High-Throughput Line Buffer Microarchitecture for Arbitrary Sized Streaming Image Processing



Abstract
:1. Introduction
2. Background
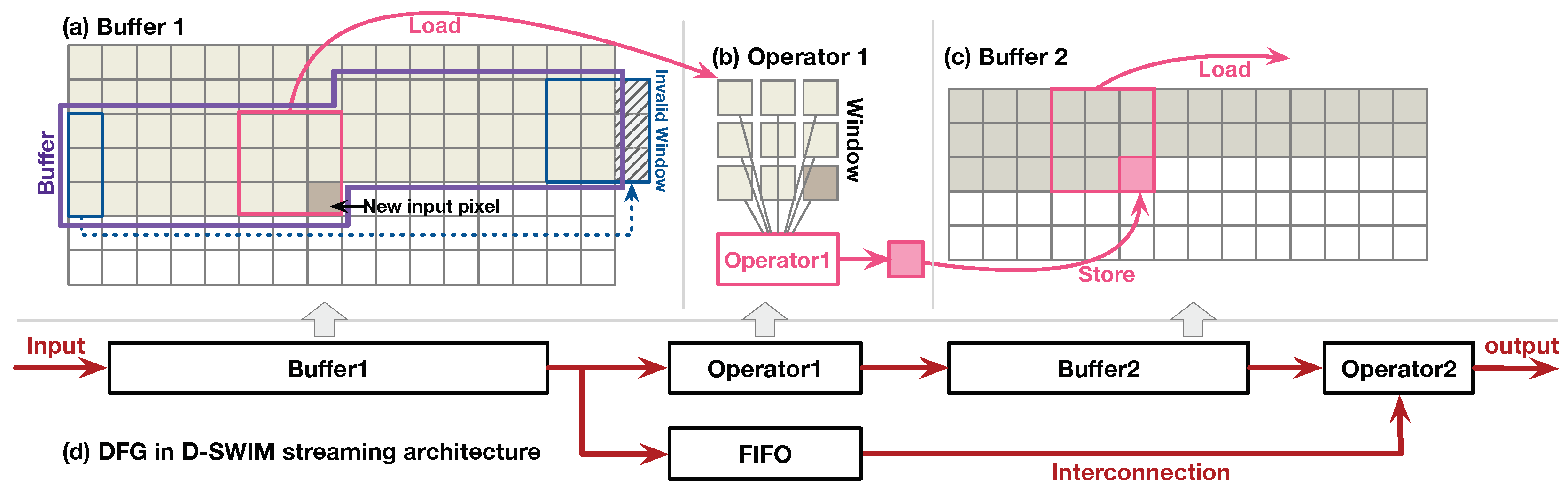
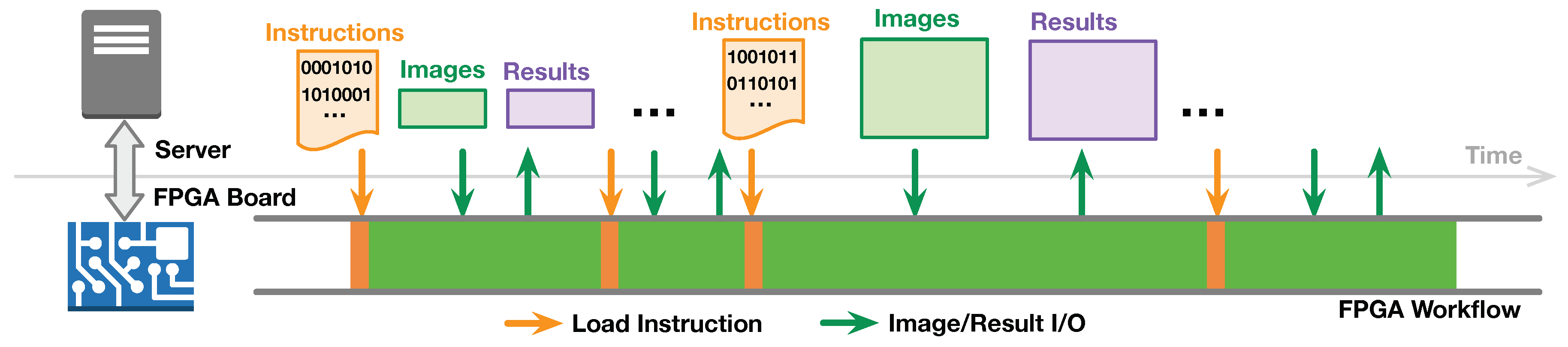
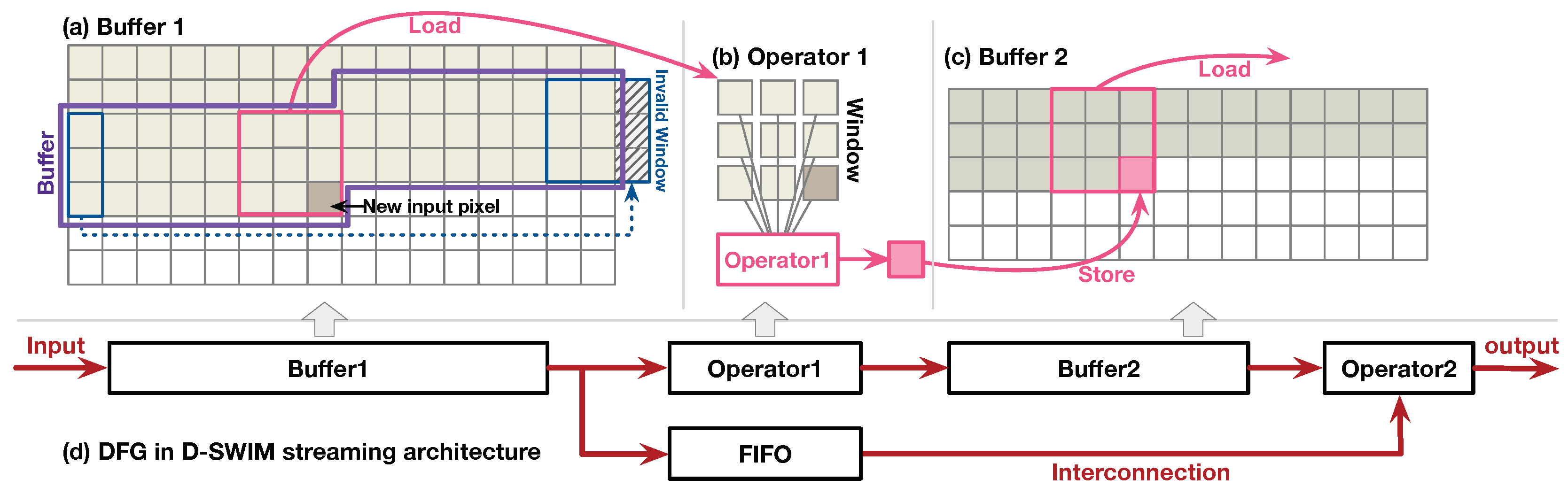
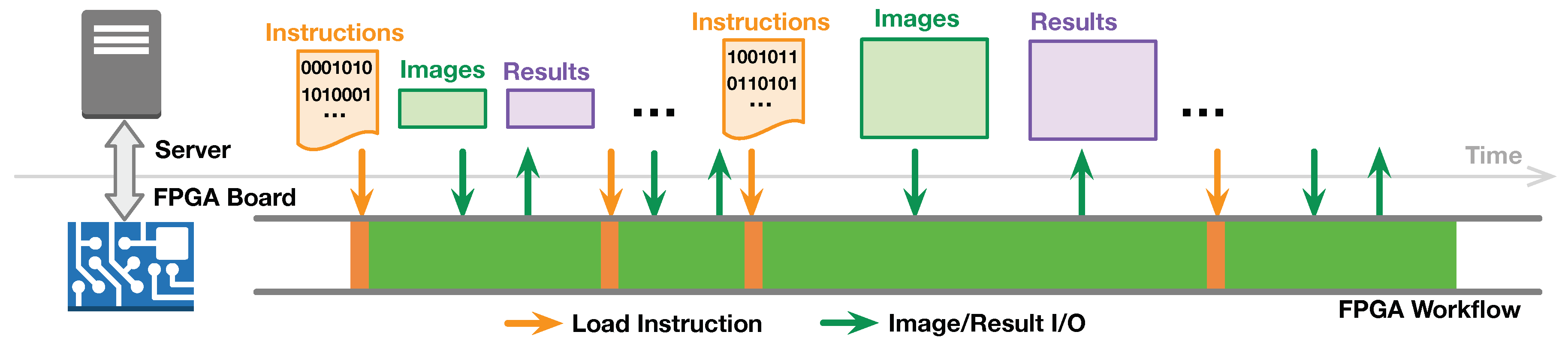
2.1. Streaming Architecture for Image Processing on FPGA
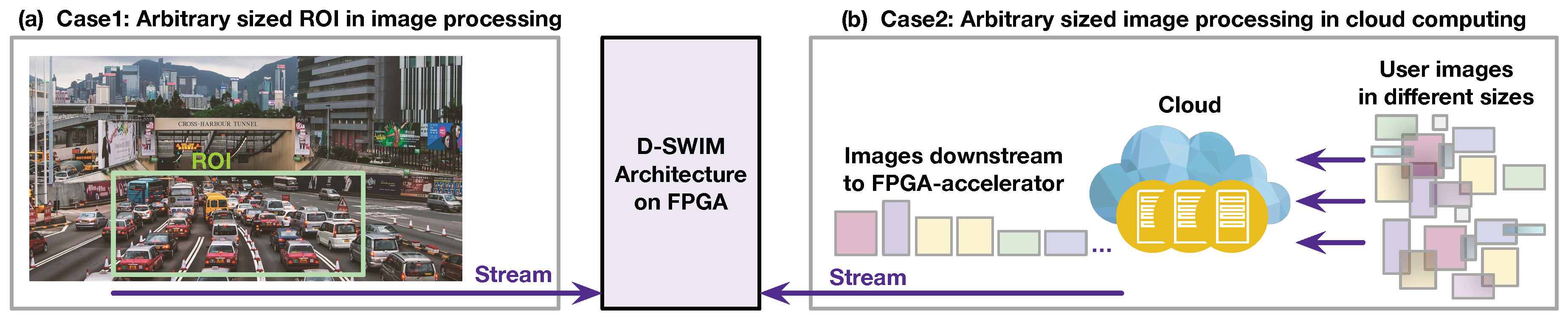
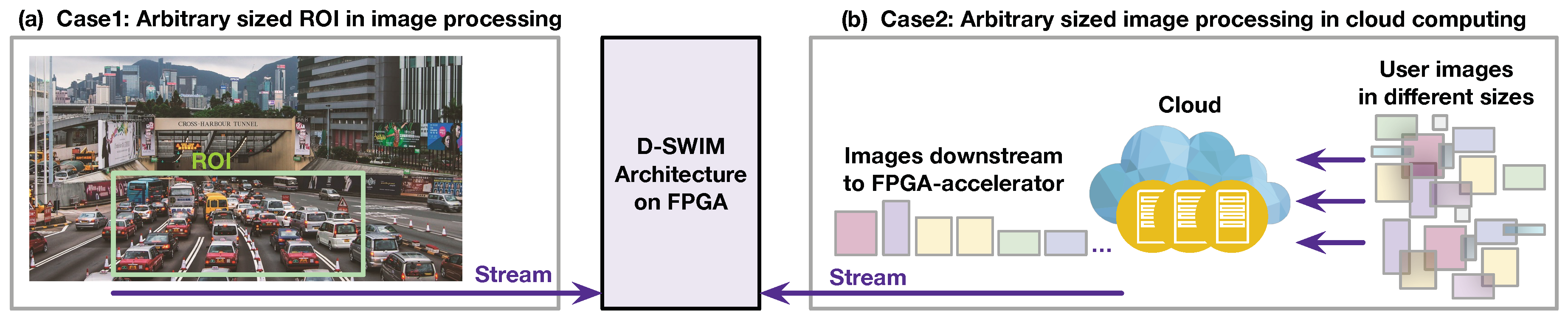
2.2. Demand on Arbitrary Sized Image Processing
2.3. Demand on Ultra-Fast Stream Processing
- Near-storage processing: High-bandwidth memory (HBM) stacks multiple DRAM dies to achieve a bandwidth of 250 / [11]. Assuming the operating frequency of FPGA is 250 MHz, the max data rate of a FPGA input stream is 1000 /. For images with 1 byte per pixel, this translates into a pixel throughput of 1000 /.
