

Clarification of the Acoustic Characteristics of Velopharyngeal Insufficiency by Acoustic Simulation Using the Boundary Element Method: A Pilot Study

 , and
, and
Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
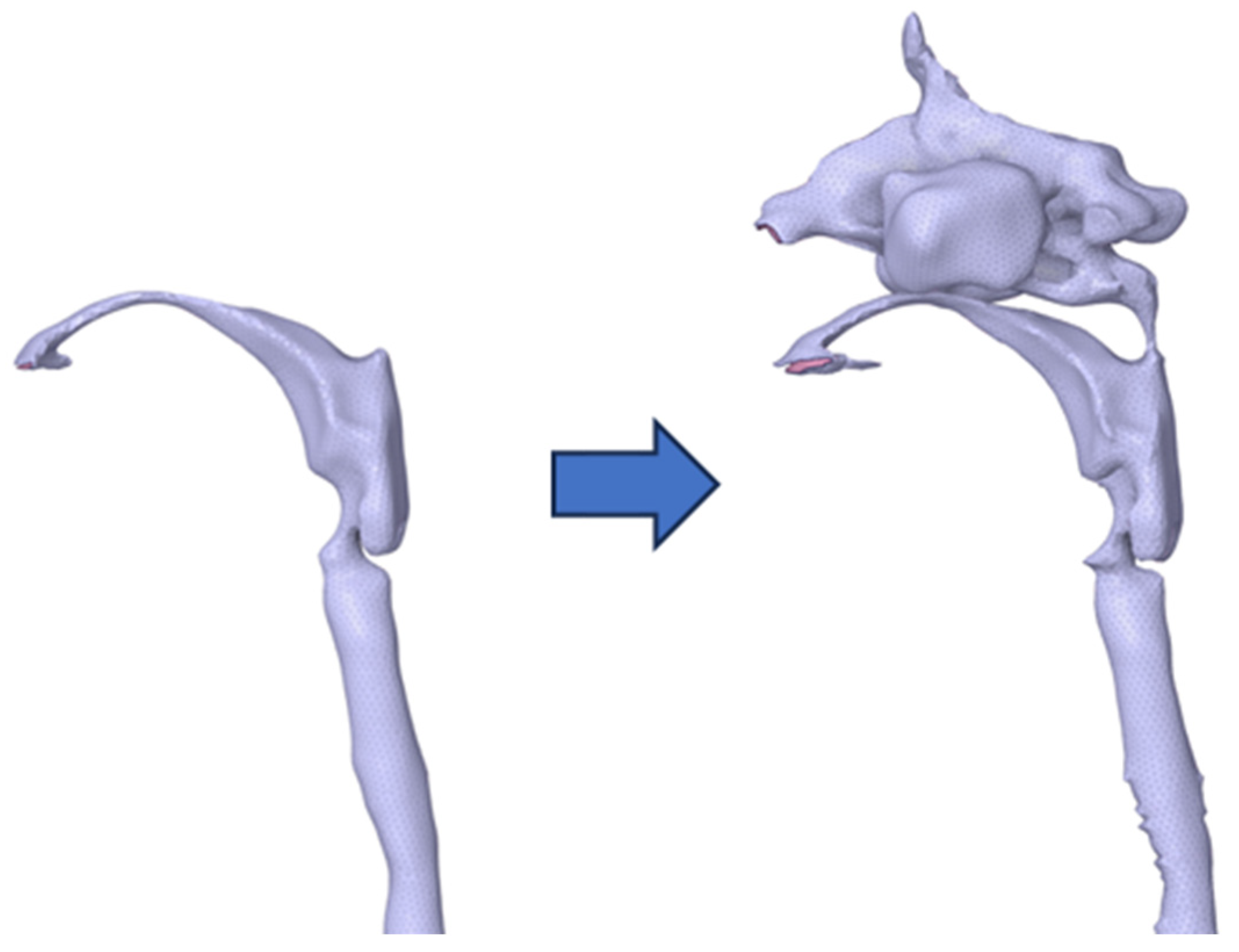
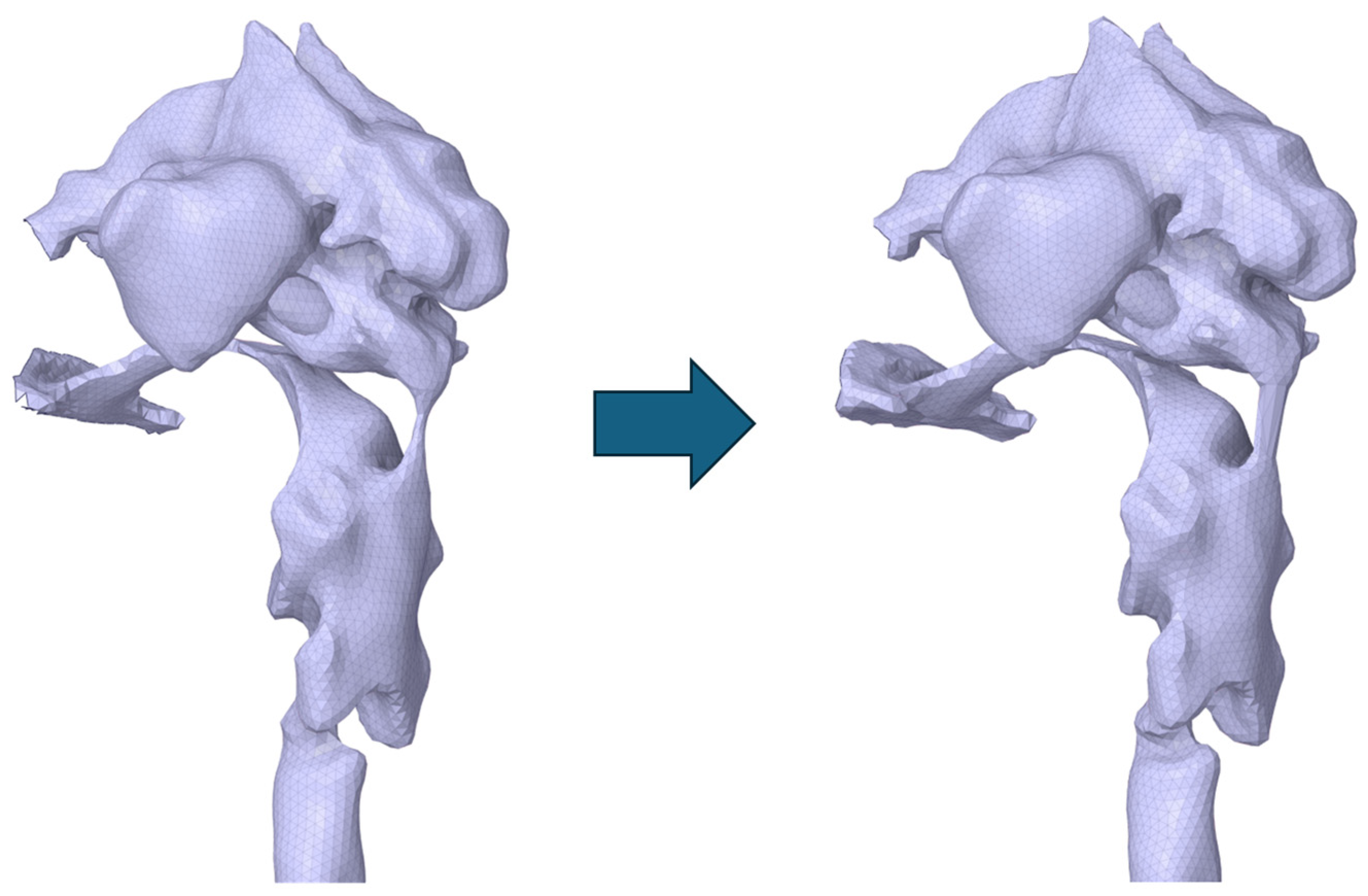
2.2. Simulation Method
2.3. Analysis Method
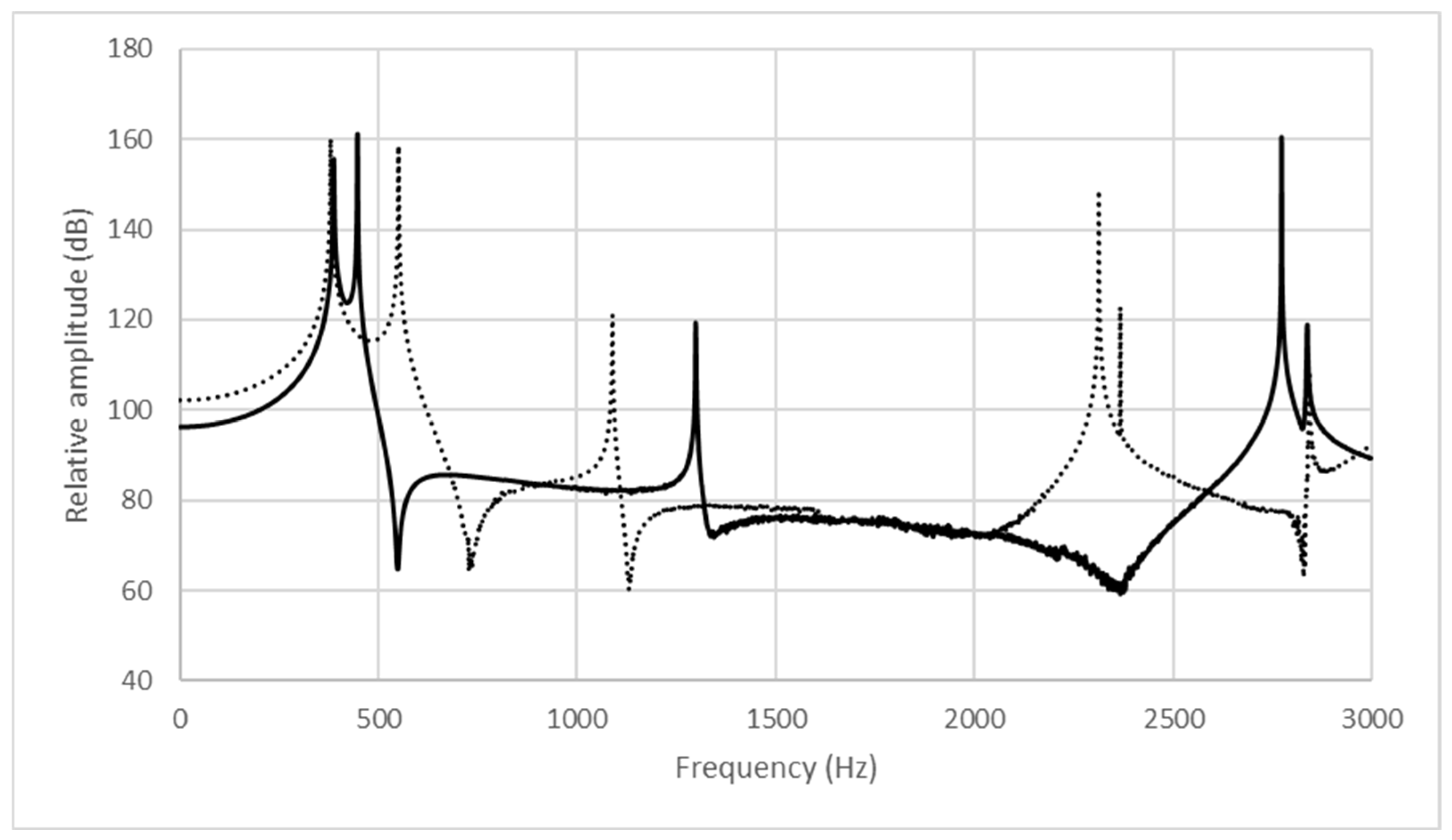
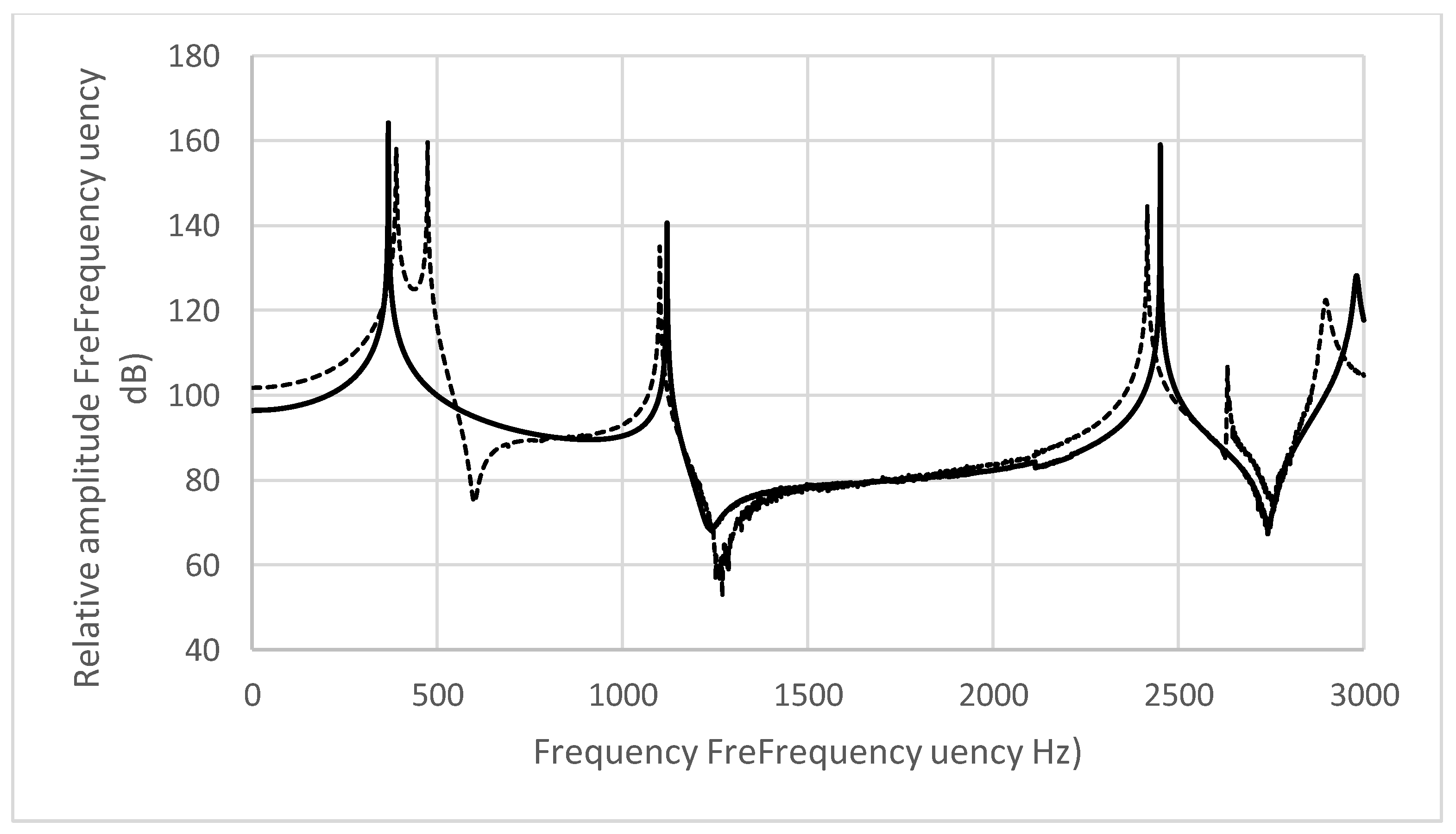
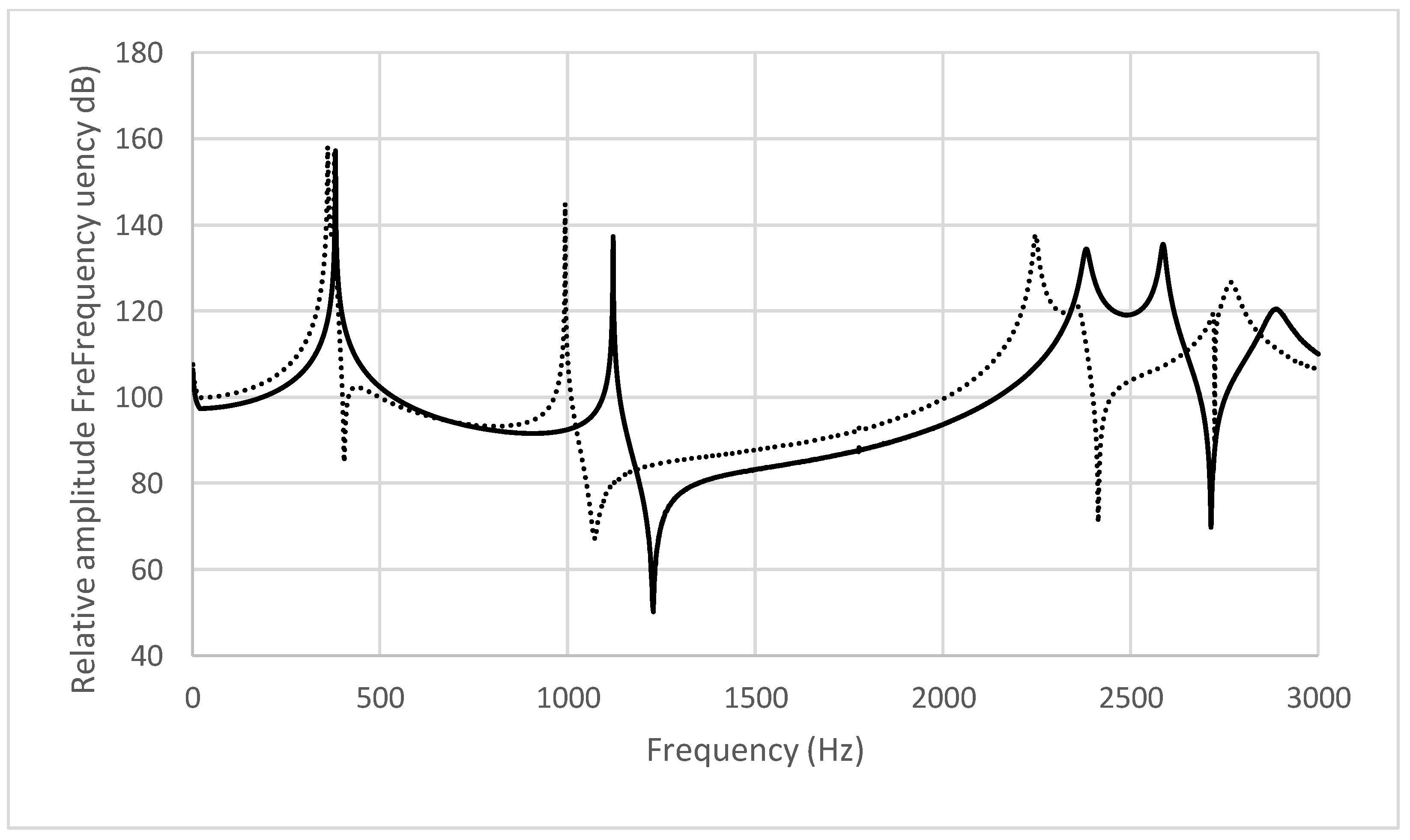
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Cullinan, W.L.; Counihan, D.T. Ratings of vowel representatives. Percept. Mot. Skill 1971, 32, 395–401. [Google Scholar] [CrossRef] [PubMed]
- Smith, S. Vocalization and added nasal resonance. Folia Phoniatr. 1951, 3, 165–169. [Google Scholar] [CrossRef] [PubMed]
- Imai, T.; Nakamura, S.; Hirahara, T.; Ifukube, T. Quantitative evaluation of the nasality in cleft palate speech. Acoust. Soc. J. 1985, 41, 69–76. [Google Scholar]
- Kent, R.D.; Read, C. The Acoustic Analysis of Speech, 2nd ed.; Singular/Thomson Learning: San Diego, CA, USA, 2002. [Google Scholar]
- Perry, J.L.; Snodgrass, T.D.; Gilbert, I.R.; Sutton, B.P.; Baylis, A.L.; Weidler, E.M.; Tse, R.W.; Ishman, S.T.; Sitzman, T.J. Establishing a clinical protocol for velopharyngeal MRI and interpreting imaging findings. Cleft Palate Craniofacial J. 2022, 61, 748–758. [Google Scholar] [CrossRef] [PubMed]
