
YOLOv8n-SMMP: A Lightweight YOLO Forest Fire Detection Model



Abstract
1. Introduction
- The neck network is optimized through a SlimNeck lightweight design, using GSConv and the VoV-GSCSP module, replacing standard convolutions and the C2f module to reduce computational overhead while maintaining performance;
- Embedding the MCA attention module between the neck and head networks, MCA enhances focus on critical regions containing flames or smoke;
- During training, replacing the Complete Intersection over Union (CIoU) loss function with MPDIoU simplifies bounding box regression through a more geometrically intuitive approach and reduces model computational complexity;
- Developing a selective pruning strategy tailored to the lightweight network structure compresses model parameters and computations significantly without compromising accuracy.
2. Materials and Methods
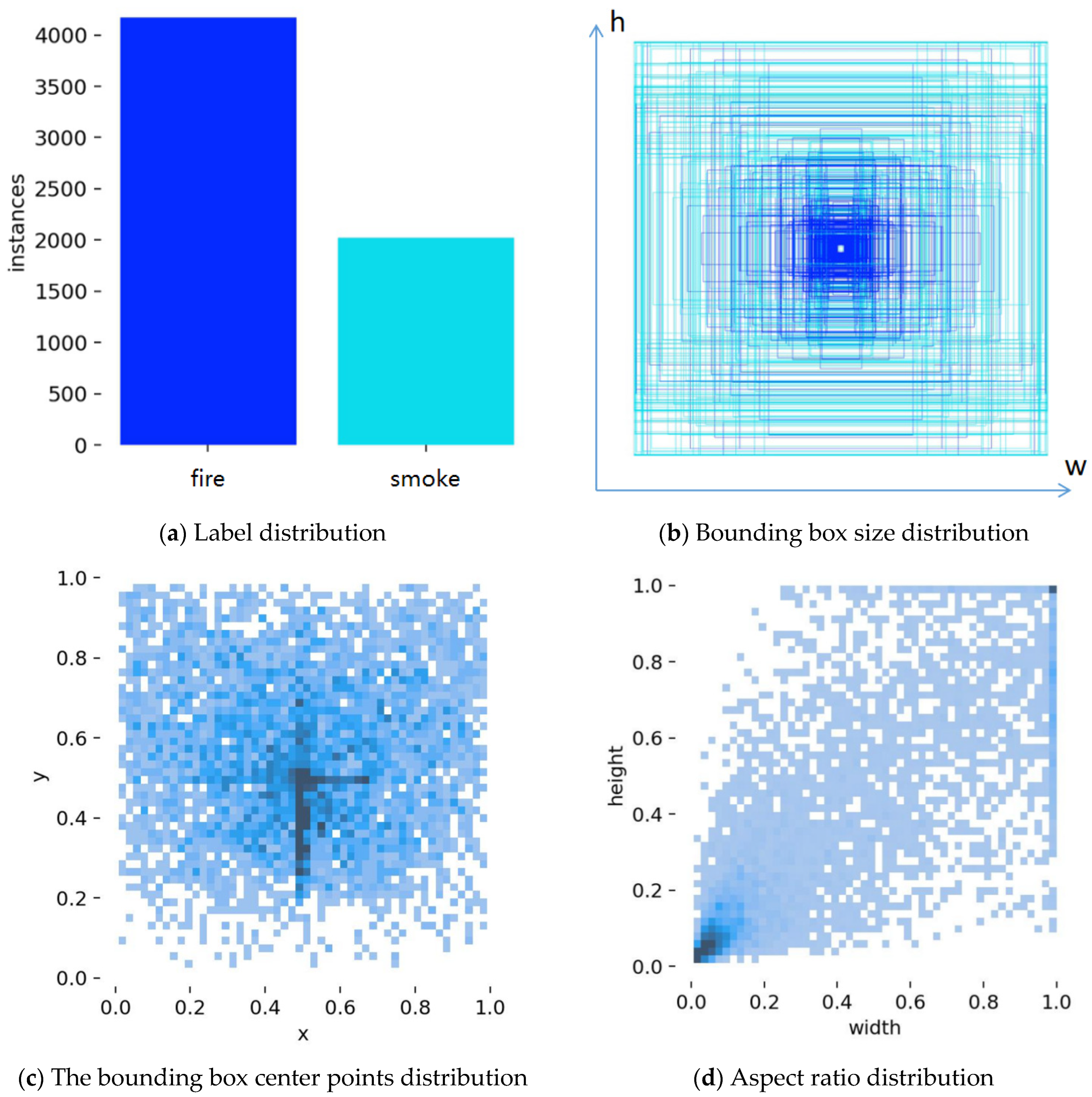
2.1. Datasets
2.2. Optimization of YOLOv8 Model
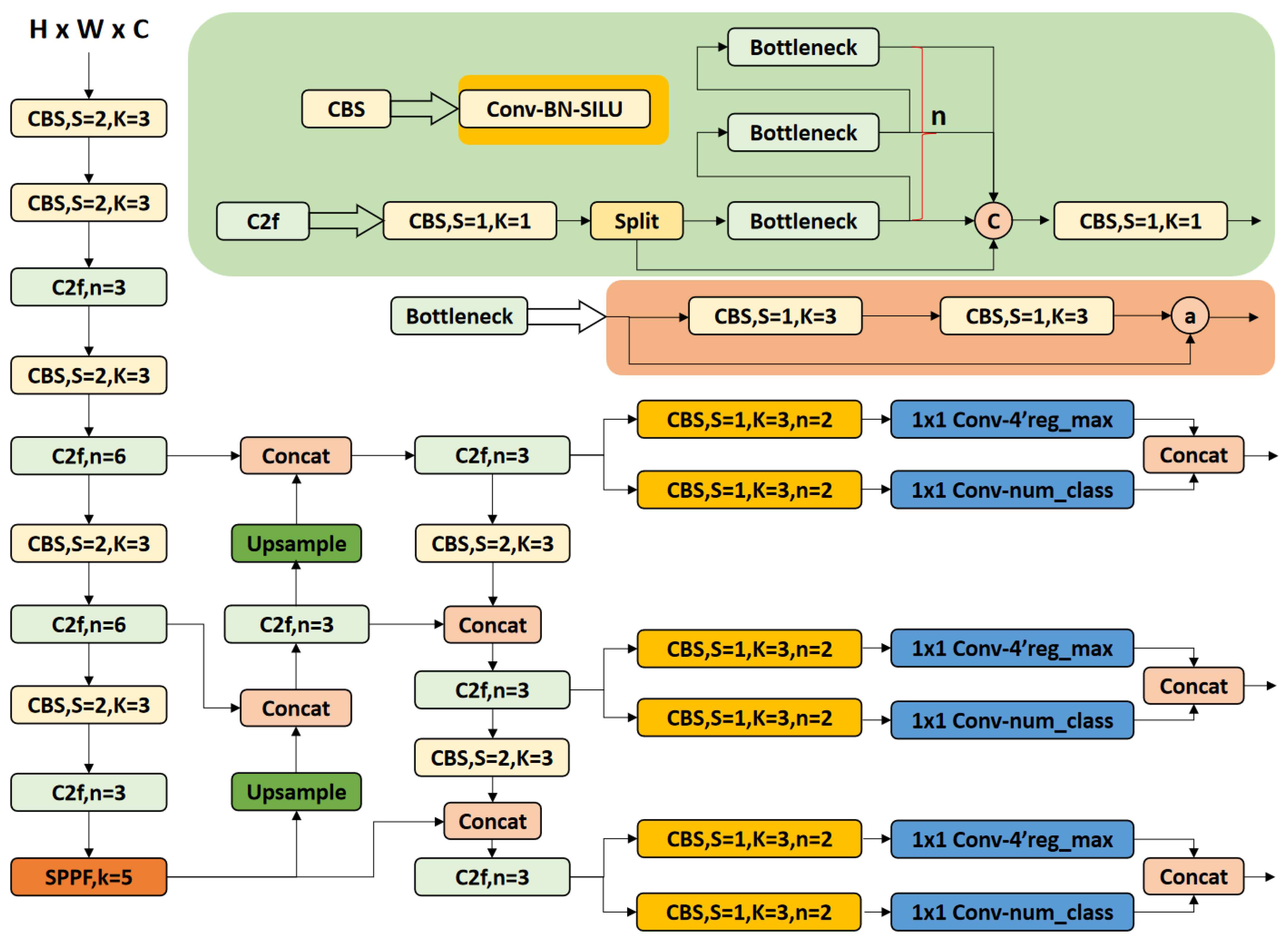
2.2.1. Baseline Model Selection and Architecture
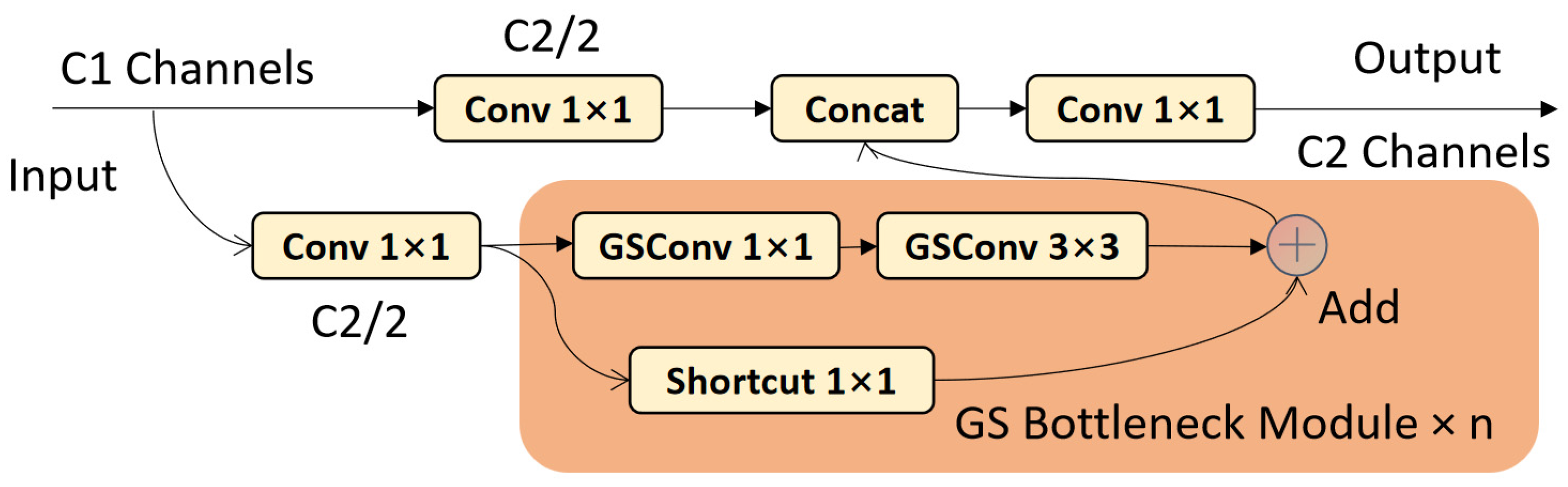
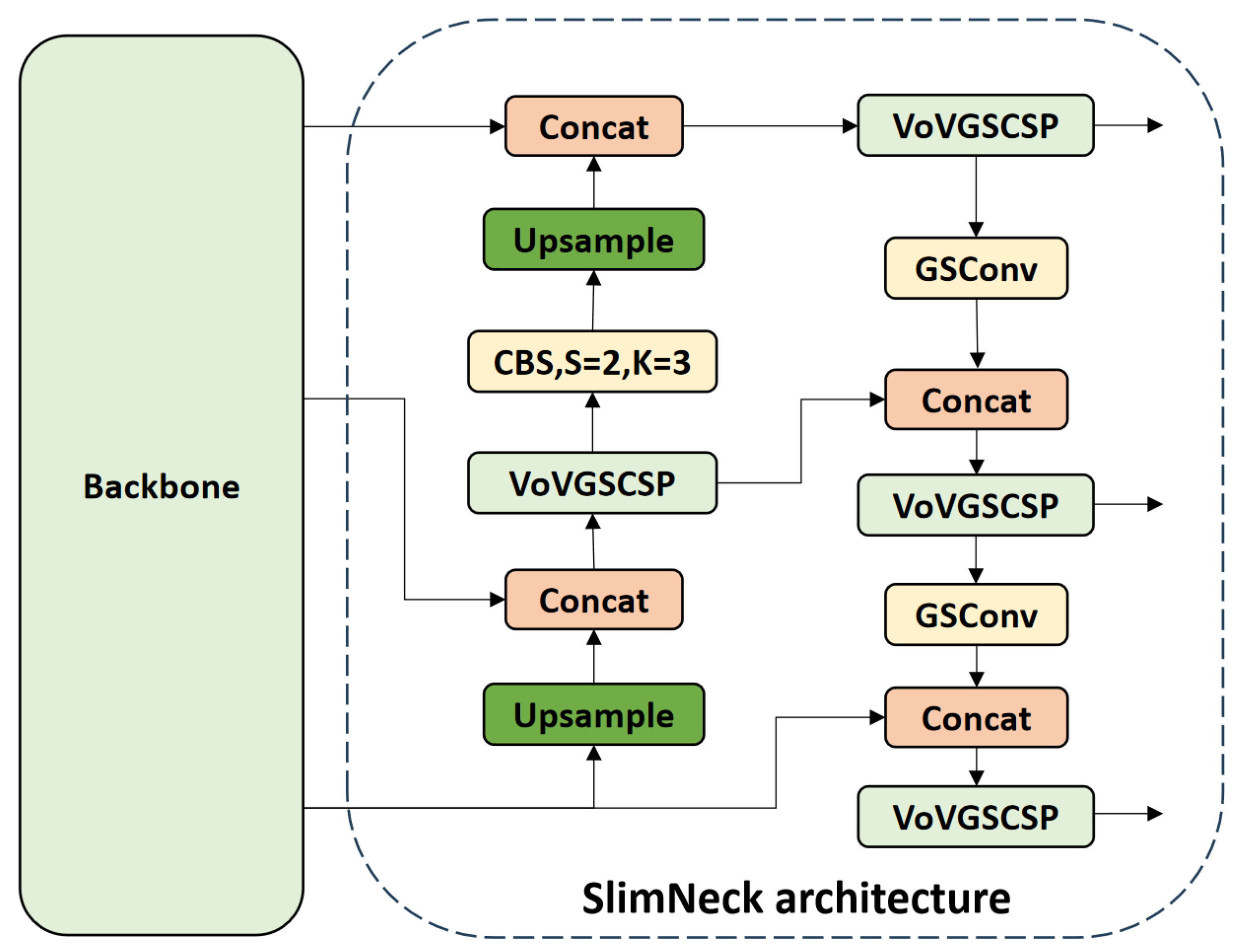
2.2.2. Introduce the SlimNeck Solution
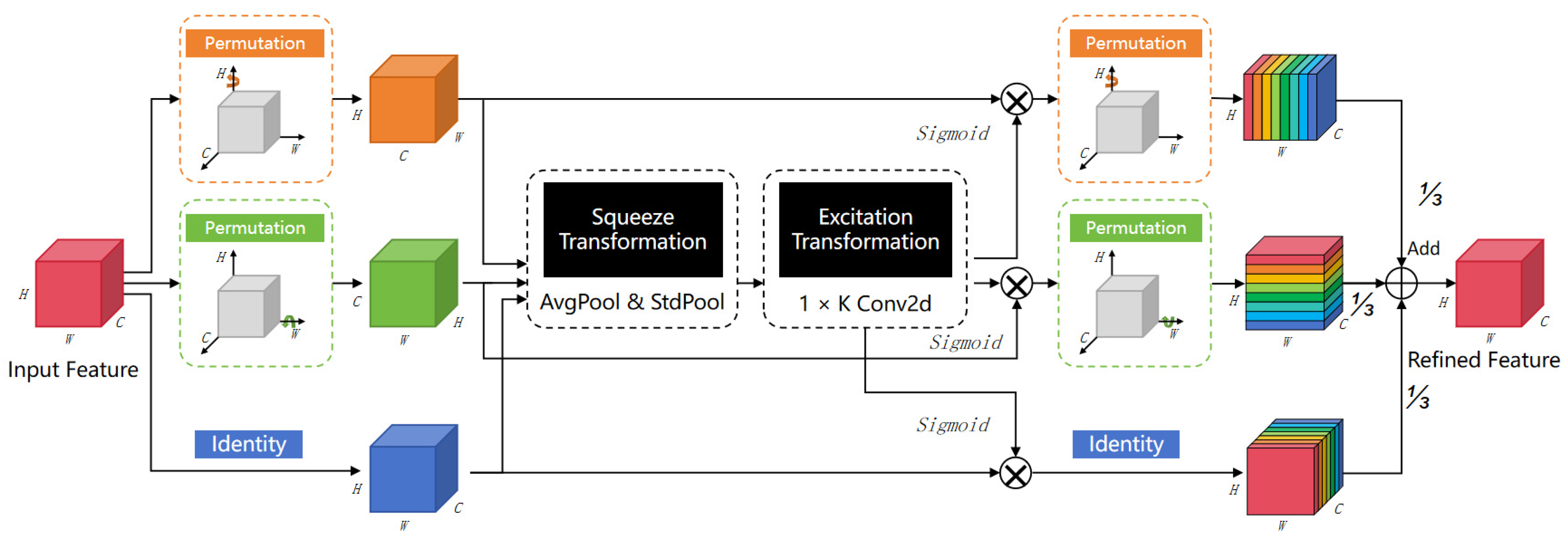
2.2.3. Integrated MCA Attention Mechanism
2.2.4. Introduced the MPDIoU Loss Function
2.2.5. Improved YOLO Network Model YOLOv8n-SMMP
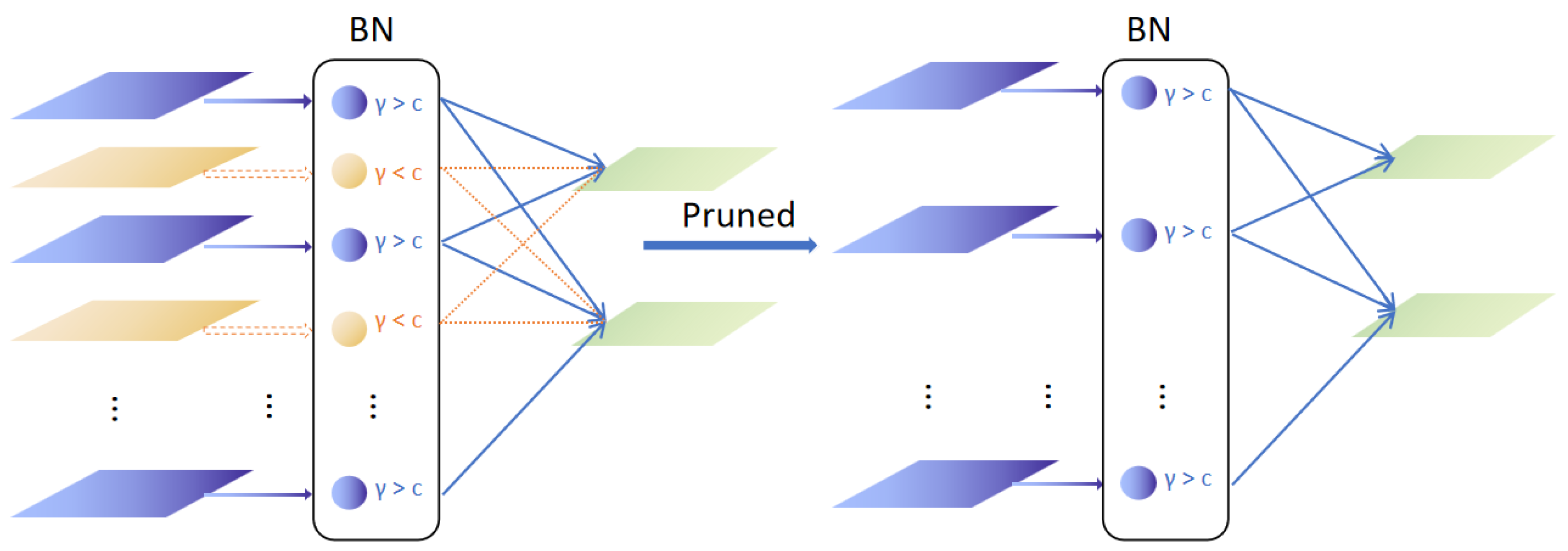
2.2.6. Pruning Algorithm Design
