In this section, we first propose a new method called structural priors by partial correlation (SPPC), where the key idea is to use partial correlation analysis to mine conditional independence information. Next, this conditional independence information is integrated into the hyper-heuristic algorithm as a structural prior.
4.1. SPPC
Due to the equivalence of zero partial correlation and CI for linear SEMs, the goal of the SPPC algorithm is to use partial correlation analysis to narrow the search space as much as possible in addition to identifying partial v-structures. The SPPC algorithm starts with an empty graph and consists of three stages: full partial correlation, local partial correlation, and identification of v-structures. Through these three stages, we can obtain the global search space (GSS), local search space (LSS), and v-structure (V). The pseudocode is shown in Algorithm 1, and we explain each stage in more detail in the following paragraphs. The three stages can be summarized as follows:
For any two nodes add an edge if the full partial correlation coefficient is significantly different from zero.
For every edge in the undirected graph built in step 1, we perform a local partial correlation analysis that looks for a d-separating set Z. If the partial correlation vanishes, we consider this edge to be a spurious link caused by v-structure effects and then remove it.
For every edge that is removed in step 2, we find the colliders contained in Z. If node U is a collider, we add two edges
| Algorithm 1: SPPC |
![Biomimetics 09 00350 i001]() |
In the first stage, we perform a full partial correlation analysis and reconstruct a Markov random field. In the full partial correlation analysis, if is less than a threshold we consider that the two nodes are correlative and connect with each other in the GSS and LSS. In contrast, if is greater than the threshold we consider that the two nodes are uncorrelated. If the data satisfy the faithfulness assumption, the GSS derived from the identified undirected graph may resemble a moral graph. Therefore, we treat the GSS as the primary search space to ensure the completeness of the search space. Unfortunately, in the GSS, all parents of colliders are connected, and the v-structures are transformed into triangles. It should be noted that these spurious links caused by v-structure effects have a more severe negative impact on the search process compared to other error edges. When dealing with large-scale problems, the GSS cannot effectively alleviate the inefficiency of the search algorithm, and it easily falls into local optima. Fortunately, the partial correlation coefficient for the CI test is easy to calculate, even when the size of the condition set is large. Therefore, to improve search efficiency, we consider further mining conditional independence information in the second stage.
In the second stage, our goal is to find a set
Z that blocks all simple paths between two nodes
Obviously, the exhaustive method is inefficient and undesirable. Therefore, heuristic strategies are usually used to find such a cut set. For example, a two-phase algorithm [
54] utilized a heuristic method based on monotone faithfulness that employs the absolute value of partial correlation as a decision criterion. However, monotone faithfulness is sometimes a bad assumption [
55]. In this paper, we propose a new heuristic strategy to determine a d-separating set, and the pseudocode is shown in Algorithm 2. To illustrate how our heuristic strategy works, some relevant concepts are briefly introduced.
| Algorithm 2: Local partial correlation |
![Biomimetics 09 00350 i002]() |
Theorem 4. For any two nodes if there is no edge between them, we can determine a d-separating set by choosing nodes only from either or [52]. Here, denotes the Markov random field of nodes . This theorem enables us to perform local partial correlation analysis on small sets, which makes the estimation results more efficient and stable. Next, the most important task of a heuristic strategy is to find an appropriate metric to tightly connect the CI test with d-separation.
Definition 5 (Simple path)
. A simple path is an adjacency path that does not contain duplicate nodes [52]. According to the definition of d-separation, for any two nodes if there exists such a cut set Z that makes the two nodes conditionally independent, we can finally find it by blocking all the simple paths between the two nodes.
Definition 6 (Active path)
. For any two nodes given a simple path U between the two nodes, the path U is blocked by Z if and only if at least one noncollider on U is in Z or at least one collider and all of its descendants are not in Z [52]. If path U is not blocked by Z, we call path U an active path on Z. Definition 7 (Open simple path). For any two nodes and given a set of conditions for a node in Z, if and are both significantly different from zero, we refer to the simple paths from to and as open. In this case, is said to have an open simple path (OSP) to on Z.
Notably, an OSP is different from an active path in a directed graph because we cannot determine whether node is a noncollider or a collider. The initial OSP is the intersection of the Markov random fields of two nodes.
