High-Level Synthesis of Online K-Means Clustering Hardware for a Real-Time Image Processing Pipeline


Abstract
1. Introduction
- Development of a synthesizable Simulink model for the K-Means clustering operation, which is currently not available as an intrinsic block in the Simulink HDL Coder/Vision HDL Coder toolbox (Matlab R2018b)
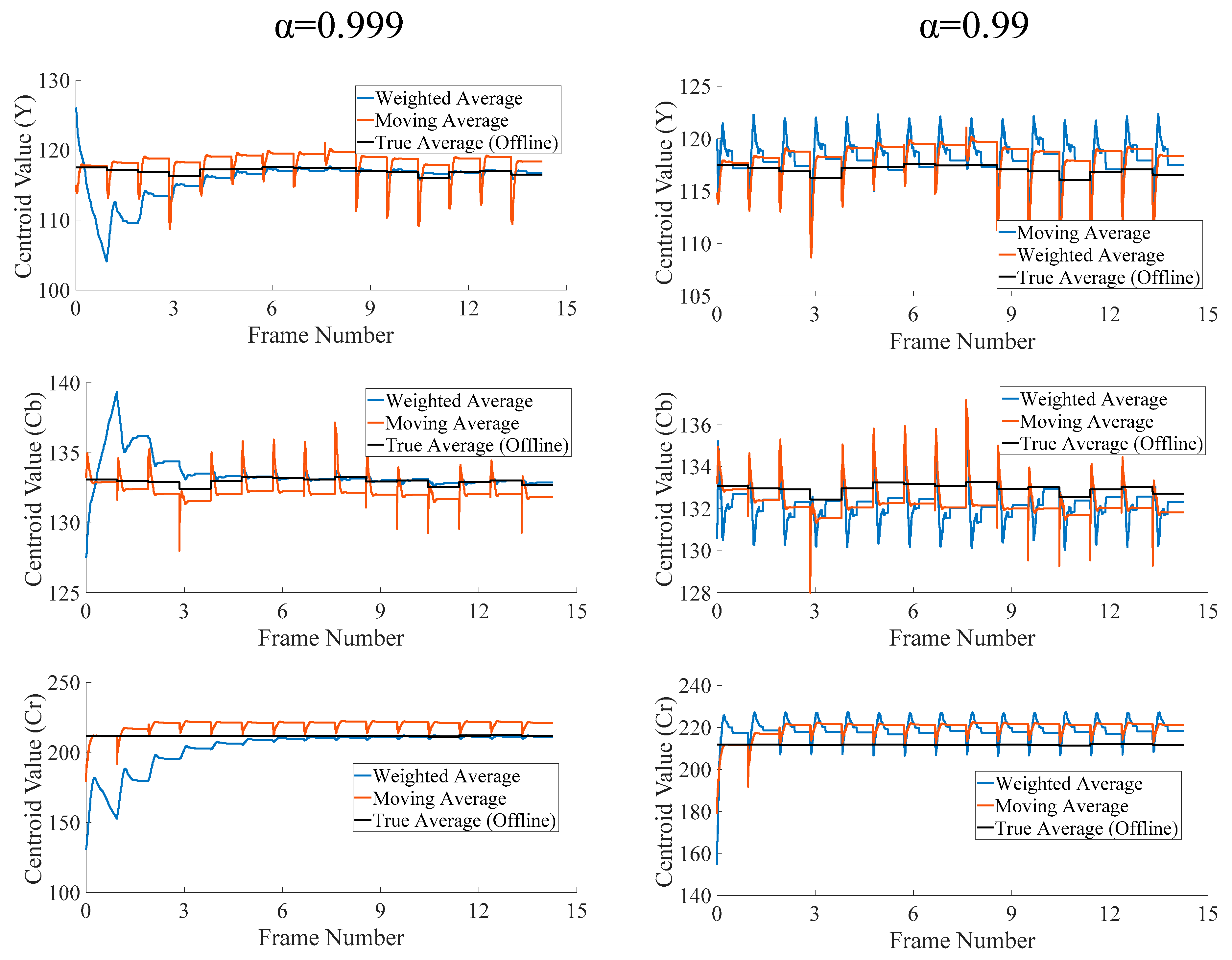
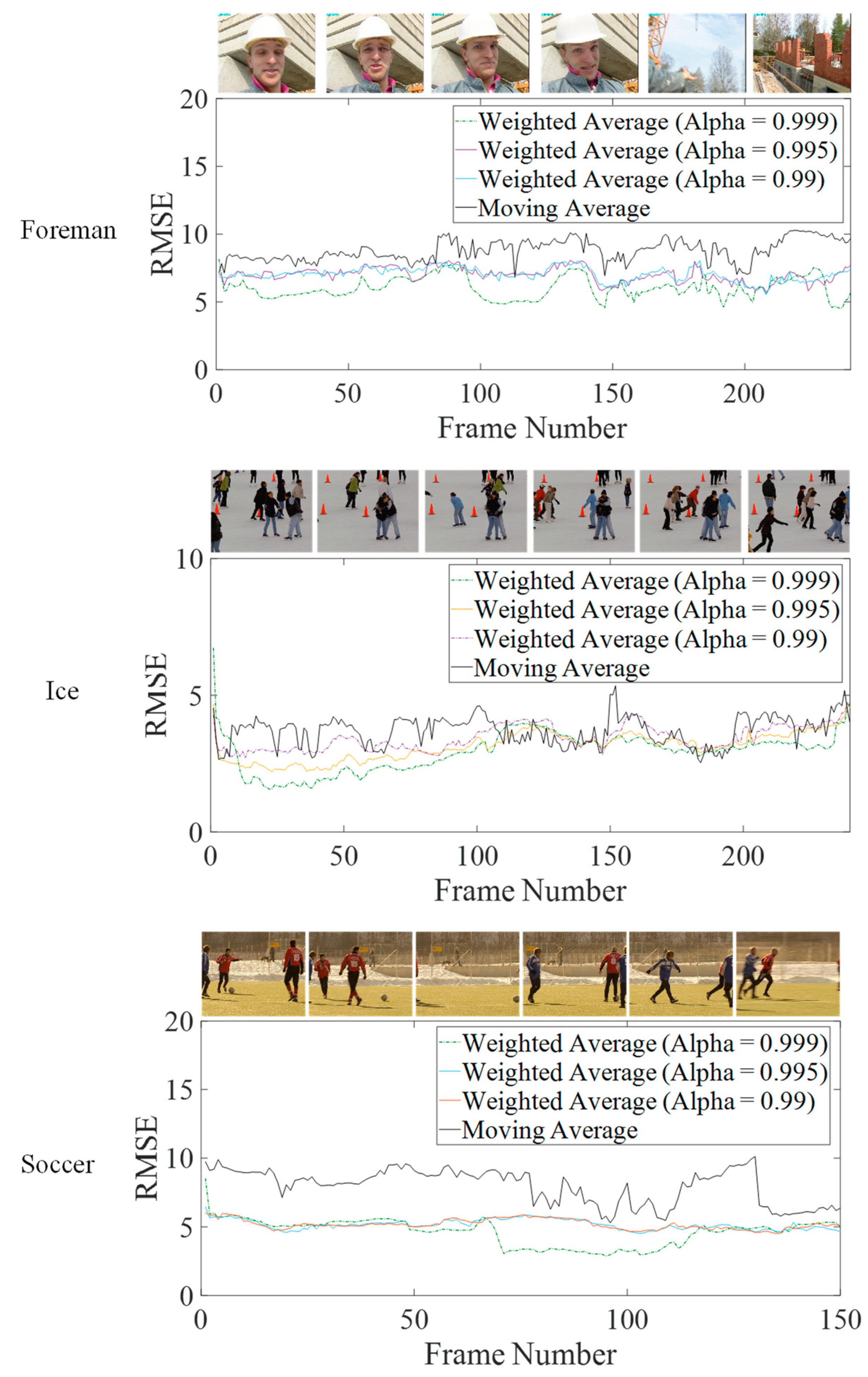
- Logic resource conservation through the use of the weighted average in the place of the moving average, which requires costly division operation
- Provision of experimental evidence to demonstrate the utility of the weighted average in preserving the result fidelity of the on-line K-Means algorithm for image segmentation
2. Background and Literature Review
3. Online K-Means Clustering Hardware Design Using Simulink
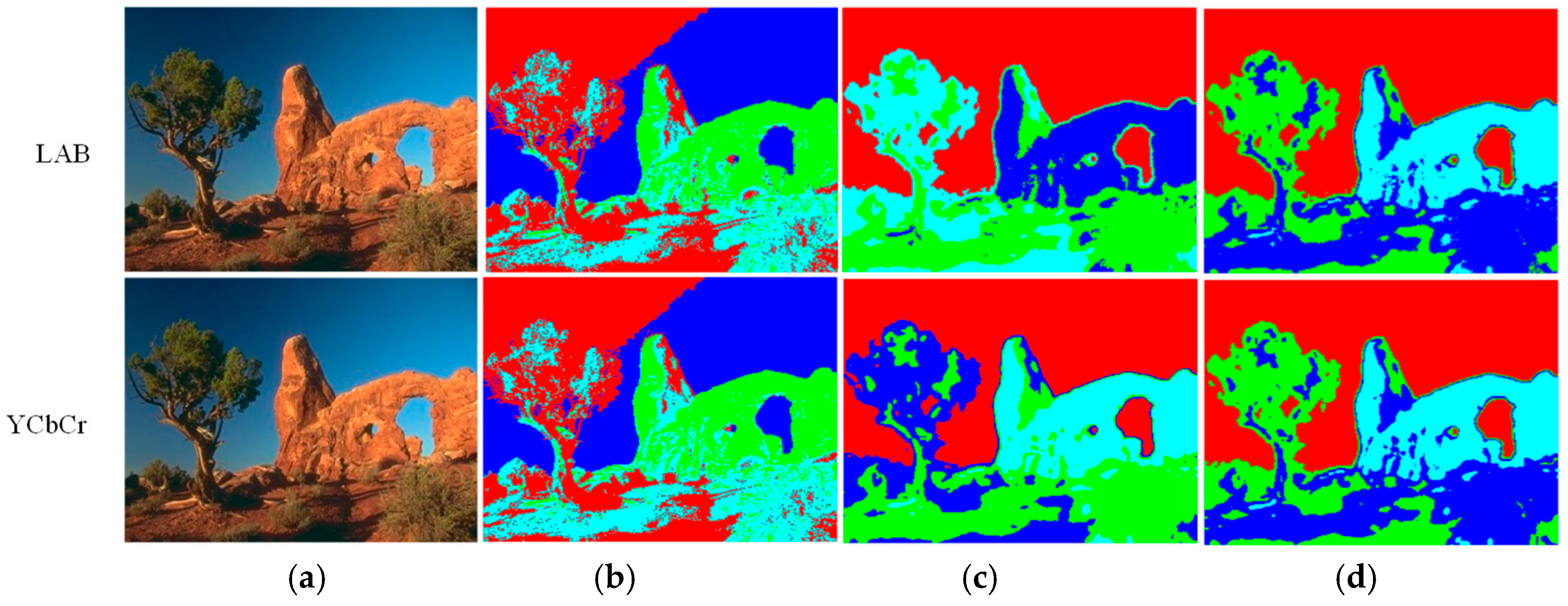
3.1. The Online K-Means Algorithm for Color-Based Image Segmentation
| Algorithm 1: Online K-Means clustering algorithm for color-based image segmentation | |
| 1: | Initialize the ‘k’ number of centroids, , , with random values. |
| 2: | Initialize the counts n1, n2, n3 .... nk to zero. |
| 3: | while ‘pixel stream continues’ do |
| 4: | p ← RGB2YCbCr(p) |
| 5: | Match the input pixel, ‘p’, to a single centroid by minimizing the distance |
| 6: | Increment ni |
| 7: | Update the matching centroid, , using moving average |
| 8: | ← + (1/ ni)(p − ) |
| 9: | Classify the input pixel, ‘p’, as ‘i’. |
| 10: | end |
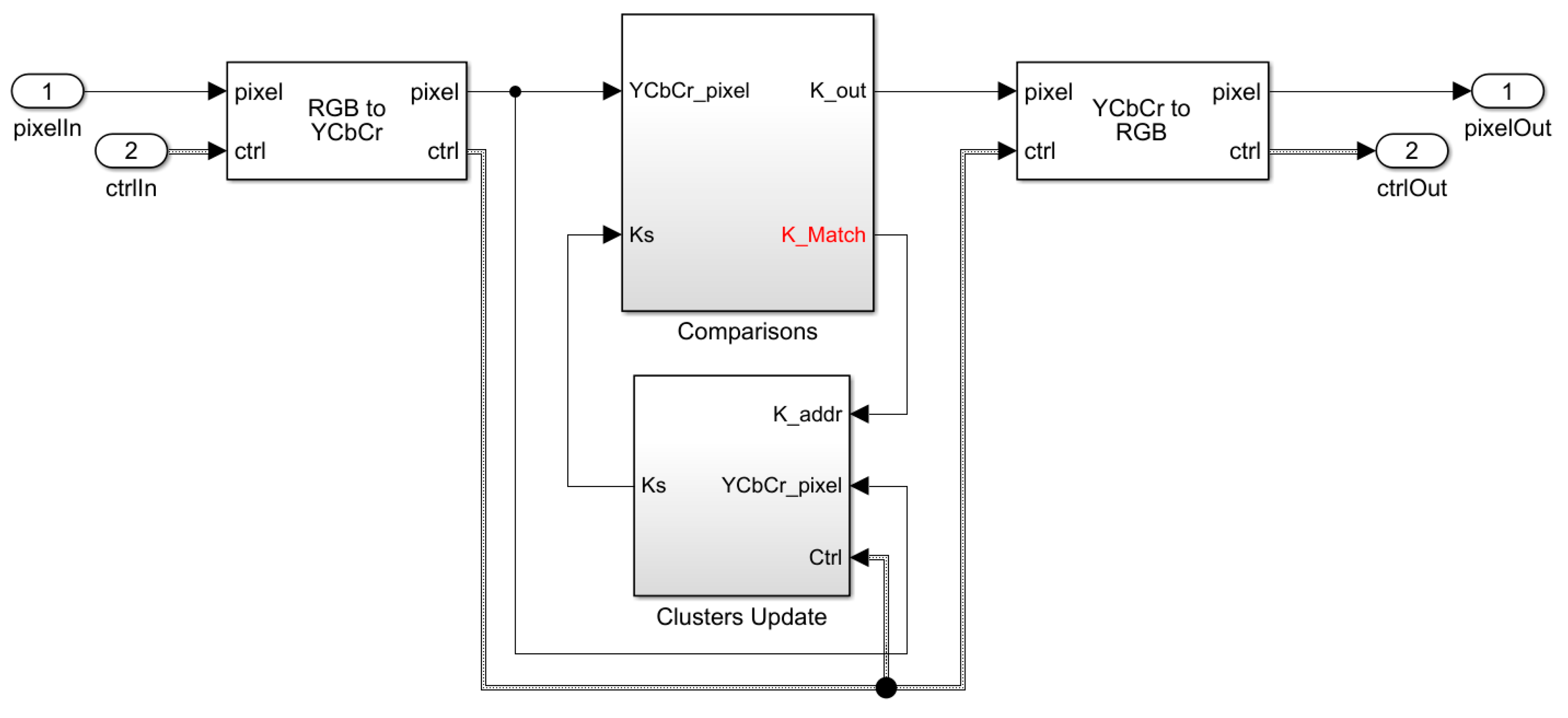
