1. Introduction
The concept of the fractal dimension holds great significance within the field of economics, specifically when examining financial markets and their intricate complexities. Originating from the wider domain of fractal geometry, the fractal dimension quantifies the non-uniformity or intricacy of datasets, providing valuable perspectives on patterns that may not be readily apparent via traditional linear models [
1]. Financial time series frequently exhibit self-similarity and volatility clustering, which are typical attributes observed in fractal formations within the realm of economics. Through the utilization of the fractal dimension, economists and financial analysts are able to assess the level of roughness or complexity exhibited by price movements, thereby augmenting their comprehension of market dynamics. Furthermore, the quantification of these nonlinear structures facilitates the enhanced forecasting of extreme economic events, such as market crashes, which frequently pose challenges for conventional econometric models [
2,
3,
4]. The incorporation of the fractal dimension into economic analysis offers a comprehensive methodology for understanding the intricate and frequently erratic characteristics of financial systems.
Within the framework of financial systems, the behaviors of individual participants can be effectively captured using time series analysis. However, the intricate interplay among these participants calls for an alternative methodology: correlation networks. The construction of these networks involves the assessment of pairwise correlations among the time series of distinct entities, thereby encapsulating the fundamental nature of their interdependent associations. In the realm of financial assets, it is noteworthy that two such assets exhibiting a propensity to ascend and descend in tandem would possess a considerable degree of positive correlation, thereby establishing a robust interconnectedness within the network [
5,
6]. In contrast, assets exhibiting inverse movements would imply a negative correlation. The structure and topology of the correlation networks provide valuable insights into the collective behavior of the market, revealing interdependencies and potential contagion pathways that may not be apparent when analyzing individual time series in isolation. Through the utilization of correlation networks, researchers and analysts have the ability to reveal systemic vulnerabilities, patterns of clustered behavior, and emergent phenomena within financial systems [
7,
8,
9]. This approach provides a more comprehensive and interconnected perspective on market dynamics that extends beyond the limitations of individual trajectories.
Fractal dimensions, originating from the domain of fractal geometry, provide a framework for scrutinizing the intricate structures and patterns exhibited by diverse phenomena. Within the realm of finance, the examination of time series data pertaining to individual assets or actors reveals their inherent dynamics. However, it is the intricate interplay among these entities that gives rise to a complex network, which is most effectively depicted through correlation networks. The networks, derived from interdependencies among financial time series, encapsulate the simultaneous fluctuations of assets and market participants. The fractal dimension of these networks serves as an indicator of their intricacy, irregularity, and scaling characteristics. In essence, it provides a quantitative assessment of how the network’s characteristics vary at various levels, thereby providing valuable insights into its hierarchical organization and interconnectedness. In light of the growing interconnectivity of financial markets, it is imperative to grasp the fractal dimensions of financial correlation networks. It functions as a conduit, amalgamating the intricacies of individual asset dynamics with broader systemic interplays, facilitating a more profound understanding of the multifaceted characteristics of financial ecosystems.
