Scalable Database Indexing and Fast Image Retrieval Based on Deep Learning and Hierarchically Nested Structure Applied to Remote Sensing and Plant Biology




Abstract
1. Introduction
2. Related Works
2.1. Image Representation
2.1.1. Hand-crafted Feature Extraction Techniques
- Color properties are extracted directly from the pixel densities over the whole image, segmented regions/bins, or sub-image. Image descriptors that characterize the color properties of an image seek to model the distribution of the pixel intensities in each channel of the image. These methods include color statistics, such as deviation, mean, and skewness, along with color histograms. Since color features are robust to background complications and are invariant to the size or orientation of an image, the color based methods have become one of the most common techniques in CBIR [9,10,11].
- Texture properties measure visual patterns in images that contain important information about the structural arrangement of surface i.e., fabric, bricks, etc. Texture descriptors seek to model the feel, appearance, and overall tactile quality of an object in an image and are defined as a structure of surfaces formed by repeating a particular element or several elements in different relative spatial distribution and synthetic structure. In general, the repetition involves local variations of scale, orientation, or other geometric and optical features of the elements [12,13].
- Shape properties can also be considered as one of the fundamental perceptual characteristics. Shape properties take on many non-geometric and geometric forms, such as moment invariants, aspect ratio, circularity, and boundary segments. There are difficulties associated with shape representation and descriptors techniques due to noise, occlusion, and arbitrary distortion, which often causes inaccuracies in extracting shape features. Nonetheless, the method has shown promising results to describe the image content [14,15].
