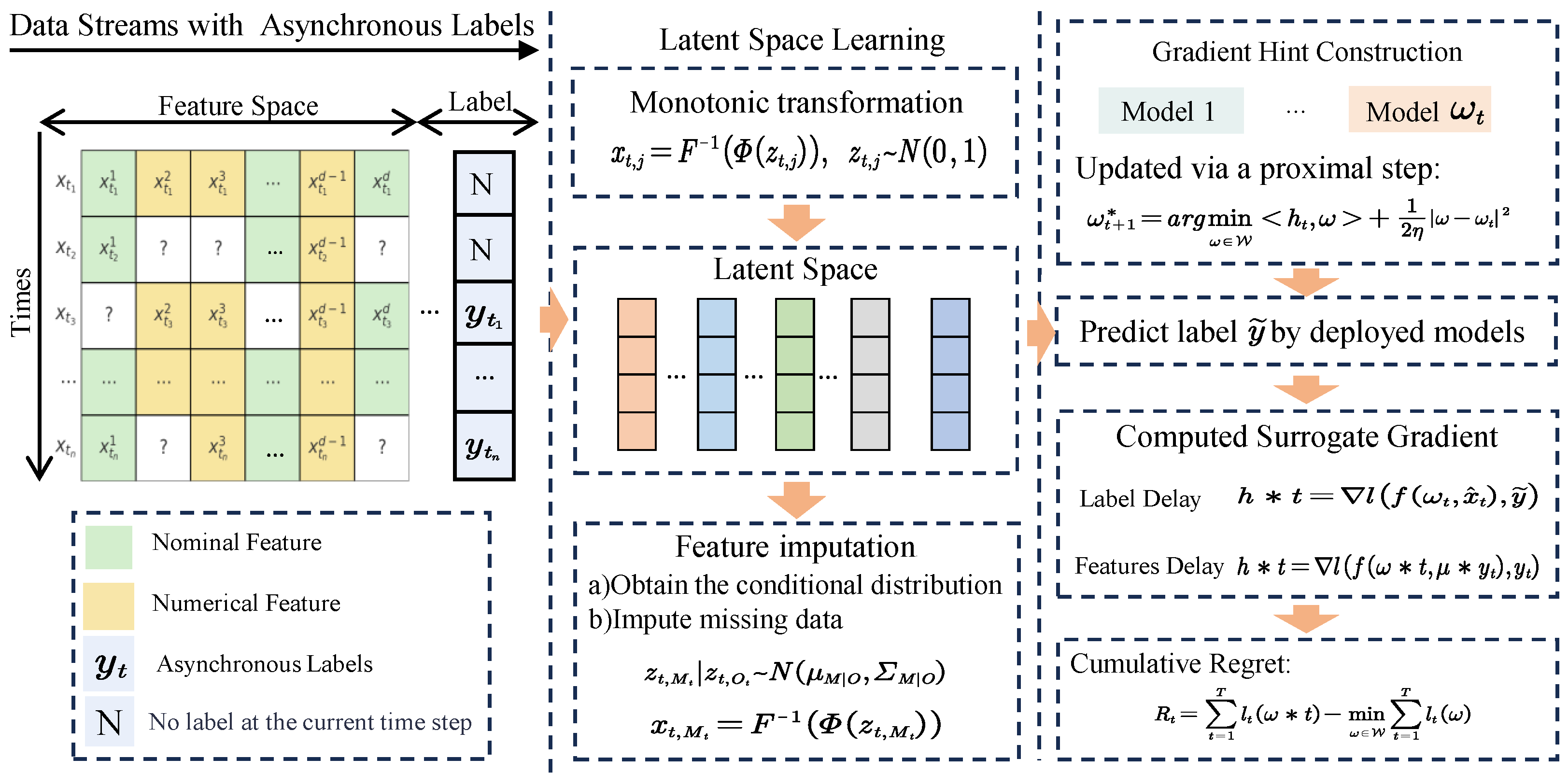
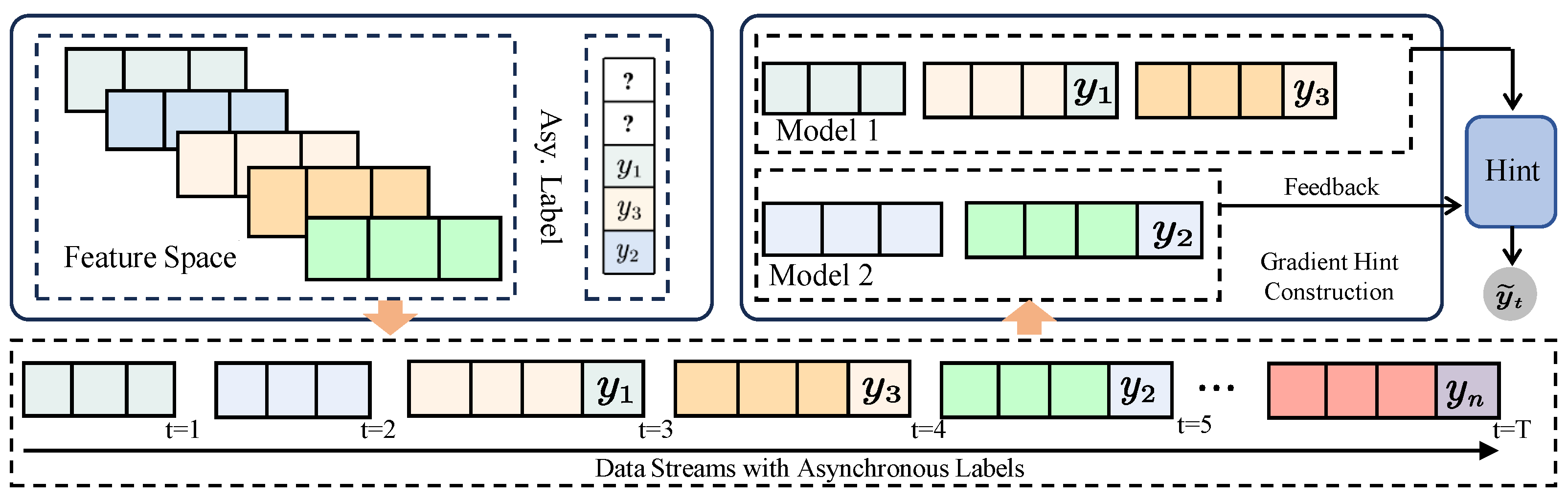
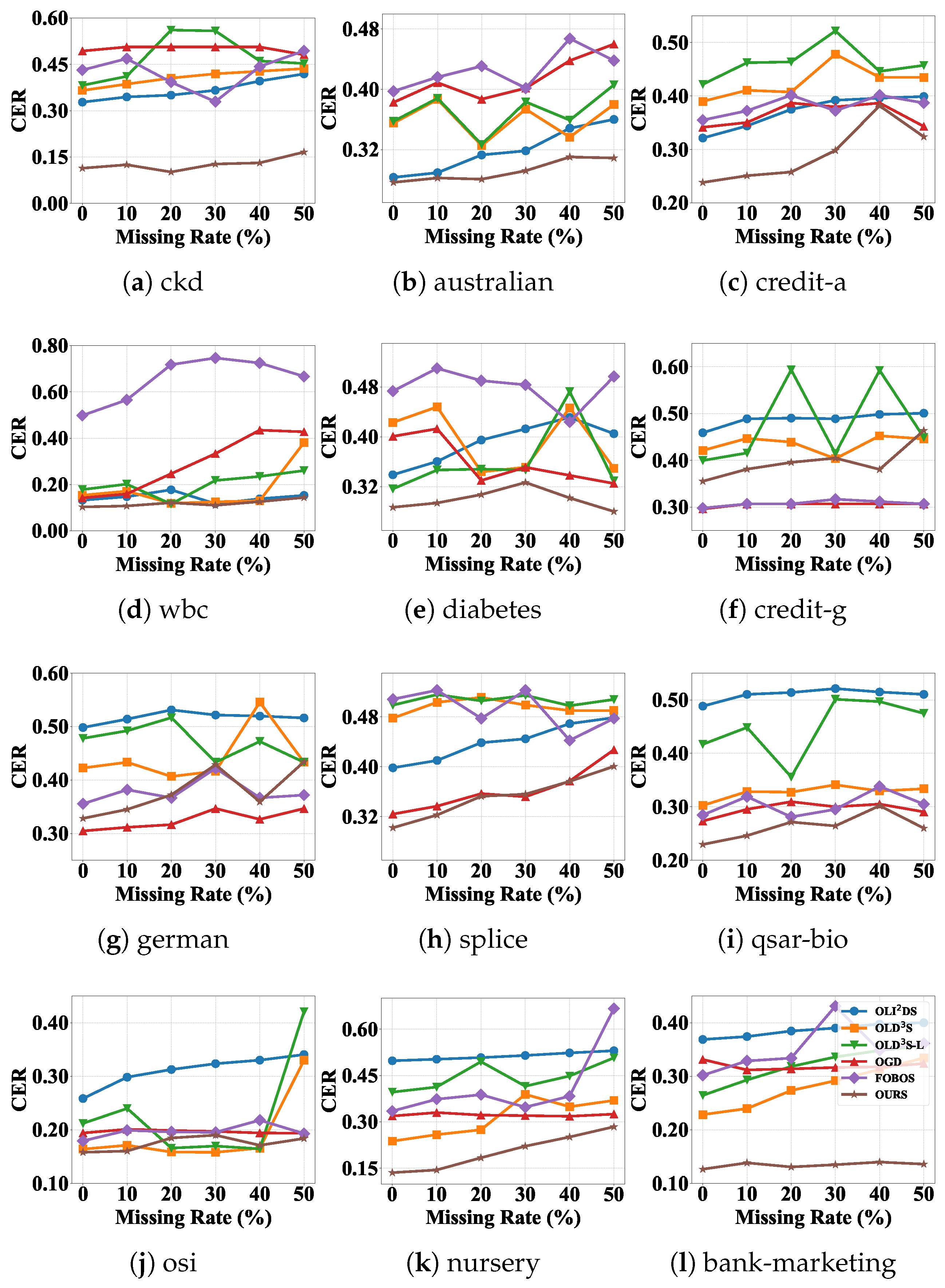
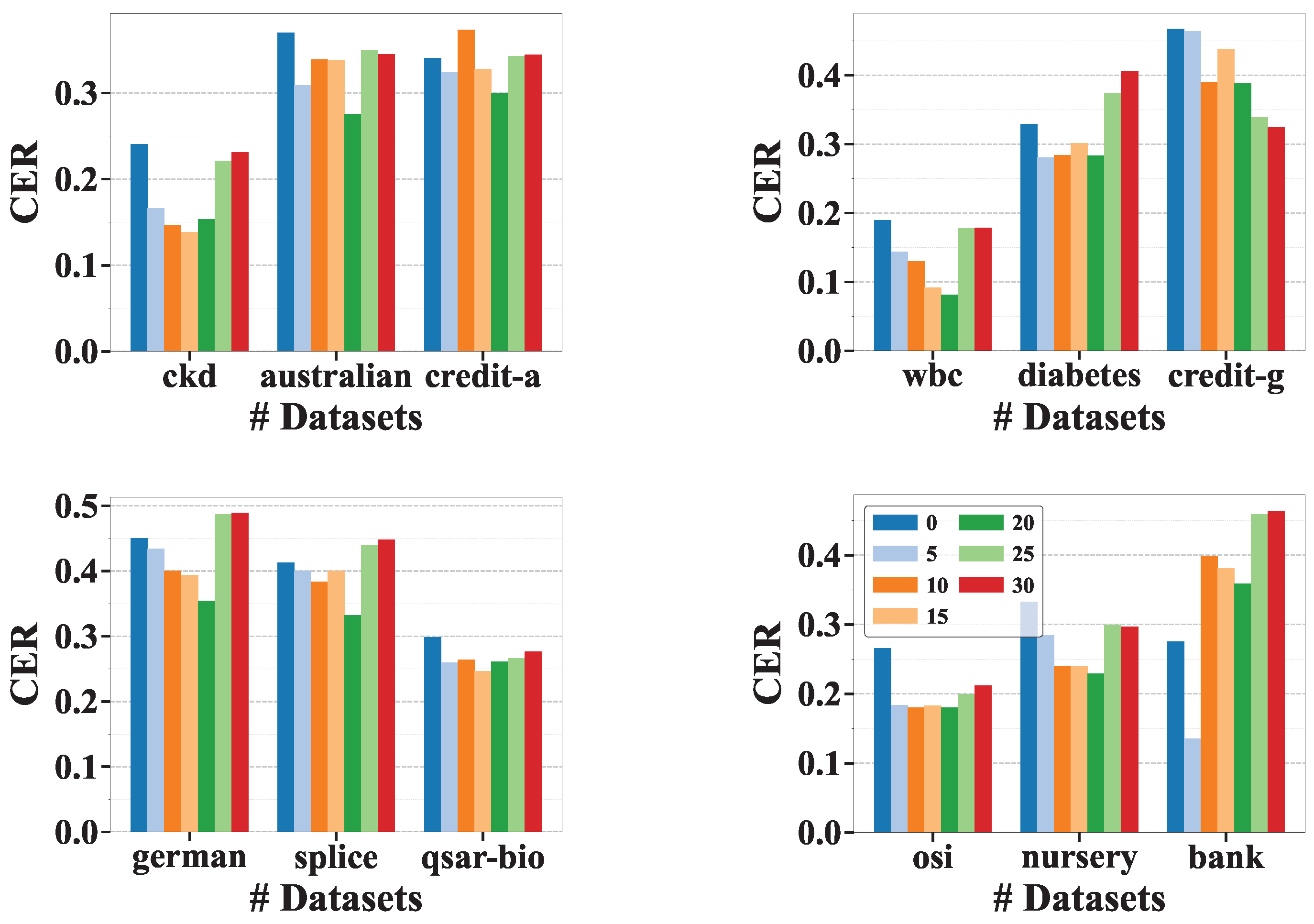
To effectively address the challenges posed by mixed-type, incomplete input features and delayed label feedback in online learning, our approach is composed of two key modules. First, we propose a latent feature encoding and imputation mechanism (
Section 4.1) based on the Extended Gaussian Copula, which transforms partially observed, heterogeneous inputs into complete and statistically consistent representations. Second, we design an online learning algorithm (
