1. Introduction
Nowadays, automated pain assessment is attracting increasing interest in the domain of medical and health care. This trend is driven by the desire to transform the inherent subjectivity of individual pain perception into objective quantification for optimizing patients’ treatment and to preserve human resources in clinical environments. A patient’s self-reporting about pain episodes and intensities that they experience currently serves as the de facto standard for pain measurement [
1,
2,
3] and engenders direct consequences on the quality of medical treatment (cf. [
1,
3]), due to the role of pain as a strong indicator of harmful physical conditions, as well as an alarm signal for certain diseases. In cases of missing communicative abilities originating from mental impairments, loss of consciousness, or infantile restrictions, respective patients may be exposed to inappropriate drug dosing or even suffer from false diagnoses (cf. [
2,
3]).
These reasons motivate an ongoing search for meaningful physical signals to implicitly detect and quantify pain based on patients’ immediate pain reaction. Previous research attempts investigated facial expressions via video recordings [
3,
4], minimally or noninvasive measurements of biopotentials (i.e., heart rate, muscle activity and skin transpiration) [
3,
5,
6,
7,
8], or combined all distinct modalities together in order to create automated pain assessment systems [
3,
9,
10]. At first, such systems mostly relied on the engineering of handcrafted features [
3,
5,
9,
10,
11], but with the rise of artificial neural networks as general-purpose technology, recent approaches [
4,
6,
7,
12,
13,
14] prefer end-to-end deep learning models concerning both feature extraction and pain classification.
Apart from the technological evolution of pain classification models, the focus has shifted from multimodal approaches [
3,
5,
6,
7,
9,
10,
11,
12] to highly specialized unimodal methods [
13,
14]. This development can be explained by the strong differences in the contribution per modality for solving the task of pain classification. For instance, there exists empirical evidence that Electrodermal Activity (EDA) is by far the most significant signal for pain classification [
5,
6,
9,
10,
11] when compared to the other modalities of Electrocardiogram (ECG), Electromyography (EMG) and the recorded facial expressions provided by the prominent heat pain database
BioVid (Part A) [
1,
2,
3]. In particular, the modality of capturing facial expressions via video recordings probably lost attention because of its dependence on being awake, its costly clinical setup (cf. [
11]) and the risk of intentional affectation.
Although the EDA signal quantifying the change in skin transpiration currently offers the highest potential for automated pain assessment, relying on a single sensor to implicitly measure pain is not reliable for decision-making in a sensitive domain such as health care. This argument is supported by the laboratory settings in which recent pain classification datasets were collected, where environmental factors are standardized and probands are in normal condition. But in a more realistic case, when patients suffer from diseases, receive medication and are exposed to external factors, pain-related body reactions may drastically change.
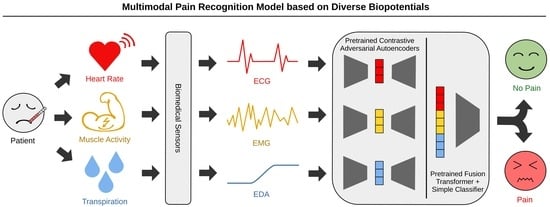
To address this problem, we propose the novel MultiModal Supervised Contrastive Adversarial AutoEncoder (MM-SCAAE) pretraining framework for multi-sensor information fusion and provide an application-specific implementation for the task of pain classification. We prove the performance of our concept using the publicly available BioVid dataset, which particularly ensures a reasonable comparison to existing methods. Due to the sustained difficulty of fine-grained pain classification, we continue working on the task of pain recognition between the no-pain baseline and individual pain intensities, as is common in the literature. Our model accesses the three biopotentials EDA, ECG and EMG (at the trapezius muscle) to accomplish the task of multimodal pain recognition.
The major contributions of our work are summarized below:
We derive a novel autoencoder variant for multimodal information fusion by combining denoising variational autoencoders with adversarial regularization and a supervised contrastive loss for global representation learning. This methodology constitutes the abstract definition of a new supervised adversarial autoencoder model that is application-independent and can easily be adopted for other multi-sensor classification tasks of time-series data.
