1. Introduction
Reynolds-averaged Navier–Stokes (RANS) simulations are widely used in scientific research and industrial applications. Due to the nonlinearity of the Navier–Stokes equations, the RANS equations include time-averaged products of the velocity fluctuations—the Reynolds stresses—in addition to the mean velocity components and the mean pressure. In total, the RANS equations thus have six additional unknowns, which are typically combined in the Reynolds stress tensor. To solve the RANS equations, i.e., to simulate a mean flow field, the Reynolds stress tensor has to be modeled, which is also known as the turbulence closure problem. The RANS equations are based on the premise that the entire spectrum of turbulence must be modeled. However, since the large and medium turbulence scales are highly domain- and boundary-condition-specific, the optimal choice of model depends strongly on the problem at hand.
The most common way to model the Reynolds stress tensor is provided by the Boussinesq hypothesis [
1], which relates the deviatoric part of the Reynolds stress tensor to the strain rate tensor through the Boussinesq eddy viscosity
[
2], thus reducing the number of additional unknowns to one. When the Boussinesq hypothesis is employed, an additional model for the eddy viscosity
must be chosen, with algebraic, one- and two-equation models available. A popular one-equation model is the Spalart–Allmaras (SA) model [
3]. Famous two equation models include the k-
and k-
models [
4]. Menter [
5] developed the Menter SST model that utilizes the advantages of the k-
and k-
models. It is now part of industrial and commercial CFD codes [
6]. For many technical flows, the Boussinesq hypothesis is already too restrictive, so more sophisticated turbulence models, such as the Reynolds stress transport model, are frequently used. Depending on the flow configuration considered, one or the other model performs better.
Adapting and modifying models for specific configurations is still an active topic of research. Raje and Sinha [
7], for example, developed an extended version of the Menter SST model for shock-induced separation under supersonic and hypersonic conditions. Menter et al. [
8] developed a generalized k-
model that allows easy adaptation of the turbulence model to new configurations. In these studies, physics-based considerations are used to extend, improve, or generalize the turbulence model. This approach can also be referred to as a knowledge-based approach.
On the contrary, data-driven approaches aim to identify/learn closure fields from high-fidelity reference data [
9]. By relating the identified fields back to the mean field quantities, improved closure models can be identified in a purely data-driven manner. Foures et al. use a data-assimilation technique to match a RANS solution to time-averaged DNS fields of a flow around an infinite cylinder [
10]. The approach is based on a variational formulation that uses the Reynolds stress term as a control parameter. In subsequent studies, a similar approach is applied based on measured particle image velocimetry (PIV) data [
11], for assimilating the flow field over a backward-facing step at a high Reynolds number (28,275) [
12]. In parallel, a Bayesian inversion-based data assimilation technique was developed called field inversion [
13]. The method is applied, for example, in Refs. [
13,
14], to identify a spatially resolved coefficient in the k-
and Spalart–Allmaras model, respectively, to match the RANS solutions to high-fidelity mean fields. In recent studies, closure fields are identified by assimilating RANS equations to LES, PIV [
15], and DNS [
16] mean fields using physics-informed neural networks.
The studies mentioned above all apply data assimilation/field inversion methods to identify closure fields or parameters in closure models that lead to an optimal match between the RANS solutions and the high-fidelity data. However, they do not relate the identified fields back to the mean field quantities, i.e., no predictive closure models have yet been identified. This first step of retrieving an optimal or best-fit closure field can be considered as collecting a priori information. Based on the information collected, data-driven approaches typically apply supervised learning algorithms in a subsequent step to determine an improved closure model [
17,
18]. The quality of the identified models can then be evaluated in an a posteriori analysis.
Machine learning algorithms allow for extracting patterns from data and building mappings between inputs and outputs [
19]. Methods that apply machine learning to closure modeling can be categorized into two groups: algorithms that learn from existing turbulence models to mimic their behaviour, and algorithms that learn from high-fidelity data to improve the accuracy of RANS closure models. The former is addressed, for example, by Xu et al. [
20], who apply a dual neural network architecture to replace the k-
closure model. The inputs of the neural network are composed of local and surrounding information, a concept known as the vector cloud neural network (VCNN) [
21]. The latter, machine learning-enhanced closure modeling, is of particular relevance for the present study and is discussed, for example, in Refs. [
17,
18]. As described above, the studies first identify an optimal closure field, which is then related to the mean field quantities in a subsequent step using a supervised learning algorithm to find an improved closure model in a purely data-driven way.
Supervised learning algorithms require training data that consist of input data points and known true outputs. The majority of the research on applying machine learning to turbulence closure models utilizes supervised learning [
22]. However, recent studies have shown a growing interest in utilizing reinforcement learning (RL) techniques for turbulence closure modeling. This shift is somewhat counter-intuitive, as the initial inclination might be to rely on supervised learning due to its established methodologies and frameworks. However, supervised learning cannot be used for problems where the true output is not known, as is often the case with closure modeling [
23].
In contrast to existing two-step methods using supervised learning, the present work is concerned with improving closure modeling in a single step based on a reinforcement learning algorithm that does not require the collection of a priori information. As demonstrated by Novati et al., multi-agent reinforced learning (MARL) is a suitable algorithm for closure model improvement [
24]. In simplified terms, reinforcement learning is based on an agent (a function) observing its environment (taking input variables), acting (returning an output), and receiving a reward for its actions. The agent tries to choose its actions in a way that maximizes the reward it receives. This approach eliminates the need to provide the algorithm a priori with information that it can learn. Multi-agent reinforcement learning applies multiple agents distributed over the domain.
Reinforcement learning has gained large popularity due to the method’s great success in achieving super human performance in games like Go [
25], Dota II [
26], and the Atari 2600 games [
27]. Moreover, the method has been successfully applied in robotics [
28], autonomous driving [
29], and non-technical tasks such as language processing [
30] or healthcare applications [
31]. Despite the success and popularity of the method in other fields, its application in fluid mechanics is limited [
32,
33].
Most studies on reinforcement learning in fluid mechanics are concerned with flow control, with both numerical [
34,
35,
36,
37,
38,
39,
40,
41,
42] and experimental studies [
43,
44]. The study by Novati et al. [
24] applies reinforcement learning to improve the subgrid-scale (SGS) turbulence modeling of a large-eddy simulation (LES) by learning from DNS data. The spatially distributed agents receive local and global information about the mean flow as state input (observing) and determine the dissipation coefficient of the Smagorinsky SGS model at the cells they are located at (acting). Agents receive a reward based on the difference between the LES solution compared to the DNS reference data. The described framework is successfully applied to different Reynolds numbers and different mesh resolutions. This approach is expanded by Kim et al. [
45] by incorporating physical constraints in order to apply the method to wall-bounded flows. Kurz et al. [
23] apply a multi-agent RL algorithm for implicitly filtered LES in a similar setup as Novati et al. [
24]. Other than Novati et al. [
24], they surpass the performance of conventional subgrid-scale models by only relying on local variables utilizing a convolutional neural network architecture. Yousif et al. [
46] apply a multi-agent DRL-based model to reconstruct flow fields from noisy data. They incorporate the momentum equations and the pressure Poisson equation and, therefore, create a physics-guided DRL model. Using noisy data (DNS and PIV measurements), it is shown that the model can reconstruct the flow field and reproduce the flow statistics.
The literature reviewed here illustrates both the success of data-driven methods for improving RANS closure modeling and the success of DRL as an optimization method in various domains including fluid mechanics. The idea of the present study is to combine the two successful methodologies and perform data-driven RANS closure modeling with DRL. It should be noted that the objective of this study is not to identify the most effective data-assimilation method. We are aware that other optimization and data-assimilation methods are capable of solving comparable optimization problems. The aim of the present study is to explore the extent to which DRL-based closure models can open up new fields of application for existing RANS turbulence models. Unlike LES, in RANS simulations, the entire turbulence spectrum must be modeled, making the approach very difficult to generalize. RANS turbulence models must, therefore, be selected on an application-specific basis and perform poorly when transferred to other applications.
In the present study, we consider a turbulent jet flow and the Spalart–Allmaras turbulence model, which is known to perform rather poorly for jet flows [
4]. Thus, it is a suitable case to investigate the extent to which the closure model can be improved with the DRL algorithm. We introduce an additional source term into the Spalart–Allmaras transport equation that serves as a degree of freedom for the algorithm. The source term allows to modify both the production and dissipation terms and, therefore, allows a very high degree of freedom for the algorithm [
47]. However, it is still bound by the transport equation of the SA model. The mean field dependence of this source term is determined by the DRL algorithm. The objective of the DRL algorithm (reward function) is to match the augmented Spalart–Allmaras RANS results with high-fidelity time-averaged LES velocity fields. Inspired by the studies of Novati et al. [
24] and Xu et al. [
20], a multi-agent approach is used, which augments the turbulence model locally and, thus, allows a model trained on one configuration to be applied to other configurations.
To address numerical difficulties that arise at the interface between the RANS solver and the machine learning-augmented turbulence model, the DRL algorithm is directly integrated into the flow solver, i.e., rewards are only awarded when the machine learning-augmented RANS solver converges. The open-source software package OpenFOAM (version 4.X) is used to solve the RANS equations.
2. Optimization Methodology
The objective of the DRL algorithm is to align RANS solutions with high-fidelity LES reference data. A brief description of the reference data is provided in
Section 2.1, followed by the governing equations in
Section 2.2. Details of the RANS simulation are given in
Section 2.3.
Section 2.4 presents the stencil approach that is the core of the optimization setup.
Section 2.5 introduces the deep reinforcement learning algorithm, and
Section 2.6 discusses the algorithm’s hyperparameter dependence.
2.1. Reference Data
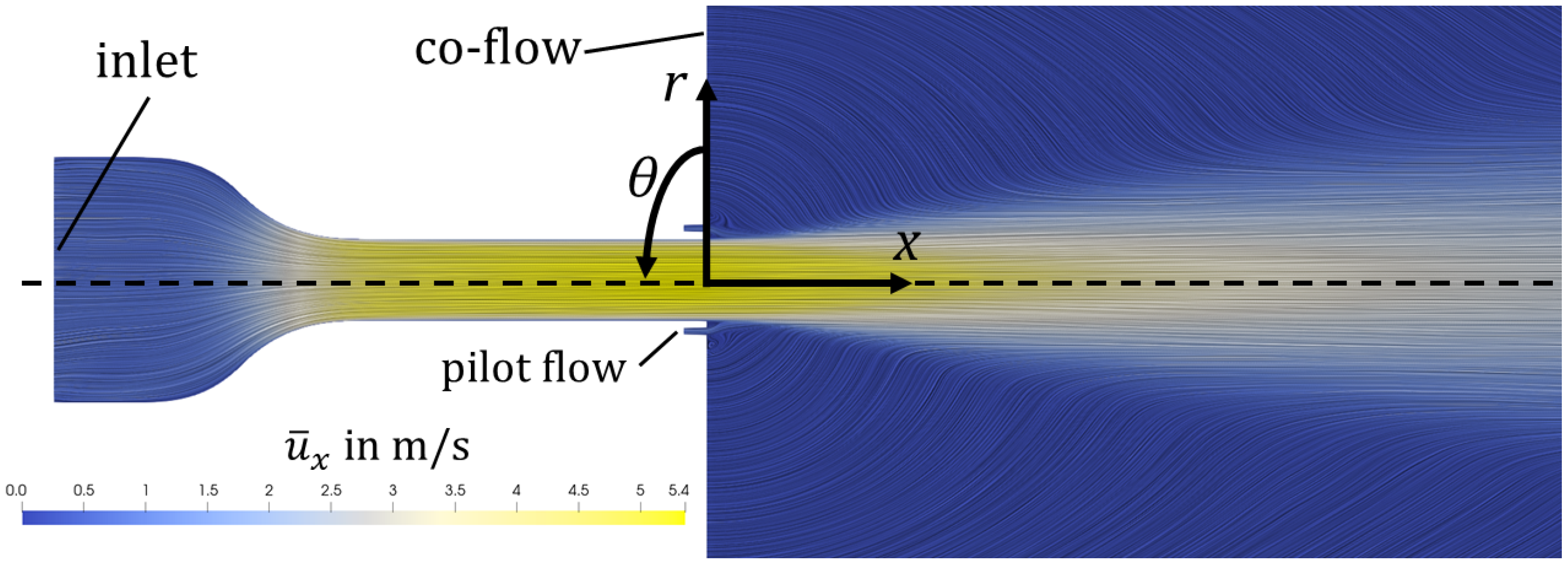
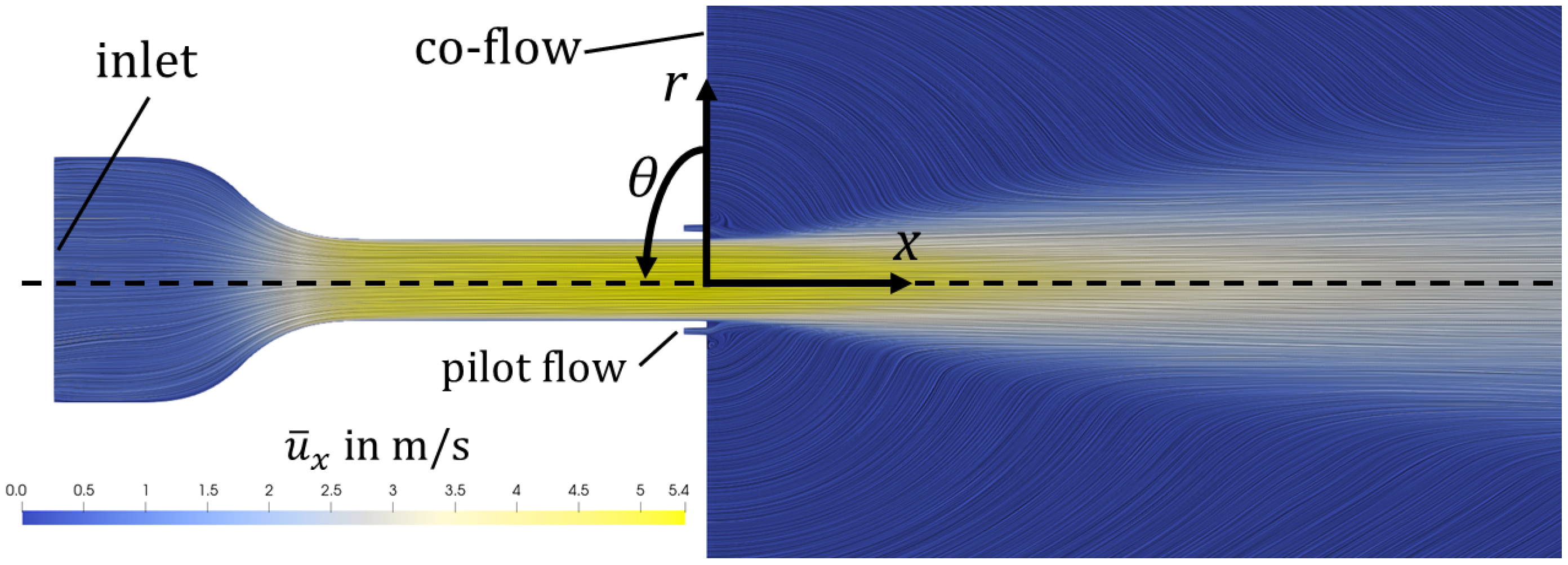
The reference data come from an LES dataset from a turbulent round jet [
48,
49]. The computational domain is shown in
Figure 1. It consists of a converging nozzle, a straight duct, an annular inlet around the nozzle, and a large cylindrical plenum. The geometric configuration represents a jet flame combustor, where, under reacting conditions, fuel is injected at the annular inlet, which is called the pilot flow nozzle. Here, under non-reacting conditions, air is injected at the pilot flow inlet. In total, the domain has three inlets: the main inlet at the converging nozzle, the annular pilot, and the co-flow inlet. The co-flow is used to prevent undesired recirculation and improves numerical stability. Although the boundary conditions and geometry of the setup hold greater technical relevance, the underlying flow fundamentals remain comparable to those of a generic round jet.
