



Estimation of Fractal Dimension and Segmentation of Body Regions for Deep Learning-Based Gender Recognition


Abstract
1. Introduction
- -
- To address the lack of color and texture information in IR images used in low illumination environments, a rough body segmentation-based gender recognition network (RBSG-Net) is proposed. In this network, rough body shape information is emphasized through a semantic segmentation network, thereby enhancing gender recognition performance.
- -
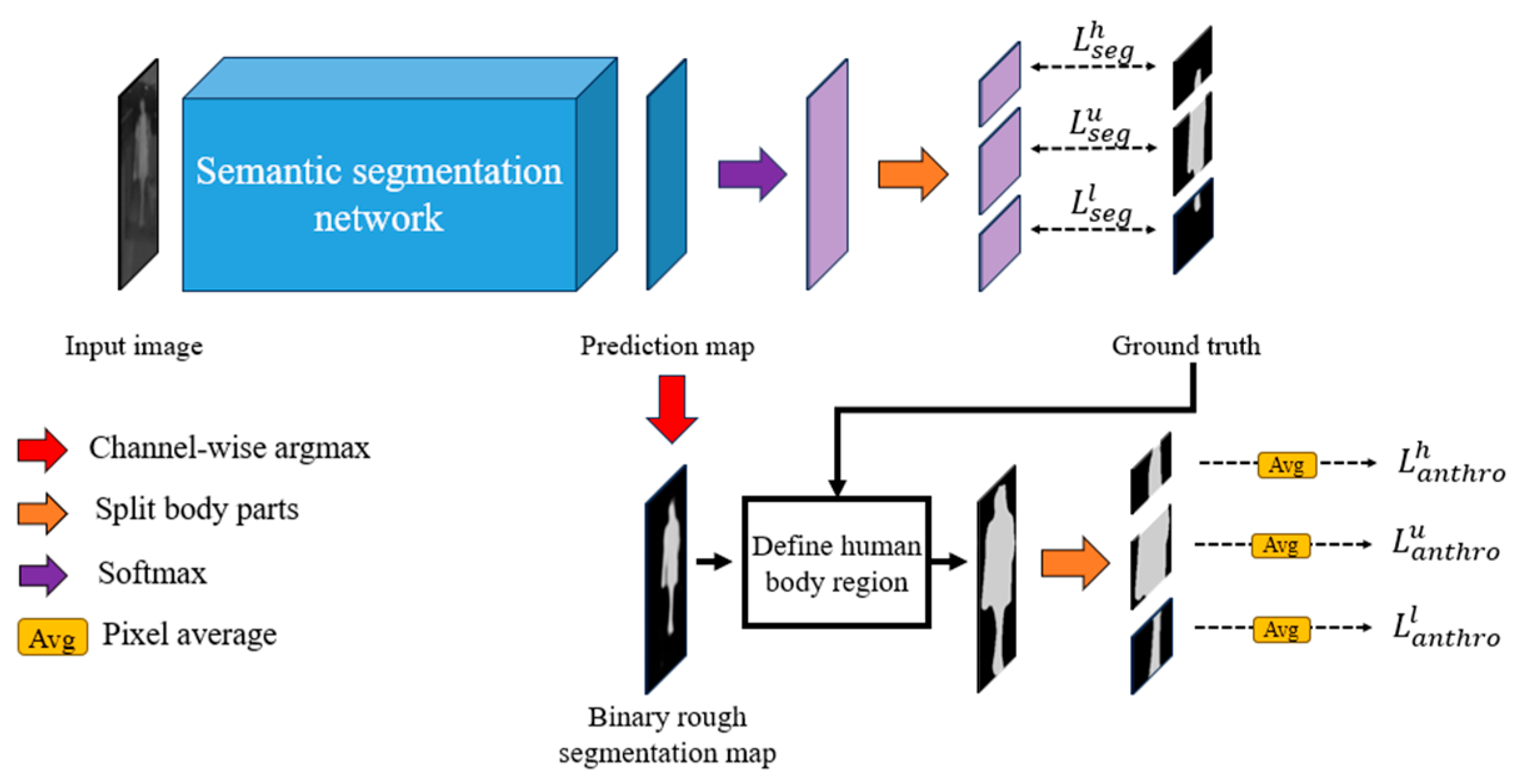
- To mitigate the degradation of body segmentation performance in IR images when the contrast between the human region and the background is low, a novel anthropometric loss based on human anthropometric information is implemented into the semantic segmentation network.
- -
- An adaptive body attention module (ABAM) is introduced, utilizing a binary rough segmentation map (BRSM) to identify the human body region in the image. The ABAM determines its attention based on anthropometric information to improve gender recognition performance by integrating segmentation and recognition tasks.
- -
- To analyze the segmentation correctness capability within the proposed framework, the fractal dimension estimation technique is introduced to gain insights into the complexity and irregularity of the body regions. Additionally, the RBSG-Net code is available on the GitHub website [8].
2. Related Work
2.1. Using Visible Light Images
2.2. Using Visible Light and IR Images
2.3. Using IR Images
2.3.1. Without Body Segmentation
2.3.2. With Body Segmentation
3. Proposed Methodology
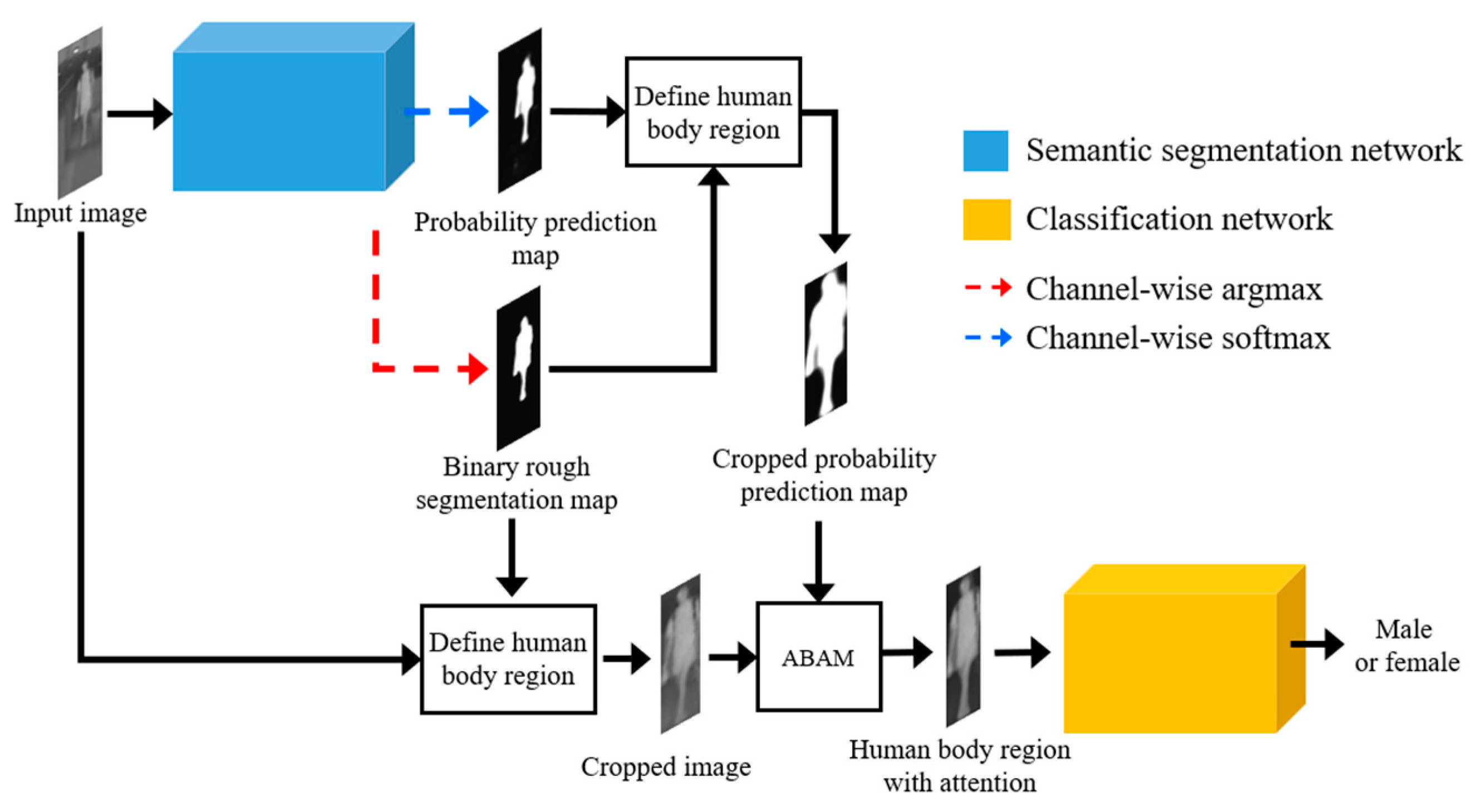
3.1. Overall Procedure of the Proposed Method
3.2. RBSG-Net
3.2.1. Semantic Segmentation Network
Model Overview
Loss Functions for Training the Semantic Segmentation Network
3.2.2. ABAM
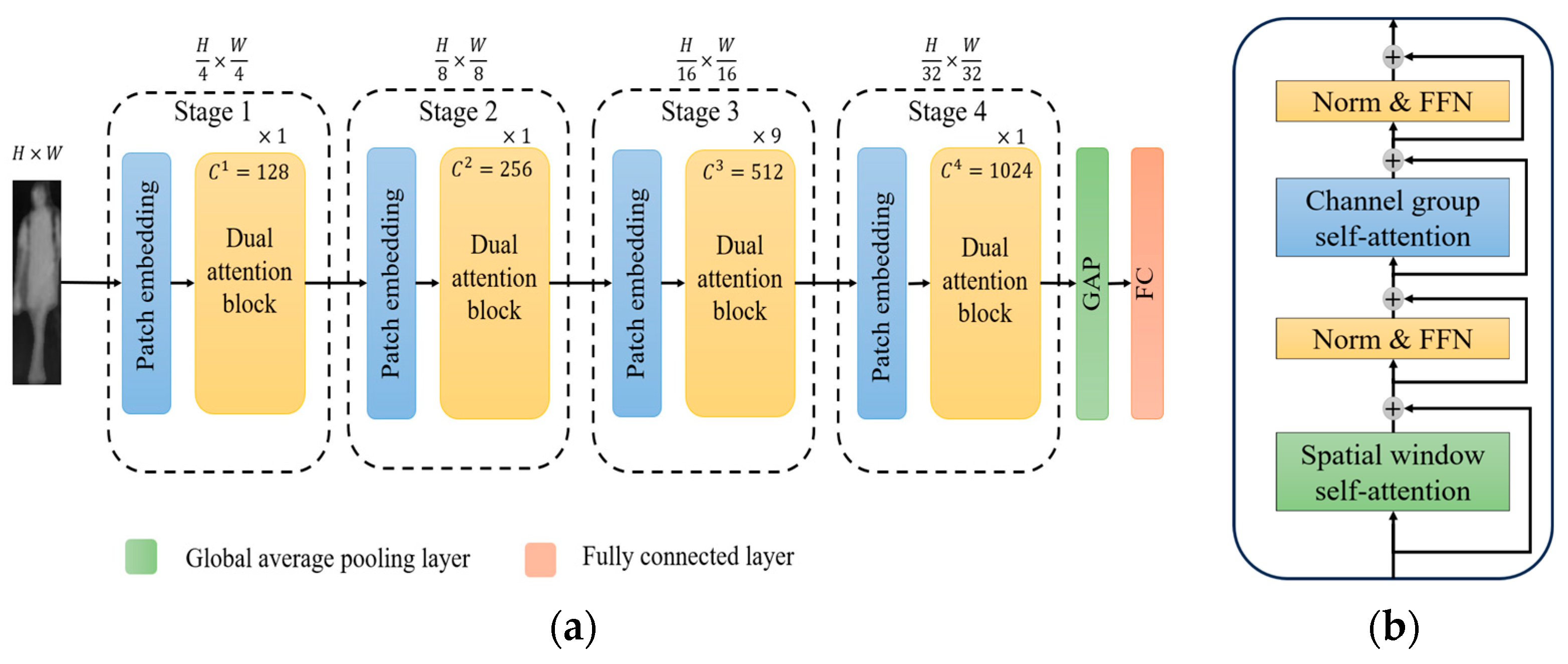
3.2.3. Gender Recognition Network
4. Experimental Results
4.1. Experimental Database and Environment
4.2. Training
4.3. Evaluation Metric and Fractal Dimension Estimation
| Algorithm 1: The Pseudocode for FD Estimation |
