
Enhancing Short-Term Berry Yield Prediction for Small Growers Using a Novel Hybrid Machine Learning Model



Abstract
1. Introduction
2. Theoretical Background
3. Material and Methods
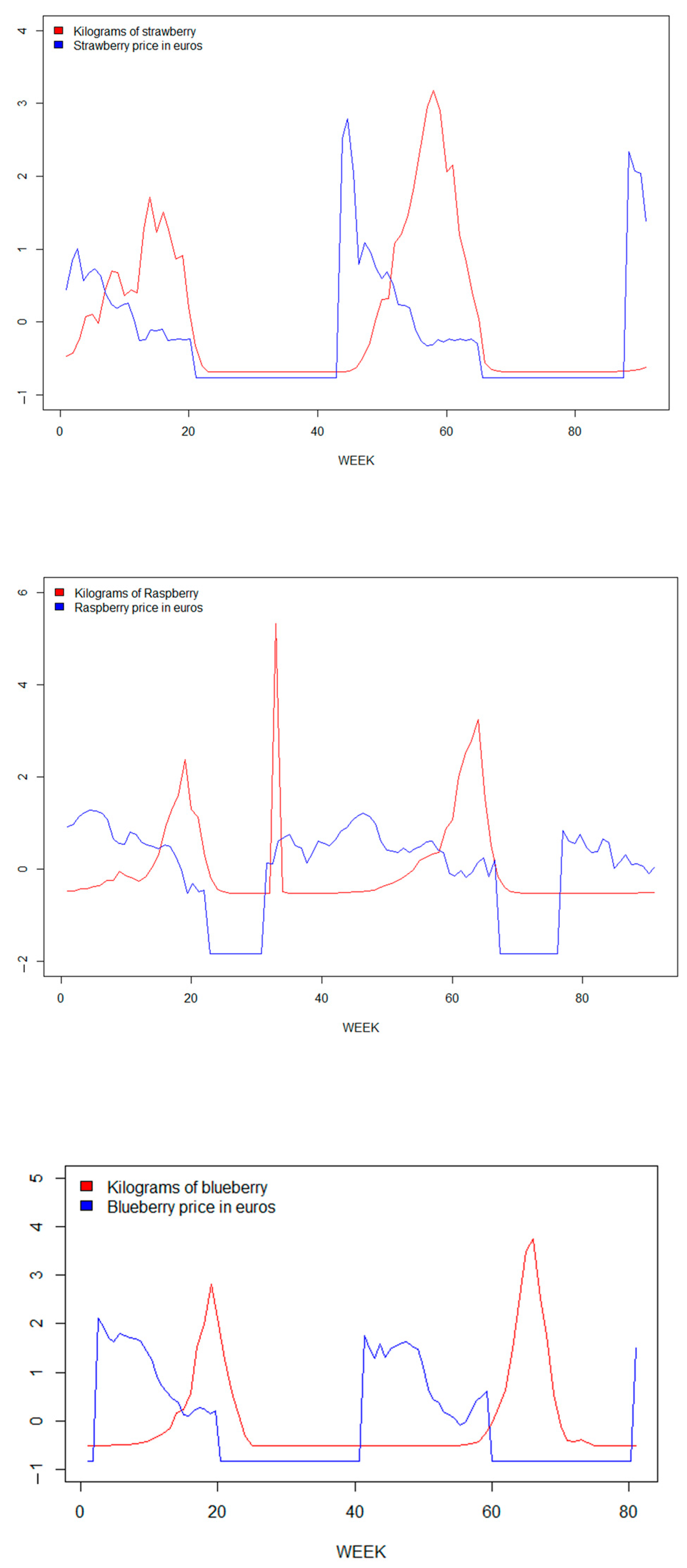
3.1. Description of the Data
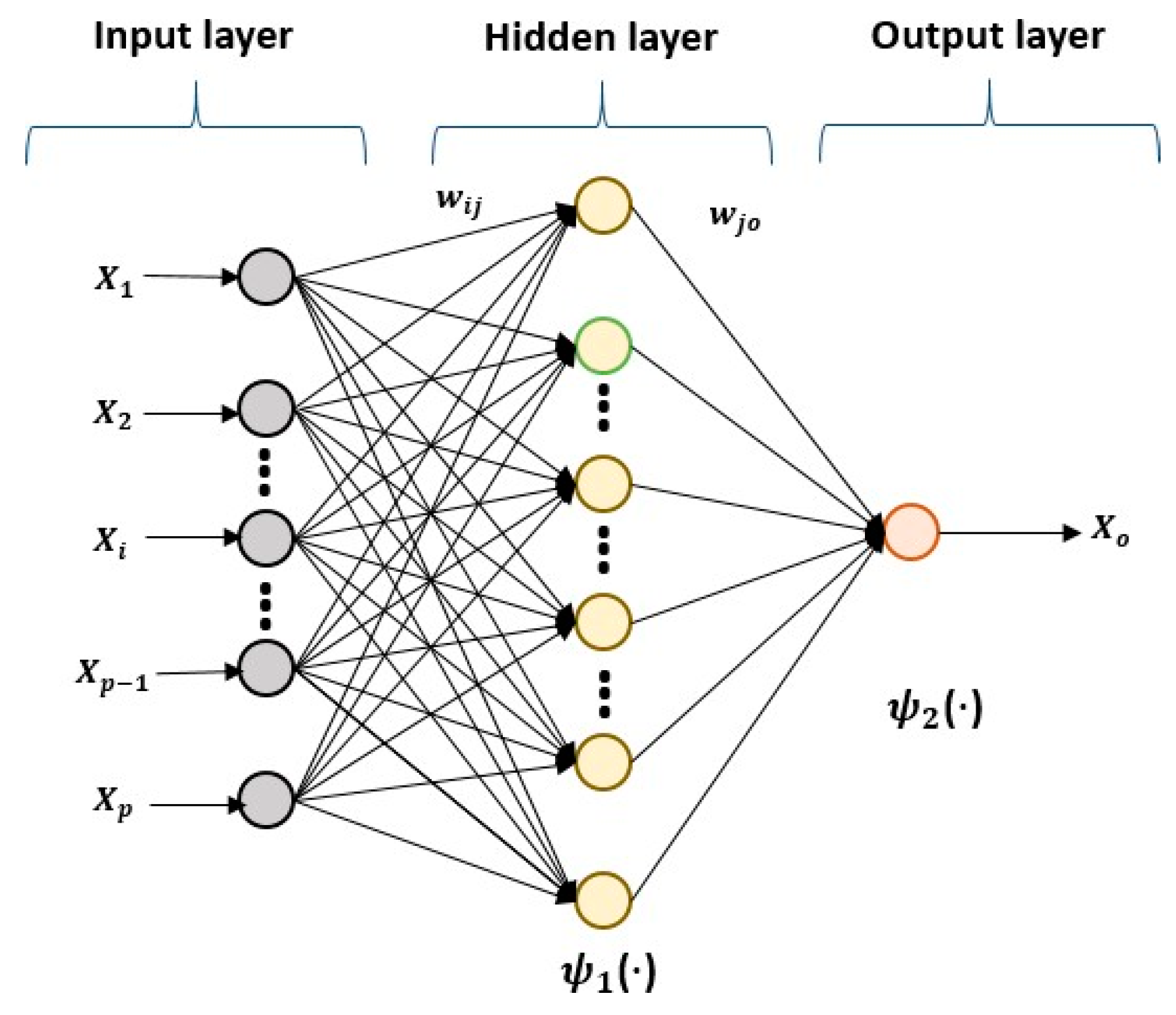
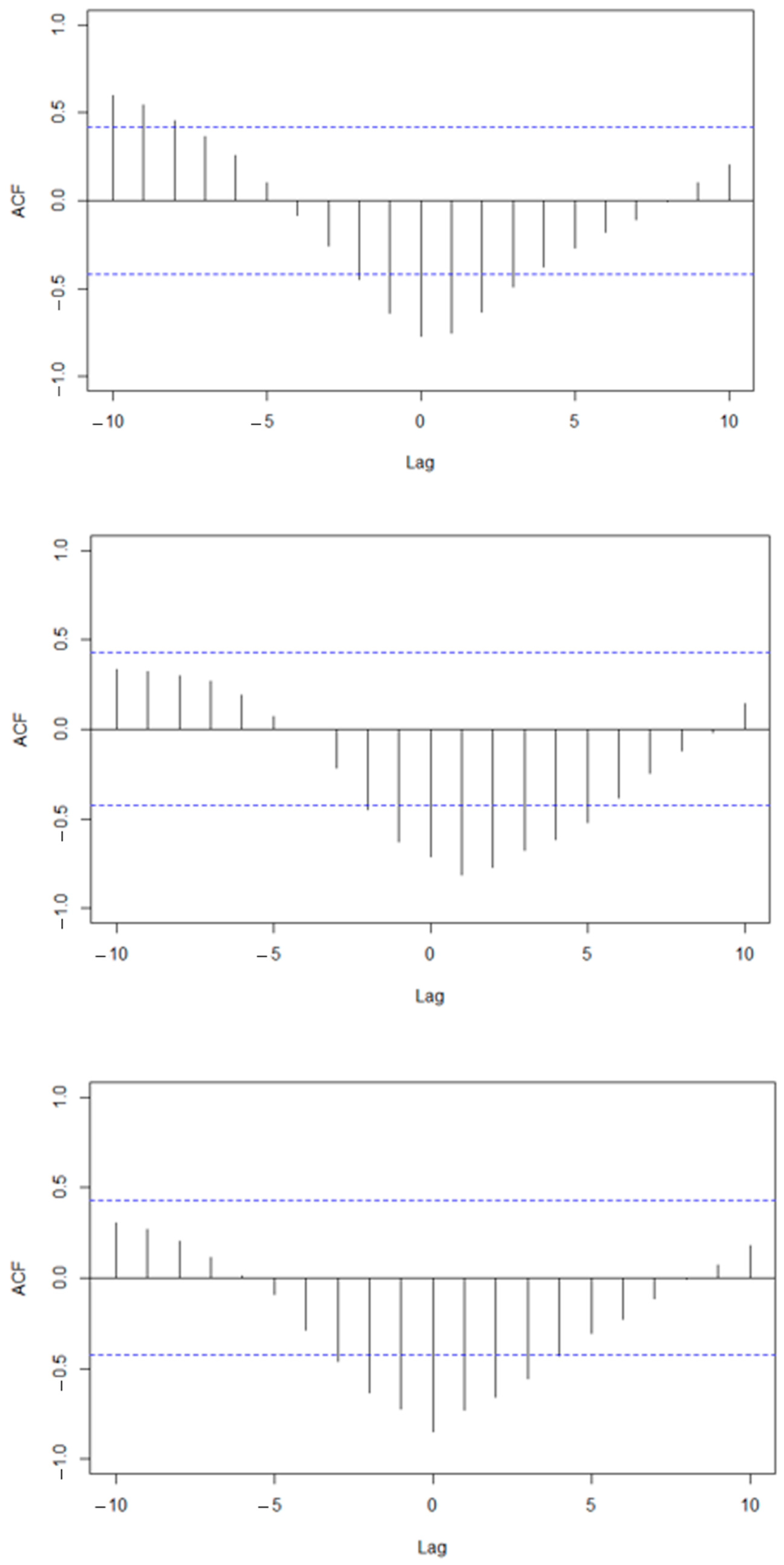
3.2. Description of the Hybrid Model
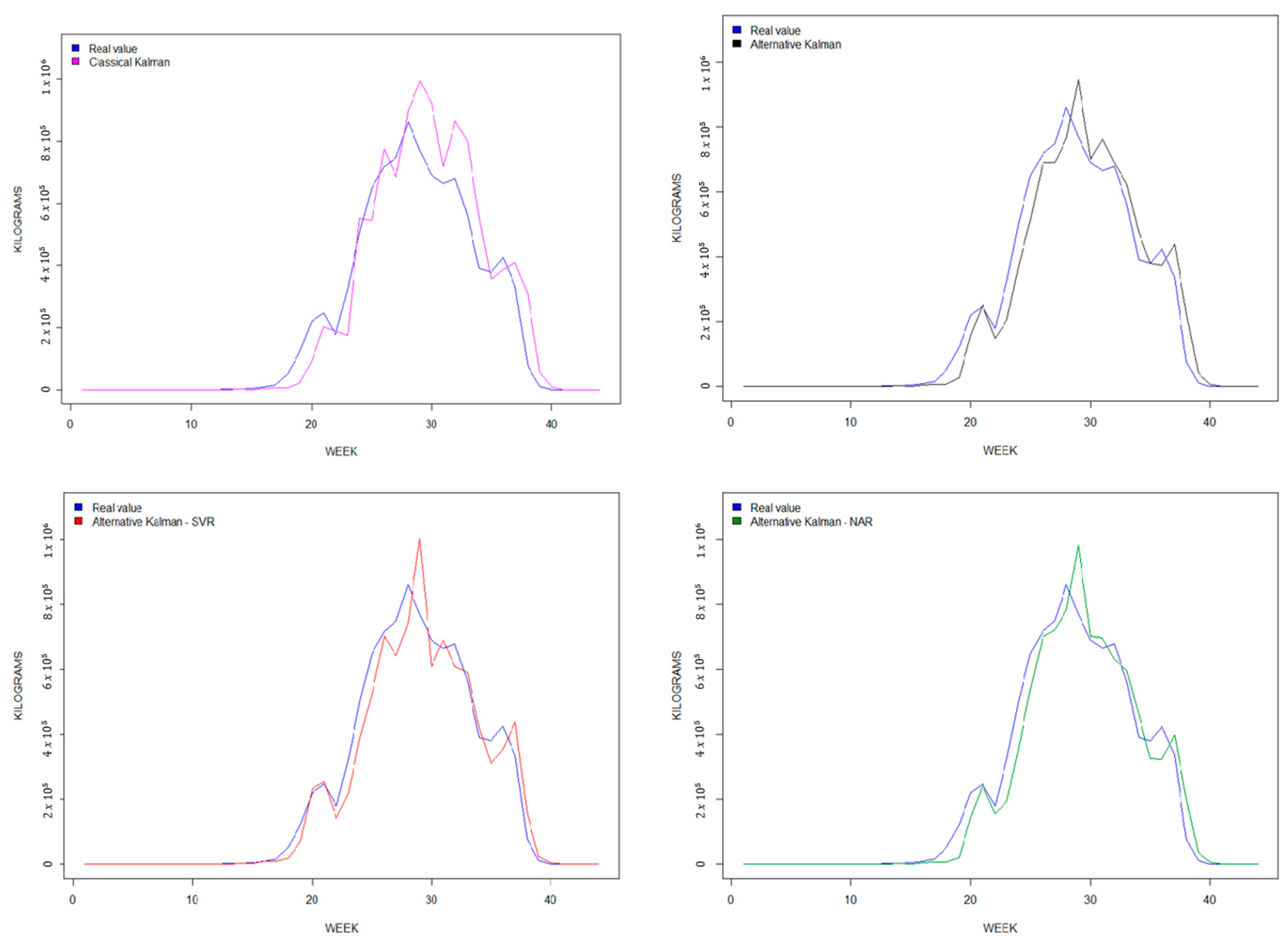
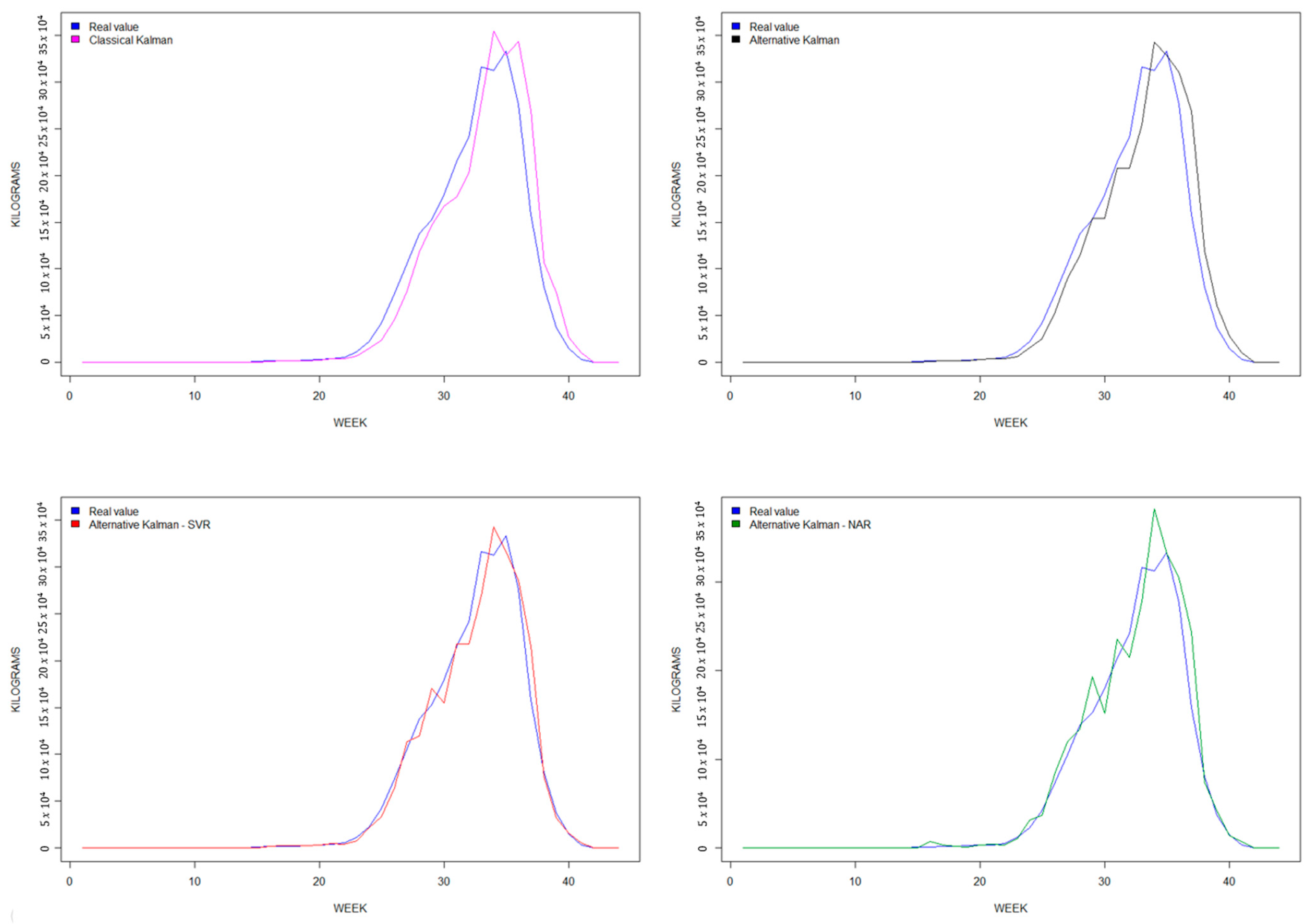
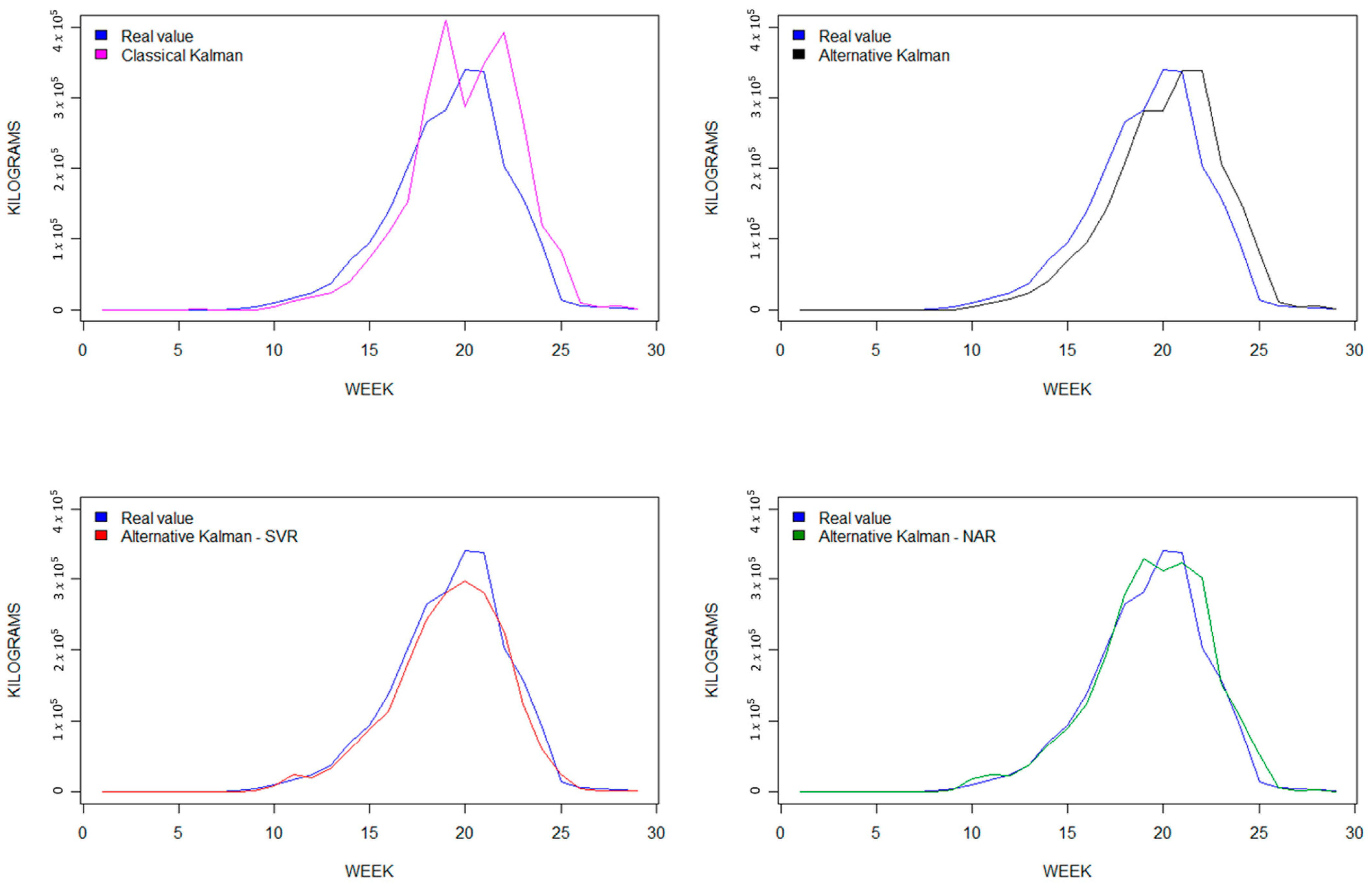
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cucagna, M.; Goldsmith, P. Value adding in the agri-food value chain. Int. Food Agribus. Manag. Rev. 2016, 21, 293–316. [Google Scholar] [CrossRef]
- Fagundes, M.V.C.; Teles, E.O.; de Melo, S.A.V.; Freires, F.G.M. Decision-making models and support systems for supply chain risk: Literature mapping and future research agend. Eur. Res. Manag. Bus. Econ. 2020, 26, 63–70. [Google Scholar] [CrossRef]
- Borrero, J.D.; Mariscal, J. A Case Study of a Digital Data Platform for the Agricultural Sector: A Valuable Decision Support System for Small Farmers. Agriculture 2022, 12, 767. [Google Scholar] [CrossRef]
- Wang, M. Short-term forecast of pig price index on an agricultural internet platform. Agribusiness 2019, 35, 492–497. [Google Scholar] [CrossRef]
- Mishra, R.; Singh, R.K.; Koles, B. Consumer decision-making in Omnichannel retailing: Literature review and future research agenda. Int. J. Consum. Stud. 2021, 45, 147–174. [Google Scholar] [CrossRef]
- Verhoef, P.C.; Kannan, P.K.; Inman, J.J. From multi-channel re-tailing to omni-channel retailing: Introduction to the special issue on multi-channel retailing. J. Retail. 2015, 91, 174–181. [Google Scholar] [CrossRef]
- Jin, D.; Caliskan-Demirag, O.; Chen, F.; Huang, M. Omnichannel retailers’ return policy strategies in the presence of competition. Int. J. Prod. Econ. 2020, 225, 107595. [Google Scholar] [CrossRef]
- Bayram, A.; Cesaret, B. Order fulfilment policies for ship-from-store implementation in omni-channel retailing. Eur. J. Oper. Res. 2021, 294, 987–1002. [Google Scholar] [CrossRef]
- Wang, K.; Li, Y.; Zhou, Y. Execution of Omni-Channel Retailing Based on a Practical Order Fulfillment Policy. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 1185–1203. [Google Scholar] [CrossRef]
- Pereira, M.M.; Frazzon, E.M. Towards a predictive approach for omni-channel retailing supply chains. IFAC-PapersOnLine 2019, 52, 844–850. [Google Scholar] [CrossRef]
- Acimovic, J.; Graves, S.C. Making better fulfilment decisions on the fly in an online retail environment. Manuf. Serv. Oper. Manag. 2015, 17, 34–51. [Google Scholar] [CrossRef]
- Ishfaq, R.; Bajwa, N. Profitability of online order fulfilment in multi-channel retailing. Eur. J. Oper. Res. 2019, 272, 1028–1040. [Google Scholar] [CrossRef]
- Ewald, C.; Zou, Y. Analytic formulas for futures and options for a linear quadratic jump diffusion model with seasonal stochastic volatility and convenience yield: Do fish jump? Eur. J. Oper. Res. 2021, 294, 801–815. [Google Scholar] [CrossRef]
