Agro-Climatic Data by County: A Spatially and Temporally Consistent U.S. Dataset for Agricultural Yields, Weather and Soils


Abstract

1. Introduction
“A funny thing about that paper [9]: many reference it, and often claim that they are using techniques that follow that paper… people have done similar things that seem inspired by that paper, but not quite the same. Either our explication was too ambiguous or people don’t have the patience to fully carry out the technique, so they take shortcuts.” (G-FEED, 1/10/2015)
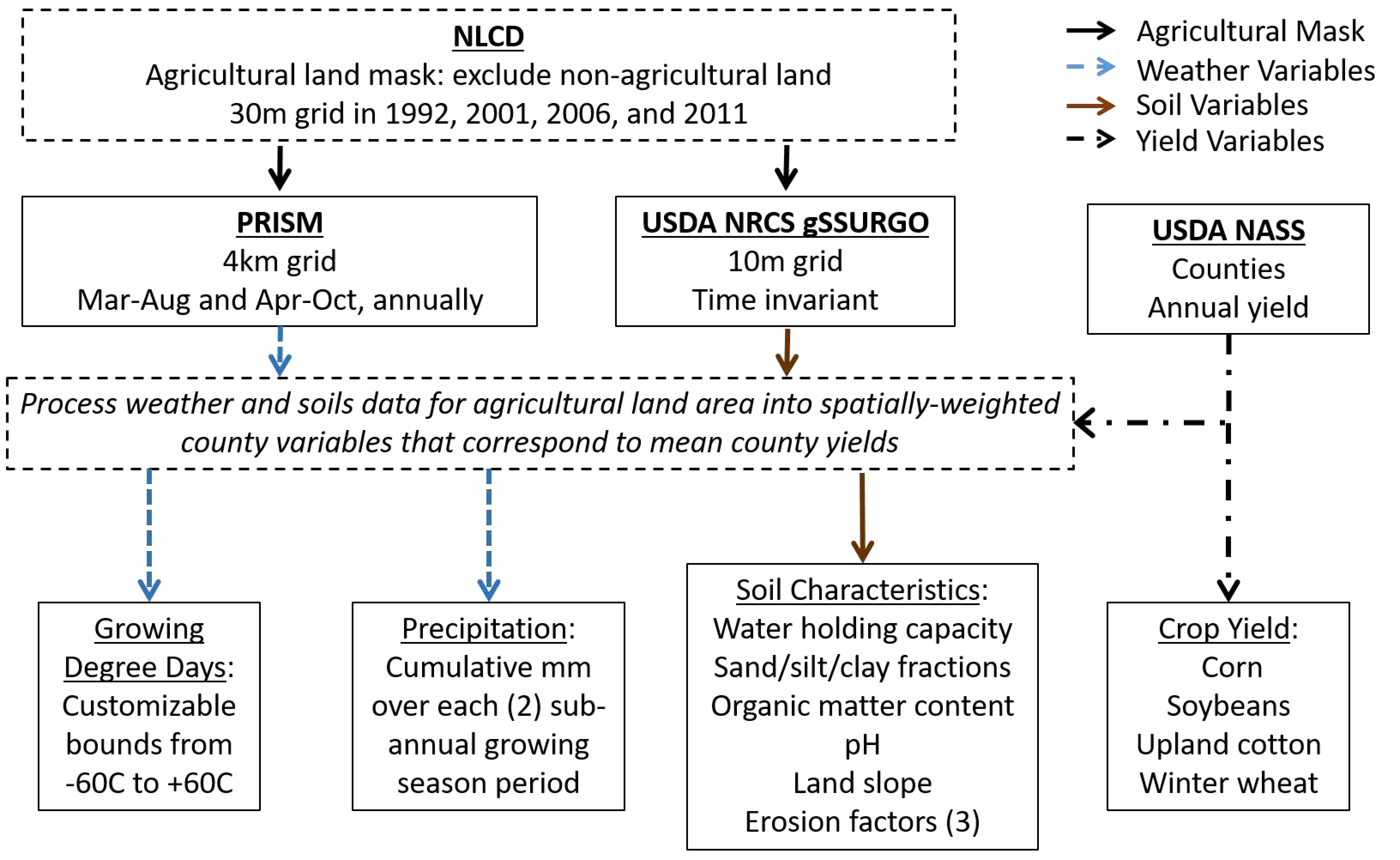
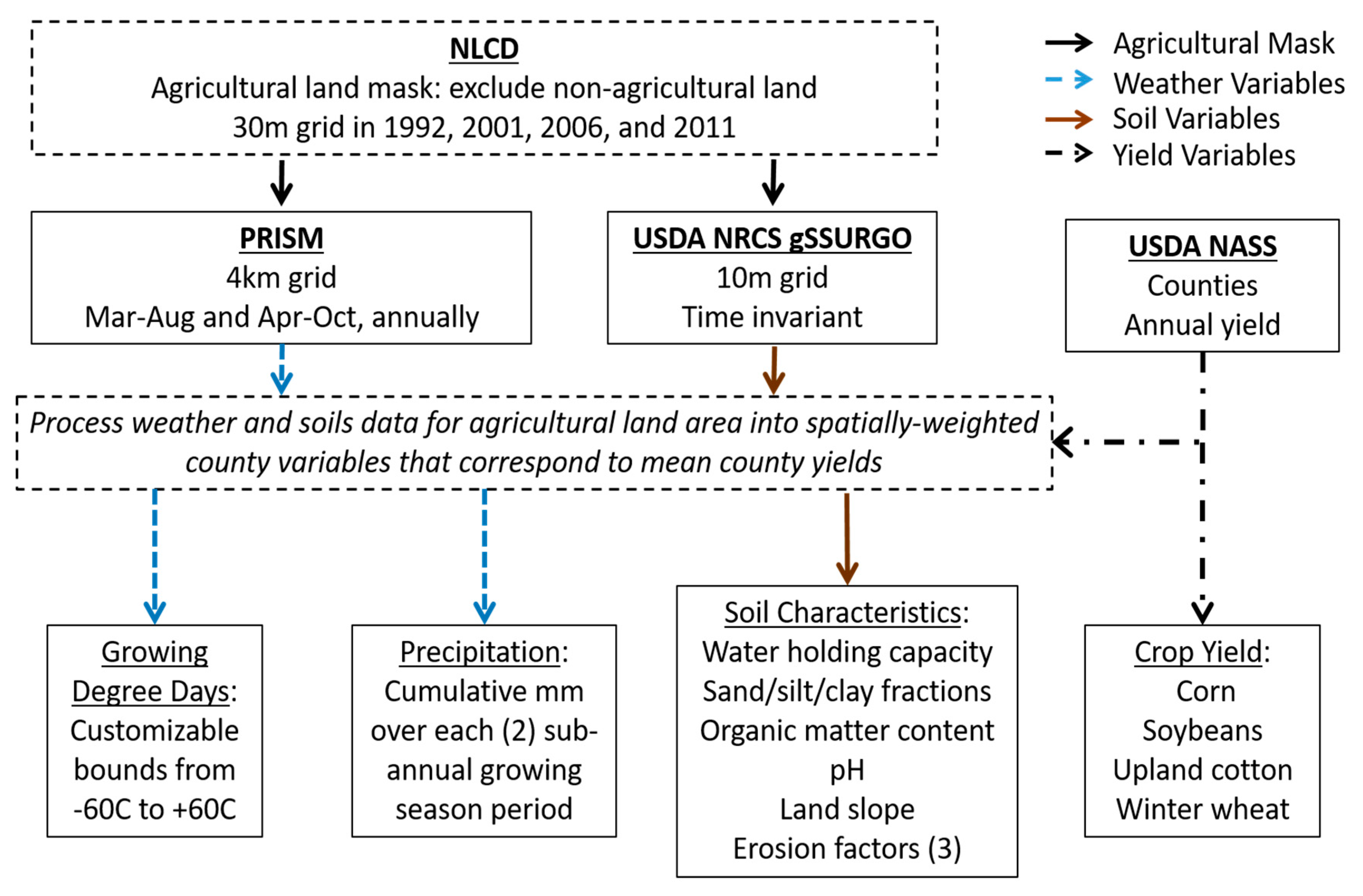
2. ACDC Dataset Outline
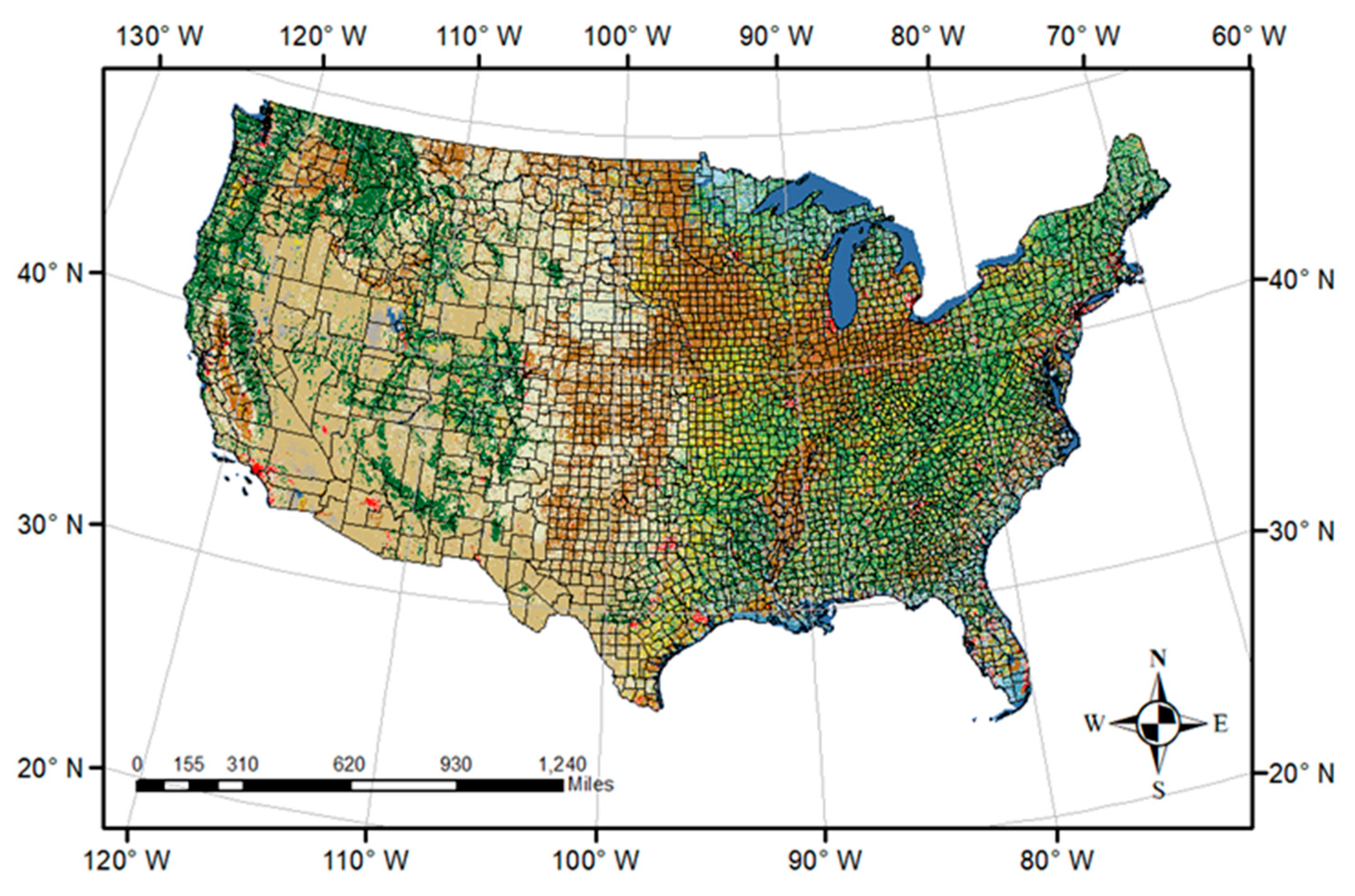
