

Statistical Considerations for the Design and Analysis of Pragmatic Trials in Aging Research

 ,
,  ,
, 

Abstract
1. Introduction
2. Study Unit and Randomization
- Parallel randomized clusters: The clusters are randomized at the beginning of the study and remain unchanged until the end of the study;
- Parallel randomized clusters with a baseline period: In this design, observations are made for a period of time before randomization;
- Stepped wedge cluster randomized studies: In this design, all groups go from control to intervention at different times, and observations are obtained before and after the switches.
3. The Dependent Variable
4. Types of Statistical Models for Pragmatic Designs
5. Sample Size Estimation
6. Multi-Arm Study Sample Size
7. Secondary or Ancillary Analyses
8. Methodological Challenges and Limitations
9. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lurie, J.D.; Morgan, T.S. Pros and Cons of Pragmatic Clinical Trials. J. Comp. Eff. Res. 2013, 2, 53–58. [Google Scholar] [CrossRef]
- Zuidgeest, M.G.P.; Goetz, I.; Groenwold, R.H.H.; Irving, E.; van Thiel, G.J.M.W.; Grobbee, D.E. Series: Pragmatic Trials and Real World Evidence: Paper 1. Introduction. J. Clin. Epidemiol. 2017, 88, 7–13. [Google Scholar] [CrossRef] [PubMed]
- Loudon, K.; Treweek, S.; Sullivan, F.; Donnan, P.; Thorpe, K.E.; Zwarenstein, M. The PRECIS-2 Tool: Designing Trials That Are Fit for Purpose. BMJ 2015, 350, h2147. [Google Scholar] [CrossRef]
- Carmona-Gonzalez, C.A.; Cunha, M.T.; Menjak, I.B. Bridging Research Gaps in Geriatric Oncology: Unraveling the Potential of Pragmatic Clinical Trials. Curr. Opin. Support. Palliat. Care 2024, 18, 3–8. [Google Scholar] [CrossRef]
- Heim, N.; van Stel, H.F.; Ettema, R.G.; van der Mast, R.C.; Inouye, S.K.; Schuurmans, M.J. HELP! Problems in Executing a Pragmatic, Randomized, Stepped Wedge Trial on the Hospital Elder Life Program to Prevent Delirium in Older Patients. Trials 2017, 18, 220. [Google Scholar] [CrossRef] [PubMed]
- Nipp, R.D.; Yao, N.A.; Lowenstein, L.M.; Buckner, J.C.; Parker, I.R.; Gajra, A.; Morrison, V.A.; Dale, W.; Ballman, K.V. Pragmatic Study Designs for Older Adults with Cancer: Report from the U13 Conference. J. Geriatr. Oncol. 2016, 7, 234–241. [Google Scholar] [CrossRef] [PubMed]
- Zuidgeest, M.G.P.; Goetz, I.; Meinecke, A.K.; Boateng, D.; Irving, E.A.; van Thiel, G.J.M.; Welsing, P.M.J.; Oude-Rengerink, K.; Grobbee, D.E. The GetReal Trial Tool: Design, Assess and Discuss Clinical Drug Trials in Light of Real World Evidence Generation. J. Clin. Epidemiol. 2022, 149, 244–253. [Google Scholar] [CrossRef] [PubMed]
- Boateng, D.; Kumke, T.; Vernooij, R.; Goetz, I.; Meinecke, A.K.; Steenhuis, C.; Grobbee, D.; Zuidgeest, M.G.P. Validation of the GetReal Trial Tool–Facilitating Discussion and Understanding More Pragmatic Design Choices and Their Implications. Contemp. Clin. Trials 2023, 125, 107054. [Google Scholar] [CrossRef]
- Wang, R. Choosing the Unit of Randomization—Individual or Cluster? NEJM Evid. 2024, 3, EVIDe2400037. [Google Scholar] [CrossRef]
- Hemming, K.; Haines, T.P.; Chilton, P.J.; Girling, A.J.; Lilford, R.J. The Stepped Wedge Cluster Randomised Trial: Rationale, Design, Analysis, and Reporting. BMJ 2015, 350, h391. [Google Scholar] [CrossRef]
- Chu, R.; Walter, S.D.; Guyatt, G.; Devereaux, P.J.; Walsh, M.; Thorlund, K.; Thabane, L. Assessment and Implication of Prognostic Imbalance in Randomized Controlled Trials with a Binary Outcome—A Simulation Study. PLoS ONE 2012, 7, e36677. [Google Scholar] [CrossRef] [PubMed]
- Heckman, J.J. Randomization as an Instrumental Variable. Rev. Econ. Stat. 1996, 78, 336. [Google Scholar] [CrossRef]
