1. Introduction
Career planning and occupation analysis require models of occupations that account for the relatedness between occupation categories, positions, and job roles. An individual’s ability to discover and review related occupations, with common work attributes and similar worker requirements, and supported by technology [
1], is a central component of career exploration and job search or transition, among other related tasks. Large databases of work-related content models are curated for this and similar purposes. Examples of these are O*NET [
2] and ESCO [
3], which have been used, for example, in career guidance [
4]. A key element of those models is the structure that is used to capture occupations and their relations. These relations can be
hierarchical, in the form of more specialized/general kinds of occupations, or
transversal, accounting for occupation profiles that have some degree of overlap or that can be connected to other occupations for various purposes, e.g., to capture career paths or opportunities for professional mobility.
Work-related content models collect and curate structured information about occupations, their associated tasks, skills, and work activities, among other descriptive characteristics. Usually, related occupations are explicitly identified by domain experts. However, the evolution of workplace dynamics and activities, especially in some domains that are affected by technology, change rapidly, which makes relevant the possibility of finding relationships between occupations in an automated fashion, e.g., via the retrieval of related occupations based on their descriptions.
Recent achievements in the field of language models have opened new opportunities for the identification of related occupations from the text collected in content models, together with other related tasks [
5]. This may be useful for the manual evaluation of the occupational relations identified by experts but also for the discovery of relations between occupations. These discoveries can be relations that may have been overlooked or disregarded by experts, or that are emerging novelties in the evolution of an occupational context. This discovery is key in career planning or counseling and can be used as a component for the potential automation of those activities for particular workers.
In this context, in this research, we aimed to evaluate the differences in using curated and explicit transversal relations among occupations with relations extracted from the text using retrieval techniques from the same databases. Answering this research question has fundamental implications for the use of these two mechanisms separately or in combination in the context of specific tasks in career planning and other related scenarios.
Our point of departure is using word and sentence embeddings that are used as representations for language models. However, the limitations of language models for some particular use cases has resulted in the widespread use of vector databases [
6] or extensions of existing databases with vector search capabilities), which are based on text representations as vector embeddings for the storage and retrieval of their contents. These vector databases are now often used in combination with Large Language Models (LLMs) in the architectural pattern known as
Retrieval Augmented Generation (RAG) [
7]. In many cases, the overall performance of an LLM-based system depends on the fitness for the task of the retrieval part of the architecture. This highlights the need to evaluate vector retrieval systems separately when a task such as finding related occupations is clearly identified.
This paper reports the results of the experimental evaluation of two open-source vector databases for the task of retrieving related occupations, analyzing the impact of the different parts of the text comprising the descriptions of the occupations and also the fundamental configuration parameters of vector databases. We found that the two different databases show higher retrieval precision for lower cutoffs in the list of results, which is adequate for RAG settings. Notably, all of the configuration elements—the similarity metric chosen, the embedding of sentences, and the elements included in the text of the documents representing occupations—are significant in the overall performance. The analysis of discoveries (understood as retrieved occupations with close similarities that are not recorded explicitly in the reference database) shows that the text-based retrieval process captures hierarchical relationships in the structure of the occupation classification, but also other relations that cross-cut classification partitions. This suggests that text-based retrieval complements explicitly curated relations that have the potential to support different career transition or change tasks.
The remainder of this paper is structured as follows.
Section 2 describes background information on occupational databases and previous related work.
Section 3 details the dataset used and the setup of the experiments carried out. The results and discussion are provided in
Section 4. Finally,
Section 5 provides the conclusions and outlook.
2. Background
Occupational databases such as ESCO and O*NET provide frameworks for describing occupations in the form of a data model that includes textual descriptions and occupation labels, but also related structured elements including tasks and skills, work activities, and interests, among others. These related elements are important as constitutive elements of the occupation itself. For example, Consoli et al. [
8] evaluated how non-routine task reorientation evolves over time to adapt the labor market. In consequence, it appears that considering the description of tasks should be integral to understanding occupations.
Van Fosen et al. [
9] used O*NET classifications to identify related occupations based on their similarity to the knowledge, skills, values, and interests held by truck drivers. Their results showed that transition occupations may be identified by searching for occupations that share skills as well as the same work activities/industry as a given one.
