1. Introduction
Wildfires pose a severe threat to human life, property, and the environment, with their increasing frequency and intensity exacerbated by climate change [
1,
2]. The rapid detection of wildfires, particularly through early smoke identification, is crucial for mitigating their devastating impacts. Recent studies have highlighted unprecedented wildfire conditions in regions like the western United States, underscoring the urgent need for improved detection methods [
3,
4]. This research focuses on enhancing wildfire smoke detection capabilities, using advanced deep learning techniques, to address the critical challenge of early fire identification in the context of changing climate patterns and environmental conditions.
Early detection is crucial in mitigating wildfire damage because it allows fast intervention before fires become uncontrollable. Wildfires are caused by a complex interplay of factors, including human activity, natural events, and climate conditions in the Anthropocene era [
5]. While complete prevention is challenging, early detection and rapid response are crucial for minimizing their impact on human health and the environment [
4]. Thus, the rapid detection and suppression of wildfires are paramount. Detecting wildfire smoke is an effective way to accomplish this. In the early stages of a wildfire, fuel such as vegetation heats up and produces smoke, which is relatively hotter than air and, therefore, less dense and rises quickly, making it easier to detect wildfires in their early stages. Even when flames are obscured by vegetation or ridgelines, the rising smoke can enter observable ranges, enabling the detection of wildfires from greater distances. Furthermore, the color and density of wildfire smoke vary depending on the materials being burned or the environmental conditions. Smoke primarily appears in shades of gray, brown, and black, contrasting the surrounding environment [
6]. Therefore, in this study, wildfire smoke is selected as the target for detection.
Wildfire monitoring methods have evolved significantly, incorporating various technologies such as human observation, satellite and drone surveillance, and fixed camera systems [
7,
8]. Each approach has its strengths and limitations. Traditional human monitoring, while direct, is prone to errors and scalability issues. Satellites offer wide coverage but are limited by spatial and temporal resolution, especially for early fire detection. Drones provide flexibility but are constrained by weather conditions and operational costs. By contrast, fixed camera systems emerge as a cost-effective solution, offering continuous, high-resolution monitoring capable of early fire detection. Their ability to cover wide areas when strategically placed, combined with relatively low maintenance costs, makes them particularly suitable for long-term, real-time wildfire monitoring when integrated with advanced smoke detection software.
Wildfire smoke detection methods include classical Red–Green–Blue (RGB), Hue–Saturation–Value (HSV), YCbCr thresholds or differences [
9,
10,
11,
12,
13], edge detection [
14,
15], and unsupervised learning techniques, particularly clustering methods [
16,
17,
18,
19]. However, these methods may fail to detect wildfires due to the different colors of smoke in other places and times, and their accuracy can be significantly affected by environmental factors such as weather conditions. It can also be challenging to distinguish wildfire smoke from objects having a similar color or shape, such as clouds and dust. Recently, there has been much research on wildfire smoke detection using artificial intelligence to overcome these limitations. Studies using machine learning techniques such as Random Forest and Support Vector Machine [
20,
21,
22,
23,
24] have been actively conducted and are ongoing. However, machine learning tends to have a relatively poorer generalization performance in image processing than deep learning and is more prone to overfitting. Therefore, although it is possible to develop highly accurate detection models using machine learning methods, it is essential to consider the significant potential for further advances.
Recent studies have explored various approaches to wildfire smoke detection, including classification-based methods [
25,
26]. While effective, these often require human intervention for precise localization. In this study, we focus on object detection techniques, which not only identify the presence of smoke but localize it within the image. This approach is crucial for developing fully automated wildfire monitoring systems, potentially reducing response times and minimizing human oversight in future applications. Deep learning research for real-time object detection has primarily relied on convolutional neural networks (CNNs), particularly the regions with convolutional neural networks (RCNN) series and the You Only Look Once (YOLO) series. Several studies have used these series for wildfire smoke detection [
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37]. In addition, research on the vision transformer (ViT), which has developed rapidly since the introduction of the transformer architecture in 2017, has become increasingly active in recent years. Nevertheless, the volume of research on the ViT for wildfire detection remains significantly less than that of CNN models [
38,
39,
40,
41]. In this study, we utilized YOLOv8, one of the latest models of the YOLO series, and the Real-time Detection Transformer (RT-DETR), an enhanced version of the detection transformer (DETR) adapted for real-time detection. It has recently been reported that the performance of the RT-DETR model on the Microsoft Common Objects in Context (COCO) dataset outperformed that of the YOLO series [
42]. However, studies comparing the YOLO and RT-DETR models have yet to be conducted in wildfire detection. One of our objectives is to conduct a comparative evaluation between the CNN and ViT models and to develop a model that achieves higher accuracy and effectiveness in detecting wildfire smoke.
A critical factor in determining the performance of deep learning models is the quantity and quality of training data. A sufficient amount of data is essential to train a deep learning model with good generalization performance. However, collecting real-world wildfire smoke imagery can be challenging due to safety and environmental concerns. The hazardous nature of wildfire environments and the unpredictable nature of their occurrence make it difficult to obtain a sufficiently diverse extensive dataset. To overcome such limitations, data augmentation techniques could be a promising alternative. These techniques encompass a variety of methods, including basic transforms that make geometric and spectroscopic changes to the images. In addition to these basic transforms, more advanced techniques involve a deep learning approach. Recent advances in generative deep learning algorithms, particularly generative adversarial networks (GANs), have proven instrumental in developing realistic synthetic images. GANs involve training a generator to create synthetic data and a discriminator to differentiate between real generated data. The interplay between these two components results in the generation of compelling synthetic images. This study used a GAN-based model, StyleGAN2 with Adaptive Discriminator Augmentation (StyleGAN2-ADA), along with fundamental transformations to overcome real-world data collection limitations and improve detection accuracy. By applying these sophisticated techniques, we aim to increase the diversity and richness of the training dataset, addressing the challenges associated with real-world data collection. This, in turn, is expected to improve the generalization performance and accuracy of the deep learning models.
In light of these challenges and opportunities, this study contributes several important advancements to the field of wildfire smoke detection. We present an effective application of object detection models, specifically YOLOv8 and RT-DETR, to the critical task of early wildfire smoke detection. By leveraging these advanced architectures, we aim to enhance detection accuracy and speed, potentially improving automated wildfire monitoring capabilities. To address the limitation of real-world wildfire smoke imagery, we introduce an improved data augmentation approach, using StyleGAN2-ADA, to enhance model robustness and generalizability across diverse conditions. Our comprehensive comparative analysis offers valuable insights into the relative strengths of CNN-based and transformer-based architecture in this domain, providing guidance for future research and practical implementations. Furthermore, we demonstrate significant advancements in early detection capabilities, potentially contributing to more efficient wildfire management strategies. Through rigorous evaluation under challenging real-world conditions, we bridge the gap between theoretical advancements and practical applications in wildfire detection. By addressing these critical aspects, our research represents a significant step forward in applying advanced AI technologies to combat the growing threat of wildfires, offering new possibilities for protecting ecosystems, communities, and resources.
2. Materials and Methods
2.1. Data Source
This study utilized two primary data sources.
The Fire Ignition Images Library (FIgLib): Provided by the High-Performance Wireless Research and Education Network, which contains wildfire imagery from Southern California from 2014 to 2023 [
43]. The FIgLib is a dataset of wildfire imagery collected by fixed cameras in Southern California, a region known for its fire risk. To prepare this data for model training and validation, we manually annotated the FIgLib images with bounding boxes using LabelMe [
44], an open-source annotation tool.
The Nevada Smoke Detection Benchmark (Nemo) dataset [
38]: This dataset includes 2859 images from nearly 900 cameras across eight western U.S. states (Nevada, California, Oregon, Washington, Utah, Idaho, Colorado, and Montana). Available on GitHub [
45], Nemo contains bounding box labels from AlertWildfire imagery. Although the Nemo dataset was pre-labeled, we comprehensively re-evaluated the annotations through visual inspection.
