Eye Movements in Medical Image Perception: A Selective Review of Past, Present and Future


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
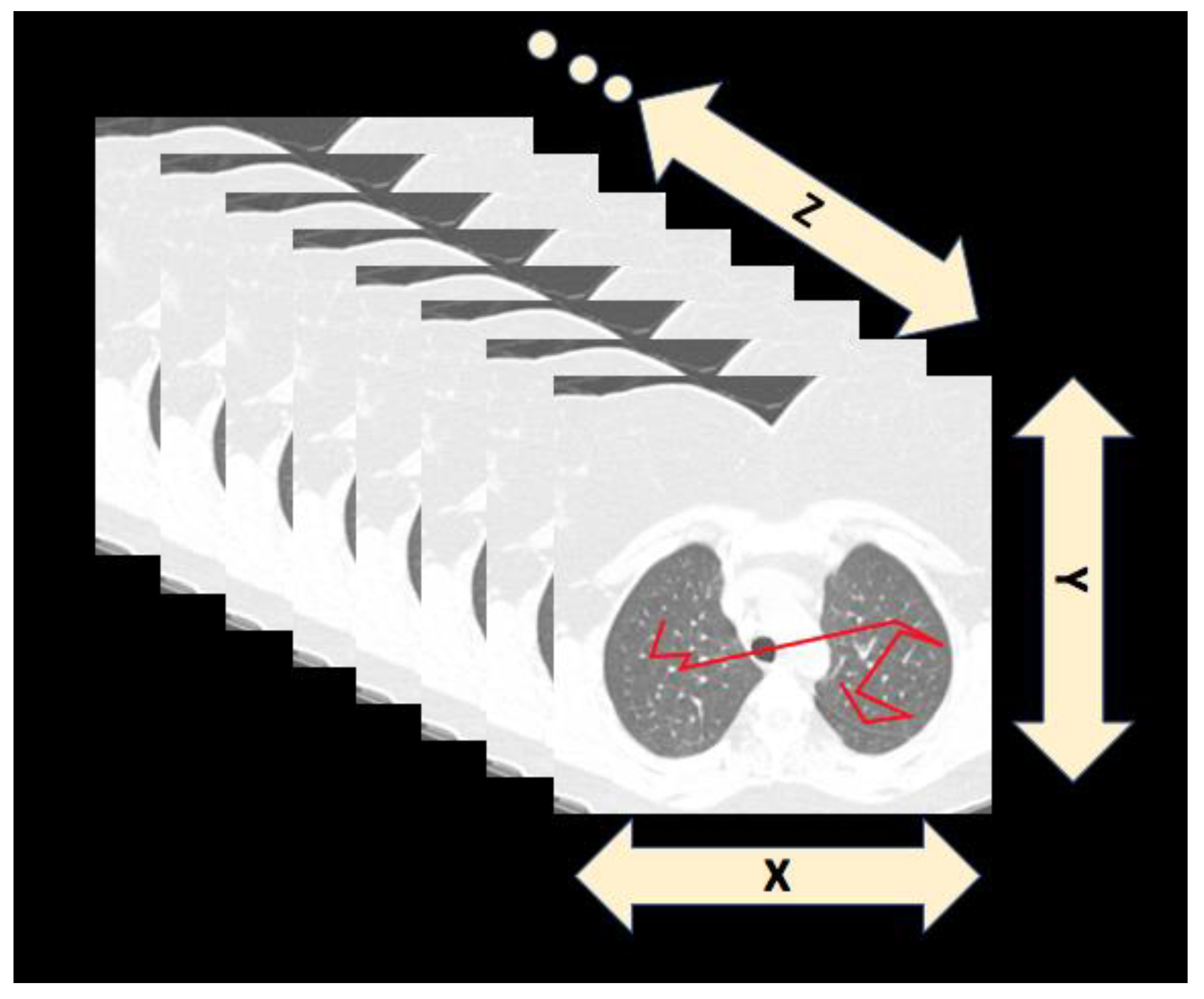
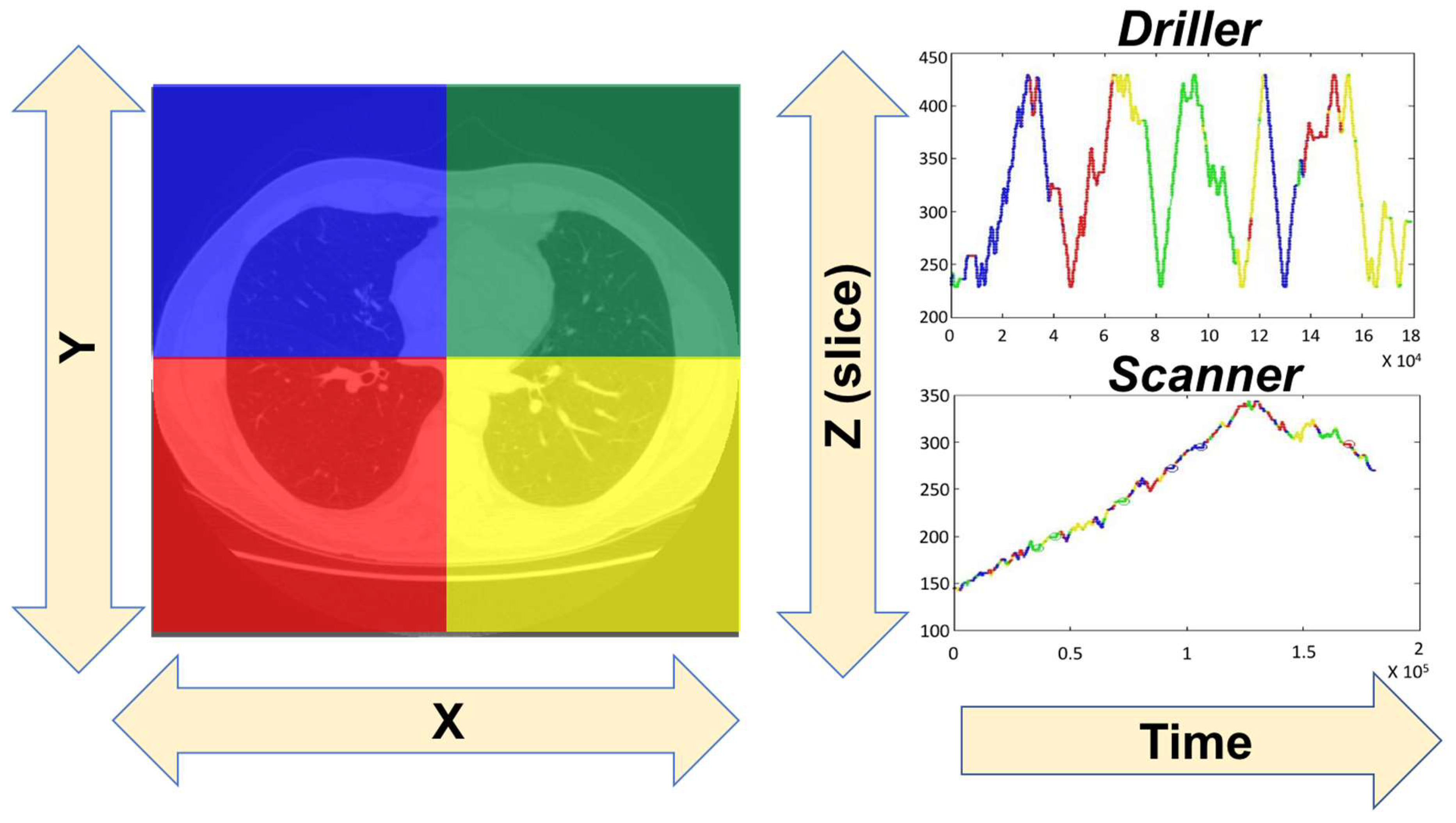
2. Scanpaths: Searching in Scenes and Medical Images
3. The Useful Field of View (UFOV)
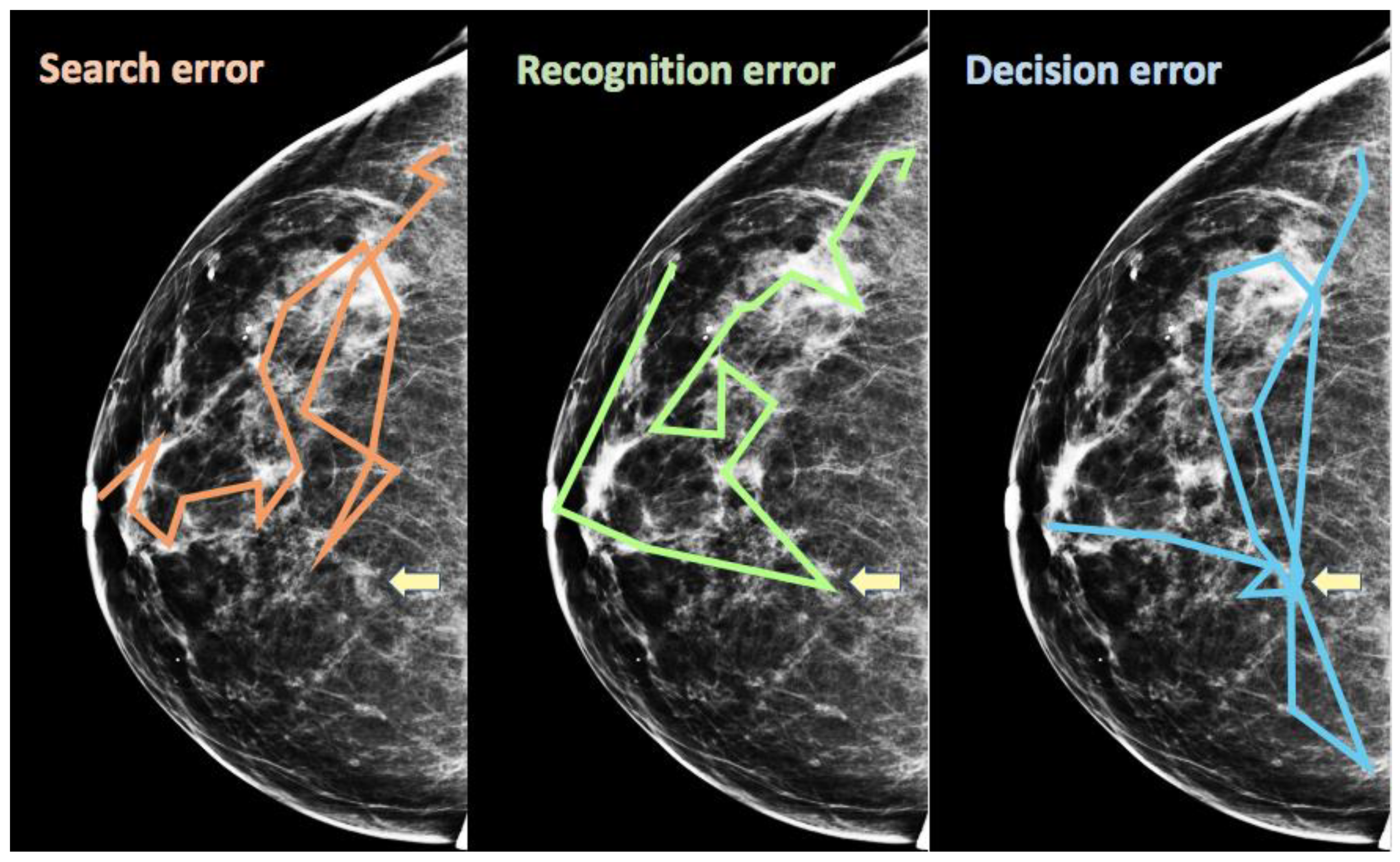
4. Scanpath Signatures of Errors in Medical Image Perception
5. Incidental Findings and Satisfaction of Search Errors
6. Scene Gist and Medical Scene Gist
7. Conclusions
Funding
Conflicts of Interest
References
- Boyer, B.; Hauret, L.; Bellaiche, R.; Graf, C.; Bourcier, B.; Fichet, G. Retrospectively detectable carcinomas: Review of the literature. J. Radiol. 2004, 85, 2071–2078. [Google Scholar] [CrossRef]
- Hoff, S.R.; Abrahamsen, A.-L.; Samset, J.H.; Vigeland, E.; Klepp, O.R.; Hofvind, S. Breast Cancer: Missed Interval and Screening-detected Cancer at Full-Field Digital Mammography and Screen-Film Mammography‚Äî Results from a Retrospective Review. Radiology 2012, 264, 378–386. [Google Scholar] [CrossRef] [PubMed]
- Martin, J.E.; Moskowitz, M.; Milbrath, J.R. Breast cancer missed by mammography. AJR Am. J. Roentgenol. 1979, 132, 737–739. [Google Scholar] [CrossRef] [PubMed]
- Pisano, E.D.; Gatsonis, C.; Hendrick, E.; Yaffe, M.; Baum, J.K.; Acharyya, S.; Conant, E.F.; Fajardo, L.L.; Bassett, L.; D’orsi, C.; et al. Diagnostic Performance of Digital versus Film Mammography for Breast-Cancer Screening. N. Engl. J. Med. 2005, 353, 1773–1783. [Google Scholar] [CrossRef] [PubMed]
- Le, M.T.; Mothersill, C.E.; Seymour, C.B.; Mcneill, F.E. Is the false-positive rate inmammography in North America too high? Br. J. Radiol. 2016, 89. [Google Scholar] [CrossRef] [PubMed]
- Seely, J.M.; Alhassan, T. Screening for breast cancer in 2018—What should we be doing today? Curr. Oncol. 2018. [Google Scholar] [CrossRef] [PubMed]
- Hedlund, L.W.; Anderson, R.F.; Goulding, P.L.; Beck, J.W.; Effmann, E.L.; Putman, C.E. Two methods for isolating the lung area for a CT scan for density information. Radiology 1982, 144, 353–357. [Google Scholar] [CrossRef] [PubMed]
- Kotsianos-Hermle, D.; Wirth, S.; Fischer, T.; Hiltawsky, K.M.; Reiser, M. First clinical use of a standardized three-dimensional ultrasound for breast imaging. Eur. J. Radiol. 2009, 71, 102–108. [Google Scholar] [CrossRef] [PubMed]
- Celebi, M.E.; Schaefer, G. Color Medical Image Analysis; Emre Celebi, M., Schaefer, G., Eds.; Springer: Dordrecht, The Netherlands, 2013. [Google Scholar]