The Reynolds number, defined as
, is calculated using the duct diameter
D, the bulk velocity
and the kinematic viscosity
. Datasets with Reynolds numbers of 10,000 and 15,000 are considered in this study. To obtain the mean fields, the LES snapshots are time- and azimuthally averaged. For further details on the LES, we refer the reader to the original publication of the data [
48,
49].
2.2. RANS Equations
Time averaging the incompressible Navier–Stokes equations yields the Reynolds-averaged Navier–Stokes equations:
where
denotes the density,
p the pressure and
the molecular kinematic viscosity. The velocity vector
is expressed in cylindrical coordinates, where
x is the axial coordinate,
r the radial coordinate, and
the azimuthal coordinate. The coordinate system is shown in
Figure 1. The vector
denotes the time-averaged mean velocity and
denotes the remaining fluctuating part such that
. The Reynolds stress tensor
introduces six additional unknowns that must be modeled in order to solve the RANS equations as a boundary value problem. This modeling requirement is known as the turbulence closure problem. An approach to modeling is the Boussinesq hypothesis [
1], which relates the deviatoric part of the Reynolds stresses to the strain rate tensor through a turbulent viscosity, known as the eddy viscosity
:
where
denotes the turbulent kinetic energy and
is the identity tensor.
Using the Boussinesq model leaves one unknown, the eddy viscosity, for which, again, several models are available in the literature. Here, we focus on the Spalart–Allmaras turbulence model [
3]. In this model, the eddy viscosity
is modeled with one transport equation. Spalart and Allmaras [
3] follow the formulation of Baldwin and Barth [
50] and introduce
as a transported quantity that is defined by
. The function
is designed so that
behaves linearly in the region near the wall, which is desirable for numerical reasons [
3]. The transport equation is given by:
where
,
,
, and
are model constants,
is the molecular viscosity,
is the density,
d is the wall distance,
is a production term, and
is a near-wall inviscid destruction term. For more details on the Spalart–Allmaras terms and model constants, see [
3,
51,
52].
To introduce a degree of freedom for the DRL algorithm, we add an extra source term into the transport equation. The source term is modeled as a function of the mean field that is identified by the DRL algorithm, which is introduced in the next chapter.
The choice of the Spalart–Allmaras model arises from its reputation for robust numerical stability [
4]. Moreover, it has been used in a range of data-driven and machine learning closure model studies as mentioned in
Section 1 [
12,
13,
14,
53]. However, it is essential to note that the model is known for its poor performance on jet flows (see Tables 4.1 and 4.4 in Ref. [
4]). Thus, the Spalart–Allmaras model applied to a jet flow is a particularly suitable case for the objective of this study, namely, to investigate the extent to which DRL can extend the scope of a closure model.
2.3. RANS Simulations
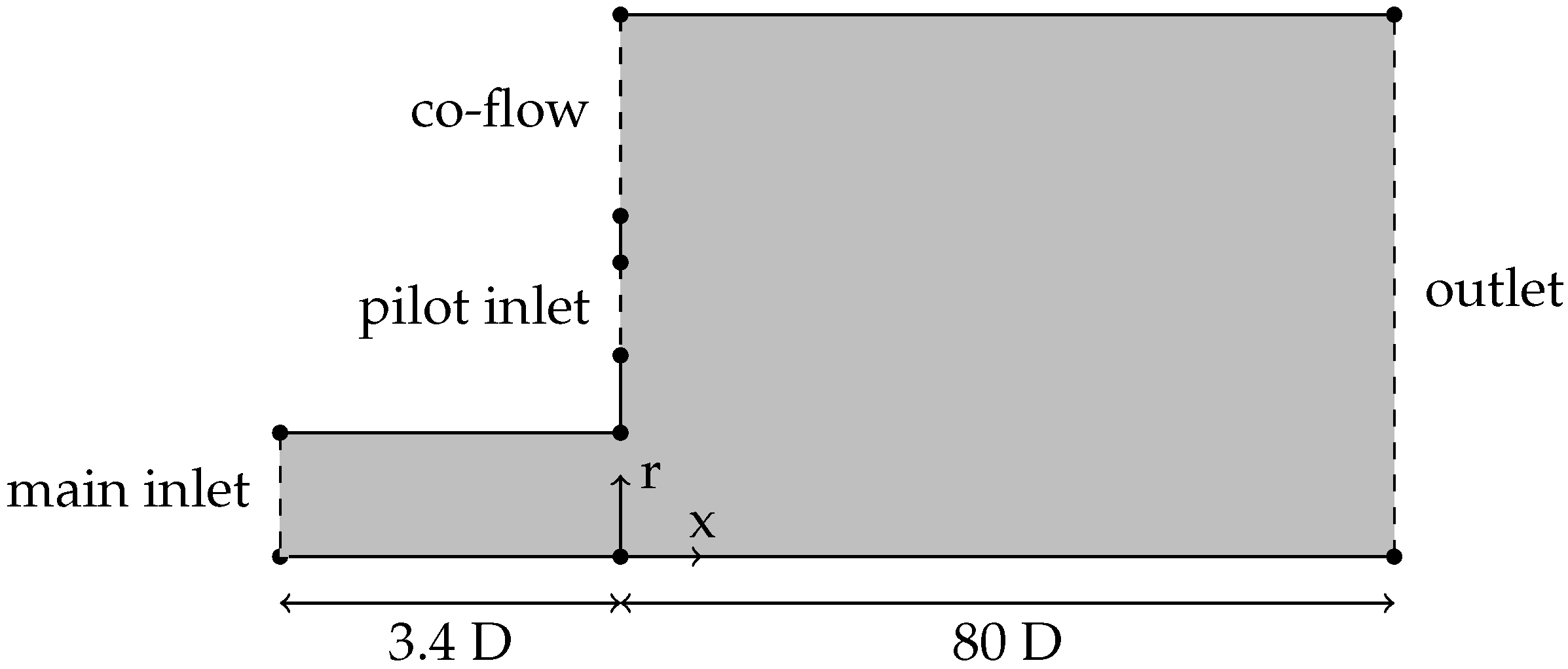
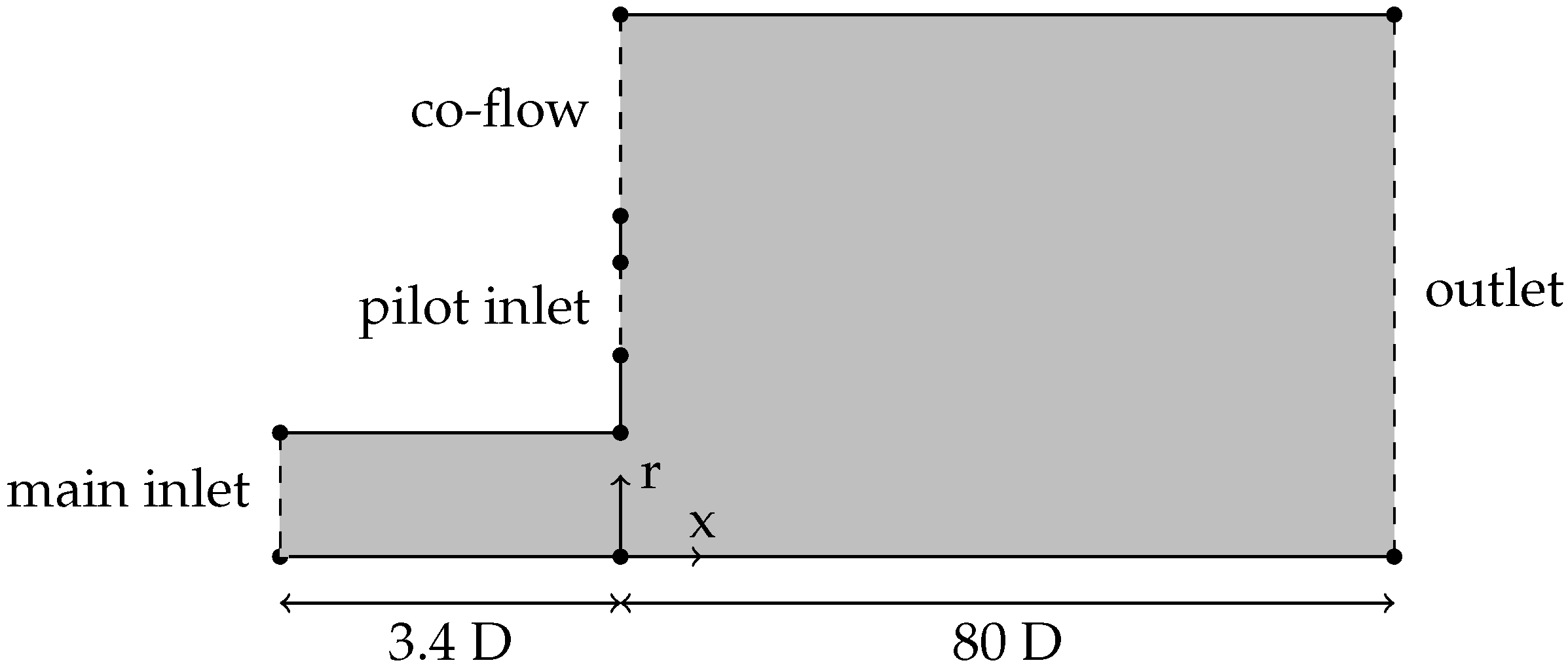
The computational domain for the RANS simulations is sketched in
Figure 2. Exploiting the axial symmetry of the mean field, the domain only contains the part above the centerline and lies in the x-r plane. The domain is created in a wedge shape with a single cell in azimuthal direction, as typically done for 2D computations with finite-volume methods. To simplify the computational domain, the converging nozzle and the annular pilot flow nozzle are omitted and replaced by inlet surfaces. The main inlet of the domain is placed at the beginning of the straight duct,
upstream from the nozzle. The mean field Equations (
1)–(
3) are solved numerically using the Semi-Implicit Method for Pressure Linked Equations (SIMPLE) solver in OpenFOAM (version 4.X). The velocity boundary conditions for the main inlet and the pilot flow inlet are set to the corresponding LES values. The co-flow inlet uses a uniform fixed-value velocity inlet. The duct wall, the two walls around the pilot flow inlet, and the wall on top of the plenum are no-slip walls. At the outlet surface, the boundary condition for the velocity is set to zero gradient condition. The boundary condition for the pressure is zero gradient for all surfaces except the outlet surface. Here, a fixed value of
is set. The boundary conditions for
are chosen according to the recommendations in Ref. [
52]. The mesh is a structured hexahedral mesh generated using the blockMesh utility [
54] and simpleGrading [
54]. For the training of the algorithm, it is of great importance to choose a mesh that is as coarse as possible. It is, however, crucial to have a numerically converged mesh to make sure that the DRL algorithm is optimizing SA model errors and not numerical errors that are related to an under-resolved mesh. Based on a grid refinement study, employing a mesh size of 11,990 cells was deemed optimal, as further resolution increased by a factor of four showed negligible impact on velocity profiles.
