1. Summary
Extremist organizations exploit social media platforms to spread ideologies and influence youth with propaganda, radicalization, and recruitment. Multiple ideologies are coming from numerous organizations from different geographical locations. Organizations like ISIS [
1] and Al Qaeda [
2] have used Twitter and other social media platforms to spread propaganda and recruitment. White supremacists have also employed Twitter and websites like Stormfront [
3] and Gab [
4] to recruit youth. A few research works like [
5] focus on the automated content restructuring of web forums for better semantic analysis on social media.
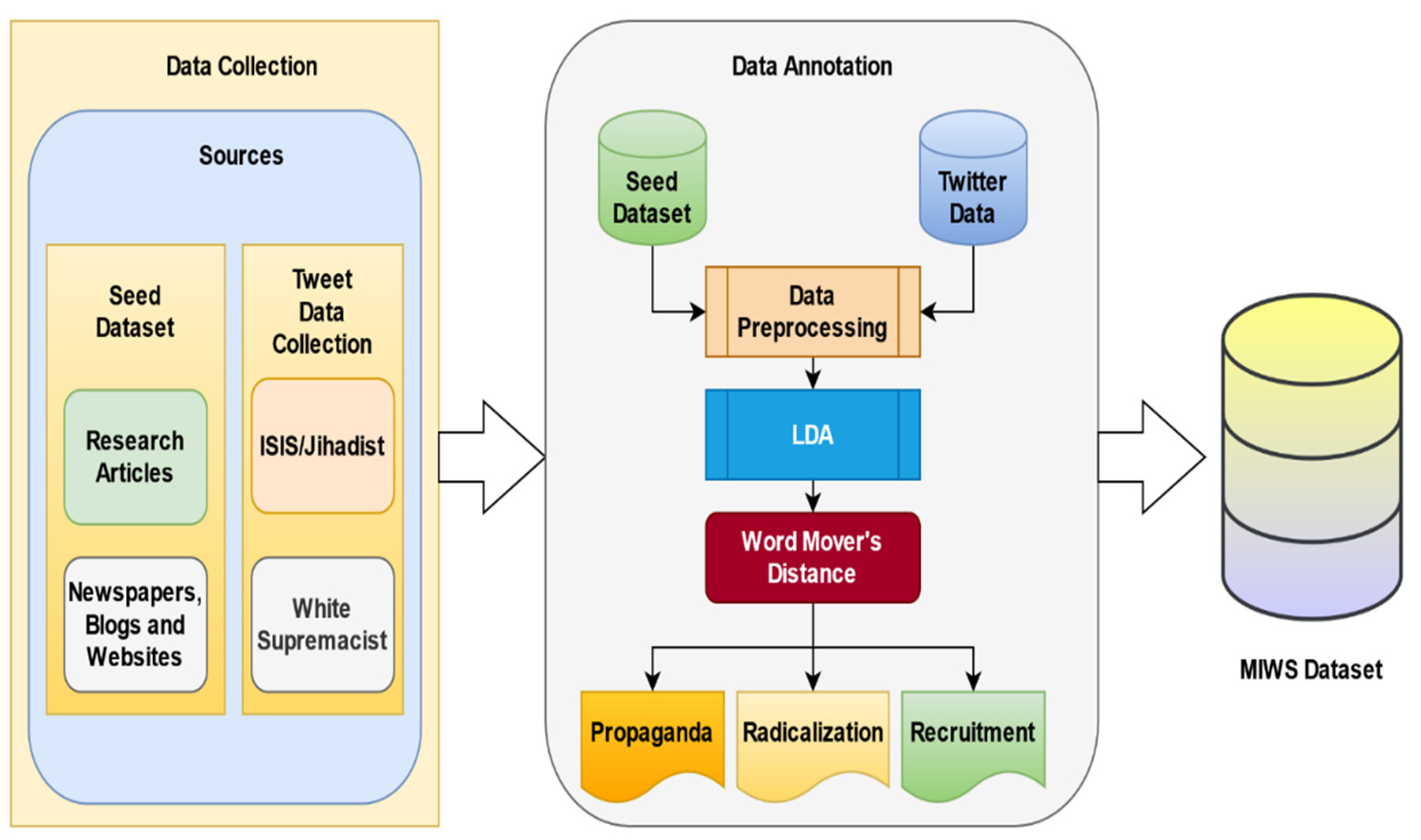
Current literature focuses on limited ideologies. Thus, it is necessary to develop an extremism text dataset containing multiple ideologies to detect extremism text. Existing literature on online extremism detection also focuses on limited class labels. Identifying and classifying text and users into binary labels like “extremist” or “non-extremist” provides lesser insight. Researchers have classified the extremist text on the social media into major types based on the objectives of social, political, or religious nature. Classification and analysis of extremist text on social media can help to curb disinformation. This work contributes to developing a multi-ideology extremist text seed dataset that can be used for extremism detection of larger extremism text datasets collected from popular social media platforms. The dataset will also be helpful for further extremism classification into propaganda, radicalization, and recruitment [
6] as seen in
Figure 1.
This dataset consists of two parts:
Seed dataset consisting of 400 examples collected from diverse sources and manually annotated with class labels as propaganda, radicalization, or recruitment.
MIWS dataset consisting of 40,000 tweets collected from Twitter and annotated with class labels as propaganda, radicalization, or recruitment from the seed dataset. Twenty thousand tweets were collected from ISIS/Jihadist ideology. Twenty thousand tweets were collected from White supremacists’ ideology.
The seed and resultant MIWS dataset with multiple ideologies are statistically validated and thus can be employed to generate a robust and accurate extremism text dataset.
