1. Introduction
One of the most important research questions in the wine related area is the ranking, rating and judging of wine. Questions such as, “Who is a reliable wine judge? Are wine judges consistent? Do wine judges agree with each other?” are required for formal statistical answers according to the Journal of Wine Economics [
1]. In the past decade, many researchers focused on these problems with small to medium sized wine datasets [
2,
3,
4,
5]. However, to the best of our knowledge, no research is being performed on analyzing the consistency of wine judges with a large-scale dataset. As a prestigious magazine in the wine field, WineSpectator.com contains more than 370,000 wine reviews. The research presented in this paper investigates the consistency of the wine being considered as “outstanding” or “extraordinary” for the past 10 years in Wine Spectator. It will not only analyze Wine Spectator as a whole but also examine all 10 reviewers in Wine Spectator and rank their consistency.
In order to process the large amount of data, techniques in data science will be utilized to discover useful information from domain-related data. Data science is a field of study that incorporates varying techniques and theories from distinct fields, such as Data Mining, Scientific Methods, Math and Statistics, Visualization, natural language processing and Domain Knowledge. Among all components in data science, domain knowledge is the key to create high quality data products by data scientists [
6,
7]. Based on different domain knowledge, new information is revealed in daily life through data science research; for instance, mining useful information from the reviews of restaurants [
8], movies [
9] and music [
10]. In this paper, the domain knowledge is about wine.
The quality of the wine is usually assured by the wine certification, which is generally assessed by physicochemical and sensory tests [
11]. Physicochemical laboratory tests routinely used to characterize wine include determination of density, alcohol or pH values, while sensory tests rely mainly on human experts [
12].
Figure 1 provides an example for a wine review in both perspectives.
Currently, almost all existing data mining research is focused on physicochemical laboratory tests [
11,
12,
13,
14,
15]. This focus is because of the dataset availability. The most popular dataset used in wine related research is stored in the UCI Machine Learning Repository [
16]. Chemical values can be measured and stored by a number, while sensory tests produce results that are difficult to enumerate with precision. However, based on
Figure 1, sensory analysis is much more interesting to wine consumers and distributors because they describe aesthetics, pleasure, complexity, color, appearance, odor, aroma, bouquet, tartness and the interactions with the senses of these characteristics of the wine [
14].
To the best of our knowledge, little related research has been conducted on the contents of wine sensory reviews, which is stored in a human language format. Ramirez [
17] did a research in finding the correlation between the length of the tasting notes and wine’s price; however, no contents of the review are analyzed. Researchers have mentioned that “it should be stressed that taste is the least understood of the human senses, thus wine classification is a difficult task” [
11]. Therefore, the key to the success of the wine sensory related research relies on consistent reviews from prestigious experts, in other words, judges that can be trusted. Several popular wine magazines provide widely accepted sensory reviews of wines produced every year, such as Wine Spectator, Wine Advocate, Decanter, Wine enthusiast and so forth. Although the sensory reviews are stored in human-language format, which requires special methods to extract attributes to represent the wine, the large amount of existing sensory reviews makes finding interesting wine patterns/information possible.
Wine sensory reviews consist of the score summaries of a wine’s overall quality and the testing note describes the wine’s style and character. The score is a rating within a 100-point scale to reflect how highly its reviewers regard the wine’s potential quality relative to other wines in the same category. Below is an example wine sensory review with bolded key attributes of the number one wine of 2014 as named in Wine Spectator.
Dow’s Vintage Port 2011 99 pts.
Powerful, refined and luscious, with a surplus of dark plum, kirsch and cassis flavors that are unctuous and long. Shows plenty of grip, presenting a long, full finish, filled with Asian spice and raspberry tart accents. Rich and chocolaty. One for the ages. Best from 2030 through 2060.
