

Advances in Contextual Action Recognition: Automatic Cheating Detection Using Machine Learning Techniques
 , ,
, ,
Abstract
:1. Introduction
2. Related Works
3. Data Preparation and Acquisition
4. Proposed Method
4.1. Definition of Key Terms
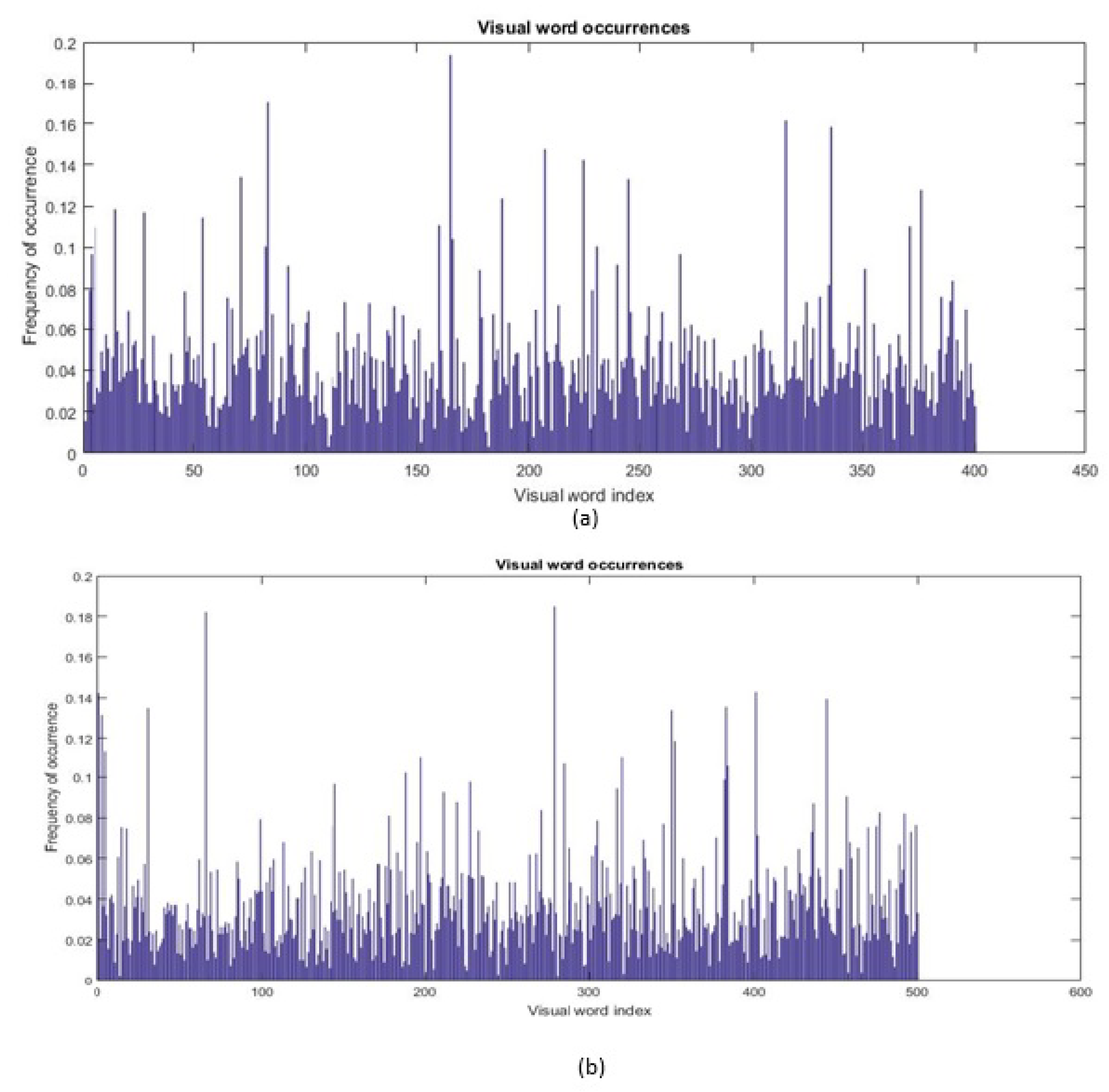
4.2. Feature Extraction
- BRISK: For each frame, we extracted the Binary Robust Invariant Scalable Key-points (BRISK) multi-scale corner features [24]. BRISK is a scale-invariant and rotation-invariant feature point detection and description technique. The BRISK features contain information about points and objects detected in a 2D gray-scale input image. An example of the detected key-points in the “use a cellular device” class is shown in Figure 2. Brisk accomplishes rotation in-variance by attempting to rotate the sample pattern by the measured orientation of the key-points. For clarity, the radials of the circles represent the orientation of the detected key-points while their size represents their scale. In our experiments, to extract BRISK features, we set the scale to 12 and specified the minimum accepted quality of corners as 10% within the designated region of interest (rectangular region for the detected corner). The minimum accepted quality of corners denotes a fraction of the maximum corner measured value in the frame. Note that increasing this value will remove inaccurate corners.