- MacIsaac, M.; Elsamna, S.; Quintana, J.; Rottgers, S.; Halsey, J. MRI assessment of velopharyngeal dysfunction: A comprehensive primer for radiologists. Pediatr. Radiol. 2025, in press. [Google Scholar] [CrossRef]
- Ito, Y.; Inamoto, Y.; Saitoh, E.; Aihara, K.; Shibata, S.; Aoyagim, Y.; Kagaya, H.; Palmer, J.B.; Gonzalez-Fernandez, M. The effect of bolus consistency on pharyngeal volume during swallowing: Kinematic analysis in three dimensions using dynamic Area Detector CT. J. Oral Rehabil. 2020, 47, 1287–1296. [Google Scholar] [CrossRef] [PubMed]
- Shiraishi, M.; Mishima, K.; Umeda, H. Development of an acoustic simulation method during phonation of the Japanese vowel /a/ by the boundary element method. J. Voice 2021, 35, 530–544. [Google Scholar] [CrossRef] [PubMed]
- Shiraishi, M.; Mishima, K.; Takekawa, M.; Mori, M.; Umeda, H. An acoustic simulation method of the Japanese vowels /i/ and /u/ by using the boundary element method. Acoustics 2023, 5, 553–562. [Google Scholar] [CrossRef]
- Zwikker, C.; Kosten, C.W. Sound Absorbent Material; Elsevier: New York, NY, USA, 1949; pp. 1–22. [Google Scholar]