- Near-sensor processing: The high-resolution image sensor represents a high pixel throughput. For instance, the up-to-date CMOS sensor Sony IMX253 is capable of capturing 68 frames per second, with a resolution of [12]. Thus, the minimum processing throughput on FPGA is 4 / ().
2.4. BRAM-Misalignment Challenge and SWIM Framework
3. Method
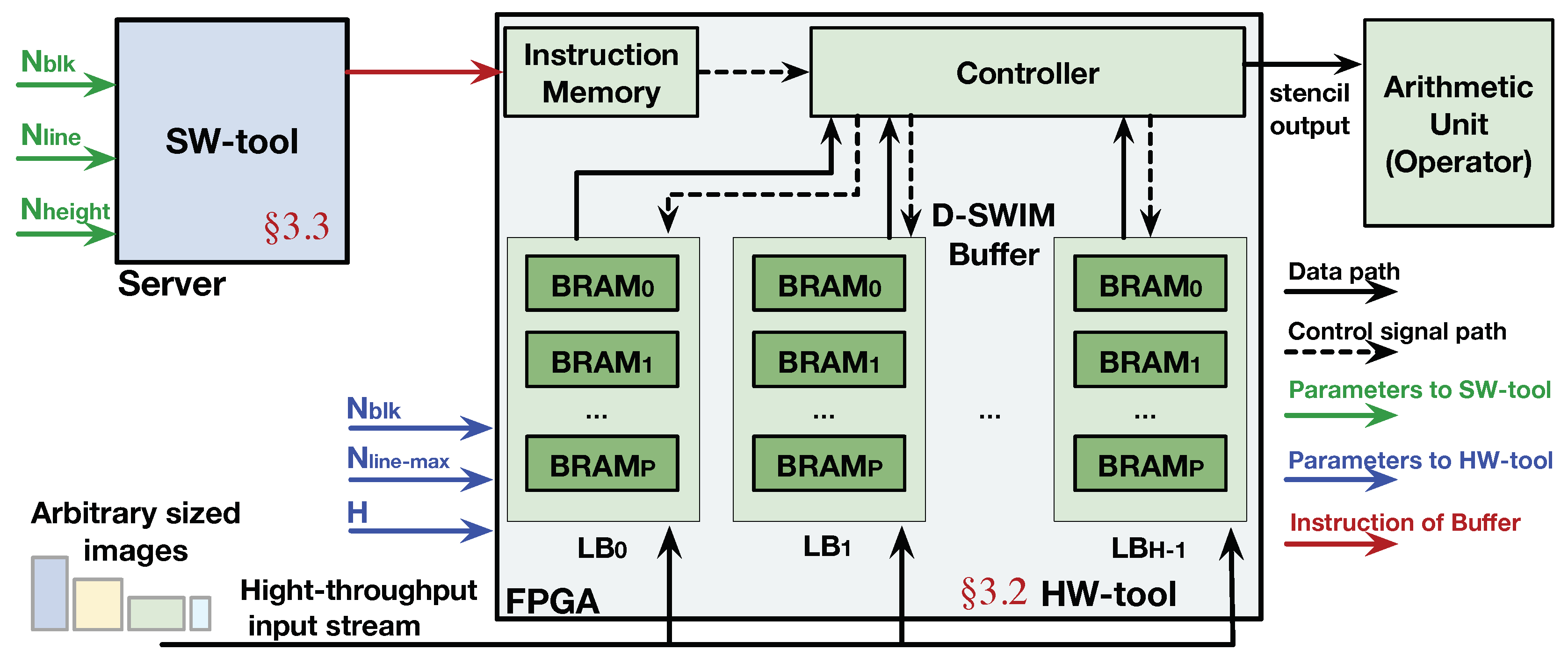
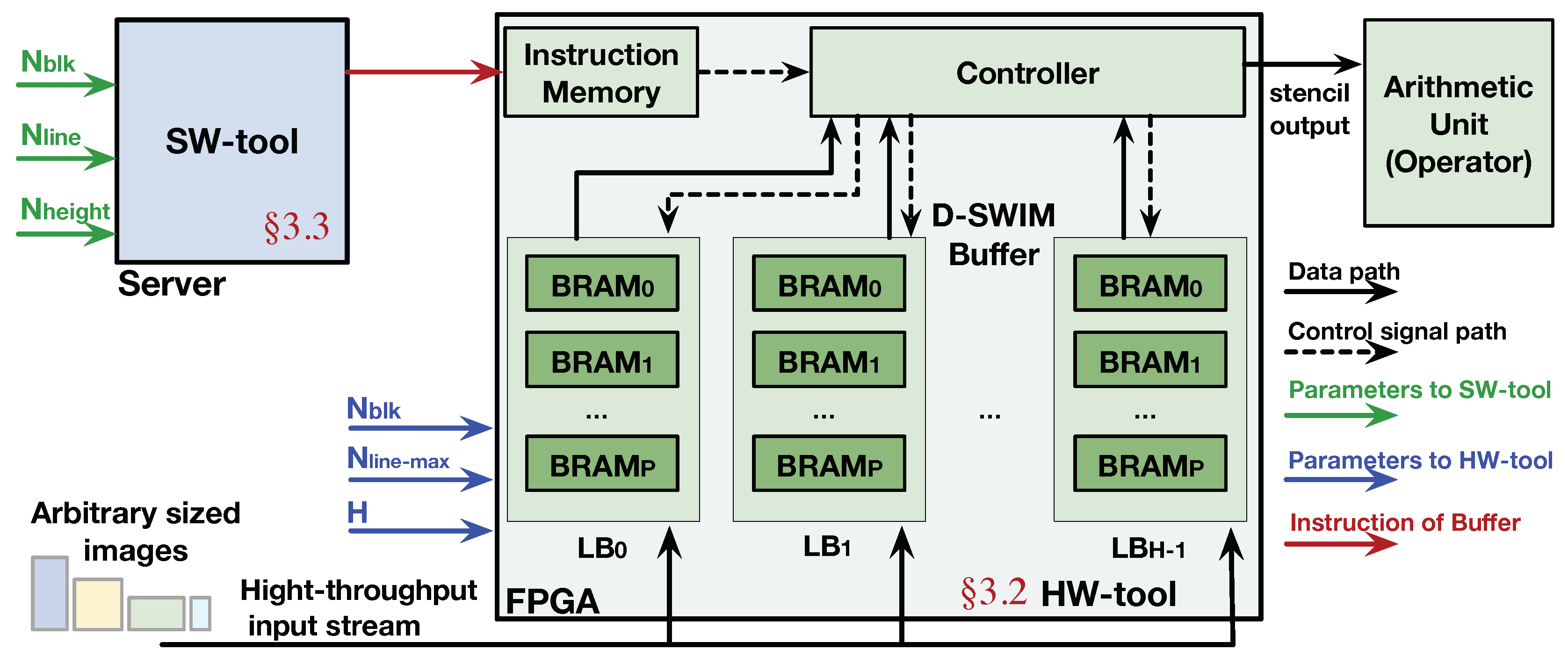
3.1. Framework Overview
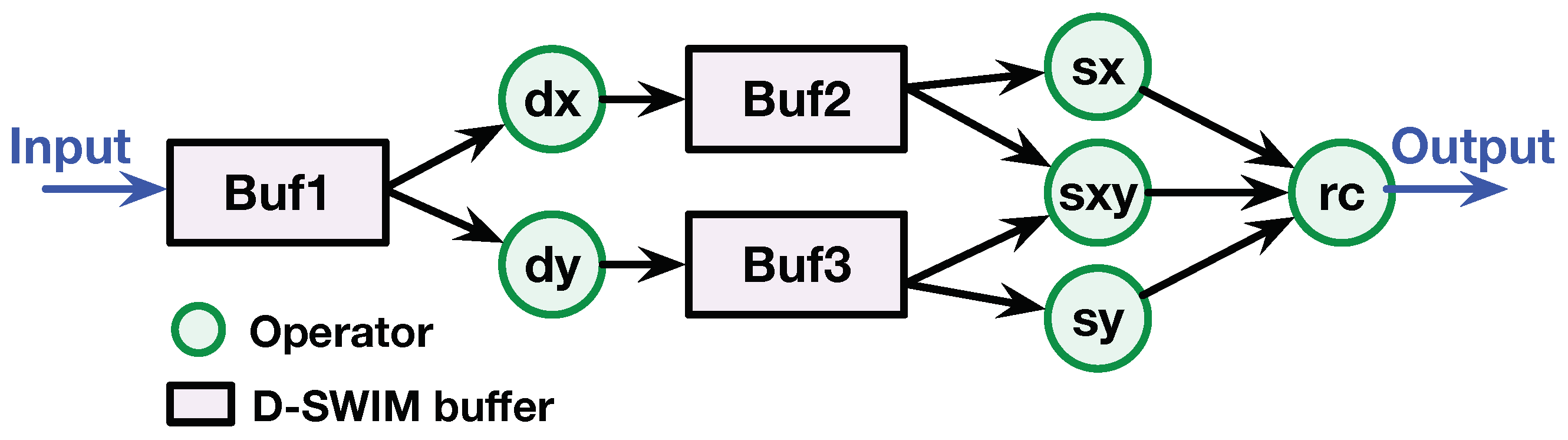
3.2. Buffer Architecture in D-SWIM
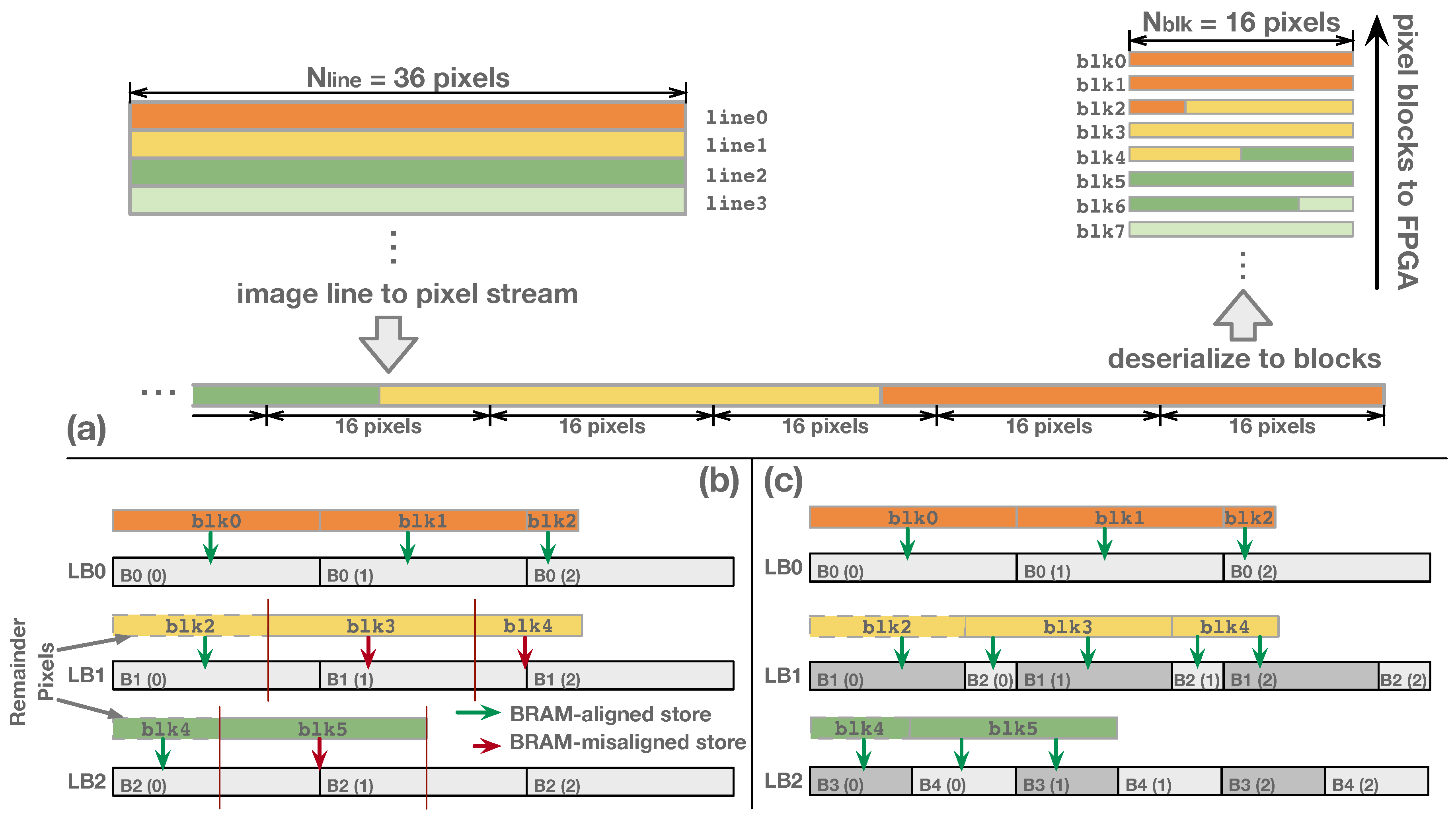
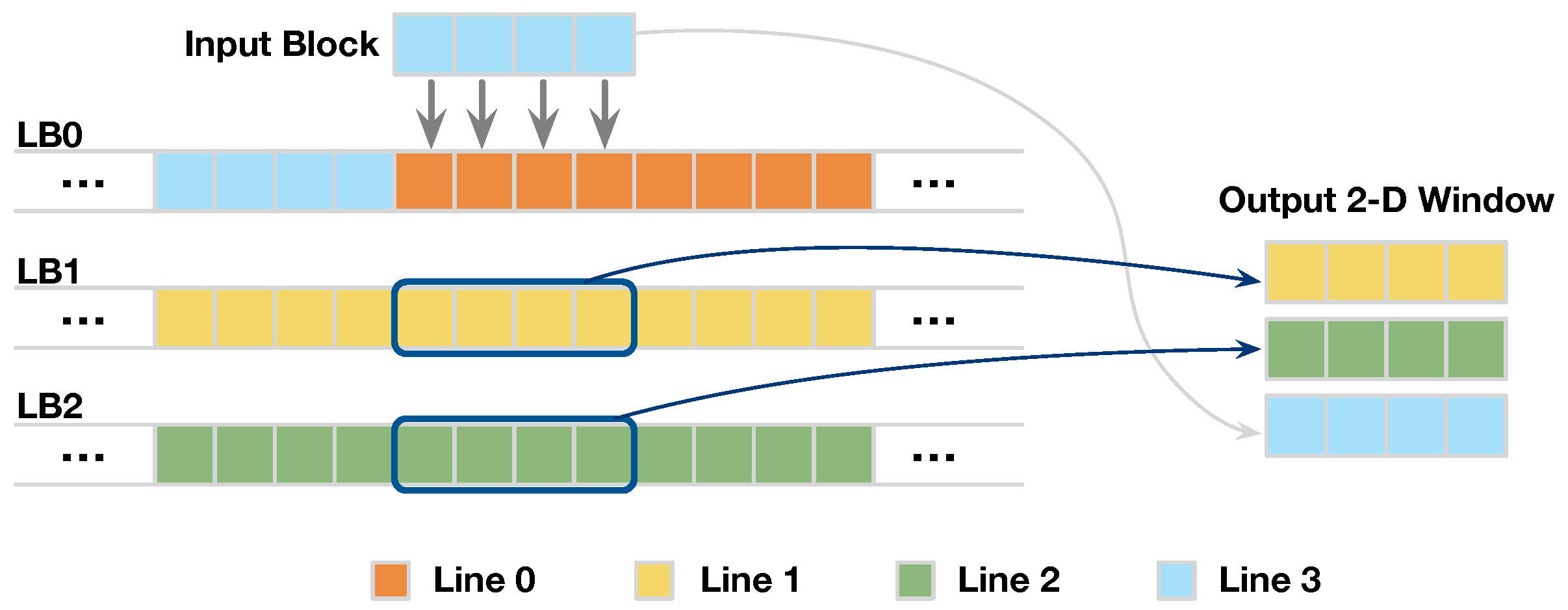
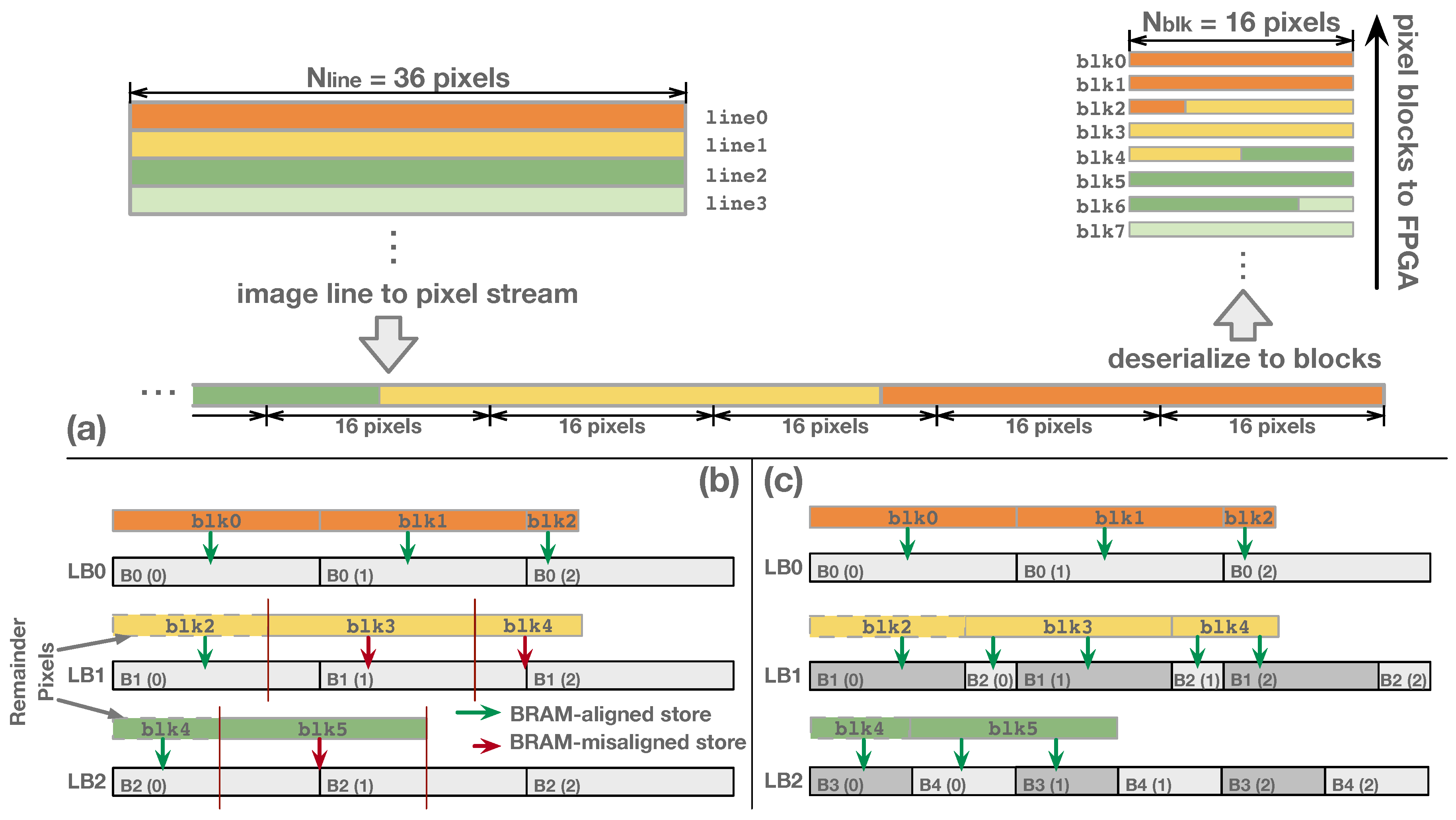
3.2.1. BRAM Organization of Line Buffer
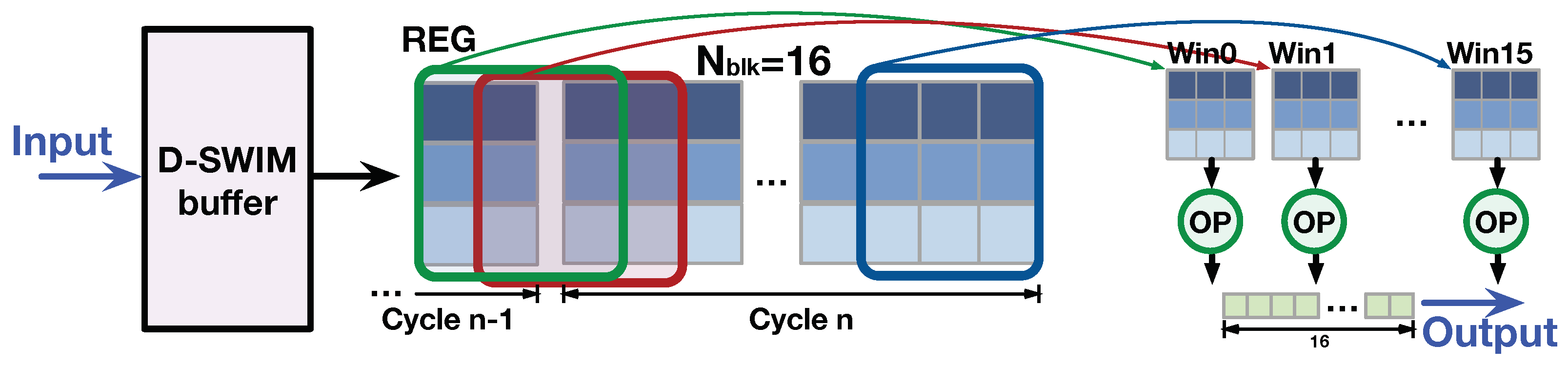
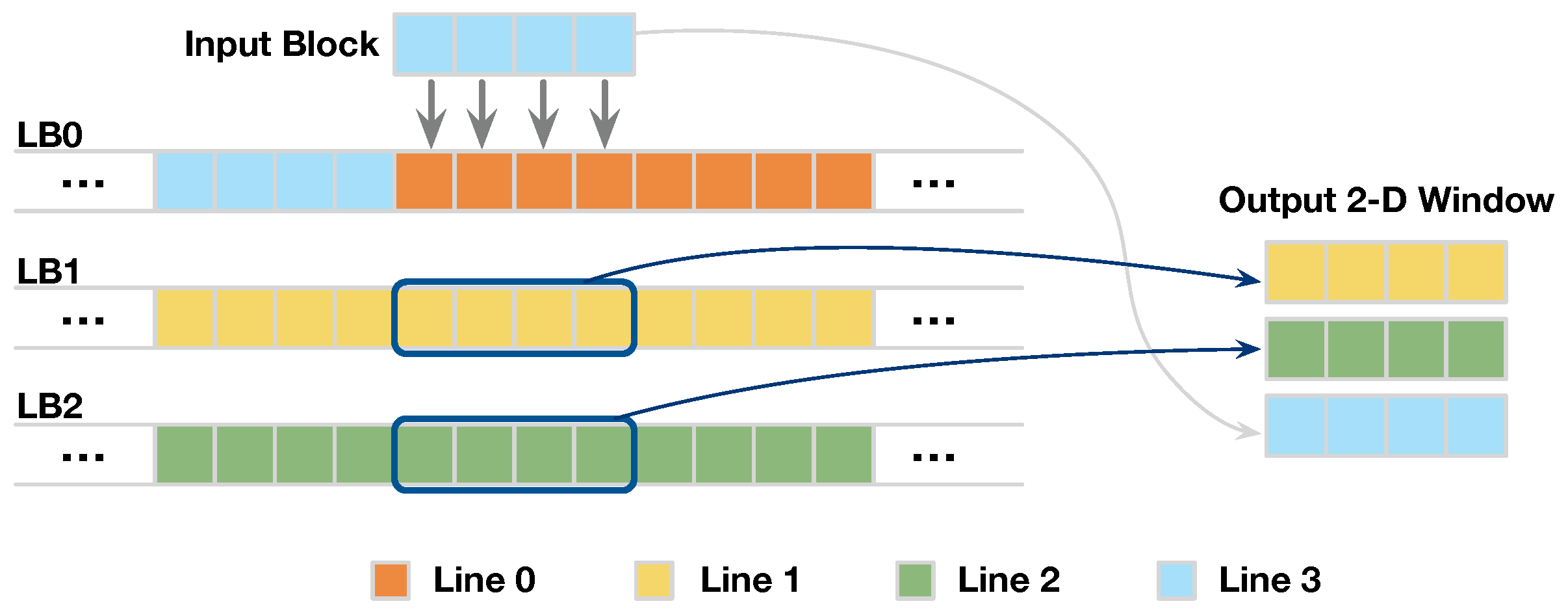
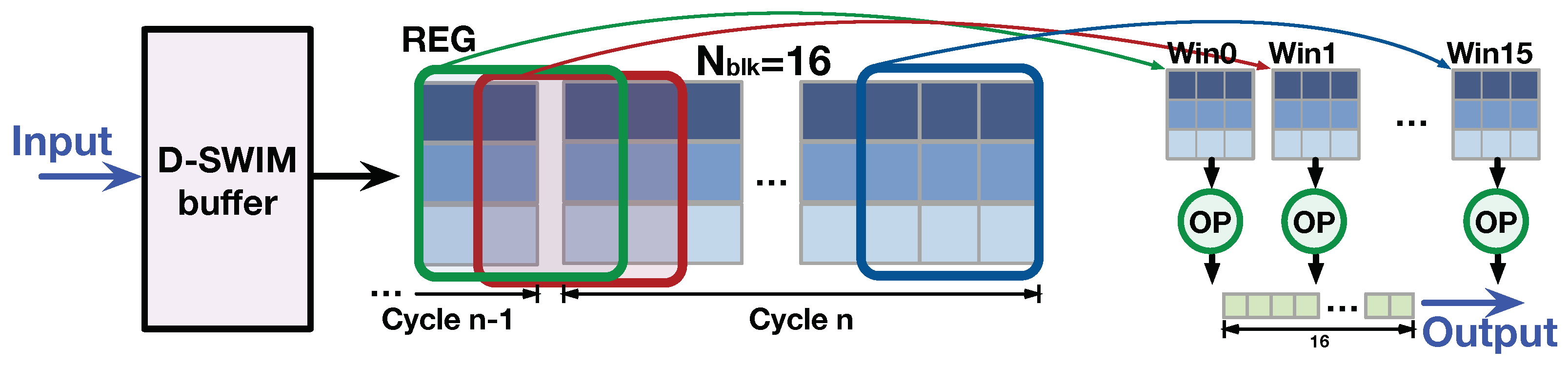
3.2.2. Line-Rolling Behavior of Line Buffers
3.3. Line Buffer Access Pattern and Control Instruction
3.3.1. Access Pattern of Line Buffer
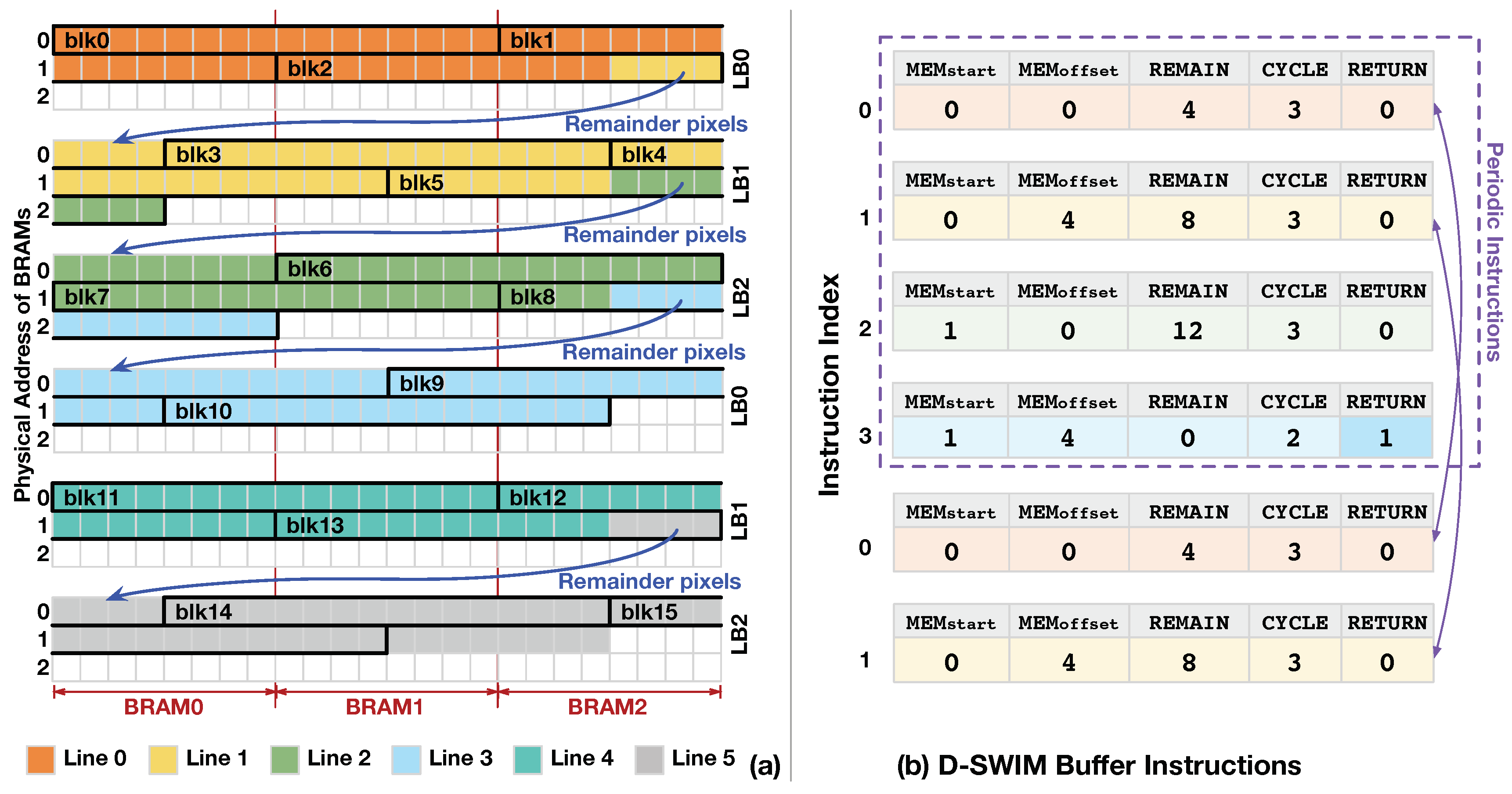
3.3.2. Control Code Generation
| Algorithm 1: Instruction Generation Algorithm in D-SWIM Streaming Architecture |
| Input: Application parameters: , Hardware information: Output: Instruction code: ; = 0; = 0; = 0; = 0;  return |
3.4. Run-Time Dynamic Programming for Arbitrary-Sized Image
4. Logic Implementation of D-SWIM
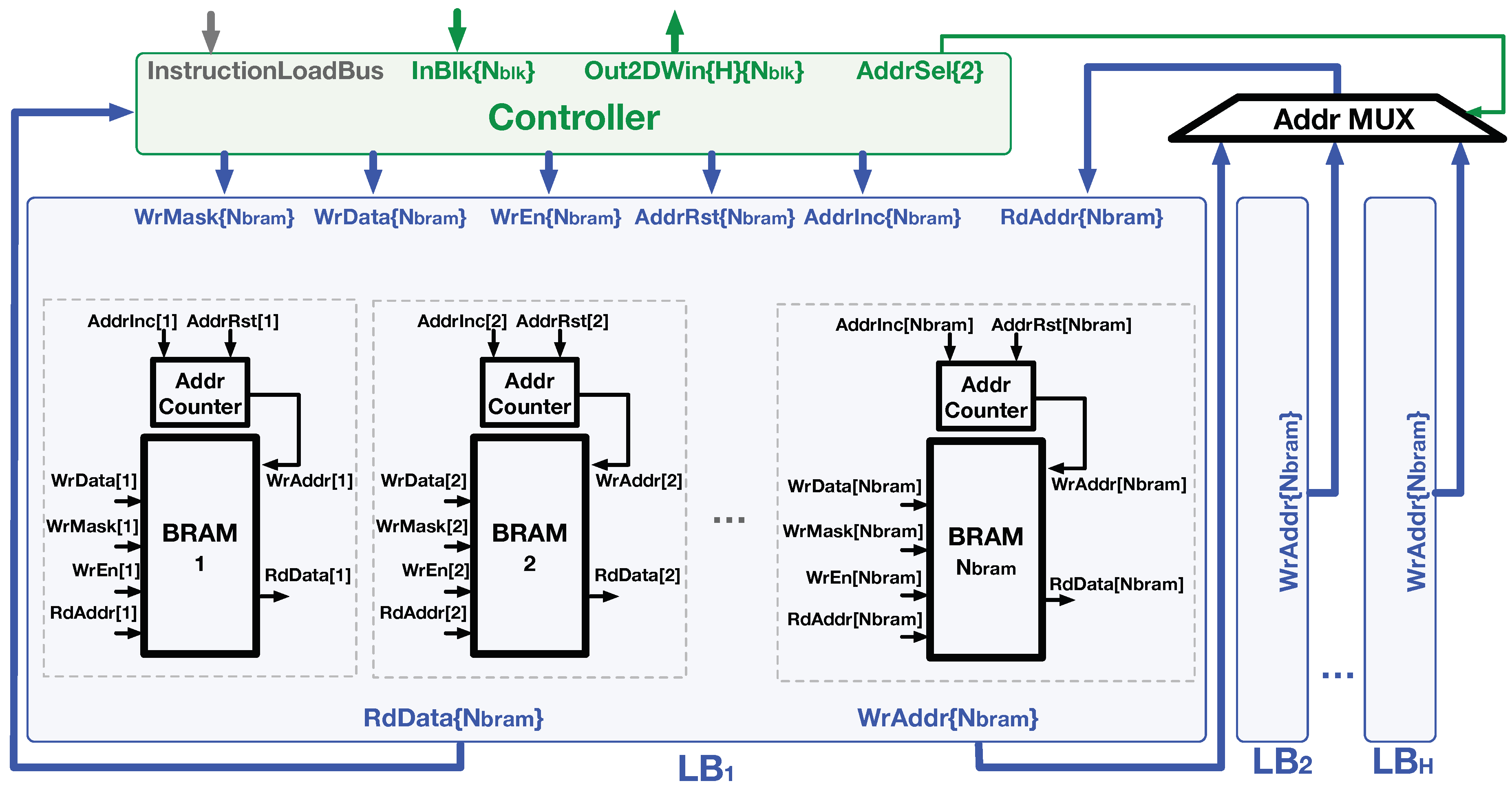
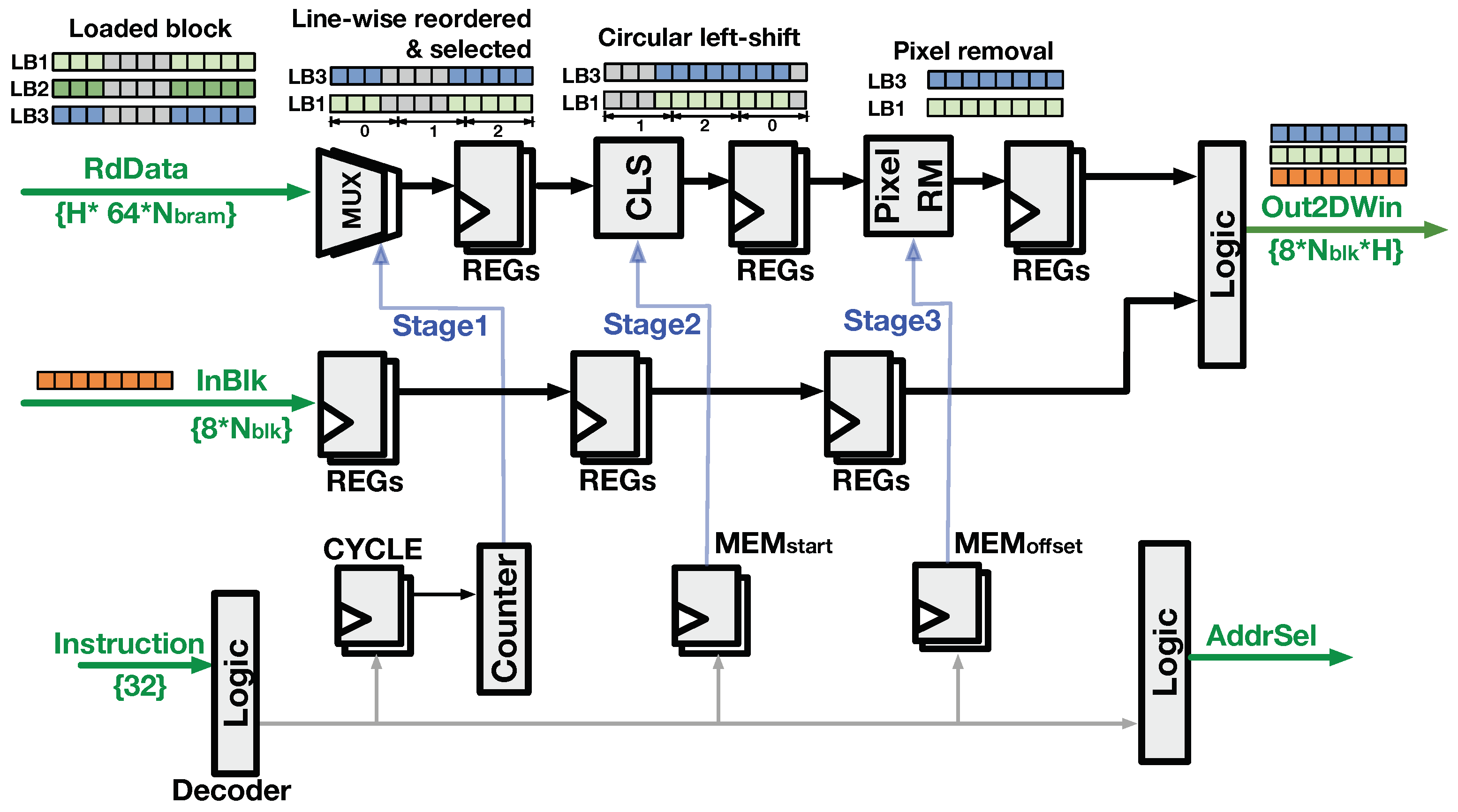
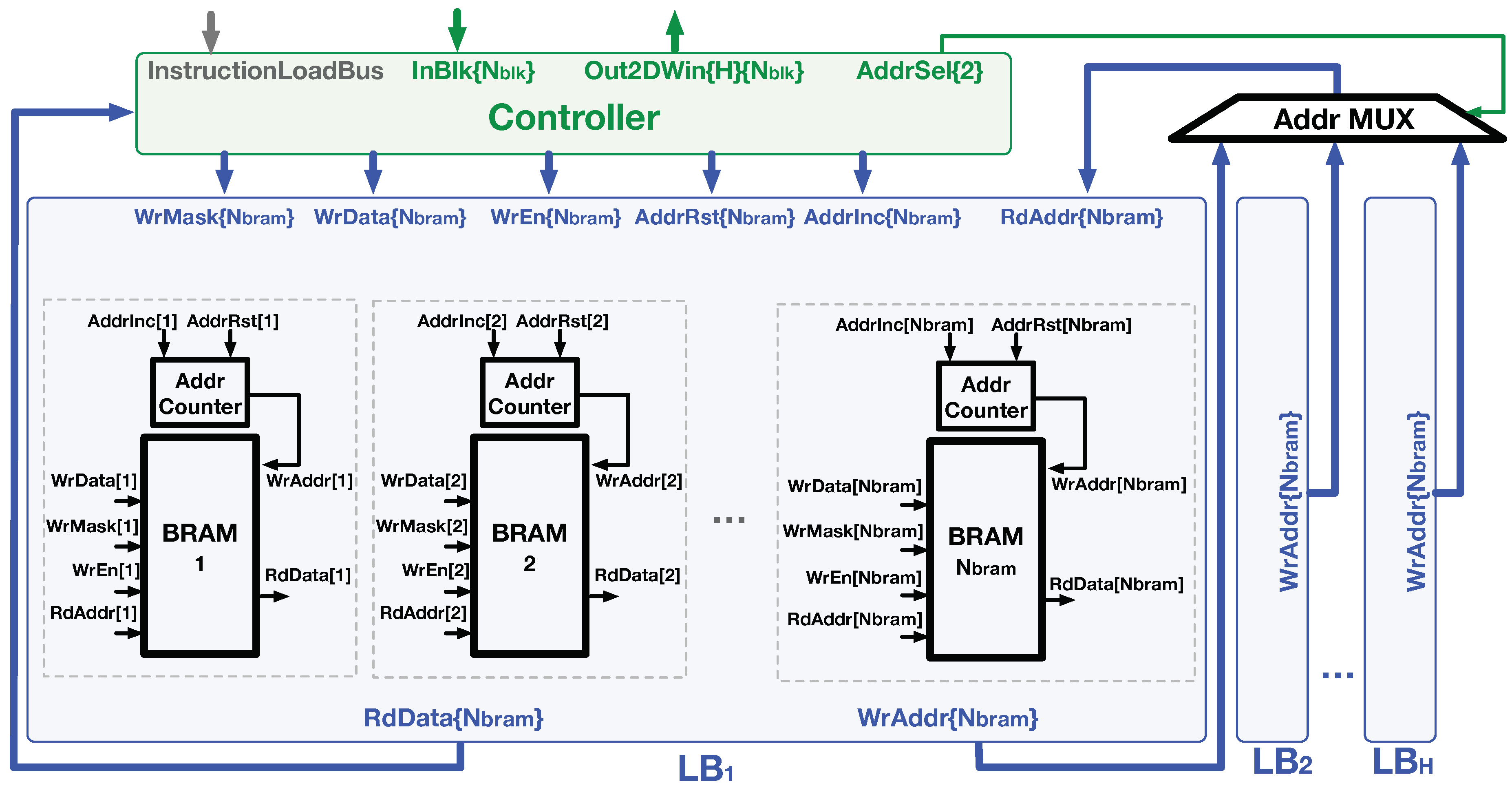
4.1. Logic of Line Buffer
4.2. Logic of Controller
