
In Situ MIMO-WPT Recharging of UAVs Using Intelligent Flying Energy Sources


Abstract
:1. Introduction
2. Related Works
3. System Description
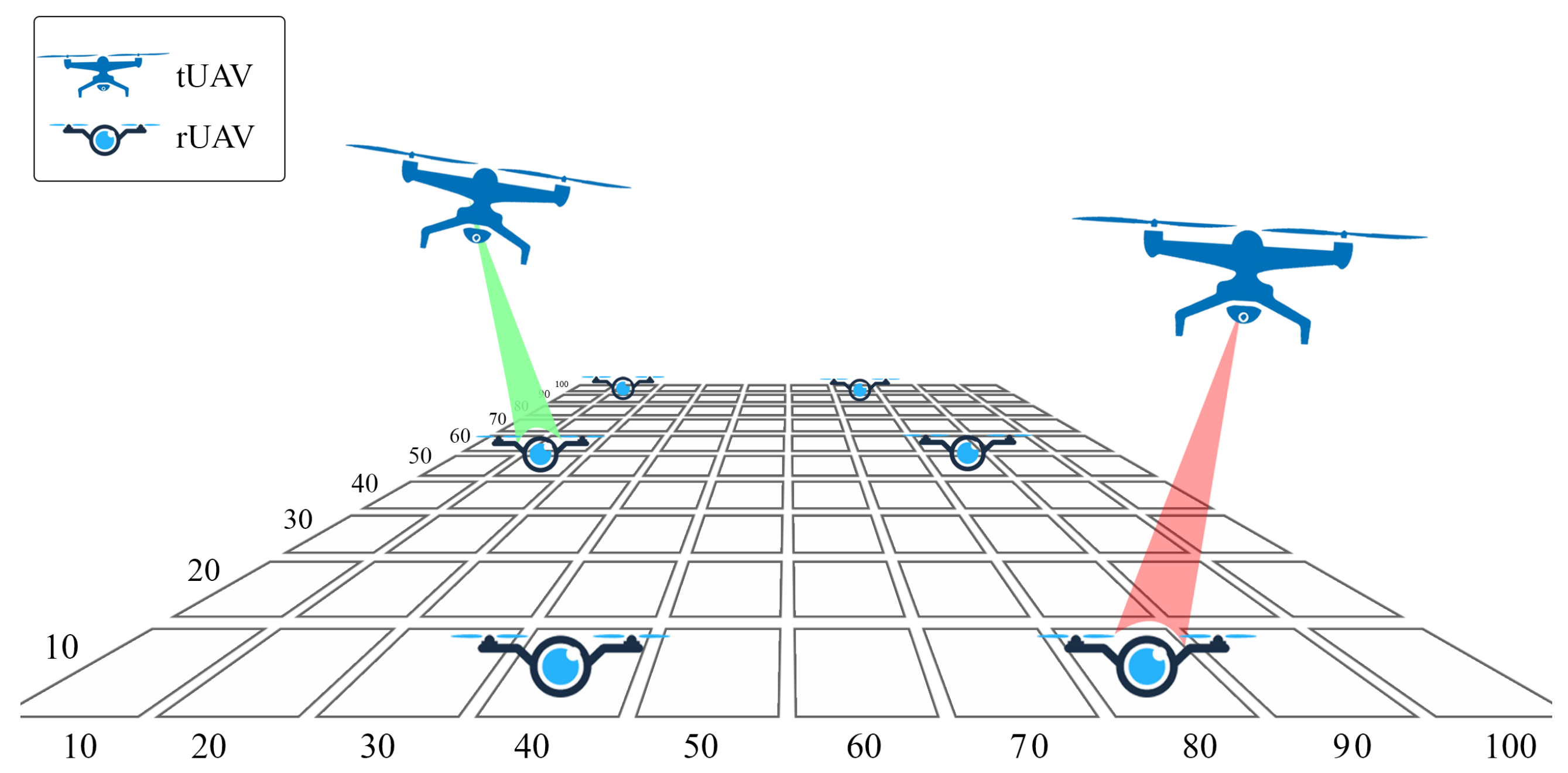
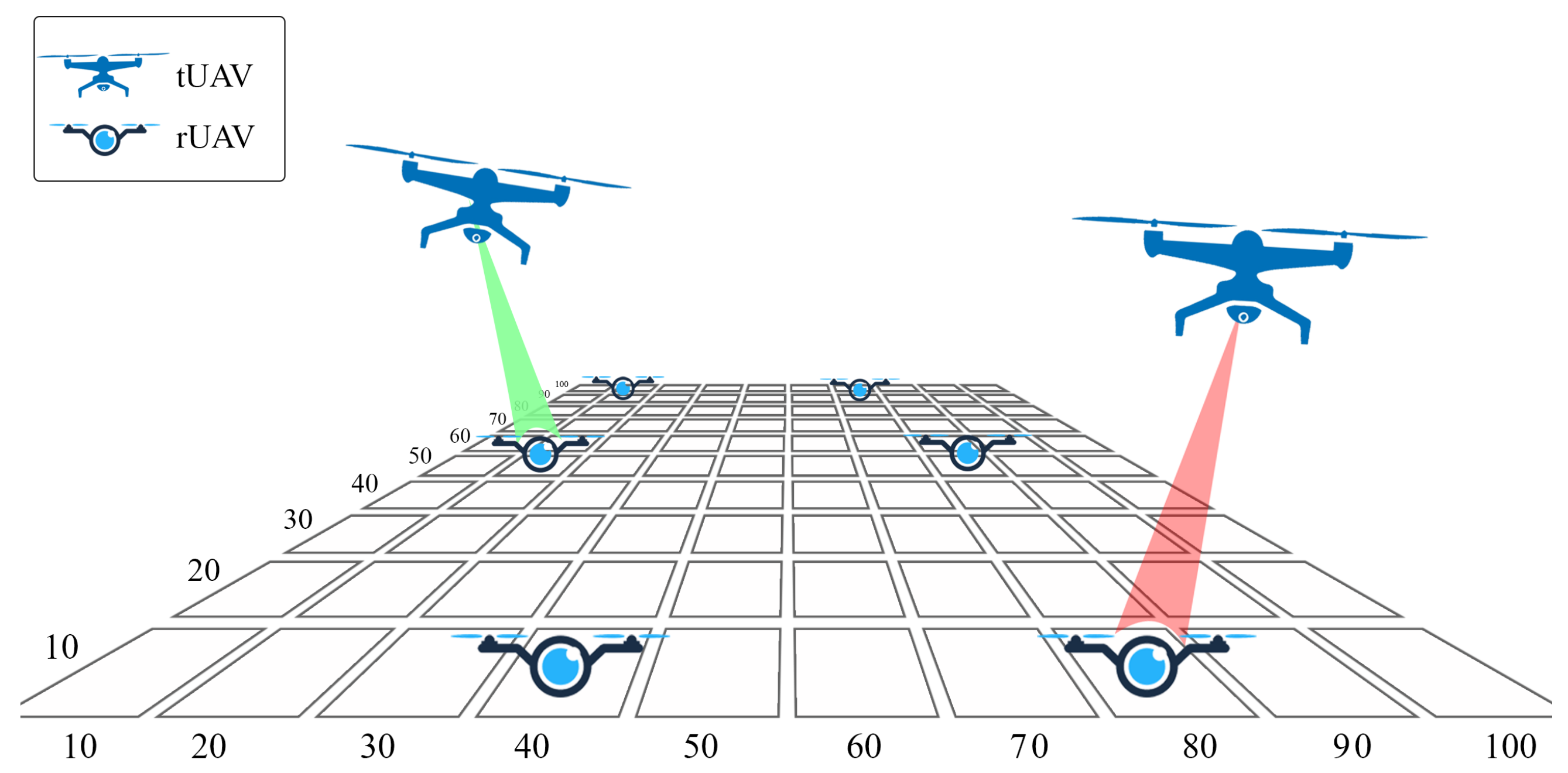
3.1. UAVs Recharging Architecture
3.2. Proposed Trajectory Selection Algorithm
- Agent (tUAV) observes the current state and takes actions. There are multiple agents in our scenario. To keep the model simple, we implemented multiple tUAV system as a single agent PPO with multiple actions.