Theorem 5. For any two nodes given a set of conditions Z, if there is no edge between the two nodes in the underlying graph and is significantly different from zero, then all active paths on Z with colliders must satisfy that every collider and all of its descendants contain a node (denoted as that belongs to Z and has an OSP to
Proof of Theorem 5. If is significantly different from zero, there must be at least one active path between and on Z, denoted as set U. For any path in U, denoted as path according to the definition of the active path, we know that all the noncolliders on u are not in Z and every collider satisfies that itself or at least one of its descendants is in Z. For any collider in u, let denote the node that satisfies the above condition. We can easily construct an active path based on path u between and on , and similarly between and Therefore, we can consider that and are both significantly different from zero, and then has an OSP to □
If path u does not contain a collider, we cannot block this path by removing nodes. Therefore, our heuristic strategy is to start with an initial set that contains the d-separation set and then block the simple paths by gradually removing nodes that have OSPs to Throughout the process, as each node with an OSP is removed, we observe the number of remaining nodes that have OSPs, and this number is used as a criterion to determine which node to delete. In this paper, we greedily choose the node with the lowest value for removal. When no node in the conditional set has an OSP, the search stops.
In the third stage, our task is to orient some edges correctly by detecting v-structures. For each edge removed in the local partial correlation analysis, we find the colliders contained in If node U is a collider, we add two edges to V.
4.2. Proposed Multi-Population Choice Function Hyper-Heuristic
Hyper-heuristics are high-level methodologies that perform a search over the space formed by a set of low-level heuristics when solving optimization problems. In general, a hyper-heuristic contains two levels—a high-level strategy and low-level heuristics—and there is a domain barrier between the two. The former comprises two main stages: a heuristic selection strategy and a move acceptance criterion. The latter involves a pool of low-level heuristics, the initial solution, and the objective function (often also the fitness or cost function). The working principle of hyper-heuristics is shown in
Figure 1.
4.2.1. The High-Level Strategy
Various combinations of heuristic selection strategies and move acceptance criteria have been reported in the literature. Classical heuristic selection strategies include choice functions, nature-inspired algorithms, multi-armed bandit (MAB)-based selection, and reinforcement learning, while move acceptance criteria include only improvement, all moves, simulated annealing, and late acceptance. In this article, we use the “choice function accept all moves” as a high-level strategy, which evaluates the performance score (F) of each LLH using three different measurements:
and
The specific calculation method is shown in Equation (10):
Parameter
reflects the previous performance of the currently selected heuristics,
The value of
is evaluated using Equation (11),
where
is the change in solution quality by
and is set to 0 when the solution quality does not improve.
is the time taken by
Parameter
attempts to capture any pairwise dependencies between heuristics. The values of
are calculated for the current heuristic
when employed immediately following
, using Equation (12),
where
is the change in solution fitness and
is the time taken by both the heuristics. Similarly,
is set to 0 when the solution does not improve.
Parameter
captures the time elapsed since the heuristic
was last selected. The value of
is evaluated using Equation (13):
The value range of parameters
and
is (0,1) and is initially set to 0.5. If the solution quality improves,
is rewarded heavily by being assigned the highest value (0.99), whereas it is harshly punished by being assigned the lowest value (0.01). If the solution quality deteriorates,
decreases linearly, and
increases by the same amount. The values of both parameters are calculated using Equations (14) and (15):
For each LLH, the respective values of F are computed using the same parameters and . The setting scheme of these two weight parameters makes the intensification component the dominating factor in the calculation of F while ensuring the diversification of the heuristic search process. However, in DAG learning problems, there is usually an order of magnitude difference between the fitness change and running time. As a result, the balance between the intensification component and the diversification cannot be guaranteed. To solve this problem, we record the values of and when the current heuristic increases the score of the optimal structure. Then, all the previously recorded values are linearly transformed into the interval where m represents the average running time of all the calls. Coefficients a and b are used to balance the fitness change and running time, taking values of 0.1 and 0.2, respectively, in this article.
4.2.2. The Low-Level Heuristics
In this section, we introduce the 13 operators that make up the low-level algorithm library, which is primarily derived from several nature-inspired meta-heuristic optimization algorithms. For example, we decompose the BNC-PSO algorithm into three operators: the mutation operator, cognitive personal operator, and cooperative global operator. In addition, we modify the three operators. First, the mutation operator works on the GSS to improve its efficiency. Second, the acceleration coefficient of the cooperative global operator increases linearly from 0.1 to 0.5 to avoid prematurity.