- Backbone pruning: Redundant standard convolutional layers in repetitive CBS blocks are pruned without compromising feature extraction. For C2f modules, the output channels of the cv1 convolution in bottleneck layers are retained, while cv2 convolutional layers are pruned. Both cv1 and cv2 layers in SPPF modules are pruned;
- Neck network pruning: A dependency graph is constructed to ensure channel alignment for cross-layer concatenation operations in GSConv and VoV-GSCSP modules, maintaining feature fusion consistency. The MCA attention layer between the neck and head networks is updated to preserve channel coherence, ensuring post-pruning functionality;
- Head network pruning: Parallel convolutional layers in classification and regression heads are pruned synchronously to maintain task decoupling.
3. Results and Discussion
3.1. Evaluation Metrics
3.2. Experimental Environment and Parameter Setting
3.2.1. Experimental Environment
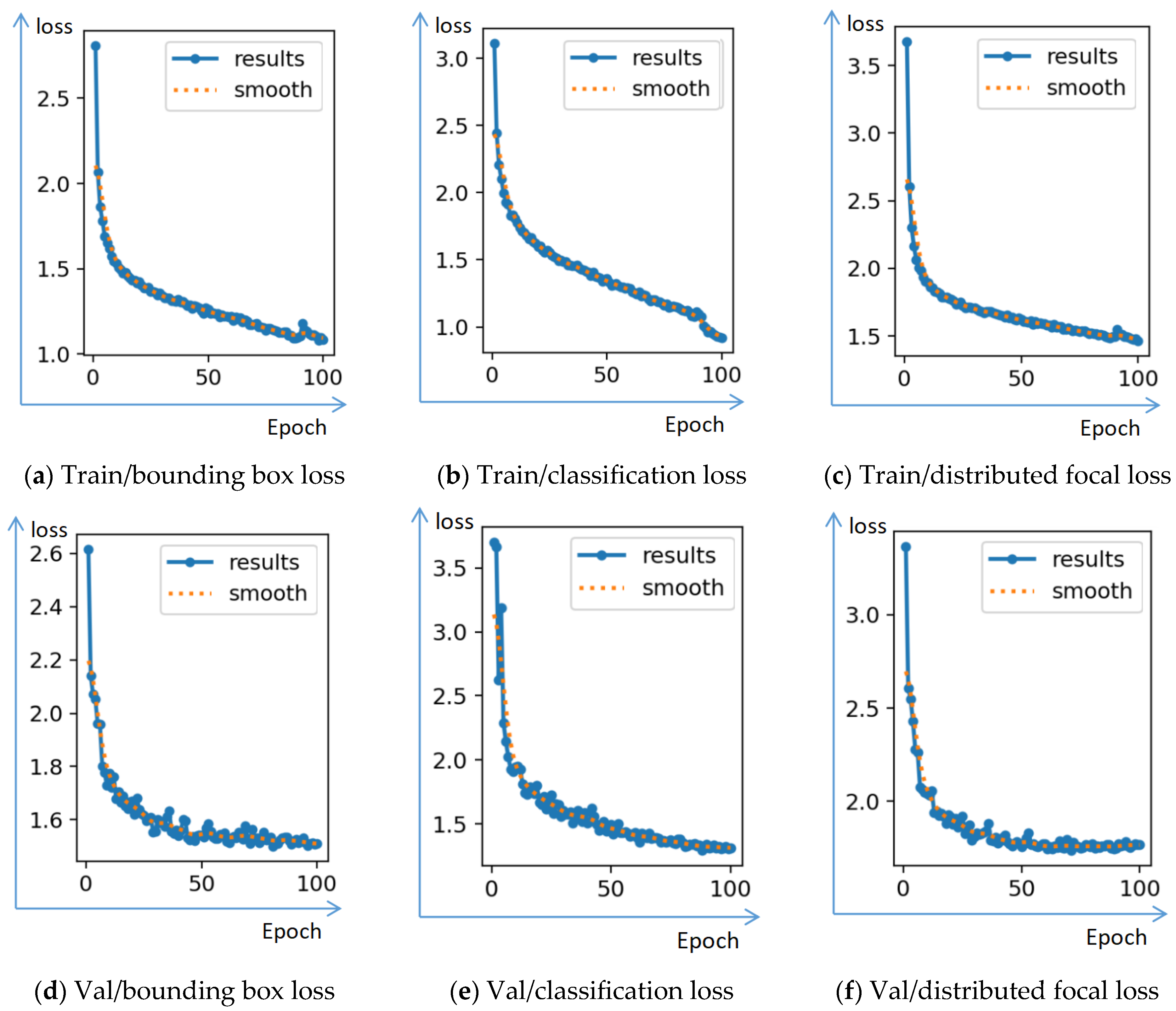
3.2.2. Experimental Parameter Setting
3.3. Experimental Results
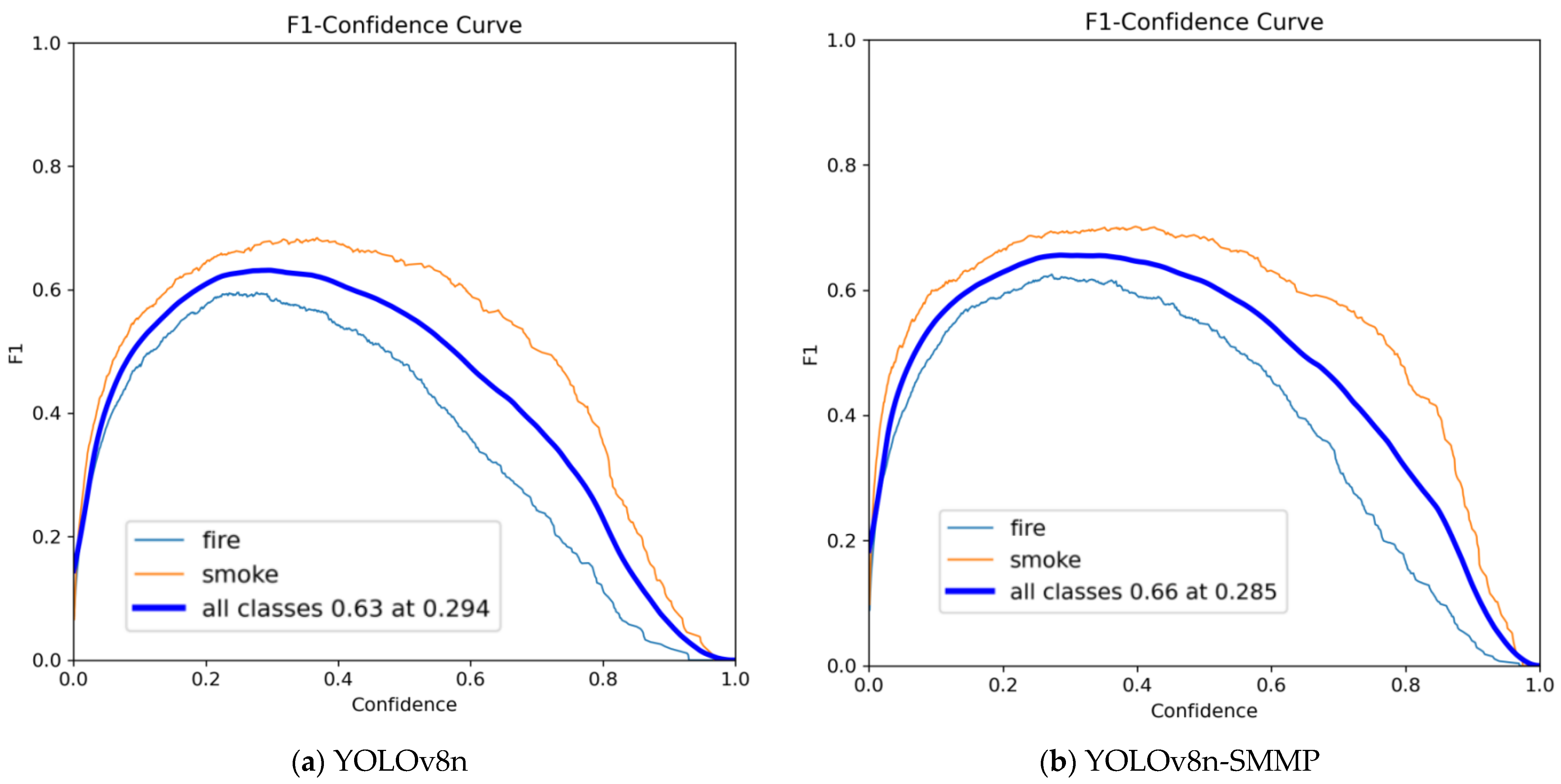
3.3.1. Ablation Experiment
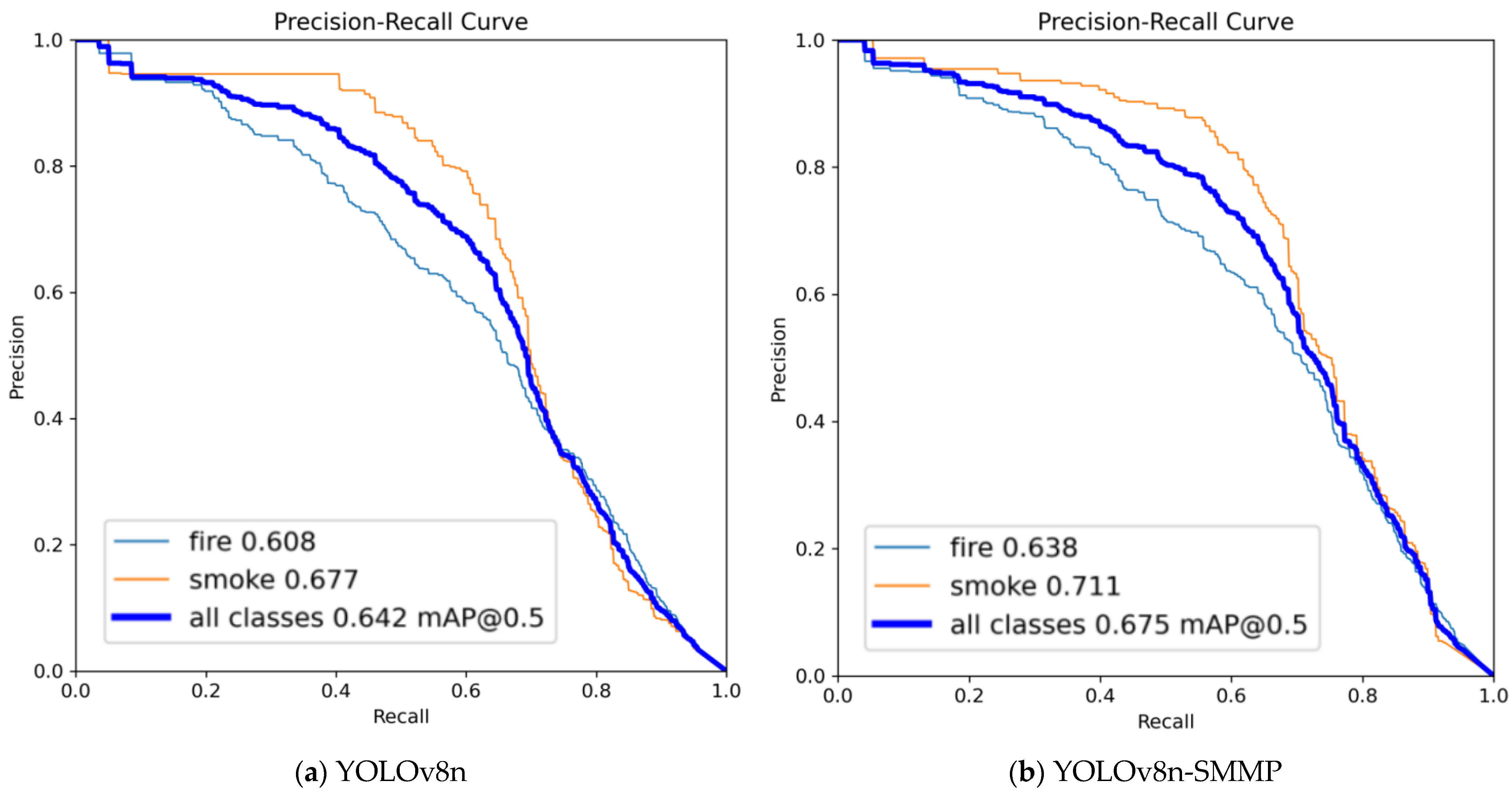
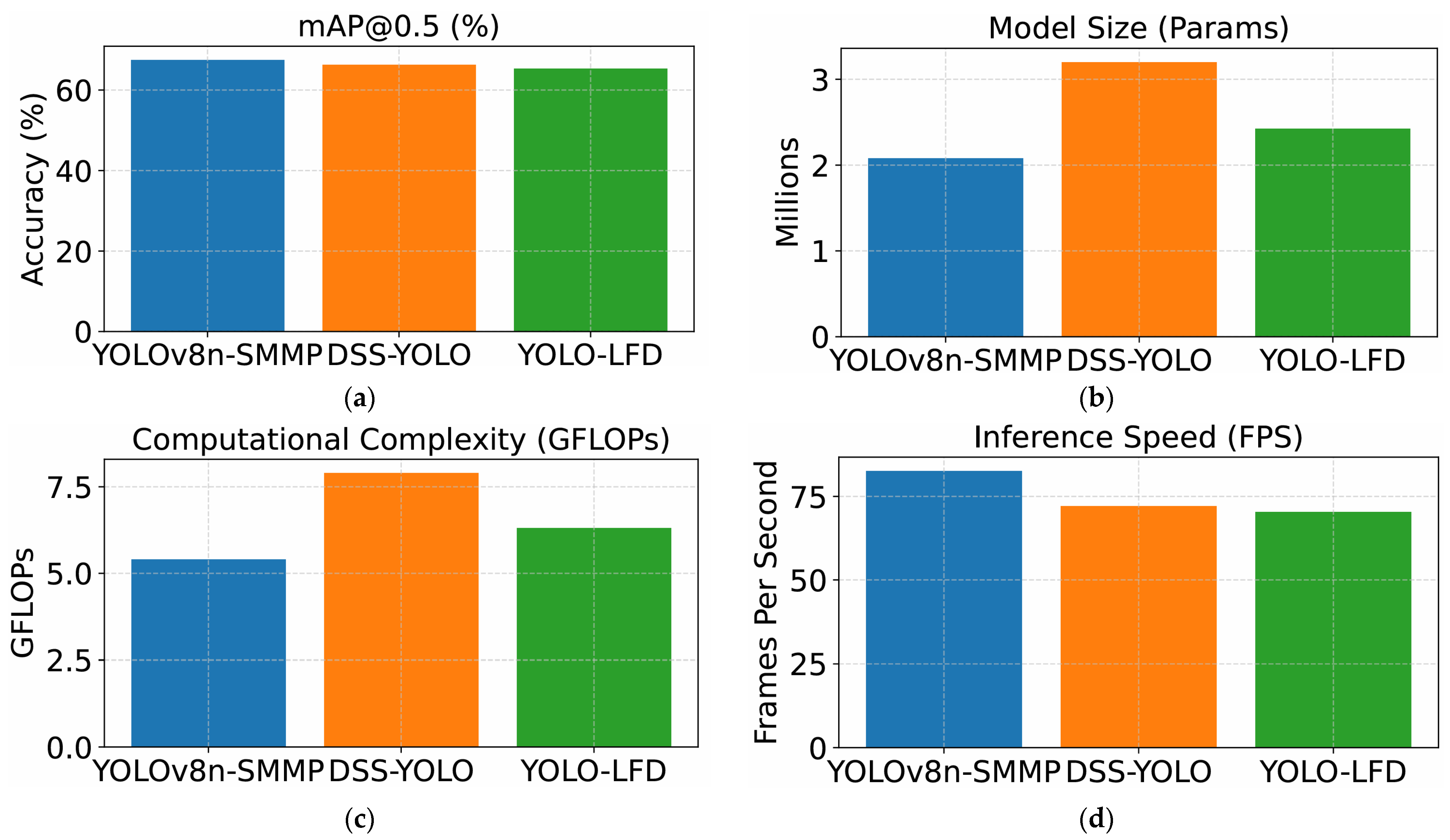
3.3.2. Comparative Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLOv8n-SMMP | YOLOv8n-SlimNeck–MCA–MPDIoU–Pruned |
| MCA | Multi-dimensional collaborative attention |
| GSConv | Group Shuffling Convolution |
| VoV-GSCSP | VoV-based GSConv Cross-Stage Partial Network |