- Sussman, J.B.; Hayward, R.A. An IV for the RCT: Using Instrumental Variables to Adjust for Treatment Contamination in Randomised Controlled Trials. BMJ 2010, 340, c2073. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Wang, R. Stepped Wedge Cluster Randomized Trials: A Methodological Overview. World Neurosurg. 2022, 161, 323–330. [Google Scholar] [CrossRef] [PubMed]
- Welsing, P.M.; Oude Rengerink, K.; Collier, S.; Eckert, L.; van Smeden, M.; Ciaglia, A.; Nachbaur, G.; Trelle, S.; Taylor, A.J.; Egger, M.; et al. Series: Pragmatic Trials and Real World Evidence: Paper 6. Outcome Measures in the Real World. J. Clin. Epidemiol. 2017, 90, 99–107. [Google Scholar] [CrossRef] [PubMed]
- Zuidgeest, M.G.P.; Welsing, P.M.J.; van Thiel, G.J.M.W.; Ciaglia, A.; Alfonso-Cristancho, R.; Eckert, L.; Eijkemans, M.J.C.; Egger, M.; WP3 of the GetReal Consortium. Series: Pragmatic Trials and Real World Evidence: Paper 5. Usual Care and Real Life Comparators. J. Clin. Epidemiol. 2017, 90, 92–98. [Google Scholar] [CrossRef] [PubMed]
- Hussey, M.A.; Hughes, J.P. Design and Analysis of Stepped Wedge Cluster Randomized Trials. Contemp. Clin. Trials 2007, 28, 182–191. [Google Scholar] [CrossRef] [PubMed]
- Meinecke, A.-K.; Welsing, P.; Kafatos, G.; Burke, D.; Trelle, S.; Kubin, M.; Nachbaur, G.; Egger, M.; Zuidgeest, M.; Work Package 3 of the GetReal Consortium. Series: Pragmatic Trials and Real World Evidence: Paper 8. Data Collection and Management. J. Clin. Epidemiol. 2017, 91, 13–22. [Google Scholar] [CrossRef] [PubMed]
- Selman, C.J.; Lee, K.J.; Whitehead, C.L.; Manley, B.J.; Mahar, R.K. Statistical Analyses of Ordinal Outcomes in Randomised Controlled Trials: Protocol for a Scoping Review. Trials 2023, 24, 286. [Google Scholar] [CrossRef]
- Ceyisakar, I.E.; van Leeuwen, N.; Dippel, D.W.J.; Steyerberg, E.W.; Lingsma, H.F. Ordinal Outcome Analysis Improves the Detection of Between-Hospital Differences in Outcome. BMC Med. Res. Methodol. 2021, 21, 4. [Google Scholar] [CrossRef]
- Spertus, J.A.; Jones, P.G.; Maron, D.J.; O’Brien, S.M.; Reynolds, H.R.; Rosenberg, Y.; Stone, G.W.; Harrell, F.E.; Boden, W.E.; Weintraub, W.S.; et al. Health-Status Outcomes with Invasive or Conservative Care in Coronary Disease. N. Engl. J. Med. 2020, 382, 1408–1419. [Google Scholar] [CrossRef] [PubMed]
- Eldridge, S.M.; Ashby, D.; Kerry, S. Sample Size for Cluster Randomized Trials: Effect of Coefficient of Variation of Cluster Size and Analysis Method. Int. J. Epidemiol. 2006, 35, 1292–1300. [Google Scholar] [CrossRef] [PubMed]
- Brown, C.A.; Lilford, R.J. The Stepped Wedge Trial Design: A Systematic Review. BMC Med. Res. Methodol. 2006, 6, 54. [Google Scholar] [CrossRef] [PubMed]
- Gurka, M.J.; Edwards, L.J. 8 Mixed Models. In Handbook of Statistics; Rao, C.R., Miller, J.P., Rao, D.C., Eds.; Epidemiology and Medical Statistics; Elsevier: Amsterdam, The Netherlands, 2007; Volume 27, pp. 253–280. [Google Scholar] [CrossRef]
- Hubbard, A.E.; Ahern, J.; Fleischer, N.L.; Van der Laan, M.; Lippman, S.A.; Jewell, N.; Bruckner, T.; Satariano, W.A. To GEE or Not to GEE: Comparing Population Average and Mixed Models for Estimating the Associations between Neighborhood Risk Factors and Health. Epidemiology 2010, 21, 467–474. [Google Scholar] [CrossRef] [PubMed]
- Liu, X. Methods and Applications of Longitudinal Data Analysis; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using Lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Zhang, E.; Zhang, W.G.; Zhang, R.G. CRAN Task View: Clinical Trial Design, Monitoring, and Analysis. Available online: https://CRAN.R-project.org/view=ClinicalTrials (accessed on 25 May 2024).
