1. Introduction
Semantic segmentation is a computer vision task that classifies each pixel of an image into a predefined set of categories, or “classes”. The assigned pixel labels constitute regions of different semantic categories, essentially forming the shapes of the objects that appear on the image. Autonomous driving, medical imaging, satellite imagery and augmented reality are some of the popular application fields on which semantic segmentation is employed.
Convolutional neural networks with encoder–decoder blocks have been the primary architectural choice for addressing the semantic segmentation task since the emergence of deep learning. As a next step, Google adapted the transformer architecture to computer vision tasks (classification) with the vision transformer (ViT) model [
1] and opened the way for a more extensive use of transformers on other visual tasks, including semantic segmentation.
A major concern in the process of producing new state-of-the-art models for the task is the increased computational complexity. The number of parameters has already grown to immense levels, which range from hundreds of millions to even billions. As a consequence, inference on architectures of that magnitude requires many, expensive, and energy-consuming hardware components (GPUs), which renders large-scale real-time applications prohibitive. For example, real-time semantic segmentation for autonomous vehicles cannot be realized, if the inference task requires seconds or hundreds of milliseconds to complete, even on a high-end GPU.
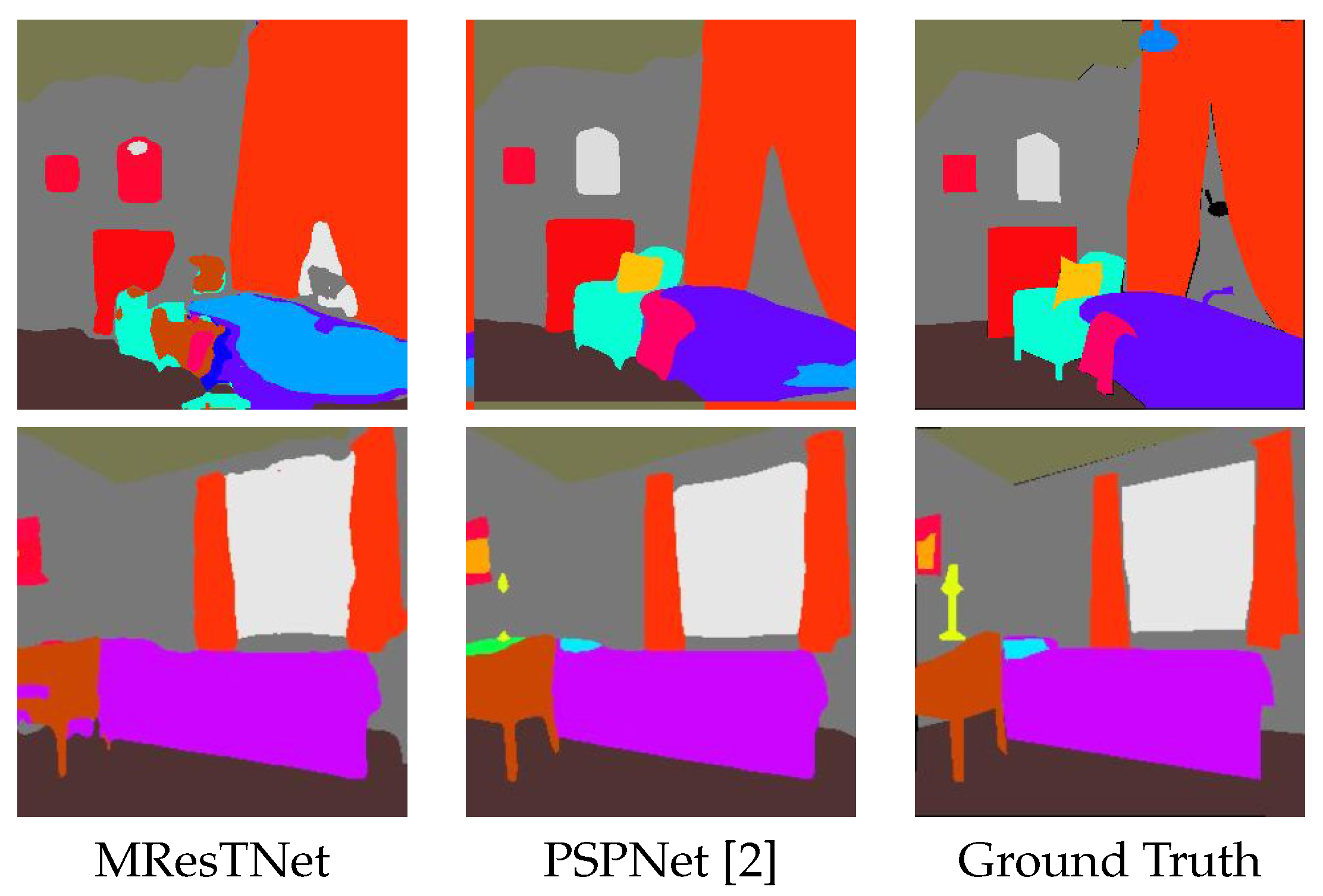
For this reason, research on high-performance yet low-cost architectures is both not only popular but also necessary. Before focusing on low complexity, real-time architectures, we present some top performing convolutional or transformer-based networks, as they have appeared and progressed in recent years, irrespective of the network size. First, PSPNet [