2.1. The Spatial and Temporal Extent of ACDC
2.2. Data Inputs and Outputs
3. Material and Methods
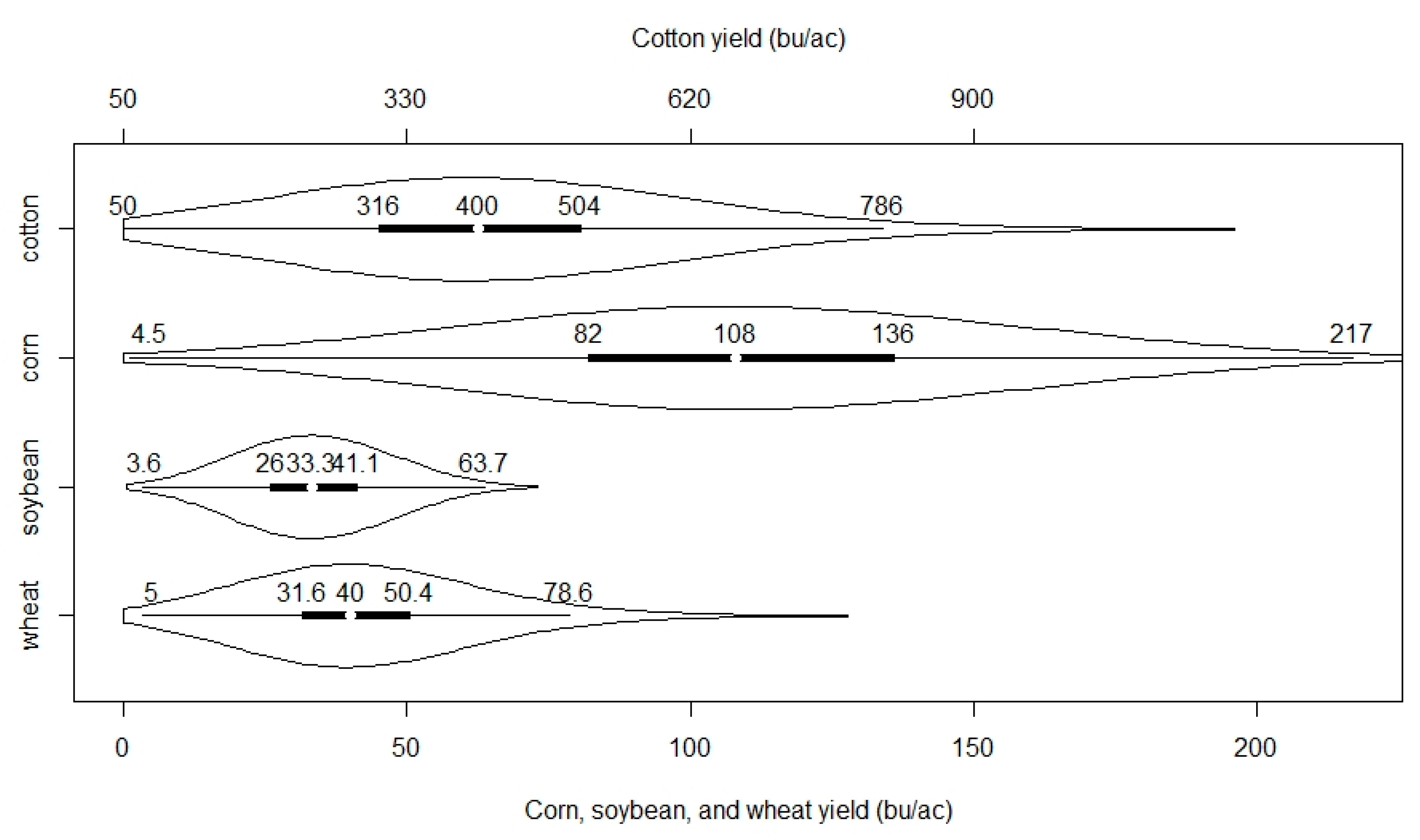
3.1. Crop Yields
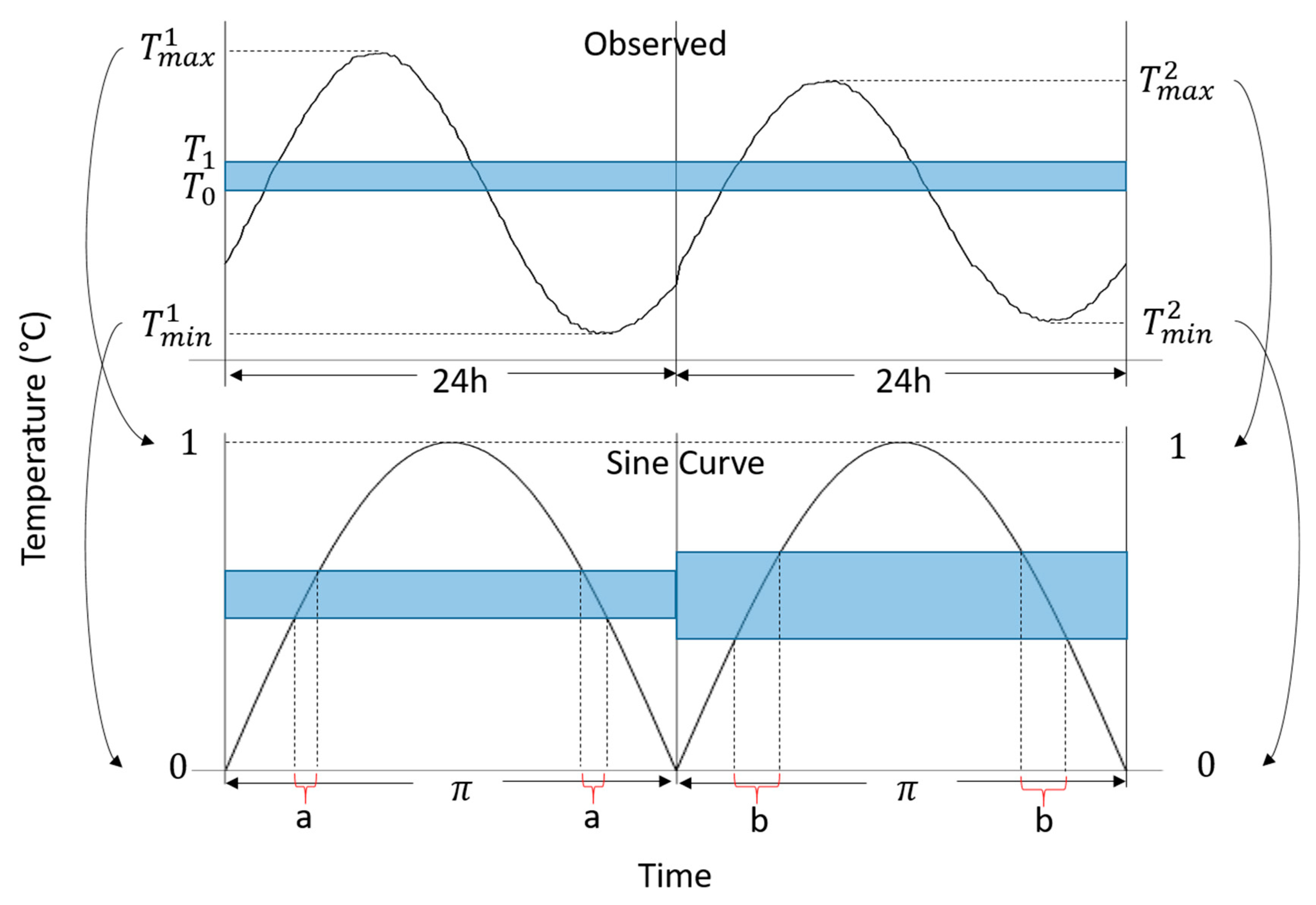
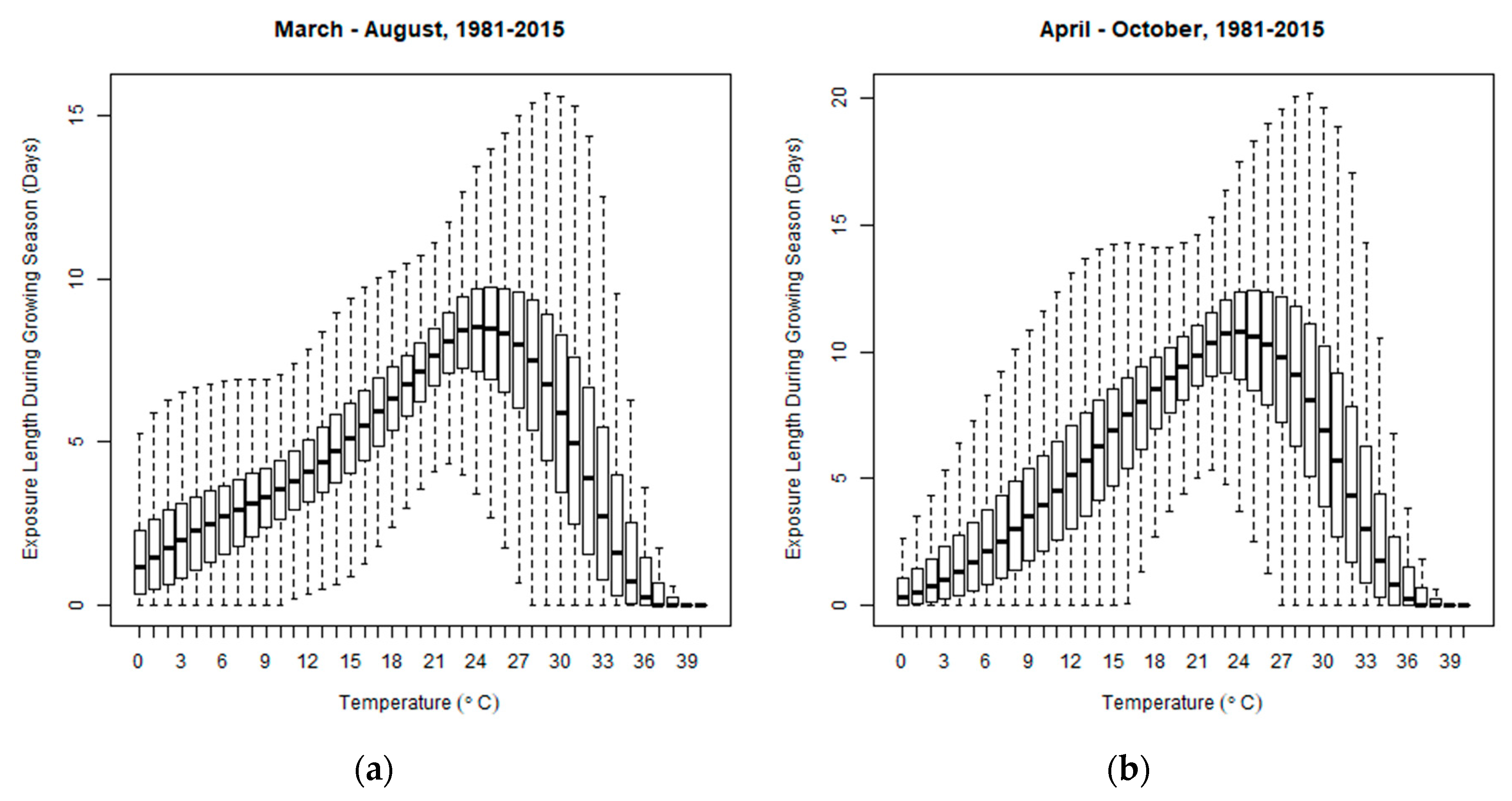
3.2. Heat Exposure Length
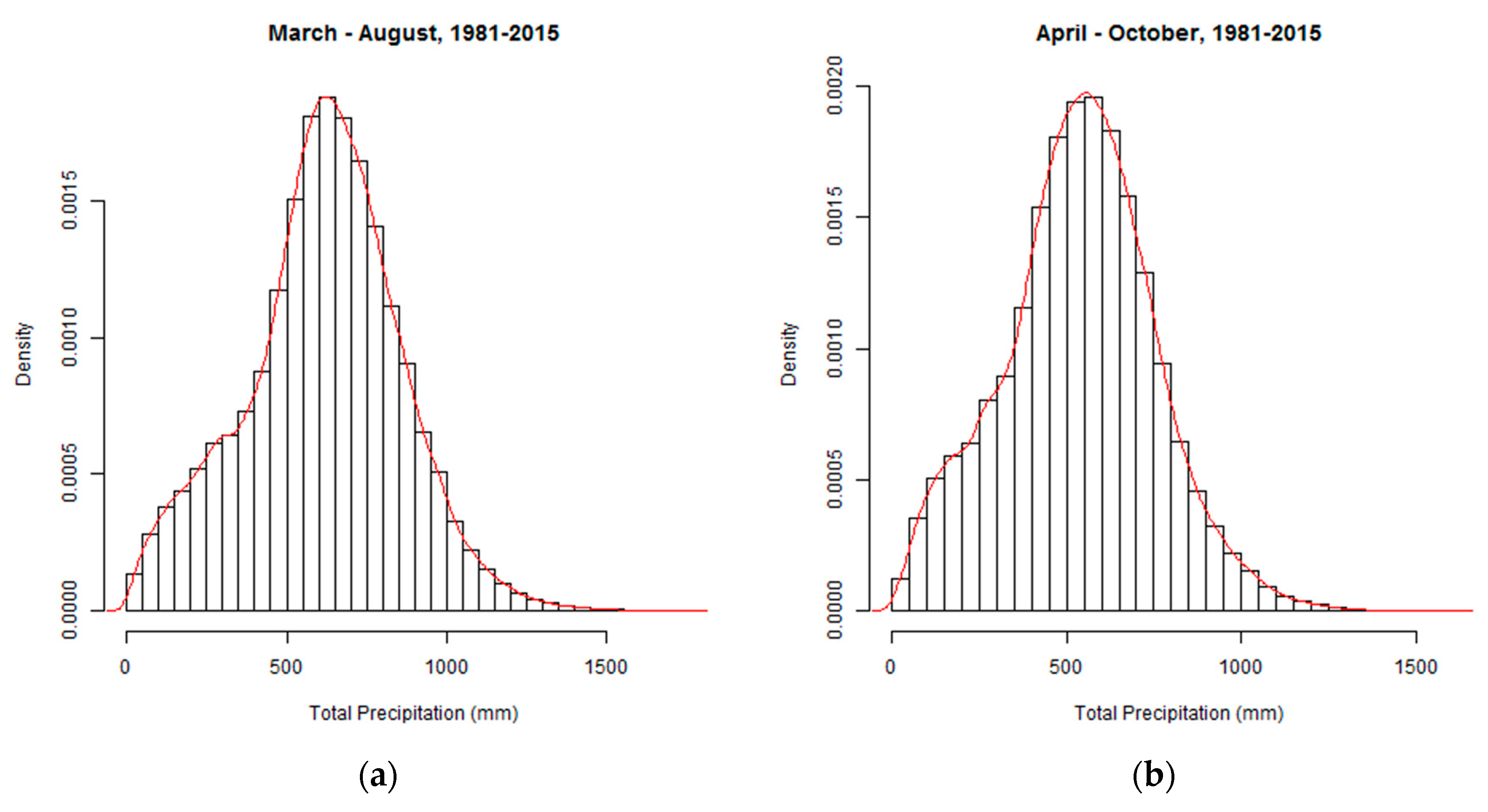
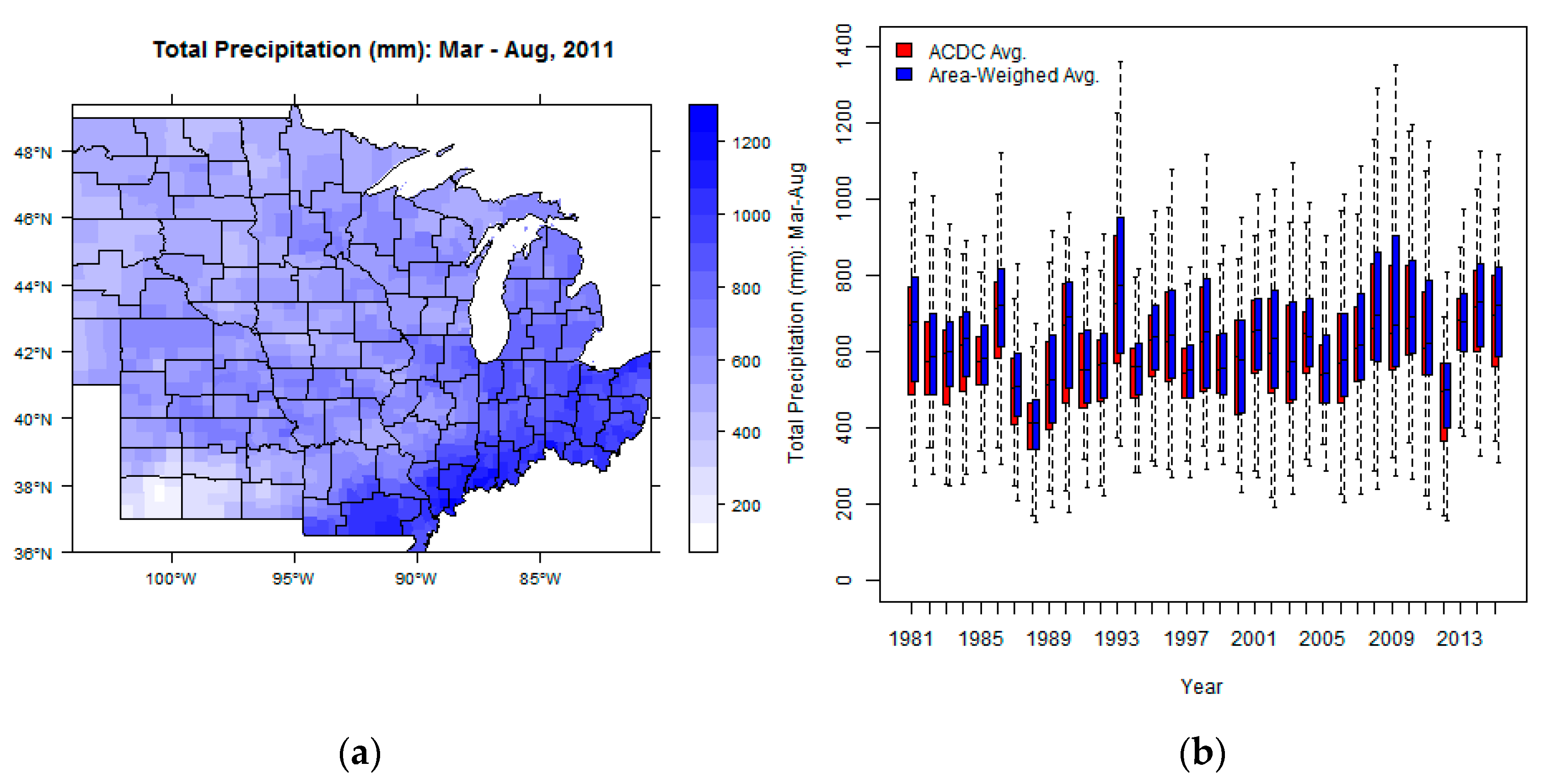
3.3. Total Precipitation
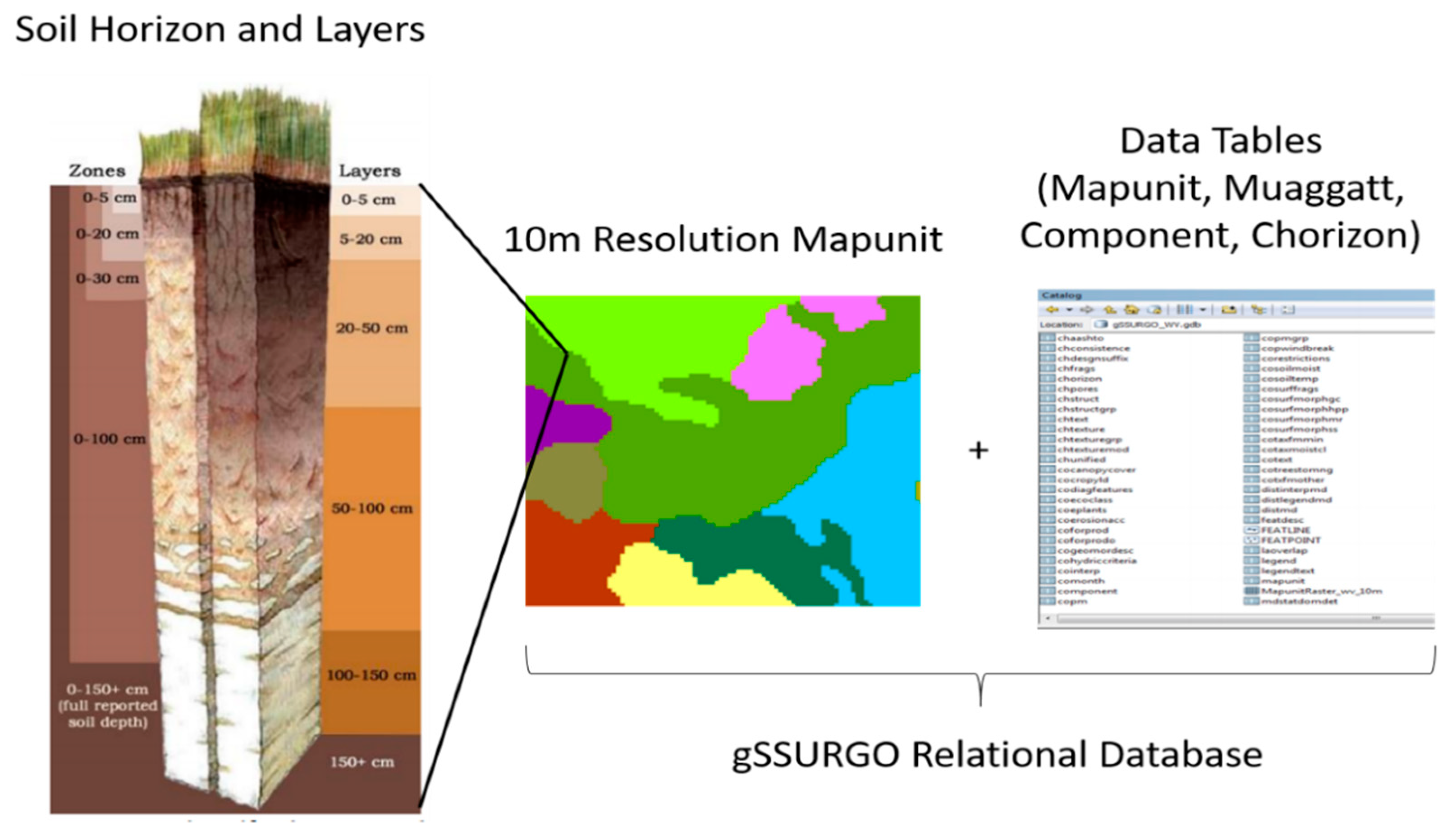
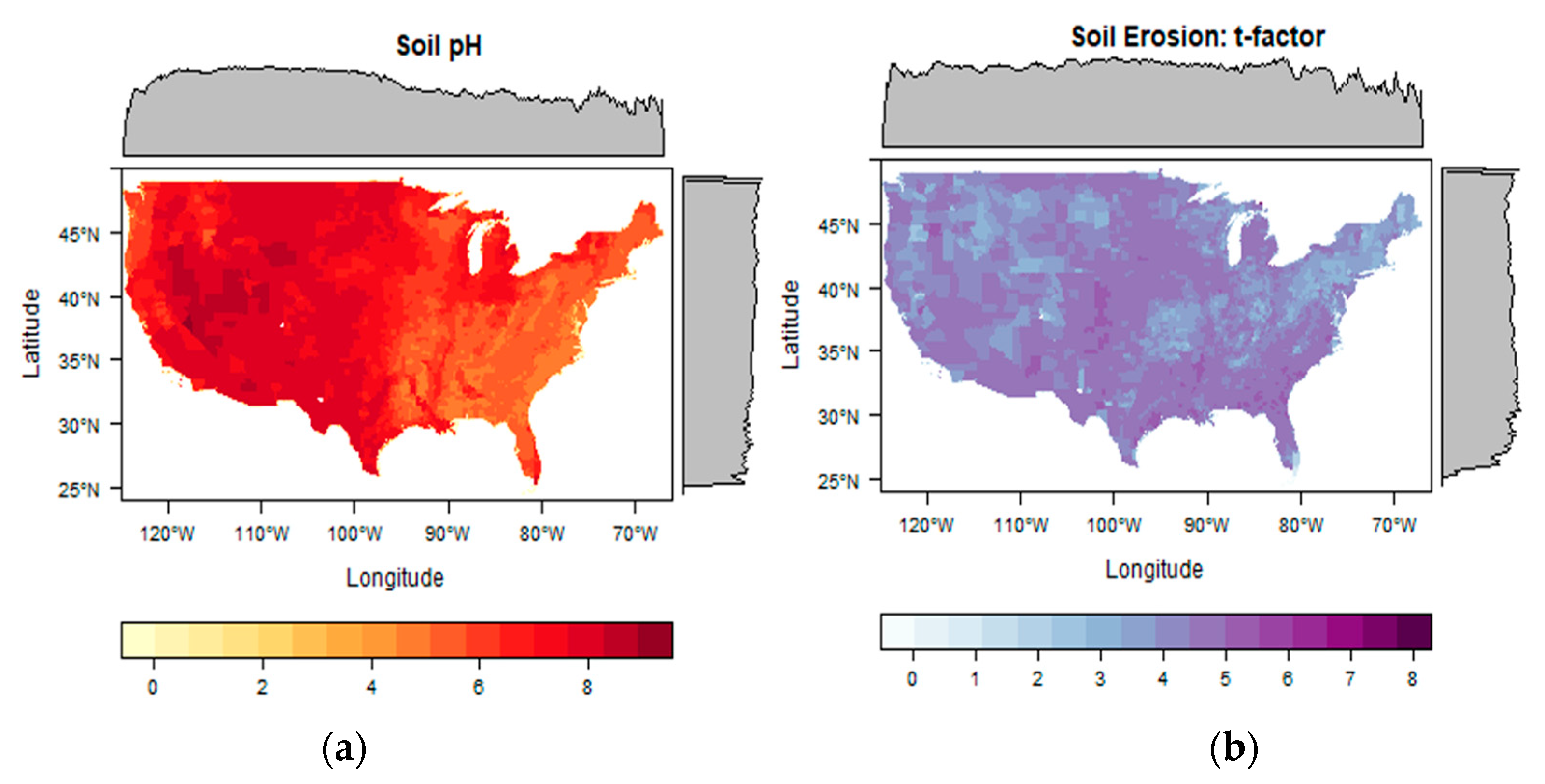
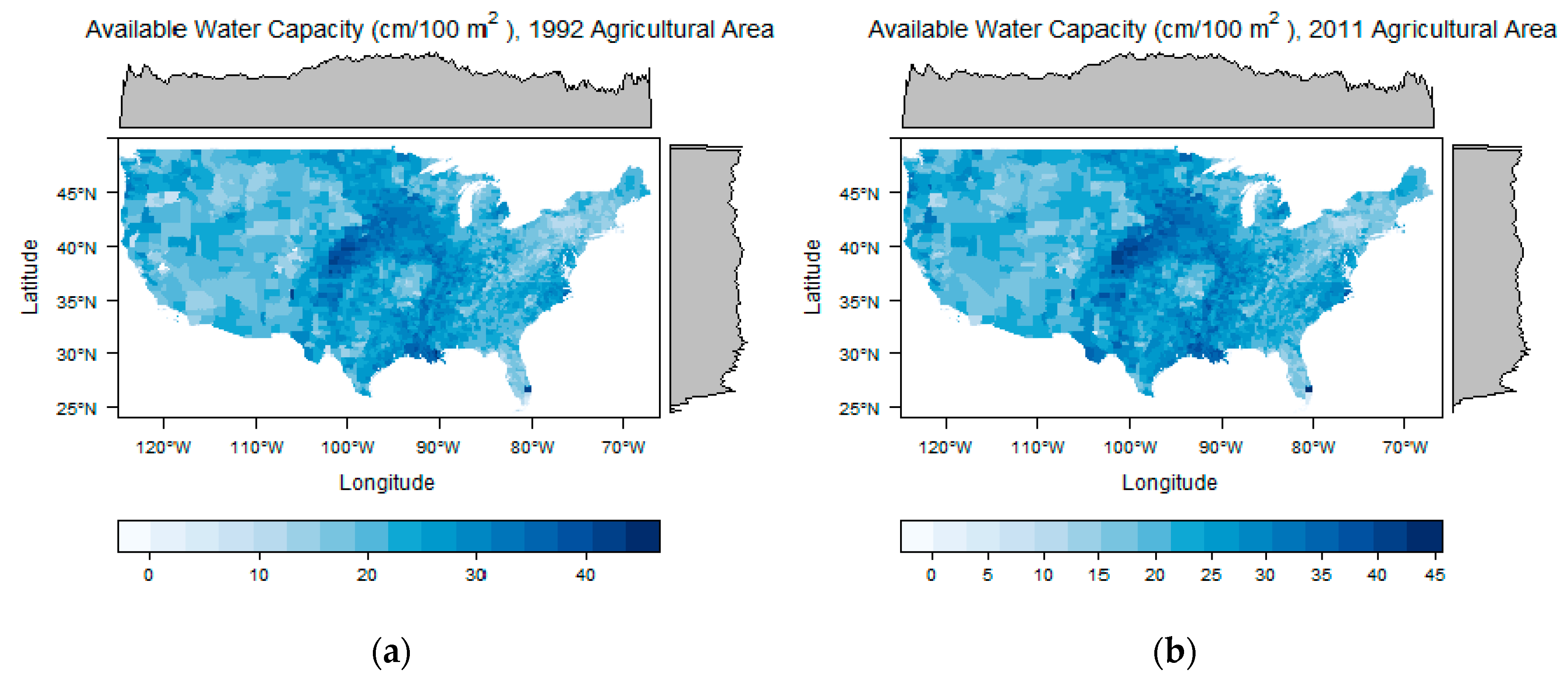
3.4. Soil Variables
4. Discussion
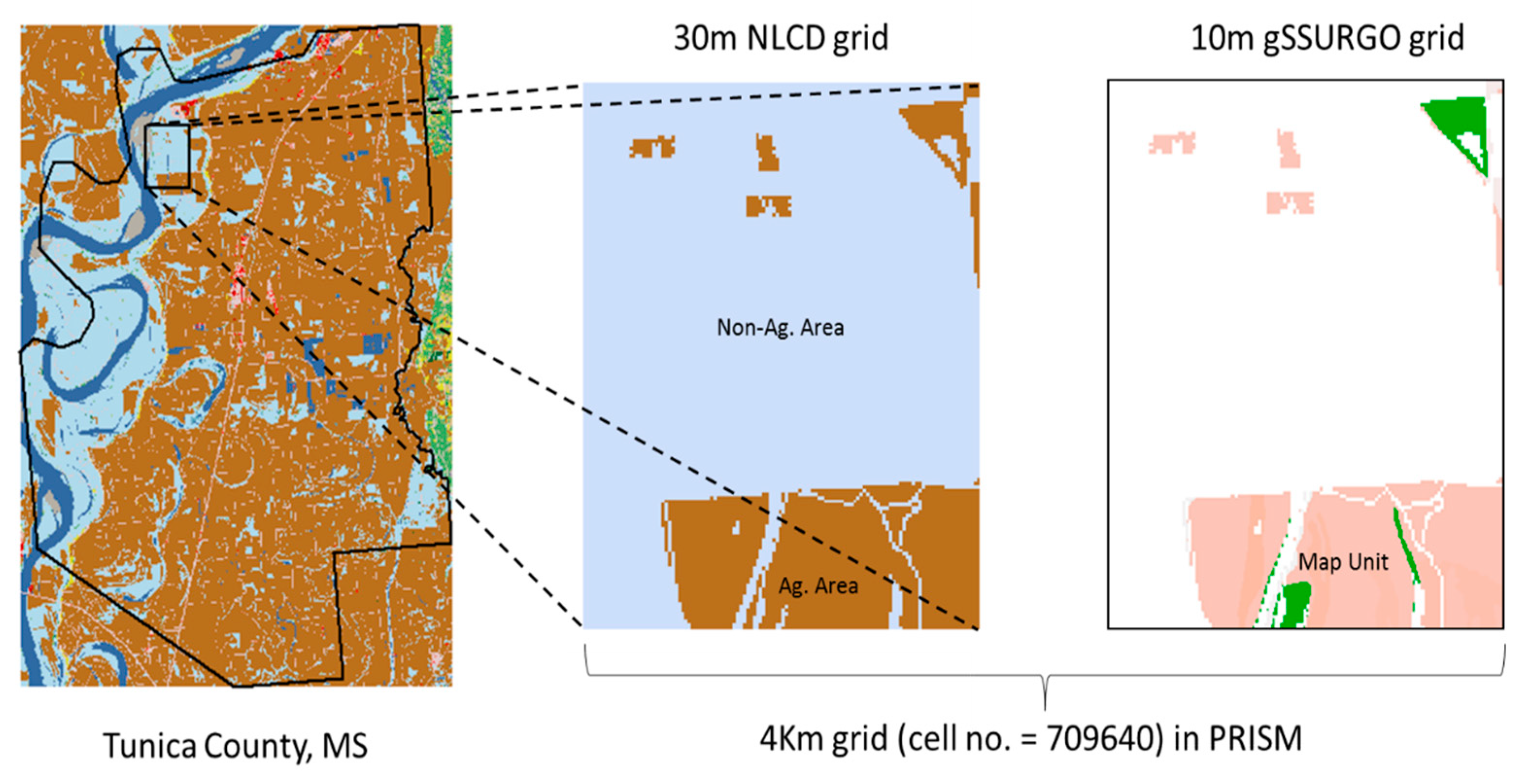
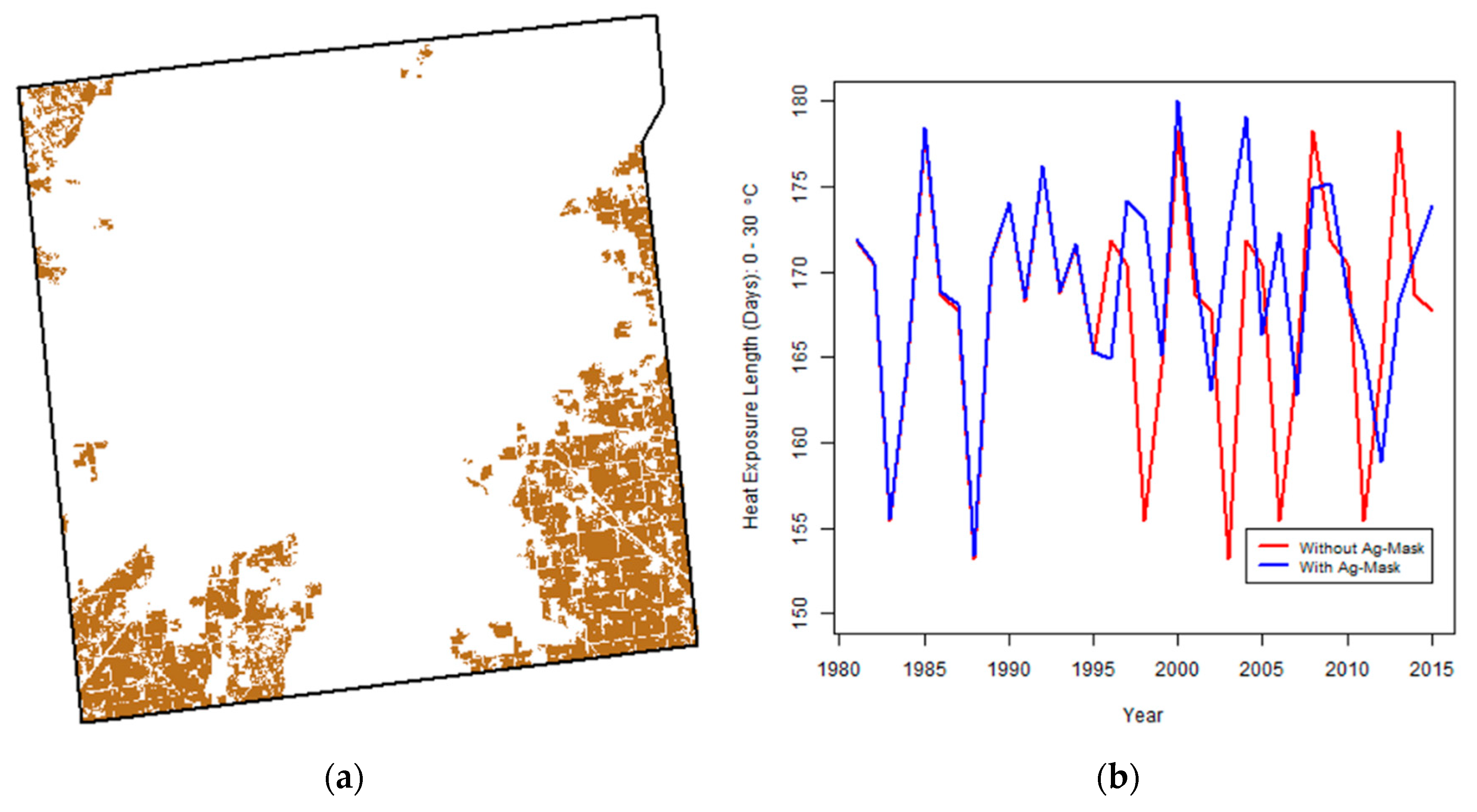
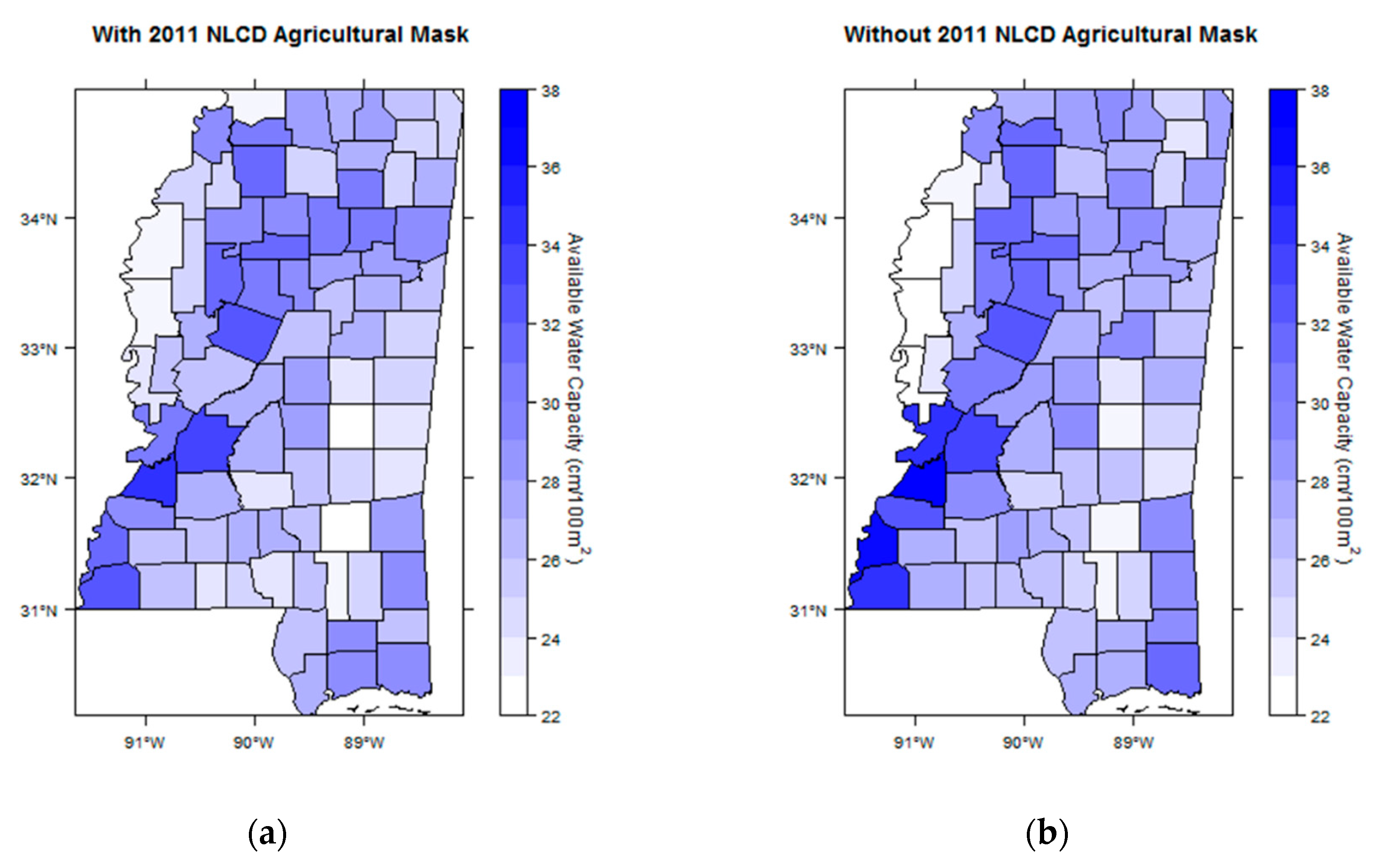
