A Semi-Supervised Based K-Means Algorithm for Optimal Guided Waves Structural Health Monitoring: A Case Study

Abstract
:
1. Introduction
2. Background
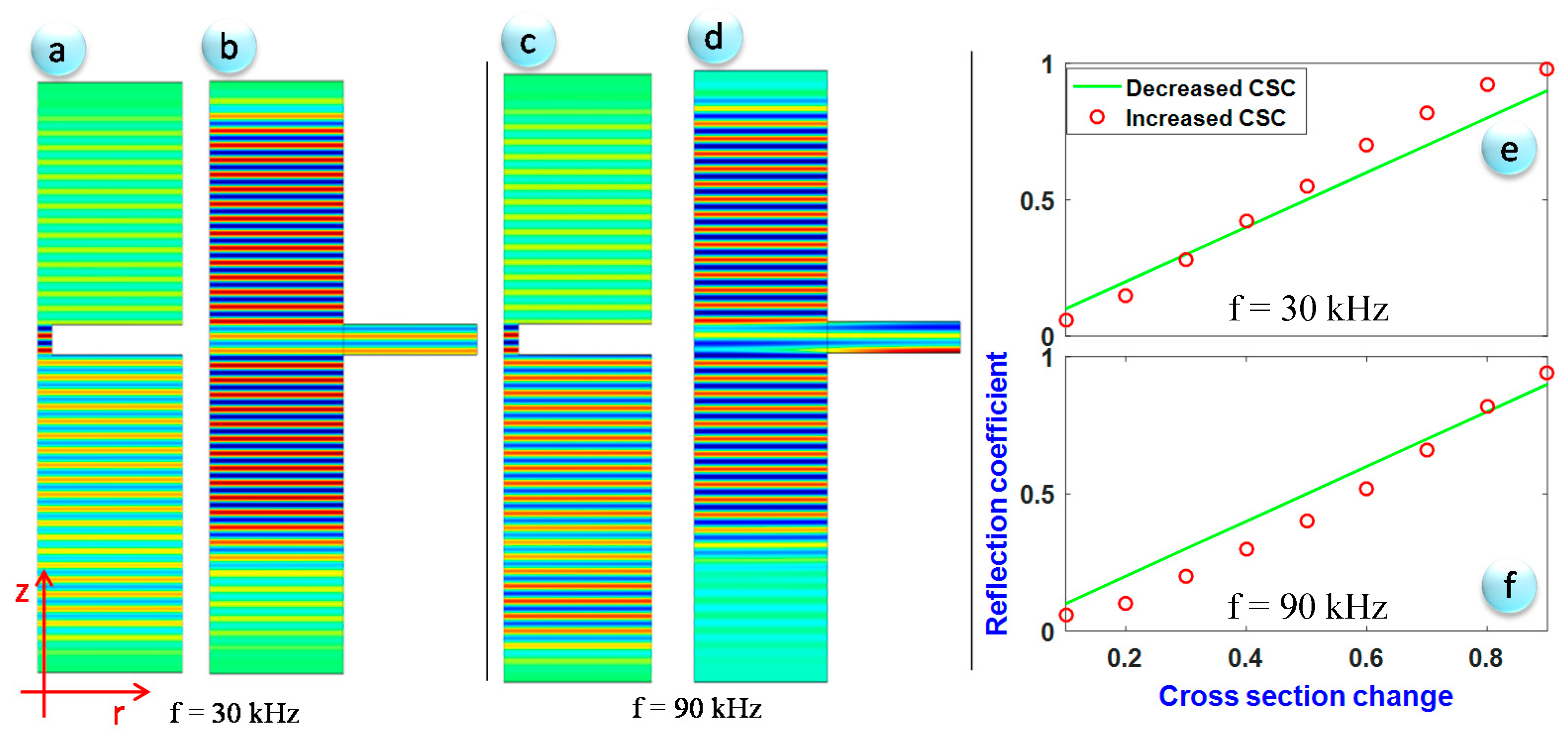
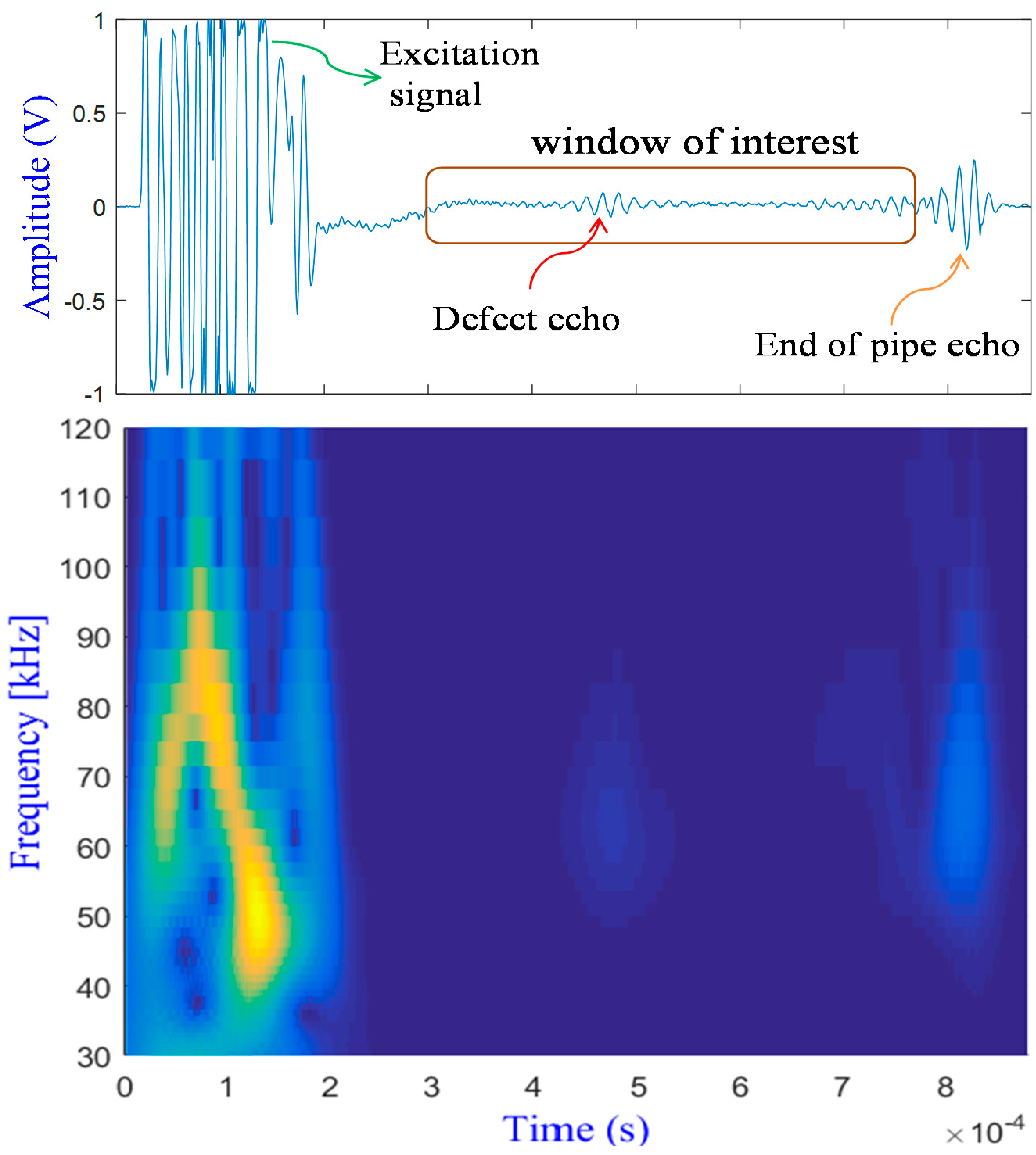
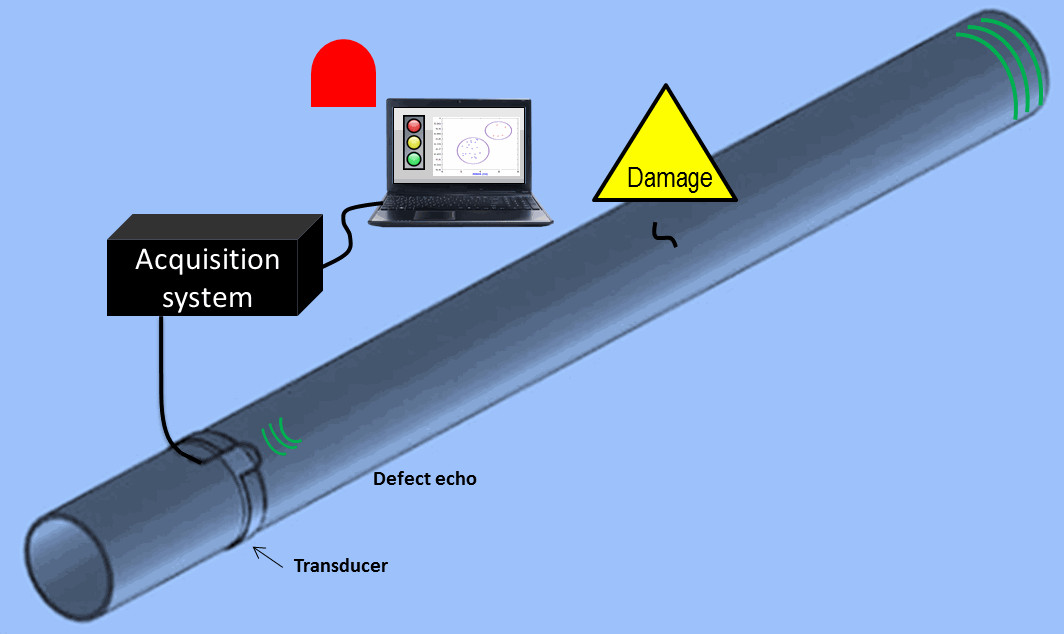