| Input: Img: input is the produced output by U-Net Output: FD 1: Determine the largest dimension of box size and adjust it to the nearest power of 2 Max_dim = max(size(Img)) ϵ = 2^[log2(Max_dim)] 2: If the size is smaller than ϵ, pad the image to match the dimension of ϵ if size(Img) < size(ϵ) pad_width = ((0, ϵ - Img.shape [0]), (0, ϵ - Img.shape[1])) padded_Img = pad(Img, pad_width, mode=‘constant’, constant_values=0) else padded_Img = Img 3: Initialize an array storing the number of boxes for each dimension size n = zeros(1, ϵ +1) 4: Compute the number of boxes, ‘N(ϵ)’ containing at least one pixel of body region n[ϵ + 1] = sum(I[:]) 5: While ϵ > 1: a. Diminish the size of ϵ: ϵ = ϵ /2 b. Update the number of ‘N(ϵ)’ 6: Compute log(N(ϵ)) and log(ϵ) for each ‘ϵ’ 7: Fit line to [(log(ϵ), log(N(ϵ)] using the least squares method 8: Fractal dimension is determined by the slope of the fitted line Return FD |
4.4. Testing the Proposed Method with the SYSU-MM01 NIR Dataset
4.4.1. Ablation Studies
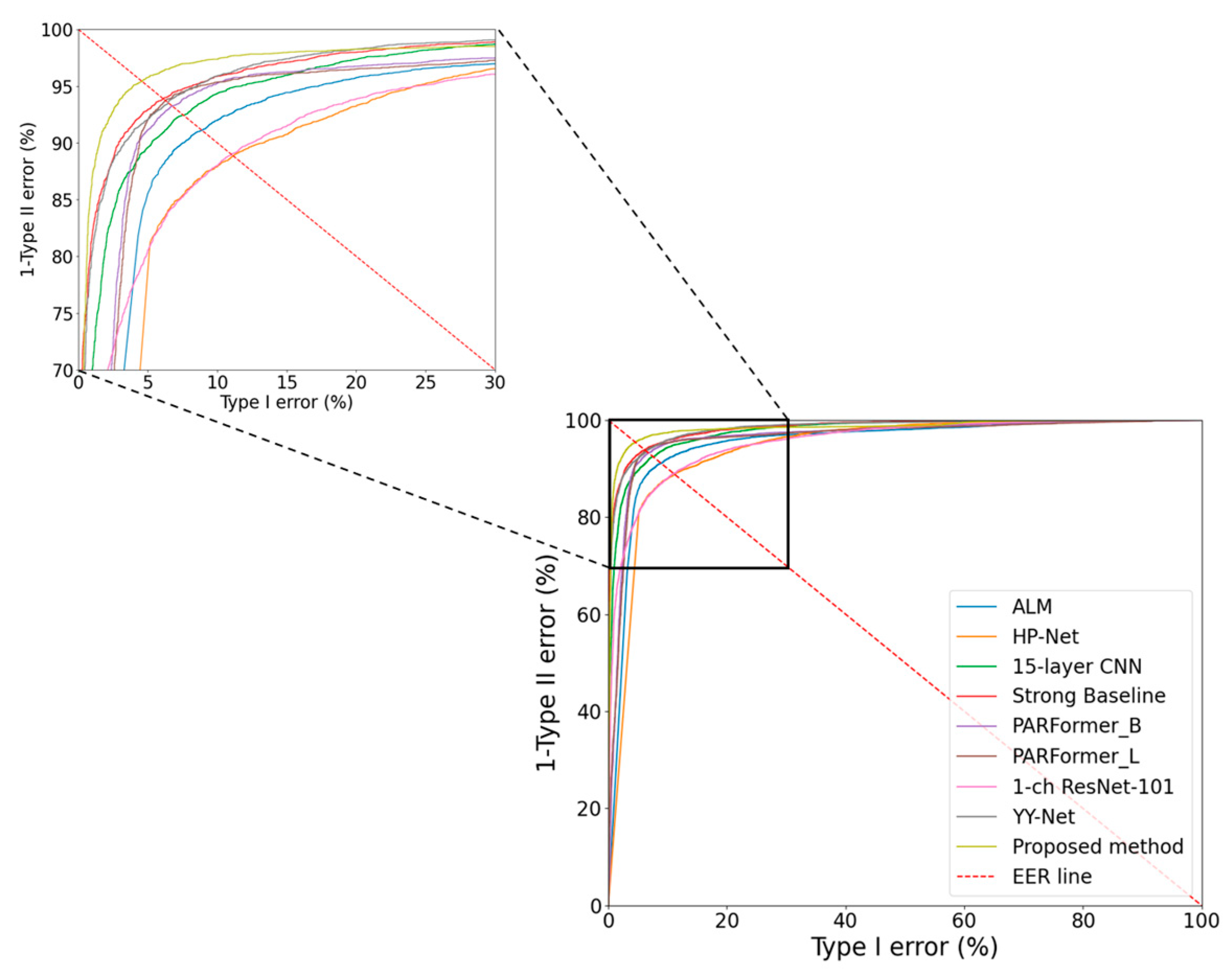
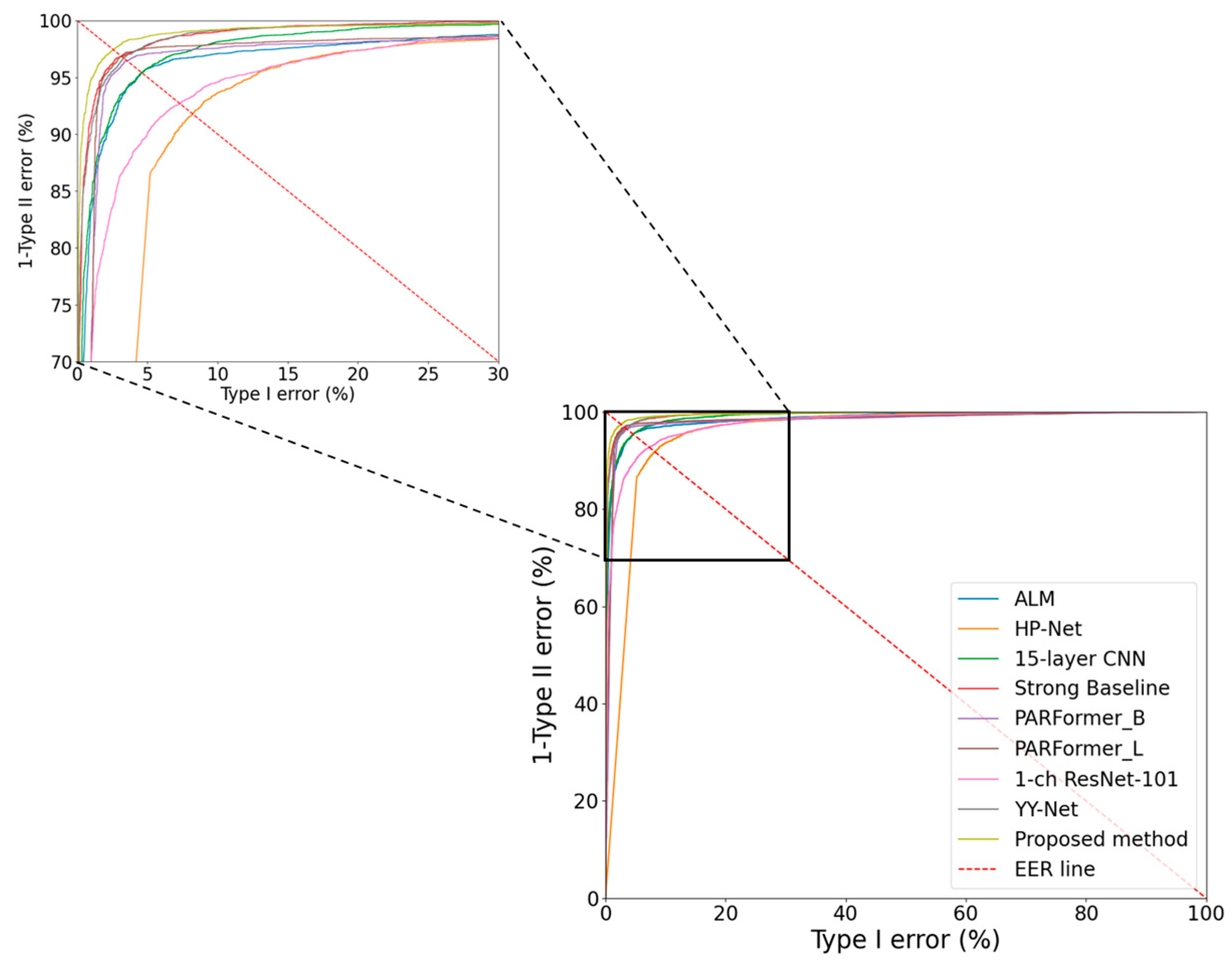
4.4.2. Comparisons of Gender Recognition Accuracy with SOTA Methods
4.4.3. Comparisons of Gender Recognition Accuracy with SOTA Methods: 5-Fold Cross-Validation
4.5. Testing of Proposed Method with DBGender-DB2 Dataset
4.5.1. Ablation Study: Comparative Analysis of RBSG-Net with Various Networks
4.5.2. Comparisons of Gender Recognition Accuracy with SOTA Methods
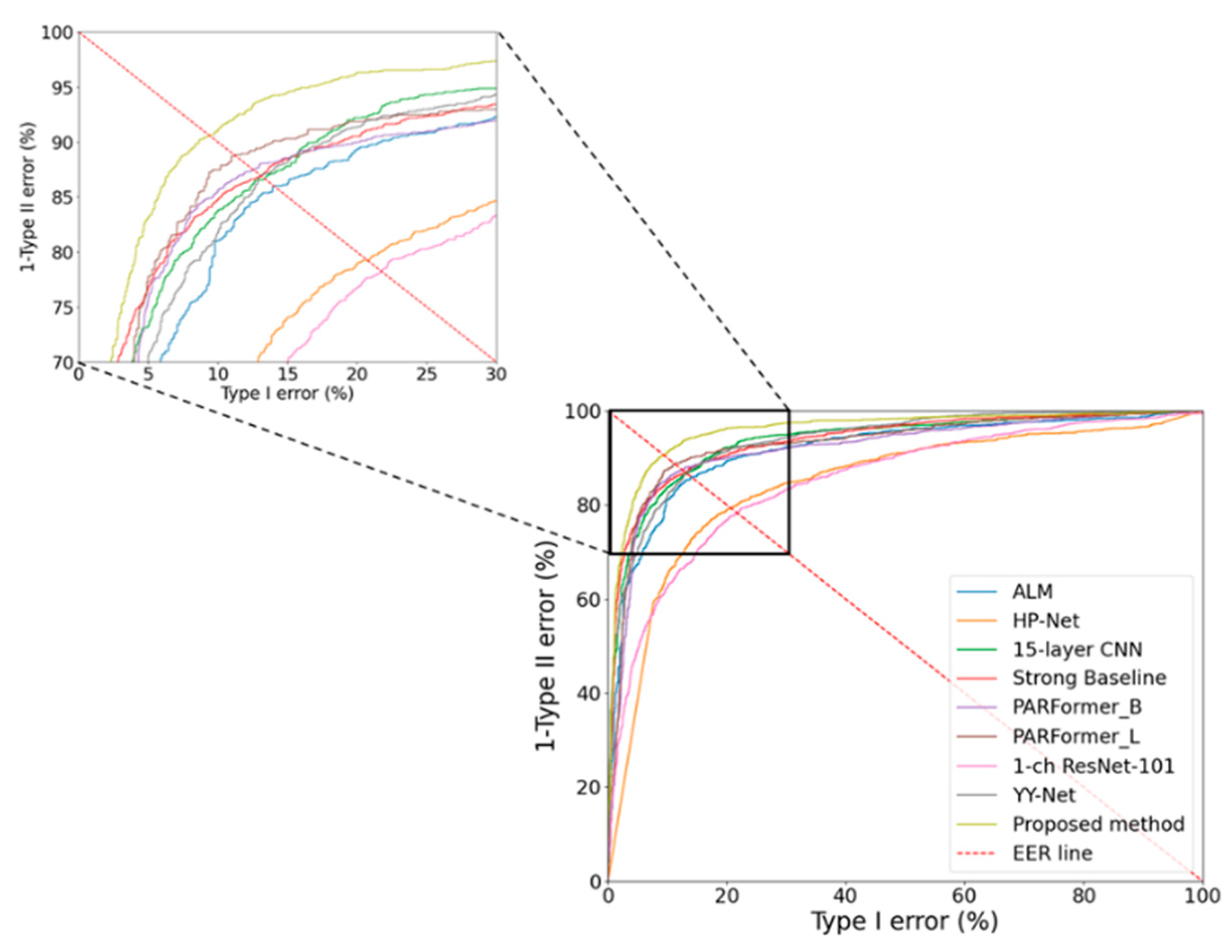
4.6. Comparison of Gender Recognition Accuracy across Heterogeneous Datasets with SOTA Methods
4.7. Testing of Proposed Method with Visible Light Images
4.7.1. Visible Light Datasets and Evaluation Metrics
4.7.2. Comparisons of Gender Recognition Accuracy with SOTA Methods
5. Discussion
5.1. Comparisons of Algorithm Computational Complexity
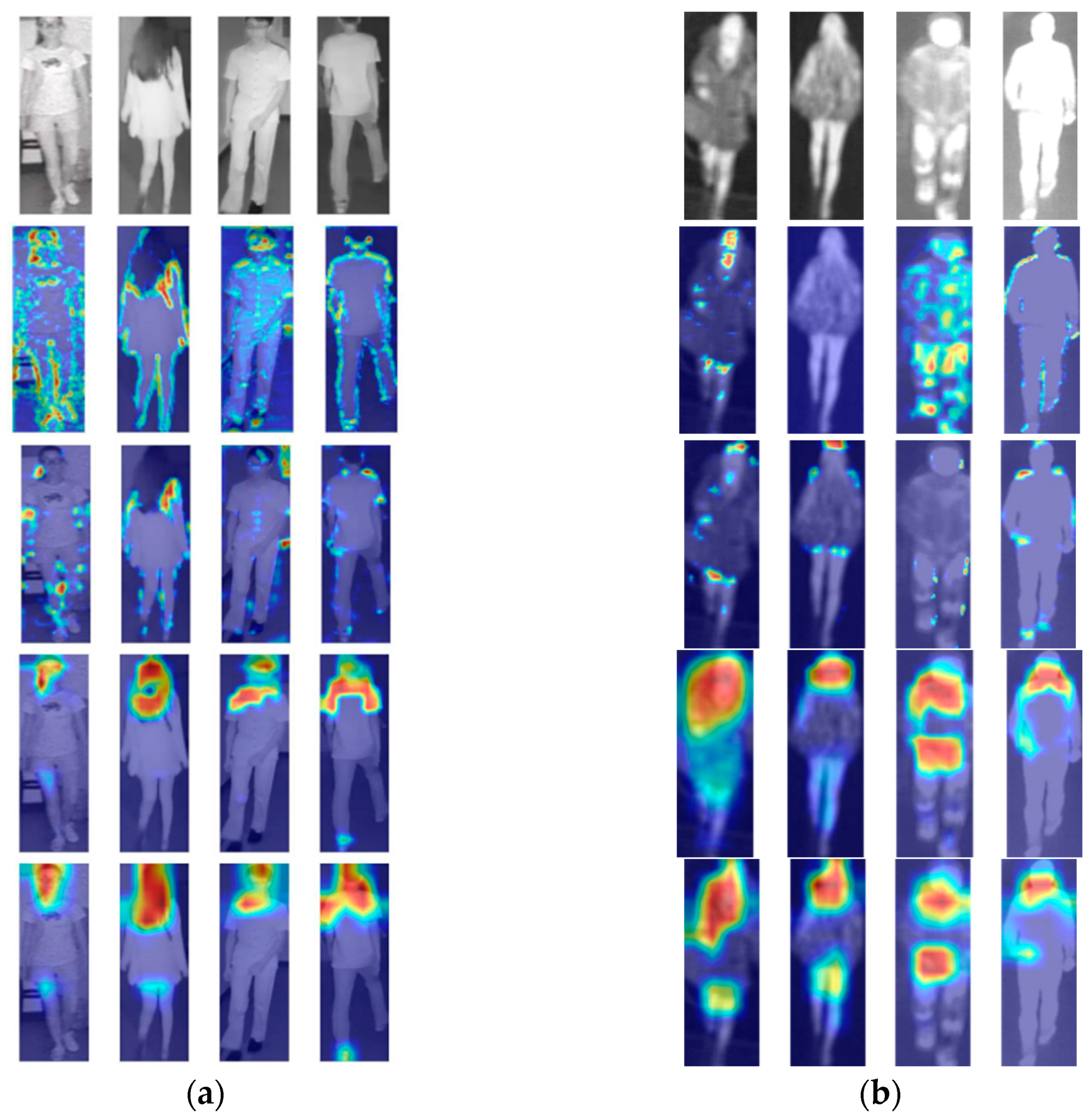
5.2. Analysis with Grad-CAM
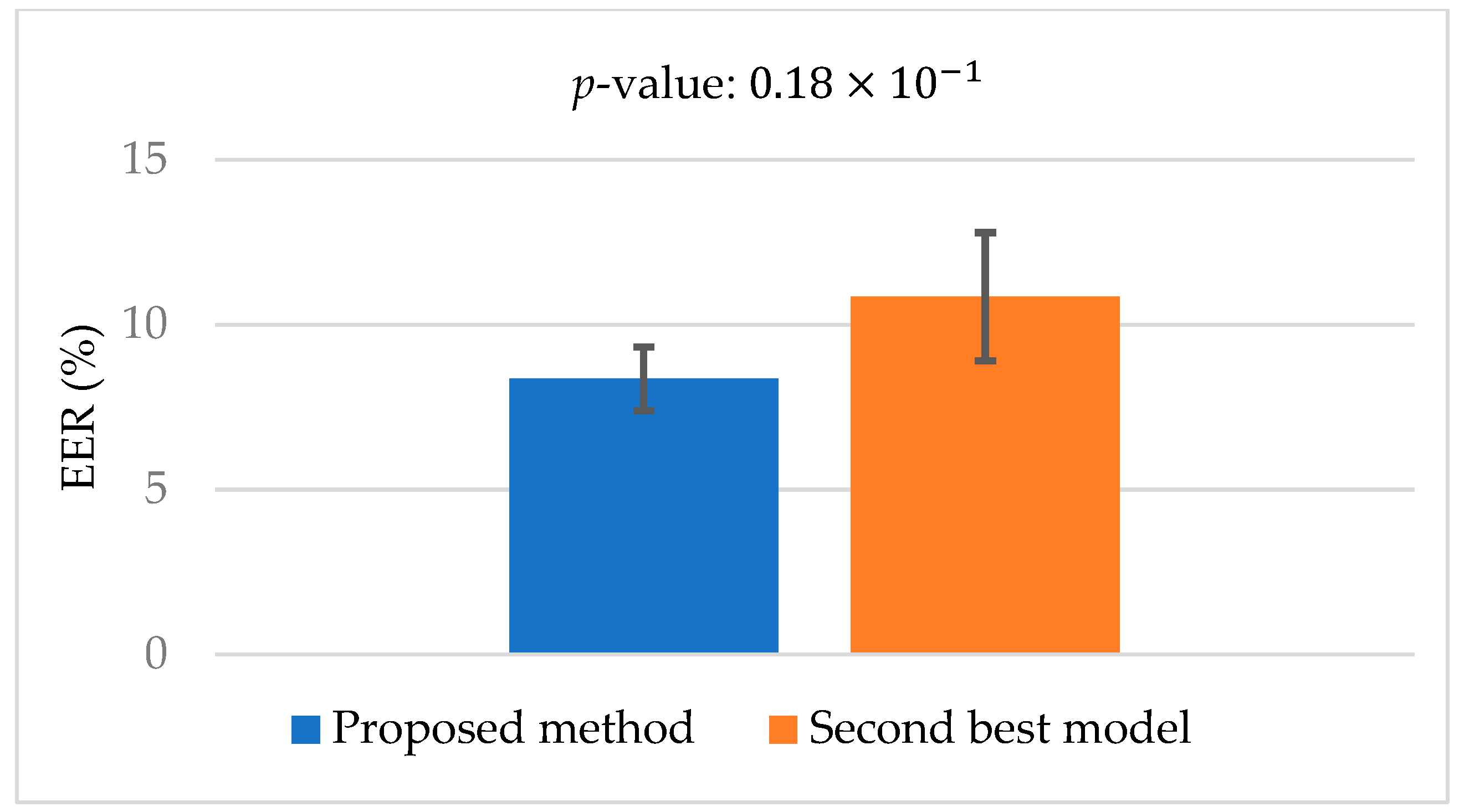
5.3. Statistical Analysis
5.4. Analysis about Correct and Incorrect Cases
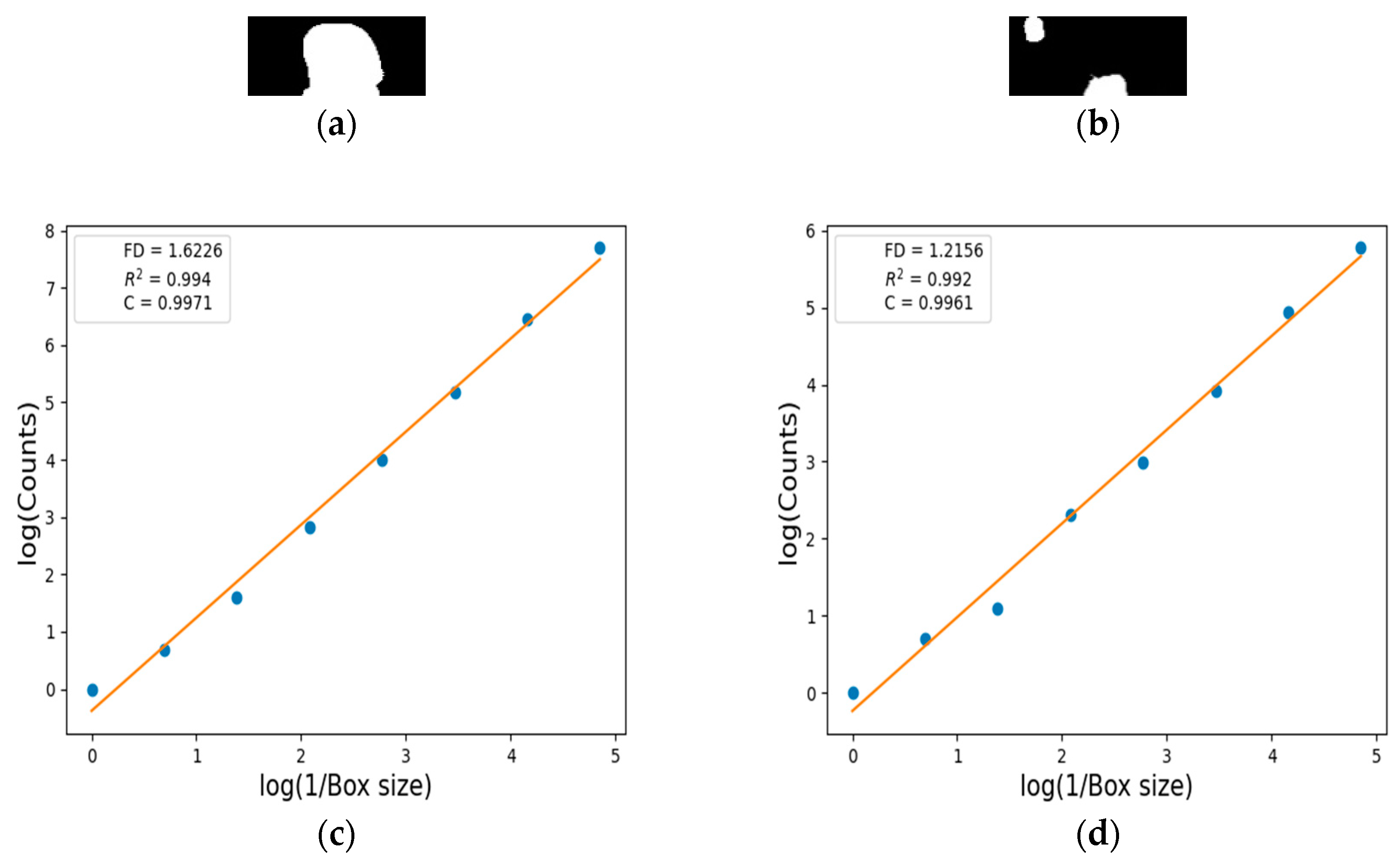