- MSER: We extracted MSER features from the proposed dataset. The maximally stable extremal regions (MSER) technique was used to extract co-variant regions from images [25]. The word “extremal” means that all pixels within a certain region have a higher or lower intensity (brightness) than those outside their boundaries. This process is achieved by arranging the pixels in ascending order according to their intensity and then assigning pixels to regions. The region boundaries were specified by applying a series of thresholds, one for each gray-scale level. Almost all the producing regions resembled an ellipse shape. The resulting region descriptors are considered MSER features. For parameters, we set the step size between intensity threshold levels at 2. Increasing this value will return fewer regions. We also considered the vector [30,14,000] for the size of the region in pixels. The vector allows for the selection of regions whose total pixels are within the vector. An example of the detected keypoints in the “exchange exam paper” class is shown in Figure 2. It depicts MSER regions, which are designated by pixel lists and are kept in the regions object. Figure 2 displays centroids and ellipses that fit into the MSER regions.
- HOG: The Histogram of Oriented Gradient is one of the most famous feature-extraction algorithms for object detection, proposed by [26]. It extracts features from a region of interest in the frame or from all locations in the frame. The shape of objects in the region is captured by collecting information about gradients. The image is divided into cells, and each group (grid) of adjacent cells forms spatial regions called blocks. The block is the foundation for the normalization and grouping of histograms. The cell is represented by angular bins according to the gradient orientation. Each pixel in the cell participates in a weighted gradient to its corresponding bin; this means that each cell’s pixel polls for a gradient bin with a vote proportional to the gradient amount at that pixel (e.g., if a pixel has a gradient orientation of 85 degrees, it will poll with a weighted gradient of 0.9 for the 85-to-95 degree bin and a weighted gradient of 0.9 for the 75-to-85 degree bin). In the experiments, we extract HOG features from blocks specified by cells and 9 orientation histogram bins to encode finer orientation details. However, an increasing number of bins increases the length of the feature vector, which then requires more time to access. A close-up of a HOG detection example is shown in Figure 2.
- SURF: Speeded-Up Robust Features (SURF) is a detector–descriptor scheme used in the fields of computer vision and image analysis [27]. The SURF detector finds distinctive interest points in the image (blobs, T-junctions, corners) based on the Hessian detector. The idea behind the Hessian detector is that it searches for strong derivatives in two orthogonal directions, thereby reducing the computational time. The Hessian detector also uses a multiple-scale iterative algorithm to localize the interest points. The SURF descriptor recaps the pixel information within a local neighborhood called “block”. The block calculates directional derivatives of the frame’s intensity. The SURF descriptor describes features unrelated to the positioning of the camera or the objects [28]. This rotational in-variance property allows for the objects to be accurately identified regardless of their perspectives or their different locations within the frame. The region of interest (ROI) is presented as a vector with the form [x y width height]. As parameters, we set the region size to (I, 2) , where the elements specify the left upper corner of the rectangular region of size . An example of the ROIs in the “using cheat sheet” class is shown in Figure 2.
