Urbanization in India: Population and Urban Classification Grids for 2011

 ,
,
Abstract
1. Introduction
2. Data Description
2.1. Input Data
2.1.1. Population Census Abstracts
“Constitution of Municipalities. (1) There shall be constituted in every State, (a) a Nagar Panchayat (by whatever name called) for a transitional area, that is to say, an area in transition from a rural area to an urban area; (b) a Municipal Council for a smaller urban area; and (c) a Municipal Corporation for a larger urban area, in accordance with the provisions of this Part: Provided that a Municipality under this clause may not be constituted in such urban area or part thereof as the Governor may, having regard to the size of the area and the municipal services being provided or proposed to be provided by an industrial establishment in that area and such other factors as he may deem fit, by public notification, specify to be an industrial township. (2) In this article, ‘a transitional area’, ‘a smaller urban area’ or ‘a larger urban area’ means such area as the Governor may, having regard to the population of the area, the density of the population therein, the revenue generated for local administration, the percentage of employment in non-agricultural activities, the economic importance or such other factors as he may deem fit, specify by public notification for the purposes of this Part.”
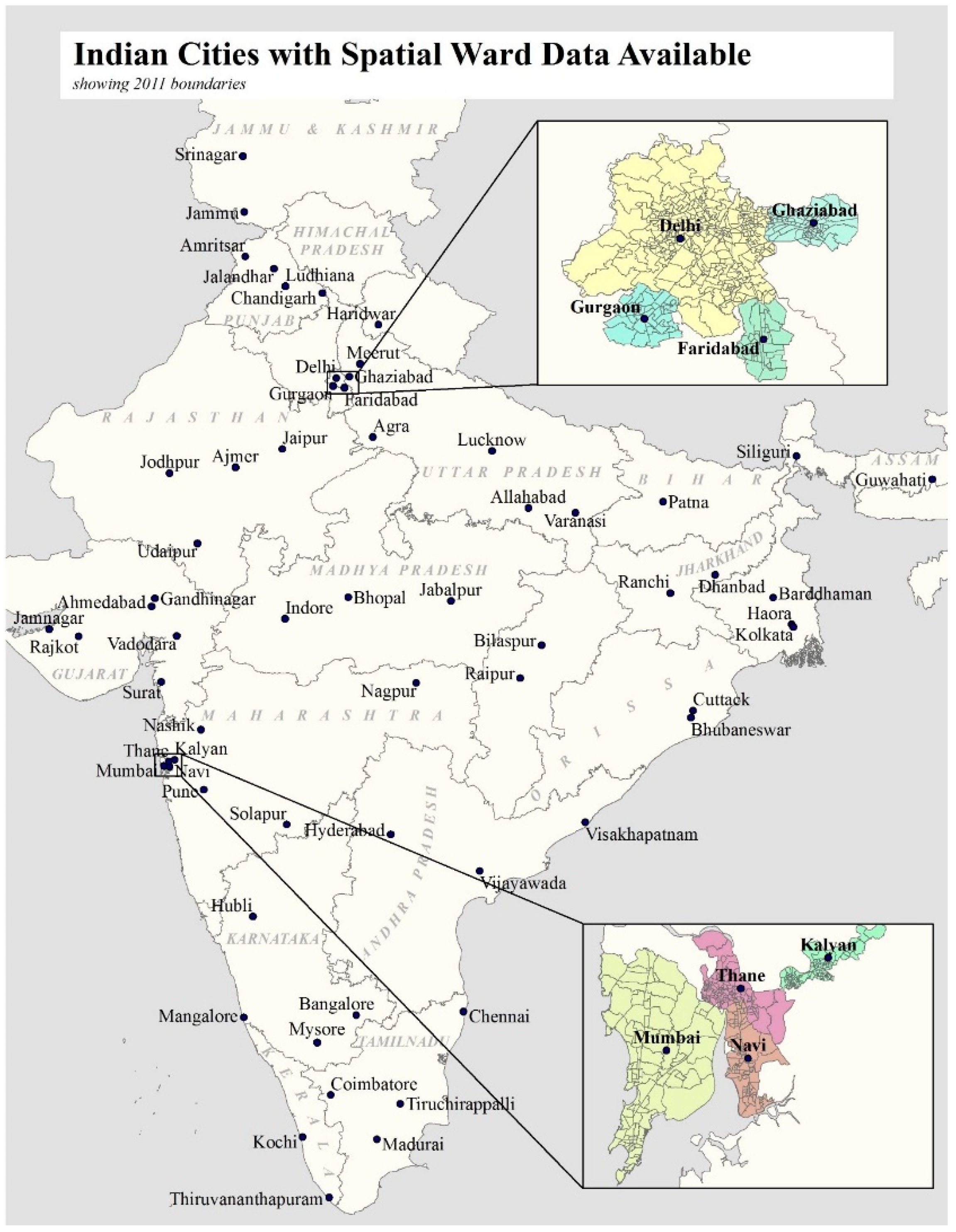
2.1.2. Boundary Data
2.1.3. Global Human Settlement Layer (GHSL) Data