| MPDIoU | Minimum Point Distance Intersection over Union |
| CBS | Conv–Batch normalization–SiLU module |
| C2f | Cross-convolution with 2 filters |
| GFLOPs | Giga floating-point operations |
References
- Anderegg, W.R.L.; Trugman, A.T.; Badgley, G.; Anderson, C.M.; Bartuska, A.; Ciais, P.; Cullenward, D.; Field, C.B.; Freeman, J.; Goetz, S.J.; et al. Climate-driven risks to the climate mitigation potential of forests. Science 2020, 368, eaaz7005. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Huang, W.; Xu, R.; Gasevic, D.; Liu, Y.; Yu, W.; Yu, P.; Yue, X.; Zhou, G.; Zhang, Y.; et al. Association between long-term exposure to wildfire-related PM2.5 and mortality: A longitudinal analysis of the UK Biobank. J. Hazard. Mater. 2023, 457, 131779. [Google Scholar] [CrossRef] [PubMed]
- Alkhatib, A.A.A. A Review on Forest Fire Detection Techniques. Int. J. Distrib. Sens. Netw. 2014, 10, 597368. [Google Scholar] [CrossRef]
- Bao, S.; Xiao, N.; Lai, Z.; Zhang, H.; Kim, C. Optimizing watchtower locations for forest fire monitoring using location models. Fire Saf. J. 2015, 71, 100–109. [Google Scholar] [CrossRef]
- Dang-Ngoc, H.; Nguyen-Trung, H. Aerial Forest Fire Surveillance—Evaluation of Forest Fire Detection Model using Aerial Videos. In Proceedings of the 2019 International Conference on Advanced Technologies for Communications (ATC), Hanoi, Vietnam, 17–19 October 2019; pp. 142–148. [Google Scholar]