- Hattori, S.; Yamamoto, K.; Fujimura, O. Nasalization of vowels in relation to nasals. J. Acoust. Soc. Am. 1958, 30, 267–274. [Google Scholar] [CrossRef]
- Dickson, D.R. An acoustic study of nasality. J. Speech Hear. Res. 1962, 5, 103–111. [Google Scholar] [CrossRef] [PubMed]
- House, A.S.; Stevens, K.N. Analog studies of the nasalization of vowels. J. Speech Hear. Disord. 1956, 21, 218–232. [Google Scholar] [CrossRef] [PubMed]
- Fant, G. Acoustic Theory of Speech Production; De Gruyter Mouton: Hague, The Netherlands, 1960. [Google Scholar]
- Kenneth, N.S. Acoustic Phonetics; MIT Press: Cambridge, MA, USA, 2000; pp. 135–137. [Google Scholar]
- Hanson, M.L. A study of nasopharyngeal competence in children with repaired cleft palates. Cleft Palate J. 1964, l, 217–231. [Google Scholar]
- Kataoka, R.; Yamashita, Y. Quantitative evaluation of hypernasality in children with cleft palate—Acoustical characteristics of hypernasality. Dent. Med. Res. 2009, 29, 14–20. [Google Scholar] [CrossRef]
- Wada, T.; Miyazaki, T. Growth and changes in maxillary arch form in complete unilateral cleft lip and palate children. Cleft Palate J. 1975, 12, 115–130. [Google Scholar]
