

Applying Self-Supervised Learning to Image Quality Assessment in Chest CT Imaging


Abstract
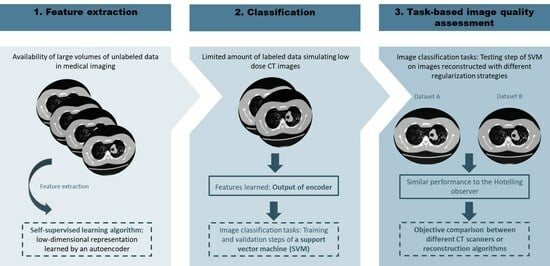
1. Introduction
2. Materials and Methods
2.1. Data
2.1.1. Signal Known Exactly (SKE)
2.1.2. Signal Known Statistically (SKS)
2.2. Hotelling Observer
2.3. Supervised Learning-Based Model Observer
2.4. SSL-Based Model Observer
2.4.1. AE
2.4.2. SVM
3. Results
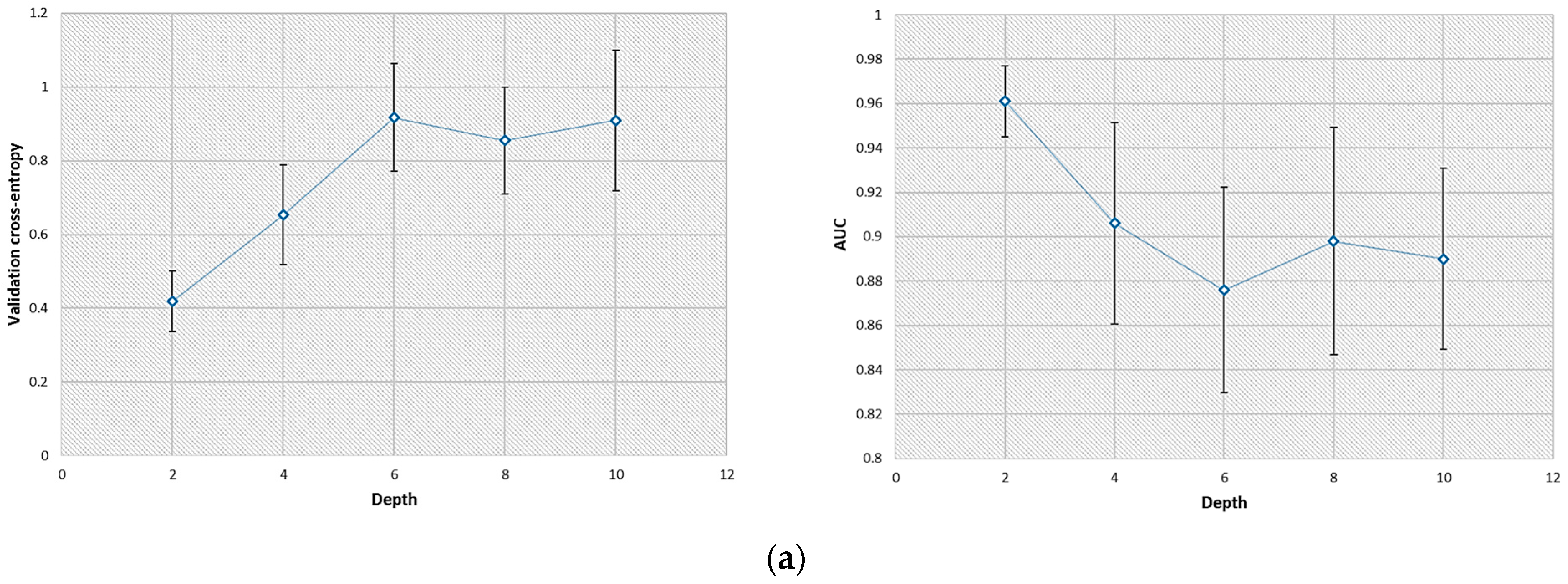
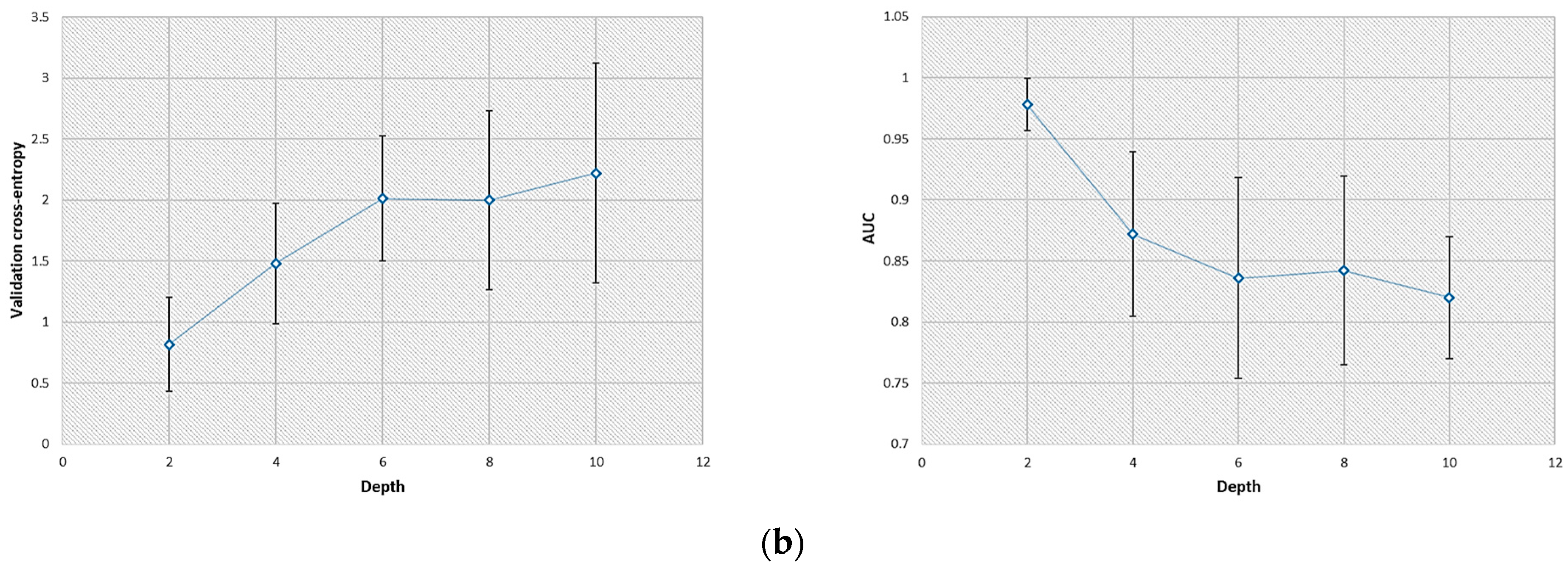
3.1. Optimal Structure of the CNN
3.2. Optimal Parameters for the SSL-Based Model Observer
3.3. Detectability Comparison between Observers
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Solomon, J.; Lyu, P.; Marin, D.; Samei, E. Noise and spatial resolution properties of a commercially available deep learning-based CT reconstruction algorithm. Med. Phys. 2020, 47, 3961–3971. [Google Scholar] [CrossRef] [PubMed]
- Funama, Y.; Nakaura, T.; Hasegawa, A.; Sakabe, D.; Oda, S.; Kidoh, M.; Nagayama, Y.; Hirai, T. Noise power spectrum properties of deep learning-based reconstruction and iterative reconstruction algorithms: Phantom and clinical study. Eur. J. Radiol. 2023, 165, 110914. [Google Scholar] [CrossRef]
- Kim, G.; Han, M.; Shim, H.; Baek, J. A convolutional neural network-based model observer for breast CT images. Med. Phys. 2020, 47, 1619–1632. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Leng, S.; Yu, L.; Carter, R.E.; McCollough, C.H. Correlation between human and model observer performance for discrimination task in CT. Phys. Med. Biol. 2014, 59, 3389–3404. [Google Scholar] [CrossRef] [PubMed]
