
Future Prediction of COVID-19 Vaccine Trends Using a Voting Classifier




Abstract
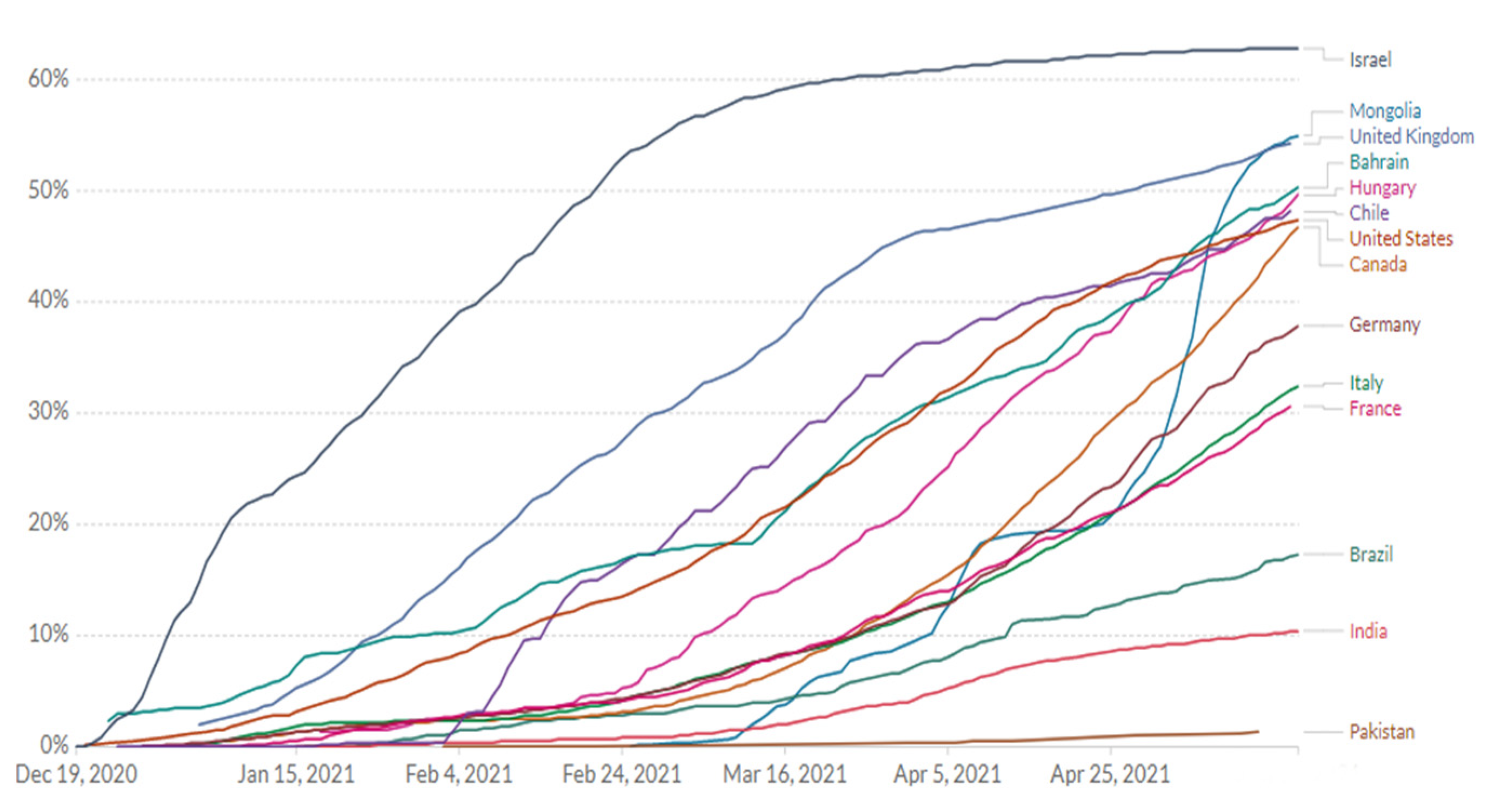
:1. Introduction
- To identify the trend of people towards the vaccination;
- To find out the accuracy of the vaccinations;
- The assess the growth in the number of new vaccinated cases.
- Different models give different forecasting results with the same dataset;
- These forecast results can be helpful in future decision-making;
- Date-wise datasets show poor accuracy than random dataset.
2. Problem Statement
3. Material and Methods
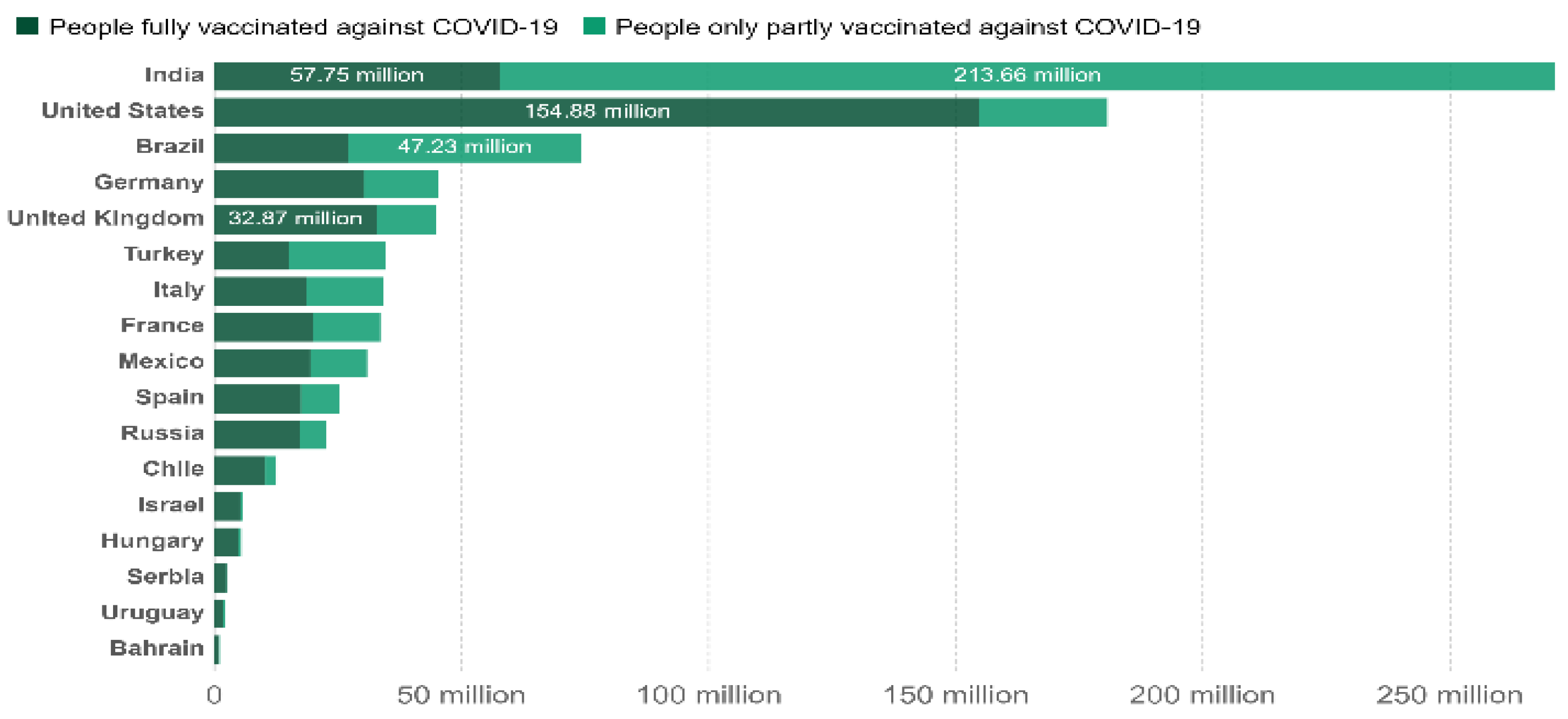
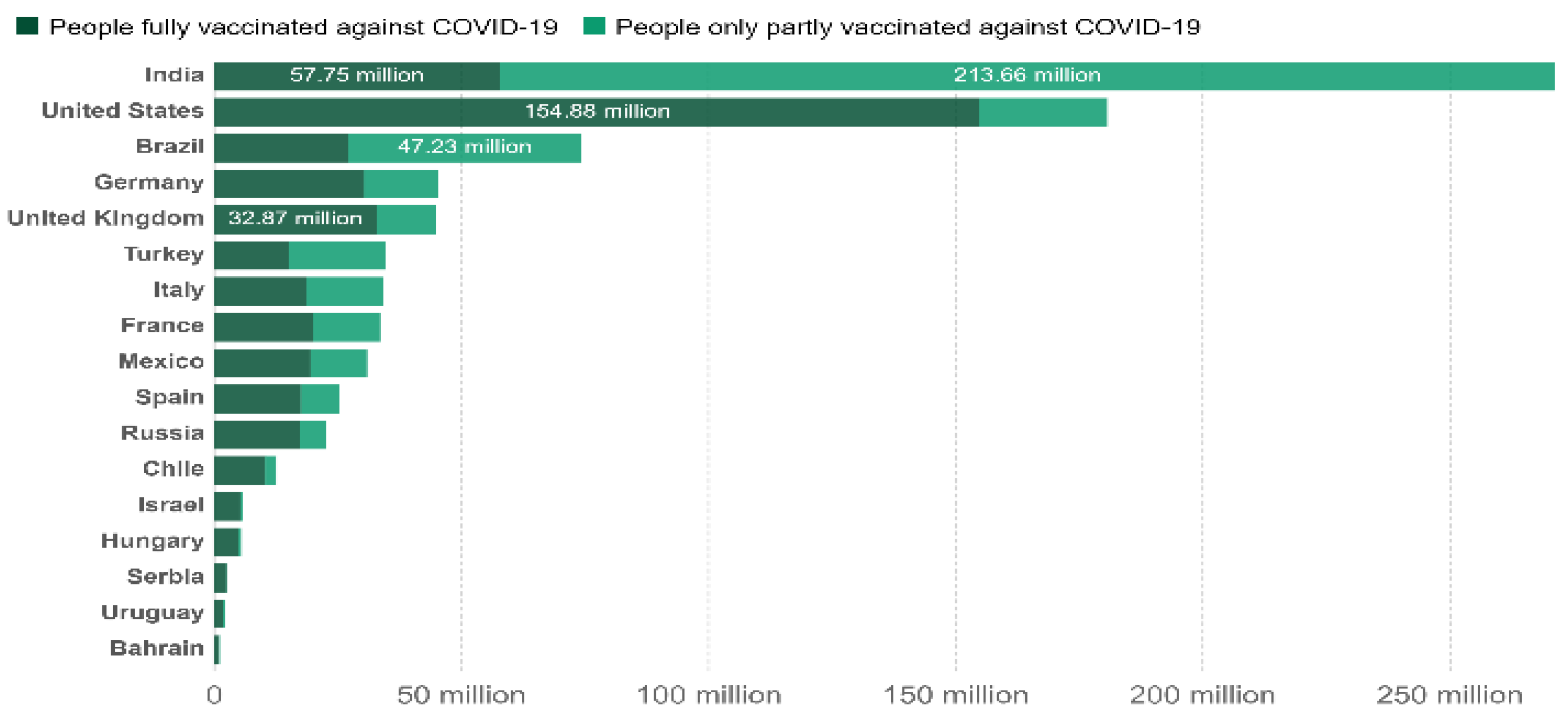
3.1. Dataset
3.2. Supervised Machine Learning Models
- Decision tree;
- Random forest;
- Support vector machine;
- K-nearest neighbor;
- Artificial neural network.