4.1. Agricultural Mask
4.2. Aggregation and Disaggregation
4.3. Computational Burden and Required Resources
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Description |
|---|---|
| stco | State FIPS + county FIPS (detailed codes in 2012 Agricultural Census) |
| year | Year: 1981–2015 |
| corn | corn yields (bu/ac): 1981–2015 |
| soybean | soybean yields (bu/ac): 1981–2015 |
| cotton | upland cotton yields (bu/ac): 1981–2015 |
| wheat | wheat yields (bu/ac): 1981–2007 |
| Variable Name | Description |
|---|---|
| gridNum | PRISM grid cell index under NLCD projection |
| stco | State FIPS + county FIPS (detailed codes in 2012 Agricultural Census) |
| numAg1992 | number of agricultural cells based on 1992 NLCD |
| numAg2001 | number of agricultural cells based on 2001 NLCD |
| numAg2006 | number of agricultural cells based on 2006 NLCD |
| numAg2011 | number of agricultural cells based on 2011 NLCD |
| Variable Name | Description |
|---|---|
| stco | State FIPS + county FIPS (detailed codes in 2012 Agricultural Census) |
| year | Year: 1981-2015 |
| gddm# | (m = negative, (−))−# Celsius degree days between −# ±0.5 °C |
| gdd0 | 0 Celsius degree days between −0.5 °C and +0.5 °C |
| gddp# | (p = positive, (+)) +# Celsius degree days between +# ±0.5 °C |
| Variable Name | Description |