The combined dataset contains 6849 images with corresponding bounding box labels. We employed a random sampling approach to split the dataset, allocating approximately 90% (6190 images) for training and 10% (659 images) for validation, ensuring a representative distribution of image characteristics in both subsets. The training data includes 259 background images without wildfire smoke, which can be a way of ensuring diversity and resolving imbalances in the data. The deliberate inclusion of diverse background images mitigates the risk of overfitting to specific scene types. This strategy enhances the ability of the model to generalize across various environments, potentially improving performance on novel backgrounds while simultaneously reducing the incidence of false positive detections.
The dataset incorporates images with challenging conditions such as haze, lens flare, noise on lens, raindrops on lens, and night scenes (
Figure 1 and
Table 1). These diverse images help minimize false positives and negatives caused by meteorological phenomena. While primarily consisting of daytime RGB images, the dataset includes a limited number of nighttime scenes. By including these diverse scenarios, we aim to improve the model’s generalization performance across adverse weather and lighting conditions. However, we acknowledge the inherent limitations of RGB-based detection in low-light environments, suggesting an area for future research.
The training data, comprising 6190 images, includes 6057 wildfire smoke bounding boxes; while the validation data, consisting of 659 images, contains 669 wildfire smoke bounding boxes. The size criteria used in the COCO dataset were adopted for size classification. “Small” is defined as 39 × 39 pixels or less; “Medium” as between 39 × 39 and 96 × 96 pixels; and “Large” as 96 × 96 pixels or more. Notably, small objects constitute a very minor percentage, approximately 0.024% or less, in an image of 3072 × 2048 pixels.
Table 2 shows the distribution of objects by size in the training and validation datasets, with small bounding boxes comprising about 8%, medium bounding boxes about 33%, and large bounding boxes about 59%. The original sizes vary, ranging from the smallest at 854 × 480 to others at 1920 × 1080 and 2048 × 1536, with the largest image having a resolution of 3072 × 2048.
2.2. Data Augmentation
2.2.1. Basic Transforms Augmentation
Basic transforms augmentation is a fundamental technique in image processing that enhances dataset diversity and model generalization. This technique encompasses a range of simple yet effective transformations that can significantly expand the diversity of the training dataset. This approach, widely adopted in object detection tasks [
46,
47,
48,
49], involves applying various transformations to original images, thereby increasing data diversity and potentially enhancing model performance. We employed the Albumentations library [
50], a high-performance Python package designed for image augmentation to implement basic transforms augmentations. Using Albumentations, we applied basic transforms augmentation to 5931 training images (without background images), effectively doubling our dataset size. The specific transformation methods, their value limits, and the applied probability values are shown in
Table 3. To illustrate the effect of these techniques,
Figure 2 presents sample images showing the changes when each augmentation method is applied.
2.2.2. Augmentation with StyleGAN2-ADA
GANs are deep learning models that train two competing networks, a generator, and a discriminator, to produce data that closely mimics a learned distribution. These networks generate data and engage in a learning process, cooperating and competing to enhance the performance of the model. The generator creates synthetic data from random noise inputs in this adversarial process. At the same time, the discriminator attempts to differentiate between the real and generated data, driving both networks to improve iteratively. This iterative learning process updates the weights, enabling the generator to produce data similar to real data. The ultimate goal of GANs is to generate new data that closely resembles the distribution of real data. They are widely used in various fields, including image generation, video generation, super-resolution, and natural language processing. GANs have also been used effectively in deep learning data augmentation. They can be used to generate fake data of various shapes and styles, which can help increase the diversity of training data and improve generalization performance. They can also generate additional training data when real data is scarce. In this way, GANs help improve the detecting performance of deep learning models and can be used creatively and innovatively in various fields.
In this study, we employed StyleGAN2-ADA for wildfire smoke image augmentation. StyleGAN2-ADA is an advanced version of the StyleGAN series, specifically designed to work effectively with limited datasets. It builds upon the StyleGAN2 architecture, which improved upon the original StyleGAN by addressing issues such as water-droplet artifacts and enhancing image quality [
51]. The key innovation of StyleGAN2-ADA lies in its adaptive discriminator augmentation (ADA) technique. This approach dynamically applies augmentations to the discriminator during training, helping to maintain the balance between generator and discriminator performance. ADA is particularly effective in scenarios with limited training data, as it reduces issues like mode collapse and enables high-quality image generation even with smaller datasets.
Figure 3 illustrates the generator architectures of StyleGAN and StyleGAN2/StyleGAN2-ADA. The main differences in StyleGAN2 include the removal of progressive growing and the introduction of weight demodulation, which replaced adaptive instance normalization (AdaIN). StyleGAN2-ADA maintains this improved architecture while incorporating the ADA technique in the training process.
Figure 3 illustrates the generator architectures of StyleGAN and StyleGAN2/StyleGAN2-ADA. The main differences in StyleGAN2 include the removal of progressive growing and the introduction of weight demodulation, which replaced adaptive instance normalization (AdaIN) [
52]. StyleGAN2-ADA maintains this improved architecture while incorporating the ADA technique in the training process.
Training a high-quality, high-resolution GAN typically requires 10
5 to 10
6 images [
53]. Discriminator overfitting is more likely to occur with limited data, necessitating specialized methods for generating high-quality images from restricted datasets. StyleGAN2-ADA addresses this limitation by effectively generating images even with small datasets. ADA increases data diversity by applying augmentation to the original image during discriminator training. Initially, the transformation intensity is used lightly, but as the number of weight updates increases, the degree of augmentation is progressively enhanced, accommodating more complex data. This process reduces issues such as mode collapse, where the discriminator identifies the generated image too simply, preventing the generator from learning how to produce a more realistic image. It helps maintain a balance between the generator and the discriminator.
Considering the limitations of our dataset size, which is typically insufficient for training high-quality GAN models, we leveraged StyleGAN2-ADA, a model specifically designed for training with limited data. The training dataset was curated from the original dataset (OD), including images with wildfire smoke bounding boxes of at least 96 × 96 pixels, excluding excessive noise or ambiguous images. This selection process facilitated the model’s learning of a consistent style for wildfire smoke generation. The final dataset comprised 1865 hand-picked images, approximately 30% of OD training images, resized to 1024 × 1024 pixels. The training lasted 25,000 kimg and 6250 ticks, and the model with the lowest Fréchet inception distance (FID) was selected to generate the images. Kimg means kilo images, signifying 1000 units of images used for training, and tick denotes each step of weight update during training. Consequently, 25,000k images were used for training, accompanied by 6250 weight updates. The augmentation methods used in the ADA process and their descriptions are shown in
Table 4.
The FID, a metric that evaluates how closely the StyleGAN2-ADA model generated images to the real images, is a criterion for assessing the image generation quality of generative models by measuring the similarity of image distributions. The pre-trained Inception v3 model [
54] was used to extract features, and the feature vectors of each dataset of real and generated images were used to compute the mean and covariance matrix. The Fréchet distance of the mean and covariance matrix between the two datasets was then computed. This metric measures the distance between two multivariate Gaussian distributions and is calculated using Equation (1) [
55]. The lower the FID, the greater the similarity between the distributions of the two datasets. Generally, a value closer to the minimum of zero indicates better performance. However, if the FID is excessively low, it results in images that are overly like real images. Therefore, adjusting the range of the FID values to produce synthetic images with distinct features is necessary.
The model generated using OD was evaluated, resulting in an FID of 24.07. This is relatively high considering that state-of-the-art models generated from large datasets such as the Canadian Institute for Advanced Research (CIFAR-10) or ImageNet have an FID of around two [
56,
57]. However, to achieve a near-zero FID is inherently challenging, considering the unique characteristics of wildfire smoke images, where the subject often blends with the background. Nonetheless, as long as the generated images are not excessively unrealistic or noisy, they remain valuable for deep learning training in wildfire smoke detection.