16,000 wine sensory reviews are produced by Wine Spectator each year. Wine Spectator’s publicly available database currently has more than 370,000 reviews. Similar size data is available on other prestigious wine review magazines such as Wine Advocate and Decanter. Therefore, more than a million wine sensory reviews are currently considered as “raw data”. It is impossible to manually pick out attributes for all wine reviews. However, extracting important key words from the wine sensory review automatically is challenging. This process needs to include not only the flavors, such as DARK PLUM, KIRSCH, CASSIS, ASIAN SPICE, RASPBERRY TART but also non-flavor notes like LONG FINISH and FULL FINISH. Furthermore, different descriptions in human language are considered to have the same attributes from an expert’s point of view, while other descriptions are considered distinct. An example would be that FRESHLY CUT APPLE, RIPE APPLE and APPLE represent the same attribute “Apple”, but GREEN APPLE is categorized as “GREEN APPLE” since it is a unique flavor.
In our previous work [
18,
19,
20,
21], a new data science application domain named “Wineinformatics” was proposed that incorporated data science and wine related datasets, including physicochemical laboratory data and wine reviews. A mechanism was developed to extract wine attributes automatically from wine sensory reviews. This produced small to medium sized (250–1000 wines) brand new datasets of wine attributes, such as wine region or grape-type specific. Then, various data science techniques were applied to discover the information that could benefit society including wine producers, distributors and consumers. This information may be used to answer