Decoding Images in the Mind’s Eye: The Temporal Dynamics of Visual Imagery



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Experimental Structure
2.2. Participants
2.3. Behavioural Data
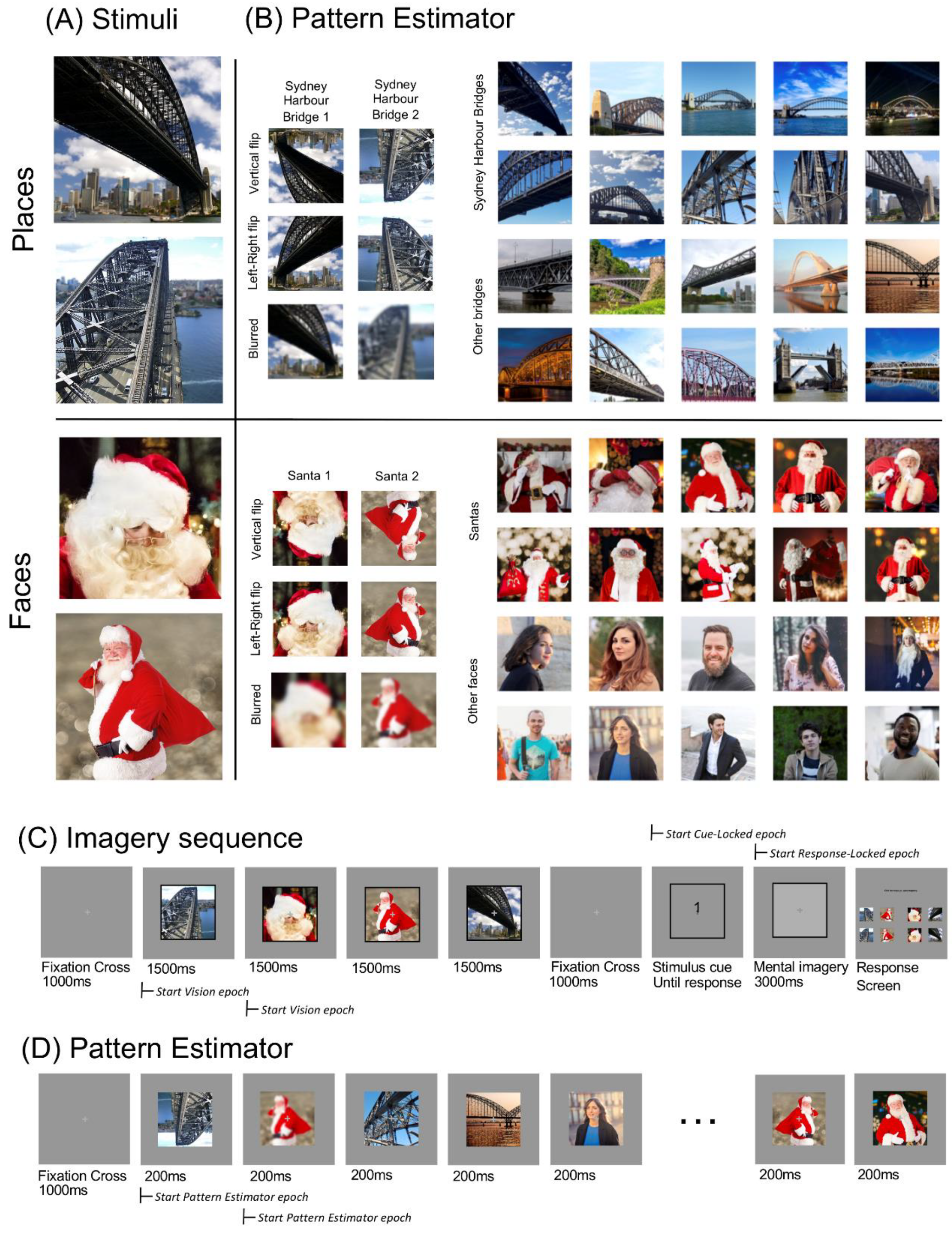
2.4. Apparatus and Stimuli
2.5. Imagery Sequence
2.6. Training
2.7. Pattern Estimator
2.8. Data Recording and Processing
2.8.1. EEG Recording
2.8.2. Pre-Processing EEG
2.8.3. Decoding Analysis
3. Results
3.1. Behavioural Results
3.1.1. Vividness of Visual Imagery Questionnaire
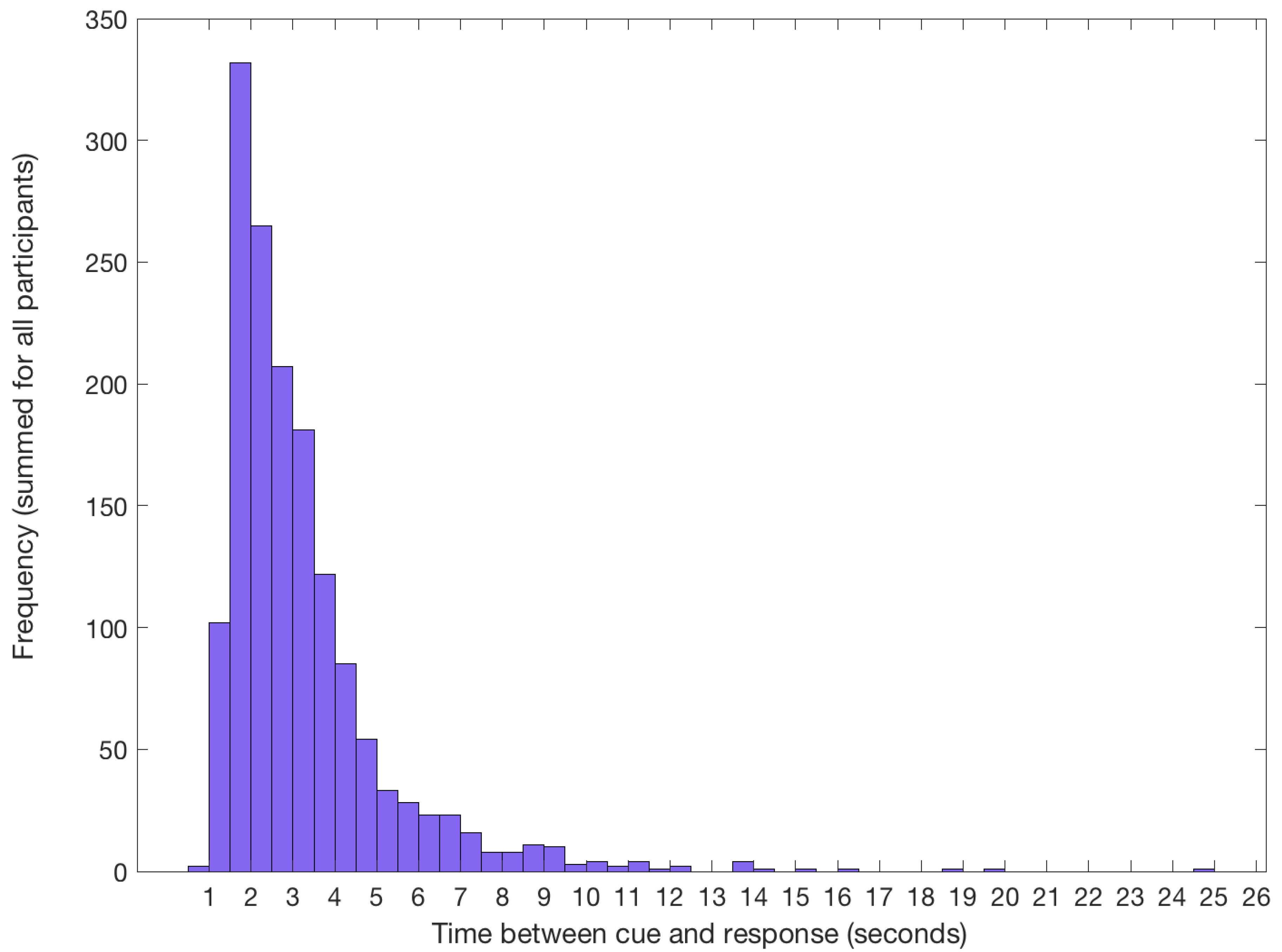
3.1.2. Target Identification
3.2. EEG Results
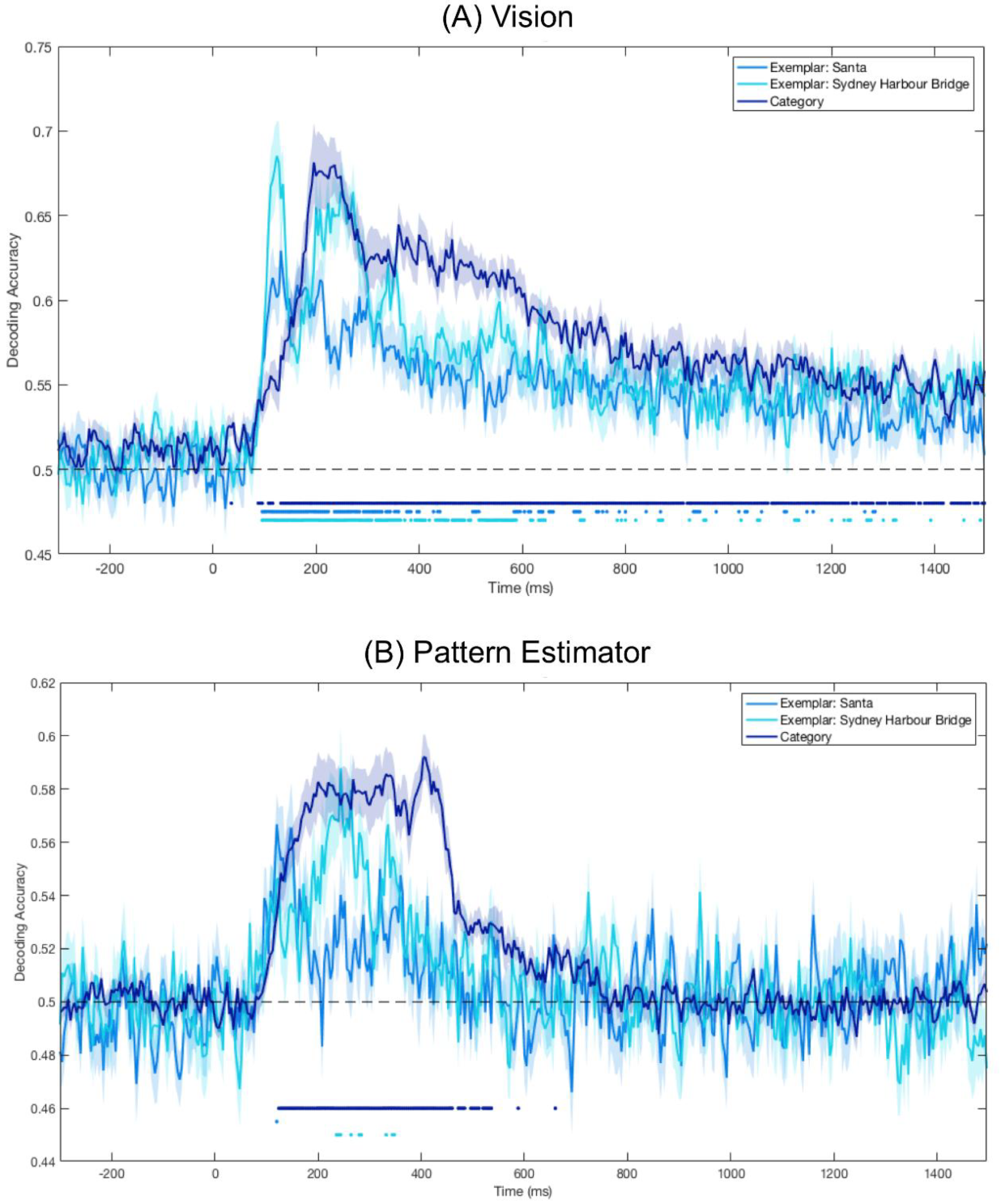
Significant Decoding of Image Category and Exemplars for Seen Images on Imagery Trials
3.3. Significant Category Decoding in Pattern Estimator
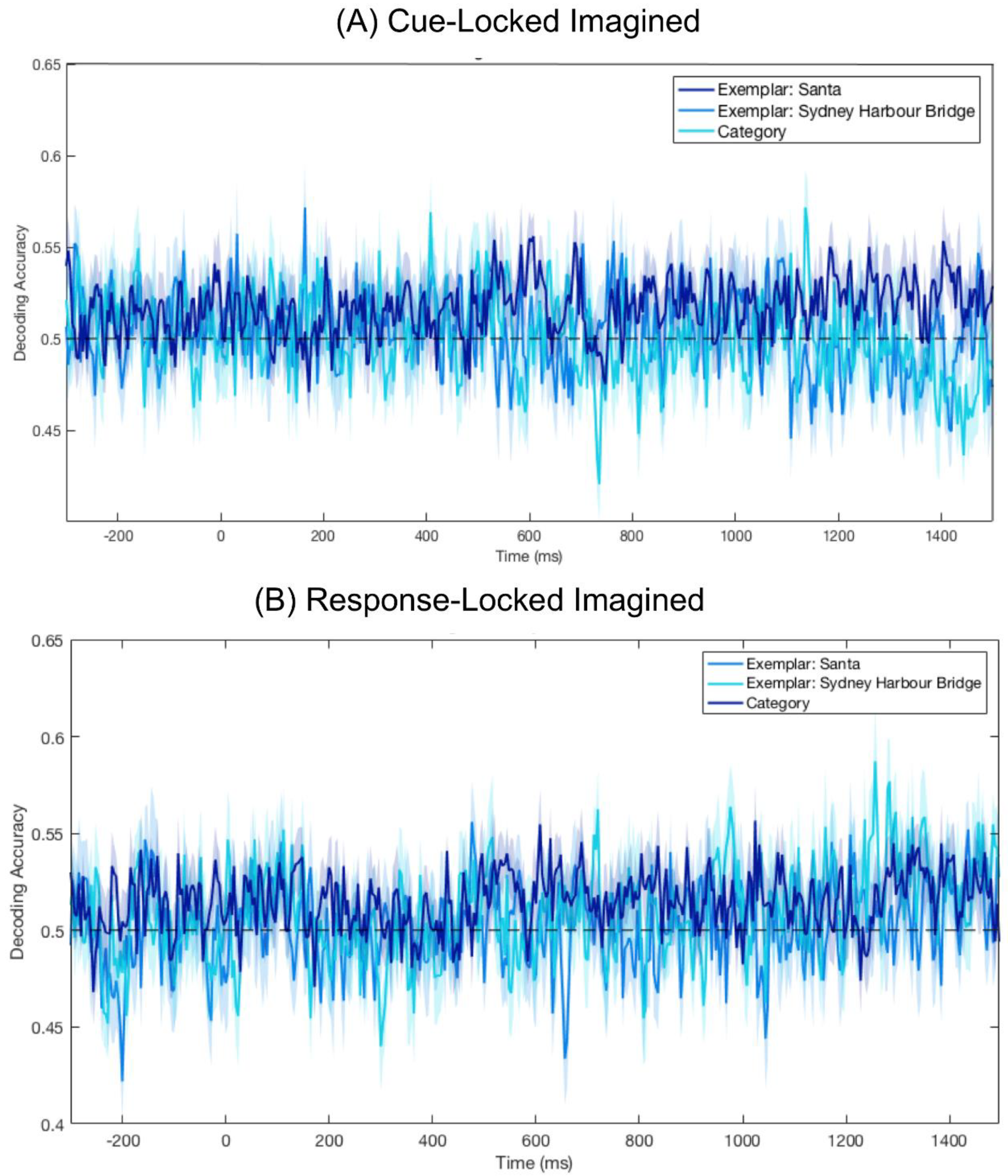
3.4. No Significant Decoding for Imagery
3.5. Differences in Vividness Did Not Affect Decoding Accuracy
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Ganis, G.; Thompson, W.L.; Mast, F.W.; Kosslyn, S.M. Visual imagery in cerebral visual dysfunction. Neurol. Clin. 2003, 21, 631–646. [Google Scholar] [CrossRef]
- Kosslyn, S.M.; Ganis, G.; Thompson, W.L. Neural foundations of imagery. Nat. Rev. Neurosci. 2001, 2, 635–642. [Google Scholar] [CrossRef] [PubMed]
- Dijkstra, N.; Mostert, P.; Lange, F.P.; Bosch, S.; van Gerven, M.A. Differential temporal dynamics during visual imagery and perception. eLife 2018, 7, e33904. [Google Scholar] [CrossRef] [PubMed]
- Ganis, G.; Thompson, W.L.; Kosslyn, S.M. Brain areas underlying visual mental imagery and visual perception: An fMRI study. Cogn. Brain Res. 2004, 20, 226–241. [Google Scholar] [CrossRef] [PubMed]
