Python Version 3.6.1 was used as a tool for analysis. Python was used because it is malleable. Moreover, the various libraries that Python has made the analysis easier. A Jupyter notebook was the environment of choice for its simple interface. The results shown are for the test sample in each case. After data cleaning and the selection of relevant features, the data were split into three sets: training, validation, and test sets in the ratio of 0.75:0.15:0.10. For the training set, seventy-five percent of the data were used to train the algorithms. For the validation set, fifteen percent of the data were held back from the training of the model and were used to give an unbiased measure of model efficiency. The validation set was used to evaluate performance on data that were unseen when test data were held back. For the test set, ten percent of the data were held back from the training of the model and were used to give an unbiased measure of final model efficiency. The test set was held back until fine-tuning of the model was complete, and thereafter, an unbiased evaluation of the final models was obtained. Whereas Dashtipour et al. [
15] used 60% as the data for training, 30% in testing, and 10% for validation, Pawluszek-Filipiak and Borkowski [
30] observed that the performance metrics of the models, the F1-score and overall accuracy, decreased as the train-test ratio decreased. This implies that as the training sample decreases, the performance metrics tend to decrease. In line with the models’ need for substantial data to train on, Poria et al. [
31] used 80% of the data for training, and the remaining 20% was partitioned equally between validation and testing. As a result, there was a need to choose a train-validation-test split ratio that not only optimized the accuracy, but also adequately measured the extent to which the model would perform on “unseen” data. These considerations informed the choice of the train-validation-test split ratio that was used.
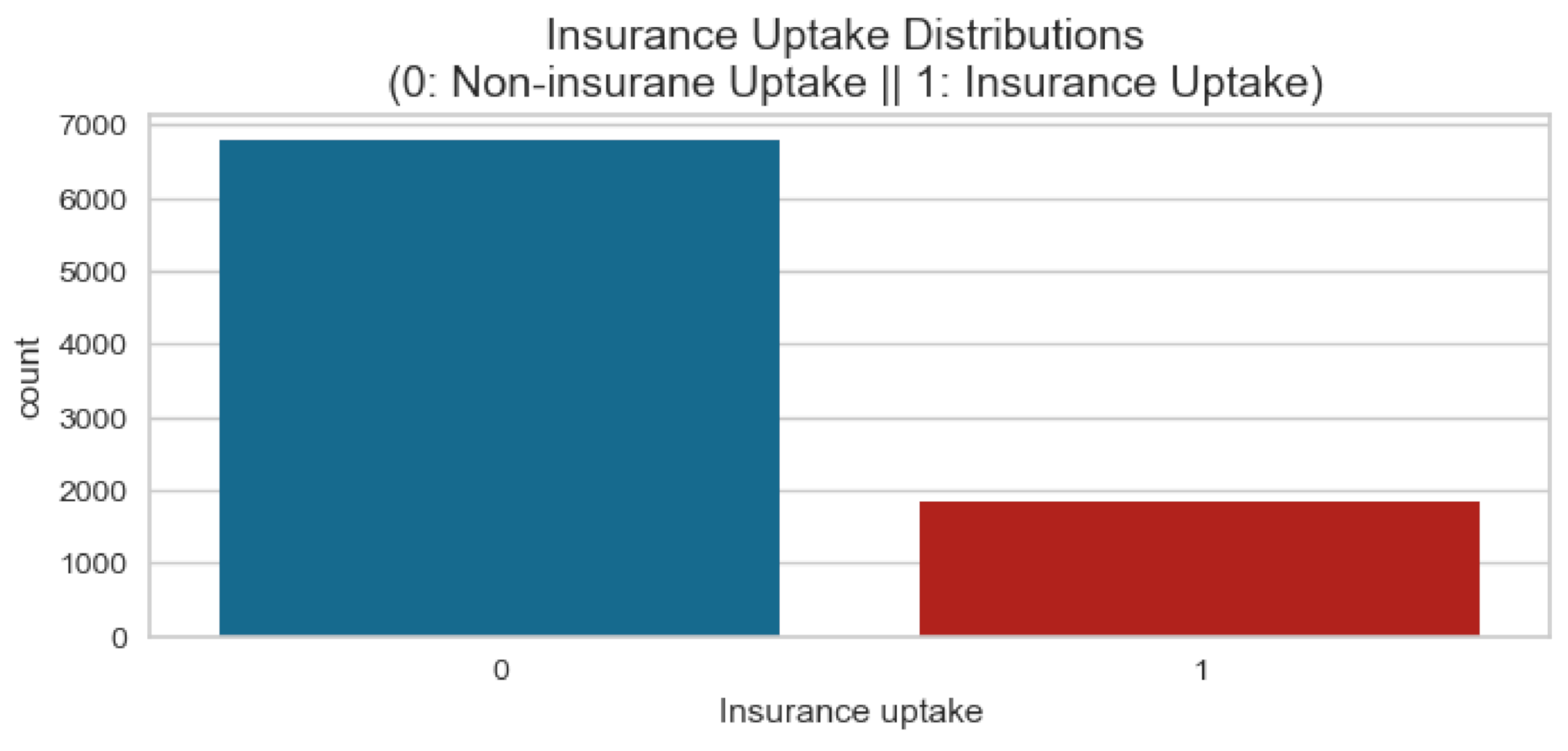
4.1. Comparison on Unbalanced Data