- Borrero, J.D.; Mariscal, J. Deterministic Chaos Detection and Simplicial Local Predictions Applied to Strawberry Production Time Series. Mathematics 2021, 9, 3034. [Google Scholar] [CrossRef]
- Storm, H.; Baylis, K.; Heckelei, T. Machine learning in agricultural and applied economics. Eur. Rev. Agric. Econ. 2020, 47, 842–849. [Google Scholar] [CrossRef]
- Amado, A.; Cortez, P.; Rita, P.; Moro, S. Research trends on big data in marketing: A text mining and topic modeling based literature analysis. Eur. Res. Manag. Bus. Econ. 2018, 24, 1–7. [Google Scholar] [CrossRef]
- Garcia, J.R.; Pacce, M.; Rodrigo, T.; de Aguirre, P.R.; Ulloa, C.A. Measuring and forecasting retail trade in real time using card transactional data. Int. J. Forecast. 2021, 37, 1235–1246. [Google Scholar] [CrossRef]
- Grogger, J. Soda taxes and the prices of sodas and other drinks: Evidence from Mexico. Am. J. Agric. Econ. 2017, 99, 481–498. [Google Scholar] [CrossRef]
- Guizzardi, A.; Pons, F.M.E.; Angelini, G.; Ranieri, E. Big data from dynamic pricing: A smart approach to tourism demand forecasting. Int. J. Forecast. 2021, 37, 1049–1060. [Google Scholar] [CrossRef]
- He, K.; Ji, L.; Wu, C.W.D.; Tso, K.F.G. Using sarima-cnn-lstm approach to forecast daily tourism demand. J. Hosp. Tour. Manag. 2021, 49, 25–33. [Google Scholar] [CrossRef]
- Hernandez-Matamoros, A.; Fujita, H.; Hayashi, T.; Perez-Meana, H. Forecasting of covid19 per regions using arima models and polynomial functions. Appl. Soft Comput. 2020, 96, 106610. [Google Scholar] [CrossRef] [PubMed]
- Jamil, R. Hydroelectricity consumption forecast for pakistan using arima modeling and supply-demand analysis for the year 2030. Renew. Energy 2020, 154, 1–10. [Google Scholar] [CrossRef]
- Li, D.; Jiang, F.; Chen, M.; Qian, T. Multi-step-ahead wind speed forecasting based on a hybrid decomposition method and temporal convolutional networks. Energy 2022, 238, 121981. [Google Scholar] [CrossRef]
- Melchior, C.; Zanini, R.; Rojas-Guerra, R.; Rockenbach, D. Forecasting brazilian mortality rates due to occupational accidents using autoregressive moving average approaches. Int. J. Forecast. 2020, 37, 825–837. [Google Scholar] [CrossRef]
- Sekadakis, M.; Katrakazas, C.; Michelaraki, E.; Kehagia, F.; Yannis, G. Analysis of the impact of COVID-19 on collisions, fatalities and injuries using time series forecasting: The case of Greece. Accid. Anal. Prev. 2021, 162, 106391. [Google Scholar] [CrossRef]
- Yang, H.; O’Connell, J. Short-term carbon emissions forecast for aviation industry in shanghai. J. Clean. Prod. 2020, 275, 122734. [Google Scholar] [CrossRef]
- Mehmood, Q.; Mial, M.; Riaz, M.; Shaheen, N. Forecasting the production of sugarcane crop of Pakistan for the year 2018–2030, using box-jenkings methodology. J. Anim. Plant Sci. 2019, 29, 1396–1401. [Google Scholar]
- Tofael, O.; Chowdhury, A.; Ramesh Chandra, H. A study of auto-regressive integrated moving average (arima) model used for forecasting the production of tomato in Bangladesh. Afr. J. Agron. 2017, 5, 301–309. [Google Scholar]