Section 4.2) tailored for asynchronous labels, which utilizes hint-based updates to adaptively learn even when full supervision is not immediately available. Together, these components ensure robustness under both input uncertainty and delayed feedback.
4.1. Latent Feature Encoding and Imputation
In real-time machine learning systems, data often arrives through streaming and in an incomplete manner. Such data typically contains mixed-type features, encompassing nominal (categorical), ordinal, and continuous variables [
17,
30]. Compounding this challenge is the fact that data collection in practice is imperfect, frequently leading to missing entries due to latency, hardware failure, user interruption, or privacy-preserving protocols. These missing values can occur in both structured input
and the associated labels
.
Our learning objective for OALN is to train an online model that maps a sequence of input instances to predictions, even when such instances are incomplete or partially observed. To support accurate and robust model training, we must therefore construct a feature representation module that can handle heterogeneous feature types; missing values in arbitrary dimensions; and statistical dependencies across features.
To address this need, we propose a probabilistic latent encoding framework based on the Extended Gaussian Copula (EGC) model, which serves as a front-end encoder for the online learner. We select the Extended Gaussian Copula owing to its formal separation of marginal distributions from the underlying dependence structure, its closed-form and bijective CDF transformations that guarantee statistically coherent and semantically consistent imputations, and its robust covariance estimation amenable to low-rank or diagonal approximations—substantially reducing storage and computational overhead in high-dimensional settings. These attributes collectively provide a theoretically sound and practically efficient encoding mechanism for online learning. This module takes partially observed mixed-type feature vectors as input and outputs fully specified, semantically consistent, and distribution-aware representations , which can be safely used in any downstream predictive task.