GAN-based data augmentation offers the advantage of generating novel data compared to a basic transforms method. However, it necessitates labeling synthetic images, which can be labor-intensive. We employed a pseudo-labeling technique on the StyleGAN2-ADA-generated images to address this. Pseudo-labeling, a semi-supervised learning approach, assigns labels to new data using a model trained on existing datasets [
58]. In this study, we applied pseudo-labeling to 20,000 StyleGAN2-ADA-generated images using a YOLOv8X model trained on the OD. To mitigate potential errors in the pseudo-labeling process, we conducted a comprehensive visual inspection of all images and their associated bounding boxes. This screening process excluded images lacking in wildfire smoke or deemed unrealistic. Label errors identified during screening were corrected using LabelMe, resulting in a final dataset of 5883 images.
Figure 4 shows examples of images generated by the StyleGAN2-ADA model, which generated various wildfire smoke images, ranging from images containing small puffs of smoke to large, thick plumes. Despite the presence of aliasing in most images, it is deemed that the attributes of wildfire smoke have been captured, and the backgrounds have been naturally generated. Some images exhibited vertical line artifacts resembling rainwater on the lens, as shown in
Figure 4d. These artifacts are considered addressable through enhancements in the model’s training dataset and the image generation process. Future research is expected to yield higher-quality images, further enhancing the utility of this approach for wildfire smoke detection and analysis.
2.2.3. Overall Dataset
To comprehensively evaluate the impact of data augmentation on wildfire smoke detection accuracy, we employed three primary dataset categories: the original dataset (OD), the dataset augmented with basic transformations (BT), and the dataset augmented with StyleGAN2-ADA generated images (SG). The OD is the baseline, comprising initial images with manually annotated bounding box labels. It provides a reference point for comparing model performance across different augmentation techniques. The BT dataset incorporates fundamental image transformations to augment the OD, enhancing data diversity and improving model generalization across varied scenarios. This augmented dataset captures a broader range of conditions, potentially improving detection robustness. The SG dataset represents an advanced data augmentation approach utilizing StyleGAN2-ADA to generate a substantial volume of high-quality synthetic images. This dataset significantly enhances the diversity and richness of the training data, potentially leading to improved model performance. Our evaluation framework incorporates various combinations of these datasets, including the OD as a baseline, to comprehensively assess how data augmentation techniques influence wildfire smoke detection accuracy (
Table 5).
2.3. Wildfire Smoke Detection Models
2.3.1. YOLOv8
YOLO is a leading model in real-time object detection, an efficient and accurate model used to perform real-time object detection and classification. Before the advent of YOLO, object detection was performed using a series of RCNNs. RCNNs have a disadvantage in detection speed due to their sequential execution of the localization and classification processes. YOLO introduces a one-stage detector structure that combines the two processes into one, predicting the location and class of an object simultaneously. This significantly reduces the computation time. As the name suggests, YOLO does not segment an image but processes the entire image through the CNN structure to generate a feature map. In this way, it learns about the target object and the surrounding information, characterized by relatively little error in the background [
59]. Due to these features, YOLO has been widely used in object detection, and several derivatives have appeared since then to improve accuracy and detection speed.
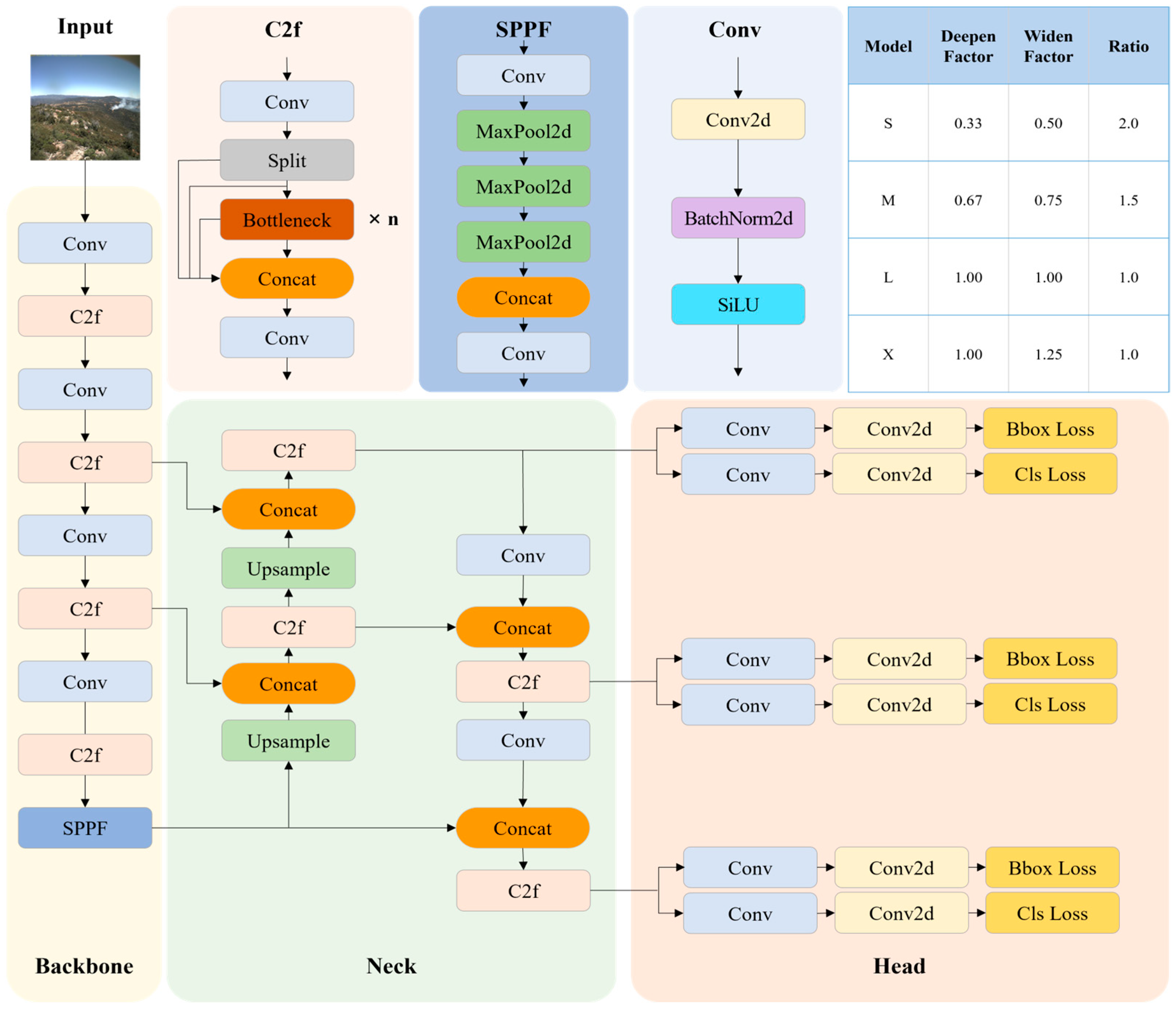
YOLOv8 was proposed in January 2023 by Ultralytics, the creators of YOLOv5. There have been several changes to this version. The backbone uses the same Cross Stage Partial Network (CSPNet) as YOLOv5. Still, it replaces the first 6 × 6 convolution in the backbone with a 3 × 3 convolution and replaces the C3 module that performs three convolution operations with the C2f module. The DarknetBottleneck inside C2f also changed the first layer from a 1 × 1 convolution to a 3 × 3 convolution. It removed two convolution steps from the neck and used a decoupled head for the head (
Figure 5). In addition to the structural changes, YOLOv8 introduces an anchor-free method that does not use the anchor box used in the previous YOLO series. An anchor box is the initial value of several preset predictable bounding boxes, and the anchor values are resized to determine the size of the actual detected object. However, in YOLOv8, the object’s center point is directly predicted without using an anchor box to speed up the non-maximum suppression (NMS) process. In addition, the mosaic augmentation technique of stitching four images together into one is partially removed, a method that does not use mosaic more than ten epochs before the end of training. With these changes, YOLOv8 improves both accuracy and inference speed compared to YOLOv5.