2] (Pyramid Scene Parsing Network) is a semantic segmentation model that utilizes pyramid pooling modules to capture contextual information at different scales. It effectively addresses challenges in scene parsing by aggregating global context information and integrating it into the segmentation process. It can utilize various backbone architectures for feature extraction that render the network either real-time or non-real-time. DeepLabV3+ [
3] is a DeepLab family network extension with features, such as atrous spatial pyramid pooling (ASPP), encoder–decoder structures, and depthwise separable convolutions for achieving high-quality segmentation results. InternImage [
4] is a large-scale CNN that incorporates deformable convolution [
5] variants that allow for capturing long-range dependencies with adaptive spatial aggregation. The HSSN framework, introduced in [
6], adapts existing segmentation networks to incorporate hierarchy information for improved network learning. It forms a tree-structured hierarchy of the latent class dependencies, representing concepts and relationships, which is used in training for mapping pixels and their classes and in inference for finding the best path from root to leaf in the class hierarchy. Finally, ref. [
7] suggests the use of the Supervised Contrastive Segmentation method that combines supervised learning with contrastive learning to achieve better segmentation results. The method can be used to train architectures containing existing base networks for mapping input to image embedding representations and networks for producing segmentation maps over the class space, without interfering with the base networks during inference.
The emergence of transformers [
8] has revolutionized deep learning-based classification, especially with the emergence of the Vision Transformer (ViT) [
1]. The Swin Transformer [
9] is a hierarchical Transformer, whose representation is computed by leveraging shifted windows that offer the ability to model at various scales. SETR [
10] is another transformer-based architecture, which employs a standard transformer encoder [