2.4. Optimisation Setup Using a Stencil Approach
The objective of the DRL algorithm is to find a function that maps mean flow quantities to the source term in the Spalart–Allmaras transport equation
and that minimizes the difference in velocity fields between the RANS and the reference LES mean field:
where
stands for an L2-norm. However, the goal of DRL is not only to find an optimal
field, but rather to identify a function
that maps flow variables to
. Since the identified function depends only on mean flow quantities, it can be directly incorporated into the turbulence closure model without the need for further closure equations. The DRL thus performs two steps at once: the search for an optimal closure field and, simultaneously, relating it to flow variables.
The functional structure can be considered as a hyperparameter and its motivation shall be discussed in the following. The most direct way to construct a function would be a local mapping that assigns a value to a set of mean field quantities at each position. However, in order to provide the function with gradient and flow information in the immediate vicinity, the function is constructed in such a way that the flow field of the surrounding region of the target position is used as input. Therefore, the information from the upstream (and downstream) of the flow is also included in the determination of .
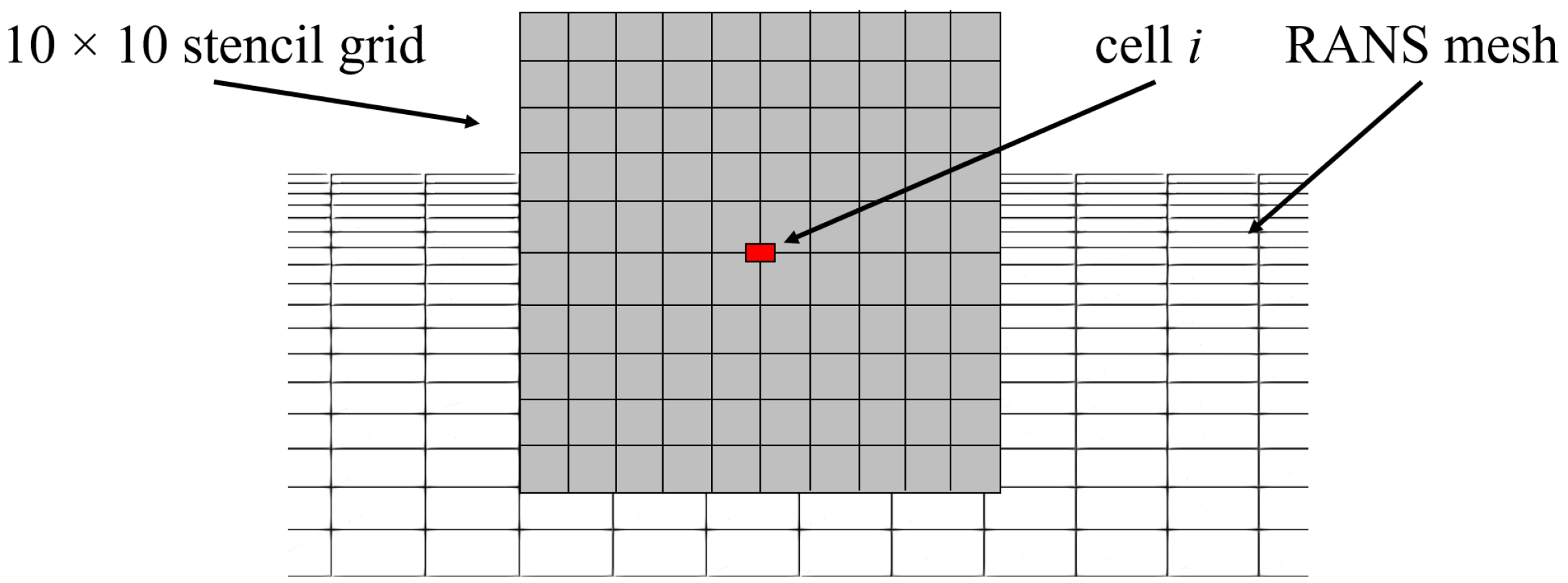
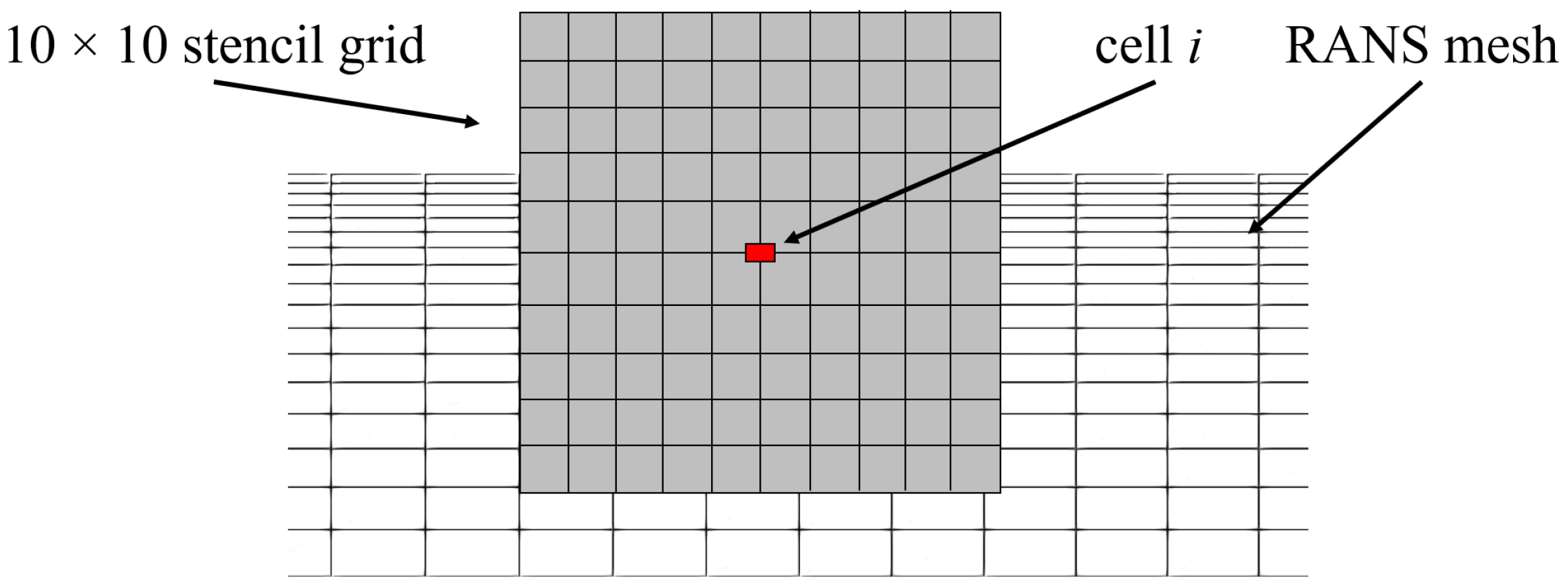
We label the surrounding of a target cell as a stencil. Here, we choose a rectangular area with an edge length of and the target cell in the center. However, we stress that the appropriate choice of stencil shape and size depends on the domain dimensions and the Reynolds number of the flow. The algorithm should learn from the significant flow features. The stencil size should therefore be large enough to capture large parts of the shear and boundary layers and geometric features such as steps and edges. The stencil size selected in this study allows one to cover the flow between the duct wall and the centerline, as well as the pilot flow inlet and parts of the nozzle, and, thus, covers key-geometric features within single stencils.
However, the use of the stencil method also presents technical challenges. Typically, numerical grids are non-uniform, so that, depending on the target cell under consideration, different numbers of grid points lie within the stencil region. To overcome this difficulty, the stencil is constructed with
equidistant points, and a routine is implemented that interpolates the mean flow quantities from the non-uniform RANS to the equidistant stencil grid. This ensures that the function
always receives the same number of input values with the same distance to the target cell. A symbolic representation of the stencil grid on top of the RANS grid is visualized in
Figure 3.
As input for the
-function on the stencil grid, we choose the mean axial and radial velocity components and the eddy viscosity as mean flow variables. The values are normalized with 1.2 of their respective maximum value. Normalization is necessary due to the internal architecture of the DRL algorithm, which requires a predefined value range for input and output. Normalization also enables generalizability of the identified
-function to other flow conditions that will be discussed later (see
Section 3). The factor
prevents the clipping of values that exceed the maximum value (internal to the DRL algorithm). Furthermore, the normalized radial coordinate of the target cell is passed to the stencil as an input variable, since it represents a decisive variable for cylinder coordinates and it supplements the algorithm with additional spatial information. It is normalized with its maximum value. One stencil vector, denoted
, thus consists of
entries: three fields (with
entries each) and one scalar. In this study,
proved to be a good choice, resulting in 301 input values for the function to be identified by the DRL algorithm. During model training, at every iteration, the stencil vector is constructed and evaluated for each cell
of the RANS simulation, resulting in the
field required to evaluate the augmented Spalart–Allmaras transport equation, Equation (
3).
For target cells that are close to the boundary, the stencil grid extends beyond the domain. To address this, boundary conditions are implemented. Along the centerline (lower boundary), mirrored data points extend beyond the RANS solution domain. Beyond solid walls, zero-velocity data points are appended. Close to the inlet and outlet, the values on the boundary are extended beyond the boundary. This approach ensures that, as the stencil grid surpasses the computational domain, the interpolated data aligns with the specified boundary conditions.
We conclude this section with a discussion of the advantages of the presented approach. The stencil approach divides the large dataset of the entire domain into smaller subsets (the stencil vectors), which presents three advantages. First, each stencil vector can be considered as a training point for the DRL algorithm. Thus, the costs associated with generating training points are substantially reduced in comparison to using the entire mesh as input to the function, since a single RANS simulation provides training points equivalent to the number of cells. Second, the dimension of a single data point for training the -function is significantly reduced. This reduction in dimensionality leads to a reduction in the complexity of the -functional architecture and enables shorter training times. Lastly, and most importantly, the proposed approach enables generalizability, since the algorithm learns from localized flow phenomena instead of the entire domain. Thus, a trained algorithm can be applied to different geometries or flow conditions.
2.5. Deep Reinforcement Learning Algorithm
To identify the
-function
that leads to a good alignment of the RANS solution with the LES mean field (Equation (
4)), deep reinforcement learning is used. Reinforcement learning is based on an agent observing its environment, acting, and receiving a reward for its actions. The agent tries to choose its actions in such a way that it maximizes the reward received. Rewards can, but do not have to, be granted after every action. They can be given after a sequence of actions. According to Sutton and Barto [
55], the two most characteristic features of reinforcement learning are trial-and-error search and delayed reward. One episode of training consists of multiple interactions in which the agent observes the state and performs an action. One round of chess, for example, consists of multiple moves. For each move, the agent receives the results of its last actions as a new state. This can be described as a closed-loop system, which is the classical design of RL frameworks.