Different versions depend on the architecture, size, and complexity of the model. The models applied in this study are YOLOv8S, YOLOv8M, YOLOv8L, and YOLOv8X, where S stands for small, M for medium, L for large, and X for extra-large, with the larger letters representing larger models. These models typically exhibit improved performance with increasing size but require more computational resources, representing a trade-off relationship. YOLOv8 does not have an implementation paper, but you can find information about it in Ultralytics’ GitHub and official documentation [
60,
61].
2.3.2. RT-DETR
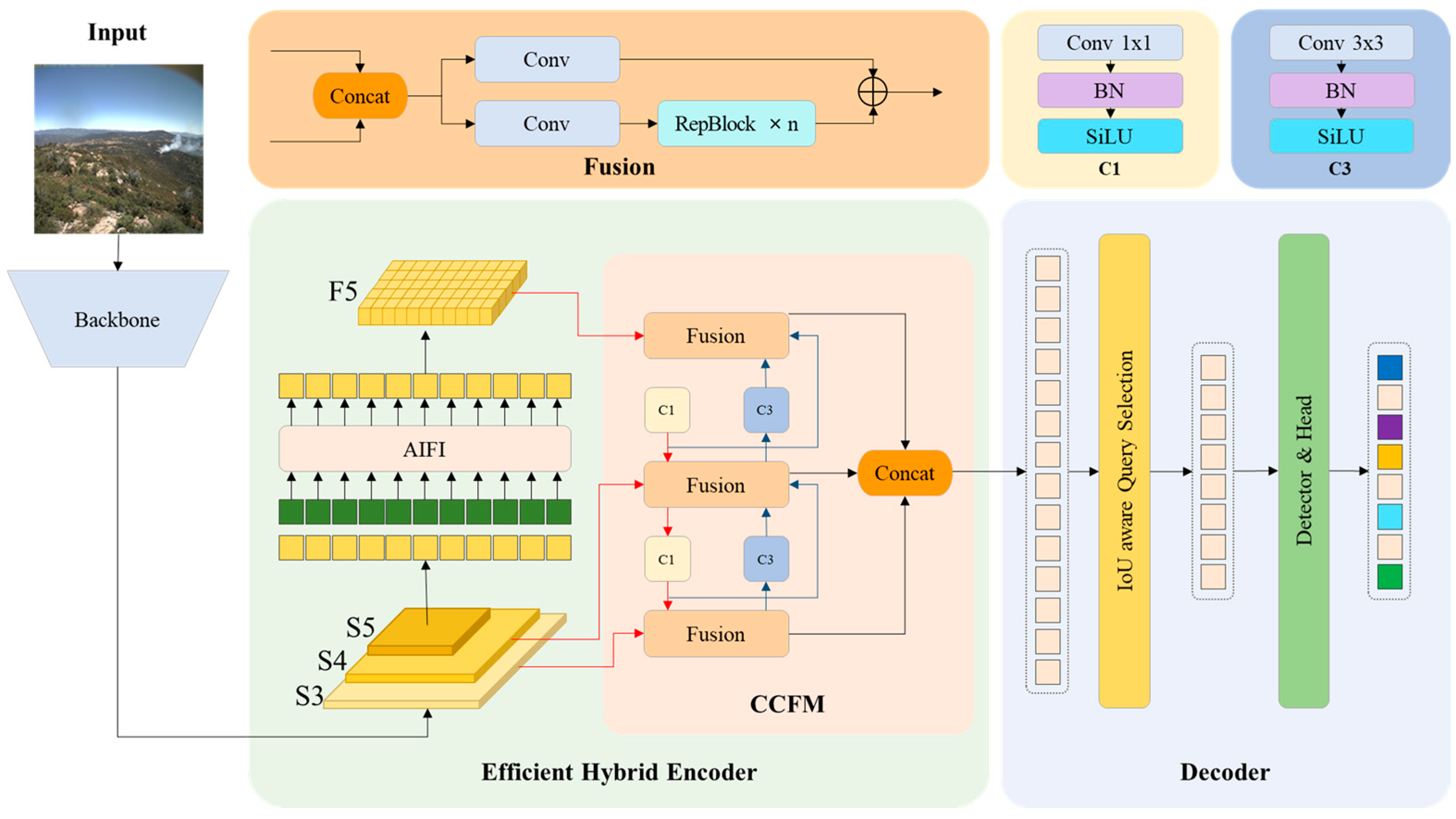
RT-DETR, a ViT model based on DETR, was introduced in July 2023. Experimental results on the COCO dataset demonstrated its superior performance to the YOLO series [
42], marking a significant advancement in transformer-based object detection. The main difference with YOLO is that RT-DETR utilizes a transformer architecture to detect objects. Transformers originated as a model used in natural language processing but have also been employed in computer vision tasks using models such as the ViT and DETR. Transformers consist of an encoder and a decoder, with the encoder extracting features from the image and the decoder performing object detection and classification. The feature map extracted from the backbone is split into patches, vectorized, and used as input to the transformer encoder. Within the encoder, a multi-head self-attention layer and a feedforward neural network (FFNN) helps consider the relationship between different locations in the input data by computing weights in parallel to model the interaction between each element in the input sequence. This makes it easier to learn global information compared to CNN models. FFNNs extract important information using weight matrices and bias vectors to capture non-linear characteristics and convert them linearly to produce an output. RT-DETR uses an efficient hybrid encoder structure, with an internal attention-based intra-scale feature interaction (AIFI) module that focuses on reducing computational redundancy and detecting objects in images and a CNN-based cross-scale feature-fusion module (CCFM) that helps to effectively combine image features extracted at different scales to obtain high-level information. IoU-aware query selection is used to select a fixed number of image features from the encoder output sequence as the decoder’s initial object query, and the decoder iteratively optimizes the object query to generate a bounding box and confidence score (
Figure 6). RT-DETR can flexibly adjust the inference speed by using different decoder layers without retraining, and it outperforms DETR in accuracy and speed. However, it still requires more computational resources compared to YOLO, which limits its practical application and has the limitation of slow learning convergence.
Depending on the backbone, RT-DETR includes RT-DETR-R50 and RT-DETR-R101 using a residual neural network (ResNet) and RT-DETR-L and RT-DETRL-X using a High-performance GPU Network v2 (HGNetv2). Like the YOLO, RT-DETR models exhibit improved performance as their complexity increases. In this study, we employed the RT-DETR-L and RT-DETR-X models, which have demonstrated superior performance on the COCO dataset.
2.4. Model Training
Each model was trained in the same environment with the same seed value, using the following hardware: Intel Core™ i9-12900K CPU, NVIDIA GeForce RTX 3090Ti (24 GB video memory) GPU, and 64 GB RAM.
Table 6 shows the model-specific hyperparameters used to train the models. All models had a uniform input image size of 1280 and were trained for 300 epochs. The batch size was set to four, except RT-DETR, which was set to two due to constraints related to memory resources. YOLO used stochastic gradient descent (SGD) for the optimizers, while RT-DETR used AdamW. Depending on the model, YOLOv8 sets the initial learning rate (lr) to 0.01 and the final lr to 0.01. For RT-DETR using AdamW, the initial lr was set to 0.0001 and the final lr to 0.01. The lr of the last epoch is set to the product of the initial lr and the final lr. Learning rate decay was applied to decrease the lr value gradually by applying cosine annealing from the initial lr to the final epoch. Equation (2) calculates the lr of the current epoch (t), which is computed using the cosine function and the entire epoch (T) [
62]. The learning rate decay is used to compromise between maintaining a high learning rate, which can quickly reduce the loss but may not find the optimal weights, and using a low learning rate, which takes a long time to converge.
Warmup is a starting process of training with small lr and gradually increasing lr as learning progresses. This is because using a learning rate that is too large at the beginning of the training can lead to numerical instability [
63]. In this study, both lr and momentum warmups were applied. The warmup epoch was set to three, during which lr and momentum were linearly increased over the first three epochs. In other words, during the initial model training, the lr starts as the product of the initial lr and the warmup bias learning rate. When the warmup epoch is reached, the lr for that epoch becomes the initial lr value. Similarly, the momentum starts as the warmup momentum, and when the warmup epoch is reached, the momentum value for that epoch becomes the set momentum value. Mosaic augmentation was applied to all models but, for YOLOv8, the close mosaic method was used in the last ten epochs before the end of training. Transfer learning was applied to all models with pre-trained weights from the COCO dataset. Utilizing transfer learning reduces training time by leveraging pre-trained weights instead of starting from random weights, leading to improved performance.
