
When Interfaces “Act for You”: An Eye-Tracking Experiment on Delegation, Transparency Cues, and Trust in Agentic Shopping Assistants





Abstract
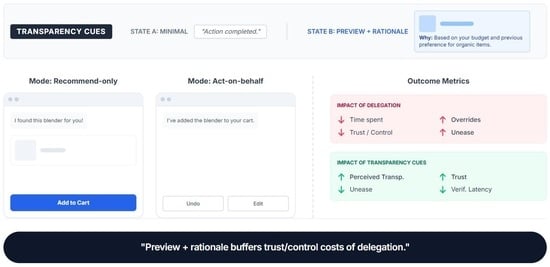
1. Introduction
2. Literature Review and Hypothesis Development
2.1. Action Autonomy in Agentic Interfaces: Delegation, Trust, Control, and Behavioral Trade-Offs
2.2. Transparency Cues as a Design Intervention: Rationale and Action Preview Effects
2.3. When Transparency Matters Most: Moderation by Autonomy and the Attention/Verification Mechanism
3. Research Methodology
3.1. Experimental Design
3.2. Participants
3.3. Experimental Materials, Apparatus and Procedure
3.4. Measurement Scales and Areas of Interest
4. Data Analysis and Results
4.1. Sample, Exclusions, and Descriptives
4.2. RQ1-Autonomy Effects (H1a–H1d)
4.3. RQ2-Transparency Effects
4.3.1. Manipulation Check: Transparency (H2a)
4.3.2. Transparency Effects (H2b–H2c)
4.4. RQ3: Autonomy × Transparency Interaction (H3)
4.5. RQ4: Eye-Tracking Outcomes
4.5.1. Attention Allocation to the Chat Interface (H4a)
4.5.2. Verification Switching Between Chat and Controls (H4b) and Verification Latency (H4c)
4.6. Consolidated Model Summary
5. Discussion
5.1. Interpretation: Autonomy Creates Efficiency but Control/Trust Costs (And When)
5.2. Transparency as Mitigation: Toward “Minimal Effective Transparency”
6. Practical Implications for Stakeholders and Design of Agentic Interfaces
7. Conclusions, Limitations, and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Variable | Type | Timepoint | Items/Operational Definition | Cronbach’s α |
|---|---|---|---|---|---|
| D1 | Participant ID | Identifier | Pre | Anonymous participant code | N/A |
| D2 | Transparency condition | Experimental factor (between) | Pre (assignment) | B0 = Minimal; B1 = Preview + rationale | N/A |
| D3 | Autonomy order | Counterbalance factor | Pre (assignment) | Recommend → Act vs. Act → Recommend | N/A |
| D4 | Autonomy mode (per task) | Experimental factor (within) | During (each task) | A0 = Recommend-only; A1 = Act-on-behalf | N/A |
| D5 | Task ID | Task marker | During | Task 1/Task 2/Task 3 | N/A |
| PRE1 | Trust Propensity (TP) | Baseline scale | Pre | TP1 rely on automated systems; TP2 trust new tech until reason not to; TP3 cautious about trusting automation (R) | α = 0.78 |
| PRE2 | Need for Control (NFC) | Baseline scale | Pre | NFC1 prefer final decision myself; NFC2 uncomfortable when system takes initiative; NFC3 stay in control each step | α = 0.81 |
| PRE3 | Privacy/Data Concern (PDC) | Baseline scale | Pre | PDC1 worry how data is used; PDC2 comfortable sharing preferences (R); PDC3 avoid tools that track behavior; PDC4 use only if data collection is clear | α = 0.84 |
| PRE4 | Shopping Self-Efficacy (SSE) | Baseline scale | Pre | SSE1 find best option without help; SSE2 confident managing coupon/cart/shipping; SSE3 complete purchases efficiently | α = 0.80 |
| ET1 | TTFF to Chat | Eye-tracking (primary) | During (each task) | Time from task start → first fixation in Chat AOI | N/A |
| ET2 | TTFF to Controls | Eye-tracking (primary) | During (each task) | Time from task start → first fixation in Controls AOI | N/A |
| ET3 | Dwell time: Chat | Eye-tracking (primary) | During (each task) | Total fixation duration in Chat AOI | N/A |
| ET4 | Dwell time: Product info | Eye-tracking (primary) | During (each task) | Total fixation duration in Product AOI | N/A |
| ET5 | Dwell time: Controls | Eye-tracking (primary) | During (each task) | Total fixation duration in Controls AOI | N/A |
| ET6 | Switches: Chat↔Controls | Eye-tracking (primary) | During (each task) | Number of transitions between Chat AOI and Controls AOI | N/A |