Huang et al. [
10] found that focusing on soft (or non-technical) skills will allow hospitality employees to transfer to other in-demand sectors more easily, but additional training on technical skills would be needed to facilitate transitions into the healthcare and IT sectors.
While there is considerable literature on the matching of job offers with occupations or their components or job seeker profiles using text [
11,
12,
13], to our knowledge, previous studies that address the matching of occupation descriptions among themselves are scarce. Notably, Dahlke et al. [
14] report a method for identifying related occupations that is grounded in the notion of the similarity of work performed. Their experiments with different methods for computing similarity (including TF, TF-IDF, and a number of word embeddings) ended with the selection of an unweighted average of task-based similarity and DWA (detailed work activity)-based similarity.
Recent work has started to leverage LLMs for the task of matching occupational descriptions. Li et al. [
15] evaluated some of these models considering that related occupations are direct neighbors in the taxonomy, showing good results with some of the models. However, our approach here differs from theirs in that we use explicitly curated related occupations, which cross-cut the taxonomy, so their results are not comparable. Also, our approach is significantly more lightweight, as it is primarily intended to complement later processing with LLMs following a RAG pattern. Further, our approach can also be useful for discovering related occupations via retrieval, and not only evaluating similarities.
Vector databases or vector search database extensions [
6] differ from relational databases in several aspects, including query processing and optimization, and storage and indexing. However, the differences between vector extensions or vector databases appears to be related to the implementation of current extensions rather than to some fundamental issues [
16]. In any case, vector search capabilities are fundamentally targeted to some particular tasks that are based on retrieval, such as recommendation, similarity search, and applications as chatbots [
17]. The fundamental strength of vector databases or extensions lies in the representation of rich data as text using pre-trained embeddings that represent data as vectors. Searching is then performed as similarity-based retrieval using vectors and usually a variant of the k-nearest neighbor algorithm, and indexing also exploits that similarity. These allow for a degree of flexibility in querying that makes it especially useful in tasks that require ranked results based on a similarity score, as is our case with text-based descriptions of occupations.
3. Materials and Methods
3.1. Dataset
The Occupational Information Network (O*NET) is a comprehensive system developed by the U.S. Department of Labor that provides information on hundreds of occupations within the U.S. economy. The database is organized around major and minor occupation groups, and provides a rich content structure including titles and descriptions, but also other elements such as work contexts, abilities, skills, and activities.
The dataset was prepared from the download of the ONET database version 28.3 (All the releases are available for download in different formats at the O*Net website:
https://www.onetcenter.org/db_releases.html, accessed on 4 June 2025). Concretely, the tables used are the following:
Occupation Data: This contains descriptions of occupations. The field titlewas included in all the configurations of the experiment and the field Description in some of them.
Task Statements: This contains descriptions of all the tasks associated with each occupation. These were grouped by occupation (O*NET-SOC Code) and concatenated as a single string, tasks.
Alternate Titles: This contains the alternate titles for each occupation. These were grouped by occupation (O*NET-SOC Code) and concatenated as a single string, alts.
Work activities: This contains descriptions of activities considered requirements for the occupation. These activities were linked to a shorter list of skills found to be relevant in studies related to career transition [
18].
We have not included textual descriptions of elements that (in the form in which they are selected and described in O*NET) either represent cross-cutting general components such as abilities, or those that broadly describe the context of the occupations, such as knowledge and interests.
3.2. Vector Database Setup
The experiments require setting up vector database collections (indexes) with different configurations. We selected configuration options that hypothetically have the potential to impact the quality of the results of similarity queries. The elements of each configuration are the following:
The word embedding used, which impacts the representation of text and, consequently, the retrieval of related documents.
The distance metric used when comparing word vectors, which impacts how document vectors representing occupations are compared.
Text elements from the O*NET dataset included as part of indexed documents, which may contribute differently to the task.
We have not included other configuration parameters of the databases that are related to performance in terms of computing or response time, because these concerns are outside the scope of our research objectives.