Within the extensive literature of financial econometrics research, a multitude of studies have been conducted with the aim of comprehending the interplay between the fractal dimensions of different time series. The primary focus of these studies lies in examining the interdependencies, both linear and nonlinear, that exist between individual time series. Nevertheless, it is worth noting that there is a discernible gap in the existing pool of knowledge pertaining to the dearth of studies exploring the potential influence of fractal dimensions of time series on the dynamics of correlation networks. The networks, which depict interactions among financial entities, play a vital role in deciphering systemic relationships and potential pathways for contagion in markets. Through the analysis of fractal dimensions, researchers have the opportunity to gain a more detailed comprehension of the influence of individual market behaviors on larger market interconnections. Engaging in such studies would provide unique perspectives on the hierarchical and multi-scalar characteristics of financial markets. Moreover, understanding the impact of fractal dimensions on correlation networks has the potential to facilitate the creation of more sophisticated models, which could improve the reliability of financial predictions and the formulation of strategies that consider both the specific behaviors of individual assets and the broader market dynamics. The objective of this study is to conduct a multidisciplinary analysis on the association between the fractal dimensions of time series, specifically pertaining to economic news sentiments, and the fractal dimension of the correlation network among companies in the Borsa Istanbul Stars segment.
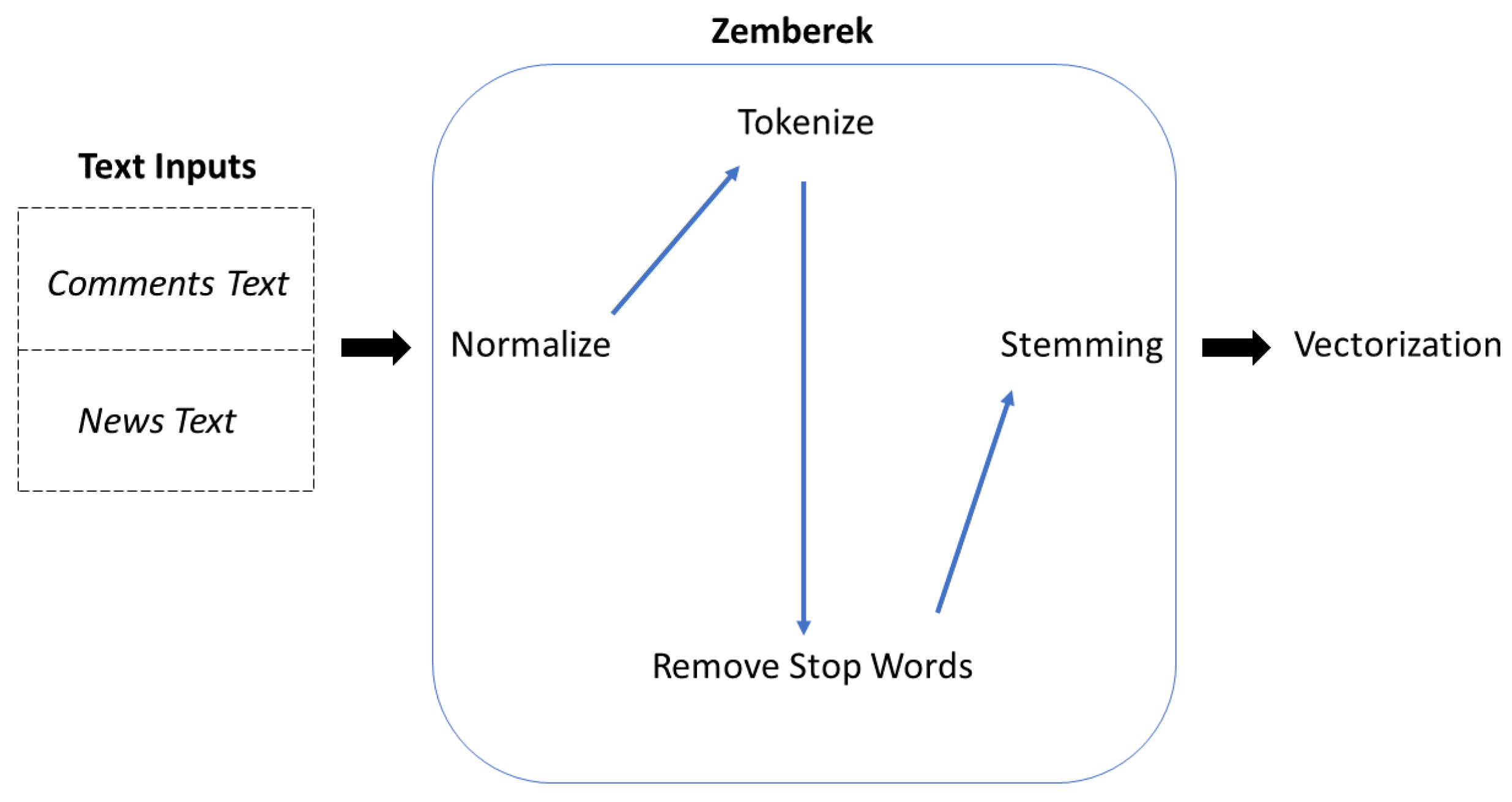
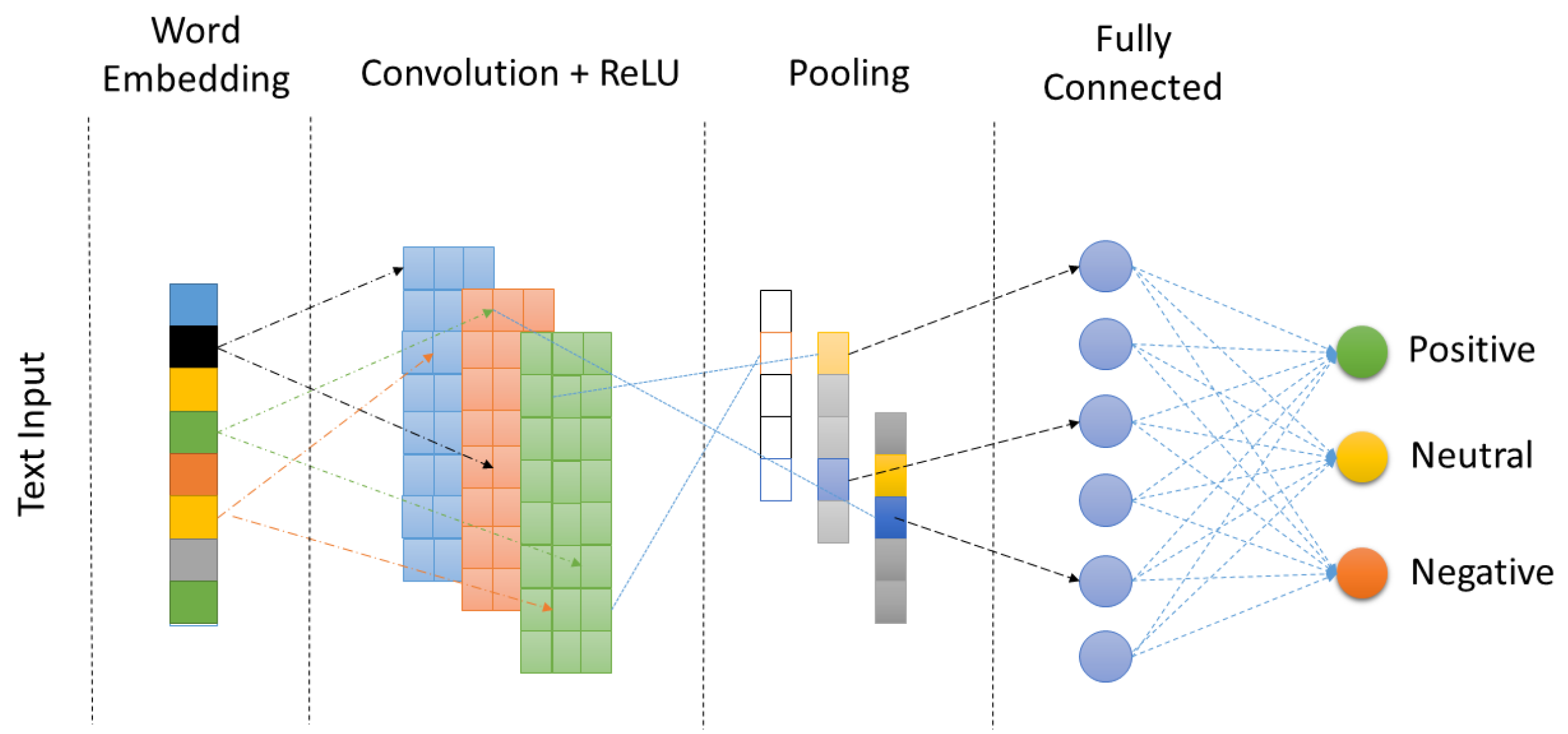
In order to fulfill the objective, we initially acquired correlation distance-based networks and topological filters of the companies that were traded in the BIST Stars segment during the year 2020. The network dynamics resulting from filtering are captured by calculating fractal dimensions using the box counting and information dimension methods. A deep network architecture was devised utilizing convolution neural networks to compute sentiment scores for economic news during the year 2020. Given the potential uncertainty surrounding the sentiment scores of news articles that undergo editorial processes, this deep learning architecture was trained, utilizing user comments on economic news shared on the public network. In the test and train stages, data pre-processing processes are conducted utilizing the Zemberek NLP framework. The fractal dimensions of the time series for the sentiment scores of economic news are computed utilizing the box counting and information dimension methodologies. The fractal dimension time series undergo independence and causality tests using the sub-time series derived from the sliding windows of varying widths.
The article is structured in the following manner: in
Section 2, we provide a comprehensive analysis of the fractional dimension approaches and their relevance in financial research. In
Section 3, the methodologies for obtaining financial correlation networks are presented, specifically focusing on the utilization of the Pearson correlation distance function. A filtering method is introduced in this context, which aims to decrease the edge weights by considering the greater value of the correlation-based relationship between companies that exhibit greater distance from each other. Next, the presentation focuses on various methodologies utilized for acquiring sentiment scores. The initial section provides an overview of the procedures involved in text pre-processing using the Zemberek framework. Subsequently, details are presented regarding the GloVE embedding method. The section also provides information regarding the deep learning network. The calculation of fractal dimensions for both networks and time series is presented.
Section 4 includes an exposition of the outcomes acquired regarding the topological and fractal dimensions of the filtered networks comprising companies traded in the BIST Stars segment during the entirety of the year 2020. The section also includes the sentiment score outcomes.
Section 5 extensively examines the detailed discussion surrounding the comparisons of fractal dimensions acquired through the utilization of sliding windows with widths of 5 and 10. Finally,
Section 6 presents overarching conclusions. The research findings have significant implications for policy and decision making, benefiting many stakeholders such as investors and financial services regulators.