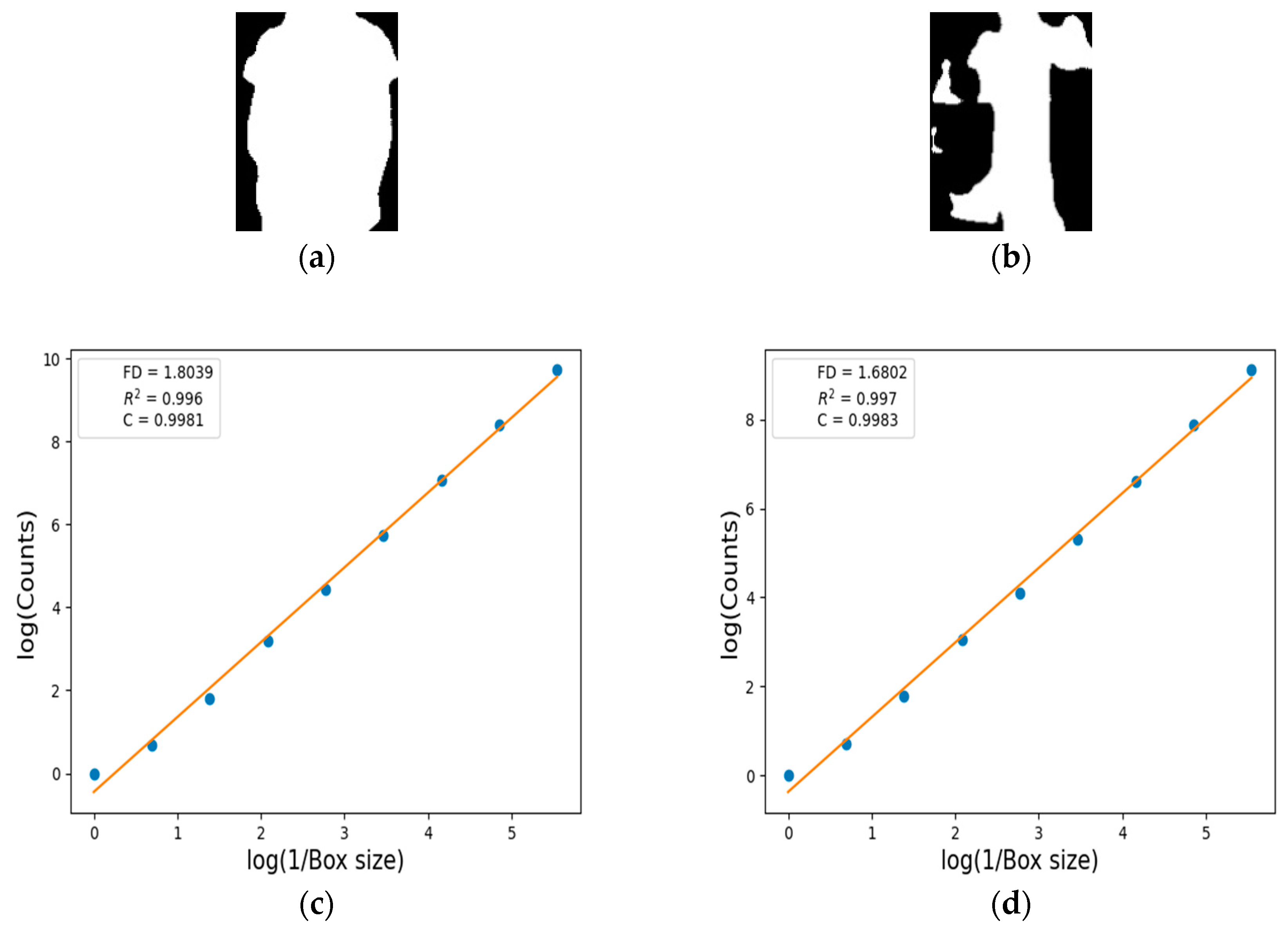
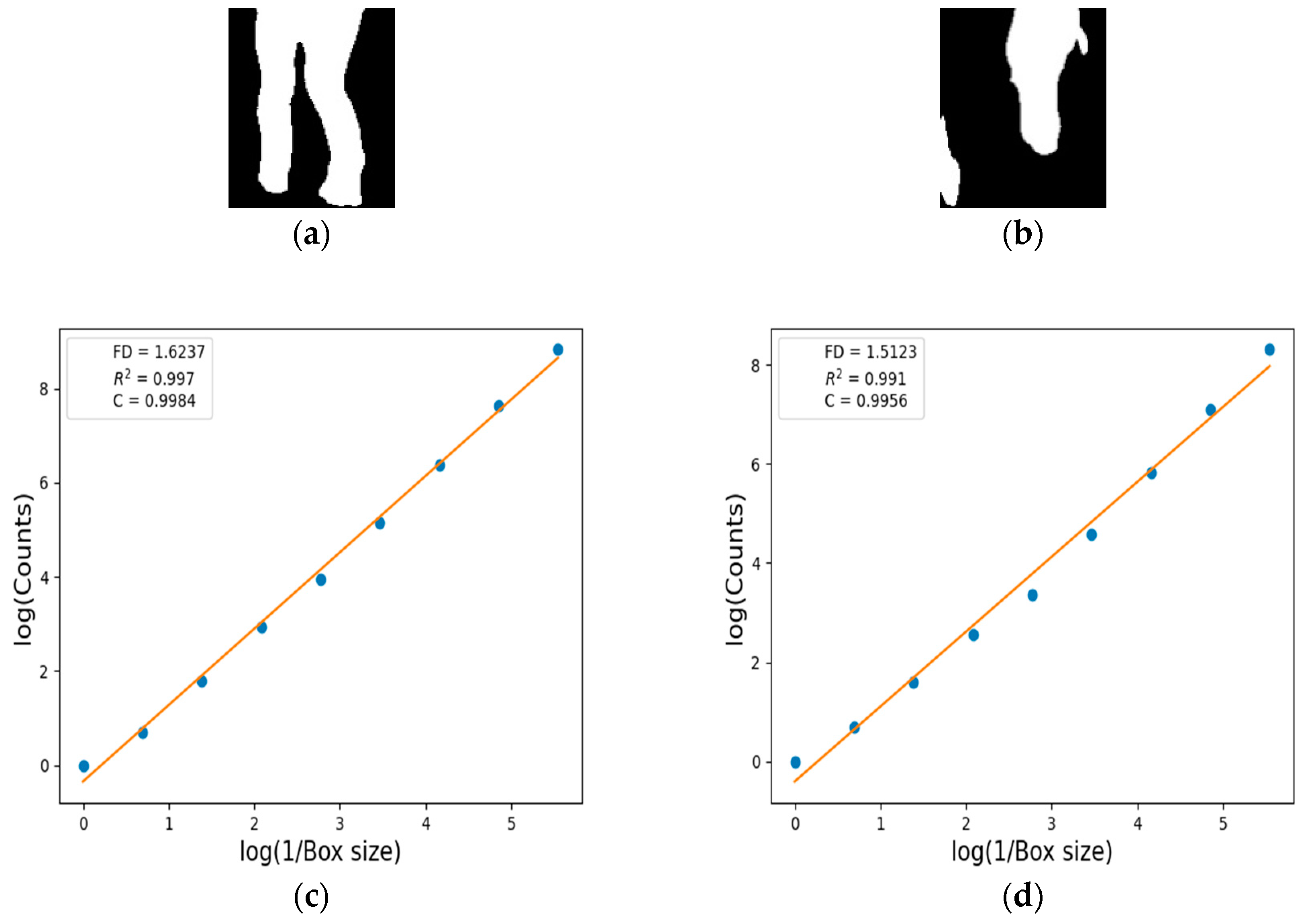
5.5. FD Estimation for Human Body Segmentation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jiao, Q.; Liu, M.; Ning, B.; Zhao, F.; Dong, L.; Kong, L.; Hui, M.; Zhao, Y. Image Dehazing Based on Local and Non-Local Features. Fractal Fract. 2022, 6, 262. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, L.; Li, Y. A Novel Adaptive Fractional Differential Active Contour Image Segmentation Method. Fractal Fract. 2022, 6, 579. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, T.; Yang, F.; Yang, Q. A Study of Adaptive Fractional-Order Total Variational Medical Image Denoising. Fractal Fract. 2022, 6, 508. [Google Scholar] [CrossRef]
- Zhang, X.; Dai, L. Image Enhancement Based on Rough Set and Fractional Order Differentiator. Fractal Fract. 2022, 6, 214. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, R.; Ren, J.; Gui, Q. Adaptive Fractional Image Enhancement Algorithm Based on Rough Set and Particle Swarm Optimization. Fractal Fract. 2022, 6, 100. [Google Scholar] [CrossRef]
- Bai, X.; Zhang, D.; Shi, S.; Yao, W.; Guo, Z.; Sun, J. A Fractional-Order Telegraph Diffusion Model for Restoring Texture Images with Multiplicative Noise. Fractal Fract. 2023, 7, 64. [Google Scholar] [CrossRef]
- Ng, C.B.; Tay, Y.H.; Goi, B.M. Vision-based human gender recognition: A survey. arXiv 2012, arXiv:1204.1611. [Google Scholar] [CrossRef]
- RBSG-Net. Available online: https://github.com/DongChan2/RBSG-Net.git (accessed on 14 February 2024).
- Deng, Y.; Luo, P.; Loy, C.C.; Tang, X. Pedestrian attribute recognition at far distance. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 789–792. [Google Scholar] [CrossRef]
- Li, D.; Zhang, Z.; Chen, X.; Ling, H.; Huang, K. A richly annotated dataset for pedestrian attribute recognition. arXiv 2016, arXiv:1603.07054. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, H.; Tian, M.; Sheng, L.; Shao, J.; Yi, S.; Yan, J.; Wang, X. HydraPlus-Net: Attentive deep features for pedestrian analysis. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 350–359. [Google Scholar] [CrossRef]