Table 1 shows the machine learning models and their respective precision scores, recall scores, F1-scores, and accuracy on the real unbalanced data. The XGB, SVM, GBM, and logistic regression classifiers had the highest accuracy (0.85) followed by random forest (0.82), KNN (0.81), and GNB (0.76), and the lowest was DT (0.75). For F1-scores, logistic regression showed the highest (0.61), then XGB (0.60), GBM (0.59), SVM (0.58), GNB (0.56), KNN (0.53), and random forest (0.48), and DT had the lowest (0.46). Despite all the accuracy scores of each of these being at least 0.75, their respective precision, recall, and F1-scores were all below 0.75. This may be an indicator of some skew in the data, hence the need for data balancing before training.
The machine learning models improved their skill on unseen data upon cross-validation. All the models improved their respective precision scores, for logistic regression from 0.69 to 0.77, GNB from 0.46 to 0.69, random forest from 0.63 to 0.76, DT from 0.43 to 0.65, SVM from 0.73 to 0.77, KNN from 0.58 to 0.75, GBM from 0.71 to 0.7720, and XGB from 0.72 to 0.76. Similarly, there was improvement in all recall scores, for logistic from 0.54 to 0.72, GNB from 0.73 to 0.75, random forest from 0.39 to 0.6748, DT from 0.4821 to 0.6493, SVM from 0.49 to 0.68, KNN from 0.49 to 0.72, GBM from 0.51 to 0.71, and XGB from 0.51 to 0.69. The F1-score improvements were: logistic regression from 0.61 to 0.74, GNB from 0.56 to 0.71, random forest from 0.48 to 0.70, DT from 0.46 to 0.65, SVM from 0.58 to 0.71, KNN from 0.53 to 0.73, GBM from 0.59 to 0.73, and XGB from 0.60 to 0.72. There was a slight improvement in accuracy for most of the machine learning models except for logistic regression and SVM. The respective changes in accuracy after the cross-validation were: logistic regression from 0.85 to 0.84 GNB from 0.76 to 0.77, random forest from 0.82 to 0.83, DT from 0.75 to 0.77, SVM from 0.85 to 0.84, KNN from 0.81 to 0.83, GBM from 0.85 to 0.84, and XGB from 0.85 to 0.84. There were not many improvements in the respective accuracy because the data were still unbalanced. This implies that with cross-validation, the accuracy generally remained the same, but the F1-scores generally rose with the k-fold cross-validation.
