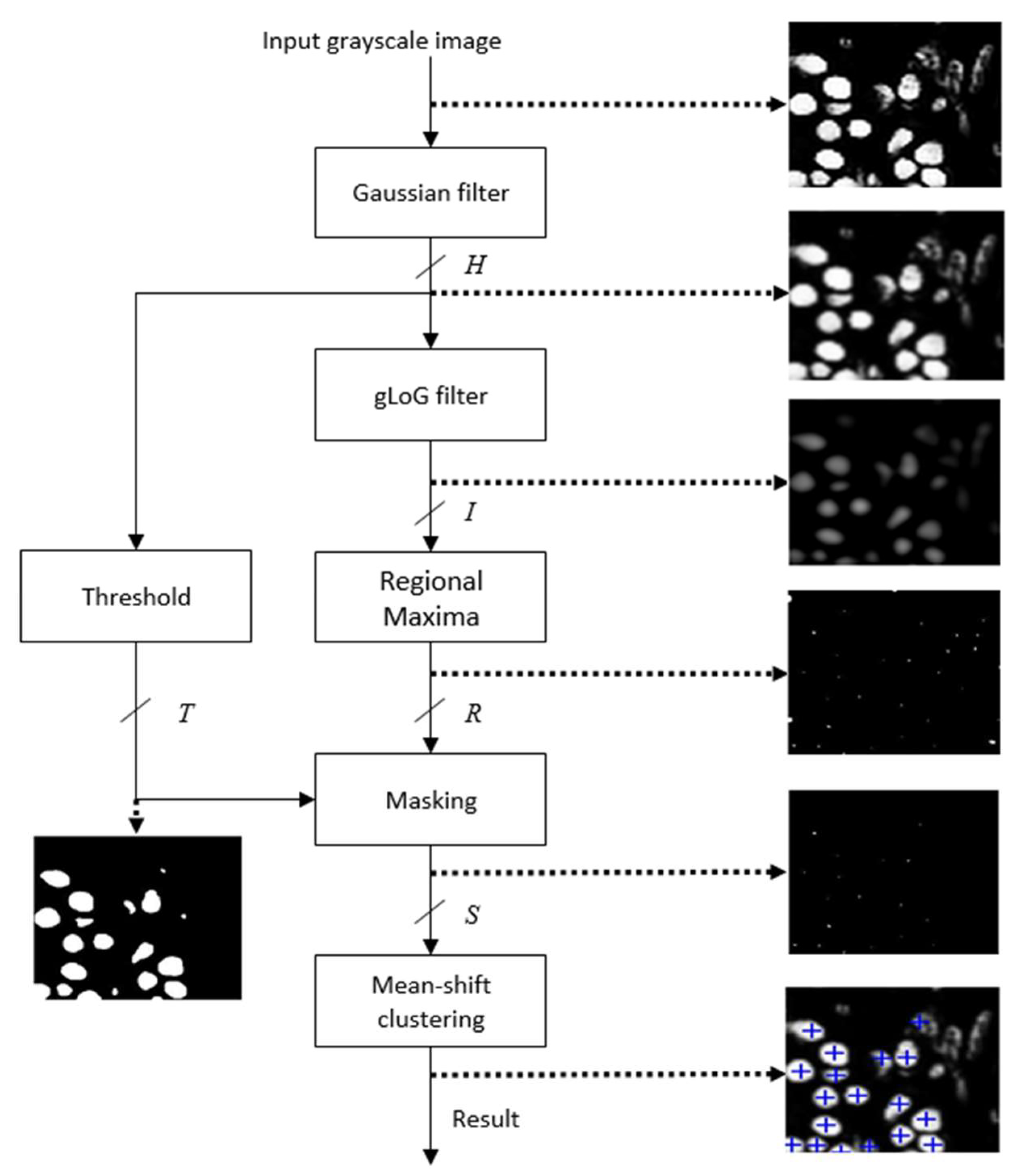
The schematic of the proposed accelerator architecture for nuclei detection is shown in
Figure 2. It has been found that [
1] the nuclei can be detected efficiently using the red channel of the H&E stained RGB image. Therefore, the red channel of the histology image is used as the input gray scale image. The architecture mainly contains six modules: Gaussian filter, gLoG filter, Regional Maxima, Thresholding, Masking and Mean-shift clustering. The Gaussian filter smooths an input image. The gLoG filter is then applied to generate response maps corresponding to different scales and orientation of the gLoG kernels. The Regional Maxima module generates nuclei seed candidates from the response maps. In order to reduce the number of false positive seeds, a mask is generated by applying the Thresholding module on the Gaussian filter output and Masking is done on the nuclei seed candidates generated from Regional Maxima module. Finally, the Mean-shift clustering module clusters the remaining seed candidates to obtain coordinates of different nuclei centers. The anticipated results of different modules are also shown in
Figure 2. Implementation details of each module is given in the following sections.
2.1. Gaussian Filter
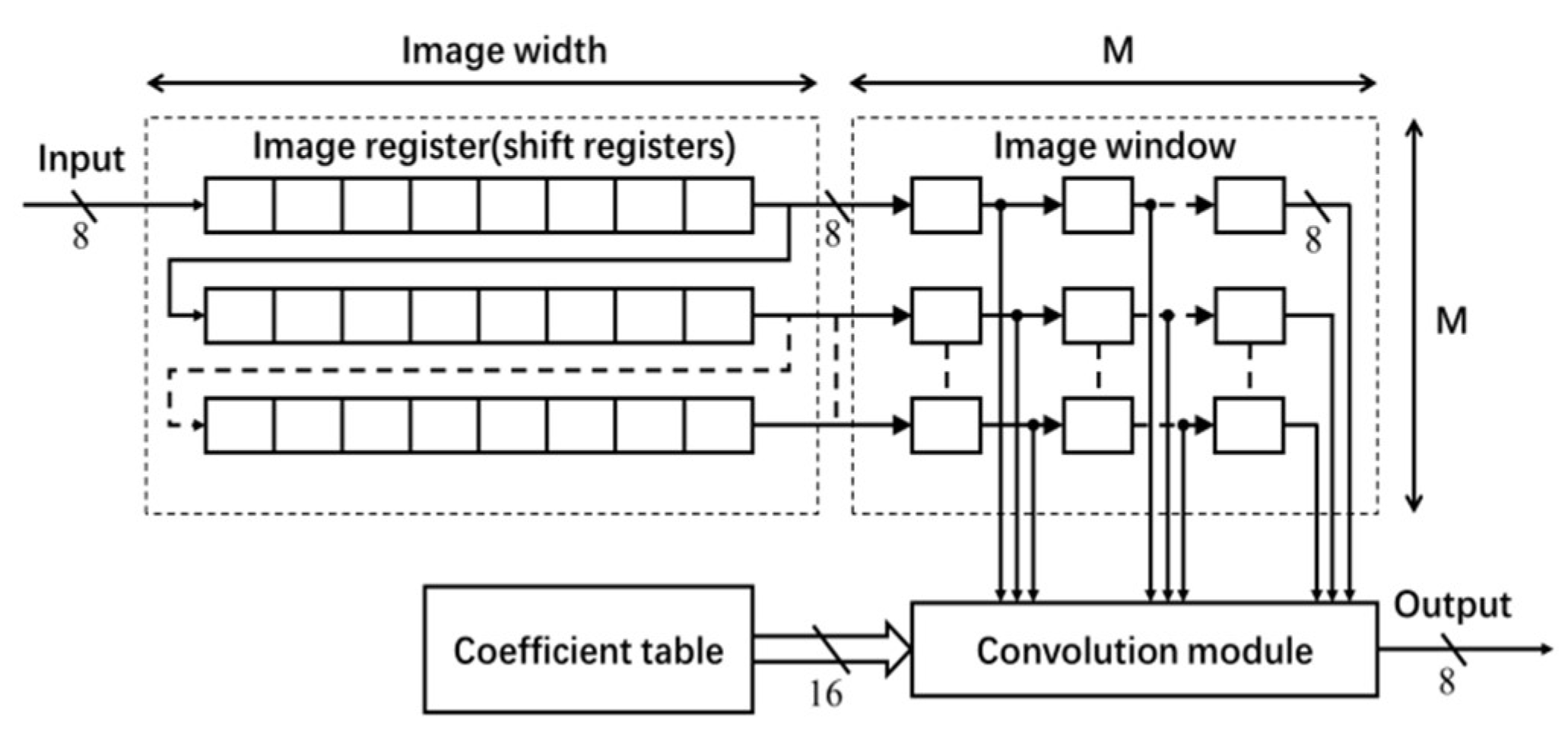
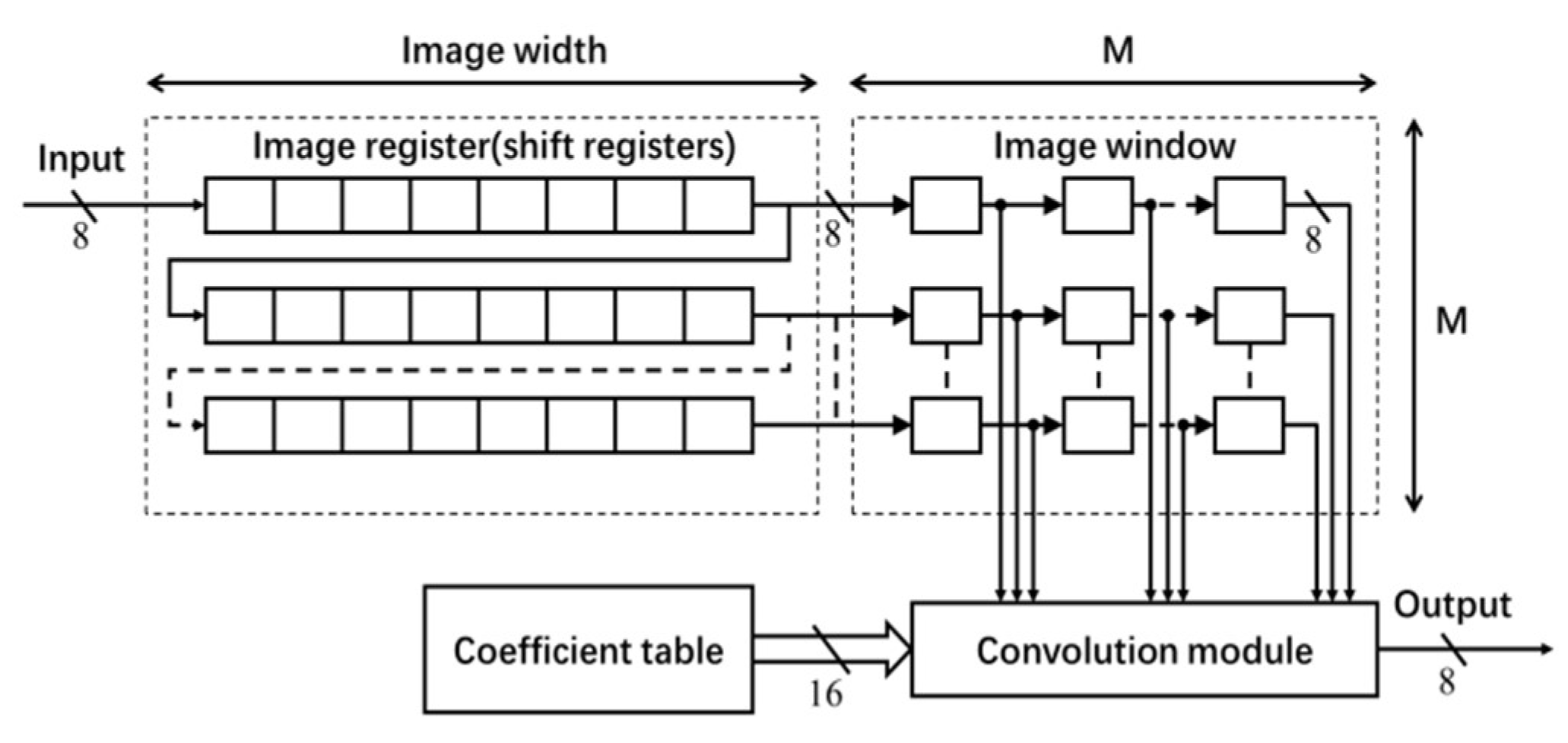
The architecture for the Gaussian filter is shown in
Figure 3, which mainly consists of a coefficient table, an image register unit, an image window and a convolution module [
3]. The coefficients of the