- SURF&HOG: We used two of the aforementioned features, SURF and HOG, in the extraction process [29]. First, we used the SURF detector to obtain objects that contain information about the interest points in the images. We created a regular-spaced grid of interest point locations over each image. This permitted dense feature extraction. Then, we computed the HOG descriptors centered on the point locations produced by the SURF detector. For clear visualization, we selected 100 points with the strongest metrics. Figure 2 shows the SURF interest points and the HOG descriptors in the “using cheat sheet” class. Bulleted lists look like this:
5. Experiments
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Oreifej, O.; Liu, Z. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Alshdaifat, E.; Alshdaifat, D.; Alsarhan, A.; Hussein, F.; El-Salhi, S.M.F.S. The effect of preprocessing techniques, applied to numeric features, on classification algorithms’ performance. Data 2021, 6, 11. [Google Scholar] [CrossRef]
- Kong, Y.; Fu, Y. Human action recognition and prediction: A survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Alam, A.; Das, A.; Tasjid, M.; Al Marouf, A. Leveraging Sensor Fusion and Sensor-Body Position for Activity Recognition for Wearable Mobile Technologies. Int. J. Interact. Mob. Technol. 2021, 15, 141–155. [Google Scholar] [CrossRef]
- Fakhrurroja, H.; Machbub, C.; Prihatmanto, A.S. Multimodal Interaction System for Home Appliances Control. Int. J. Interact. Mob. Technol. 2020, 14, 44. [Google Scholar] [CrossRef]
- Perrett, T.; Masullo, A.; Burghardt, T.; Mirmehdi, M.; Damen, D. Temporal-relational crosstransformers for few-shot action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 475–484. [Google Scholar]
- Fernando, B.; Gould, S. Learning end-to-end video classification with rank-pooling. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 1187–1196. [Google Scholar]
- Shimada, A.; Kondo, K.; Deguchi, D.; Morin, G.; Stern, H. Kitchen scene context based gesture recognition: A contest in ICPR2012. In International Workshop on Depth Image Analysis and Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 168–185. [Google Scholar]
- Hussein, F.; Piccardi, M. V-JAUNE: A framework for joint action recognition and video summarization. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2017, 13, 1–19. [Google Scholar] [CrossRef]
- Liu, X.; Li, Y.; Li, Y.; Yu, S.; Tian, C. The study on human action recognition with depth video for intelligent monitoring. In Proceedings of the 2019 Chinese Control And Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 5702–5706. [Google Scholar]
- Cluskey, G., Jr.; Ehlen, C.R.; Raiborn, M.H. Thwarting online exam cheating without proctor supervision. J. Acad. Bus. Ethics 2011, 4, 1–7. [Google Scholar]
- Wang, J.; Tong, Y.; Ling, M.; Zhang, A.; Hao, L.; Li, X. Analysis on test cheating and its solutions based on extenics and information technology. Procedia Comput. Sci. 2015, 55, 1009–1014. [Google Scholar] [CrossRef]