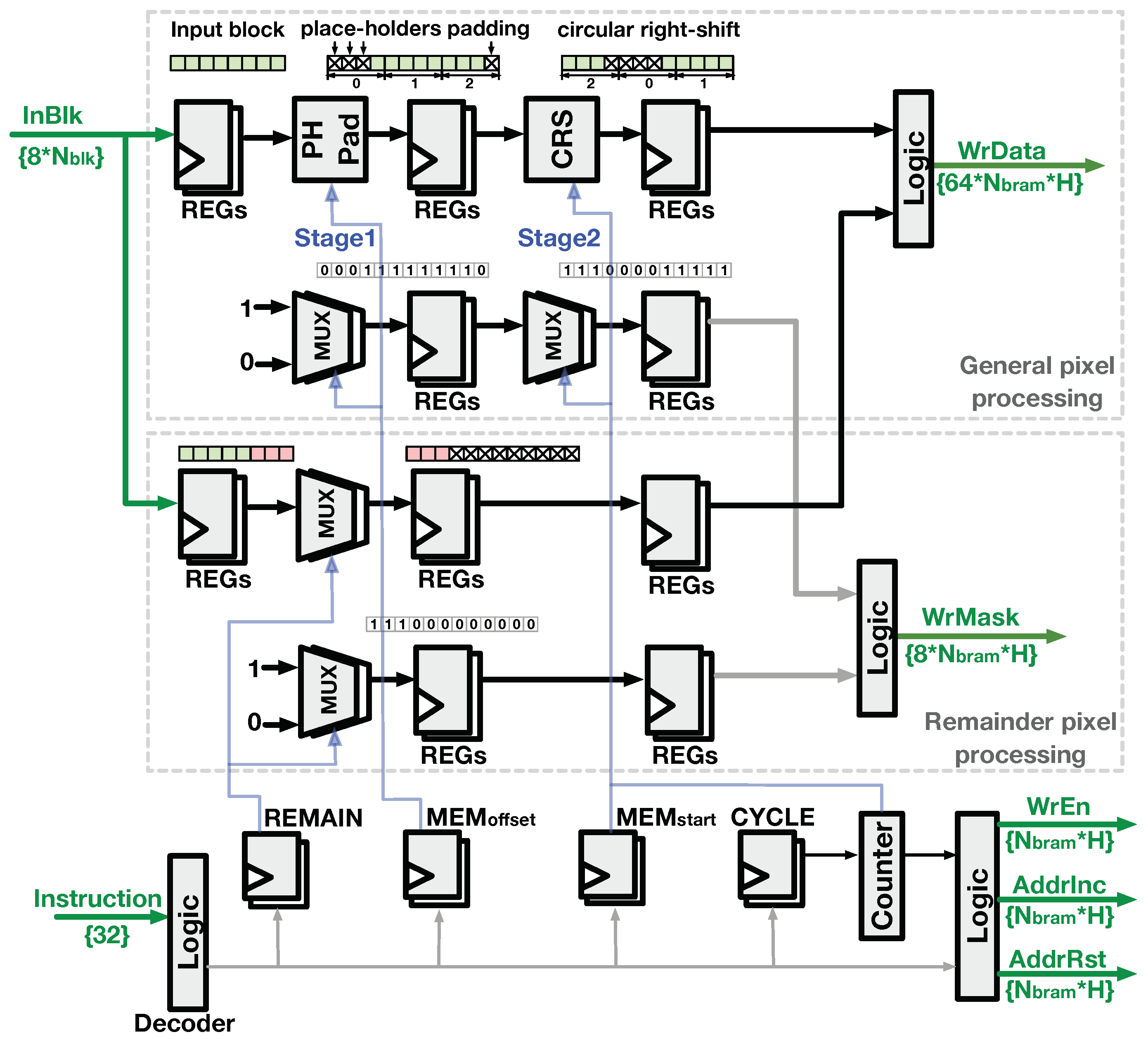
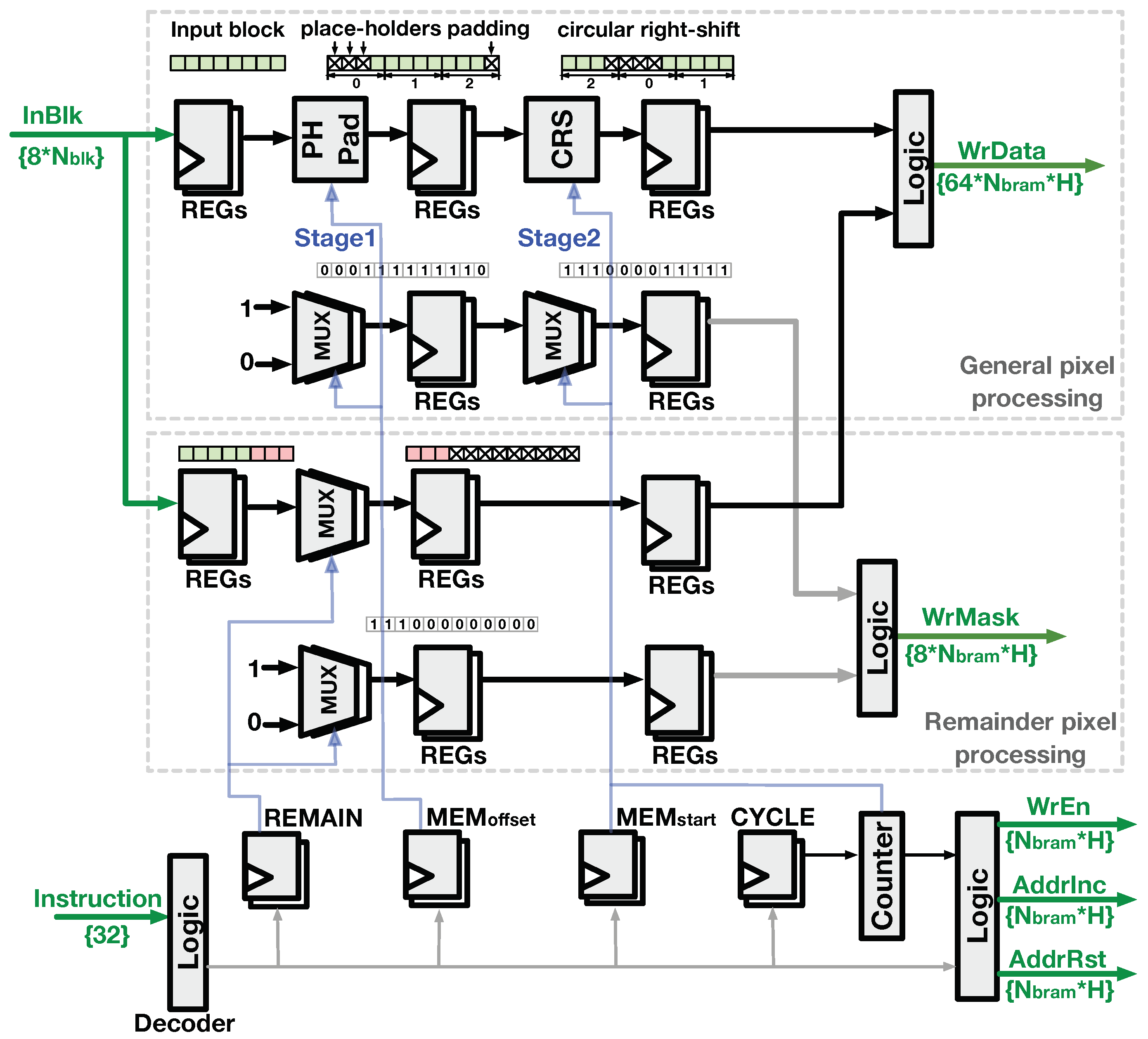
4.2.1. Buffer-Write Logic
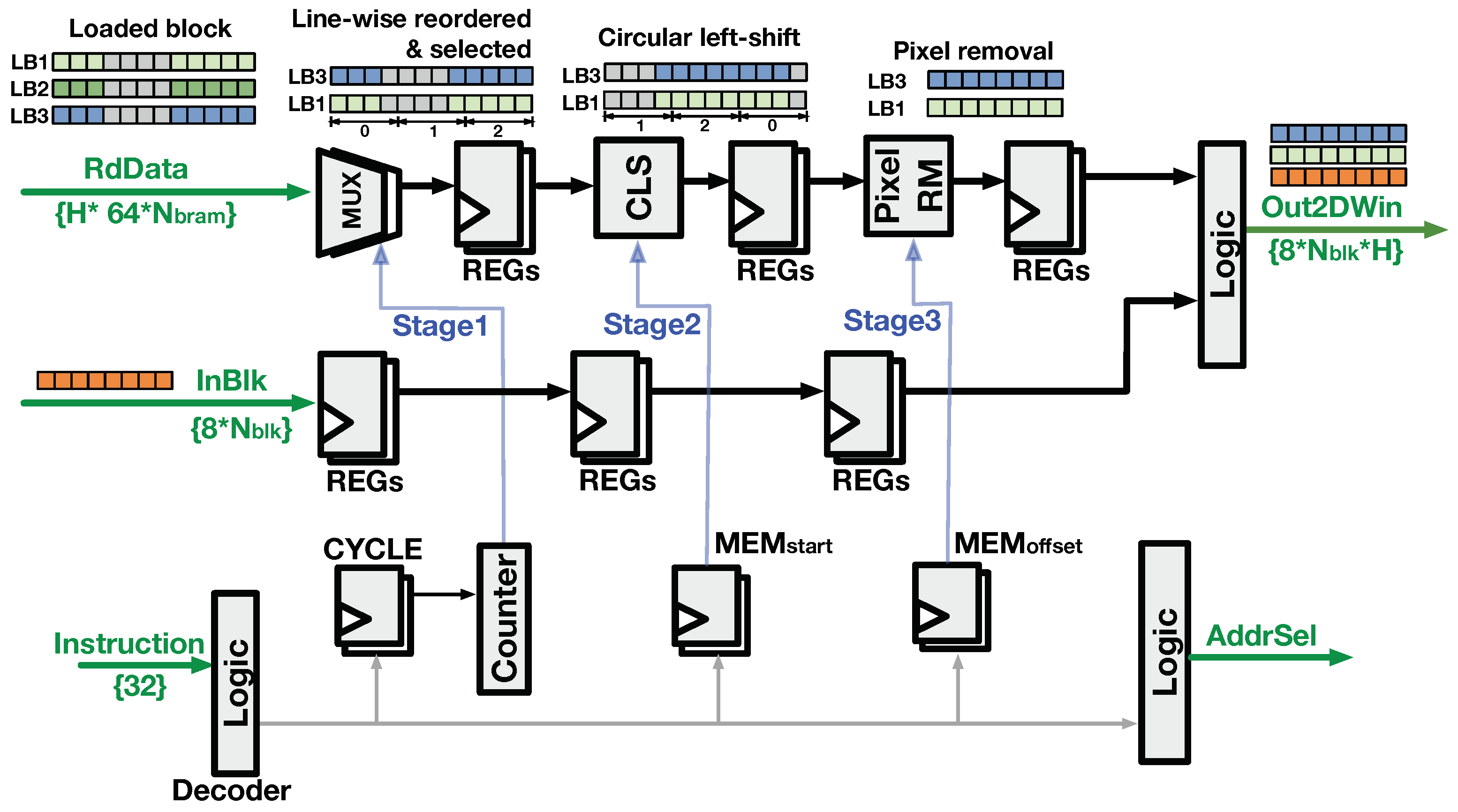
4.2.2. Buffer-Read Logic
5. Evaluation
5.1. Experiment Setup and Evaluation Metric
5.2. Evaluation of Buffer Hardware
5.2.1. Resource Evaluation
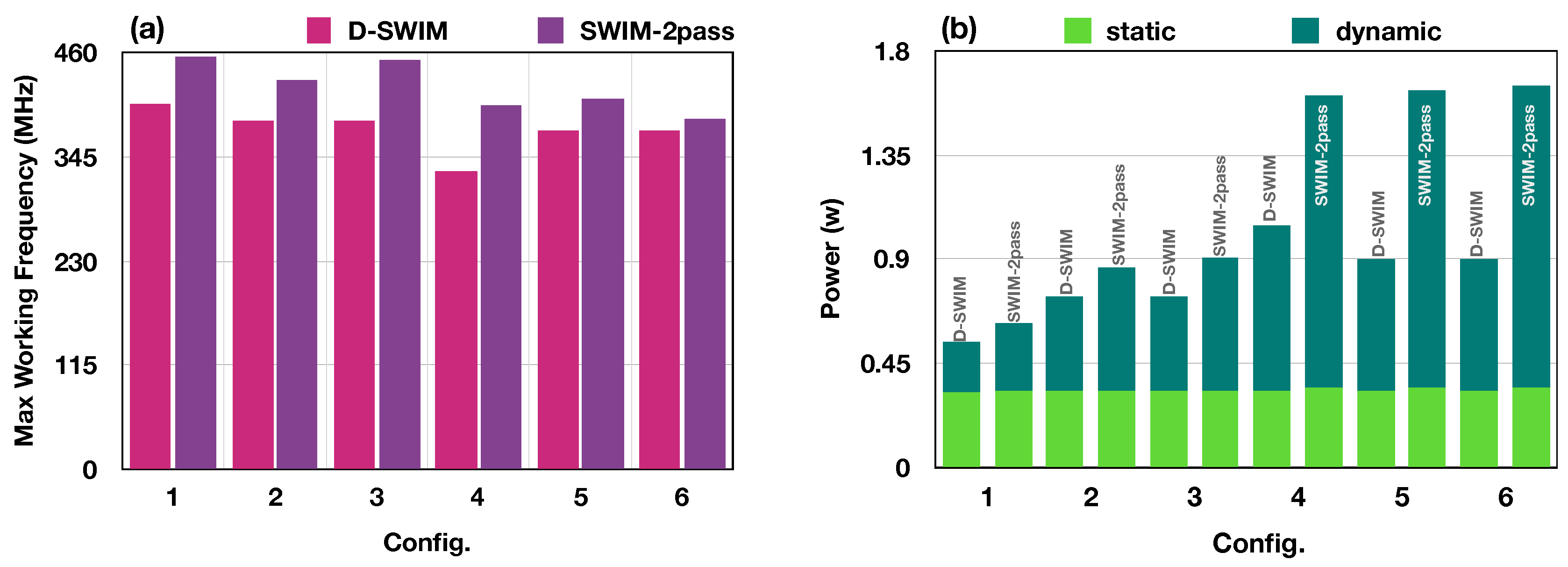
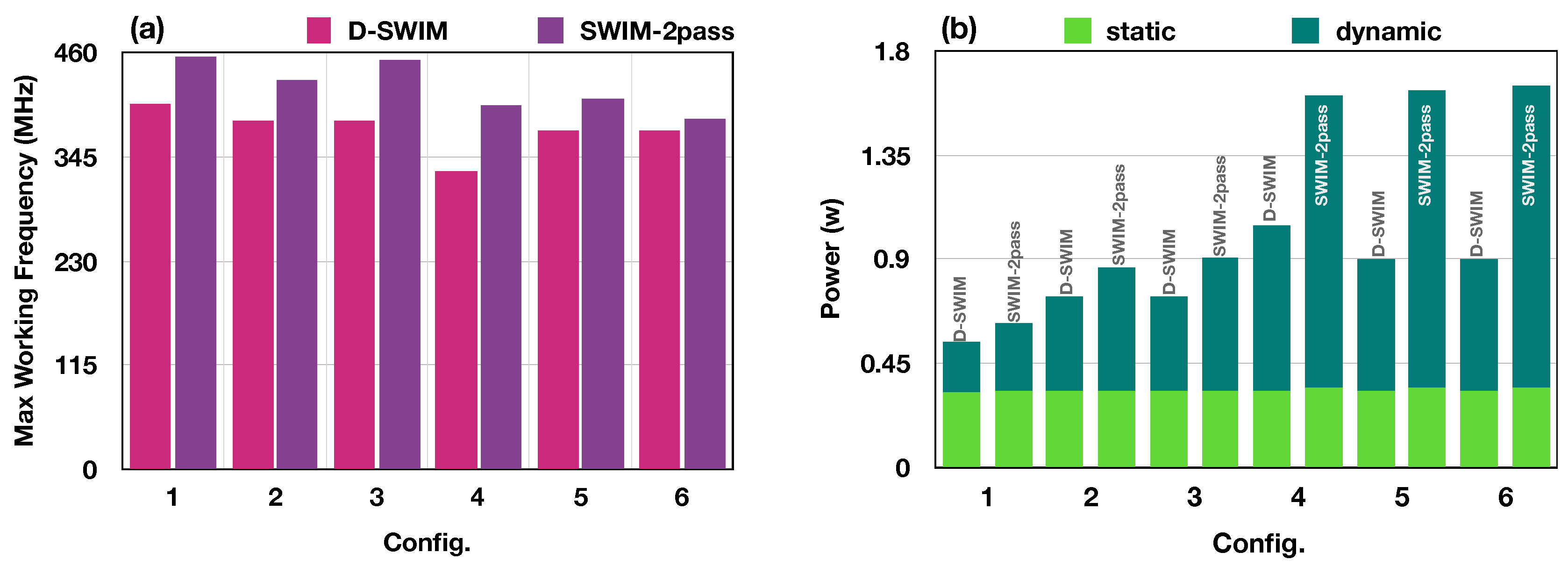
5.2.2. Timing and Power Evaluation
5.3. Evaluation of Dynamic Programming in D-SWIM
5.4. Case Study of Image Processing with D-SWIM
5.4.1. Conv2D
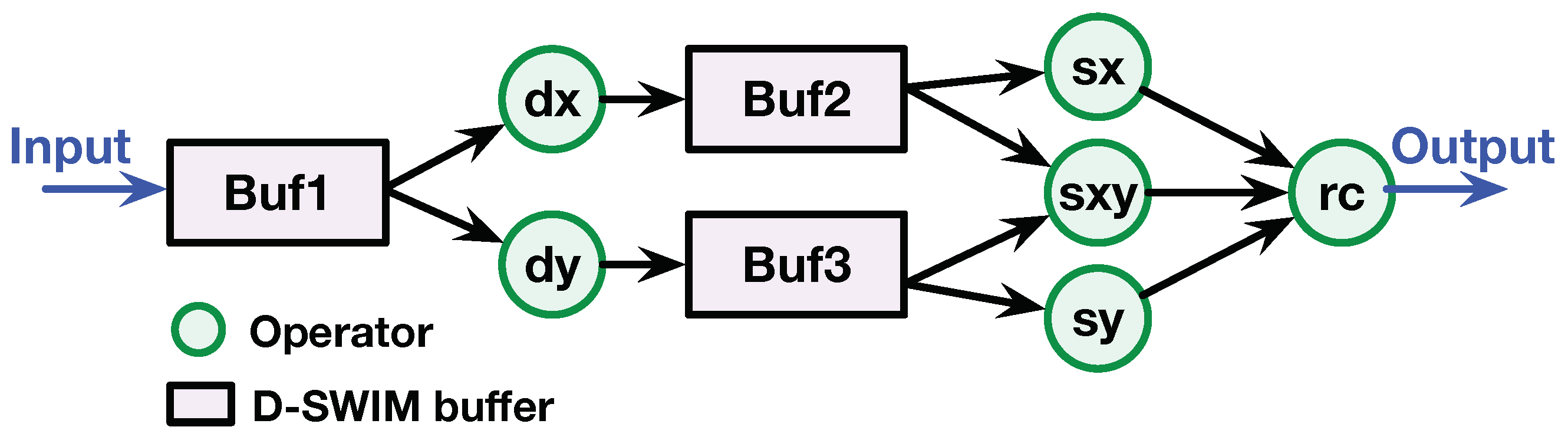
5.4.2. Harris Corner (HC) Detector
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| BRAM | Block Random Access Memory |
| CLS | Circular Left Shift |
| CRS | Circular Right Shift |
| DFG | Data Flow Graph |
| DNN | Deep Neural Networks |
| DRAM | Dynamic Random Access Memory |
| DSL | Domain Specific Languages |
| DSP | Digital Signal Processing |
| FIFO | First-In, First-Out |
| FPGA | Field Programmable Gate Array |
| GPPS | Giga Pixels Per Second |
| GOPS | Giga Operations Per Second |
| LB | Line Buffer |
| LUT | Look-up Table |
| REG | Register |
| ROI | Region of Interest |
| RTL | Register Transfer Level |
| SDP | Simple Dual Port |
| SWIM | Stream-Windowing Interleaved Memory |
| TDP | True Dual Port |
References
- Guo, C.; Meguro, J.; Kojima, Y.; Naito, T. A multimodal ADAS system for unmarked urban scenarios based on road context understanding. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1690–1704. [Google Scholar] [CrossRef]