Gaussian filter are generated offline. The normalized filter coefficients (in floating-point data type) are converted into fixed-point data type. In this implementation, 16-bit fixed-point representation (with fraction length of 14) has been used (without any significant loss of accuracy). The filter coefficients are stored in ROM IP core on the FPGA board.
To enable the process of shifting the window of 2-D filter coefficients for a raster scan of the entire image,
M shift register IP cores of length equal to the image width (see
Figure 3) are used for generating a Serial-In-Parallel-Output (SIPO) image register unit [
3]. Each shift register stores one row of image data. Input to this register unit is an 8-bit image pixel data comes at a rate of one pixel per clock. The
M pixels from each shift register are transferred to the image window to access randomly in convolution.
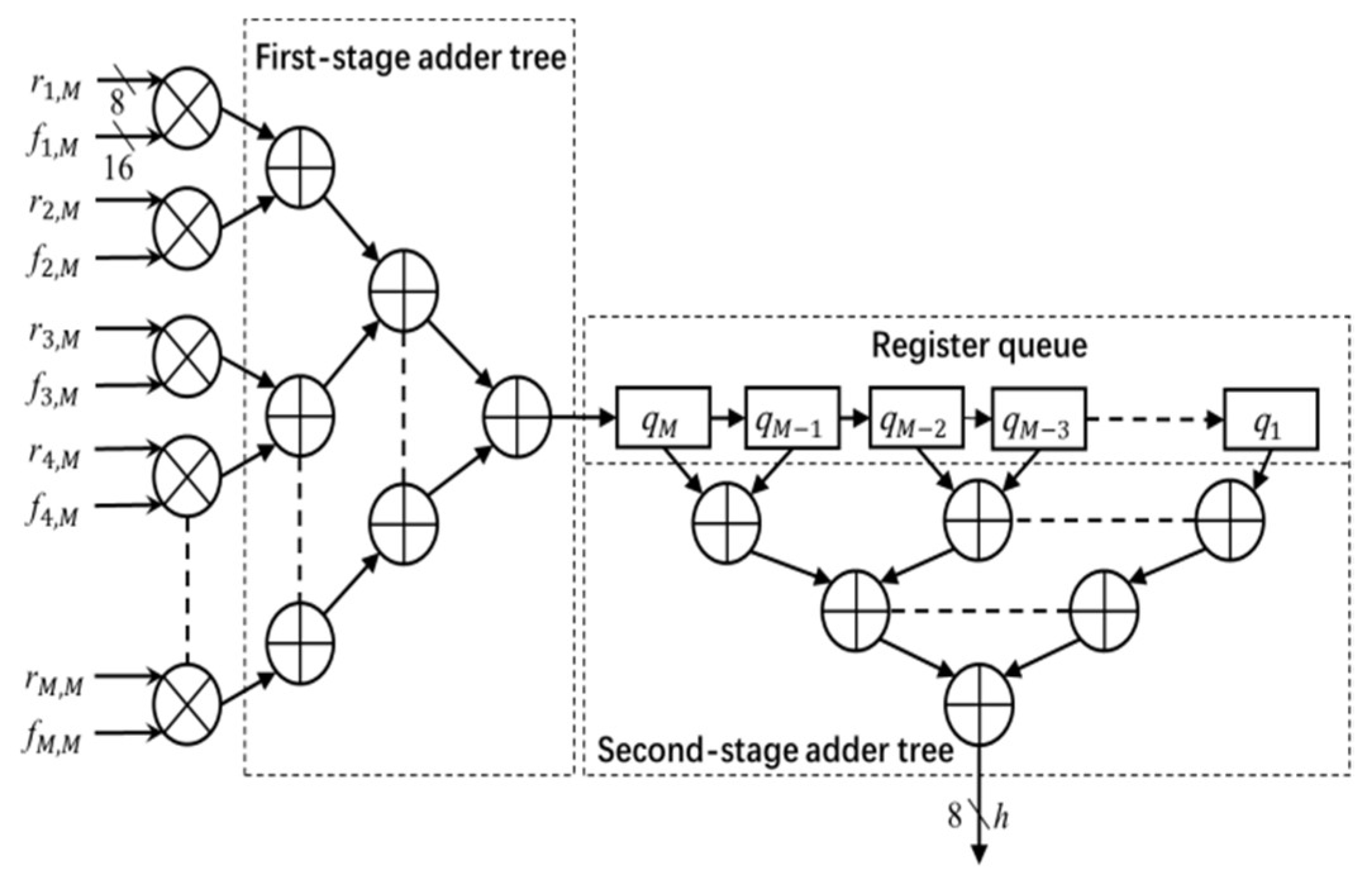
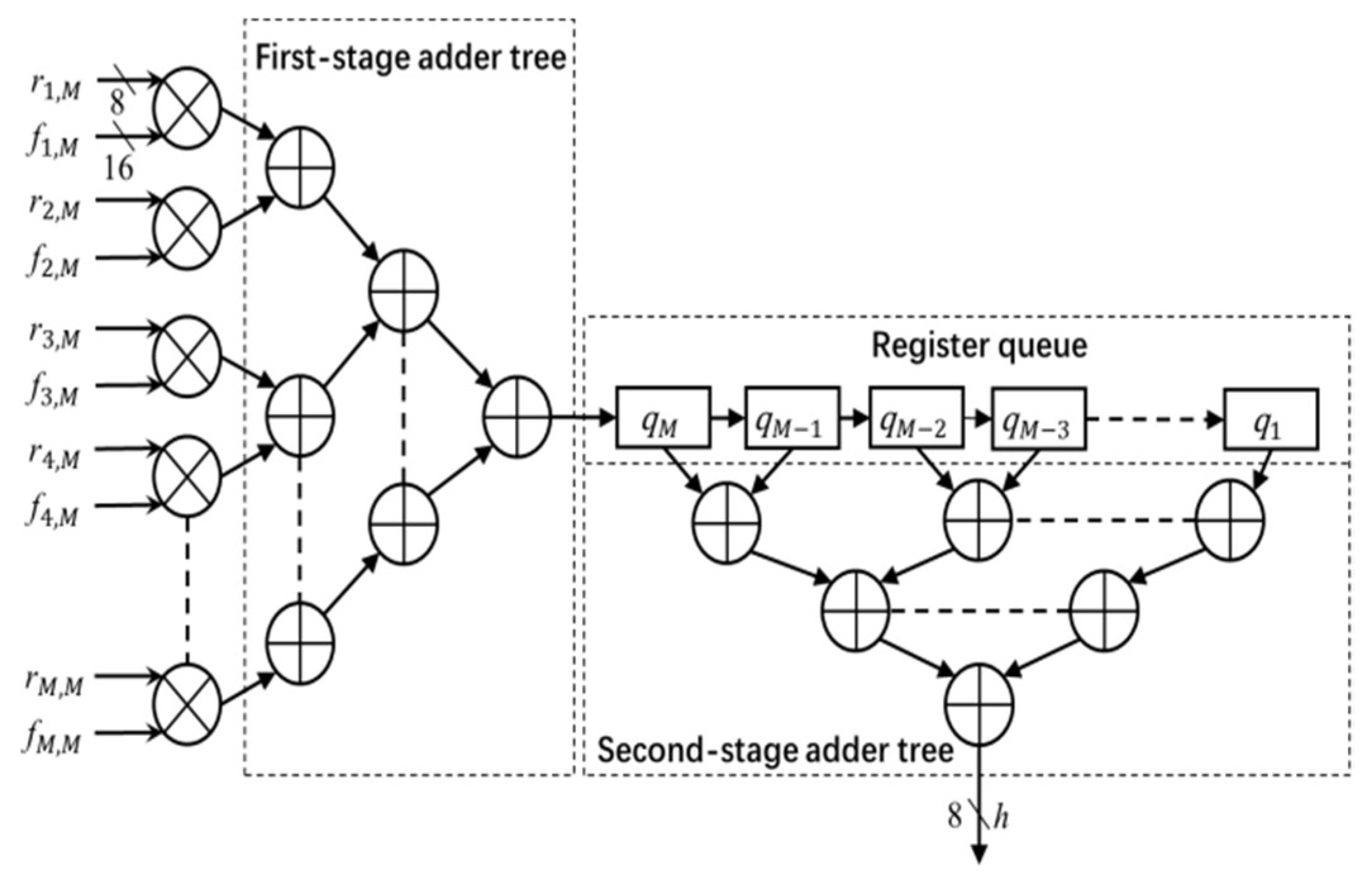
The architecture of the convolution module is shown in
Figure 4. The module uses the image data
r (stored in the image window) and filter coefficients
f (stored in the coefficient table) to calculate the output
h. The entire convolution process with
M ×
M size filter is divided into
M cycles. In each cycle, one column (e.g.,
ith column) of the image window data
r and coefficient table data
f pass through the multiplier array and first stage adder tree, and is then stored in the register queue. In each subsequent cycle, the register data shifts right by one unit, and the next columns of image data and filter coefficients go through the module and the output is stored in the register queue. This process continues for
