1. Introduction
With the rapid development of IoT- and AI-integrated technologies, researchers and developers have been driven to create intelligent location-based IoT applications for smart cities, transportation, intelligent buildings, smart agriculture, military applications, etc. Location-based services (LBS) are among these applications, and they are regarded as crucial ones since LBS makes it possible to determine the precise location of moving objects in enclosed spaces. Many people spend a day in indoor environments because of work, school, shopping, etc. Therefore, LBIoTSs play a significant role in this era by locating objects in indoor environments and providing crucial information for many intelligent applications, for example, locating an older person who is living alone in a house, locating a human in a shopping mall, automatically taking students’ attendance on a smart campus, locating a person using a wearable sensor in a hospital, locating people inside a building during a fire, etc. [
1,
2].
Regarding localization, there are two environments: outdoor and indoor. GPS technology is well performed in outdoor environments; however, it is inappropriate for indoor localization due to several reasons [
3,
4]. The GPS will not work accurately in the indoor environment due to the multipath fading effect and less accuracy in estimation [
5]. Due to the above reasons, researchers have developed indoor localization algorithms based on deterministic algorithms, probabilistic algorithms, and filters. Many widely used deterministic and probabilistic algorithms can be found in related works, such as trilateration, multilateration, the Levenberg–Marquardt algorithm, and Kalman filters [
6]. The drawbacks of the mentioned algorithms are lower accuracy, inefficiency, complex hardware systems, and most of the time, they are impractical to deploy in robust indoor environments.
Similar works exist on using ML techniques for indoor localization applications. The existing works can be categorized as supervised regressor-based, classifier-based, deep learning-based, and unsupervised learning-based approaches. The works [
7] used a supervised regressor to find the location. In contrast, different types of regressors, such as Decision Tree Regression, Random Forest Regression, Linear Regression, Polynomial Regression, Support Vector Regression, and Extra Tree Regression, have been employed. The results indicate that RFR, SVR, and ETR perform better than other algorithms. While various ML-based frameworks have been proposed, certain algorithms need to be carefully analyzed, taking into consideration the practicality of implementing them on real hardware devices. There is a high impact of RSSI data filtering on localization accuracy. In the literature, many works have proposed linear and non-linear filters to filter the collected data. The works [
8,
9] used moving average filters, and [
10,
11] used Kalman and extended Kalman filters when smoothing RSSI data. Though Kalman filters outperform moving average filters, the moving average filters are widely used due to their simplicity [
12].
The works [
12,
13,
14,
15,
16] have used supervised classifiers for indoor localization. Neural Networks (NN), Feed Forward Neural Networks (FFNNs), SVM, and kNN are used as ML algorithms. According to [
16], NN is good in accuracy, but it requires high computational power. The kNN also gives a reasonable accuracy. MATLAB, a Python-based IDE, has been used to implement these algorithms. During the evaluation of performances, confusion matrices are used. One crucial observation is that a standard ML algorithm cannot be proposed for all indoor applications because the outperformed algorithm varies due to many reasons, such as wireless technology, signal measurement techniques, the types of filters used, the environment’s robustness, the computational power of devices, the dataset’s size, the dataset’s hyperparameter tuning aspects, etc.
This paper investigates how to use supervised classifiers for indoor localization, where locations are estimated as categorical data with improved RSSI linearization. We introduced a novel linearization and filtering mechanism with ML framework to improve the localization accuracy in robust indoor localization systems. For this experiment, we used a publicly available testbed and its dataset [
17]. In this case, we consider the location estimation as a classification-type ML problem, and where the specific location (zone) of an existing person will be predicted. This testbed consists of 13 BLE ibeacon nodes implemented inside a library. In addition, high security, a low cost, and minimal power consumption are all benefits of Bluetooth positioning technology; yet, Bluetooth has poor signal reliability and a limited communication range. More details on the dataset and testbed will be discussed later in this paper. We used the RSSI dataset for pre-processing using a moving average filter and weighted least-squares method. Afterward, the dataset was trained by the supervised classifiers FFNN, SVM, and kNN, and we evaluated each algorithm’s performance on localization. However, this study was limited to one particular BLE dataset, and other wireless technologies were not considered.
This paper is organized as follows: firstly, the background theory of wireless indoor localization will be discussed in the background section. Secondly, related works in ML for indoor localization and the mathematical model will be discussed. Thirdly, our novel system model is proposed. In the fourth section, we elaborate on the steps of data pre-processing and the ML-model development and training. The fifth section discusses the model evaluation in detail, including the hyperparameter tuning for each model. Finally, we conclude the findings.
Wireless indoor localization is a technique that estimates the objects’ location by using distance measurements. Primarily, indoor localization systems can be categorized as device-free and device-based localization. Typically, these location localization techniques require distance measurements as input for the algorithm. The widely used distance measurement techniques in positioning systems are the Angle of Arrival (AoA), Time of Arrival (ToA), Time of Flight (ToF), Time Difference of Arrival (TDoA), Channel State Information (CSI), and Received Signal Strength Indicator (RSSI). When comparing the above distance measurement techniques, there are pros and cons. For instance, the AoA system uses a set of antennae to determine the signal propagation angle, since more hardware is needed and implementation cost is high. The AoA technology typically requires complex hardware such as antenna arrays calibrated to get the correct position. The RSSI level correlates the distance between the transmitter and the receiver. Additionally, the signal intensity weakens as it goes away from the transmitter; it is frequently used to calculate the separation between a transmitter and the receiver of the nodes. Because the transmitting signal is vulnerable to environmental noise and multipath fading, RSSIs generally lead to inaccurate values and errors in localization systems; therefore, strong signal processing techniques should apply before it is processed through ML algorithms. Once it has a distance measure, it can feed as the input for the algorithm. Before being fed into the algorithms, it requires strong signal filtering. Specific algorithms require a bare minimum number of anchor nodes. For instance, trilateration requires at least three anchor nodes in the system [
17,
18,
19].
2. Related Works
This section provides an overview of related studies carried out on Indoor Localization estimation techniques with different machine-learning algorithms.
Aigerim et al. employed an ML classifier-based approach for indoor localization. The experiment tested the RSSI data collected from mobile devices (Sony Xperia XA1) and BLE product iTAG sent-out signals. The location column showed the iTAG at the building’s entrance. Students assisted in the collection of the dataset. Three groups of twelve students each had an iTAG device formed. They entered the constrained space with their iTAGs turned on. Three marked locations represented the building’s entrance—inside, in the vestibule, and outside—on an 18.35 m × 3 m long hallway. Signals were collected using two Sony Xperia XA1 smartphones, which were located at the beginning and end of the 2.35 m long “in vestibule” space. The collection of RSSIs lasted for twenty minutes. The raw RSSIs and filtered RSSIs were the two datasets. Actual RSSIs from a smartphone are known as raw RSSIs. To smooth RSSIs, a feedback filter is used. The filtered data were trained using Naive Bayes and Support Vector Machine algorithms, and their results showed 0.95 accuracy for SVM when it had four vectors.