2.1. Guided Waves Based SHM
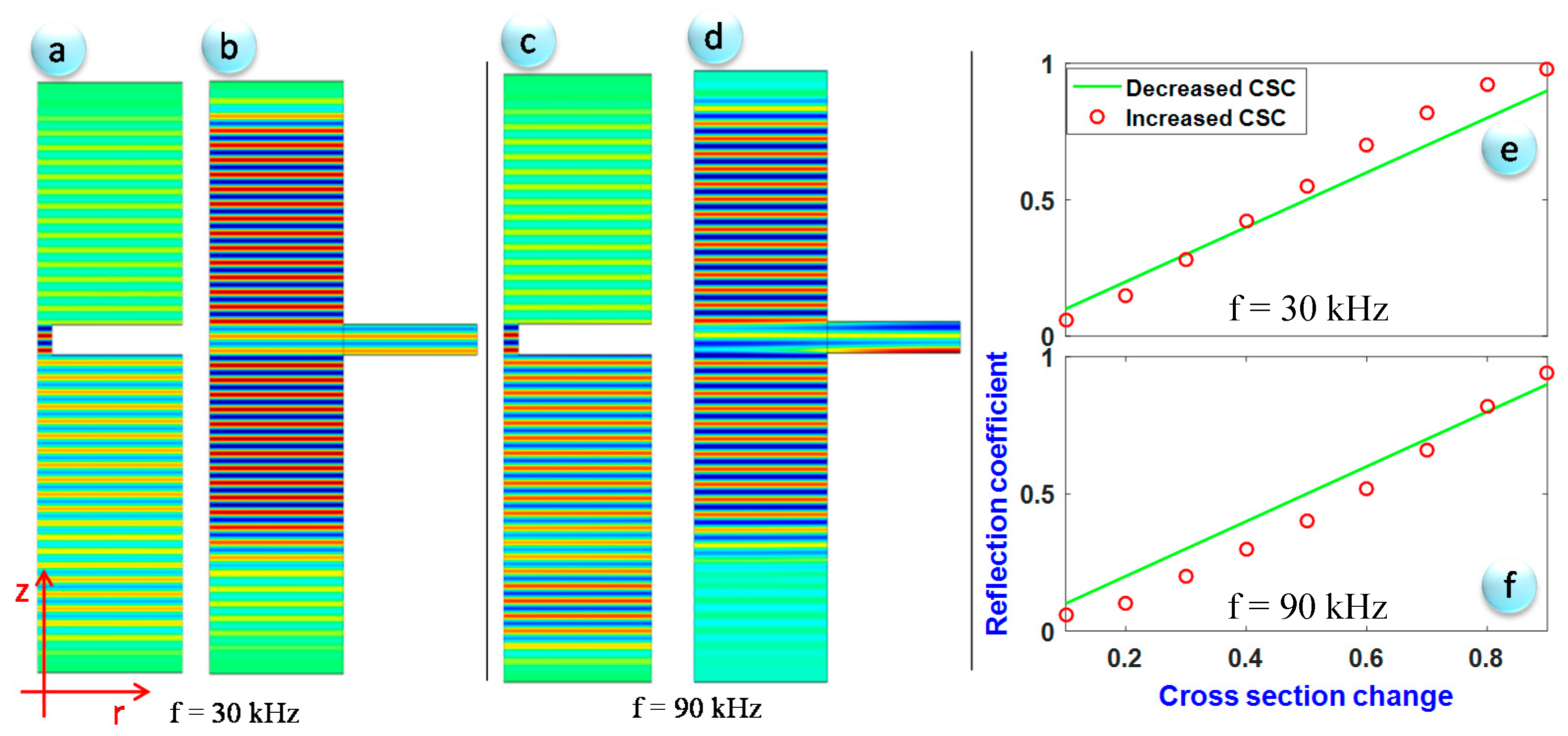
2.2. Damage Detection Approach
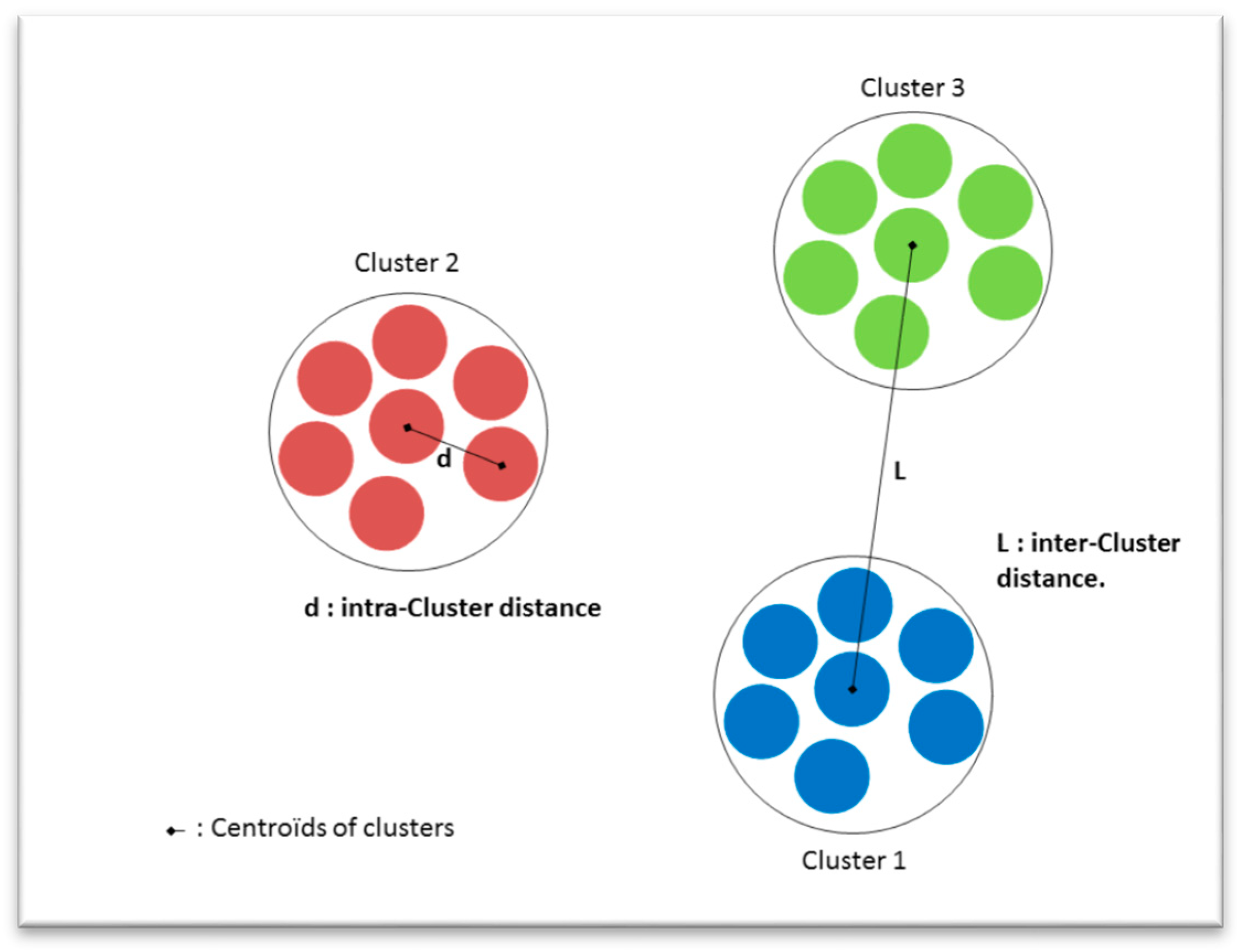
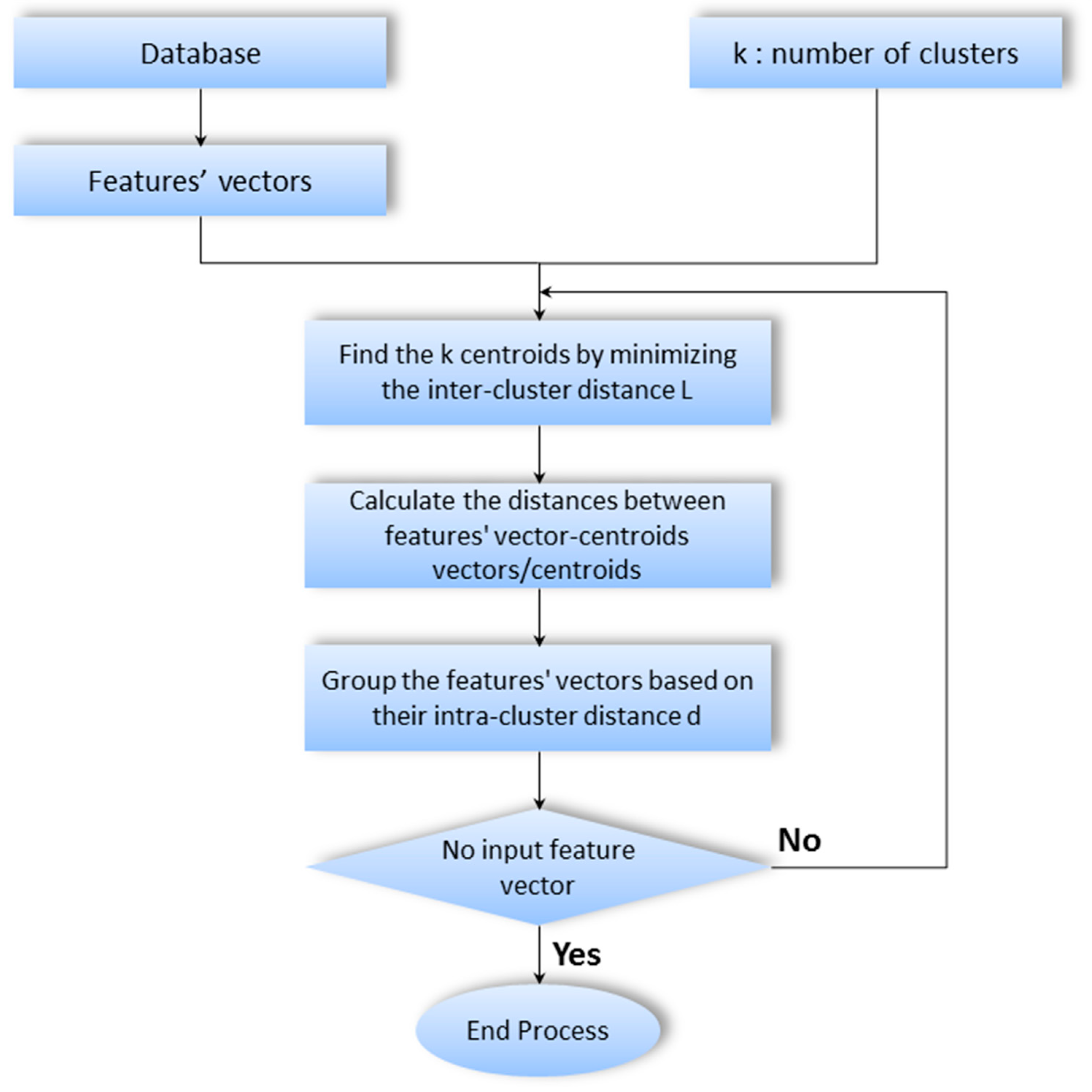
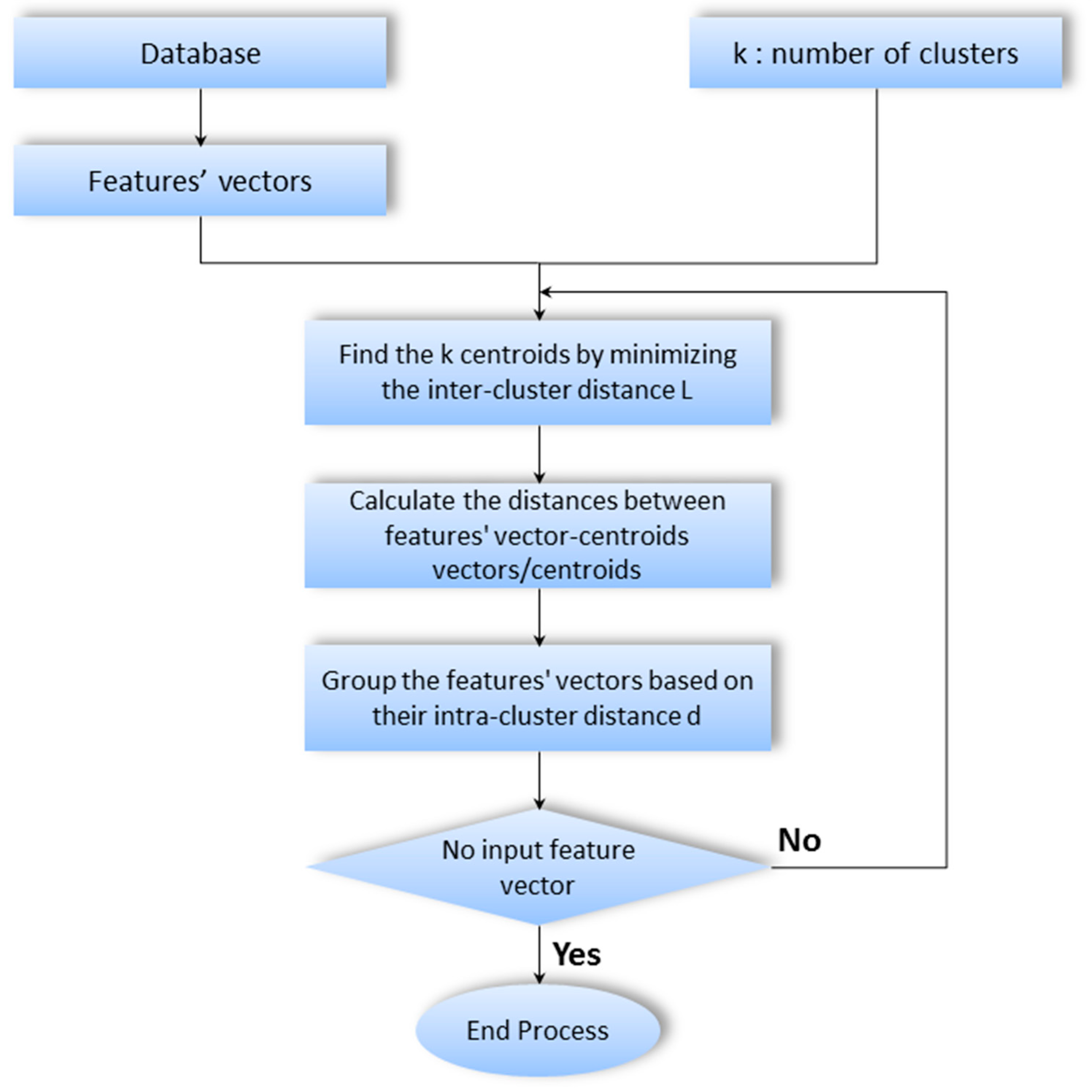
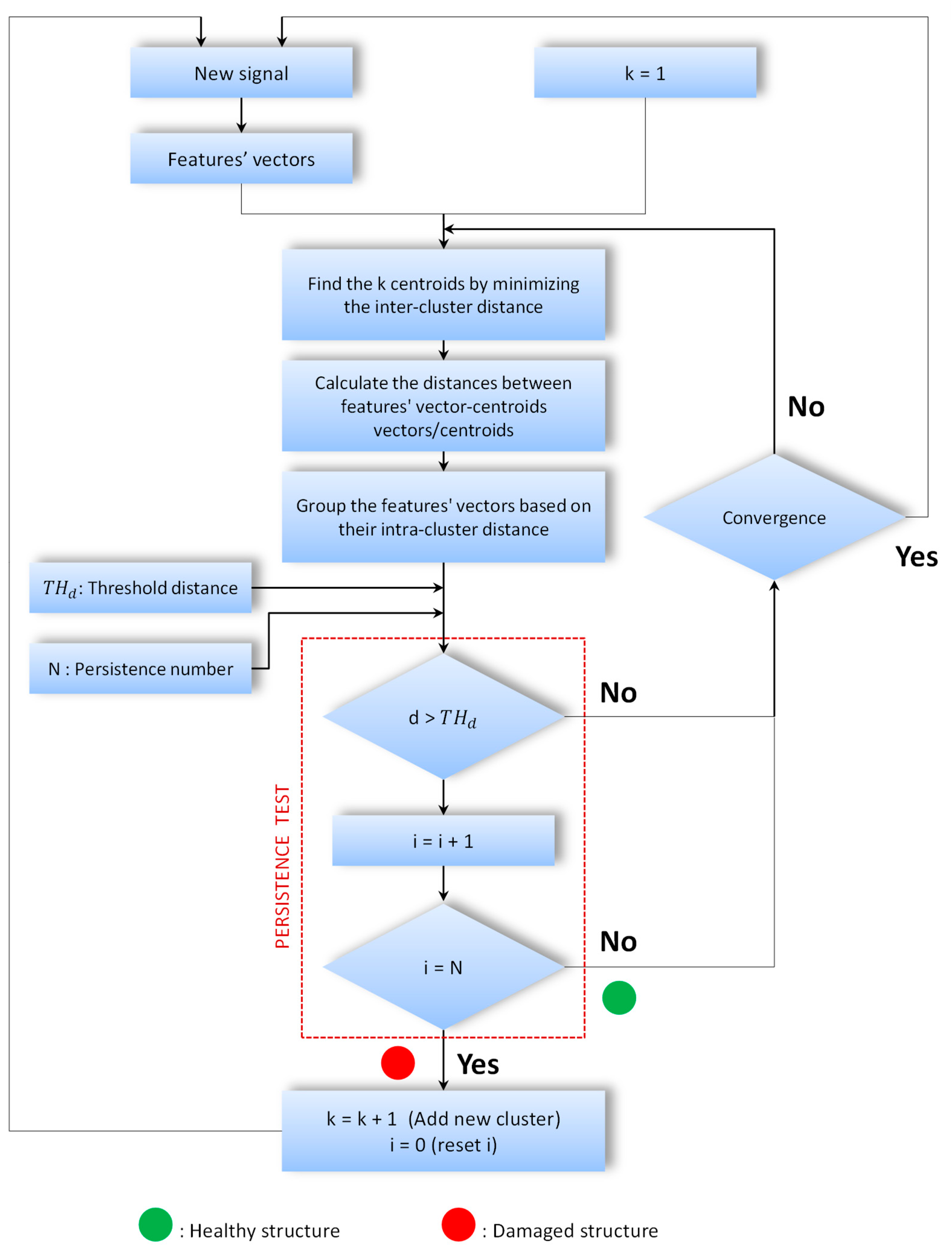
3. K-Means Based Method
3.1. Classical K-Means Clustering
- Randomly choose k points (centers) from the input data set;
- Extract feature vectors from data;
- Assign each feature vector to the closet center;
- Compute the new centers of the formed clusters.