| ET7 | Verification latency (A1 only) | Eye-tracking (primary) | During (A1 tasks) | Assistant action timestamp → first fixation in updated cart/controls AOI | N/A |
| BL1 | Task completion time | Behavioral log (primary) | During (each task) | Task start → task complete event | N/A |
| BL7 | Override count | Behavioral log (primary) | During (each task) | Count of reversals (remove/replace item; undo cart add; change shipping; remove/change coupon) | N/A |
| BL8 | Any override | Behavioral log (primary) | During (each task) | Whether ≥1 override occurred | N/A |
| POST1 | State Trust (ST) | Post-task scale | Post-task (each task) | ST1 trusted choices; ST2 reliable; ST3 rely for similar tasks; ST4 needed to double-check (R) | α = 0.86 |
| POST2 | Perceived Control (PC) | Post-task scale | Post-task (each task) | PC1 felt in control; PC2 outcome reflected intentions; PC3 assistant reduced my control (R) | α = 0.83 |
| POST3 | Delegation Unease (DA) | Post-task scale | Post-task (each task) | DA1 uneasy; DA2 worried it might do something unwanted; DA3 comfortable delegating (R) | α = 0.88 |
| POST4 | Perceived Transparency (PT) | Manipulation check | Post-task (each task) | PT1 understood what it did/would do; PT2 understood why | α = 0.76 |
| END3 | Overall Trust/Acceptance (OT) | End scale | End | OT1 overall trust; OT2 would use; OT3 would recommend; OT4 would avoid act-on-behalf assistant (R) | α = 0.87 |
| END4 | Willingness to Delegate (WTD) | End scale | End | WTD1 low-risk; WTD2 medium-risk; WTD3 high-risk actions | α = 0.82 |
References
- Wang, J.; Fang, W.; Qiu, H.; Wang, Y. The Impact of Automation Failure on Unmanned Aircraft System Operators’ Performance, Workload, and Trust in Automation. Drones 2025, 9, 165. [Google Scholar] [CrossRef]
- Lee, J.; Abe, G.; Sato, K.; Itoh, M. Developing Human-Machine Trust: Impacts of Prior Instruction and Automation Failure on Driver Trust in Partially Automated Vehicles. Transp. Res. Part F Traffic Psychol. Behav. 2021, 81, 384–395. [Google Scholar] [CrossRef]
- Balfe, N.; Sharples, S.; Wilson, J.R. Understanding Is Key: An Analysis of Factors Pertaining to Trust in a Real-World Automation System. Hum. Factors 2018, 60, 477–495. [Google Scholar] [CrossRef]
- Miller, C.A.; Parasuraman, R. Designing for Flexible Interaction Between Humans and Automation: Delegation Interfaces for Supervisory Control. Hum. Factors 2007, 49, 57–75. [Google Scholar] [CrossRef]
- Bekler, M.; Yilmaz, M.; Ilgın, H.E. Assessing Feature Importance in Eye-Tracking Data within Virtual Reality Using Explainable Artificial Intelligence Techniques. Appl. Sci. 2024, 14, 6042. [Google Scholar] [CrossRef]
- Kohn, S.C.; de Visser, E.J.; Wiese, E.; Lee, Y.C.; Shaw, T.H. Measurement of Trust in Automation: A Narrative Review and Reference Guide. Front. Psychol. 2021, 12, 604977. [Google Scholar] [CrossRef]
- Miller, D.; Johns, M.; Mok, B.; Gowda, N.; Sirkin, D.; Lee, K.; Ju, W. Behavioral Measurement of Trust in Automation: The Trust Fall. In Proceedings of the Human Factors and Ergonomics Society; Human Factors an Ergonomics Society Inc.: Washington, DC, USA, 2016; pp. 1842–1846. [Google Scholar]
- Yao, X.; Chen, C.H.; Liu, B.; Ma, G.; Yu, X. An Explainable Eye-Tracking-Based Framework for Enhanced Level-Specific Situational Awareness Recognition in Air Traffic Control. Adv. Eng. Inform. 2026, 69, 103928. [Google Scholar] [CrossRef]
- Nagendran, M.; Festor, P.; Komorowski, M.; Gordon, A.C.; Faisal, A.A. Eye Tracking Insights into Physician Behaviour with Safe and Unsafe Explainable AI Recommendations. NPJ Digit. Med. 2024, 7, 202. [Google Scholar] [CrossRef] [PubMed]