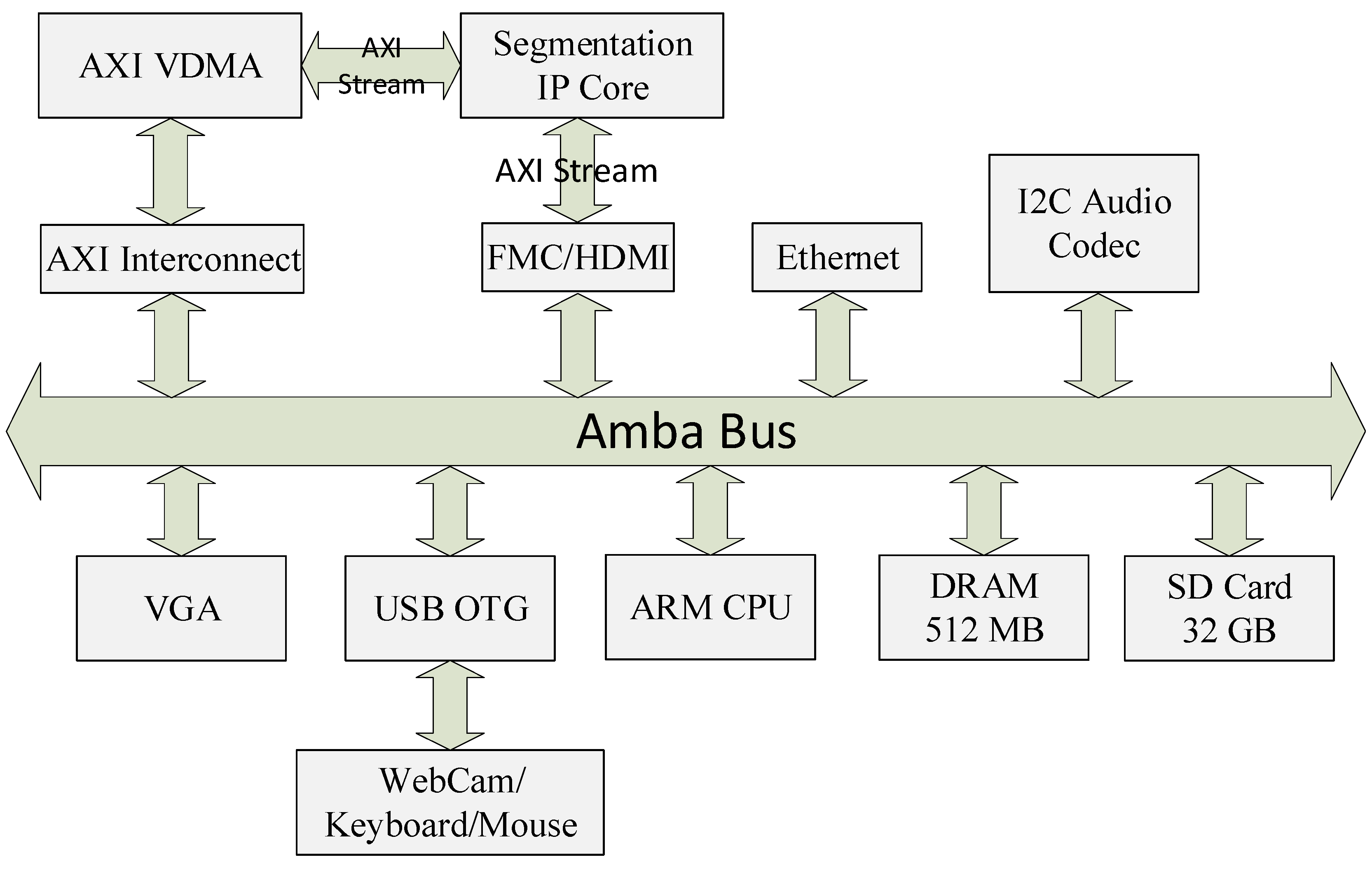
3.2. Simulink Design Entry and High-Level Synthesis
3.2.1. Comparisons Module
3.2.2. Clusters Update Module
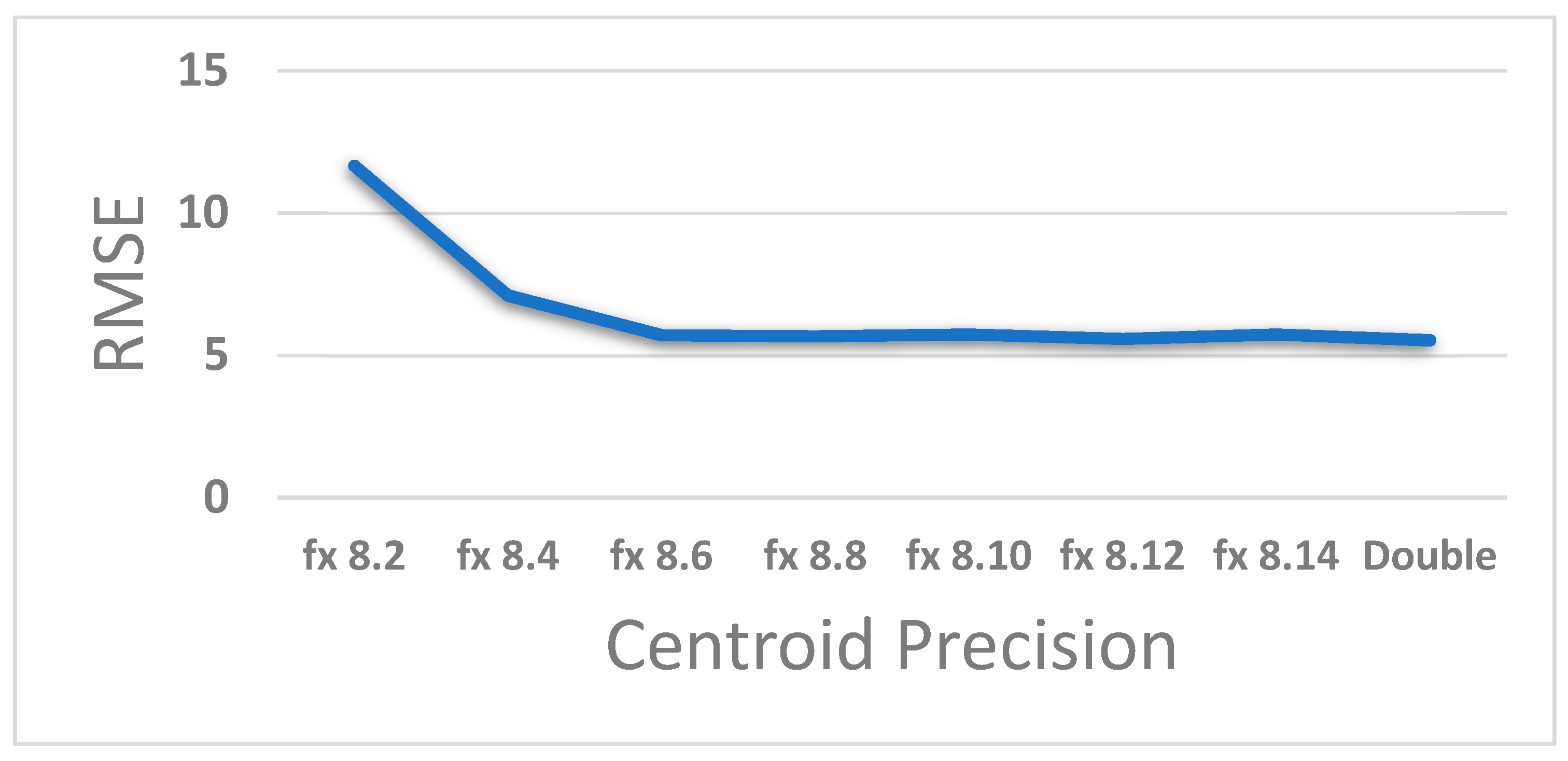
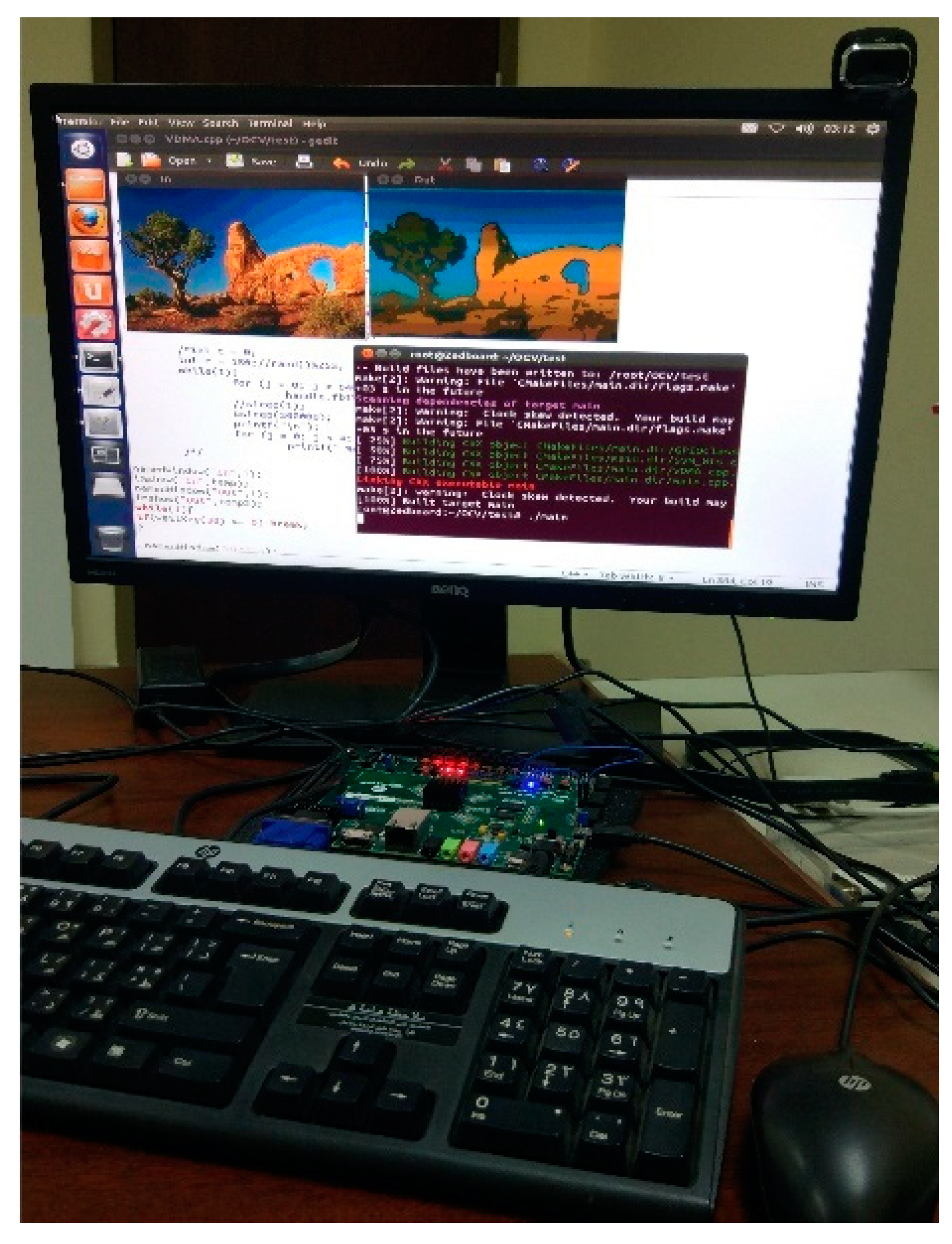
4. Results
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- New Eyes for the IoT—[Opinion]. IEEE Spectr. 2018, 55, 24. [CrossRef]
- Lubana, E.S.; Dick, R.P. Digital Foveation: An Energy-Aware Machine Vision Framework. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2018, 37, 2371–2380. [Google Scholar] [CrossRef]
- Seib, V.; Christ-Friedmann, S.; Thierfelder, S.; Paulus, D. Object class and instance recognition on RGB-D data. In Proceedings of the Sixth International Conference on Machine Vision (ICMV 13), London, UK, 16–17 November 2013; p. 7. [Google Scholar]
- Muslim, F.B.; Ma, L.; Roozmeh, M.; Lavagno, L. Efficient FPGA Implementation of OpenCL High-Performance Computing Applications via High-Level Synthesis. IEEE Access 2017, 5, 2747–2762. [Google Scholar] [CrossRef]
- Hai, J.C.T.; Pun, O.C.; Haw, T.W. Accelerating video and image processing design for FPGA using HDL coder and simulink. In Proceedings of the 2015 IEEE Conference on Sustainable Utilization and Development in Engineering and Technology (CSUDET), Selangor, Malaysia, 15–17 October 2015; pp. 1–5. [Google Scholar]
- Yuheng, S.; Hao, Y. Image Segmentation Algorithms Overview. arXiv, 2017; arXiv:1707.02051. [Google Scholar]