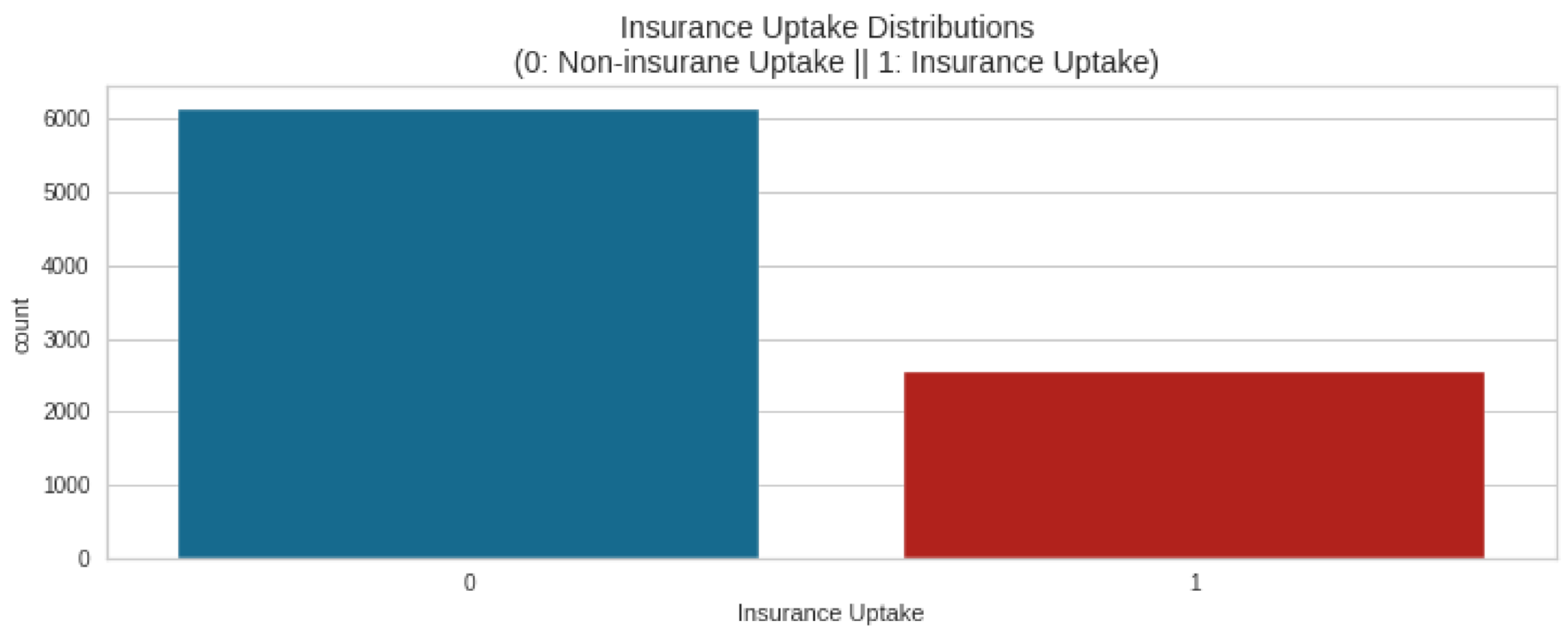
4.2. Comparison on Balanced Data
Table 2 shows the machine learning models and their respective precision scores, recall scores, F1-scores, and accuracy on the real unbalanced data, but with cross-validation test_size = 0.1 and validation_score = 0.15. Stratification was based on
y, which is the insurance uptake in this case, with a set the random_for reproducibility. This stratifies the parameter by making a split so that the proportion of values in the sample produced will be the same as the proportion of values provided to the parameter; it ensures that in cross-validation, the skews within the folds are similar. High accuracy was observed among logistic, GBM, XGB, and SVM (0.84), then KNN and random forest (0.83), and finally, GNB and DT (0.77). On the other hand, for F1-scores, logistic had the highest (0.74), while the lowest was DT (0.65).
Table 3 shows the machine learning models and their respective precision scores, recall scores, F1-scores, and accuracy on the oversampled data. Random forest leads with the highest accuracy of 0.95 followed by DT (0.92), KNN (0.82), SVM (0.82), GBM and XGB (0.79), logistic regression (0.78), and lastly, GNB (0.74). However, upon hyperparameter tuning, the accuracy GBM and XGB increases. Nevertheless, random forest showed the highest precision score, recall score, F1-score, and accuracy; hence, it can be taken as the optimal model in this instance. Here, random forest is more robust than the other classifiers. This could be explained by it being an ensemble algorithm. The findings corroborate those of Han et al. [
32], who asserted that ensemble algorithms tend to perform better than stand-alone algorithms. However, GBM and XGB give lower accuracy than the DT classifier, unlike our expectation. Hence, we could conclude that for this kind of oversampled data, ensemble trees by bagging tend to perform better than by boosting.
Table 4 shows the machine learning models and their respective precision scores, recall scores, F1-scores, and accuracy on the real downsampled data. The highest accuracy score was observed for XGB (0.87), then GBM (0.86), while the lowest was DT (0.72). For F1-scores, XGB had (0.87), then GBM (0.86), logistic (0.83), KNN, GNB, and random forest (0.82), and finally, DT (0.72). In the case of undersampled data, XGB and GBM showed higher accuracy than other models (0.87 and 0.86, respectively). Both of them are tree based ensemble learners, which are assembled by boosting. This allows us to construe that for the kind of data used, tree based learners assembled by boosting are more robust than others. This corroborates Golden et al. [
25], who found GBM to perform better than other algorithms.
