

NLU-V: A Family of Instruction Set Extensions for Efficient Symmetric Cryptography on RISC-V



Abstract
1. Introduction
- The extension and adaptation of the 8-bit NLU ISE approach to 32 bits.
- A novel cryptographic ISE for the open-source RISC-V processor.
- Improved performance for block ciphers on 32-bit RISC-V using the novel ISE, which is showcased through case studies.
- Additional AES sBox (substitution layer) support for the non-linear instruction of the NLU.
- RISC-V GNU compiler toolchain adjustments to support the proposed RISC-V ISE (which was not provided in the previous NLU work).
- Publicly available NLU-V implementation, including the RISC-V core and the modified RISC-V GNU compiler toolchain.
2. Related Work and Background
3. Architecture
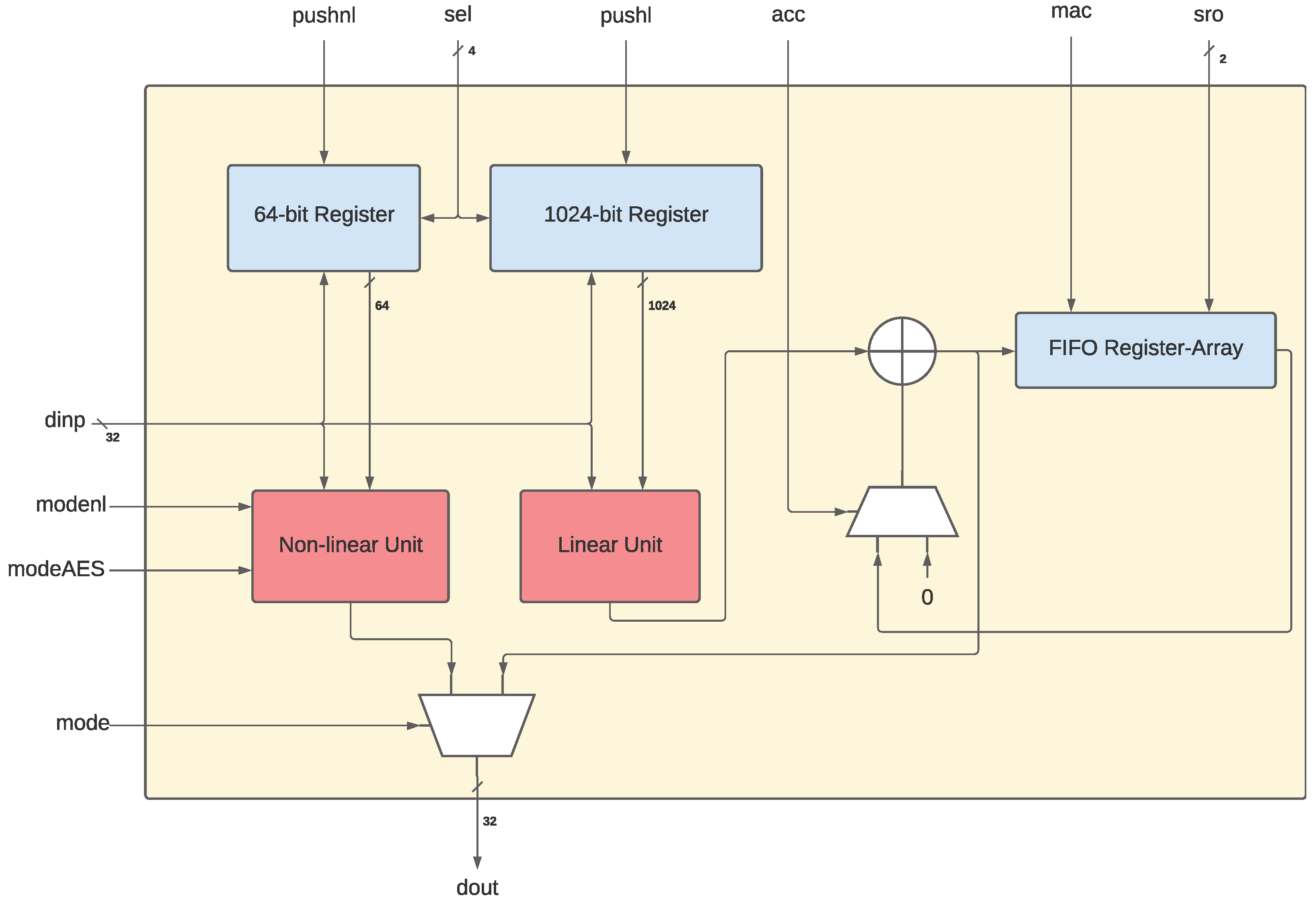