M times. After
M cycles, the outputs of every column (stored in register queue) are added by the second stage adder to calculate the convolution output
h (pixel value in the Gaussian filter output image
H). In this work,
h is truncated into 8-bit precision and the output image
H is stored in the FPGA block RAM.
2.2. 2-D gLoG Filter
Because the cell nuclei in digital histopathological images typically have circular or elliptical shapes, the 2-D gLoG filters are used for nuclei detection [
1]. The nuclei are detected by convolving the image
H with a 2-D gLoG filter. The gLoG filters are generated from a bank of gLoG kernels
as defined below [
1]:
where
is a 2-D Gaussian function defined as follows.
Note that
a,
b and
c are functions of scale
and orientation
θ of the Gaussian kernels [
1,
4]. By changing the scales and the orientation, a set of gLoG kernels can be obtained. In this paper, we generate gLoG kernels
with
ranging from 6 to 12 insteps of 0.5 and nine orientations
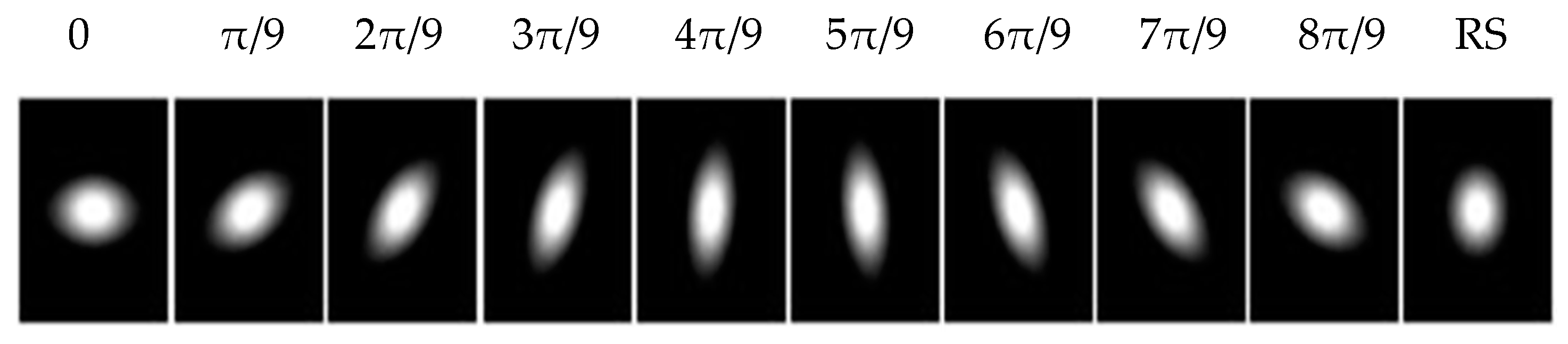
. The nine gLoG filters corresponding to nine orientations are generated by adding up gLoG kernels of the same orientation, but with different scales. Special kernels, whose
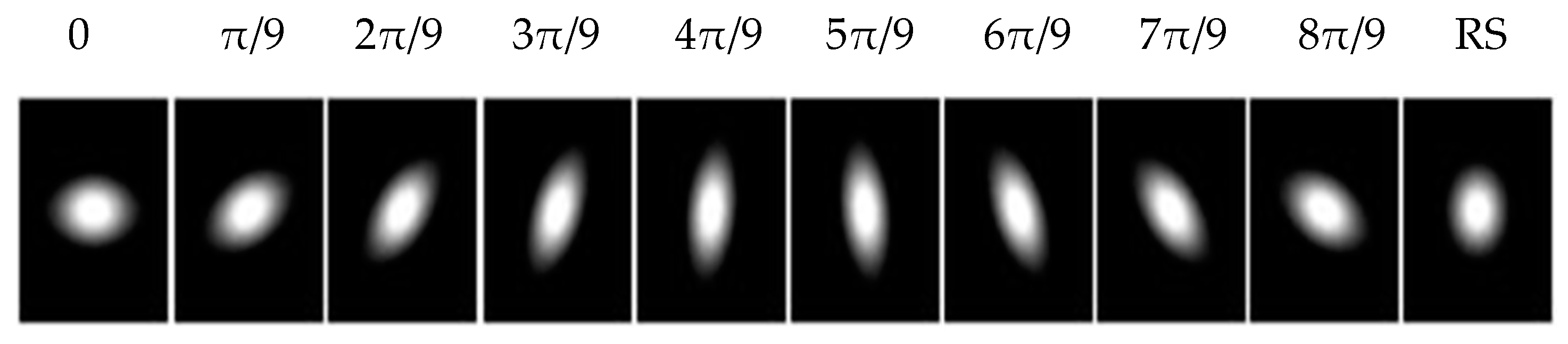
are rotational symmetric and their structures are independent of the orientation, are summed separately to form a rotationally symmetric gLoG filter. In this paper, 10 gLoG filters are used (see
Figure 5), with nine filters of different orientations and one rotationally symmetric (RS) filter. A total of 10 response maps, with one response map from each gLoG filter, are generated.
