
Deep Learning for Single-Shot Structured Light Profilometry: A Comprehensive Dataset and Performance Analysis

 ,
, 
Abstract
1. Introduction
- Without a common ground for comparison, it becomes challenging to determine whether accuracy, robustness, or efficiency improvements result from algorithmic advancements or dataset-specific idiosyncrasies;
- The lack of a standardised dataset impedes the reproducibility and replicability of experiments. Other researchers aiming to validate or build upon existing methods may struggle to obtain similar or consistent results because of disparities in dataset characteristics. This hinders the field’s progress and slows the adoption of novel techniques;
- Different datasets often demand tailored evaluation metrics for their specific challenges. Without a common dataset, there is no consensus on which evaluation metrics are most appropriate for assessing the performance of DL-SLP methods. Consequently, comparing performance across studies becomes convoluted and lacks a clear reference point;
- Real-world applications of structured light profilometry require robustness to diverse scenarios and environments. Research groups’ reliance on distinct datasets may result in models that perform well on specific datasets but struggle when confronted with different scenes.
2. Materials and Methods
2.1. Creation of the Dataset
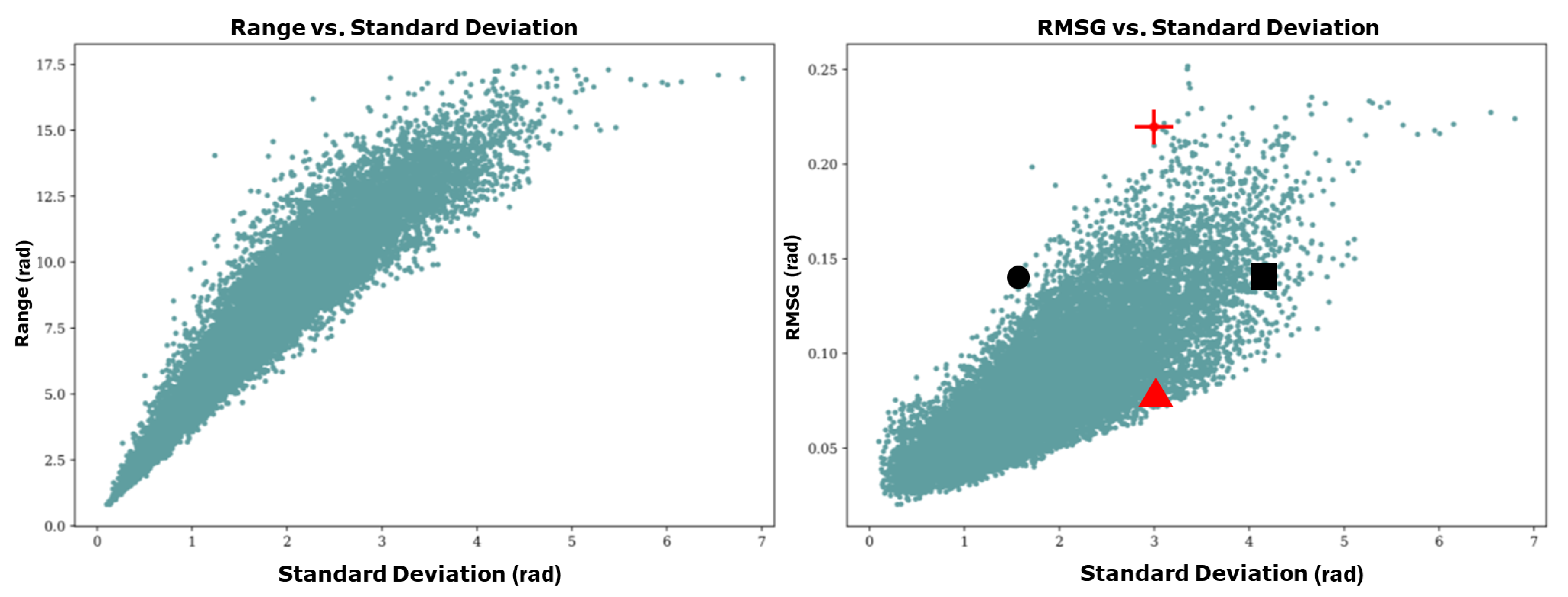
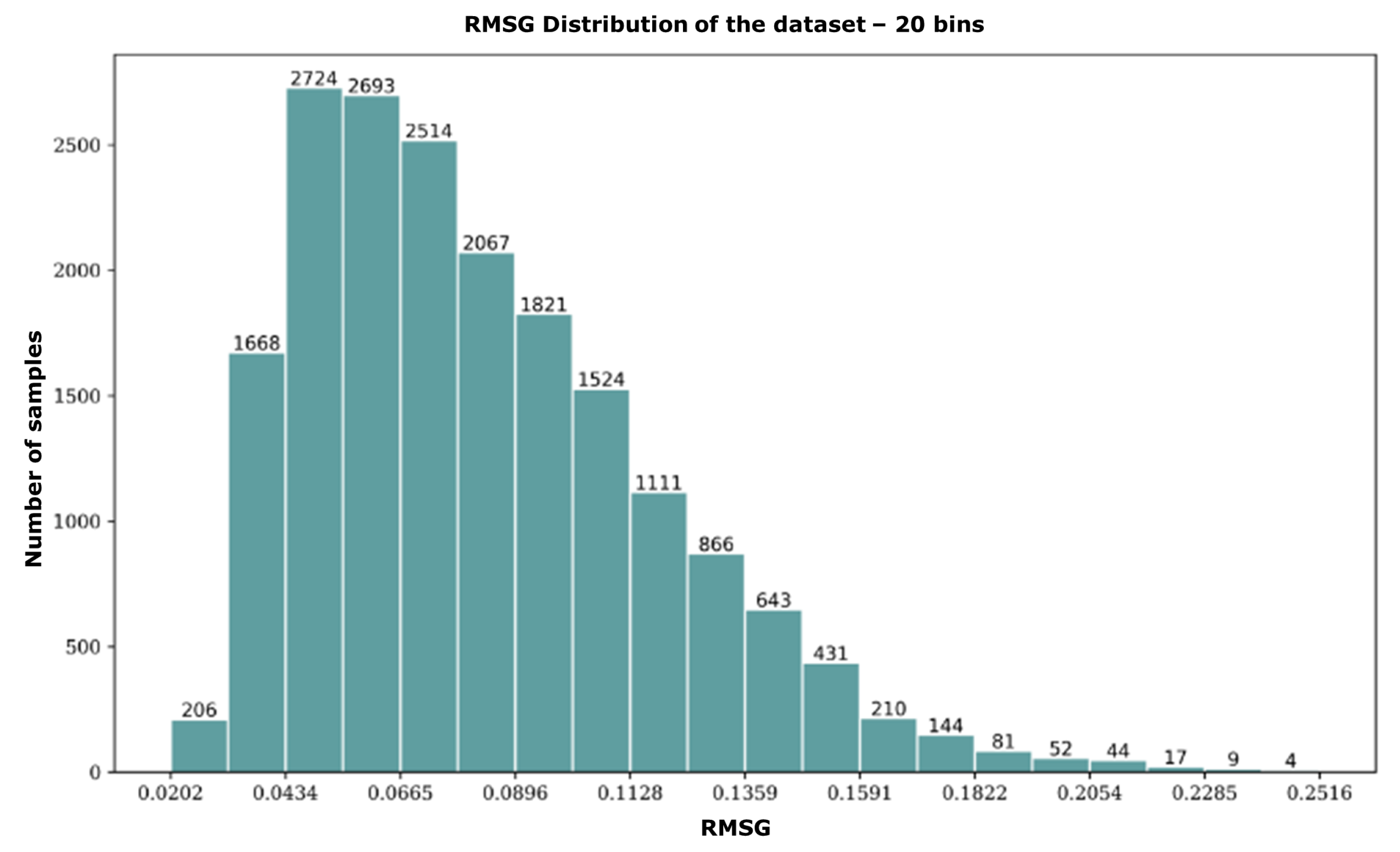
2.2. Data Analysis
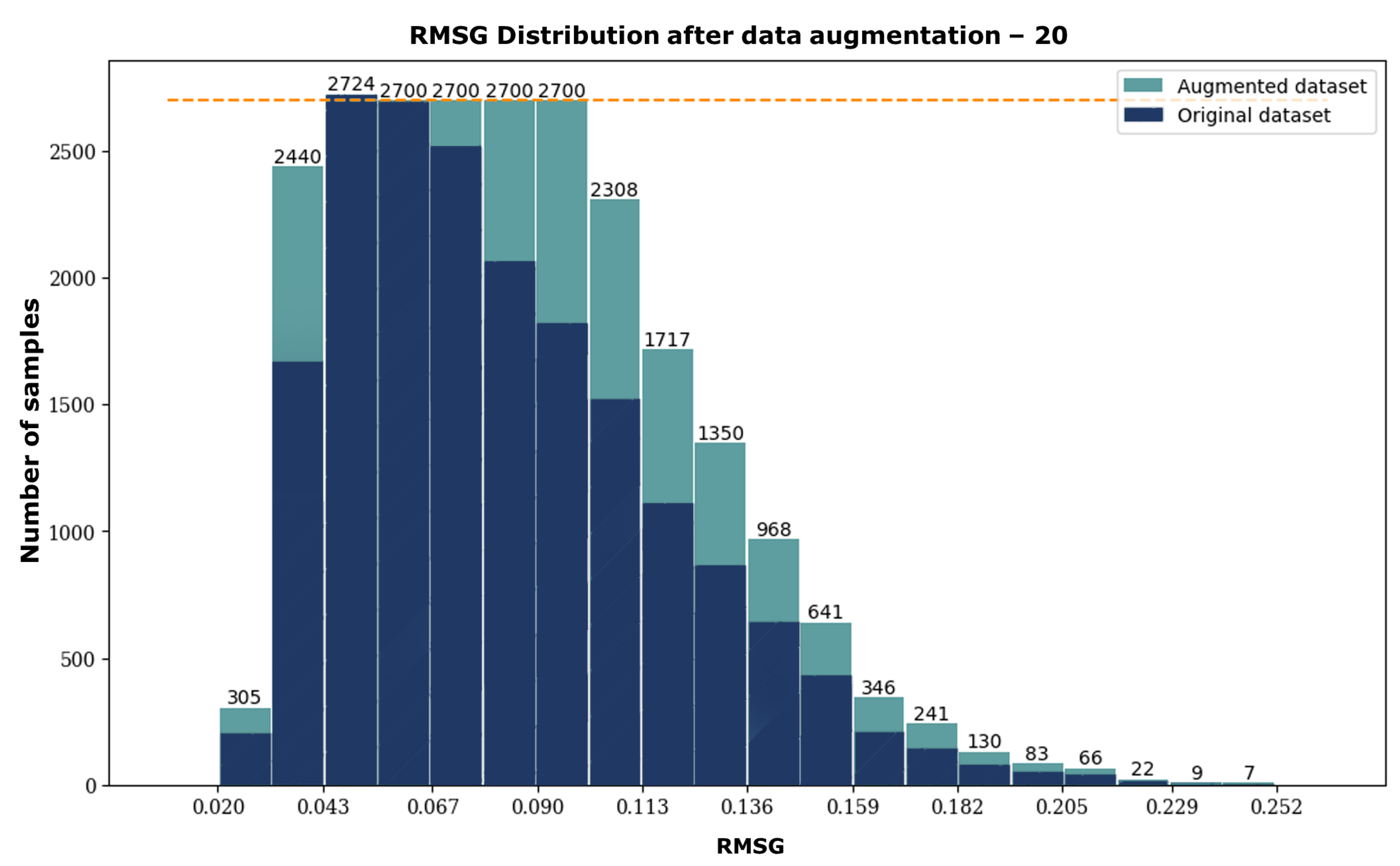
2.3. Data Manipulation
2.4. Asymmetry Index
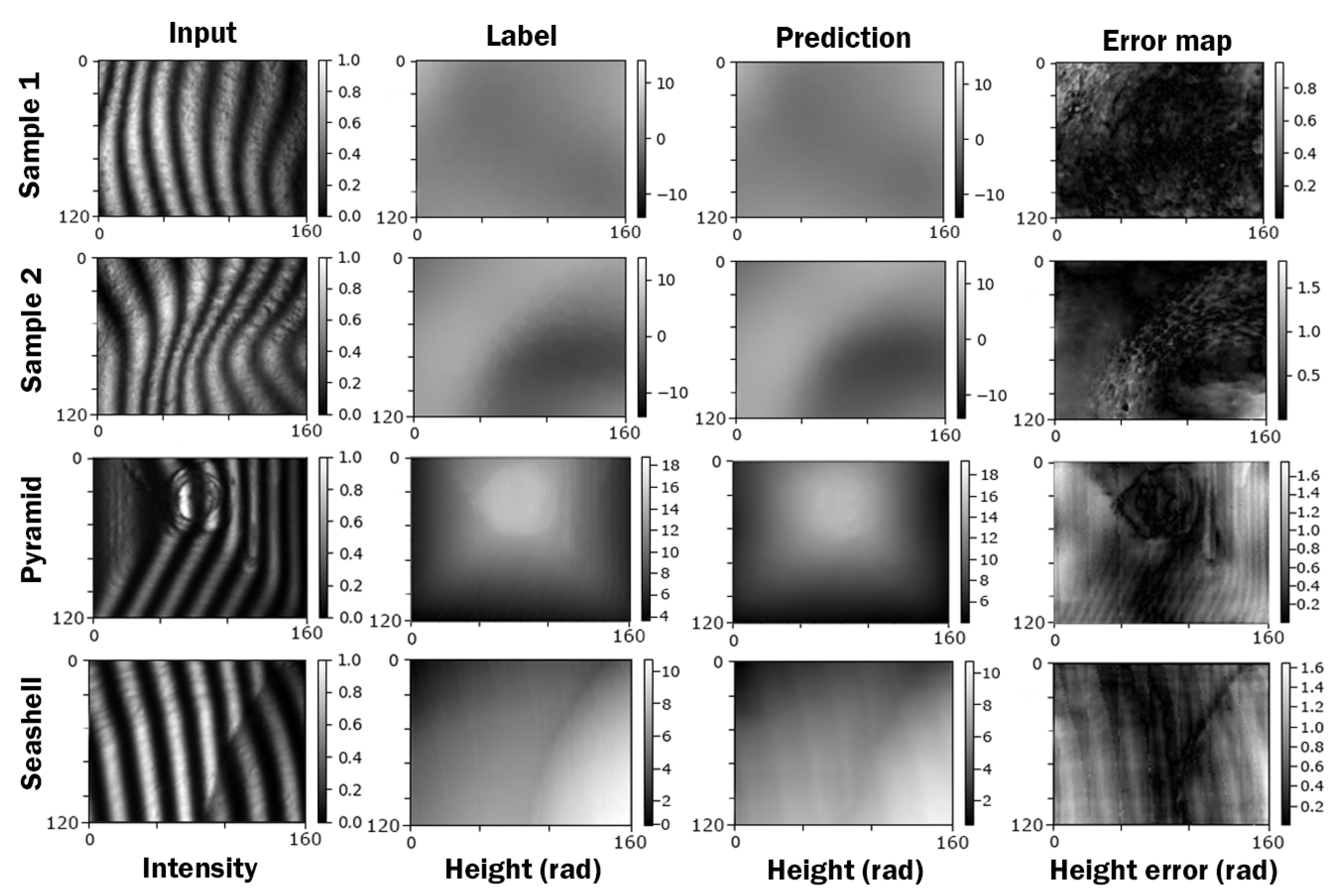
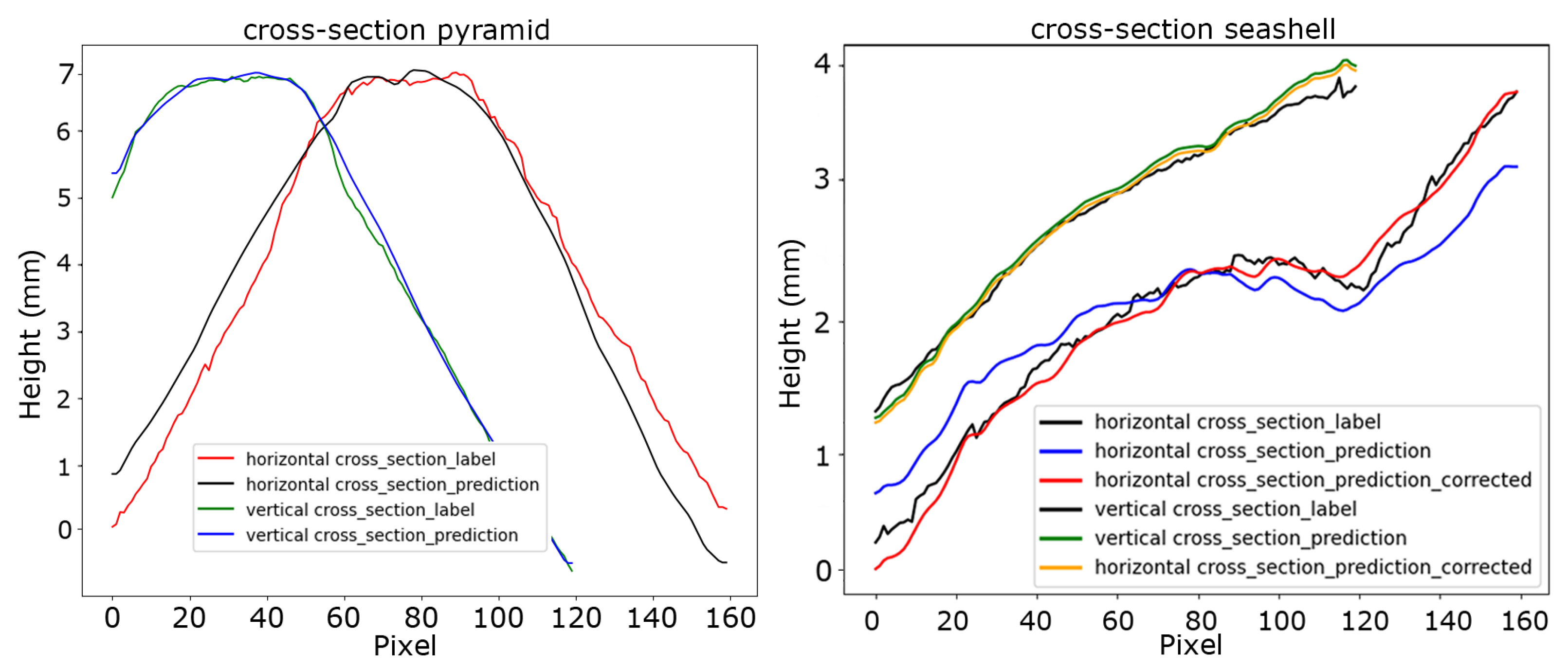
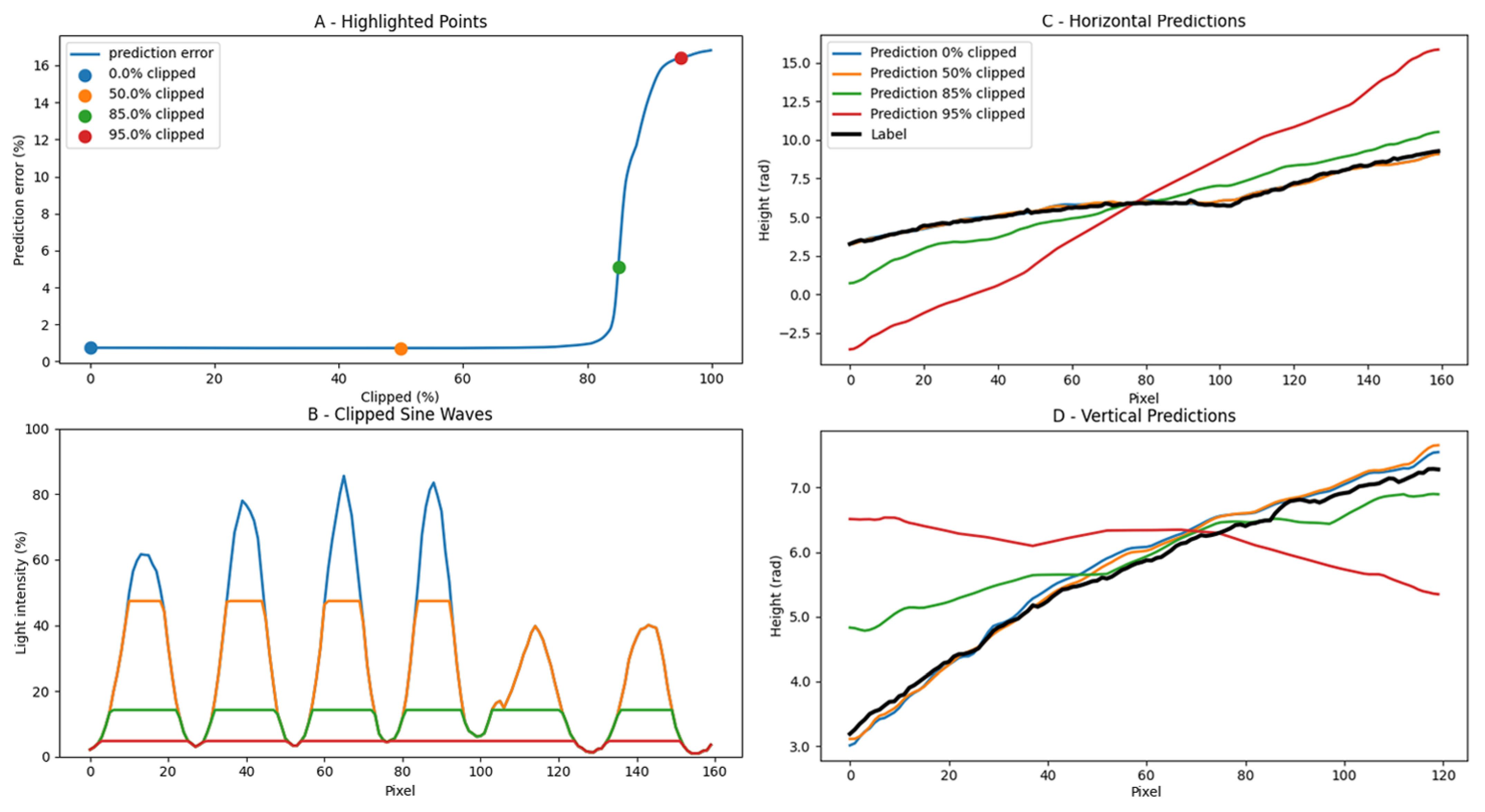
3. Results
Sine Wave Robustness
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Van der Jeught, S.; Dirckx, J.J.J. Deep neural networks for single shot structured light profilometry. Opt. Express 2019, 27, 17091. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.; Wang, Y.; Wang, Z. Single-shot 3d shape reconstruction using structured light and deep convolutional neural networks. Sensors 2020, 20, 3718. [Google Scholar] [CrossRef]