- Rosenfeld, A. Multiresolution Image Processing and Analysis; Springer Science & Business Media: Berlin, Germany, 2013; Volume 12. [Google Scholar]
- Wang, M.; Ng, H.C.; Chung, B.M.; Varma, B.S.C.; Jaiswal, M.K.; Tsia, K.K.; Shum, H.C.; So, H.K.H. Real-time object detection and classification for high-speed asymmetric-detection time-stretch optical microscopy on FPGA. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016; pp. 261–264. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.S. An automatic RTL compiler for high-throughput FPGA implementation of diverse deep convolutional neural networks. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017; pp. 1–8. [Google Scholar]
- Pu, J.; Bell, S.; Yang, X.; Setter, J.; Richardson, S.; Ragan-Kelley, J.; Horowitz, M. Programming heterogeneous systems from an image processing DSL. ACM Trans. Archit. Code Optim. (TACO) 2017, 14, 26. [Google Scholar] [CrossRef]
- Chugh, N.; Vasista, V.; Purini, S.; Bondhugula, U. A DSL compiler for accelerating image processing pipelines on FPGAs. In Proceedings of the 2016 International Conference on Parallel Architecture and Compilation Techniques (PACT), Haifa, Israel, 11–15 September 2016; pp. 327–338. [Google Scholar]
- Reiche, O.; Schmid, M.; Hannig, F.; Membarth, R.; Teich, J. Code generation from a domain-specific language for C-based HLS of hardware accelerators. In Proceedings of the 2014 International Conference on Hardware/Software Codesign and System Synthesis, New Delhi, India, 12–17 October 2014; ACM: New York, NY, USA, 2014; p. 17. [Google Scholar]