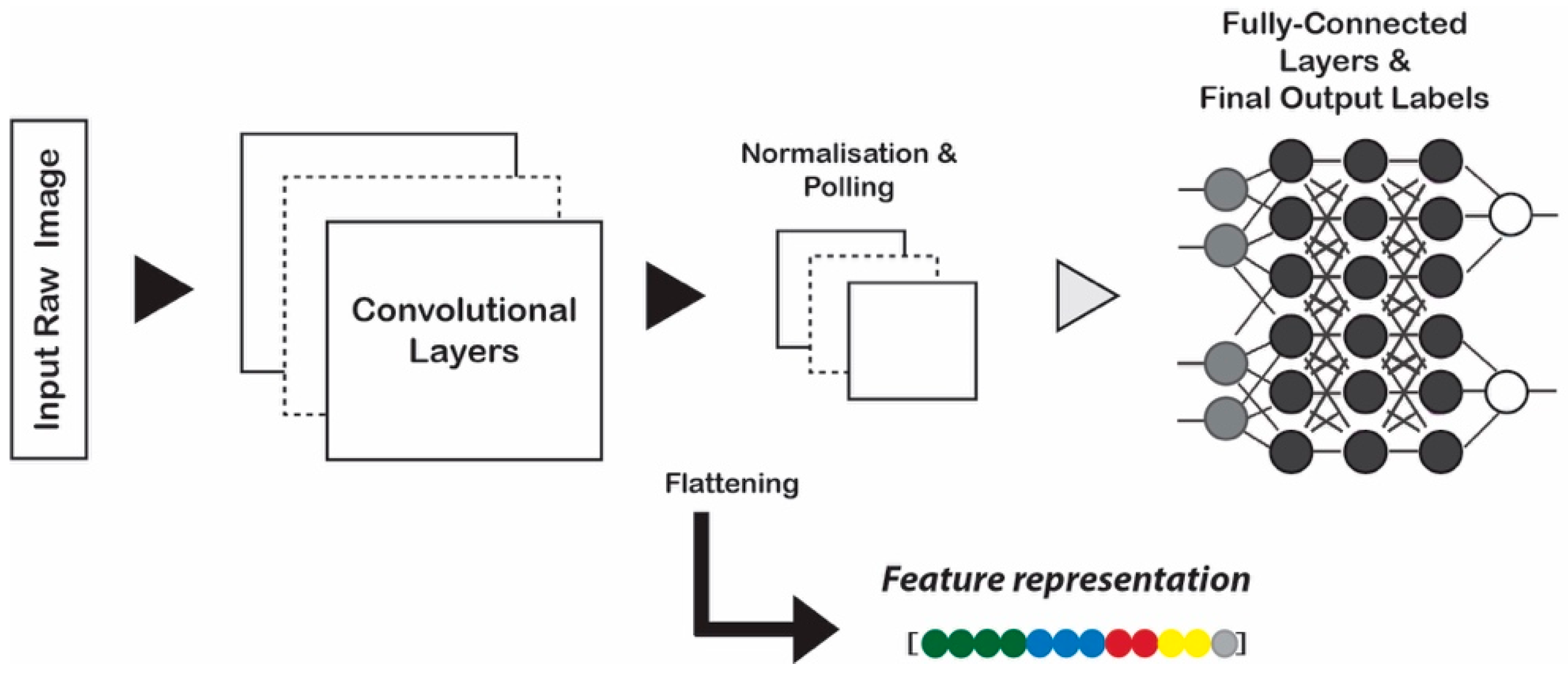
2.1.2. Learning-based Features Using Deep Convolutional Neural Network
2.2. Feature Indexing and Image Scoring
3. Methodology
3.1. Representation Learning Using Residual Learning Model
3.2. Feature Indexing Based on Hierarchical Nested Data Clusters
3.3. Fast Searching and Similarity Measure Based on Recursive Data Density Estimation
4. Experiments and Results
4.1. Datasets
4.2. Performance and Accuracy
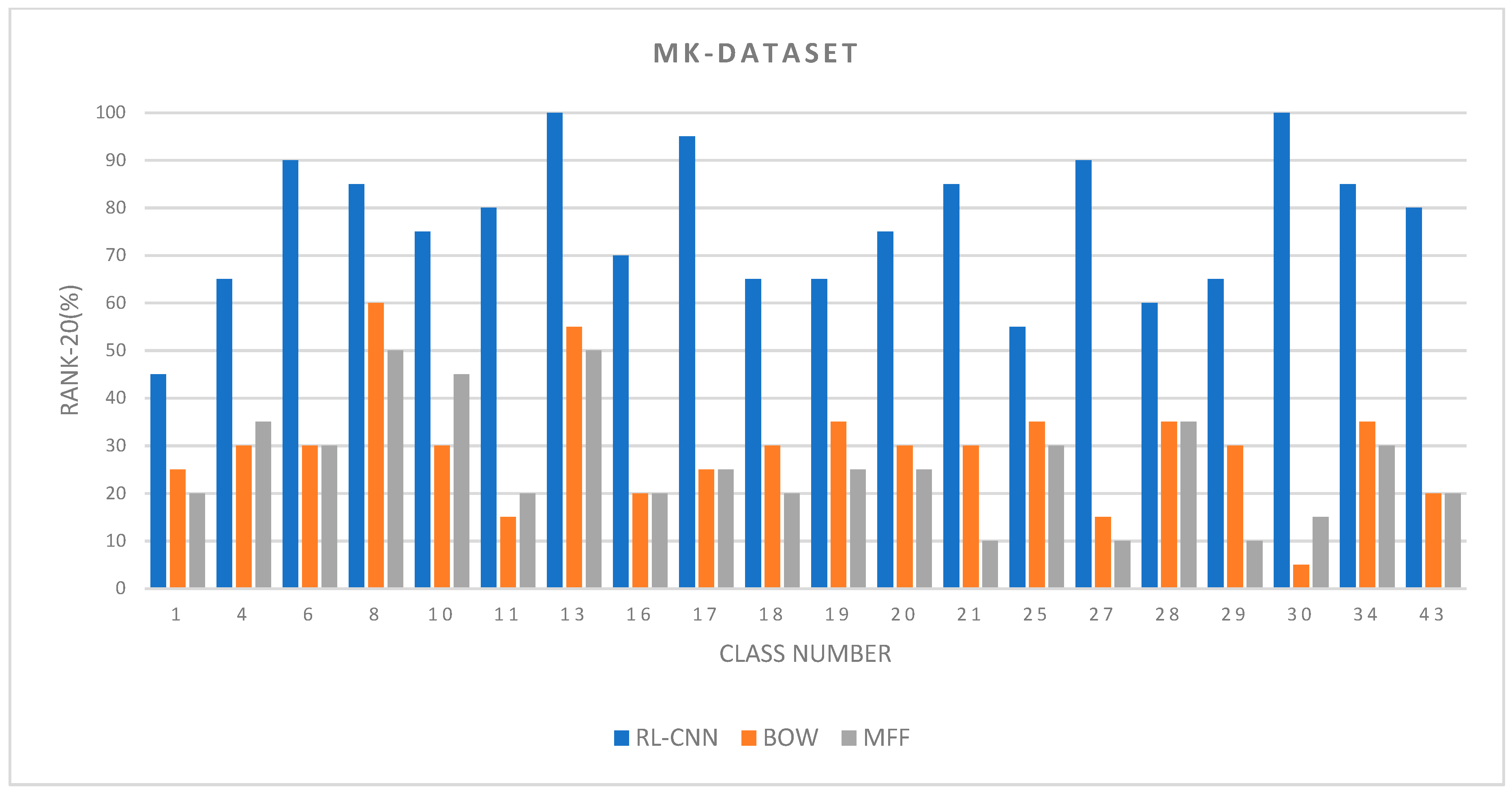
4.2.1. Retrieval Performance on MalayaKew Leaf-Dataset
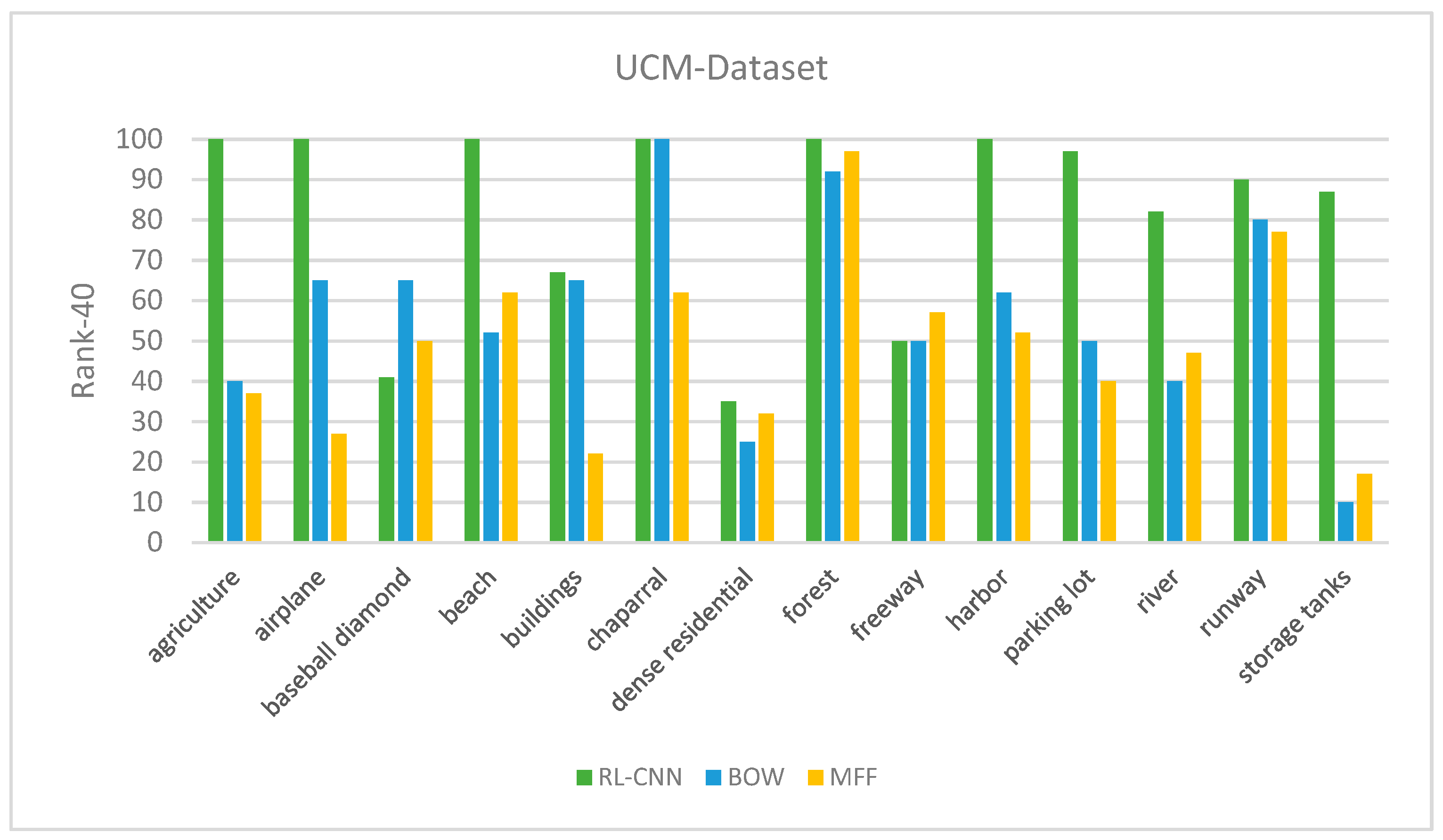
4.2.2. Retrieval Performance on UCM Dataset
4.3. Retrieval Time Per Query
4.4. Discussion, Challenges and Future Work
5. Conclusions
- Fast Retrieval time: The proposed approach improves the retrieval process and is over 16 times faster than the traditional brute-force sequential searching which is vital for large-scale databases.
