1. Introduction
In everyday communication, individuals adapt their speech patterns in response to varying environmental noise levels, utilizing auditory feedback to ensure the effective self-monitoring of their speech production [
1]. This vocal adjustment, termed the Lombard effect [
2], is an automatic reflex triggered when speakers encounter disruptive background noise that compromises effective communication [
3,
4,
5]. This phenomenon, often resulting in what is known as Lombard speech, manifests as an increase in voice sound levels, fundamental frequency alterations [
6,
7,
8], changes in formant frequency, articulation shifts, vowel duration elongation [
9,
10], and heightened vowel intensity [
11,
12]. Importantly, these vocal modifications have been shown to enhance the intelligibility of Lombard speech compared to speech produced in noise-free conditions [
8]. However, striving to repair communication hindered by noise can lead to increased vocal effort. One commonly used metric for assessing vocal effort is the equivalent continuous A-weighted sound pressure level (SPL) of speech measured at a distance of 1 m from the speaker’s mouth under anechoic conditions [
13]. Typically, conversational speech registers around 60 dBA at 1 m, but this level escalates in response to environmental noise. Up to a noise level of approximately 30–40 dB(A), speech is minimally affected, with a modest increase of 0.24 dB(A)/dB(A) [
5,
14,
15]. Beyond this threshold, as noise levels exceed approximately 43 dB(A), the average power of speech undergoes a more significant increment of about 0.65 dB(A) per 1 dB increase in noise level [
16], reaching saturation at high noise levels due to physiological limitations (“ceiling effect”) [
17]. This rate of increase in speech level per noise level is referred to as the Lombard slope. Additionally, it is worth highlighting that an individual’s quality of life (QoL) is closely intertwined with their communication abilities, with particularly notable improvements observed in individuals possessing higher communication skills, as underscored in Maniaci’s et al. study (2021) [
18].
Given that the Lombard effect results in heightened vocal effort in response to challenging acoustic environments, it is reasonable to anticipate that increased noise levels will lead to heightened vocal discomfort and communication disruption. Bottalico et al. (2017) [
16] identified that at the point at which the Lombard effect is triggered, the threshold of perceived disturbance and the threshold of discomfort do not align. Specifically, communication disruption is perceived at a lower noise level than the one associated with the activation of the Lombard effect (37.4 dB(A) and 43.3 dB(A), respectively), while discomfort is perceived at a higher level (49.5 dB(A)).
Despite extensive exploration of the Lombard effect under various conditions [
19], it is still not known how noises with different frequency characteristics influence this phenomenon. The human auditory system registers frequencies ranging from 20 to 20,000 Hz, yet the most critical frequencies for speech intelligibility fall within the 500 to 4000 Hz range [
20]. Notably, human auditory sensitivity varies with frequency, with the highest sensitivity found in the speech critical frequency range of 1000 to 4000 Hz and reduced sensitivity both above and below this range [
21,
22].
Since speech self-monitoring depends on auditory perception filtered through the auditory system, and the auditory system’s sensitivity varies by frequency, it is logical to surmise that the energy content of noises would exert different effects on the Lombard effect’s vocal response, as well as the disturbance and discomfort elicited by noise at different frequencies. Existing evidence suggests that the vocal response in the Lombard effect is sensitive to frequency content, especially frequencies critical for speech [
19,
23]. Likewise, the varying energy content of noise may also impact speech intelligibility differently. Noise with an acoustic spectrum resembling that of speech is expected to result in more degraded speech perception. Therefore, this study aims to investigate whether distinct Lombard slopes (defined as the Voice level vs. Noise level) emerge when broadband noise is characterized by low (LF) (20–500 Hz), medium (MF) (500–4000 Hz), and high frequency (HF) (4000–20,000 Hz) energy content. This study also aims to explore the relationship between these Lombard slopes and perceived communication disturbance, vocal comfort, as well as speech intelligibility. The research questions guiding this investigation are as follows:
Is there a difference in the Lombard slope when the noise energy resides mostly at low, medium, and high frequencies?