The implementation of our designed MM-SCAAE framework achieves new state-of-the-art performance for multimodal pain recognition on the BioVid dataset regarding all four binary classification tasks (i.e., ‘no pain’ vs. ‘pain intensity’). Specifically, our model reaches an accuracy of and an -score of for the most relevant task of ‘no pain’ versus ‘highest pain’ using the three biophysiological measurements EDA, ECG and EMG.
Our empirical results indicate that a grouped-prediction estimate stemming from multiple short-term observations (here: s) may serve as key ingredient for the practical applicability of current pain assessment methods. In particular, the performance of our model can be boosted to the maximal accuracy of ≈95% for the task of ‘no pain’ versus ‘highest pain’ by approaching the full group size of twenty samples (i.e., in total a period of 110 s) per patient.
The organization of this paper is as follows:
Section 2 provides an overview of the proposed MM-SCAAE framework and explains the theoretical foundations for each model component in detail.
Section 3 relates our concept to previous works from a technological and an application-specific perspective.
Section 4 introduces the BioVid dataset used for pain classification, presents the preliminaries for the intended analyses and elucidates the results of the conducted experiments.
Section 5 discusses the implications of our work and offers prospects of promising future research directions. Finally,
Section 6 concludes with the major findings of the present paper.
3. Related Work
Autoencoders: Previous work [
23] on VAEs advocated for maximizing the log-likelihood of the data distribution without latent regularization against a prior, with the precondition that the approximation ability of the encoder network is sufficient. More recently, a Probabilistic Autoencoder (PAE) [
45] has been used to decouple the VAE objectives but formulate a two-stage training of first optimizing solely the reconstruction ability and then learning a bijective mapping to construct a useful latent space using Normalizing Flows (NF)s [
46,
47]. However, PAEs mainly focus on exact likelihood computation with regard to realistic modeling and generation of data samples, whereas our approach aims to conserve class-discriminative characteristics merely directed by reconstruction ability, allowing for less costly model architectures and training. Sacrificing reconstruction quality in favor of other purposes is not a novelty, for instance,
-VAE systematically oversizes prior regularization to encourage the disentanglement of latent variables, which potentially eases subsequent classification tasks [
28]. Moreover, the clustering technique Class-Variational Learning (CVL) [
48] constructs a class-discriminative equivariant latent space by combining the aim of reconstruction ability with the decomposition of sample mixtures using a CapsNet encoder. In an opposite direction, Thiam et al.’s pain assessment model [
12] introduced an adaptive prior distribution for latent space regularization based on an exponential running mean of the empirical posterior. We think that this harbors the risk of forward latent space collapse by approaching the mass center of the posterior. Instead, we encourage a latent space alignment with a zero-mean Gaussian but allow the model to iteratively adjust the prior’s mean variance over the latent factors. In general, there is still controversy around weighting autoencoder objectives favoring likelihood/mutual information maximization [
23,
45,
49] or privileging task-specific goal adjustments [
24,
25,
26,
28,
48], with an ongoing lack of clear guidance.
A common pattern we observe with autoencoder models constitutes the stochastic construction of the latent space with many similar inputs mapped to a few locally stochastic neighborhoods inducing enhanced generalizability and generative abstraction, which can be categorized as Vicinal Risk Minimization [
50] strategy. The most straightforward realization of this pattern represents VAE [
20,
21] with its stochastic encoding and latent space regularization, but also DAE [
30,
31,
32,
36] implicitly creates local neighborhoods around its encodings through random input distortions. In fact, even the general concept of bounded rationality shares a similar spirit by penalizing exact bijective relations between original and latent representations [
25], which was previously integrated into Thiam et al.’s autoencoder model [
12]. In addition to the prominent variational and denoising criteria of autoencoders, our approach establishes a higher-level arrangement of local neighborhoods within class-associated partitions based on the supervised contrastive learning objective.
Information Fusion: The general task of information fusion concerns a superior system which consumes multiple feature streams of possibly variable granularity and learns to extract, combine and route latent information in order to fulfill a single or several objectives. This problem formulation is strongly related to the task of meta-learning [
24,
26], where sample-wise information from a multimodal dataset, consisting of several single-task datasets, must be extracted, optionally combined and routed to the proper expert agent system(s). In particular, we will propose dedicated data augmentation methods (see
Section 4.3) to artificially constitute a meta-learning dataset during training with the aid of modality dropout and replacement operations. As a consequence, we enrich the major task of pain classification with the implicit sub-tasks of robust and resilient information fusion. Also note that the multi-task latent space with subsequent selection network in [
24,
26] for the probabilistic assignment to expert agents can be directly interpreted as a late fusion network.