|---|---|
| stco | State FIPS + county FIPS (detailed codes in 2012 Agricultural Census) |
| year | Year: 1981–2015 |
| ppt | total precipitation (mm) |
| Variable Name | Description |
|---|---|
| stco | State FIPS + county FIPS (detailed codes in 2012 Agricultural Census) |
| whc | available water capacity (cm/100 m2) (awc in gSSURGO) |
| sand | sand proportion (%) (sandtotal in gSSURGO) |
| silt | silt proportion (%) (silttotal in gSSURGO) |
| clay | clay proportion (%) (claytotal in gSSURGO) |
| om | organic matter in 2 mm top soil (%) (om in gSSURGO) |
| kwfactor | soil erodibility factor by water adjusted for rock fragments (kwfact in gSSURGO) |
| kffactor | soil erodibility factor by water (kffact in gSSURGO) |
| spH | soil pH (ph1to1h2o_r in gSSURGO) |
| slope | slope (m) (slopelenusle in gSSURGO) |
| tfactor | soil loss tolerance factor (tons/acre/yr) (tfact in gSSURGO) |
Appendix B
- ESRI (Environmental Systems Research Institute), 2016. Average Nearest Neighbor. ArcMap 10.3. Mannual. Available at: http://desktop.arcgis.com/en/arcmap/10.3/tools/spatial-statistics-toolbox/average-nearest-neighbor.htm.
- gSSURGO, Soil Survey Staff, 2015. The Gridded Soil Survey Geographic (gSSURGO) Database for the Conterminous United States. United State Department of Agriculture, Natural Resources Conservation Service. Available onle at https://gdg.sc.egov.usda.gov/. November 16, 2015 (FY2016 official release).
- NLCD (National Land Cover Database), 2011. The National Land Cover Database for the Conterminous United States, Multi-resolution Land Characteristics Consortium (MRLC). Available online at https://www.mrlc.gov/index.php.
- PRISM Climate Group, Oregon State University. 2004. Parameter-elevation Relationships on Independent Slopes Model (PRISM). http://prism.oregonstate.edu/, created 4 Feb 2004.
- United States Department of Agriculture-National Agricultural Statistics Service (USDA-NASS), available online at https://www.nass.usda.gov/.