- Moscariello, A.; Takx, R.A.; Schoepf, U.J.; Renker, M.; Zwerner, P.L.; O’Brien, T.X.; Allmendinger, T.; Vogt, S.; Schmidt, B.; Savino, G.; et al. Coronary CT angiography: Image quality, diagnostic accuracy, and potential for radiation dose reduction using a novel iterative image reconstruction technique‚Äîcomparison with traditional filtered back projection. Eur. Radiol. 2011, 21, 2130–2138. [Google Scholar] [CrossRef]
- Eddleman, C.S.; Jeong, H.J.; Hurley, M.C.; Zuehlsdorff, S.; Dabus, G.; Getch, C.G.; Batjer, H.H.; Bendok, B.R.; Carroll, T.J. 4D radial acquisition contrast-enhanced MR angiography and intracranial arteriovenous malformations: Quickly approaching digital subtraction angiography. Stroke 2009, 40, 2749–2753. [Google Scholar] [CrossRef] [PubMed]
- Brunye, T.T.; Drew, T.; Weaver, D.L.; Elmore, J.G. A Review of Eye Tracking for Understanding and Improving Diagnostic Interpretation. Cogn. Res. Princ. Implic. (CRPI) 2019, 4, 7. [Google Scholar] [CrossRef] [PubMed]
- Van der Gijp, A.; Ravesloot, C.J.; Jarodzka, H.; van der Schaaf, M.F.; van der Schaaf, I.C.; van Schaik, J.P.; Ten Cate, T.J. How visual search relates to visual diagnostic performance: A narrative systematic review of eye-tracking research in radiology. Adv. Health Sci. Educ. Theory Pract. 2017, 22, 765–787. [Google Scholar] [CrossRef] [PubMed]
- Krupinski, E.A. Current Perspectives in Medical Image Perception. Atten. Percept. Psychophys. 2010, 72, 1205–1217. [Google Scholar] [CrossRef] [PubMed]
- Noton, D.; Stark, L. Scanpaths in eye movements during pattern perception. Science 1971, 171, 308–311. [Google Scholar] [CrossRef]
- Noton, D.; Stark, L. Scanpaths in saccadic eye movements while viewing and recognizing patterns. Vis. Res. 1971, 11, 929–942. [Google Scholar] [CrossRef]
- Yarbus, A.L. Eye Movements and Vision; Plenum: New York, NY, USA, 1967. [Google Scholar]
- Greene, M.R.; Liu, T.; Wolfe, J.M. Reconsidering Yarbus: Pattern classification cannot predict observer’s task from scan paths. Vis. Res. 2012, 62, 1–8. [Google Scholar] [CrossRef]
- Bahle, B.; Mills, M.; Dodd, M.D. Human Classifier: Observers can deduce task solely from eye movements. Atten. Percept. Psychophys. 2017, 79, 1415–1425. [Google Scholar] [CrossRef]
- Damiano, C.; Wilder, J.; Walther, D.B. Mid-level feature contributions to category-specific gaze guidance. Atten. Percept. Psychophys. 2019, 81, 35–46. [Google Scholar] [CrossRef]
- Kardan, O.; Berman, M.G.; Yourganov, G.; Schmidt, J.; Henderson, J.M. Classifying mental states from eye movements during scene viewing. J. Exp. Psychol. Hum. Percept. Perform. 2015, 41, 1502–1514. [Google Scholar] [CrossRef]
- Võ, M.L.H.; Aizenman, A.M.; Wolfe, J.M. You think you know where you looked? You better look again. J. Exp. Psychol. Hum. Percept. Perform. 2016, 42, 1477–1481. [Google Scholar] [CrossRef]