- Kosslyn, S.M.; Pascual-Leone, A.; Felician, O.; Camposano, S.; Keenan, J.P.; Thompson, W.L.; Ganis, G.; Sukel, K.E.; Alpert, N.M. The role of Area 17 in visual imagery: Convergent evidence from PET and rTMS. Science 1999, 284, 167–170. [Google Scholar] [CrossRef]
- Lee, S.H.; Kravitz, D.J.; Baker, C.I. Disentangling visual imagery and perception of real-world objects. Neuroimage 2012, 59, 4064–4073. [Google Scholar] [CrossRef]
- Slotnick, S.D.; Thompson, W.L.; Kosslyn, S.M. Visual mental imagery induces retinotopically organized activation of early visual areas. Cereb. Cortex 2005, 15, 1570–1583. [Google Scholar] [CrossRef]
- Albers, A.M.; Kok, P.; Toni, I.; Dijkerman, H.C.; de Lange, F.P. Shared representations for working memory and mental imagery in early visual cortex. Curr. Biol. 2013, 23, 1427–1431. [Google Scholar] [CrossRef]
- Goldenberg, G.; Podreka, I.; Steiner, M.; Willmes, K.; Suess, E.; Deecke, L. Regional cerebral blood flow patterns in visual imagery. Neuropsychologia 1989, 27, 641–664. [Google Scholar] [CrossRef]
- Knauff, M.; Kassubek, J.; Mulack, T.; Greenlee, M.W. Cortical activation evoked by visual mental imagery as measured by fMRI. Neuroreport 2000, 11, 3957–3962. [Google Scholar] [CrossRef]
- Mechelli, A.; Price, C.J.; Friston, K.J.; Ishai, A. Where bottom-up meets top-down: Neuronal interactions during perception and imagery. Cereb. Cortex 2004, 14, 1256–1265. [Google Scholar] [CrossRef] [PubMed]
- Reeder, R.R.; Perini, F.; Peelen, M.V. Preparatory Activity in Posterior Temporal Cortex Causally Contributes to Object Detection in Scenes. J. Cogn. Neurosci. 2015, 27, 2117–2125. [Google Scholar] [CrossRef] [PubMed]