- Ng, C.-B.; Tay, Y.-H.; Goi, B.-M. A convolutional neural network for pedestrian gender recognition. In Advances in Neural Networks—ISNN 2013, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7951, pp. 558–564. [Google Scholar] [CrossRef]
- Antipov, G.; Berrani, S.-A.; Ruchaud, N.; Dugelay, J.-L. Learned vs. handcrafted features for pedestrian gender recognition. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, QLD, Australia, 26–30 October 2015; pp. 1263–1266. [Google Scholar] [CrossRef]
- Cai, L.; Zhu, J.; Zeng, H.; Chen, J.; Cai, C.; Ma, K.-K. HOG-assisted deep feature learning for pedestrian gender recognition. J. Frankl. Inst. 2018, 355, 1991–2008. [Google Scholar] [CrossRef]
- Raza, M.; Zonghai, C.; Rehman, S.U.; Zhenhua, G.; Jikai, W.; Peng, B. Part-wise pedestrian gender recognition via deep convolutional neural networks. In Proceedings of the 2nd IET International Conference on Biomedical Image and Signal Processing (ICBISP), Wuhan, China, 13–14 May 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Luo, P.; Wang, X.; Tang, X. Pedestrian parsing via deep decompositional network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, NSW, Australia, 3–6 December 2013; pp. 2648–2655. [Google Scholar] [CrossRef]
- Ng, C.B.; Tay, Y.-H.; Goi, B.-M. Pedestrian gender classification using combined global and local parts-based convolutional neural networks. Pattern Anal. Appl. 2018, 22, 1469–1480. [Google Scholar] [CrossRef]
- Raza, M.; Sharif, M.; Yasmin, M.; Khan, M.A.; Saba, T.; Fernandes, S.L. Appearance based pedestrians’ gender recognition by employing stacked auto encoders in deep learning. Future Gener. Comput. Syst. 2018, 88, 28–39. [Google Scholar] [CrossRef]
- Tang, C.; Sheng, L.; Zhang, Z.; Hu, X. Improving pedestrian attribute recognition with weakly-supervised multi-scale attribute-specific localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4997–5006. [Google Scholar] [CrossRef]