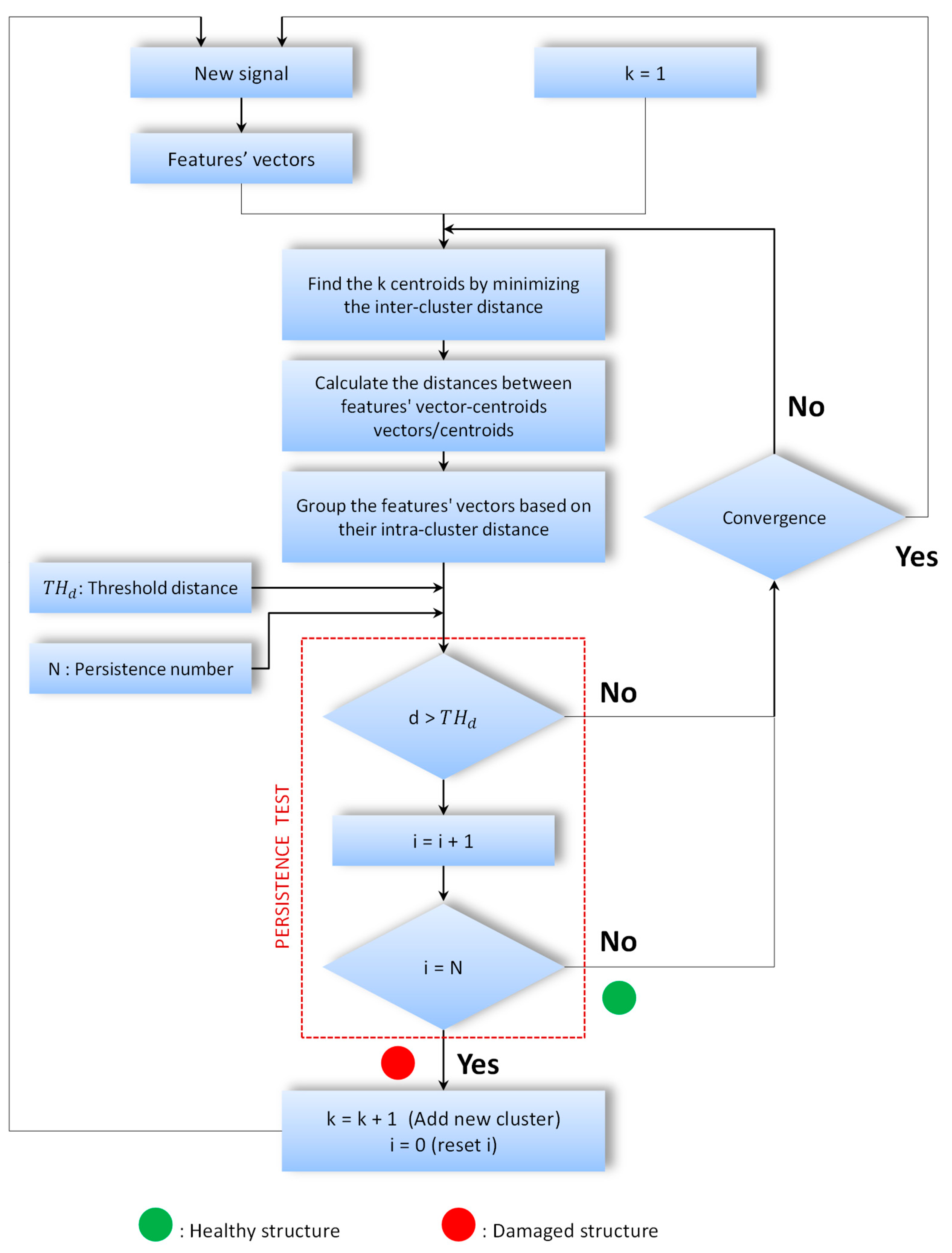
3.2. Proposed Online Damage Detection Method
- : threshold of limit value of the distance that can be considered in the same cluster;
- i: counter of signal distances that exceed ;
- k: number of clusters;
- N: persistence number to reach a new cluster;
- d: the Euclidian distance between the new signal feature vector and the centroid of its cluster.
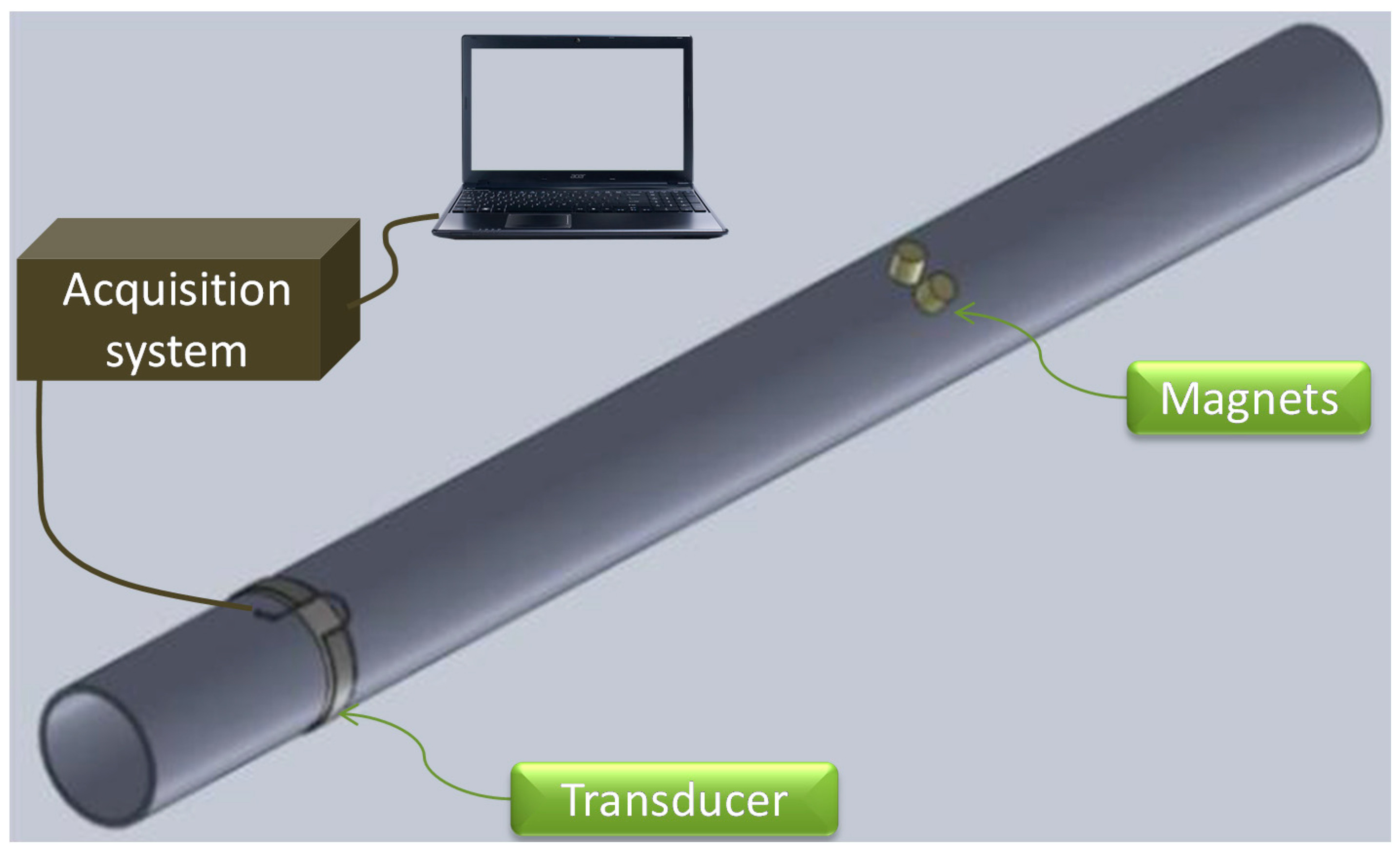
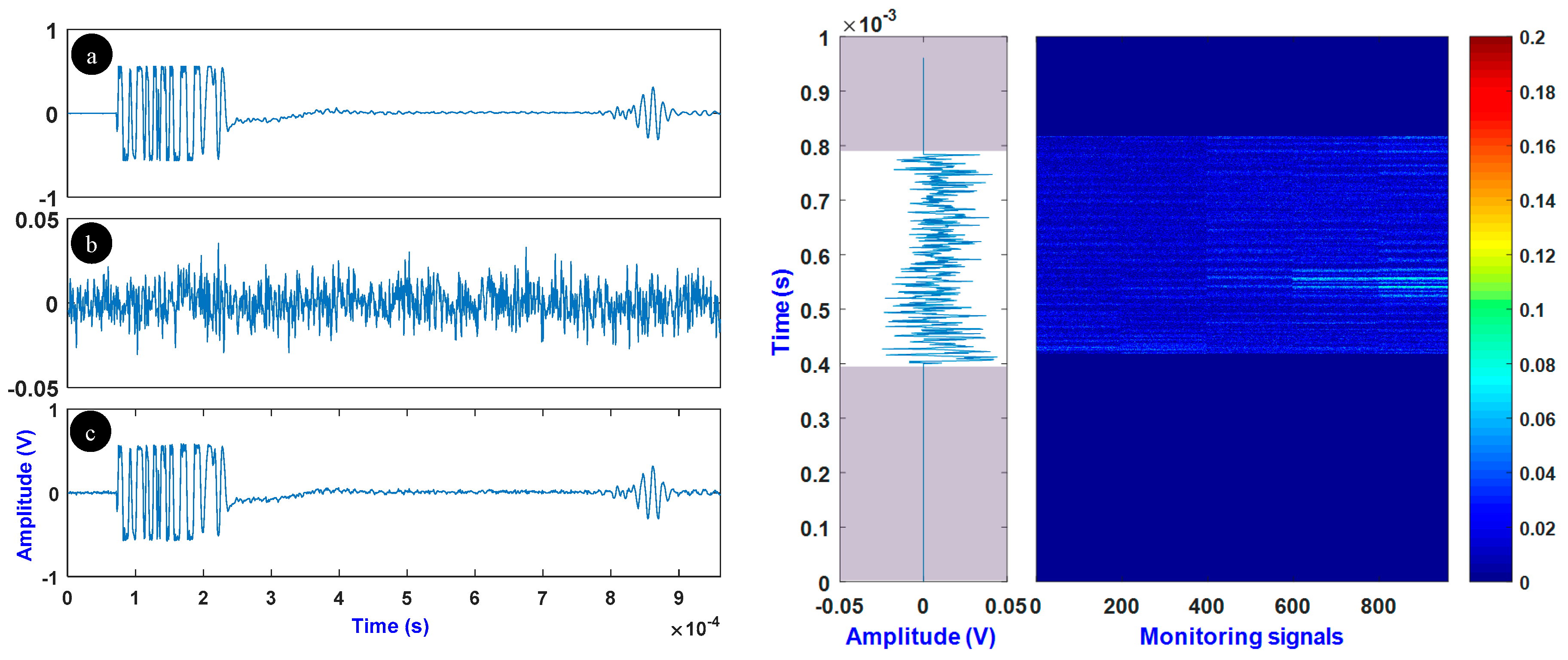
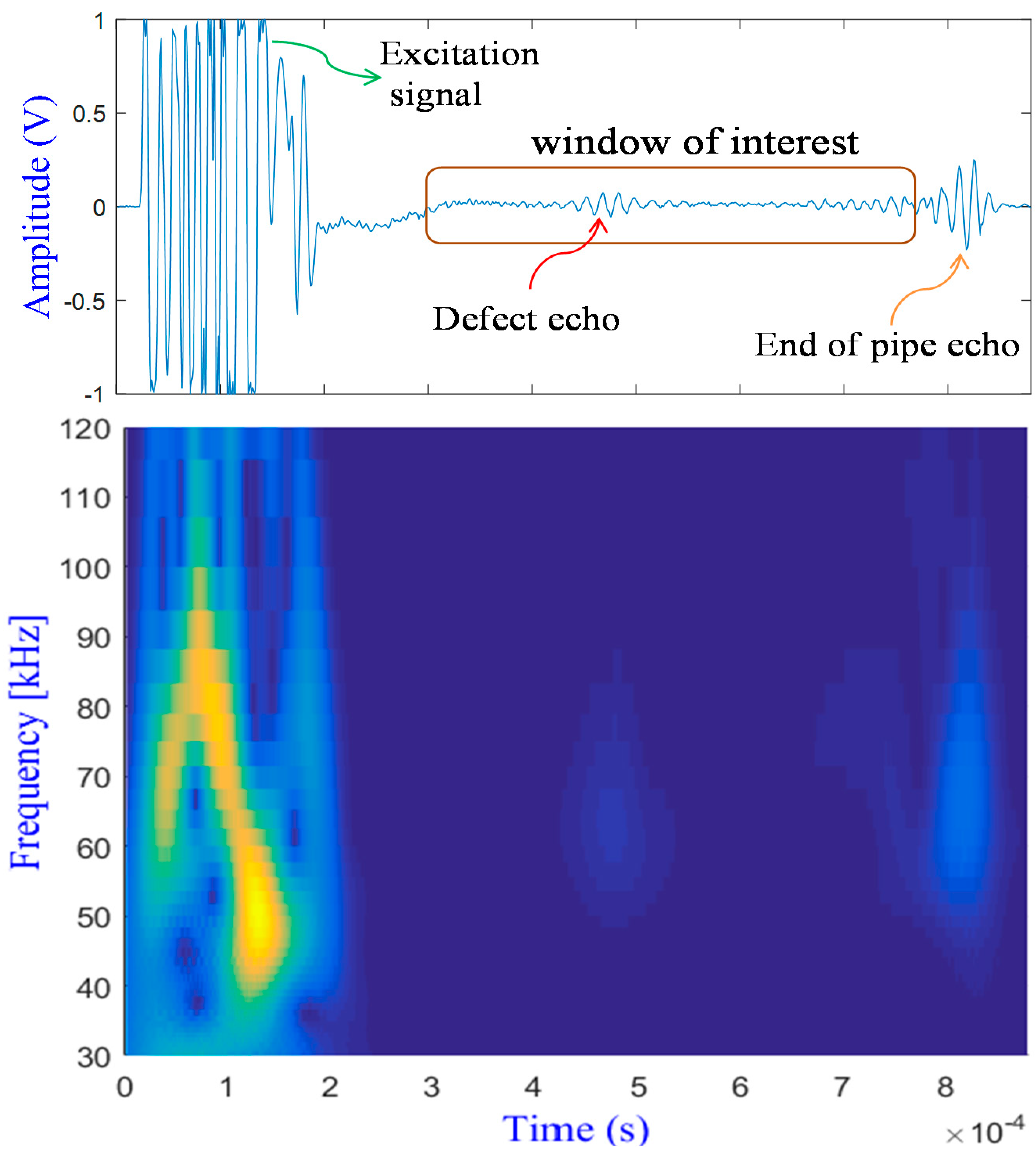
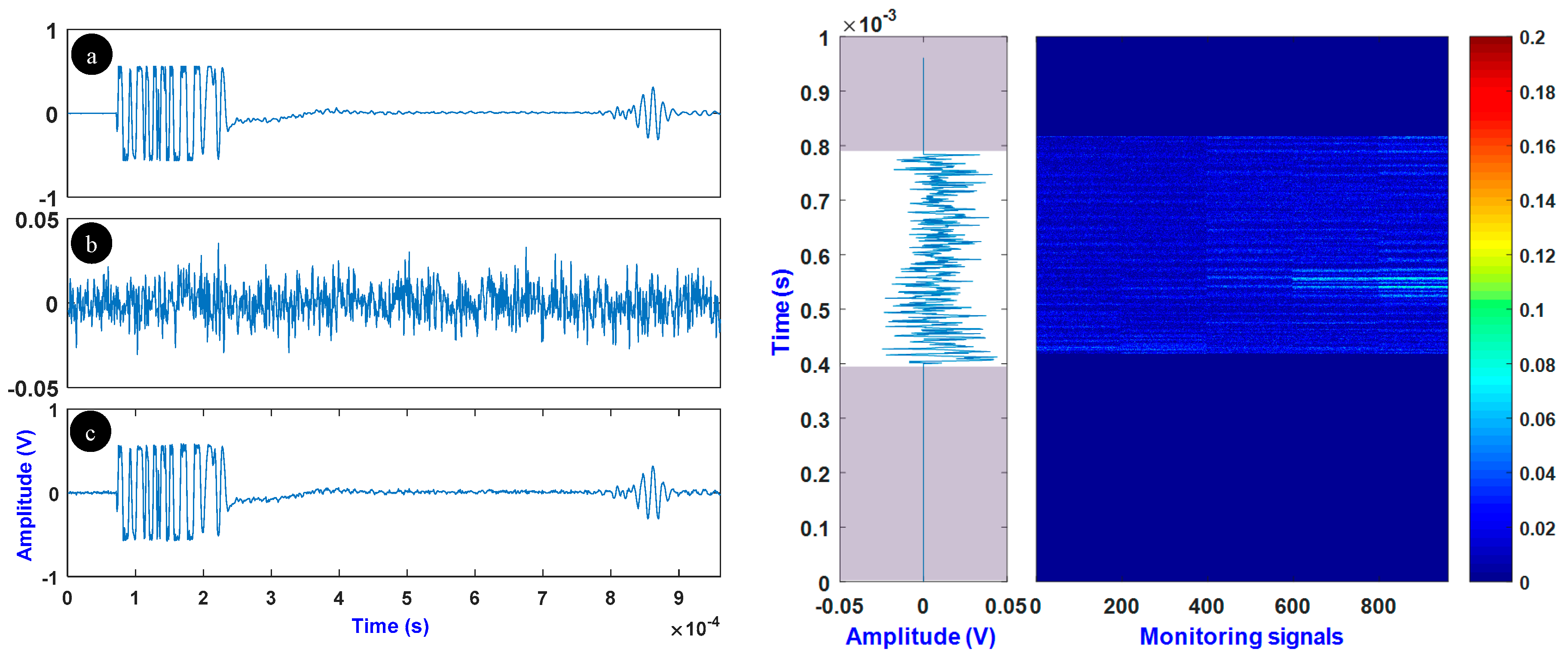
4. Experiments and Database Building