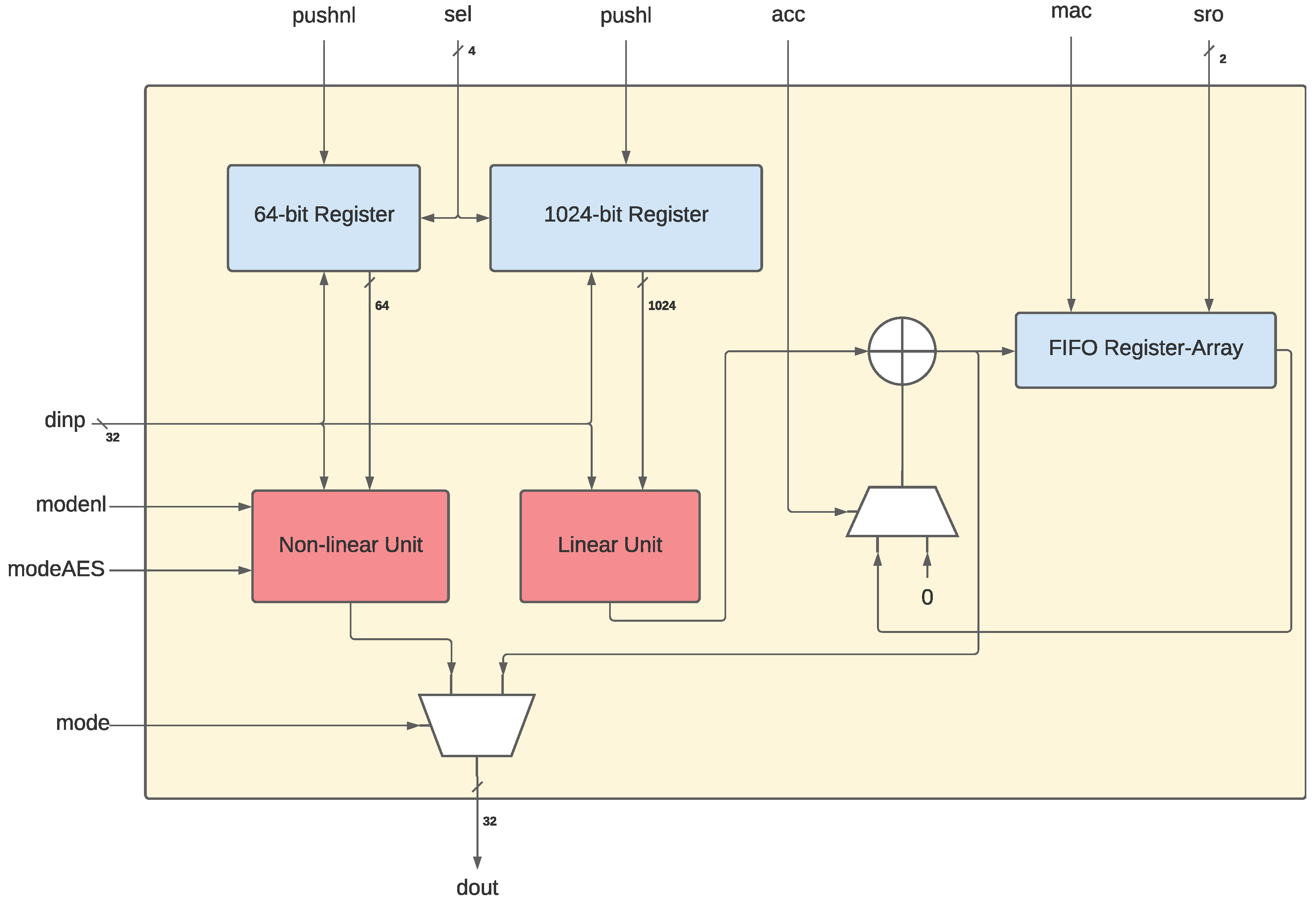
3.1. The Non-Linear/Linear Instruction Set Extension—NLU
3.1.1. NLU Input/Output
3.1.2. The Non-Linear/Linear Units
3.2. Adapting the NLU for RISC-V: The NLU-V
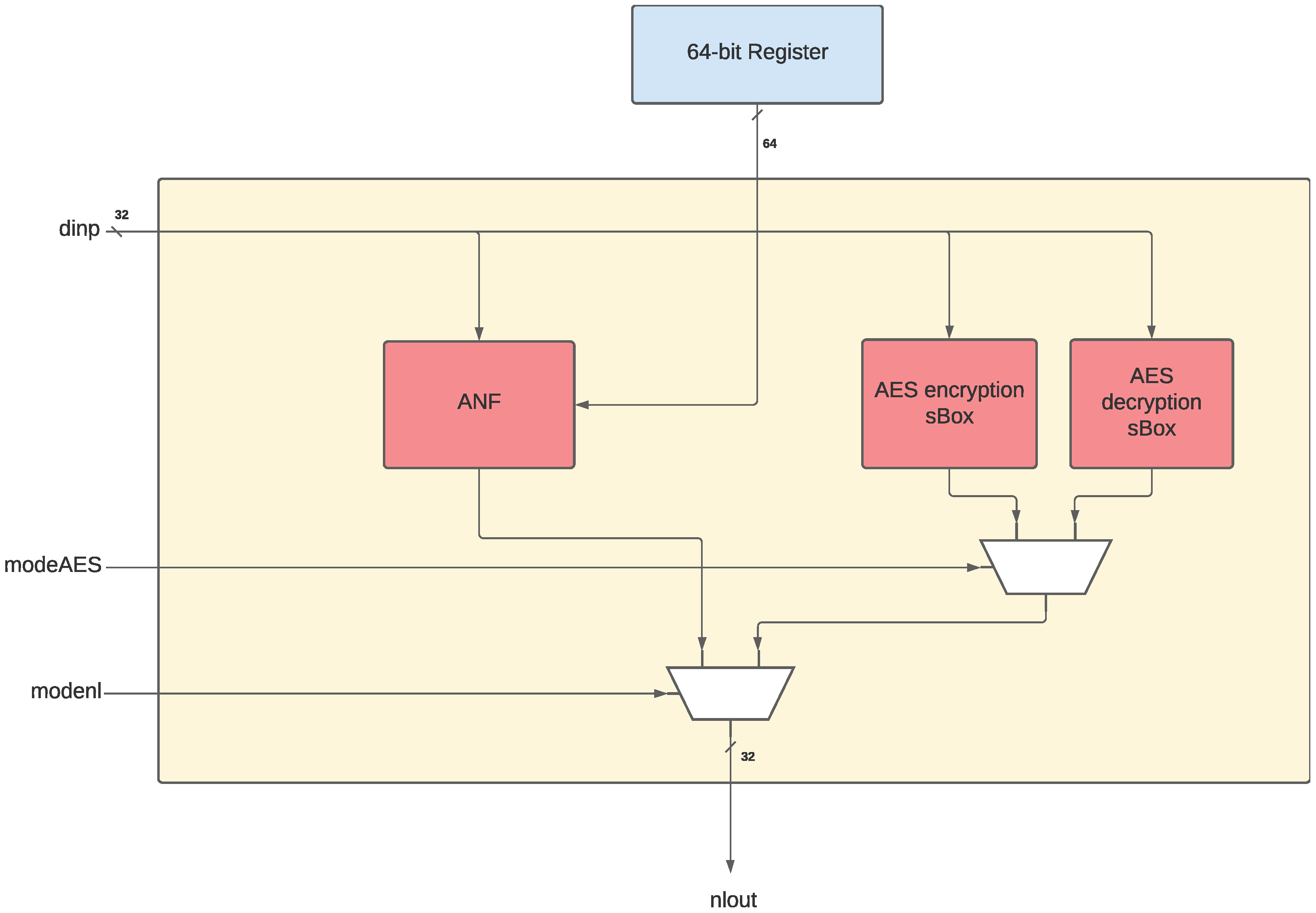
3.2.1. The Non-Linear Unit
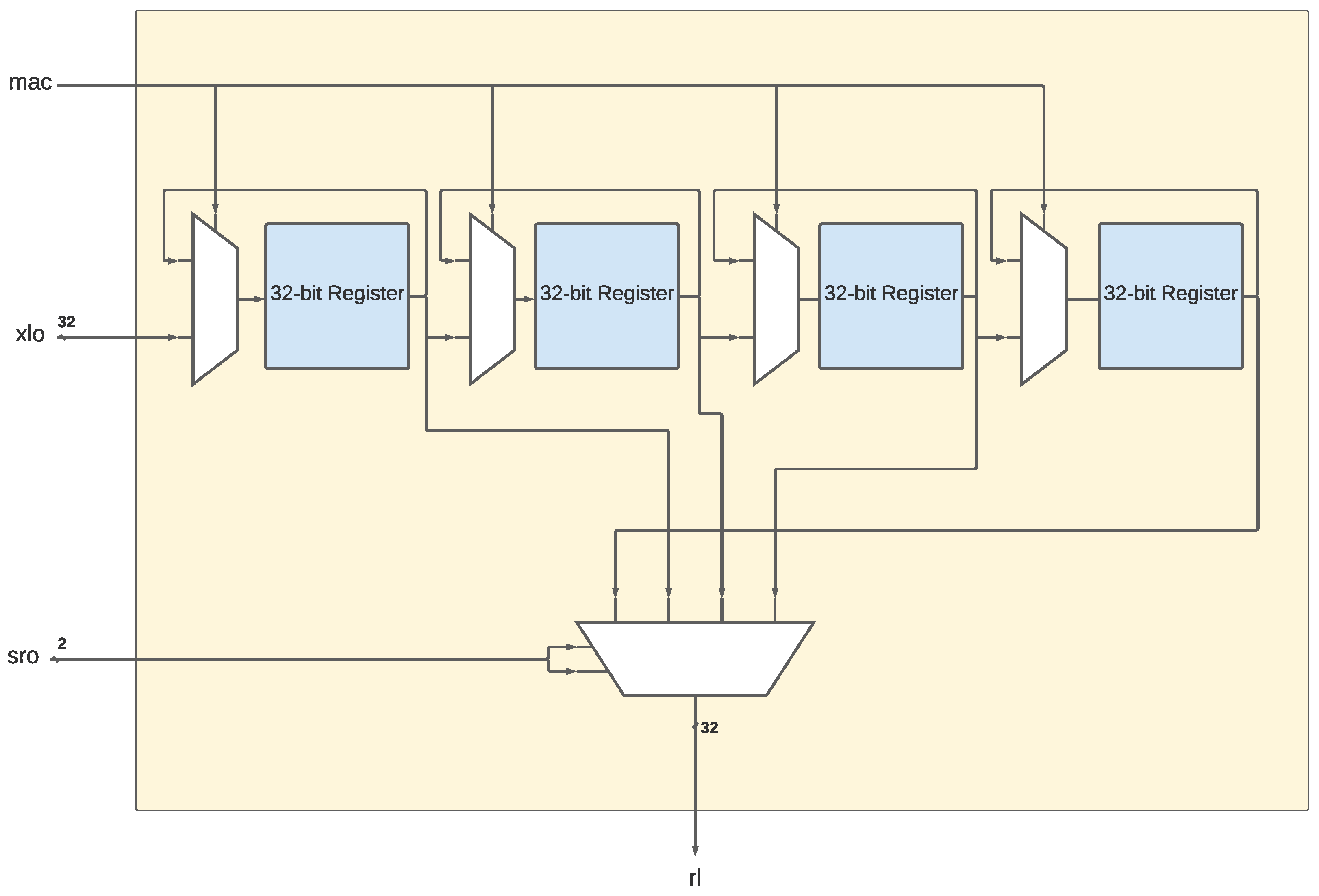
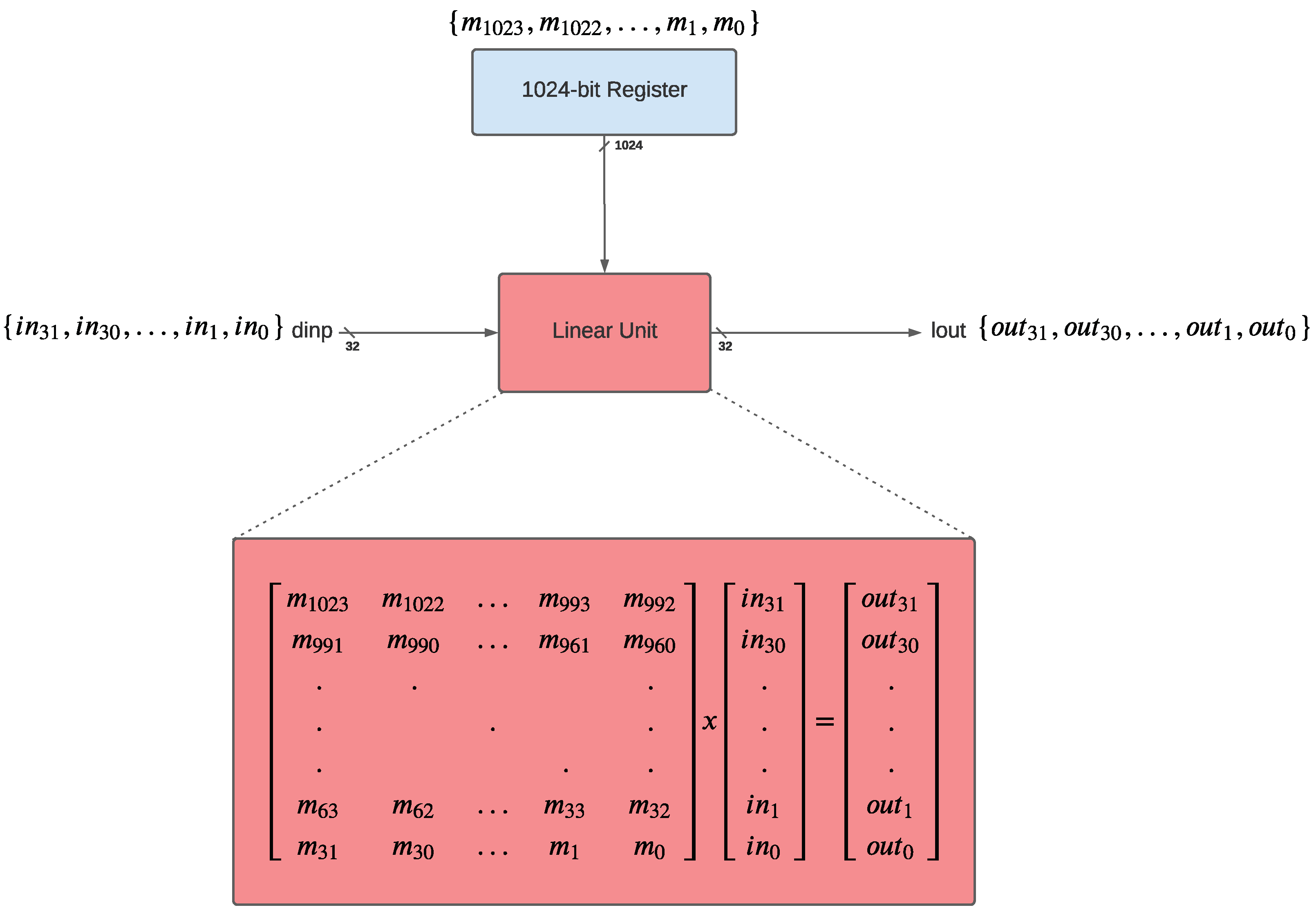
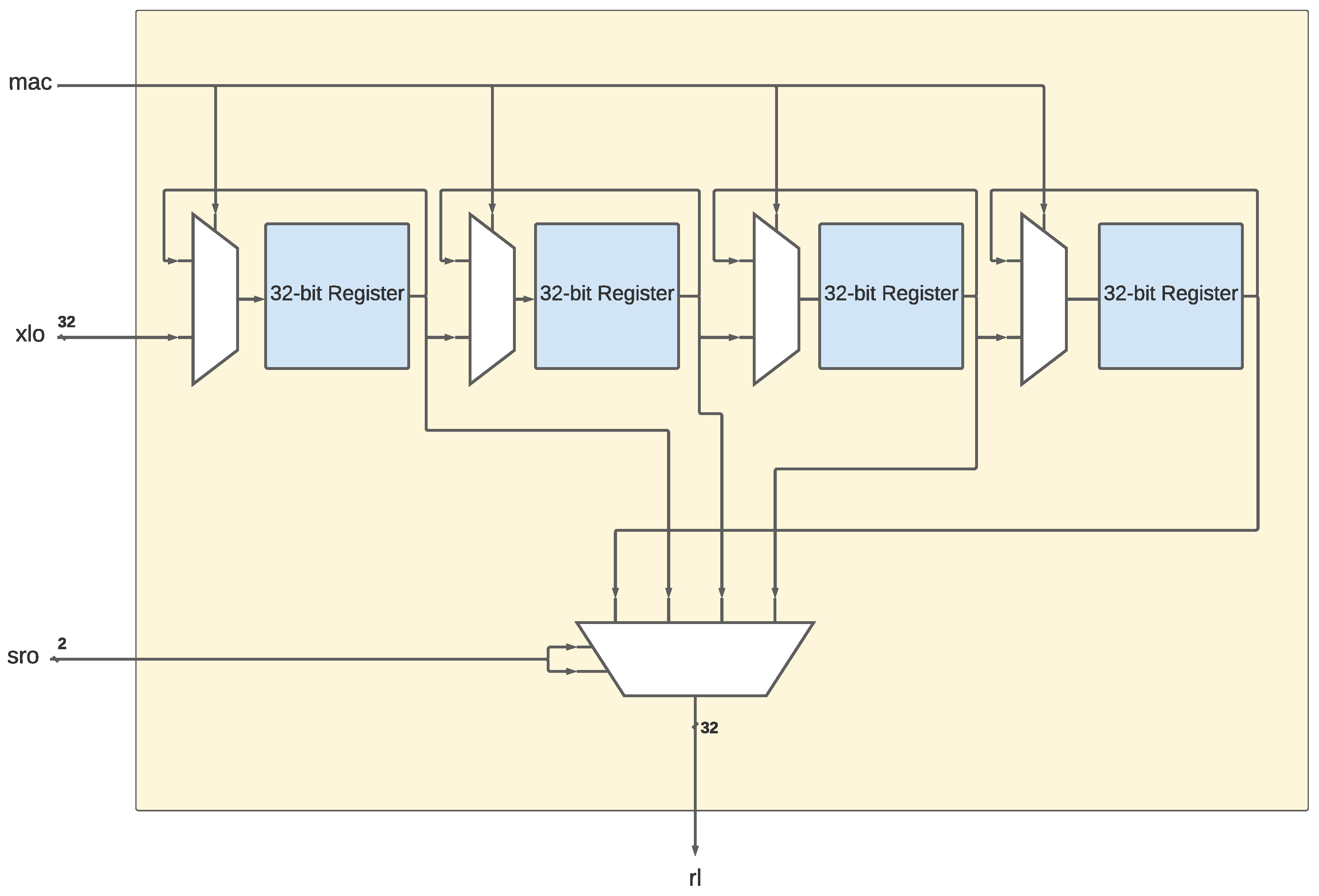
3.2.2. The Linear Unit
3.2.3. The Configuration Register
3.2.4. Input Signals
3.2.5. The NLU-V Instructions
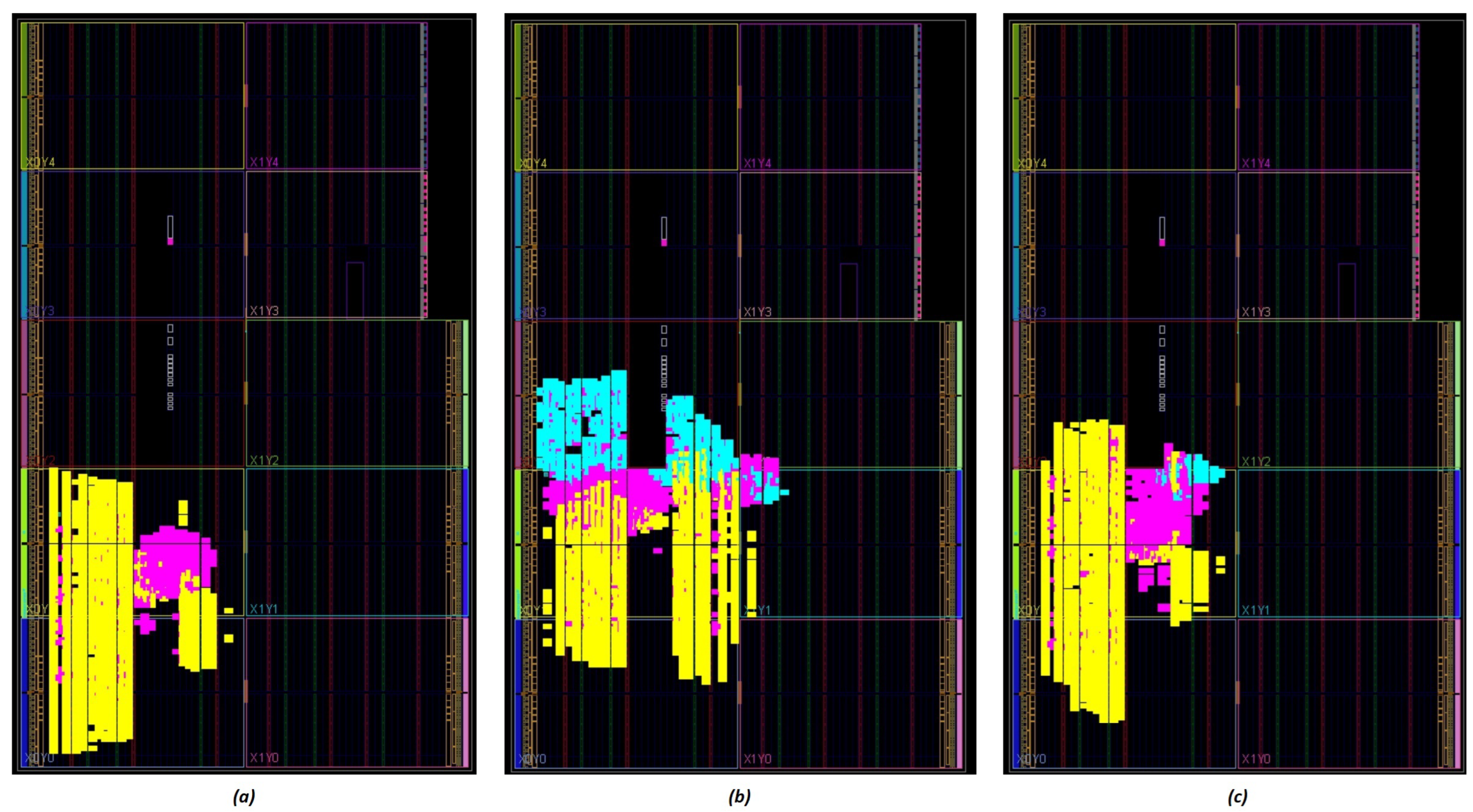
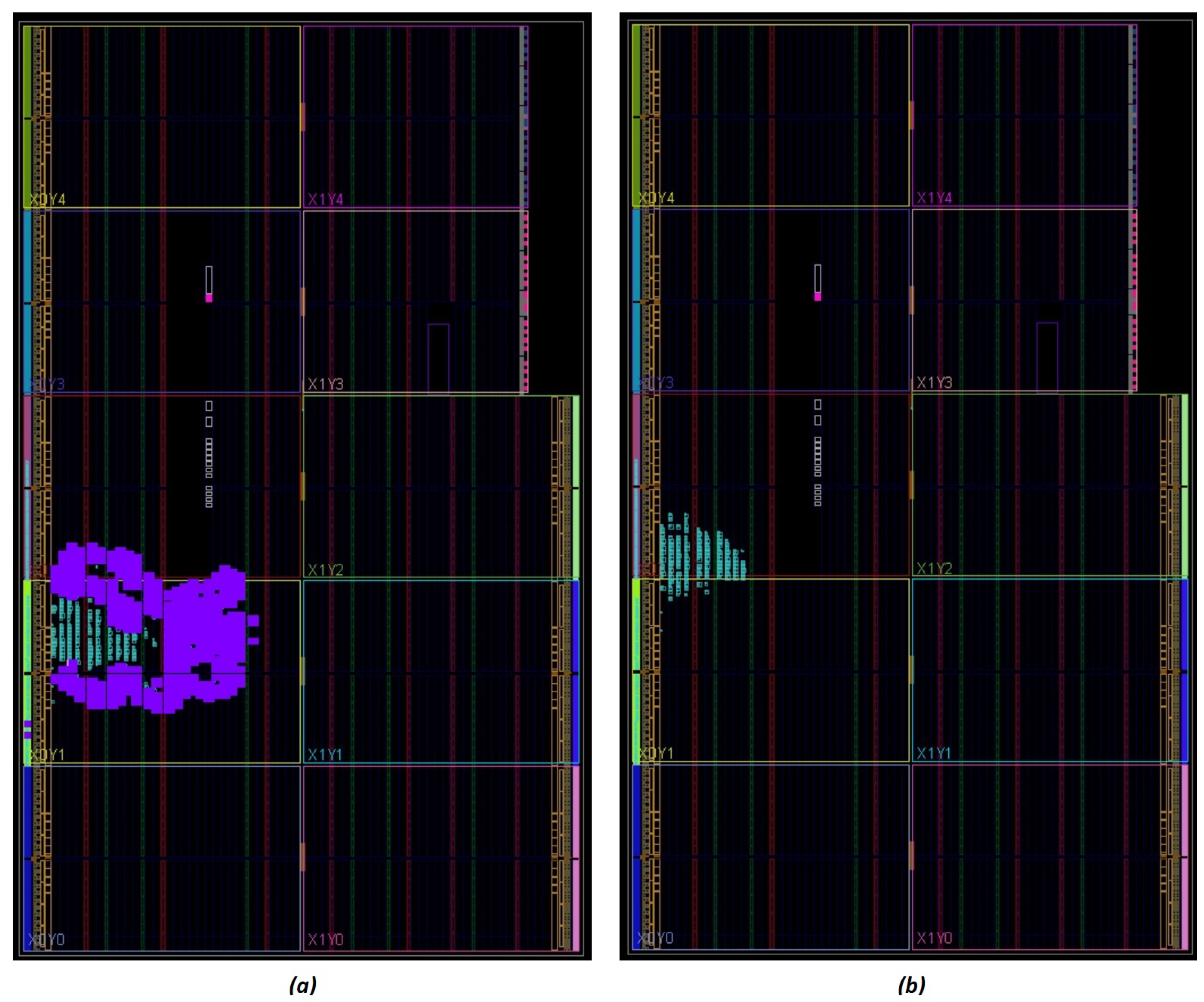
4. Results and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bogdanov, A.; Knudsen, L.R.; Leander, G.; Paar, C.; Poschmann, A.; Robshaw, M.J.B.; Seurin, Y.; Vikkelsoe, C. PRESENT: An Ultra-Lightweight Block Cipher. In Cryptographic Hardware and Embedded