2.2. Output Data
3. Methods
3.1. Matching Spatial Units with Census Tabulations
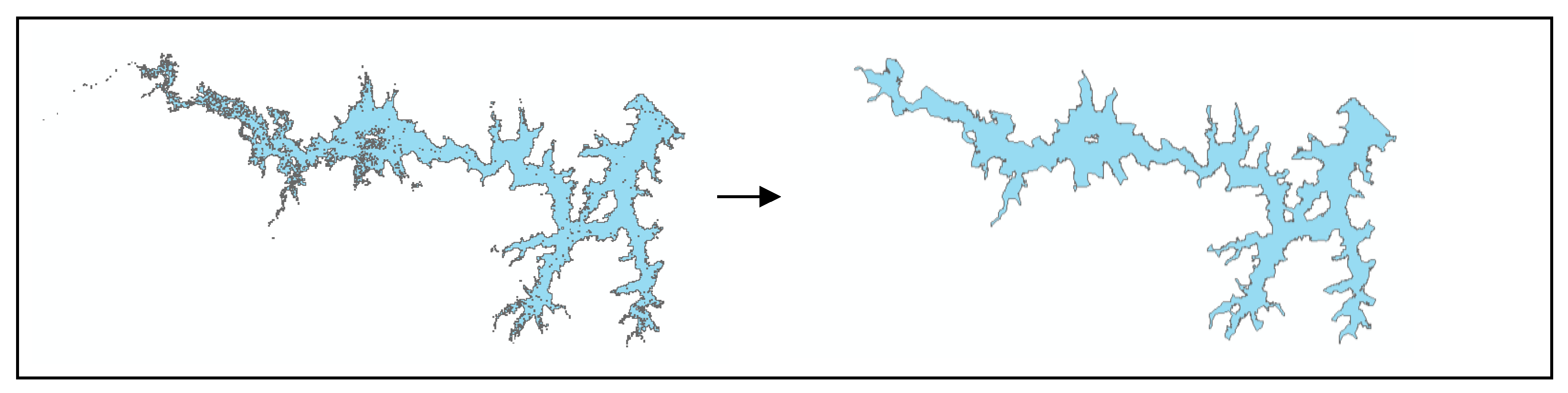
3.2. On the Use of Thiessen Polygons
3.3. Transforming Vector Polygons to Raster Grids
- A land area grid which indicates the total land area in each grid cell. (As noted above, water bodies are removed).
- A land area grid that indicates the land area of a grid cell in a given Indian state. This allows for the land area of border zones (as well as in coastal areas) to be treated fractionally.
