
Nowcasting India Economic Growth Using a Mixed-Data Sampling (MIDAS) Model (Empirical Study with Economic Policy Uncertainty–Consumer Prices Index)

 ,
,  ,
,  , , , , , , , , , , and
, , , , , , , , , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Step Weighting
2.2. Almon (PDL) Weighting
2.3. Beta Weighting
3. Data and Theory
4. Methodology
5. Empirical Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A







References
- Ghysels, E.; Horan, C.; Moencch, E. Forecasting through the rearview mirror: Data revisions and bond return predictability. Rev. Financ. Stud. 2018, 31, 678–714. [Google Scholar] [CrossRef]
- Evans, M. Where Are We Now? Real-Time Estimates of the Macroeconomic. Int. J. Cent. Bank 2005, 1, 127–175. [Google Scholar]
- Giannone, D.; Reichlin, V.; Small, D. Nowcasting: The real-time informational content of macroeconomic data. J. Monet. Econ. 2008, 55, 665–676. [Google Scholar] [CrossRef]
- Banbura, M.; Giannone, D.; Modugno, M.; Reichlin, L. Now-casting and the real-time data flow. In Handbook of Economic Forecasting; Elsevier: Amsterdam, The Netherlands, 2013; Volume 2, pp. 195–237. [Google Scholar]
- Olli-Matti, L.; Annika, L. Nowcasting Finnish GDP Growth Using Financial Variables: A MIDAS Approach; BoF Economics Review; Bank of Finland: Helsinki, Finland, 2020. [Google Scholar]
- Gunay, M. Nowcasting Turkish GDP with MIDAS: Role of Functional Form of the Lag Polynomial; Working Paper; Central Bank of the Republic of Turkey: Ankara, Turkey, 2020. [Google Scholar]
- Barsoun, F.; Stankiewicz, S. Forecasting GDP Growth Using Mixed-Frequency Models with Switching Regimes; Working Paper Series; University of Konstanz: Konstanz, Germany, 2013. [Google Scholar]
- Jardet, C.; Meunier, B. Nowcasting World GDP Growth with High-Frequency Data; Working paper; Banque de France: Paris, France, 2020. [Google Scholar]
- Rufino, C.C. Nowcasting Philippine Economic Growth Using MIDAS Regression Modeling. DLSU Bus. Econ. Rev. 2019, 29, 14–23. [Google Scholar]
- Bok, B.; Caratelli, D.; Giannone, D.; Sbordone, A.M.; Tambalotti, A. Macroeconomic Nowcasting and Forecasting with Big Data. Annu. Rev. Econ. 2018, 10, 615–643. [Google Scholar] [CrossRef] [Green Version]
- Thorsrud, L.A. Words are the New Numbers: A Newsy Coincident Index of the Business Cycle. J. Bus. Econ. Stat. 2018, 38, 393–409. [Google Scholar] [CrossRef]
- Babii, A.; Ghysels, E.; Striaukas, J. Machine Learning Time Series Regressions with an Application to Nowcasting. J. Bus. Econ. Stat. 2021, 1–23. [Google Scholar] [CrossRef]
- Lyer, T.; Gupta, S. Nowcasting Economic Growth in India: The Role of Rainfall; ADB Economics Working Paper Series; Asian Development Bank: Mandaluyong, Philippines, 2019. [Google Scholar]
- Bhadury, S.; Ghosh, S.; Kumar, P. Nowcasting Indian GDP Growth Using a Dynamic Factor Model; Reserve Bank of India: Mumbai, India, 2020. [Google Scholar]
- Bragoli, D.; Fosten, J. Nowcasting Indian GDP. Oxf. Bull. Econ. Stat. 2018, 80, 259–282. [Google Scholar] [CrossRef] [Green Version]
- Baker, S.R.; Bloom, N.; Davis, S.J. Measuring Economic Policy Uncertainty. Q. J. Econ. 2016, 131, 1593–1636. [Google Scholar] [CrossRef]
- Ghysels, E.; Pedro, S.; Rossen, V. The MIDAS Touch: Mixed Data Sampling Regression Models; University of North Carolina and UCLA Discussion Paper; 2004; Available online: https://rady.ucsd.edu/faculty/directory/valkanov/pub/docs/midas-touch.pdf (accessed on 13 October 2021).
- Ghysels, E.; Pedro, S.; Rossen, V. Predicting volatility: Getting the most out of return data sampled at different frequencies. J. Econom. 2006, 131, 59–95. [Google Scholar] [CrossRef] [Green Version]
- Andreou, E.; Ghysels, E.; Andros, K. Should macroeconomic forecasters use daily financial data and how? J. Bus. Econ. Stat. 2013, 3, 240–251. [Google Scholar] [CrossRef]
- Economic Policy Uncertainty. Available online: www.policyuncertainty.com (accessed on 10 June 2021).