Contrastive learning was previously adopted for the task of unsupervised information fusion by, among others, aligning multi-channels of visual entities [
51,
52], exploiting temporal dependencies between concurrent videos of varying viewpoints [
53], understanding scenes of 3D point clouds [
54] and performing multimodal sentiment analysis [
52]. Concerning the processing of time-series data, other works addressed representation learning for robust classification [
55] and multivariate anomaly detection [
56]. Another approach conducted SupCon learning for multimodal information fusion with regard to the combination of audio-visual channels with textual input to shape a global representation [
57]. Note that the terminology of
multiview samples in the context of contrastive learning has the ambiguous meaning of
multi-channel inputs of the same data instance [
51,
53,
54] or
data augmentations to enlarge the batch size for contrastive loss computation [
42,
43]. In our pain classification approach, we characterize distinct biophysiological signals for measuring pain reaction as multimodal data to emphasize their sensory variety, which is a consistent interpretation with recent work [
57]. Hence, we link
multiview to its
meaning. Related to our focus on class-discriminative feature extraction and combination, Tian et al.’s contrastive framework [
51] aims to filter solely channel-invariant entity information from the output of channel-specific encoders. Liu et al.’s TupleInfoNCE [
52] training procedure pursues the goal of intensifying the combined usage of modality information based on data augmentation for the creation of positive samples and a modality replacement operation for hard negative mining. Both positive and negative sample generation are parameterized and follow an auxiliary update cycle [
52]. Since the task of pain recognition traditionally provides scarce training data and therefore requires time-consuming Leave-One-Subject-Out cross validation, involving comprehensive hyperparameter search circles is usually unfeasible. From a technological perspective, Mai et al.’s work [
57] represents the approach most akin to our general multimodal fusion framework by applying SupCon training on lately fused entity encodings and by performing diverse data augmentation techniques to cope with a limited amount of labeled data. The key difference between both approaches lies in the role of the modalities. In the work of Mai et al. [
57] (and also in [
52]), each modality means an essential part of a specific object, while our model instead maps multiple modalities to the identical object class, allowing for intended sensory redundancy. The assumed supplementary relationship of sensory measurements in pain reaction can be characterized as
crossmodal embedding [
52], where modalities contribute to a majority voting for pain class prediction. In particular, the sensory redundancy improves failure resistance at runtime, conditions representation learning on all sensory inputs during training and allows for the extension of measurement equipment. Unlike to Mai et al. [
57], we prefer a single but more complex fusion network as trade-off between modeling capacity and computational efforts. Yu et al. [
56] jointly trained an autoencoder architecture with an adversarial feature discrimination objective instead of a traditional contrastive loss in order to detect anomalies within multivariate time series. Despite the novelty of adversarial contrastive learning, their approach lacks mathematical foundations and dedicated experiments that explain its relationship to theoretically grounded contrastive loss functions such as
–SupInfoNCE.
Pain Recognition: In the pain recognition literature there are already various works on classifying the pain intensities of the BioVid dataset. These works propose methods that build upon facial expressions obtained from video recordings [
3,
4], use measured biopotentials [
3,
5,
6,
7,
8] or combine all of those modalities together [
3,
9,
10]. Regarding the used methodology, early works [
3,
5,
9,
10,
11] rely on comprehensive preprocessing schemes for producing handcrafted features and employ rather simple machine learning methods, i.e., random forests, logistic regression and linear Support Vector Machines (SVM)s, for executing classification tasks.