- Jia, J.; Huang, H.; Yang, W.; Chen, X.; Huang, K. Rethinking of pedestrian attribute recognition: Realistic datasets with efficient method. arXiv 2020, arXiv:2005.11909. [Google Scholar] [CrossRef]
- Roxo, T.; Proença, H. YinYang-Net: Complementing face and body information for wild gender recognition. IEEE Access 2022, 10, 28122–28132. [Google Scholar] [CrossRef]
- Fang, H.-S.; Li, J.; Tang, H.; Xu, C.; Zhu, H.; Xiu, Y.; Li, Y.-L.; Lu, C. AlphaPose: Whole-body regional multi-person pose estimation and tracking in real-time. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7157–7173. [Google Scholar] [CrossRef] [PubMed]
- Fan, X.; Zhang, Y.; Lu, Y.; Wang, H. PARFormer: Transformer-based multi-task network for pedestrian attribute recognition. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 411–423. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical vision Transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Park, K.R. Body-based gender recognition using images from visible and thermal cameras. Sensors 2016, 16, 156. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Park, K.R. Enhanced gender recognition system using an improved Histogram of Oriented Gradient (HOG) feature from quality assessment of visible light and thermal images of the human body. Sensors 2016, 16, 1134. [Google Scholar] [CrossRef] [PubMed]
- Baek, N.R.; Cho, S.W.; Koo, J.H.; Truong, N.Q.; Park, K.R. Multimodal camera-based gender recognition using human-body image with two-step reconstruction network. IEEE Access 2019, 7, 104025–104044. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Baghezza, R.; Bouchard, K.; Gouin-Vallerand, C. Recognizing the age, gender, and mobility of pedestrians in smart cities using a CNN-BGRU on thermal images. In Proceedings of the ACM Conference on Information Technology for Social Good, Limassol, Cyprus, 7–9 September 2022; pp. 48–54. [Google Scholar] [CrossRef]
- Wang, L.; Shi, J.; Song, G.; Shen, I. Object detection combining recognition and segmentation. In Proceedings of the 8th Asian Conference on Computer Vision (ACCV), Tokyo, Japan, 18–22 November 2007; pp. 189–199. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Gordon-Rodriguez, E.; Loaiza-Ganem, G.; Pleiss, G.; Cunningham, J.P. Uses and abuses of the cross-entropy loss: Case studies in modern deep learning. arXiv 2020, arXiv:2011.05231. [Google Scholar] [CrossRef]