- Feng, S.; Chen, Q.; Gu, G.; Tao, T.; Zhang, L.; Hu, Y.; Yin, W.; Zuo, C. Fringe pattern analysis using deep learning. Adv. Photonics 2019, 1, 025001. [Google Scholar] [CrossRef]
- Yao, P.; Gai, S.; Da, F. Coding-Net: A multi-purpose neural network for Fringe Projection Profilometry. Opt. Commun. 2021, 489, 126887. [Google Scholar] [CrossRef]
- Wang, F.; Wang, C.; Guan, Q. Single-shot fringe projection profilometry based on deep learning and computer graphics. Opt. Express 2021, 29, 8024. [Google Scholar] [CrossRef]
- Wang, K.; Dou, J.; Kemao, Q.; Kemao, Q.; Di, J.; Di, J.; Zhao, J. Y-Net: A one-to-two deep learning framework for digital holographic reconstruction. Opt. Lett. 2019, 44, 4765–4768. [Google Scholar] [CrossRef]
- Nguyen, M.T.; Ghim, Y.S.; Rhee, H.G. DYnet++: A deep learning based single-shot phase-measuring deflectometry for the 3D measurement of complex free-form surfaces. IEEE Trans. Ind. Electron. 2023, 71, 2112–2121. [Google Scholar] [CrossRef]
- Nguyen, A.H.; Rees, O.; Wang, Z. Learning-based 3D imaging from single structured-light image. Graph. Model. 2023, 126, 101171. [Google Scholar] [CrossRef]