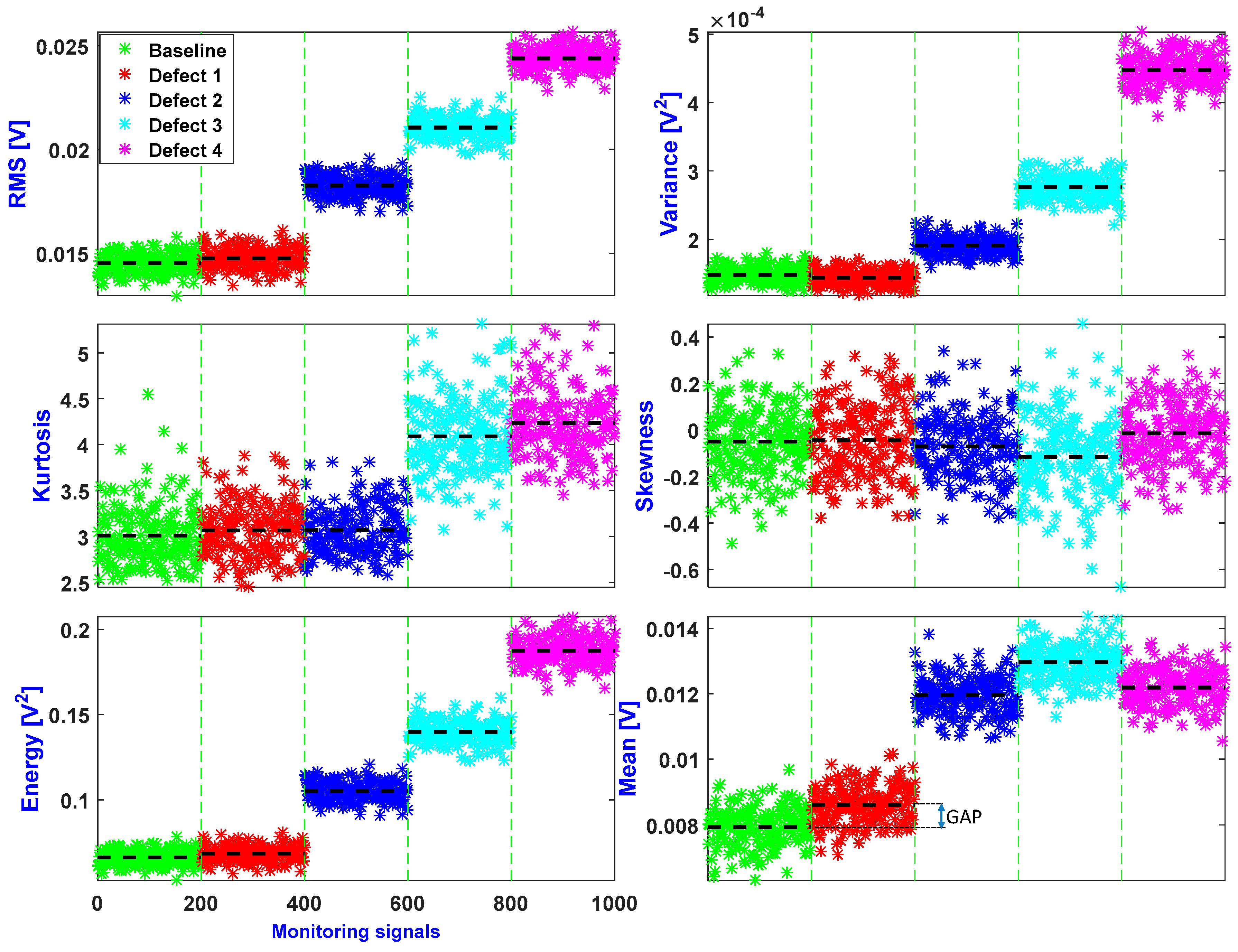
5. Results and Discussion
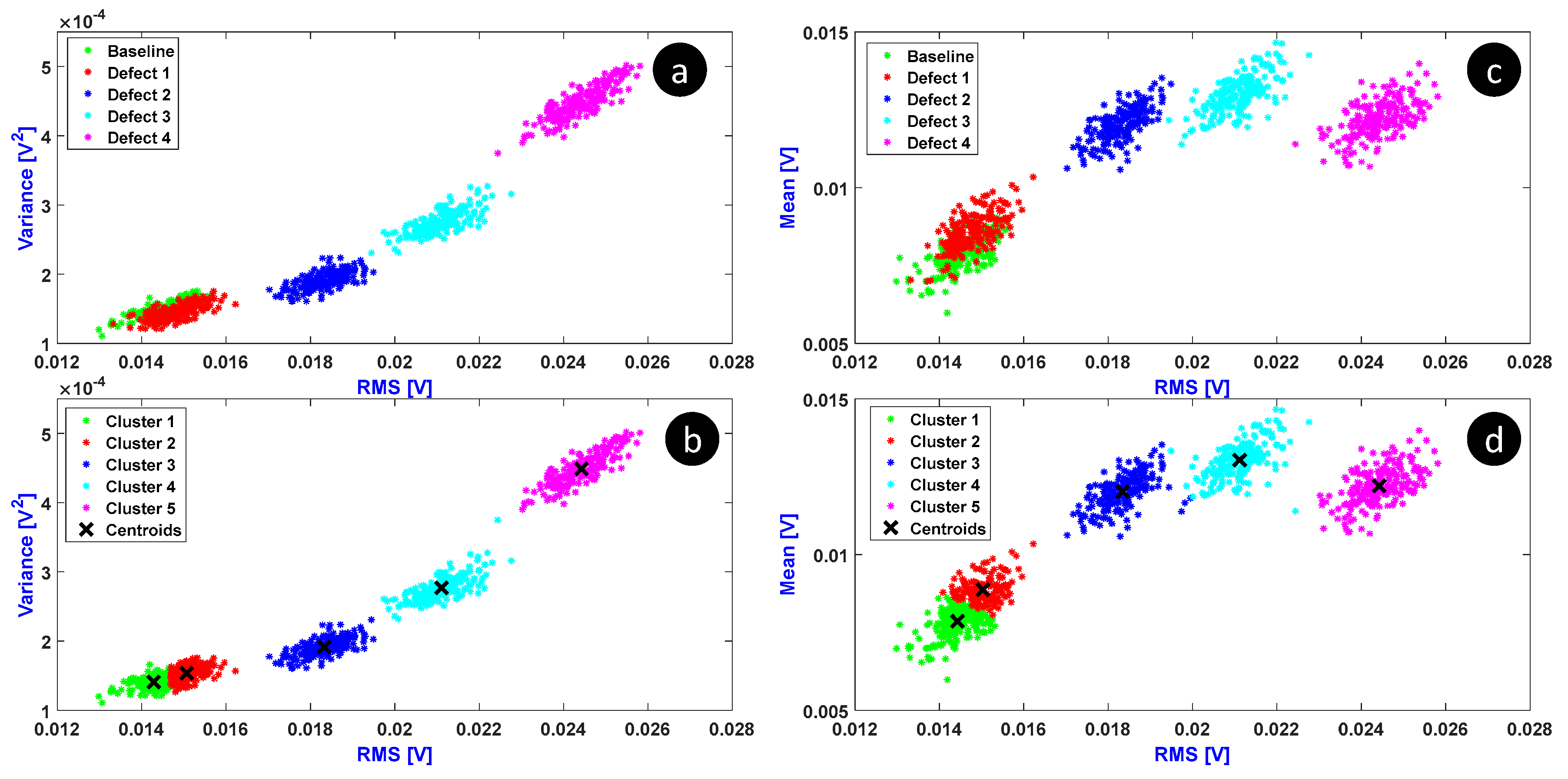
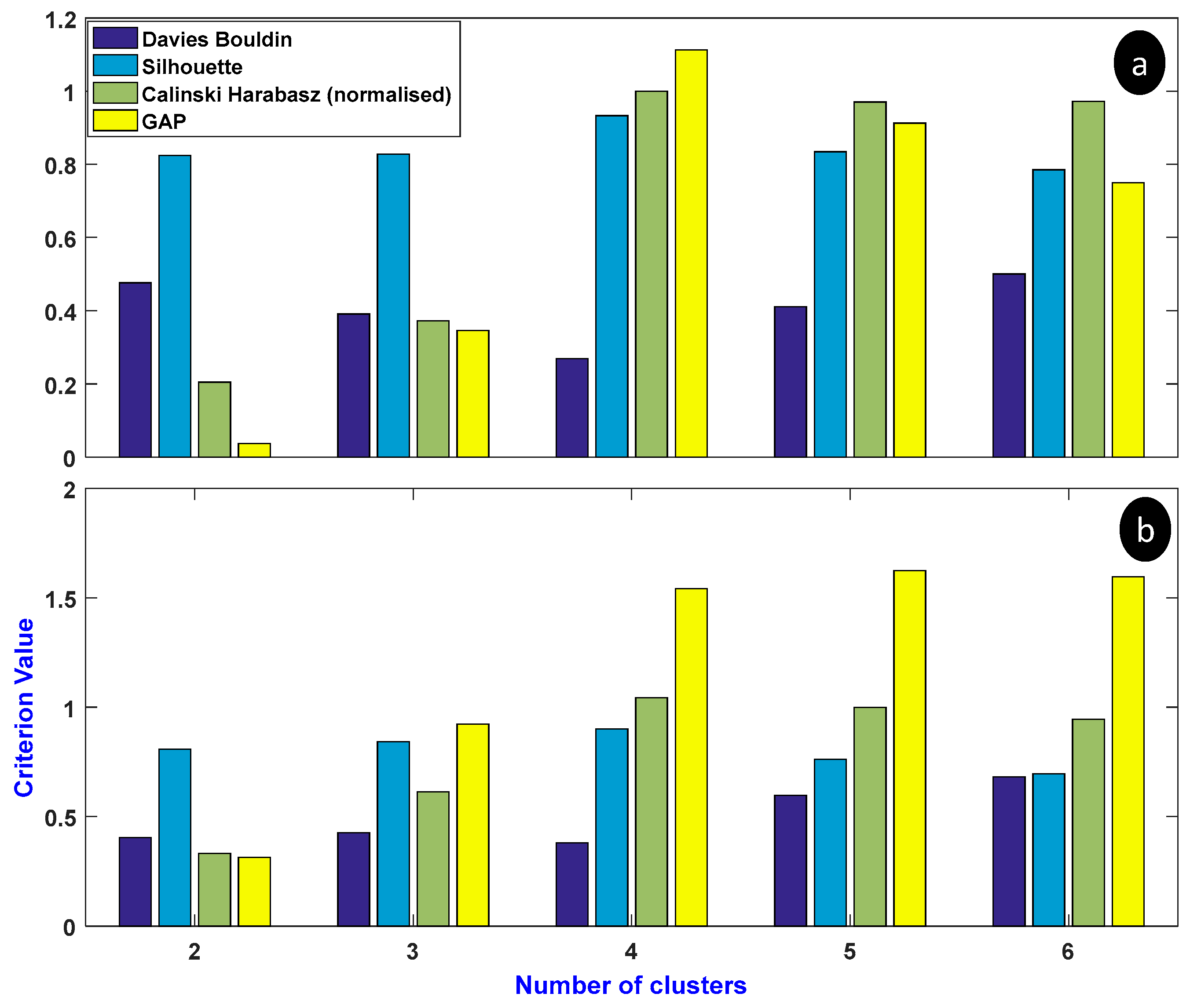
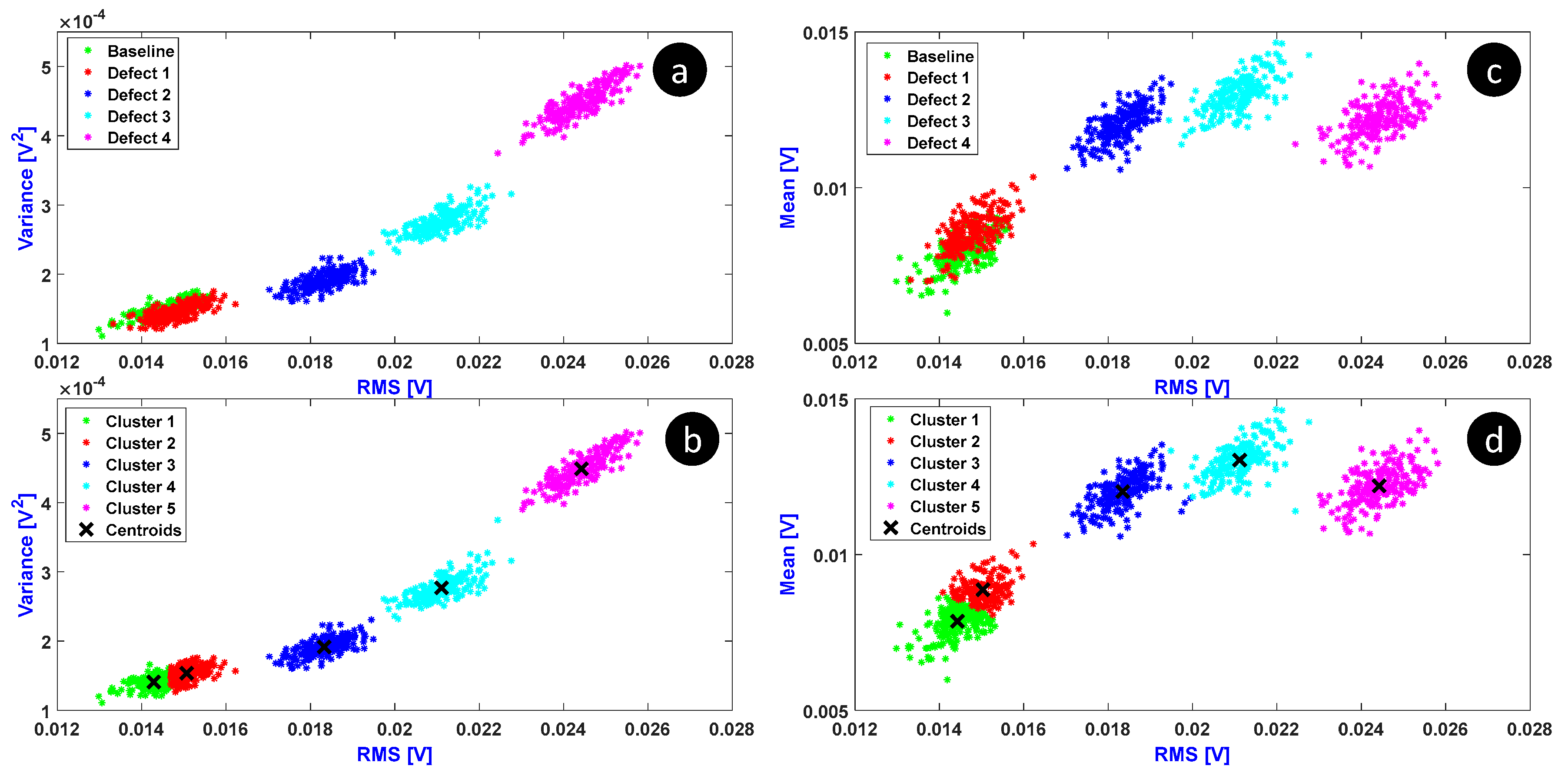
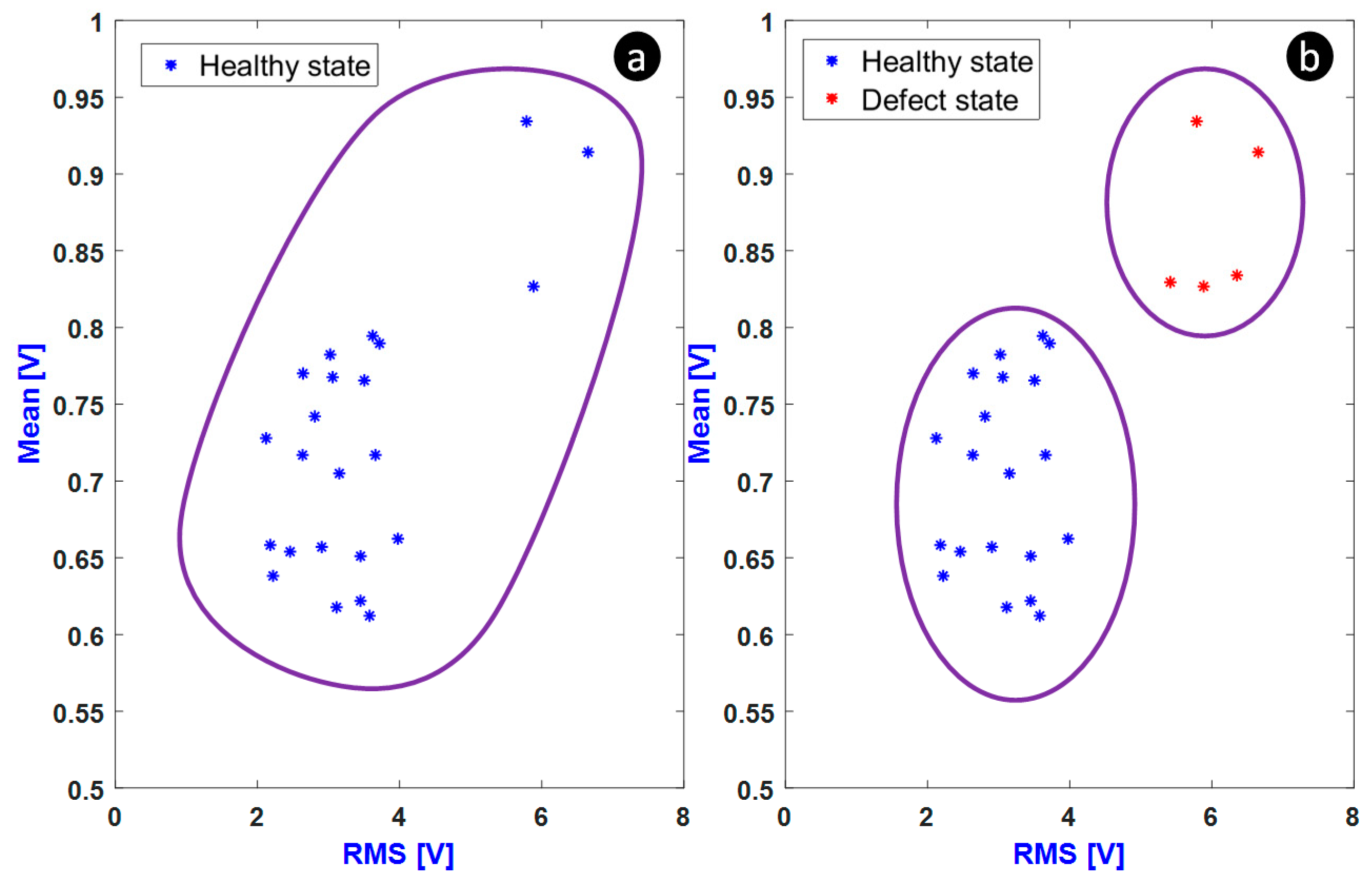
5.1. Classical K-Means
5.2. Novel Proposed Method
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Farrar, C.R.; Worden, K. An introduction to structural health monitoring. Philos. Trans. R. Soc. Lond. A Math. Phys. Eng. Sci. 2017, 365, 303–315. [Google Scholar] [CrossRef]