For hardware implementation, the architecture of the gLoG filter module is similar to that of the Gaussian filter described in the previous section, except the filter size and coefficients. In this work, the size of the gLoG filter is set to 25 × 25 in order to match the size of typical nuclei in the input data. As the gLoG filter coefficients are independent of the image data, they are calculated offline, converted into 16-bit precision (with 14-bit fractional value), and stored in ROM IP cores on the FPGA. The output response map (denoted by I) from each gLoG filter is stored with 8-bit precision in the block RAM on the FPGA.
2.3. Regional Maxima Calculation
Regional maxima are connected components of pixels with a constant grayscale value,
t, whose external boundary pixels all have a value less than
t [
5,
6]. As the regional maxima in a gLoG filter response map
I are usually around the nuclei centers, they are detected in this module and considered as candidate pixels to calculate the nuclei centers.
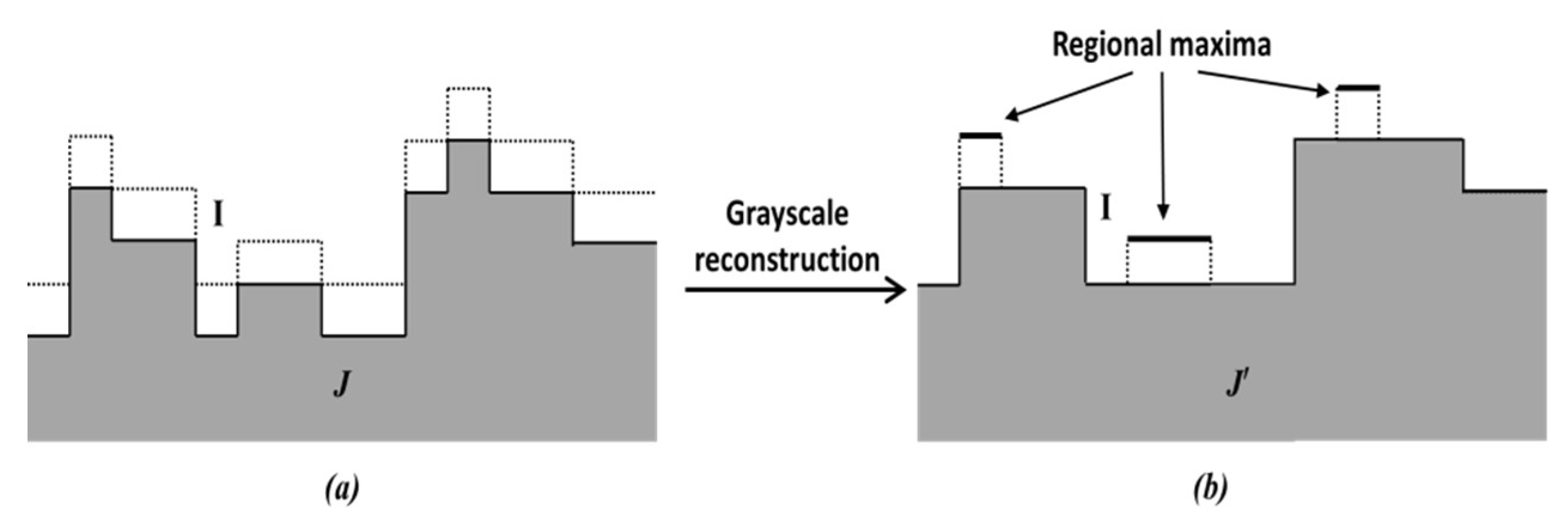
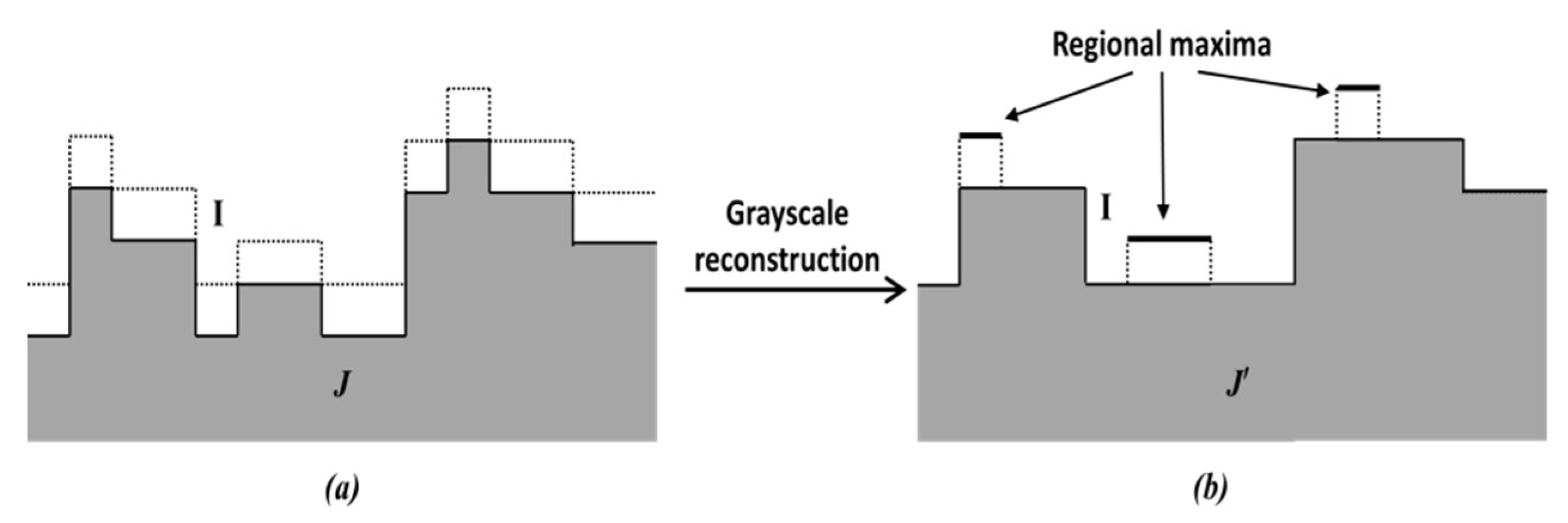
The principle of regional maxima calculation used in this paper is shown in
Figure 6. In
Figure 6a, the response map
I (denoted by dotted lines) is used as the mask image. A marker image
(shown by full lines) is generated and stored in an FPGA block RAM (if
J < 0, it is set to 0). A
hybrid grayscale reconstruction algorithm [
6], described below, is then performed on the marker image
J, and let the output be denoted by
. After that,
is calculated, and where the outcome value is 1, the corresponding pixel is considered as the regional maxima. This is illustrated in
Figure 6b.