- Liu, X.; Yang, L.; Chu, X.; Zhou, L. A novel phase unwrapping method for binocular structured light 3D reconstruction based on deep learning. Optik 2023, 279, 170727. [Google Scholar] [CrossRef]
- Nguyen, A.H.; Ly, K.L.; Lam, V.K.; Wang, Z. Generalized Fringe-to-Phase Framework for Single-Shot 3D Reconstruction Integrating Structured Light with Deep Learning. Sensors 2023, 23, 4209. [Google Scholar] [CrossRef]
- Yang, T.; Zhang, Z.; Li, H.; Li, X.; Zhou, X. Single-shot phase extraction for fringe projection profilometry using deep convolutional generative adversarial network. Meas. Sci. Technol. 2021, 32, 015007. [Google Scholar] [CrossRef]
- Nguyen, H.; Tran, T.; Wang, Y.; Wang, Z. Three-dimensional Shape Reconstruction from Single-shot Speckle Image Using Deep Convolutional Neural Networks. Opt. Lasers Eng. 2021, 143, 106639. [Google Scholar] [CrossRef]
- Song, J.; Liu, K.; Sowmya, A.; Sun, C. Super-Resolution Phase Retrieval Network for Single-Pattern Structured Light 3D Imaging. IEEE Trans. Image Process. 2023, 32, 537–549. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhou, C.; Qi, X.; Li, H. UHRNet: A Deep Learning-Based Method for Accurate 3D Reconstruction from a Single Fringe-Pattern. arXiv 2023, arXiv:2304.14503. [Google Scholar] [CrossRef]