Research Goal of Our Datasets
The aim of the seed dataset is to classify multi-ideology extremism text into different classes such as propaganda, radicalization, and recruitment.
Seed dataset can be used to automatically annotate large extremism text datasets collected from social media platforms.
MIWS dataset is constructed and automatically annotated using seed dataset into propaganda, radicalization, and recruitment.
MIWS can also be used to train the classifier that detects extremism text and further classifies extremism text into propaganda, radicalization, and recruitment.
MIWS dataset can be further used to analyze the geographical location of extremism text to understand the spread of extremism.
2. Data Description
There are 400 records in the seed dataset collected from diverse sources such as research articles, newspapers, blogs, and websites. There are 200 records for ISIS/Jihadist ideology and 200 for White supremacist ideology in the seed dataset. In the MIWS dataset, there are 20,000 tweets of ISIS/Jihadist ideology and 20,000 tweets from White Supremacist ideology. The details can be seen in
Table 1 and
Table 2.
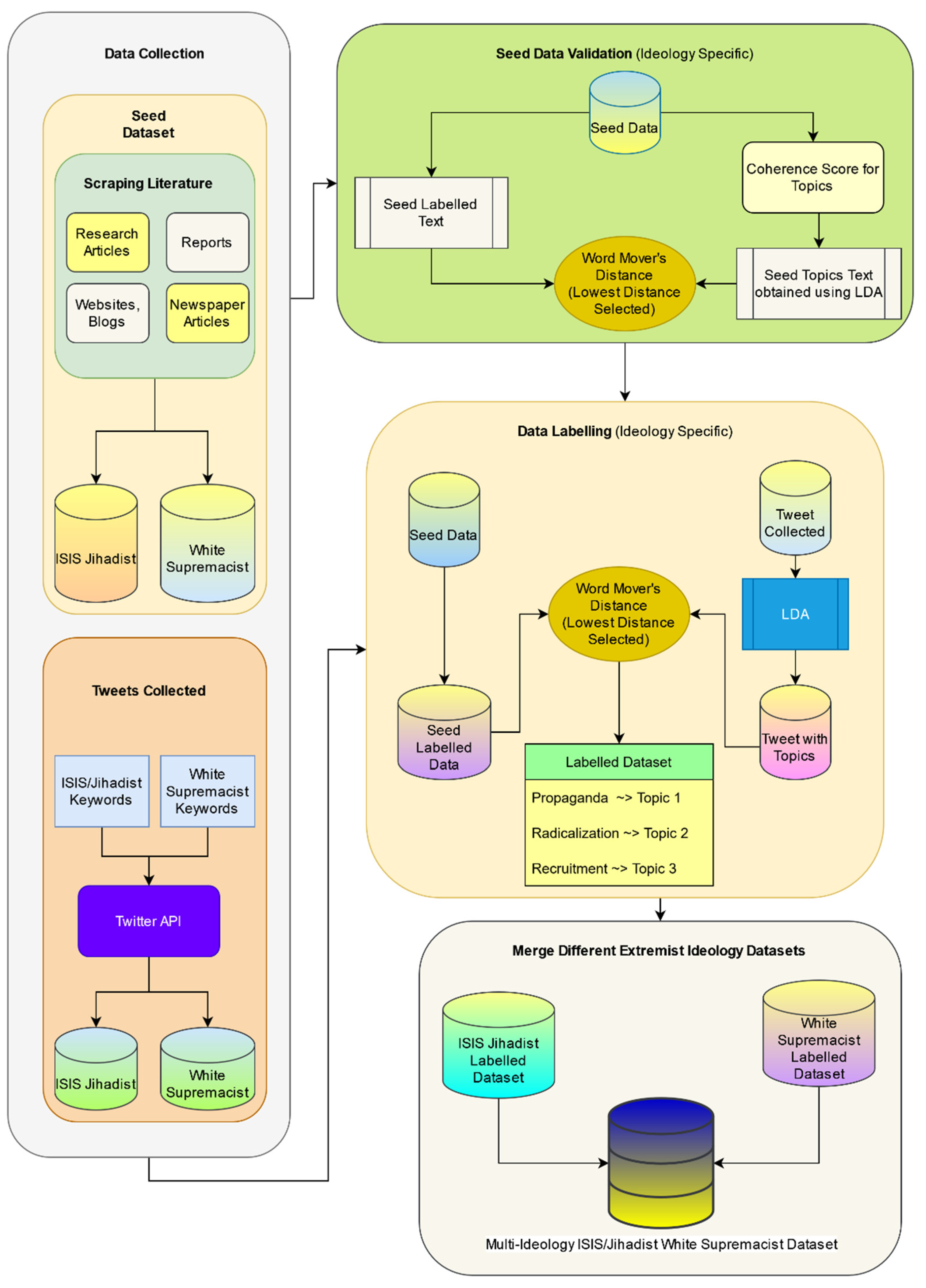
3. Methods
Figure 2 shows the process flow for construction of seed and MIWS dataset. It contains four phases: data collection, seed data validation, data labelling and merging of data from different extremist ideology. Data collection is performed in two parts: first, seed data collection (explained in
Section 3.1) and then collection of tweets or MIWS data collection (explained in
Section 6.1). Seed data validation (explained in
Section 5) is performed individually for each ideology. Similarly, data labelling (explained in
Section 6) is done on each ideology separately. The reason behind this segregation is that the corpuses of both ideologies are different and the LDA topics (explained in
Section 5) are based on the probability of keywords within the document of a particular corpus. In the last phase, merging of the ISIS/Jihadist and White supremacist labelled datasets is carried out (explained in
Section 6).