3.2.1. Random Forest
- A random sampling of data for bootstrap sampling;
- Generate N number of individual decision trees based on a random input selection.
3.2.2. Support Vector Machine (SVM)
3.2.3. Decision Tree
3.2.4. K-Nearest Neighbor (KNN)
3.2.5. Artificial Neural Network (ANN)
3.3. Testing Matrix
3.3.1. Precision, Recall, and F-Measure
3.3.2. Logarithmic Loss (LL)
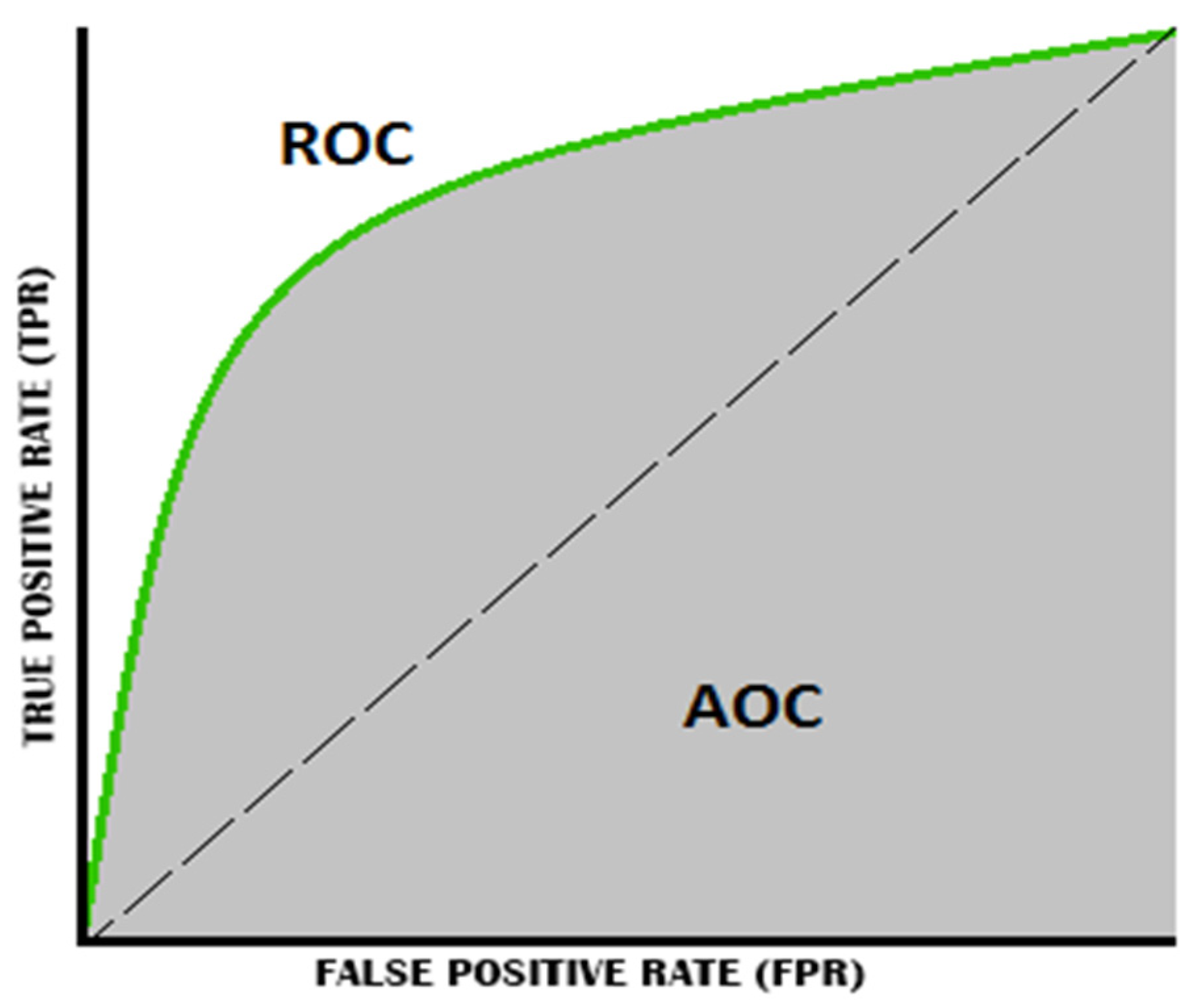
3.3.3. Area under the Curve (AUC)
3.3.4. Voting Classifier
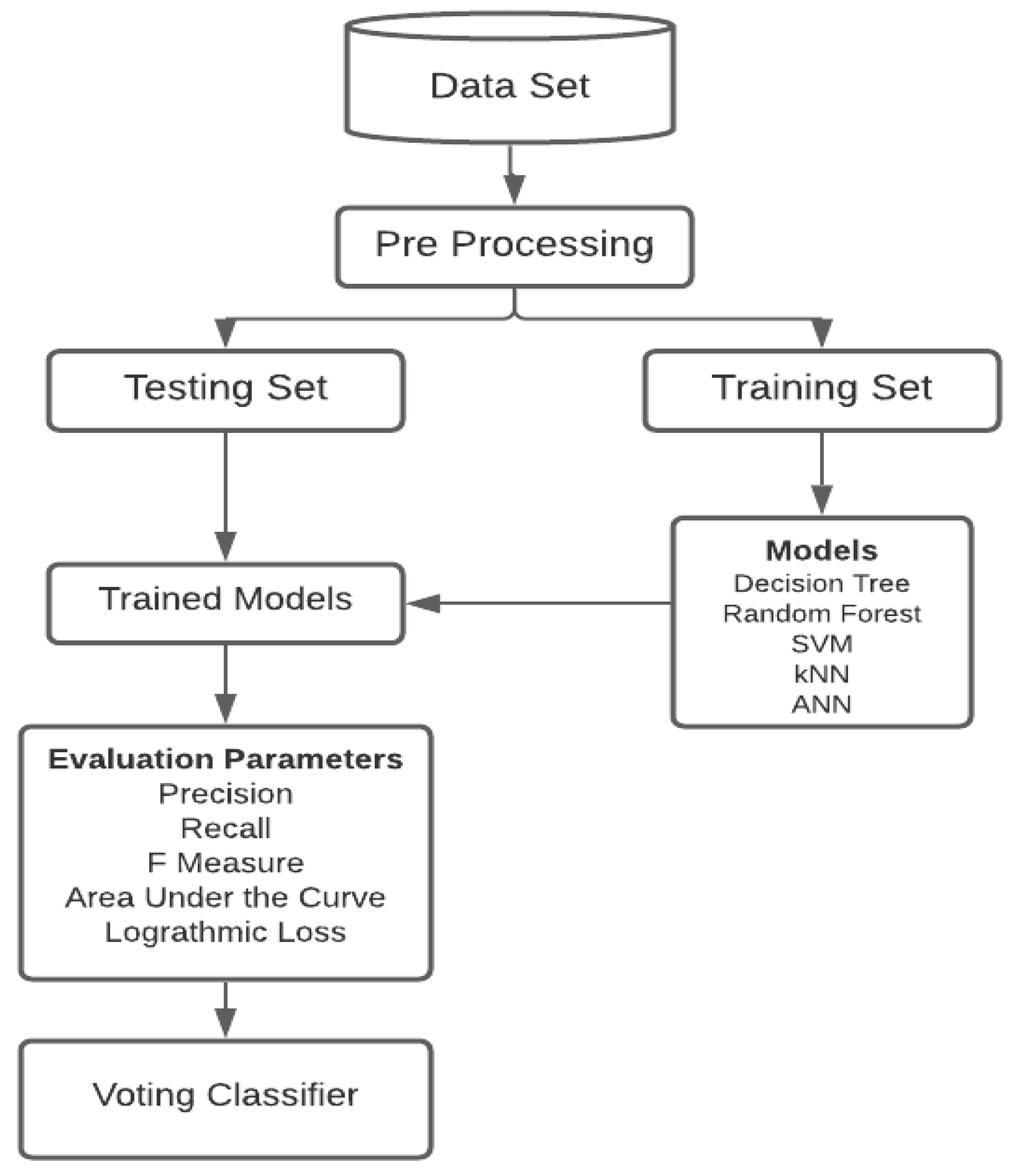
4. Methodology
5. Performance and Results
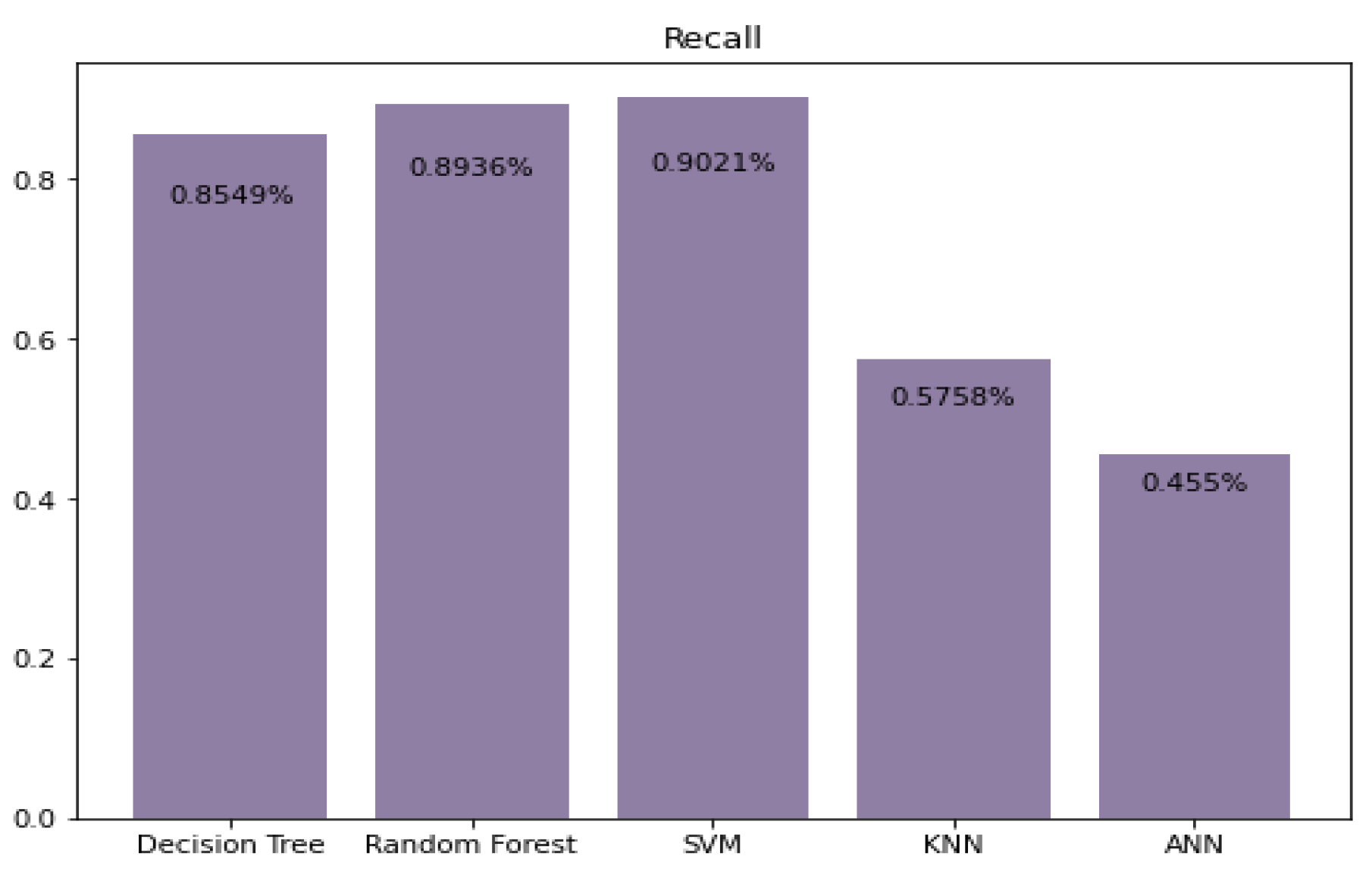
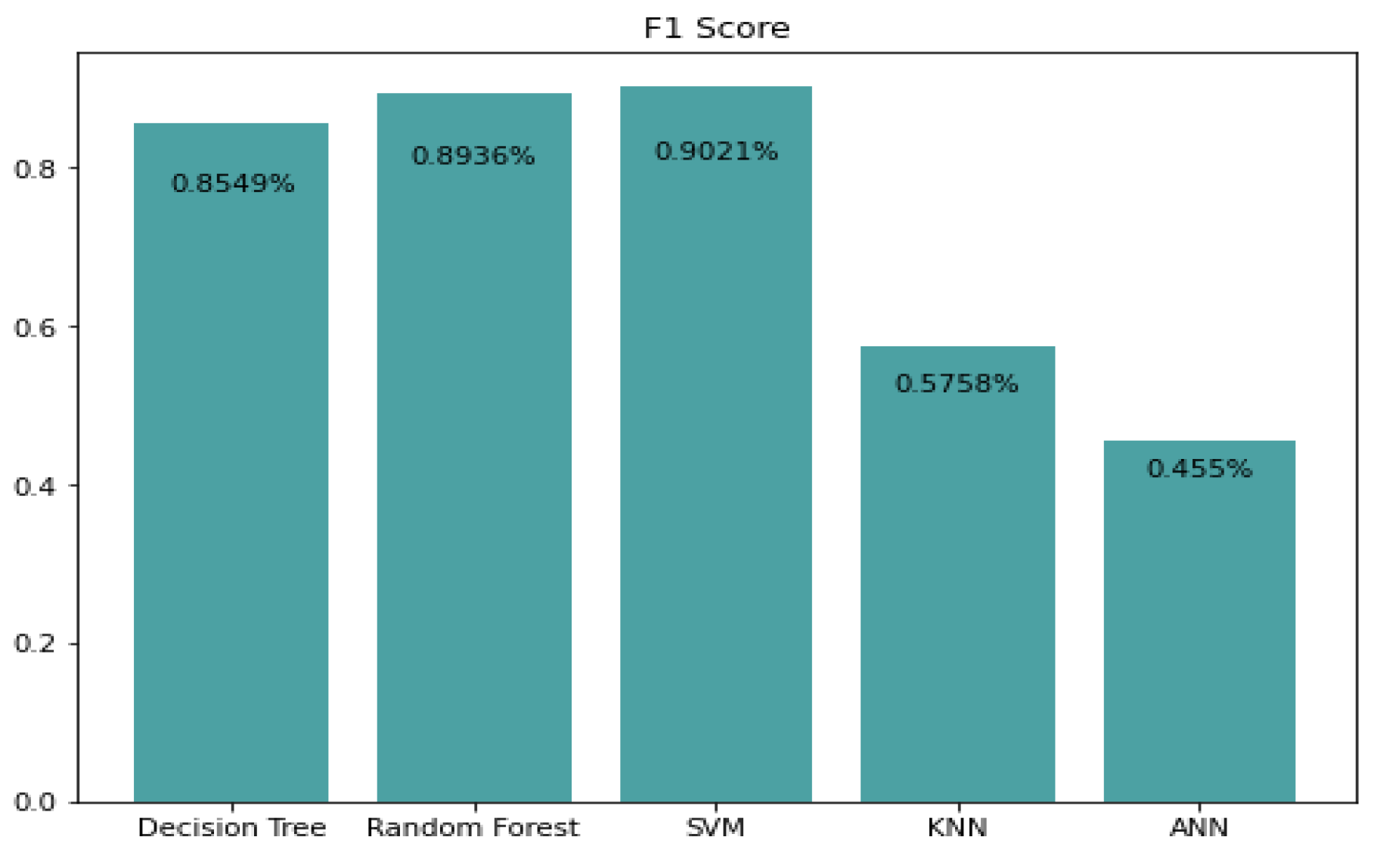
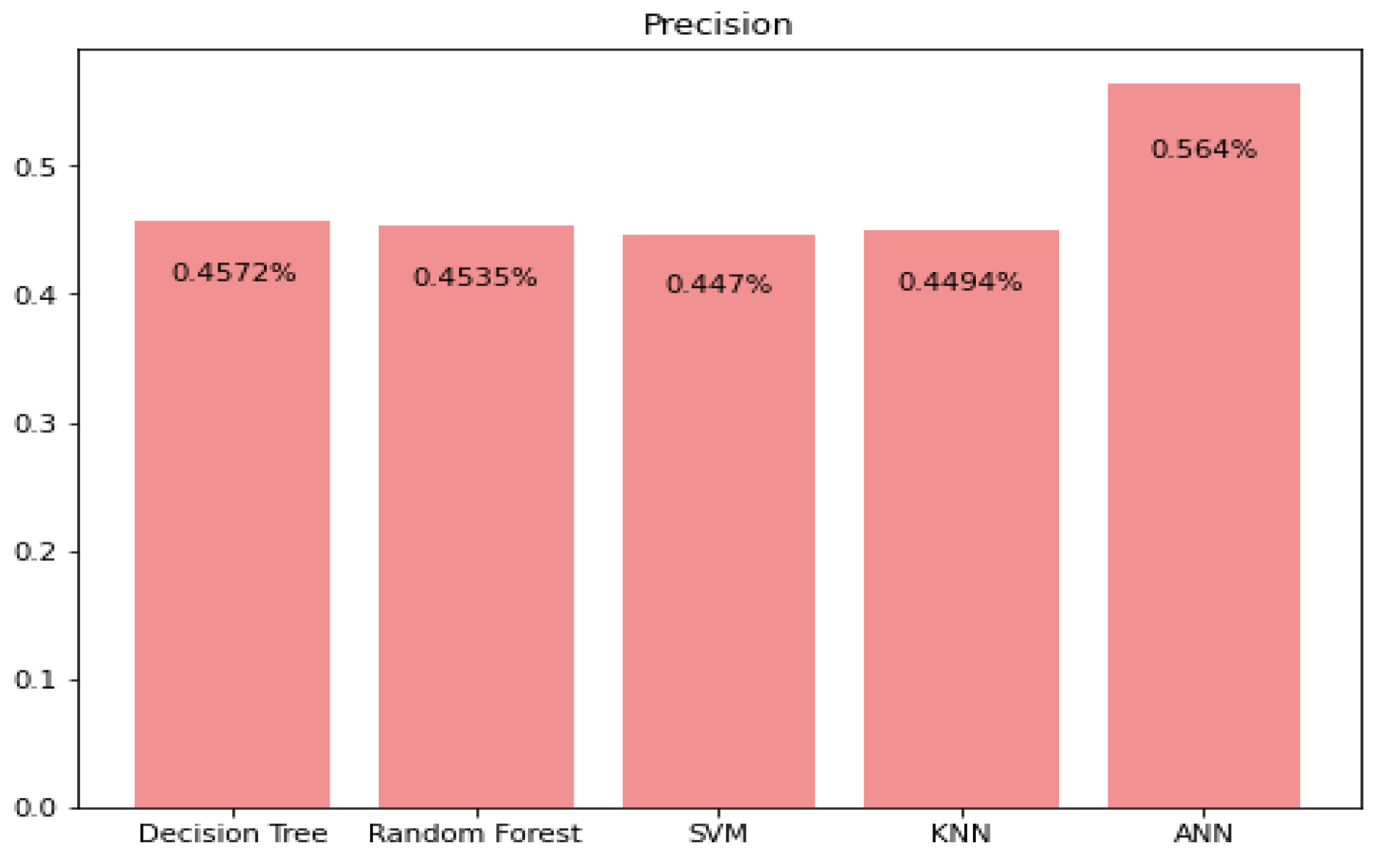
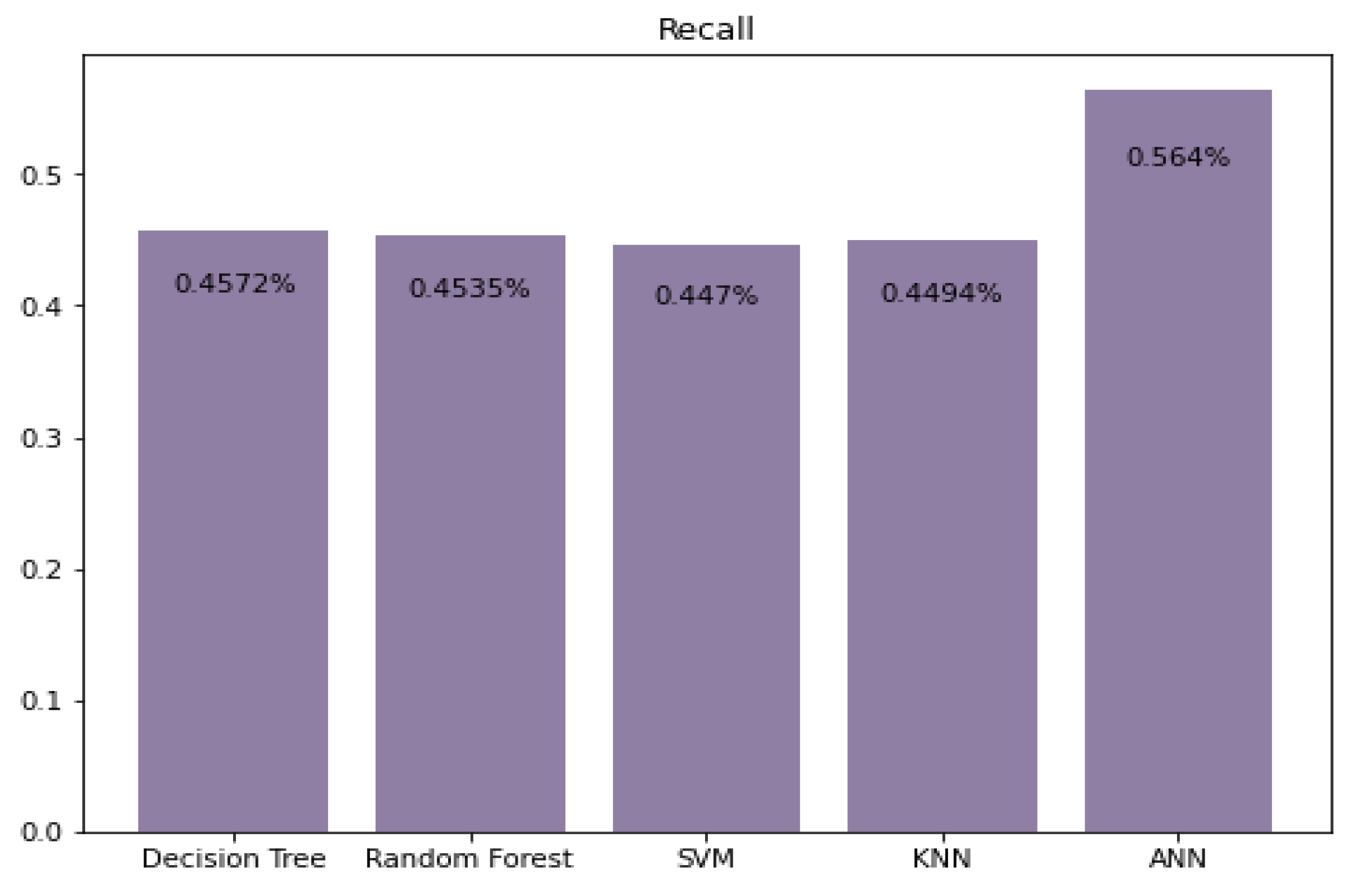
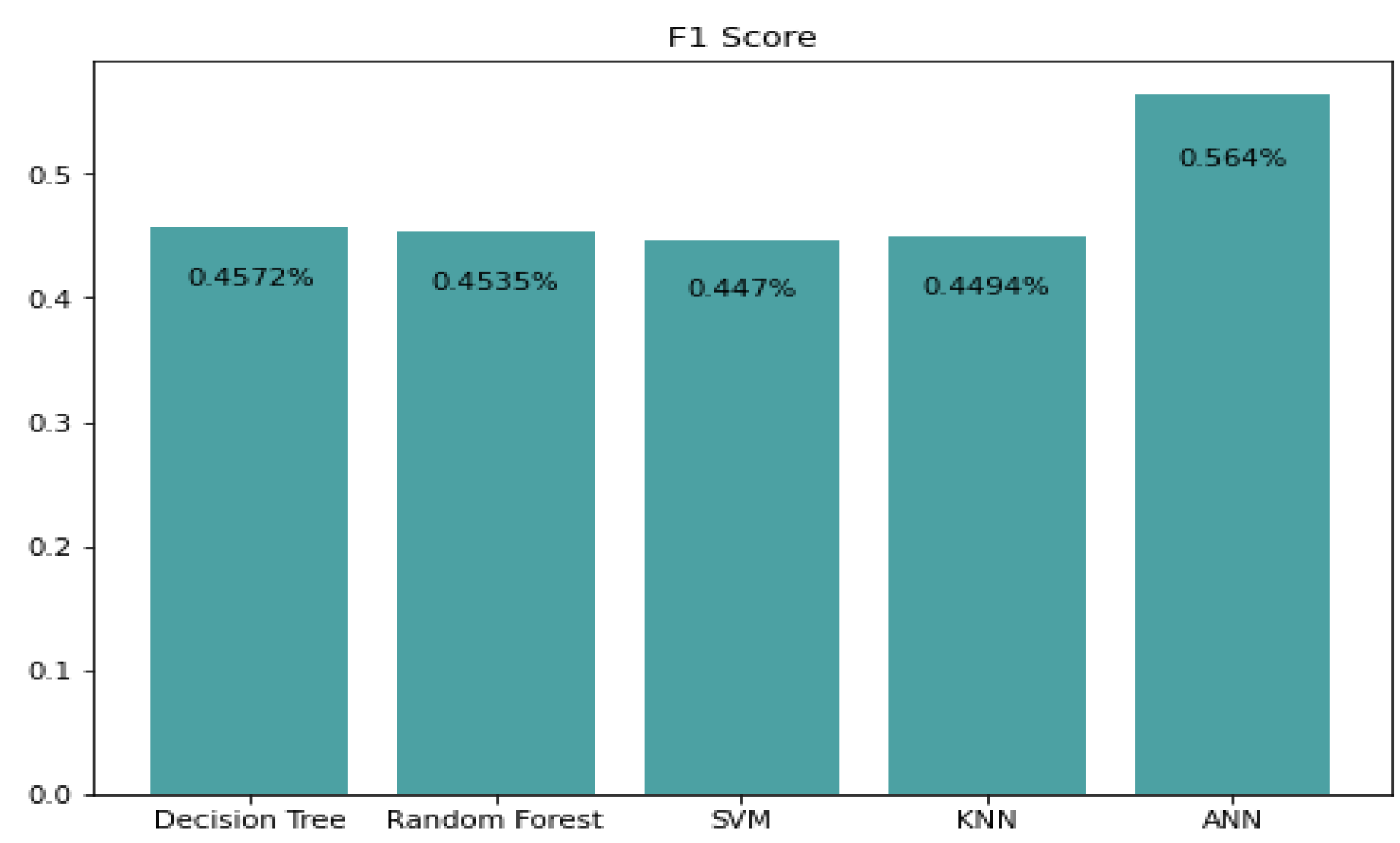