Thiam et al. [
6] presented the first approach which substituted the engineering of handcrafted features with Convolutional Neural Networks (CNN)s and restricted signal preprocessing solely to dimensionality reduction. More precisely, they constructed modality-specific CNN-based feature extractors for biophysiological input signals and tested them in unimodal and multimodal classification settings. In the multimodal setting, they used a linear network layer for late fusion. The experimental results revealed that modalities significantly differ in their contribution to solving the task; in addition, multimodal fusion models may suffer from inconsistencies between distinct modalities. Preceding their work, Thiam et al. [
7] designed a denoising convolutional autoencoder with a gating network for late fusion, which were jointly trained with the pain classification objective. More recently, Thiam et al. [
12] enhanced their previous multimodal fusion model by enlarging the gating network with the aid of an attention module and by involving VAEs with adaptive prior distributions. The key difference between these models and our approach lies in the transformer architecture of MM-SCAAE’s late fusion network, and in the metric-learning SupCon regularization, which merely aligns with the downstream task. Utilizing the well-known high capacity of a transformer architecture for late fusion in order to detect interdependencies between feature vectors allows for avoiding the engineering of sophisticated gating mechanisms. The combination of the late-fusion transformer network with the SupCon loss should facilitate the robust representation learning known from the general SAAE framework.
In the most recent works, the focus has shifted from generic multimodal methods to complex unimodal models. Lu et al. [
13] proposed a highly specialized encoder architecture dedicated to one specific biophysiological modality consisting of a MSCNN, a squeeze-and-excitation residual network and a transformer network. Li et al. [
14] refined this model through the addition of a multi-scale cross-attention mechanism to the transformer encoder. The major weakness of both approaches originates from their highly complex feature extraction networks and the fixation on a single pain-reaction channel. This means that their models are barely scalable to multi-sensor systems, and do not provide a potential fusion functionality for multiple input signals. The second aspect is especially controversial in a sensitive environment such as medical care.
To enhance the robustness of automated pain assessment in terms of sensor failure tolerance and to increase their trustworthiness in pain-level predictions, we prefer a multimodal pain recognition system based on several biopotentials. For this reason, our generic MM-SCAAE framework supports the straightforward expansion to auxiliary biophysiological measurements, with the inherent option to tailor unimodal autoencoders to specific input types.
5. Discussion
5.1. Perspectives on Pain Assessment
Our proposed MM-SCAAE framework opens new perspectives on the reliability of automated pain recognition systems through the integration of multiple biopotentials into the decision-making process, and by proving state-of-the-art performance on multimodal pain recognition using the BioVid dataset. Nevertheless, the current superiority of unimodal models [
13,
14] with highly specialized network architectures based on the EDA signal points to the major limitation of multimodal approaches, which lies in their proportional scaling to the number of involved sensors. This means that despite the architectural flexibility of MM-SCAAE to subsume unimodal feature extractors, there remains a strict trade-off between model capability and computational requirements.
Regarding the practical realization of pain assessment systems, we believe that multimodal approaches are crucial for trustworthiness and acceptance in health care. Individual sensor contribution may vary, particularly in clinical environments in the real world, as a result of patients’ conditions, medical treatments or external factors. Hence, we propose our MM-SCAAE model for future research attempts to broaden the inclusion of other biopotentials into automated pain assessment. The demonstrated gain in pain recognition accuracy by means of grouped-prediction estimates stemming from multiple samples of length 5.5 s also reveals a potential mismatch between dataset benchmarking based on short-term observations and evaluation for practical applicability. More precisely, we argue that an approximate pain recognition performance of 95% for an extended observation window of around 110 s is still acceptable for the vast majority of clinical applications, since patients would instead need to articulate their subjective pain perception for proper diagnosis. In cases of non-communicative patients (e.g., infants, mentally impaired or unconscious persons), the performance gain established through the grouped-prediction estimate may significantly improve the quality of pain diagnosis. Thus, we are convinced that the collection of real-word datasets with enlarged observation periods is the key to closing the gap between pain research and its practical application.
5.2. Generic Multi-Sensor Pretraining for Time-Series Classification
The pain recognition experiments demonstrated that a key benefit of our pretraining model is that it refrains from comprehensive signal preprocessing in terms of feature engineering (cf. [
3,
5,
9,
10,
11]) and dimensionality reduction (cf. [
6,
7,
8,
12]). In particular, MM-SCAAE directly applies a kind of dimensionality reduction on the raw input signals by means of the introductory MSCNN, which was inspired by the state-of-the-art works [
13,
14] on unimodal pain recognition. Moreover, our model merely needs half of the pretraining epochs of former methods [
6,
12,
13,
14]. These circumstances may serve as indicators for the general capacity of MM-SCAAE.