The experimental setup included two open source databases that are widely used: ChromaDB (
https://www.trychroma.com/, accessed on 4 June 2025) and MilvusDB (
https://milvus.io/, accessed on 4 June 2025). In both cases, the setup was done locally, since query performance or scalability concerns are not part of the objectives of the experiments. The setup in both cases consisted of creating one collection per combination of the elements listed above. In both cases, Python 3.11. development interfaces were used. Chromadb 0.5.23 and Milvus-lite 2.4.10 have the same concept of collection, which represents a database of documents stored as word vectors using some particular embedding, plus arbitrary metadata or additional information (which can include the text in original form, titles or other). These collections are queried through indexes, for which distance metrics can be configured.
Table 1 shows the pre-trained embeddings used in the experiments, all of them available in the sentence-transformers Python 3.11. package and with open access versions in the HuggingFace site (
https://huggingface.co/, accessed on 4 June 2025). The all-* models were trained on all available training data (more than 1 billion training pairs) and are designed as general purpose models. The all-mpnet-base-v2 model provides the best quality, while all-MiniLM-L6-v2 is 5 times faster and still offers good quality according to the documentation of the library (
https://www.sbert.net/docs/sentence_transformer/pretrained_models.html, accessed on 4 June 2025). We have searched for domain-specific open access language models at the HuggingFace repository specifically trained or fine-tuned with occupational data or related text. We found no O*NET specific model, but we found several in the domain. Concretely, we have included in the experiments the embeddings of JobBERT [
19] and CareerBERT [
12]. JobBERT is a model for job titles, that augments the pre-trained language model all-mpnet-base-v2 with co-occurrence information from skill labels extracted from vacancies. CareerBERT is a model intended for job recommendations and trained on a corpus that combines data from the European Skills, Competences, and Occupations (ESCO) taxonomy and EURopean Employment Services (EURES) job advertisements. We have used the embeddings of two of its variants, as a baseline only, since the model is based on previous models trained on German language corpora, which would likely provide worse results. A third model, SkillBERT was also identified, but it was unavailable from HuggingFace at the time of carrying out the experiments.
Table 2 provides the different distance metrics used. These were limited by the available ones in each of the databases for local settings.
3.3. Experimental Setting
We used here as ground truth the related occupations actually reported in O*NET. Concretely, performance is considered to be related to the retrieval of those related occupations in the k top positions of the results from vector database queries. The metrics were computed by sampling metrics for some values , thus using those values as cutoff points for the list of results.
To evaluate the performance, we used precision (
1), recall (
2), and
(
3) measures as base metrics, which are commonly used in information retrieval systems. These measures were taken for different values of documents retrieved, e.g.,
, taking into account only the first
most relevant documents retrieved. We used the average precision (
AveP) metric to consider the order in which the occupations retrieved were ranked (according to their similarity scores). Note that
rel(k) is an indicator function equaling 1 if the item at rank k is a relevant document, and zero otherwise.
Due to the experimental setup, the number of retrieved documents in is .
In the evaluation, we took the size of the occupation database minus one (the occupation itself for which related occupations are retrieved) as the number of queries; therefore, we report the averages of the metrics above per collection.
Despite focusing on matching related occupations, we also extracted samples of occupations retrieved in high positions that are not among the ones listed in O*NET. It can be hypothesized that those may be occupations that are actually related but still not curated in O*NET, or might for some reason have been overlooked. We used a small distance threshold to limit the number of these potential discoveries collected for analysis and discussion.
4. Results and Discussion
4.1. Experiment Results
Table 3 details the scores for the best overall configurations for each of the databases. The precisions in general (as expected) are best for smaller
, which shows that manually curated relations are also relevant overall, because they are retrieved with high ranking when using the alternative approach of vector-based retrieval based on textual descriptions.
