Many studies have been published in the literature on the use of geometric features for point cloud classification. Weinmann et al. [
6] published a comprehensive study on using different geometric features for point cloud classification, choosing the most appropriate neighbourhood and different classifiers. Among these features, the features that positively affect the accuracy have been selected using specific feature selection methods. Oakland 3D Point Cloud Dataset [
7], comprising mobile laser scanning data, and Paris-rue-Lille Database [
8], which uses the same type of data, were used as the data set. In the study conducted by Vosselman et al. [
9], 19 geometric feature features were used. Vaihingen and Rotterdam datasets of the International Society for Photogrammetry and Remote Sensing were used as the dataset. The classification method is Conditional Random Field. As a result of the study, group-based classification has higher accuracy than point-based classification. Guo et al. [
5] proposed an ensemble learning method known as JointBoost; ensemble learning methods create a robust classifier by combining multiple weak classifiers. In the first step of the classification, classification is made with the JointBoost method. In the second step, unreliable or mis-classified points are reclassified by using the K-Nearest Neighbour method. Thus, an improvement was achieved as a result of the classification. In the study published by Cabo et al. [
10], controlled classification was applied in forest and residential areas. In the study, five geometric features were used from the point cloud: linearity, flatness, sphericity, horizontality and height change. Some popular supervised classification algorithms were used, such as Support Vector Machines (SVM), Random Forest (RF), Logistic Regression, and linear discriminant analysis. In another study published by Becker et al. [
11], a controlled classification of point clouds was applied using geometric features. In the study, besides the 15 geometric properties, the color information of the points is added to the feature space, while RF and Gradient Increment Trees were selected as the classifier algorithm. The classes targeted as a result of the classification are ground, higher plants, roads, cars, buildings and manmade objects in a photogrammetric point cloud. In the study conducted by Lin et al. [
12], the aerial point cloud was classified by using SVM according to three geometric features: linearity, flatness, and sphericity. The proposed method aimed at increasing the classification accuracy by weighting the covariance matrix used in the calculation, and the targeted classes are divided into buildings and outdoor structures. In the study of Chen et al. [
13], both spectral information and 3D spatial information of LiDAR data were used. In the study, a two-stage classification process was carried out to remove noise that reduces classification accuracy. In the first stage, classification based on spectral information was applied using spectral reflection or vegetation index. In the second stage, classification based on spatial data was carried out using the K-Nearest Neighbors (K-NN) algorithm. Atik et al. [
14] published a comprehensive study on the performance of eight supervised machine learning methods using geometric features. In the study, the effect of the support area obtained in different scales on the classification accuracy was examined. Moreover, the importance of geometric features was examined according to the data and scale. Dublin City, Oakland3D and Vaihingen data sets obtained with LiDAR were used in the study. Reymann et al. [
15] evaluated how multiple echo and intensity information in datasets obtained by LiDAR technology can improve scene classification performance. The density information of the LiDAR data was interpreted, and geometric features were obtained by using Euclidean distances. In addition, a supervised classification process was performed with the Random Forest algorithm by using the density feature and multi-eco features. In the study published by Atik and Duran [
16], photogrammetric point cloud classification was made with the popular recurrent neural network algorithms LSTM and BiLSTM, and was carried out on a new photogrammetric dataset proposed in the study. In the classification, not only geometric features but also color information was used; thus, the effect of color information was also examined. The F-1 score building, low vegetation, high vegetation and ground was obtained as 0.85, 0.91, 0.67 and 0.86, respectively.