- Kok, E.M.; Aizenman, A.M.; Võ, M.L.H.; Wolfe, J.M. Even if I showed you where you looked, remembering where you just looked is hard. J. Vis. 2017, 17, 2. [Google Scholar] [CrossRef] [PubMed]
- Kundel, H.L.; Nodine, C.F.; Krupinski, E.A. Computer-displayed eye position as a visual aid to pulmonary nodule interpretation. Investig. Radiol. 1990, 25, 890–896. [Google Scholar] [CrossRef]
- Donovan, T.; Manning, D.J.; Crawford, T. Performance changes in lung nodule detection following perceptual feedback of eye movements. Proc. SPIE 2008, 6917. [Google Scholar] [CrossRef]
- Drew, T.; Williams, L.H. Simple eye-movement feedback during visual search is not helpful. Cogn. Res. Princ. Implic. 2017, 2, 44. [Google Scholar] [CrossRef] [PubMed]
- Peltier, C.; Becker, M.W. Eye movement feedback fails to improve visual search performance. Cogn. Res. Princ. Implic. 2017, 2, 47. [Google Scholar] [CrossRef]
- Aizenman, A.; Drew, T.; Ehinger, K.A.; Georgian-Smith, D.; Wolfe, J.M. Comparing search patterns in digital breast tomosynthesis and full-field digital mammography: An eye tracking study. J. Med. Imaging 2017, 4, 045501. [Google Scholar] [CrossRef]
- Den Boer, L.; van der Schaaf, M.F.; Vincken, K.L.; Mol, C.P.; Stuijfzand, B.G.; van der Gijp, A. Volumetric Image Interpretation in Radiology: Scroll Behavior and Cognitive Processes. Adv. Health Sci. Educ. 2018, 23, 783–802. [Google Scholar] [CrossRef]
- D’Ardenne, N.M.; Nishikawa, R.M.; Wu, C.C.; Wolfe, J.M. Occulomotor Behavior of Radiologists Reading Digital Breast Tomosynthesis (DBT). In Proceedings of the SPIE Medical Imaging, San Diego, CA, USA, 6–21 February 2019. [Google Scholar]
- Mercan, E.; Shapiro, L.G.; Brunyé, T.T.; Weaver, D.L.; Elmore, J.G. Characterizing Diagnostic Search Patterns in Digital Breast Pathology: Scanners and Drillers. J. Digit. Imaging 2018, 31, 32–41. [Google Scholar] [CrossRef]
- Timberg, P.; Lång, K.; Nyström, M.; Holmqvist, K.; Wagner, P.; Förnvik, D.; Tingberg, A.; Zackrisson, S. Investigation of viewing procedures for interpretation of breast tomosynthesis image volumes: A detection-task study with eye tracking. Eur. Radiol. 2013, 23, 997–1005. [Google Scholar] [CrossRef][Green Version]
- Venjakob, A.C.; Mello-Thoms, C.R. Review of prospects and challenges of eye tracking in volumetric imaging. J. Med. Imaging 2015, 3. [Google Scholar] [CrossRef]
- Drew, T.; Vo, M.L.-H.; Olwal, A.; Jacobson, F.; Seltzer, S.E.; Wolfe, J.M. Scanners and drillers: Characterizing expert visual search through volumetric images. J. Vis. 2013, 13. [Google Scholar] [CrossRef] [PubMed]