- Cardoso, J.S.; Corte-Real, L. Toward a generic evaluation of image segmentation. IEEE Trans. Image Process. 2005, 14, 1773–1782. [Google Scholar] [CrossRef]
- Pereyra, M.; McLaughlin, S. Fast Unsupervised Bayesian Image Segmentation with Adaptive Spatial Regularisation. IEEE Trans. Image Process. 2017, 26, 2577–2587. [Google Scholar] [CrossRef]
- Isa, N.A.M.; Salamah, S.A.; Ngah, U.K. Adaptive fuzzy moving K-means clustering algorithm for image segmentation. IEEE Trans. Consum. Electron. 2009, 55, 2145–2153. [Google Scholar] [CrossRef]
- Ghosh, N.; Agrawal, S.; Motwani, M. A Survey of Feature Extraction for Content-Based Image Retrieval System. In Proceedings of the International Conference on Recent Advancement on Computer and Communication, Bhopal, India, 26–27 May 2017; pp. 305–313. [Google Scholar]
- Belongie, S.; Carson, C.; Greenspan, H.; Malik, J. Color- and texture-based image segmentation using EM and its application to content-based image retrieval. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 7 January 1998; pp. 675–682. [Google Scholar]
- Farid, M.S.; Lucenteforte, M.; Grangetto, M. DOST: A distributed object segmentation tool. Multimed. Tools Appl. 2018, 77, 20839–20862. [Google Scholar] [CrossRef]
- Carson, C.; Belongie, S.; Greenspan, H.; Malik, J. Blobworld: Image segmentation using expectation-maximization and its application to image querying. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1026–1038. [Google Scholar] [CrossRef]
- Liang, J.; Guo, J.; Liu, X.; Lao, S. Fine-Grained Image Classification with Gaussian Mixture Layer. IEEE Access 2018, 6, 53356–53367. [Google Scholar] [CrossRef]