8] and different convolutional decoders. The SETR-PUP variation progressively upsamples the encoded information until producing the output segmentation masks, while the SETR-MLA aggregates streams from different decoder layers. Segmenter [
11] is a Vision Transformer (ViT) [
1]-based semantic segmentation model, with a standard ViT encoder and either a point-wise linear or a transformer (multi-head self-attention)-based decoder. Several model scales are presented, ranging from tiny to large, with varying performance and complexity, with the tiny architectures being suitable for real-time inference. The SegFormer model [
12] consists of a hierarchical Transformer encoder that generates high-resolution coarse features and low-resolution fine features and an MLP decoder for fusing the multi-level information. It uses smaller (
) sized patches compared to the standard ViT encoder patches (
) and sequences reduced self-attention blocks for faster yet efficient processing. The model is constructed at different scales from MiT-B0 to MiT-B5, with MiT-B0 being small enough for real-time applications. BiSeNet [
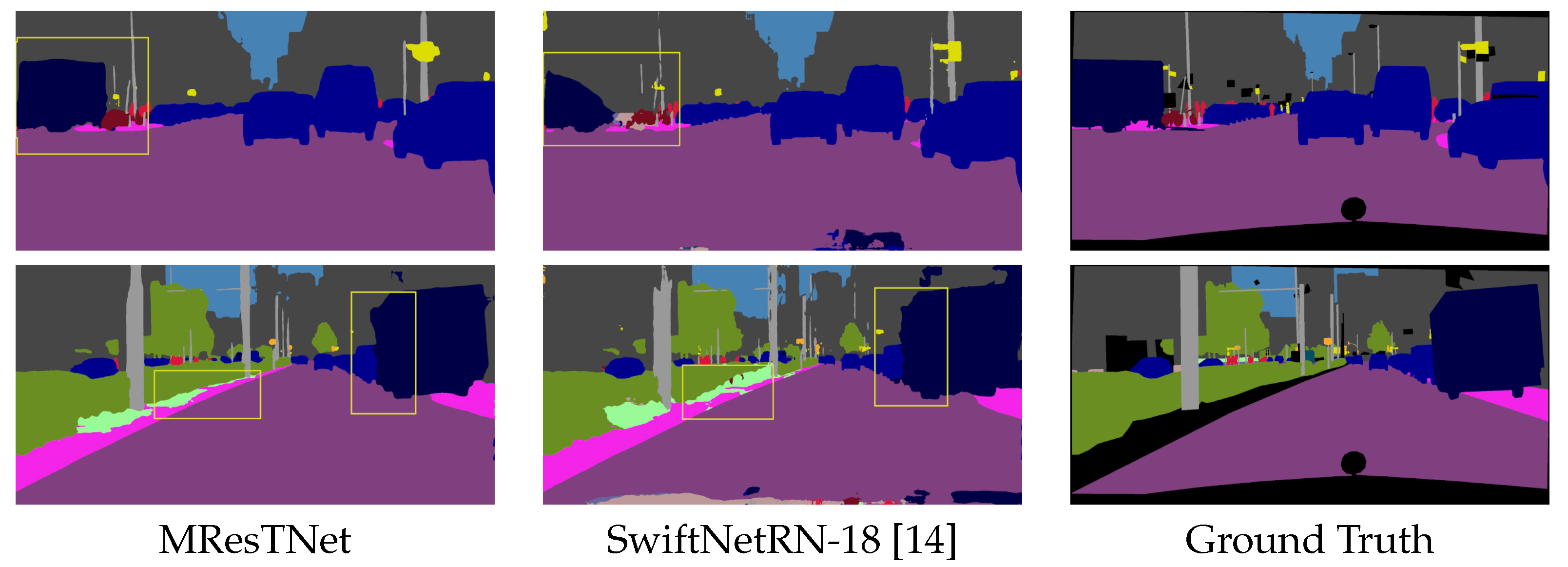
13] is a versatile semantic segmentation model that offers a good trade-off between efficiency and accuracy, making it well suited for various computer vision tasks, where real-time performance is crucial. It consists of two separate pathways, one for capturing global contextual information and one for fine-grained spatial details, which are combined with the bilateral fusion module. SwiftNetRN-18 [
14] is a SwiftNet variation that employs a ResNet-18 backbone along with SwiftNet family features, such as depthwise separable convolutions, channel attention mechanisms, and feature fusion modules, in order to achieve accurate semantic segmentation with real-time efficiency. DDRNet [