- Aamir, M.; Shabri, A. Modelling and forecasting monthly crude oil price of Pakistan: A comparative study of arima, garch and arima kalman model. In AIP Conference Proceedings; AIP Publishing LLC: New York, NY, USA, 2016; Volume 1750, p. 060015. [Google Scholar]
- Das, S. Time-varying industry beta in indian stock market and forecasting errors. Int. J. Emerg. Mark. 2015, 10, 521–534. [Google Scholar] [CrossRef]
- Muhammad, A. Using the kalman filter with arima for the COVID-19 pandemic dataset of Pakistan. Data Brief 2020, 31, 105854. [Google Scholar]
- Selvaraj, J.; Arunachalam, V.; Coronado-Franco, K.; Romero-Orjuela, L.; Ramirez-Yara, Y. Time-series modeling of fishery landings in the colombian pacific ocean using an arima model. Reg. Stud. Mar. Sci. 2020, 39, 101477. [Google Scholar] [CrossRef]
- Xu, D.-w.; Wang, Y.-d.; Jia, L.-m.; Qin, Y.; Dong, H.-h. Real-time road traffic state prediction based on arima and kalman filter. Front. Inf. Technol. Electron. Eng. 2017, 18, 287–302. [Google Scholar] [CrossRef]
- Borrero, J.D.; Mariscal, J. Predicting Time Series Using an Automatic New Algorithm of the Kalman Filter. Mathematics 2022, 10, 2915. [Google Scholar] [CrossRef]
- Wang, Z.-X.; Zhao, Y.-F.; He, L.-Y. Forecasting the monthly iron ore import of china using a model combining empirical mode decomposition, non-linear autoregressive neural network, and autoregressive integrated moving average. Appl. Soft Comput. 2020, 94, 106475. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, Y. Corn cash price forecasting with neural networks. Comput. Electron. Agric. 2021, 184, 106120. [Google Scholar] [CrossRef]
- Sunayana, S.; Kumar, R. Forecasting of municipal solid waste generation using non-linear autoregressive (nar) neural models. Waste Manag. 2021, 121, 206–214. [Google Scholar] [CrossRef]
- Alsumaiei, A.A.; Alrashidi, M.S. Hydrometeorological drought forecasting in hyper-arid climates using nonlinear autoregressive neural networks. Water 2020, 12, 2611. [Google Scholar] [CrossRef]
- Khan, F.; Gupta, R. Arima and nar based prediction model for time series analysis of COVID-19 cases in India. J. Saf. Sci. Resil. 2020, 1, 12–18. [Google Scholar] [CrossRef]
- Taheri, S.; Brodie, G.; Gupta, D. Optimised ann and svr models for online prediction of moisture content and temperature of lentil seeds in a microwave fluidised bed dryer. Comput. Electron. Agric. 2021, 182, 106003. [Google Scholar] [CrossRef]
- Yu, Z.; Yang, K.; Luo, Y.; Shang, C. Spatial-temporal process simulation and prediction of chlorophyll-a concentration in dianchi lake based on wavelet analysis and long-short term memory network. J. Hydrol. 2020, 582, 124488. [Google Scholar] [CrossRef]
- Valente, J.; Maldonado, S. Svr-ffs: A novel forward feature selection approach for high-frequency time series forecasting using support vector regression. Expert Syst. Appl. 2020, 160, 113729. [Google Scholar] [CrossRef]
- Yu, L.; Liang, S.; Chen, R.; Lai, K.K. Predicting monthly biofuel production using a hybrid ensemble forecasting methodology. Int. J. Forecast. 2019, 38, 3–20. [Google Scholar] [CrossRef]
- Chen, W.; Xu, H.; Jia, L.; Gao, Y. Machine learning model for bitcoin ex- change rate prediction using economic and technology determinants. Int. J. Forecast. 2021, 37, 28–43. [Google Scholar] [CrossRef]