- Lowe, M.J.; Alleyne, D.N.; Cawley, P. Defect detection in pipes using guided waves. Ultrasonics 1998, 36, 147–154. [Google Scholar] [CrossRef]
- Zhu, W.; Rose, J.L.; Barshinger, J.N.; Agarwala, V.S. Ultrasonic guided wave NDT for hidden corrosion detection. J. Res. Nondestruct. Eval. 1998, 10, 205–225. [Google Scholar] [CrossRef]
- Alleyne, D.N.; Pavlakovic, B.; Lowe, M.J.S.; Cawley, P. The use of guided waves for rapid screening of chemical plant pipework. J. Korean Soc. NDT 2002, 22, 589–598. [Google Scholar]
- Rose, J.L.; Avioli, M.J.; Mudge, P.; Sanderson, R. Guided wave inspection potential of defects in rail. Ndt E Int. 2004, 37, 153–161. [Google Scholar] [CrossRef]
- Rose, J.L.; Soley, L.E. Ultrasonic guided waves for anomaly detection in aircraft components. Mater. Eval. 2000, 58, 1080–1086. [Google Scholar]
- Castaings, M.; Hosten, B. Ultrasonic guided waves for health monitoring of high-pressure composite tanks. Ndt E Int. 2008, 41, 648–655. [Google Scholar] [CrossRef]
- Black, S. Structural Health Monitoring: Composites Get Smart, Composites World. September 2008. Available online: https://www.compositesworld.com/articles/structural-health-monitoring-composites-get-smart (accessed on 30 December 2018).
