
Mixture of Attention Variants for Modal Fusion in Multi-Modal Sentiment Analysis

Abstract
1. Introduction
2. Related Work
2.1. Single-Modality Sentiment Analysis
2.1.1. Text Sentiment Analysis
2.1.2. Image Sentiment Analysis
2.1.3. Speech Emotion Analysis
2.2. Multi-Modal Sentiment Analysis
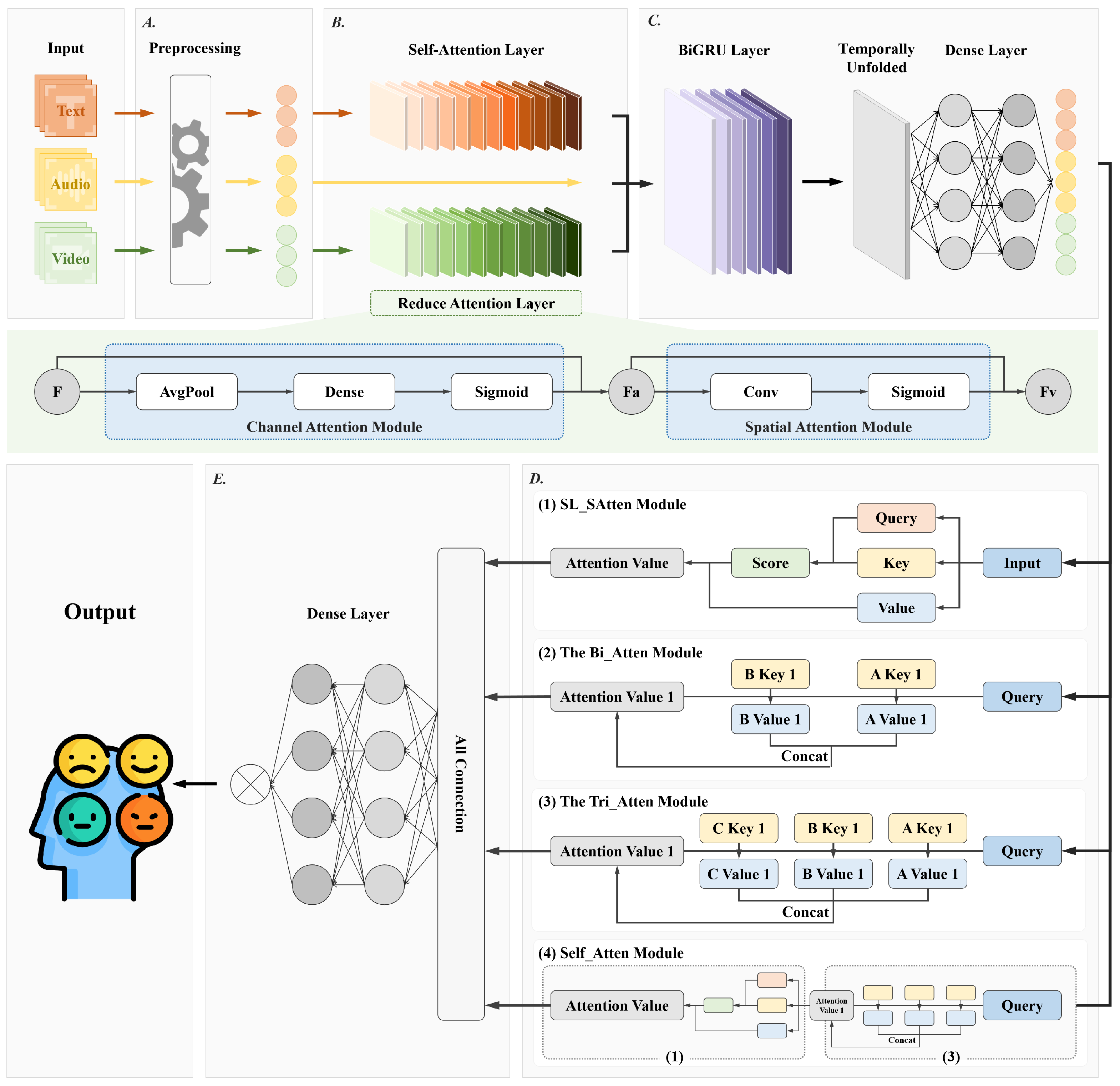
3. Method
3.1. Problem Definition
3.2. Model
3.2.1. Single-Modal Feature Representation
| Algorithm 1: MAVMF architecture |
 |
3.2.2. Single-Modal Attention
3.2.3. Contextual Feature Extraction
3.2.4. Multi-Modal Feature Fusion
3.2.5. Multi-Modal Sentiment Classification
4. Experiments
4.1. Data
4.2. Parameter Tuning
4.3. Baseline Models
- (1)
- GME-LSTM [48]: This model is composed of two modules. One is the gated multi-modal embedding module, which can perform information fusion in noisy environments. The other is an LSTM module with temporal attention, which can perform word-level fusion with a higher fusion resolution.