- Friedman, L.M.; Furberg, C.D.; DeMets, D.L.; Reboussin, D.M.; Granger, C.B. Fundamentals of Clinical Trials; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar] [CrossRef]
- Singh, J.; Liddy, C.; Hogg, W.; Taljaard, M. Intracluster Correlation Coefficients for Sample Size Calculations Related to Cardiovascular Disease Prevention and Management in Primary Care Practices. BMC Res. Notes 2015, 8, 89. [Google Scholar] [CrossRef] [PubMed]
- Donner, A.; Birkett, N.; Buck, C. Randomization by Cluster. Sample Size Requirements and Analysis. Am. J. Epidemiol. 1981, 114, 906–914. [Google Scholar] [CrossRef] [PubMed]
- Hemming, K.; Kasza, J.; Hooper, R.; Forbes, A.; Taljaard, M. A Tutorial on Sample Size Calculation for Multiple-Period Cluster Randomized Parallel, Cross-over and Stepped-Wedge Trials Using the Shiny CRT Calculator. Int. J. Epidemiol. 2020, 49, 979–995. [Google Scholar] [CrossRef] [PubMed]
- Grayling, M.J.; Wason, J.M. A Web Application for the Design of Multi-Arm Clinical Trials. BMC Cancer 2020, 20, 80. [Google Scholar] [CrossRef]
- Oude Rengerink, K.; Kalkman, S.; Collier, S.; Ciaglia, A.; Worsley, S.D.; Lightbourne, A.; Eckert, L.; Groenwold, R.H.H.; Grobbee, D.E.; Irving, E.A.; et al. Series: Pragmatic Trials and Real World Evidence: Paper 3. Patient Selection Challenges and Consequences. J. Clin. Epidemiol. 2017, 89, 173–180. [Google Scholar] [CrossRef]
- Marler, J.R. Secondary Analysis of Clinical Trials—A Cautionary Note. Prog. Cardiovasc. Dis. 2012, 54, 335–337. [Google Scholar] [CrossRef] [PubMed]
- Rothwell, P.M. Treating Individuals 2. Subgroup Analysis in Randomised Controlled Trials: Importance, Indications, and Interpretation. Lancet 2005, 365, 176–186. [Google Scholar] [CrossRef]
- Irving, E.; van den Bor, R.; Welsing, P.; Walsh, V.; Alfonso-Cristancho, R.; Harvey, C.; Garman, N.; Grobbee, D.E.; GetReal Work Package 3. Series: Pragmatic Trials and Real World Evidence: Paper 7. Safety, Quality and Monitoring. J. Clin. Epidemiol. 2017, 91, 6–12. [Google Scholar] [CrossRef] [PubMed]
- Lau, S.W.J.; Huang, Y.; Hsieh, J.; Wang, S.; Liu, Q.; Slattum, P.W.; Schwartz, J.B.; Huang, S.-M.; Temple, R. Participation of Older Adults in Clinical Trials for New Drug Applications and Biologics License Applications From 2010 Through 2019. JAMA Netw. Open 2022, 5, e2236149. [Google Scholar] [CrossRef] [PubMed]
- Worsley, S.D.; Oude Rengerink, K.; Irving, E.; Lejeune, S.; Mol, K.; Collier, S.; Groenwold, R.H.H.; Enters-Weijnen, C.; Egger, M.; Rhodes, T.; et al. Series: Pragmatic Trials and Real World Evidence: Paper 2. Setting, Sites, and Investigator Selection. J. Clin. Epidemiol. 2017, 88, 14–20. [Google Scholar] [CrossRef] [PubMed]