Systems, Proceedings of the CHES 2007, Vienna, Austria, 10–13 September 2007; Paillier, P., Verbauwhede, I., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 450–466. [Google Scholar] [CrossRef]
- FIPS 197. Advanced Encryption Standard (AES). 2001. Available online: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.197.pdf (accessed on 15 February 2022).
- Engels, S.; Kavun, E.B.; Paar, C.; Yalçın, T.; Mihajloska, H. A Non-Linear/Linear Instruction Set Extension for Lightweight Ciphers. In Proceedings of the 2013 IEEE 21st Symposium on Computer Arithmetic, Austin, TX, USA, 7–10 April 2013; pp. 67–75. [Google Scholar] [CrossRef]
- Atmel. ATmega8 Datasheet. 2013. Available online: https://ww1.microchip.com/downloads/en/DeviceDoc/Atmel-2486-8-bit-AVR-microcontroller-ATmega8_L_datasheet.pdf (accessed on 15 February 2022).
- Marshall, B.; Page, D.; Pham, T.H. A lightweight ISE for ChaCha on RISC-V. Cryptology ePrint Archive, Paper 2021/1030. 2021. Available online: https://eprint.iacr.org/2021/1030 (accessed on 15 February 2022).
- Marshall, B.; Page, D.; Hung Pham, T. A Lightweight ISE for ChaCha on RISC-V. In Proceedings of the 2021 IEEE 32nd International Conference on Application-specific Systems, Architectures and Processors (ASAP), Virtual Conference, 7–9 July 2021; pp. 25–32. [Google Scholar] [CrossRef]
- Marshall, B.; Page, D.; Pham, T. Implementing the Draft RISC-V Scalar Cryptography Extensions. In Proceedings of the Hardware and Architectural Support for Security and Privacy (HASP ’20), Virtual, Greece, 17 October 2020. [Google Scholar] [CrossRef]
