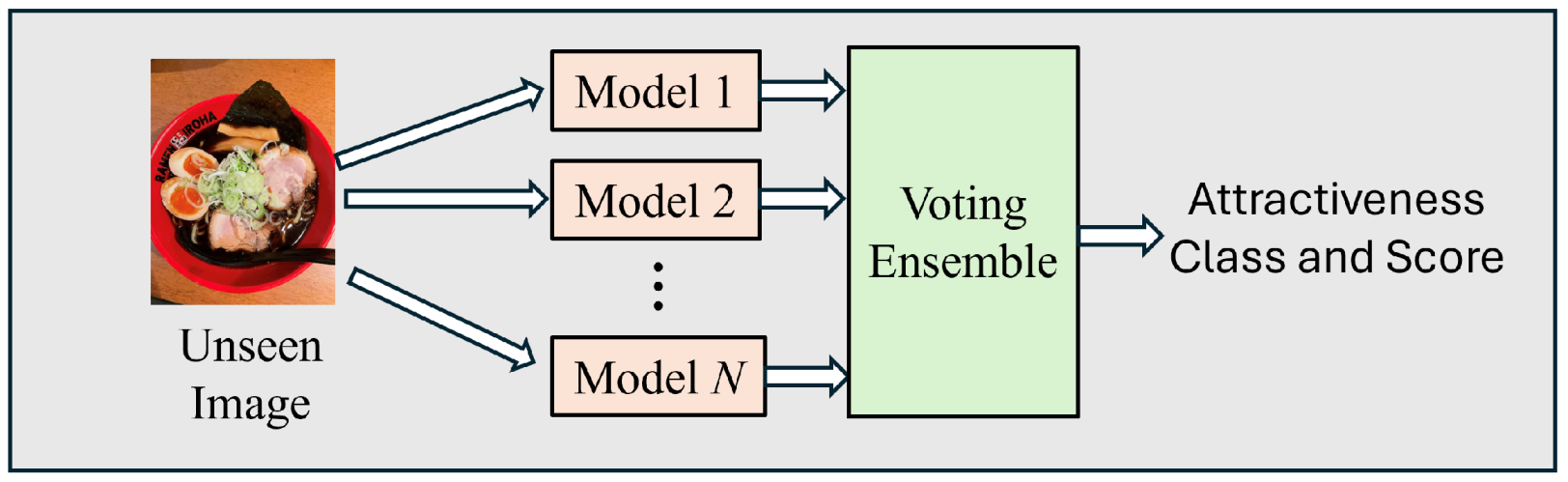
4.4.1. Quantitative Evaluation
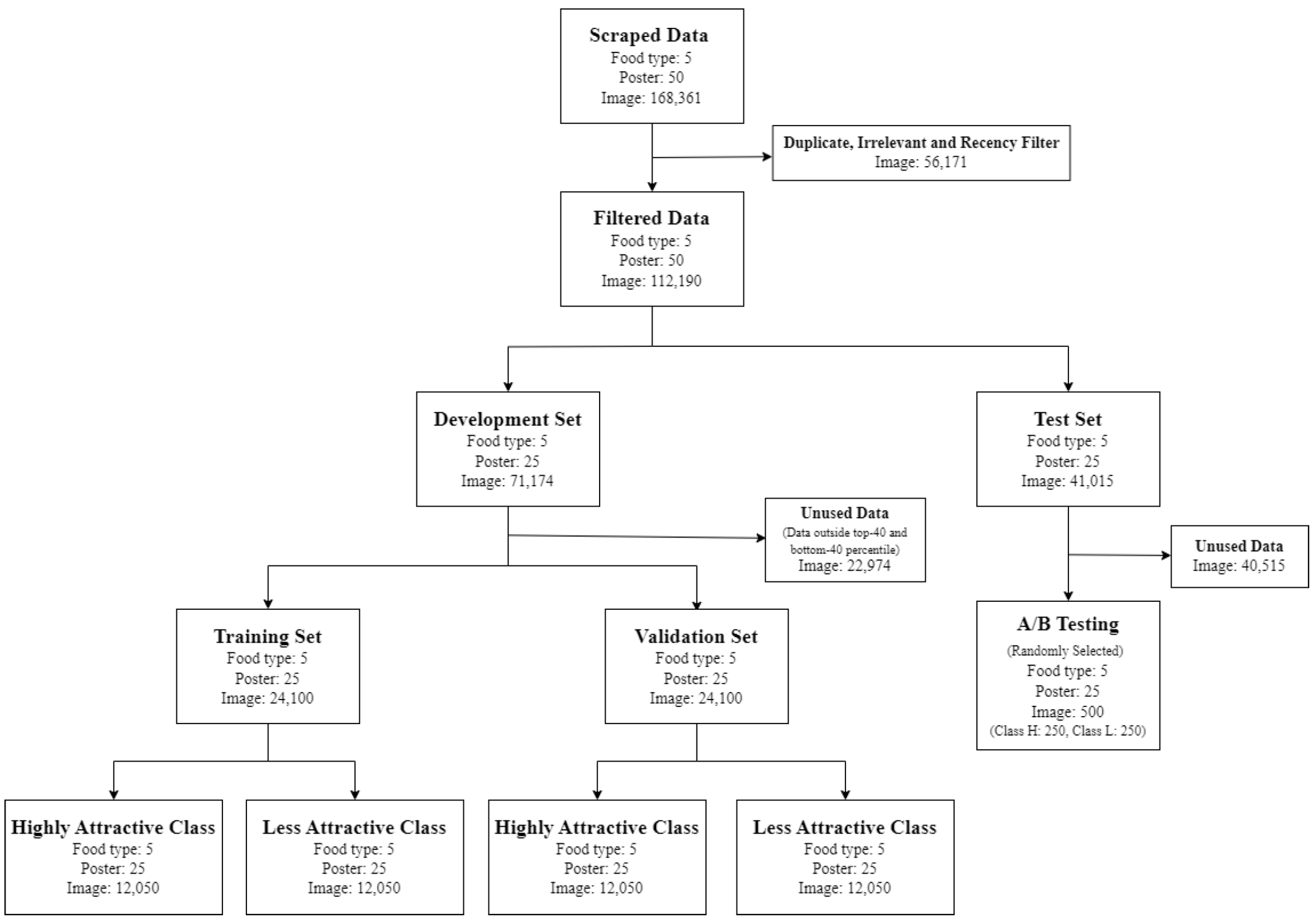
The proposed attractiveness assessment models were evaluated on 100 images for each food category, corresponding to 50 pairs in A/B testing, totaling 500 images. Similar to human evaluators in A/B testing, the models were tasked with selecting the more attractive image in each pair by comparing the predicted attractiveness scores. For the individual model, the attractiveness score is equal to the predicted probability of class H. For the ensemble model, the attractiveness score is calculated from the ratio of class H predictions made by the individual models to the total number of models.
The A/B testing results from the models are compared with (1) automatically labeled classes based on the number of likes and (2) the voting results of the human participants in A/B testing. The results are presented in
Table 6 and
Table 7, respectively. Yellow backgrounds indicate the best individual model results for each food category, while blue backgrounds indicate the ensemble results.
Table 6 presents the performance of various models in predicting the visual appeal of food images across five categories: sushi, ramen, pizza, burger, and cake. The predictions are compared against automatically labeled attractiveness classes. In this table, the consistency is calculated from the ratio of the number of images in class H that the model selects as more attractive in A/B testing to the number of testing pairs. For ensemble models, the best consistency of 90% is obtained in the sushi category, while the worst consistency of 66% is obtained in the cake category. The information from
Table 1 and
Table 6 shows that the prediction performance tends to increase as the number of training samples increases.
Next, in