- Seltzer, S.E.; Judy, P.F.; Adams, D.F.; Jacobson, F.L.; Stark, P.; Kikinis, R.; Swensson, R.G.; Hooton, S.; Head, B.; Feldman, U. Spiral CT of the chest: Comparison of cine and film-based viewing. Radiology 1995, 197, 73–78. [Google Scholar] [CrossRef] [PubMed]
- Baker, J.A.; Lo, J.Y. Breast Tomosynthesis: State-of-the-Art and Review of the Literature. Acad. Radiol. 2011, 18, 1298–1310. [Google Scholar] [CrossRef] [PubMed]
- Drew, T.; Aizenman, A.M.; Thompson, M.B.; Kovacs, M.D.; Trambert, M.; Reicher, M.A.; Wolfe, J.M. Image toggling saves time in mammography. J. Med. Imaging 2016, 3, 011003. [Google Scholar] [CrossRef] [PubMed]
- Levi, D.M. Crowding-An essential bottleneck for object recognition: A mini-review. Vis. Res. 2008, 48, 635–654. [Google Scholar] [CrossRef]
- Manassi, M.; Whitney, D. Multi-level Crowding and the Paradox of Object Recognition in Clutter. Curr. Biol. 2018, 28, R127–R133. [Google Scholar] [CrossRef]
- Hulleman, J.; Olivers, C.N.L. The impending demise of the item in visual search. Behav. Brain Sci. 2017, 40, e132. [Google Scholar] [CrossRef]
- Sanders, A.F. Some aspects of the selective process in the functional visual field. Ergonomics 1970, 13, 101–117. [Google Scholar] [CrossRef]
- Ikeda, M.; Takeuchi, T. Influence of foveal load on the functional visual field. Percept. Psychophys. 1975, 18, 255–260. [Google Scholar] [CrossRef]
- Sanders, A.F.; Houtmans, M.J.M. Perceptual modes in the functional visual field. Acta Psychol. 1985, 58, 251–261. [Google Scholar] [CrossRef]
- Kundel, H.L.; Nodine, C.F.; Thickman, D.; Toto, L. Searching for lung nodules. A comparison of human performance with random and systematic scanning models. Investig. Radiol. 1987, 22, 417–422. [Google Scholar] [CrossRef]
- Carmody, D.P.; Nodine, C.F.; Kundel, H.L. An analysis of perceptual and cognitive factors in radiographic interpretation. Perception 1980, 9, 339–344. [Google Scholar] [CrossRef] [PubMed]
- Ebner, L.; Tall, M.; Choudhury, K.R.; Ly, D.L.; Roos, J.E.; Napel, S.; Rubin, G.D. Variations in the functional visual field for detection of lung nodules on chest computed tomography: Impact of nodule size, distance, and local lung complexity: Impact. Med. Phys. 2017, 44, 3483–3490. [Google Scholar] [CrossRef] [PubMed]
- Krupinski, E.A. Visual scanning patterns of radiologists searching mammograms. Acad. Radiol. 1996, 3, 137–144. [Google Scholar] [CrossRef]
- Kelly, B.S.; Rainford, L.A.; Darcy, S.P.; Kavanagh, E.C.; Toomey, R.J. The Development of Expertise in Radiology: In Chest Radiograph Interpretation, “Expert” Search Pattern May Predate “Expert” Levels of Diagnostic Accuracy for Pneumothorax Identification. Radiology 2016, 280, 252–260. [Google Scholar] [CrossRef] [PubMed]
