1. Introduction
The Earth’s forest ecosystems provide irreplaceable ecological services. Their core value lies in supporting the fundamental habitats that shape biodiversity patterns, participating in the dynamic regulation of the global carbon cycle, acting as carbon sinks in climate regulation, strengthening soil structure stability through root networks, reducing the erosive effects of surface runoff on soil matrices, and forming a crucial replenishment mechanism for regional water cycles. However, forest fires threaten forests by destroying vegetation, reducing biodiversity, worsening global warming, and releasing harmful smoke and particles that impact human health. Therefore, protecting forests and preventing fires have become urgent issues that need to be addressed globally.
Conventional fire detection methods, including smoke, heat, and infrared detection, are mainly intended for identifying indoor and outdoor fire indicators. These sensors detect changes in smoke concentration and temperature, with limitations in their detection conditions, making them more suitable for indoor use. Infrared sensors transform reflected infrared energy into electrical impulses to trigger outdoor fire alerts. For instance, Le et al. [
1] introduced a system to decrease false alarms in traditional manual detection processes. However, these technologies are prone to environmental interference, have limited range, and result in high costs and slow response times, restricting their use in complex environments. Advancements in computer vision and fire detection have shifted the focus from sensor-based to image-based detection, offering faster, more accurate wildfire detection with enhanced perception and positioning capabilities, making this a leading fire detection method.
Optical remote sensing is crucial for extensive surveillance, such as tracking forest fires. Hao et al. [
2] introduced YOLO-SR, a method that fuses super-resolution images with deep learning for infrared small target detection, enhancing input image quality and network structure to boost the detection of faint targets, achieving 95.2% mAP@0.5. Wang et al. [
3] created the Smoke-Unet model, pinpointing RGB, SWIR2, and AOD spectral bands as the most crucial for detecting smoke in Landsat-8 imagery. Ding et al. [
4] proposed FSF Net, using Mask-RCNN-ResNet50-FPN for semantic segmentation and XGBoost for thresholding in forest fire smoke detection with MODIS data. Jin et al. [
5] created a U-Net model incorporating physical local context and global index methods for accurate fire detection, and introduced YOLOv5 to filter false positives, proposing an adaptive fusion algorithm for improved robustness, stability, and generality. Chen et al. [
6] proposed the Att Mask R-CNN model for tree canopy detection and segmentation in remote sensing images. This model outperformed Mask R-CNN and MS R-CNN, achieving an mAP of 65.29%, mIoU of 80.44%, and an overall recognition rate of 90.67% on six tree-species datasets. The study also utilized segmentation masks to count pixels and estimate the vertical projection area of tree canopies.
At present, the monitoring of forest fires mainly relies on camera detection technology. This technology captures real-time images of forest areas through cameras installed at high altitudes, and analyzes the images using image processing and recognition algorithms to detect and warn of potential fire risks in a timely manner. Abdusalomov et al. [
7] proposed an improved YOLOv3 approach for fire detection and categorization. By refining the algorithm and integrating a real-time camera system, they realized precise, all-weather fire detection, identifying 1 m × 0.3 m fire spots up to 50 m away. Lin et al. [
8] proposed LD-YOLO for early forest fire detection, incorporating techniques like GhostConv, Ghost-DynamicConv, DySample, SCAM, and a lightweight self-attention detection head for high accuracy and speed, and low complexity. Geng et al. [
9] introduced YOLOv9-CBM, optimizing YOLOv9 for fewer false alarms and missed detections. Utilizing the new CBM Fire dataset with 2000 images, they enhanced detection with SE Attention, BiFPN, and MPDIoU loss. YOLOv9-CBM boosted recall by 7.6% and mAP by 3.8%. Yun et al. [
10] presented FFYOLO to address low accuracies and high computational costs, using CPDA for feature extraction, a hybrid classification–detection head (MCDH) for accuracy–speed balance, MPDIoU loss for better regression and classification, and GSConv for parameter reduction, with knowledge distillation for improved generalization. He et al. [
11] introduced DCGC-YOLO based on an improved YOLOv5, incorporating dual-channel grouped convolution bottlenecks and IoU K-means clustering for anchor box optimization. Liu et al. [
12] proposed CF-YOLO based on YOLOv7, improving the SPPCSPC module for better small-target detection, combining C2f with DSConv for faster inference. Khan et al. [
13] introduced the FFireNet model, leveraging MobileNetV2 for transfer learning and appending a fully connected layer for image classification, thereby enhancing the precision of forest fire detection and lowering the incidence of false positives.
Compared to cameras installed in fixed locations, unmanned aerial vehicle (UAV) services demonstrate the following advantages in fire detection: Firstly, UAVs have flexibility and mobility. They can specify terrain areas and provide real-time fire information. Secondly, they can be deployed quickly, without being limited by installation location like fixed cameras. Thirdly, the compact size of drones and their ability to carry multiple sensors can greatly expand the monitoring field of view, covering vast and remote forest areas that are difficult to reach manually, thereby providing comprehensive and detailed views of fire scenes. Finally, UAVs have low economic costs, and significantly save manpower and resources compared to traditional monitoring methods, improving monitoring efficiency and cost-effectiveness.