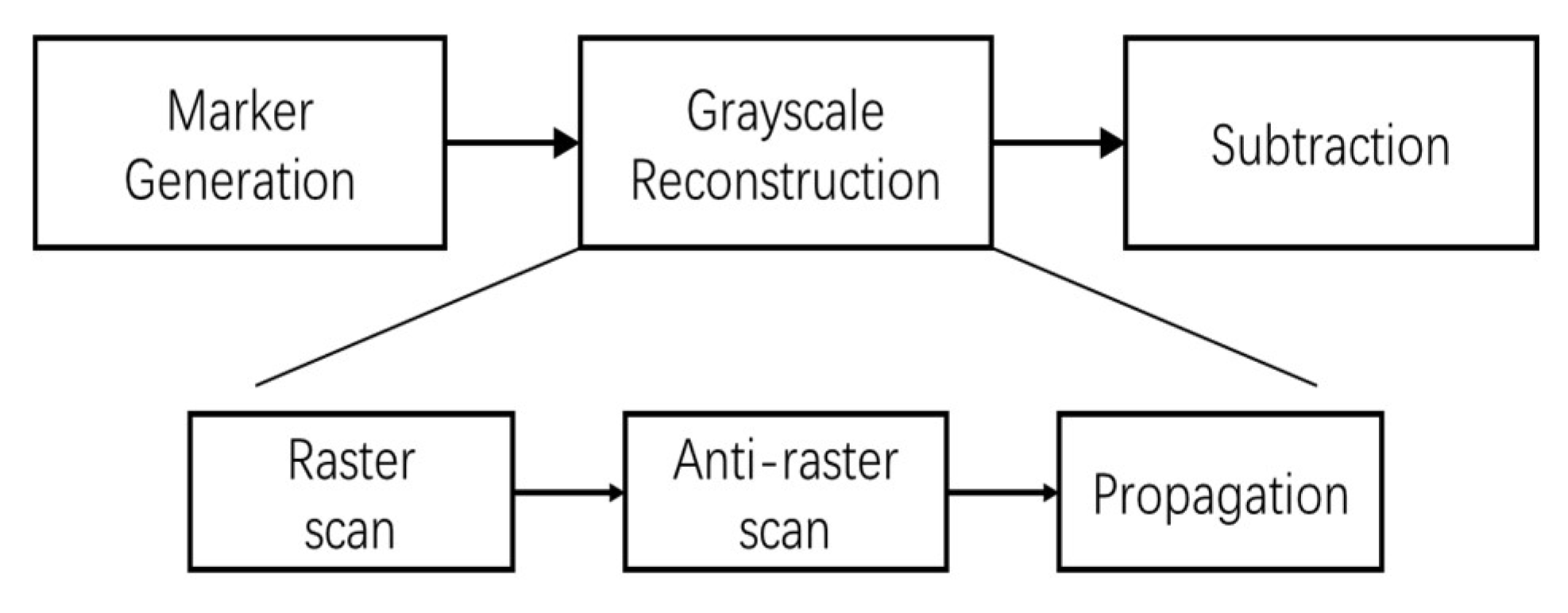
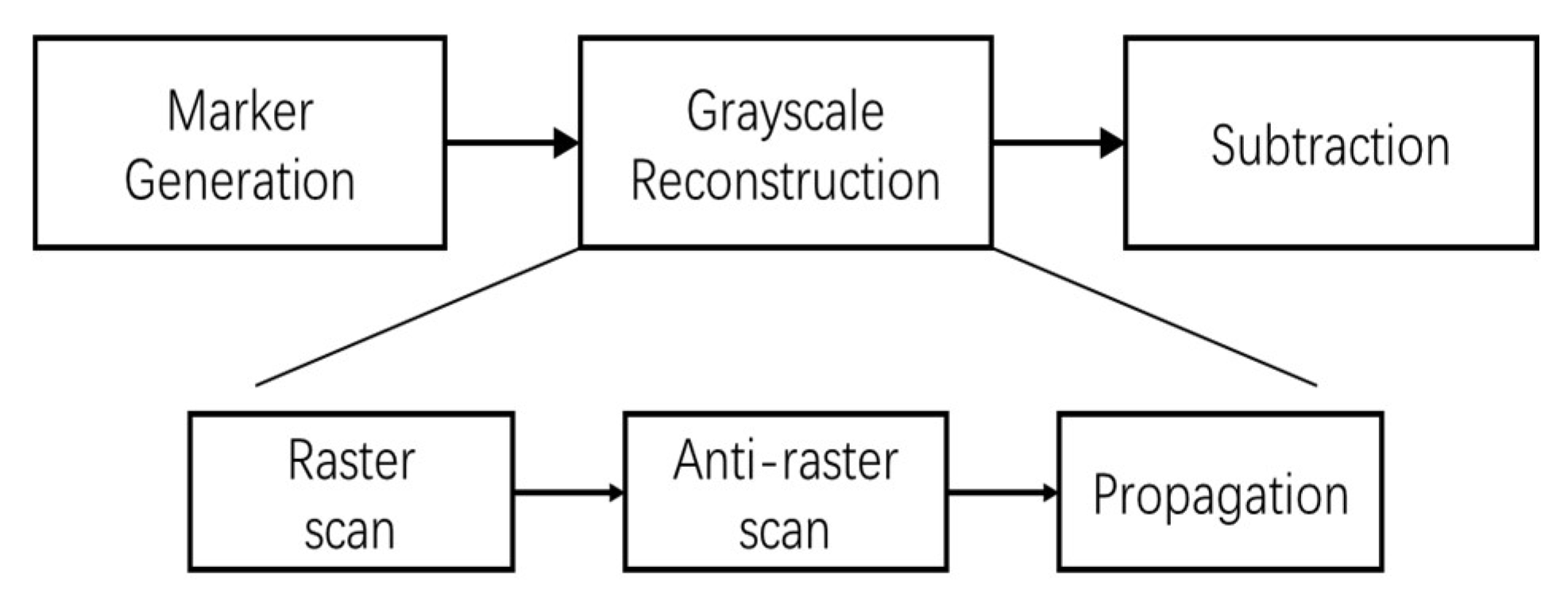
Figure 7 shows the block schematic of the
Regional Maxima module, which has 3 parts:
Marker generation,
Grayscale Reconstruction and
Subtraction. Function of
Marker Generation (
) and
Subtraction parts are mentioned in the previous paragraph. The
Grayscale Reconstruction of the marker image
J is done in 3 steps,
Raster scan,
Anti-raster scan and
Propagation, which are explained in the following.