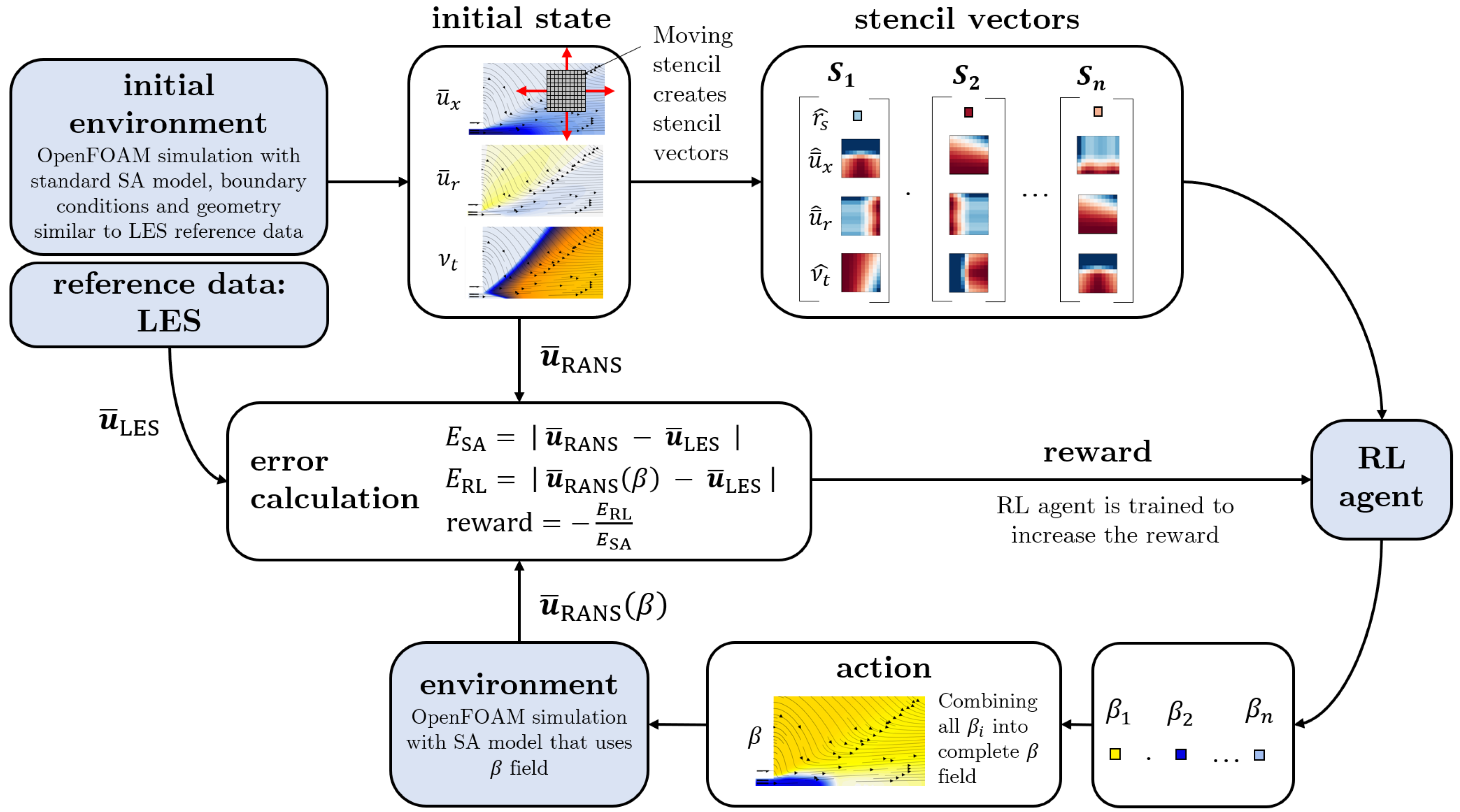
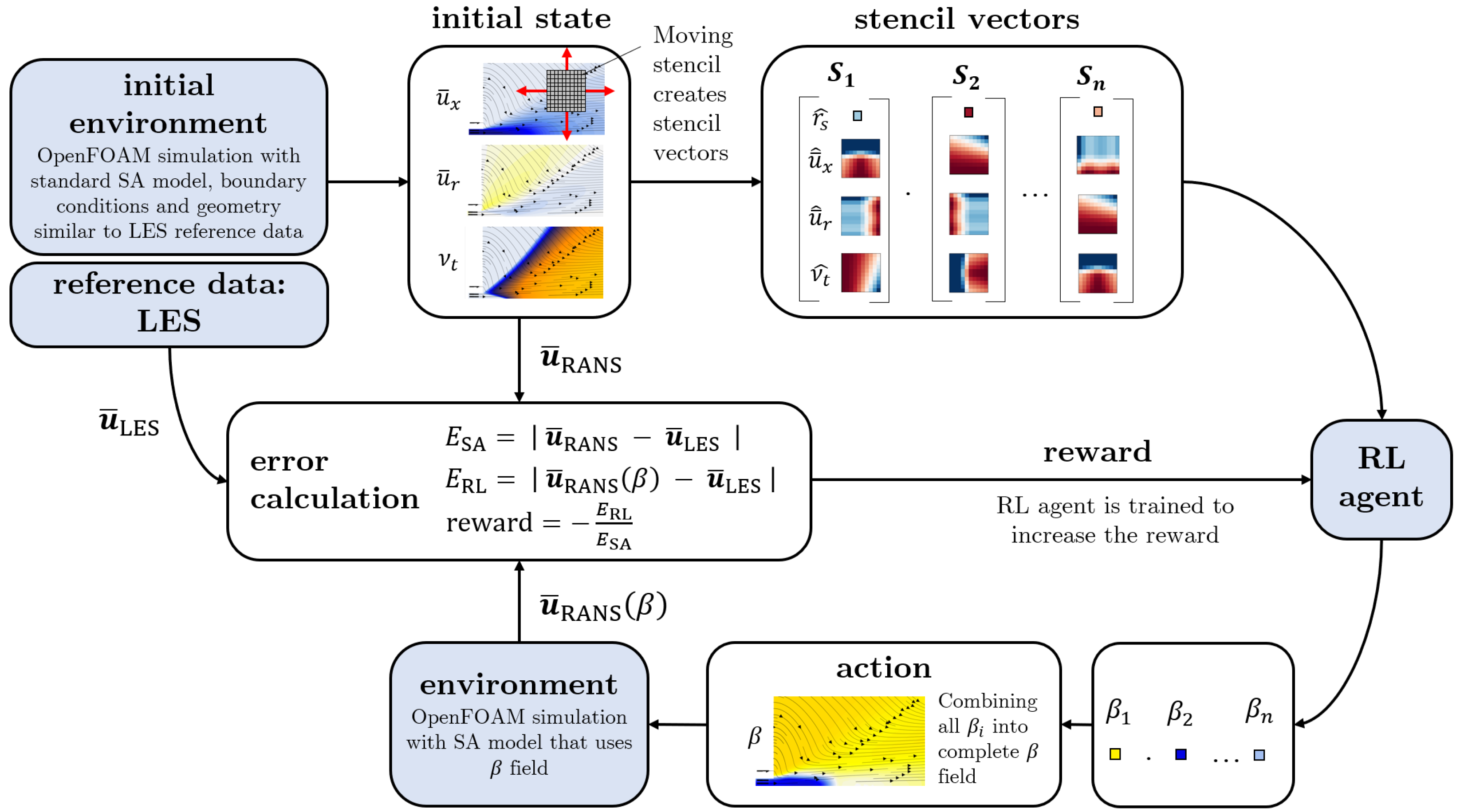
In this work, a simplified single-step open-loop implementation of reinforcement learning is used and is visualized in
Figure 4.
First, an initial run of the environment is performed: a RANS simulation with the standard Spalart–Allmaras eddy viscosity model is run until convergence. The resulting velocity and eddy viscosity field are referred to as initial states which determine the reference error
The initial run is just performed once. Subsequently, for each cell, the stencil vector is computed and the reinforcement learning agent applies the function
to determine the
value at every point. With the complete
field, the RANS solver is run for a predefined number of iterations. The resulting mean field allows for the calculation of the distance to the reference data in a predefined range
and
The distance to the reference data allows us to define a reward function to be maximized by the DRL algorithm
Dividing the distance to the reference data
by the reference error
serves as normalization and enhances the transferability of trained agents to new cases. Formulating the function with negative values yields optimal results. After the reward is calculated, it is passed to the agent, together with the stencil vectors and the determined
values to train the agent’s algorithm. Depending on how the reward changed with respect to the preceding episode, the agent is trained in order to increase the expected reward. In the next episode, the agent receives the same stencil vectors as in the previous episode and determines new
values. The chosen algorithm implements the agent as a neural network [
56]. The goal of the algorithm is to maximize the reward (Equation (
7)) by finding parameters of the neural network
that minimize the error
:
.
The algorithm presented in this study is referred to as having a single-step open-loop design. Although the function is evaluated multiple times in one episode to compute a value of the source term for each cell in the domain, it is termed a single-step design because only a single RANS solution is processed per episode. The RANS solution with the augmented SA model is used only to compute the reward and is not decomposed again. The subsequent episodes start again with the initial state. Consequently, this approach simplifies the DRL algorithm into an optimization tool.
For the DRL algorithm, we used the proximal policy optimization (PPO) [
57]. It was selected because it is known for its good sample efficiency, which means that it can achieve good performance with limited training data, which is a crucial requirement for this work. Additionally, it naturally handles continuous state and action spaces, it has been proven to be applicable in a single-step open-loop configuration [
58,
59], and it is the most common DRL algorithm used in the context of fluid dynamics [
32,
60]. To implement the PPO algorithm, we used the open-source package tensorforce by Kuhnle et al. [
56]. For further implementation details, refer to Refs. [
56,
57].
To evaluate the effectiveness of the algorithm, we also computed the relative error reduction RER of the error achieved with the trained model compared to the initial state
The method introduced in this work shares similarities with other publications, which are outlined below. In the present work, we use the local surrounding of a point as input data, comparable to the methods of Xu et al. [
20] and Zhou et al. [
21]. We combine this approach with the concept of multi-agent reinforcement learning that was also used by Novati et al. [
24] and Yousif et al. [
46]. Our method is configured in an open-loop design that is comparable to those of Viquerat et al. [
58] and Ghraieb et al. [
59]. The approach presented in this study does not include rotational invariance. However, it can be easily implemented, similarly to other studies [
21,
24].
2.6. Hyperparameters
The PPO implementation of the DRL algorithm in the tensorforce library has multiple hyperparameters. Applying the algorithm with the default values did not lead to successful results, and selecting appropriate hyperparameters turned out to be crucial to achieving well-performing models. In our analysis, we identified three influential hyperparameters for which non-default values were required to achieve large error reductions: baseline optimizer (BO) learning rate, batch size, and regularization.
The DRL algorithm uses two neural networks. They are termed the policy network and the baseline network. The policy network determines the output value of
and is called the
function in this work. The baseline network estimates so-called state values that are required for training the policy network [
56]. The first influential hyperparameter is the learning rate of the baseline optimizer (BO), which determines the learning rate of the optimizer that updates the parameters of the baseline network [
56]. By default, the tensorforce library uses a BO learning rate of
. The second influential hyperparameter is the batch size. It determines how many training points (stencil vectors) are used in a batch to update the agent’s parameters. For this hyperparameter, there is no default setting as it is very data specific. It has to be set manually. The third influential hyperparameter is the L2 regularization coefficient. It penalizes large network weight values. By default, the tensorforce library uses no L2 regularization.
A hyperparameter study was conducted to determine a well-functioning model. The results are shown in
Table 1 and
Table 2. The tables show that well-performing models are in two groups: The first group is characterized by small batch sizes of ≈1000, a disabled L2 regularization, and larger BO learning rates ≈
(
Table 1). The second group is characterized by larger batch sizes of ≈3000, an L2 regularization of 0.01, and small BO learning rates of ≈
(
Table 2). From this, we conclude that the algorithm performance is very sensitive to hyperparameters. Small changes can cause drastic performance losses. As using default hyperparameters does not result in a functioning model, hyperparameter studies are necessary.