- Shirai, T.; Shibutani, K.; Akishita, T.; Moriai, S.; Iwata, T. The 128-Bit Blockcipher CLEFIA (Extended Abstract). In Fast Software Encryption; Biryukov, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 181–195. [Google Scholar] [CrossRef]
- Daemen, J.; Knudsen, L.; Rijmen, V. The Block Cipher Square. In Fast Software Encryption; Biham, E., Ed.; Springer: Berlin/Heidelberg, Germany, 1997; pp. 149–165. [Google Scholar] [CrossRef]
- Hong, D.; Sung, J.; Hong, S.; Lim, J.; Lee, S.; Koo, B.S.; Lee, C.; Chang, D.; Lee, J.; Jeong, K.; et al. HIGHT: A New Block Cipher Suitable for Low-Resource Device. In Cryptographic Hardware and Embedded Systems, Proceedings of the CHES 2006, Yokohama, Japan, 10–13 October 2006; Goubin, L., Matsui, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 46–59. [Google Scholar] [CrossRef]
- De Cannière, C.; Dunkelman, O.; Knežević, M. KATAN and KTANTAN—A Family of Small and Efficient Hardware-Oriented Block Ciphers. In Cryptographic Hardware and Embedded Systems, Proceedings of the CHES 2009, Lausanne, Switzerland, 6–9 September 2009; Clavier, C., Gaj, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 272–288. [Google Scholar] [CrossRef]
- Gong, Z.; Nikova, S.; Law, Y.W. KLEIN: A New Family of Lightweight Block Ciphers. In RFID. Security and Privacy; Juels, A., Paar, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–18. [Google Scholar] [CrossRef]
- Rivest, R.L.; Robshaw, M.J.; Sidney, R.; Yin, Y.L. The RC6TM Block Cipher. In Proceedings of the First Advanced Encryption Standard (AES) Conference, Ventura, CA, USA, 20–22 August 1998; p. 16. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=61b9b24c25c2e1e4cf4acbf93a7578121429d758 (accessed on 15 February 2022).