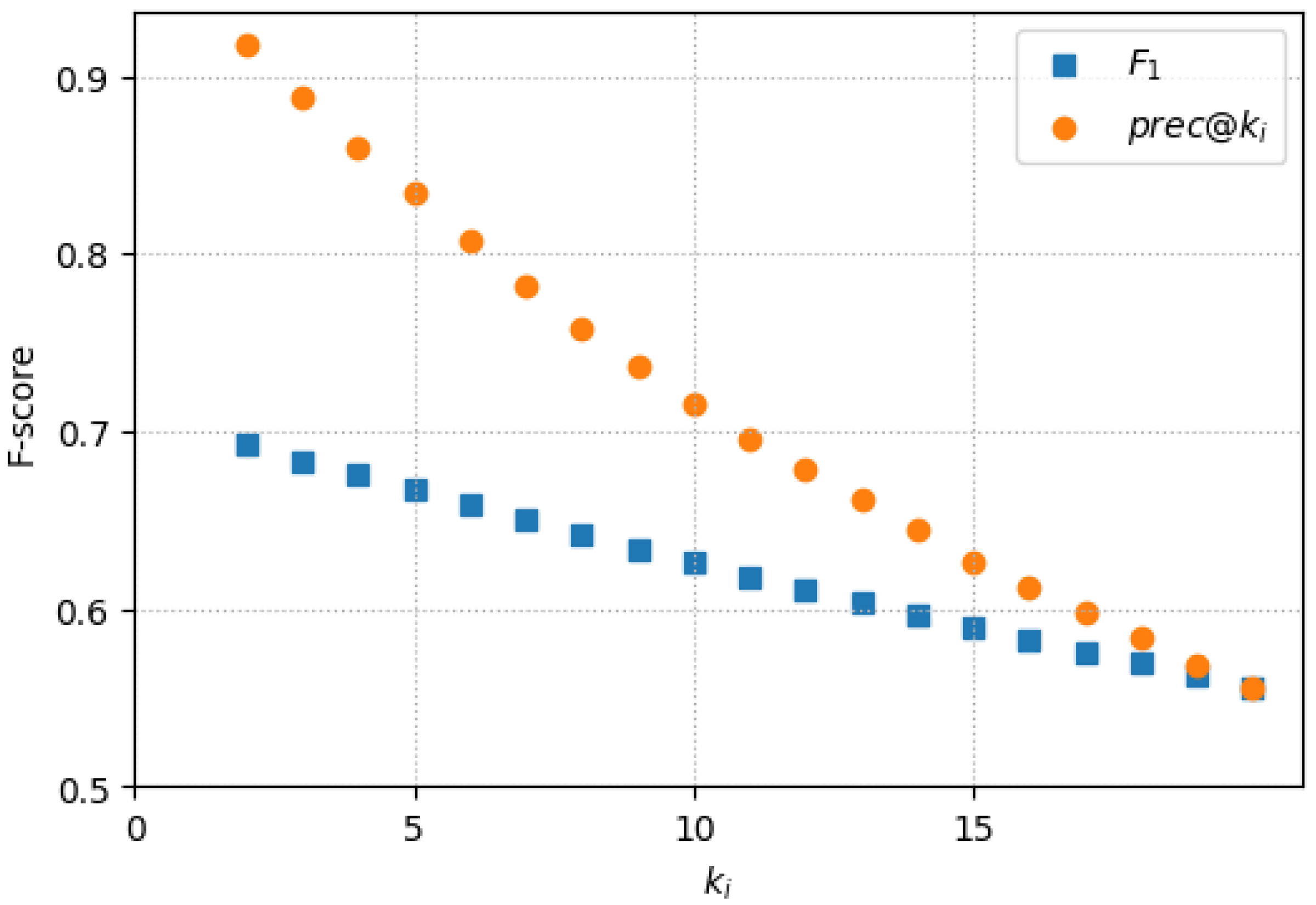
Figure 1 shows details of the metrics for the best configurations depending on
. In general, the precisions are high (above 0.8) for
. This is important because vector databases in RAG configurations are typically used to fetch samples for few-shot prompting patterns [
20]. In consequence, the best configurations provide results with high precision for these kinds of arrangements. Scenarios in which few-shot prompting could benefit high-precision-related competences are those that use Chain-of-Thought (CoT) [
21] patterns, e.g., when considering related career paths for a person that depart from a previous history of occupations. The metrics in
Table 4 show that text-based retrieval only partially matches manually curated relations. This highlights that those relations capture only some of the relations that are latent in textual descriptions, which calls for examining those (as performed in the next subsection).
Detailed average scores (across all
) for each configuration are provided for Milvus and Chroma in
Table 4. The average metrics clearly show very small differences between the two databases used in the experiments, which can be interpreted as evidence that the concrete implementation mechanisms of those databases do not play a major role in the quality of the results (they do in terms of the performance of the computations, but that is outside the scope of the objectives of this research).