4. Discussion
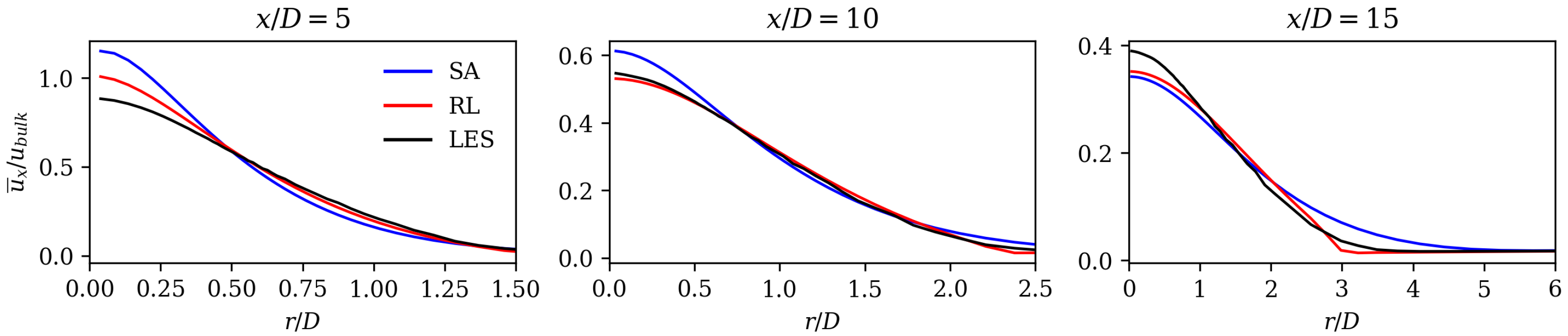
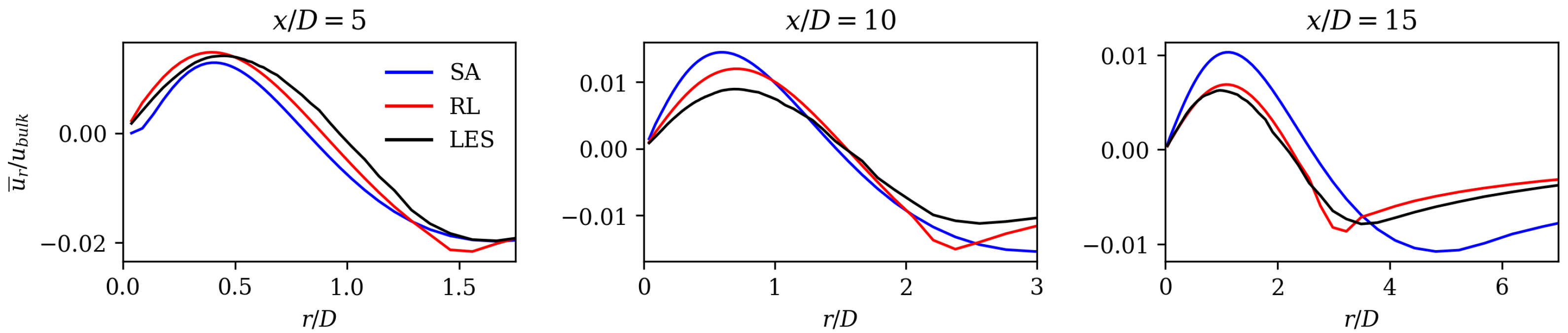
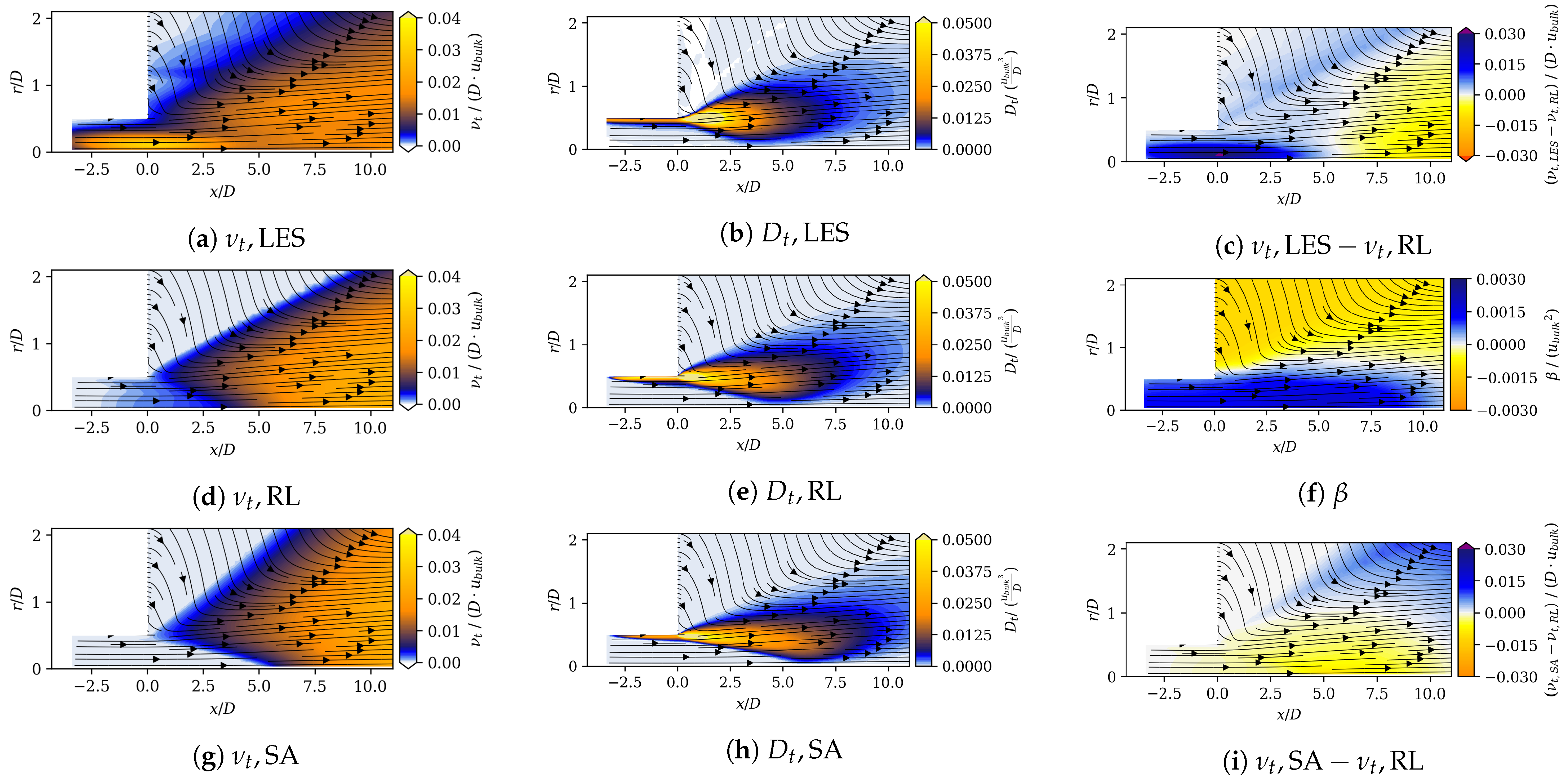
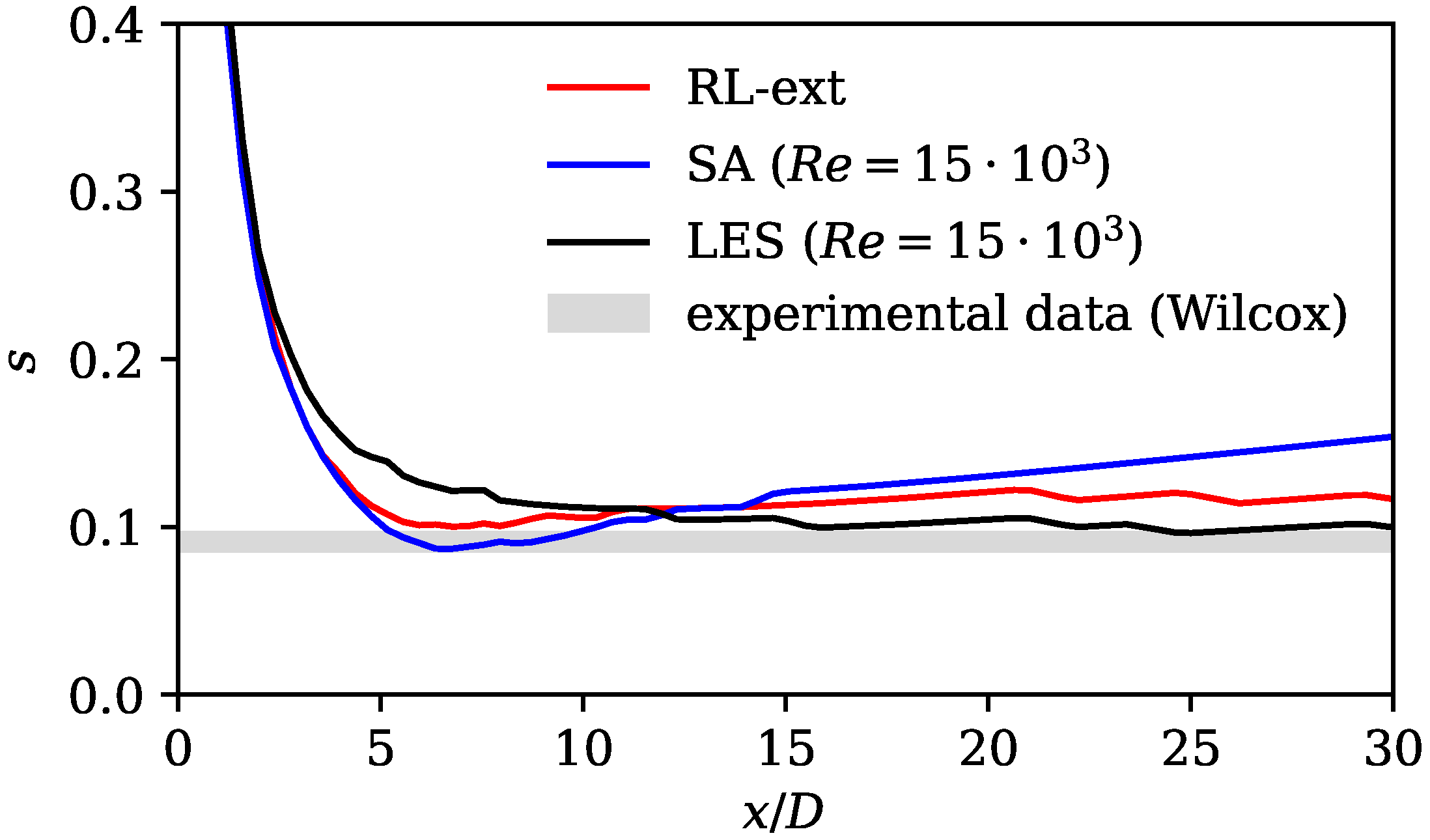
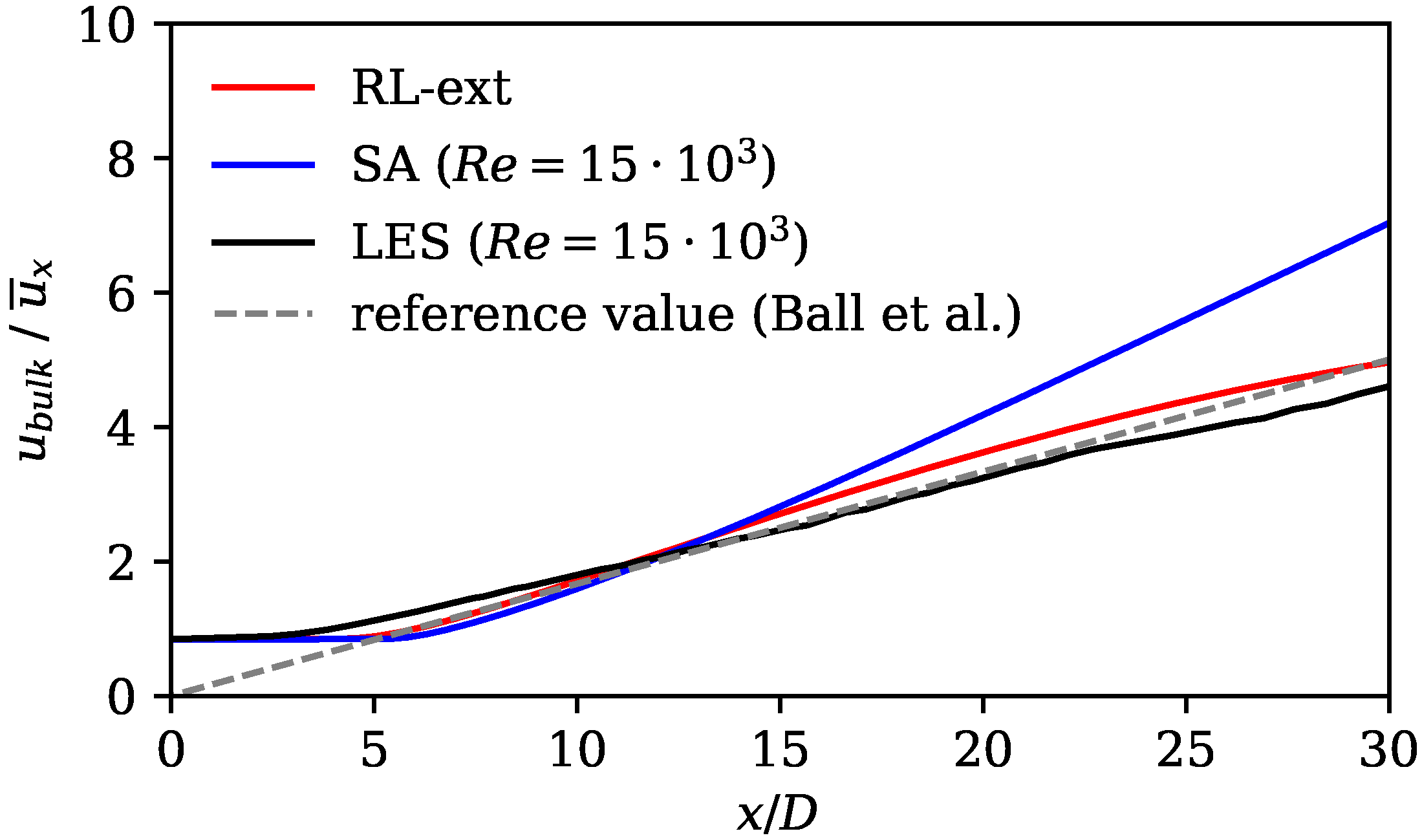
In the following paragraphs, we compare the augmented Spalart–Allmaras model against jet flow-specific closure models, which are tailored for improved accuracy through physics-based reasoning. Subsequently, we compare it with other data-driven methods applied to jet flows. We also highlight the similarities of our methodology with other publications, followed by a discussion of its strengths and limitations.