- Lim, C.H.; Korkishko, T. mCrypton—A Lightweight Block Cipher for Security of Low-Cost RFID Tags and Sensors. In Information Security Applications; Song, J.S., Kwon, T., Yung, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 243–258. [Google Scholar] [CrossRef]
- Guo, J.; Peyrin, T.; Poschmann, A.; Robshaw, M. The LED Block Cipher. In Cryptographic Hardware and Embedded Systems, Proceedings of the CHES 2011, Nara, Japan, 28 September–1 October 2011; Preneel, B., Takagi, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 326–341. [Google Scholar] [CrossRef]
- Shibutani, K.; Isobe, T.; Hiwatari, H.; Mitsuda, A.; Akishita, T.; Shirai, T. Piccolo: An Ultra-Lightweight Blockcipher. In Cryptographic Hardware and Embedded Systems, Proceedings of the CHES 2011, Nara, Japan, 28 September–1 October 2011; Preneel, B., Takagi, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 342–357. [Google Scholar] [CrossRef]
- Anderson, R.; Biham, E.; Knudsen, L. Serpent: A Proposal for the Advanced Encryption Standard. NIST AES Propos. 1998, 174, 1–23. Available online: https://www.cl.cam.ac.uk/~rja14/Papers/serpent.pdf (accessed on 15 February 2022).
- RISC-V. RISC-V Specifications. 2021. Available online: https://riscv.org/technical/specifications/ (accessed on 15 February 2022).
- RISC-V. RISC-V Specifications Volume 1, Unprivileged Spec v. 20191213. 2019. Available online: https://github.com/riscv/riscv-isa-manual/releases/download/Ratified-IMAFDQC/riscv-spec-20191213.pdf (accessed on 15 February 2022).
- RISC-V. RISC-V Specifications Volume 2, Privileged Spec v. 20211203. 2021. Available online: https://github.com/riscv/riscv-isa-manual/releases/download/Priv-v1.12/riscv-privileged-20211203.pdf (accessed on 15 February 2022).
- Marshall, B.; Newell, G.R.; Page, D.; Saarinen, M.J.O.; Wolf, C. The Design of Scalar AES Instruction Set Extensions for RISC-V. Cryptology ePrint Archive, Report 2020/930. 2020. Available online: https://ia.cr/2020/930 (accessed on 15 February 2022).
- Asanović, K.; Avizienis, R.; Bachrach, J.; Beamer, S.; Biancolin, D.; Celio, C.; Cook, H.; Dabbelt, D.; Hauser, J.; Izraelevitz, A.; et al. The Rocket Chip Generator; Technical Report UCB/EECS-2016-17; EECS Department, University of California: Berkeley, CA, USA, 2016; Available online: http://www2.eecs.berkeley.edu/Pubs/TechRpts/2016/EECS-2016-17.html (accessed on 15 February 2022).
- Marshall, B. SCARV: A Side-Channel Hardened RISC-V Platform. 2021. Available online: https://github.com/scarv/scarv (accessed on 30 March 2022).
- Bernstein, D.J. ChaCha, A Variant of Salsa20. In Proceedings of the Workshop Record of SASC, Lausanne, Switzerland, 13–14 February 2008; pp. 3–5. Available online: https://cr.yp.to/chacha/chacha-20080120.pdf (accessed on 30 March 2022).
- Alkim, E.; Evkan, H.; Lahr, N.; Niederhagen, R.; Petri, R. ISA Extensions for Finite Field Arithmetic—Accelerating Kyber and NewHope on RISC-V. Cryptology ePrint Archive, Report 2020/049. 2020. Available online: https://ia.cr/2020/049 (accessed on 15 February 2022).
- Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS—Kyber: A CCA-Secure Module-Lattice-Based KEM. Cryptology ePrint Archive, Report 2017/634. 2017. Available online: https://ia.cr/2017/634 (accessed on 15 February 2022).
- Alkim, E.; Avanzi, R.; Bos, J.; Ducas, L.; de la Piedra, A.; Pöppelmann, T.; Schwabe, P.; Stebila, D. NewHope. 2020. Available online: https://newhopecrypto.org/index.shtml (accessed on 30 March 2022).
- Claire Wolf Symbiotic GmbH. RISC-V Bitmanip Extension Document Version 0.94-Draft. 2021. Available online: https://raw.githubusercontent.com/riscv/riscv-bitmanip/master/bitmanip-draft.pdf (accessed on 29 March 2022).
- RISC-V Foundations Bitmanip Extension Working Group. RISC-V Bitmanip (Bit Manipulation) Extension. 2021. Available online: https://github.com/riscv/riscv-bitmanip/tree/main-history (accessed on 30 March 2022).
- RISC-V. RISC-V Exchange: Cores & SoCs. 2021. Available online: https://riscv.org/exchange/cores-socs/ (accessed on 21 February 2022).
- Edgecombe, G. Icicle—32-bit RISC-V Implementation. 2019. Available online: https://github.com/grahamedgecombe/icicle (accessed on 15 February 2022).
- The Regents of the University of California. RISC-V GNU Compiler Tool Chain. 2016. Available online: https://github.com/riscv-collab/riscv-gnu-toolchain (accessed on 15 February 2022).
- Fiaz, F.; Masud, S. Design and Implementation of A Hardware Divider in Finite Field. In Proceedings of the National Conference on Emerging Technologies, Karachi, Pakistan, 18 December 2004; Available online: https://www.researchgate.net/publication/237228696_Design_and_Implementation_of_a_Hardware_Divider_in_Finite_Field (accessed on 15 February 2022).
- Ward, R.W.; Molteno, D.T.C.A. Efficient Hardware Calculation of Inverses in GF(28). 2015. Available online: https://api.semanticscholar.org/CorpusID:27223451 (accessed on 15 February 2022).