3.1. Seed Data Collection
For data collection of a seed dataset, we collected research articles from existing literature, examples from extremist identification websites, and blogs recognizing influential propagandists, radicals, and extremist recruiters [
7].
3.2. Sources
The seed dataset is collected based on ISIS/Jihadist and White supremacist ideologies. The primary objective of the seed dataset is to collect text examples of propaganda, radicalization, and recruitment. Multiple newspaper articles, journal papers, book chapters, and websites are selected. Proper sources for text examples of propaganda, radicalization, and recruitment are selected using a snowballing technique [
8].
Table 3 provides few examples from the seed dataset.
3.2.1. Research Articles and Reports
The seed text selected from the journal paper explicitly provides identification of extremist text as propaganda, radicalization, or recruitment [
9,
10,
14], which are limited in numbers. Journal papers were selected from a database similar to our work in [
6,
15]. The search was limited to the period January 2015 to December 2020. Some older studies were also included using a snowballing technique. A total of 105 research articles and reports were surveyed, of which 18 were selected for this work.
3.2.2. Newspaper, Blogs, and Websites
A snowballing technique was also used to search and select newspaper articles, blogs, and websites for the seed dataset. Most seed examples are also chosen from newspaper articles, blogs [
16], or counter-extremism websites [
7,
17]. Some websites classify users as propagandists or recruiters. The tweet or post of such users was considered as propaganda or recruitment. A total of 86 newspaper articles, blogs, and websites were surveyed, of which 32 were selected for this work.
3.3. Seed Data Features
The features of seed data include SOURCE, TYPE_OF_SOURCE, TEXT, LABEL, IDEOLOGY, GEOGRAPHICAL_LOCATION, and AUTHOR_COUNTRY_AFFLIATION.
SOURCE contains information like author name, article name, or website link of source.
TYPE_OF_SOURCE indicates whether a source is a research article, newspaper article, blog, or website.
TEXT contains actual text, tweet, or speech that is extremist provided by the source.
LABEL denotes whether the text is propaganda, radicalization, or recruitment as mentioned by the source.
IDEOLOGY mentions to which extremist ideology the text belongs.
GEOGRAPHICAL_LOCATION is a manually analyzed field that indicates any country mentioned in the text.
AUTHOR_COUNTRY_AFFLILIATION country indicates the country to which the author belongs.
4. Data Pre-Processing
The following steps were carried out for data pre-processing as seen in
Figure 3:
Removal of stopwords.
Prepositions can affect the outcome of NLP algorithms, so they are removed.
Removal of URLs.
This work does not focus on the use of URLs, so regular expressions are used to remove URLs.
Removal of emojis, hashtags, retweets, and digits.
Emojis and digits are not considered in this research work, and symbols like hashtags, @, and retweets are out-of-scope for this research work. Thus, they are removed in pre-processing.
Lemmatization and lowercase.
Lemmatization is used to ensure that meaningful words get selected for analysis. The remaining documents are converted into lowercase, so the case of terms does not affect the outcome of algorithms.
5. Seed Data Validation
5.1. LDA with Coherence Score
In this research work, data validation implies verifying manual annotation using the topic modeling LDA technique [
18]. Topic modeling is a method to identify documents in an unsupervised way. The documents are determined based on the set of keywords that are present in the corpus. Thus, the relevance of the document can be established just by looking at those sets of keywords. Latent Dirichlet allocation (LDA) is the most popular topic modeling technique. LDA works in two parts: words belonging to a document and calculating the probability of words belonging to that topic. Thus, LDA is used to determine the importance of specific words in extremism data. We further evaluate the strength of the topic with a coherence score [
19]. A coherence score is used to emphasize the semantic similarity between high-scoring words in the topic. Thus, the higher the coherence scores the more the semantic similarity within the words in the topic. Word mover’s distance [
20] is also used to find the relationship between LDA topics of the seed and seed labels. Thus, the empirical annotation is statistically validated. Topic coherence points to the co-occurrence of words within documents in the corpus, indicating semantic relation between the words [
19].