5. Discussions
The objective of this study was to investigate the complex connections between the sentiments expressed in economic news and the correlation networks among enterprises in the BIST Stars segment. The fluctuation of economic sentiment frequently mirrors larger macro-economic factors and investor views, hence exerting significant impacts on stock market dynamics. Through the utilization of fractal dimensions as a framework of analysis, our objective is to comprehensively grasp the intricacies and diverse characteristics of these relationships. The fractal dimension is a valuable metric for assessing the level of irregularity and complexity. It provides a detailed comprehension of how economic news feelings can propagate and influence the interdependent network of corporate relationships inside the BIST Stars segment. In the following sections, we conduct a more comprehensive analysis of the implications derived from our findings.
The examination of correlation networks among enterprises within the BIST Stars section for the year 2020, employing sliding windows of widths 5 and 10, yielded significant findings pertaining to the evolving topological configuration of these networks. In
Table 1, we present autocorrelation results for the local and global measures concerning different sliding time windows sizes.
The global efficiency measure, which assesses the network’s capacity to efficiently exchange information, exhibited a negligible autocorrelation value of when analyzed using a sliding window of width 5. This finding indicates that the global efficiency of these networks displayed apparent randomness when observed over this shorter time period. In a similar vein, the autocorrelation values of both the global efficiency and the average weighted clustering coefficient for the sliding window of width 10 exhibit values that are close to zero, albeit extremely small. This finding further supports the idea of swift topological transformations occurring across consecutive time frames. It is worth mentioning that the average weighted clustering coefficient has an extremely low autocorrelation for both window widths. This is particularly evident in the case of the 10-width window, where the value of highlights a remarkably active local clustering structure. This implies that the interconnections and interdependencies among enterprises in the BIST Stars segment had substantial variations over the course of the year, suggesting that the network’s topological structure was not stable over the time periods examined. The observed variability may be indicative of the fundamental economic, political, or sector-specific occurrences that exerted an impact on the interconnections among these corporations over the year 2020.
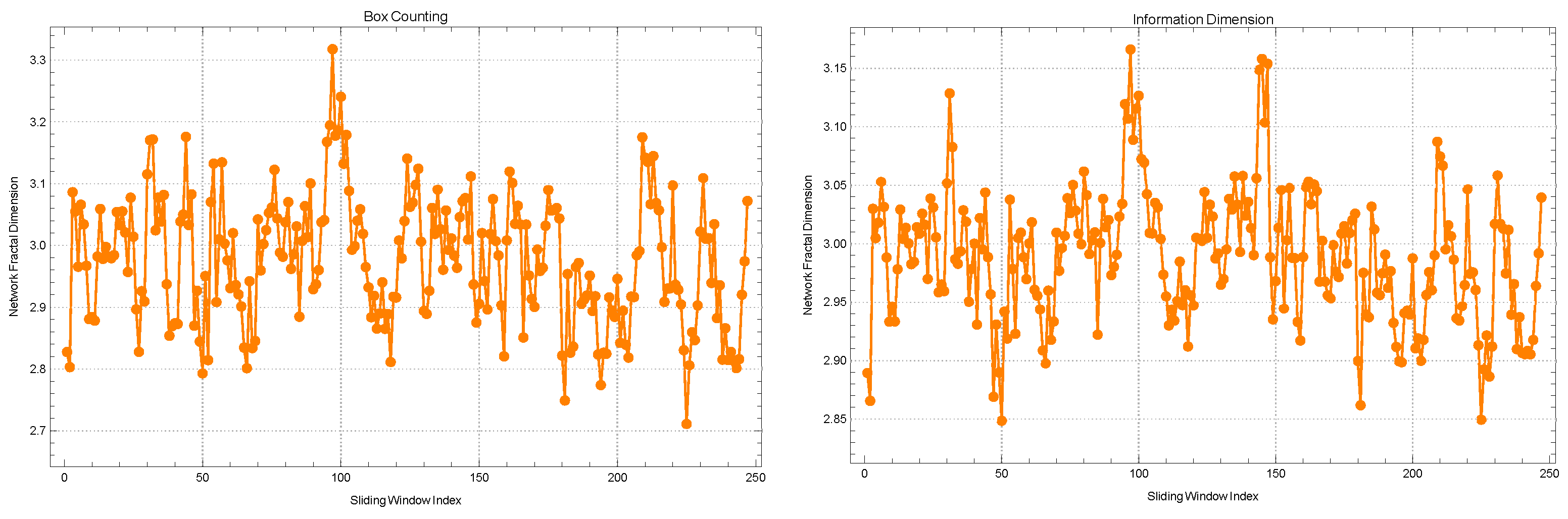
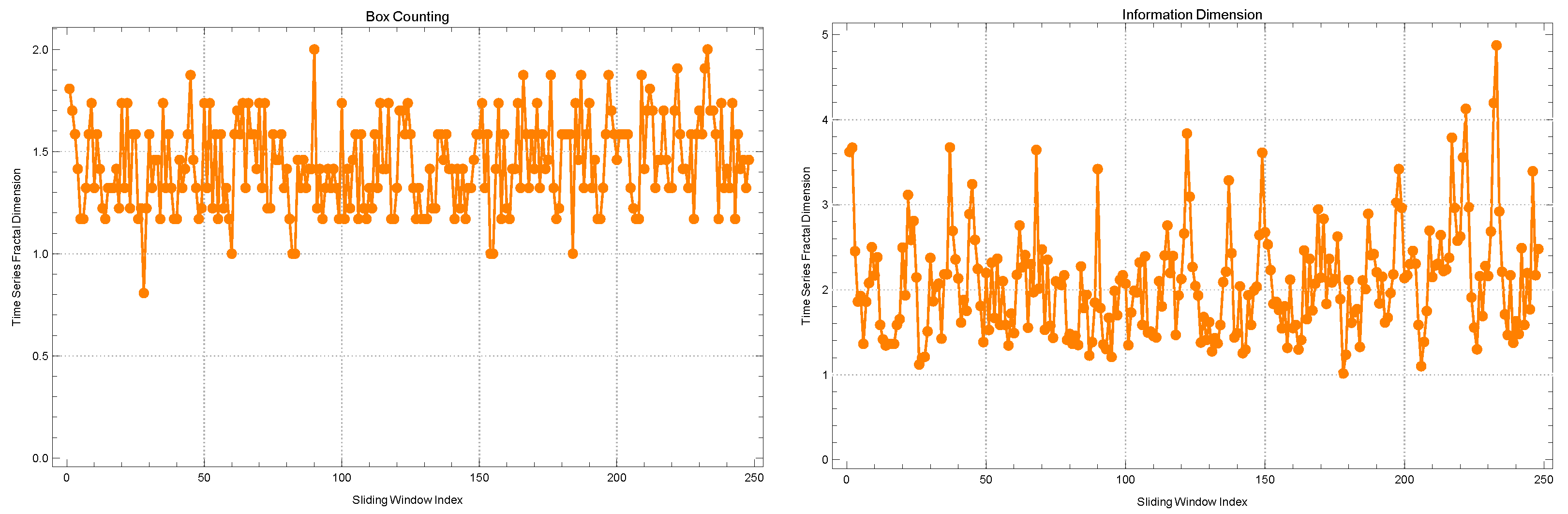
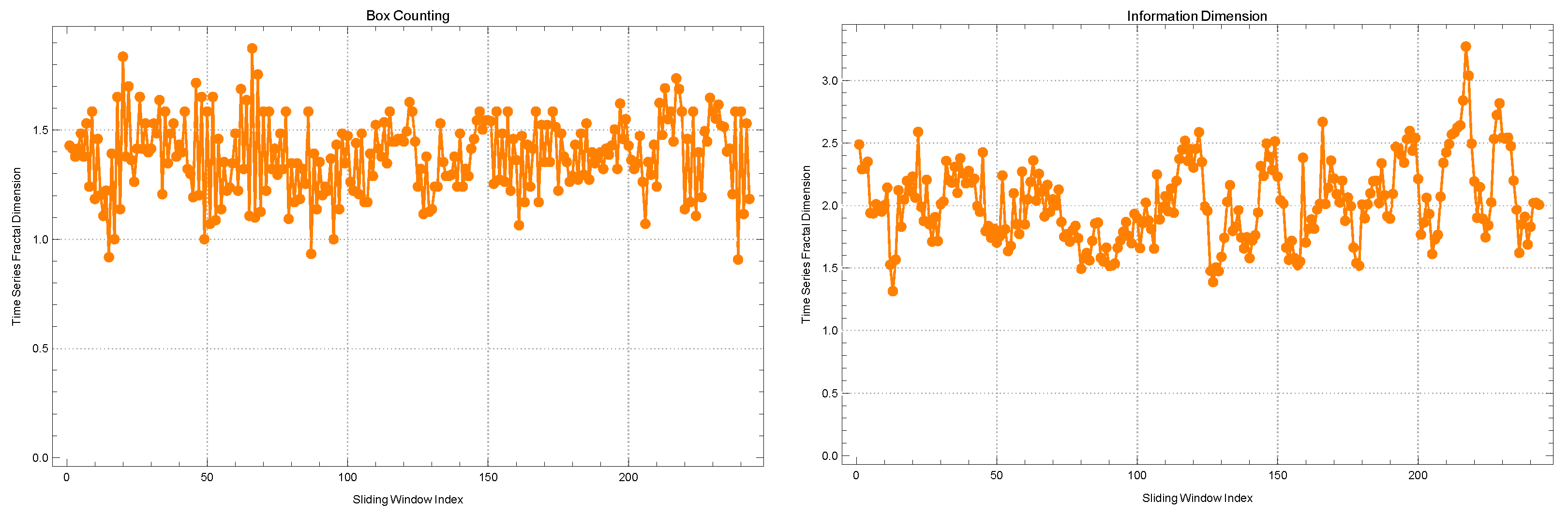
The examination of correlation networks among companies traded in the BIST Stars segment during 2020 involved the utilization of sliding windows with widths of 5 and 10. Notably, distinct observations were made when evaluating the alterations in fractal dimensions through two different methods: the box-counting method and the information dimension method, as outlined in
Table 2.
Based on the application of the box-counting method, it has been observed that the average change in fractal dimensions is calculated to be . This value suggests a relatively high level of complexity within the networks under consideration. The observed standard deviation of indicates a moderate level of variability in the complexity observed across various time slices. This variability could potentially be attributed to the changing dynamics of the market. The kurtosis value of and the skewness value of contribute to the overall characterization of this narrative by providing measures of the distribution’s shape and asymmetry. The observed kurtosis value, which is slightly less than 3, indicates that the distribution of these changes demonstrates a lower degree of “tailedness” and “peakiness” compared to a standard normal distribution. The observed positive skewness, although relatively small in magnitude, indicates a subtle tendency of the distribution to lean towards higher values of fractal dimensions. The autocorrelation value of is remarkably low, indicating a lack of correlation between the fractal dimensions obtained in consecutive time windows. This observation supports the notion of a dynamically changing topological structure within the 5-width window.
