Wineinformatics: Regression on the Grade and Price of Wines through Their Sensory Attributes

Abstract
:1. Introduction
2. Materials and Methods
2.1. The Data
2.2. Evaluation Metrics
2.3. Methods
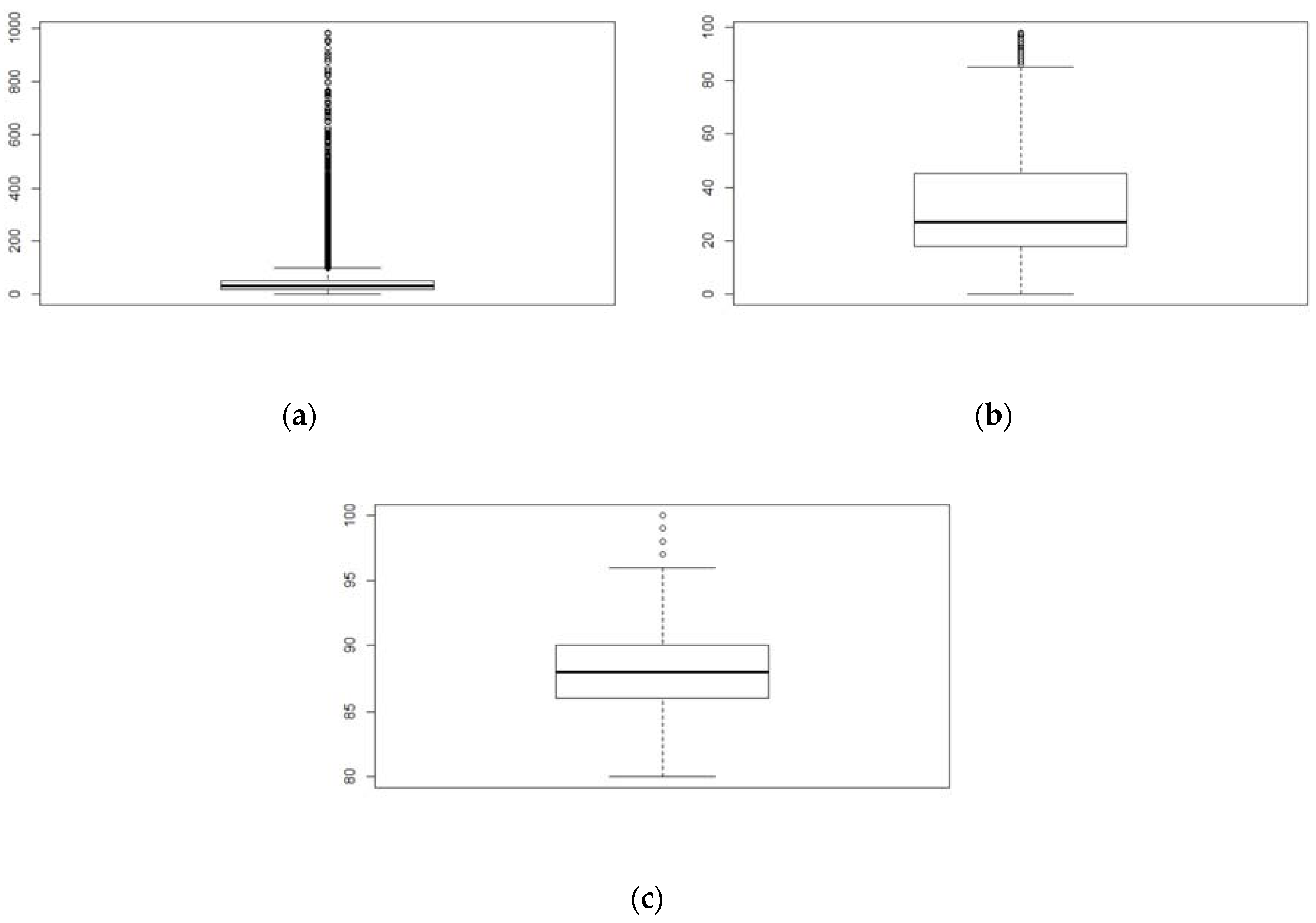
3. Results
3.1. Regression
3.2. Classification
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Wine Institute. World Wine Production by Country. Available online: https://www.wineinstitute.org/files/WorldWineProductionbyCountry.pdf (accessed on 28 September 2018).