In order to make their model lightweight, the following researchers used different improvement methods. Xiao et al. [
14] developed the FL-YOLOv7 lightweight model to overcome the computational constraints in UAV-based forest fire detection. They integrated C3GhostV2, SimAm, ASFF, and WIoU techniques to reduce parameters and computational burden, simultaneously improving the precision and efficiency of detecting small targets. Small target fires are easily masked by background noise in UAV forest images, making recognition difficult. Meleti et al. [
15] proposed a model for detecting obscured wildfires using RGB cameras on drones, which integrated a pre-trained CNN encoder and a 3D convolutional decoder, achieving a Dice score of 85.88%, precision of 92.47%, and accuracy of 90.67%. Chen et al. [
16] introduced the YOLOv7-based lightweight model LMDFS. By replacing standard convolution with Ghost Shuffle Convolution (GSConv) and creating GSELAN and GSSPPFCSPC modules, their model reduced parameters, sped up convergence, and achieved lightweight performance, with strong results. Zhou et al. [
17] created a forest fire detection technique employing the compact YOLOv5 model. This method substitutes YOLOv5’s backbone with the lightweight MobileNetV3s and incorporates a semi-supervised knowledge distillation algorithm to reduce model memory and enhance detection accuracy. Liu et al. [
18] introduced the FF Net model to tackle issues like the interference and high false positive and negative rates in forest fire detection. It integrates attention mechanisms based on the VIF net architecture. By improving the M-SSIM loss function, it better processes high-resolution images and highlights flame areas. Yang et al. [
19] proposed an advanced model to address the issue of identifying smoke from forest fires in unmanned aerial vehicle imagery. The model utilizes K-means++ to optimize anchor box clustering, PConv technology to improve network efficiency, and introduces a coordinate attention mechanism and small object detection head to identify small-sized smoke. Shamta [
20] constructed a deep-learning-based surveillance system for forest fires, utilizing drones with cameras for image capture, YOLOv8 and YOLOv5 for object detection, and CNN-RCNN for image classification. To improve the smoke detection accuracy in unmanned aerial vehicle forest fire monitoring, researchers have proposed various enhancement methods. Saydirasulovich et al. [
21] improved the YOLOv8 model. Through the incorporation of technologies like GSConv and BiFormer, the model’s detection accuracy was enhanced, thereby significantly improving its ability to detect forest fire smoke. Choutri et al. [
22] proposed a fire detection and localization framework based on drone images and the YOLO model, using YOLO-NAS to achieve high-precision detection, and developed a stereo-vision-based localization method. The model achieved a score of 0.71 for mAP@0.5 and an F1 score of 0.68. Luan et al. [
23] presented an enhanced YOLOX architecture that includes a multi-tiered feature extraction framework, CSP-ML, and CBAM attention module. This upgrade aimed to refine feature detection in intricate fire scenarios, reduce interference from the background, and integrate an adaptive feature extraction component to preserve critical data during the fusion process, thereby bolstering the network’s learning proficiency. Niu et al. [
24] introduced FFDSM, a refined YOLOv5s Seg model that enhances feature extraction in intricate fire scenarios by employing ECA and SPPFCSPC. ECA captures key features and adjusts weights, improving target expression and discrimination. SPPFCSPC extracts multi-scale features for comprehensive perception and precise target localization.
Although UAVs provide significant advantages in forest fire detection, they face a number of technical hurdles. Firstly, unlike traditional images, the images captured by UAVs may appear blurry, due to limitations such as flight altitude and weather conditions, making it difficult to provide sufficiently clear details [
25,
26] when dealing with small-sized target objects, which poses obstacles for early detection and accurate assessment of fires. Secondly, UAV images often feature closely packed objects that merge together, leading to occlusion and increasing detection complexity. Finally, UAVs require models to be as lightweight as possible while maintaining high detection accuracy, in order to adapt to their limited computing resources and storage capabilities.
In response to the aforementioned issues, a lightweight UAV forest fire detection model utilizing YOLOv8 is proposed. Building upon earlier findings, this article presents a series of enhancements, which are outlined below:
- (1)
To enhance detection precision, we propose the MLCA approach, which fortifies the model’s capability to discern local intricacies and global configurations, while lessening the computational burden, suitable for intricate applications such as object detection.
- (2)
To enhance the processing of small targets and low-resolution images, we introduce SPDConv. Its core idea is to preserve fine-grained information during downsampling by replacing the traditional stride convolution and pooling, improving object detection and image analysis performance.