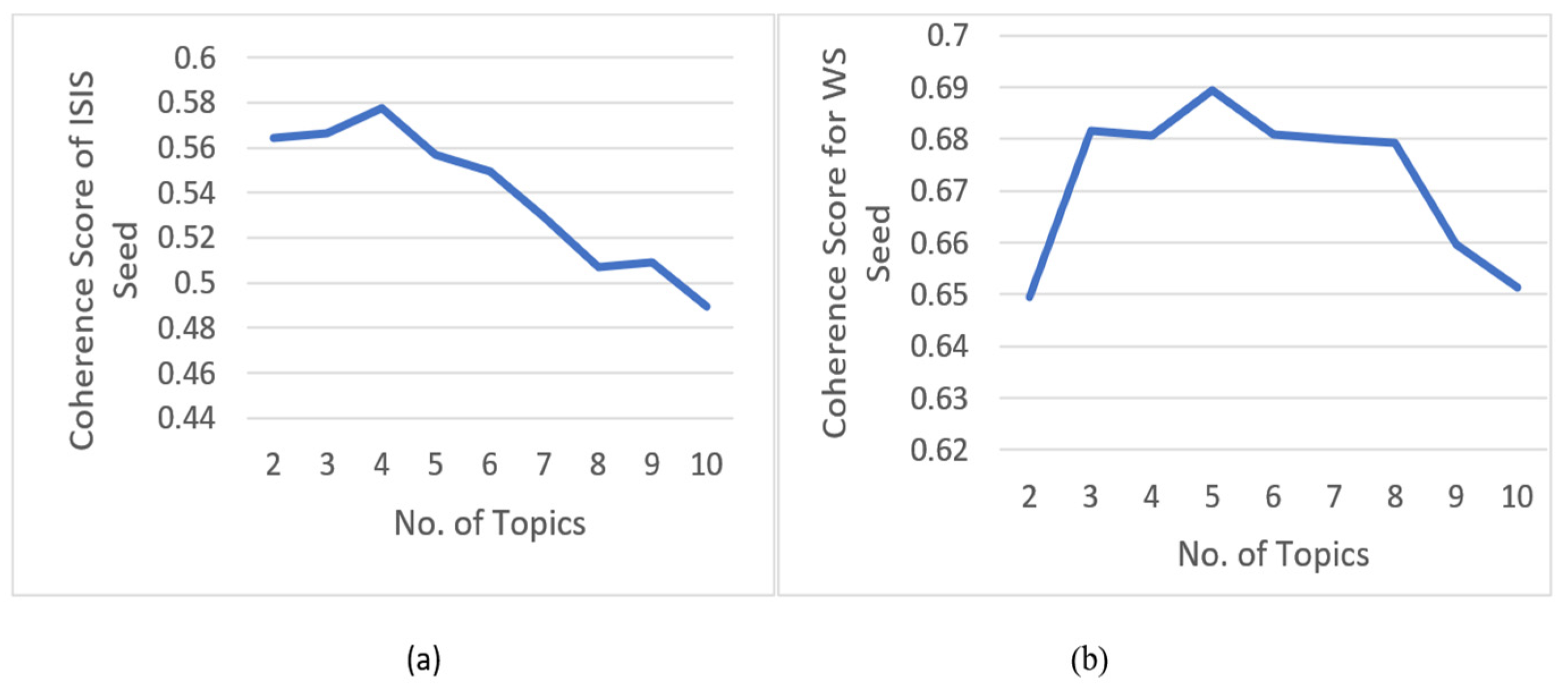
Figure 4a,b show topic coherence for the number of topics for the seed dataset.
As seen in
Figure 4a,b, a coherence score was used to determine an optimal number of topics for the seed dataset. As observed, the number for topics 3, 4, and 5 shows the highest coherence of around 0.55 for ISIS and 0.68 for White supremacists. The literature [
8,
9,
14] indicates extremism has three main types: propaganda, radicalization, and recruitment. Hence, we chose three topics (k) within extremist speech or text. The LDA optimization is also performed using GridSearchCV with 3, 4, and 5 topics. The best LDA model found using GridSearchCV contains only three topics.
5.2. Word Mover’s Distance (WMD) Using Google News Pretrained Vector
Word mover’s distance is used to verify the similarity between seed labels and topics created using LDA. WMD calculates similarity or dissimilarity between documents, even if there are no words in common [
18]. The intuition behind WMD is that it determines the smallest semantic distance required for one document to reach another [
18]. Word embeddings like Word2Vec are necessary to calculate the semantic distance between documents. The advantages of WMD are it does not use hyperparameters, the distance between documents can be broken down to the difference between words, and it works with popular word embeddings like Word2Vec.
In this study, to calculate the WMD, the topic corpus and label corpus are compared using a Google News pretrained vector.
Table 4 and
Table 5 show the results.
5.3. Inference
The comparison of seed labels and seed topics produces acceptable results. The propaganda of ISIS/Jihadist has the lowest distance of 0.8100 to topic 0 of ISIS/Jihadist. Similarly, the radicalization sub-corpus is at the lowest distance of 0.8107 from topic 1 of ISIS/Jihadist. The recruitment sub-corpus has the lowest distance of 0.7871 from topic 2 of ISIS/Jihadist.
A similar comparison is made for the White supremacist seed label and White supremacist seed topics. The propaganda sub-corpus of the WS seed is at a distance of 0.7894 from topic 1 of the WS Seed. Topic 2 of the WS seed is near to the recruitment sub-corpus at a distance of 0.9463, while Topic 0 is near radicalization at a distance of 0.9071.
6. Multi-Ideology ISIS/Jihadist White Supremacist (MIWS) Dataset
The MIWS dataset is constructed with tweets collected from Twitter for ISIS and White supremacist ideology. It can be used to train the classifier that detects extremism text and further classifies extremism text into propaganda, radicalization, and recruitment.
6.1. MIWS Data Collection
To collect relevant tweets and metadata, we constructed different search queries with different keywords. We used popular keywords that are associated with extremist ideologies like “munafiq”, “kuffar”, “white genocide”, and “anti-white”, as mentioned in
Table 6. These keywords are referenced from [
8,
21,
22,
23,
24,
25]. We also used some new keywords like “kufr army”, “wesupporttaliban”, “talibanourguardians”, “globalists”, “zog” etc., to collect recent tweets. The geographical locations were found by manually searching locations from collected tweets. If no locations were present in the tweet, it was labeled as “undefined”.
The following are different metadata collected from tweets using Twitter API.
TWEET_ID: It is the unique id for a tweet.
CREATED_AT: Time at which tweet was created or posted.
USERNAME: Username of the posted tweet.
NAME: Name, if provided by the user.
TWEET: The tweet in UTF-8 format.
GEO_ENABLED: Boolean value for geographical data about the tweet.
Due to the Twitter data sharing policy, only Tweet_ID, Created_At, and Geo_Enabled can be shared publicly.
Table 7 is a snapshot of collected tweets with geographical location and dominant topic.
Table 8 shows that 20,000 tweets were collected for each ISIS/Jihadist and White supremacist ideology.