the following questions: “Why do wines achieve a 90+ rating? What are the shared similarities among groups of wine and what wines are suggested to the consumer? What are the differences in character between wines from Bordeaux, France and Napa, United States?”
In this paper, a new dataset will be constructed which contains more than 100,000 wines. It will consist of ALL wines from 2006–2015 with 80+ scores. This new dataset will be used to investigate the consistency of the wine being considered as “outstanding” or “extraordinary” in Wine Spectator. Furthermore, individual reviewers will be examined to rate and rank their consistency and discover the preferred wine characteristics for each reviewer. We believe this is the first paper that performs Quantitative Analysis of Wine Reviewers in a large-scale dataset.
3. Results
3.1. Naïve Bayes
Naïve Bayes has been identified as the most suitable white-box classification algorithm in Wineinformatics from the previous research (Chen et al., 2016B) [
21] since the algorithm usually constructs the most reliable model and equips the ability to explain the importance of each attribute.
The Naïve Bayes algorithm is applied to determine the consistency for each of Wine Spectator’s wine reviewers. All reviews are collected for each reviewer (summarized in
Table 2) and five-fold cross validation is run, which will select 20% of the data as the testing dataset and use the other 80% of the data to train the Naïve Bayes algorithm for prediction of the testing dataset. The process will be executed 5 times in total. Each time it will select a testing dataset that has never been included in the previous cross-validation. Therefore, all data will be tested exactly