Apart from the concrete use case of pain recognition, we declare MM-SCAAE as generic model for multi-sensor pretraining which can be tailored by implementing application-specific autoencoder components. Ideally, we would plug in as many sensors as available to maximize the confidence in model predictions, and the model should apply a relevance-weighted information fusion. To make this scenario feasible, MM-SCAAE delivers a rather lightweight architecture which linearly scales with the sensor count. Specifically, the enrichment of AAEs with a SupCon objective also constitutes a generic model type, forming an interesting future research direction.
5.3. Supervised Contrastive Adversarial AutoEncoder (SCAAE)
Adversarial regularization is superior for distribution discrimination compared to the trivial KL-divergence regularizer of VAEs, since adversarial regularization cannot be easily tricked (see
Section 2.2.2), and its computational effort is negligible for small two-layer MLPs like we used in the MM-SCAAE framework. During our experiments, we especially did not encounter training instabilities, as is known from the generally error-prone GAN [
35] training procedure. As a unique characteristic, the integration of the SupCon objective enhances the primary SAAE [
34] framework through class partitioning of latent spaces. For further information about the performance of SCAAE, we refer to
Appendix D, where we provide an empirical verification for its effectiveness and generative capabilities. Due to the restricted scope of this paper, we did not explore unsupervised or semi-supervised contrastive AAEs. However, we hypothesize that—even without label information—diverse representation learning algorithms may benefit from auxiliary contrastive regularizations. We hope that future research efforts will evolve the theoretical framework of contrastive AAEs.
5.4. Limitations of This Study and Future Work
The BioVid dataset focuses on short-term measurements of biophysiological pain reactions with a length of 5.5 s. We hypothesize that longer observations of certain modalities could change their individual contribution. In particular, we are convinced that a longer observation of the heart rate for better capturing its variability should facilitate pain classification. Hence, we identify the need for collecting new datasets which account for the latency in the pain reaction of certain modalities. Moreover, we empirically verified the performance of our proposed approach with experiments on the heat pain dataset BioVid, because it is publicly available and its usage is widely spread. However, it could be an interesting future research perspective to investigate the performance of our MM-SCAAE pretraining framework on pain recognition datasets with diverse pain reasons (e.g., electric shock or tactile pressure). Nevertheless, only the gathering of real-world datasets with distinctive pain reasons will eventually allow for the reliable evaluation of state-of-the-art pain recognition models for practical applicability.
Although our model empirically proved resilience against partial sensor failure, our experiments on modality significance emphasized that performance can still dramatically degenerate if highly contributing sensors are unavailable. However, such degeneration effects should constantly reduce with the inclusion of further sensors. Thus, a promising direction for future work is the exploration of other sensors in the clinical setting (e.g., for respiration or blood pressure) to assure trustworthy pain recognition. Our experimental results demonstrated the generalizability of the proposed MM-SCAAE framework in the challenging domain of pain recognition, where datasets are typically scarce and highly biased through the use of small subject groups. In the case of BioVid, for instance, the whole dataset stems from measurements of merely 87 patients. Moreover, we restrict the application scope of the designed MM-SCAAE pretraining model to multimodal time-series classification. Since we strictly focus in our study on the task of pain recognition, we encourage future research efforts that investigate the general capacity of the MM-SCAAE framework and its sensitivity to parameter settings for a wide spectrum of time-series classification tasks. Due to the introduction of an ordinal SupCon loss, it would be especially interesting to exploit inter-class relationships for improving performance in ordinal classification tasks.
The core contribution of our study concerns the technical realization of automated pain recognition systems based on the BioVid heat pain database, which originates from a controlled experiment with healthy probands and standardized environmental factors. We briefly mentioned in our work that in realistic clinical settings patients suffer from diseases, receive medication and may be exposed to external factors, which may drastically change pain-related body reactions. Nevertheless, we did not provide a structural guidance for the hard requirements on pain recognition systems that may arise in a real-world setting. More precisely, our technically oriented study did neither examine the influence of interference factors (e.g., mental conditions, diseases or medication) nor cover the aspect of patient diversity (e.g., ethnic or cultural background) on the resulting performance of pain recognition models. It is necessary to address all these aspects in future research attempts to promote trustworthiness in automated pain recognition. Due to the intrusion of such systems into the subjective perception of individuals, practical applications must ultimately be accompanied with medical ethics and regulatory compliance to prevent the potential misuse of this sensitive information.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