- (2)
- MARN [51]: This model captures the inter-relationships among text, images, and speech in a time series through multiple attention modules and stores the information in a long short-term hybrid memory.
- (3)
- TFN [47]: This model encodes intra-modal and inter-modal information by embedding subnetworks within a single modality and tensor fusion strategy.
- (4)
- MFRN [58]: This model first stores the modality information through a long short-term fusion memory network and fully considers the information of other modalities when encoding a certain modality, thereby enhancing the modality interactivity. Then, it further considers the information of other modalities when encoding a single modality through a modality fusion recurrent network. Finally, further information fusion is achieved through the attention mechanism.
- (5)
- Multilogue-Net [59]: Based on a recurrent neural network, this model captures the context of utterances and the relevance of the current speaker and listener in the utterance through multi-modal information.
- (6)
- DialogueRNN [60]: This model tracks the states of independent parties throughout the dialogue process and processes the information through a global GRU, party GRU, and emotion GRU units and uses it for emotion classification.
- (7)
- AMF-BiGRU [61]: This model first extracts the connections between contexts in each modality through the BiGRU, merges information through cross-modal attention, and finally uses multi-modal attention to select contributions from the merged information.
- (1)
- MFRN [58]: As described above.
- (2)
- Graph-MFN [62]: This model’s concept is similar to that of the MFN model, except that Graph-MFN uses a dynamic fusion graph to replace the fusion block in the MFN model.
- (3)
- CIM-Att [63]: This model first uses the BiGRU to extract the intra-modal context features, inputs these context features into the CIM attention module to capture the associations between pairwise modalities, and then concatenates the context features and CIM module features for sentiment classification.
- (4)
- AMF-BiGRU [61]: As described above.
- (5)
- MAM [64]: This model first uses the CNN and BiGRU to extract features from the text, speech, and image signals and then applies cross-modal attention and self-attention for information fusion and contribution selection.
5. Results
5.1. CMU-MOSI
5.2. CMU-MOSEI
5.3. Modality Analysis
5.4. Ablation Study
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Morency, L.P.; Mihalcea, R.; Doshi, P. Towards multimodal sentiment analysis: Harvesting opinions from the web. In Proceedings of the 13th International Conference on Multimodal Interfaces, Alicante, Spain, 14–18 November 2011; pp. 169–176. [Google Scholar]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages. IEEE Intell. Syst. 2016, 31, 82–88. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef]
- Prakash, A.; Chitta, K.; Geiger, A. Multi-modal fusion transformer for end-to-end autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7077–7087. [Google Scholar]
- Li, X.; Lu, G.M.; Yan, J.J.; Zhang, Z.Y. A Comprehensive Review on Multimodal Dimensional Emotion Prediction. Acta Autom. Sin. 2018, 44, 2142–2159. [Google Scholar]
- Grimaldo, F.; Lozano, M.; Barber, F. MADeM: A multi-modal decision making for social MAS. In Proceedings of the AAMAS (1), Estoril, Portugal, 12–16 May 2008; pp. 183–190. [Google Scholar]