once. The final evaluation metrics are calculated based on the average of each cross-validation results. Having more consistent wine reviews from each wine reviewer will lead to a more accurate classification model which will yield better evaluation results for the testing dataset.
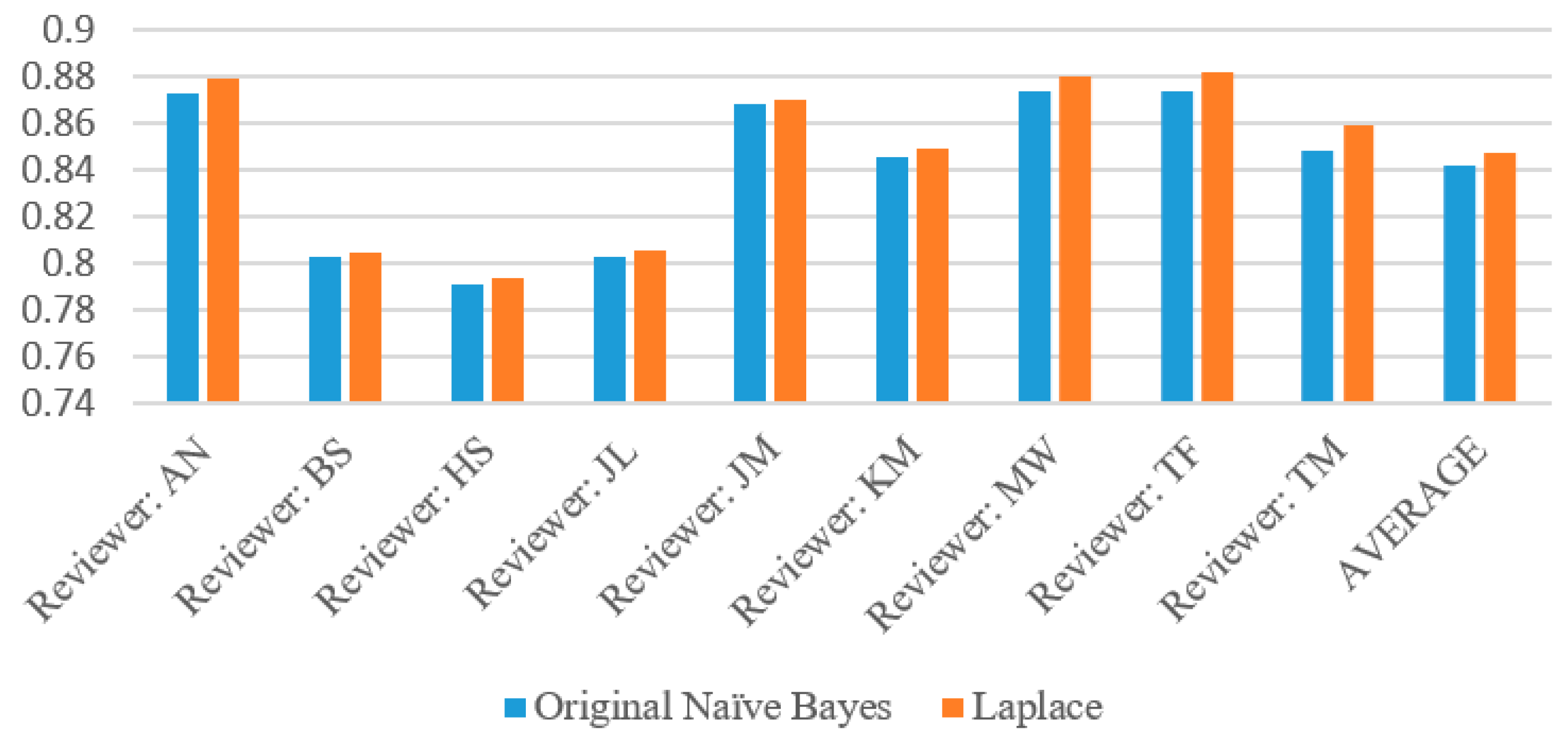
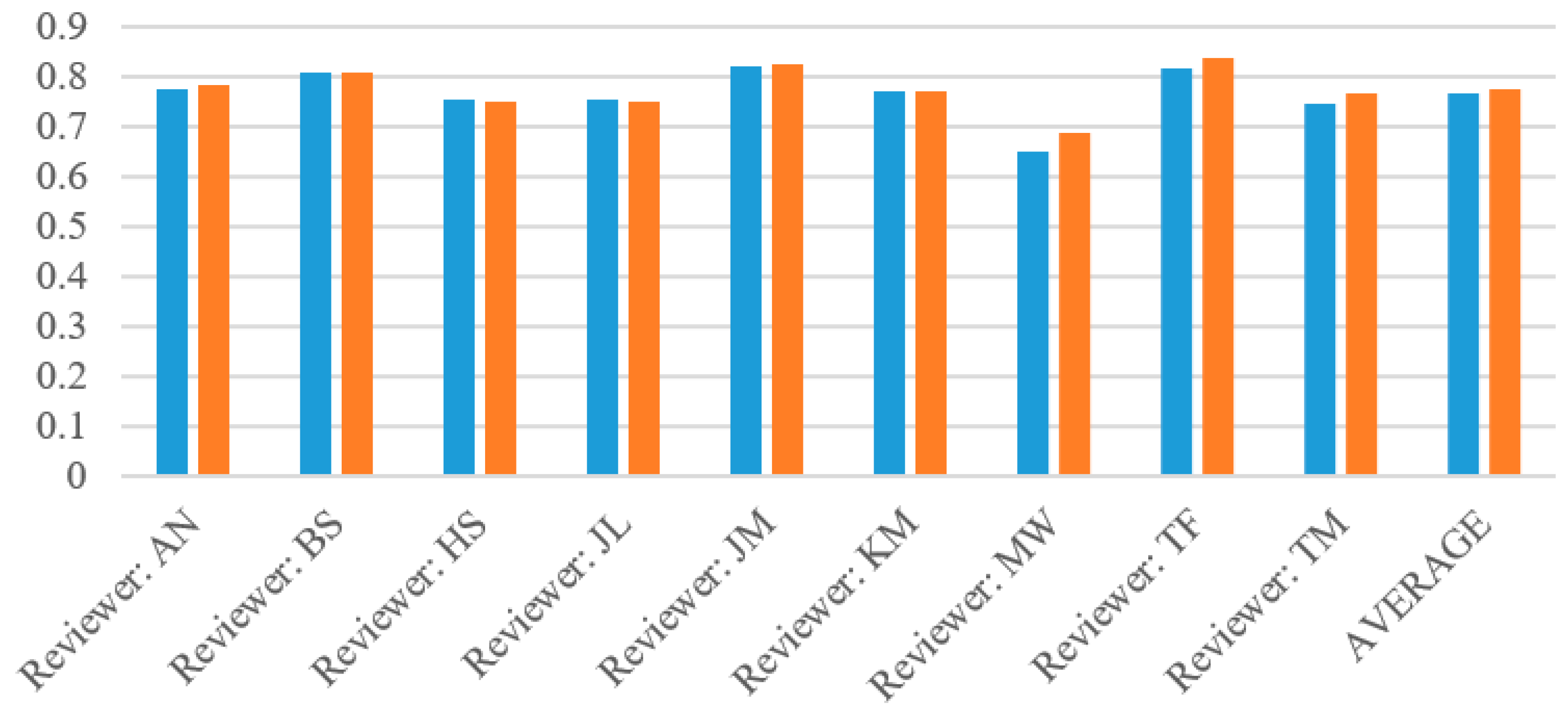
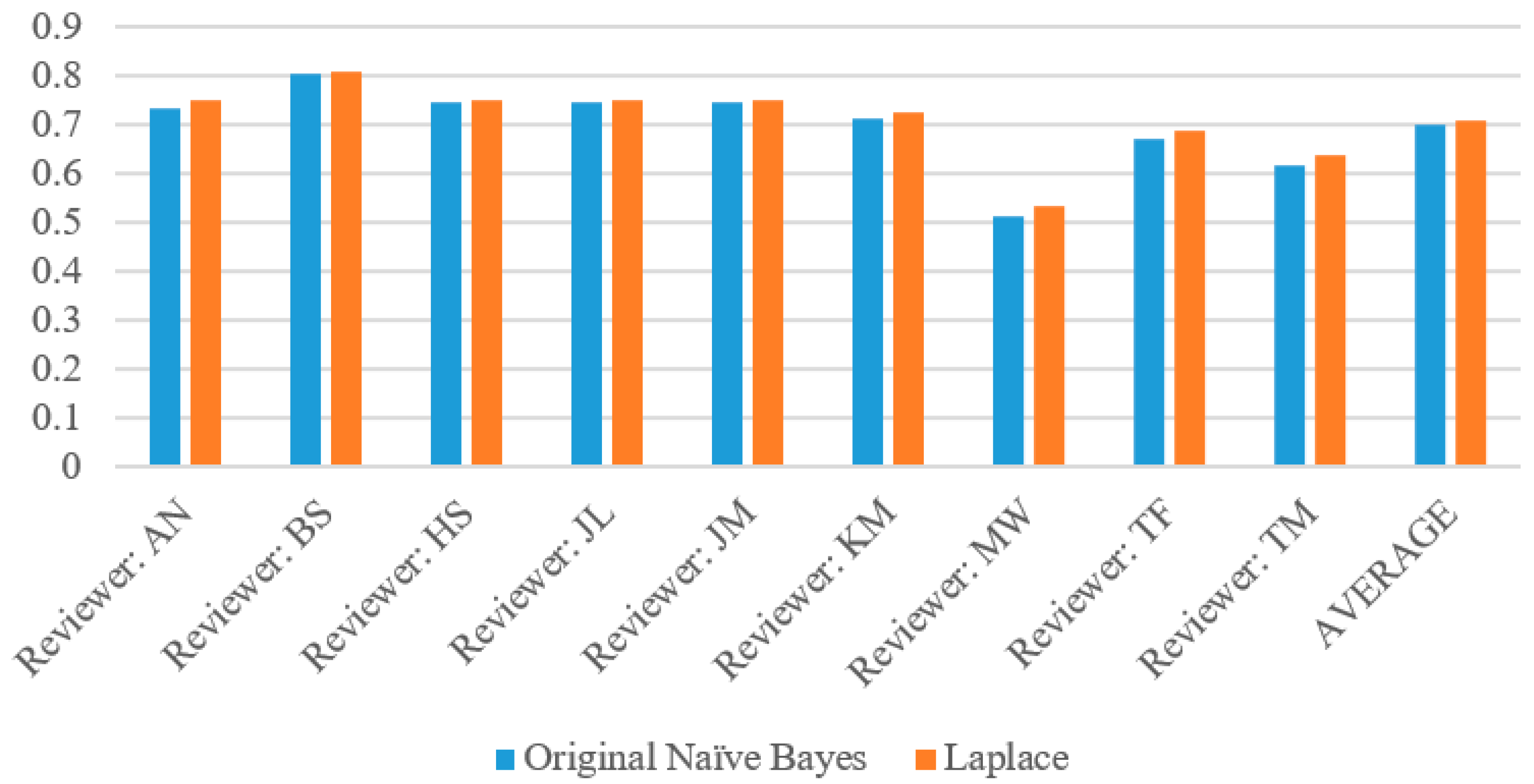
The complete evaluation results for each wine reviewer based on Naïve Bayes algorithm with and without Laplace are given in
Table 4. Across all reviewers, the Naïve Bayes Original algorithm performed slightly worse than the Laplace. This is due to the parameter (
k = 1) adding slightly extra weight to zero attribute probabilities so that the above or below probability does not go to zero. Among all of these reviewers, there were only 49 instances of the probabilities of the original Naïve Bayes tied (specifically, with both at zero) and zero instances of Laplace’s probabilities tied. These are the instances where both the above and below probabilities had zero attributes (which Laplace corrected for), so the program was forced to perform a virtual coin flip whereas the Laplace implementation did not have this problem.
The most reliable reviewer in this instance was Tim Fish, who had an accuracy of 87.37% with the original version of the algorithm and 88.16% with the Laplace version, as
Table 4 demonstrates. However, MaryAnn Worobiec was a very close second with 87.36% and 88.04% respectively. Mining this type of information can give insight into which reviewers give precise descriptions in their reviews and with enough data collected on the reviewers, one could rank them by their reliability. In this case, by order of accuracy as shown in