- Serot, J.; Berry, F.; Ahmed, S. Implementing stream-processing applications on fpgas: A dsl-based approach. In Proceedings of the 2011 International Conference on Field Programmable Logic and Applications (FPL), Chania, Greece, 5–7 September 2011; pp. 130–137. [Google Scholar]
- Wong, J.S.; Shi, R.; Wang, M.; So, H.K.H. Ultra-low latency continuous block-parallel stream windowing using FPGA on-chip memory. In Proceedings of the 2017 International Conference on Field Programmable Technology (ICFPT), Melbourne, VIC, Australia, 11–13 December 2017; pp. 56–63. [Google Scholar]
- Özkan, M.A.; Reiche, O.; Hannig, F.; Teich, J. FPGA-based accelerator design from a domain-specific language. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–9. [Google Scholar]
- Salehian, S.; Yan, Y. Evaluation of Knight Landing High Bandwidth Memory for HPC Workloads. In Proceedings of the Seventh Workshop on Irregular Applications: Architectures and Algorithms, Denver, CO, USA, 12–17 November 2017; ACM: New York, NY, USA, 2017; p. 10. [Google Scholar]
- Mono Camera Sensor Performance Review 2018-Q1. Available online: https://www.ptgrey.com/support/downloads/10722 (accessed on 6 March 2019).
- Xilinx. UG473-7 Series FPGAs Memory Resources. Available online: https://www.xilinx.com/support/documentation/user_guides/ug473_7Series_Memory_Resources.pdf (accessed on 6 March 2019).