References
- IPCC (Intergovernmental Panel on Climate Change). Summary for Policymakers. In Climate Change 2014: Mitigation of Climate Change. Contribution of Working Group III to the Fifth Assessment Report of the intergovernmental Panel on Climate Change; Edenhofer, O., R. Pichs-Madruga, Y., Sokona, E., Farahani, S., Kadner, K., Seyboth, A., Adler, I., Baum, S., Brunner, P., Eds.; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- McCarl, B.A.; Thayer, A.W.; Jones, J.P.H. The Challenge of Climate Change Adaptation for Agriculture: An Economically Oriented Review. Am. J. Agric. Econ. 2016, 48, 321–344. [Google Scholar] [CrossRef]
- Deschênes, O.; Greenstone, M. The Economic Impacts of Climate Change: Evidence from Agricultural Output and Random Fuctuations in Weather. Am. Econ. Rev. 2007, 97, 354–385. [Google Scholar] [CrossRef]
- Le, T.T.H. Effects of Climate Change on Rice Yield and Rice Market in Vietnam. Am. J. Agric. Econ. 2016, 48, 366–382. [Google Scholar] [CrossRef]
- Hendricks, N.P.H.; Smith, A.; Sumner, D.A. Crop Supply Dynamics and the Illusion of Partial Adjustment. Am. J. Agric. Econ. 2014, 96, 1469–1491. [Google Scholar] [CrossRef]
- Mendelsohn, R.; Nordhaus, W.D.; Shaw, D. The Impact of Global Warning on Agriculture: A Ricardian Analysis. Am. Econ. Rev. 1994, 84, 753–771. [Google Scholar]
- Holzworth, D.P.; Snow, V.; Janssen, S.; Athanasiadis, I.N.; Donatelli, M.; Hoogenboom, G.; White, J.W.; Thorburn, P. Agricultural Production Systems Modelling and Software: Current Status and Future Prospects. Environ. Model. Softw. 2014, 72, 276–286. [Google Scholar] [CrossRef]
- Dell, M.; Jones, B.; Olken, B. What Do We Learn from the Weather? The New Climate-Economy Literature. J. Econ. Lit. 2013, 52, 740–798. [Google Scholar] [CrossRef]
- Schlenker, W.; Roberts, M.J. Nonlinear Temperature Effects Indicate Severe Damages to U.S. Crop Yields under Climate Change. Proc. Natl. Acad. Sci. USA 2009, 106, 15594–15598. [Google Scholar] [CrossRef]
- Yun, S.D.; Gramig, B.M. Days Suitable for Field Work in the US Corn Belt: Climate, Soils and Spatial Heterogeneity. In Proceedings of the 2016 Annual Meetings of Agriculture & Applied Economics Association, Boston, MA, USA, 31 July–2 August 2016. [Google Scholar]
- Rosenzweig, C.; Elliott, J.; Deryng, D.; Ruane, A.C.; Müller, C.; Arneth, A.; Boote, K.J.; Folberth, C.; Glotter, M.; Khabarov, N.; et al. Assessing Agricultural Risks of Climate Change in the 21st Century in a Global Gridded Crop Model Intercomparison. Proc. Natl. Acad. Sci. USA 2014, 111, 3268–3273. [Google Scholar] [CrossRef] [PubMed]
- Villoria, N.B.; Elliott, J.; Müller, C.; Shin, J.; Zhao, L.; Song, C. Rapid Aggregation of Global Gridded Crop Model Outputs to Facilitate Cross-disciplinary Analysis of Climate Change Impacts in Agriculture. Environ. Model. Softw. 2016, 75, 193–201. [Google Scholar] [CrossRef]
- Baskerville, A.G.L.; Emin, P. Rapid Estimation of Heat Accumulation from Maximum and Minimum Temperatures Published by: Ecological Society of America. Ecology 1969, 50, 514–517. [Google Scholar] [CrossRef]
- Wilson, L.T.; Barnett, W.W. Degree-days: An Aid in Crop and Pest Management. Calif. Agric. 1983, 37, 4–7. [Google Scholar]
- Zalom, F.; Goodell, P.; Wilson, L.T.T.; Barnett, W.; Bentley, W. Degree-days, the Calculation and Use of Heat Units in Pest Management. In University of California Division of Agriculture and Natural Resources Leaflet 21370; University of California: Berkeley, CA, USA, 1983. [Google Scholar]
- Muchow, R.C.; Sinclair, T.R.; Bennett, J.M. Temperature and Solar-Radiation Effects on Potential Maize Yield across Locations. Agron. J. 1990, 82, 338–343. [Google Scholar] [CrossRef]
- Thom, H.C.S. Normal Degree Days above any Base by the Universal Truncation Coefficient. Mon. Weather Rev. 1966, 94, 461–465. [Google Scholar] [CrossRef]
- Roberts, M.J.; Schlenker, W.; Eyer, J. Agronomic Weather Measures in Econometric Models of Crop Yield with Implications for Climate Change. Am. J. Agric. Econ. 2013, 95, 236–243. [Google Scholar] [CrossRef]
- Snyder, R.L. Hand Calculating Degree Days. Agric. For. Meteorol. 1985, 35, 353–358. [Google Scholar] [CrossRef]
- Andrews, S.S.; Karlen, D.L.; Cambardella, C.A. The Soil Management Assessment Framework. Soil Sci. Soc. Am. J. 2004, 68, 1945–1962. [Google Scholar] [CrossRef]
- Buman, R.A.; Alesii, B.A.; Hatfield, J.L.; Karlen, D.L. Profit, Yield, and Soil Quality Effects of Tillage Systems in Corn-Soybean Rotations. J. Soil Water Conserv. 2004, 59, 260–270. [Google Scholar]
- Hess, G.R.; Campbell, C.L.; Fiscus, D.A.; Hellcamp, A.S.; McQuaid, B.F.; Munster, M.J.; Peck, S.L.; Shafer, S.R. A Conceptual Model and Indicators for Assessing the Ecological Condition of Agricultural Lands. J. Environ. Qual. 2000, 29, 728–737. [Google Scholar] [CrossRef]
- Wolkowski, D. Soil Quality and Crop Production System. New Horiz. soil Sci. 2005. [Google Scholar]
- Yun, S.D.; Gramig, B.M.; Delgado, M.S.; Florax, J.G.M.R. Does Spatial Correlation Matter in Econometric Models of Crop Yield Response and Weather? In Proceedings of the 2015 Annual Meetings of Agriculture & Applied Economics Association, San Francisco, CA, USA, 26–28 July 2015. [Google Scholar]
- Montgomery, D.R. Soil Erosion and Agricultural Sustainability. Proc. Natl. Acad. Sci. USA 2007, 104, 13268–13272. [Google Scholar] [CrossRef]
- Baylis, K.R.; Paulson, N.D.; Piras, G. Spatial Approaches to Panel Data in Agricultural Economics: A Climate Change Application. J. Agric. Appl. Econ. 2011, 43, 325–338. [Google Scholar] [CrossRef]
| 1 | These high-resolution satellite imagery data often called raster data, grid-cell data, big data, or GIS data. |
| 2 | The full article is available from http://www.g-feed.com/2015/01/searching-for-critical-thresholds-in.html (retrieved 2/1/2018). |
| 3 | For the metadata description of these files, refer to: https://www.agcensus.usda.gov/Publications/2012/Online_Resources/Ag_Atlas_Maps/mapfiles/ag_co_metadata_faq_12.html (Accessed on 28 February 2017). |
| 4 | The NLCD projection is given by "+proj = aea + lat_1=29.5 +lat_2 = 45.5 + lat_0 = 23 + lon_0 = −96 +x_0 = 0 + y_0 = 0 + ellps = GRS80 + towgs84 = 0,0,0,0,0,0,0 + units = m + no_defs". The NLCD uses the Albers conical equal area, GRS 1980 Spheroid, NAD83 Datum. The detailed projection can be referred from https://www.mrlc.gov/faq_dau.php (retrieved 5 March 2018). |
| 5 | The PRISM releases daily data as an unstable form first, and then confirm them as stable form. Currently, a few years of the PRISM data after 2015 is available. These will be updated in ACDC for the next version. |
| 6 | The “overlay” is one of the raster calculation techniques to project one piece of raster data on a different resolution piece of raster data. |
| 7 | |
| 8 | The USDA-Natural Resources Conservation Service provides the soils meta data information and documentation in detail: https://www.nrcs.usda.gov/wps/portal/nrcs/detail/soils/survey/geo/?cid= nrcs142p2_053631 (retrieved 28 February 2018). |
| 9 | The gSSURGO user guide can be accessed from the USDA-NRCS website: https://www.nrcs.usda.gov/wps/ PA_NRCSConsumption/download?cid=nrcseprd362255&ext=pdf, (retrieved 28 February 2018). |
| 10 | The authors thank an anonymous reviewer for pointing this out. |













| Data Source/Filter | Crop Yields (bu/ac) | Weather | Soil | |
|---|---|---|---|---|
| GDD | Precipitation | |||
| USDA-NASS a | Corn, Soybean, Cotton, Wheat | - | - | - |
| NLCD ag land mask | - | 1992, 2001, 2006, and 2011 | ||
| PRISM | - | Daily min/max + sine method = 1 °C interval | Daily total precipitation (mm) | - |
| gSSURGO | - | - | - | Soil composition (sand, clay, silt in %); Slope (m); Soil pH; Organic matter (%); K-factor; T-factor (tons/acre/yr); available water capacity (cm/100 m2) |
| Area weighted | - | NLCD-PRISM bridge file b | NLCD-PRISM bridge file b | - |
| Dataset file name | yielddata.csv | gddMarAug.csv gddAprOct.csv | pptMarAug.csv pptAprOct.csv | soil1992.csv; soil2001.csv; soil2006.csv; soil2011.csv; |
| Bridge variable(s) c | stco, year | stco, year | stco, year | stco |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yun, S.D.; Gramig, B.M. Agro-Climatic Data by County: A Spatially and Temporally Consistent U.S. Dataset for Agricultural Yields, Weather and Soils. Data 2019, 4, 66. https://doi.org/10.3390/data4020066
Yun SD, Gramig BM. Agro-Climatic Data by County: A Spatially and Temporally Consistent U.S. Dataset for Agricultural Yields, Weather and Soils. Data. 2019; 4(2):66. https://doi.org/10.3390/data4020066
Chicago/Turabian StyleYun, Seong Do, and Benjamin M. Gramig. 2019. "Agro-Climatic Data by County: A Spatially and Temporally Consistent U.S. Dataset for Agricultural Yields, Weather and Soils" Data 4, no. 2: 66. https://doi.org/10.3390/data4020066
APA StyleYun, S. D., & Gramig, B. M. (2019). Agro-Climatic Data by County: A Spatially and Temporally Consistent U.S. Dataset for Agricultural Yields, Weather and Soils. Data, 4(2), 66. https://doi.org/10.3390/data4020066