Table 5, these would be TF, MW, AN, JM, TM, KM, JL, BS, HS. To the best of our knowledge, this is the very first paper to rank different judges based on their large amount of reviews through data science methods.
Due to the skew of these datasets, with the vast majority of wines being below 90, or in the “false” prediction category, our results generally reflected high specificity, mediocre precision and low recall. However, reviewer Bruce Sanderson remained the most consistent for our predictions despite the skew, with precision, recall and specificity all within one percentage point for both the original Naïve Bayes and the Laplace correction.
Figure 5,
Figure 6,
Figure 7 and
Figure 8 show the accuracy, precision, recall and specificity respectively of each reviewer as summarized from
Table 4. The graphs of accuracy and specificity highly correlate due to the greater sample size of below 90 wines. All of the reviewers had a very high precision, generally around 80%, with the exception of MaryAnn Worobiec, one of the two higher scoring reviewers. The recall graph appears very similar to the precision graph for each reviewer.
We also ran through the program in order to test which attributes for each reviewer correlated at positively (were likely to have a 90 or higher rating) at least 90% of the time with at least 30 instances of the attribute. For example,
Table 6 shows that the attribute Intense correlates to an above 90 rating 90.9% of the time with 33 instances and each of the other attributes meet the same requirement. The purpose of this is to determine which words certain reviewers are likely to use when they describe a highly rated wine.