Upon transitioning to the information dimension method, it is worth noting that a marginally elevated average fractal dimension of is observed. The incrementally greater value suggests that the information dimension method may potentially capture a slightly more intricate network complexity compared to the box-counting method within this particular context. The observed standard deviation of indicates a relatively lower level of variability in the fractal dimension values obtained from different windows using the specified methodology. The observed kurtosis value of surpasses that obtained through the box-counting method. This suggests that the distribution in question exhibits a higher degree of “peakiness" or leptokurtosis when compared to a normal distribution. Consequently, there is potential for the presence of more extreme values within this distribution. The positive skewness value of indicates a distribution with a slightly more pronounced right tail. This suggests that there may be a few instances where the fractal dimension was exceptionally high during certain time windows. The autocorrelation coefficient for this particular method exhibits an extremely small value of , indicating an exceedingly minimal level of temporal correlation between successive windows.
In summary, it can be observed that both methodologies demonstrate a notable fractal dimension, suggesting an intricate interconnectedness among companies within the BIST Stars segment. However, when considering the variance, distribution shape, and autocorrelation, it becomes apparent that the market exhibits swift and intricate changes in its correlation structure throughout the analyzed timeframe of 2020.
When the analysis is expanded to a sliding window of width 10 for the correlation networks of companies in the BIST Stars segment for the year 2020, certain patterns of continuity and variation become apparent in the fractal dimensions as determined by both the box-counting and information dimension methods.
Utilizing the box-counting method, the computed average fractal dimension is recorded as , exhibiting a slight increase in comparison to the value obtained from the 5-width window. The observed data indicate a persistent and elevated degree of intricacy in the interconnectedness of the companies, even when considering an extended time period. The observed decrease in the standard deviation to , when compared to the 5-width window, suggests a higher level of uniformity in complexity across these wider windows. This could potentially show more consistent market dynamics over these longer time periods. The current kurtosis and skewness values are and , indicating an increase compared to the previous sliding window. The observed increase in kurtosis suggests a distribution that is even more leptokurtic, namely the presence of a few periods characterized by significant deviations from the mean fractal dimension. The observed positive skewness indicates a tendency for the deviations to be more pronounced towards the higher values, suggesting the presence of a few instances characterized by particularly complex correlation networks within certain time frames. The autocorrelation value of is exceptionally low, aligning with the observation of swift topological alterations detected in the shorter sliding window.
In relation to the information dimension method for the 10-width window, it is observed that the average fractal dimension experiences a slight increase, reaching a value of . The slight increase, similar to the previous set, could potentially be attributed to the method’s ability to detect and capture the subtle intricacies of network complexity. The observed standard deviation of indicates a high level of consistency in the data, suggesting that the values are tightly clustered around the mean. This level of clustering appears to be even tighter when compared to the shorter sliding window. The kurtosis and skewness values, specifically and , respectively, indicate that the distribution, although slightly affected by the 5-width window, still exhibits a leptokurtic shape with a slight rightward tail. The autocorrelation value registers a negligible variation, of approximately , highlighting the persistent and evolving characteristics of the market during the extended time period.