- Pezzarossa, L.; Kristensen, A.T.; Schoeberl, M.; Sparsø, J. Using dynamic partial reconfiguration of FPGAs in real-Time systems. Microprocess. Microsyst. 2018, 61, 198–206. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; Volume 15, pp. 10–5244. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Design Parameters | Description | Use Scope |
|---|---|---|
| Number of pixels in one stream block | HW & SW | |
| Number of pixels in the image line (image width) | SW | |
| Image height | SW | |
| Largest possible value of | HW | |
| H | Height in the vertical axis of the 2D stencil pattern | HW |
| Section | Bit-Length | Description |
|---|---|---|
| Start BRAM index of line-initial block | ||
| Start position (inside BRAM) of line-initial block | ||
| of the current image line | ||
| Number of blocks in the current image line | ||
| 1 | Flag to reset the instruction-fetch address |
| Config. | Parameters | D-SWIM | SWIM | SWIM-2pass | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| H | LUT | REG | BRAM | LUT | REG | BRAM | LUT | REG | BRAM | ||||||
| 1 | 630 | 3 | 8 | 3 | 1950 (1.45) | 2140 (1.35) | 6 (0.75) | 4 | 1346 | 1589 | 8 | 4 | 1346 | 1589 | 8 |
| 2 | 630 | 3 | 16 | 3 | 3427 (1.33) | 3553 (1.29) | 9 (0.56) | 8 | 3895 | 5127 | 32 | 4 | 2650 | 2653 | 16 |
| 3 | 1020 | 3 | 16 | 3 | 3427 (1.30) | 3553 (1.16) | 9 (0.56) | 4 | 2643 | 3051 | 16 | 4 | 2643 | 3051 | 16 |