- Fletcher, S.G. Diagnosing Speech Disorders from Cleft Palate; Grune & Stratton: New York, NY, USA, 1978; pp. 79–83. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Minimum Cross-Sectional Area of the Coupling Site in the Vocal Tract Model During Phonation of /i/ (mm2) | Minimum Cross-Sectional Area of the Coupling Site in the Vocal Tract Model During Phonation of /u/ (mm2) | ||||
|---|---|---|---|---|---|
| Participant No. | Sex | Before Modification | After Modification | Before Modification | After Modification |
| 1 | Male | 2.82 | 14.52 | 7.91 | 13.55 |
| 2 | Male | 0 | 0.37 | 0 | 3.35 |
| 3 | Male | 0 | 15.86 | 0 | 1.58 |
| 4 | Female | 0.45 | 3.54 | 12.01 | 14.47 |
| 5 | Female | 0 | 6.34 | 0 | 2.55 |
| 6 | Female | 1.44 | 13.99 | 4.12 | 10.74 |
| /i/ | F1 | F2 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Participant No. | Sex | Intensity Around 250 Hz | Intensity Around 500 Hz | Simulation Value (Hz) | Actual Voice (Hz) | Discrimination Threshold (%) | Enlarged | Percent Change (%) | Intensity | Simulation Value (Hz) | Actual Voice (Hz) | Discrimination Threshold (%) | Enlarged | Percent Change (%) | Intensity |
| 1 | Male | Increase | Decrease | 356 | 351 | 1.4 | 365↑ | 2.5↑ | Decrease | 2196 | 2031 | 7.5 | 1992↓ | 9.3↑ | Decrease |