- Dhanachandra, N.; Manglem, K.; Chanu, Y.J. Image Segmentation Using K-means Clustering Algorithm and Subtractive Clustering Algorithm. Procedia Comput. Sci. 2015, 54, 764–771. [Google Scholar] [CrossRef]
- Qureshi, M.N.; Ahamad, M.V. An Improved Method for Image Segmentation Using K-Means Clustering with Neutrosophic Logic. Procedia Comput. Sci. 2018, 132, 534–540. [Google Scholar] [CrossRef]
- Bahadure, N.B.; Ray, A.K.; Thethi, H.P. Performance analysis of image segmentation using watershed algorithm, fuzzy C-means of clustering algorithm and Simulink design. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 1160–1164. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV 2001), Vancouver, BC, Canada, 7–14 July 2001; Volume 412, pp. 416–423. [Google Scholar]
- Benetti, M.; Gottardi, M.; Mayr, T.; Passerone, R. A Low-Power Vision System With Adaptive Background Subtraction and Image Segmentation for Unusual Event Detection. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 3842–3853. [Google Scholar] [CrossRef]
- Liu, Z.; Zhuo, C.; Xu, X. Efficient segmentation method using quantised and non-linear CeNN for breast tumour classification. Electron. Lett. 2018, 54, 737–738. [Google Scholar] [CrossRef]
- Genovese, M.; Napoli, E. ASIC and FPGA Implementation of the Gaussian Mixture Model Algorithm for Real-Time Segmentation of High Definition Video. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2014, 22, 537–547. [Google Scholar] [CrossRef]