- Scalability: The model is constructed in a hierarchical structure. The feature indexing in a hierarchical form can handle a dynamic image database and can be easily integrated into the server-client architecture.
- Unsupervised data mining: The proposed technique does not require any prior knowledge of image repositories or any human intervention. However, in future work, human input/feedback can potentially improve the performance.
- Recursive similarity measurement: The similarity measurements are done recursively, which significantly reduces memory cost in high-scale multimedia CBIR systems.
- Discriminative power for quantifying images: Transfer learning is applied by utilizing a pre-trained deep neural network model merely as a feature extractor. The results indicate that the generic descriptors extracted from the CNNs are effective and powerful, and performed consistently better than conventional content-based retrieval systems.
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CBIR | Content Based Image Retrieval |
| BOVW | Bag of Visual Words |
| SIFT | Scale Invariant Feature Transform |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| TL | Transfer Learning |
| RDE | Recursive Density Estimation |
| SPM | Spatial Pyramid Matching |
| LLC | Local Linear Constraint |
| FV | Fisher Vector |
| VLAD | Vector of Locally Aggregated Descriptors |
| MFF | Multiple Feature Fusion |
| IR | Information Retrieval |
| RL | Representation Learning |
References
- Virlet, N.; Sabermanesh, K.; Sadeghi-Tehran, P.; Hawkesford, M.J. Field Scanalyzer: An automated robotic field phenotyping platform for detailed crop monitoring. Funct. Plant Biol. 2017, 44, 143. [Google Scholar] [CrossRef]
- Busemeyer, L.; Mentrup, D.; Möller, K.; Wunder, E.; Alheit, K.; Hahn, V.; Maurer, H.P.; Reif, J.C.; Würschum, T.; Müller, J.; et al. BreedVision—A Multi-Sensor Platform for Non-Destructive Field-Based Phenotyping in Plant Breeding. Sensors 2013, 13, 2830–2847. [Google Scholar] [CrossRef] [PubMed]
- Kirchgessner, N.; Liebisch, F.; Yu, K.; Pfeifer, J.; Friedli, M.; Hund, A.; Walter, A. The ETH field phenotyping platform FIP: A cable-suspended multi-sensor system. Funct. Plant Biol. 2017, 44, 154. [Google Scholar] [CrossRef]
- Larson, R.R. Introduction to Information Retrieval. J. Am. Soc. Inf. Sci. 2010, 61, 852–853. [Google Scholar] [CrossRef]
- Datta, R.; Joshi, D.; Li, J.; Wang, J.Z. Image retrieval: Ideas, influences, and trends of the new age. ACM Comput. Surv. 2008, 40, 5–60. [Google Scholar] [CrossRef]
- Lew, M.; Sebe, N.; Djeraba, C.; Jain, R. Content-based multimedia information retrieval: State of the art and challenges. ACM Trans. Multimed. Comput. Commun. Appl. 2006, 2, 1–19. [Google Scholar] [CrossRef]
- Smeulders, A.W.M.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Alzu’bi, A.; Amira, A.; Ramzan, N. Semantic content-based image retrieval: A comprehensive study. J. Vis. Commun. Image Represent. 2015, 32, 20–54. [Google Scholar] [CrossRef]
- Yu, H.; Li, M.; Zhang, H.-J.; Feng, J. Color texture moments for content-based image retrieval. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; pp. 929–932. [Google Scholar]
- Lin, C.-H.; Chen, R.-T.; Chan, Y.-K. A smart content-based image retrieval system based on color and texture feature. J. Image Vis. Comput. 2009, 27, 658–665. [Google Scholar] [CrossRef]
- Singh, S.M.; Hemach, K.; Hemachandran, K. Content-Based Image Retrieval using Color Moment and Gabor Texture Feature. IJCSI Int. J. Comput. Sci. 2012, 9, 299–309. [Google Scholar]
- Guo, Y.; Zhao, G.; Pietikainen, M. Discriminative features for texture description. Pattern Recognit. 2012, 45, 3834–3843. [Google Scholar] [CrossRef]