Despite being the same data source, the learners had different metrics for oversampled and undersampled data. The accuracy for the learners when the data were oversampled, vis à vis when undersampled, were: logistic (0.78, 0.83), GNB (0.74, 0.82), random forest (0.95, 0.82), DT (0.92, 0.72), SVM (0.82, 0.81), KNN (0.82, 0.82), GBM (0.79, 0.86), XGB (0.78, 0.87). This could imply that when the data were undersampled, the learners presumed different distributions from when oversampled, despite being the same data. However, SVM and KNN did not seem to show remarkable differences in accuracy when the data were either undersampled or oversampled.
4.3. Area under the Receiver Operating Characteristic Curves and Confusion Matrices
Upon imputing the optimized hyperparameters, the models were retrained, and AUCs and confusion matrices for the various models were drawn.
Table 5 shows the values of TP, TN, FP, and FN that were extracted from the confusion matrices for various models. For TP, random forest led (190), then XGB (179), while KNN gave the least (150). This means that it is more likely for a random forest model to predict that one would take up insurance coverage and that that person does take up coverage compared to other models. For TN, DT was the highest (204), then random forest (201). For FN, DT was the lowest (1), then random forest (4), while logistic regression was the highest (51). For FP, random forest was the lowest (14), followed by XGB (25), while KNN and GNB were the highest (both 45). This implies that random forest is least likely to make type II errors in predicting uptake compared with other classifiers. Random forest seems to be the most robust since it had the highest true positives and the least false positives. Nevertheless, other tree based classifiers seemed to do well on the data.
Moreover,
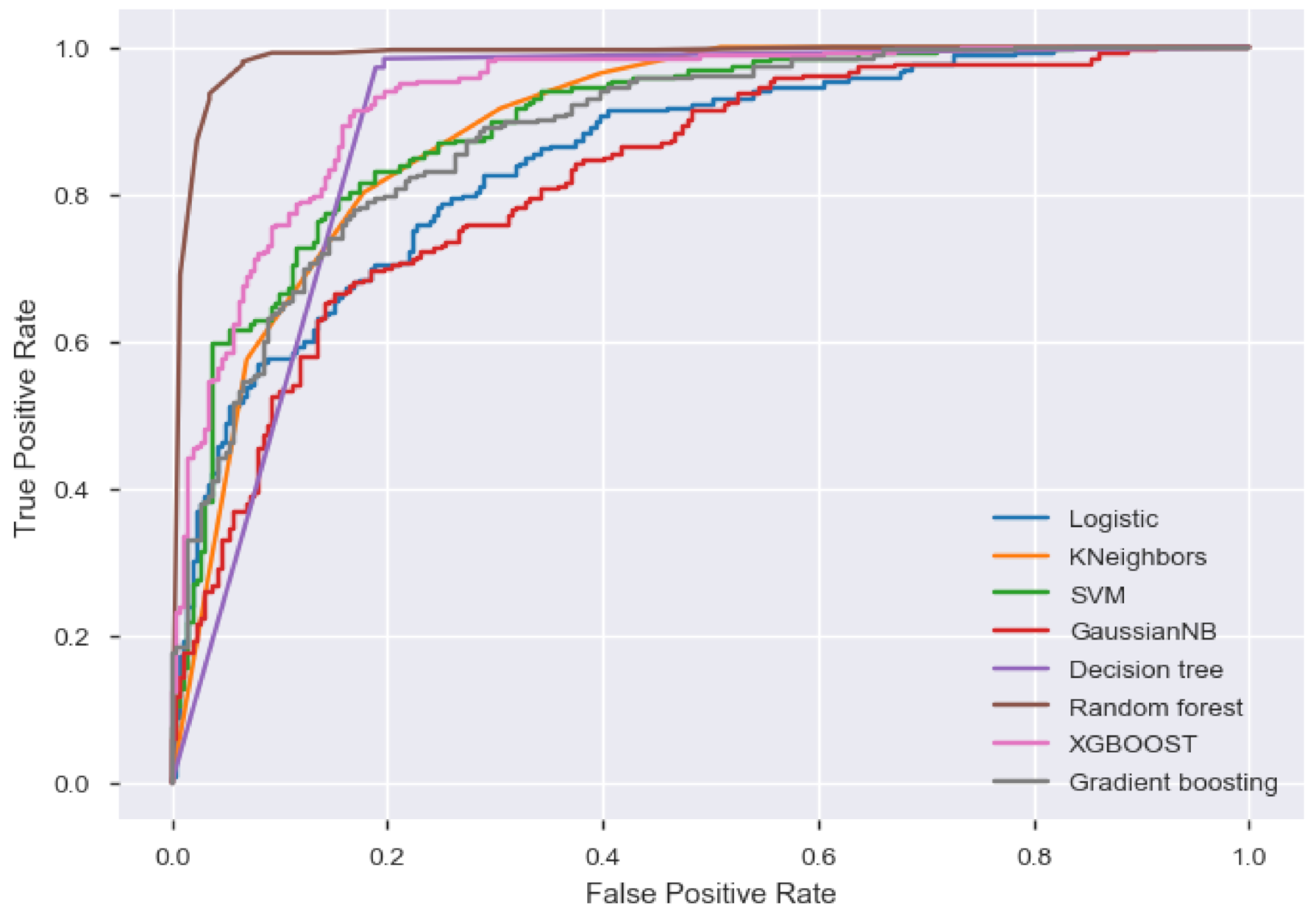
Figure 3 shows the areas under the receiver operating characteristics curve (AUCs) for the various models. The AUCs under the various models were: 0.8481 for logistic regression, 0.8914 for the K nearest neighbors classifier, 0.8220 for GNB, 0.8940 for SVM, 0.8962 for DT, 0.9866 for random forest, 0.9300 for XGB (referred to as XGBOOST in the figure), and 0.8823 for GBM. Based on the AUCs, random forest performed best compared to all other models since it gave the highest area under the receiver operating characteristics curve, followed by XGB classifier. This corroborates Blanco et al. [
24], who found random forest to be a stronger model in the prediction of the efficiency of fullerene derivative based ternary organic solar cells. This implies that ensemble tree based models tend to perform better than others for this kind of data since both random forest and XGB are tree based models and are both ensemble algorithms.
4.5. Feature Importance
Feature importance in this study was employed to get an understanding of how the features contributed to the model predictions. As previously proposed by Casalicchio et al. [