- Croxford, A.J.; Moll, J.; Wilcox, P.D.; Michaels, J.E. Efficient temperature compensation strategies for guided wave structural health monitoring. Ultrasonics 2010, 50, 517–528. [Google Scholar] [CrossRef]
- Rizzo, P.; Sorrivi, E.; di Scalea, F.L.; Viola, E. Wavelet-based outlier analysis for guided wave structural monitoring: Application to multi-wire strands. J. Sound Vibr. 2007, 307, 52–68. [Google Scholar] [CrossRef]
- Eybpoosh, M.; Berges, M.; Noh, H.Y. An energy-based sparse representation of ultrasonic guided-waves for online damage detection of pipelines under varying environmental and operational conditions. Mech. Syst. Signal Process. 2017, 82, 260–278. [Google Scholar] [CrossRef]
- Yaacoubi, S.; Chehami, L.; Aouini, M.; Declercq, N.F. Ultrasonic guided waves for reinforced plastics safety. Reinf. Plastics. 2017, 61, 87–91. [Google Scholar] [CrossRef]
- Cawley, P.; Lowe, M.J.S.; Alleyne, D.N.; Pavlakovic, B.; Wilcox, P. Practical long range guided wave inspection-applications to pipes and rail. Mater. Eval. 2003, 61, 66–74. [Google Scholar]
- Eybpoosh, M.; Berges, M.; Noh, H.Y. Sparse representation of ultrasonic guided-waves for robust damage detection in pipelines under varying environmental and operational conditions. Struct. Control Heal. Monit. 2016, 23, 369–391. [Google Scholar] [CrossRef]
- Hossein Abadi, H.Z.; Amir fattahi, R.; Nazari, B.; Mirdamadi, H.R.; Atashipour, S.A. GUW-based structural damage detection using WPT statistical features and multiclass SVM. Appl. Acoust. 2014, 86, 59–70. [Google Scholar] [CrossRef]
- Sahu, S.K.; Jena, S.K. A study of K-Means and C-Means clustering algorithms for intrusion detection product development. Int. J. Innov. Manag. Technol. 2014, 5, 207. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Loohach, R.; Garg, K. Effect of distance functions on simple k-means clustering algorithm. Int. J. Comput. Appl. 2012, 49, 7–9. [Google Scholar] [CrossRef]
- Singh, A.; Yadav, A.; Rana, A. K-means with three different distance metrics. Int. J. Comput. Appl. 2013, 67. [Google Scholar] [CrossRef]
- Kim, Y.G.; Moon, H.S.; Park, K.J.; Lee, J.K. Generating and detecting torsional guided waves using magnetostrictive sensors of crossed coils. Ndt E Int. 2011, 44, 145–151. [Google Scholar] [CrossRef]
- Salmanpour, M.S.; Sharif Khodaei, Z.; Aliabadi, M.H. Guided wave temperature correction methods in structural health monitoring. J. Intell. Mater. Syst. Struct. 2017, 28, 604–618. [Google Scholar] [CrossRef]
- Alguri, K.S.; Melville, J.; Harley, J.B. Baseline-free guided wave damage detection with surrogate data and dictionary learning. J. Acoust. Soc. Am. 2018, 143, 3807–3818. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Harley, J.B.; Bergés, M.; Greve, D.W.; Oppenheim, I.J. Robust ultrasonic damage detection under complex environmental conditions using singular value decomposition. Ultrasonics 2015, 58, 75–86. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimkhanlou, A.; Dubuc, B.; Salamone, S. Damage localization in metallic plate structures using edge-reflected lamb waves. Smart Mater. Struct. 2016, 25, 085035. [Google Scholar] [CrossRef]
- Rostami, J.; Tse, P.W.; Fang, Z. Sparse and Dispersion-Based Matching Pursuit for Minimizing the Dispersion Effect Occurring When Using Guided Wave for Pipe Inspection. Materials 2017, 10, 622. [Google Scholar] [CrossRef] [PubMed]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1990. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 2, 224–227. [Google Scholar] [CrossRef]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. B 2001, 63, 411–423. [Google Scholar] [CrossRef]
- Bholowalia, P.; Kumar, A. EBK-means: A clustering technique based on elbow method and k-means in WSN. Int. J. Comput. Appl. 2014, 105, 9. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Cluster (%) | Healthy | Defect 1 | Defect 2 | Defect 3 | Defect 4 | |
|---|---|---|---|---|---|---|
| Real Cluster (%) | ||||||
| Healthy | 52.5 | 47.5 | 0 | 0 | 0 | |
| Defect 1 | 47.5 | 52.5 | 0 | 0 | 0 | |
| Defect 2 | 0 | 0 | 99 | 1 | 0 | |
| Defect 3 | 0 | 0 | 0.5 | 99.5 | 0 | |
| Defect 4 | 0 | 0 | 0 | 0 | 100 | |
| Predicted Cluster (%) | Healthy | Defect 1 | Defect 2 | Defect 3 | Defect 4 | |
|---|---|---|---|---|---|---|
| Real Cluster (%) | ||||||
| Healthy | 71 | 29 | 0 | 0 | 0 | |
| Defect 1 | 35 | 65 | 0 | 0 | 0 | |
| Defect 2 | 0 | 0 | 98 | 2 | 0 | |
| Defect 3 | 0 | 0 | 1.5 | 98.5 | 0 | |
| Defect 4 | 0 | 0 | 0 | 0 | 100 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bouzenad, A.E.; El Mountassir, M.; Yaacoubi, S.; Dahmene, F.; Koabaz, M.; Buchheit, L.; Ke, W. A Semi-Supervised Based K-Means Algorithm for Optimal Guided Waves Structural Health Monitoring: A Case Study. Inventions 2019, 4, 17. https://doi.org/10.3390/inventions4010017
Bouzenad AE, El Mountassir M, Yaacoubi S, Dahmene F, Koabaz M, Buchheit L, Ke W. A Semi-Supervised Based K-Means Algorithm for Optimal Guided Waves Structural Health Monitoring: A Case Study. Inventions. 2019; 4(1):17. https://doi.org/10.3390/inventions4010017
Chicago/Turabian StyleBouzenad, Abd Ennour, Mahjoub El Mountassir, Slah Yaacoubi, Fethi Dahmene, Mahmoud Koabaz, Lilian Buchheit, and Weina Ke. 2019. "A Semi-Supervised Based K-Means Algorithm for Optimal Guided Waves Structural Health Monitoring: A Case Study" Inventions 4, no. 1: 17. https://doi.org/10.3390/inventions4010017
APA StyleBouzenad, A. E., El Mountassir, M., Yaacoubi, S., Dahmene, F., Koabaz, M., Buchheit, L., & Ke, W. (2019). A Semi-Supervised Based K-Means Algorithm for Optimal Guided Waves Structural Health Monitoring: A Case Study. Inventions, 4(1), 17. https://doi.org/10.3390/inventions4010017