- Ding, M.; Xiao, B.; Codella, N.; Luo, P.; Wang, J.; Yuan, L. DaViT: Dual attention vision Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 74–92. [Google Scholar] [CrossRef]
- Yang, J.; Li, C.; Zhang, P.; Dai, X.; Xiao, B.; Yuan, L.; Gao, J. Focal self-attention for local-global interactions in vision Transformers. arXiv 2021, arXiv:2107.00641. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Wu, A.; Zheng, W.-S.; Yu, H.-X.; Gong, S.; Lai, J. RGB-infrared cross-modality person re-identification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5390–5399. [Google Scholar]
- FLIR Tau2. Available online: https://www.flir.com/products/tau-2/?vertical=lwir&segment=oem (accessed on 10 January 2024).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar] [CrossRef]
- GeForce RTX 4070 Family. Available online: https://www.nvidia.com/en-us/geforce/graphics-cards/40-series/rtx-4070-family (accessed on 15 January 2024).
- Dwyer, B.; Nelson, J.; Solawetz, J. Roboflow (Version 1.0) [Software]. 2022. Available online: https://roboflow.com (accessed on 14 February 2024).
- Zhang, Y.; Chen, C.; Shi, N.; Sun, R.; Luo, Z.-Q. Adam can converge without any modification on update rules. In Proceedings of the 36th Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 28386–28399. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar] [CrossRef]
- Lewkowycz, A. How to decay your learning rate. arXiv 2021, arXiv:2103.12682. [Google Scholar] [CrossRef]
- Brouty, X.; Garcin, M. Fractal properties; information theory, and market efficiency. Chaos Solitons Fractals 2024, 180, 114543. [Google Scholar] [CrossRef]
- Yin, J. Dynamical fractal: Theory and case study. Chaos Solitons Fractals 2023, 176, 114190. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar] [CrossRef]