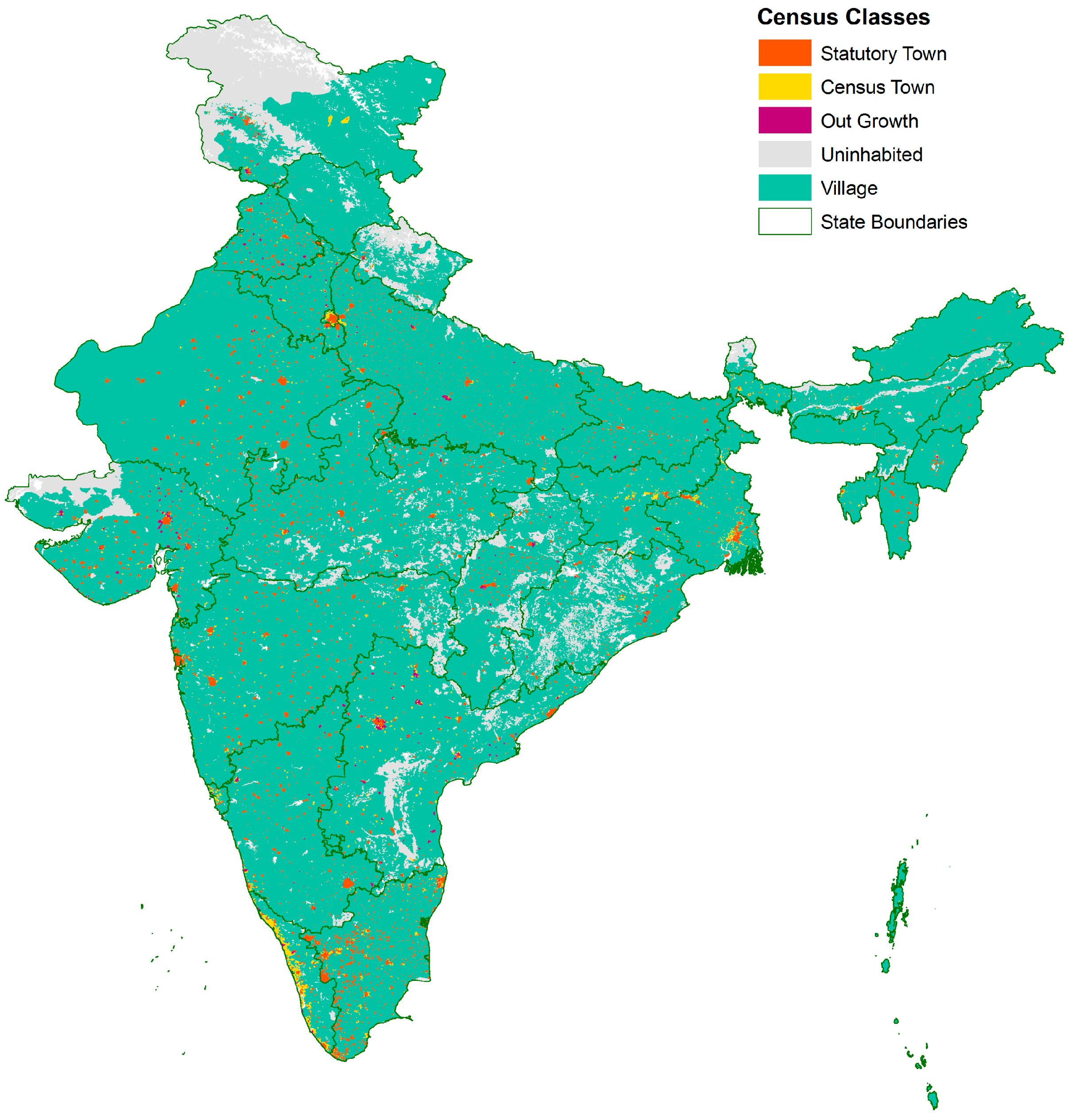
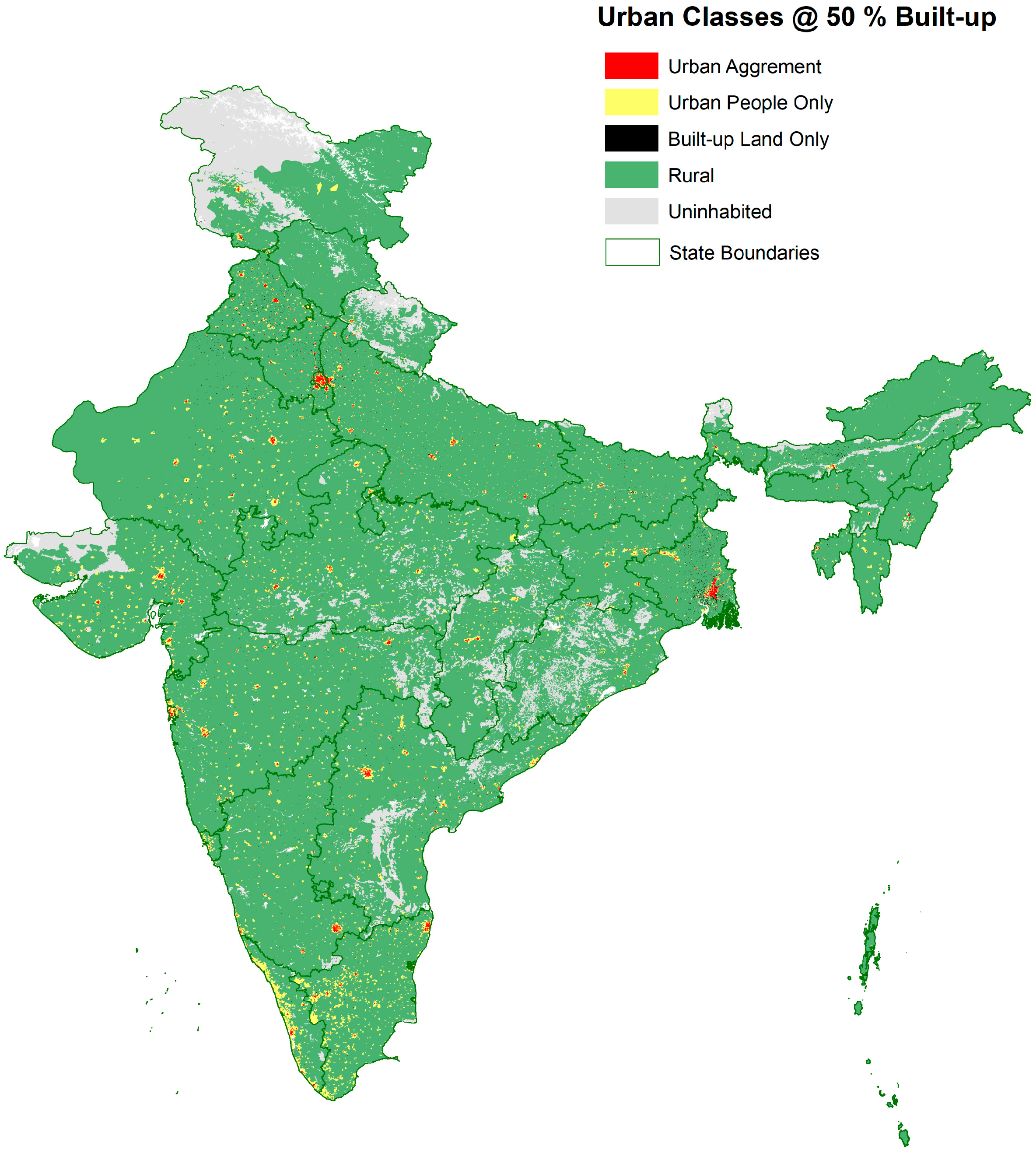
3.4. Construction of Urban Classes
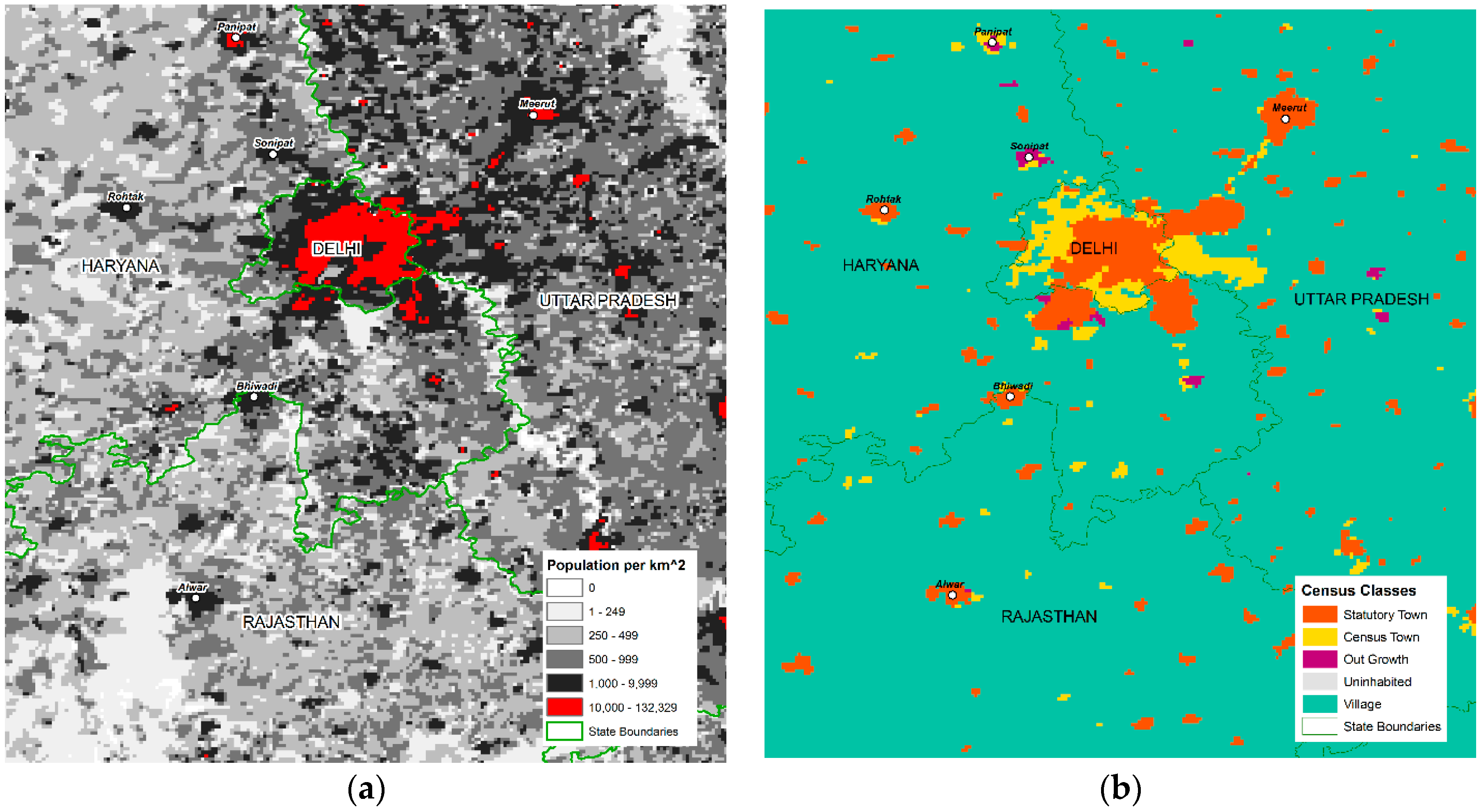
3.4.1. Census-Only Grids
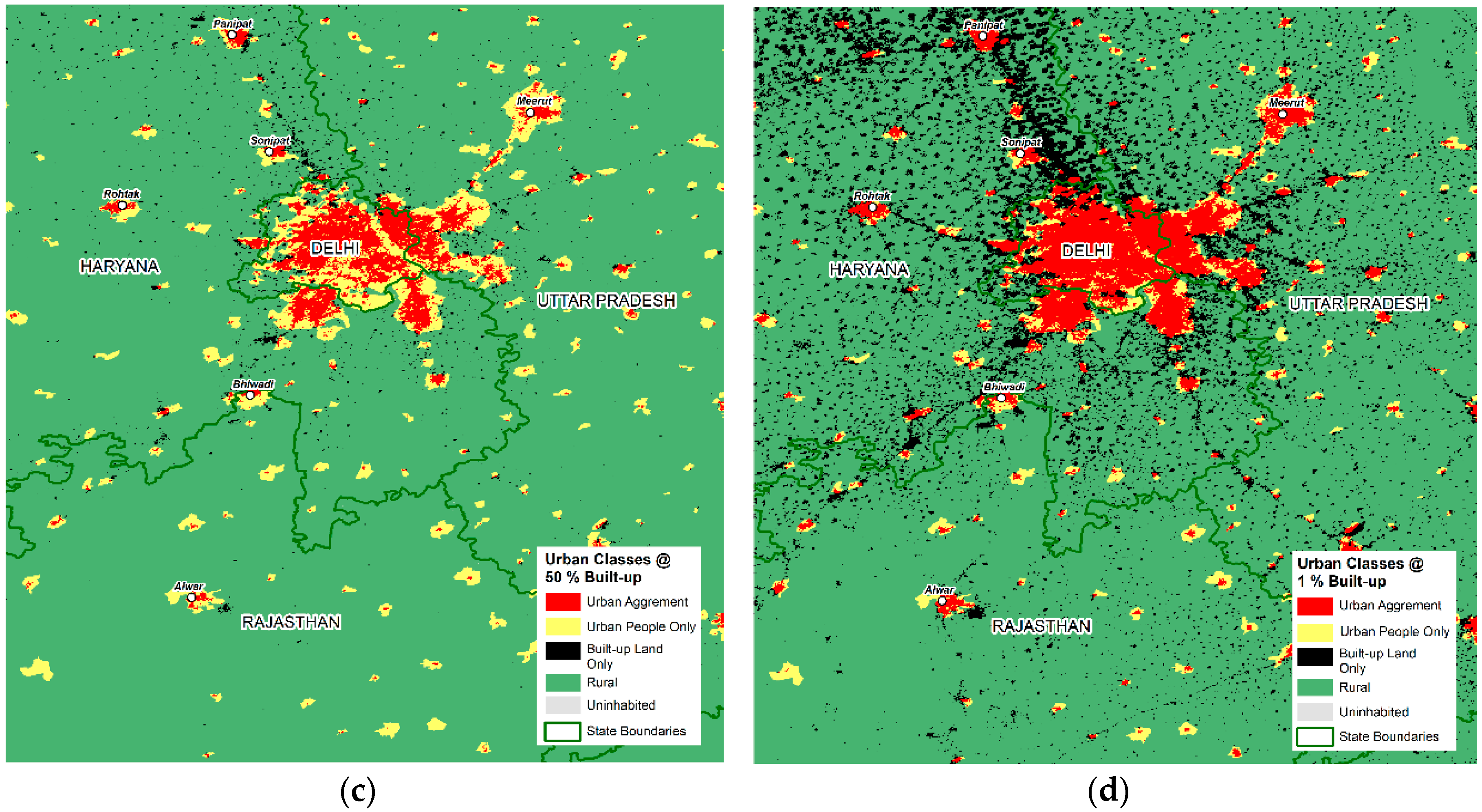
3.4.2. Census and GHSL-Based Classification
4. User Notes
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Census of India. Available online: http://www.censusindia.gov.in/DigitalLibrary/MFTableSeries.aspx (accessed on 4 December 2018).