The choice of hyperparameters was guided by both empirical results and computational constraints. For instance, the input size of 1280 was selected to balance between detection accuracy and computational efficiency. The learning rate and warmup strategy were chosen to ensure stable training, particularly in the early stages, while the use of transfer learning with pre-trained weights on the COCO dataset helped to accelerate convergence and improve overall performance.
2.5. Model Evaluation
In object detection, performance is evaluated using the Intersection over Union (IoU). The IoU is the ratio of the intersection and union between the ground truth bounding box and the predicted bounding box.
A higher IoU value, indicating a larger overlap area, signifies more accurate object detection by the model. Object detection metrics based on the IoU include precision and recall, respectively representing the percentage of objects detected correctly by the model and the percentage of actual objects detected by the model. A true positive (TP) represents the number of objects correctly detected by the model when the IoU of the ground truth bounding box and the predicted bounding box is above the IoU threshold. Conversely, a false positive (FP) represents the number of objects below the IoU threshold, indicating false detection.
Recall represents the percentage of objects correctly detected by the model, indicating how many actual objects were successfully detected. It is calculated using false negatives (FN), representing the number of undetected objects.
Precision and recall exhibit a trade-off relationship, meaning that an increase in one of these metrics often leads to a decrease in the other. The threshold for the confidence score, which represents the probability of a bounding box belonging to a particular class, determines the precision and recall values. Setting a high threshold can reduce recall by removing low-confidence bounding boxes that detect real objects. Lowering the threshold can reduce precision by including unnecessary bounding boxes that are not real objects. Considering these factors, it is possible to construct a precision–recall curve by systematically adjusting the confidence score threshold. This approach allows for visualizing the performance of the model in object detection. The average precision (AP) metric quantifies the model’s accuracy and is calculated as the area under the precision–recall curve. AP is a commonly used evaluation metric in the object detection field, and it comprehensively evaluates the overall performance of a model by considering both precision and recall together.
The evaluation metrics used in this study include AP@0.33, AP@0.5, and AP@0.5:0.95, which are computed based on different IoU thresholds. Specifically, AP@0.33 considers IoU values greater than or equal to 0.33 as TP; AP@0.5 uses an IoU threshold of 0.5; and AP@0.5:0.95 calculates the average precision by incrementally increasing the IoU threshold from 0.5 to 0.95 in steps of 0.05. These metrics comprehensively assess object detection performance at varying levels of IoU overlap. AP@0.33 is not common in general object detection tasks, but it was employed in this study due to the specific characteristics of wildfire smoke. Wildfire smoke has a unique appearance, and its boundaries can be challenging to define precisely due to its ambiguous shape. Therefore, the definition of wildfire smoke bounding boxes may vary between annotators and observers. To accommodate this inherent ambiguity in delineating wildfire smoke boundaries, including AP@0.33 allows for a more lenient IoU threshold. Another reason for using AP@0.33 is related to the specific objectives of wildfire smoke detection. Wildfire smoke detection primarily aims at rapidly identifying the presence of wildfire smoke to estimate the ignition location of wildfires and support decision-making processes. Considering this objective, an IoU threshold of 0.33 may be deemed sufficient for detecting the existence of wildfire smoke, even if it does not precisely match the boundaries of the smoke. This threshold allows for a more liberal detection criterion, aligning with the emphasis on quick detection in wildfire management scenarios. In the evaluation of the model, the detection rate was considered. The detection rate measures the percentage of detections within a wildfire smoke scene. It reflects the proportion of “hits”, where a hit is defined as a correct detection of wildfire smoke in the scene without considering false positives. Conversely, a “fail” is defined as a false negative, representing cases where wildfire smoke was present but not detected by the model. This metric provides insights into how effectively the model identifies wildfire smoke within the scenes it analyzes. This can be thought of as a binary classification task. A similar metric is recall, but recall is the percentage of objects detected relative to the bounding box, which may give slightly different results. In the context of wildfire smoke detection, it is crucial to reduce false positives and minimize false negatives. Detecting wildfires accurately is of utmost importance because failure to detect a fire can lead to serious safety concerns or allow the fire to escalate into a larger and more destructive blaze. Therefore, this metric evaluates the absolute rate of wildfire smoke detection, emphasizing the significance of correctly identifying the presence of wildfires.
A frames per second (FPS) rate was used to assess each model’s real-time object detection capability. FPS refers to the number of frames that can be processed in one second, quantifying how fast a model works. The standard frame rate for video technology is typically 30 FPS. Therefore, models that achieved a processing speed of 30 FPS or higher were considered capable of real-time object detection according to this standard. A higher FPS also indicates a less computationally intensive model, which has the advantage that the model can be applied to hardware with relatively low computing power. The hardware used for speed measurements was the same as for training. The average of five FPS measurements, each with a batch size of one, was calculated for evaluation.
3. Results
3.1. Evaluation Results with OD
Table 7 summarizes the results of the detection accuracy metrics and inference speeds for each model trained on the OD. Regarding AP@0.33, YOLOv8X demonstrated superior performance with a score of 0.962, followed closely by YOLOv8L and YOLOv8M, both achieving 0.951. Across this metric, YOLOv8 variants consistently outperformed RT-DETR models, with RT-DETR-X recording the lowest AP@0.33 score of 0.908. For AP@0.5, YOLOv8L model achieved the highest score of 0.903, followed by YOLOv8M and YOLOv8S with scores of 0.896 and 0.893, respectively. Similarly, RT-DETR-X recorded the lowest score at 0.821. AP@0.5:0.95 measures how closely the model can detect objects to the actual bounding boxes, with YOLOv8X achieving the highest score of 0.580, indicating its superior accuracy. Other YOLOv8 models also outperformed RT-DETR models, with RT-DETR-X again recording the lowest score of 0.452. This suggests that RT-DETR-X tends to predict bounding boxes with relatively lower IoU values.
Regarding the AP scores, YOLOv8X performed exceptionally well, with the highest scores in AP@0.33 and AP@0.5:0.95. This suggests that YOLOv8X can detect objects effectively at low and high thresholds, making it the top-performing model. On the other hand, the detection rate favored the RT-DETR series over the YOLO series. RT-DETR-X achieved a detection rate of 0.983, while RT-DETR-L achieved 0.973, outperforming the YOLOv8 models. In summary, when quantitatively comparing the models, the YOLOv8 series achieved the highest AP scores, while the RT-DETR series achieved the highest detection rate. These results show that the YOLOv8 models generally achieved higher AP scores, while RT-DETR models demonstrated higher detection rates. This difference in performance metrics suggests that each model type has its own strengths and weaknesses in wildfire smoke detection. A more detailed analysis of these differences and their underlying causes will be discussed in
Section 4.1.
YOLOv8S is the fastest model at 143 FPS, while YOLOv8X is the slowest at 25 FPS. RT-DETR-X is at 46 FPS, similar to YOLOv8L at 43 FPS. As mentioned earlier, the threshold for real-time object detection is typically 30 FPS, and all models except YOLOv8X met this threshold. Where processing data at 24 FPS or less is acceptable, or if there is access to hardware with greater computing power, YOLOv8X can be used for real-time object detection. Therefore, it is essential to consider the trade-off between the performance of the hardware being used, accuracy, and FPS when selecting the most suitable model.
Additionally, our models demonstrated robust performance in detecting multiple smoke targets within a single image. For instance, in images containing several smoke plumes, such as those from different stages of a wildfire or multiple concurrent fires, both YOLOv8 and RT-DETR successfully identified and localized individual smoke plumes. This capability further underscores the effectiveness of the models in real-world scenarios where complex fire situations may occur.