- Hess, A.; Spinler, S.; Winkenbach, M. Real-time demand forecasting for an urban delivery platform. Transp. Res. Part E Logist. Transp. Rev. 2021, 145, 102147. [Google Scholar] [CrossRef]
- Jin, Z.; Guo, K.; Sun, Y.; Lai, L.; Liao, Z. The industrial asymmetry of the stock price prediction with investor sentiment: Based on the comparison of predictive effects with svr. J. Forecast. 2020, 39, 1166–1178. [Google Scholar] [CrossRef]
- Das, P.; Chanda, K. Bayesian network based modeling of regional rainfall from multiple local meteorological drivers. J. Hydrol. 2020, 591, 125563. [Google Scholar] [CrossRef]
- Dhiman, H.; Deb, D.; Guerrero, J. Hybrid machine intelligent svr variants for wind forecasting and ramp events. Renew. Sustain. Energy Rev. 2019, 108, 369–379. [Google Scholar] [CrossRef]
- Abbasi, M.; Farokhnia, A.; Bahreinimotlagh, M.; Roozbahani, R. A hybrid of random forest and deep auto-encoder with support vector regression methods for accuracy improvement and uncertainty reduction of long-term streamflow prediction. J. Hydrol. 2020, 597, 125717. [Google Scholar] [CrossRef]
- Barzegar, R.; Aalami, M.; Adamowski, J. Coupling a hybrid cnn-lstm deep learning model with a boundary corrected maximal overlap discrete wavelet transform for multiscale lake water level forecasting. J. Hydrol. 2021, 598, 126196. [Google Scholar] [CrossRef]
- Lee, T.; Shin, J.-y.; Kim, J.-S.; Singh, V. Stochastic simulation on re-producing long-term memory of hydroclimatological variables using deep learning model. J. Hydrol. 2020, 582, 124540. [Google Scholar] [CrossRef]
- Piri, J.; Pirzadeh, B.; Keshtegar, B.; Givehchi, M. A hybrid statistical regression technical for prediction wastewater inflow. Comput. Electron. Agric. 2021, 184, 106115. [Google Scholar] [CrossRef]
- Wu, T.; Zhang, W.; Jiao, X.; Guo, W.; Alhaj Hamoud, Y. Evaluation of stacking and blending ensemble learning methods for estimating daily reference evapotranspiration. Comput. Electron. Agric. 2021, 184, 106039. [Google Scholar] [CrossRef]
- Balli, S. Data analysis of COVID-19 pandemic and short-term cumulative case forecasting using machine learning time series methods. Chaos Solitons Fractals 2021, 142, 110512. [Google Scholar] [CrossRef]
- Dubois, A.; Teytaud, F.; Verel, S. Short term soil moisture forecasts for potato crop farming: A machine learning approach. Comput. Electron. Agric. 2021, 180, 105902. [Google Scholar] [CrossRef]
- Liu, Y.; Duan, Q.; Wang, D.; Zhang, Z.; Liu, C. Prediction for hog prices based on similar sub-series search and support vector regression. Comput. Electron. Agric. 2019, 157, 581–588. [Google Scholar] [CrossRef]
- Priyadarshi, R.; Panigrahi, A.; Routroy, S.; Garg, G. Demand forecasting at retail stage for selected vegetables: A performance analysis. J. Model. Manag. 2019, 14, 1042–1063. [Google Scholar] [CrossRef]
- Shao, Y.; Xiong, T.; Li, M.; Hayes, D.; Zhang, W.; Xie, W. China’s missing pigs: Correcting china’s hog inventory data using a machine learning approach. Am. J. Agric. Econ. 2020, 103, 1082–1098. [Google Scholar] [CrossRef]