- Ishai, A.; Ungerleider, L.G.; Haxby, J.V. Distributed Neural Systems for the Generation of Visual Images. Neuron 2000, 28, 979–990. [Google Scholar] [CrossRef]
- Chen, W.; Kato, T.; Zhu, X.H.; Ogawa, S.; Tank, D.W.; Ugurbil, K. Human primary visual cortex and lateral geniculate nucleus activation during visual imagery. Neuroreport 1998, 9, 3669–3674. [Google Scholar] [CrossRef] [PubMed]
- Harrison, S.A.; Tong, F. Decoding reveals the contents of visual working memory in early visual areas. Nature 2009, 458, 632–635. [Google Scholar] [CrossRef] [PubMed]
- Pearson, J.; Clifford, C.W.; Tong, F. The functional impact of mental imagery on conscious perception. Curr. Biol. 2008, 18, 982–986. [Google Scholar] [CrossRef] [PubMed]
- Ishai, A.; Ungerleider, L.G.; Martin, A.; Haxby, J.V. The representation of objects in the human occipital and temporal cortex. J. Cogn. Neurosci. 2000, 12 (Suppl. 2), 35–51. [Google Scholar] [CrossRef]
- Kosslyn, S.M.; Thompson, W.L. When is early visual cortex activated during visual mental imagery? Psychol. Bull. 2003, 129, 723–746. [Google Scholar] [CrossRef]
- Bartolomeo, P.; Bourgeois, A.; Bourlon, C.; Migliaccio, R. (Eds.) Visual and Motor Mental Imagery After Brain Damage; Springer: New York, NY, USA, 2013. [Google Scholar]
- Bridge, H.; Harrold, S.; Holmes, E.A.; Stokes, M.; Kennard, C. Vivid visual mental imagery in the absence of the primary visual cortex. J. Neurol. 2012, 259, 1062–1070. [Google Scholar] [CrossRef]