- Hernándeza, J.A.; Ochoab, A.; Muñozd, J.; Burlaka, G. Detecting cheats in online student assessments using Data Mining. In Proceedings of the Conference on Data Mining|DMIN, Las Vegas, NV, USA, 26–29 June 2006; Volume 6, p. 205. [Google Scholar]
- Diederich, J. Computational methods to detect plagiarism in assessment. In Proceedings of the 2006 7th International Conference on Information Technology Based Higher Education and Training, Ultimo, Australia, 10–13 July 2006; pp. 147–154. [Google Scholar]
- Chen, M. Detect multiple choice exam cheating pattern by applying multivariate statistics. In Proceedings of the International Conference on Industrial Engineering and Operations Management, Bogota, Colombia, 25–26 October 2017; Volume 2017, pp. 173–181. [Google Scholar]
- Atoum, Y.; Chen, L.; Liu, A.X.; Hsu, S.D.; Liu, X. Automated online exam proctoring. IEEE Trans. Multimed. 2017, 19, 1609–1624. [Google Scholar] [CrossRef]
- Indi, C.S.; Pritham, K.; Acharya, V.; Prakasha, K. Detection of Malpractice in E-exams by Head Pose and Gaze Estimation. Int. J. Emerg. Technol. Learn. 2021, 16, 47. [Google Scholar] [CrossRef]
- Sharma, N.K.; Gautam, D.K.; Rathore, S.; Khan, M. CNN implementation for detect cheating in online exams during COVID-19 pandemic: A CVRU perspective. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Kock, E.; Sarwari, Y.; Russo, N.; Johnsson, M. Identifying cheating behaviour with machine learning. In Proceedings of the 2021 Swedish Artificial Intelligence Society Workshop (SAIS), Stockholm, Sweden, 14–15 June 2021; pp. 1–4. [Google Scholar]
- Genemo, M.D. Suspicious activity recognition for monitoring cheating in exams. Proc. Indian Natl. Sci. Acad. 2022, 88, 1–10. [Google Scholar] [CrossRef]
- El Kohli, S.; Jannaj, Y.; Maanan, M.; Rhinane, H. Deep Learning: New Approach for Detecting Scholar Exams Fraud. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 46, 103–107. [Google Scholar] [CrossRef]
- Noorbehbahani, F.; Mohammadi, A.; Aminazadeh, M. A systematic review of research on cheating in online exams from 2010 to 2021. Educ. Inf. Technol. 2022, 27, 8413–8460. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary robust invariant scalable keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide-baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up robust features. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Jegham, I.; Khalifa, A.B.; Alouani, I.; Mahjoub, M.A. Safe driving: Driver action recognition using surf keypoints. In Proceedings of the 2018 30th International Conference on Microelectronics (ICM), Sousse, Tunisia, 16–19 December 2018; pp. 60–63. [Google Scholar]
- Madan, R.; Agrawal, D.; Kowshik, S.; Maheshwari, H.; Agarwal, S.; Chakravarty, D. Traffic Sign Classification using Hybrid HOG-SURF Features and Convolutional Neural Networks. In Proceedings of the ICPRAM, Prague, Czech Republic, 19–21 February 2019; pp. 613–620. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action | No. of Sequences | No. of Frames |