| 4 | Female | Increase | Decrease | 374 | 370 | 1.1 | 378↑ | 1.1↑ | Increase | 2510 | 2649 | 5.5 | 2511↑ | 0.0↑ | Decrease |
| 6 | Female | Increase | Increase | 401 | 442 | 10.2 | 381↓ | 5.0↓ | Increase | 2775 | 2882 | 3.9 | 2315↓ | 16.6↓ | Decrease |
| /i/ | F1 | F2 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Participant No. | Sex | Intensity Around 250 Hz | Intensity Around 500 Hz | Simulation Value (Hz) | Actual Voice (Hz) | Discrimination Threshold (%) | Coupled | Percent Change (%) | Intensity | Simulation Value (Hz) | Actual Voice (Hz) | Discrimination Threshold (%) | Coupled | Percent Change (%) | Intensity |
| 2 | Male | Increase | Decrease | 365 | 342 | 6.3 | 360↓ | 1.4↓ | Increase | 2204 | 2356 | 6.9 | 2191↓ | 0.6↓ | Increase |
| 3 | Female | Increase | Decrease | 317 | 336 | 6 | 349↑ | 10.1↑ | Decrease | 2347 | 2180 | 7.1 | 2368↑ | 0.9↑ | Decrease |
| 5 | Female | Increase | Decrease | 368 | 358 | 2.7 | 389↑ | 5.7↑ | Decrease | 2451 | 2579 | 5.2 | 2416↓ | 1.4↓ | Decrease |
| /u/ | F1 | F2 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Participant No. | Sex | Intensity Around 250 Hz | Intensity Around 500 Hz | Simulation Value (Hz) | Actual Voice (Hz) | Discrimination Threshold (%) | Enlarged | Percent Change (%) | Intensity | Simulation Value (Hz) | Actual Voice (Hz) | Discrimination Threshold (%) | Enlarged | Percent Change (%) | Intensity |