- Zhu, L.; Zhu, Z.; Zhang, C.; Xu, Y.; Kong, X. Multimodal sentiment analysis based on fusion methods: A survey. Inf. Fusion 2023, 95, 306–325. [Google Scholar] [CrossRef]
- Song, X.J. A Study on Multimodal Emotion Recognition Based on Text, Speech, and Video. Master’s Thesis, Shandong University, Shandong, China, 2019. [Google Scholar]
- Liu, B. Sentiment Analysis and Opinion Mining; Springer Nature: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Ting, W.; Yang, W.Z. A Review of Text Sentiment Analysis Methods. J. Comput. Eng. Appl. 2021, 57, 11–24. [Google Scholar]
- Lin, J.H.; Gu, Y.L.; Zhou, Y.M.; Yang, A.M.; Chen, J. A Study on Constructing an Emotion Dictionary Based on Emoji. Comput. Technol. Dev. 2019, 29, 181–185. [Google Scholar]
- Mike, T.; Kevan, B.; Georgios, P.; Di, C.; Arvid, K. Sentiment in short strength detection informal text. JASIST 2010, 61, 2544–2558. [Google Scholar]
- Saif, H.; He, Y.; Fernandez, M.; Alani, H. Contextual semantics for sentiment analysis of Twitter. Inf. Process. Manag. 2016, 52, 5–19. [Google Scholar] [CrossRef]
- Li, Y.S.; Wang, L.M.; Chai, Y.M.; Liu, Z. A Study on Dynamic Emotion Dictionary Construction Method Based on Bidirectional LSTM. Microcomput. Syst. 2019, 40, 503–509. [Google Scholar]
- Kanayama, H.; Nasukawa, T. Fully automatic lexicon expansion for domain-oriented sentiment analysis. In Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, Sydney, Australia, 22–23 July 2006; pp. 355–363. [Google Scholar]
- Rao, Y.; Lei, J.; Wenyin, L.; Li, Q.; Chen, M. Building emotional dictionary for sentiment analysis of online news. World Wide Web 2014, 17, 723–742. [Google Scholar] [CrossRef]
- Qi, C.; Li, Z.; Jing, J.; Huang, X.Y. A Review Analysis Method Based on Support Vector Machine and Topic Model. J. Softw. 2019, 30, 1547–1560. [Google Scholar]
- Gang, Z.; Zan, X. A Study on Sentiment Analysis Model of Product Reviews Based on Machine Learning. Res. Inf. Secur. 2017, 3, 166–170. [Google Scholar]
- Kiritchenko, S.; Zhu, X.; Mohammad, S.M. Sentiment analysis of short informal texts. J. Artif. Intell. Res. 2014, 50, 723–762. [Google Scholar] [CrossRef]
- Da Silva, N.F.; Hruschka, E.R.; Hruschka, E.R., Jr. Tweet sentiment analysis with classifier ensembles. Decis. Support Syst. 2014, 66, 170–179. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Okada, M.; Yanagimoto, H.; Hashimoto, K. Sentiment Classification with Gated CNN and Spatial Pyramid Pooling. In Proceedings of the 2018 7th International Congress on Advanced Applied Informatics (IIAI-AAI), Yonago, Japan, 8–13 July 2018; pp. 133–138. [Google Scholar]
- Meng, J.; Long, Y.; Yu, Y.; Zhao, D.; Liu, S. Cross-domain text sentiment analysis based on CNN_FT method. Information 2019, 10, 162. [Google Scholar] [CrossRef]
- Jiang, M.; Zhang, W.; Zhang, M.; Wu, J.; Wen, T. An LSTM-CNN attention approach for aspect-level sentiment classification. J. Comput. Methods Sci. Eng. 2019, 19, 859–868. [Google Scholar] [CrossRef]
- Zhou, H.; Yu, Y.; Jia, Y.Y.; Zhao, W.L. A Study on Sentiment Classification of Online Consumer Reviews Based on Deep LSTM Neural Network. Chin. J. Med Libr. Inf. 2018, 27, 23–29. [Google Scholar]
- Luo, L.X. Network text sentiment analysis method combining LDA text representation and GRU-CNN. Pers. Ubiquitous Comput. 2019, 23, 405–412. [Google Scholar] [CrossRef]