- Rubin, G.D.; Roos, J.E.; Tall, M.; Harrawood, B.; Bag, S.; Ly, D.L.; Seaman, D.M.; Hurwitz, L.M.; Napel, S.; Roy Choudhury, K. Characterizing Search, Recognition, and Decision in the Detection of Lung Nodules on CT Scans: Elucidation with Eye Tracking. Radiology 2015, 274, 276–286. [Google Scholar] [CrossRef] [PubMed]
- Dreiseitl, S.; Pivec, M.; Binder, M. Differences in examination characteristics of pigmented skin lesions: Results of an eye tracking study. Artif. Intell. Med. 2012, 54, 201–205. [Google Scholar] [CrossRef] [PubMed]
- Bertram, R.; Kaakinen, J.; Bensch, F.; Helle, L.; Lantto, E.; Niemi, P.; Lundbom, N. Eye Movements of Radiologists Reflect Expertise in CT Study Interpretation: A Potential Tool to Measure Resident Development. Radiology 2016, 281, 805–815. [Google Scholar] [CrossRef]
- Kundel, H.L.; Nodine, C.F.; Carmody, D. Visual scanning, pattern recognition and decision-making in pulmonary nodule detection. Investig. Radiol. 1978, 13, 175–181. [Google Scholar] [CrossRef]
- Hu, C.H.; Kundel, H.L.; Nodine, C.F.; Krupinski, E.A.; Toto, L.C. Searching for bone fractures: A comparison with pulmonary nodule search. Acad. Radiol. 1994, 1, 25–32. [Google Scholar] [CrossRef]
- Kundel, H.L.; Nodine, C.F.; Krupinski, E.A. Searching for lung nodules. Visual dwell indicates locations of false-positive and false-negative decisions. Investig. Radiol. 1989, 24, 472–478. [Google Scholar] [CrossRef]
- Beigelman-Aubry, C.; Hill, C.; Grenier, P.A. Management of an incidentally discovered pulmonary nodule. Eur. Radiol. 2007, 17, 449–466. [Google Scholar] [CrossRef] [PubMed]
- Lumbreras, B.; Donat, L.; Hernández-Aguado, I. Incidental findings in imaging diagnostic tests: A systematic review. Br. J. Radiol. 2010, 83, 276–289. [Google Scholar] [CrossRef] [PubMed]
- Heller, R.E. Counterpoint: A Missed Lung Nodule Is a Significant Miss. J. Am. Coll. Radiol. 2017, 14, 1552–1553. [Google Scholar] [CrossRef] [PubMed]
- Oren, O.; Kebebew, E.; Ioannidis, J.P.A. Curbing Unnecessary and Wasted Diagnostic Imaging. JAMA 2019, 321, 245–246. [Google Scholar] [CrossRef]
- Pandharipande, P.V.; Herts, B.R.; Gore, R.M.; Mayo-Smith, W.W.; Harvey, H.B.; Megibow, A.J.; Berland, L.L. Authors’ Reply. J. Am. Coll. Radiol. 2016, 13, 1025–1027. [Google Scholar] [CrossRef] [PubMed]
- Pandharipande, P.V.; Herts, B.R.; Gore, R.M.; Mayo-Smith, W.W.; Harvey, H.B.; Megibow, A.J.; Berland, L.L. Rethinking Normal: Benefits and Risks of Not Reporting Harmless Incidental Findings. J. Am. Coll. Radiol. 2016, 13, 764–767. [Google Scholar] [CrossRef] [PubMed]