- Bloom, N. The Impact of Uncertainty Shocks. Econometrica 2009, 77, 623–685. [Google Scholar] [CrossRef] [Green Version]
- Basu, S.; Bundick, B. Uncertainty Shocks in a Model of Effective Demand; American Economic Association: Nashville, TN, USA, 2012. [Google Scholar]
- Stock, J.H.; Watson, M.W. Disentangling the Channels of the 2007–09 Recession. Brook. Pap. Econ. Act. 2012, 2012, 81–135. [Google Scholar] [CrossRef] [Green Version]
- Jurado, K.; Ludvigson, S.; Ng, S. Measuring Uncertainty. Am. Econ. Rev. 2015, 105, 1177–1216. [Google Scholar] [CrossRef]
- Ahir, H.; Bloom, N.; Furceri, D. The World Uncertainty Index; International Monetary Fund: Washington, DC, USA, 2018; pp. 1–33. [Google Scholar]
- Perron, P. The Great Crash, the Oil Price Shock, and the Unit Root Hypothesis. Econometrica 1989, 57, 1361. [Google Scholar] [CrossRef]
- Perron, P.; Timothy, J.; Vogelsang, T. Testing for a Unit Root in a Time Series with a Changing Mean: Corrections and Extensions. J. Bus. Econ. Stat. 1992, 10, 467–470. [Google Scholar]
- Vogelsang, T.J.; Perron, P. Additional Tests for a Unit Root Allowing for a Break in the Trend Function at an Unknown Time. Int. Econ. Rev. 1998, 39, 1073. [Google Scholar] [CrossRef] [Green Version]
- Perron, P. Dealing with Structural Breaks, in Palgrave Handbook of Econometrics. Econom. Theory 2006, 1, 278–352. [Google Scholar]
- Dickey, D.A.; Fuller, W.A. Likelihood ratio statistics for autoregressive time series with a unit root. Econometrica 1981, 49, 1057–1072. [Google Scholar] [CrossRef]
- Mishra, P.; Al Khatib, A.M.G.; Sardar, I.; Mohammed, J.; Karakaya, K.; Dash, A.; Ray, M.; Narsimhaiah, L.; Dubey, A. Modeling and forecasting of sugarcane production in India. Sugar Tech 2021. [Google Scholar] [CrossRef]