For the BFO algorithm, we choose only two operators: the chemotactic operator and the elimination and dispersal operator. Addition, deletion, and reversion operators are three candidate directions for each bacterium to select in the chemotactic process, and for large DAG learning, these local operations can be blind and inefficient. Therefore, we consider these three operations to be used only to manipulate the parent set of a node. Specifically, the addition operation continuously adds possible parents to the selected node to improve the score, and its search space is the GSS. Correspondingly, the deletion operation and the reversion operation perform sequential deletion or parent–child transformation of the parent set of the selected node to improve the score. The elimination and dispersal operator is a global search operator, and we need to redesign a restart scheme only for the parent set of a selected node. For a selected node, we perform a local restart of the optimal structure in the population as a bacterial elimination and dispersal operation. First, we remove all the parent nodes of the selected node, calculate the score at this point, and record the structure at this point as the starting point for the restart. Second, in the search space, an addition chemotaxis operation is performed on the selected node to find a potential parent set, which is subsequently sorted by partial correlation values. Note that we are not updating the starting point structure in this step. Third, we add the nodes of the potential parent set one by one to the selected node, and if a node can improve the score, we add both itself and its parent and update the structure. Fourth, for the parent nodes that have been added, we greedily remove the one that has the greatest negative impact on the score and update the structure until the score cannot be improved. The nodes that have the greatest negative impact are achieved by the deletion chemotactic operation. Finally, we perform a reversion operation. The startup of the elimination and dispersal operator is controlled by the parameter
, which increases linearly from 0.1 to 1 and is computed using Equation (16),
where
L represents the number of iterations in which the global maximum score did not improve, and
represents the maximum number of iterations allowed without increasing the global maximum score.
We decompose the ABC algorithm into three operators: worker bees, onlooker bees, and scout bees. Worker bees and onlooker bees, as local search operators, continue to work on the GSS. We redesign the scout bees to accommodate large-scale DAG learning. For a selected node, we perform a local restart of the optimal structure in the population. First, we record the parent set of the selected node. Second, a parent node is selected, and a parent–child transformation is performed with the selected node. Third, the addition, deletion, and reversion chemotaxis operations are performed successively. If the score of the new structure is higher than the score of the optimal structure, the structure is updated as a new starting point. Finally, we skip to step 2 and continue until all parent nodes have been tested. The startup of the scout is controlled by the parameter when the individual best score does not improve for consecutive iterations.
Inspired by the moth–flame optimization algorithm, we randomly arrange the individual historical optimal solutions as flames and design moths to fly around them, which is equivalent to moths learning from the flames. The learning mode is the same as that of the BNC-PSO algorithm. Similarly, we adopt the learner phase from the teaching–learning-based optimization algorithm. In the current generation, each student is randomly assigned a collaborator to learn from if they are better than themselves, with the learning mode aligned with that of the BNC-PSO algorithm.
To make efficient use of structural priors, expert knowledge operators are designed. In this operator, a fixed proportion of individuals are selected to be guided by expert knowledge or a structural prior, i.e., all identified v-structures are given. For large-scale DAG learning, an insufficient sample size often leads to overfitting problems. To reduce the complexity of the model, pruning operators are designed to remove all edges if the score change caused by these edges is less than a threshold . This threshold is shared by all operators as the basis for judging whether the score has improved. In addition, a more efficient neighborhood perturbation operator is designed to operate on the LSS.
4.2.3. Framework of Our Algorithm
In this section, we describe the workflow of our proposed multi-population choice function hyper-heuristic (MCFHH) algorithm, the framework of which is shown in Algorithm 3. The MCFHH algorithm starts by randomly generating the initial valid population, and the initial valid population is obtained by performing several local hill-climbing operations on V. Next, we divide the population evenly into several groups, and each group runs its own choice function individually. Our algorithm terminates when the optimal score does not improve in successive generations or the maximum number of allowed iterations is reached. In addition, we introduce the migration operator and search space switching operator when running the algorithm.
The migration operator runs only after a certain number of iterations, and we set it to a minimum value between 100 and N. In the migration operation, we record the optimal structure of each subgroup and then swap the best with the worst. To avoid inbreeding, we use the inbreeding rate as a parameter to limit immigration operations. For DAG learning, we measure the inbreeding rate using the Hamming distance between the optimal individual of each subgroup and the globally optimal individual. In this paper, if the Hamming distance is less than 4, we assume that the optimal individual of the subgroup and the globally optimal individual are close relatives. The inbreeding rate is defined as the number of close relatives of a globally optimal individual divided by the number of subgroups, which, in this paper, is limited to no more than 0.6.