Singh et al. contributed to investigating mobile phone-based indoor localization using ML techniques. They set up an indoor experimental testbed, gathered 3110 RSSI data points, and assessed the effectiveness of many machine learning methods. The algorithm was tested with kNN, RFR, Multilayer and Perceptron, and ZeroR. It was concluded that the proposed methods surpassed other indoor localization methods, with a mean error as exact as 0.76 m. The study also suggested a hybrid instance-based strategy that, compared to conventional instance-based methods, accelerates performance by a factor of ten without sacrificing accuracy. Furthermore, the proposed study was examined on its precision, crucial usage in real-world settings, and how it was affected by less-dense datasets. Finally, by analyzing their performance in an online, in-motion experiment, they showed that these techniques are suitable for real-world deployment [
20].
Kaur et al. investigated RSSI- and ML-based approaches for indoor localization. In this study, the researchers used Neural Networks to carry out localization strategies based on the RSSI measurements. The RSSI dataset was collected from the experiment in [
14], and the position estimate outcomes were compared with two approaches (the ANN and the Decision Tree). The proposed study first employed an Artificial Neural Network with three inputs to estimate the position of each RSSI’s triplet. Then, it calculated the mean’s error value for each position acquired. A similar process was performed for the ANN design with four inputs, where they estimated the position for each of the four inputs and determined the mean’s error value for these estimates. In summary, the tested algorithms achieved better precision than the Decision Tree algorithm [
21].
Jun et al. contributed by applying a weighted least-squares Techniques to RSSI-based localization to improve its accuracy. The study employed a weighted multilateration approach to make it more resilient to errors and less dependent on an ideal channel model. Two weighted least-squares techniques based on the conventional hyperbolic and circular positioning algorithms were used to estimate the precise location. These methods specifically took the accuracy of the various data into account. Through extensive real-world testing on different wireless network types and numerical simulations, these methodologies were contrasted against the conventional hyperbolic and circular positioning methods (a wireless sensor network, a Wi-Fi network, and a Bluetooth network). The methods yielded an increased tolerance to environmental changes as well as improved localization results, with very little additional processing expense [
14].
Xudong et al. proposed a deep learning-based method for indoor localization in multi-floor environments. In this research work, they presented an improved algorithm based on deep learning, namely CNNLoc, a Convolutional Neural Network (CNN)-based indoor localization system with WiFi fingerprints for multi-story buildings and multi-floor localization. The authors contributed explicitly towards creating a novel classification model by fusing a one-dimensional CNN and a stacked auto-encoder (SAE). While the CNN was trained to attain high accuracy rates in the positioning phase efficiently, the SAE was used to precisely extract critical characteristics from sparse Received Signal Strength (RSS) data. Further, they assessed the proposed system using several cutting-edge techniques on the UJIIndoorLoc and Tampere datasets. The findings demonstrated that the CNNLoc outperformed the existing methods, with success rates of 100% for building-level localization and also 95% for floor-level localization, respectively, where the results showed very high accuracy. Further, in [
22], a framework for indoor localization with NN based on smartphones was proposed.
Table 1 shows the comparison study of the existing works and finding.
All the above works provided the potential to use ML techniques in the localization problem. Yet, the comparative analysis of the performance of multiple algorithms, linearization of RSSI signals, and hyperparameter tuning was lacking in the present works. Further, the performance of the model also highly depends on the dataset, wireless technology used, filter techniques, and linearization used. Advanced ML techniques, such as Deep Learning, require a large dataset for more accurate results. Additionally, the nature of the dataset causes overfitting and underfitting in ML models.
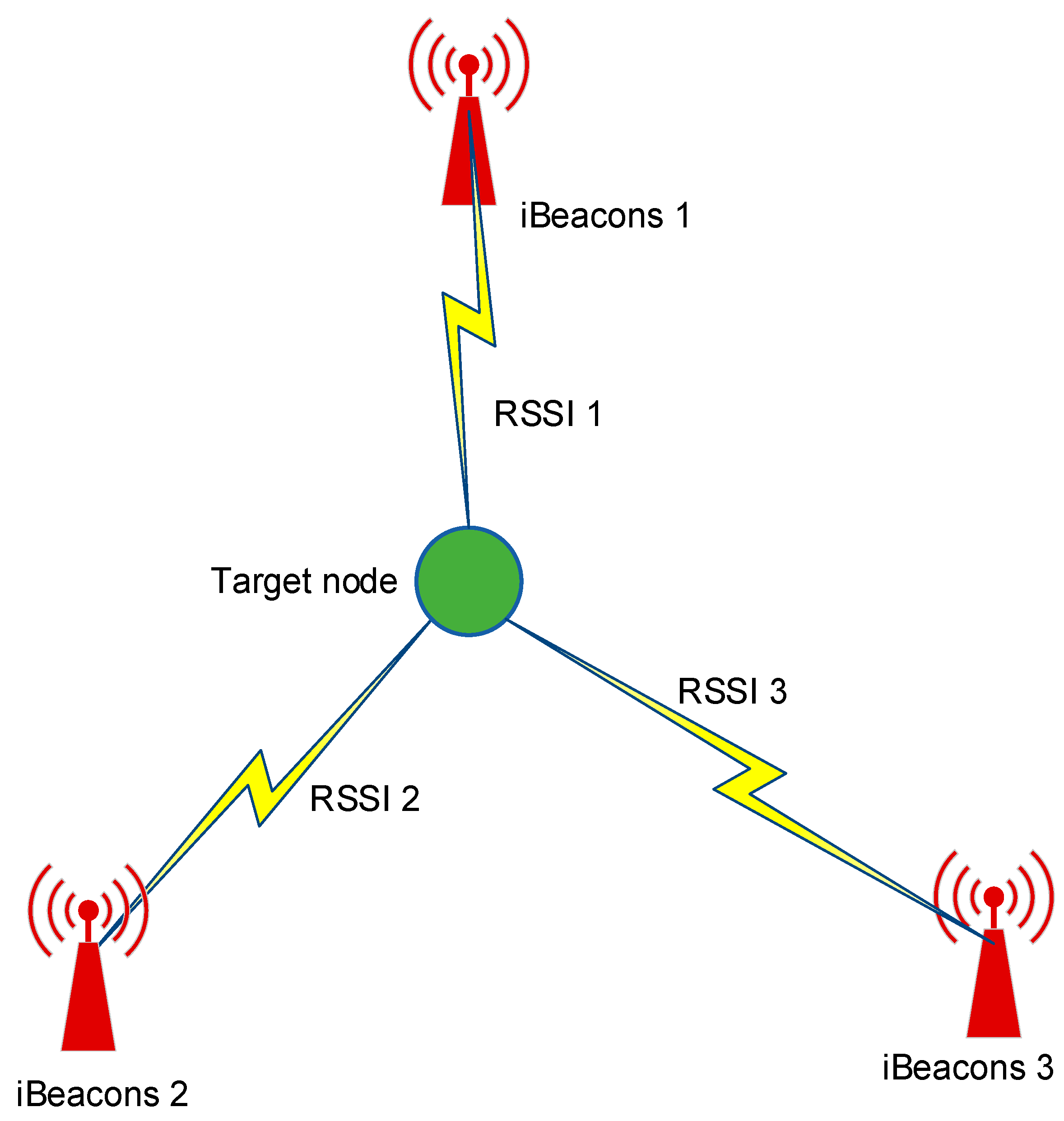
Received Signal Strength Indicator
The Received Signal Strength Indicators (RSSI) is a well-known location estimation approach, in which the power-intensity value is assessed from the beacons and measured in dBm. The RSSI measurements for one particular location of the target node are collected, as shown in
Figure 1.