- Clayton, E.W.; Haga, S.; Kuszler, P.; Bane, E.; Shutske, K.; Burke, W. Managing incidental genomic findings: Legal obligations of clinicians. Genet. Med. 2013, 15, 624–629. [Google Scholar] [CrossRef]
- Drew, T.; Vo, M.L.-H.; Wolfe, J.M. The Invisible Gorilla Strikes Again: Sustained Inattentional Blindness in Expert Observers. Psychol. Sci. 2013, 24, 1848–1853. [Google Scholar] [CrossRef] [PubMed]
- Simons, D.J.; Chabris, C.F. Gorillas in our midst: Sustained inattentional blindness for dynamic events. Perception 1999, 28, 1059–1074. [Google Scholar] [CrossRef] [PubMed]
- Mack, A.; Rock, I. Inattentional Blindness; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Most, S.B.; Simons, D.J.; Scholl, B.J.; Jimenez, R.; Clifford, E.; Chabris, C.F. How not to be seen: The contribution of similarity and selective ignoring to sustained inattentional blindness. Psychol. Sci. 2001, 12, 9–17. [Google Scholar] [CrossRef] [PubMed]
- Wolfe, J.M.; Alaoui-Soce, A.; Schill, H. How did I miss that? Developing mixed hybrid visual search as a ‘model system’ for incidental finding errors in radiology. Cogn. Res. Princ. Implic. (CRPI) 2017, 2, 35. [Google Scholar] [CrossRef] [PubMed]
- Tuddenham, W.J. Visual search, image organization, and reader error in roentgen diagnosis. Studies of the psycho-physiology of roentgen image perception. Radiology 1962, 78, 694–704. [Google Scholar] [CrossRef] [PubMed]
- Berbaum, K.S.; Franken, E.A., Jr.; Dorfman, D.D.; Rooholamini, S.A.; Coffman, C.E.; Cornell, S.H.; Cragg, A.H.; Galvin, J.R.; Honda, H.; Kao, S.C. Time course of satisfaction of search. Investig. Radiol. 1991, 26, 640–648. [Google Scholar] [CrossRef]
- Berbaum, K.S.; Franken, E.A., Jr.; Dorfman, D.D.; Rooholamini, S.A.; Kathol, M.H.; Barloon, T.J.; Behlke, F.M.; Sato, Y.U.T.A.K.A.; Lu, C.H.; El-Khoury, G.Y.; et al. Satisfaction of search in diagnostic radiology. Investig. Radiol. 1990, 25, 133–140. [Google Scholar] [CrossRef]
- Samuel, S.; Kundel, H.L.; Nodine, C.F.; Toto, L.C. Mechanism of satisfaction of search: Eye position recordings in the reading of chest radiographs. Radiology 1995, 194, 895–902. [Google Scholar] [CrossRef] [PubMed]
- Cain, M.S.; Adamo, S.H.; Mitroff, S.R. A taxonomy of errors in multiple-target visual search. Vis. Cogn. 2013, 21, 899–921. [Google Scholar] [CrossRef]
- Berbaum, K.S.; Franken, E.A.; Caldwell, R.T.; Shartz, K. Satisfaction of search in traditional radiographic imaging. In The Handbook of Medical Image Perception and Techniques; Krupinski, E.A., Samei, E., Eds.; Cambridge U Press: Cambridge, UK, 2010; pp. 107–138. [Google Scholar]
