Res. Board 2017, 2666, 29–37. [Google Scholar] [CrossRef]
- Li, Y.; Steiner, M.; Wang, L.; Zhang, Z.-L.; Bao, J.; Steiner, M. Exploring venue popularity in foursquare. In Proceedings of the 2013 Proceedings IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 3357–3362. [Google Scholar]
- Yang, F.; Jin, P.J.; Cheng, Y.; Zhang, J.; Ran, B. Origin-destination estimation for non-commuting trips using location-based social networking data. Int. J. Sustain. Transp. 2014, 9, 551–564. [Google Scholar] [CrossRef]
- Scellato, S.; Noulas, A.; Lambiotte, R.; Mascolo, C. Socio-spatial properties of online location-based social networks. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Muhammad, R.; Zhao, Y.; Liu, F. Spatiotemporal analysis to observe gender based check-in behavior by using social media big data: A case study of Guangzhou, China. Sustainability 2019, 11, 2822. [Google Scholar] [CrossRef]
- Popular Times and Visit Duration-Google My Business Help Google. Available online: https://www.google.com/maps (accessed on 1 January 2018).
- Tafidis, P.; Teixeira, J.; Bahmankhah, B.; Macedo, E.; Guarnaccia, C.; Coelho, M.C.; Bandeira, J.M. Can Google maps popular times be an alternative source of information to estimate traffic-related impacts? Transp. Res. Board 2018, 97, 1–8. [Google Scholar]
- Meeks, W.; Dasgupta, S. Geospatial information utility: An estimation of the relevance of geospatial information to users. Decis. Support Syst. 2004, 38, 47–63. [Google Scholar] [CrossRef]
- Kisilevich, S.; Keim, D.; Rokach, L. A GIS-based decision support system for hotel room rate estimation and temporal price prediction: The hotel brokers’ context. Decis. Support Syst. 2013, 54, 1119–1133. [Google Scholar] [CrossRef]
- Wang, L.; Gopal, R.; Shankar, R.; Pancras, J. On the brink: Predicting business failure with mobile location-based checkins. Decis. Support Syst. 2015, 76, 3–13. [Google Scholar] [CrossRef]
- Rodas, D.D. Identification of Spatio-Temporal Factors Affecting Arrivals and Departures of Shared Vehicles. Master’s Thesis, Technical University of Munich, Munich, Germany, 2017. [Google Scholar]
- Willing, C.; Klemmer, K.; Brandt, T.; Neumann, D. Moving in time and space–location intelligence for carsharing decision support. Decis. Support Syst. 2017, 99, 75–85. [Google Scholar] [CrossRef]
- Chen, Y.; Mahmassani, H.S.; Frei, A. Incorporating social media in travel and activity choice models: Conceptual framework and exploratory analysis. Int. J. Urban Sci. 2017, 22, 180–200. [Google Scholar] [CrossRef]
- Hasan, S.; Ukkusuri, S.V. Urban activity pattern classification using topic models from online geo-location data. Transp. Res. Part C Emerg. Technol. 2014, 44, 363–381. [Google Scholar] [CrossRef]
- Hasnat, M.; Hasan, S. Identifying tourists and analyzing spatial patterns of their destinations from location-based social media data. Transp. Res. Part C Emerg. Technol. 2018, 96, 38–54. [Google Scholar] [CrossRef]
- Llorca, C.; Ji, J.; Molloy, J.; Moeckel, R. The usage of location based big data and trip planning services for the estimation of a long-distance travel demand model. Predicting the impacts of a new high speed rail corridor. Res. Transp. Econ. 2018, 72, 27–36. [Google Scholar] [CrossRef]
- Yang, F.; Ding, F.; Qu, X.; Ran, B. Estimating Urban Shared-Bike Trips with Location-Based Social Networking Data. Sustainability 2019, 11, 3220. [Google Scholar] [CrossRef]
- Yang, L.; Durarte, C.M. Identifying tourist-functional relations of urban places through foursquare from Barcelona. GeoJournal 2019. [Google Scholar] [CrossRef]
- Liu, X.; Andris, C.; Rahimi, S. Place niche and its regional variability: Measuring spatial context patterns for points of interest with representation learning. Comput. Environ. Urban Syst. 2019, 75, 146–160. [Google Scholar] [CrossRef]
- Weerdenburg, D.V.; Scheider, S.; Adams, B.; Spierings, B.; Zee, E.V.D. Where to go and what to do: Extracting leisure activity potentials from Web data on urban space. Comput. Environ. Urban Syst. 2019, 73, 143–156. [Google Scholar] [CrossRef]
- Deveaud, R.; Albakour, M.-D.; Macdonald, C.; Ounis, I. Experiments with a venue-centric model for personalisedand time-aware venue suggestion. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management-CIKM’15, Melbourne, Australia, 19–23 October 2015; pp. 53–62. [Google Scholar]
- Manotumruksa, J.; MacDonald, C.; Ounis, I. Predicting contextually appropriate venues in location-based social networks. In Proceedings of the International Conference of the Cross-Language Evaluation Forum for European Languages, Évora, Portugal, 5–8 September 2016; pp. 96–109. [Google Scholar]
- Noulas, A.; Scellato, S.; Lathia, N.; Mascolo, C. Mining user mobility features for next place prediction in location-based services. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10 December 2012; pp. 1038–1043. [Google Scholar]