The impact of domain-specific fine-tuning can be appreciated by comparing the results for the JobBERT and CareerBERT models. In the case of CareerBERT, the results are all lower than the worst results for all the configurations and the two variants tested. This was expected because the underlying models, such as gbert-base, are trained on German language corpora and evaluation sets [
22]. In fact, the best of these models reaches a 0.45 f-score, which is only slightly worse. This might be attributed to the common roots of both languages or contamination in training datasets. On the contrary, the JobBERT configuration slightly outperformed most of the configurations of the non-specific models. However, as can be appreciated from the metrics in
Table 4, the differences are small when compared to its base model, all_mpnet_base_v2. This points to a hypothetical potential impact of fine-tuning if performed with an O*NET corpus, but this does not invalidate the overall implications of the results.
The influence of the similarity metrics, embedding model, and test composition was analyzed using the Kruskal–Wallis H-test, separately for each of the databases. Regular multiway ANOVA could not be applied because some of the groups did not met the assumptions of normality and equal variances. The KW test evidenced that all the configuration elements showed statistically significant differences between two or more groups.
We used the estimation mutual information for the evaluation metrics to evaluate the relative influence of each of the configuration elements. The MI implementation used from the library scikit-learn is based on parametric methods based on entropy estimation from k-nearest neighbor distances. The results show that the most influential feature is the composition of text elements; the second is the sentence embedding, with the distance metric having negligible scores.
Regarding the ranking of related occupations according to their similarity, the mean average precision remains around 0.25 for the larger models, and between 0.12 and 0.16 for the smaller model. These relatively low scores can be interpreted as an indication that related occupations explicit in the database are generally not the most similar from the perspective of their descriptions; i.e., the embeddings in the databases consider aspects that may not be related to the criteria used by expert curators. This is consistent with the findings in the following section.
4.2. Potential Discoveries
The performance metrics discussed in the previous section assume that the related occupations that are explicitly provided and curated in the O*NET database are exhaustive for every context specific task. However, it can be hypothesized that those may miss some related occupations for various reasons (e.g., changes in the labor market or overlooked relations in the curation process) or that their curation may be adequate only for some particular tasks and not for others. Here, we approach that analysis by first selecting “discoveries” as strong relations between occupations that are different to those manually curated, and then examining those from the perspective of their position in the hierarchical structure of the database.
We considered as potential discoveries those related occupations retrieved from a configuration in the experiments with a high similarity that did not match related occupations in the ground truth (the O*NET database). The threshold of distance was set to 0.05 to locate only those discoveries that were very close to the occupation considered. With that threshold, around 50K were found in ChromaDB, and more than 72K in MilvusDB across all different configurations. This could be attributed to the implementation and default parameters of the corresponding retrieval algorithms.
Table 5 provides a listing of representative examples of discoveries that appear in both Milvus and ChromaDB. In some of the cases, we can see that related occupations belong to the same major group (the prefix of the code) in the SOC structure of O*NET, and also in the minor group and even broad occupation. For example, 25- refers to “Educational Instruction and Library Occupations”, and all the occupations that start with 25-1 are postsecondary teachers. This suggest that some of the related discoveries are actually included in the hierarchical taxonomy of the database. However, this is not the case for 29-2057.00, which belongs to the major group “Healthcare Practitioners and Technical Occupations”, and 51-9083.0, which belongs to the major group “Production Occupations”. In the latter case, relatedness appears to come from the domain.
We found a total of 18,226 pairs of unique discoveries appearing in both databases. In order to understand their relation to the hierarchical structure of O*NET, they were classified according to their position in the hierarchy. O*NET structures detailed occupations into broad occupations, which are in turn structured in minor and major groups, which map to the Standard Occupational Classification (SOC). These groupings are parts of the standard codes in O*NET.
Table 6 shows the distribution of pairs of discoveries found with respect to their position in the SOC hierarchy. Discoveries that match at the detailed level are likely to be variants that do not add value in a career change context. In the case of discoveries that match occupations in the same major, minor, and broad occupations, these represent occupations that are very close in context; as an example, 13-2050 (Financial Analysts and Advisors) groups financial and Investment Analysts, Personal Financial Advisors, Insurance Underwriters, and Financial Risk Specialists, which can be considered closely related paths rather than paths for career shifts. This is different in the case of discoveries in the same major or major+minor groups, because these groups often represent divergent expertise, sectors, or capacities. For example, the major group 11 (Management Occupations) is highly diverse. The finding that more than 68% of the discoveries are not even in the same major group confirms that matching based on text is potentially useful in career shift or re-skilling, because these discoveries show paths across broad categories of occupations.