The RSSI value defines the distance between beacons and the target node, and the value increases accordingly as the distance increases. The logarithmic distance loss model is calculated as Equation (1) [
5]:
where
is defined as the received power [dBm] at a distance
[m] from the transmitter,
is defined as a zero-mean Gaussian random variable with the variance of
,
refers to the received power [dBm] at the reference distance
from the transmitter, and
is the path loss exponent, which varies from 2 in free space to 4 in indoor environments. The localization algorithm is applied to estimate the location of the target node with the distances to different beacons. In this study, we proposed a weighted least-squares method for improved RSSI-based localization. The basic idea of the proposed algorithm was to find the position
of the target node that decreased the sum of the squared error values. Let
be the location of beacons, such that
), where
is the total number of beacons and
is the estimated location of the beacons. Therefore, the square of the distance between the target node and the beacon node
is calculated as
The starting point is used at the beacon
, such that,
. Therefore, for
,
Therefore, Equation (3) can be written in Matrix as
The above, Equation (4), can be written as
where
and
defines the random vector as
Thus, the location of the target node is estimated by using the linear least-square method as
The localization is dependent on . The expression is a square, non-singular, and invertible matrix if the beacons are reasonably far from the target node.
We applied weighted least-squares in Equation (5) as
where
R defines the covariance matrix of the vector
and is written as
Therefore, the value of the covariance matrix
R is evaluated as
Now, by using the channel condition model, the estimated location
of Equation (1) is
where
defines the lognormal random variable, along with parameters
and
. The
jth moment of a lognormal random variable of parameters
is given by
.
Then, we put Equations (12) and (13) in Equation (10) as