3.2. Model Comparison Based on Data Augmentation Methods
This section presents a comparative model performance analysis after applying various data augmentation techniques. We evaluated model performance across four dataset configurations: OD, OD + BT, OD + SG, and OD + BT + SG. For these evaluations, we focused on two high-performing models: YOLOv8X, which exhibited the highest AP@0.33 and AP@0.5:0.95 scores on the original dataset; and RT-DETR-X, which achieved the highest detection rate.
The results for each augmented dataset are presented in
Table 8. For the YOLOv8X model, the analysis revealed intriguing patterns:
BT: Unexpectedly, the OD + BT dataset showed lower performance metrics than the OD alone for YOLOv8X. This result can be attributed to the nature of basic transformations, which modify existing images in the dataset. While intended to increase data diversity, this approach may lead to overrepresentation of certain smoke patterns or scenes, as it essentially duplicates existing wildfire smoke instances with variations. This overrepresentation can potentially cause overfitting, where the model becomes too specialized in recognizing these specific, augmented patterns at the expense of generalization to novel, unseen data. The decrease in performance suggests that, for some models, particularly complex ones like YOLOv8X, the additional augmented data may skew the learning process, emphasizing certain features or patterns that are not as relevant or generalizable to the validation set. This highlights the importance of carefully balancing data augmentation techniques to enhance model robustness without compromising its ability to generalize new, unseen wildfire smoke scenarios.
SG: The OD + SG dataset configuration demonstrated significant improvements, particularly in AP@0.5:0.95 and detection rate. AP@0.33 was the highest and identical for the OD and OD + SG datasets. This suggests that the synthetic images generated by StyleGAN2-ADA effectively expanded the dataset’s diversity, helping the model generalize better to various smoke appearances and backgrounds.
Combined Augmentation (BT + SG): The OD + BT + SG configuration showed mixed results. While it achieved the best performance in AP@0.5 (0.900) and detection rate (0.991), it unexpectedly resulted in slight decreases in AP@0.33 (0.956 vs. 0.962) and AP@0.5:0.95 (0.579 vs. 0.580) compared to the OD. These contrasting results across different metrics suggest a complex interaction between data augmentation techniques and model performance. The combination of the BT and SG dataset appears to improve certain aspects of detection (AP@0.5 and detection rate) while slightly compromising others (AP@0.33 and AP@0.5:0.95).
These observations underscore the complexity of data augmentation effects on model performance. YOLOv8X, being a complex model, shows high sensitivity to data augmentation techniques. The slight performance decreases in some metrics with the OD + BT + SG dataset highlights the importance of carefully evaluating augmentation strategies across multiple performance metrics. While augmentation can generally improve model robustness and performance, it is critical to fine-tune these methods based on specific model architecture and the desired balance of performance metrics.
Quantitatively, the OD + SG and OD + BT + SG datasets emerged as the most effective datasets for YOLOv8X, each excelling in two metrics. The common feature of these datasets is the inclusion of StyleGAN2-ADA augmented data, indicating its substantial contribution to enhanced model performance, particularly in improving detection rate and AP@0.5.
For the RT-DETR-X model, the impact of data augmentation techniques was notably different:
BT: The OD + BT dataset showed nearly identical AP@0.33 and detection rates compared to the OD, but also showed significantly increased AP@0.5 and AP@0.5:0.95. This suggests that RT-DETR-X’s architecture can be more robust in terms of the types of variations introduced by basic transformations.
SG: The OD + SG configuration improved all metrics except AP@0.5 relative to the OD. While AP@0.5 in the OD + SG dataset was marginally lower (0.001) than in the OD + BT, AP@0.33 increased by 0.018 to 0.924. This underscores the effectiveness of GAN-generated images in enhancing the model’s overall performance, particularly in detecting small or ambiguous smoke instances.
Combined Augmentation (BT + SG): The OD + BT + SG dataset demonstrated the highest accuracy across all metrics, with notable improvements over the OD. AP@0.33 improved by 0.026, AP@0.5 by 0.030, AP@0.5:0.95 by 0.076, and the detection rate increased by 0.012, resulting in 16 additional detected scenes. This synergistic effect suggests that the combination of augmentation techniques provides a rich and diverse dataset that aligns well with RT-DETR-X’s architectural strengths.
The data augmentation results reveal an interesting discrepancy between improvements in average precision (AP) and detection rate. While AP metrics show modest gains (generally within 1–3%), detection rates exhibit more substantial improvements (up to 2.4% for YOLOv8X). This disparity stems from the fundamental differences between these metrics: AP evaluates both the presence and accurate localization of smoke, whereas detection rate solely focuses on identifying smoke presence, regardless of precise boundaries. In the context of wildfire smoke detection, this discrepancy highlights that data augmentation significantly enhances the ability of the models to identify the presence of smoke, which is paramount for early warning systems; while the precision of bounding box localization saw more modest gains. This pattern aligns with the primary goal of wildfire detection systems, where rapid identification of potential fires often takes precedence over pinpoint accuracy of smoke localization.
The differential impact of augmentation techniques on YOLOv8X and RT-DETR-X can be attributed to their architectural differences. YOLOv8X, with its CNN-based architecture, appears to benefit more from the diverse, high-quality synthetic images generated by StyleGAN2-ADA. These images likely provide a wide range of smoke appearances and contexts that enhance the feature extraction capabilities of YOLOv8X. On the other hand, RT-DETR-X’s transformer-based architecture seems to leverage both basic transformations and GAN-generated images effectively.
Contrary to basic transformation, using StyleGAN2-ADA for data augmentation is believed to have generated a diverse range of wildfire smoke images. Additionally, the noise introduced during image creation likely enhanced model accuracy. In wildfire detection using fixed cameras, unexpected noise sources such as varying weather conditions, flying insects, and foreign objects on the camera lens are frequently encountered. Therefore, the evaluation dataset also includes images with noise. It is posited that the noise present in images generated using StyleGAN2-ADA plays a role in reducing false positives by mimicking real-world noise conditions, which is expected to be beneficial in practical, real-world scenarios. The observed performance enhancement is attributed to incorporating diverse training images through data augmentation. This approach facilitates learning a wider variety of wildfire smoke objects and backgrounds. In wildfire smoke detection, where missing a single incident can be critical, even a slight increase in accuracy is deemed significant.
In conclusion, while both models show improvements with data augmentation, the nature and extent of these improvements vary. This study suggests that while basic transformation methods contribute to accuracy improvement, advanced deep learning-based augmentation methods like StyleGAN2-ADA substantially enhance model performance. This is particularly valuable in scenarios like wildfire smoke detection, where data collection is challenging. Future research utilizing more sophisticated models for generating wildfire smoke images is anticipated to yield even more accurate detection models than those developed in this study. Exploring more tailored augmentation strategies specific to model architecture could enhance wildfire smoke detection performance.
4. Discussion
4.1. Comparative Analysis of YOLOv8 and RT-DETR Performance
The performance differences between the YOLOv8 and RT-DETR models can be attributed to their distinct architectural characteristics. These differences not only affect their overall performance but influence their capabilities in detecting objects of various sizes and in different scenarios. The YOLOv8 model, based on a CNN, demonstrates superior overall performance, particularly in AP scores. This can be attributed the ability of a CNN to capture local features and spatial hierarchies effectively. The convolutional layers in YOLOv8 are particularly adept at detecting texture, shape, and color patterns characteristic of larger, more defined smoke plumes. The anchor-free approach and decoupled head of YOLOv8 contribute to more accurate bounding box predictions, especially for larger objects with clear boundaries.
Conversely, the RT-DETR model, built on a transformer architecture, excels in small object detection. This superiority can be traced to the transformer’s global attention mechanism, which allows the model to simultaneously consider relationships across the entire image. The self-attention layers in RT-DETR can effectively capture long-range dependencies, enabling it to detect subtle smoke patterns that might be overlooked by the more locally focused convolutional filters of YOLOv8. This global context is crucial for small objects like incipient smoke plumes. RT-DETR’s IoU-aware query selection mechanism further enhances its performance on small objects. This mechanism selects queries with high IoU regardless of object size as initial object queries for the decoder, effectively improving detection accuracy for small, potentially overlooked objects. This is particularly evident in its performance on objects smaller than 39 × 39 pixels, significantly outperforming the YOLOv8 variants.