- Xu, S.; Chan, H.; Zhang, T. Forecasting the demand of the aviation industry using hybrid time series sarima-svr approach. Transp. Res. Part E Logist. Transp. Rev. 2018, 122, 169–180. [Google Scholar] [CrossRef]
- Nichiforov, C.; Stamatescu, I.; Fagarasan, I.; Stamatescu, G. Energy consumption forecasting using arima and neural network models. In Proceedings of the 5th International Symposium on Electrical and Electronics Engineering (ISEEE), Galaţi, Romania, 20–22 October 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Khan, M.M.H.; Muhammad, N.S.; El-Shafie, A. Wavelet based hybrid ann-arima models for meteorological drought forecasting. J. Hydrol. 2020, 590, 125380. [Google Scholar] [CrossRef]
- Li, Z.; Han, J.; Song, Y. On the forecasting of high frequency financial time series based on arima model improved by deep learning. J. Forecast. 2020, 39, 1081–1097. [Google Scholar] [CrossRef]
- Fang, Y.; Guan, B.; Wu, S.; Heravi, S. Optimal forecast combination based on ensemble empirical mode decomposition for agricultural commodity futures prices. J. Forecast. 2020, 39, 877–886. [Google Scholar] [CrossRef]
- Gopal, P.; Bhargavi, R. A novel approach for efficient crop yield prediction. Comput. Electron. Agric. 2019, 165, 104968. [Google Scholar] [CrossRef]
- Sujjaviriyasup, T.; Pitiruek, K. Hybrid arima-support vector machine model for agricultural production planning. Appl. Math. Sci. 2013, 7, 2833–2840. [Google Scholar] [CrossRef]
- Wang, Z.; Walsh, K.; Koirala, A. Mango fruit load estimation using a video based mangoyolo-kalman filter-hungarian algorithm method. Sensors 2019, 19, 2742. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Crane-Droesch, A. Machine learning methods for crop yield prediction and climate change impact assessment in agriculture. Environ. Res. Lett. 2018, 13, 114003. [Google Scholar] [CrossRef]
- Jeong, J.H.; Resop, J.P.; Mueller, N.D.; Fleisher, D.H.; Yun, K.; Butler, E.E.; Timlin, D.J.; Shim, K.-M.; Gerber, J.S.; Reddy, V.R. Random forests for global and regional crop yield predictions. PLoS ONE 2016, 11, e0156571. [Google Scholar] [CrossRef]
- Zheng, C.; Abd-Elrahman, A.; Whitaker, V. Remote Sensing and Machine Learning in Crop Phenotyping and Management, with and Emphasis on Applications in Strawberry. Remote Sens. 2021, 13, 531. [Google Scholar] [CrossRef]
- Johansen, K.; Morton, M.J.L.; Malbeteau, Y.; Aragon, B.; Al-Mashharawi, S.; Ziliani, M.G.; Angel, Y.; Fiene, G.; Negrão, S.; Mousa, M.A.A.; et al. Predicting Biomass and Yield in a Tomato Phenotyping Experiment Using UAV Imagery and Random Forest. Front. Artif. Intell. 2020, 3, 28. [Google Scholar] [CrossRef]
- Nevavuori, P.; Narra, N.; Lipping, T. Crop yield prediction with deep convolutional neural networks. Comput. Electron. Agric. 2019, 163, 104859. [Google Scholar] [CrossRef]
- Silva, P.T.P.; Oliveira, G.E.; Peloia, P.R.; Carvalho, R.C.; Gonçalves, F.M.A. Yield prediction of experimental plots based on the harvest of specific fruit clusters for selection of fresh market tomato hybrids. Hortic. Bras. 2021, 39, 58–64. [Google Scholar] [CrossRef]