- Minh, D.L.; Sadeghi-Niaraki, A.; Huy, H.D.; Min, K.; Moon, H. Deep learning approach for short-term stock trends prediction based on two-stream gated recurrent unit network. IEEE Access 2018, 6, 55392–55404. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, Y.; Tong, Y. Study of sentiment classification for Chinese microblog based on recurrent neural network. Chin. J. Electron. 2016, 25, 601–607. [Google Scholar] [CrossRef]
- Colombo, C.; Del Bimbo, A.; Pala, P. Semantics in visual information retrieval. IEEE Multimed. 1999, 6, 38–53. [Google Scholar] [CrossRef]
- Jindal, S.; Singh, S. Image sentiment analysis using deep convolutional neural networks with domain specific fine tuning. In Proceedings of the 2015 International Conference on Information Processing (ICIP), Pune, India, 16–19 December 2015; pp. 447–451. [Google Scholar]
- Yang, J.; She, D.; Sun, M.; Cheng, M.M.; Rosin, P.L.; Wang, L. Visual sentiment prediction based on automatic discovery of affective regions. IEEE Trans. Multimed. 2018, 20, 2513–2525. [Google Scholar] [CrossRef]
- Yang, J.; She, D.; Lai, Y.K.; Rosin, P.L.; Yang, M.H. Weakly supervised coupled networks for visual sentiment analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Lake Salt City, UT, USA, 18–22 June 2018; pp. 7584–7592. [Google Scholar]
- Kumar, A.; Jaiswal, A. Image sentiment analysis using convolutional neural network. In Proceedings of the Intelligent Systems Design and Applications: 17th International Conference on Intelligent Systems Design and Applications (ISDA 2017), Delhi, India, 14–16 December 2017; Springer: Berlin/Heidelberg, Germany, 2018; pp. 464–473. [Google Scholar]
- Truong, Q.T.; Lauw, H.W. Visual sentiment analysis for review images with item-oriented and user-oriented CNN. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1274–1282. [Google Scholar]
- You, Q.; Jin, H.; Luo, J. Visual sentiment analysis by attending on local image regions. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Wu, L.; Qi, M.; Jian, M.; Zhang, H. Visual sentiment analysis by combining global and local information. Neural Process. Lett. 2020, 51, 2063–2075. [Google Scholar] [CrossRef]
- Zheng, R.; Li, W.; Wang, Y. Visual sentiment analysis by leveraging local regions and human faces. In Proceedings of the MultiMedia Modeling: 26th International Conference, MMM 2020, Daejeon, Republic of Korea, 5–8 January 2020; Part I 26. Springer: Berlin/Heidelberg, Germany, 2020; pp. 303–314. [Google Scholar]
- Li, L.; Li, S.; Cao, D.; Lin, D. SentiNet: Mining visual sentiment from scratch. In Proceedings of the Advances in Computational Intelligence Systems: Contributions Presented at the 16th UK Workshop on Computational Intelligence, Lancaster, UK, 7–9 September 2016; Springer: Berlin/Heidelberg, Germany, 2017; pp. 309–317. [Google Scholar]
- Li, W.F. A Study on Social Emotion Classification Based on Multimodal Fusion. Master’s Thesis, Chongqing University of Posts and Telecommunications, Chongqing, China, 2019. [Google Scholar]
- Navas, E.; Hernáez, I.; Luengo, I. An objective and subjective study of the role of semantics and prosodic features in building corpora for emotional TTS. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1117–1127. [Google Scholar] [CrossRef]
- Xu, X.; Hu, Y.C.; Wang, Q.M. Speech Emotion Recognition System and Method Based on Machine Learning. Available online: https://wenku.baidu.com/view/8469574cb2717fd5360cba1aa8114431b80d8ed4?fr=xueshu_top&_wkts_=1706505509577&needWelcomeRecommand=1 (accessed on 1 January 2020).