Here, is dependent on the actual location and estimation location of the target node and the iBeacons. Therefore, the proposed weighted least-squares method solves the non-linear problem of RSSI-based localization and provides a precise estimation of the target location.
4. Model Training and Evaluation
In this work, we followed the machine learning life cycle to develop the models for location estimation. We started with data pre-processing, where row RSSI data were linearized and filtered. Additionally, we trained our models with the row RSSI dataset to understand the proposed filtering effect in location estimation accuracy. Then, the dataset was trained using ML models implemented using the scikit-learn ML library available in Python 3. All the models were developed on a Jupyter Notebook. Each stage of the implementation is explained as follows.
4.1. Data Pre-Processing
The RSSI dataset consisted of 5191 data and was filtered using the moving average filters. The moving average (MA) filter is the most common and widely used filter in digital signal processing because it is the most accessible digital filter in this kind of application. The row RSSI data in both the time and frequency domains are shown in
Figure 3. Where we have only plotted the RSSI data received from three access points to understand the fluctuation and nature of the signals. The RSSI values received from access points one, two and three are shown in black, orange and blue color in the
Figure 3.
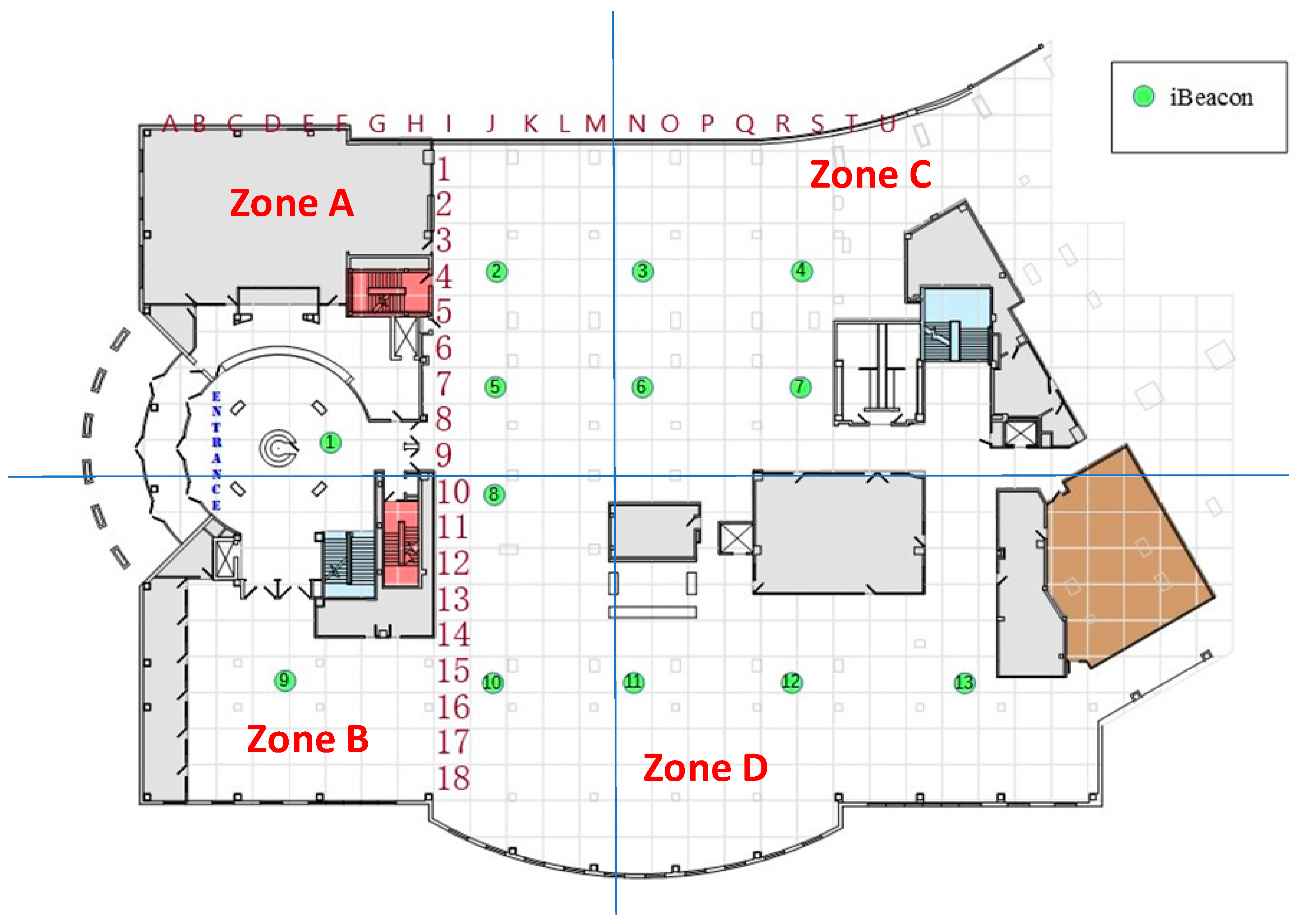
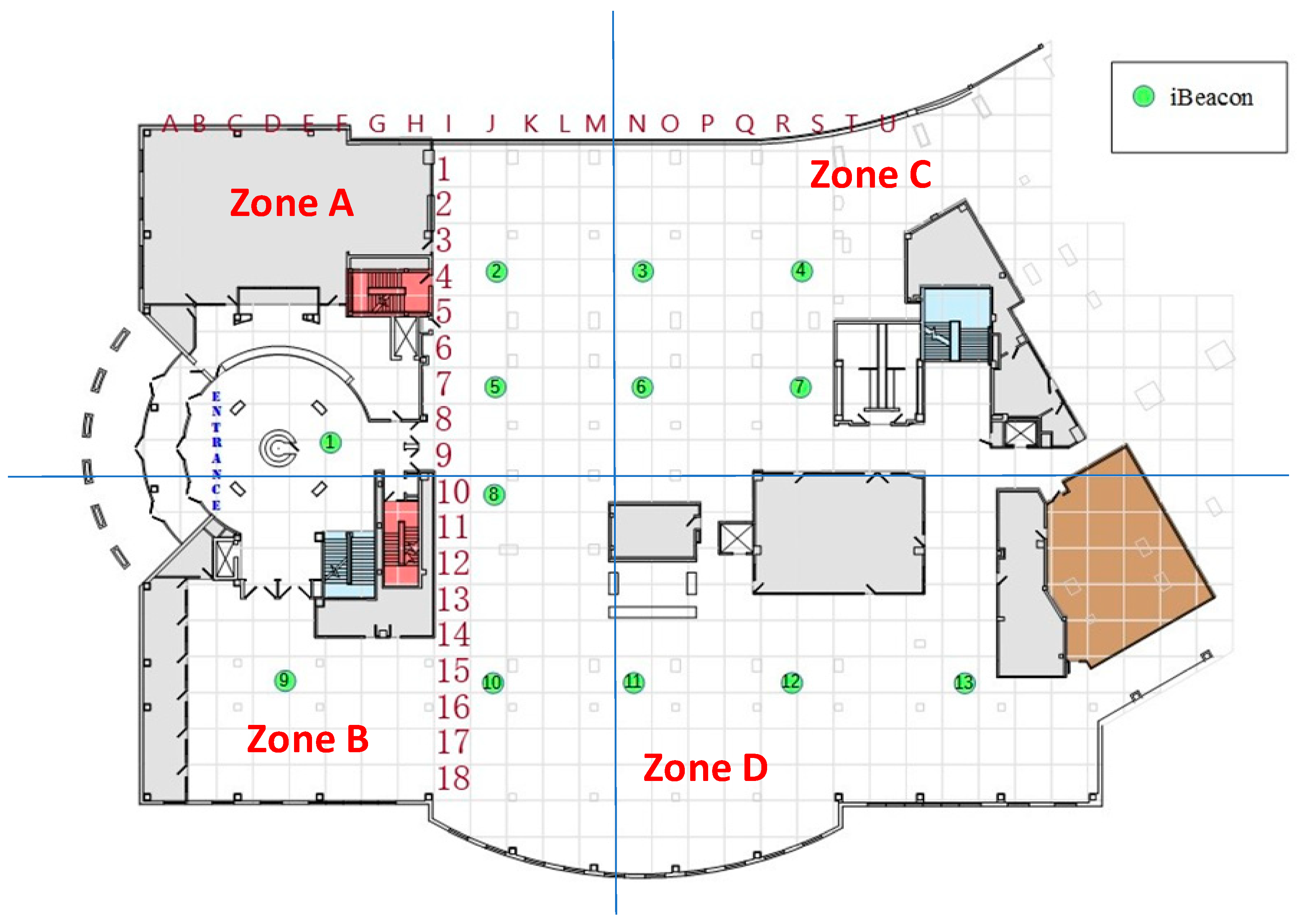
After the filtering, four columns were added to the dataset, as shown in
Table 2, where zones A, B, C, and D were shown as per
Figure 2. This modification was performed as we needed to train our ML models as a classification task.
Table 2 shows the original dataset, where the location column denotes the location ID allocated for each location, and OO2, PO1, PO2 and PO3 are the RSSI levels received by the anchor nodes.
Table 3 shows the dataset modified for classification purposes, where four new columns are added.