- Ouslander, J.G.; Bonner, A.; Herndon, L.; Shutes, J. The Interventions to Reduce Acute Care Transfers (INTERACT) Quality Improvement Program: An Overview for Medical Directors and Primary Care Clinicians in Long Term Care. J. Am. Med. Dir. Assoc. 2014, 15, 162–170. [Google Scholar] [CrossRef] [PubMed]
- Levy, C.; Zimmerman, S.; Mor, V.; Gifford, D.; Greenberg, S.A.; Klinger, J.H.; Lieblich, C.; Linnebur, S.; McAllister, A.; Nazir, A.; et al. Pragmatic Trials in Long-Term Care: Implementation and Dissemination Challenges and Opportunities. J. Am. Geriatr. Soc. 2022, 70, 709–717. [Google Scholar] [CrossRef]
- Kalkman, S.; van Thiel, G.J.M.W.; Zuidgeest, M.G.P.; Goetz, I.; Pfeiffer, B.M.; Grobbee, D.E.; van Delden, J.J.M.; Work Package 3 of the IMI GetReal Consortium. Series: Pragmatic Trials and Real World Evidence: Paper 4. Informed Consent. J. Clin. Epidemiol. 2017, 89, 181–187. [Google Scholar] [CrossRef]
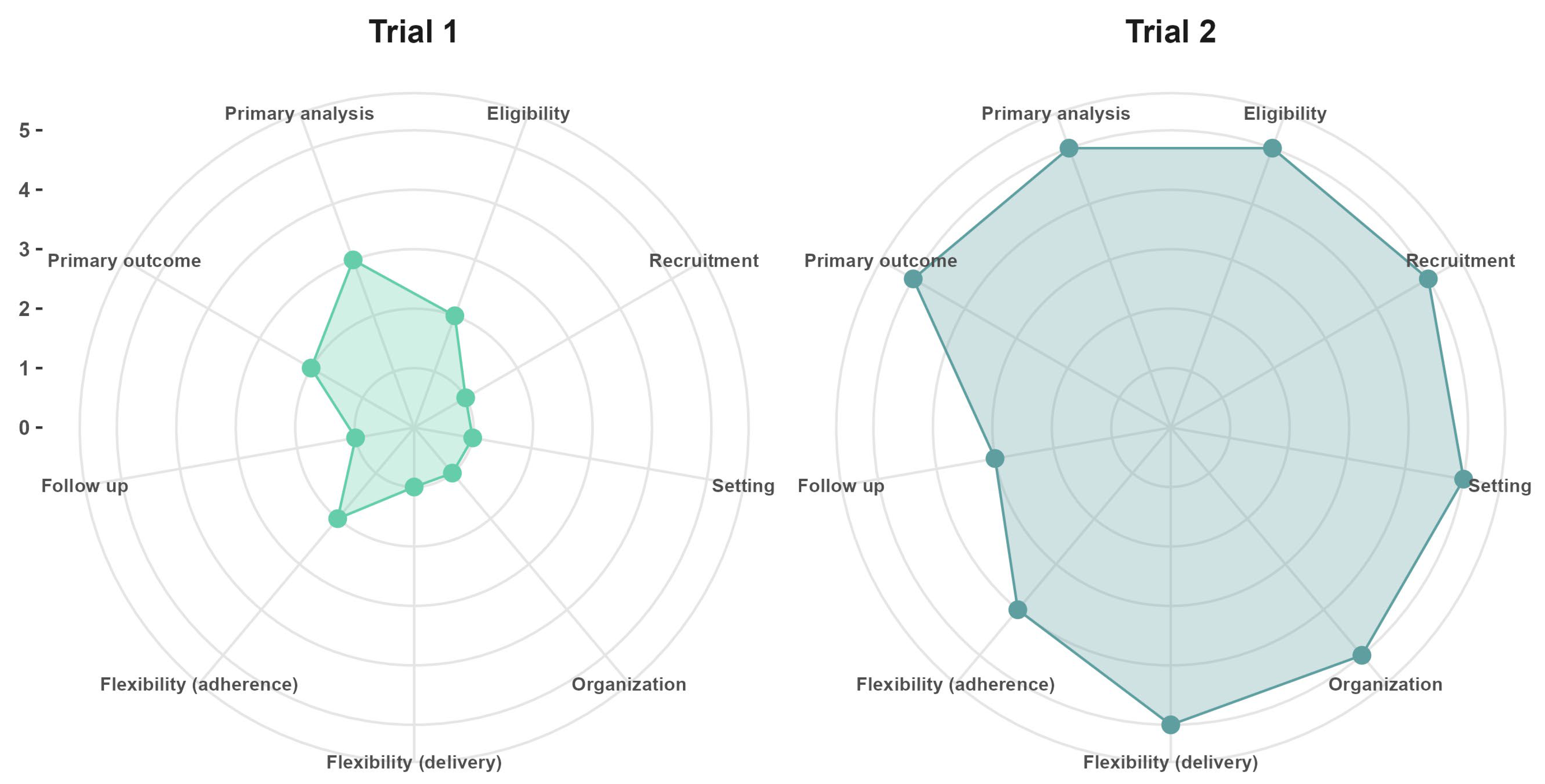

{kind=link}
| Type of Model | Use in CRTs | Statistical Model | Basic R Code (lme4 package) |
|---|---|---|---|
| Model with random intercept and fixed slope | It is useful for modeling a heterogeneous initial effect (intercept) among clusters or subjects, but with a homogeneous effect of the independent variable. It serves when assuming that members of a cluster have different initial values in the dependent variable. | where is the dependent variable for subject and group ; is the fixed intercept; is the fixed coefficient of the variable is the random intercept effect for group and is the error. | Model1 <- glmer (y ~ x + (1|cluster), family = binomial, data = data) (1|cluster): Indicates the random slope for each observation of the variable x and the random intercept for each cluster or subject. |
| Model with fixed intercept and random slope | It is useful for modeling that the effect of a dependent variable will be heterogeneous among the clusters or subjects, but that all subjects or clusters have similar values at the beginning of the study. | where is the dependent variable for subject and group ; is the fixed intercept; is the fixed coefficient of the variable is the random slope effect for group ; and is the error. | Model2 <- glmer (y ~ x + (x|1), family = binomial, data = data) (x|1): Indicates the random slope for each observation of the variable x. |
| Model with random intercept and random slope | This model, known as a random effects model, is used to model the initial differences in the values of the dependent variable among clusters or subjects as well as the heterogeneous effect of the independent variable among clusters or subjects. | where is the dependent variable for subject and group is the fixed intercept; is the fixed coefficient of the variable ; is the random intercept effect for group is the random slope effect for group ; and is the error. | Model3 <- glmer (y ~ x + (x|cluster), family = binomial, data = data) (x|cluster): Indicates the random slope for each observation of the variable x and the random intercept for each cluster or subject. |