Is there a difference in the slope of the perceived communication disturbance from noise when the noise energy resides mostly at low, medium, and high frequencies?
Is there a difference in the slope on the perceived comfort associated with noise levels when the noise energy resides mostly at low, medium, and high frequencies?
Is there a difference in the slope on the intelligibility associated with noise levels when the noise energy resides mostly at low, medium, and high frequencies?
We hypothesize that the medium frequency range, where hearing sensitivity is highest and most of the critical information for human speech is contained, exerts the most significant detrimental effects on vocal effort, disturbance, discomfort, and speech intelligibility.
2. Materials and Methods
2.1. Participants
The study included 20 participants aged between 18 and 32 years, with an average age of 22.4 (SD = 3.9). The participants consisted of an equal number of males (10) and females (10). Among them, 17 were native speakers of American English, while three were advanced speakers of American English. Three participants had undergone speech therapy during their childhood, and none reported a history of hearing impairment. All participants provided informed consent to participate in the experiment, which was approved by the Institutional Review Board of the University of Illinois Urbana-Champaign under Protocol No. 18179.
2.2. Room Acoustics and Procedure
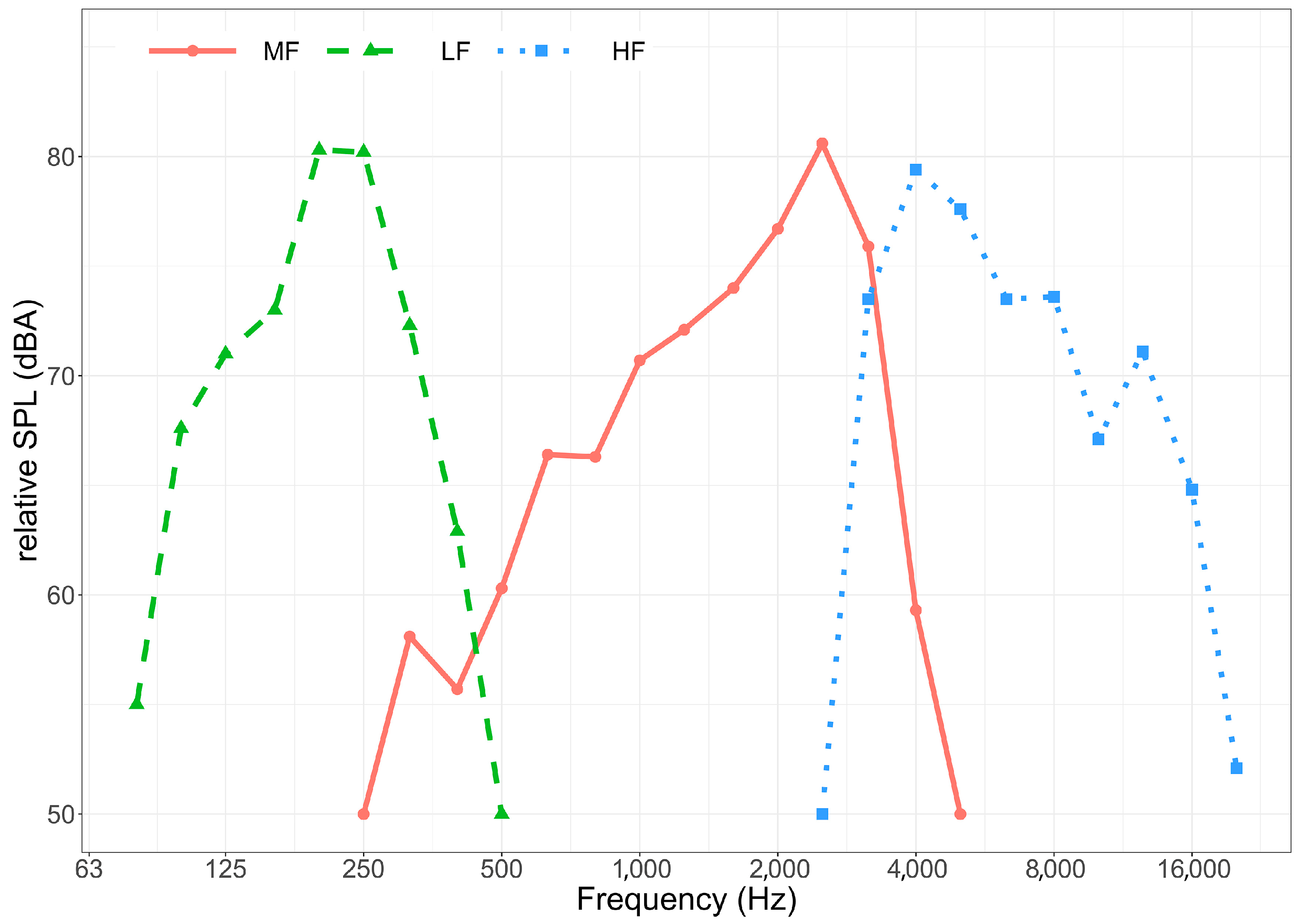
The experiment took place in a single-wall soundproof booth. Participants were seated facing a human listener positioned 2.5 m away, simulating a real communication setting. Two directional loudspeakers (KRK Systems studio monitor model Rokit5 G3) were placed 2.5 m from the participants, directed at a 45° angle from the mouth axes. These speakers emitted broadband noises at different frequencies: low frequencies (LF) (20–500 Hz), medium frequencies (MF) (500–4000 Hz), and high frequencies (HF) (4000–20,000 Hz). The spectra of the three types of noise are shown in
Figure 1.
A total of twelve conditions were randomly presented and recorded for each participant. Each condition was formed by a unique combination of one of three different frequency ranges and four levels with 10 dB steps (45 dB(A), 55 dB(A), 65 dB(A), and 75 dB(A)). The noise levels were measured using the ears of a Head and Torso Simulator with a Mouth Simulator (HATS, 45BC KEMAR, GRAS, Holte, Denmark) located in the participant’s seat in the booth. The measurements were analyzed using the NTI XL2 Audio and Acoustic Analyzer.