- Moro, V.; Berlucchi, G.; Lerch, J.; Tomaiuolo, F.; Aglioti, S.M. Selective deficit of mental visual imagery with intact primary visual cortex and visual perception. Cortex 2008, 44, 109–118. [Google Scholar] [CrossRef]
- Zago, S.; Corti, S.; Bersano, A.; Baron, P.; Conti, G.; Ballabio, E.; Lanfranconi, S.; Cinnante, C.; Costa, A.; Cappellari, A.; et al. A cortically blind patient with preserved visual imagery. Cogn. Behav. Neurol. 2010, 23, 44–48. [Google Scholar] [CrossRef] [PubMed]
- Fulford, J.; Milton, F.; Salas, D.; Smith, A.; Simler, A.; Winlove, C.; Zeman, A. The neural correlates of visual imagery vividness—An fMRI study and literature review. Cortex 2018, 105, 26–40. [Google Scholar] [CrossRef] [PubMed]
- Stokes, M.; Saraiva, A.; Rohenkohl, G.; Nobre, A.C. Imagery for shapes activates position-invariant representations in human visual cortex. Neuroimage 2011, 56, 1540–1545. [Google Scholar] [CrossRef] [PubMed]
- Cui, X.; Jeter, C.B.; Yang, D.; Montague, P.R.; Eagleman, D.M. Vividness of mental imagery: Individual variability can be measured objectively. Vis. Res. 2007, 47, 474–478. [Google Scholar] [CrossRef] [PubMed]
- Grootswagers, T.; Wardle, S.G.; Carlson, T.A. Decoding Dynamic Brain Patterns from Evoked Responses: A Tutorial on Multivariate Pattern Analysis Applied to Time Series Neuroimaging Data. J. Cogn. Neurosci. 2017, 29, 677–697. [Google Scholar] [CrossRef] [PubMed]
- Haynes, J.D. A primer on pattern-based approaches to fMRI: Principles, pitfalls, and perspectives. Neuron 2015, 87, 257–270. [Google Scholar] [CrossRef]
- Naselaris, T.; Olman, C.A.; Stansbury, D.E.; Ugurbil, K.; Gallant, J.L. A voxel-wise encoding model for early visual areas decodes mental images of remembered scenes. Neuroimage 2015, 105, 215–228. [Google Scholar] [CrossRef]