Table 7, we compared the models’ judgments in A/B testing with the human participants’ judgments. In this table, the consistency is calculated as the ratio of the number of pairs where the model and the majority of the human participants select the same image as the more attractive image to the number of testing pairs. The results indicate that the ensemble models demonstrate consistent alignment with human judgments, with rates of 84% for sushi, 76% for ramen, 72% for pizza, 80% for burger, and 68% for cake images.
The results in
Table 6 align with those obtained in
Table 7 because of the high consistency between the automatic class labeling and A/B testing results from human voters, as previously shown in
Table 2. For burger, the results in
Table 6 and
Table 7 are exactly the same. The most significant difference in the results between
Table 6 and
Table 7 is sushi, which has a consistency with A/B testing results that is 6% lower than the consistency with the automatic class labeling. Four out of the five food categories have ensemble consistencies lower than those of the best individual models. The reason for this is that the performance of each individual model in the ensemble process is diverse. For example, in the case of pizza, the consistency of each individual model in
Table 7 varies from 50%, 62%, 64%, 74%, to 80%. Theoretically, if we assume that all individual models are independent, the expected consistency obtained from the ensemble model is 78.6%. The experimental result has a consistency of 72%, which is 6.6% lower than the expected result. On the other hand, for sushi, the consistency of each individual model listed in
Table 7 exhibits less variation (68%, 70%, 72%, 80%, and 82%) and a higher mean compared to the previous example. Theoretically, the expectation of the consistency obtained from the ensemble model is 89.2%. In this case, the expectation of ensemble consistency is higher than that of all individual consistencies. The experiment achieved a consistency of 84%, which is 5.2% lower than the expectation.