- Perner, P. Advances in data mining. applications and theoretical aspects. Comput. Vis. 2013, 7987, 107–121. [Google Scholar] [CrossRef]
- Yoshimura, Y.; Krebs, A.; Ratti, C. Noninvasive bluetooth monitoring of visitors’ length of stay at the louvre. IEEE Pervasive Comput. 2017, 16, 26–34. [Google Scholar] [CrossRef]
- Nunes, N.; Ribeiro, M.; Prandi, C.; Nisi, V. Beanstalk: A community based passive wi-fi tracking system for analysing tourism dynamics. In Proceedings of the ACM SIGCHI Symposium on Engineering Interactive Computing Systems, Lisbon, Portugal, 26–29 June 2017; pp. 93–98. [Google Scholar]
- Pang, Y.; Kashiyama, T.; Yabe, T.; Tsubouchi, K.; Sekimoto, Y. Development of people mass movement simulation framework based on reinforcement learning. Transp. Res. Part C Emerg. Technol. 2020, 117, 102706. [Google Scholar] [CrossRef]
- Schulz, M.; Wegemer, D.; Hollick, M. Nexmon: The c-based firmware patching framework. Res. Gate 2017. [Google Scholar] [CrossRef]
- IEEE Standards Association. IEEE Standard for Information Technology–Telecommunications and Information Exchange Between Systems–Local and Metropolitan Area Networks–Specific Requirements; IEEE: New York, NY, USA, 2010; IEEE Std 802 (Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) specifications Amendment 6: Wireless. Access in Vehicular Environments). [Google Scholar]
- Ji, Y.; Zhao, J.; Zhang, Z.; Du, Y. Estimating bus loads and OD flows using location-stamped farebox and Wi-Fi signal data. J. Adv. Transp. 2017, 2017, 1–10. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Yelp | https://www.yelp.com |
| Google Maps | https://www.google.com/maps |
| Google Location API | https://developers.google.com/maps/documentation/geolocation/intro |
| Overpass API | https://wiki.openstreetmap.org/wiki/Overpass_API |
| OSM Dump | https://www.geofabrik.de (pbf file) |
| Population | https://www.zensus2011.de (German nationwide census, 2011) |
| Workplaces | https://www.muenchen.de (Munich, 2016) |
| Variable Name | Description |
|---|---|
| - | Index |
| Name | Name of venue |
| lat_conv | Latitude |
| lon_conv | Longitude |
| Price_index | Price level from Yelp |
| compound_rating | Weighted sum of ratings obtained from Yelp and Google Maps |
| total_reviews | Sum of reviews at Yelp and Google Maps |
| * | Type of amenity (e.g., cafe_fastfood) |
| * | Tags attached (e.g., Caribbean) |
| roads_* nodes_* ways_* | OSM data on length of different classes of roads and number of venues within prespecified area |
| workplaces | Workplaces data within prespecified area |
| population | Population data within prespecified area |
| * | Working hours (−2 h, −1 h, current hour, +1 h, +2 h) |
| * | Venue popularity data 24 h/7 days (e.g., (‘sun’, 1)) |
| Selenium | Emulation of user activity in browser |
| Beautiful Soup | Parsing of HTML and XML documents |
| Pandas | High performance and easy to use data structures and data analysis tools |
| Geopandas | Extension of pandas library for work with spatial data |
| Osmread | Reading of OpenStreetMap XML and PBF data files |
| Osmnx | Retrieving, constructing, analyzing and visualizing street networks |
| Scikit-learn | Tools for data mining and data analysis |
| Tslearn | Tools for data mining and data analysis of time series |
| Matplotlib | Data visualization |
| StatsModels | Estimation and evaluation of statistical models |
| No Transformation | Box–Cox ( = 0) | Box–Cox ( = −1.4) | |
|---|---|---|---|
| Mean Squared Error (MSE) | 119.29 | 0.59 | 0.02 |
| 0.50 | 0.59 | 0.61 | |
| MSE (Coefficient of Variation [CV]) | 154.16 | 0.76 | 0.03 |
| (CV) | 0.34 | 0.45 | 0.47 |
| MSE (test set) | 162.34 | 0.70 | 0.02 |
| (test set) | 0.33 | 0.47 | 0.49 |
| No Transformation | Box–Cox ( = 0) | Box–Cox ( = −0.2) | |
|---|---|---|---|
| MSE | 141.80 | 0.72 | 0.34 |
| 0.42 | 0.46 | 0.46 | |
| MSE (CV) | 153.89 | 0.78 | 0.39 |
| (CV) | 0.34 | 0.43 | 0.43 |
| MSE (test set) | 161.83 | 0.75 | 0.38 |
| (test set) | 0.32 | 0.45 | 0.45 |
| Item | Cost, EUR |
|---|---|
| Raspberry Pi Zero W | 10 |
| Micro SD card (16 GB) | 6.49 |
| Power Bank (5000 mAh) | 8.99 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Timokhin, S.; Sadrani, M.; Antoniou, C. Predicting Venue Popularity Using Crowd-Sourced and Passive Sensor Data. Smart Cities 2020, 3, 818-841. https://doi.org/10.3390/smartcities3030042
Timokhin S, Sadrani M, Antoniou C. Predicting Venue Popularity Using Crowd-Sourced and Passive Sensor Data. Smart Cities. 2020; 3(3):818-841. https://doi.org/10.3390/smartcities3030042
Chicago/Turabian StyleTimokhin, Stanislav, Mohammad Sadrani, and Constantinos Antoniou. 2020. "Predicting Venue Popularity Using Crowd-Sourced and Passive Sensor Data" Smart Cities 3, no. 3: 818-841. https://doi.org/10.3390/smartcities3030042
APA StyleTimokhin, S., Sadrani, M., & Antoniou, C. (2020). Predicting Venue Popularity Using Crowd-Sourced and Passive Sensor Data. Smart Cities, 3(3), 818-841. https://doi.org/10.3390/smartcities3030042