Upon synthesizing the aforementioned findings, it can be observed that the utilization of a 10-width sliding window provides insights into the topological structure of the BIST Stars segment in the year 2020. This structure exhibits a level of intricacy and dynamism that is comparable to what is observed when employing a 5-width window. However, the presence of subtle nuances, particularly the persistent fractal dimensions, provides valuable insights into the potential stability of market dynamics over extended periods of time.
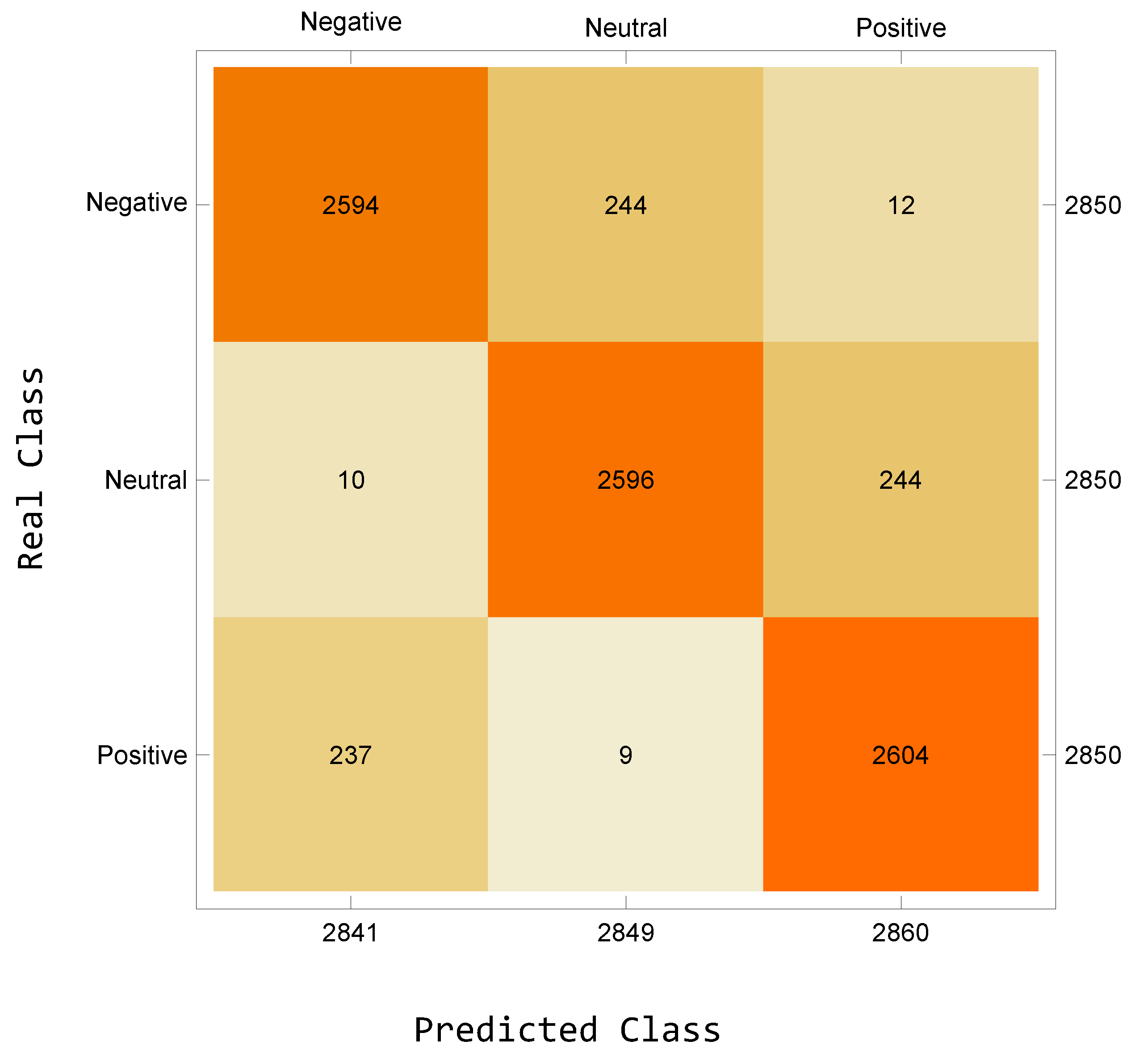
The study involved training a deep learning network to determine sentiment scores by utilizing GloVE embedding and CNN network. The confusion matrix depicted in
Figure 9 presents the classification outcomes of the network that underwent training using user comments obtained from the general network. Based on the obtained results, the accuracy of the trained network is determined to be
. Additionally, the precision is calculated to be
, the recall is measured at
, and the F1 score is computed as
. The results indicate that the network, once trained, can be utilized with efficacy in the assessment of sentiment scores for news articles.
The statistical measurements reported in
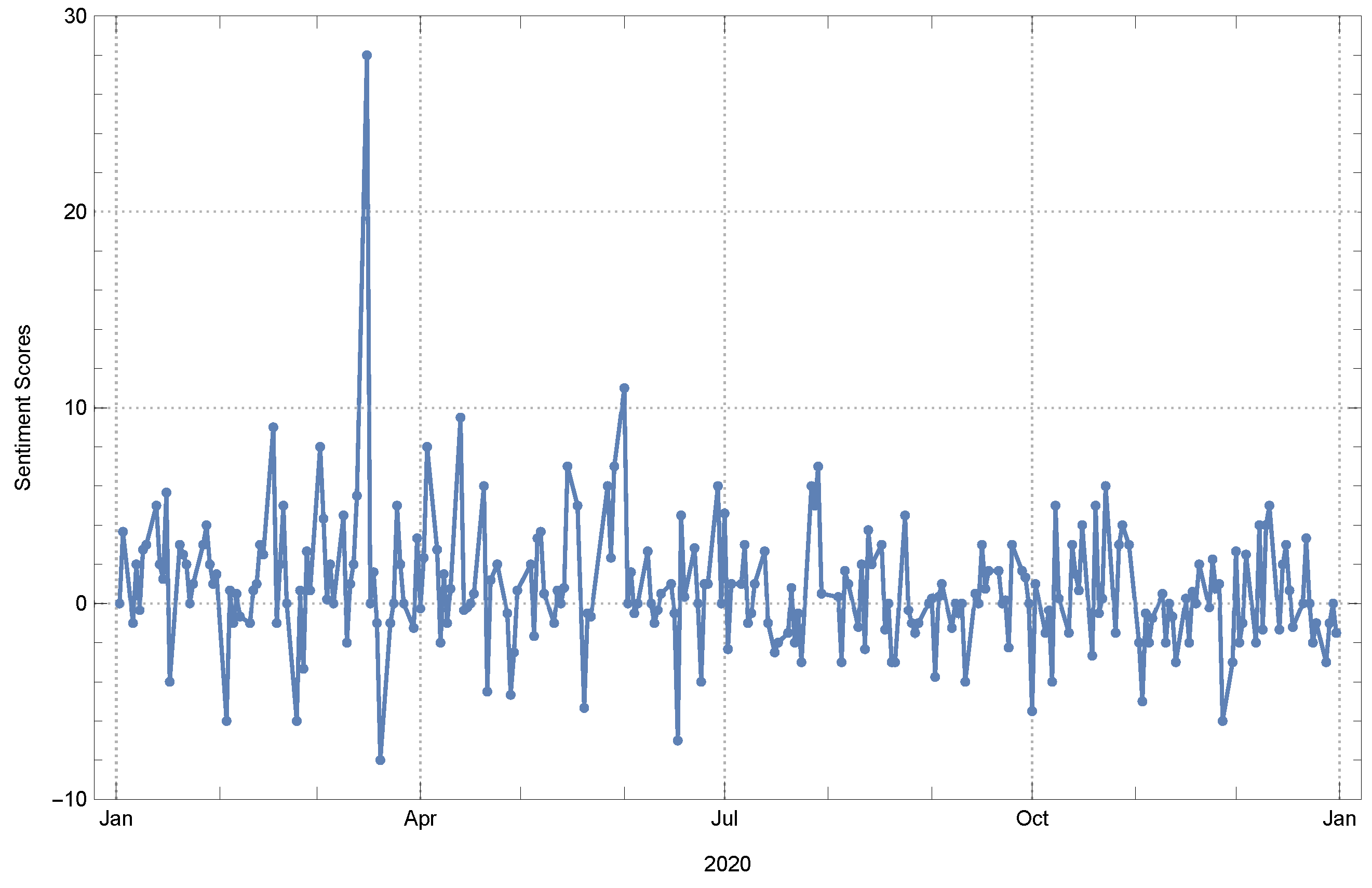
Table 3 pertain to a time series analysis that include sentiment scores of economic news as observations, sourced from the “Dünya Newspaper” website. Similarly to the methodology employed for calculating the network fractal dimension, the fractal dimensions of the present time series were computed by considering window sizes of 5 and 10.