| 1 | Male | Decrease | Decrease | 371 | 364 | 1.9 | 385↑ | 3.8↑ | Decrease | 1127 | 1198 | 6.3 | 1135↑ | 0.7↑ | Decrease |
| 4 | Female | Decrease | Increase | 449 | 447 | 0.4 | 478↑ | 6.5↑ | Decrease | 1403 | 1333 | 5.0 | 1705↑ | 21.5↑ | Decrease |
| 6 | Female | Increase | Increase | 432 | 472 | 9.3 | 426↓ | 1.4↓ | Increase | 2072 | 1906 | 8.0 | 1997↓ | 3.6↓ | Increase |
| /u/ | F1 | F2 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Participant No. | Sex | Intensity Around 250 Hz | Intensity Around 500 Hz | Simulation Value (Hz) | Actual Voice (Hz) | Discrimination Threshold (%) | Coupled | Percent Change (%) | Intensity | Simulation Value (Hz) | Actual Voice (Hz) | Discrimination Threshold (%) | Coupled | Percent Change (%) | Intensity |
| 2 | Male | Decrease | Decrease | 445 | 436 | 2.0 | 478↑ | 7.4↑ | Decrease | 1102 | 1222 | 11.0 | 1018↓ | 7.6↓ | Decrease |
| 3 | Male | Increase | Decrease | 381 | 375 | 1.6 | 360↓ | 5.5↓ | Increase | 1121 | 1261 | 12.5 | 993↓ | 11.4↓ | Increase |