4.2. Model Training
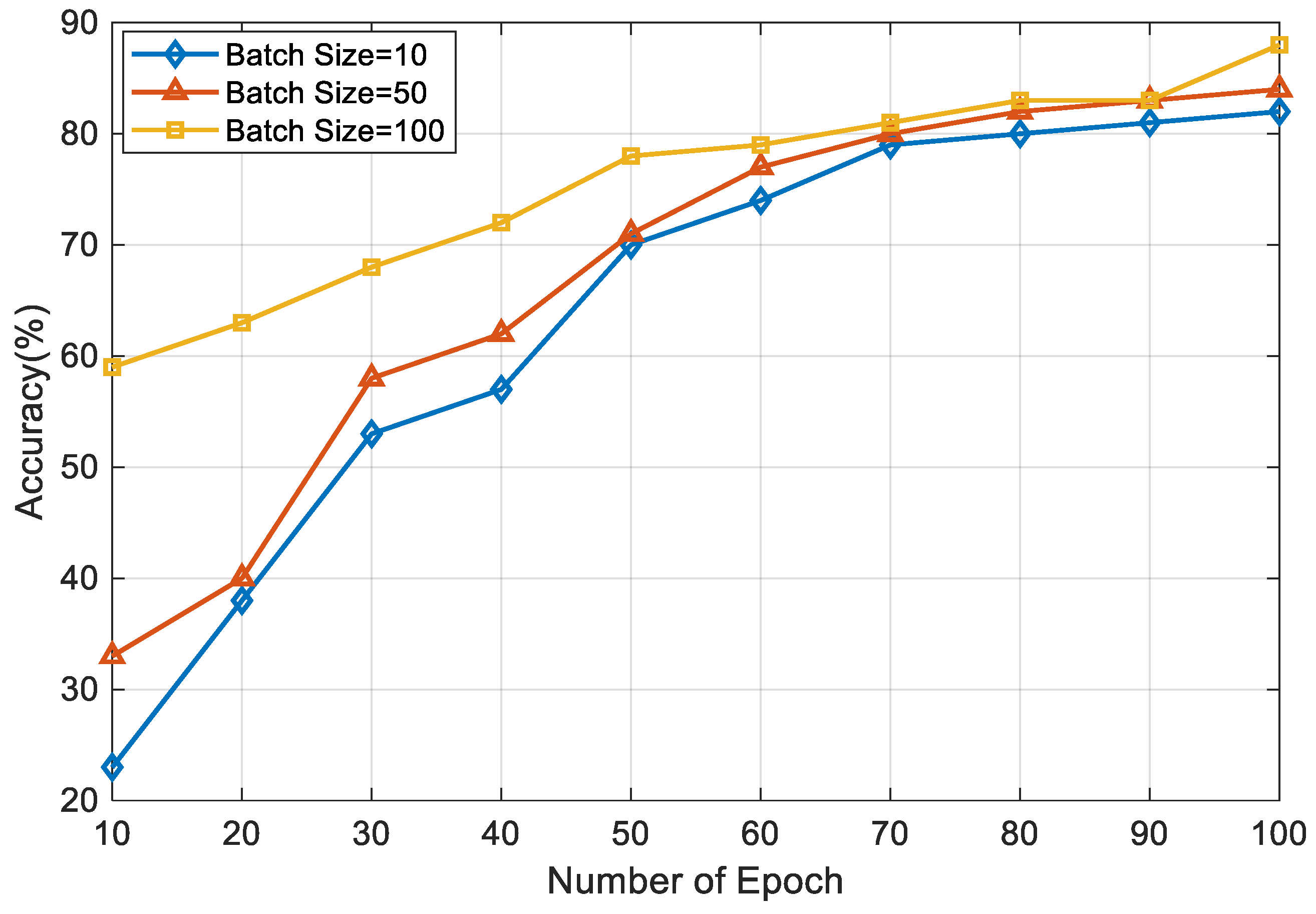
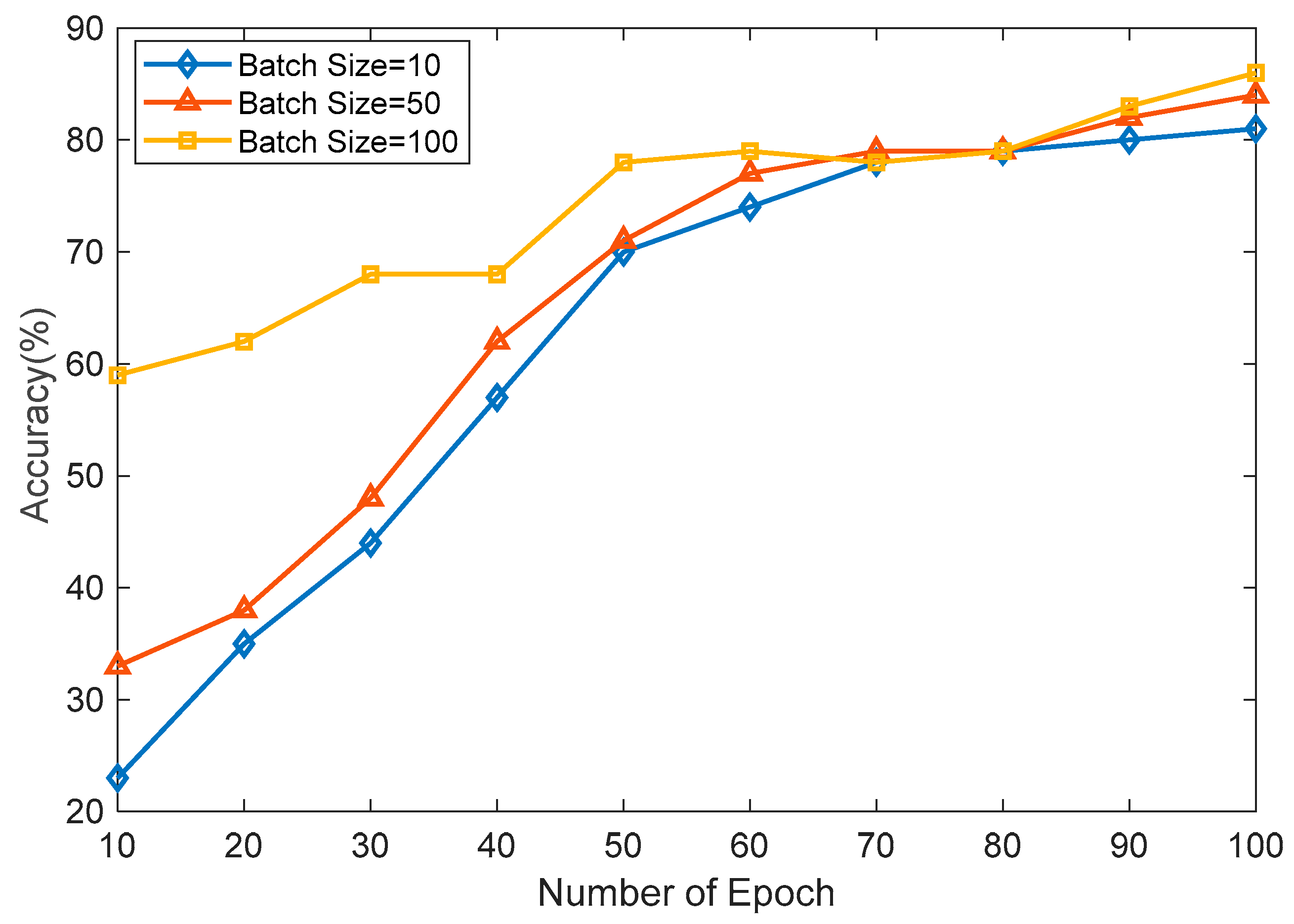
The filtered RSSI dataset was trained using FFNN, SVM, and kNN, respectively. The proposed FFNN architecture comprised two fully connected layers and one output layer, as shown in
Figure 4. This FFNN had three layers, where, thirteen inputs were presented at the input layer as it had thirteen beacon node inputs. And it had one hidden layer and the output layer. The first fully connected layer included twenty neurons, while the second fully connected layer had seventeen neurons. For all simulations, the network architecture had four completely linked levels and one categorization layer. Using the neural network toolkit in MATLAB 2020, the FFNN was implemented. Moreover, the FFNN was trained underneath three different hyper-parameters values of the learning rate (LR), batch size, and epochs. The activation function of the FFNN is very important as it is accountable for transforming the node’s summed weighted input into the node’s activation. Here, we used the ReLU activation function, which will output the input directly if it is positive; otherwise, it is zero. Moreover, ReLU is easy to train and provides better performance. To increase the model’s accuracy during the simulations, the ReLU activation function in fully connected layers and the SoftMax function in the final layer were both utilized. We re-trained our model data-interpolating techniques to generate new samples between existing data points. This did not increase the accuracy significantly, but we observed smoother representation of the signal variations. This information is mentioned in the manuscript.