- Bhadury, S.; Beyer, R.; Pohit, S. A New Approach to Nowcasting Indian Gross Value Added; Working Paper NO. 115; National Council of Applied Economic Research: New Delhi, India, 2018. [Google Scholar]
- Mishra, P.; Yonar, A.; Yonar, H.; Kumari, B.; Abotaleb, M.; Das, S.S.; Patil, S.G. State of the art in total pulse production in major states of India using ARIMA techniques. Curr. Res. Food Sci. 2021. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
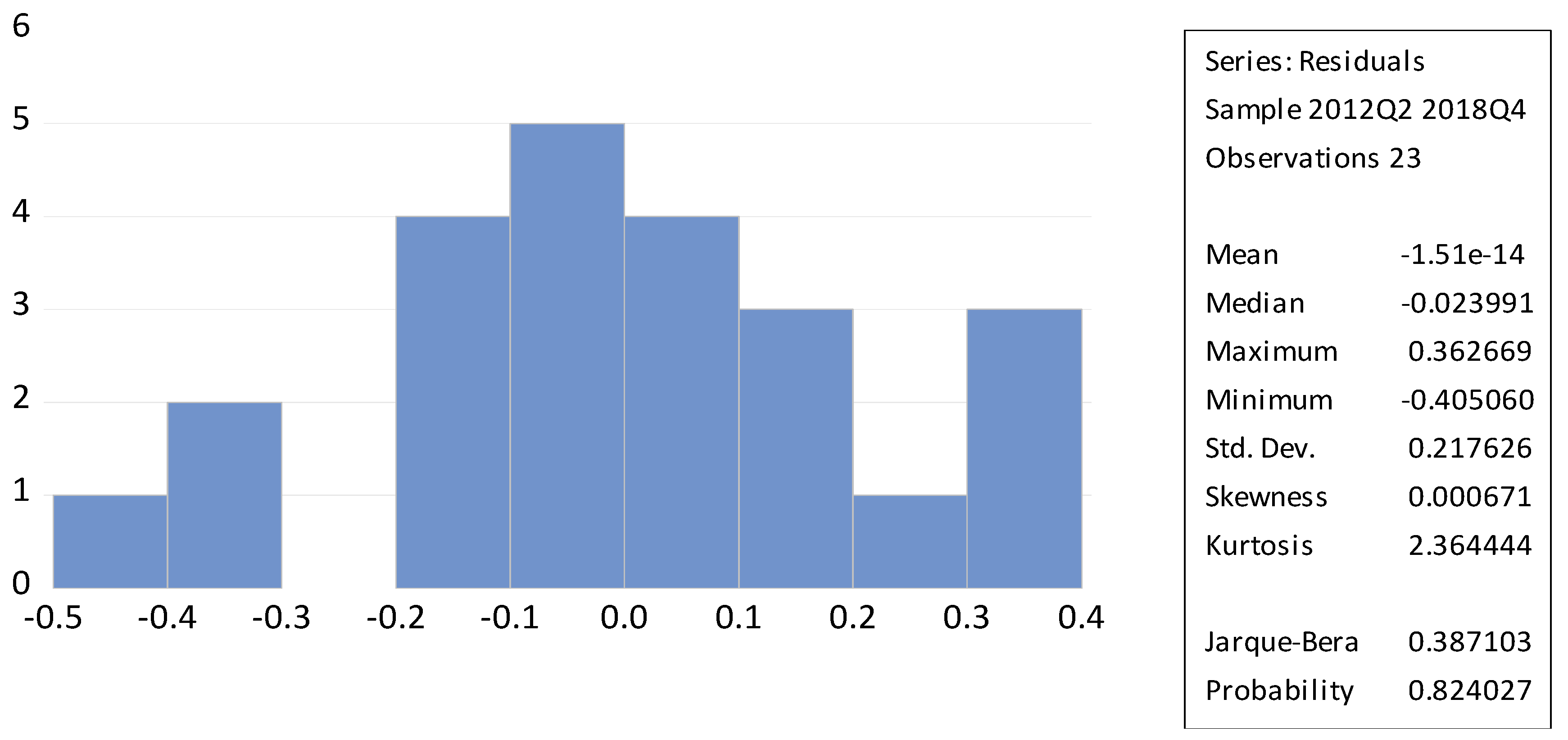{kind=link}
{kind=link}
{kind=link}
{kind=link}
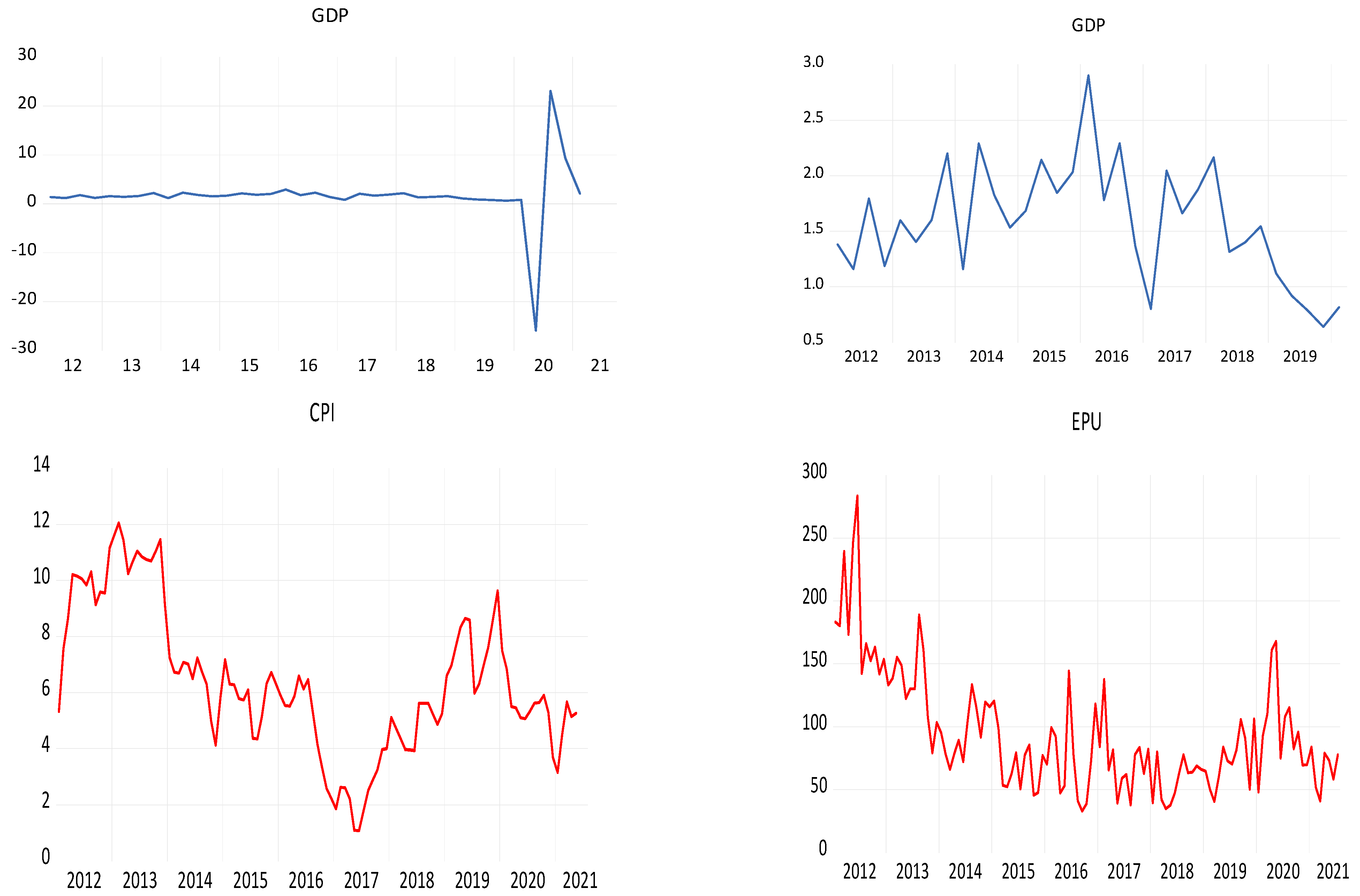
| Variables | Normality | Mean | Standard Deviation | Maximum | Minimum | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|