- (3)
To reduce the number of parameters and boost computational efficiency, we introduce the C2f-PConv technique. By integrating partial convolution (PConv) within the C2f module, PConv operates on a subset of the input channels for spatial feature extraction, which effectively enhances efficiency by reducing unnecessary computations and memory usage.
- (4)
To enhance detection capabilities for tiny objects and those subject to occlusions, we present the W-IoU method. W-IoU refines the detection of small objects and the recognition of low-quality images by adaptively modifying the weight allocation of target boxes within the loss computation.
2. Methods
2.1. YOLOv8
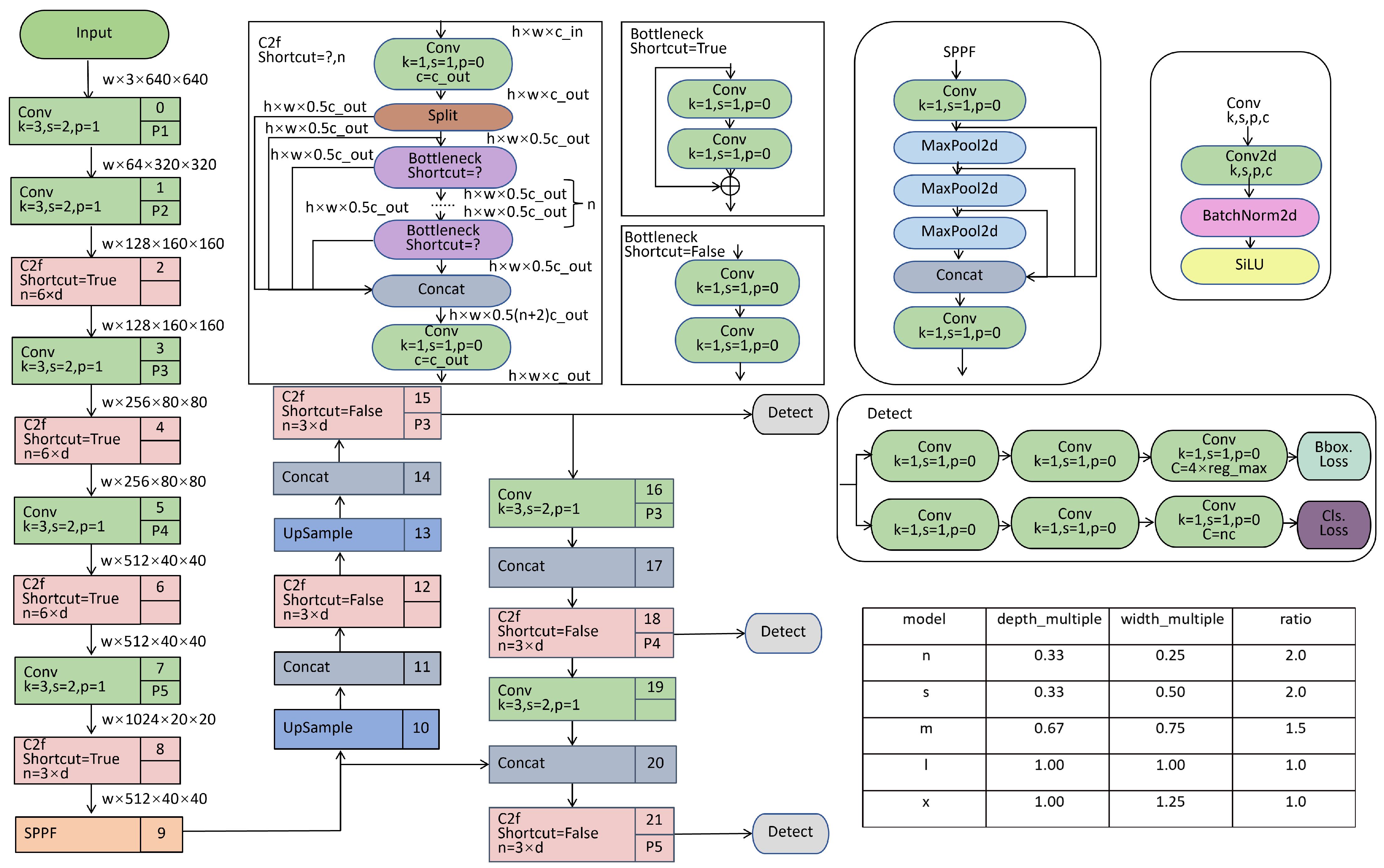
Building on the previous background, this paper chose YOLOv8 as the base model. Introduced by the Ultralytics group in 2023, YOLOv8 represents a state-of-the-art model for object detection, with its fundamental structure depicted in
Figure 1. It introduced several optimizations over previous versions of YOLO, aiming to provide higher detection accuracy and faster inference speed. Unlike earlier YOLO versions, YOLOv8 uses an anchor-free object detection method. The model forecasts the center, width, and height of objects directly, rather than using anchor boxes for estimating object positions and dimensions. This approach streamlines calculations, decreases the dependency on anchor boxes, and improves both the pace and precision of detection.