- Tsutsumi-Morita, Y.; Heuvelink, E.; Khaleghi, S.; Bustos-Korts, D.; Marcelis, L.F.M.; Vermeer, K.M.C.A.; Van Dijk, H.; Millenaar, F.F.; Van Voorn, G.A.K.; Van Eeuwijk, F.A. Yield dissection models to improve yield: A case study in tomato. Silico Plants 2021, 3, diab012. [Google Scholar] [CrossRef]
- Jo, J.S.; Kim, D.S.; Jo, W.J.; Sim, H.S.; Lee, H.J.; Moon, Y.H.; Woo, U.J.; Jung, S.B.; Kim, S.; Mo, X.; et al. Prediction of strawberry fruit yield based on cultivar-specific growth models in the tunnel-type greenhouse. Hortic. Environ. Biotechnol. 2022, 63, 467–476. [Google Scholar] [CrossRef]
- Obsie, E.Y.; Qu, H.; Drummond, F. Wild blueberry yield prediction using a combination of computer simulation and machine learning algorithms. Comput. Electron. Agric. 2020, 178, 105778. [Google Scholar] [CrossRef]
- Sim, H.S.; Kim, D.S.; Ahn, M.G.; Ahn, S.R.; Kim, S.K. Prediction of strawberry growth and fruit yield based on environmental and growth data in a greenhouse for soil cultivation with applied autonomous facilities. Hortic. Sci. Technol. 2020, 38, 840–849. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
- Johnson, M.D.; Hsieh, W.W.; Cannon, A.J.; Davidson, A.; Bédard, F. Crop yield forecasting on the Canadian Prairies by remotely sensed vegetation indices and machine learning methods. Agric. For. Meteorol. 2016, 218, 74–84. [Google Scholar] [CrossRef]
- Kamilaris, A.; Kartakoullis, A.; Prenafeta-Boldu, F.X. A review on the practice of big data analysis in agriculture. Comput. Electron. Agric. 2017, 143, 23–37. [Google Scholar] [CrossRef]
- Hara, P.; Piekutowska, M.; Niedbała, G. Selection of Independent Variables for Crop Yield Prediction Using Artificial Neural Network Models with Remote Sensing Data. Land 2021, 10, 609. [Google Scholar] [CrossRef]
- Abraham, E.; Reis, J.; de Souza, A.; Morais, M.; Vendrametto, O.; Neto, P.; Toloi, R. Time series prediction with artificial neural networks: An analysis using brazilian soybean production. Agriculture 2020, 10, 475. [Google Scholar] [CrossRef]
- Chu, X.; Li, Y.; Tian, D.; Feng, J.; Mu, W. An optimized hybrid model based on artificial intelligence for grape price forecasting. Br. Food J. 2019, 121, 3247–3265. [Google Scholar] [CrossRef]
- Mahto, A.; Alam, M.A.; Biswas, R.; Ahmed, J.; Alam, S.I. Short-term forecasting of agriculture commodities in context of indian market for sustainable agriculture by using the artificial neural network. J. Food Qual. 2021, 2021, 9939906. [Google Scholar] [CrossRef]
- Maldaner, L.; Corredo, L.; Canata, T.; Molin, J. Predicting the sugarcane yield in real-time by harvester engine parameters and machine learning approaches. Comput. Electron. Agric. 2021, 181, 105945. [Google Scholar] [CrossRef]
- Yin, H.; Jin, D.; Gu, Y.H.; Park, C.J.; Han, S.K.; Yoo, S.J. STL-ATTLSTM: Vegetable Price Forecasting Using STL and Attention Mechanism-Based LSTM. Agriculture 2020, 10, 612. [Google Scholar] [CrossRef]
- INE. Instituto Nacional de Estadística. (2022), Censo Agrario Año. 2020. Available online: https://www.ine.es/censoagrario2020/presentacion/index.htm (accessed on 31 August 2022).