5.1. Precision, Recall, and F1 Score Prediction
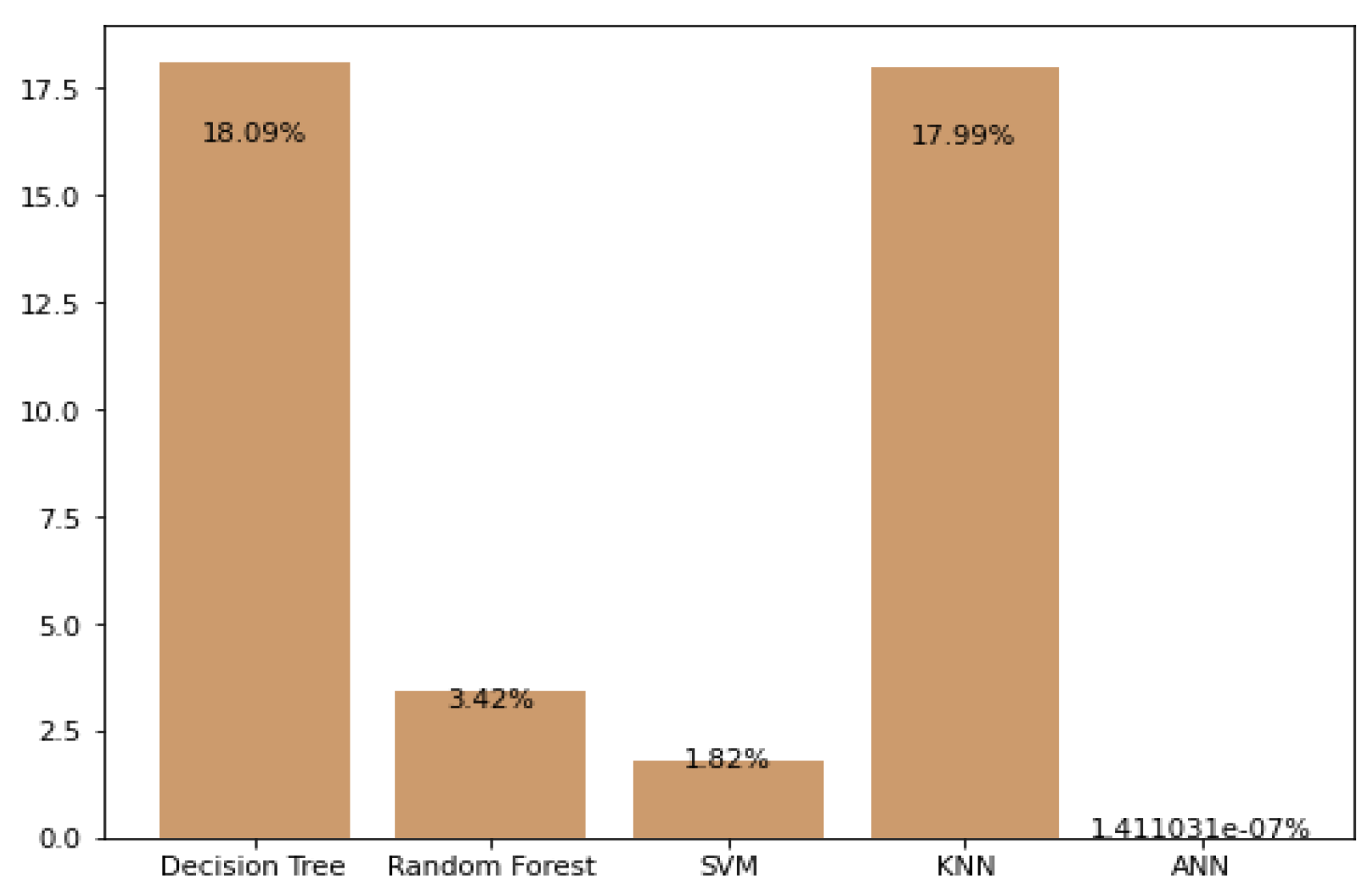
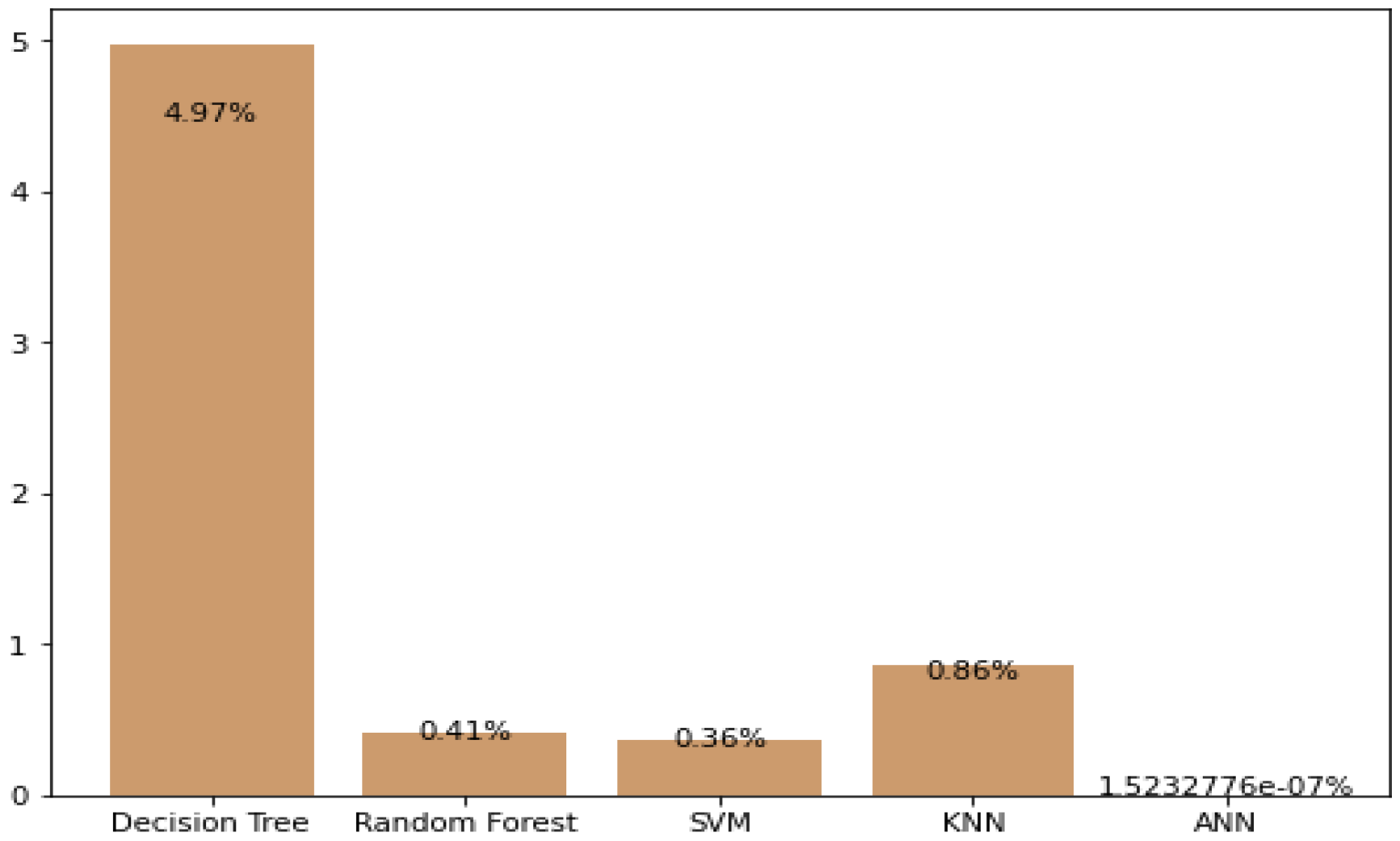
5.2. Prediction Using Logarithmic Loss
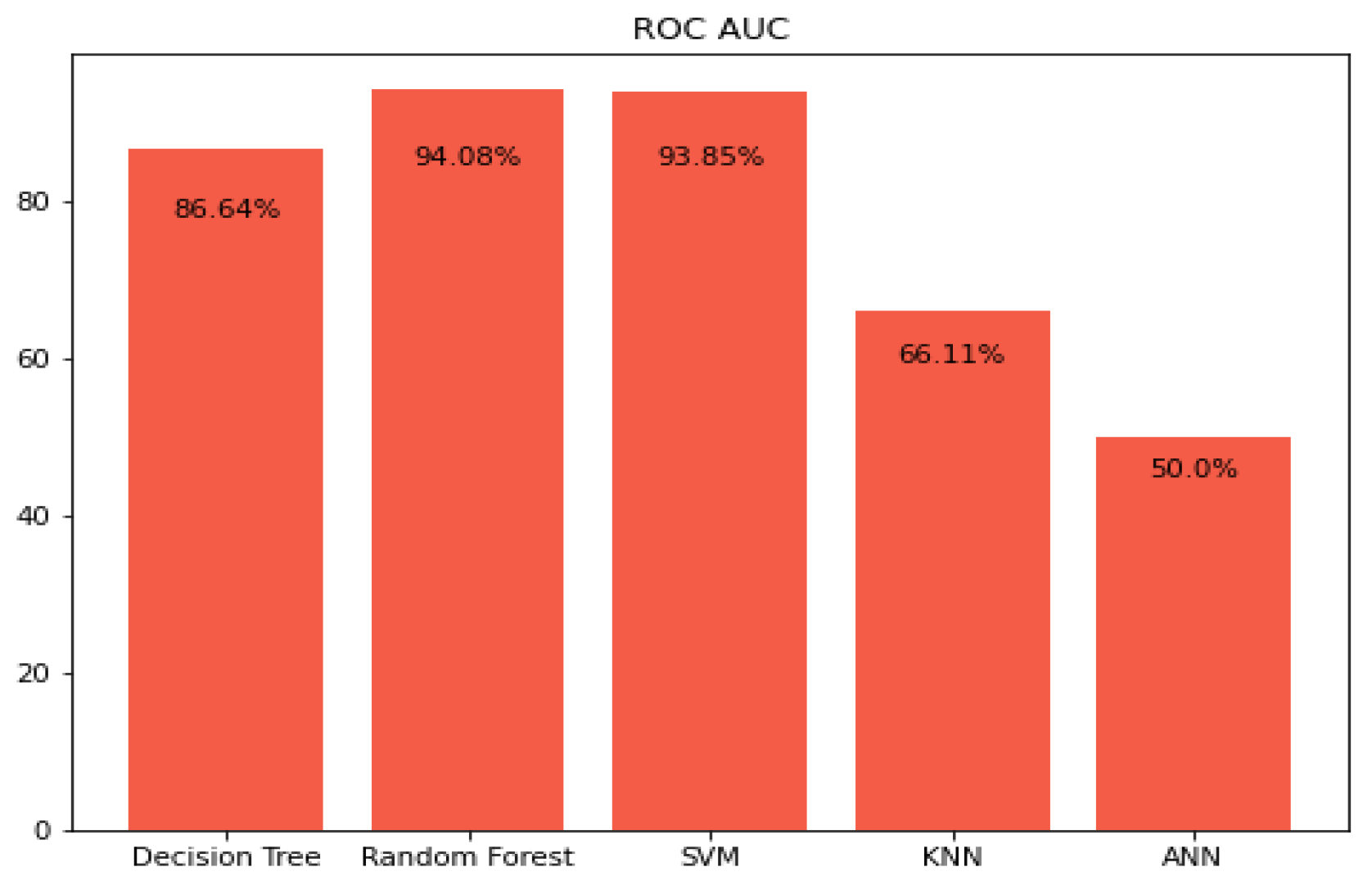
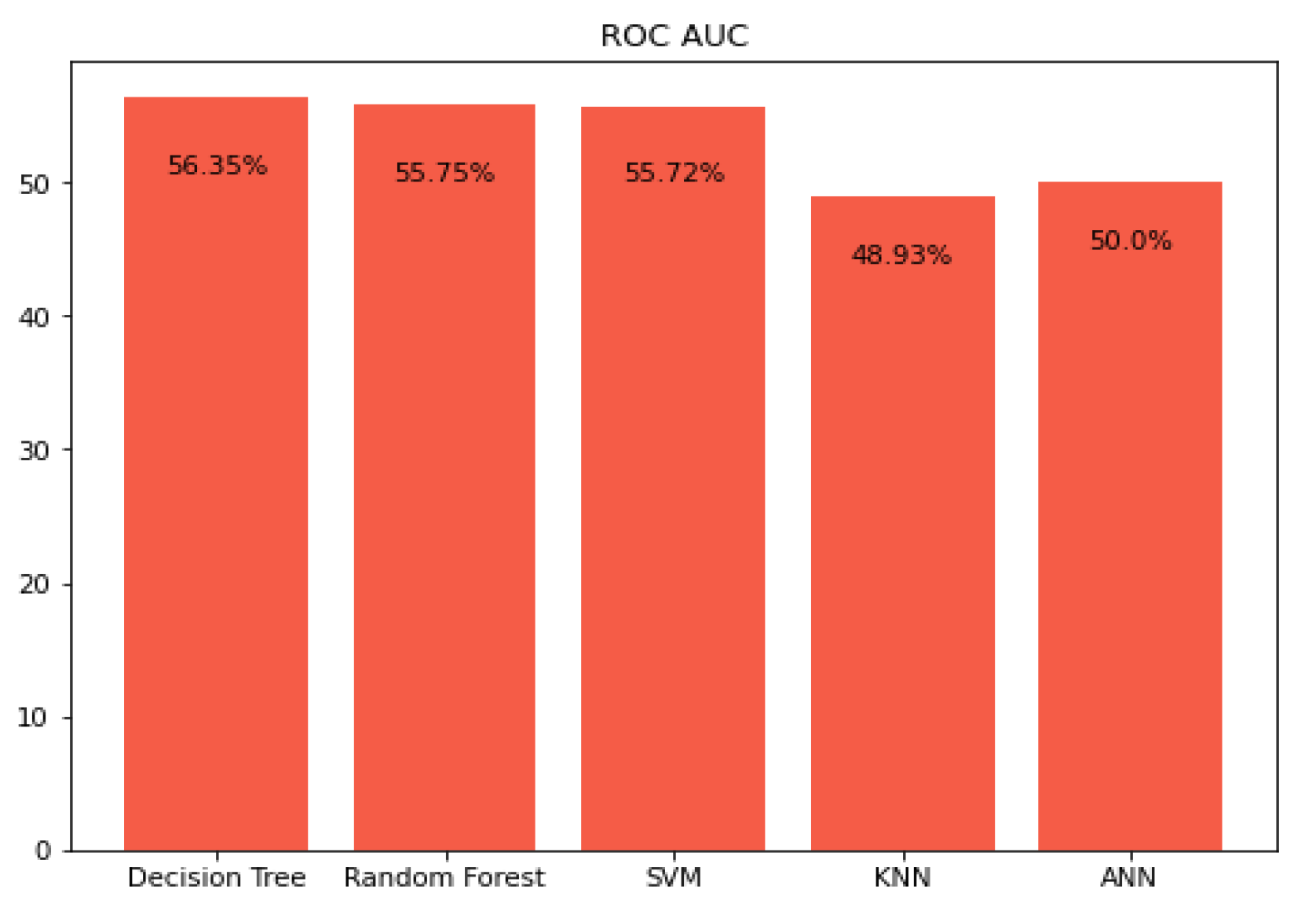
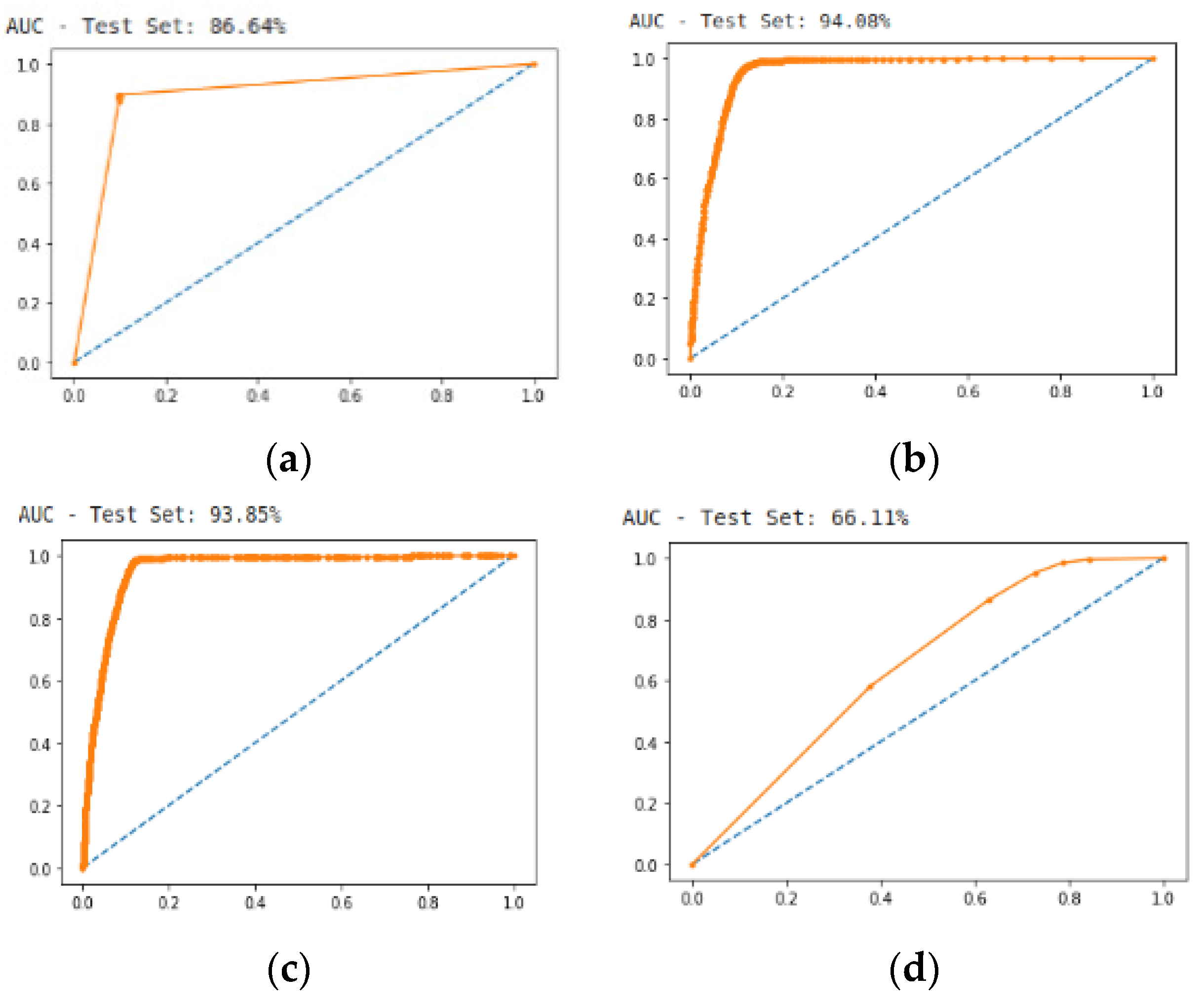
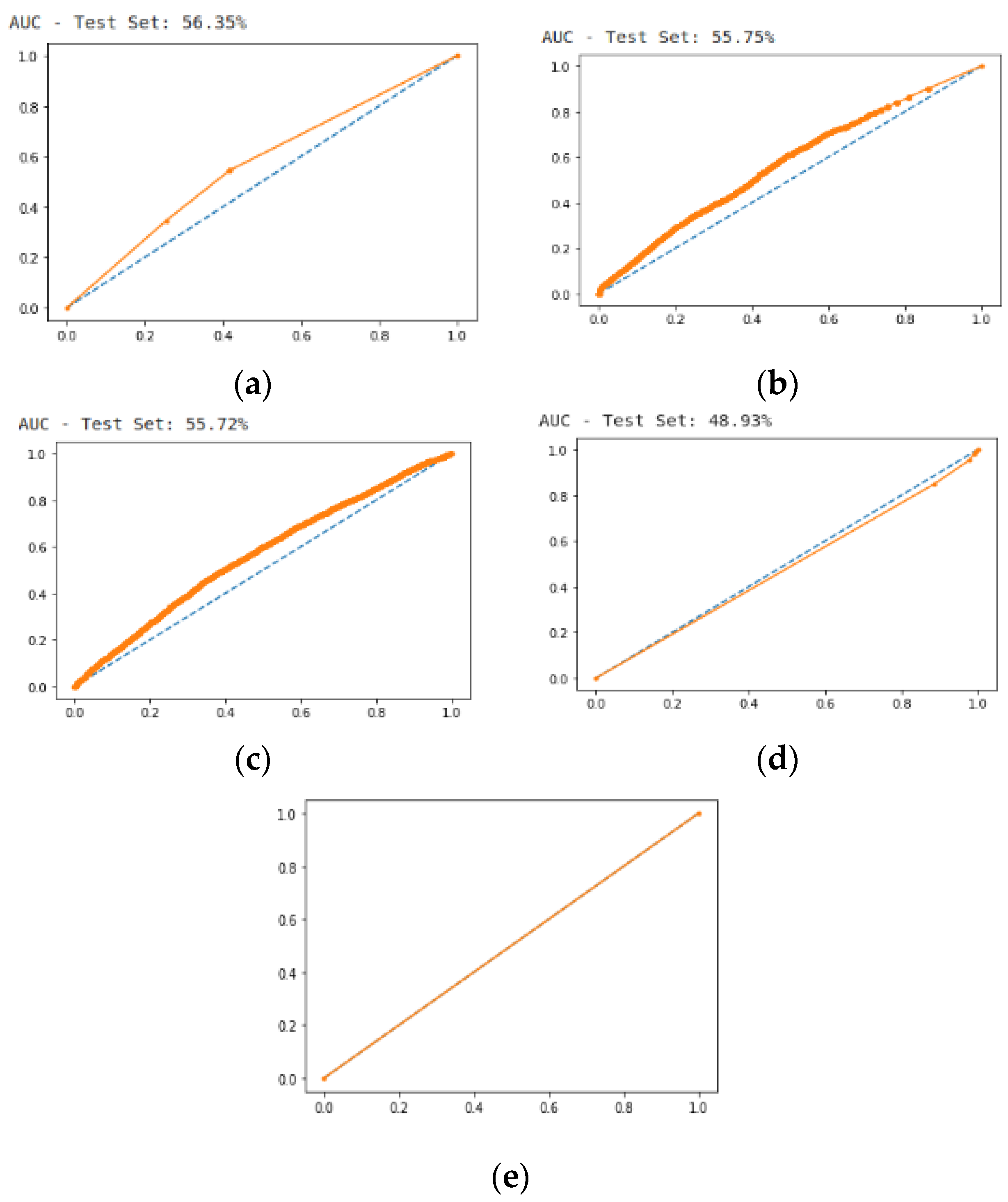
5.3. Prediction Using Area under the Curve ROC-AUC
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, J.M.; Harman, M.; Ma, L.; Liu, Y. Machine Learning Testing: Survey, Landscapes and Horizons. Available online: https://doi.org/10.1109/tse.2019.2962027 (accessed on 8 August 2021). [CrossRef] [Green Version]