It is worth noting that some variations in performance exist across different cuisine categories, which may be attributable to factors such as the diversity of visual styles, cultural influences, or the specific characteristics of the training data within each category. However, the overall results are encouraging and underscore the promise of our approach in developing scalable and efficient solutions for computational aesthetic assessment, particularly in the domain of food images.
Moreover, we conduct a fine-grained evaluation to observe the consistency between the model-generated attractiveness scores and the human voting results in A/B testing. Let
P be the image that receives more votes from human participants, and let
N be the image that receives fewer votes. We calculate scores for comparison based on the differences in the number of votes between images
P and
N from both the human participants and the ensemble model, as detailed in Equations (
1) and (
2).
In the equations,
and
represent the number of votes for image
P in the A/B testing from the human participants and the ensemble model, respectively. Similarly,
and
represent the number of votes for image
N.
shows the difference in attractiveness for each testing pair in the A/B testing. The terms
and
indicate the score differences obtained from the human participants and the ensemble model, respectively. We categorized the values of
into six classes, referred to as
-class, as shown in
Table 8. The consistency of the
-class obtained from the model and the human results is illustrated as confusion matrices in
Table 9 and
Table 10.
Table 9 shows results from ensemble models.
Table 10 shows results from the best individual models. In these tables, a green background indicates that the votes from the model and humans are exactly the same. Light green signifies that votes from the model and humans differ by one or two levels of the
-class. A red background indicates that the winner of attractiveness voted by the model differs from that voted by the humans.
It can be concluded from the results in
Table 9 across all five food categories that 25.6% of the samples have a
from the model voting in the same
-class as from the human voting, 66.8% are within one level of
-class difference, and 87.6% are within two levels of
-class difference. On the other hand, for the best individual model in
Table 10, 20.0% of the samples have a
from the model voting in the same
-class as from the human voting, 60.0% are within one level of
-class difference, and 89.2% are within two levels of
-class difference. The fine-grained results from the ensemble model are closer to the human votes than those from the best individual models.
Additionally, considering the attractive vote winner that differs between the model and humans, there are a total of 60 samples where the ensemble model votes differ from those of the humans in the A/B testing. We found that in 71.6% of these cases, the -class is F1, which indicates that the ensemble models selected most of the incorrect images in the A/B testing with low confidence.
These results show the efficiency of our approach in leveraging Instagram to increase the number of likes and create labeled datasets for training aesthetic assessment models. The high degree of alignment between the models’ predictions and human perceptions highlights the potential of our method to capture and encode visual appeal accurately without the need for labor-intensive manual annotation.
4.4.2. Qualitative Evaluation
To analyze the factors that play important roles in image attractiveness, 32 sample images from the proposed framework’s attractiveness grading results are illustrated in
Figure 9. Food images within the same category, which are quite similar to each other, are grouped together, resulting in 12 groups for use in comparison. Color settings and lighting intensity impact attractiveness, as demonstrated in the Ramen-A (samples 8 and 9), Ramen-C (samples 13 and 14), and Pizza-A (samples 15, 16, and 17) groups. A warmer tone of lighting is shown to reduce attractiveness, as seen in the Ramen-A group, where sample 9 has a lower attractiveness score than sample 8, and in the Ramen-C group, where sample 14 scores lower than sample 13. Additionally, lighting temperature affects attractiveness scores; overly bright or dark lighting reduces the attractiveness score. This is demonstrated in the Pizza-A group, where sample 17 has a higher attractiveness score than samples 15 and 16. The number of foods in the image also affects attractiveness scores. This is evident in the Sushi-A (samples 1, 2, and 3) and Pizza-B (samples 18, 19, and 20) groups, where focusing on a single piece of sushi or pizza yields a higher attractiveness score. Similarly, results from the Cake-B group (samples 31 and 32) show that images containing both a drink and a cake have lower attractiveness scores compared to those focusing solely on a cake. In the case of burgers, results from the Burger-A (samples 21, 22, 23, and 24) and Burger-B (samples 25, 26, and 27) groups demonstrate that presenting more meats in the images can lead to higher attractiveness scores.
For an in-depth analysis of the results, gradient-weighted class activation mapping (Grad-CAM) [
45] is used. Grad-CAM is a technique that produces class activation maps highlighting important regions in an image for a classifier to predict each class probability. Let
and
represent the activation maps for classes H and L, respectively.
Figure 10 shows an example of Grad-CAM analysis from five models for one image.
highlights the regions that positively influence attractiveness, while
highlights regions that negatively influence attractiveness. Since each model learns the differences between two classes of attractiveness from different datasets, the important regions identified by each model may vary. For instance, consider the sliced meat region in the ramen image shown in
Figure 10. In models 4 and 5, this region positively influences attractiveness, whereas in model 1, a similar region negatively influences attractiveness.