Latent Mapping of Mixed-Type Features. To enable unified modeling of heterogeneous input data , which may consist of categorical, ordinal, and continuous variables, we adopt a latent variable framework wherein each observed feature is represented as a transformation of a latent Gaussian variable. The core assumption is that there exists a latent vector , from which the observed values are generated via a decoding function specific to the type of each variable.
For categorical features
, we define a latent sub-vector
and apply the Gaussian-max transformation:
where
is a learnable shift vector. This operation retains the unordered nature of nominal variables without imposing an artificial structure, while also allowing the modeling of arbitrary categorical distributions through the learned biases
.
For ordinal or continuous features
, we adopt a monotonic transformation based on the Gaussian Copula [
48]:
where
is the empirical cumulative distribution function of the observed data and
is the standard normal CDF [
49]. In an offline setting,
can be obtained by sorting the full dataset and directly accumulating quantiles; however, in an online streaming environment where it is infeasible to retain all historical samples, one typically discretizes the variable’s domain into bins and maintains the count per bin along with the total sample count. Upon arrival of each new sample, only the corresponding bin count and the overall count are incrementally updated, and the empirical CDF at any value is estimated by dividing the cumulative bin counts below that value by the current total. This scheme supports constant- or logarithmic-time updates, satisfying the real-time requirements of high-throughput data streams while approximately preserving the original marginal distribution. The transformation thus embeds data into a latent Gaussian space without altering its marginal properties.
By applying these transformations across all variables, we obtain a full latent representation , where D is the sum of the dimensions required for each variable’s encoding. This provides a consistent and information-rich representation of the instance, regardless of missing values.
Joint Latent Modeling and Dependency Structure. After constructing the latent representation for all input variables, we assume the complete latent vector follows a multivariate Gaussian distribution:
where
captures all pairwise dependencies among the latent sub-components. This joint distribution enables the model to learn global correlations between variables of different types, including cross-type dependencies such as correlations between categorical and continuous variables.
Unlike heuristic encoding methods that treat features independently or separately model each type, the EGC framework leverages the joint covariance structure to support statistical coupling between all dimensions. This is particularly important in the presence of missing data, as the unobserved variables can be inferred based on their conditional relationship to the observed ones. Furthermore, the use of empirical marginals in the decoding process ensures that the generated values maintain fidelity to the original data distribution, even when imputed.
This formulation bridges the gap between traditional multivariate Gaussian models (which are not suitable for categorical data) and purely non-parametric imputation methods (which lack a principled latent structure). The result is a model that is both expressive and grounded in probabilistic inference, making it especially well-suited for online learning tasks with noisy, sparse, or mixed-type inputs.
Probabilistic Inference and Feature Imputation. Given an instance with observed entries indexed by and missing entries indexed by , the goal is to infer the missing values using the posterior distribution of the corresponding latent variables , conditioned on the observed latent components .
The first step is to map the observed variables into the latent space. For ordinal and continuous features, this is achieved by applying the inverse transformation
. For categorical variables, the observed value corresponds to an inequality constraint region in
, defined by
This results in a partially observed latent vector
, from which we compute the posterior of the missing latent dimensions using standard Gaussian conditioning:
where
.
After obtaining the conditional distribution, we perform imputation by drawing samples (in the case of multiple imputation) or using the conditional mean (for single imputation), and mapping the latent variables back to the data space. For continuous and ordinal features, this is achieved via ; for categorical variables, the imputed class is determined by the argmax operation.
The EGC model thus supports two practical modes: (1) Single imputation, which is efficient and appropriate for real-time prediction tasks where one consistent input is required. (2) Multiple imputation, which is valuable when capturing uncertainty is important, such as in Bayesian learning or ensemble settings.