- Schmidt, D.; Freund, M.; Velten, K. End-User Software for Efficient Sensor Placement in Jacketed Wine Tanks. Fermentation 2018, 4, 42. [Google Scholar] [CrossRef]
- Sommer, S.; Cohen, S.D. Comparison of Different Extraction Methods to Predict Anthocyanin Concentration and Color Characteristics of Red Wines. Fermentation 2018, 4, 39. [Google Scholar] [CrossRef]
- Er, Y.; Atasoy, A. The classification of white wine and red wine according to their physicochemical qualities. Int. J. Intell. Syst. Appl. Eng. 2016, 4, 23–26. [Google Scholar] [CrossRef]
- Cortez, P.; Cerdeira, A.; Almeida, F.; Matos, T.; Reis, J. Modeling wine preferences by data mining from physicochemical properties. Decis. Support Syst. 2009, 47, 547–553. [Google Scholar] [CrossRef] [Green Version]
- Ebeler, S.E. Linking flavor chemistry to sensory analysis of wine. In Flavor Chemistry; Springer: Boston, MA, USA, 1999; pp. 409–421. [Google Scholar]
- Chen, B.; Velchev, V.; Nicholson, B.; Garrison, J.; Iwamura, M.; Battisto, R. (2015, December). Wineinformatics: Uncork Napa’s Cabernet Sauvignon by Association Rule Based Classification. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 565–569. [Google Scholar]
- Chen, B.; Le, H.; Rhodes, C.; Che, D. Understanding the Wine Judges and Evaluating the Consistency through White-Box Classification Algorithms. In Industrial Conference on Data Mining; Springer: Cham, Germany, 2016; pp. 239–252. [Google Scholar]
- Wariishi, N.; Flanagan, B.; Suzuki, T.; Hirokawa, S. Sentiment Analysis of Wine Aroma. In Proceedings of the 2015 IIAI 4th International Congress on Advanced Applied Informatics (IIAI-AAI), Okayama, Japan, 12–16 July 2015; pp. 207–212. [Google Scholar]
- Flanagan, B.; Wariishi, N.; Suzuki, T.; Hirokawa, S. Predicting and visualizing wine characteristics through analysis of tasting notes from viewpoints. In International Conference on Human-Computer Interaction; Springer: Cham, Germany, 2015; pp. 613–619. [Google Scholar]
- About Our Tastings. Available online: https://www.winespectator.com/display/show/id/scoring-scale (accessed on 28 September 2018).
- Chen, B.; Rhodes, C.; Yu, A.; Velchev, V. The Computational Wine Wheel 2.0 and the TriMax Triclustering in Wineinformatics. In Industrial Conference on Data Mining; Springer: Cham, Germany, 2016; pp. 223–238. [Google Scholar]
- Chen, B.; Rhodes, C.; Crawford, A.; Hambuchen, L. Wineinformatics: Applying data mining on wine sensory reviews processed by the computational wine wheel. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop (ICDMW), Shenzhen, China, 14 December 2014; pp. 142–149. [Google Scholar]
- Wine Spectator’s 100-Point Scale. Available online: http://www.winespectator.com/display/show/id/scoring-scale (accessed on 28 September 2018).