Based on these results, there are several reviewers that do not have positively correlated attributes. From this, we can conclude that certain reviewers have words that they are likely to fall back on when describing quality wines and we can use this information to make more accurate predictions about those particular reviewers and perhaps their biases. Unsurprisingly, nearly all of the attributes are generic praise such as “beauty,” and we can use this in our prediction models. However, an attribute such as “Turkish Coffee” may have a high rating in general or only for the particular reviewer and this requires further research.
3.2. Support Vector Machines (SVM)
The SVM algorithm had the most successful results but we cannot trace how it arrives at these results, due to the black-box nature of the algorithm. The average accuracy for the SVM is 87.2% for this dataset while the average accuracy for the Naïve Bayes is 84.2%, three percent higher. Again, reviewers MW and TF had the most successful results with the SVM as they did with the Naïve Bayes algorithm, both with more than 91% accuracy.
This is similar to previous tests where the SVM performs the most successfully. We can use this information as a guideline for programming our white-box classification algorithms. For example, the closer our algorithm is to the SVM ideal, the more reliable it is for us to use and because it would be a white-box algorithm, we could trace how it arrives at its conclusions.
In our test of the accuracy of each reviewer using the SVM, we also tested only the aforementioned nine reviewers because the tenth, Gillian Sciaretta, lacking an adequate sample size of reviews (she had only seven reviews in the 90–94 category and zero for the 95–100 category). We used LibSVM and tested with the C parameter in order to measure the rate of true positives, false positives, true negatives and false negatives. We realized that when the parameter is a low amount (approaching zero), the SVM’s dimension fails to label any of the reviews as positive. We found that the SVM gave the most accurate results when we set the C parameter between 100 and 200.
Table 7 describes the summary of the peak performance of the results.
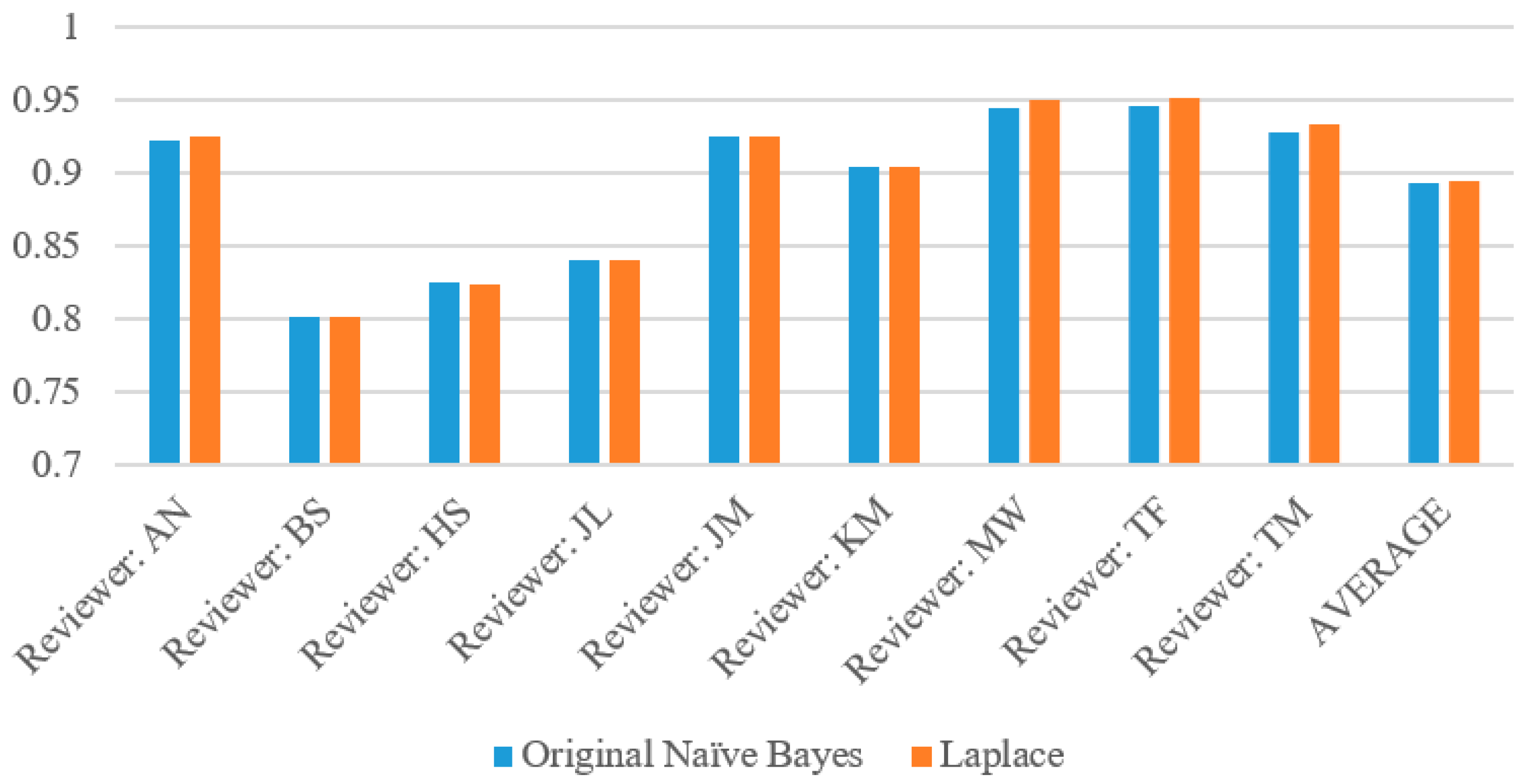
Figure 8 is derived from
Table 7 and shows all four evaluation metrics for each reviewer. Most of the rest of the reviews have very high specificity, high accuracy, low precision and very low recall. We believe this is the case because Sanderson’s reviews were evenly balanced between above-90 and below-90 cases, with 49.3% of his reviews falling below 90, which demonstrates that this reviewer is more likely to rate the wines that he reviews higher.
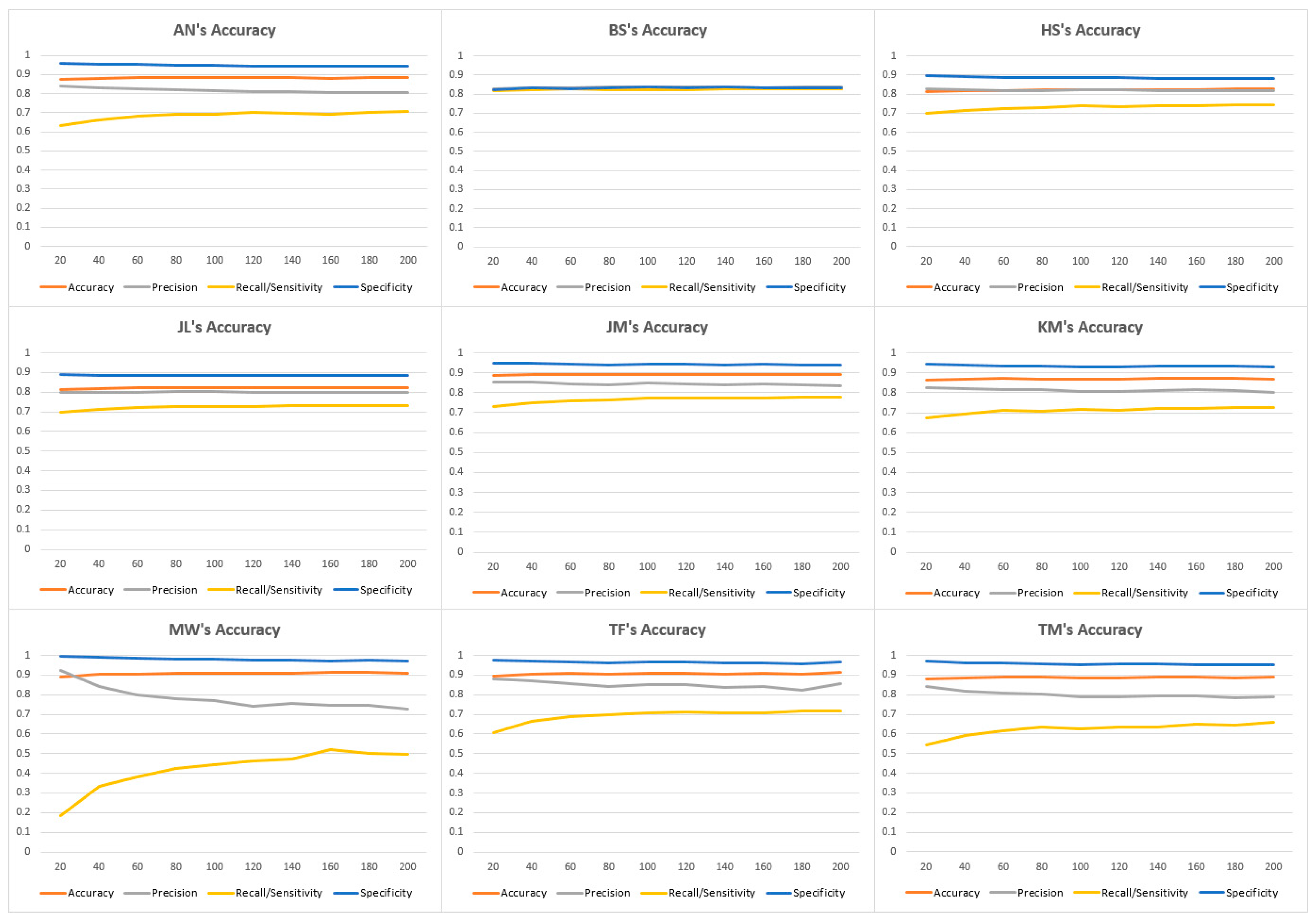
Most of the reviewers resemble Alison Napjus’s curve, as illustrated by
Figure 9. Some of the more exaggerated versions of this curve, such as MaryAnn Worobiec in
Figure 9, happen when the reviewer is extremely likely to rate reviews below 90 (in her instance, 86.9% of her ratings are below 90).
Table 8 demonstrates the reviewers’ rankings by SVM accuracy. From our results, we found that the most consistent reviewer is MaryAnn Worobiec because her reviews consistently have 91% accuracy.