- Cichy, R.M.; Pantazis, D.; Oliva, A. Resolving human object recognition in space and time. Nat. Neurosci. 2014, 17, 455–462. [Google Scholar] [CrossRef]
- Marks, D.F. Visual imagery differences and eye movements in the recall of pictures. Percept. Psychophys. 1973, 14, 407–412. [Google Scholar] [CrossRef]
- Haxby, J.V.; Gobbini, M.I.; Furey, M.L.; Ishai, A.; Schouten, J.L.; Pietrini, P. Distributed and overlapping representations of faces and objects in ventral temporal cortex. Science 2001, 293, 2425–2430. [Google Scholar] [CrossRef]
- Kanwisher, N.; McDermott, J.; Chun, M.M. The fusiform face area: A module in human extrastriate cortex specialized for face perception. J. Neurosci. 1997, 17, 4302–4311. [Google Scholar] [CrossRef] [PubMed]
- Brainard, D.H. The Psychophysics Toolbox. Spat. Vis. 1997, 10, 433–436. [Google Scholar] [CrossRef] [PubMed]
- Kleiner, M.; Brainard, D.; Pelli, D. What′s new in Psychtoolbox-3? Perception 2007, 36, 14. [Google Scholar]
- Pelli, D.G. The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spat. Vis. 1997, 10, 437–442. [Google Scholar] [CrossRef]
- Oostenveld, R.; Praamstra, P. The five percent electrode system for high-resolution EEG and ERP measurements. Clin. Neurophysiol. 2001, 112, 713–719. [Google Scholar] [CrossRef]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef]
- Lopez–Calderon, J.; Luck, S.J. ERPLAB: An open-source toolbox for the analysis of event-related potentials. Front. Hum. Neurosci. 2014, 8, 213. [Google Scholar] [CrossRef]