- Bhagat, R.B.; Mohanty, S. Emerging Pattern of Urbanization and the Contribution of Migration in Urban Growth in India. Asian Popul. Stud. 2009, 5, 1744–1749. [Google Scholar] [CrossRef]
- Denis, E.; Marius-Gnanou, K. Toward a Better Appraisal of Urbanization in India. Cybergeo Eur. J. Geogr. 2011, 59. [Google Scholar] [CrossRef]
- Deuskar, C.; Stewart, B. Measuring Global Urbanization using a Standard Definition of Urban Areas: Analysis of Preliminary Results. In Proceedings of the Land and Poverty Conference 2016: Scaling up Responsible Land Governance, Washington, DC, USA, 14–18 September 2016. [Google Scholar]
- Balk, D.; Pozzi, F.; Yetman, G.; Deichmann, U.; Nelson, A. The distribution of people and the dimension of place: Methodologies to improve the global estimation of urban extents. In Proceedings of the International Society for Photogrammetry and Remote Sensing, Urban Remote Sensing Conference, Tempe, AZ, USA, 14–16 March 2005. [Google Scholar]
- Pesaresi, M.; Huadong, G.; Blaes, X.; Ehrlich, D.; Ferri, S.; Gueguen, L.; Halkia, M.; Kauffmann, M.; Kemper, T.; Lu, L.; et al. A global human settlement layer from optical HR/VHR RS data: Concept and first results. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2102–2131. [Google Scholar] [CrossRef]
- IPCC. Climate Change 2014: Impacts, Adaptation, and Vulnerability. Part A: Global and Sectoral Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Field, C.B., Barros, V.R., Dokken, D.J., Mastrandrea, M.D., Bilir, T.E., Chatterjee, M., Ebi, K.L., Estrada, Y.O., Genova, R.C., et al., Eds.; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- IPCC. Climate Change 2014: Impacts, Adaptation, and Vulnerability. Part B: Regional Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Barros, V.R., Field, C.B., Dokken, D.J., Mastrandrea, M.D., Bilir, T.E., Chatterjee, M., Ebi, K.L., Estrada, Y.O., Genova, R.C., et al., Eds.; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Jha, A.K.; Bloch, R.; Lamond, J. Cities and Flooding: A Guide to Integrated Urban Flood Risk Management for the 21st Century; The World Bank: Washington, DC, USA, 2012. [Google Scholar]
- World Bank. World Bank’s India Disaster Risk Management Program; Working Paper 102550: Washington, DC, USA, 2016. [Google Scholar]
- Revi, A.; Satterthwaite, D.E.; Aragón-Durand, F.; Corfee-Morlot, J.; Kiunsi, R.B.R.; Pelling, M.; Roberts, D.C.; Solecki, W. Urban areas. In Climate Change 2014: Impacts, Adaptation, and Vulnerability. Part A: Global and Sectoral Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Field, C.B., Barros, V.R., Dokken, D.J., Mastrandrea, M.D., Bilir, T.E., Chatterjee, M., Ebi, K.L., Estrada, Y.O., Genova, R.C., et al., Eds.; Cambridge University Press: Cambridge, UK, 2014; Chapter 8; pp. 535–612. [Google Scholar] [CrossRef]
- Kundu, A. India’s Sluggish Urbanization and Its Exclusionary Development. In Urban Growth in Emerging Economies: Lessons from the BRICS; McGranahan, G., Martine, G., Eds.; Routledge: New York, NY, USA, 2014; pp. 191–232. [Google Scholar]
- Kundu, A.; Saraswati, L.R. Changing Patterns of Migration in India: A Perspective on Urban Exclusion. In International Handbook of Migration and Population Distribution; White, M.J., Ed.; Springer: Dordrecht, The Netherlands, 2016; Chapter 15; pp. 311–332. [Google Scholar]
- Pradhan, K.C. Unacknowledged Urbanisation: The New Census Towns in India. An Introduction to the Dynamics of Ordinary Towns. In Subaltern Urbanisation in India; Denis, E., Zerah, M.H., Eds.; Springer: New Delhi, India, 2017; Chapter 2; pp. 39–66. [Google Scholar] [CrossRef]
- Center for International Earth Science Information Network—CIESIN—Columbia University. Gridded Population of the World, Version 4 (GPWv4): Population Count; NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NY, USA, 2016. [CrossRef]
- District Census Handbooks. Available online: www.censusindia.gov.in/2011census/dchb/DCHB.html (accessed on 4 December 2018).
- Census of India 2011: Administrative Atlas, Office of the Registrar General & Census Commissioner, India. Available online: www.censusindia.gov.in/2011census/maps/atlas/administrative_atlas.html (accessed on 4 December 2018).