- Bontempi, G.; Ben Taieb, S.; Le Borgne, Y.-A. Machine learning strategies for time series forecasting. In Proceedings of the European Business Intelligence Summer School, Brussels, Belgium, 15–21 July 2012; Aufaure, M.A., Zimányi, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 62–77. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and machine learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tigga, N.P.; Garg, S. Prediction of type 2 diabetes using machine learning classification methods. Procedia Comput. Sci. 2020, 167, 706–716. [Google Scholar] [CrossRef]
- Singh, S.N.; Thakral, S. Using data mining tools for breast cancer prediction and analysis. In Proceedings of the 4th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 14–15 December 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Omran, N.F.; Ghany, S.F.A.-E.; Saleh, H.; Ali, A.A.; Gumaei, A.; Al-Rakhami, M. Applying deep learning methods on time-series data for forecasting COVID-19 in Egypt, Kuwait, and Saudi Arabia. Complexity 2021, 2021, 6686745. [Google Scholar] [CrossRef]
- Zoabi, Y.; Deri-Rozov, S.; Shomron, N. Machine learning-based prediction of COVID-19 diagnosis based on symptoms. NPJ Digit. Med. 2021, 4, 3. [Google Scholar] [CrossRef]
- Son, C.; Hegde, S.; Smith, A.; Wang, X.; Sasangohar, F. Effects of COVID-19 on college students’ mental health in the United States: Interview survey study. J. Med. Internet Res. 2020, 22, e21279. [Google Scholar] [CrossRef] [PubMed]
- Jean, S.-S.; Lee, P.-I.; Hsueh, P.-R. Treatment options for COVID-19: The reality and challenges. J. Microbiol. Immunol. Infect. 2020, 53, 436–443. [Google Scholar] [CrossRef] [PubMed]