- Sherstjuk, V.; Zharikova, M.; Sokol, I. Forest Fire Monitoring System Based on UAV Team, Remote Sensing, and Image Processing. In Proceedings of the 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018; pp. 590–594. [Google Scholar]
- Fralenko, V.P. Neural Network Methods for Detecting Wild Forest Fires. Sci. Tech. Inf. Process. 2024, 51, 497–505. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, B.-R.; Park, S. Synergistic use of multi-satellite remote sensing to detect forest fires: A case study in South Korea. Remote Sens. Lett. 2023, 14, 491–502. [Google Scholar] [CrossRef]
- Güney, C.O.; Mert, A.; Gülsoy, S. Assessing fire severity in Turkey’s forest ecosystems using spectral indices from satellite images. J. For. Res. 2023, 34, 1747–1761. [Google Scholar] [CrossRef]
- Zhang, J.; Li, W.; Yin, Z.; Liu, S.; Guo, X. Forest fire detection system based on wireless sensor network. In Proceedings of the 2009 4th IEEE Conference on Industrial Electronics and Applications, Xi’an, China, 25–27 May 2009; pp. 520–523. [Google Scholar]
- Sridhar, P.; Thangavel, S.K.; Parameswaran, L.; Oruganti, V.R.M. Fire Sensor and Surveillance Camera-Based GTCNN for Fire Detection System. IEEE Sens. J. 2023, 23, 7626–7633. [Google Scholar] [CrossRef]
- Lin, M.X.; Chen, W.L.; Liu, B.S.; Hao, L.N. An Intelligent Fire-Detection Method Based on Image Processing. Adv. Eng. Forum 2011, 2–3, 172–175. [Google Scholar] [CrossRef]