- Corbane, C.; Pesaresi, M.; Politis, P.; Syrris, V.; Florczyk, A.J.; Soille, P.; Maffenini, L.; Burger, A.; Vasilev, V.; Rodriguez, D.; et al. Big earth data analytics on Sentinel-1 and Landsat imagery in support to global human settlements mapping. Big Earth Data 2017, 1, 118–144. [Google Scholar] [CrossRef]
- Balk, D.; Leyk, S.; Jones, B.; Montgomery, M.; Clark, A. Understanding Urbanization: A study of census and satellite-derived urban classes in the United States, 1990–2010. PLoS ONE 2018, 13, e0208487. [Google Scholar] [CrossRef] [PubMed]
- Uhl, J.H.; Zoraghein, H.; Leyk, S.; Balk, D.; Corbane, C.; Syrris, V.; Florczyk, A.J. Exposing the urban continuum: Implications and cross-comparison from an interdisciplinary perspective. Int. J. Dig. Earth 2018. [Google Scholar] [CrossRef]
- European Commission. State of European Cities 2016. Cities Leading the Way to a Better Future; European Union and UN Habitat: Luxembourg, 2016. [Google Scholar] [CrossRef]
- Pesaresi, M.; Corbane, C.; Julea, A.; Florczyk, A.J.; Syrris, V.; Soille, P. Assessment of the added-value of sentinel-2 for detecting built-up areas. Remote Sens. 2016, 8, 299. [Google Scholar] [CrossRef]
- Pesaresi, M.; Ehrlich, D.; Ferri, S.; Florczyk, A.; Freire, S.; Halkia, M.; Julea, A.; Kemper, T.; Soille, P.; Syrris, V. Operating Procedure for the Production of the Global Human Settlement Layer from Landsat Data of the Epochs 1975, 1990, 2000, and 2014; JRC Technical Report EUR 27741 EN 2016; Joint Research Centre: Ispra (VA), Italy, 2016. [Google Scholar] [CrossRef]
- Pesaresi, M.; Syrris, V.; Julea, A. A new method for earth observation data analytics based on symbolic machine learning. Remote Sens. 2016, 8, 399. [Google Scholar] [CrossRef]
- Leyk, S.; Uhl, J.H.; Balk, D.L.; Jones, B. Assessing the Accuracy of Multi-Temporal Built-Up Land Layers across Rural-Urban Trajectories in the United States. Remote Sens. Environ. 2018, 204, 898–917. [Google Scholar] [CrossRef] [PubMed]
- Denis, E.; Zérah, M.H. Subaltern Urbanization in India: An Introduction to the Dynamics of Ordinary Towns; Springer: New Delhi, India, 2018. [Google Scholar]
- Mennis, J. Generating Surface Models of Population Using Dasymetric Mapping. Prof. Geogr. 2003, 55, 31–42. [Google Scholar]
- NASA Socioeconomic Data and Applications Center (SEDAC), Documentation for the Gridded Population of the World, Version 4 (GPWv4), Revision 10 Data Sets, November 2017. Center for International Earth Science Information Network (CIESIN), Columbia University. Available online: http://sedac.ciesin.columbia.edu/downloads/docs/gpw-v4/gpw-v4-documentation-rev10.pdf (accessed on 1 December 2018).
- O’Neill, B.C.; Kriegler, E.; Ebi, K.L.; Kemp-Benedict, E.; Riahi, K.; Rothman, D.S.; Ruijven, B.J.; Vuuren, D.P.; Birkmann, J.; Kok, K.; et al. The roads ahead: Narratives for shared socioeconomic pathways describing world futures in the 21st century. Glob. Environ. Chang. 2015, 42, 169–180. [Google Scholar] [CrossRef]
- Jones, B.; O’Neill, B.C. Spatially explicit global population scenarios consistent with the Shared Socioeconomic Pathways. Environ. Res. Lett. 2016, 11, 084003. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| States & Union Territories | Format | Urban Classification * | Village | ||||
|---|---|---|---|---|---|---|---|
| Polygon | Point | Statutory Town | Census Town | Ward | Outgrowth | ||
| Andamans & Nicobars | - | 560 | 1 | 4 | - | - | 555 |
| Andhra Pradesh | 26,927 | 2090 | 125 | 228 | 287 | 209 | 27,800 |
| Arunachal Pradesh | - | 5616 | 26 | 1 | - | - | 5589 |
| Assam | 22,746 | 4137 | 88 | 126 | 89 | 29 | 26,395 |
| Bihar | 45,159 | 0 | 139 | 60 | 76 | 4 | 44,874 |
| Chandigarh | 38 | 0 | 1 | 5 | 28 | 2 | 5 |
| Chhattisgarh | 18,528 | 2255 | 168 | 14 | 110 | 40 | 20,126 |
| Dadra & Nagar Haveli | 71 | 0 | 1 | 5 | - | - | 65 |
| Daman & Diu | 27 | 0 | 2 | 6 | - | - | 19 |
| Delhi | 256 | 0 | 3 | 110 | - | - | 112 |
| Goa | 414 | 0 | 14 | 56 | 7 | 7 | 334 |
| Gujarat | 19,040 | 0 | 195 | 153 | 377 | 127 | 18,225 |
| Haryana | 7080 | 0 | 80 | 74 | 83 | 15 | 6841 |
| Himachal Pradesh | 13,103 | 7693 | 56 | 3 | 8 | 8 | 20,689 |
| Jammu & Kashmir | 6766 | 241 | 86 | 36 | 232 | 93 | 6553 |
| Jharkhand | 32,884 | 0 | 40 | 188 | 111 | 1 | 32,394 |
| Karnataka | 30,232 | 0 | 220 | 127 | 459 | 69 | 29,340 |