Figure 1 depicts the YOLOv8 framework, which comprises four primary elements: the Input layer, Backbone, Neck, and Head. The Input layer handles image preprocessing, such as scaling and data augmentation. The Backbone network extracts image features utilizing convolutional layers (Conv), C2f blocks, and the Spatial Pyramid Pooling Fast (SPPF) block. The C2f module enhances feature representation by utilizing inter-layer connections. Within the Neck component, YOLOv8 merges the advantages of the Feature Pyramid Network (FPN) with the Path Aggregation Network (PAN) to refine feature extraction. Finally, the Head section employs a decoupled architecture to independently handle object classification and detection responsibilities. YOLOv8 further refines its loss function by incorporating Binary Cross Entropy (BCE) for classification tasks. For regression purposes, it employs Dynamic Focus Loss (DFL) alongside Complete Intersection over Union Loss (CIoU). These innovations bolster the model’s efficacy in dealing with complex situations. In conclusion, YOLOv8 boosts accuracy and speed, while streamlining the network architecture and adopting an anchor-free detection strategy, rendering it more proficient in tackling difficult object detection challenges. Despite YOLOv8’s notable achievements in object detection, it does encounter certain constraints, particularly in certain specialized scenarios. For example, in crowded environments or with severe occlusion, the performance of YOLOv8 may decrease. This is because the anchor box mechanism and loss function design of YOLOv8 can result in the model being less robust to such situations. In addition, YOLOv8 also faces challenges when processing low-resolution images or small targets. Conventional convolution and pooling methods tend to discard detailed information during downsampling, impacting the model’s proficiency in detecting fine details. We have made improvements to the model to address the aforementioned issues.
2.2. Mixed Local Channel Attention
To enhance detection accuracy without adding computational complexity, we introduce Mixed Local Channel Attention (MLCA) [
27,
28]. MLCA [
29] is a lightweight attention mechanism that integrates local spatial and channel information. This approach employs a two-phase pooling combined with 1D convolution, which diminishes computational expenses, while enhancing the model’s capability to encapsulate both local and global characteristics, suited for tasks such as object recognition.
The design objectives of MLCA were to avoid accuracy loss when reducing the channel dimension, while addressing the high computational resource demands of traditional attention mechanisms. Compared to global attention, MLCA combines local pooling and 1D convolution, reducing the need for extensive computations across the entire feature map. This not only conserves resources, but also avoids increasing the network’s parameter count and computational burden. The mechanism improves the representation of key regions, enabling the model to focus on crucial details, offering an efficient and accurate solution for resource-limited environments like embedded systems or mobile devices.
Another key advantage of MLCA is its incorporation of an attention mechanism during information fusion. In each branch, MLCA extracts both global and local features through 1D convolution, then combines these two types of information using a weighting factor of 0.5. The integrated features are restored to their original resolution via unpooling and are then multiplied with the initial input to generate the final output. This merging technique enhances the model’s capacity for information integration and feature representation, as well as boosting the distinguishing capabilities of features. It is especially useful in complex object detection tasks, significantly boosting accuracy, particularly for detecting small or occluded objects.
As illustrated in
Figure 2a, the input features of MLCA undergo a two-stage pooling process. During the initial phase, local spatial details are gathered through local average pooling, resulting in a feature map with dimensions
(with
C denoting the channel count and k representing the pooling window’s dimensions). Subsequently, the feature map is split into two streams: one dedicated to extracting global context, and the other to maintaining local spatial information. Both branches undergo 1D convolution and unpooling, and are then fused to create the mixed attention information, as shown in
Figure 2b. In this phase, the kernel size k is linked to the number of channels
C. This configuration enables MLCA to capture local cross-channel interaction information, which is especially useful for detecting small objects. The kernel size is chosen based on the following formula, where k is the selection criterion:
Here, is a hyperparameter, typically set to 2, and b is the offset of the result.
2.3. Space-to-Depth Convolution
To improve the handling of small objects and images with low resolution, we utilize the SPDConv technique [
30]. SPDConv (Space-to-Depth Convolution), introduced by Sunkara et al. [
31], is a novel CNN module aimed at improving traditional CNN performance in handling small objects and low-resolution images. This technique is substituted for traditional strided convolutions and pooling, preventing the degradation of detailed information during the downsampling process. Such an approach significantly improves object detection and image analysis, being particularly beneficial for images with low resolution and minute objects.
In traditional CNNs, excessive downsampling (e.g., through pooling or convolutions with strides greater than 1) reduces resolution, affecting the model’s responsiveness to minor objects. SPDConv addresses this by replacing strided convolutions and pooling layers, preventing excessive downsampling and preserving more spatial information, making it particularly effective for low-resolution images.