| 5 | Female | Increase | Decrease | 495 | 464 | 6.3 | 527↑ | 6.5↑ | Decrease | 1220 | 1292 | 6.0 | 1136↓ | 6.9↓ | Increase |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shiraishi, M.; Mishima, K.; Takekawa, M.; Mori, M.; Umeda, H. Clarification of the Acoustic Characteristics of Velopharyngeal Insufficiency by Acoustic Simulation Using the Boundary Element Method: A Pilot Study. Acoustics 2025, 7, 26. https://doi.org/10.3390/acoustics7020026
Shiraishi M, Mishima K, Takekawa M, Mori M, Umeda H. Clarification of the Acoustic Characteristics of Velopharyngeal Insufficiency by Acoustic Simulation Using the Boundary Element Method: A Pilot Study. Acoustics. 2025; 7(2):26. https://doi.org/10.3390/acoustics7020026
Chicago/Turabian StyleShiraishi, Mami, Katsuaki Mishima, Masahiro Takekawa, Masaaki Mori, and Hirotsugu Umeda. 2025. "Clarification of the Acoustic Characteristics of Velopharyngeal Insufficiency by Acoustic Simulation Using the Boundary Element Method: A Pilot Study" Acoustics 7, no. 2: 26. https://doi.org/10.3390/acoustics7020026
APA StyleShiraishi, M., Mishima, K., Takekawa, M., Mori, M., & Umeda, H. (2025). Clarification of the Acoustic Characteristics of Velopharyngeal Insufficiency by Acoustic Simulation Using the Boundary Element Method: A Pilot Study. Acoustics, 7(2), 26. https://doi.org/10.3390/acoustics7020026