The performance trade-offs between these models are evident in their detection rates and precision. RT-DETR tends to have a higher overall detection rate, which can be attributed to its ability to consider more candidate regions, essentially casting a wider net in its detection process. This approach increases recall but potentially at the cost of reduced precision, resulting in lower overall AP scores compared to YOLOv8. RT-DETR generates more bounding boxes, leading to improved recall as well as increased false positives (
Figure 7). On the other hand, the YOLO models demonstrate a more conservative detection approach, prioritizing the minimization of false positives, which may result in missed detections of faint or small wildfire smoke plumes. These differences are particularly noticeable in complex scenes where multiple small, ambiguous objects might be present. While YOLOv8 demonstrates balanced performance across various object sizes and clear superiority in overall AP scores, RT-DETR shows particular strength in detecting small objects in complex scenes. Understanding these architectural differences and their impact on performance is crucial for selecting the appropriate model for specific wildfire detection scenarios. It also highlights the potential benefits of leveraging model architecture in a complementary manner for comprehensive wildfire smoke detection systems. Future improvements in model design could focus on combining the strengths of both approaches to create more robust and versatile detection systems.
4.2. Early Detection Capability
This study evaluates the efficacy of our proposed models in early-stage wildfire smoke detection, focusing on their ability to identify smoke plumes in their beginning stages. We benchmarked the detection times of our models against those reported in two previous studies that utilized the same FIgLib video dataset, directly comparing performance improvements. Our comprehensive analysis covers 84 wildfire videos with frames at 1-min intervals. The results are presented in
Table 9 for the initial 16 videos and
Table A1 for the remaining 68 videos. Guede-Fernández et al. [
30] trained RetinaNet and Faster RCNN models on the FIgLib data for wildfire smoke detection. Their FRCNN with 5000 iterations, incorporating warmup on the version 3 dataset with augmentation and empty images (FRCNN_5000_WUP_3AE) model, achieved an AP@0.5 of 0.812 on their validation dataset. Yazdi et al. [
38] analyzed the FRCNN, RetinaNet, and DETR models using the AlertWildfire dataset. Their DETR-sc model, trained on single-class smoke annotations, and the DETR-dg model, trained on multi-class smoke density annotations with additional collage images for improved background diversity, recorded AP@0.5 values of 0.772 and 0.322, respectively. The relatively low AP for DETR-dg likely stems from class misclassification in their multi-class, smoke-density-based dataset. We compared these reported detection times with our YOLOv8X (OD + BT + SG) and RT-DETR-X (OD + BT + SG) models.
As shown in
Table 9, our YOLOv8X model demonstrated superior performance in the initial set of 16 videos, with an average detection time of 1.63 ± 2.06 min. This was significantly faster than the FRCNN model (6.63 ± 5.85 min) and the DETR models (DETR-dg: 3.5 ± 3.01 min, DETR-sc: 3.125 ± 3.18 min). The RT-DETR-X model also showed impressive results, with an average detection time of 2.25 ± 2.49 min. Extending our analysis to encompass all 84 videos (
Table 9 and
Table A1 combined), we observed consistent performance advantages of our models, reinforcing the robustness of our approach across a broader range of wildfire scenarios. YOLOv8X maintained its lead with an average detection time of 1.52 ± 2.00 min across all videos, significantly outperforming FRCNN (7.00 ± 6.31 min) and DETR-sc (3.67 ± 4.19 min). RT-DETR-X also demonstrated consistent performance, with an average detection time of 2.40 ± 2.82 min over the entire dataset.
The enhanced capabilities of our models were particularly pronounced in several challenging cases, demonstrating significant improvements in detection speed and accuracy. For instance, in the video ‘20190716-FIRE-bl-s-mobo-c’ (
Table 9), YOLOv8X detected smoke 18 min faster than FRCNN. Similarly, for ‘20160722-FIRE-mw-e-mobo-c’, YOLOv8X was 8 min faster than the DETR models.
Table A1 shows cases like ‘20191006_FIRE_lp-e-mobo-c’, where YOLOv8X detected smoke 28 min earlier than DETR-sc. While YOLOv8X generally performed better, RT-DETR-X showed advantages in specific scenarios. For example, RT-DETR-X detected smoke 2 min earlier than YOLOv8X in ‘20160722-FIRE-mw-e-mobo-c’ (
Table 9). This suggests that each model may have specific strengths in different wildfire scenarios.
Despite these improvements, it is crucial to acknowledge the limitations inherent in our models, which provide opportunities for future refinement. YOLOv8X encountered difficulties detecting smoke in ‘20190712_FIRE_om-e-mobo-c’, where faint smoke rising behind a mountain ridge was indistinguishable from cloud formations (
Figure 8a). This case highlights the challenges in differentiating smoke from similar atmospheric phenomena in complex topographical settings. In the case of ‘20191005_FIRE_hp-s-mobo-c’, RT-DETR-X demonstrated superior performance by detecting wildfire smoke instantaneously, whereas YOLOv8X required 12 min for detection. This scene, featuring very small smoke and its position closely attached to the left side of the image, seemed to favor the transformer model’s global image processing capability (
Figure 8b). The superior performance of RT-DETR-X in this instance can be attributed to the transformer architecture’s capacity for global image processing. This approach detects subtle, small-scale features that may elude the more locally focused convolutional approach employed by the YOLO models. This difference in architectural design explains why RT-DETR-X could quickly detect the smoke while YOLOv8X required significantly more time.
The comprehensive results in
Table 9 and
Table A1 indicate that while YOLOv8X exhibits the fastest overall wildfire smoke detection capabilities, RT-DETR-X also achieves substantial reductions in detection times compared to previous methodologies. This suggests that each model has different strengths in various detection scenarios. The distinct yet complementary strengths exhibited by these models suggest promising avenues for further enhancement by developing ensemble methods or integrated model architectures, potentially combining the strengths of both CNN and transformer-based approaches. These substantial improvements in early detection capabilities have far-reaching implications for wildfire management and response strategies. By enabling more rapid intervention, these advancements could significantly mitigate the ecological, economic, and social impacts caused by wildfires through more timely and effective containment efforts.
4.3. Evaluation Results Based on the Object Size
Building on the architectural differences discussed in
Section 4.1, this section focuses on how these differences manifest in the detection of objects of varying sizes. As expected from the previous analysis, we observe distinct performance patterns for the YOLOv8 and RT-DETR models across different object size categories.
Table 10 shows the detection results based on bounding box size. The detection rate was calculated based on the size of the ground truth labels, as it is crucial to accurately detect even small smoke in the early stages of wildfire smoke detection. TP was considered if the IoU was greater than or equal to 0.33. The detection rate in the previous model evaluation was based on the image. Still, the object detection rate is based on the bounding box, so there is a difference in accuracy.
Upon obtaining the object detection rate, RT-DETR-X showed the highest detection rate of 0.893 for small objects, YOLOv8M showed 0.978 for medium objects, and YOLOv8X showed 0.959 for large objects. It is worth noting that small objects have a significant variation across models. The difference between the maximum and minimum detection rates by model is 0.143 for small objects, which is a substantial deviation compared to 0.028 for medium objects and 0.015 for large objects.
This significant variation in small object detection performance highlights the challenge for detecting smaller smoke objects. The RT-DETR-X model particularly excels in detecting small objects, successfully detecting 50 out of 56 bounding boxes, resulting in a detection rate of 0.893. This is approximately 13.6% higher than the YOLOv8M and YOLOv8L models, which have the highest detection rates among the YOLOv8 variants (
Figure 9). The RT-DETR-L model also performed well, successfully detecting 49 out of 56 bounding boxes. The superior performance of the transformer-based RT-DETR models compared to the CNN-based YOLO models can be attributed to the inherent characteristics of the self-attention mechanism within the transformer architecture. This mechanism allows the model to consider intricate relationships among pixels within small image regions, leading to better feature extraction for small objects.