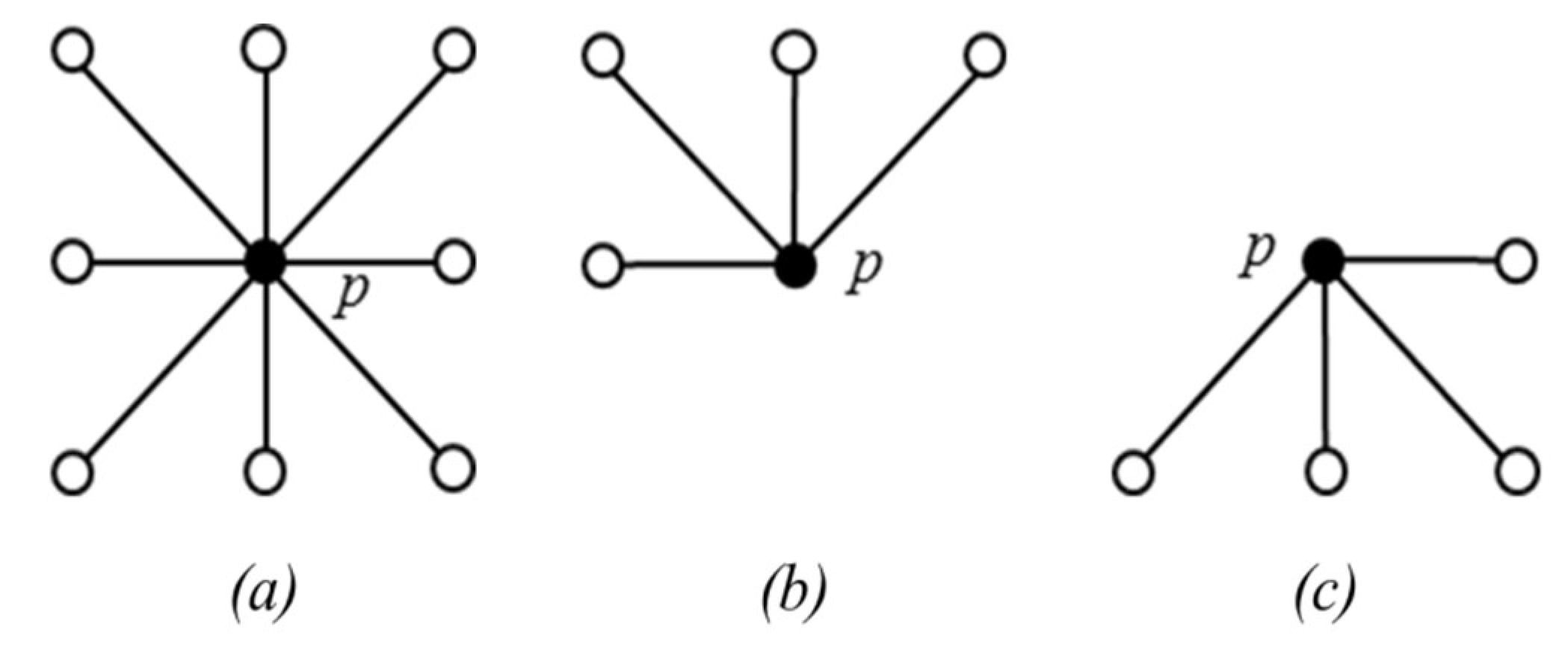
After generating the mask I and the marker J, a raster scan of these two images is performed. Let p denote pointer of the current pixel in the scanning, and q denote its neighbor’s pixel positions.
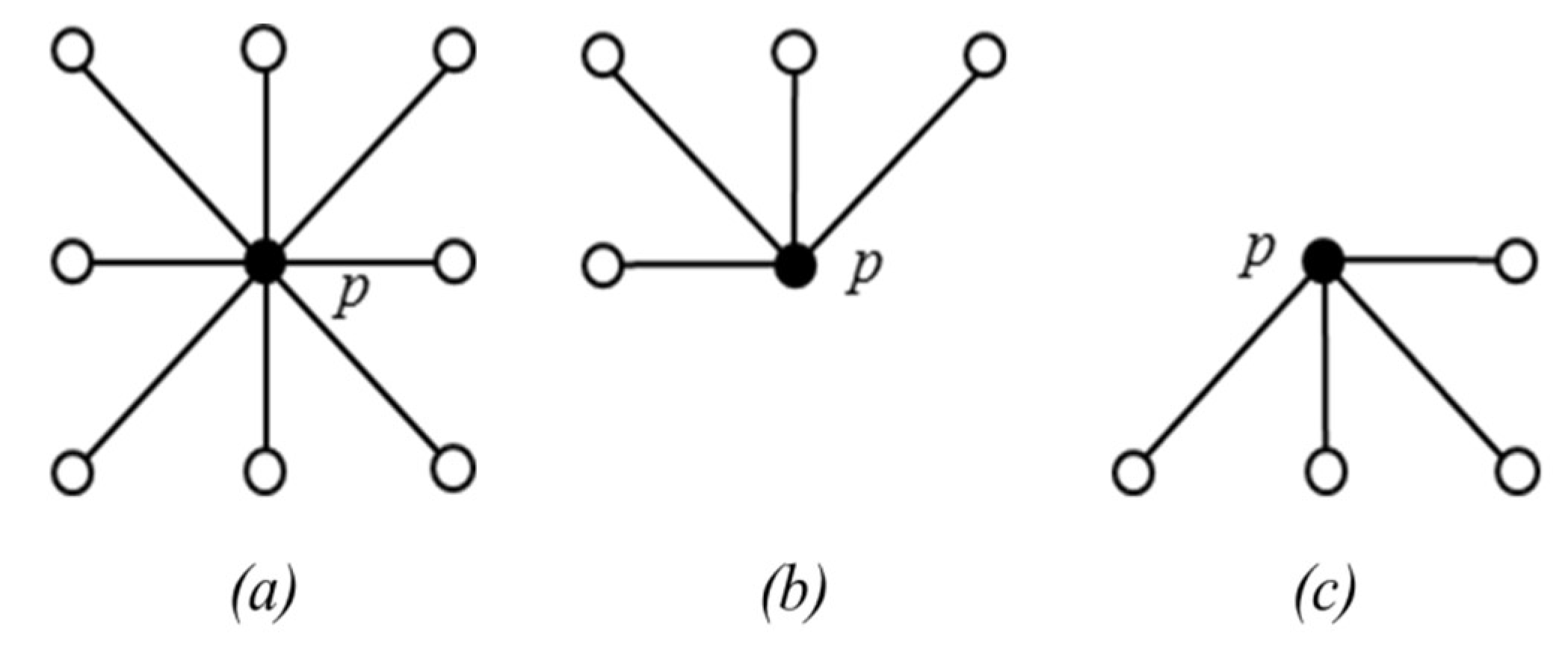
The eight neighbors of
p are denoted as
(see
Figure 8a). The 4 neighbors reached before
p in a scan order are denoted as
(see
Figure 8b). The maximum value of
is then calculated and denoted as
s. Finally, the
is updated with
. After the raster scan, an anti-raster scan (scanning from the bottom pixel) of
I (i.e., the original image) and updated
J is performed in a similar way. This time, it checks if for a pixel
p, there exists a pixel
such that
and
, the
q value is stored in the FIFO (First In First Out) queue.
After the anti-raster scan, the propagation step is performed on the FIFO structure. In the beginning, the FIFO is checked, if it is empty, the process of grayscale reconstruction is completed; if it is not, the point which is at the beginning of the FIFO is popped out and denoted as p. The values of and , are read from images I and J. If there exist any , such that and , the minimum value between and is given to and the q is put into the queue. Then another round of the loop begins. This process continues until there are no data in the queue. The updated J is the grayscale reconstructed marker image and is denoted as .
Finally, a binary response map is calculated for each gLoG output, and stored in the FPGA RAM, where a binary value of 1 indicates the regional maxima.