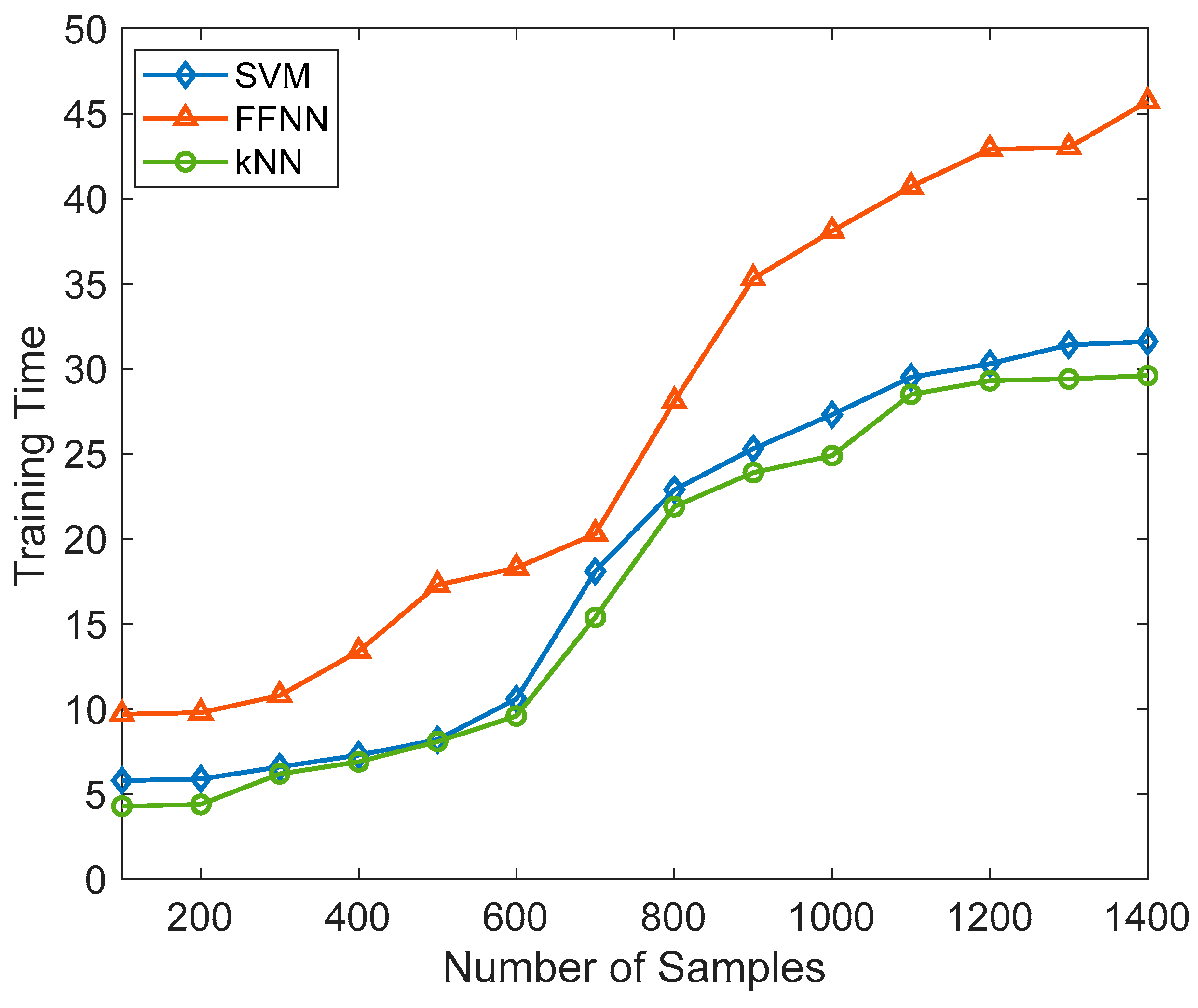
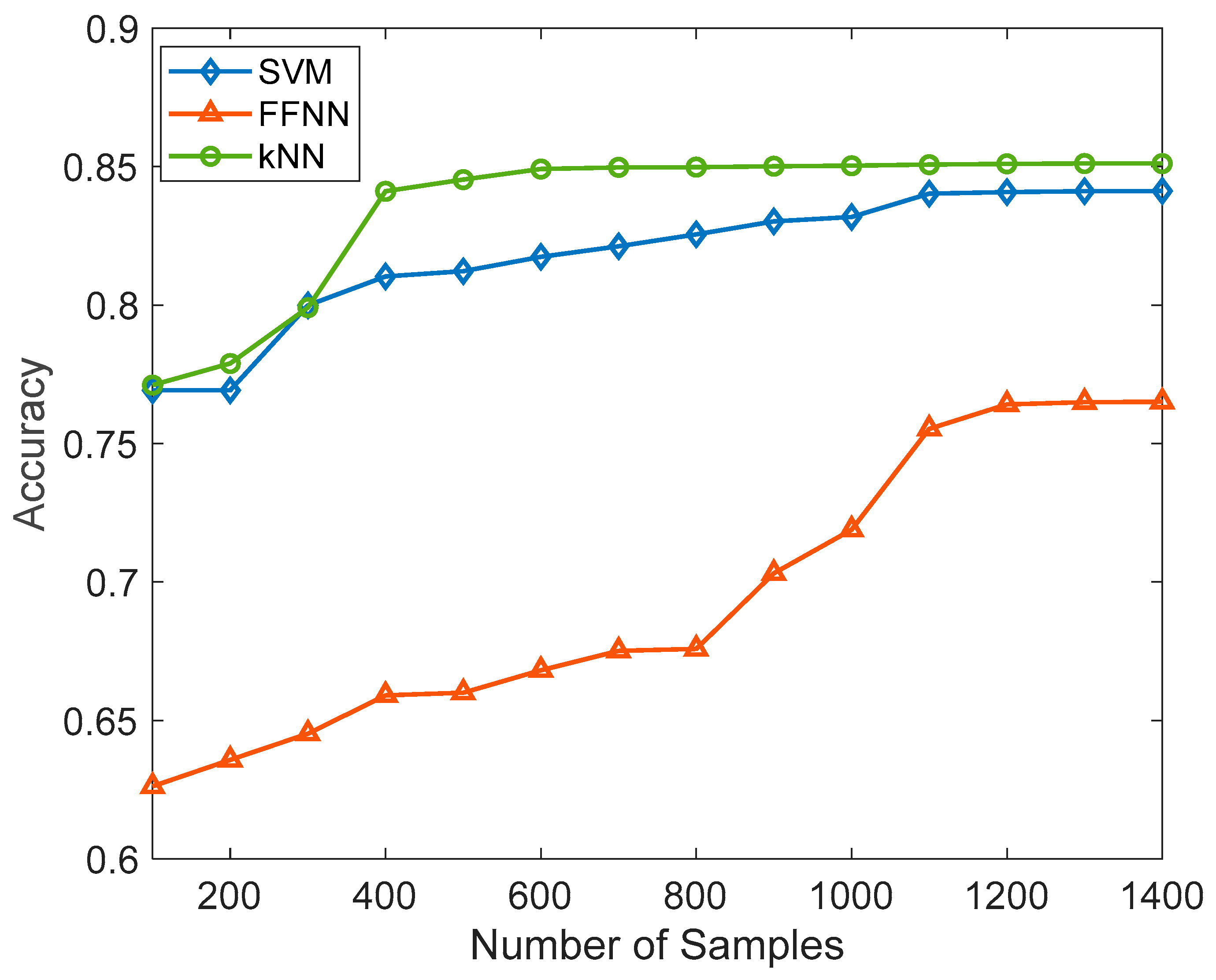
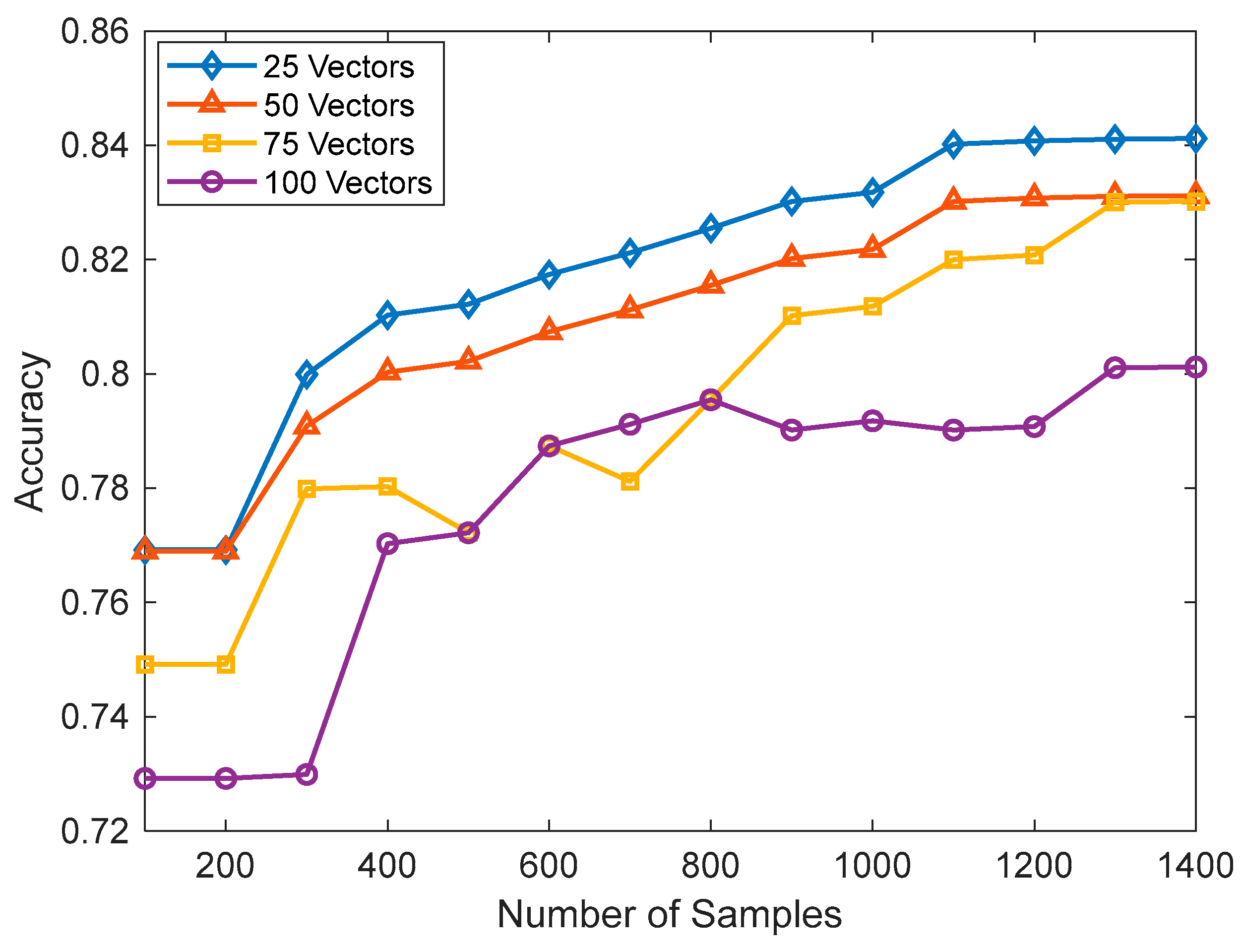
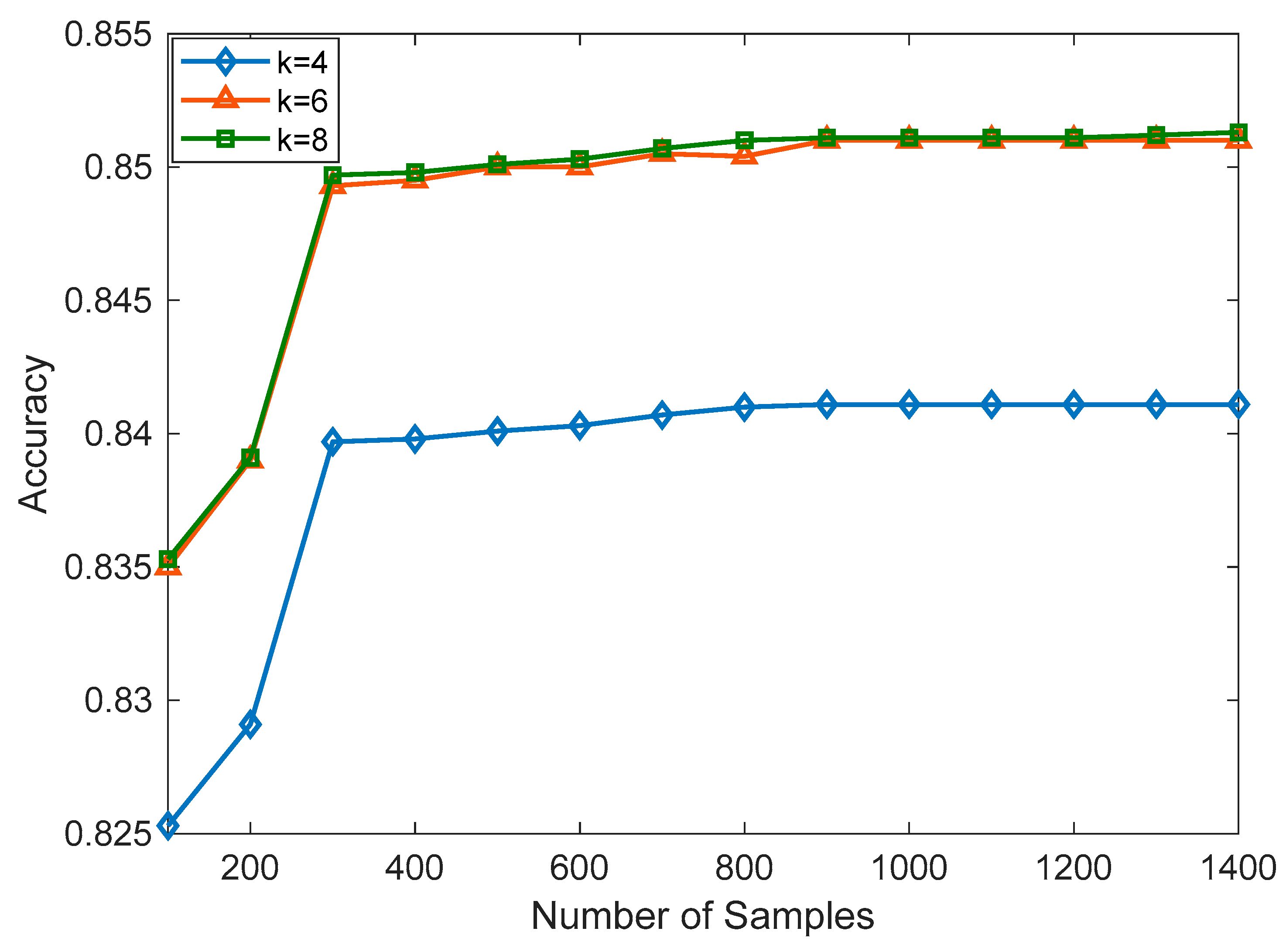
In SVM, the choice of kernel function determined the mapping of data into a higher-dimensional space; here, we used a linear kernel, and the regularization parameter(C) was set to 0.01. The most important hyperparameter to consider when making predictions in k-NN was the number of nearest neighbors. It determines the size of the neighborhood used to classify or regress new data points. We kept k as 5 during our experiment. Both the