- Ahonen, T.; Matas, J.; He, C.; Pietikainen, M. Rotation invariant image description with local binary pattern histogram fourier features. In Proceedings of the 16th Scandinavian Conference on Image Analysis (SCIA 2009), Oslo, Norway, 15–18 June 2009; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Mezaris, V.; Kompatsiaris, I.; Strintzis, M.G. An ontology approach to object-based image retrieval. In Proceedings of the 2003 International Conference on Image Processing (Cat. No.03CH37429), Barcelona, Spain, 14–17 September 2003. [Google Scholar]
- Nikkam, P.S.; Reddy, B.E. A Key Point Selection Shape Technique for Content based Image Retrieval System. Int. J. Comput. Vis. Image Process. 2016, 6, 54–70. [Google Scholar] [CrossRef]
- Zhou, W.; Li, H.; Tian, Q. Recent Advance in Content-based Image Retrieval: A Literature Survey. arXiv, 2017; arXiv:1706.06064. [Google Scholar]
- Tsai, C.F. Bag-of-words representation in image annotation: A review. ISRN Artif. Intell. 2012, 2012. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L. Surf: Speeded Up Robust Features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. Brisk: Binary Robust Invariant Scalable Keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Perronnin, F.; Liu, Y.; Sánchez, J. Large-scale image retrieval with compressed fisher vectors. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Jegou, H.; Douze, M.; Schmid, C. Aggregating local descriptors into a compact image representation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Bengio, Y. Learning Deep Architectures for AI. Found. Trends® Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Tzelepi, M.; Tefas, A. Deep convolutional learning for Content Based Image Retrieval. Neurocomputing 2018, 275, 2467–2478. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Johnson, R.; Zhang, T. Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding. In Proceedings of the Twenty-Ninth Conference on Neural Information Processing Systems (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Mesnil, G. A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval. In Proceedings of the 23rd ACM International Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional Neural Networks for Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Borji, A.; Cheng, M.-M.; Jiang, H.; Li, J. Salient Object—A Benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [PubMed]
- Tzelepi, M.; Tefas, A. Deep convolutional image retrieval: A general framework. Signal Process. Image Commun. 2018, 63, 30–43. [Google Scholar] [CrossRef]
- Wan, J.; Wang, D.; Hoi, S.; Wu, P.; Zhu, J. Deep learning for content-based image retrieval: A comprehensive study. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 157–166. [Google Scholar]
- Sun, S.; Zhou, W.; Tian, Q.; Li, H. Scalable Object Retrieval with Compact Image Representation from Generic Object Regions. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2016, 12, 29. [Google Scholar] [CrossRef]
- Lai, H.; Pan, Y.; Liu, Y.; Yan, S. Simultaneous Feature Learning and Hash Coding with Deep Neural Networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3270–3278. [Google Scholar]
- Gong, Y.; Wang, L.; Guo, R.; Lazebnik, S. Multi-scale Orderless Pooling of Deep Convolutional Activation Features. In Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; Volume 8695, pp. 392–407. [Google Scholar]
- Ng, J.Y.-H.; Yang, F.; Davis, L.S. Exploiting local features from deep networks for image retrieval. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 53–61. [Google Scholar]
- Mohedano, E.; McGuinness, K.; O’Connor, N.E.; Salvador, A.; Marques, F.; Giro-i-Nieto, X. Bags of Local Convolutional Features for Scalable Instance Search. In Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, New York, NY, USA, 6–9 June 2016; ACM Press: New York, NY, USA, 2016; pp. 327–331. [Google Scholar]