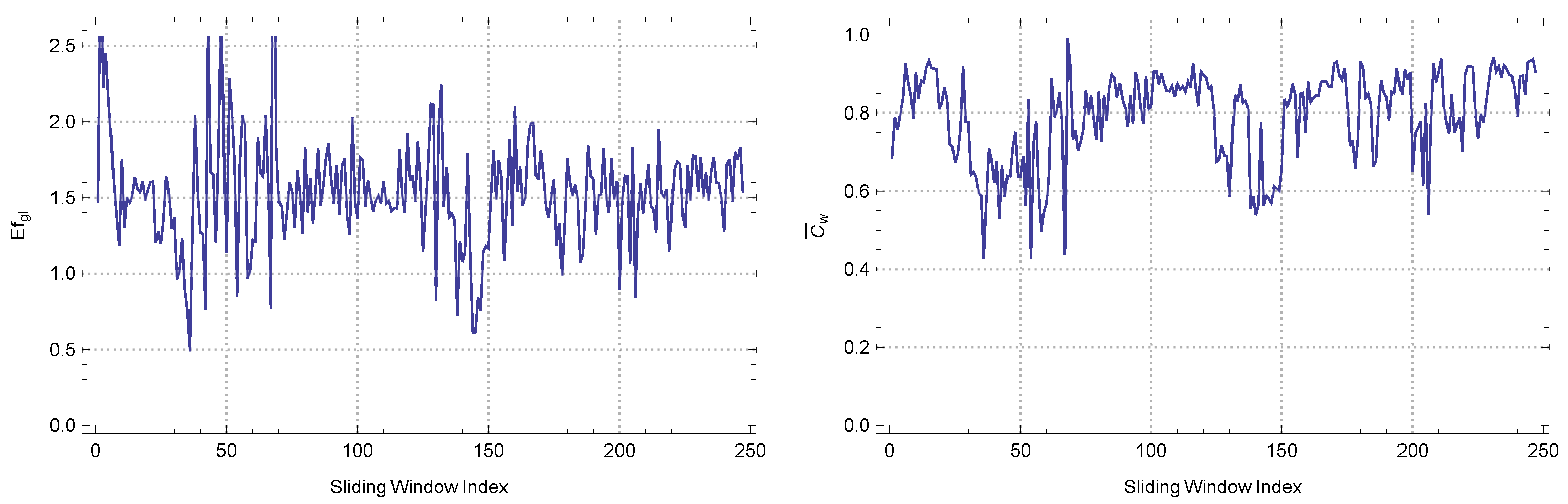
Through the application of sliding windows of width 5, an examination of the time series of sentiment scores derived from economic news in the year 2020 has been conducted. This analysis has employed both the box-counting and information dimension methods, which have yielded noteworthy observations regarding the dynamism and complexity of the sentiment fluctuations.
The calculated average fractal dimension, obtained through the box-counting method, is . The observed value indicates a moderate degree of complexity in the sub-time series, which highlights the intricate and multifaceted characteristics of economic news and its associated sentiments. The standard deviation of suggests that there is variability in the complexity measure across various time frames. This variability indicates that there are periods of both relative calm and turbulence in economic sentiment. The observation gains additional depth with the inclusion of the kurtosis value of and the skewness value of . A kurtosis value below 3 indicates that the observed changes in sentiment have a distribution with a flattened peak and lighter tails in comparison to a normal distribution. This suggests a relatively lower occurrence of extreme fluctuations in sentiment. The observed positive skewness, albeit small in magnitude, suggests a distribution that exhibits a slight inclination towards more positive shifts in sentiment. The autocorrelation coefficient of , while approaching zero, indicates a minimal correlation between successive time windows. This implies a subtle persistence in sentiment trends at a minute level.
When considering the information dimension method, the observed results exhibit a heightened level of significance. The observed average fractal dimension of suggests a notable increase in complexity as measured by this particular method. A higher standard deviation of is equal to increased variability, implying more prominent fluctuations in sentiment over time. The kurtosis value of exhibits noteworthy characteristics. The observed distribution shows a high degree of leptokurtosis, implying that it possesses more pronounced peaks and heavier tails compared to a normal distribution. This suggests the occurrence of notable shifts in sentiment, both positive and negative, that deviate significantly from the mean. The skewness value of , which is significantly higher compared to the box-counting method, suggests a distribution that exhibits a more prominent positive tail. This indicates the presence of episodes with a strong positive sentiment. The extremely low autocorrelation value of highlights the dynamic and volatile nature of the sentiment fluctuations observed in these economic news articles.
In the context of synthesis, it is worth noting that both methods under consideration effectively capture the complex dynamics of economic sentiment during the year 2020. However, it is noteworthy that the information dimension method in particular places a strong emphasis upon the existence of notable outliers representing positive sentiment. The data suggest that, throughout the year 2020, the economic news experienced fluctuations, with certain notable instances or timeframes characterized by significant levels of optimism.