15] (dilated dense residual network) is another convolutional neural network architecture for semantic segmentation that uses dilated convolutions, residual blocks with dense connections, where each layer is connected to every other layer in a feed-forward manner and hierarchical feature fusion mechanisms that capture multi-scale information by combining features from different network layers. The authors present versions of the architecture with varying levels of complexity, one of which, the DDRNet-23-slim, qualifies for accurate real-time inference. LETNet [
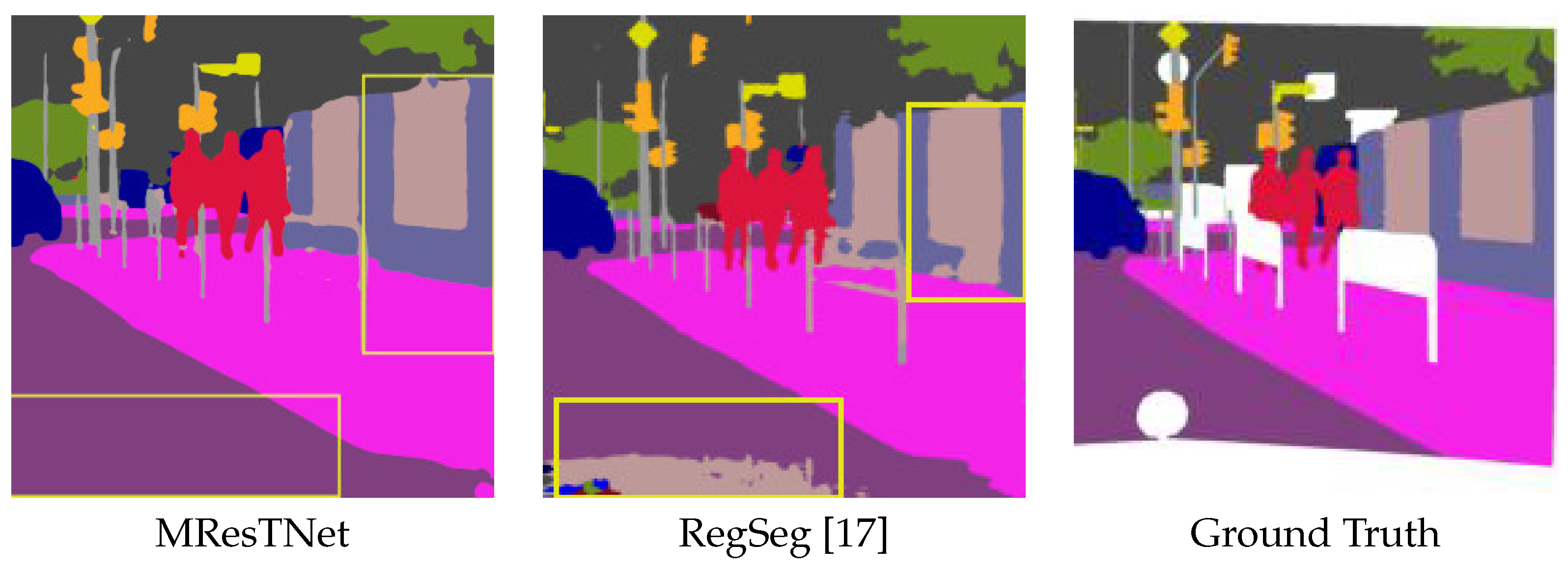
16] is a CNN encoder–decoder architecture with a transformer-based bottleneck block and skip connections between the encoder and decoder. The authors also propose the lightweight dilated bottleneck (LDB), a block positioned in the encoder and decoder parts, which is a series of convolutional layers, with residual connections, channel attention, and shuffling mechanisms for collecting more feature information while keeping the number of layers low. RegSeg [
17] is based on SE-ResNeXt architectural blocks, which use dilated convolutions for a larger effective field-of-view and optimize the dilation rates with gradient descent applied over a differentiable neural architecture search method. PIDNet [
18] is another convolutional approach focusing on real-time performance. The architecture consists of three branches (P, I, and D), aiming to extract high-resolution feature maps, long-range dependencies, and boundary regions, respectively, which are aggregated with multistage convolutional architectural blocks until producing the segmented feature maps. CLUSTSEG [
19] views the image segmentation tasks as pixel clustering problems. The proposed framework applies a recursive clustering procedure with a transformer-based cross-attention acting as a cluster solver where queries are considered cluster centers. A different approach, based on prototype-based classification, is adopted by [
20]. The authors suggest a model that can be based on either CNN or transformer backbones, where a set of non-learnable class prototypes are used for making dense predictions. Segmentation is achieved by pixel-wise prediction based on distance between pixels and class prototypes.