- Oosterhof, N.N.; Connolly, A.C.; Haxby, J.V. CoSMoMVPA: Multi-Modal Multivariate Pattern Analysis of Neuroimaging Data in Matlab/GNU Octave. Front. Neuroinform. 2016, 10, 27. [Google Scholar] [CrossRef]
- King, J.R.; Dehaene, S. Characterizing the dynamics of mental representations: The temporal generalization method. Trends Cogn. Sci. 2014, 18, 203–210. [Google Scholar] [CrossRef]
- Maris, E.; Oostenveld, R. Nonparametric statistical testing of EEG-and MEG-data. J. Neurosci. Methods 2007, 164, 177–190. [Google Scholar] [CrossRef]
- Smith, S.M.; Nichols, T.E. Threshold-free cluster enhancement: Addressing problems of smoothing, threshold dependence and localisation in cluster inference. Neuroimage 2009, 44, 83–98. [Google Scholar] [CrossRef] [PubMed]
- Stelzer, J.; Chen, Y.; Turner, R. Statistical inference and multiple testing correction in classification-based multi-voxel pattern analysis (MVPA): Random permutations and cluster size control. Neuroimage 2013, 65, 69–82. [Google Scholar] [CrossRef] [PubMed]
- North, B.V.; Curtis, D.; Sham, P.C. A note on the calculation of empirical P values from Monte Carlo procedures. Am. J. Hum. Genet. 2002, 71, 439–441. [Google Scholar] [CrossRef] [PubMed]
- Amedi, A.; Malach, R.; Pascual-Leone, A. Negative BOLD differentiates visual imagery and perception. Neuron 2005, 48, 859–872. [Google Scholar] [CrossRef] [PubMed]
- Crawford, H.J. Hypnotizability, daydreaming styles, imagery vividness, and absorption: A multidimensional study. J. Pers. Soc. Psychol. 1982, 42, 915–926. [Google Scholar] [CrossRef]