- Wright, J.L.; Chen, J.Y.C.; Barnes, M.J.; Hancock, P.A. The Effect of Agent Reasoning Transparency on Complacent Behavior: An Analysis of Eye Movements and Response Performance. In Proceedings of the Human Factors and Ergonomics Society; Human Factors an Ergonomics Society Inc.: Washington, DC, USA, 2017; Volume 2017-October, pp. 1594–1598. [Google Scholar]
- Ehsan, U.; Passi, S.; Liao, Q.V.; Chan, L.; Lee, I.H.; Muller, M.; Riedl, M.O. The Who in XAI: How AI Background Shapes Perceptions of AI Explanations. In Proceedings of the Conference on Human Factors in Computing Systems—Proceedings; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar]
- Rodriguez Rodriguez, L.; Bustamante Orellana, C.E.; Chiou, E.K.; Huang, L.; Cooke, N.; Kang, Y. A Review of Mathematical Models of Human Trust in Automation. Front. Neuroergon. 2023, 4, 1171403. [Google Scholar] [CrossRef]
- Kang, Y.; Chen, J.; Liu, L.; Sharma, K.; Mazzarello, M.; Mora, S.; Duarte, F.; Ratti, C. Decoding Human Safety Perception with Eye-Tracking Systems, Street View Images, and Explainable AI. Comput. Environ. Urban Syst. 2026, 123, 102356. [Google Scholar] [CrossRef]
- Lin, C.T.; Fan, H.Y.; Chang, Y.C.; Ou, L.; Liu, J.; Wang, Y.K.; Jung, T.P. Modelling the Trust Value for Human Agents Based on Real-Time Human States in Human-Autonomous Teaming Systems. Technologies 2022, 10, 115. [Google Scholar] [CrossRef]
- Herrmann, T.; Pfeiffer, S. Keeping the Organization in the Loop: A Socio-Technical Extension of Human-Centered Artificial Intelligence. AI Soc. 2023, 38, 1523–1542. [Google Scholar] [CrossRef]
- Dodig-Crnkovic, G.; Burgin, M. A Systematic Approach to Autonomous Agents. Philosophies 2024, 9, 44. [Google Scholar] [CrossRef]
- Richardson, L.S.; Fidock, J.; Gunawan, I. Systematic Literature Review of Levels of Automation (Autonomy) Taxonomy: Critiques and Recommendations. Int. J. Hum. Comput. Interact. 2025, 41, 15824–15843. [Google Scholar] [CrossRef]
- Buldeo Rai, H.; Touami, S.; Dablanc, L. Autonomous E-Commerce Delivery in Ordinary and Exceptional Circumstances. The French Case. Res. Transp. Bus. Manag. 2022, 45, 100774. [Google Scholar] [CrossRef]
- Langer, M.; Baum, K.; Schlicker, N. Effective Human Oversight of AI-Based Systems: A Signal Detection Perspective on the Detection of Inaccurate and Unfair Outputs. Minds Mach. 2025, 35, 1. [Google Scholar] [CrossRef]
- Hancock, P.A. Avoiding Adverse Autonomous Agent Actions. Hum. Comput. Interact. 2022, 37, 211–236. [Google Scholar] [CrossRef]
- Schömbs, S.; Pareek, S.; Goncalves, J.; Johal, W. Robot-Assisted Decision-Making: Unveiling the Role of Uncertainty Visualisation and Embodiment. In Proceedings of the Conference on Human Factors in Computing Systems—Proceedings; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar]
- Melo, G.; Nascimento, N.; Alencar, P.; Cowan, D. Identifying Factors That Impact Levels of Automation in Autonomous Systems. IEEE Access 2023, 11, 56437–56452. [Google Scholar] [CrossRef]
- Halvachi, H.; Asghar, A.; Shirehjini, N.; Kakavand, Z.; Hashemi, N.; Shirmohammadi, S. The Effects of Interaction Conflicts, Levels of Automation, and Frequency of Automation on Human-Automation Trust and Acceptance. arXiv 2023, arXiv:2307.05512. [Google Scholar]
- Chen, V.; Liao, Q.V.; Wortman Vaughan, J.; Bansal, G. Understanding the Role of Human Intuition on Reliance in Human-AI Decision-Making with Explanations. Proc. ACM Hum. Comput. Interact. 2023, 7, 3610219. [Google Scholar] [CrossRef]
- Wang, P.; Ding, H. The Rationality of Explanation or Human Capacity? Understanding the Impact of Explainable Artificial Intelligence on Human-AI Trust and Decision Performance. Inf. Process. Manag. 2024, 61, 103732. [Google Scholar] [CrossRef]