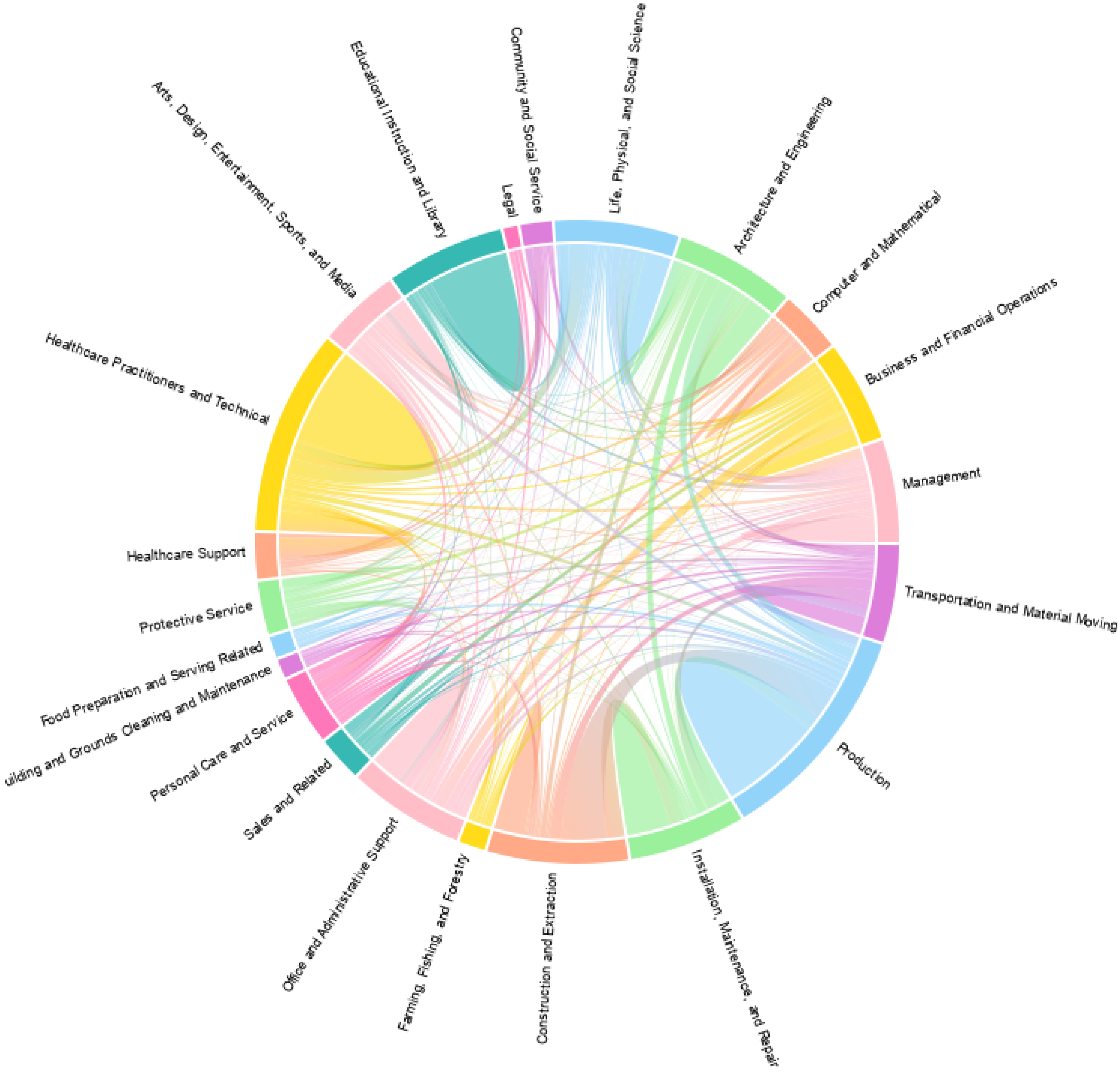
Figure 2 shows the connections of the discoveries across major occupational groups in O*NET. While it appears that some connections are stronger (e.g., the case of Architecture and Engineering with Installation, Maintenance and Repair), it is apparent that the retrieval procedures obtain connections across widely diverse areas. In some cases, they can be understood as career progressions, as the relations from Management, but in other cases, they cross domains and areas of activity. These require further investigation from career experts, but they are clearly reflecting paths with a potential to suggest re-skilling or career change.