- Md Naziri, S.Z.; Mei, Y.; Idris, N. The Verilog HDL-based Design of Multiplicative Inverse Value of GF(28) Auto-Generator Using Extended Euclid Algorithm Method for Advanced Encryption Standard Algorithm. In Integrated Electronics: Designs and Systems; Penerbit Universiti Malaysia Perlis: Kangar, Malaysia, 2013; Volume 1, pp. 77–90. Available online: https://www.researchgate.net/publication/265729275_The_Verilog_HDL-based_Design_of_Multiplicative_Inverse_Value_of_GF28_Auto-generator_using_Extended_Euclid_Algorithm_Method_for_Advanced_Encryption_Standard_Algorithm (accessed on 15 February 2022).
- Chen, T.C.; Wei, S.W.; Tsai, H.J. Arithmetic Unit for Finite Field GF(2m). IEEE Trans. Circuits Syst. I Regul. Pap. 2008, 55, 828–837. [Google Scholar] [CrossRef]
- Sarkar, P.; Roy, B.; Choudhury, P.; Barua, R. Polynomial Division Using Left Shift Register. Comput. Math. Appl. 1998, 35, 27–31. [Google Scholar] [CrossRef]
- Canright, D. A Very Compact S-Box for AES. In Cryptographic Hardware and Embedded Systems, Proceedings of the CHES 2005, Edinburgh, UK, 29 August–1 September 2005; Rao, J.R., Sunar, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 441–455. [Google Scholar] [CrossRef]
- Canright, D. A Very Compact Rijndael S-Box. 2005. Available online: https://core.ac.uk/download/pdf/36694529.pdf (accessed on 15 February 2022).
- Moradi, A.; Poschmann, A.; Ling, S.; Paar, C.; Wang, H. Pushing the Limits: A Very Compact and a Threshold Implementation of AES. In Advances in Cryptology, Proceedings of the EUROCRYPT 2011, Tallinn Estonia, 15–19 May 2011; Springer: Berlin/Heidelberg, Germany; Volume 6632, pp. 69–88. [CrossRef]
- Gao, S.; Marshall, B.; Page, D.; Pham, T. FENL: An ISE to Mitigate Analogue Micro-architectural Leakage. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2020, 73–98. [Google Scholar] [CrossRef]
- Uzuner, H. NLU-V. 2022. Available online: https://github.com/UzunerH/MasterThesisCode (accessed on 30 March 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instruction | Syntax | Description |
|---|---|---|
| NLDNL | NLDNL d, u | |
| Load non-linear configuration | ||
| NLDL | NLDL d, u | |
| Load linear configuration | ||
| NNLANF | NNLANF d, s | |
| NLU non-linear ANF operation | ||
| NNLAESE | NNLAESE d, s | |
| NLU non-linear AES-sBox encryption | ||
| NNLAESD | NNLAESD d, s | |
| NLU non-linear AES-sBox decryption | ||
| NMU | NMU d, s | |
| NLU multiply | ||
| NMA0 | NMA0 d, s | |
| NLU multiply-and-add FIFO zero | ||
| NMA1 | NMA1 d, s | |
| NLU multiply-and-add FIFO one | ||
| NMA2 | NMA2 d, s | |
| NLU multiply-and-add FIFO two | ||
| NMA3 | NMA3 d, s | |
| NLU multiply-and-add FIFO three |
| FLOP_LATCH * | LUT | MUXFX ** | DMEM | ||
|---|---|---|---|---|---|
| NLU-V-only (w/o LU) | nlunit32 (w/o LU) | 64 | 942 | - | 64 |
| NLU-V-only | nlunit32 | 1088 | 4520 | - | 32 |
| Icicle-only | icicle32 | 974 | 2128 | 3230 | 4184 |
| rv32 | 778 | 1735 | 30 | 88 | |
| Icicle + NLU-V (w/o LU) | icicle32 | 1051 | 3140 | 3229 | 4248 |
| rv32 | 855 | 2746 | 29 | 152 | |
| nlunit32 | 64 | 252 | - | 64 | |
| Icicle + NLU-V | icicle32 | 2115 | 6762 | 3235 | 4216 |
| rv32 | 1919 | 6365 | 35 | 120 | |
| nlunit32 (w/o LU) | 1088 | 3406 | - | 32 | |
| LoC Gain | Time | Flash Memory | ||
|---|---|---|---|---|
| LoCs | in % | (Clock Cycles) | (Words) | |
| PRESENT RV32I | 349 | 0 | 42,862 | 593 |
| PRESENT NLU-V | 197 | 44 | 13,898 | 201 |
| AES RV32I | 298 | 0 | 25,824 | 542 |
| AES NLU-V | 228 | 23 | 19,056 | 234 |
| Time-Area-Product (TAP) | TAP Gain in % | |
|---|---|---|
| PRESENT RV32I | 0 | |
| PRESENT NLU-V | 89 | |
| AES RV32I | 0 | |
| AES NLU-V | 68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uzuner, H.; Kavun, E.B. NLU-V: A Family of Instruction Set Extensions for Efficient Symmetric Cryptography on RISC-V. Cryptography 2024, 8, 9. https://doi.org/10.3390/cryptography8010009
Uzuner H, Kavun EB. NLU-V: A Family of Instruction Set Extensions for Efficient Symmetric Cryptography on RISC-V. Cryptography. 2024; 8(1):9. https://doi.org/10.3390/cryptography8010009
Chicago/Turabian StyleUzuner, Hakan, and Elif Bilge Kavun. 2024. "NLU-V: A Family of Instruction Set Extensions for Efficient Symmetric Cryptography on RISC-V" Cryptography 8, no. 1: 9. https://doi.org/10.3390/cryptography8010009
APA StyleUzuner, H., & Kavun, E. B. (2024). NLU-V: A Family of Instruction Set Extensions for Efficient Symmetric Cryptography on RISC-V. Cryptography, 8(1), 9. https://doi.org/10.3390/cryptography8010009