- Hong, Y.; Pan, H.; Sun, W.; Jia, Y. Deep dual-resolution networks for real-time and accurate semantic segmentation of road scenes. arXiv 2021, arXiv:2101.06085. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with Transformers. In Proceedings of the advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021; pp. 12077–12090. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 11966–11976. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Jégou, H. DeiT III: Revenge of the ViT. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 516–533. [Google Scholar] [CrossRef]
- Abbas, F.; Yasmin, M.; Fayyaz, M.; Asim, U. ViT-PGC: Vision Transformer for pedestrian gender classification on small-size dataset. Pattern Anal. Appl. 2023, 26, 1805–1819. [Google Scholar] [CrossRef]
- Li, D.; Chen, X.; Huang, K. Multi-attribute learning for pedestrian attribute recognition in surveillance scenarios. In Proceedings of the Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 111–115. [Google Scholar] [CrossRef]
- Lin, Y.; Zheng, L.; Zheng, Z.; Wu, Y.; Hu, Z.; Yan, C.; Yang, Y. Improving person re-identification by attribute and identity learning. Pattern Recognit. 2019, 95, 151–161. [Google Scholar] [CrossRef]
- Guo, H.; Zheng, K.; Fan, X.; Yu, H.; Wang, S. Visual Attention Consistency Under Image Transforms for Multi-Label Image Classification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 729–739. [Google Scholar] [CrossRef]
- Fayyaz, M.; Yasmin, M.; Sharif, M.; Raza, M. J-LDFR: Joint low-level and deep neural network feature representations for pedestrian gender classification. Neural Comput. Appl. 2021, 33, 361–391. [Google Scholar] [CrossRef]
- Cai, L.; Zeng, H.; Zhu, J.; Cao, J.; Wang, Y.; Ma, K.-K. Cascading scene and viewpoint feature learning for pedestrian gender recognition. IEEE Internet Things J. 2021, 8, 3014–3026. [Google Scholar] [CrossRef]
- Jetson TX2 Module. Available online: https://developer.nvidia.com/embedded/jetson-tx2 (accessed on 1 February 2024).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Student’s t-test. Available online: https://en.wikipedia.org/wiki/Student%27s_t-test (accessed on 21 February 2024).