- Carlson, T.; Tovar, D.A.; Alink, A.; Kriegeskorte, N. Representational dynamics of object vision: The first 1000 ms. J. Vis. 2013, 13, 1. [Google Scholar] [CrossRef]
- Grootswagers, T.; Robinson, A.K.; Carlson, T.A. The representational dynamics of visual objects in rapid serial visual processing streams. Neuroimage 2019, 188, 668–679. [Google Scholar] [CrossRef]
- Marti, S.; Dehaene, S. Discrete and continuous mechanisms of temporal selection in rapid visual streams. Nat. Commun. 2017, 8, 1955. [Google Scholar] [CrossRef]
- Contini, E.W.; Wardle, S.G.; Carlson, T.A. Decoding the time-course of object recognition in the human brain: From visual features to categorical decisions. Neuropsychologia 2017, 105, 165–176. [Google Scholar] [CrossRef]
- Linde-Domingo, J.; Treder, M.S.; Kerrén, C.; Wimber, M. Evidence that neural information flow is reversed between object perception and object reconstruction from memory. Nat. Commun. 2019, 10, 179. [Google Scholar] [CrossRef]
- Robinson, A.K.; Venkatesh, P.; Boring, M.J.; Tarr, M.J.; Grover, P.; Behrmann, M. Very high density EEG elucidates spatiotemporal aspects of early visual processing. Sci. Rep. 2017, 7, 16248. [Google Scholar] [CrossRef] [PubMed]
- Dijkstra, N.; Bosch, S.E.; van Gerven, M.A. Vividness of Visual Imagery Depends on the Neural Overlap with Perception in Visual Areas. J. Neurosci. 2017, 37, 1367–1373. [Google Scholar] [CrossRef] [PubMed]
- Dijkstra, N.; Hinne, M.; Bosch, S.E.; van Gerven, M.A.J. Individual differences in the influence of mental imagery on conscious perception. bioRxiv 2019. [Google Scholar] [CrossRef]
- Keogh, R.; Pearson, J. Mental Imagery and Visual Working Memory. PLoS ONE 2011, 6, e29221. [Google Scholar] [CrossRef] [PubMed]