- Wei, R.; Yan, R.; Qu, H.; Li, X.; Ye, Q.; Fu, L. SVMFN-FSAR: Semantic-Guided Video Multimodal Fusion Network for Few-Shot Action Recognition. Big Data Min. Anal. 2025, 8, 534–550. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV 2015), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN 2018. In Proceedings of the IEEE International Conference on Computer Vision, Salt Lake City, UT, USA, 2–4 April 2018. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. ISBN 978-3-319-46447-3. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection 2016. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. What is YOLOv5: A deep look into the internal features of the popular object detector. arXiv 2024, arXiv:2407.20892. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Mark Liao, H.-Y. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Proceedings of the Computer Vision—ECCV 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer Nature: Cham, Switzerland, 2025; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Frizzi, S.; Bouchouicha, M.; Ginoux, J.; Moreau, E.; Sayadi, M. Convolutional neural network for smoke and fire semantic segmentation. IET Image Process. 2021, 15, 634–647. [Google Scholar] [CrossRef]
- Bohush, R.P.; Ablameyko, S.V. Algorithm for forest fire smoke detection in video. J. Belarusian State Univ. Math. Inform. 2021, 1, 91–101. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, Y. Real-time forest smoke detection using hand-designed features and deep learning. Comput. Electron. Agric. 2019, 167, 105029. [Google Scholar] [CrossRef]