- Van der Jeught, S.; Muyshondt, P.G.; Lobato, I. Optimized loss function in deep learning profilometry for improved prediction performance. J. Phys. Photonics 2021, 3, 024014. [Google Scholar] [CrossRef]
- Trusiak, M.; Kujawinska, M. Deep learning enabled single-shot absolute phase recovery in high-speed composite fringe pattern profilometry of separated objects. Opto-Electron. Adv. 2023, 6, 230172. [Google Scholar] [CrossRef]
- Hou, L.; Xi, D.; Luo, J.; Qin, Y. Deep learning-based correction of defocused fringe patterns for high-speed 3D measurement. Adv. Eng. Inform. 2023, 58, 102221. [Google Scholar] [CrossRef]
- Fu, Y.; Huang, Y.; Xiao, W.; Li, F.; Li, Y.; Zuo, P. Deep learning-based binocular composite color fringe projection profilometry for fast 3D measurements. Opt. Lasers Eng. 2024, 172, 107866. [Google Scholar] [CrossRef]
- Li, Y.; Qian, J.; Feng, S.; Chen, Q.; Zuo, C. Deep-learning-enabled dual-frequency composite fringe projection profilometry for single-shot absolute 3D shape measurement. Opto-Electron. Adv. 2022, 5, 210021. [Google Scholar] [CrossRef]
- Bai, S.; Luo, X.; Xiao, K.; Tan, C.; Song, W. Deep absolute phase recovery from single-frequency phase map for handheld 3D measurement. Opt. Commun. 2022, 512, 128008. [Google Scholar] [CrossRef]
- Qiao, G.; Huang, Y.; Song, Y.; Yue, H.; Liu, Y. A single-shot phase retrieval method for phase measuring deflectometry based on deep learning. Opt. Commun. 2020, 476, 126303. [Google Scholar] [CrossRef]
- Nguyen, H.; Wang, Z. Accurate 3D Shape Reconstruction from Single Structured-Light Image via Fringe-to-Fringe Network. Photonics 2021, 8, 459. [Google Scholar] [CrossRef]
- Soons, J.A.M.; Dirckx, J.J.J.; Van der Jeught, S. Real-time microscopic phase-shifting profilometry. Appl. Opt. 2015, 54, 4953–4959. [Google Scholar] [CrossRef]
- Metrology, M.L. Root Mean Square Surface Slope-Michigan Metrology. Available online: https://michmet.com/glossary-term/root-mean-square-surface-slope/#:~:text=Sdq%20is%20a%20general%20measurement,surface%2C%20evaluated%20over%20all%20directions (accessed on 18 December 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Objects Type(s) | Dataset Size (# Images) | Generation Process |
|---|---|---|---|
| FP672 Nguyen et al. [2] | Four Disney dolls (together and separately) | 672 images | Manual |
| FP1000 Li et al. [19] | Bust/doll/small items | 1000 images | Manual |
| FP147 Song et al. [13] | Busts | 147 images | Manual |
| Unnamed Bai et al. [20] | Dental casts (eight casts) | 2755 images | Manual |
| Unnamed Qiao et al. [21] | Phone case glass (Samsung, iPhone, glass plates) | 1200 images | Manual |
| Unnamed Nguyen at al. [22] | Clay sculptures | 1500 images | Manual |
| GDD | Random Gaussian Disc | 24,157 images | Automatic |
| Channels | Number of Parameters | Loss Train | Loss Validation | |
|---|---|---|---|---|
| CNN [2] | 16, 16, 32, 64, 128 | 448k | 0.05071 | 0.05108 |
| Dense-Net [2] | 16, 32, 64, 128, 64, 32, 16 | 1213k | 0.01690 | 0.01758 |
| U-Net [19] | 16, 32, 64, 128, 64, 32, 16 | 454k | 0.05000 | 0.05033 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Evans, R.G.; Devlieghere, E.; Keijzer, R.; Dirckx, J.J.J.; Van der Jeught, S. Deep Learning for Single-Shot Structured Light Profilometry: A Comprehensive Dataset and Performance Analysis. J. Imaging 2024, 10, 179. https://doi.org/10.3390/jimaging10080179
Evans RG, Devlieghere E, Keijzer R, Dirckx JJJ, Van der Jeught S. Deep Learning for Single-Shot Structured Light Profilometry: A Comprehensive Dataset and Performance Analysis. Journal of Imaging. 2024; 10(8):179. https://doi.org/10.3390/jimaging10080179
Chicago/Turabian StyleEvans, Rhys G., Ester Devlieghere, Robrecht Keijzer, Joris J. J. Dirckx, and Sam Van der Jeught. 2024. "Deep Learning for Single-Shot Structured Light Profilometry: A Comprehensive Dataset and Performance Analysis" Journal of Imaging 10, no. 8: 179. https://doi.org/10.3390/jimaging10080179
APA StyleEvans, R. G., Devlieghere, E., Keijzer, R., Dirckx, J. J. J., & Van der Jeught, S. (2024). Deep Learning for Single-Shot Structured Light Profilometry: A Comprehensive Dataset and Performance Analysis. Journal of Imaging, 10(8), 179. https://doi.org/10.3390/jimaging10080179