- Vahdatian, P.; Latifi, M.; Ahsan, M. Designing Trustworthy Recommender Systems: A Glass-Box, Interpretable, and Auditable Approach. Electronics 2025, 14, 4890. [Google Scholar] [CrossRef]
- Shin, D. The Effects of Explainability and Causability on Perception, Trust, and Acceptance: Implications for Explainable AI. Int. J. Hum. Comput. Stud. 2021, 146, 102551. [Google Scholar] [CrossRef]
- Andrei, N.; Scarlat, C.; Ioanid, A. Transforming E-Commerce Logistics: Sustainable Practices through Autonomous Maritime and Last-Mile Transportation Solutions. Logistics 2024, 8, 71. [Google Scholar] [CrossRef]
- Spatola, N. The Efficiency-Accountability Tradeoff in AI Integration: Effects on Human Performance and over-Reliance. Comput. Hum. Behav. Artif. Hum. 2024, 2, 100099. [Google Scholar] [CrossRef]
- Xu, G.; Murthy, S.V.; Jia, B. Enhancing Intuitive Decision-Making and Reliance Through Human–AI Collaboration: A Review. Informatics 2025, 12, 135. [Google Scholar] [CrossRef]
- Pfaa, M.; Thomson, R.H.; Hooman, R.R. Measures for Explainable AI: Explanation Goodness, User Satisfaction, Mental Models, Curiosity, Trust, and Human-AI Performance. Front. Comput. Sci. 2023, 5, 1096257. [Google Scholar] [CrossRef]
- Olateju, O.O.; Okon, S.U.; Olaniyi, O.O.; Samuel-Okon, A.D.; Asonze, C.U. Exploring the Concept of Explainable AI and Developing Information Governance Standards for Enhancing Trust and Transparency in Handling Customer Data. J. Eng. Res. Rep. 2024, 26, 244–268. [Google Scholar] [CrossRef]
- Shabankareh, M.; Khamoushi Sahne, S.S.; Nazarian, A.; Foroudi, P. The Impact of AI Perceived Transparency on Trust in AI Recommendations in Healthcare Applications. Asia-Pac. J. Bus. Adm. 2025. [Google Scholar] [CrossRef]
- Ferrario, A.; Loi, M. How Explainability Contributes to Trust in AI. In Proceedings of the ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1457–1466. [Google Scholar]
- Muthusubramanian, M.; Jangoan, S.; Kumar Sharma, K.; Krishnamoorthy, G.; Financial Services, D.; America, H. Demystifying Explainable AI: Understanding, Transparency and Trust. Int. J. Multidiscip. Res. 2024, 6, 1–13. [Google Scholar]
- Sahu, G.; Gaur, L. Decoding the Recommender System: A Comprehensive Guide to Explainable AI in E-Commerce. In Studies in Computational Intelligence; Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2024; Volume 1094, pp. 33–52. [Google Scholar]
- Chaudhary, M.; Gaur, L.; Singh, G.; Afaq, A. Introduction to Explainable AI (XAI) in E-Commerce. In Studies in Computational Intelligence; Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2024; Volume 1094, pp. 1–15. [Google Scholar]
- Hoesterey, S.; Onnasch, L. The Effect of Risk on Trust Attitude and Trust Behavior in Interaction with Information and Decision Automation. Cogn. Technol. Work 2023, 25, 15–29. [Google Scholar] [CrossRef]
- Cymek, D.H. Redundant Automation Monitoring: Four Eyes Don’t See More Than Two, If Everyone Turns a Blind Eye. Hum. Factors 2018, 60, 902–921. [Google Scholar] [CrossRef]
- Bahner, J.E.; Hüper, A.D.; Manzey, D. Misuse of Automated Decision Aids: Complacency, Automation Bias and the Impact of Training Experience. Int. J. Hum. Comput. Stud. 2008, 66, 688–699. [Google Scholar] [CrossRef]
- Castner, N.; Arsiwala-Scheppach, L.; Mertens, S.; Krois, J.; Thaqi, E.; Kasneci, E.; Wahl, S.; Schwendicke, F. Expert Gaze as a Usability Indicator of Medical AI Decision Support Systems: A Preliminary Study. NPJ Digit. Med. 2024, 7, 199. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Kroon, A.C.; Möller, J.; de Vreese, C.H.; Boerman, S.C. When Recommendations Are Explainable: An Eye-Tracking Study Comparing How and What to Explain. Inf. Syst. Front. 2025, 28, 297–315. [Google Scholar] [CrossRef]