33], the effect of features, their respective contributions, as well as their respective attributions describe how and, to some degree, the extent to which each feature contributes to the prediction of the model. Furthermore, Pesantez-Narvaez et al. [
34] added that the contribution of each feature to the outcome as given by the feature importance is based on Gini impurity. Feature importance was taken to identify important features that contribute to the greatest extent to the prediction of uptake. This enabled the analysis and comparison of the feature importance across various observations in the data. The feature importance was obtained from the random forest model, and since random forest is a tree based model, it gave the extent to which each feature contributed to reducing the weighted Gini impurity.
Based on the AUC and accuracy, random forest seemed to be the most robust in uptake prediction. Moreover, random forest showed the highest AUC, and hence, this model was used to extract the importance of each feature in the uptake prediction.
Table 7 shows the feature importance from Phase I’s random forest model in predicting the insurance uptake. All the features show non-zero importance, but their rank from the most important to the least important is having a bank product, wealth quintile, subregion, level of education, age, group, most trusted provider, nature of residence, numeracy, household size, marital status, second most trusted provider, ownership of a phone, having a set emergency fund, having electricity as a light source, gender, nature of residential area, whether it is urban or rural, being a youth, and having a smartphone.
The result suggests that the most important factor is whether one has a bank product or not. This implies that individuals who have a bank product tend to have higher insurance uptake compared to those who do not. This could also imply that many individuals who had a bank product also had an insurance product. The second most important feature is the wealth quintile. This implies that the material wealth of an individual plays a critical role since the wealthier an individual, the higher would be the ability to pay for the insurance premiums. The ability to pay is a great factor in determining uptake. However, the potential loss of profit as a result of the misclassification of an insurance uptake client as non-uptake is higher than the potential loss of profit as a result of misclassifying non-uptake as an insurance uptake client. Hence, we suggest that cost-sensitive learning could be done based on these features, as was the case in Petrides et al. [
12]. The subregion being the third factor could be construed to imply that the insurance products are not evenly distributed nationally. Interestingly, being a youth and having a smartphone did not show much importance in determining uptake, although much of the population is young. This could imply that the insurance products on the market are not appealing to youths, or they could be too expensive for them. More could be done on product engineering to make insurance products more affordable and more appealing so that more of the young populace could benefit from insurance.