- Borrero, J.D.; Zabalo, A. Identification and Analysis of Strawberries’ Consumer Opinions on Twitter for Marketing Purposes. Agronomy 2021, 11, 809. [Google Scholar] [CrossRef]
- Borrero, J.D. Agri-food Cooperatives’ Online marketing: Evaluation of the Strategies Utilized by Spanish and UK Food Retailers pre and post COVID-19 pandemic. CIRIEC-España Rev. Econ. Pública Soc. Y Coop. 2022, 107, 169–195. [Google Scholar] [CrossRef]
- Smyl, S. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. Int. J. Forecast. 2020, 36, 75–85. [Google Scholar] [CrossRef]
- Xu, W.; Peng, H.; Zeng, X.; Zhou, F.; Tian, X.; Peng, X. A hybrid modelling method for time series forecasting based on a linear regression model and deep learning. Appl. Intell. 2019, 49, 3002–3015. [Google Scholar] [CrossRef]
- Zhai, H.; Tian, R.; Cui, L.; Xu, X.; Zhang, W. A Novel Hierarchical Hybrid Model for Short-Term Bus Passenger Flow Forecasting. J. Adv. Transp. 2020, 2020, 7917353. [Google Scholar] [CrossRef]
- Firmino, P.R.A.; de Mattos Neto, P.S.G.; Ferreira, T.A.E. Error modeling approach to improve time series forecasters. Neurocomputing 2015, 153, 242–254. [Google Scholar] [CrossRef]
- Khashei, M.; Bijari, M. A novel hybridization of artificial neural networks and ARIMA models for time series forecasting. Appl. Soft Comput. 2011, 11, 2664–2675. [Google Scholar] [CrossRef]
- Mokhtarzad, M.; Eskandari, F.; Vanjani, N.J.; Arabasadi, A. Drought forecasting by ANN, ANFIS, and SVM and comparison of the models. Environ. Earth Sci. 2017, 76, 729. [Google Scholar] [CrossRef]
- Ruiz-Aguilar, J.; Turias, I.; Jimenez-Come, M. Hybrid approaches based on sarima and artificial neural networks for inspection time series forecasting. Transp. Res. Part E Logist. Transp. Rev. 2014, 67, 1–13. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Hamilton, J.D. Chapter 50 state-space models. Handbook of Econometrics 1994, 4, 3039–3080. [Google Scholar] [CrossRef]
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. Trans. ASME J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Trenn, S. Multilayer perceptrons: Approximation order and necessary number of hidden units. IEEE Trans. Neural Netw. 2008, 19, 836–844. [Google Scholar] [CrossRef]
- Sun, Z.; Li, K.; Li, Z. Prediction of horizontal displacement of foundation pit based on nar dynamic neural network. IOP Conf. Ser. Mater. Sci. Eng. 2020, 782, 042032. [Google Scholar] [CrossRef]
- Wongsathan, R.; Seedadan, I. A hybrid arima and neural networks model for pm-10 pollution estimation: The case of chiang mai city moat area. Procedia Comput. Sci. 2016, 86, 273–276. [Google Scholar] [CrossRef]
- Kierczynska, S. Relations between producers and processors in terms of fruit production and prices of fruits for processing in Poland. J. Agribus. Rural Dev. 2019, 54, 307–317. [Google Scholar] [CrossRef]
- Willer, H.; Schaak, D.; Lernoud, J. Organic farming and market development in europe and the european union. In Organics International: The World of Organic Agriculture; Frick and Bonn: Frick, Switzerland, 2018; pp. 217–250. [Google Scholar]
- Castillo, C.; Pérez, R.; Vallejo-Orti, M. The impact of recent gully filling practices on wheat yield at the campiña landscape in southern Spain. Soil Tillage Res. 2021, 212, 105041. [Google Scholar] [CrossRef]
- Feng, L.; Wang, Y.; Zhang, Z.; Du, Q. Geographically and temporally weighted neural network for winter wheat yield prediction. Remote Sens. Environ. 2021, 262, 112514. [Google Scholar] [CrossRef]
- Kassem, Y.; Gökcekus, H.; Alassi, E. Identifying most influencing input parameters for predicting cereal production using an artificial neural network model. Model. Earth Syst. Environ. 2021, 8, 1157–1170. [Google Scholar] [CrossRef]
- Piekutowska, M.; Niedbala, G.; Piskier, T.; Lenartowicz, T.; Pilarski, K.; Wojciechowski, T.; Pilarska, A.A.; Czechowska-Kosacka, A. The application of multiple linear regression and artificial neural network models for yield prediction of very early potato cultivars before harvest. Agronomy 2021, 11, 885. [Google Scholar] [CrossRef]
- Shafiee, S.; Lied, L.; Burud, I.; Dieseth, J.A.; Alsheikh, M.; Lillemo, M. Sequential forward selection and support vector regression in comparison to lasso regression for spring wheat yield prediction based on uav imagery. Comput. Electron. Agric. 2021, 183, 106036. [Google Scholar] [CrossRef]
- Khiem, N.M.; Takahashi, Y.; Dong, K.T.P.; Yasuma, H.; Kimura, N. Predicting the price of vietnamese shrimp products exported to the us market using machine learning. Soil Tillage Res. 2021, 87, 411–423. [Google Scholar] [CrossRef]
- Wang, B.; Liu, P.; Chao, Z.; Junmei, W.; Chen, W.; Cao, N.; O’Hare, G.; Wen, F. Research on hybrid model of garlic short-term price forecasting based on big data. Comput. Mater. Contin. 2018, 57, 283–296. [Google Scholar] [CrossRef]
- Abd-Elrahman, A.; Wu, F.; Agehara, S.; Britt, K. Improving Strawberry Yield Prediction by Integrating Ground-Based Canopy Images in Modeling Approaches. ISPRS Int. J. Geo-Inf. 2021, 10, 239. [Google Scholar] [CrossRef]
- Abolghasemi, M.; Beh, E.; Tarr, G.; Gerlach, R. Demand forecasting in supply chain: The impact of demand volatility in the presence of promotion. Comput. Ind. Eng. 2020, 142, 106380. [Google Scholar] [CrossRef]