SVM and kNN were trained using a Jypiter notebook and Python 3 programming language. To build the model, the scikit learn and Pandas library were used. The models were built on an Intel (R) Core (TM) i5-10210U CPU @ 1.60 GHz 2.11 GHz personal computer. During training, the dataset of 5191 was split as 70% for training and 30% for testing. The linear kernel was used for SVM, and the number of vectors was set as 25 in the initial phase. Further, the number of vectors was increased in the model so we could observe the effect of the number of vectors on the accuracy. Initially, the k value of kNN was set to be 4, and we gradually increased the value of k to observe the changes in the accuracy. Further, we also happened to experiment with Logistic Regression (LR), Decision Tree Classifier (DTC), and Random Forest Classifier (RFC). LR yielded an accuracy of 54.2%, DTC demonstrated 76.4% accuracy, and RFC achieved 78.7% accuracy.
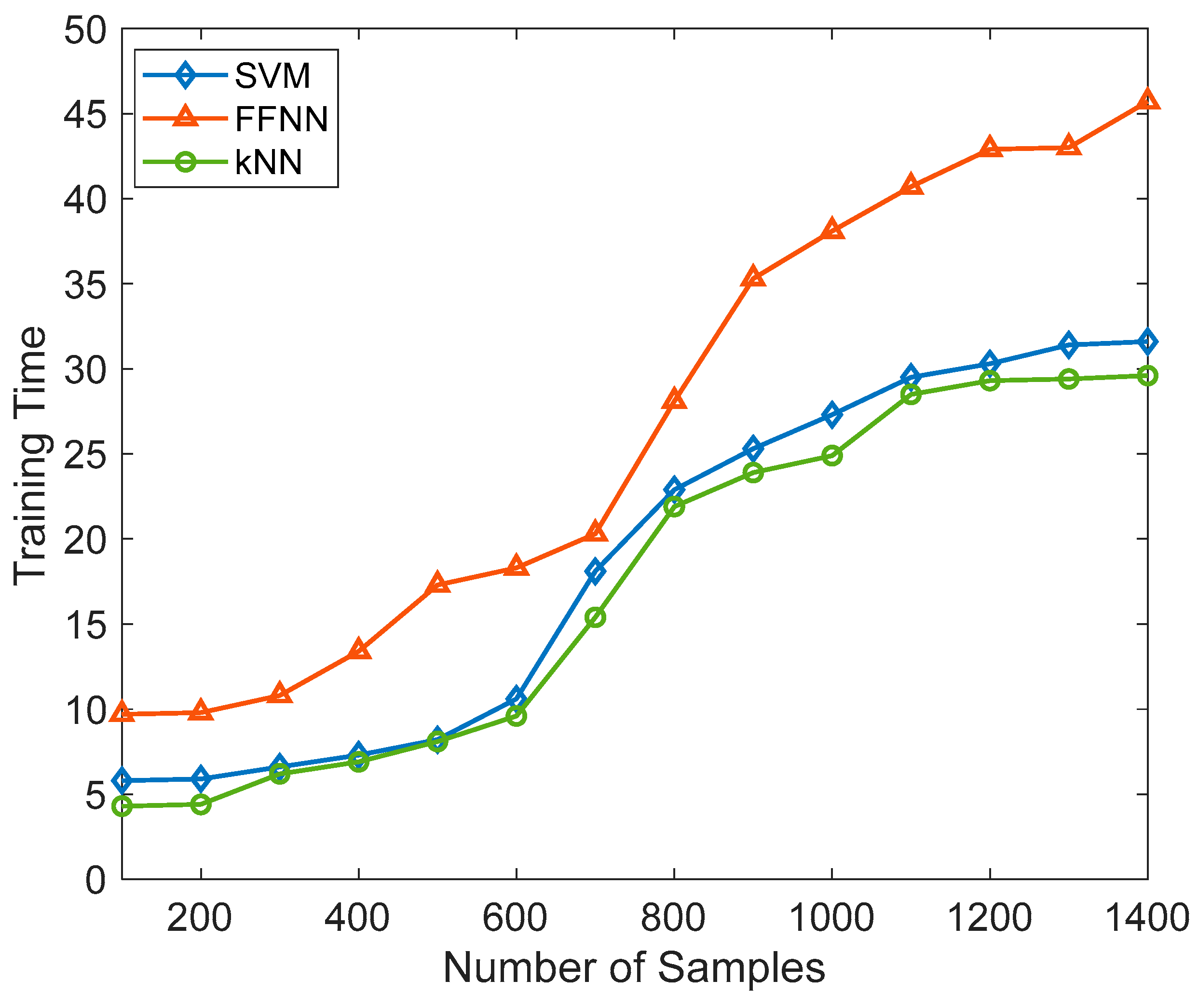
All the algorithms evaluated the accuracy, precision, sensitivity, and F1 score. In SVM, the number of support vectors changed from 25 to 75 as a hyperparameter tuning.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}