- Liu, H.; Zhao, Y.; Xie, G. Image segmentation implementation based on FPGA and SVM. In Proceedings of the 2017 3rd International Conference on Control, Automation and Robotics (ICCAR), Nagoya, Japan, 24–26 April 2017; pp. 405–409. [Google Scholar]
- Liang, P.; Klein, D. Online EM for unsupervised models. In Proceedings of the Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Boulder, CO, USA, 1–3 June 2009; pp. 611–619. [Google Scholar]
- Liberty, E.; Sriharsha, R.; Sviridenko, M. An Algorithm for Online K-Means Clustering. arXiv, 2014; arXiv:1412.5721. [Google Scholar]
- Hussain, H.M.; Benkrid, K.; Seker, H.; Erdogan, A.T. FPGA implementation of K-means algorithm for bioinformatics application: An accelerated approach to clustering Microarray data. In Proceedings of the 2011 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), San Diego, CA, USA, 6–9 June 2011; pp. 248–255. [Google Scholar]
- Kutty, J.S.S.; Boussaid, F.; Amira, A. A high speed configurable FPGA architecture for K-mean clustering. In Proceedings of the 2013 IEEE International Symposium on Circuits and Systems (ISCAS2013), Beijing, China, 19–23 May 2013; pp. 1801–1804. [Google Scholar]
- Raghavan, R.; Perera, D.G. A fast and scalable FPGA-based parallel processing architecture for K-means clustering for big data analysis. In Proceedings of the 2017 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 21–23 August 2017; pp. 1–8. [Google Scholar]
- Canilho, J.; Véstias, M.; Neto, H. Multi-core for K-means clustering on FPGA. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–4. [Google Scholar]