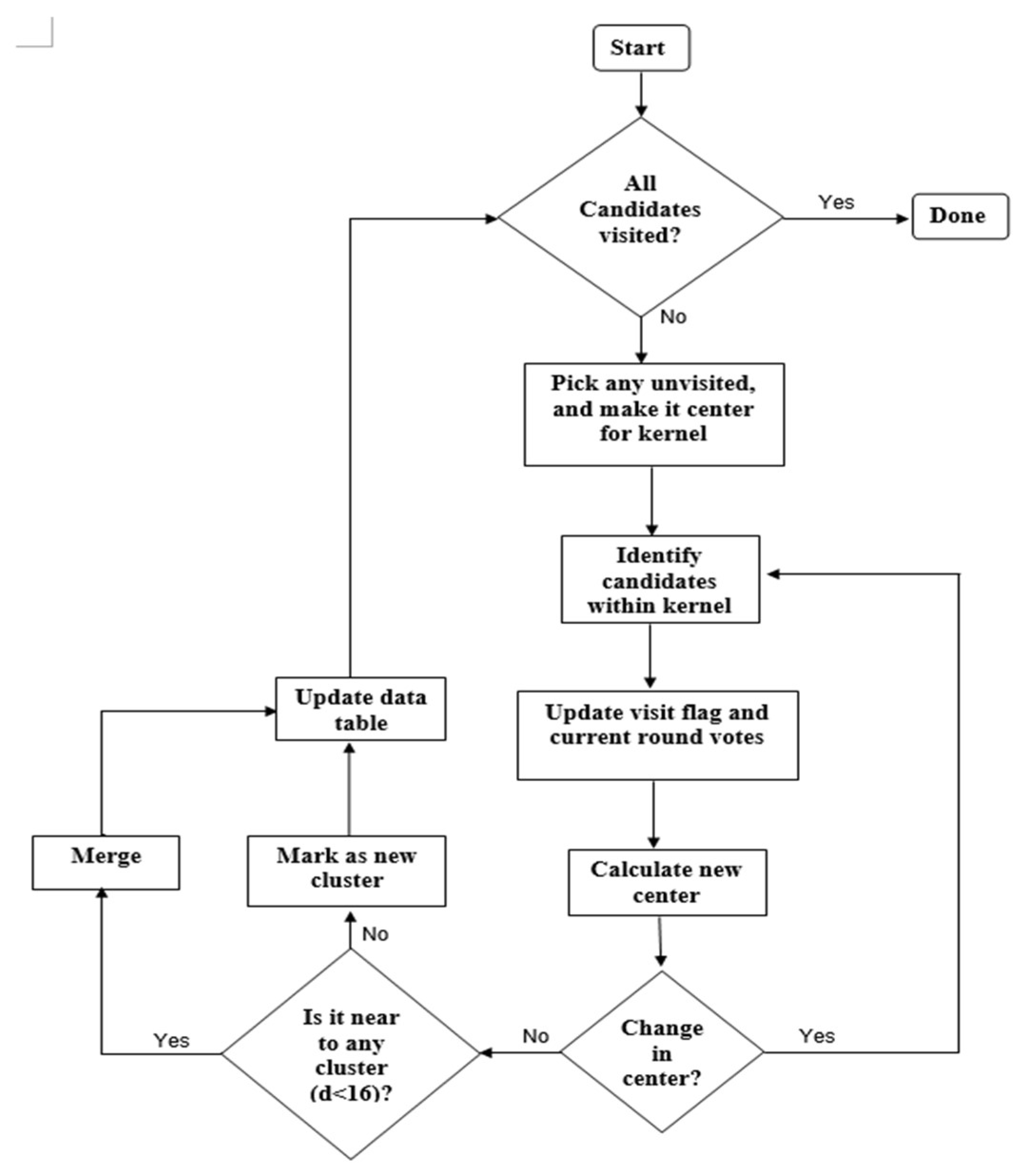
2.6. Mean-Shift Clustering
For one nuclear region, there can be more than one candidate nuclei in S [
1]. As the candidates corresponding to a nucleus are geometrically close, they can be clustered to obtain one center for each nucleus. In this paper, the nuclei candidates are clustered using a mean-shift (MS) clustering algorithm [
7], and center for each nucleus is obtained by calculating the mean coordinate of members of the corresponding cluster.
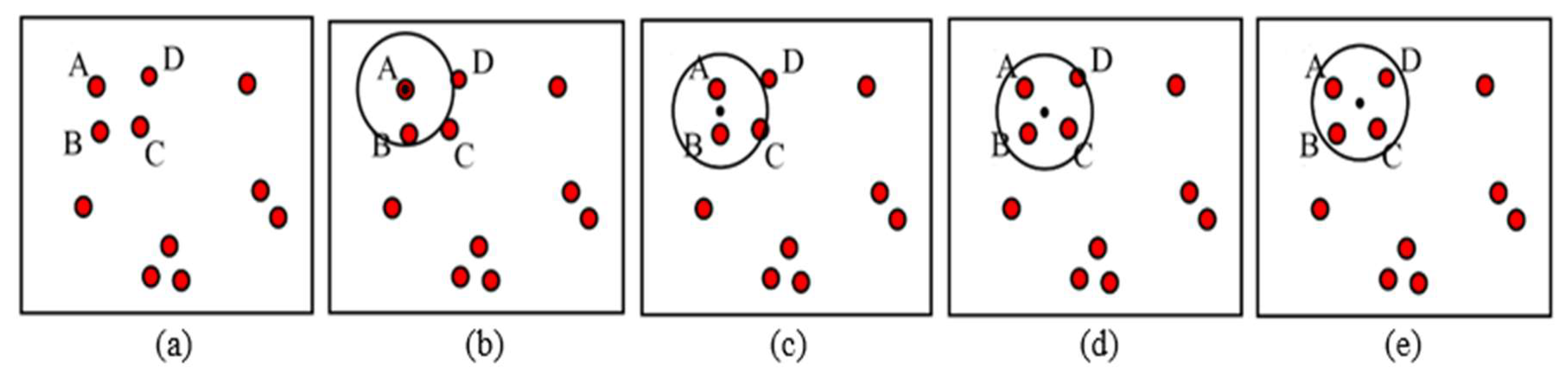
The MS clustering is like a hill climbing algorithm which involves shifting a certain type of kernel iteratively to a higher density region until convergence. This is illustrated in
Figure 9, where the nuclei candidates are shown with red dots. To start the algorithm, pick any unvisited candidate, let it be A and place the kernel center at A. Check if any other candidates are within the kernel (of radius
r). In this example, candidate B is within the kernel (see
Figure 9b). Calculate the mean of A, B and shift the kernel center to mean position (see
Figure 9c). Now re-check if any new candidate is included within the kernel.
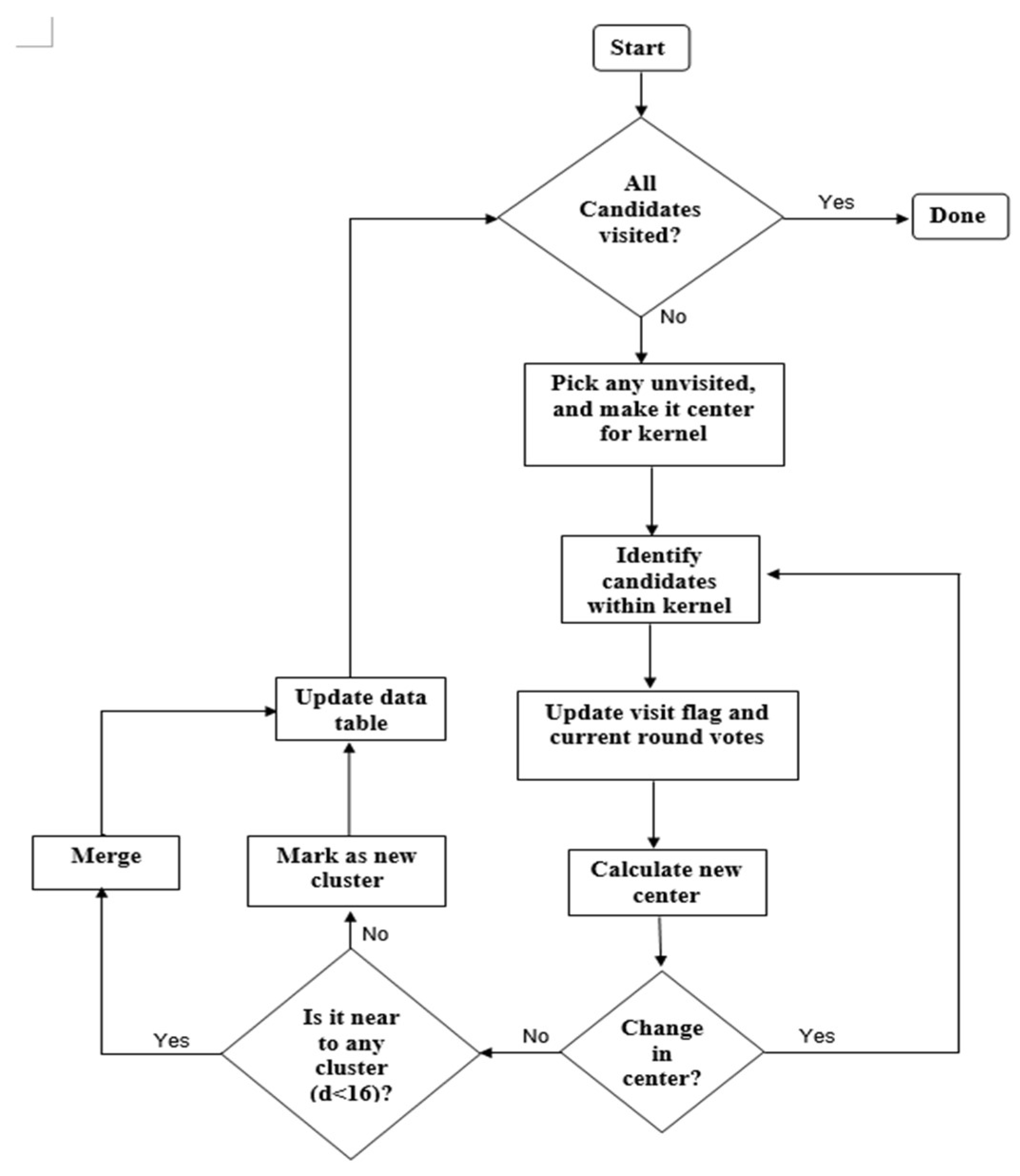
Figure 9c shows that candidate C is within the kernel. The mean of {A, B, C} is calculated, and the kernel is shifted to the new mean position. The iteration continues until the kernel is settled and no new candidate is included. After convergence, all candidates within the kernel are clustered and the center of the kernel is considered as the nucleus for that cluster. The MS clustering then picks up another unvisited candidate and generates a cluster in a similar manner. The process is continued until all the candidates are clustered. The overall flowchart of the MS clustering is shown in
Figure 10.