- Basturk, N.S. Forest fire detection in aerial vehicle videos using a deep ensemble neural network model. Aircr. Eng. Aerosp. Technol. 2023, 95, 1257–1267. [Google Scholar] [CrossRef]
- Hou, Z.; Yang, C.; Sun, Y.; Ma, S.; Yang, X.; Fan, J. An object detection algorithm based on infrared-visible dual modal feature fusion. Infrared Phys. Technol. 2024, 137, 105107. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Y.; Zhu, C. YOLO-LFD: A Lightweight and Fast Model for Forest Fire Detection. Comput. Mater. Contin. 2025, 82, 3399–3417. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, J.; Xu, Y.; Xie, L. Mcan-YOLO: An Improved Forest Fire and Smoke Detection Model Based on YOLOv7. Forests 2024, 15, 1781. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, L.; Chen, Z. FFD-YOLO: A modified YOLOv8 architecture for forest fire detection. Signal Image Video Process. 2025, 19, 265. [Google Scholar] [CrossRef]
- Yun, B.; Zheng, Y.; Lin, Z.; Li, T. FFYOLO: A Lightweight Forest Fire Detection Model Based on YOLOv8. Fire 2024, 7, 93. [Google Scholar] [CrossRef]
- Wang, H.; Fu, X.; Yu, Z.; Zeng, Z. DSS-YOLO: An improved lightweight real-time fire detection model based on YOLOv8. Sci. Rep. 2025, 15, 8963. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv 2016, arXiv:1510.00149. [Google Scholar] [CrossRef]