|---|---|---|
| 1 Use of cellular device | 13 | 3192 |
| 2 Exchange exam paper | 4 | 744 |
| 3 looking at another student’s exam paper | 8 | 1734 |
| 4 Using cheats sheet | 8 | 1626 |
| 5 Not cheating | 14 | 954 |
| Features | BRISK | HOG | ||||||
|---|---|---|---|---|---|---|---|---|
| Vocabulary | 400 | 500 | 600 | 700 | 400 | 500 | 600 | 700 |
| 1 Use of cellular device | 65% | 86% | 69% | 69% | 80% | 69% | 51% | 67% |
| 2 Exchange exam paper | 63% | 84% | 86% | 92% | 69% | 94% | 86% | 88% |
| 3 looking at another student’s exam paper | 57% | 73% | 78% | 94% | 75% | 80% | 92% | 94% |
| 4 Using cheats sheet | 84% | 55% | 84% | 80% | 80% | 80% | 82% | 88% |
| 5 Not cheating | 100% | 98% | 100% | 96% | 98% | 86% | 98% | 100% |
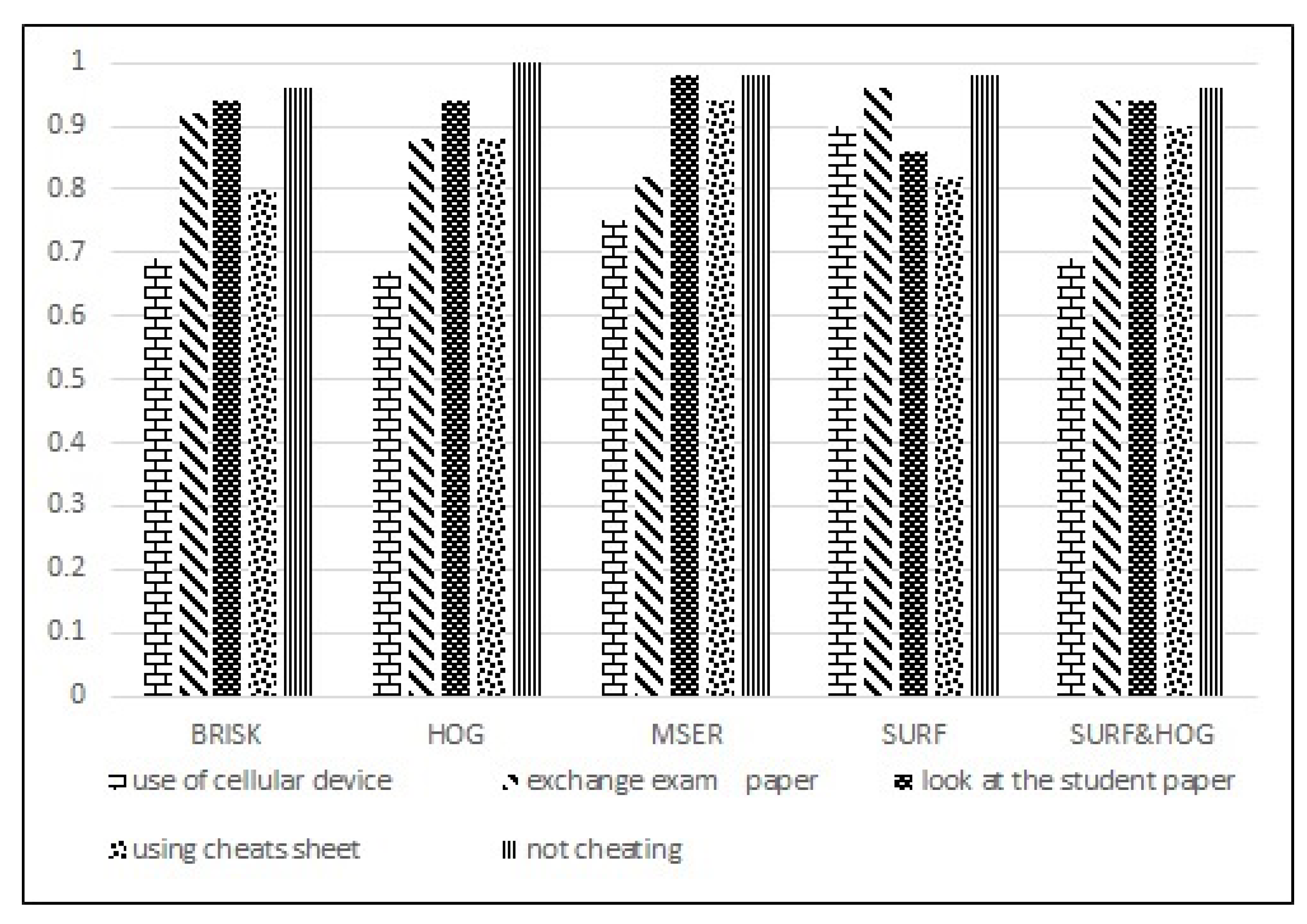
| Average Accuracy | 74% | 79% | 84% | 86% | 80% | 82% | 82% | 87% |
| Features | MSER | SURF | SURF & HOG | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vocabulary | 400 | 500 | 600 | 700 | 400 | 500 | 600 | 700 | 400 | 500 | 600 | 700 |
| 1 Use of cellular device | 75% | 73% | 73% | 92% | 65% | 90% | 82% | 69% | 61% | 75% | 69% | 67% |
| 2 Exchange exam paper | 82% | 98% | 94% | 96% | 75% | 96% | 73% | 75% | 92% | 84% | 94% | 86% |
| 3 looking at another student’s exam paper | 98% | 78% | 78% | 84% | 75% | 86% | 86% | 82% | 67% | 98% | 94% | 92% |
| 4 Using cheats sheet | 94% | 67% | 78% | 80% | 73% | 82% | 94% | 78% | 82% | 82% | 90% | 100% |
| 5 Not cheating | 98% | 96% | 100% | 76% | 94% | 98% | 100% | 90% | 100% | 100% | 96% | 76% |
| Average Accuracy | 89% | 82% | 85% | 86% | 76% | 91% | 87% | 79% | 80% | 88% | 89% | 84% |
| Features | Accuracy |
|---|---|
| BRISK | 86% |
| HOG | 87% |
| MSER | 89% |
| SURF | 91% |
| SURF&HOG | 89% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hussein, F.; Al-Ahmad, A.; El-Salhi, S.; Alshdaifat, E.; Al-Hami, M. Advances in Contextual Action Recognition: Automatic Cheating Detection Using Machine Learning Techniques. Data 2022, 7, 122. https://doi.org/10.3390/data7090122
Hussein F, Al-Ahmad A, El-Salhi S, Alshdaifat E, Al-Hami M. Advances in Contextual Action Recognition: Automatic Cheating Detection Using Machine Learning Techniques. Data. 2022; 7(9):122. https://doi.org/10.3390/data7090122
Chicago/Turabian StyleHussein, Fairouz, Ayat Al-Ahmad, Subhieh El-Salhi, Esra’a Alshdaifat, and Mo’taz Al-Hami. 2022. "Advances in Contextual Action Recognition: Automatic Cheating Detection Using Machine Learning Techniques" Data 7, no. 9: 122. https://doi.org/10.3390/data7090122
APA StyleHussein, F., Al-Ahmad, A., El-Salhi, S., Alshdaifat, E., & Al-Hami, M. (2022). Advances in Contextual Action Recognition: Automatic Cheating Detection Using Machine Learning Techniques. Data, 7(9), 122. https://doi.org/10.3390/data7090122