Across all models, the detection rates for medium and large objects were consistently higher than those for small objects. YOLOv8M achieved the highest detection rate for medium-sized objects, while YOLOv8X demonstrated the highest rate for large objects. This indicates that while the YOLOv8 series performs well overall, the RT-DETR models have a distinct advantage in detecting smaller objects, which is crucial for early wildfire smoke detection. One important observation is that these detection rates do not account for false positives. However, considering the relatively high accuracy scores of the YOLOv8 and RT-DETR models, they may be preferable choices, particularly when minimizing false positives is essential.
4.4. Model Ensemble Based on Object Size
Our analysis reveals an opportunity for performance enhancement through model ensembling based on object size. The results in
Table 10 demonstrate that different models excel in detecting objects of varying sizes. RT-DETR-X shows superior performance in detecting small objects. By contrast, YOLOv8M excels with medium-sized objects, and YOLOv8X performs exceptionally well with large objects. Leveraging these complementary strengths, we propose an ensemble approach that could outperform any single model. This approach aligns with recent advancements in ensemble learning for wildfire detection, where multiple models are combined to leverage their individual strengths and mitigate their weaknesses [
64,
65]. By combining RT-DETR-X, YOLOv8M, and YOLOv8X, our theoretical analysis suggests the ability to detect a higher number of wildfire smoke objects across different size categories. This ensemble approach shows particular promise for improving detection across all object sizes; it could accurately detect 50 out of 56 small objects, 218 out of 223 medium-sized objects, and 374 out of 390 large objects, totaling 642 out of 669 objects. This results in an object detection rate of approximately 0.960 (642/669). This represents a substantial improvement in the object detection rate compared to the best-performing single model, YOLOv8X, which achieved a rate of 0.906. The ensemble method thus offers an increase of 0.054 in detection rate, highlighting its potential to enhance overall detection performance significantly.
While this ensemble method offers exciting possibilities for maximizing detection accuracy, it is essential to consider the practical implications. The use of multiple models for inference demands significant computational resources. In an ideal scenario with perfect parallel processing, the detection frame rate would be limited by the slowest model, YOLOv8X, at 25 FPS. However, a more realistic sequential inference approach would result in a lower frame rate. Given current computational limitations, this ensemble approach may not be immediately feasible for real-time applications. However, it presents a promising direction for future research as computing capabilities advance. The potential for significantly improved detection accuracy across various object sizes makes this an attractive area for further investigation and development.
This ensemble strategy highlights the complementary strengths of different model architecture and underscores the importance of considering object size in wildfire smoke detection. Considering the various characteristics of smoke plumes at multiple stages and distances could significantly enhance overall detection performance. As computational power increases and model optimization techniques improve, such ensemble methods could become viable for real-time wildfire smoke detection systems, offering a more robust and accurate solution to this critical environmental challenge.
4.5. Detection Performance on Challenging Conditions
In this section, we aim to explain the impact of data augmentation on model performance under challenging conditions. Our analysis focuses on how augmentation techniques affect the ability of the models to detect wildfire smoke in scenarios that typically pose difficulties for detection systems. We evaluated the models using 67 images with challenging conditions, as previously shown in
Table 1.
Table 11 presents a quantitative overview of false positives and false negatives for different model configurations across challenging conditions. This data provides insight into the effectiveness of our augmentation strategies. The results demonstrate that data augmentation techniques generally improved model performance, particularly in reducing false negatives. For the YOLOv8X model, false negatives decreased from four in the original dataset (OD) to two in the fully augmented dataset (OD + BT + SG). Similarly, the RT-DETR-X model showed an improvement with false negatives, reducing from four to one. This reduction in false negatives is crucial in wildfire detection scenarios, where missing a fire could have severe consequences. However, the impact on false positives was more complex. While YOLOv8X maintained a consistent number of false positives across different augmentation strategies, RT-DETR-X showed some fluctuation, with a slight increase in false positives when basic transformations were applied, followed by a reduction when StyleGAN2-ADA was introduced.
To illustrate these effects more concretely, we present several case studies that highlight the impacts of data augmentation on detection performance in specific challenging conditions.
Figure 10 demonstrates the improvement in detection capability under hazy conditions. In this scenario, YOLOv8X(OD) failed to detect the smoke plume, likely due to the reduced contrast and visibility caused by haze. However, both the YOLOv8X and RT-DETR-X models trained on augmented datasets successfully identified the smoke, indicating that the augmentation process enhanced the ability of the models to recognize smoke patterns in low-visibility conditions. The benefits of augmentation are further exemplified in
Figure 11, which shows the performance of the models in conditions with raindrops on the camera lens. Initially, YOLOv8X(OD) produced a false positive, mistaking the raindrops for smoke. After training on augmented data, this false positive was eliminated, suggesting that the augmentation process improved the ability of the model to distinguish between smoke and water droplets on the lens. Interestingly, the RT-DETR-X model consistently produced false positives in this scenario, regardless of the augmentation strategy employed. While data augmentation generally improved performance, it also introduced new challenges in certain scenarios.
Figure 12 illustrates a case where augmentation led to the introduction of false positives in an image with lens flare. This suggests that the augmentation process may have increased the sensitivity of the models to certain visual artifacts that share characteristics with smoke plumes.
The differential impact of augmentation on the YOLOv8X and RT-DETR-X models is noteworthy. While both models generally benefited from augmentation, RT-DETR-X showed a more pronounced improvement in reducing false negatives but also demonstrated greater susceptibility to false positives in certain conditions. This difference may be attributed to the architectural distinctions between the two models and their varying responses to augmented data. Our analysis reveals that data augmentation, particularly the combination of basic transformations and StyleGAN2-ADA generated images, significantly enhances the ability of the models to detect smoke in challenging conditions such as haze and rain. The reduction in false negatives is particularly crucial for early wildfire detection systems, where missing a fire could have severe consequences. However, the increased sensitivity resulting from augmentation can also lead to new types of false positives, as seen in the lens flare example. This highlights the complex nature of applying data augmentation in real-world scenarios and underscores the need for careful balancing of augmentation strategies. These findings have important implications for the development and deployment of wildfire smoke detection systems. While data augmentation proves to be a powerful tool for improving model performance, it also necessitates careful consideration of potential side effects. Future work should focus on refining augmentation techniques to maintain the benefits of improved detection while mitigating the risk of introducing new types of false positives.
5. Conclusions
This study contributes to the advancement of automated wildfire smoke detection by integrating deep learning models with data augmentation techniques. We evaluated the performance of the YOLOv8 and RT-DETR models in wildfire smoke detection, finding that YOLOv8X performed well overall, while RT-DETR-X excelled in detecting small-scale smoke plumes. The application of data augmentation techniques, especially StyleGAN2-ADA, helped address the challenge of limited real-world wildfire smoke imagery. This approach improved the ability of the models to generalize across various wildfire smoke scenarios. Our method reduced average detection times to 1.52 min for YOLOv8X and 2.40 min for RT-DETR-X, showing improvement over previous methods. This reduction in detection time could potentially enhance wildfire management and response strategies. The models showed consistent performance under various challenging conditions, including fog, rain, and camera noise, suggesting their potential for practical applications. However, the issue of false positives in complex scenarios remains a challenge that requires further investigation.
As we continue to refine and expand upon this research, the ultimate goal remains clear: to develop increasingly accurate, reliable, and efficient systems for early wildfire smoke detection. This aim is particularly crucial in our current era of changing climate and growing environmental challenges. By enhancing our capacity to respond to and mitigate the impact of wildfires, we hope to contribute to more effective environmental monitoring and disaster prevention strategies. Future research should focus on further reducing false-positive rates, improving detection accuracy in diverse environmental conditions, and exploring the integration of these models into comprehensive wildfire monitoring systems. Additionally, investigating the potential of emerging object detection models and refining data augmentation techniques specific to wildfire scenarios could yield further improvements. Through ongoing research and collaboration, we aim to leverage technological advancements to better protect our communities and natural resources from the devastating impacts of wildfires.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}