4.3. Limitations
An important limitation of the research presented here is that it does not consider any concrete context-specific task in which the retrieval of related occupations may occur. For example, if the task were finding a career shift or transition [
23] plan from an individual, then considerations as the most similar in skills could be more important than the domain. However, if the aim were career growth in the same domain, then the effects of some parts of the text used for the retrieval would be different. This was not considered because it could not be performed from the ground truth available in O*NET, but it should be considered when using our results for design decisions in concrete applications. In this direction, the results described here can be considered to inform sub-tasks of relatedness retrieval that have to be complemented with contextual evaluations.
It is difficult to assess the extent to which the limitations of the content of the O*NET database itself affect the performance of the retrieval metrics. Handel et al. [
24] discuss that O*NET’s coverage of certain content areas, such as technology and employee involvement practices, is too sparse, while other content is redundant. These and other weaknesses may affect the retrieval due to the coverage, granularity, or details of different occupations. However, we have not found alternative databases that could be used in our experimental setting that may mitigate this potential limitation. It is worth mentioning in this regard that the O*NET Data Collection Program aimed at populating and updating the O*NET database includes procedures for maintaining data that are valid, reliable, current, and regularly updated.
5. Conclusions and Outlook
Occupational databases such as O*NET that implement data curation processes and describe occupations through structured descriptions can be used as document corpora to leverage natural language processing tools. Retrieving related occupations is a key sub-task within different application contexts that can be implemented either via text retrieval or via querying explicit available curated relations, or as a combination of both approaches. Vector databases represent text using pre-trained embeddings and are becoming increasingly adopted for retrieval tasks. In consequence, it is important to understand the extent to which text retrieval overlaps with queries based on curated relations in occupational databases. In this study, we evaluated that overlap for the task of matching occupations with related ones, contrasting retrieved occupations with those explicitly included in O*NET. We approached the task as a retrieval one and used two open source vector databases for the experiments. Because vector databases are typically used as a component of RAG-based systems, the results are relevant for assessing the retrieval component in LLM tasks that involve either few-shot prompting or, more generically, adding context to conversations or agentic systems. Moreover, the comparison is important for understanding the implications of using regular text-based RAG as an alternative or in combination with GraphRAG approaches [
25] in which graph representations of relations are used for the task.
The overall metrics obtained clearly highlight that text-based retrieval using vector representations only partially overlaps with retrieval based on curated, explicit relations. The results also evidence an absence of important differences in the overall results of the two databases, which points to the configuration of the documents and the retrieval mechanism as the determinants of performance. This is consistent with the statistical significance of the three elements considered in the configurations: distance metrics, sentence embeddings, and the pieces of text selected to compose the documents. The examination of the mean average precision, which accounts for the ranking given by the similarities, and an inspection of some of the related occupations highly ranked not in the database leads to the conclusion that the approach is considering similar traits as those used by the curators, but also others. While, at first glance, this may appear as a weakness of the approach, it combines a degree of incorporation of potential discoveries that may be helpful in a RAG setting. The analysis of discoveries (understood as retrieved related occupations that are not in the set of manually curated relations) reveals that text retrieval brings related occupations across major occupation groupings, thus capturing relations that have potential interest in different career or upskilling scenarios. The analysis of those relations, however, requires expert knowledge for their assessment, beyond the research objectives of this paper, and is thus left for future work.
The work presented here has addressed only the use of vector databases, leveraging the capabilities of word embeddings to relate similar occupation descriptions. Because vector databases are commonly used in combination with LLMs in the RAG or GraphRAG patterns, future work should assess that combination, accounting for the separate contribution of the retrieval part and the capabilities of the LLM. Further, the configuration of text elements is arguably highly dependent on the structure of the occupational database, which requires further experimentation with other occupational databases such as ESCO that have important differences in terms of both their database schemas and also their contents, scope, and coverage.







{kind=link}
{kind=link}