- Berbaum, K.S.; Franken, E.A.; Caldwell, R.T.; Shartz, K.; Madsen, M. Satisfaction of search in radiology. In The Handbook of Medical Image Perception and Techniques, 2nd ed.; Samei, E., Krupinski, E.A., Eds.; Cambridge U Press: Cambridge, UK, 2019; pp. 121–166. [Google Scholar]
- Berbaum, K.S.; Franken, E.A., Jr.; Dorfman, D.D.; Miller, E.M.; Krupinski, E.A.; Kreinbring, K.; Caldwell, R.T.; Lu, C.H. Cause of satisfaction of search effects in contrast studies of the abdomen. Acad. Radiol. 1996, 3, 815–826. [Google Scholar] [CrossRef]
- Berbaum, K.S.; Franken, E.A., Jr.; Dorfman, D.D.; Miller, E.M.; Caldwell, R.T.; Kuehn, D.M.; Berbaum, M.L. Role of faulty visual search in the satisfaction of search effect in chest radiography. Acad. Radiol. 1998, 5, 9–19. [Google Scholar] [CrossRef]
- Drew, T.; Williams, L.H.; Aldred, B.; Heilbrun, M.E.; Minoshima, S. Quantifying the costs of interruption during diagnostic radiology interpretation using mobile eye-tracking glasses. J. Med. Imaging 2018, 5, 031406. [Google Scholar] [CrossRef]
- Williams, L.H.; Drew, T. Distraction in diagnostic radiology: How is search through volumetric medical images affected by interruptions? Cogn. Res. Princ. Implic. 2017, 2, 12. [Google Scholar] [CrossRef] [PubMed]
- Kundel, H.L. How to minimize perceptual error and maximize expertise in medical imaging. Proc. SPIE 2007, 6515. [Google Scholar] [CrossRef]
- Kundel, H.L.; Nodine, C.F. Interpreting chest radiographs without visual search. Radiology 1975, 116, 527–532. [Google Scholar] [CrossRef] [PubMed]
- Kundel, H.L.; Nodine, C.F.; Conant, E.F.; Weinstein, S.P. Holistic component of image perception in mammogram interpretation: Gaze-tracking study. Radiology 2007, 242, 396–402. [Google Scholar] [CrossRef] [PubMed]
- Kundel, H.L.; Nodine, C.F.; Krupinski, E.A.; Mello-Thoms, C. Using gaze-tracking data and mixture distribution analysis to support a holistic model for the detection of cancers on mammograms. Acad. Radiol. 2008, 15, 881–886. [Google Scholar] [CrossRef] [PubMed]
- Nodine, C.F.; Mello-Thoms, C. The role of expertise in radiologic image interpretation. In The Handbook of Medical Image Perception and Techniques; Krupinski, E.A., Samei, E., Eds.; Cambridge U Press: Cambridge, UK, 2010; pp. 139–156. [Google Scholar]
- Nodine, C.F.; Mello-Thoms, C. Acquiring expertise in radiologic image interpretation. In The Handbook of Medical Image Perception and Techniques, 2nd ed.; Samei, E., Krupinski, E.A., Eds.; Cambridge U Press: Cambridge, UK, 2019; pp. 139–156. [Google Scholar]
- Posner, M.I. Orienting of attention. Quart. J. Exp. Psychol. 1980, 32, 3–25. [Google Scholar] [CrossRef]