In each condition, participants were asked to read a six-sentence excerpt from the Rainbow passage [
24] displayed on a vertical screen in front of them. Following that, the participants’ speech intelligibility was evaluated by having them listen and repeat the sentences of the QuickSin test [
25] emitted by a HATS with a normal vocal effort of 60 dB(A) at a distance of 1 m (ISO 9921). The order of the intelligibility test lists and the order of the noise conditions were randomized for each participant. Participants were instructed to speak as if they were talking to the person seated in front of them. The speech was recorded using a measurement microphone placed 15 cm from the speaker’s mouth.
After each noise condition, participants were asked to rate the amount of communication disturbance and vocal comfort they had experienced. They marked their responses on a visual analog scale ranging from “Not at All” to “Extremely,” corresponding numerically to a range of 0 to 100. The following questions were asked:
Disturbance: How disturbed was your communication by the noise in this condition? (The extremes of the lines were “extremely disturbed” to the left and “not at all disturbed” to the right.)
Comfort: How comfortable was it to speak in this condition? (The extremes of the lines were “extremely” to the left and “not at all” to the right.)
2.3. Analysis
Speech signal analysis was conducted using MATLAB (R2022a). For each noise condition, the equivalent Sound Pressure Level (SPL) was measured, and the mean SPL value was calculated for each subject. To evaluate the variation in vocal behavior across different noise conditions compared to each subject’s typical vocal behavior (mean SPL value per subject), within-subject centering was performed. This involved subtracting the average SPL among all conditions from each mean SPL value, resulting in a variable termed ΔSPL.
To assess the Voice-to-Noise Ratio (VNR) in the recordings, the distributions of the voice and noise sources were analyzed using Expectation–Maximization (EM) algorithms for Gaussian mixtures [
26,
27]. The EM algorithms for Gaussian mixtures are iterative statistical techniques used in unsupervised machine learning to estimate the parameters of a mixture model comprising multiple Gaussian distributions. In our case, the distribution of sound levels encompassed a mixture of voice and noise levels. The algorithm estimated the mean values of the two distributions, and the difference between these mean levels provided an estimation of the VNR. The analysis was performed on a time history of the SPL with a time step of 0.05 s, considering the subset of the dataset for each noise condition.