Table 9 shows the count of tweets for some keywords. In extremist tweets, words like ‘munafiq’, ‘munafiqeen’, ‘kuffar’, and ‘white lives matter’ are frequently mentioned.
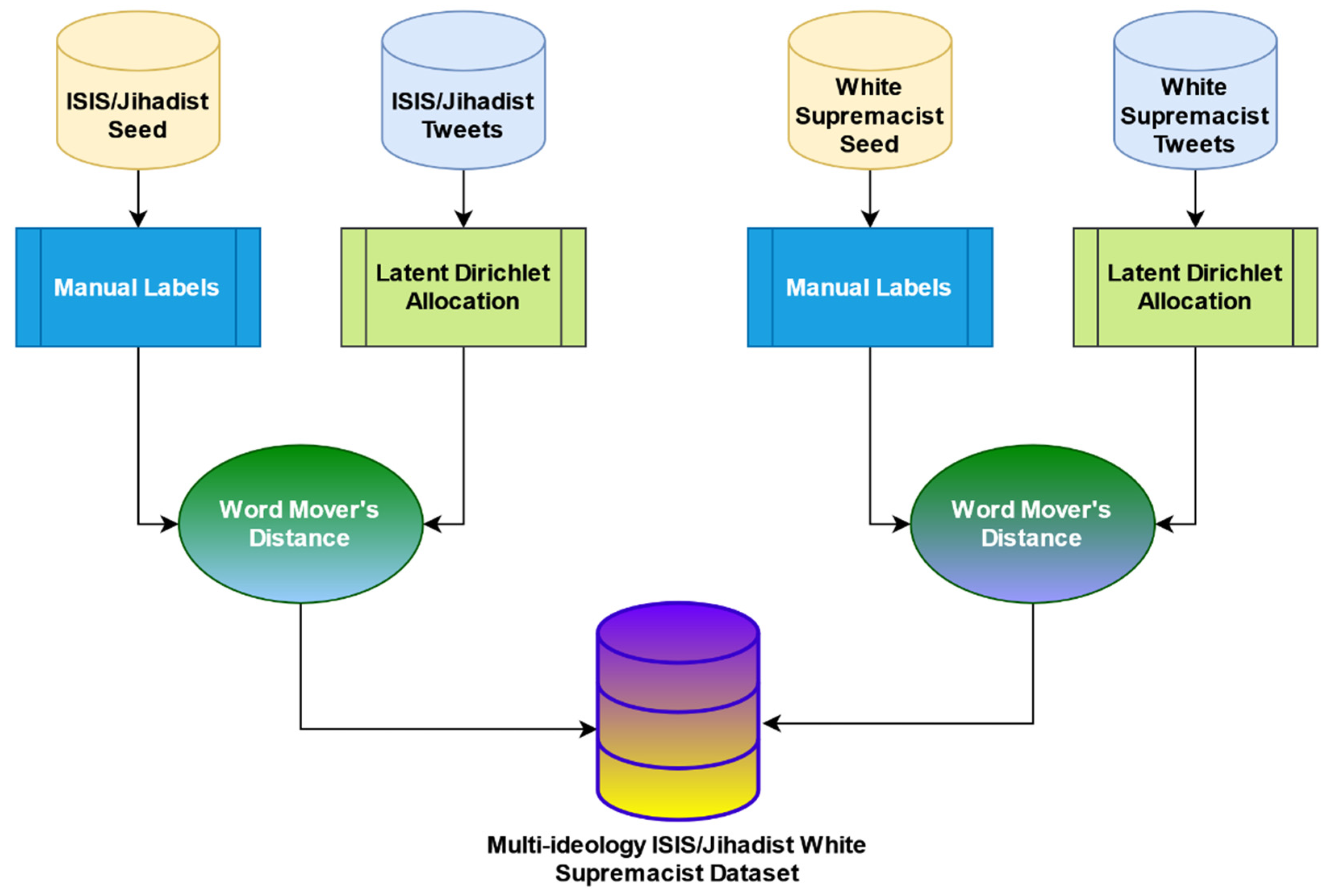
6.2. Construction of MIWS Using Seed Dataset
As described in
Section 6.1, tweets related to specific ideologies extracted from Twitter are merged to form the MIWS dataset as seen in
Figure 5.
6.2.1. Data Pre-Processing
Data pre-processing is carried out as mentioned in
Section 4.
6.2.2. Data Labeling/Annotation
The following steps are performed for data annotation:
6.2.3. LDA on Collected Tweets
As shown in
Figure 5, a comparison of labeled topics from the seed dataset and topics from Twitter collected data is performed. To extract topics, the Latent Dirichlet Allocation [
26] method is used. To confirm the best possible topics, GridSearchCV is used. Hyperparameter tuning is performed to select optimal parameters for the best model.
Table 10 provides the best parameters for the LDA model applied to collected data based on ideology.
6.2.4. Comparison between Seed Labels and Topics of Collected Tweets
It is required to compare topics based on the ideology. Labeled topics from the ISIS/Jihadist seed and White supremacist seed are compared with topics from ISIS/Jihadist and White supremacists collected tweets. This was done to maintain uniformity and accuracy across ideologies.
Word mover’s distance (WMD) is used to compare collected tweets and seed labels. WMD presents semantically meaningful comparisons of words from local co-occurrences in sentences. Thus, the lower the distance the more the similarity among sentences. To leverage WMD’s properties, the Word2Vec vector pretrained on Google News is used [
27]. As seen from
Table 11 and
Table 12, the lower the distance between the topic and labels the more similar they are than the others. Thus, the corresponding label is given to that topic.