| Kerala | 1871 | 0 | 59 | 461 | 173 | 16 | 1018 |
| Lakshadweep | - | 27 | - | 6 | - | - | 21 |
| Madhya Pradesh | 56,346 | 0 | 364 | 112 | 295 | 86 | 54,903 |
| Maharashtra | 45,926 | 0 | 256 | 278 | 898 | 3 | 43,665 |
| Manipur | 493 | 2170 | 28 | 23 | 7 | 7 | 2582 |
| Meghalaya | - | 6861 | 10 | 12 | - | - | 6839 |
| Mizoram | - | 853 | 23 | - | - | - | 830 |
| Nagaland | - | 1454 | 19 | 7 | - | - | 1428 |
| Odisha | 53,283 | 0 | 107 | 116 | 171 | 57 | 51,311 |
| Puducherry | 101 | 0 | 6 | 4 | 1 | 1 | 90 |
| Punjab | 13,055 | 0 | 143 | 74 | 261 | 61 | 12,581 |
| Rajasthan | 45,287 | 0 | 185 | 112 | 291 | 39 | 44,672 |
| Sikkim | 484 | 0 | 8 | 1 | - | - | 451 |
| Tamil Nadu | 17,450 | 0 | 721 | 376 | 373 | 14 | 15,979 |
| Tripura | 917 | 0 | 16 | 26 | - | 875 | |
| Uttar Pradesh | 108,336 | 0 | 648 | 267 | 593 | 63 | 106,774 |
| Uttarakhand | 16,835 | 293 | 74 | 41 | 49 | 19 | 16,793 |
| West Bengal | 41,482 | 0 | 129 | 781 | 286 | 13 | 40,202 |
| Total | 625,137 | 34,250 | 4041 | 3893 | 5265 | 983 | 640,930 |
| Theme | Data File | Concept | Format (Resolution) | Type | Values |
|---|---|---|---|---|---|
| Population Counts | Pop | De jure population as indicated by the census | Raster (1 km) | Integer | 0–136,626 persons 1 |
| Area | Area 2 | Actual land area of each grid cell | Raster (1 km) | Integer | |
| Area, delineating border cells | Actual land area of each grid cell delineating border cell (e.g., coastline, between states) | Raster (1 km) | Integer | ||
| Urban Classifications | Census Classes | Census designations of settlement type | Raster | Categorical | Statutory Town, Census Town, Outgrowth, Village, Uninhabited |
| Census + GHSL | Census designations of settlement type combined with built-up area thresholds 3 | Vector (based on 250 m raster and variable resolution vector inputs) | Categorical | Urban Agreement (UA), Urban People Only (UPO), Built-up Land Only (BULO), Rural Extents, Uninhabited |
| Census Classification | Population | Area | Population Density | Built-Up | ||
|---|---|---|---|---|---|---|
| Count | % | km2 | % | % | ||
| Statutory Town | 318,562,520 | 26.3% | 80,109 | 2.5% | 3977 | 14.4 |
| Census Town | 54,280,980 | 4.5% | 26,234 | 0.8% | 2069 | 10.2 |
| Outgrowth | 4,264,979 | 0.4% | 3436 | 0.1% | 1241 | 8.7 |
| Village | 833,746,498 | 68.9% | 2,850,979 | 87.2% | 292 | 0.6 |
| Uninhabited | 0 | 0.0% | 307,377 | 9.4% | - | 0.1 |
| Threshold | Urban Classification | Population | Area | Population Density | Built-Up | ||
|---|---|---|---|---|---|---|---|
| Count | % | km2 | % | % | |||
| 50 | Urban Agreement (UAg) | 130,203,192 | 10.8% | 12,569 | 0.4% | 10,359 | 78.3 |
| Urban People Only (UPO) | 246,902,934 | 20.4% | 96,238 | 3.0% | 2566 | 4.7 | |
| Built-Up Land Only (BULO) | 5,554,092 | 0.5% | 5061 | 0.2% | 1097 | 66.8 | |
| Rural Extent (RE) | 828,194,760 | 68.4% | 2,830,261 | 87.5% | 293 | 0.4 | |
| Uninhabited | - | 290,373 | 9.0% | 0.1 | |||
| 1 | Urban Agreement (UAg) | 241,523,146 | 19.9% | 40,706 | 1.3% | 5933 | 35.3 |
| Urban People Only (UPO) | 135,582,980 | 11.2% | 68,101 | 2.1% | 1991 | 0.0 | |
| Built-Up Land Only (BULO) | 86,191,197 | 7.1% | 140,894 | 4.4% | 612 | 11.3 | |
| Rural Extent (RE) | 747,557,654 | 61.7% | 2,697,763 | 83.4% | 277 | 0.0 | |
| Uninhabited | - | 287,038 | 8.9% | 0.0 | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balk, D.; Montgomery, M.R.; Engin, H.; Lin, N.; Major, E.; Jones, B. Urbanization in India: Population and Urban Classification Grids for 2011. Data 2019, 4, 35. https://doi.org/10.3390/data4010035
Balk D, Montgomery MR, Engin H, Lin N, Major E, Jones B. Urbanization in India: Population and Urban Classification Grids for 2011. Data. 2019; 4(1):35. https://doi.org/10.3390/data4010035
Chicago/Turabian StyleBalk, Deborah, Mark R. Montgomery, Hasim Engin, Natalie Lin, Elizabeth Major, and Bryan Jones. 2019. "Urbanization in India: Population and Urban Classification Grids for 2011" Data 4, no. 1: 35. https://doi.org/10.3390/data4010035
APA StyleBalk, D., Montgomery, M. R., Engin, H., Lin, N., Major, E., & Jones, B. (2019). Urbanization in India: Population and Urban Classification Grids for 2011. Data, 4(1), 35. https://doi.org/10.3390/data4010035