- Walker, R.M.; Yeung, D.Y.L.; Lee, M.J.; Lee, I.P. Assessing Information-Based Policy Tools: An Eye-Tracking Laboratory Experiment on Public Information Posters. J. Comp. Policy Anal. Res. Pract. 2020, 22, 558–578. [Google Scholar] [CrossRef]
- Peters, T.M.; Biermeier, K.; Scharlau, I. Assessing Healthy Distrust in Human-AI Interaction: Interpreting Changes in Visual Attention. Front. Psychol. 2026, 16, 1694367. [Google Scholar] [CrossRef] [PubMed]
- Mbelekani, N.Y.; Bengler, K. Learning Design Strategies for Optimizing User Behaviour Towards Automation: Architecting Quality Interactions from Concept to Prototype. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2023; Volume 14048 LNCS, pp. 90–111. [Google Scholar]
- He, J.; Liu, J. Not All Transparency Is Equal: Source Presentation Effects on Attention, Interaction, and Persuasion in Conversational Search. arXiv 2025, arXiv:2512.12207. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Q.; Chen, S.; Wang, C. How to Rationally Select Your Delegatee in PoS. arXiv 2023, arXiv:2310.08895. [Google Scholar] [CrossRef]
- Mohr, D.L.; Wilson, W.J.; Freund, R.J. Statistical Methods; Academic Press: Amsterdam, The Netherlands, 2021; ISBN 0-323-89988-9. [Google Scholar]
- Carter, B.T.; Luke, S.G. Best Practices in Eye Tracking Research. Int. J. Psychophysiol. 2020, 155, 49–62. [Google Scholar] [CrossRef]
- Worthy, D.A.; Lahey, J.N.; Priestley, S.L.; Palma, M.A. An Examination of the Effects of Eye-Tracking on Behavior in Psychology Experiments. Behav. Res. Methods 2024, 56, 6812–6825. [Google Scholar] [CrossRef]
- Duchowski, A.T.; Duchowski, A.T. Eye Tracking Methodology: Theory and Practice; Springer: Berlin/Heidelberg, Germany, 2017; ISBN 3-319-57883-9. [Google Scholar]
- Balaskas, S.; Rigou, M. The Effects of Emotional Appeals on Visual Behavior in the Context of Green Advertisements: An Exploratory Eye-Tracking Study. In Proceedings of the 27th Pan-Hellenic Conference on Progress in Computing and Informatics, Lamia, Greece, 24–26 November 2023; pp. 141–149. [Google Scholar]
- Gazepoint GP3 Eye-Tracker. Available online: https://www.gazept.com (accessed on 3 February 2026).
- Cuve, H.C.; Stojanov, J.; Roberts-Gaal, X.; Catmur, C.; Bird, G. Validation of Gazepoint Low-Cost Eye-Tracking and Psychophysiology Bundle. Behav. Res. Methods 2021, 54, 1027. [Google Scholar] [CrossRef] [PubMed]
- Brand, J.; Diamond, S.G.; Thomas, N.; Gilbert-Diamond, D. Evaluating the Data Quality of the Gazepoint GP3 Low-Cost Eye Tracker When Used Independently by Study Participants. Behav. Res. Methods 2021, 53, 1502–1514. [Google Scholar] [CrossRef] [PubMed]
- Olsen, A. The Tobii I-VT Fixation Filter. Tobii Technol. 2012, 21, 4–19. [Google Scholar]
- Salvucci, D.D.; Goldberg, J.H. Identifying Fixations and Saccades in Eye-Tracking Protocols. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications, Palm Beach Gardens, FL, USA, 6–8 November 2000; pp. 71–78. [Google Scholar]
- Komogortsev, O.V.; Gobert, D.V.; Jayarathna, S.; Gowda, S.M. Standardization of Automated Analyses of Oculomotor Fixation and Saccadic Behaviors. IEEE Trans. Biomed. Eng. 2010, 57, 2635–2645. [Google Scholar] [CrossRef] [PubMed]
- Bisong, E. Building Machine Learning and Deep Learning Models on Google Cloud Platform; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using Lme4. J. Stat. Softw. 2015, 67, 48. [Google Scholar] [CrossRef]