As illustrated in
Figure 3, the architecture of SPDConv is comprised of two primary elements: the Space-to-Depth (SPD) block and a convolution layer without stride. The process can be outlined in these primary stages:
2.3.1. Space-to-Depth (SPD) Layer
The key operation of the SPD layer is to convert the spatial information of the input feature map into depth information. This process involves dividing the feature map into multiple sub-feature maps, and then merging them along the channel axis, which decreases the spatial dimensions, while boosting the channel count. For example, with an input feature map X of dimensions (S, S,
), the SPD layer converts it to a new feature map
with dimensions
. This transformation can be represented by the following formula:
Here, the scale is the downsampling factor. The
Figure 3c shows an example when downsampling factor is set to 2, the SPD layer converts feature map into four sub-feature maps
,
,
,
, each with the shape
.
Figure 3d represents the resulting new feature map
.
2.3.2. Non-Strided Convolution Layer
After the SPD layer, SPDConv applies a convolutional layer with a stride of 1. Unlike conventional convolutions with strides greater than 1, the non-strided convolution effectively avoids information loss, while further extracting features through learned parameters. Following the convolutional layer, the channel count in the feature map is decreased from to , with the spatial resolution staying constant at .
Conventional convolution methods (including strided convolutions and pooling layers) usually lead to the sacrificing of detailed data, particularly in the handling of low-resolution imagery or tiny objects. By converting spatial information to depth, SPDConv decreases the spatial dimensions while increasing the channel depth, retaining more data and lowering the chance of data loss. For small object detection, SPDConv improves the identification of small items by shrinking spatial dimensions and augmenting the channel depth.
2.4. CSP Bottleneck with 2 Convolutions-Partial Convolution
The C2f module leverages residual connections, skip connections, and multi-layer convolution structures to capture hierarchical features from the input image, improving the model’s efficacy in intricate scene analysis. The method combines features between layers, minimizes the transfer of unnecessary information, and enhances the model’s capability to identify objects at various scales. The feature map is divided along its channel axis, with deep convolution applied to harvest local and global features across different scales. While this architecture improves the efficiency of computational resource usage to a degree, it encounters difficulties in intricate situations such as deformation and occlusion, because of the convolutional kernel’s static receptive field. Traditional convolution (as shown in
Figure 4a) is the most basic form of convolution. It retrieves features by sliding a filter (or convolutional kernel) across the input feature map and computing the dot product of the filter with the corresponding local area at every location. Traditional convolution can capture both the global and local features of the input data. However, UAVs typically have small form factors and limited power budgets, making them unable to bear the heavy computational load and energy consumption brought by traditional convolutions.
Depthwise separable convolution (illustrated in
Figure 4b) is a variant aimed at reducing computational cost. It splits traditional convolution into two steps: depthwise convolution, and pointwise convolution. Although it reduces computational costs, it may compromise expressive power, potentially affecting the model’s performance.
The partial convolution [
32] (PConv, depicted in
Figure 4c) gathers spatial features by applying filters to a selection of input channels, with the remaining channels remaining unaffected. This method can considerably decrease computational expense and memory usage without a substantial loss in performance, and it facilitates the trade-off between efficiency and effectiveness by choosing a suitable portion ratio.
In order to improve detection performance and efficiency, we introduce C2f-PConv [
33]. C2f-PConv employs PConv technology to decrease unnecessary computation and memory usage, while maintaining feature extraction proficiency, thus lowering the model’s computational complexity and parameter count.
It enhances computational efficiency by minimizing redundant computations and memory accesses. Unlike traditional convolution, PConv applies the operation to only a subset of channels in the input feature map, leaving the others unchanged. This reduces the FLOPs of PConv:
where
h represents the height of the feature map,
w is the width,
k is the size of the convolution kernel, and
is the number of input feature map channels. This approach greatly reduces computational complexity, and for a typical partial ratio of
, the FLOPs of PConv are only
of those in conventional convolution.
Additionally, PConv requires less memory access compared to conventional convolution. With a partial ratio of
, the memory access is only
of that needed by standard convolution. The formula is as follows:
This design enables PConv to effectively avoid unnecessary computations during feature extraction, thereby improving processing speed and efficiency. In the C2f-PConv structure (illustrated in
Figure 5), it replaces the convolution operations in the C2f module with PConv, which reduces redundant computations and memory accesses, while preserving feature extraction capabilities. This enhancement allows the C2f module to maintain efficient computational performance, even when handling larger or more complex objects. Through the flexible sampling mechanism of partial convolution, C2f-PConv can adapt to local variations in the input image, while overcoming the limitations imposed by the fixed receptive field in standard convolution.
2.5. W-IoU Loss
In YOLOv8, W-IoU tackles the challenges of small object detection and low-quality images by dynamically adjusting the weights of different object boxes in the loss function [
34,
35]. In complex tasks like UAV-based forest fire detection and scanning electron microscope (SEM) image object detection, W-IoU improves detection performance, especially in the presence of small objects and occlusions, by optimizing anchor boxes of varying quality.