Ishiko et al. [
66] added terms to the Spalart–Allmaras and Menter SST turbulence models to improve the accuracy of free-jet and wall-jet flows. They achieved an improvement in axial velocity decay similar to that of the RL model. Georgiadis et al. [
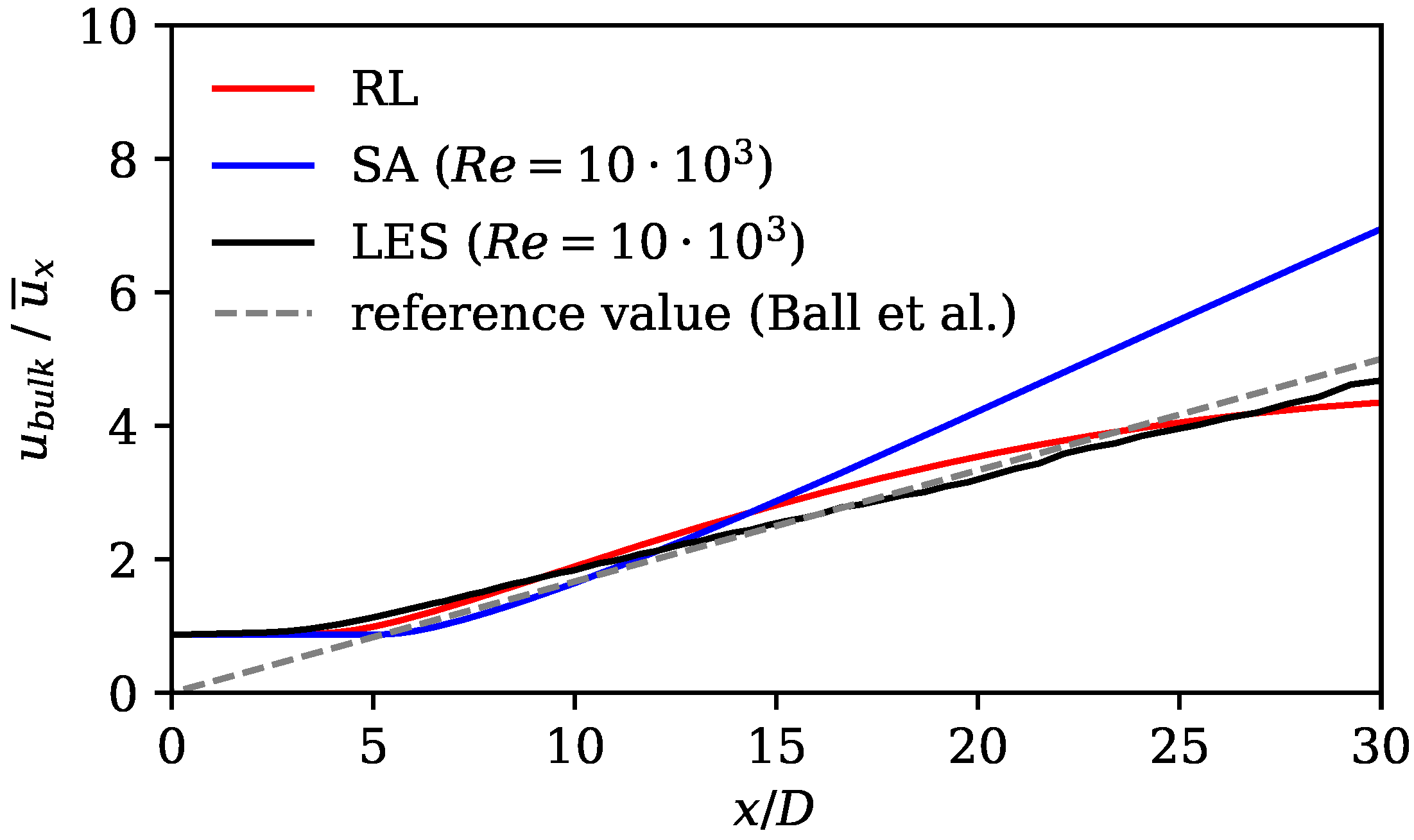
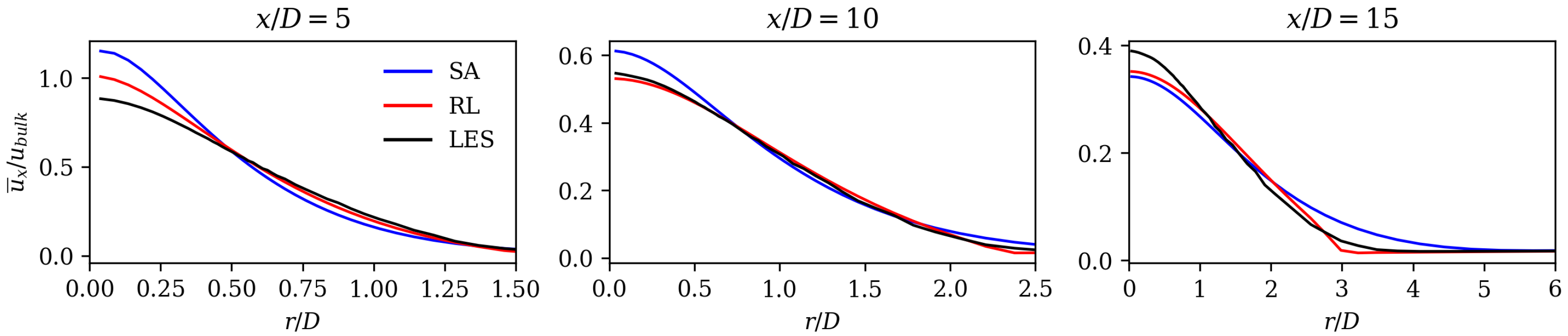
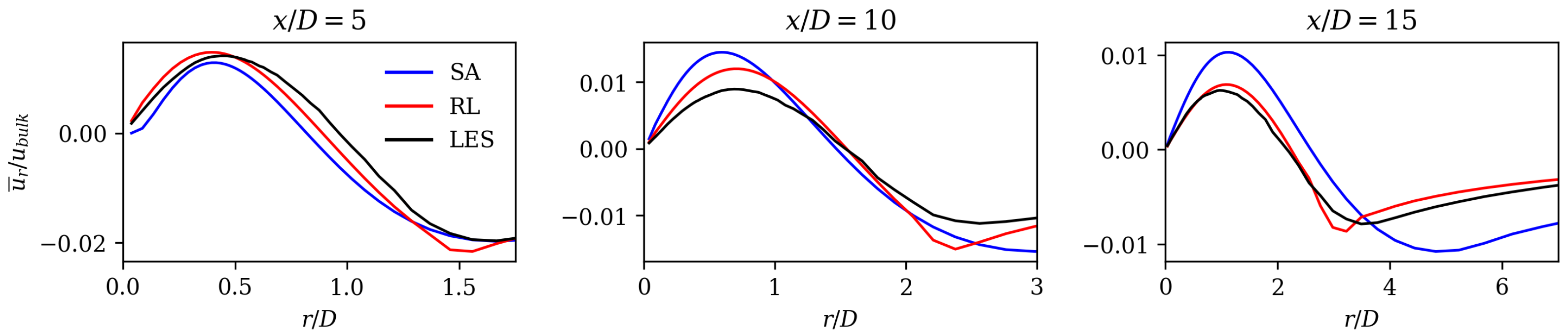
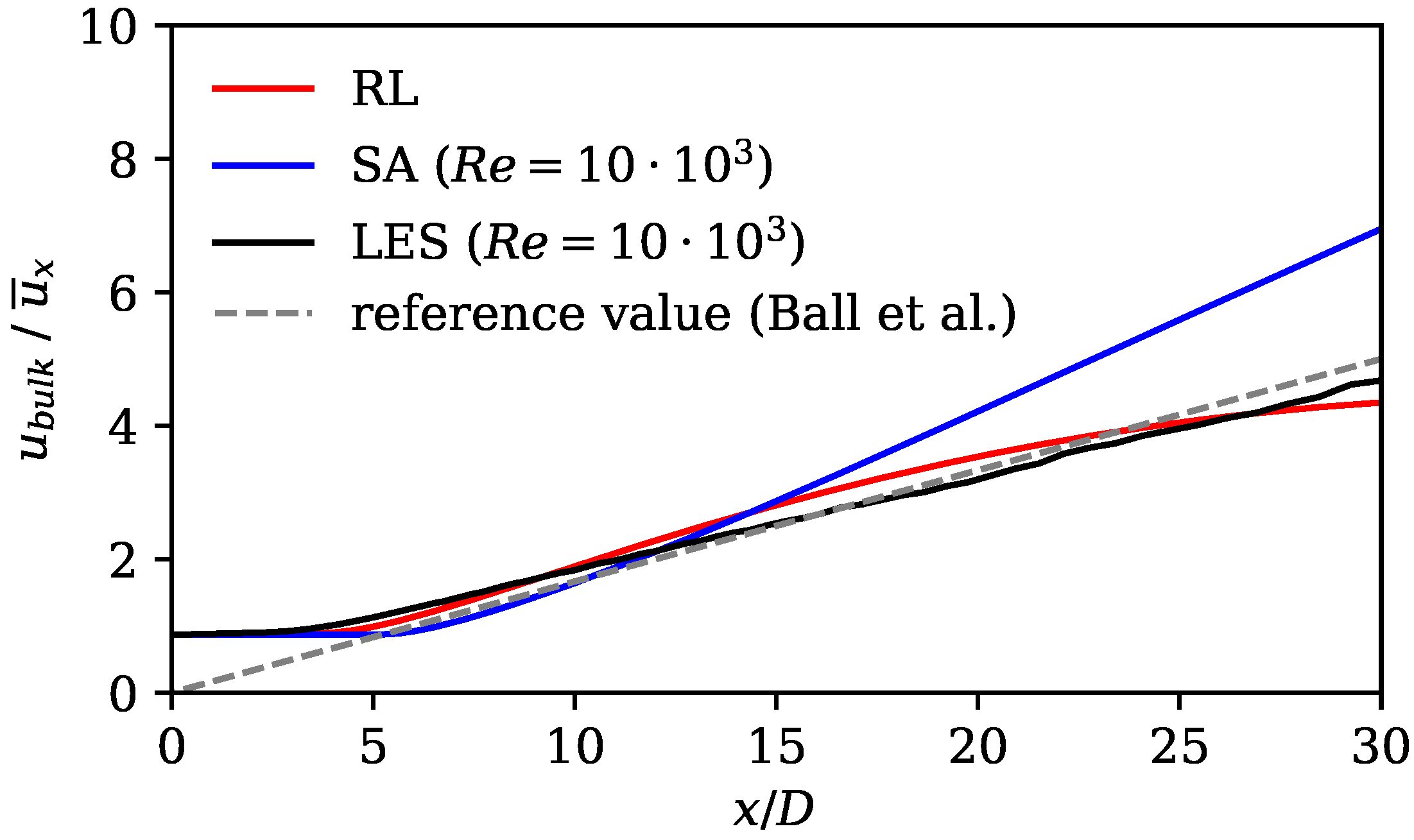
67] compare the performance of turbulence models that were specifically designed for jet flows with standard two-equation models. They also observed delayed axial velocity decay for standard models. The RL model compensates for this disadvantage, as it shows an earlier axial velocity decay (see
Figure 7). Its match in axial velocity is comparable to the turbulence models that were designed for jet flows (see Ref. [
67]).