An example of the application of the EM algorithms is shown in
Figure 2. In the Figure, a histogram of the SPLs acquired by the microphone with a time step of 0.05 s is shown together with the overall density curve. The EM algorithms estimated the Gaussian mixtures (the green and the red lines) that best fit the overall density curve (black line). In our case, the green Gaussian curve represents the speech levels, while the red Gaussian curve represents the noise levels.
Statistical analysis was carried out using R3.6.0 software and the lme4 package (version 1.1–10) [
28]. Linear mixed-effects models were fitted to the response variables ΔSPL, self-reported disturbance, self-reported vocal discomfort, and intelligibility scores (IS), with predictors including the noise level (Ln) (dBA), the type of noise (LF, MF, and HF), and their interaction. The listener ID was treated as a random factor. Participants reported their level of communication disturbance and discomfort by marking a visual analog scale. The score was obtained by measuring the distance between the left end of the line and the mark and then converting it to a percentage ranging from 0 (no disturbance or discomfort) to 100 (maximum disturbance or discomfort). Intelligibility scores were measured as the percentage of words correctly identified from the QuickSin test for each acoustic condition. The models’ output included estimates of the fixed effects coefficients, the associated standard error, the test statistic (t), and the
p-value.
3. Results
A total of 20 participants (10 males and 10 females) were tested by reading the Rainbow passage and repeating sentences pronounced by the HATS in 12 different noise conditions (comprising three frequency ranges and four levels). Initially, the Voice-to-Noise Ratio (VNR) in the recordings was evaluated. The average VNR across the various noise conditions was found to be 11.4 dB, with a standard deviation of 3.6 dB. This result indicates that the impact of noise on the equivalent level was negligible.
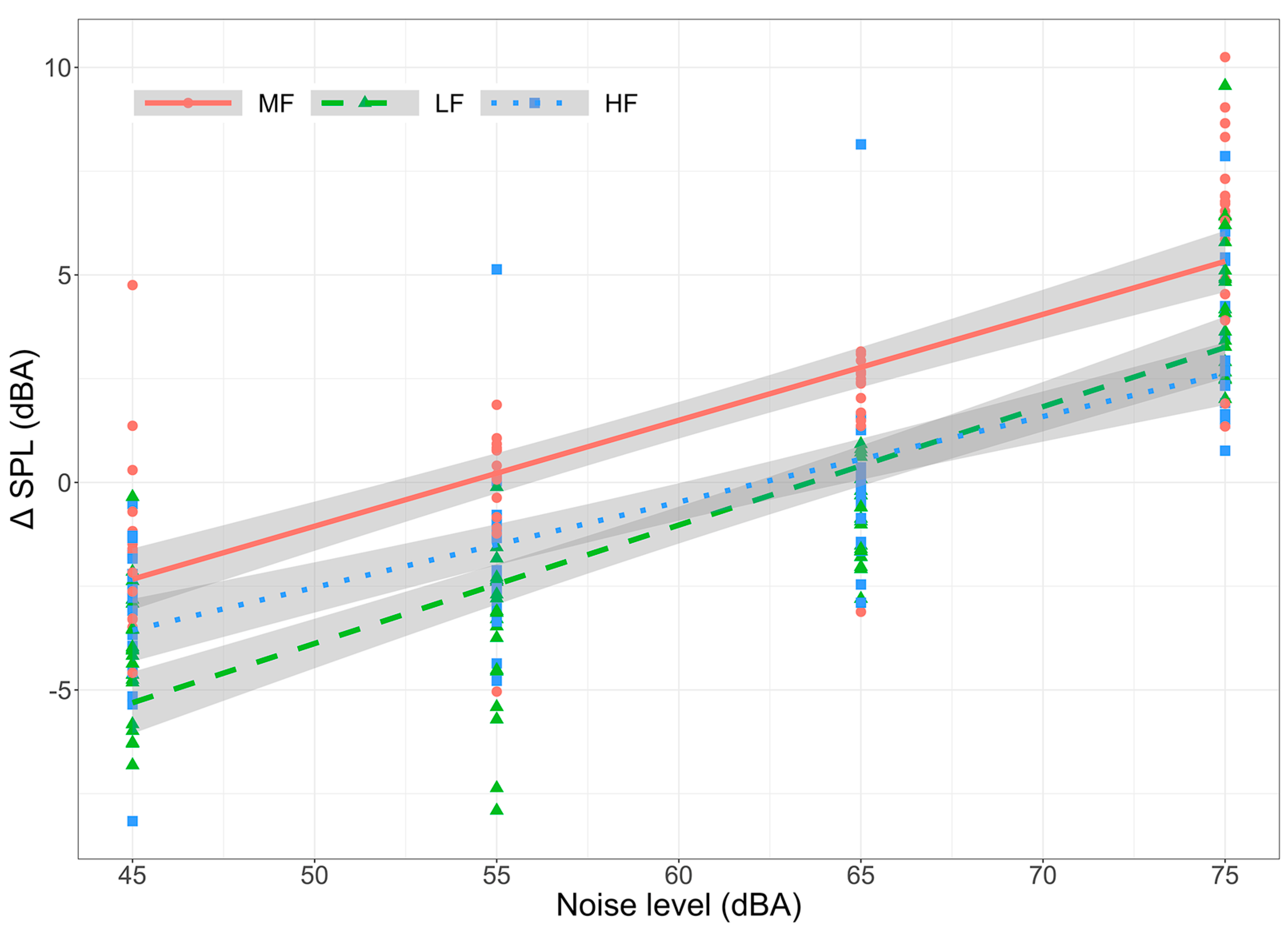
The model results for ΔSPL and Ln are presented in
Table 1, while the relationship between ΔSPL, grouped by noise frequency content, is depicted in
Figure 3. The model demonstrated a statistically significant association between ΔSPL and Ln, with ΔSPL increasing as Ln increased across all frequency ranges. Regarding the effect of noise type, there was a significant