| J-B | |||||||
| GDP% | 343.6 *** | 1.64 | 5.98 | 23.12 | −25.29 | −1.39 | 17.66 |
| EPU | 61.6 *** | 94.09 | 46.82 | 283.68 | 32.88 | 1.37 | 5.31 |
| CPI% | 2.89 | 6.37 | 2.57 | 12.06 | 1.08 | 0.32 | 2.54 |
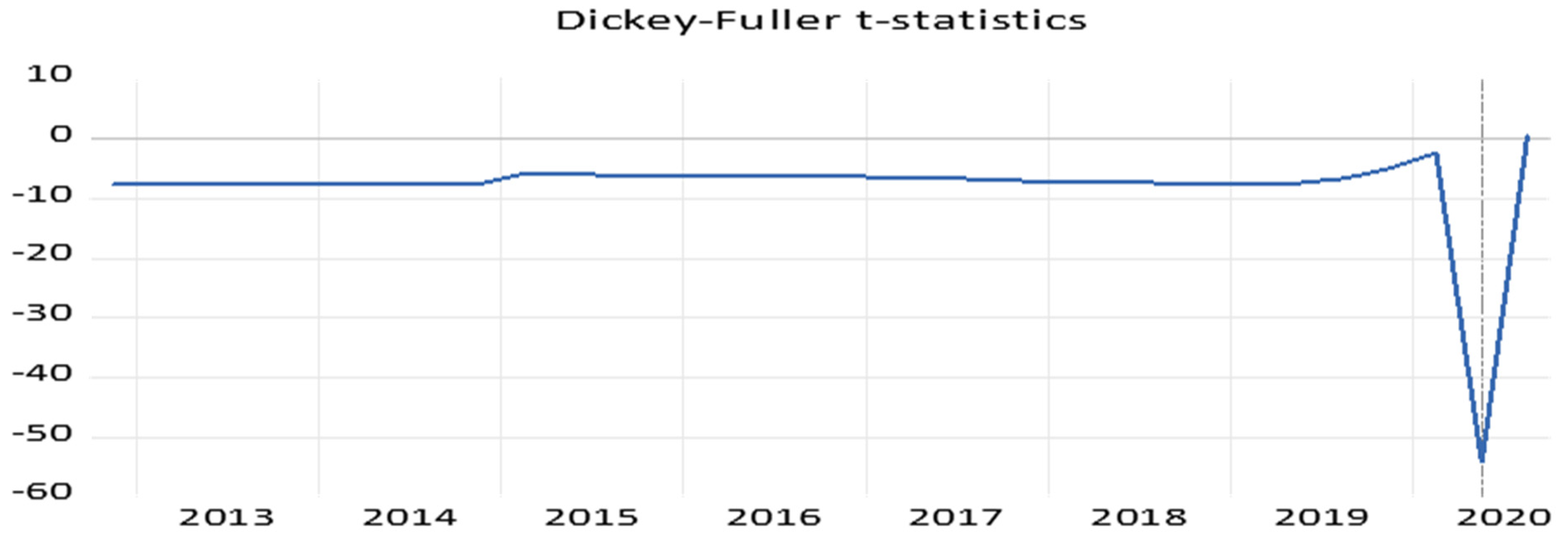
| GDP | Stationary | GDP (−1) | C | TREND | INCPT BREAK | TREND BREAK | BREAKDUM | Integrated |
|---|---|---|---|---|---|---|---|---|
| t-statistics | −54.25 *** | −4.9 *** | 10.76 *** | −1.97 * | 23.23 *** | −16.95 *** | −46.80 *** | I(0) |
| Break Date | 2020 Q2 |
| Test | Normality | ACF2 | ADF |
|---|---|---|---|
| J-B | Non Constant–Non Trend | ||
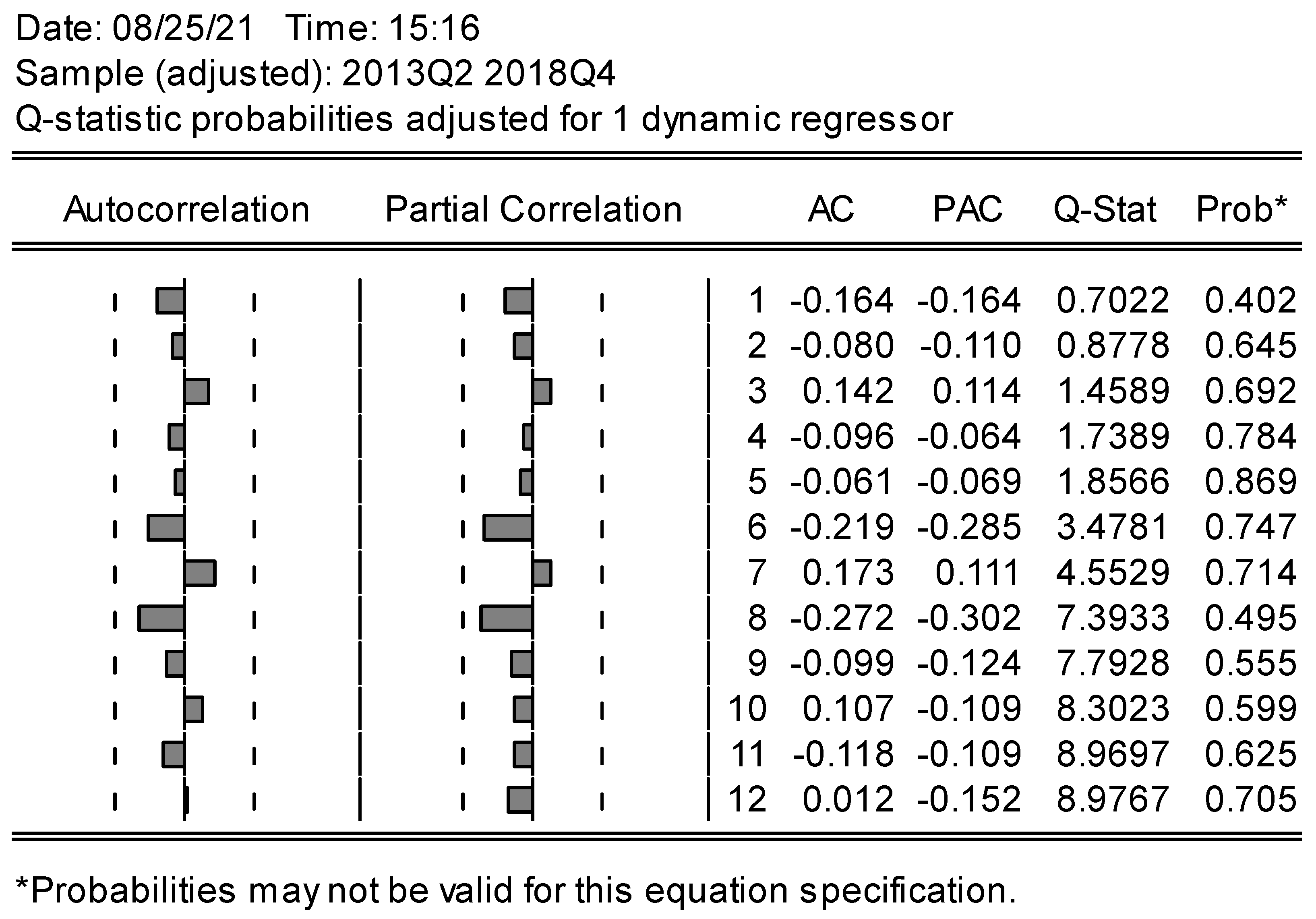
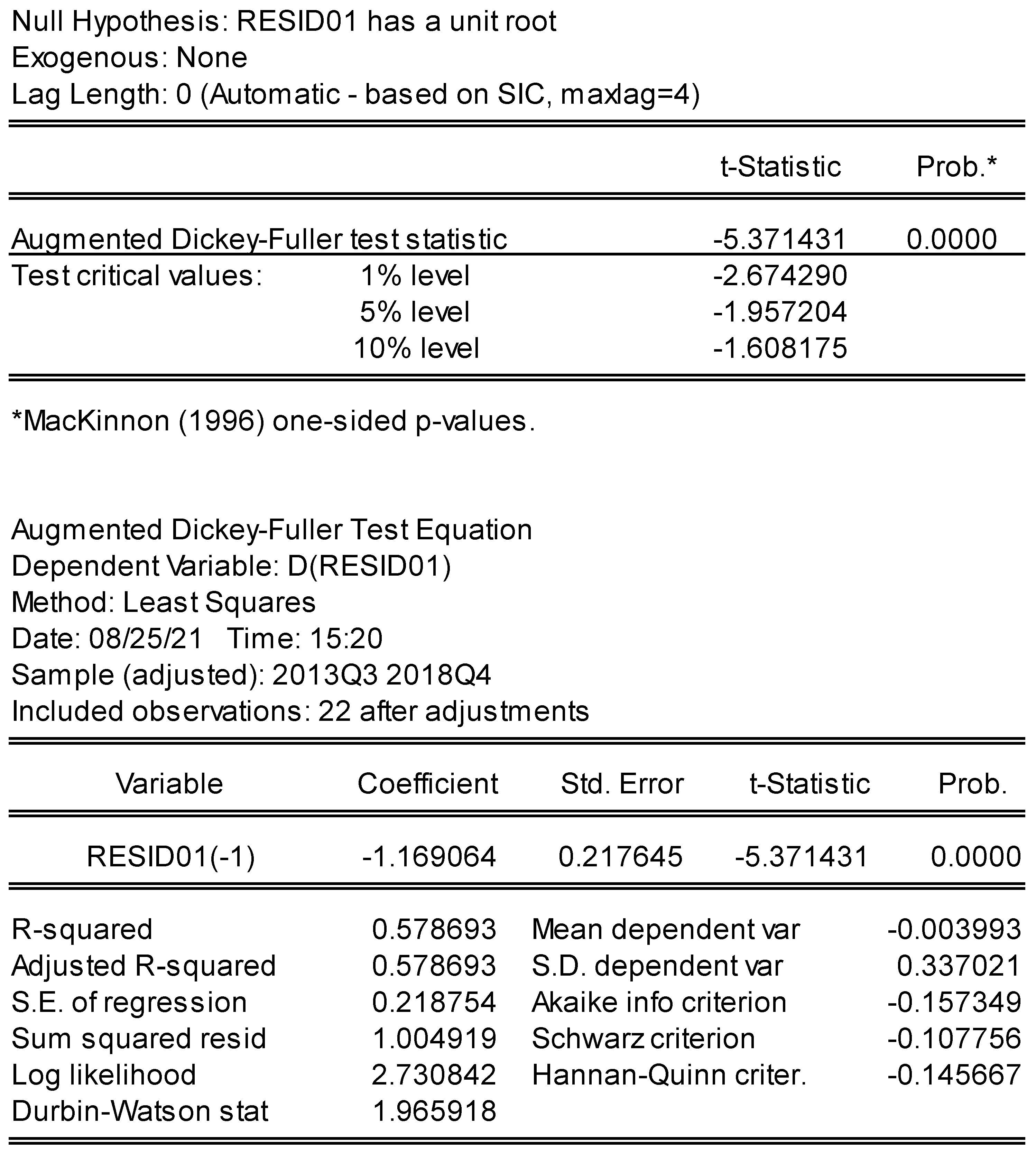
| Residuals (PROB) | 0.824 | 0.645 | 000 *** |
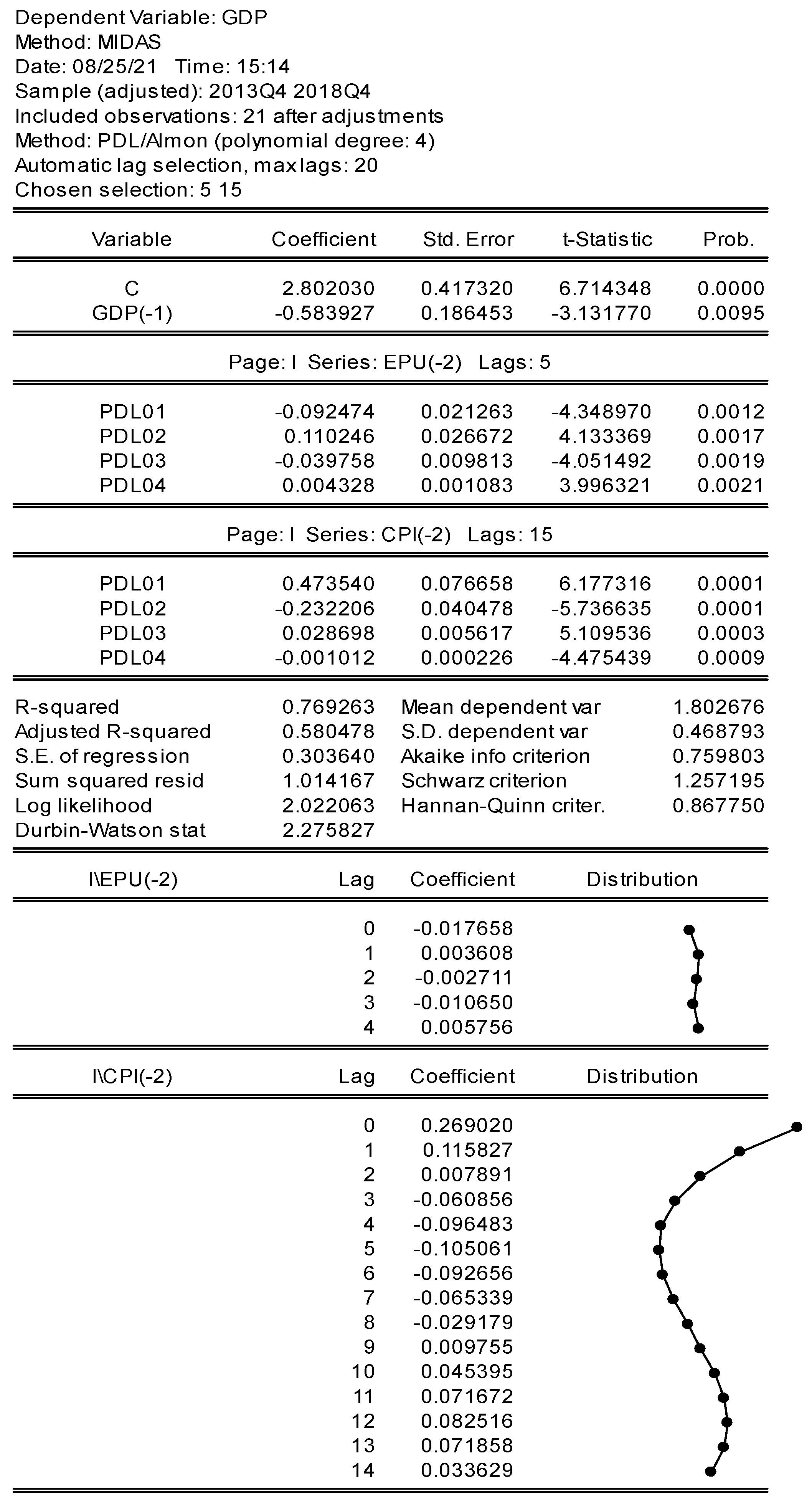
| Dependent Variable: GDP (2013Q4 2018Q4) | |||