In this paper, we present a low-cost deep learning architecture, featuring transformer and CNN architectural features, that combines relatively a low computational cost with a robust semantic segmentation performance. The novel offerings are:
A novel low-cost real-time architecture based on transformers and CNN that achieves the best performance among the state-of-the-art peers.
A complete ablation study that explores the offerings of convolutional blocks in a transformer framework.
The introduction of a multi-resolution framework in a transformer-based architecture.
Automated tuning of hyper-parameters using specialized networks, such as the fuser and the scaler.
An outline of the paper is given as follows. In
Section 2, the novel architecture MResTNet is presented. In
Section 3, we ablate over a number of architectural options in order to determine the optimal structure of the proposed network. In
Section 4, the final results on the Cityscapes and ADE20K datasets are presented.
Section 5 concludes the paper summarizing the offerings.
3. Ablation Study
The design choices and architectural components of a semantic segmentation model significantly impact the performance and the generalization ability of the network. In this study, we systematically analyze the contributions of various components within our semantic model. We aim to gain insights into the effect of individual design choices in terms of performance and network computational complexity.
This study was conducted over the Cityscapes dataset [
28] and the networks were trained for 216 epochs, employing the SGD optimizer, with a polynomial decay rate, initialized at
, of power
, decaying at every step. The final selected model was trained for 864 epochs, with the same optimizer and learning rate parameters, with the exception of the decaying step size, which was set to 4. The model was developed in Python 3.10.12 using PyTorch 1.7.1 on a PC with i9-11900F, 64 GB RAM, an NVidia RTX A6000 GPU 48 GB, running Ubuntu Linux 22.04.
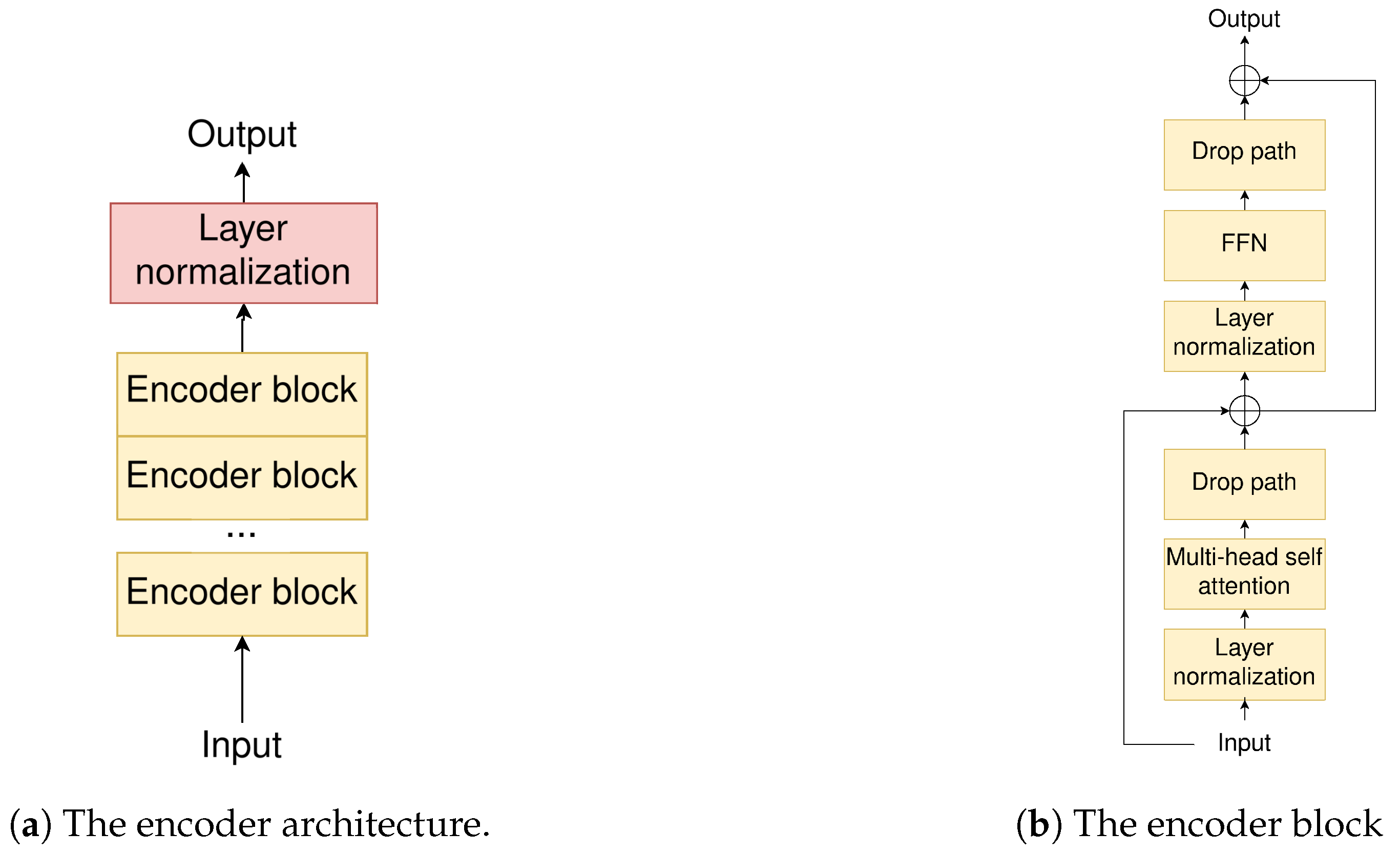
The baseline model for the study is an encoder–decoder model containing only the described ViT encoder and transformer decoder parts. First, we studied several architectural variants by adding a parallel MultiRes decoding path to the baseline model and extending it with the fuser and scaler blocks. We also experimented with the scaler architecture, since it allowed for several options that significantly affected the model