- Anggraeni, W.; Mahananto, F.; Sari, A.Q.; Zaini, Z.; Andri, K.B. Forecasting the price of indonesias rice using hybrid artificial neural network and autoregressive integrated moving average (hybrid nns-arimax) with exogenous variables. Procedia Comput. Sci. 2019, 161, 677–686. [Google Scholar] [CrossRef]
- Chiu, L.-Y.; Rustia, D.J.; Lu, C.-Y.; Lin, T.-T. Modelling and forecasting of greenhouse whitefly incidence using time-series and arimax analysis. IFAC-PapersOnLine 2019, 52, 196–201. [Google Scholar] [CrossRef]
- Alarcon, V.J. Hindcasting and forecasting total suspended sediment con- centrations using a narx neural network. Sustainability 2021, 13, 363. [Google Scholar] [CrossRef]
- Bucci, A. Cholesky-ann models for predicting multivariate realized volatility. J. Forecast. 2020, 39, 865–876. [Google Scholar] [CrossRef]
- Canchala, T.; Alfonso-Morales, W.; Carvajal-Escobar, Y.; Cerón, W.L.; Caicedo-Bravo, E. Monthly rainfall anomalies forecasting for southwestern Colombia using artificial neural networks approaches. Water 2020, 12, 2628. [Google Scholar] [CrossRef]
- Heidari, E.; Daeichian, A.; Sobati, M.; Movahedirad, S. Prediction of the droplet spreading dynamics on a solid substrate at irregular sampling intervals: Nonlinear auto-regressive exogenous artificial neural network approach (narx-ann). Chem. Eng. Res. Des. 2020, 156, 263–272. [Google Scholar] [CrossRef]
- Ma, Q.; Liu, S.; Fan, X.; Chai, C.; Wang, Y.; Yang, K. A time series pre-diction model of foundation pit deformation based on empirical wavelet transform and narx network. Mathematics 2020, 8, 1535. [Google Scholar] [CrossRef]
- Mustapa, R.; Dahlan, N.; Yassin, A.; Mohd Nordin, A.H. Quantification of energy savings from an awareness program using narx-ann in an educational building. Energy Build. 2020, 215, 109899. [Google Scholar] [CrossRef]
- Yetkin, M.; Kim, Y. Time series prediction of mooring line top tension by the narx and volterra model. Appl. Ocean Res. 2019, 88, 170–186. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Stephan, D.; Hinkelmann, R. Multivariate narx neural network in prediction gaseous emissions within the influent chamber of wastewater treatment plants. Atmos. Pollut. Res. 2019, 10, 1812–1822. [Google Scholar] [CrossRef]
- Hennig, M.; Grafinger, M.; Hofmann, R.; Gerhard, D.; Dumss, S.; Rosenberger, P. Introduction of a time series machine learning methodology for the application in a production system. Adv. Eng. Inform. 2021, 47, 101197. [Google Scholar] [CrossRef]
- Larrea, M.; Porto, A.; Irigoyen, E.; Barragán, A.J.; Andújar, J.M. Extreme learning machine ensemble model for time series forecasting boosted by pso: Application to an electric consumption problem. Neurocomputing 2020, 452, 465–472. [Google Scholar] [CrossRef]
- Milunovich, G. Forecasting australia’s real house price index: A comparison of time series and machine learning methods. J. Forecast. 2020, 39, 1098–1118. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, M.; Yang, Y. Machine learning for multiphase flowrate estimation with time series sensing data. Meas. Sens. 2020, 10, 100025. [Google Scholar] [CrossRef]
- Zhong-Kai, F.; Wen-Jing, N.; Zheng-Yang, T.; Yang, X.; Hai-Rong, Z. Evolutionary artificial intelligence model via cooperation search algorithm and extreme learning machine for multiple scales nonstationary hydrological time series prediction. J. Hydrol. 2021, 595, 126062. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | R2 | MAE | RMSE |
|---|---|---|---|
| Classical Kalman filter (KF) | 0.899 | 52,906.00 | 90,847.01 |
| Alternative Kalman filter (AKF) | 0.953 | 36,901.74 | 62,269.74 |
| Hybrid AKF-SVR | 0.954 | 35,147.71 | 61,339.73 |
| Hybrid AKF-NAR | 0.954 | 35,640.53 | 61,311.99 |
| Model | R2 | MAE | RMSE |
|---|---|---|---|
| Classical Kalman filter (KF) | 0.938 | 12,576.67 | 25,323.00 |
| Alternative Kalman filter (AKF) | 0.947 | 11,037.77 | 23,419.50 |
| Hybrid AKF-SVR | 0.980 | 6772.14 | 14,248.64 |
| Hybrid AKF-NAR | 0.960 | 9324.95 | 20,425.92 |
| Model | R2 | MAE | RMSE |
|---|---|---|---|
| Classical Kalman filter (KF) | 0.783 | 27,351.50 | 51,876.18 |
| Alternative Kalman filter (AKF) | 0.880 | 22,108.33 | 38,562.61 |
| Hybrid AKF-SVR | 0.973 | 10,677.06 | 18,150.67 |
| Hybrid AKF-NAR | 0.958 | 10,768.47 | 22,706.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Borrero, J.D.; Borrero-Domínguez, J.-D. Enhancing Short-Term Berry Yield Prediction for Small Growers Using a Novel Hybrid Machine Learning Model. Horticulturae 2023, 9, 549. https://doi.org/10.3390/horticulturae9050549
Borrero JD, Borrero-Domínguez J-D. Enhancing Short-Term Berry Yield Prediction for Small Growers Using a Novel Hybrid Machine Learning Model. Horticulturae. 2023; 9(5):549. https://doi.org/10.3390/horticulturae9050549
Chicago/Turabian StyleBorrero, Juan D., and Juan-Diego Borrero-Domínguez. 2023. "Enhancing Short-Term Berry Yield Prediction for Small Growers Using a Novel Hybrid Machine Learning Model" Horticulturae 9, no. 5: 549. https://doi.org/10.3390/horticulturae9050549
APA StyleBorrero, J. D., & Borrero-Domínguez, J.-D. (2023). Enhancing Short-Term Berry Yield Prediction for Small Growers Using a Novel Hybrid Machine Learning Model. Horticulturae, 9(5), 549. https://doi.org/10.3390/horticulturae9050549