- Palmer, J. Multi-Target Classification and Regression in Wineinformatics. Ph.D. Thesis, University of Central Arkansas, Conway, AR, USA, 2018. [Google Scholar]
- Fradkin, D.; Muchnik, I. Support vector machines for classification. DIMACS Ser. Discret. Math. Theor. Comput. Sci. 2006, 70, 13–20. [Google Scholar]
- Martin, L. A Simple Introduction to Support Vector Machines; Michigan State University: East Lansing, MI, USA, 2011. [Google Scholar]
- Smits, G.F.; Jordaan, E.M. Improved SVM regression using mixtures of kernels. In Proceedings of the 2002 International Joint Conference on Neural Networks, Honolulu, HI, USA, 12–17 May 2002; Volume 3, pp. 2785–2790. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria. Available online: https://www.R-project.org (accessed on 28 September 2018).
- Microsoft and R. C. Team, Microsoft R Open, Microsoft, Redmond, Washington, 2017. Available online: https://mran.microsoft.com/ (accessed on 28 September 2018).
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. Kernlab-an S4 package for kernel methods in R. J. Stat. Softw. 2004, 11, 1–20. [Google Scholar] [CrossRef]
- Mauricio Zambrano-Bigiarini, hydroGOF: Goodness-of-Fit Functions for Comparison of Simulated and Observed Hydrological Time Series, 2017, r Package Version 0.3-10. Available online: http://hzambran.github.io/hydroGOF/ (accessed on 28 September 2018).
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 27. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Category | Grade | Price | |
|---|---|---|---|
| Four-class dataset | 1 | ≤84 | ≤$18 |
| 2 | 85~89 | $19~$29 | |
| 3 | 90~94 | $29~$50 | |
| 4 | 95~100 | >50 | |
| Two-class dataset | 1 | <90 | ≤$29 |
| 1 | ≥90 | >$29 |
| Kernel | ME | MAE | MSE | RMSE | NMAE | NRMSE | r | r2 |
|---|---|---|---|---|---|---|---|---|
| Linear | −0.07 | 1.64 | 4.27 | 2.07 | 8.2% | 10.4% | 0.73 | 0.54 |
| RBF/Laplace | 0.00 | 4.59 | 4.02 | 2.00 | 8.0% | 10.0% | 0.75 | 0.56 |
| Kernel | ME | MAE | MSE | RMSE | NMAE | NRMSE | r | r2 |
|---|---|---|---|---|---|---|---|---|
| Linear | −9.56 | 20.53 | 2082.15 | 45.63 | 41.8% | 93.0% | 0.44 | 0.19 |
| RBF/Laplace | −9.88 | 20.52 | 2133.56 | 46.19 | 41.8% | 94.2% | 0.43 | 0.18 |
| Kernel | ME | MAE | MSE | RMSE | NMAE | NRMSE | r | r2 |
|---|---|---|---|---|---|---|---|---|
| Linear | −3.80 | 13.07 | 325.25 | 18.03 | 64.3% | 88.7% | 0.50 | 0.25 |
| RBF/Laplace | −3.75 | 12.94 | 318.64 | 17.85 | 63.6% | 87.8% | 0.51 | 0.27 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Palmer, J.; Chen, B. Wineinformatics: Regression on the Grade and Price of Wines through Their Sensory Attributes. Fermentation 2018, 4, 84. https://doi.org/10.3390/fermentation4040084
Palmer J, Chen B. Wineinformatics: Regression on the Grade and Price of Wines through Their Sensory Attributes. Fermentation. 2018; 4(4):84. https://doi.org/10.3390/fermentation4040084
Chicago/Turabian StylePalmer, James, and Bernard Chen. 2018. "Wineinformatics: Regression on the Grade and Price of Wines through Their Sensory Attributes" Fermentation 4, no. 4: 84. https://doi.org/10.3390/fermentation4040084
APA StylePalmer, J., & Chen, B. (2018). Wineinformatics: Regression on the Grade and Price of Wines through Their Sensory Attributes. Fermentation, 4(4), 84. https://doi.org/10.3390/fermentation4040084