- State (S) is defined based on the observed information of rUAVs and the current location of tUAV. Thus, we define the system state as where is the location of tUAVs, is a vector that denotes the locations of rUAV1 to rUAVz and is a vector that denotes their battery levels.
- Action (a) is defined as flying to hovering above certain rUAVs. Hence, the number of possible actions is equal to number of rUAVs. The PPO algorithm implements a function approximator that takes state S and returns the probabilities of taking each action in the action space.
- Revenue (R) is the combination of rewards and penalties after taking action a at state S and moving to state . It returns a reward for the energy that all rUAVs receive from tUAV and/or applies a penalty if an rUAV has to move to a terrestrial charging station due to low battery. R is formulated as:where are adjusting weights, is the total harvested power by rUAVs noted in (5), T is the time step and is the number of out of charge rUAVs which should be replaced and resulted in service interruption. represents the low battery thresholds of rUAVs and is defined aswhere is the battery capacity of rUAV. denotes the full battery if the battery is more than 97% charged. Finally, Q indicates the conflict between the tUAVs if their distance from each other is less than a threshold. This can force them to not charge the same rUAV in the same time and also avoid a crash. The second PPO function approximator is the critic that takes observation S and returns the expectation of the discounted long-term reward [46,47].
| Algorithm 1: tUAV Trajectory Algorithm. |
|
4. Performance Evaluation
4.1. Simulation Setup
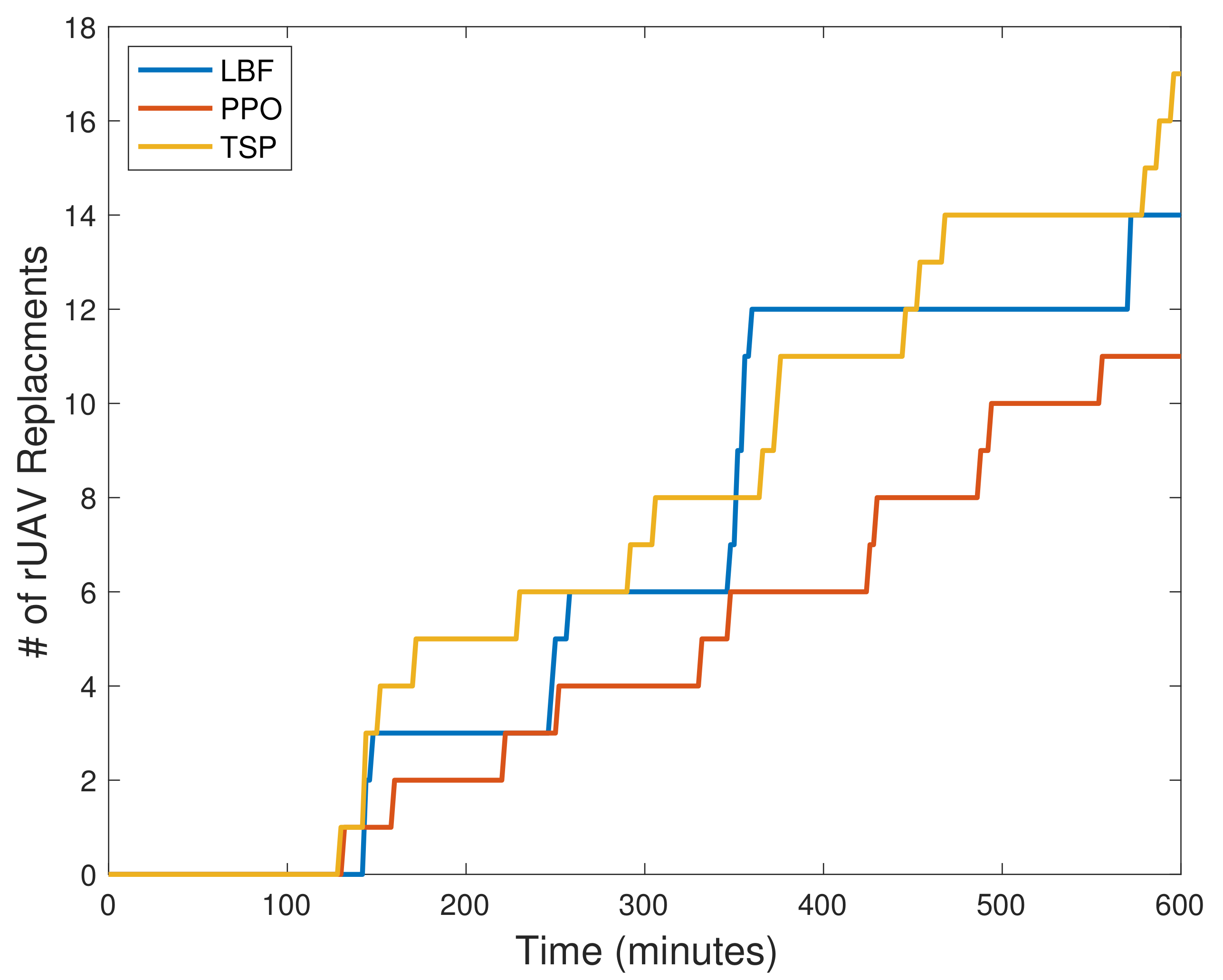
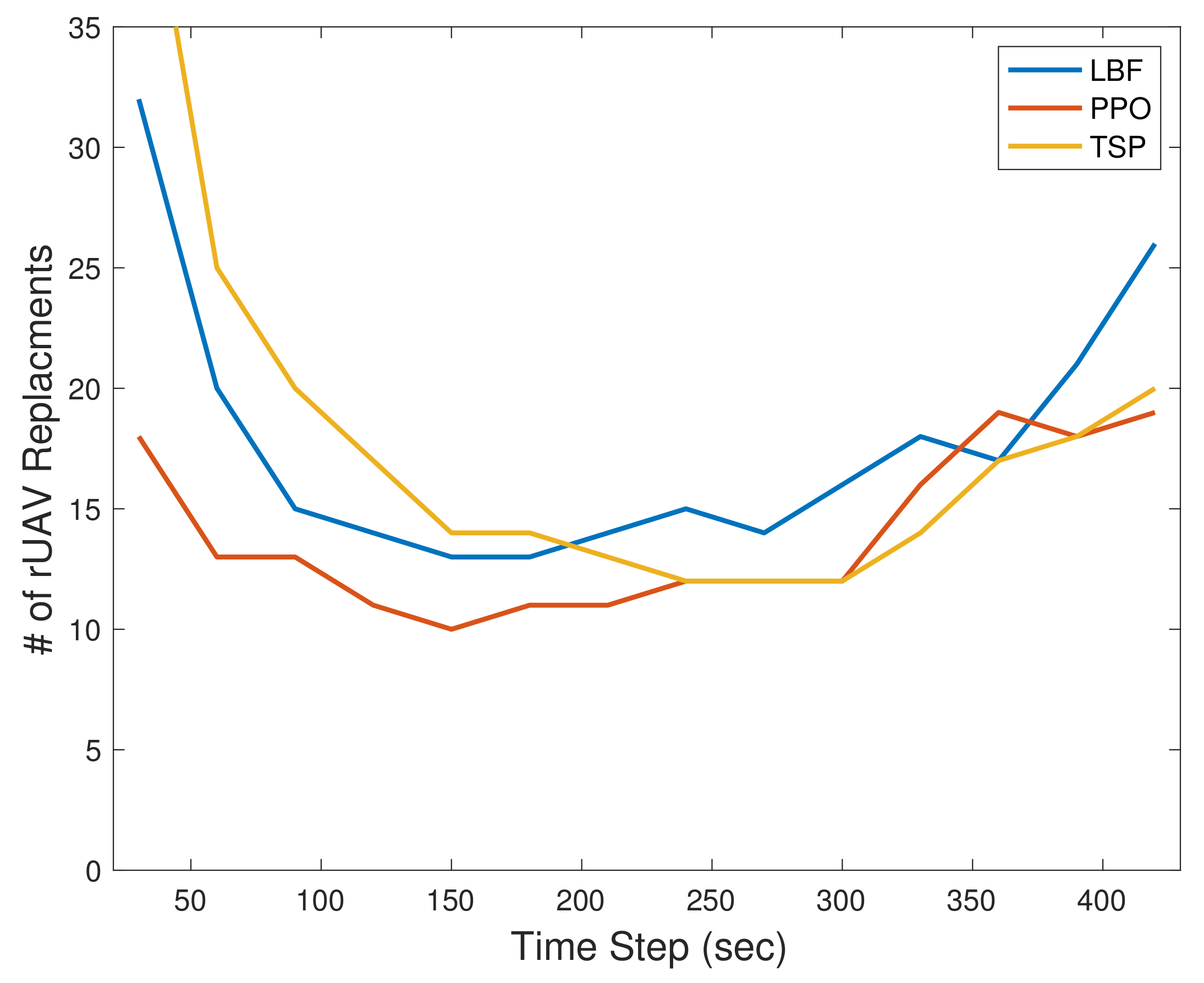
- Traveling Salesman Problem (TSP): Each tUAV recharges a group of three rUAVs periodically and in order. The groups and orders should be selected so that the traveling times of the tUAVs are minimized. We solve the TSP using an iterative approach to find the best two groups to be served by the two tUAVs.
- Lowest Battery First (LBF): The tUAVs target to serve the rUAVs with the minimum battery level at each time step.