difference between the intercepts of the models for MF and LF, although the difference between the slopes was not significant. The intercepts of the regression models for MF and HF were not significantly different, while the difference between the slopes approached statistical significance, with the slope for MF noise being 0.05 dB/dB higher.
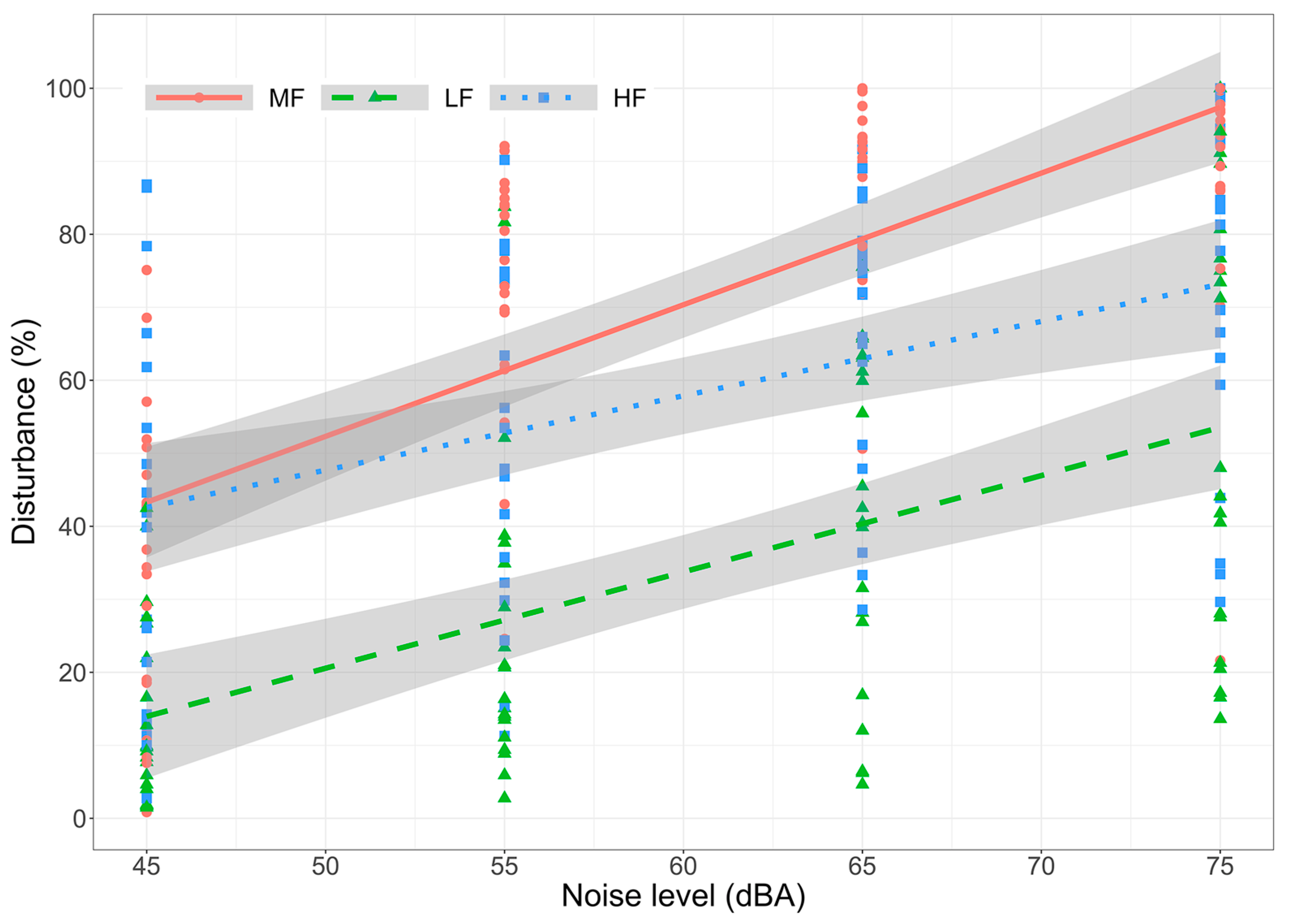
The model results for self-reported disturbance in communication and Ln are presented in
Table 2, and the relationship between disturbance and Ln, grouped by noise frequency content, is illustrated in
Figure 4. The model revealed a statistically significant relationship between disturbance and Ln, with disturbance increasing as Ln increased across all frequency ranges. Regarding the effect of noise type, there was no significant difference between the intercepts of the models for MF and LF, but the difference between the slopes approached statistical significance, with the slope for MF noise being 0.48 dB/dB higher. The regression models for MF and HF noise were significantly different in both intercepts and slopes. Specifically, the model for HF had a higher intercept and a smaller slope compared to the model for MF.