- Edwards, B.; Biddle, N.; Gray, M.; Sollis, K. COVID-19 vaccine hesitancy and resistance: Correlates in a nationally representative longitudinal survey of the Australian population. PLoS ONE 2021, 16, e0248892. [Google Scholar] [CrossRef]
- Forni, G.; Mantovani, A. COVID-19 vaccines: Where we stand and challenges ahead. Cell Death Differ. 2021, 28, 626–639. [Google Scholar] [CrossRef]
- Kara, M.; Öztürk, Z.; Akpek, S.; Turupcu, A. COVID-19 Diagnosis from chest CT scans: A weakly supervised CNN-LSTM approach. AI 2021, 2, 330–341. [Google Scholar] [CrossRef]
- Villavicencio, C.; Macrohon, J.; Inbaraj, X.; Jeng, J.-H.; Hsieh, J.-G. COVID-19 Prediction applying supervised machine learning algorithms with comparative analysis using WEKA. Algorithms 2021, 14, 201. [Google Scholar] [CrossRef]
- Hussain, A.A.; Bouachir, O.; Al-Turjman, F.; Aloqaily, M. Notice of Retraction: AI Techniques for COVID-19. IEEE Access 2020, 8, 128776–128795. [Google Scholar] [CrossRef]
- Nistal, R.; de la Sen, M.; Gabirondo, J.; Alonso-Quesada, S.; Garrido, A.; Garrido, I. A Study on COVID-19 Incidence in Europe through Two SEIR Epidemic Models Which Consider Mixed Contagions from Asymptomatic and Symptomatic Individuals. Appl. Sci. 2021, 11, 6266. [Google Scholar] [CrossRef]
- All COVID-19 Vaccines Tweets. 2021. Available online: https://www.kaggle.com/gpreda/all-covid19-vaccines-tweets (accessed on 24 April 2021).