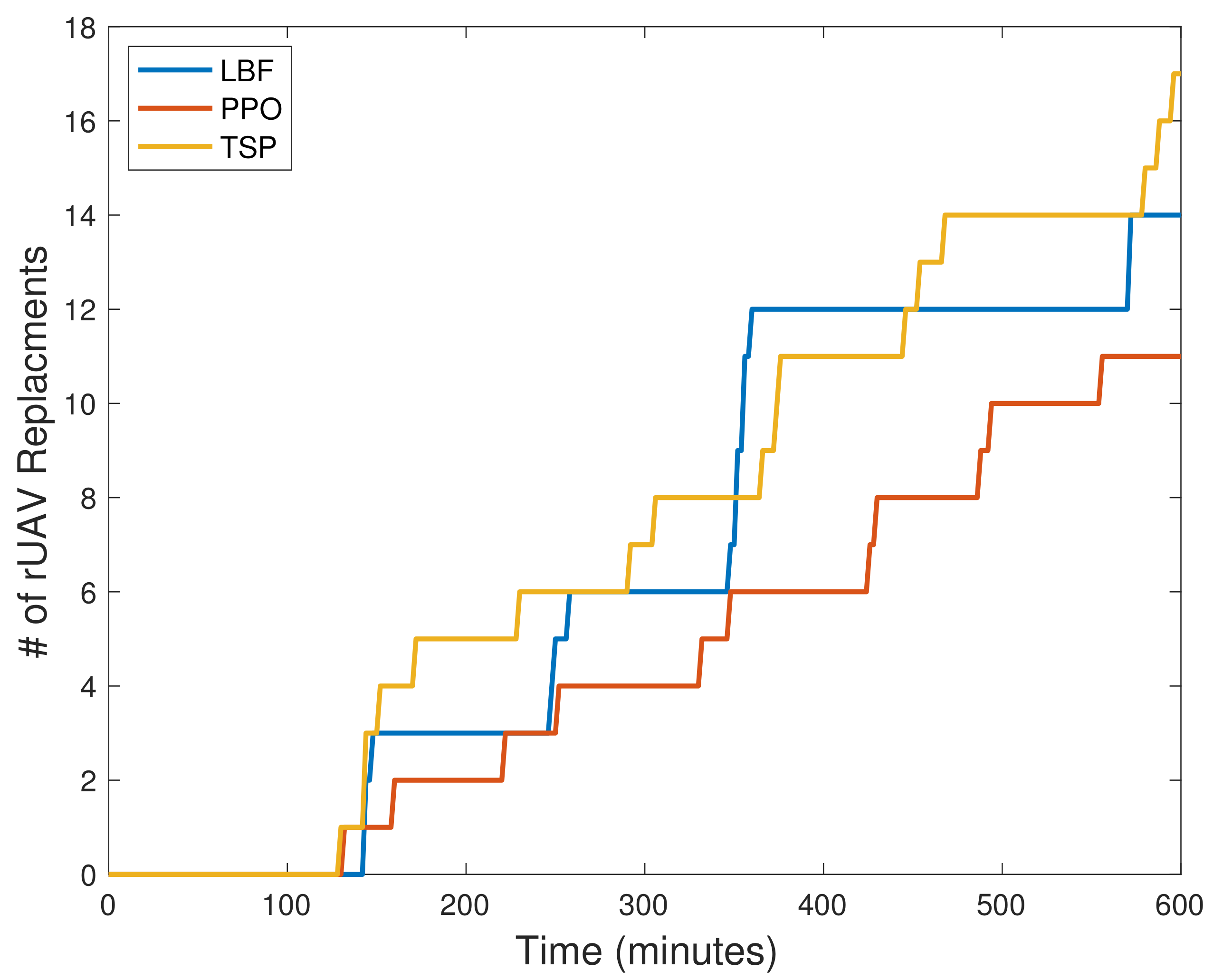
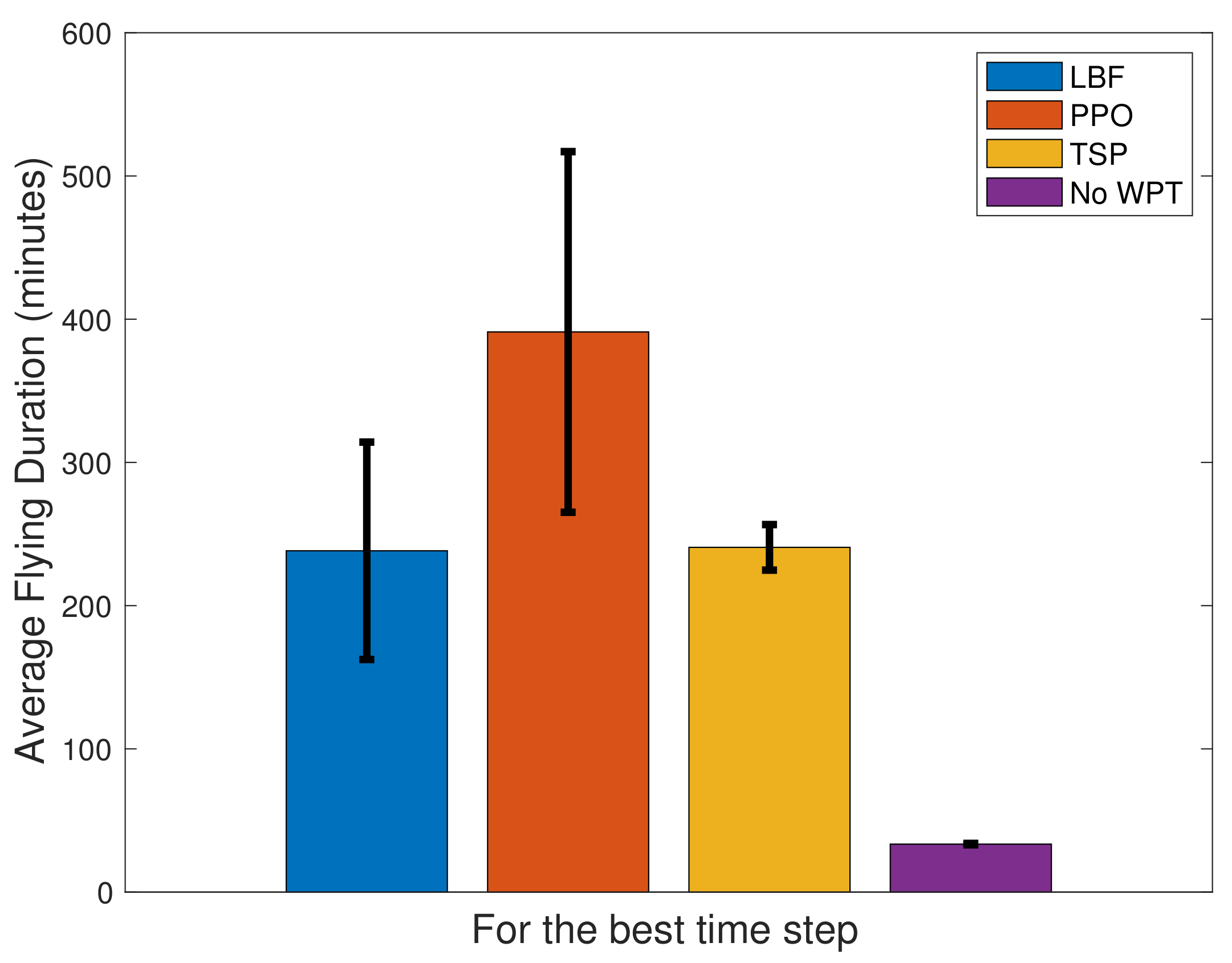
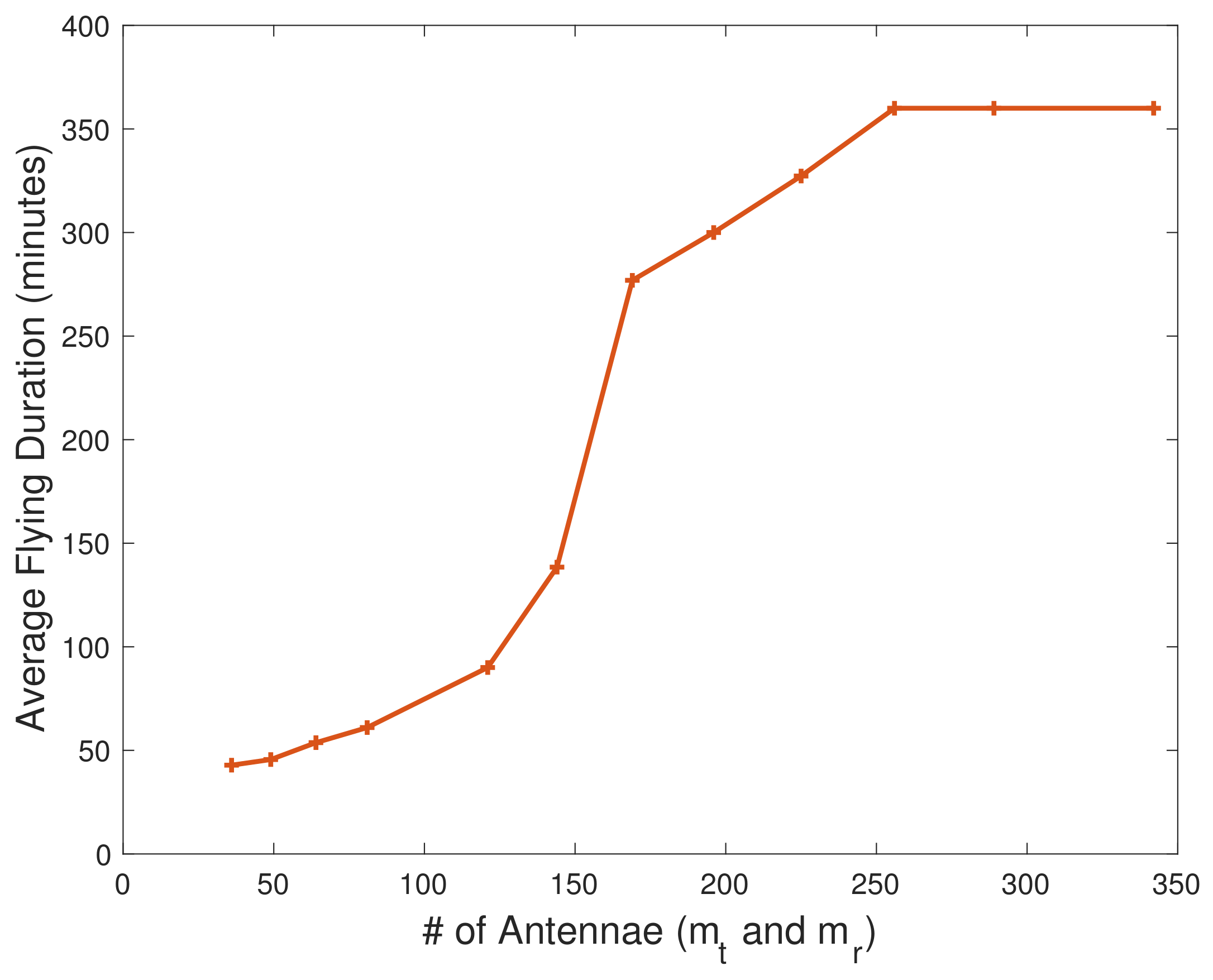
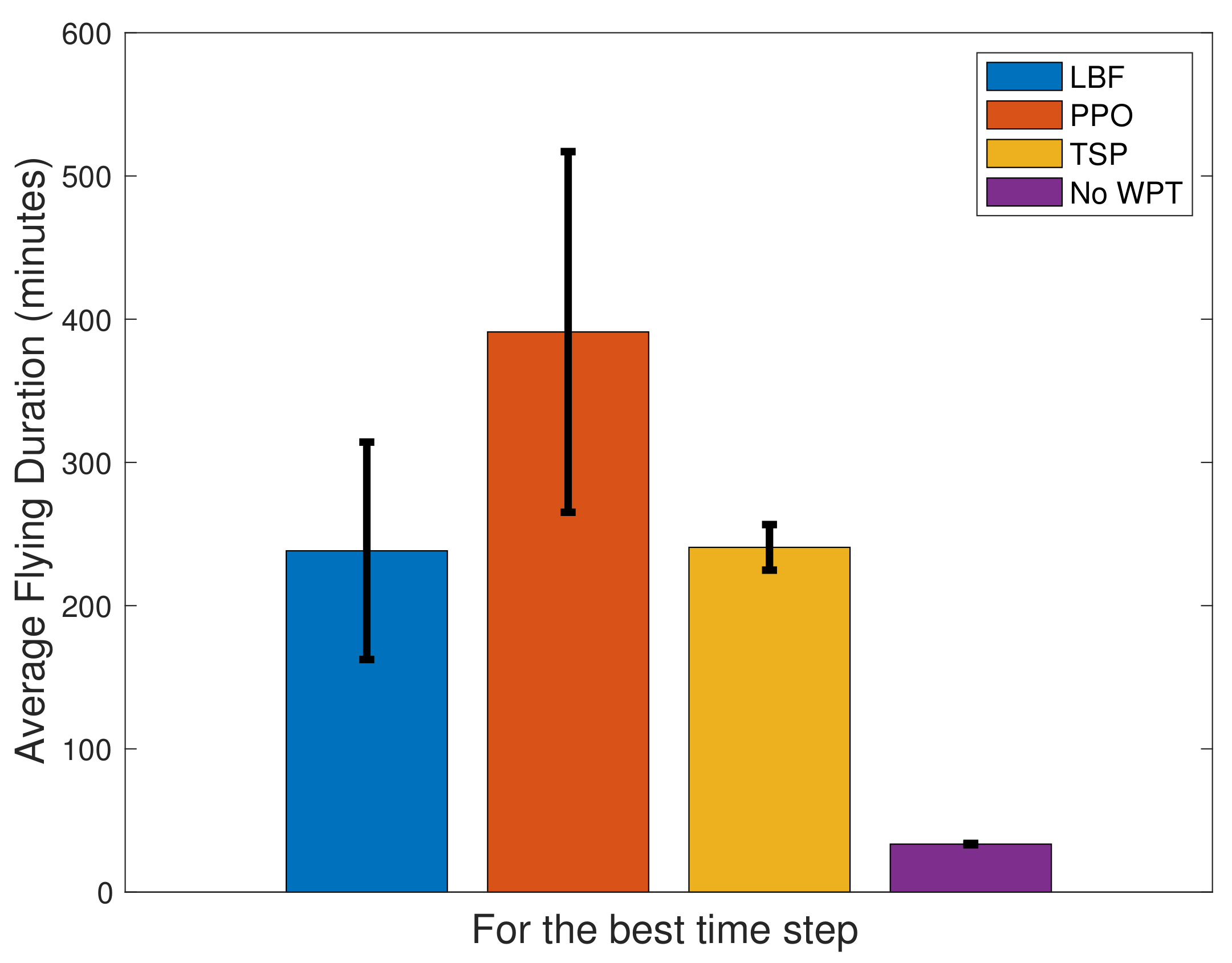
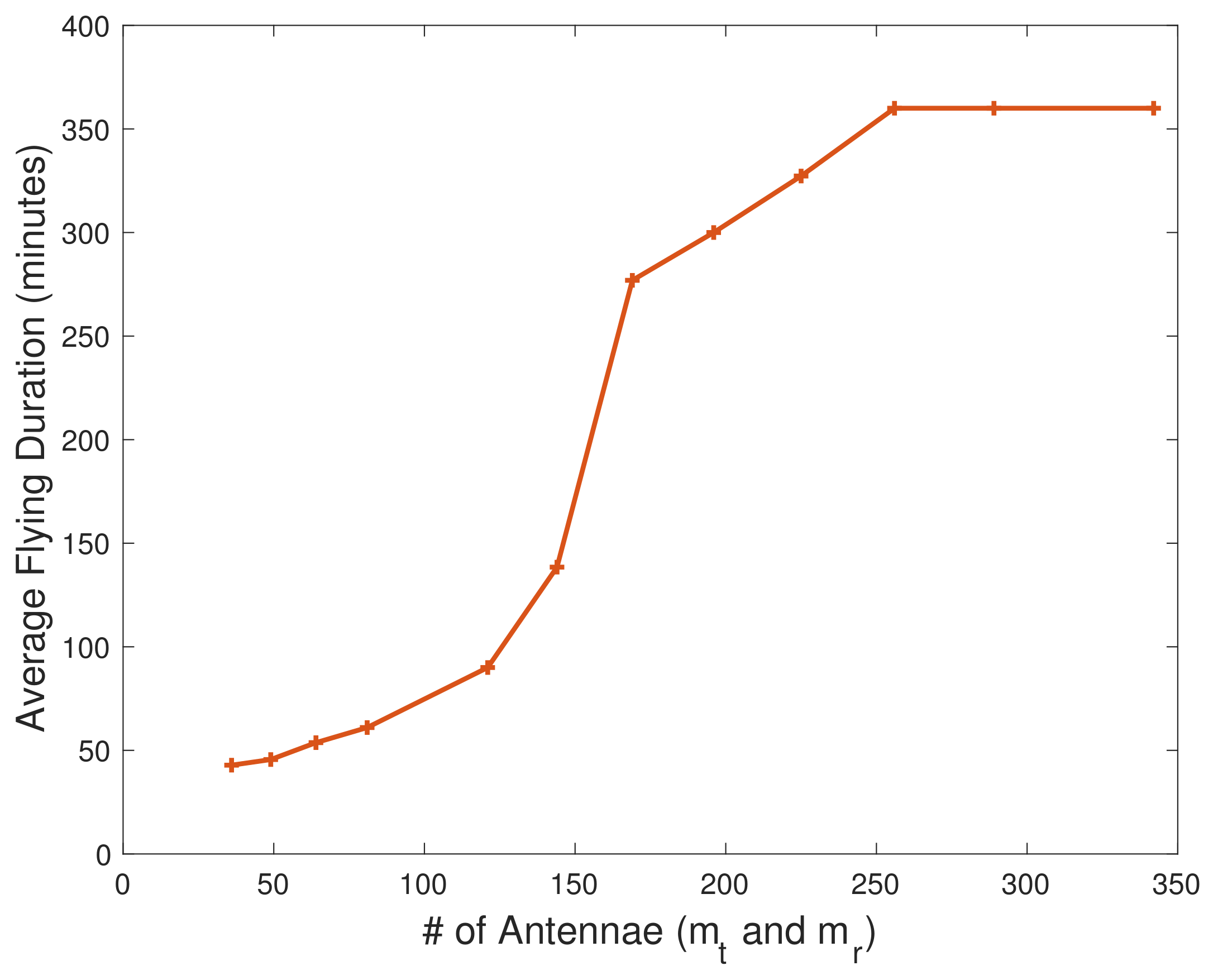
4.2. Results
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Silver, B.; Mazur, M.; Wisniewski, A.; Babicz, A. Welcome to the Era of Drone-Powered Solutions: A Valuable Source of New Revenue Streams for Telecoms Operators. 2017. Available online: https://www.pwc.com/gx/en/communications/pdf/communications-review-july-2017.pdf (accessed on 10 March 2020).