- Keogh, R.; Pearson, J. The sensory strength of voluntary visual imagery predicts visual working memory capacity. J. Vis. 2014, 14, 7. [Google Scholar] [CrossRef] [PubMed]
- Pearson, J.; Naselaris, T.; Holmes, E.A.; Kosslyn, S.M. Mental Imagery: Functional Mechanisms and Clinical Applications. Trends Cogn. Sci. 2015, 19, 590–602. [Google Scholar] [CrossRef] [PubMed]
- Baddeley, A.D.; Andrade, J. Working memory and the vividness of imagery. J. Exp. Psychol. Gen. 2000, 129, 126–145. [Google Scholar] [CrossRef] [PubMed]
- Borst, G.; Kosslyn, S.M. Individual differences in spatial mental imagery. Q. J. Exp. Psychol. 2010, 63, 2031–2050. [Google Scholar] [CrossRef] [PubMed]




© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shatek, S.M.; Grootswagers, T.; Robinson, A.K.; Carlson, T.A. Decoding Images in the Mind’s Eye: The Temporal Dynamics of Visual Imagery. Vision 2019, 3, 53. https://doi.org/10.3390/vision3040053
Shatek SM, Grootswagers T, Robinson AK, Carlson TA. Decoding Images in the Mind’s Eye: The Temporal Dynamics of Visual Imagery. Vision. 2019; 3(4):53. https://doi.org/10.3390/vision3040053
Chicago/Turabian StyleShatek, Sophia M., Tijl Grootswagers, Amanda K. Robinson, and Thomas A. Carlson. 2019. "Decoding Images in the Mind’s Eye: The Temporal Dynamics of Visual Imagery" Vision 3, no. 4: 53. https://doi.org/10.3390/vision3040053
APA StyleShatek, S. M., Grootswagers, T., Robinson, A. K., & Carlson, T. A. (2019). Decoding Images in the Mind’s Eye: The Temporal Dynamics of Visual Imagery. Vision, 3(4), 53. https://doi.org/10.3390/vision3040053