- Li, Z.; Jin, J.; Wang, L. High-performance K-means Implementation based on a Coarse-grained Map-Reduce Architecture. CoRR 2016, arXiv:1610.05601. [Google Scholar]
- Khawaja, S.G.; Akram, M.U.; Khan, S.A.; Ajmal, A. A novel multiprocessor architecture for K-means clustering algorithm based on network-on-chip. In Proceedings of the 2016 19th International Multi-Topic Conference (INMIC), Islamabad, Pakistan, 5–6 December 2016; pp. 1–5. [Google Scholar]
- Kumar, P.; Miklavcic, J.S. Analytical Study of Colour Spaces for Plant Pixel Detection. J. Imaging 2018, 4, 42. [Google Scholar] [CrossRef]
- Guo, D.; Ming, X. Color clustering and learning for image segmentation based on neural networks. IEEE Trans. Neural Netw. 2005, 16, 925–936. [Google Scholar] [CrossRef]
- Sawicki, D.J.; Miziolek, W. Human colour skin detection in CMYK colour space. IET Image Process. 2015, 9, 751–757. [Google Scholar] [CrossRef]
- Wang, X.; Tang, Y.; Masnou, S.; Chen, L. A Global/Local Affinity Graph for Image Segmentation. IEEE Trans. Image Process. 2015, 24, 1399–1411. [Google Scholar] [CrossRef]
- Scharr, H.; Minervini, M.; French, A.P.; Klukas, C.; Kramer, D.M.; Liu, X.; Luengo, I.; Pape, J.-M.; Polder, G.; Vukadinovic, D.; et al. Leaf segmentation in plant phenotyping: A collation study. Mach. Vis. Appl. 2016, 27, 585–606. [Google Scholar] [CrossRef]