| 4 | 1020 | 3 | 32 | 3 | 7656 (1.18) | 6338 (0.94) | 15 (0.47) | 8 | 8745 | 12662 | 60.5 | 4 | 6491 | 6743 | 32 |
| 5 | 1020 | 5 | 16 | 5 | 5608 (1.04) | 4931 (0.80) | 15 (0.47) | 8 | 5367 | 6142 | 32 | 8 | 5367 | 6142 | 32 |
| 6 | 1375 | 5 | 16 | 5 | 5608 (0.87) | 4931 (0.69) | 15 (0.44) | 16 | 10,833 | 13,305 | 64 | 8 | 6452 | 7182 | 34 |
| Image Size | Computation Time | D-SWIM Programming Time | SWIM Reconfiguration Time | ||||||
|---|---|---|---|---|---|---|---|---|---|
| H×W (pixel) | (pixel) | (cycle) | (μs) | (cycle) | (μs) | Proportion | (cycle) | (μs) | Proportion |
| 431 × 392 | 8 | 21,227 | 60.649 | 8 | 0.023 | 0.04% | 465,500 | 1330 | 95.64% |
| 431 × 392 | 16 | 10,614 | 30.326 | 16 | 0.046 | 0.15% | 465,500 | 1330 | 97.77% |
| 431 × 392 | 32 | 5307 | 15.163 | 32 | 0.091 | 0.60% | 465,500 | 1330 | 98.87% |
| 1342 × 638 | 8 | 107,360 | 306.743 | 4 | 0.011 | 0.00% | 465,500 | 1330 | 81.26% |
| 1342 × 638 | 16 | 53,680 | 153.371 | 8 | 0.023 | 0.01% | 465,500 | 1330 | 89.66% |
| 1342 × 638 | 32 | 26,840 | 76.686 | 16 | 0.046 | 0.06% | 465,500 | 1330 | 94.55% |
| Work | Device | Precision | Hardware Consumption | Throughput | Efficiency | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (pixel) | (bit/pixel) | LUT | REG | BRAM | DSP | (MHz) | (GPPS) | LUT | REG | ||
| Design1 [10] | Intel-5SGXEA7 | 32 | 8 | 47,045 | 73,584 | 363 | 0 | 303.6 | 9.71 | 20.7 | 1.3 |
| Design2 [7] | Xilinx-XC7Z045 | 1 | 8 | 288 | 521 | 2 | 0 | 349.9 | 0.35 | 121.5 | 6.7 |