He et al. [
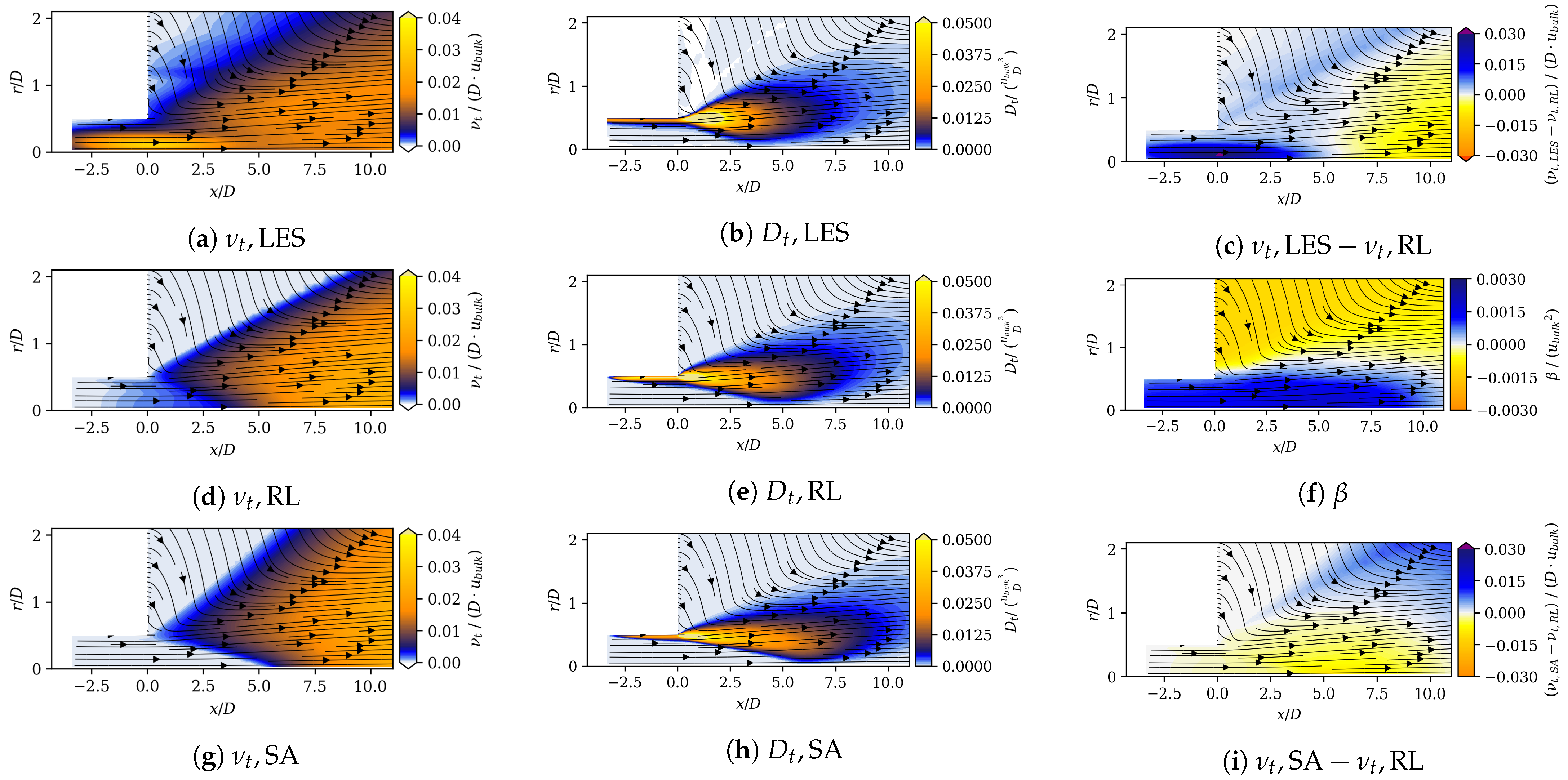
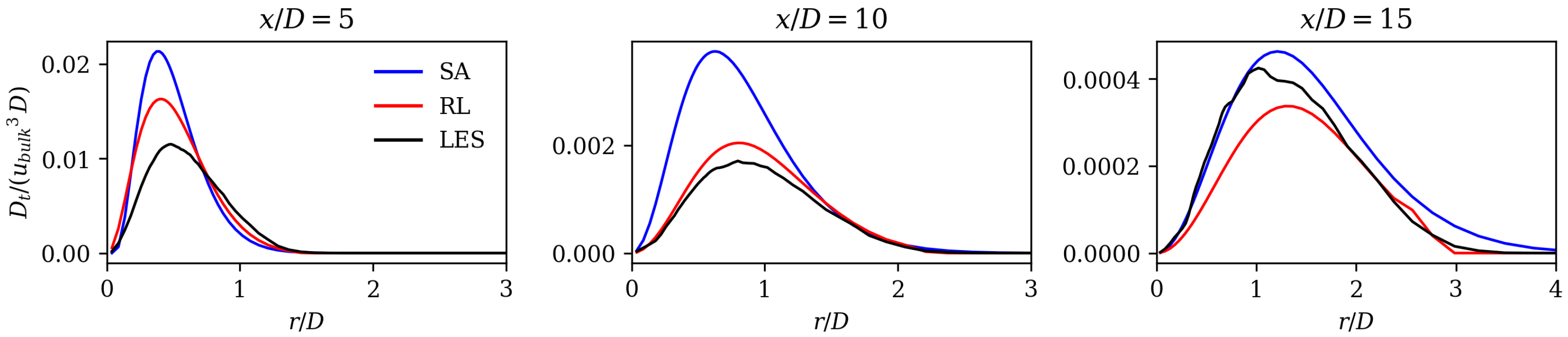
68] present an adjoint-based data assimilation model that determines a spatially varying correction that is multiplied by the production term of the Spalart–Allmaras governing equation. The eddy viscosity field of the RL model and of the adjoint-based data assimilation model show similar shapes: close to the duct outlet, the eddy viscosity increases, and further downstream, it decreases compared to the SA model [
68]. Compared with the results of this work, the approach by He et al. [
68] gives a better match in velocities. One fundamental difference is that their model receives reference field data explicitly, as it is implanted in the adjoint-based data assimilation model. In this work, the RL algorithm is not aware of the reference data field directly. It receives a global error that is based on the difference of the velocity fields. The performance of the method can be further improved by increasing the degree of freedom for optimization. He et al. [
69] use the adjoint-based data assimilation model to optimize an anisotropic Reynolds stress forcing and exceed the performance of He et al. [
68]. In conclusion, both of the data-driven methods discussed that were applied to jet flows [
68,
69] demonstrate superior performance in matching the reference velocity field compared to the RL model introduced in this work. However, it should be noted that they incorporate greater knowledge of the reference field [
68] and have greater degrees of freedom [
69].
Despite the success of the current framework, it has two disadvantages: high sensitivity to hyperparameters and high computational costs of performing extensive hyperparameter searches: Small changes in hyperparameter values, simulation setup, or other components of the framework caused substantial performance losses. Conducting extensive hyperparameter searches can quickly become infeasible, due to the high computational costs of training. To get a usable and realistic response (velocity fields) to the agent’s action ( field), the OpenFOAM environment needs to be run for a sufficient number of iterations. For this work, about 50 different hyperparameter configurations were tested to find the best performing model.
One aspect that is known to improve both training speed as well as overall model performance is efficiently leveraging invariants, as highlighted in [
23] and demonstrated in [
70]. This could be taken into account in future work.
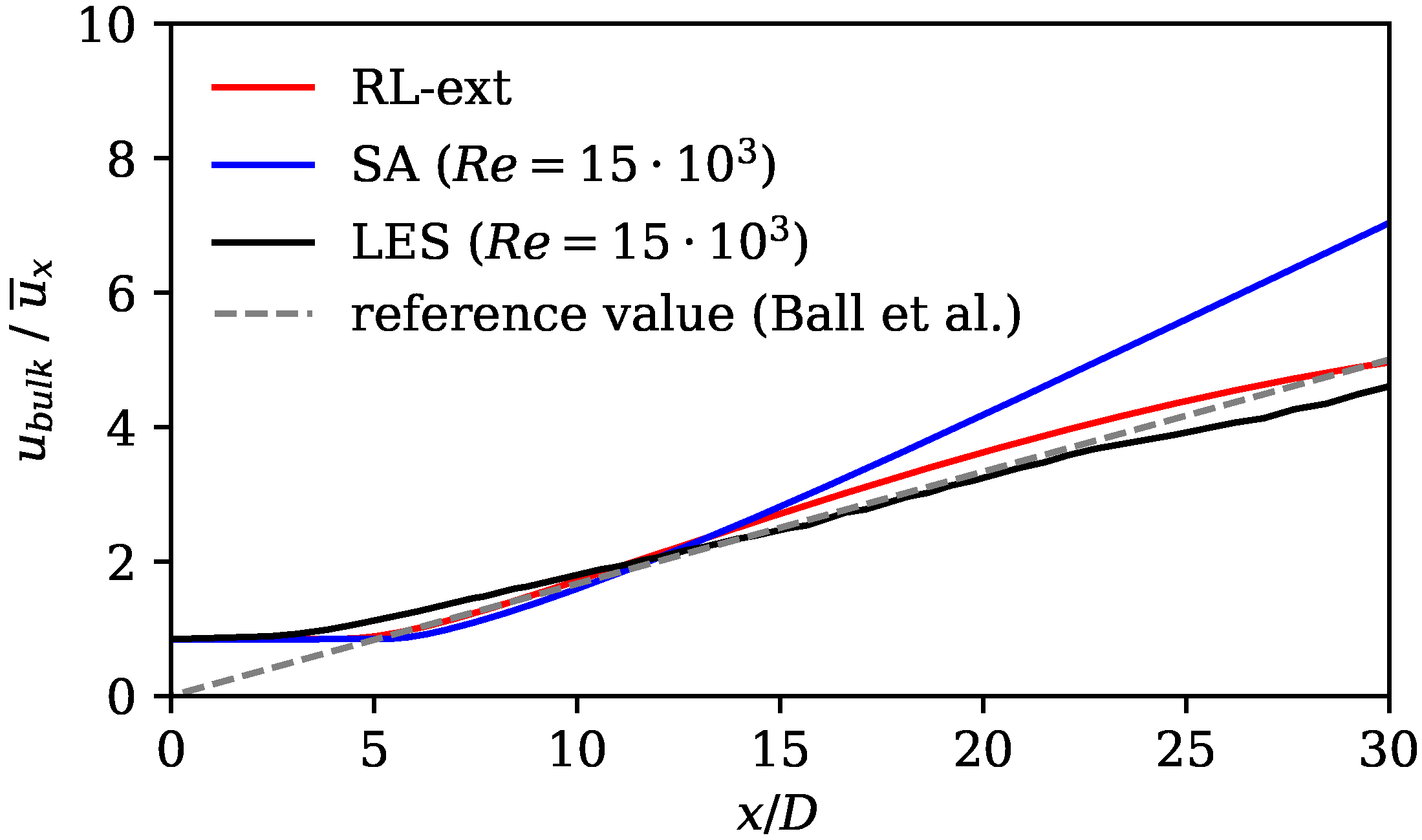
The extrapolation experiment shows that the model is able to extrapolate to a flow with a higher Reynolds number when it is trained on the same geometry. Future studies should investigate whether the model can gain additional robustness by training on two Reynolds numbers in one training run [
37]. However, full extrapolation capabilities of the method can only be tested on other flow configurations.
The challenges faced in this work appear to be commonly experienced by others who apply DRL to fluid mechanical problems; Garnier et al. [
32] list computational cost and robustness as one of the major challenges other researchers faced. Besides these disadvantages, the proposed method not only generates a solution, but also identifies a model that has the potential to be applied in other cases. An additional advantage of the proposed method is its inherent numerical stability, which stems from its integration of OpenFOAM. Throughout the training process, the algorithm is not rewarded for generating
fields that lead to diverging simulations. This ensures that the results obtained from the method maintain numerical stability.
5. Conclusions
In the present study, deep reinforcement learning (DRL) for closure model improvement is investigated. The introduced DRL algorithm searches for an optimal closure field and simultaneously relates it to flow variables by constructing a function that maps the flow field in a surrounding region to a local eddy viscosity source term. This term is directly incorporated into the Spalart–Allmaras turbulence model. The framework is trained and applied to a jet flow configuration at Re = 10,000. Mean fields of high-fidelity LES data are used as reference data. The augmented SA model is applied to a simplified RANS simulation of the reference domain.