- Angelov, P.; Sadeghi-Tehran, P. Look-a-Like: A Fast Content-Based Image Retrieval Approach Using a Hierarchically Nested Dynamically Evolving Image Clouds and Recursive Local Data Density. Int. J. Intell. Syst. 2016, 32, 82–103. [Google Scholar] [CrossRef]
- Angelov, P.; Sadeghi-Tehran, P. A Nested Hierarchy of Dynamically Evolving Clouds for Big Data Structuring and Searching. Procedia Comput. Sci. 2015, 53, 1–8. [Google Scholar] [CrossRef]
- Cai, J.; Liu, Q.; Chen, F.; Joshi, D.; Tian, Q. Scalable Image Search with Multiple Index Tables. In Proceedings of the International Conference on Multimedia Retrieval, Glasgow, UK, 1–4 April 2014; p. 407. [Google Scholar]
- Nister, D.; Stewenius, H. Scalable Recognition with a Vocabulary Tree. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2161–2168. [Google Scholar]
- Zhou, W.; Lu, Y.; Li, H.; Song, Y.; Tian, Q. Spatial coding for large scale partial-duplicate web image search. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 511–520. [Google Scholar]
- Wu, Z.; Ke, Q.; Isard, M.; Sun, J. Bundling features for large scale partial-duplicate web image search. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 25–32. [Google Scholar]
- Bartolini, I.; Patella, M. Windsurf: the best way to SURF. Multimed. Syst. 2018, 24, 459–476. [Google Scholar] [CrossRef]
- Zhang, J.; Peng, Y.; Ye, Z. Deep Reinforcement Learning for Image Hashing. arXiv, 2018; arXiv:1802.02904. [Google Scholar]
- Liu, H.; Wang, R.; Shan, S.; Chen, X. Deep Supervised Hashing for Fast Image Retrieval. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2064–2072. [Google Scholar]
- Jiang, K.; Que, Q.; Kulis, B. Revisiting Kernelized Locality-Sensitive Hashing for Improved Large-Scale Image Retrieval. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4933–4941. [Google Scholar]
- Tang, J.; Li, Z.; Wang, M. Neighborhood discriminant hashing for large-scale image retrieval. IEEE Trans. Image Process. 2015, 24, 2827–2840. [Google Scholar] [CrossRef] [PubMed]
- Datar, M.; Immorlica, N.; Indyk, P.; Mirrokni, V.S. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the Twentieth Annual Symposium on Computational Geometry, Brooklyn, NY, USA, 8–11 June 2004; pp. 253–262. [Google Scholar]
- Cao, Z.; Long, M.; Wang, J.; Yu, P.S. HashNet: Deep Learning to Hash by Continuation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5609–5618. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the 14th European Conference Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; Volume 9908, pp. 630–645. [Google Scholar]
- Sharif Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 24–27 June 2014; pp. 806–813. [Google Scholar]
- Olivas, E.S. Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2009. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, L.; Qi, X.; Xing, F.; Kurc, T.; Saltz, J.; Foran, D.J. Parallel content-based sub-image retrieval using hierarchical searching. Bioinformatics 2013, 30, 996–1002. [Google Scholar] [CrossRef] [PubMed]
- Distasi, R.; Vitulano, D.; Vitulano, S. A Hierarchical Representation for Content-based Image Retrieval. J. Vis. Lang. Comput. 2000, 11, 369–382. [Google Scholar] [CrossRef]
- Jiang, F.; Hu, H.M.; Zheng, J.; Li, B. A hierarchal BoW for image retrieval by enhancing feature salience. Neurocomputing 2016, 175, 146–154. [Google Scholar] [CrossRef]
- You, J.; Li, Q. On hierarchical content-based image retrieval by dynamic indexing and guided search. In Proceedings of the 2009 8th IEEE International Conference on Cognitive Informatics (ICCI’09), Hong Kong, China, 15–17 June 2009; pp. 188–195. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Angelov, P. Anomalous System State Identification. U.S. Patent US9390265B2, 15 May 2012. [Google Scholar]