- Posner, M.I.; Cohen, Y. Components of attention. In Attention and Performance X; Bouma, H., Bouwhuis, D.G., Eds.; Erlbaum: Hillside, NJ, USA, 1984; pp. 55–66. [Google Scholar]
- Taylor, T.L.; Klein, R.M. On the causes and effects of inhibition of return. Psychon. Bull. Rev. 1999, 5, 625–643. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Horowitz, T.S. What attributes guide the deployment of visual attention and how do they do it? Nat. Rev. Neurosci. 2004, 5, 495–501. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Horowitz, T.S. Five factors that guide attention in visual search. Nat. Hum. Behav. 2017, 1, 0058. [Google Scholar] [CrossRef]
- Carmody, D.P.; Nodine, C.F.; Kundel, H.L. Finding lung nodules with and without comparative visual scanning. Percept. Psychophys. 1981, 29, 594–598. [Google Scholar] [CrossRef]
- Nodine, C.F.; Mello-Thoms, C.; Kundel, H.L.; Weinstein, S.P. Time course of perception and decision making during mammographic interpretation. AJR Am. J. Roentgenol. 2002, 179, 917–923. [Google Scholar] [CrossRef] [PubMed]
- Evans, K.K.; Birdwell, R.L.; Wolfe, J.M. If You Don’t Find It Often, You Often Don’t Find It: Why Some Cancers Are Missed in Breast Cancer Screening. PLoS ONE 2013, 8, e64366. [Google Scholar] [CrossRef] [PubMed]
- Evans, K.; Haygood, T.M.; Cooper, J.; Culpan, A.-M.; Wolfe, J.M. A half-second glimpse often lets radiologists identify breast cancer cases even when viewing the mammogram of the opposite breast. Proc. Natl. Acad. Sci. USA 2016, 113, 10292–10297. [Google Scholar] [CrossRef] [PubMed]
- Brennan, P.C.; Gandomkar, Z.; Ekpo, E.U.; Tapia, K.; Trieu, P.D.; Lewis, S.J.; Wolfe, J.M.; Evans, K.K. Radiologists can detect the ‘gist’ of breast cancer before any overt signs of cancer appear. Sci. Rep. 2018, 8, 8717. [Google Scholar] [CrossRef] [PubMed]





© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.-C.; Wolfe, J.M. Eye Movements in Medical Image Perception: A Selective Review of Past, Present and Future. Vision 2019, 3, 32. https://doi.org/10.3390/vision3020032
Wu C-C, Wolfe JM. Eye Movements in Medical Image Perception: A Selective Review of Past, Present and Future. Vision. 2019; 3(2):32. https://doi.org/10.3390/vision3020032
Chicago/Turabian StyleWu, Chia-Chien, and Jeremy M. Wolfe. 2019. "Eye Movements in Medical Image Perception: A Selective Review of Past, Present and Future" Vision 3, no. 2: 32. https://doi.org/10.3390/vision3020032
APA StyleWu, C.-C., & Wolfe, J. M. (2019). Eye Movements in Medical Image Perception: A Selective Review of Past, Present and Future. Vision, 3(2), 32. https://doi.org/10.3390/vision3020032