- Courbariaux, M.; Bengio, Y.; David, J.-P. BinaryConnect: Training Deep Neural Networks with binary weights during propagations. Adv. Neural Inf. Process. Syst. 2015, 28, 3123–3131. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9908, pp. 525–542. ISBN 978-3-319-46492-3. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Fire Detection Dataset. Available online: https://www.kaggle.com/datasets/atulyakumar98/test-dataset (accessed on 2 April 2025).
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L.; Fulé, P. Aerial Images for Pile Fire Detection Using Drones (UAVs) 2020; IEEE DataPort: Porto, Portugal, 2020. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Wu, H.; Wu, D.; Zhao, J. An intelligent fire detection approach through cameras based on computer vision methods. Process Saf. Environ. Prot. 2019, 127, 245–256. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A lightweight-design for real-time detector architectures. J. Real-Time Image Process. 2024, 21, 62. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, Y.; Cheng, Z.; Song, Z.; Tang, C. MCA: Multidimensional collaborative attention in deep convolutional neural networks for image recognition. Eng. Appl. Artif. Intell. 2023, 126, 107079. [Google Scholar] [CrossRef]
- Ma, S.; Xu, Y. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. arXiv 2017, arXiv:1708.06519. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Environment | Type |
|---|---|
| CPU | Intel-Core i7-11700 |
| GPU | NVIDIA GeForce GTX 4080 |
| Memory | 24GB |
| Operating system | Linux-Ubuntu20.04 |
| Deep learning framework | PyTorch1.11 |
| Expansion pack | CUDA11.3, CUDnn8.0.4, OpenCV4.6.0.6, Torch_Pruning, etc. |
| IDE | PyCharm |
| YOLOv8n | MCA | SlimNeck | MPDIoU | Prune | Map@0.5/(%) | Params/106 | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| √ | 64.2 | 3.01 | 8.1 | 62.3 | ||||
| √ | √ | 65.9 | 3.06 | 8.1 | 60.8 | |||
| √ | √ | 64.6 | 2.82 | 7.4 | 63.5 | |||
| √ | √ | 66.7 | 3.01 | 8.1 | 63 | |||
| √ | √ | 64.7 | 2.16 | 5.5 | 76.1 | |||
| √ | √ | √ | 66.8 | 2.88 | 7.4 | 62.1 | ||
| √ | √ | √ | √ | 67.0 | 2.88 | 7.4 | 69.1 | |
| √ | √ | √ | √ | √ | 67.5 | 2.08 | 5.4 | 82.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, N.; Gao, D.; Zhu, Z. YOLOv8n-SMMP: A Lightweight YOLO Forest Fire Detection Model. Fire 2025, 8, 183. https://doi.org/10.3390/fire8050183
Zhou N, Gao D, Zhu Z. YOLOv8n-SMMP: A Lightweight YOLO Forest Fire Detection Model. Fire. 2025; 8(5):183. https://doi.org/10.3390/fire8050183
Chicago/Turabian StyleZhou, Nianzu, Demin Gao, and Zhengli Zhu. 2025. "YOLOv8n-SMMP: A Lightweight YOLO Forest Fire Detection Model" Fire 8, no. 5: 183. https://doi.org/10.3390/fire8050183
APA StyleZhou, N., Gao, D., & Zhu, Z. (2025). YOLOv8n-SMMP: A Lightweight YOLO Forest Fire Detection Model. Fire, 8(5), 183. https://doi.org/10.3390/fire8050183