|---|---|---|---|
| Variable | Coefficient | Std. Error | t-Statistics |
| C | 2.80203 | 0.41732 | 6.714348 *** |
| GDP (−1) | −0.583927 | 0.186453 | −3.131770 *** |
| EPU(−2) Lags: 5 | |||
| PDL1 | −0.092474 | 0.021263 | −4.348970 *** |
| PDL2 | 0.110246 | 0.026672 | 4.133369 *** |
| PDL3 | −0.039758 | 0.009813 | −4.051492 *** |
| PDL4 | 0.004328 | 0.001083 | 3.996321 *** |
| CPI(−2) Lags: 15 | |||
| PDL1 | 0.47354 | 0.076658 | 6.177316 *** |
| PDL2 | −0.232206 | 0.040478 | −5.736635 *** |
| PDL3 | 0.028698 | 0.005617 | 5.109536 *** |
| PDL4 | −0.001012 | 0.000226 | −4.475439 *** |
| Adg. R-Squared | 0.580478 | Log Likelihood | 2.022063 |
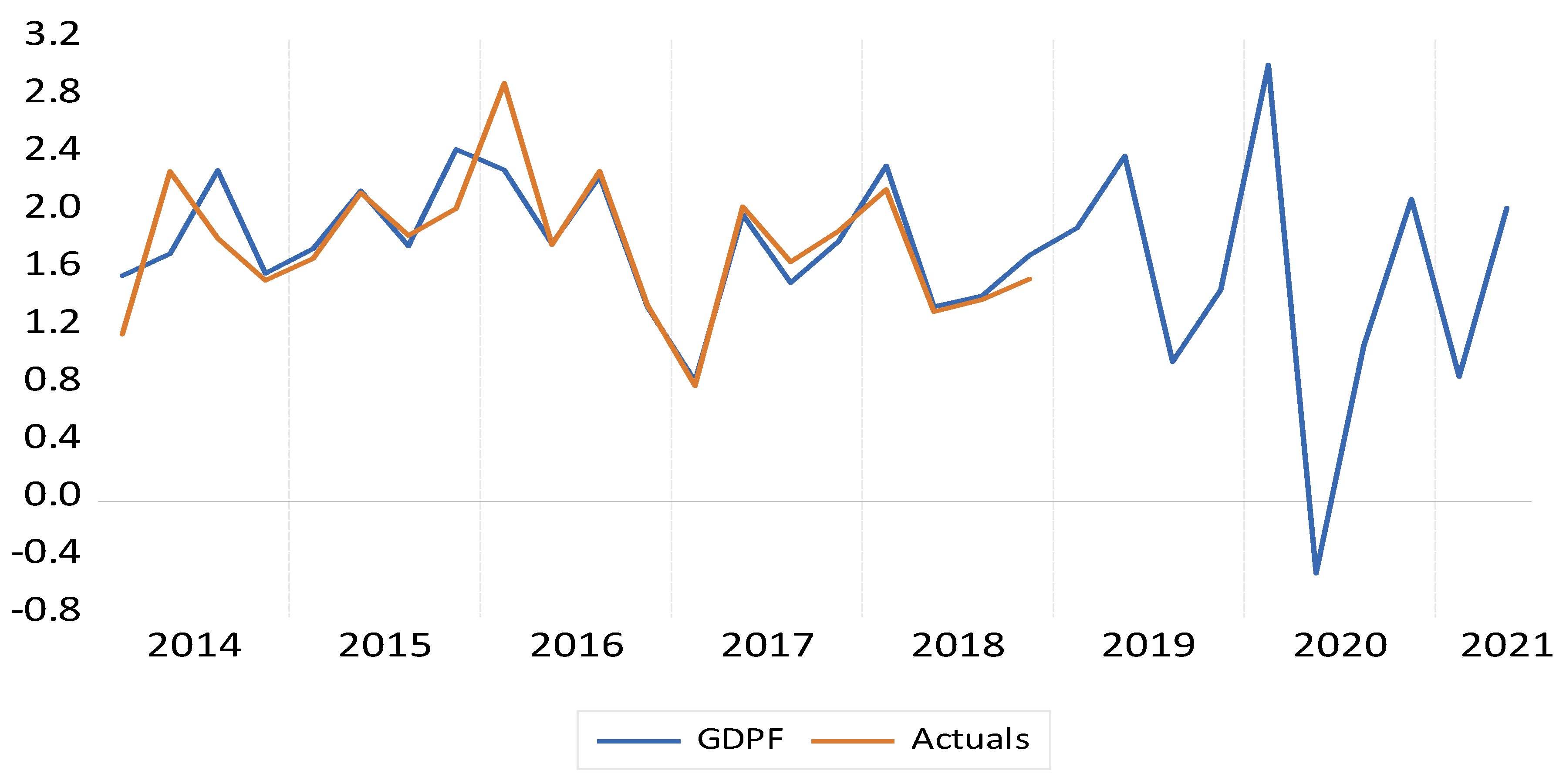
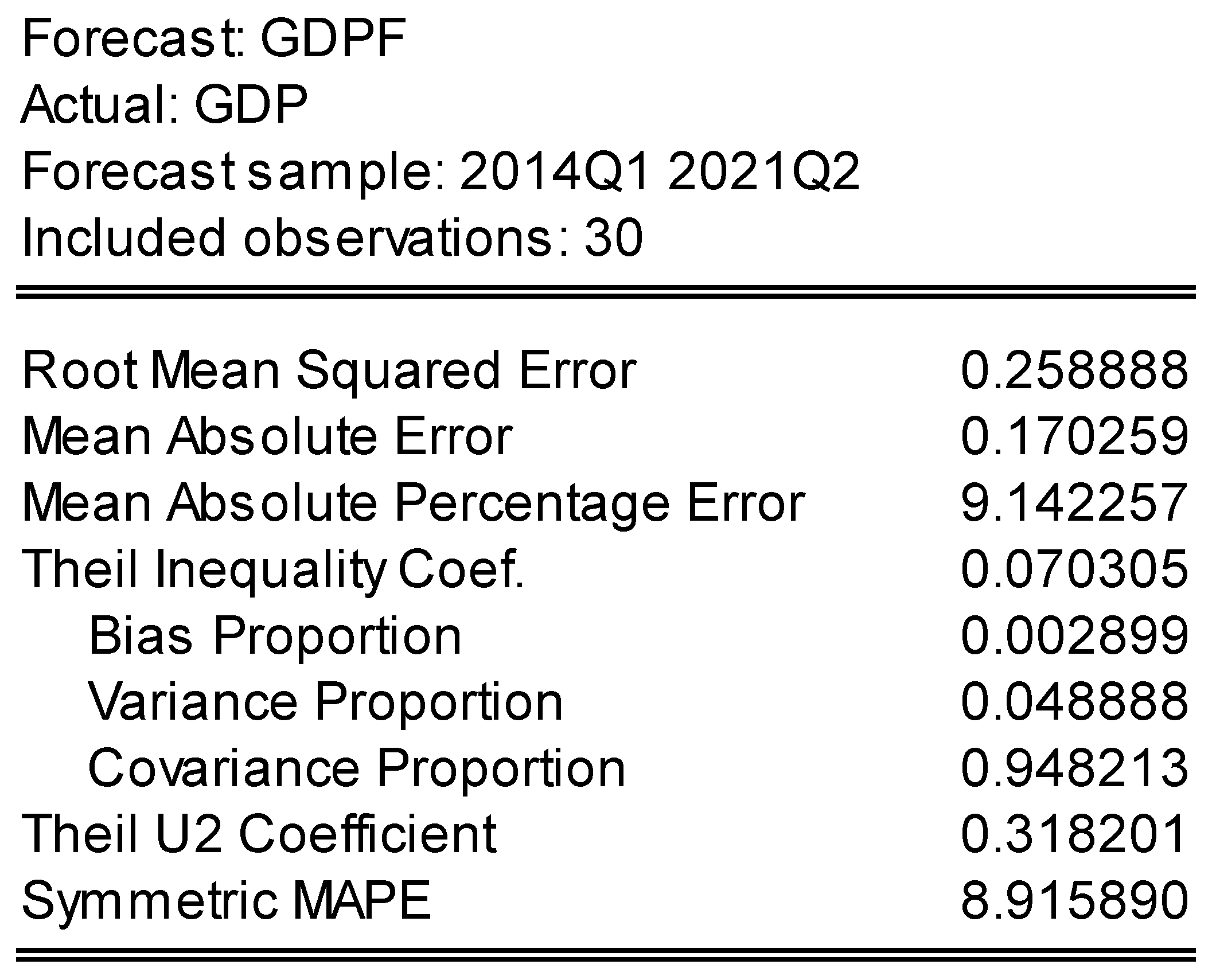
| In of Sample (Training Data) | Out of Sample (Testing Data) | ||||
|---|---|---|---|---|---|