For large-scale DAG learning, the GSS cannot guarantee the completeness of the search space when the sample size is insufficient. Therefore, we introduce a search space switching operator. The search space switching operator is executed only once when the number of iterations without an increase in the highest score reaches
After execution, all global search operators operate within the complete search space (CSS) to correct errors caused by possible incompleteness in the GSS, and the number of iterations without an increase in the highest score is recalculated. This switching scheme is a balanced strategy that can improve efficiency in the early stage of the algorithm and improve accuracy in the late stage of the algorithm.
| Algorithm 3: MCFHH |
![Biomimetics 09 00350 i003]() |









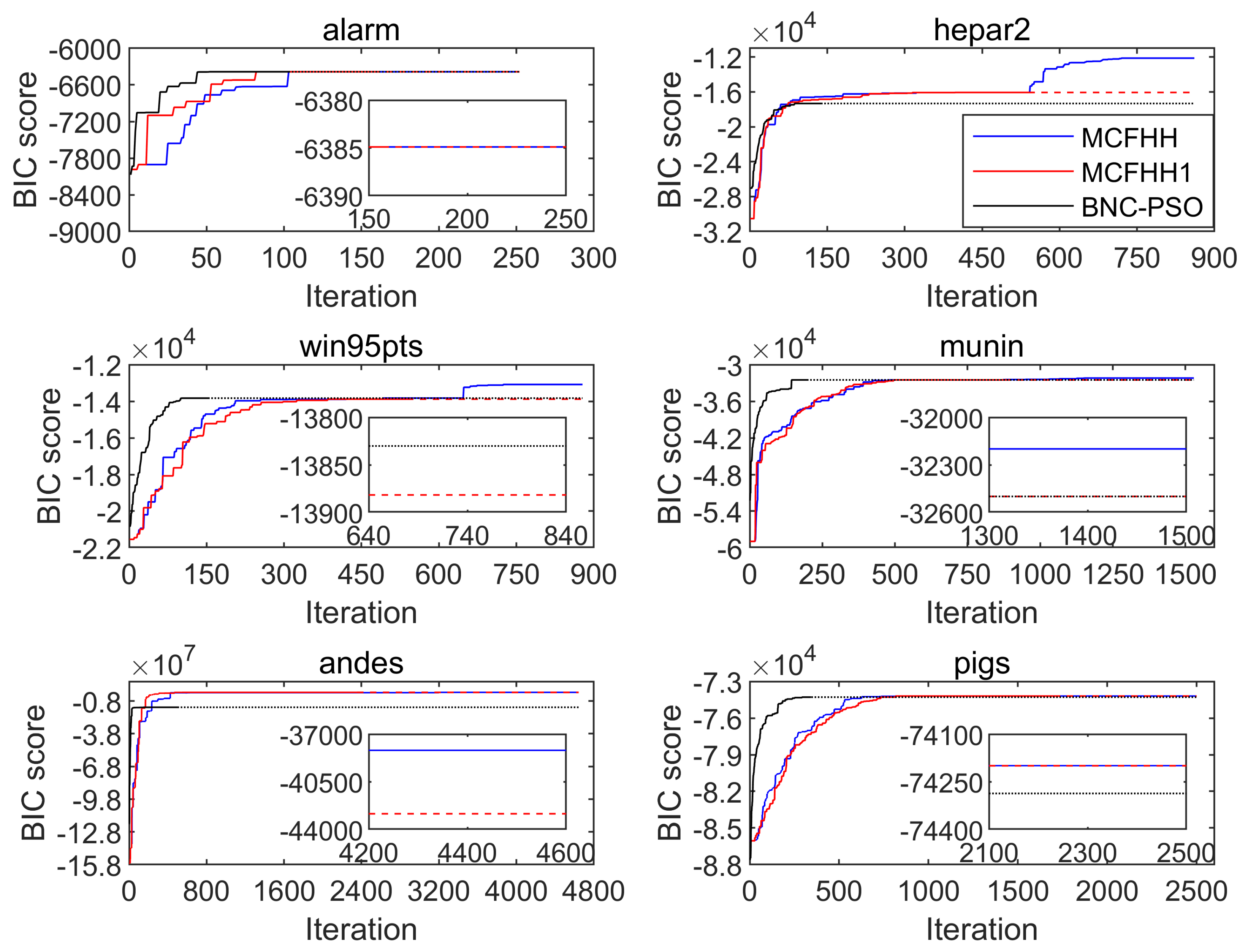

{kind=link}
{kind=link}