performance. We then studied the effect of the loss function on the model training. We used a cross-entropy loss as well as a combination of cross-entropy and dice loss. Finally, in an attempt to create the smallest possible model that would maintain a high prediction performance, with respect to the dominant metrics of the field (mean intersection over union—mIoU), in comparison to other SOTA methods, we created and evaluated significantly smaller models.
3.1. Architectural Variants
Our baseline model is a ViT encoder–decoder model, with the previously described encoder and decoder. We gradually added MultiRes blocks, scaler, and fuser to evaluate performance against complexity scaling. For evaluating architectures without Scaler and Fuser, we simply added the two parallel decoded outputs.
As depicted in
Table 1, each of these blocks gradually improves the performance, without large model-size overhead. In particular, the fuser and the scaler have a relatively insignificant size impact. Our primary goal is to extend the decoding capability of the model’s decoder side. We focus on the decoder side, since we do not need pre-training, while encoder side changes are not treated fairly without pre-training.
We firstly extend the existing decoder with more decoder blocks. The baseline decoder has two blocks and we add two more. It is natural to assume that the extra network decoder capacity alone, due to the additional blocks, would be enough to improve the output accuracy metrics. If more network capacity was the only target, simply adding ViT decoder layers with the same additional parameters would still bring performance improvements. As seen in
Table 1, this “extended decoder” architecture does not yield any significant improvements, while the “dual decoder” does. It is reasonable to deduce that the convolutional decoder preserves and restores the encoded spatial information and feature arrangement, while their inherent gradual upscaling operation recovers fine details.
Replacing the standard decoder convolutions with MultiRes blocks introduces yet another significant performance improvement, considering the scale of the model. By processing multiple resolutions in a hierarchical manner, MultiRes blocks can decode both fine-grained details and coarse contextual information more efficiently.
Table 1 supports this upgrade, by showing the number of parameters and the mean intersection over union (mIoU) (semantic segmentation quality index).