- Prasetyo, E.; Adityo, R.D.; Suciati, N.; Fatichah, C. Mango leaf image segmentation on HSV and YCbCr color spaces using Otsu thresholding. In Proceedings of the 2017 3rd International Conference on Science and Technology—Computer (ICST), Yogyakarta, Indonesia, 11–12 July 2017; pp. 99–103. [Google Scholar]
- Shaik, K.B.; Ganesan, P.; Kalist, V.; Sathish, B.S.; Jenitha, J.M.M. Comparative Study of Skin Color Detection and Segmentation in HSV and YCbCr Color Space. Procedia Comput. Sci. 2015, 57, 41–48. [Google Scholar] [CrossRef]
- Sajid, H.; Cheung, S.S. Universal Multimode Background Subtraction. IEEE Trans. Image Process. 2017, 26, 3249–3260. [Google Scholar] [CrossRef]
- Estlick, M.; Leeser, M.; Theiler, J.; Szymanski, J.J. Algorithmic transformations in the implementation of K- means clustering on reconfigurable hardware. In Proceedings of the 2001 ACM/SIGDA Ninth International Symposium on Field Programmable Gate Arrays, Monterey, CA, USA, 11–13 February 2001; pp. 103–110. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Sequence | Resolution | Number of Frames | RMSE | |
|---|---|---|---|---|
| Moving Average | Weighted Average = 0.999 | |||
| Akiyo | 352 × 288 | 300 | 11.82 | 7.14 |
| Container | 352 × 288 | 300 | 7.51 | 7.13 |
| Foreman | 352 × 288 | 300 | 9.04 | 6.44 |
| Carphone | 352 × 288 | 382 | 6.62 | 5.77 |
| Claire | 176 × 144 | 494 | 9.56 | 6.75 |
| Hall | 352 × 288 | 300 | 5.96 | 4.21 |
| Highway | 352 × 288 | 2000 | 7.26 | 4.61 |
| Soccer | 352 × 288 | 150 | 8.06 | 4.71 |
| Ice | 352 × 288 | 240 | 3.75 | 3.01 |
| Tennis | 352 × 288 | 150 | 8.63 | 6.83 |
| Design | FPGA | Slice LUT | Slice Registers | BRAM | DSP | Dynamic Power | |