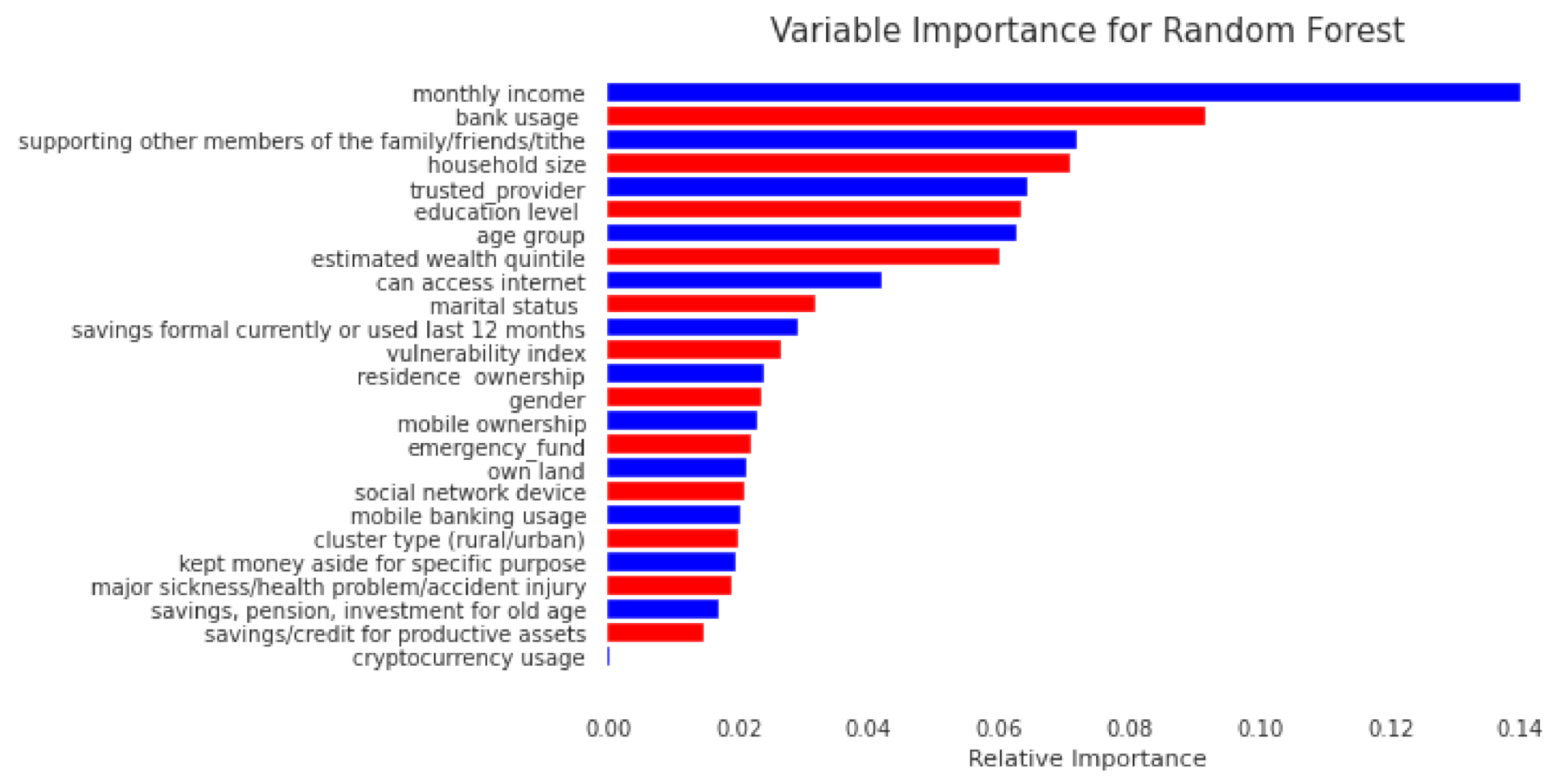
Figure 4 shows the feature importance as extracted from the Phase II analysis. Though bank usage is still an important feature in the prediction of insurance uptake, income has the highest contribution in reducing the weighted Gini impurity, implying that it is the most important feature. Other important factors include the willingness and ability to support others, household size, trusted financial service provider, age, and level of education. Unlike in the Phase I analysis, cryptocurrency usage had a non-zero contribution in the prediction of insurance uptake, though its contribution was least among the variables with non-zero contribution to the insurance uptake.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