6.2.5. Inference
Similarity of ISIS/Jihadist seed labels and ISIS/Jihadist tweet topics is shown in
Table 11. The propaganda of the ISIS/Jihadist seed has the lowest distance of 0.8455 to topic 1 of the ISIS/Jihadist tweet topics. Similarly, the radicalization sub-corpus is at the lowest distance of 0.8575 from topic 0 of the ISIS/Jihadist tweet topics. The recruitment sub-corpus has the lowest distance of 0.8464 from topic 2 of the ISIS/Jihadist tweet topics.
A similar comparison is made for White supremacist tweets, as seen in
Table 12. The propaganda seed sub-corpus is at a distance of 0.7924 from topic 2 of the WS tweets. Topic 0 of the WS tweets is near the recruitment seed sub-corpus at a distance of 0.8032, while topic 1 is near radicalization at a distance of 0.8021.
6.2.6. Merging of Datasets
Topic 0 of ISIS/Jihadist and topic 1 of WS are labeled as radicalization and contain 10,120 tweets. Radicalization includes more politically aligned tweets. Topic 1 of ISIS/Jihadist and Topic 2 of WS are labeled as propaganda, consisting of 19,523 tweets; thus, propaganda is the largest class of all three classes. Propaganda contains religious keywords, achievements, and glorification of ideology. Topic 2 of ISIS/Jihadist and topic 0 of WS, labeled as recruitment, contains 10,893 tweets. General hate, discussion about the degradation of old or religious ways, and incitement against a particular group are observed in recruitment.
Table 13 shows a few tweets and their annotated labels with ideology, while
Table 14 shows the statistical summary for seed and MIWS datasets.
After annotating, the data from both ideologies are merged to form a new dataset called the merged ISIS/Jihadist and White supremacist (MIWS) dataset.
6.3. Data Validation of MIWS Dataset
Data Validation is performed on the complete MIWS dataset. To validate the dataset, WMD is used. For validation, a comparison between labels is performed. This provides three different results. The WMD for propaganda and radicalization is at 5.4632, while for propaganda and recruitment, the WMD is at 3.4831. Lastly, the WMD between recruitment and radicalization is 4.6590. These results show that there is a significant difference between MIWS propaganda, radicalization, and recruitment labels.
7. Discussion and Implications
The MIWS dataset proposes multi-ideology and multi-class classification, especially in extremism types like propaganda, radicalization, and recruitment. These types of text are mostly disinformation targeted at vulnerable youth. Thus, it is vital to counter extremist text and malicious disinformation on social media. However, there are only a few standard datasets related to extremism, such as the ISIS Kaggle dataset [
28], Stormfront dataset [
29], and Gab dataset [
30]. There are also a few custom datasets that are publicly unavailable such as Jaki et al. [
31], Fraiwan et al. [
32], and Ferrara et al. [
33]. Most of these datasets are popular in the literature but have a few limitations. They are old, obsolete, most tweets and posts in the datasets are deleted or suspended, and classification is limited to extremist-non-extremist, hate-no hate [
30,
33,
34].
MIWS tries to address these issues. The data collected for MIWS is recent and influenced by more recent events, writing styles, and expressions on social media. Most tweets collected are available online and more information about the extremist text can be gathered [
7,
35]. The dataset is annotated into propaganda, radicalization, and recruitment, which provides a clear view of conversation and topics in the extremist text. A tweet of recruitment can now be addressed distinctly from propaganda or a radical opinion which are part of disinformation spread by extremists. This helps in taking measures for effective handling of disinformation control or curbing its outreach.
This dataset is one of its kind, which also caters to multiple ideologies of extremism and tries to present the diversities of the writing and presenting styles by the activists from ISIS and White supremacist groups, which are the most popular extremist ideologies [
36].
Academicians, researchers, and law enforcement agencies can use the MIWS dataset to identify and analyze extremist posts and disinformation on Twitter or any other website. Identifying extremist text as propaganda, radicalization, and recruitment can further help explore the topics and events related to extremism for adequate control of disinformation. The automatic classification that can be offered with this dataset can reduce the time taken for analysis and encourage law enforcement agencies and social media networks to take rapid action against such tweets or posts.
MIWS dataset can be used in alliance with [
37] to identify the high prevalence of extremism in a particular geographical area using different semantic models like SpaCy. This could extend [
37] to decide about help provided to countries regarding more recent events and extremist propaganda, radicalization, and recruitment taking place in that country. MIWS dataset can be used in addition to Global Terrorism Dataset (GTD) [
38] to analyze propaganda, radicalization, and recruitment leading to terrorist events and their after effects. In order for it to work with the GTD, the MIWS needs to be kept updated frequently.
8. Limitations
This research work presents two different datasets, so the limitations of each dataset are as below:
8.1. Seed Dataset
Size of seed dataset: A limited number of studies exclusively identify extremism as propaganda, radicalization, and recruitment. This limits the size of the seed dataset.
Limited class labels: Extremist text has multiple class labels like irrelevant, violent, or racist, but only popular class labels, i.e., propaganda, radicalization, and recruitment, are used for this study.
Limited ideologies: There are different ideologies as well as extremist organizations with different agendas. However, we only considered popular ideologies, which are ISIS/Jihadist and White supremacist ideologies.
8.2. MIWS
Class imbalance: There is a significant imbalance in class labels which may affect evaluation and prediction.
Suspended tweets: As extremist tweets violate Twitter’s hate speech policy, they may be removed from Twitter. Thus, recollection of tweets is an issue.
False positives: The tweets are collected using extremist keywords. Hence, false positives like sarcastic, satirical, or critical tweets might get inadvertently selected, reducing accuracy.