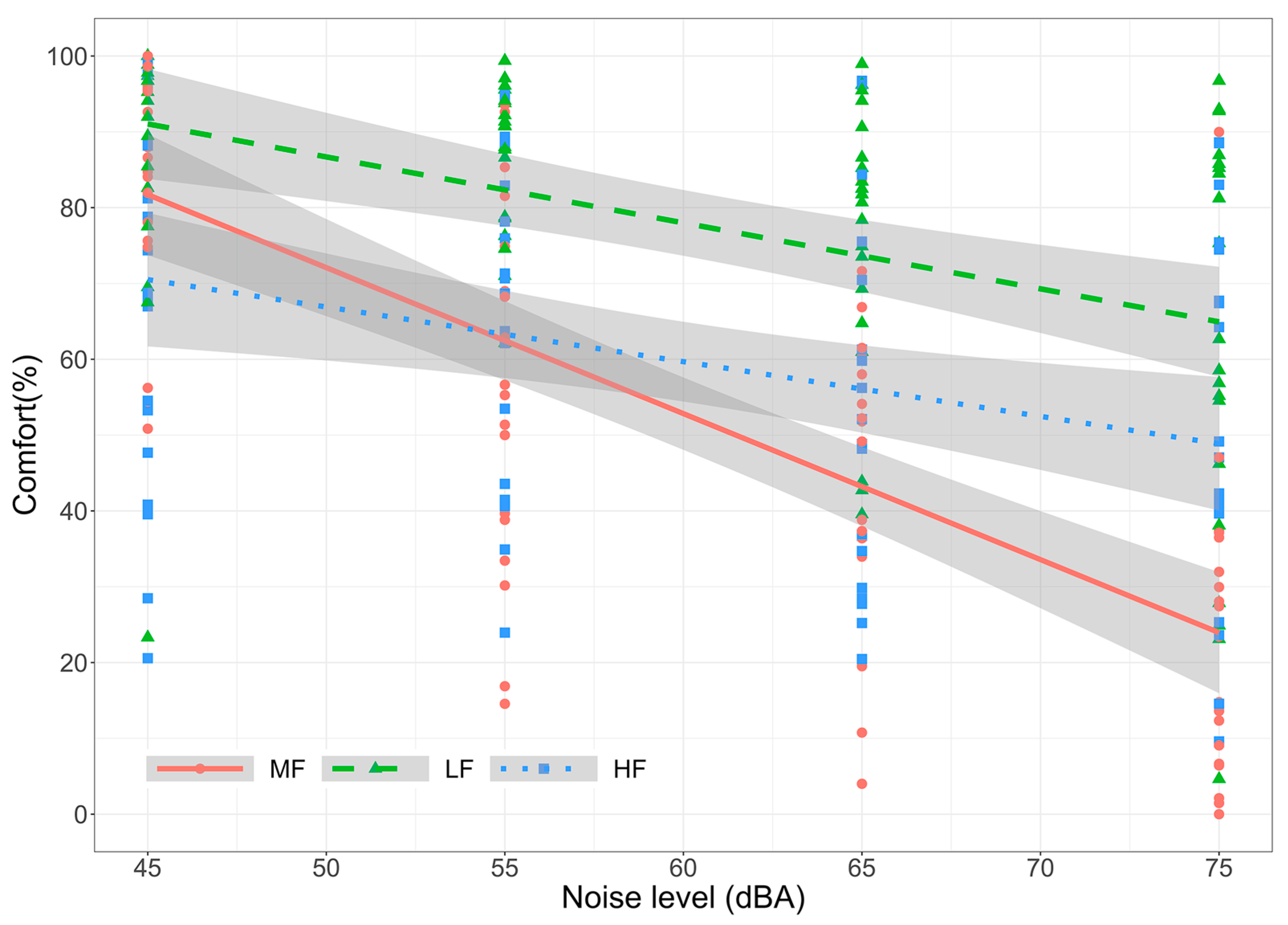
The model results for self-reported comfort in communication and Ln are shown in
Table 3, and the relationship between comfort and Ln, grouped by noise frequency content, is presented in
Figure 5. The model indicated a statistically significant relationship between comfort and Ln, with comfort decreasing as Ln increased across all frequency ranges. Concerning the effect of the noise type, there was a statistically significant difference between the intercepts and slopes of both the models for MF and LF, as well as MF and HF. In particular, the model for MF had a slope of 1.06 dB/dB higher compared to the model for LF and 1.20 dB/dB higher compared to the model for MF.
The model results for Intelligibility Scores (IS) and Ln are provided in
Table 4, and the relationship between IS, grouped by noise frequency content, is depicted in
Figure 6. The model demonstrated a statistically significant relationship between IS and Ln, with IS decreasing as Ln increased across all frequency ranges. Concerning the effect of noise type, there was a statistically significant difference between the intercepts and slopes of the models for MF and LF, as well as MF and HF. Specifically, the model for MF had a slope of 2.17%/dB higher compared to the model for LF, and 2.35%/dB higher compared to the model for MF.