- COVID-19 World Vaccination Progress. 2021. Available online: https://www.kaggle.com/gpreda/covid-world-vaccination-progress (accessed on 24 April 2021).
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Kulkarni, Y.V.; Sinha, P.K. Effective Learning and Classification Using Random Forest Algorithm. Available online: https://shodhganga.inflibnet.ac.in/handle/10603/125758. (accessed on 8 August 2021).
- Liu, Y.; Wang, Y.; Zhang, J. New machine learning algorithm: Random forest. In Information Computing and Applications. ICI-CA 2012; Lecture Notes in Computer Science; Liu, B., Ma, M., Chang, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7473, pp. 246–252. [Google Scholar] [CrossRef]
- Kausar, N.; Samir, B.B.; Abdullah, A.; Ahmad, I.; Hussain, M. A Review of classification approaches using support vector machine in intrusion detection. In Informatics Engineering and Information Science. ICIEIS 2011. Communications in Computer and Information Science; Abd Manaf, A., Sahibuddin, S., Ahmad, R., Mohd Daud, S., El-Qawasmeh, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 253, pp. 24–34. [Google Scholar] [CrossRef]
- Song, Y.-Y.; Lu, Y. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130–135. [Google Scholar] [CrossRef]
- Sun, B.; Du, J.; Gao, T. Study on the improvement of K-nearest-neighbor algorithm. In Proceedings of the 2009 International Conference on Artificial Intelligence and Computational Intelligence, Shanghai, China, 7–8 November 2009; Volume 4, pp. 390–393. [Google Scholar] [CrossRef]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN model-based approach in classification. In On the Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE. OTM 2003; Meersman, R., Tari, Z., Schmidt, D.C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2888, pp. 986–996. [Google Scholar] [CrossRef]
- Wang, S.-C. Artificial neural network. In Interdisciplinary Computing in Java Programming; The Springer International Series in Engineering and Computer Science; Springer: Boston, MA, USA, 2003; Volume 743, pp. 81–100. [Google Scholar] [CrossRef]
- Rahman, A.S.A.; Belhaouari, S.B.; Bouzerdoum, A.; Baali, H.; Alam, T.; Eldaraa, A.M. Breast mass tumor classification using deep learning. In Proceedings of the IEEE International Conference on Informatics, IoT, and Enabling Technologies (ICIoT), Doha, Qatar, 2–5 February 2020; pp. 271–276. [Google Scholar] [CrossRef]
- Zaidi, S.A.J.; Buriro, A.; Riaz, M.; Mahoob, A. Implementation and comparison of text-based image retrieval schemes. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 611–618. [Google Scholar] [CrossRef]
- Rolls, E.T. The storage and recall of memories in the hippocampo-cortical system. Cell Tissue Res. 2018, 373, 577–604. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Q.; Ma, Y.; Zhao, K.; Tian, Y. A Comprehensive Survey of Loss Functions in Machine Learning. Available online: https://doi.org/10.1007/s40745-020-00253-5 (accessed on 8 August 2021). [CrossRef]
- Pruessner, J.C.; Kirschbaum, C.; Meinlschmid, G.; Hellhammer, D.H. Two formulas for computation of the area under the curve represent measures of total hormone concentration versus time-dependent change. Psychoneuroendocrinology 2003, 28, 916–931. [Google Scholar] [CrossRef]
- Li, L.; Greene, T.; Hu, B. A simple method to estimate the time-dependent receiver operating characteristic curve and the area under the curve with right censored data. Stat. Methods Med. Res. 2016, 27, 2264–2278. [Google Scholar] [CrossRef]
- Kumar, U.K.; Nikhil, M.S.; Sumangali, K. Prediction of breast cancer using voting classifier technique. In Proceedings of the IEEE International Conference on Smart Technologies and Management for Computing, Communication, Controls, Energy and Materials (ICSTM), Chennia, India, 2–4 August 2017; pp. 108–114. [Google Scholar] [CrossRef]
- Samuel, J.; Ali, G.; Rahman, M.; Esawi, E.; Samuel, Y. COVID-19 Public sentiment insights and machine learning for tweets classification. Information 2020, 11, 314. [Google Scholar] [CrossRef]
- Levashenko, V.; Rabcan, J.; Zaitseva, E. Reliability evaluation of the factors that influenced COVID-19 patients’ condition. Appl. Sci. 2021, 11, 2589. [Google Scholar] [CrossRef]
- Iqbal, M.J.; Faye, I.; Said, A.M.; Samir, B.B. Data Mining of Protein Sequences with Amino Acid Position-Based Feature Encoding Technique. In Proceedings of the First International Conference on Advanced Data and Information Engineering (DaEng-2013); Herawan, T., Deris, M., Abawajy, J., Eds.; Springer: Singapore, 2014; Volume 285. [Google Scholar] [CrossRef]
- Sallahi, N.; Park, H.; El Mellouhi, F.; Rachdi, M.; Ouassou, I.; Belhaouari, S.; Arredouani, A.; Bensmail, H. Using unstated cases to correct for COVID-19 pandemic outbreak and its impact on easing the intervention for Qatar. Biology 2021, 10, 463. [Google Scholar] [CrossRef] [PubMed]
- El-Harbawi, M.; Samir, B.B.; Babaa, M.-R.; Mutalib, M.I.A. A new QSPR model for predicting the densities of ionic liquids. Arab. J. Sci. Eng. 2014, 39, 6767–6775. [Google Scholar] [CrossRef]
- Mehboob, S.; Zaidi, S.A.; Rizwan, M.; Dilshad, U.; Lashari, N.; Adeel, M.; Sanwal, G. Sentiment base emotions classification of celebrity tweets by using R language. Pak. J. Eng. Technol. 2020, 3, 95–99. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Sample Tweets (Feedback about Vaccination) |
|---|---|
| 12/20/2020 | same folks said daikon paste could treat a cytokine storm #PfizerBioNTech |
| 12/13/2020 | While the world has been on the wrong side of history this year, hopefully, the biggest vaccination effort we’ve ev… |
| 12/12/2020 | #coronavirus #SputnikV #AstraZeneca #PfizerBioNTech #Moderna #Covid_19 Russian vaccine is created to last 2–4 years… |
| 12/12/2020 | Facts are immutable, Senator, even when you’re not ethically sturdy enough to acknowledge them. (1) You were born i… |
| 12/12/2020 | Explain to me again why we need a vaccine @BorisJohnson @MattHancock #whereareallthesickpeople #PfizerBioNTech… |
| 12/20/2020 | Same folks said daikon paste could treat a cytokine storm #PfizerBioNTech |
| 12/13/2020 | While the world has been on the wrong side of history this year, hopefully, the biggest vaccination effort we’ve ev… |
| 12/12/2020 | #coronavirus #SputnikV #AstraZeneca #PfizerBioNTech #Moderna #Covid_19 Russian vaccine is created to last 2–4 years… |
| …… | …….. |
| …… | …….. |
| 4/8/2021 | @Reuters EMBARRASING Moscow Russia everything is open business as usual. Ontario reporting 3215 cases of #COVID19 1… |
| 4/8/2021 | #Germany is negotiating with #Russia to purchase the #SputnikV #vaccine. |
| Country | Date | Daily Vaccine | Daily Recoveries |
|---|---|---|---|
| USA | 3/22/2021 | 126,509,736 | 82,772,416 |
| India | 3/22/2021 | 48,494,594 | 40,631,153 |
| Brazil | 3/5/2021 | 10,169,160 | 7,701,146 |
| Russia | 3/3/2021 | 5,489,342 | 4,287,423 |
| Italy | 2/14/2021 | 3,055,592 | 1,743,683 |
| Iran | 3/27/2021 | 103,006 | 103,006 |
| Portugal | 3/27/2021 | 1,598,988 | 1,107,360 |
| Pakistan | >3/27/2021 | 26,471 | 120 |
| China | 3/21/2021 | 1,818,286 | 1263 |
| Malaysia | 3/22/2021 | 452,919 | 581 |
| … | … | … | … |
| Indonesia | 3/26/2021 | 10,412,824 | 7,179,014 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaidi, S.A.J.; Tariq, S.; Belhaouari, S.B. Future Prediction of COVID-19 Vaccine Trends Using a Voting Classifier. Data 2021, 6, 112. https://doi.org/10.3390/data6110112
Zaidi SAJ, Tariq S, Belhaouari SB. Future Prediction of COVID-19 Vaccine Trends Using a Voting Classifier. Data. 2021; 6(11):112. https://doi.org/10.3390/data6110112
Chicago/Turabian StyleZaidi, Syed Ali Jafar, Saad Tariq, and Samir Brahim Belhaouari. 2021. "Future Prediction of COVID-19 Vaccine Trends Using a Voting Classifier" Data 6, no. 11: 112. https://doi.org/10.3390/data6110112
APA StyleZaidi, S. A. J., Tariq, S., & Belhaouari, S. B. (2021). Future Prediction of COVID-19 Vaccine Trends Using a Voting Classifier. Data, 6(11), 112. https://doi.org/10.3390/data6110112