| D-SWIM | Xilinx-XC7VX690 | 16 | 8 | 4514 | 4232 | 9 | 76 | 283 | 4.5 | 100.3 | 10.7 |
| Work | Device | Precision | Hardware Consumption | Throughput | Efficiency | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (pixel) | (bit/pixel) | LUT | REG | BRAM | DSP | (MHz) | (GPPS) | LUT | REG | ||
| Design1 [10] | Intel-5SGXEA7 | 4 | 8 | 135,808 | 192,397 | 493 | 36 | 303.4 | 1.2 | 0.9 | 0.1 |
| Design2 [7] | Xilinx-XC7Z045 | 1 | 8 | 23,331 | 31,102 | 8 | 254 | 239.4 | 0.24 | 1.0 | 0.1 |
| D-SWIM | Xilinx-XC7VX690 | 16 | 8 | 16769 | 14439 | 27 | 444 | 267 | 4.2 | 25.5 | 3.0 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, R.; Wong, J.S.J.; So, H.K.-H. High-Throughput Line Buffer Microarchitecture for Arbitrary Sized Streaming Image Processing. J. Imaging 2019, 5, 34. https://doi.org/10.3390/jimaging5030034
Shi R, Wong JSJ, So HK-H. High-Throughput Line Buffer Microarchitecture for Arbitrary Sized Streaming Image Processing. Journal of Imaging. 2019; 5(3):34. https://doi.org/10.3390/jimaging5030034
Chicago/Turabian StyleShi, Runbin, Justin S.J. Wong, and Hayden K.-H. So. 2019. "High-Throughput Line Buffer Microarchitecture for Arbitrary Sized Streaming Image Processing" Journal of Imaging 5, no. 3: 34. https://doi.org/10.3390/jimaging5030034
APA StyleShi, R., Wong, J. S. J., & So, H. K.-H. (2019). High-Throughput Line Buffer Microarchitecture for Arbitrary Sized Streaming Image Processing. Journal of Imaging, 5(3), 34. https://doi.org/10.3390/jimaging5030034