Summarizing all the above, so far, we evaluated the dual decoder against the single transformer decoder, but not against the single convolutional decoder. However, in order to establish the necessity of both decoders, we have to evaluate this dual-model against the convolutional decoder alone. The “convolutional decoder” of
Table 1 shows exactly that it yields no improvement. The Transformer decoder cannot be left out of the model, since it incorporates global context into the segmentation process more effectively, since transformers excel at capturing long-range dependencies between pixels. Semantic segmentation does require capturing contextual information from the distant regions of the input image to accurately classify each pixel.
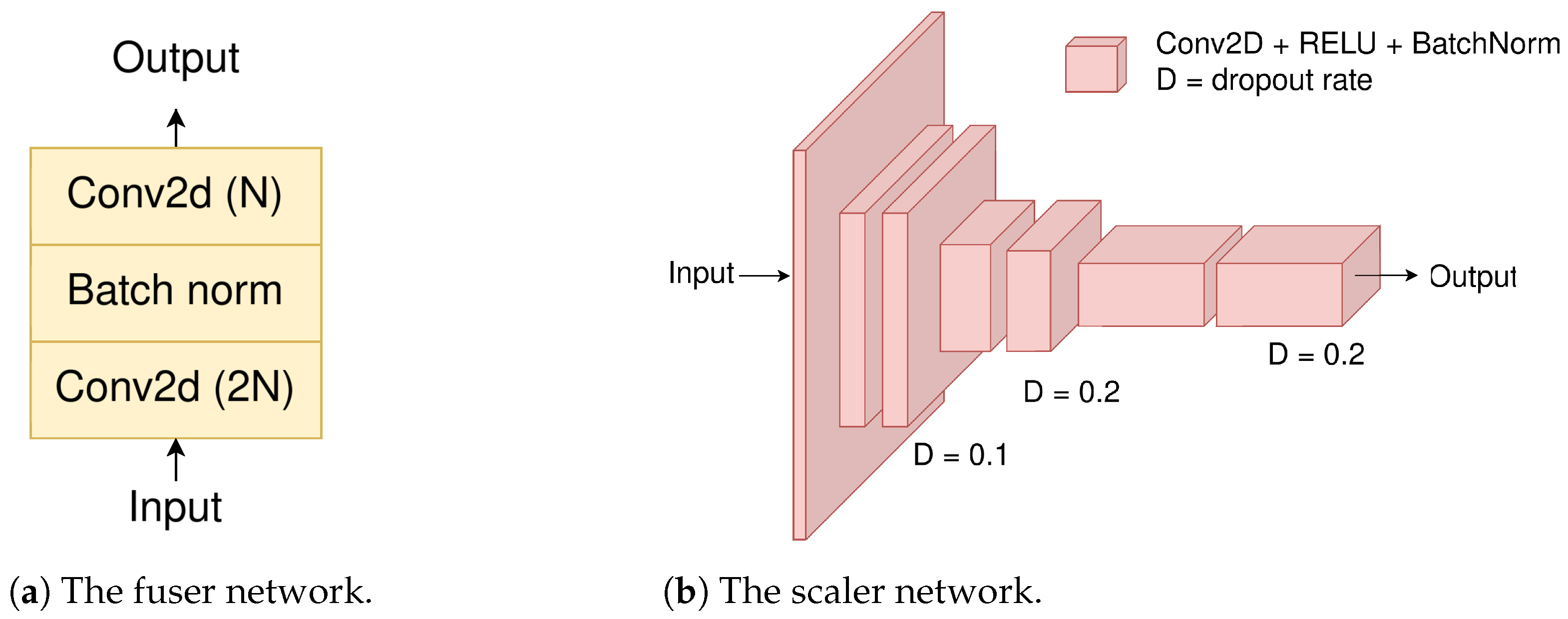
The power of the two approaches can be better harvested with the fuser and scaler blocks. Looking at
Table 1, it is clear that the Fuser improves the performance. The fuser block (
Figure 5a) convolutionally merges the two decoded outputs.