By combining expressive latent modeling with exact Gaussian inference, our approach provides a principled and effective mechanism for handling missing features in online learning scenarios. This imputed feature vector will serve as the input to the label-delayed learning module described in the next section.
4.2. Handling Asynchronous Labels
The central challenge in asynchronous online learning lies in the absence of immediate supervision [
31]. Instead of deferring updates until true labels arrive, we propose a paradigm shift: enable timely model updates by constructing
informative surrogate gradients using whatever partial information is currently available. This simple but powerful idea—learning through approximate signals—forms the foundation of our OALN and enables provably effective learning even under severely delayed or missing labels.
Hint-Driven Online Learning under Delayed Supervision. In many practical online learning scenarios, full instance–label pairs are not observed synchronously. Specifically, at time step
t, the learner receives a (possibly imputed) feature vector
, while the corresponding ground-truth label
may only arrive after an unknown delay
, or may be missing entirely due to supervision dropout. This asynchronous label setting violates the standard assumption of immediate feedback, rendering conventional update rules such as
inapplicable when
is unavailable [
50]. Here,
denotes the model parameter at time
t,
is the learning rate,
is the prediction function, and
is a convex loss function, such as logistic or hinge loss.
To overcome this limitation, we propose a general-purpose solution based on gradient hint construction, the general principle of which is shown in
Figure 2. At each time
t, the learner forms a surrogate gradient vector
, which approximates the true gradient
using partially observed information. The model is then updated via a proximal step:
where
is a compact convex feasible set, and
denotes the standard inner product.
This update can be interpreted as an implicit Euler step over a linearized surrogate loss, balancing descent direction with proximity to the current model . When the actual label becomes available, the learner can retroactively refine , or use it to update future hints. This mechanism naturally interpolates between different feedback regimes: when , it recovers full-information gradient descent; when , it performs no update. Such flexibility enables learning under irregular, delayed, and partial supervision, which are common in streaming and edge intelligence settings.
Construction and Regret Analysis of Hint Gradients. The construction of the hint vector is the core mechanism that enables learning under delayed supervision in the OALN algorithm. At each time step t, the learner must determine how to approximate the true loss gradient , despite potentially missing parts of the instance–label pair . The strategy for computing depends on which elements are currently available.
When the feature vector
is observed but the label
has not yet arrived, we estimate a soft pseudo-label
using an ensemble of previously deployed models
, such as via confidence-weighted majority voting or exponential decay averaging [
51]. Concretely, each model
is assigned a confidence weight:
where
denotes the cumulative loss of model
s over a sliding window up to time
t, and
is a decay parameter. These weights are then normalized, and updated online after each labeled feedback via exponential smoothing:
where
is a smoothing coefficient that governs the trade-off between the prior confidence
and the newly observed loss-based weight. This scheme ensures that higher-performing models contribute more strongly to
, while poor performers are gradually down-weighted.
The surrogate gradient is then computed using
where
is the prediction function, and
is a convex loss.
Alternatively, when only the label
is received and the corresponding features
are missing, we approximate the input using a class-wise prototype:
where
denotes the historical index set for label
y. The hint gradient is computed as
In the case where both and are unavailable at time t, the learner defers the update entirely, or adopts a temporal smoothing strategy such as reusing the previous update direction . This ensures continuity in learning while awaiting supervision.
To formally analyze the performance impact of hint-based updates, we consider the cumulative regret after
T steps:
where
if the label is eventually received, and
is a convex, bounded parameter space.
We assume that (i) the loss
is convex and
L-Lipschitz in
; (ii) each hint satisfies
; and (iii) the hypothesis space has the following diameter:
Then, the expected regret is bounded by
Choosing and yields , confirming that the OALN algorithm achieves no-regret learning even with approximate supervision.
This result demonstrates that as long as hint gradients approximate the true gradients with bounded error, the model remains competitive. Coupled with the latent feature imputation from
Section 4.1, our framework provides a principled approach to online learning under dual uncertainty: incomplete inputs and delayed feedback.



 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}