| Purpose | Link to the Resource |
|---|---|
| R Packages for Statistical Analysis | |
| table1: baseline characteristics | https://CRAN.R-project.org/package=table1 (access date: 21 May 2024) |
| lme4: linear mixed effects models | https://CRAN.R-project.org/package=lme4 (access date: 21 May 2024) |
| nlme: non-linear mixed effects models | https://CRAN.R-project.org/package=nlme (access date: 21 May 2024) |
| rms: regression modeling strategies | https://CRAN.R-project.org/package=rms (access date: 21 May 2024) |
| mice: imputation of missing data | https://CRAN.R-project.org/package=mice (access date: 21 May 2024) |
| geeCRT: bias-corrected generalized estimating equations for cluster randomized trials | https://CRAN.R-project.org/package=geeCRT (access date: 21 May 2024) |
| Sample Size and Power Calculation | |
| Cluster clinical trials | https://douyang.shinyapps.io/swcrtcalculator/ (access date: 21 May 2024) |
| Multi-arm trials | https://mjgrayling.shinyapps.io/multi-arm/ (access date: 21 May 2024) |
| Non-inferiority studies with binary outcomes | https://search.r-project.org/CRAN/refmans/dani/html/sample.size.NI.html (access date: 21 May 2024) |
| Non-inferiority studies with continuous outcomes | https://search.r-project.org/CRAN/refmans/epiR/html/epi.ssninfc.html (access date: 21 May 2024) |
| Studies with ordinal outcomes | https://search.r-project.org/CRAN/refmans/Hmisc/html/popower.html (access date: 21 May 2024) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kammar-García, A.; Fernández-Urrutia, L.A.; Guevara-Díaz, J.A.; Mancilla-Galindo, J. Statistical Considerations for the Design and Analysis of Pragmatic Trials in Aging Research. Geriatrics 2024, 9, 75. https://doi.org/10.3390/geriatrics9030075
Kammar-García A, Fernández-Urrutia LA, Guevara-Díaz JA, Mancilla-Galindo J. Statistical Considerations for the Design and Analysis of Pragmatic Trials in Aging Research. Geriatrics. 2024; 9(3):75. https://doi.org/10.3390/geriatrics9030075
Chicago/Turabian StyleKammar-García, Ashuin, Liliana Aline Fernández-Urrutia, Jorge Alberto Guevara-Díaz, and Javier Mancilla-Galindo. 2024. "Statistical Considerations for the Design and Analysis of Pragmatic Trials in Aging Research" Geriatrics 9, no. 3: 75. https://doi.org/10.3390/geriatrics9030075
APA StyleKammar-García, A., Fernández-Urrutia, L. A., Guevara-Díaz, J. A., & Mancilla-Galindo, J. (2024). Statistical Considerations for the Design and Analysis of Pragmatic Trials in Aging Research. Geriatrics, 9(3), 75. https://doi.org/10.3390/geriatrics9030075