- Fotouhi, A.; Ding, M.; Hassan, M. Flying Drone Base Stations for Macro Hotspots. IEEE Access 2018, 6, 19530–19539. [Google Scholar] [CrossRef]
- Fotouhi, A.; Qiang, H.; Ding, M.; Hassan, M.; Giordano, L.G.; Garcia-Rodriguez, A.; Yuan, J. Survey on UAV Cellular Communications: Practical Aspects, Standardization Advancements, Regulation, and Security Challenges. IEEE Commun. Surv. Tutorials 2019, 21, 3417–3442. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Y.; Wu, Q.; Zhang, R. Accessing From the Sky: A Tutorial on UAV Communications for 5G and Beyond. Proceedings of the IEEE 2019, 107, 2327–2375. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Y.; Lyu, J.; Zhang, R. Cellular-Connected UAV: Potential, Challenges, and Promising Technologies. IEEE Wirel. Commun. 2019, 26, 120–127. [Google Scholar] [CrossRef]
- Li, B.; Fei, Z.; Zhang, Y. UAV Communications for 5G and Beyond: Recent Advances and Future Trends. IEEE Internet Things J. 2019, 6, 2241–2263. [Google Scholar] [CrossRef] [Green Version]
- Tran, D.H.; Vu, T.; Chatzinotas, S.; Shahbazpanahi, S.; Ottersten, B. Coarse Trajectory Design for Energy Minimization in UAV-Enabled Wireless Communications with Latency Constraints. IEEE Trans. Veh. Technol. 2020, 69, 9483–9496. [Google Scholar] [CrossRef]
- Salehi, S.; Bokani, A.; Hassan, J.; Kanhere, S.S. AETD: An Application Aware, Energy Efficient Trajectory Design for Flying Base Stations. In Proceedings of the 2019 IEEE 14th Malaysia International Conference on Communication (MICC), Selangor, Malaysia, 2–4 December 2019. [Google Scholar]
- Li, K.; Ni, W.; Wang, X.; Liu, R.P.; Kanhere, S.S.; Jha, S. Energy-efficient cooperative relaying for unmanned aerial vehicles. IEEE Trans. Mob. Comput. 2015, 15, 1377–1386. [Google Scholar] [CrossRef]
- Abdulla, A.E.; Fadlullah, Z.M.; Nishiyama, H.; Kato, N.; Ono, F.; Miura, R. An optimal data collection technique for improved utility in UAS-aided networks. In Proceedings of the IEEE INFOCOM 2014—IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 736–744. [Google Scholar]
- Zhan, C.; Zeng, Y.; Zhang, R. Energy-efficient data collection in UAV enabled wireless sensor network. IEEE Wirel. Commun. Lett. 2017, 7, 328–331. [Google Scholar] [CrossRef] [Green Version]
- Abdulla, A.E.; Fadlullah, Z.M.; Nishiyama, H.; Kato, N.; Ono, F.; Miura, R. Toward fair maximization of energy efficiency in multiple UAS-aided networks: A game-theoretic methodology. IEEE Trans. Wirel. Commun. 2014, 14, 305–316. [Google Scholar] [CrossRef]
- Morton, S.; D’Sa, R.; Papanikolopoulos, N. Solar powered UAV: Design and experiments. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 2460–2466. [Google Scholar] [CrossRef]
- Zeng, Y.; Clerckx, B.; Zhang, R. Communications and Signals Design for Wireless Power Transmission. IEEE Trans. Commun. 2017, 65, 2264–2290. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Zhou, Y.; Ning, Z.; Gharavi, H. Wireless Power Transfer and Energy Harvesting: Current Status and Future Prospects. IEEE Wirel. Commun. 2019, 26, 163–169. [Google Scholar] [CrossRef]
- Brown, W.C. Experiments involving a microwave beam to power and position a helicopter. IEEE Trans. Aerosp. Electron. Syst. 1969, 5, 692–702. [Google Scholar] [CrossRef]
- Shinohara, N. Beam control technologies with a high-efficiency phased array for microwave power transmission in Japan. Proc. IEEE 2013, 101, 1448–1463. [Google Scholar] [CrossRef] [Green Version]
- Strassner, B.; Chang, K. Microwave power transmission: Historical milestones and system components. Proc. IEEE 2013, 101, 1379–1396. [Google Scholar] [CrossRef]
- Jull, G.W.; Lillemark, A.; Turner, R. SHARP (stationary high altitude relay platform) telecommunications missions and systems. In Proceedings of the GLOBECOM’85-Global Telecommunications Conference, New Orleans, LA, USA, 2–5 December 1985; Volume 2, pp. 955–959. [Google Scholar]
- Hua, M.; Li, C.; Huang, Y.; Yang, L. Throughput Maximization for UAV-enabled Wireless Power Transfer in Relaying System. In Proceedings of the 2017 9th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 11–13 October 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Ansari, N.; Wu, D.; Sun, X. FSO as backhaul and energizer for drone-assisted mobile access networks. ICT Express 2020, 6, 139–144. [Google Scholar] [CrossRef]
- Nangia, R.K. ‘Greener’ civil aviation using air-to-air refuelling—Relating aircraft design efficiency and tanker offload efficiency. Aeronaut. J. (1968) 2007, 111, 589–592. [Google Scholar] [CrossRef]
- Federal Communications Commission. FCC-Use of Spectrum Bands Above 24 GHz For Mobile Radio Services. 2016. Available online: https://apps.fcc.gov/edocs_public/attachmatch/FCC-16-89A1.pdf (accessed on 7 July 2021).
- Hoseini, S.A.; Bokani, A.; Hassan, J.; Salehi, S.; Kanhere, S.S. Energy and Service-Priority aware Trajectory Design for UAV-BSs using Double Q-Learning. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Bushnaq, O.M.; Kishk, M.A.; Celik, A.; Alouini, M.S.; Al-Naffouri, T.Y. Optimal Deployment of Tethered Drones for Maximum Cellular Coverage in User Clusters. IEEE Trans. Wirel. Commun. 2021, 20, 2092–2108. [Google Scholar] [CrossRef]
- Lee, D.; Zhou, J.; Lin, W.T. Autonomous battery swapping system for quadcopter. In Proceedings of the 2015 International Conference on Unmanned Aircraft Systems (ICUAS), Denver, CO, USA, 9–12 June 2015; pp. 118–124. [Google Scholar] [CrossRef]
- Shukla, H. This Wireless Power Technology Could Change New Zealand’s Transmission System. 2020. Available online: https://mercomindia.com/this-wireless-new-zealand-transmission-system/ (accessed on 23 June 2021).
- Delbert, C. The Dawn of Wireless Electricity Is Finally Upon Us. Here’s How New Zealand Will Do It. 2021. Available online: https://www.popularmechanics.com/science/a33522699/wireless-electricity-new-zealand/ (accessed on 23 June 2021).
- Boyle, A. PowerLight Is Hitting Its Targets with a Power Beaming System That Uses Lasers. 2021. Available online: https://www.geekwire.com/2021/powerlight-hitting-targets-power-beaming-system-uses-laser-light/ (accessed on 23 June 2021).
- Bennett, T. TransGrid Deploys Drones to Perform Power Line Work. 2020. Available online: https://www.itnews.com.au/news/transgrid-deploys-drones-to-perform-power-line-work-559095 (accessed on 23 June 2021).