- Brown-Schmidt, S.; Naveiras, M.; De Boeck, P.; Cho, S.-J. Statistical Modeling of Intensive Categorical Time-Series Eye-Tracking Data Using Dynamic Generalized Linear Mixed-Effect Models with Crossed Random Effects. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 2020; Volume 73, pp. 1–31. ISBN 0079-7421. [Google Scholar]
- Silva, B.B.; Orrego-Carmona, D.; Szarkowska, A. Using Linear Mixed Models to Analyze Data from Eye-Tracking Research on Subtitling. Transl. Spaces 2022, 11, 60–88. [Google Scholar] [CrossRef]
- Mézière, D.C.; Yu, L.; Reichle, E.D.; Von Der Malsburg, T.; McArthur, G. Using Eye-tracking Measures to Predict Reading Comprehension. Read. Res. Q. 2023, 58, 425–449. [Google Scholar] [CrossRef]
- Orquin, J.L.; Ashby, N.J.S.; Clarke, A.D.F. Areas of Interest as a Signal Detection Problem in Behavioral Eye-tracking Research. J. Behav. Decis. Mak. 2016, 29, 103–115. [Google Scholar] [CrossRef]
- Holmqvist, K.; Nyström, M.; Andersson, R.; Dewhurst, R.; Jarodzka, H.; Van de Weijer, J. Eye Tracking: A Comprehensive Guide to Methods and Measures; Oup Oxford: Oxford, UK, 2011; ISBN 0-19-162542-6. [Google Scholar]
- Friedrich, M.; Rußwinkel, N.; Möhlenbrink, C. A Guideline for Integrating Dynamic Areas of Interests in Existing Set-up for Capturing Eye Movement: Looking at Moving Aircraft. Behav. Res. Methods 2017, 49, 822–834. [Google Scholar] [CrossRef]
- Müller, H.-G.; Stadtmüller, U. Generalized Functional Linear Models. arXiv 2005, arXiv:math/0505638. [Google Scholar] [CrossRef]
- Barr, D.J. Analyzing ‘Visual World’Eyetracking Data Using Multilevel Logistic Regression. J. Mem. Lang. 2008, 59, 457–474. [Google Scholar] [CrossRef]
- Bender, R.; Lange, S. Adjusting for Multiple Testing—When and How? J. Clin. Epidemiol. 2001, 54, 343–349. [Google Scholar] [CrossRef] [PubMed]
- Khuri, A.I.; Mukherjee, B.; Sinha, B.K.; Ghosh, M. Design Issues for Generalized Linear Models: A Review. arXiv 2006, arXiv:math/0701088. [Google Scholar] [CrossRef]





| Autonomy Mode (Within-Subject) | B0 Minimal (No Preview/Rationale) | B1 Preview + Rationale (Brief “What/Why” + Action Preview) |
|---|---|---|
| A0 Recommend-only (assistant suggests; user executes) | Chat content: Product recommendation (+optional coupon/shipping suggestion). User action: Participant clicks Add-to-cart/coupon/shipping. Interface cue: Cart/order module remains unchanged until user action. | Chat content: Recommendation + brief constraint-based rationale + preview of intended action sequence. User action: Participant clicks Add-to-cart/coupon/shipping. Interface cue: Cart/order module remains unchanged until user action. |
| A1 Act-on-behalf (assistant executes; user can undo/edit) | Chat content: Assistant executes predefined actions (add-to-cart; apply coupon if applicable; select shipping; proceed to review) and confirms completion. Interface cue: Cart/order module updates automatically; user can undo/edit. | Chat content: Same executed actions + brief rationale + action preview (constraint checks + planned action chain). Interface cue: Cart/order module updates automatically; user can undo/edit. |
| Transparency | Autonomy | Trust | Control | Unease | Perceived Transparency | Time (s) | Override Count | Any Override % (n) | Chat Gaze Share | Dwell Chat (ms) | Chat–Controls Switches |
|---|---|---|---|---|---|---|---|---|---|---|---|
| B0 minimal | A0 recommend-only | 3.97 (0.50) | 4.59 (0.64) | 3.72 (0.49) | 4.18 (0.54) | 176.83 (28.60) | 0.41 (0.63) | 33.3% (18) | 0.278 (0.047) | 15,294 (2994) | 7.09 (2.77) |
| B0 minimal | A1 act-on-behalf | 3.61 (0.47) | 4.03 (0.58) | 4.44 (0.59) | 4.29 (0.72) | 150.14 (32.21) | 0.89 (1.02) | 57.4% (31) | 0.282 (0.057) | 17,521 (4295) | 13.11 (3.18) |