- Li, B.; Dimitriadis, D.; Stolcke, A. Acoustic and lexical sentiment analysis for customer service calls. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5876–5880. [Google Scholar]
- Li, W.Q. A Comparative Study of Speech Enhancement Algorithms and Their Applications in Feature Extraction. Master’s Thesis, Shandong University, Shandong, China, 2020. [Google Scholar]
- He, J.; Liu, Y.; He, Z.W. Advances in Multimodal Emotion Recognition. Appl. Res. Comput. Jisuanji Yingyong Yanjiu 2018, 35, 3201–3205. [Google Scholar]
- Poria, S.; Cambria, E.; Gelbukh, A. Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2539–2544. [Google Scholar]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. Mosi: Multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos. arXiv 2016, arXiv:1606.06259. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor fusion network for multimodal sentiment analysis. arXiv 2017, arXiv:1707.07250. [Google Scholar]
- Chen, M.; Wang, S.; Liang, P.P.; Baltrušaitis, T.; Zadeh, A.; Morency, L.P. Multimodal sentiment analysis with word-level fusion and reinforcement learning. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 163–171. [Google Scholar]
- Poria, S.; Cambria, E.; Hazarika, D.; Majumder, N.; Zadeh, A.; Morency, L.P. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long papers), Vancouver, Canada, 30 July–4 August 2017; pp. 873–883. [Google Scholar]
- Poria, S.; Peng, H.; Hussain, A.; Howard, N.; Cambria, E. Ensemble application of convolutional neural networks and multiple kernel learning for multimodal sentiment analysis. Neurocomputing 2017, 261, 217–230. [Google Scholar] [CrossRef]
- Zadeh, A.; Liang, P.P.; Poria, S.; Vij, P.; Cambria, E.; Morency, L.P. Multi-attention recurrent network for human communication comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wang, D.; Guo, X.; Tian, Y.; Liu, J.; He, L.; Luo, X. TETFN: A text enhanced transformer fusion network for multimodal sentiment analysis. Pattern Recognit. 2023, 136, 109259. [Google Scholar] [CrossRef]
- Yang, B.; Wu, L.; Zhu, J.; Shao, B.; Lin, X.; Liu, T.Y. Multimodal sentiment analysis with two-phase multi-task learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2015–2024. [Google Scholar] [CrossRef]
- Wu, T.; Peng, J.; Zhang, W.; Zhang, H.; Tan, S.; Yi, F.; Ma, C.; Huang, Y. Video sentiment analysis with bimodal information-augmented multi-head attention. Knowl. Based Syst. 2022, 235, 107676. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Bell, P.; Lai, C. Cross-Attention is Not Enough: Incongruity-Aware Multimodal Sentiment Analysis and Emotion Recognition. arXiv 2023, arXiv:2305.13583. [Google Scholar]
- He, Y.; Sun, L.; Lian, Z.; Liu, B.; Tao, J.; Wang, M.; Cheng, Y. Multimodal Temporal Attention in Sentiment Analysis. In Proceedings of the 3rd International on Multimodal Sentiment Analysis Workshop and Challenge, Lisboa, Portugal, 10 October 2022; pp. 61–66. [Google Scholar]
- Mai, S.; Zeng, Y.; Zheng, S.; Hu, H. Hybrid contrastive learning of tri-modal representation for multimodal sentiment analysis. IEEE Trans. Affect. Comput. 2022, 14, 2276–2289. [Google Scholar] [CrossRef]
- Liu, Q. Study on Emotion Analysis Method Based on Multimodal Information Fusion. 2019. Available online: https://kns.cnki.net/kcms2/article/abstract?v=dFlgZ3unFPiOMAnTaqVHESvFy9yv01Hjk3IFI1xuIzn5BPQf5EAkVa1UDnqDorqJ7K6I8-P3WE6Wl9Yof-6g4u6lJPeMLt7zn8B0OubMKMFrUmR95rJDYPPvuBYrEVSuNDZcWhNIViNlwlDmr0ElJA==&uniplatform=NZKPT&language=CHS (accessed on 1 January 2020).
- Shenoy, A.; Sardana, A. Multilogue-net: A context aware rnn for multi-modal emotion detection and sentiment analysis in conversation. arXiv 2020, arXiv:2002.08267. [Google Scholar]