W-IoU comes in three variants (v1, v2, and v3), each providing tailored optimization approaches for various contexts.
W-IoU v1 introduces a distance metric as the attention criterion, minimizing excessive penalties on geometric metrics like aspect ratio and position. In small object detection, it reduces the overemphasis on high-quality anchor boxes, improving the model’s robustness by adjusting the attention weight of anchor boxes using this distance metric. The formula is as follows:
The boundary box loss based on represents the loss using IoU, IoU is calculated as the quotient of the overlap area to the combined area of the predicted and actual bounding boxes. is the area of their union. When both and are zero, this can cause vanishing gradients during backpropagation. For the predicted bounding boxes, x and y represent the center coordinates, while and refer to the center coordinates of the ground truth bounding box. and are the width and height of the ground truth box, respectively. is the weighted intersection parallel ratio loss, and is the weight factor for this loss.
In W-IoU v2, the model introduces a monotonic attention coefficient aimed at dynamically adjusting the weight, reducing the influence of easy samples on the training process, and accelerating convergence.
In this context, denotes the dynamically adjusted attention coefficient, while refers to the enhanced Intersection over Union loss.
W-IoU v3 is the final version of this approach, building upon the foundation of v2 by introducing an outlier degree (
) and a dynamic focusing mechanism (
r). W-IoU v3 introduces the concept of outlier degree, to dynamically assess the quality of anchor boxes and modify the gradient weights for individual boxes accordingly. This approach is especially useful for dealing with low-quality samples and image noise, reducing the influence of poor anchor boxes on gradient updates. As a result, it accelerates model convergence and improves overall performance. W-IoU v3 shows outstanding performance in object detection, especially in tasks involving occlusion, small objects, and complex backgrounds, where it displays strong robustness. The formula for this mechanism is as follows:
In this context, denotes the outlier degree, reflecting the quality of the anchor boxes, while r is the dynamically adjusted focusing factor.
The parameter scheme of W-IoU is shown in
Figure 6. W-IoU v3 introduces an anomaly score and a dynamic non-monotonic focusing mechanism, addressing the issue that traditional loss functions struggle to handle low-quality anchor boxes. This optimization improves the gradient update process and enhances the model’s adaptability to complex scenes. W-IoU v3 mitigates the adverse effects of subpar anchor boxes in training, guaranteeing that YOLOv8 sustains robust detection precision and consistency, particularly in the presence of noisy visuals or significant object obstructions.
In summary, W-IoU effectively optimizes the object detection performance of YOLOv8 by introducing a dynamic focusing mechanism and outlier degree. It demonstrates significant advantages in handling small objects, complex backgrounds, low-quality samples, and occlusion issues, providing more stable and precise training results for YOLOv8. By dynamically adjusting the weights, W-IoU speeds up the model’s convergence and boosts its robustness to difficult samples, improving its adaptability and performance in real-world scenarios.
2.6. An Improved UAV Forest Fire Detection Model Based on YOLOv8
This paper proposes an enhanced UAV forest fire detection model based on YOLOv8, tailored for lightweight forest fire detection using UAVs.
First, SPDConv is used to replace conventional static convolutions, decreasing the computational load while improving performance, particularly for small objects and low-resolution images.
Next, MLCA is introduced before the three detection heads. This mechanism combines local and channel-wise information, enhancing the model’s ability to capture key features. As a result, this enhancement significantly boosts the precision and resilience of object detection, particularly in intricate and evolving wildfire scenarios.
Furthermore, a C2f-PConv structure is designed, replacing the traditional C2f with the C2f-PConv. The PConv operation replaces the convolutional operations in the C2f module, minimizing redundant computations and memory access, while preserving feature extraction capabilities. This modification allows the C2f module to maintain efficient computational performance when handling larger-scale or more complex targets.
By incorporating W-IoU, the model becomes more sensitive to the boundaries of fire and smoke regions, leading to better alignment of object boundaries. This enhancement increases detection accuracy and speeds up the model’s convergence in complex scenarios.
The YOLO model presented in this study seeks to improve UAV forest fire detection capability, optimizing the trade-off between detection performance and computational efficiency. Our model begins with the input image and progressively downsamples the feature map using a sequence of convolutional blocks. The C2f-PConv module is integrated into the structure to achieve efficient processing of multi-branch features. The feature map undergoes Split operation segmentation in the intermediate stage, followed by feature merging using Concat and Upsampling to achieve multi-scale feature fusion. Then, the feature expression ability is further enhanced through the MLCA module. Finally, the detection results are output through the Detect layer. The structure of the YOLO model is shown in
Figure 7.