| B1 preview + rationale | A0 recommend-only | 4.52 (0.46) | 4.68 (0.60) | 3.24 (0.56) | 5.19 (0.58) | 179.73 (29.09) | 0.35 (0.56) | 31.5% (17) | 0.333 (0.050) | 19,964 (2615) | 6.33 (3.14) |
| B1 preview + rationale | A1 act-on-behalf | 5.12 (0.51) | 4.83 (0.52) | 3.88 (0.63) | 5.16 (0.51) | 150.15 (29.60) | 0.74 (0.76) | 55.6% (30) | 0.382 (0.056) | 25,000 (3916) | 9.24 (3.49) |
| Transparency | n (Tasks) | n (Participants) | Action Verification Latency (ms) |
|---|---|---|---|
| B0 minimal | 54 | 36 | 850.0 (169.8) |
| B1 preview + rationale | 54 | 36 | 522.6 (157.8) |
| DV | Term | β | 95% CI | p-Value |
|---|---|---|---|---|
| Trust (ST) | Autonomy | −0.345 | [−0.505, −0.185] | <0.001 |
| Trust (ST) | Transparency | +0.552 | [+0.354, +0.751] | <0.001 |
| Trust (ST) | Autonomy × Transparency | +0.960 | [+0.738, +1.183] | <0.001 |
| Control (PC) | Autonomy | −0.614 | [−0.829, −0.400] | <0.001 |
| Control (PC) | Transparency | +0.085 | [−0.139, +0.310] | 0.454 |
| Control (PC) | Autonomy × Transparency | +0.719 | [+0.423, +1.015] | <0.001 |
| Unease (DA) | Autonomy | +0.753 | [+0.543, +0.963] | <0.001 |
| Unease (DA) | Transparency | −0.476 | [−0.697, −0.256] | <0.001 |
| Unease (DA) | Autonomy × Transparency | −0.090 | [−0.381, +0.200] | 0.540 |
| Time (s) | Autonomy | −25.832 | [−30.541, −21.123] | <0.001 |
| Time (s) | Transparency | +3.258 | [−2.733, +9.250] | 0.284 |
| Time (s) | Autonomy × Transparency | −3.598 | [−10.172, +2.977] | 0.282 |
| Logistic GLMM | ||||
| DV | Term | OR | 95% CI | p |
| Any override | Autonomy | 3.034 | [1.338, 6.875] | 0.0079 |
| Any override | Transparency | 0.918 | [0.408, 2.066] | 0.836 |
| Any override | Autonomy × Transparency | 1.010 | [0.332, 3.073] | 0.986 |
| DV | Autonomy | Δ (B1 − B0) | SE | 95% CI | p-Value |
|---|---|---|---|---|---|
| Trust (ST) | A0 recommend-only | 0.552 | 0.100 | [0.354, 0.751] | <0.0001 |
| Trust (ST) | A1 act-on-behalf | 1.513 | 0.100 | [1.314, 1.711] | <0.0001 |
| Control (PC) | A0 recommend-only | 0.085 | 0.114 | [−0.139, 0.310] | 0.454 |
| Control (PC) | A1 act-on-behalf | 0.805 | 0.114 | [0.580, 1.030] | <0.0001 |
| DV | Key Term | β | 95% CI | p-Value | Decision |
|---|---|---|---|---|---|
| Perceived transparency (PT) | Transparency | +1.019 | [0.796, 1.241] | <0.001 | Supported |
| Trust (ST) | Transparency | +0.552 | [0.354, 0.751] | <0.001 | Supported |
| Control (PC) | Transparency | +0.085 | [−0.139, 0.310] | 0.454 | Not supported (main effect) |
| Unease (DA) | Transparency | −0.476 | [−0.697, −0.256] | <0.001 | Supported |
| Time (s) (secondary) | Transparency | +3.258 | [−2.733, 9.250] | 0.284 | Not supported |
| Logistic GLMM | |||||
| DV | Key term | OR | 95% CI | p-value | Decision |
| Any override | Transparency | 0.918 | [0.408, 2.066] | 0.836 | Not supported |
| DV | Model | Interaction Term (β/OR) | 95% CI | p | H3 Supported? |
|---|---|---|---|---|---|
| Trust (ST) | LMM | β = +0.960 | [+0.738, +1.183] | <0.001 | Yes |
| Control (PC) | LMM | β = +0.719 | [+0.423, +1.015] | <0.001 | Yes |
| Unease (DA) | LMM | β = −0.090 | [−0.381, +0.200] | 0.540 | No |
| Any override | Logistic GLMM | OR = 1.010 | [0.332, 3.073] | 0.986 | No |
| Time (s) (secondary) | LMM | β = −3.598 | [−10.172, +2.977] | 0.282 | No (secondary) |
| DV | Autonomy | Δ (B1 − B0) | SE | 95% CI | p-Value |
|---|---|---|---|---|---|
| Trust (ST) | A0 recommend-only | 0.552 | 0.100 | [0.354, 0.751] | <0.0001 |
| Trust (ST) | A1 act-on-behalf | 1.513 | 0.100 | [1.314, 1.711] | <0.0001 |
| Control (PC) | A0 recommend-only | 0.085 | 0.114 | [−0.139, 0.310] | 0.454 |
| Control (PC) | A1 act-on-behalf | 0.805 | 0.114 | [0.580, 1.030] | <0.0001 |
| DV | Term | Effect (Scale) | 95% CI | p-Value | Decision? |
|---|---|---|---|---|---|