|---|---|---|---|---|---|---|---|
| Hussain [25] | Xilinx Virtex-IV | 2208 | 3022 | 90 Kb | - | - | |
| Kutty [26] | Xilinx Virtex-VI | 2110 | 8011 | 288 Kb | 112 | - | |
| Raghavan [27] | Xilinx Virtex-6 | 6916 | 14,132 | - | 88 | - | |
| Cahnilho [28] | Xilinx Zynq-7000 | 1583 | 1016 | 36 Kb | 7 | - | |
| Li [29] | Xilinx Zynq-7000 | 178,185 | 208,152 | 5742 Kb | 412 | - | |
| Proposed | Full IP | Xilinx Zynq-7000 | 3402 | 2443 | 0 | 62 | 86 mW |
| AXI | 458 | 538 | 0 | 0 | 4 mW | ||
| CSC | 719 | 1014 | 0 | 14 | 7 mW | ||
| Clusters Update | 1643 | 876 | 0 | 48 | 72 mW | ||
| Comparisons | 582 | 15 | 0 | 0 | 3 mW | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Badawi, A.; Bilal, M. High-Level Synthesis of Online K-Means Clustering Hardware for a Real-Time Image Processing Pipeline. J. Imaging 2019, 5, 38. https://doi.org/10.3390/jimaging5030038
Badawi A, Bilal M. High-Level Synthesis of Online K-Means Clustering Hardware for a Real-Time Image Processing Pipeline. Journal of Imaging. 2019; 5(3):38. https://doi.org/10.3390/jimaging5030038
Chicago/Turabian StyleBadawi, Aiman, and Muhammad Bilal. 2019. "High-Level Synthesis of Online K-Means Clustering Hardware for a Real-Time Image Processing Pipeline" Journal of Imaging 5, no. 3: 38. https://doi.org/10.3390/jimaging5030038
APA StyleBadawi, A., & Bilal, M. (2019). High-Level Synthesis of Online K-Means Clustering Hardware for a Real-Time Image Processing Pipeline. Journal of Imaging, 5(3), 38. https://doi.org/10.3390/jimaging5030038