- Angelov, P. Evolving Rule-Based Models: A Tool for Design of Flexible Adaptive Systems; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Angelov, P.; Sadeghi-Tehran, P.; Ramezani, R. A Real-time Approach to Autonomous Novelty Detection and Object Tracking in Video Stream. Int. J. Intell. Syst. 2011, 26, 189–205. [Google Scholar] [CrossRef]
- Zhang, C.; Huang, L. Content-Based Image Retrieval Using Multiple Features. J. Comput. Inf. Technol. 2014, 22, 1–10. [Google Scholar] [CrossRef]
- Wang, X.-Y.; Zhang, B.-B.; Yang, H.-Y. Content-based image retrieval by integrating color and texture features. Multimed. Tools Appl. 2012, 68, 545–569. [Google Scholar] [CrossRef]
- Yue, J.; Li, Z.; Liu, L.; Fu, Z. Content-based image retrieval using color and texture fused features. Math. Comput. Model. Int. J. 2011, 54, 1121–1127. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Building the Gist of A Scene: The Role of Global Image Features in Recognition. Prog. Brain Res. 2006, 155, 23–36. [Google Scholar] [PubMed]
- Huang, J.; Kumar, S.R.; Mitra, M.; Zhu, W.-J.; Zabih, R. Image indexing using color correlograms. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, USA, 17–19 June 1997; pp. 762–768. [Google Scholar]
- Wang, J.; Yang, J.; Yu, K.; Lv, F.; Huang, T.; Gong, Y. Locality-Constrained Linear Coding For Image Classification. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Han, S.; Chee, L.; Chan, S.; Wilkin, P.; Remagnino, P. Deep-Plant: Plant Identification with Convolutional Neural Networks. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; ACM: New York, NY, USA; pp. 270–279. [Google Scholar]
- Yu, H.; Yang, W.; Xia, G.-S.; Liu, G. A Color-Texture-Structure Descriptor for High-Resolution Satellite Image Classification. Remote Sens. 2016, 8, 259. [Google Scholar] [CrossRef]
- Li, Y.; Tao, C.; Tan, Y. Unsupervised multilayer feature learning for satellite image scene classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 157–161. [Google Scholar] [CrossRef]
- Romero, A. Unsupervised deep feature extraction for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1349–1362. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | mAP (%) |
|---|---|---|
| MalayaKew | FE-CNN | 88.1% |
| BOVW | 66.2% | |
| MFF | 52.6% | |
| UCM | FE-CNN | 90.5% |
| BOVW | 86.2% | |
| MFF | 69.8% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadeghi-Tehran, P.; Angelov, P.; Virlet, N.; Hawkesford, M.J. Scalable Database Indexing and Fast Image Retrieval Based on Deep Learning and Hierarchically Nested Structure Applied to Remote Sensing and Plant Biology. J. Imaging 2019, 5, 33. https://doi.org/10.3390/jimaging5030033
Sadeghi-Tehran P, Angelov P, Virlet N, Hawkesford MJ. Scalable Database Indexing and Fast Image Retrieval Based on Deep Learning and Hierarchically Nested Structure Applied to Remote Sensing and Plant Biology. Journal of Imaging. 2019; 5(3):33. https://doi.org/10.3390/jimaging5030033
Chicago/Turabian StyleSadeghi-Tehran, Pouria, Plamen Angelov, Nicolas Virlet, and Malcolm J. Hawkesford. 2019. "Scalable Database Indexing and Fast Image Retrieval Based on Deep Learning and Hierarchically Nested Structure Applied to Remote Sensing and Plant Biology" Journal of Imaging 5, no. 3: 33. https://doi.org/10.3390/jimaging5030033
APA StyleSadeghi-Tehran, P., Angelov, P., Virlet, N., & Hawkesford, M. J. (2019). Scalable Database Indexing and Fast Image Retrieval Based on Deep Learning and Hierarchically Nested Structure Applied to Remote Sensing and Plant Biology. Journal of Imaging, 5(3), 33. https://doi.org/10.3390/jimaging5030033