Overall, the Naïve Bayes algorithm has provided very good results, with reviewers MaryAnn Worobiec and Tim Fish providing 88% accuracy; these reviewers reached 91% in the SVM as well. We can conclude that these two reviewers have the most reliability among the ones we have tested in determining whether the wine they have sampled would have a rating higher or lower than 90. They fit the model of our computational wine wheel’s choice of attributes more accurately than any of the other reviewers based on this information and a point of expansion may be to investigate these reviewers further or examine what attributes can improve the accuracy of the rest of the reviewers.
3.3. Comparison of Naïve Bayes and SVM
In order to compare the results obtained from two different classification methods,
Table 9 is summarized from
Table 4,
Table 5,
Table 7 and
Table 8. SVM, the black box classification algorithm, produced higher accuracy results as expected. The average accuracy found in SVM reaches 87.21%; compare with the average accuracy found in Naïve Bayes (84.72%), SVM performed around 2.5% more accurate in average. All reviewers have better accuracy results; MW showed the biggest difference (improve 3.34%) while AN showed the least changes (improve 0.47%).
In terms of ranking of the reviewers, both methods give similar results. MW and TF are ranked 1st and 2nd in both SVM and Naïve Bayes. BS, HS and JL are ranked 7th, 8th and 9th in both classification methods. The middle rank 3rd, 4th and 5th show some minor differences. SVM ranked JM, TM and AN 3rd, 4th and 5th; while Naïve Bayes ranked AN, JM and TM 3rd, 4th and 5th. However, the accuracy between the three reviewers is very little. The results demonstrate in
Table 9 suggest both methods have the capability to rank reviewers and be able to capture information between the reviews and the wines’ score.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}