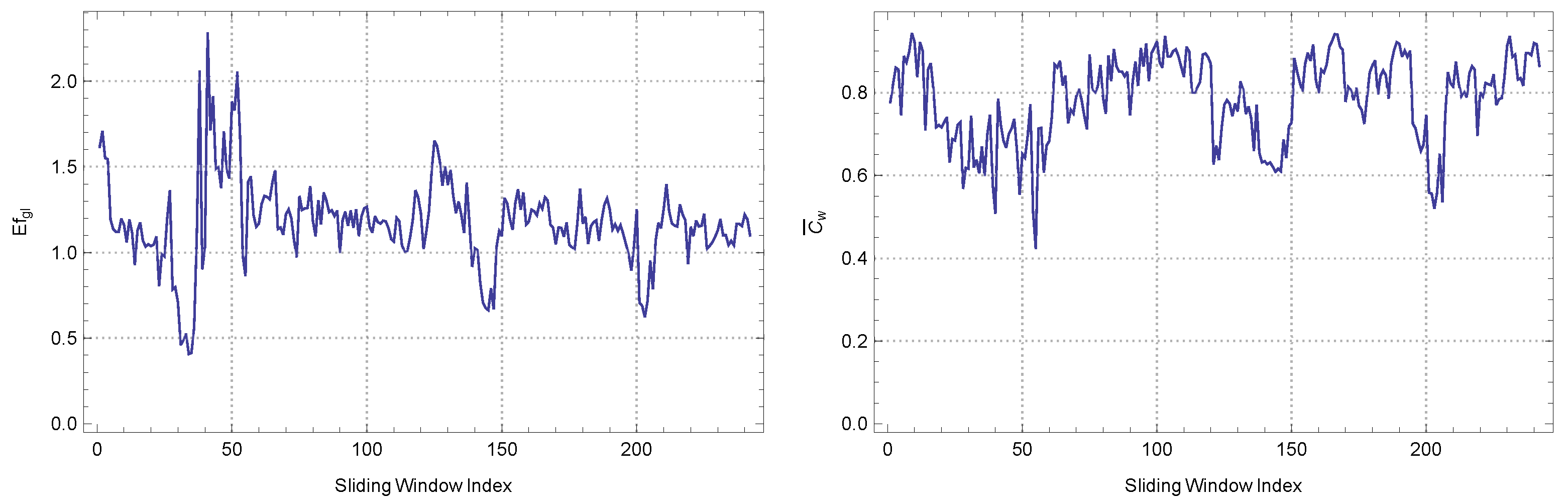
When considering the sentiment scores of economic news from 2020, an analysis was conducted using a 10-width sliding window. By employing the box-counting and information dimension methods, a more comprehensive understanding of the underlying sentiment dynamics over a wider timeframe was obtained.
According to the analysis conducted using the box-counting method, it has been observed that the mean fractal dimension has exhibited a slight decrease to a value of when compared to the results obtained using a window width of 5. The data imply that, as the time frame expands, there is a slight decrease in observed complexity. This may suggest that sentiment variations tend to stabilize or become more consistent over extended durations. The standard deviation of provides evidence supporting the notion of greater consistency in sentiment patterns across extended time periods. The observed phenomenon could potentially suggest the presence of relatively consistent patterns in sentiment within the economic news domain, particularly when noticed during extended time periods. The kurtosis value of indicates that the distribution has a relatively moderate level of peakedness compared to a normal distribution. This finding, where the kurtosis is less than 3, suggests that there are fewer instances of extreme sentiment fluctuations observed over the extended time period. The slight negative skewness of reveals a deviation from our previous findings, indicating a minor tail on the negative side of the distribution. This suggests the presence of occasional periods characterized by a more pronounced negative sentiment. The autocorrelation value of remains consistently low across the shorter window, suggesting a lack of significant sentiment continuity between these longer intervals.
In the context of the information dimension method, it is noted that the average fractal dimension undergoes a decrease to a value of . The observed decline, while retaining its intricate complexity, suggests that certain subtle fluctuations identified within the shorter time frame are smoothed out when considering the longer time frame. The decrease in the standard deviation, specifically , indicates a convergence of sentiment patterns. The kurtosis of the sentiment scores is currently , which suggests that the distribution is approaching that of a normal distribution. This indicates that the shifts in sentiment scores are becoming more evenly spread out without any significant outliers. The positive skewness value of 0.510735 indicates that there are still occurrences of optimistic sentiment that marginally surpass the pessimistic ones. The autocorrelation, which is extremely close to zero at , highlights the fleeting nature of sentiments even when considering the larger context.
In comparison to the preceding examination, the utilization of a 10-width window reveals a marginally more uniform and seamless sentiment landscape pertaining to the economic news of 2020. The patterns suggest a tendency towards a stabilized sentiment, as evidenced by a reduction in extreme fluctuations when the analysis is extended to a 10-day timeframe. However, it is important to note that the information dimension method highlights the underlying patterns of rapid shifts in sentiment, showcasing the ever-changing characteristics of economic news sentiment.
Independence tests are utilized in order to assess the potential association between the fractal dimension of the sentiment score time series of economic news and the fractal dimension of the network. The study employed statistical tests including Blomqvist
, Kendall
, and Spearman Rank.
Table 4 presents the outcomes of the independence tests conducted on 5-width sliding windows, while
Table 5 displays the outcomes of the independence tests conducted on 10-width sliding windows.
The analysis reveals a significant correlation between the fractal dimension of the sentiment score time series of economic news and the fractal dimension of the network for companies in the BIST Stars segment. This correlation is consistently observed across both 5-width and 10-width sliding windows, as indicated by the results of the independence tests.
In the case of the 5-width window, when employing the box-counting method, it is noteworthy to observe remarkably minuscule p-values. In a similar vein, the application of the information dimension technique using the identical window width yields notably low p-values. When applying the box-counting method to a 10-width window, the statistical analysis reveals p-values for Blomqvist , Kendall , and Spearman Rank. The information dimension method for this longer window yields p-values of Blomqvist , Kendall , and Spearman rank at extremely small values.
When considering both sliding window widths and methods, it is evident that the consistently low p-values indicate a strong and reliable non-random relationship between the fractal dimensions of the sentiment score time series and the network. The observed data imply a notable correlation between the fluctuation of sentiment in economic news and the network configuration of the BIST Stars segment companies.
The findings demonstrate a consistent pattern across various window widths, suggesting a persistent and robust association between the time series and network regardless of the level of analysis granularity. Additionally, it is worth noting that, although the exact p-values differ, they all exhibit remarkably low values. This emphasizes the strength and reliability of the observed correlation regardless of the specific methodology or window duration employed. The aforementioned statement highlights the significant correlation between market sentiment, as reflected in the news, and the complex dynamics of the financial network. This further supports the notion that the overall economic narrative has a profound impact on financial market structures, and conversely, financial market structures also exert influence on the broader economic narrative.
The Granger causality tests were conducted to assess the predictive capacity of the fractal dimension of the sentiment score time series on the fractal dimension of the correlation network. This analysis was performed for two different window widths (5-window and 10-window) and utilizing both the box-counting and information dimension methods and results are presented in
Table 6.
In the 5-window analysis utilizing the box counting method, the F-test value is . This value is accompanied by a statistically significant p-value. In a similar vein, upon employing the information dimension method with the identical window width, the F-test value exhibited an increase to , while the p-value demonstrated a decrease to a more pronounced level of significance, specifically . The observed results suggest that the sentiment score time series, quantified by the information dimension, exhibits a higher level of predictive capability on the network’s fractal dimension compared to the box-counting method.