In this paper, the MS kernel is defined as a circle with radius
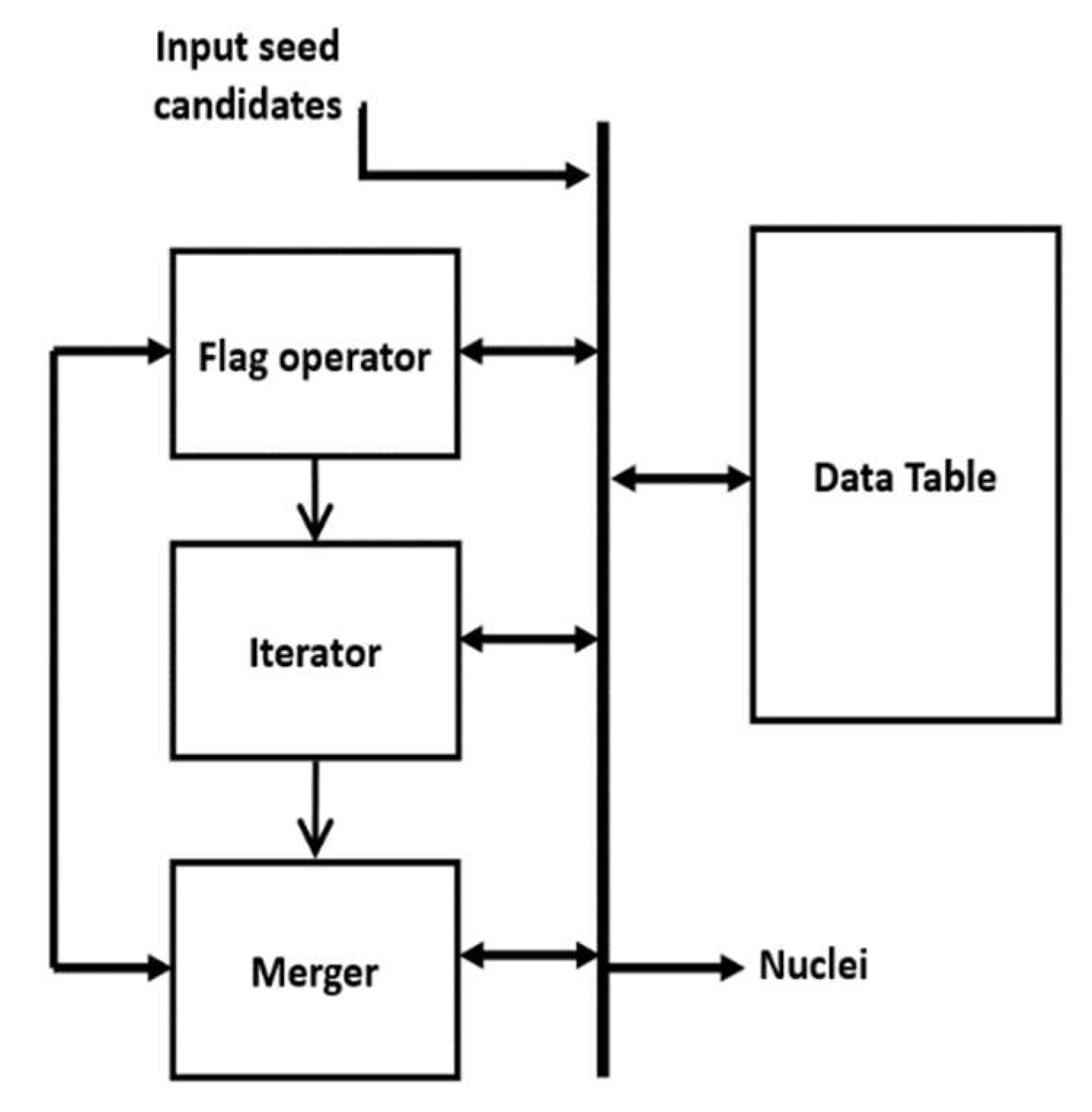
r = 8 pixels. The implemented architecture of the MS clustering is shown in
Figure 11. The architecture has four modules:
Flag operator,
Iterator,
Merger and
Data table. The
Data table structure is shown in
Table 1, which stores the seed candidates, four intermediate parameters for each candidate (
visit-flag, current-round votes, maximum votes and cluster number) and
identified Nuclei.
Visit-Flag identifies candidates that are visited in the clustering process (flag is set to 1 for visited candidates and 0 for unvisited candidates).
Current-round votes indicate the number of iterations done in current clustering when a candidate is within the kernel geometry.
is set to zero at the beginning of each cluster generation.
Maximum votes store the maximum value of
current-round votes a candidate has achieved in all previous cluster generation and the
cluster number (
L) denotes the cluster that has obtained maximum votes for a seed candidate. The table entries are updated at the end of each cluster generation.
Identified nuclei (
N) stores the center of each converged cluster.
In the beginning, the flag operator checks the visit-flags table. If there are any unvisited candidates (whose visit-flag is 0), it picks one of those unvisited candidates randomly (Si) and gives it to the iterator. The iterator places the kernel center at candidate Si and finds all the candidates within the kernel geometry (i.e., distance < r). For those candidates (within the kernel), visit flag is set to 1 and current-round vote value is increased by 1. The iteration is repeated with the center of kernel shifted to mean position of candidates within the kernel. The process repeats until kernel center is converged (i.e., no change in mean position). The final converged point is then sent to the Merger module.
The
Merger module scans through the
Identified nuclei column. If there exists a previously generated Nuclei
whose distance to the current convergent point
is smaller than a threshold (e.g., 16 pixels), then
should merge with
. The value for the merged nuclei
is changed to the mean coordinate of
and
. In
cluster number column, if
, the
maximum votes value for corresponding candidates are changed to
. If there are no
Identified nuclei within the threshold distance to
, then
becomes a new Nuclei and added to
Identified nuclei column. Finally, the comparison between
current round votes and
maximum votes are done. For a candidate
if
then
is changed to
and
to
k (indicating that candidate
Si belongs to the new cluster
). Example data format can be seen in
Table 1.
After the operations in the Merger module finished, the Flag operator module scans through the Visited-flags table to check whether there are any unvisited candidates. If there are unvisited candidates, the Iterator is enabled again to generate a new cluster, otherwise, the Clustering module is disabled, and the MS clustering is done. The mean coordinate of the candidates belonging to one cluster (corresponding to a nucleus) is considered as the seed coordinate of the detected nuclei.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}