4. Discussion
This study presents an efficient method for UAV forest fire detection through several innovative improvements to the YOLOv8 model. By introducing MLCA, SPDConv convolution module, C2f-PConv feature extraction structure, and W-IoU loss function, we markedly enhance the precision and efficiency of the model for detecting forest fires, particularly for small targets and intricate situations.
The empirical findings show that the refined model attains a significant upgrade in detection precision as well as in its lightweight operational capabilities. Specifically, precision improved by 2.17%, recall by 5.5%, and mAP@0.5 by 1.9%. In addition, the number of parameters decreased by 43.8% to only 5.96 M, and Model Size and GFlops were only 12.19 MB and 18.1, which makes the model more practical and reliable in actual UAV monitoring.
Although MLCA, C2f-PConv, SPDConv, and W-IoU perform well, they also have certain limitations. Indeed, while the Multi-Layer Channel Attention (MLCA) mechanism is adept at amalgamating channel and spatial information, along with local and global contextual cues to enhance the network’s expressive capabilities, its intricate design can lead to a higher level of implementation complexity. This complexity has the potential to escalate the computational demands placed on the model, which might be a concern in terms of efficiency and resource utilization, especially in real-time applications or on devices with limited computational power. Meanwhile, the effectiveness of MLCA also depends on specific tasks and datasets, and may not be applicable to all situations.
Secondly, C2f-PConv performs well in handling situations containing missing values or irregular data, but it has high requirements for data integrity. If the data loss is too severe, PConv may not be able to effectively extract features.
Thirdly, the SPDConv structure improves performance by reducing the number of feature maps, but it is mainly suitable for low resolution and small target scenes. For high-resolution or large-sized targets, SPDConv may not be able to fully leverage its advantages. Furthermore, the incorporation of SPDConv into the model necessitates alterations to the standard convolutional layer. These modifications can add to the overall complexity of the model, potentially affecting its ease of implementation and computational efficiency.
Additionally, the W-IoU loss function introduces weight factors for weighted calculation, making the loss function more widely applicable in object detection tasks. Nonetheless, the computation of W-IoU is somewhat intricate, potentially prolonging the model’s training duration. Additionally, the utility of W-IoU is contingent on the appropriate choice of weighting coefficients. Certainly, improper tuning of the weight factors can adversely affect the model’s efficacy.
Given the current model’s exceptional ability to detect small objects and in scenarios with low-resolution imagery, we acknowledge the potential for further improvements, particularly in its fire detection performance during extreme and low-visibility conditions. To tackle these hurdles, future investigations will concentrate on two primary directions. Firstly, efforts will be directed at bolstering the model’s robustness to ensure high accuracy and consistency across a range of weather conditions. The second priority is to investigate and incorporate more sophisticated preprocessing and post-processing methods to further refine the precision and efficacy of fire detection. By delving into cutting-edge algorithms and technologies, including adaptive learning rate scheduling, model pruning, and quantization, we aim to create an effective and robust fire detection system, offering enhanced reliability for the domain of public safety.
5. Conclusions
Based on the YOLOv8 architecture, we innovatively propose an improved UAV forest fire detection model, which is specifically optimized for the challenges in detecting forest fire images captured by UAVs. The primary objective is to address the limitations of conventional models in handling low-resolution and small target images, and to decrease the quantity and dimensions of model parameters to facilitate more efficient deployment on UAV platforms.
To maintain detailed information within the image, we introduce SPDConv. The utilization of this technology effectively prevents information loss during downsampling, substantially enhancing the model’s capability to detect low-resolution and small target images.
We introduce the C2f-PConv module. This component is used to perform convolutional operations on a subset of channels within the input feature map, preserving the other channels unaltered. Such a design not only reduces extraneous computation and memory consumption but also significantly boosts the model’s computational efficiency, concurrently reducing the parameter count.
In order to enhance the detection capability of UAV images while reducing computational burden, MLCA has been introduced. MLCA is a lightweight attention mechanism that combines local spatial information and channel information. The approach refine’s the model’s ability to discern both local and global features, simultaneously curbing the computational load via a two-stage pooling mechanism and one-dimensional convolutional processes. This strategy leads to an overall enhancement in the performance of image detection tasks.
To tackle the challenge of targets that are obscured and not accurately identified, we introduce the W-IoU loss function. The W-IoU loss function is capable of refining anchor boxes with varying qualities and can dynamically modify the weights associated with different target boxes within the loss computation. This flexibility markedly improves the model’s ability to detect, especially in cases with tiny objects and instances of obstructions.
In summary, to counteract the problem of blurry images obtained from UAVs, we employ SPDConv technology. This innovation helps maintain the detailed information within the images, thereby enhancing the detection ability for low-resolution and small target objects. Moreover, the integration of MLCA aims to heighten the model’s sensitivity to both local and global feature details. To tackle the issue of occlusion from closely packed objects in images, we introduce W-IoU. In response to the limited computing resources and storage capacity of drones, we introduce the C2f-PConv module, which reduces redundant calculations by flexibly applying convolution operations. In addition, the introduction of MLCA improves detection capability without increasing computational burden.