In the transition to the 10-window results, it is observed that the box-counting method produced an F-test value of . This value indicates a statistically significant relationship. The corresponding p-value is calculated to be , further supporting the significance of the observed relationship. The information dimension method, when applied to a window of the same width, yielded an F-test value of . The corresponding p-value was calculated to be . Both methods exhibit the strong rejection of the null hypothesis that the sentiment score time series do not Granger-cause the network fractal dimension. However, it is important to mention that, in this instance, the box-counting method demonstrates a slightly higher F-test value in comparison to the information dimension method.
In summary, the empirical findings consistently indicate that the fractal dimension of sentiment scores has a Granger-causal relationship with the fractal dimension of the correlation network, regardless of window widths and methods employed. The strength of the observed causality exhibits slight variations based on the selected methodology and window width. Notably, the information dimension method demonstrates a marginal advantage in the 5-window configuration, while the box counting method prevails in the 10-window arrangement.
Utilizing a nonlinear autoregressive distributed lag (NARDL) model for analyzing the connection between time series proves beneficial due to its ability to effectively capture nonlinear relationships commonly found in financial and economic data. The series, which represents the fractional dimension of company networks in the BIST Stars segment, and the series, which reflects the sentiments in Turkish economic news, are expected to display intricate and ever-changing interactions. With NARDL, one can delve into the analysis of both short- and long-term effects. It also helps uncover the asymmetrical relationships, like the varying impact of positive and negative sentiment shifts in economic news on the dynamics of the stock market network. This approach enables the discovery of profound insights, such as the varying market responses to positive or negative news, and the evolution of these responses across different time frames. Having a deep understanding of the intricacies of financial markets is essential, as investor sentiment and market reactions often defy simple patterns. When conducting NARDL tests, we utilize the Akaike information criterion (AIC) and Bayesian information criterion (BIC) to determine the most suitable lags. In this case, we selected a maximum lag of 4. For model diagnostics, we utilize the Jarque–Bera (JB), Lagrange multiplier (LM), and ARCH tests on each model.
In
Table 7, the results are presented from the model
for the time series with a window length of 5 and fractional dimensions derived from box dimensions.
According to the NARDL model results, there is a noteworthy correlation between the fractional network dimensions of BIST Stars segment companies () and Turkish economic news sentiments (), both assessed using a 5-length windows and box dimension. Based on the statistical analysis, the model demonstrates a strong overall fit with a high F-statistic of and an extremely low p-value of less than . With a significant negative coefficient of , there appears to be a strong inverse relationship between and its own past values. This suggests a potential mean-reverting tendency in the series. Positive and negative changes in Turkish economic news sentiments have significant positive coefficients, indicating that both types of sentiment shifts have similar and substantial impacts on the series. The model’s R-squared value of suggests that a substantial amount of the variation in the dependent variable can be accounted for by the model. Nevertheless, the results of the short-run and long-run asymmetry tests, with p-values of and , respectively, indicate that there is no substantial asymmetry in the impact of positive and negative sentiment changes. This suggests that both positive and negative sentiment changes have a symmetrical influence on in both the short and long term. The symmetry is further reinforced by the long-run coefficients for and , which are almost the same and extremely significant.
In
Table 8, the results are presented from the model
for the time series with a window length of 10 and fractional dimensions derived from box dimensions.
In this case, the model demonstrates a strong level of fit, as evidenced by the significant F-statistic value () and an extremely low p-value (lesser than ), indicating that the model is highly effective in predicting the relationship between and . The coefficients unveil intriguing dynamics. Based on the data, it appears that there is a strong inverse relationship between and its own past values. This suggests that the series may have a mean-reverting characteristic. The coefficients for both positive () and negative () changes in Turkish economic news sentiments are significant, with values of and , respectively. This suggests that both the positive and negative news sentiments have a considerable impact on . Nevertheless, the coefficients for and are not as significant, indicating that the initial impact of news sentiments is more noticeable than their delayed effects. With an R-squared value of , it is clear that the model has a strong explanatory power and can account for a substantial amount of the variability in the dependent variable. Various diagnostic tests indicate that there are no significant problems related to normality, autocorrelation, or heteroskedasticity. This suggests that the model is robust. In addition, the short-run asymmetry test and long-run asymmetry test, both with p-values of and , respectively, indicate that there is no significant asymmetry in the short or long run. It can be observed that the effects of both positive and negative changes in on are symmetrical across both time horizons. Based on the significant long-run coefficients for and , it is evident that there is a strong long-term relationship between these variables.
The results from the model
for the time series with a window length of 5 and fractional dimensions derived from information dimensions are presented in
Table 9.
The model’s F-statistic is remarkably high at , and the p-value is incredibly small at less than . These results suggest an extremely strong fit, indicating that the model accurately captures the relationship between and . The coefficients indicate complex relationships. With a negative coefficient of , there is a strong inverse relationship between and its own past values. This suggests that the series may exhibit a mean-reverting nature. The coefficients for both positive and negative changes in economic news sentiments are highly significant, indicating that both positive and negative news have a significant and immediate impact on . It is worth noting that the coefficients for positive changes ( and ) show a combination of significance, suggesting that the initial impact of positive news on is stronger than its effects in the long run, albeit with a slightly diminishing influence over time. The model’s high R-squared value of indicates that it effectively captures almost all of the variability in the dependent variable, showcasing its robust explanatory capability. The short-run and long-run asymmetry tests yielded p-values of and , respectively. These results indicate that there is no significant asymmetry in the impact of positive and negative news sentiments on . This suggests that the influence of these sentiments is symmetrical in both the short and long term. Based on the model diagnostics tests, it appears that the model is generally reliable. However, there is a potential concern regarding the ARCH effect, as the p-value is quite low (). This could suggest potential volatility clustering in the residuals that may need to be addressed.
Finally, the results from the model
for the time series with a window length of 10 and fractional dimensions derived from information dimensions are presented in
Table 10.
With an F-statistic of and a p-value of less than , the model demonstrates a strong overall fit, suggesting a highly predictive relationship between and . Notable findings from the coefficients reveal a noteworthy negative coefficient for (), indicating a robust inverse correlation with its previous values, which implies a tendency for the series to revert to its mean. Positive and negative changes in Turkish economic news sentiments have strong positive coefficients ( and , respectively), suggesting that changes in economic news, regardless of their nature, have a significant impact on . The coefficients indicate that economic news sentiments have a significant and immediate effect on the fractional dimension of the BIST Stars segment companies. The R-squared value of , along with an adjusted R-squared of , indicates that the model explains a substantial amount of the variation in the dependent variable, indicating its strong ability to provide explanations. Based on the model diagnostic tests, there are no significant concerns regarding normality, autocorrelation, or heteroskedasticity in the residuals. This suggests that the model is reliable. Based on the short-run and long-run asymmetry tests, it appears that there is no significant asymmetry in the impact of positive and negative news sentiments on , both in the short and long term. The p-values for these tests are and , respectively. The symmetry is further reinforced by the long-run coefficients for and , which are both highly significant and have similar magnitudes.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}