- Majumder, N.; Poria, S.; Hazarika, D.; Mihalcea, R.; Gelbukh, A.; Cambria, E. Dialoguernn: An attentive rnn for emotion detection in conversations. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6818–6825. [Google Scholar]
- Lai, X.M.; Tang, H.; Chen, H.Y.; Li, S.S. Feature Fusion Based on Attention Mechanism - Multi-modal Emotion Analysis Using Bidirectional Gated Recurrent Unit. Comput. Appl. 2021, 41, 1268. [Google Scholar]
- Zadeh, A.B.; Liang, P.P.; Poria, S.; Cambria, E.; Morency, L.P. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2236–2246. [Google Scholar]
- Akhtar, M.S.; Chauhan, D.S.; Ghosal, D.; Poria, S.; Ekbal, A.; Bhattacharyya, P. Multi-task learning for multi-modal emotion recognition and sentiment analysis. arXiv 2019, arXiv:1905.05812. [Google Scholar]
- Song, Y.F.; Ren, G.; Yang, Y.; Fan, X.C. Multi-task Multi-modal Emotion Analysis Based on Attention-driven Multilevel Hybrid Fusion. Appl. Res. Comput. Jisuanji Yingyong Yanjiu 2022, 39. [Google Scholar]
- Bao, G.B.; Li, G.L.; Wang, G.X. Bimodal Interaction Attention for Multi-modal Emotion Analysis. Comput. Sci. Explor. 2022, 16, 909. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Description | CMU-MOSI | CMU-MOSEI | ||
|---|---|---|---|---|
| Training Set | Test Set | Training Set | Test Set | |
| # Video | 62 | 31 | 2250 | 679 |
| # Utterance | 1447 | 752 | 16216 | 4625 |
| # Pos Utterance | 709 | 467 | 11498 | 3281 |
| # Neg Utterance | 738 | 285 | 4718 | 1344 |
| Parameter | Value |
|---|---|
| BiGRU unit | 300 |
| BiGRU dropout | 0.5 |
| fully connected unit | 100 |
| fully connected dropout | 0.5 |
| activation function | tanh |
| learning rate | 0.001 |
| batch processing | 32 |
| number of iterations | 64 |
| optimization function | Adam |
| loss function | categorical cross-entropy |
| Network Model | CMU-MOSI | |
|---|---|---|
| Accuracy (%) | F-1 | |
| GME-LSTM [48] | 76.50 | 73.40 |
| MARN [51] | 77.10 | 77.00 |
| TFN [47] | 77.10 | 77.90 |
| MFRN [58] | 78.10 | 77.90 |
| Multilogue-Net [59] | 81.19 | 80.10 |
| DialogueRNN [60] | 79.80 | 79.48 |
| AMF-BiGRU [61] | 82.05 | 82.02 |
| MAVMF | 82.31 | 82.20 |
| Network Model | CMU-MOSEI | |
|---|---|---|
| Accuracy (%) | F-1 | |
| MFRN [58] | 77.90 | 77.40 |
| Graph-MFN [62] | 76.90 | 77.00 |
| CIM-Att [63] | 79.80 | 77.60 |
| AMF-BiGRU [61] | 78.48 | 78.18 |
| MAM [64] | 81.00 | 78.90 |
| MAVMF | 81.10 | 79.48 |
| Network Model | CMU-MOSI | |
|---|---|---|
| Accuracy (%) | F-1 | |
| MAVMF_Concat | 70.74 | 71.01 |
| MAVMF_SAtten | 73.01 | 73.05 |
| MAVMF_RAtten | 73.27 | 73.24 |
| MAVMF_RAtten_SAtten | 75.00 | 74.95 |
| MAVMF_BiGRU | 80.32 | 80.21 |
| MAVMF_SL-SAtten | 80.72 | 81.09 |
| MAVMF_Bi-Atten | 81.12 | 81.10 |
| MAVMF_Tri-Atten | 81.38 | 81.41 |
| MAVMF_Self-Atten | 81.78 | 82.06 |
| MAVMF | 82.31 | 82.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, C.; Zhang, X.; Song, D.; Shen, Y.; Mao, C.; Wen, H.; Zhu , D.; Cai, L. Mixture of Attention Variants for Modal Fusion in Multi-Modal Sentiment Analysis. Big Data Cogn. Comput. 2024, 8, 14. https://doi.org/10.3390/bdcc8020014
He C, Zhang X, Song D, Shen Y, Mao C, Wen H, Zhu D, Cai L. Mixture of Attention Variants for Modal Fusion in Multi-Modal Sentiment Analysis. Big Data and Cognitive Computing. 2024; 8(2):14. https://doi.org/10.3390/bdcc8020014
Chicago/Turabian StyleHe, Chao, Xinghua Zhang, Dongqing Song, Yingshan Shen, Chengjie Mao, Huosheng Wen, Dingju Zhu , and Lihua Cai. 2024. "Mixture of Attention Variants for Modal Fusion in Multi-Modal Sentiment Analysis" Big Data and Cognitive Computing 8, no. 2: 14. https://doi.org/10.3390/bdcc8020014
APA StyleHe, C., Zhang, X., Song, D., Shen, Y., Mao, C., Wen, H., Zhu , D., & Cai, L. (2024). Mixture of Attention Variants for Modal Fusion in Multi-Modal Sentiment Analysis. Big Data and Cognitive Computing, 8(2), 14. https://doi.org/10.3390/bdcc8020014