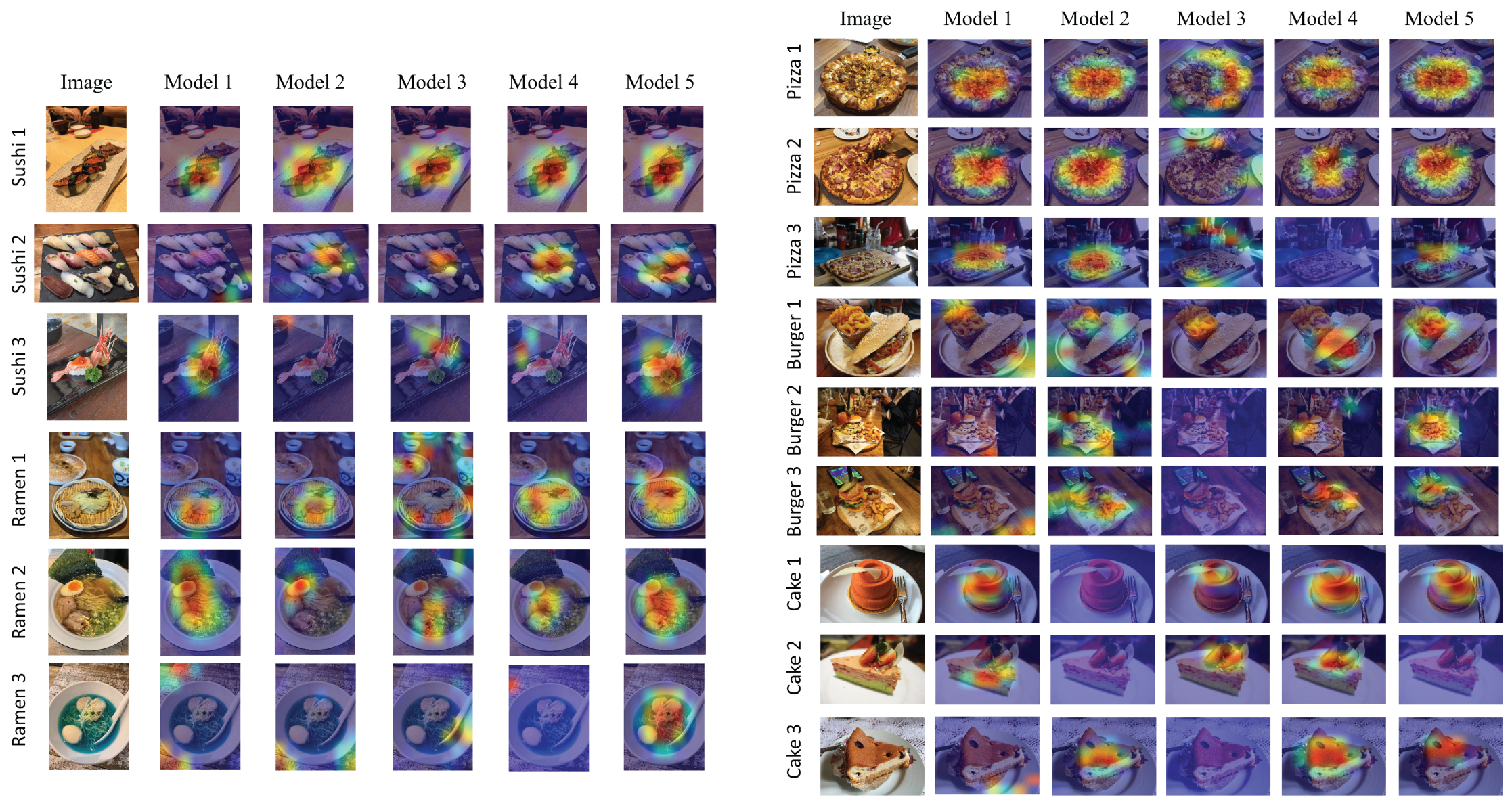
Figure 11 displays examples of
from fifteen food images extracted from five models, revealing patterns in their focus areas. In the case of Sushi 1, all models focus on the same area, demonstrating high confidence in the prediction. For Sushi 2, four out of five models focus on the salmon sushi, which is the most colorful piece in the image. In the Ramen 1 image, four models concentrate on the noodles, while one model focuses on surrounding objects, such as gyoza or a wooden plate. Similarly, in the Ramen 3 image, which features blue-colored soup, four models indicate that it is unattractive. From Pizza 1, four models focus on the toppings, while one model highlights the pizza crust. For Burger 1, four models focus on the fries, while one model focuses on the burger itself. Finally, in Cake 2, two models focus on the strawberry topping, while only one model concentrates on the body of the cake.
To summarize, by applying Grad-CAM, the proposed framework can not only analyze the level of food attractiveness but also identify the locations in the image that make it more or less attractive. This framework reveals insights into food image attractiveness that allow users to choose the most appropriate food images for advertising.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}