- Wing. Available online: https://wing.com/en_au/australia/canberra/ (accessed on 23 June 2021).
- Metz, C. Police Drones Are Starting to Think for Themselves. 2020. Available online: https://www.nytimes.com/2020/12/05/technology/police-drones.html (accessed on 23 June 2021).
- Banga, B. Global Autonomous Drone Wireless Charging and Infrastructure Market to Reach $249.3 Million by 2024. 2020. Available online: https://www.bloomberg.com/press-releases/2020-01-07/global-autonomous-drone-wireless-charging-and-infrastructure-market-to-reach-249-3-million-by-2024 (accessed on 23 June 2021).
- Hassan, J.; Bokani, A.; Kanhere, S.S. Recharging of Flying Base Stations using Airborne RF Energy Sources. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference Workshop (WCNCW), Marrakech, Morocco, 15–18 April 2019; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Hoseini, S.A.; Hassan, J.; Bokani, A.; Kanhere, S.S. Trajectory Optimization of Flying Energy Sources using Q-Learning to Recharge Hotspot UAVs. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 683–688. [Google Scholar] [CrossRef]
- Xu, J.; Bi, S.; Zhang, R. Multiuser MIMO Wireless Energy Transfer With Coexisting Opportunistic Communication. IEEE Wirel. Commun. Lett. 2015, 4, 273–276. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Zhang, R. A General Design Framework for MIMO Wireless Energy Transfer with Limited Feedback. IEEE Trans. Signal Process. 2016, 64, 2475–2488. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Liu, A.; Xu, K.; Xia, X. Energy and Information Beamforming in Airborne Massive MIMO System for Wireless Powered Communications. Sensors 2018, 18, 3540. [Google Scholar] [CrossRef] [Green Version]
- Tse, D.; Viswanath, P. Chapter 07: MIMO I: Spatial Multiplexing and Channel Modeling; Fundamentals of Wireless Communication; Cambridge University Press: Cambridge, UK, 2005; pp. 290–331. [Google Scholar]
- Hoseini, S.A.; Ding, M.; Hassan, M.; Chen, Y. Analyzing the Impact of Molecular Re-Radiation on the MIMO Capacity in High-Frequency Bands. IEEE Trans. Veh. Technol. 2020, 69, 15458–15471. [Google Scholar] [CrossRef]
- Hamdy, M.N. Beamformers Explained. 2020. Available online: https://www.commscope.com/globalassets/digizuite/542044-Beamformer-Explained-WP-114491-EN.pdf (accessed on 7 July 2021).
- Agrawal, T.; Srivastava, S. Two element MIMO antenna using Substrate Integrated Waveguide (SIW) horn. In Proceedings of the 2016 International Conference on Signal Processing and Communication (ICSC), Noida, India, 26–28 December 2016; pp. 508–511. [Google Scholar] [CrossRef]
- Aoki, T.; Yuan, Q.; Quang-Thang, D.; Okada, M.; Hsu, H.M. Maximum transfer efficiency of MIMO-WPT system. In Proceedings of the 2018 IEEE Wireless Power Transfer Conference (WPTC), Montreal, QC, Canada, 3–7 June 2018; pp. 1–3. [Google Scholar]
- Carvalho, A.; Carvalho, N.; Pinho, P.; Goncalves, R. Wireless power transmission and its applications for powering Drone. In Proceedings of the 8th Congress of the Portuguese Committee of URSI, Lisbon, Portugal, 28 November 2014. [Google Scholar]
- Brown, W.C. The history of wireless power transmission. Sol. Energy 1996, 56, 3–21. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- MathWorks. Proximal Policy Optimization Agents. Available online: https://www.mathworks.com/help/reinforcement-learning/ug/ppo-agents.html (accessed on 30 May 2021).
- Yan, C.; Xiang, X.; Wang, C. Towards Real-Time Path Planning through Deep Reinforcement Learning for a UAV in Dynamic Environments. J. Intell. Robot. Syst. 2019, 98, 297–309. [Google Scholar] [CrossRef]
- Yijing, Z.; Zheng, Z.; Xiaoyi, Z.; Yang, L. Q learning algorithm based UAV path learning and obstacle avoidence approach. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 3397–3402. [Google Scholar]
- Challita, U.; Saad, W.; Bettstetter, C. Deep reinforcement learning for interference-aware path planning of cellular-connected UAVs. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–7. [Google Scholar]
- Schulman, J.; Klimov, O.; Wolski, F.; Dhariwal, P.; Radford, A. Proximal Policy Optimization. 2017. Available online: https://openai.com/blog/openai-baselines-ppo/ (accessed on 15 August 2021).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulation Component | Value |
|---|---|
| Transmit power of each sub-band | 1 |
| Antenna element gain | 16 dBi |
| Number of antenna on tUAV | 256 |
| Number of antenna on rUAV | 256 |
| Number of sub-bands N | 200 |
| Sub-band’s width | 10 |
| Cell side | 10 m |
| Charging Wave Frequency range | 25–27 |
| Learning rate | 0.4 |
| Discount factor | 0.95 |
| rUAV power consumption | 50 ± 10 |
| rUAV battery capacity | 30 Watt-hour (108 ) |
| Time step | 30 or more s |
| Revenue adjusting weights () | 0.001, −10,000, −0.0001, −0.00003, −10,000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoseini, S.A.; Hassan, J.; Bokani, A.; Kanhere, S.S. In Situ MIMO-WPT Recharging of UAVs Using Intelligent Flying Energy Sources. Drones 2021, 5, 89. https://doi.org/10.3390/drones5030089
Hoseini SA, Hassan J, Bokani A, Kanhere SS. In Situ MIMO-WPT Recharging of UAVs Using Intelligent Flying Energy Sources. Drones. 2021; 5(3):89. https://doi.org/10.3390/drones5030089
Chicago/Turabian StyleHoseini, Sayed Amir, Jahan Hassan, Ayub Bokani, and Salil S. Kanhere. 2021. "In Situ MIMO-WPT Recharging of UAVs Using Intelligent Flying Energy Sources" Drones 5, no. 3: 89. https://doi.org/10.3390/drones5030089
APA StyleHoseini, S. A., Hassan, J., Bokani, A., & Kanhere, S. S. (2021). In Situ MIMO-WPT Recharging of UAVs Using Intelligent Flying Energy Sources. Drones, 5(3), 89. https://doi.org/10.3390/drones5030089