The scaler block increases even more the accuracy metric (mIoU), since it acts as a balancing factor between the decoded outputs, selecting the best elements each one has to offer in the overall decoding. The scaler produces a 2D feature map that has the same size as that of the input after patching has been applied. The scaler output values end up in the range of 0.6–0.7, with a mean value of ∼0.65. This shows that the scaler output is neither too small (∼0) nor too high (∼1), cases that would have rendered the use of one of the two decoders unnecessary.
In
Table 2, we compare the effect of using the actual predicted scaler output against using fixed scaler values. We make our evaluation on the Cityscapes validation set. The first column shows the result of using the scale produced by the scaler, while for all the other columns, a fixed scaler value was used instead. The experiment clearly shows that the predicted scaler output produces better results by appropriately scaling both decoders. Setting a fixed value produces sub-optimal results and degrades the performance.
In addition,
Figure 6 visualizes the scaler output, resized to the original image size (the actual scaler output size is the same as that after input patching, which in this case is
). The first column shows the actual output, while in the second, the values are linearly normalized to
for better visualization. The final column is the input image. The scaler acts differently on image features and it is evident that edge information receives higher scaler values, for the transformer decoder.
3.2. Scaler Variants
As seen in
Table 1, the use of fuser and scaler enhances the performance, without any significant complexity overhead. We can investigate further alternative structures for these blocks in order to experiment with further performance improvements. The Fuser does not leave much room for investigation, since it is a block that is applied to the decoded 2D masks. The simplest and most obvious choice is the one already made. However, the Scaler, which is applied to the input, or in a more abstract description, to the information before the encoding, does allow for architectural experimentation.
The Scaler design (
Figure 5b), that was described earlier on, can be replaced by a feed-forward network (
Figure 7). Applying the scaler to the flattened 2D input would require a very large feed-forward network, so it is more appropriate to apply it to the patch-embedded input, which is already flattened and much smaller in dimension. Since encoding can benefit from the positional embeddings (lost inductive bias), we can assume that using the positional embeddings in the scaler block would be beneficial as well. Consequently, we gather that we can apply the feed-forward scaler after the positional embedding addition, just before the encoding. The feed-forward scaler consists of three dense contracting layers, which reduce the dimensionality to a single scaler value that later scales the decoded outputs.
The results are depicted in
Table 3. The complexity shown in the Table reflects the whole model, incorporating the respective scaler. The CNN scaler performs better, with an overhead that we can afford to spend.
3.3. Loss Function Ablation
We have trained our model using the cross-entropy loss and with a weighted combination of cross-entropy and dice loss. The dice loss alone proved incapable of providing considerable results.
The cross-entropy loss is a standard for classification problems with multiple classes
where
is the cross-entropy loss.
N is the total number of pixels.
C is the number of classes.
is the ground truth label (1 if the pixel belongs to class c, 0 otherwise) for pixel i and class c.
is the predicted probability of pixel i belonging to class c.
The Dice loss for multiple classes is formulated as follows:
where:
N is the total number of pixels.
is the ground truth label for pixel i.
is the predicted label for pixel i.
The dice loss usually alleviates the class imbalances present in the data. In the datasets used in our experiments, not all classes are equally represented. Thus, we would have expected that employing the dice loss would improve performance. Unfortunately, this did not happen in our simulations (see
Table 4). Most likely, the answer is related to the fact that the dice loss itself is not as smooth as other loss functions, such as cross-entropy, an issue that becomes more serious in multiple-class classification problems. Optimizing the loss function in such a scenario is more challenging, especially when using gradient-based methods, such as stochastic gradient descent (SGD), which is used in our experiments.
3.4. Model Size Ablation
Table 5 depicts the complexity of each architectural block used. It is clear that the encoder is the dominant part in terms of complexity and it is the ideal candidate for intervention in order to scale down the model. For this reason, we trained a scaled-down version of the model, using 8 instead of 12 encoder blocks.
Table 6 shows the results of scaling the model down. This smaller model presents a direction of further improving an even more scaled-down model. Nonetheless, in the context of this study, we proceed with the larger of the two in order not to lose performance.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}