4. Discussion and Conclusions
This study aimed to examine the impact of broadband noise at different frequency ranges and levels on the Lombard effect, perceived communication disturbance and vocal comfort, and speech intelligibility. The findings support the hypothesis that as background noise increases, vocal level and communication disturbance increases, while comfort and intelligibility decreases. Specifically, the study hypothesized that medium-frequency noise would have the greatest effect on vocal effort, disturbance discomfort, and speech intelligibility.
The results confirmed that medium-frequency noise led to the highest increase in vocal level, perceived disturbance, and discomfort, as well as the most significant decrease in speech intelligibility. Although the rate of vocal increase was comparable between low-frequency and medium-frequency noise, low-frequency noise generated lower sound pressure levels (SPL), indicating lower vocal effort. This suggests that participants increased their vocal level to a similar extent with increasing noise, but the level used in response to medium-frequency noise was higher. High-frequency noise required a vocal effort similar to that of medium frequencies at low noise levels but with a less steep slope compared to medium-frequency conditions. This can be attributed to the fact that the medium-frequency range is where hearing sensitivity is highest and where the speech signal is most intense.
In terms of disturbance caused by increasing noise levels, this study found the greatest increase in communication disturbance with medium-frequency noise. While medium frequencies showed similar perceived disturbance to high-frequency noise at the lowest level (45 dB), the disturbance increased significantly faster with medium-frequency noise as the level increased. The growth rate of disturbance for low and medium frequencies approached statistical significance, with medium frequencies exhibiting a slightly higher rate. However, the communication disturbance generated by medium-frequency noise was on average 30% higher across all levels considered (45–75 dBA).
Regarding comfort, low- and high-frequency noises had minimal effects on vocal comfort, showing a weak slope compared to medium-frequency noise. In contrast, medium-frequency noise resulted in a steep negative slope. When the noise level was lowest, the perceived comfort in speaking in that environment was high, but it decreased significantly (by about 60%) as the noise level increased. The disturbance and discomfort results can be attributed to the fact that when the frequency range essential for speech perception is masked, listeners perceive greater disturbance in listening to speech and lower comfort in producing speech.
Regarding speech intelligibility, the findings confirmed the sensitivity range of human hearing [
21]. The range of 500–4000 Hz, which contains most of the information in human speech, overlaps with the energetic content of the medium-frequency noise used in the study. In conditions with medium-frequency noise, speech intelligibility decreased dramatically with increasing noise levels, dropping from approximately 80% of speech correctly understood at a 45 dB noise level to about 5% at the highest level. On the other hand, low- and high-frequency noises had minimal impact on speech intelligibility, with nearly flat slopes. Both types of noise maintained high intelligibility even at the highest noise level. Notably, speech intelligibility in the presence of high-frequency noise was hardly affected by increasing noise levels. This suggests that 45 dBA of high-frequency noise is sufficient to mask the high-frequency content of the speech spectrum when participants maintained a normal vocal effort of 60 dBA at a one-meter distance in an anechoic condition.
In conclusion, the findings revealed distinct patterns for each frequency range.
In terms of the Lombard effect, the medium-frequency noise exhibited the highest increase in sound pressure level (SPL) as the background noise level increased. Participants displayed a lower SPL response, indicating lower vocal effort, with low-frequency noise. Moreover, the rate of vocal increase was smaller for low-frequency noise compared to the other types of noise. High-frequency noise led to a similar vocal effort as medium frequencies at low noise levels but with a less steep slope as the noise level increased.
Regarding speech intelligibility, this study demonstrated that increasing noise with medium-frequency content had the most significant and rapid negative impact on intelligibility. In contrast, low-frequency and high-frequency noise had minimal effects on speech intelligibility, with only minor changes observed as the noise level increased.
These results highlight the frequency-specific nature of the Lombard effect, communication disturbance, vocal comfort, and speech intelligibility. Medium-frequency noise had the most pronounced influence on vocal responses and communication outcomes, while low- and high-frequency noise had relatively minor effects. These findings contribute to our understanding of how different frequency ranges impact speech-related behaviors in the presence of background noise.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}