Regarding the validation phase, we allocated the 3253 forest fire images among a training set, a testing set, and a validation set, adhering to an 8:1:1 division. The outcomes of our experiments indicate that our model achieved a precision of 87.5%, a recall of 87.5%, and an mAP@0.5 of 89.3% on the FLAME dataset. These metrics represent improvements of 2.17%, 5.5%, and 1.9% over the baseline YOLOv8 model. Concurrently, the model’s parameter count was decreased by 43.8%, and the GFLOPs were lowered by 36.7%, which streamlines more effective deployment on mobile devices.
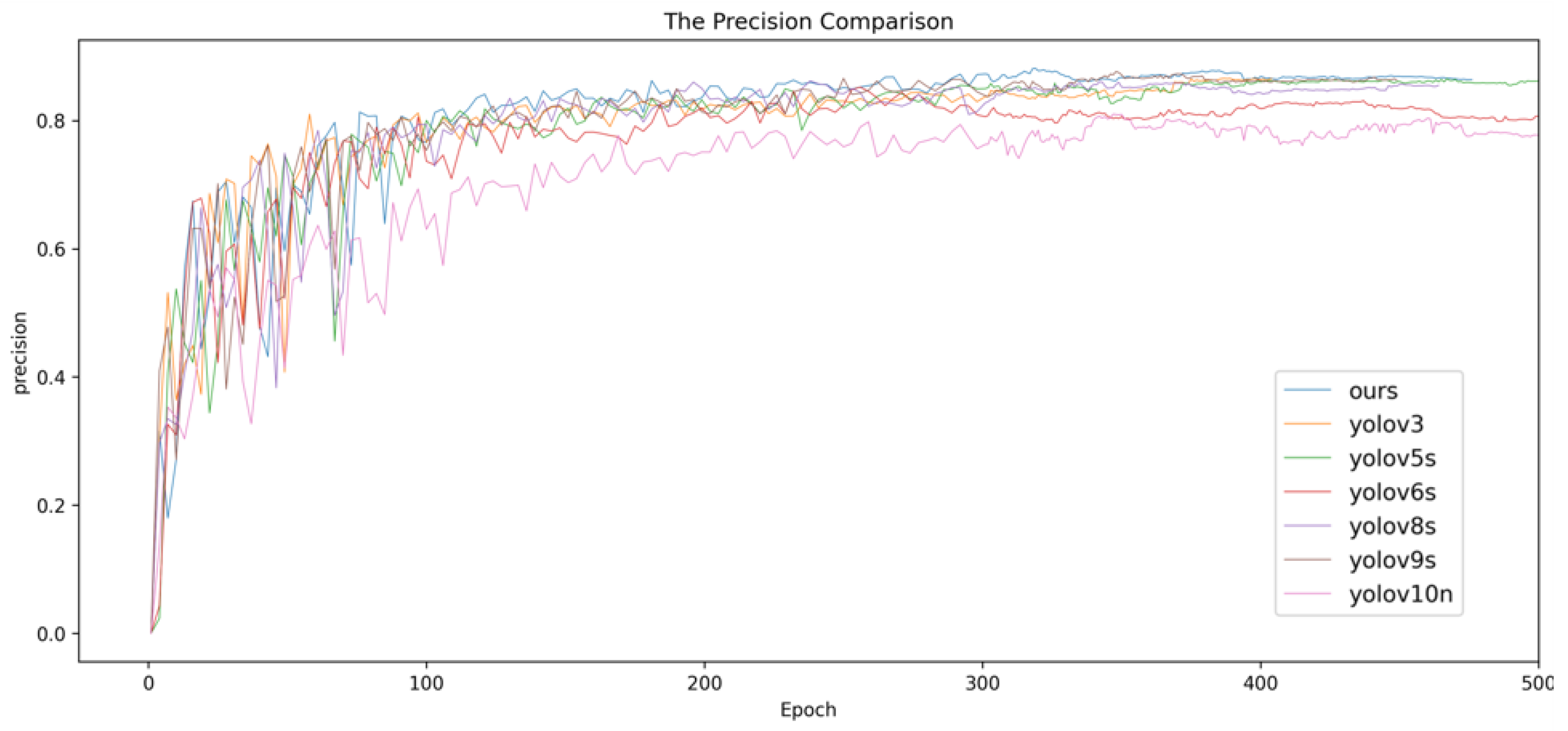
In comparison to conventional detection models such as YOLOv3, YOLOv5, YOLOv6, YOLOv7, YOLOv9, YOLOv10, RT-DETR and YOLO-World, our model exhibits well performance across key metrics including precision, recall, and mAP@0.5. These advancements enhance the precision of forest fire detection in drone imagery while also decreasing the model’s intricacy and scale, playing a vital role in ensuring swift and precise forest fire detection.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}