9. Conclusions
The presented work contributes to the detection of extremist text on social media, characterizes the major types of extremism text, and thus contributes to curbing the spread of disinformation. This research work contributes to the construction of extremism text, multi-ideology multi-class seeds, and the MIWS dataset. To the best of our understanding, the seed dataset collected from research articles, blogs, and counter-extremism websites is the first of its kind, which can be used further to classify any extremism text into radicalization, recruitment, and propaganda.
This hypothesis is validated by constructing the MIWS dataset from recent tweets collected from Twitter and can be used to classify any extremism text into radicalization, recruitment, and propaganda. The presented seed dataset is also statistically validated using a coherence score and WMD. The MIWS dataset is validated using WMD. This makes the it statistically proven for further research on extremism text detection and analysis.
10. Future Work
There are still a few areas that can be improved:
Size of seed dataset: The size of the seed dataset can be extended with labeled extremism text from the latest research.
Languages: A greater number of languages such as Arabic and Urdu can be considered for extremist tweet collection.
Removal of class imbalance: More data collection with different keywords can address an issue of class imbalance within the MIWS dataset.
Evaluation using pre-trained networks: Pre-trained networks like BERT and ELMO can be used to evaluate and predict the MIWS dataset.
Data validation using statistical techniques: Statistical validation can be made significant using tests like the Chi-Square test.
Inclusion of additional ideologies and classes: More extremist ideologies with classes like neutral or irrelevant may be added to the MIWS dataset in the future.
Author Contributions
Conceptualization, S.A., S.P. and K.K.; methodology, M.G.; investigation, M.G.; resources, S.A., S.P., K.K., and M.G; data curation, M.G.; writing—original draft preparation, M.G., S.A., and S.P.; writing—review and editing, S.A., S.P., and K.K. All authors have read and agreed to the published version of the manuscript.
Funding
This study is partly funded by Research Support Grant from Symbiosis International (Deemed University).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Multi-ideology ISIS/Jihadist White Supremacist Dataset is publicly available extremism dataset. The data presented in this study is openly available at
https://doi.org/10.5281/zenodo.5687447.
Acknowledgments
The authors would like to thank Symbiosis International (Deemed University) for permitting us to carry out our research and to use resources to accomplish the objectives.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Baele, S.; Boyd, K.; Coan, T. ISIS Propaganda; Oxford University Press: Oxford, UK, 2020. [Google Scholar]
- Dornbierer, A. How al-Qaeda Recruits Online. The Diplomat, 2011. Available online: https://thediplomat.com/2011/09/how-al-qaeda-recruits-online/ (accessed on 15 May 2020).
- Stormfront. Available online: www.stormfront.org (accessed on 20 August 2020).
- Gab Social Media. 2020. Available online: https://gab.com/ (accessed on 10 October 2020).
- Korobiichuk, I.; Syerov, Y.; Fedushko, S. The Method of Semantic Structuring of Virtual Community Content. In Mechatronics 2019: Recent Advances towards Industry 4.0; Springer International Publishing: Cham, Switzerland, 2020; pp. 11–18. [Google Scholar]
- Gaikwad, M.; Ahirrao, S.; Phansalkar, S.; Kotecha, K. Online Extremism Detection: A Systematic Literature Review with Emphasis on Datasets, Classification Techniques, Validation Methods, and Tools. IEEE Access 2021, 9, 48364–48404. [Google Scholar] [CrossRef]
- ISIS Recruiters, Propagandists, and Inciters to Violence Operating on Twitter|Counter Extremism Project. Counter Extremism. 1 January 2021. Available online: https://www.counterextremism.com/content/isis-recruiters-propagandists-and-inciters-violence-operating-twitter (accessed on 22 March 2021).
- Naderifar, M.; Goli, H.; Ghaljaie, F. Snowball Sampling: A Purposeful Method of Sampling in Qualitative Research. Strides Dev. Med. Educ. 2017, 14. [Google Scholar] [CrossRef] [Green Version]
- Chatfield, A.T.; Reddick, C.G.; Brajawidagda, U. Tweeting propaganda, radicalization and recruitment: Islamic state supporters multi-sided twitter networks. In ACM International Conference Proceeding Series; Association for Computing Machinery: Phoenix, Arizona, 2015; pp. 239–249. [Google Scholar] [CrossRef]
- Ray, B.; Marsh, G.E. Recruitment by extremist groups on the Internet. First Monday 2001, 6. [Google Scholar] [CrossRef]
- Thompson, A. Inside Atomwaffen As It Celebrates a Member for Allegedly Killing a Gay Jewish College Student. ProPublica, 2018. Available online: https://www.propublica.org/article/atomwaffen-division-inside-white-hate-group (accessed on 5 May 2021).
- White Nationalist Recruitment on IU’s Campus. No Space for Hate. 2020. Available online: https://nospace4hate.btown-in.org/recruitment-on-campus/ (accessed on 20 December 2020).
- Homeland Security. The Atomwaffen Division: The Evolution of the White Supremacy Threat. Homeland Security Today, 2020. Available online: https://www.hstoday.us/subject-matter-areas/counterterrorism/the-atomwaffen-division-the-evolution-of-the-white-supremacy-threat/ (accessed on 10 October 2020).
- Windsor, L. The Language of Radicalization: Female Internet Recruitment to Participation in ISIS Activities. Terror. Polit. Violence 2018, 32, 506–538. [Google Scholar] [CrossRef]
- Gaikwad, M.; Ahirrao, S.; Phansalkar, S.P.; Kotecha, K. A Bibliometric Analysis of Online Extremism Detection. Libr. Philos. Pract. 2020, 2020, 1–16. [Google Scholar]
- Johnson, B. Shared Themes, Tactics in White Supremacist and Islamist Extremist Propaganda—Homeland Security Today. Homeland Security Today, 2020. Available online: https://www.hstoday.us/subject-matter-areas/counterterrorism/shared-themes-recruitment-tactics-in-white-supremacist-and-islamist-extremist-propaganda/ (accessed on 10 March 2021).