| Horizon (Quarter) | H = 1 | H = 4 | H = 10 | H = Last Point | |
| RMSE | 0.258 | 0.778 | 0.937 | 11.51 | 1.24 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mishra, P.; Alakkari, K.; Abotaleb, M.; Singh, P.K.; Singh, S.; Ray, M.; Das, S.S.; Rahman, U.H.; Othman, A.J.; Ibragimova, N.A.; et al. Nowcasting India Economic Growth Using a Mixed-Data Sampling (MIDAS) Model (Empirical Study with Economic Policy Uncertainty–Consumer Prices Index). Data 2021, 6, 113. https://doi.org/10.3390/data6110113
Mishra P, Alakkari K, Abotaleb M, Singh PK, Singh S, Ray M, Das SS, Rahman UH, Othman AJ, Ibragimova NA, et al. Nowcasting India Economic Growth Using a Mixed-Data Sampling (MIDAS) Model (Empirical Study with Economic Policy Uncertainty–Consumer Prices Index). Data. 2021; 6(11):113. https://doi.org/10.3390/data6110113
Chicago/Turabian StyleMishra, Pradeep, Khder Alakkari, Mostafa Abotaleb, Pankaj Kumar Singh, Shilpi Singh, Monika Ray, Soumitra Sankar Das, Umme Habibah Rahman, Ali J. Othman, Nazirya Alexandrovna Ibragimova, and et al. 2021. "Nowcasting India Economic Growth Using a Mixed-Data Sampling (MIDAS) Model (Empirical Study with Economic Policy Uncertainty–Consumer Prices Index)" Data 6, no. 11: 113. https://doi.org/10.3390/data6110113
APA StyleMishra, P., Alakkari, K., Abotaleb, M., Singh, P. K., Singh, S., Ray, M., Das, S. S., Rahman, U. H., Othman, A. J., Ibragimova, N. A., Ahmed, G. F., Homa, F., Tiwari, P., & Balloo, R. (2021). Nowcasting India Economic Growth Using a Mixed-Data Sampling (MIDAS) Model (Empirical Study with Economic Policy Uncertainty–Consumer Prices Index). Data, 6(11), 113. https://doi.org/10.3390/data6110113