| H4a (primary): gaze_share_chat | autonomy | β = +0.0092 | [−0.0099, +0.0284] | 0.3417 | - |
| cond_transparency | β = +0.0545 | [+0.0343, +0.0748] | <0.001 | Yes | |
| autonomy × cond_transparency | β = +0.0458 | [+0.0194, +0.0722] | 0.0008 | ||
| H4a (secondary): dwell_chat_ms | autonomy | β = +2471.9 ms | [+1121.0, +3822.9] | 0.0004 | |
| cond_transparency | β = +4669.4 ms | [+3355.5, +5983.3] | <0.001 | Yes | |
| autonomy × cond_transparency | β = +2810.9 ms | [+958.1, +4663.6] | 0.0031 | ||
| H4b: switch_chat_controls (count) | autonomy | IRR = 1.90 | [1.67, 2.16] | <0.001 | |
| cond_transparency | IRR = 0.893 | [0.768, 1.040] | 0.143 | No | |
| autonomy × cond_transparency | IRR = 0.788 | [0.654, 0.950] | 0.0126 | ||
| H4c (A1-only): action_verify_latency_ms | cond_transparency | β = −331 ms | [−396, −266] | <0.001 | Yes |
| DV (Scale) | Autonomy (A1 vs. A0) | Transparency (B1 vs. B0) | Autonomy × Transparency |
|---|---|---|---|
| Self-report | |||
| Trust (ST) | β = −0.345 [−0.505, −0.185], p < 0.001 | β = +0.552 [+0.354, +0.751], p < 0.001 | β = +0.960 [+0.738, +1.183], p < 0.001 |
| Control (PC) | β = −0.614 [−0.829, −0.400], p < 0.001 | β = +0.085 [−0.139, +0.310], p = 0.454 | β = +0.719 [+0.423, +1.015], p < 0.001 |
| Unease (DA) | β = +0.753 [+0.543, +0.963], p < 0.001 | β = −0.476 [−0.697, −0.256], p < 0.001 | β = −0.090 [−0.381, +0.200], p = 0.540 |
| Perceived transparency (PT) (manipulation check) | β = +0.102 [−0.128, +0.331], p = 0.383 | β = +1.019 [+0.796, +1.241], p < 0.001 | β = −0.148 [−0.463, +0.167], p = 0.355 |
| Behavioral logs | |||
| Time (s) | β = −25.832 [−30.541, −21.123], p < 0.001 | β = +3.258 [−2.733, +9.250], p = 0.284 | β = −3.598 [−10.172, +2.977], p = 0.282 |
| Any override (binary) | OR = 3.034 [1.338, 6.875], p = 0.0079 | OR = 0.918 [0.408, 2.066], p = 0.836 | OR = 1.010 [0.332, 3.073], p = 0.986 |
| Eye-tracking | |||
| Gaze share to chat | β = +0.0092 [−0.0099, +0.0284], p = 0.342 | β = +0.0545 [+0.0343, +0.0748], p < 0.001 | β = +0.0458 [+0.0194, +0.0722], p = 0.0008 |
| Chat dwell (ms) | β = +2471.9 [+1121.0, +3822.9], p = 0.0004 | β = +4669.4 [+3355.5, +5983.3], p < 0.001 | β = +2810.9 [+958.1, +4663.6], p = 0.0031 |
| Chat↔Controls switches (count) | IRR = 1.90 [1.67, 2.16], p < 0.001 | IRR = 0.893 [0.768, 1.040], p = 0.143 | IRR = 0.788 [0.654, 0.950], p = 0.0126 |
| Action verification latency (ms) (A1-only) | — | β = −331 [−396, −266], p < 0.001 | — |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Share and Cite
Balaskas, S.; Komis, K.; Yfantidou, I.; Skandali, D. When Interfaces “Act for You”: An Eye-Tracking Experiment on Delegation, Transparency Cues, and Trust in Agentic Shopping Assistants. Multimodal Technol. Interact. 2026, 10, 22. https://doi.org/10.3390/mti10030022
Balaskas S, Komis K, Yfantidou I, Skandali D. When Interfaces “Act for You”: An Eye-Tracking Experiment on Delegation, Transparency Cues, and Trust in Agentic Shopping Assistants. Multimodal Technologies and Interaction. 2026; 10(3):22. https://doi.org/10.3390/mti10030022
Chicago/Turabian StyleBalaskas, Stefanos, Kyriakos Komis, Ioanna Yfantidou, and Dimitra Skandali. 2026. "When Interfaces “Act for You”: An Eye-Tracking Experiment on Delegation, Transparency Cues, and Trust in Agentic Shopping Assistants" Multimodal Technologies and Interaction 10, no. 3: 22. https://doi.org/10.3390/mti10030022
APA StyleBalaskas, S., Komis, K., Yfantidou, I., & Skandali, D. (2026). When Interfaces “Act for You”: An Eye-Tracking Experiment on Delegation, Transparency Cues, and Trust in Agentic Shopping Assistants. Multimodal Technologies and Interaction, 10(3), 22. https://doi.org/10.3390/mti10030022