- Cohen, J. A power primer. Psychol. Bull. 1992, 112, 1155–1159. [Google Scholar] [CrossRef] [PubMed]
- Mandelbrot, B. How long is the coast of Britain? Statistical self-similarity and fractional dimension. Science 1967, 156, 636–638. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Fold | Training Set | Validation Set | Test Set | |||
|---|---|---|---|---|---|---|---|
| People (M/F) | Images (M/F) | People (M/F) | Images (M/F) | People (M/F) | Images (M/F) | ||
| SYSU-MM01 NIR | 1 | 221 (125/96) | 7011 (4018/2993) | 24 (13/11) | 760 (380/380) | 245 (137/108) | 7724 (4338/3386) |
| 2 | 221 (122/99) | 6968 (3862/3106) | 24 (15/9) | 756 (476/280) | 245 (138/107) | 7771 (4398/3373) | |
| DBGender-DB2 thermal | 1 | 297 (186/111) | 2970 (1860/1110) | 33 (16/17) | 330 (160/170) | 82 (52/30) | 820 (520/300) |
| 2 | 297 (180/117) | 2970 (1800/1170) | 32 (21/11) | 320 (210/110) | 83 (53/30) | 830 (530/300) | |
| 3 | 297 (183/114) | 2970 (1830/1140) | 32 (21/11) | 320 (210/110) | 83 (50/33) | 830 (500/330) | |
| 4 | 297 (183/114) | 2970 (1830/1140) | 33 (23/10) | 330 (230/100) | 82 (48/34) | 820 (480/340) | |
| 5 | 297 (184/113) | 2970 (1840/1130) | 33 (19/14) | 330 (190/140) | 82 (51/31) | 820 (510/310) | |
| Lseg | Lanthro | EER |
|---|---|---|
| 5.395 | ||
| ✓ | 4.997 | |
| ✓ | 5.194 | |
| ✓ | ✓ | 4.320 |
| λanthro | EER |
|---|---|
| 0.01 | 4.840 |
| 0.1 | 4.606 |
| 0.05 | 4.320 |
| Case | Human Body Region Extractor | ABAM | EER |
|---|---|---|---|
| 1 | 5.410 | ||
| 2 | ✓ | 5.180 | |
| 3 | ✓ | 4.863 | |
| 4 | ✓ | ✓ | 4.320 |
| Case | Adaptive BAM | Non-Adaptive BAM | EER |
|---|---|---|---|
| 1 | 4.863 | ||
| 2 | ✓ | 5.581 | |
| 3 | ✓ | 4.320 |
| Method | EER |
|---|---|
| DeepLabV3Plus [46] | 5.347 |
| HRNet [47] | 4.878 |
| DDRNet [48] | 5.339 |
| SegFormer [49] | 5.239 |
| U-Net [31] | 4.320 |
| w/o segmentation | 5.410 |
| Model | EER | ||
|---|---|---|---|
| w/o | w/ | ||
| CNN | InceptionV3 [50] | 5.284 | 5.149 |
| ResNet-101 [28] | 5.411 | 4.913 | |
| ConvNeXt-Base [51] | 5.135 | 4.777 | |
| Transformer | Swin-Base [24] | 6.257 | 5.693 |
| DeiT-Large [52] | 7.303 | 6.920 | |
| DaViT-Base [33] | 5.410 | 4.320 | |
| Method | EER |
|---|---|
| HP-Net [11] | 11.404 |
| 1-ch ResNet-101 [27] | 11.312 |
| ALM [19] | 8.757 |
| Strong Baseline [20] | 6.067 |
| 15-layer CNN [29] | 7.221 |
| YY-Net [21] | 6.422 |
| PARFormer-B [23] | 6.777 |
| PARFormer-L [23] | 6.319 |
| RBSG-Net (proposed) | 4.320 |
| Method | EER |
|---|---|
| HP-Net [11] | 7.650 |
| 1-ch ResNet-101 [27] | 7.053 |
| ALM [19] | 4.530 |
| Strong Baseline [20] | 2.970 |
| 15-layer CNN [29] | 4.394 |
| YY-Net [21] | 2.925 |
| PARFormer-B [23] | 3.489 |
| PARFormer-L [23] | 2.929 |
| RBSG-Net (proposed) | 2.429 |
| Method | EER |
|---|---|
| DeepLabV3Plus [46] | 9.224 |
| HRNet [47] | 9.361 |
| DDRNet [48] | 9.055 |
| SegFormer [49] | 9.307 |
| U-Net [31] | 8.303 |
| w/o segmentation | 9.491 |
| Method | EER | ||
|---|---|---|---|
| w/o | w/ | ||
| CNN | InceptionV3 [50] | 10.271 | 9.776 |
| ResNet-101 [28] | 13.476 | 12.167 | |
| ConvNeXt-Base [51] | 9.687 | 9.356 | |
| Transformer | Swin-Base [24] | 14.151 | 13.870 |
| DeiT-Large [52] | 10.561 | 9.523 | |
| DaViT-Base [33] | 9.491 | 8.303 | |
| Method | EER |
|---|---|
| HP-Net [11] | 20.811 |
| 1-ch ResNet-101 [27] | 21.315 |
| ALM [19] | 13.348 |
| Strong Baseline [20] | 12.536 |
| 15-layer CNN [29] | 12.872 |
| YY-Net [21] | 12.784 |
| PARFormer-B [23] | 12.743 |
| PARFormer-L [23] | 11.668 |
| RBSG-Net (proposed) | 8.303 |
| Models | Training Dataset → Test Dataset | |
|---|---|---|
| S → D | D → S | |
| HP-Net [11] | 54.325 | 48.706 |
| 1-ch ResNet-101 [27] | 40.014 | 46.809 |
| ALM [19] | 51.260 | 42.970 |
| Strong Baseline [20] | 41.098 | 33.904 |
| 15-layer CNN [29] | 43.071 | 40.735 |
| YY-Net [21] | 37.983 | 32.989 |
| PARFormer-B [23] | 33.777 | 30.199 |
| PARFormer-L [23] | 30.838 | 28.337 |
| RBSG-Net (proposed) | 22.777 | 26.728 |
| Protocol | Training Set (M/F) | Validation Set (M/F) | Test Set (M/F) |
|---|---|---|---|
| 1 | 9500 (5240/4260) | 1900 (1034/866) | 7600 (4147/3453) |
| 2 | 13,555 (6778/6777) | 3389 (1694/1695) | 888 (600/288) |
| Method | Mean Accuracy |
|---|---|
| ALM [19] | 92.28 |
| DeepMar [54] | 92.33 |
| APR [55] | 92.84 |
| VAC [56] | 92.85 |
| Strong Baseline [20] | 93.13 |
| YY-Net [21] | 93.39 |
| DaViT-Base [33] | 93.74 |
| DeiT-Large [52] | 94.91 |
| RBSG-Net (proposed) | 95.10 |
| Method | Overall Accuracy | Mean Accuracy |
|---|---|---|
| Upper body (CNN) [15] | 82.8 | 81.4 |
| Full body (CNN) [15] | 82.0 | 80.7 |
| HDFL [14] | 74.3 | - |
| SSAE [18] | 82.4 | 81.6 |
| U+M+L (CNN-3) [17] | 81.3 | - |
| J-LDFR [57] | 82.0 | 77.3 |
| CSVFL [58] | 85.2 | - |
| DaViT-Base [33] | 86.2 | 84.6 |
| DeiT-Large [52] | 90.9 | 90.5 |
| ViT-PGC [53] | 91.7 | 90.7 |
| RBSG-Net (Proposed) | 92.7 | 91.3 |
| Models | Processing Time per an Image (ms) | Number of Parameters (M) | GFLOPs | Memory Usage (MB) | |
|---|---|---|---|---|---|
| Desktop | Jetson TX2 | ||||
| HP-Net [11] | 89.746 | 922.345 | 20.799 | 10.306 | 80.173 |
| 1-ch ResNet-101 [27] | 6.026 | 73.425 | 42.498 | 7.627 | 162.827 |
| ALM [19] | 7.051 | 60.053 | 11.021 | 2.113 | 42.793 |
| Strong Baseline [20] | 3.501 | 41.934 | 23.510 | 4.047 | 89.919 |
| 15-layer CNN [29] | 1.762 | 14.155 | 6.996 | 1.335 | 26.728 |
| YY-Net [21] | 6.503 | 84.656 | 47.018 | 8.095 | 200.975 |
| PARFormer-B [23] | 6.961 | 156.662 | 86.680 | 15.169 | 336.421 |
| PARFormer-L [23] | 9.229 | 296.868 | 194.900 | 34.082 | 747.369 |
| RBSG-Net (proposed) | 16.980 | 345.798 | 117.917 | 58.168 | 454.951 |
| Results | Head | Upper Body | Lower Body | |||
|---|---|---|---|---|---|---|
| Figure 19a | Figure 19b | Figure 20a | Figure 20b | Figure 21a | Figure 21b | |
| FD | 1.6226 | 1.2156 | 1.8039 | 1.6802 | 1.6237 | 1.5123 |
| R2 | 0.994 | 0.992 | 0.996 | 0.997 | 0.997 | 0.991 |
| C | 0.9971 | 0.9961 | 0.9981 | 0.9983 | 0.9984 | 0.9956 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, D.C.; Jeong, M.S.; Jeong, S.I.; Jung, S.Y.; Park, K.R. Estimation of Fractal Dimension and Segmentation of Body Regions for Deep Learning-Based Gender Recognition. Fractal Fract. 2024, 8, 551. https://doi.org/10.3390/fractalfract8100551
Lee DC, Jeong MS, Jeong SI, Jung SY, Park KR. Estimation of Fractal Dimension and Segmentation of Body Regions for Deep Learning-Based Gender Recognition. Fractal and Fractional. 2024; 8(10):551. https://doi.org/10.3390/fractalfract8100551
Chicago/Turabian StyleLee, Dong Chan, Min Su Jeong, Seong In Jeong, Seung Yong Jung, and Kang Ryoung Park. 2024. "Estimation of Fractal Dimension and Segmentation of Body Regions for Deep Learning-Based Gender Recognition" Fractal and Fractional 8, no. 10: 551. https://doi.org/10.3390/fractalfract8100551
APA StyleLee, D. C., Jeong, M. S., Jeong, S. I., Jung, S. Y., & Park, K. R. (2024). Estimation of Fractal Dimension and Segmentation of Body Regions for Deep Learning-Based Gender Recognition. Fractal and Fractional, 8(10), 551. https://doi.org/10.3390/fractalfract8100551