- Southern Poverty Law Center. Southern Poverty Law Center. 2021. Available online: https://www.splcenter.org/ (accessed on 5 May 2021).
- Liu, H.; Xu, L.; Yang, M.; Yan, M.; Zhang, X. Predicting component failures using latent Dirichlet allocation. Math. Probl. Eng. 2015, 2015, 562716. [Google Scholar] [CrossRef] [Green Version]
- Kumar, K. Evaluation of Topic Modeling: Topic Coherence. DataScience, 2018. Available online: https://datascienceplus.com/evaluation-of-topic-modeling-topic-coherence/ (accessed on 10 October 2020).
- Wu, L.; Yen, I.E.; Xu, K.; Xu, F.; Balakrishnan, A.; Chen, P.Y.; Ravikumar, P.; Witbrock, M.J. Word Mover’s Embedding: From Word2Vec to Document Embedding. arXiv 2018, arXiv:1811.01713. [Google Scholar]
- Kaati, L.; Omer, E.; Prucha, N.; Shrestha, A. Detecting Multipliers of Jihadism on Twitter. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 954–960. [Google Scholar] [CrossRef]
- Berger, J.M.; Aryaeinejad, K.; Looney, S. There and Back Again: How White Nationalist Ephemera Travels Between Online and Offline Spaces. RUSI J. 2020, 165, 114–129. [Google Scholar] [CrossRef]
- Glossary of Terms and Acronyms Radicalization and Violent Extremism. Radicalization Prevention in Prisons. 2018. Available online: http://www.r2pris.org/glossary.html (accessed on 10 October 2020).
- Habib, R.R. Taliban’s Takeover of Afghanistan Should Not Be Celebrated. The Express Tribune, 2021. Available online: https://tribune.com.pk/article/97460/talibans-takeover-of-afghanistan-should-not-be-celebrated (accessed on 25 August 2021).
- Charles, C. (Main)streaming Hate: Analyzing White Supremacist Content and Framing Devices on YouTube; University of Central Florida: Orlando, FL, USA, 2020. [Google Scholar]
- Kochedykov, D.; Apishev, M.; Golitsyn, L.; Vorontsov, K. Fast and Modular Regularized Topic Modelling. In Proceedings of the 21st Conference of Open Innovations Association FRUCT, Helsinki, Finland, 6–10 November 2017; pp. 182–193. [Google Scholar] [CrossRef]
- Rehurek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- ActiveGalaxy. ISIS Related Dataset. Kaggle, 2016. Available online: https://www.kaggle.com/activegalaxy/isis-related-tweets (accessed on 10 October 2020).
- de Gibert, O.; Perez, N.; García-Pablos, A.; Cuadros, M. Hate Speech Dataset from a White Supremacy Forum. September 2018. Available online: http://arxiv.org/abs/1809.04444 (accessed on 10 October 2020).
- Kennedy, B.; Atari, M.; Davani, A.M.; Yeh, L.; Omrani, A.; Kim, Y.; Coombs, K.; Havaldar, S.; Portillo-Wightman, G.; Gonzalez, E.; et al. The Gab Hate Corpus: A Collection of 27k Posts Annotated for Hate Speech. Psyarxiv, 2020. Available online: https://psyarxiv.com/hqjxn/ (accessed on 10 October 2020).
- Jaki, S.; de Smedt, T. Right-Wing German Hate Speech on Twitter: Analysis and Automatic Detection. October 2019. Available online: http://arxiv.org/abs/1910.07518 (accessed on 10 October 2020).
- Fraiwan, M. Identification of Markers and Artificial Intelligence-Based Classification of Radical Twitter Data. Appl. Comput. Inform. 2020. [Google Scholar] [CrossRef]
- Ferrara, E.; Wang, W.-Q.; Varol, O.; Flammini, A.; Galstyan, A. Predicting Online Extremism, Content Adopters, and Interaction Reciprocity; Springer: Cham, Switzerland, 2016; pp. 22–39. [Google Scholar]
- Ahmad, S.; Asghar, M.Z.; Alotaibi, F.M.; Awan, I. Detection and Classification of Social Media-Based Extremist Affiliations Using Sentiment Analysis Techniques. Hum.-Cent. Comput. Inf. Sci. 2019, 9, 24. [Google Scholar] [CrossRef] [Green Version]
- ADL. White Supremacists Double down on Propaganda in 2019. ADL, 2020. Available online: https://www.adl.org/blog/white-supremacists-double-down-on-propaganda-in-2019 (accessed on 10 August 2020).
- Berger, J.M. Nazis vs. ISIS on Twitter: A Comparative Study of White Nationalist and ISIS Online Social Media Networks. 2016. Available online: https://extremism.gwu.edu/sites/g/files/zaxdzs2191/f/downloads/Nazisv.ISIS.pdf (accessed on 10 October 2020).
- Sadik-Zada, E.R. An Ode to ODA against all Odds? A Novel Game-Theoretical and Empirical Reappraisal of the Terrorism-Aid Nexus. Atl. Econ. J. 2021, 49, 221–240. [Google Scholar] [CrossRef]
- LaFree, G.; Dugan, L. Introducing the Global Terrorism Database. Terror. Polit. Violence 2007, 19, 181–204. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}