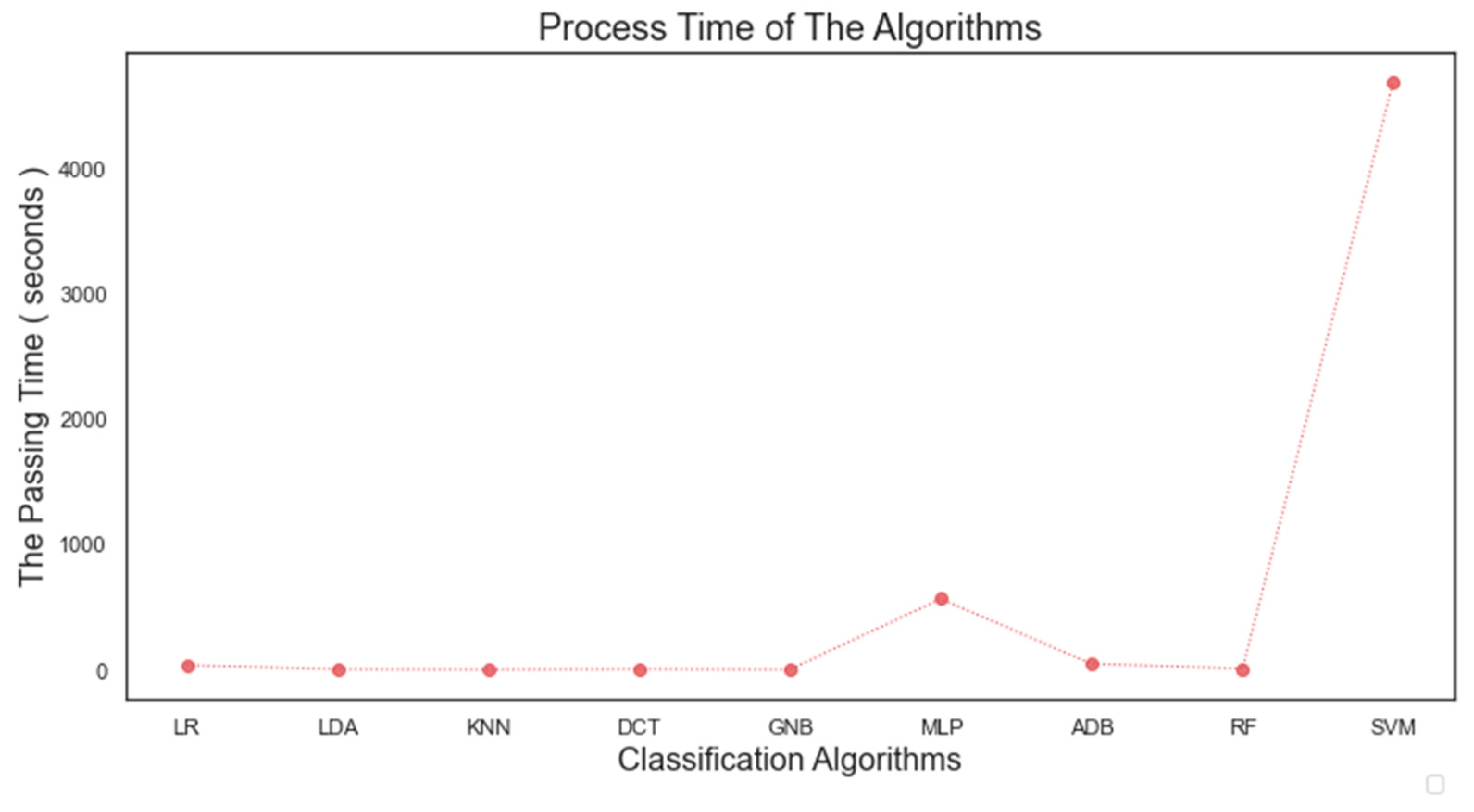
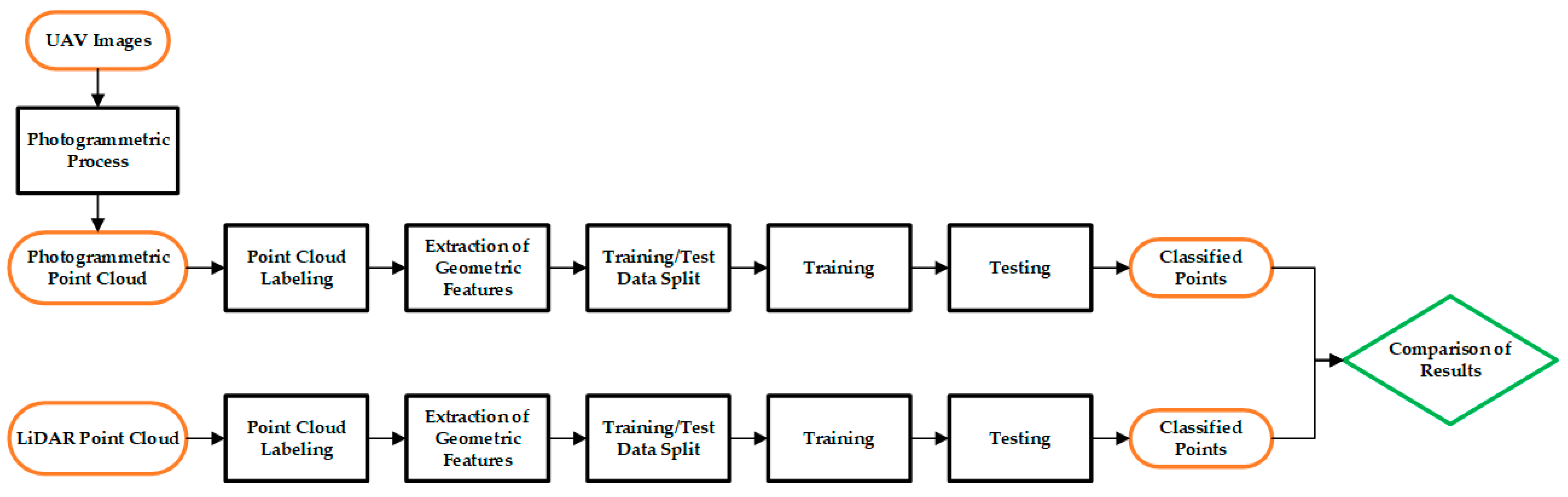
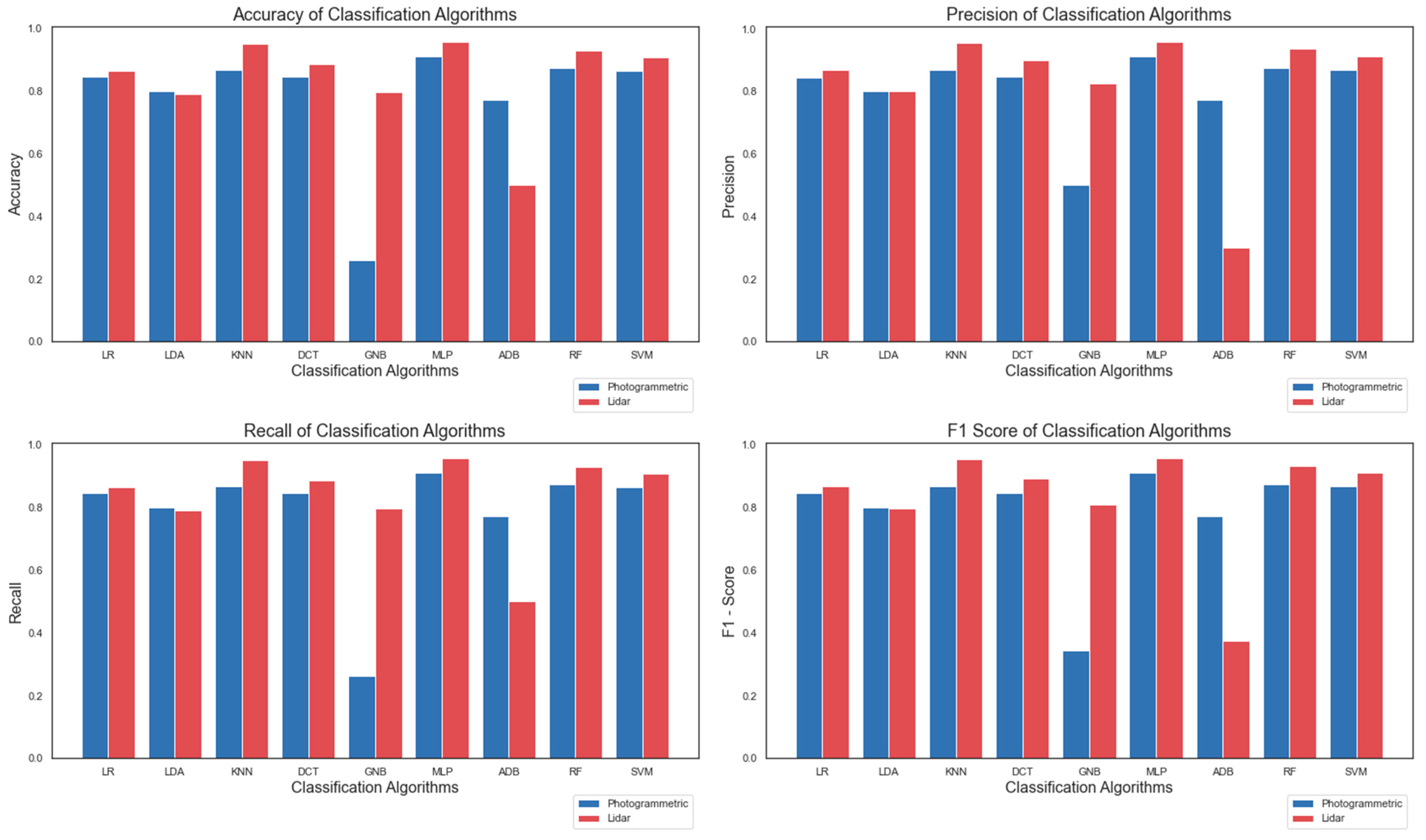
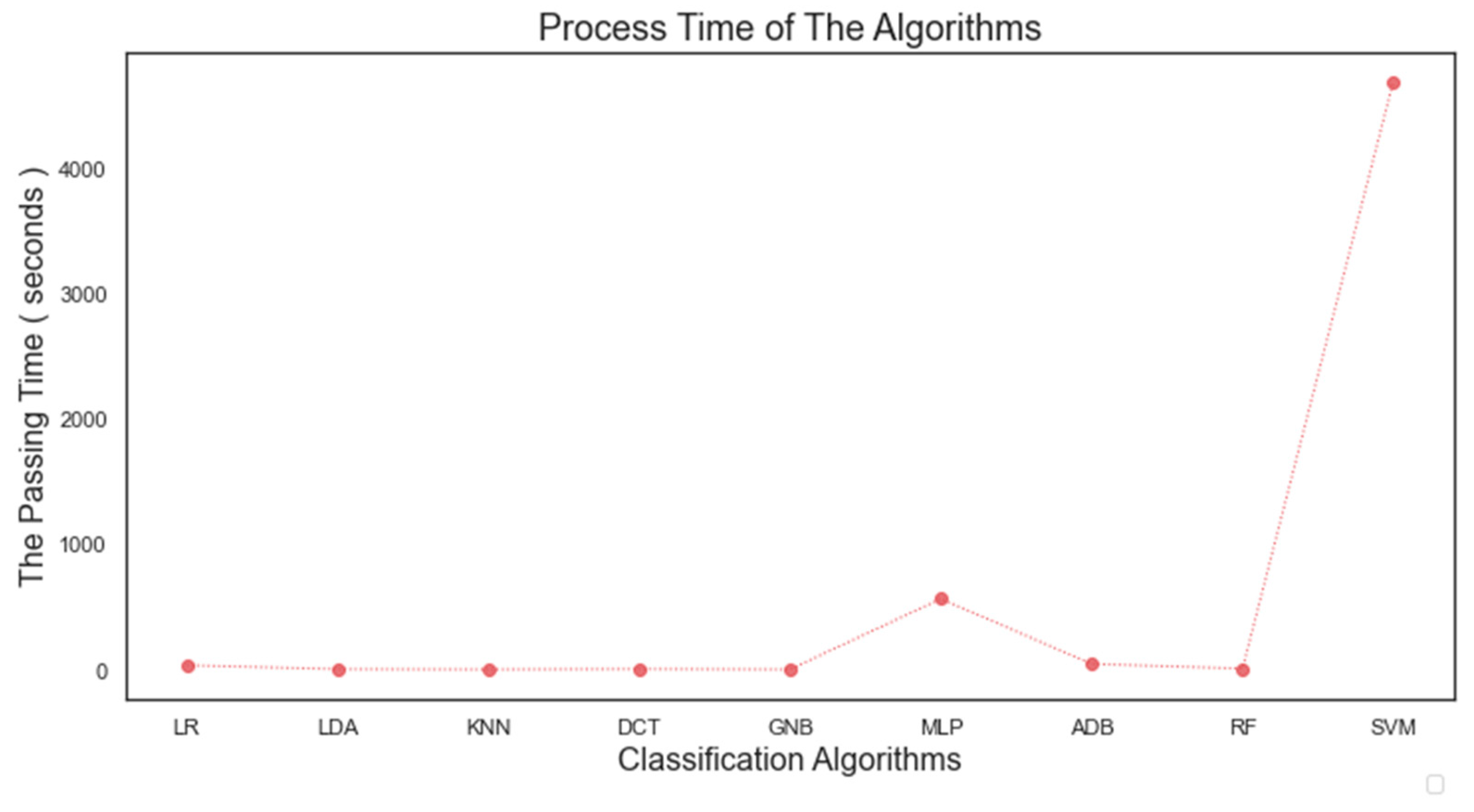
In this study, point clouds obtained from two different sensors (UAV camera and LiDAR) belonging to the same region were classified by different machine learning methods. Thus, it was possible to compare the classification results of point clouds under the same conditions. In this aspect, the study fills an existing gap in the literature. Nine machine learning algorithms were applied for classification purposes: Logistic Regression (LR), linear discriminant analysis (LDA), K-Nearest Neighbors (K-NN), decision tree (DTC), gaussian Naïve Bayes (GNB), Multilayer Perceptron (MLP), AdaBoost (ADB), Random Forest (RF) and Support Vector Machines (SVM). A total of 22 geometric features of the point clouds were calculated and the feature spaces of the points were formed. In the photogrammetric point cloud, color information is also included in the feature space. Random points belonging to different classes selected from the study area were used as training and test data. The points chosen from the point cloud are divided into four classes as building, ground, high vegetation and low vegetation. The usage of geometric features in the classification of point clouds obtained from different sensors has been investigated.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}