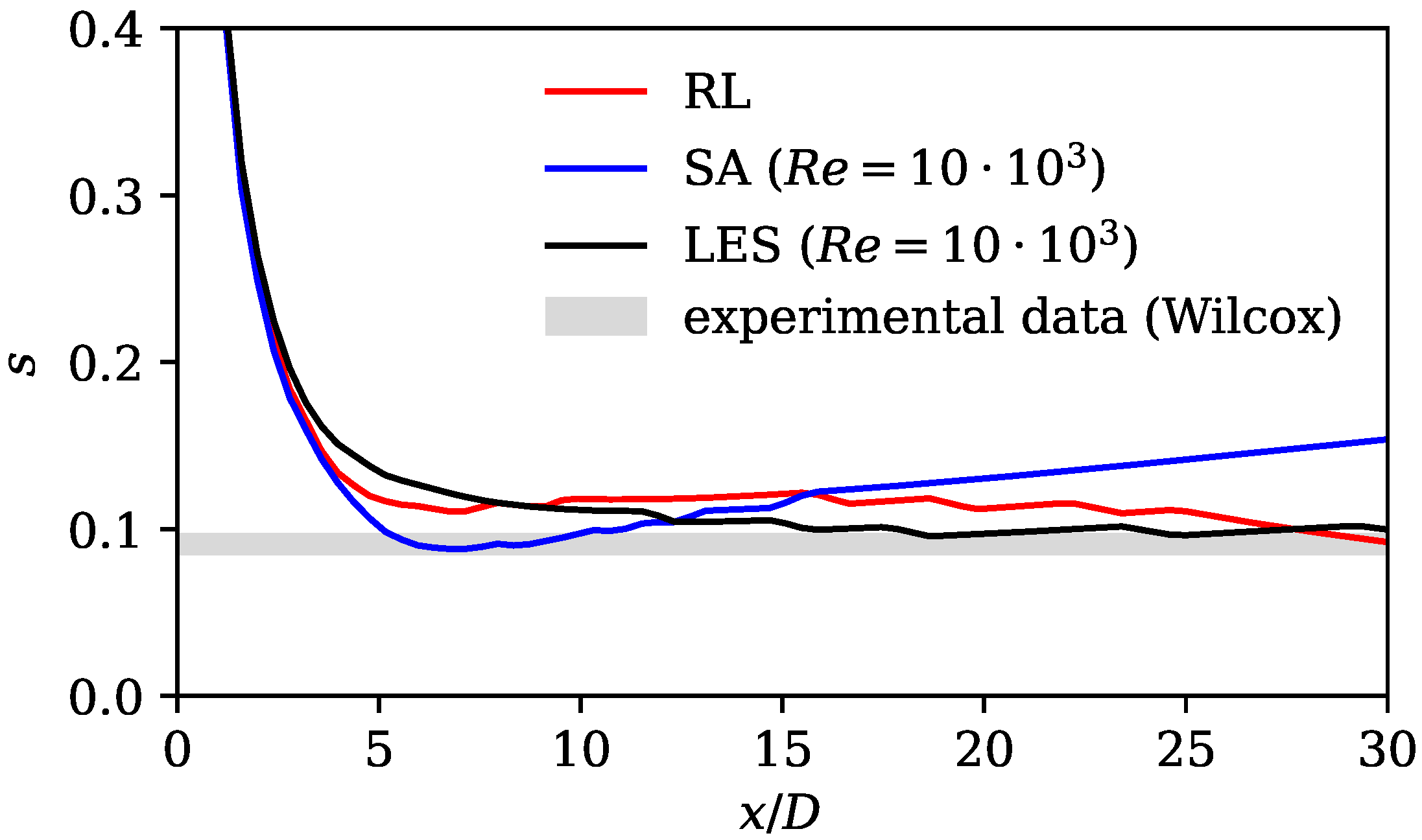
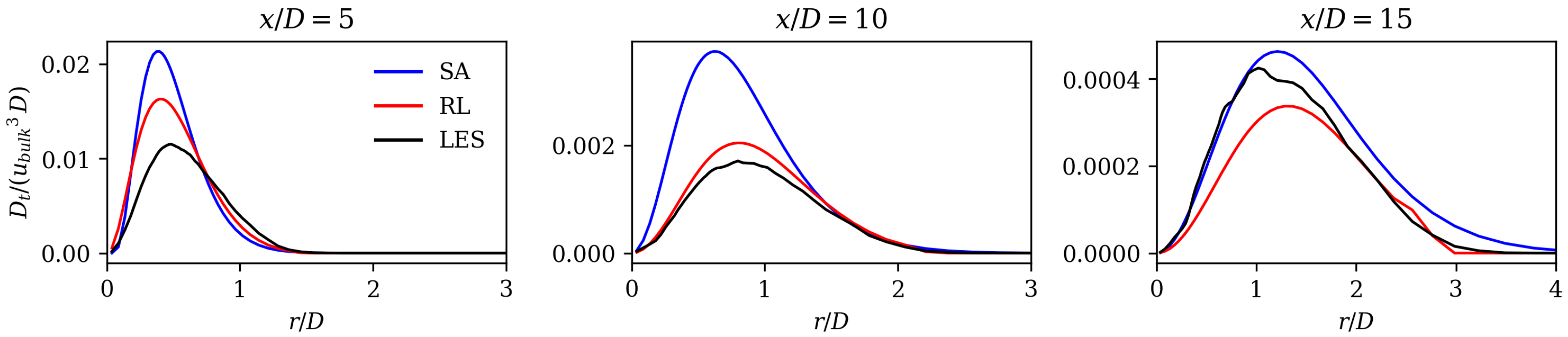
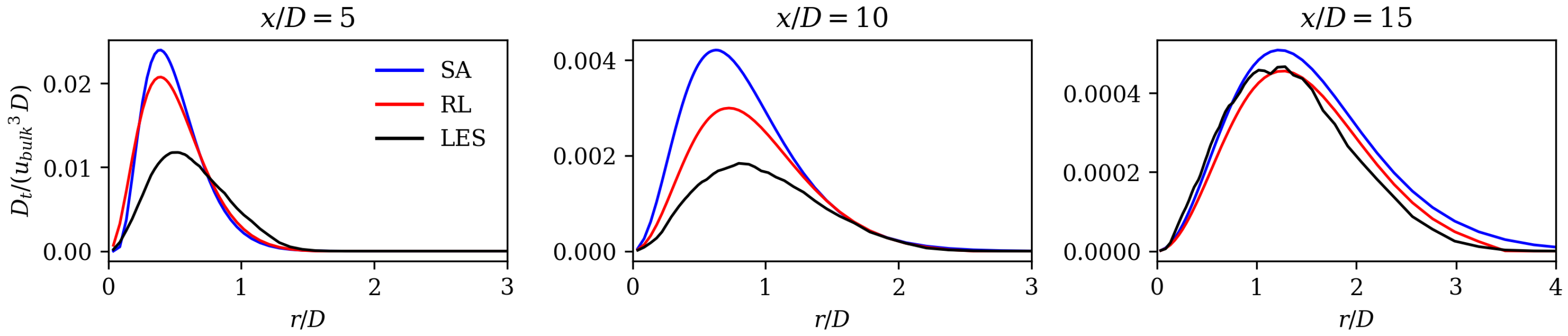
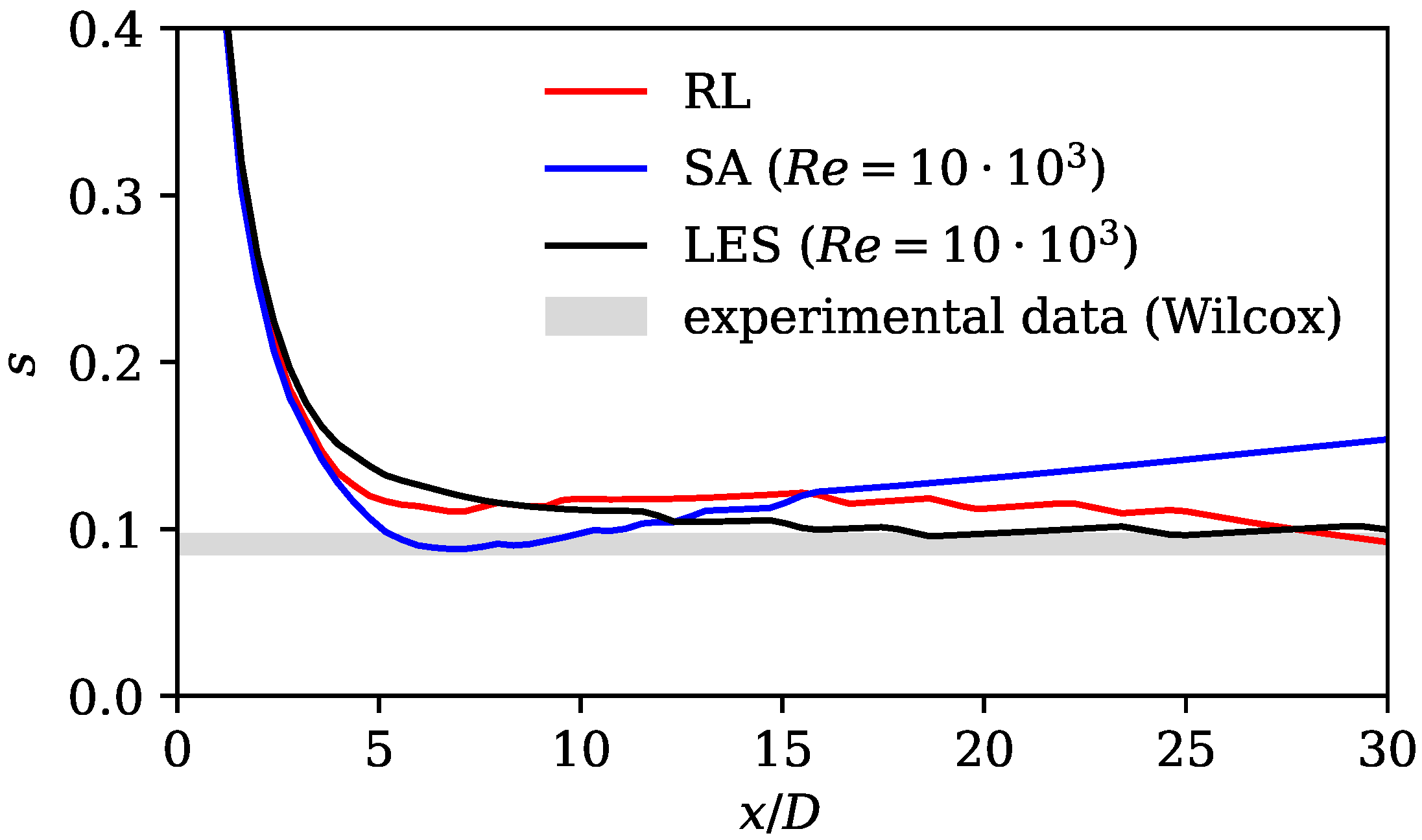
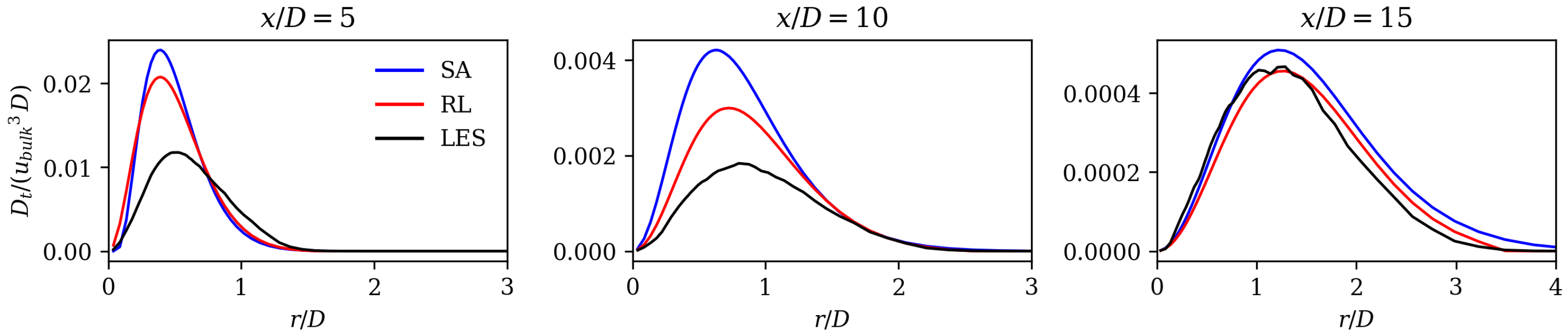
The results show substantially improved alignment with the LES reference data and the literature on jet flows. This is shown by analyzing velocity profiles, spreading rates, axial velocity decay rates, and mean field dissipation rates. The error calculated by subtracting the norm of the RANS velocity field and the LES mean fields is improved by the framework by 48%. Moreover, we observe that the RL model counteracts the well-known shortcomings of the SA model without applying physics-based reasoning. The performance of the RL model in the investigated flow region is comparable to that of the models that were tailored for jet flows. In the extrapolation experiment, the model is trained on the Re data and then applied to the Re = 15,000 case. Here, an error reduction of 35% is achieved, proving that the framework is capable of extrapolating to moderately changed flow regimes.
The biggest challenge of this framework is its sensitivity to hyperparameters. Small changes in the hyperparameter values caused substantial changes in model performance. Finding feasible hyperparameter search procedures and identifying critical hyperparameters will remain a big challenge for future applications of reinforcement learning closure models.
Investigating a round jet flow serves as an initial platform to explore the capabilities of the DRL framework. In future studies, more complex flow configurations, including separated flows, are required to fully assess the applicability of DRL for closure modeling.
The introduced reinforcement learning stencil framework successfully identifies a model that has predictive capabilities when applied to the same configuration at a higher Reynolds number, while ensuring numerical stability because it uses OpenFOAM as an interface. The success is encouraging to test the extrapolation capabilities of the method to other geometries and configurations in future studies.
In conclusion, despite facing challenges, this study confirms that deep reinforcement learning represents a promising and novel approach to data-driven closure modeling, which is worth investigating further in more complex configurations.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}