- Granstedt, J.L.; Zhou, W.; Anastasio, M.A. Approximating the Hotelling Observer with Autoencoder-Learned Efficient Channels for Binary Signal Detection Tasks. arXiv 2020, arXiv:2003.02321. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Li, H.; Anastasio, M.A. Approximating the Ideal Observer and Hotelling Observer for Binary Signal Detection Tasks by Use of Supervised Learning Methods. IEEE Trans. Med. Imaging 2019, 38, 2456–2468. [Google Scholar] [CrossRef] [PubMed]
- Gallas, B.D.; Barrett, H.H. Validating the use of channels to estimate the ideal linear observer. J. Opt. Soc. Am. A Opt. Image Sci. Vis. 2003, 20, 1725–1738. [Google Scholar] [CrossRef] [PubMed]
- Barrett, H.H.; Denny, J.L.; Wagner, R.F.; Myers, K.J. Objective assessment of image quality. II. Fisher information, Fourier crosstalk, and figures of merit for task performance. J. Opt. Soc. Am. A Opt. Image Sci. Vis. 1995, 12, 834–852. [Google Scholar] [CrossRef] [PubMed]
- Kopp, F.K.; Catalano, M.; Pfeiffer, D.; Fingerle, A.A.; Rummeny, E.J.; Noël, P.B. CNN as model observer in a liver lesion detection task for x-ray computed tomography: A phantom study. Med. Phys. 2018, 45, 4439–4447. [Google Scholar] [CrossRef]
- Zhou, W.; Li, H.; Anastasio, M.A. Learning the Hotelling observer for SKE detection tasks by use of supervised learning methods. In Medical Imaging 2019: Image Perception, Observer Performance, and Technology Assessment; SPIE: San Diego, CA, USA, 2019; Volume 10952, pp. 41–46. [Google Scholar] [CrossRef]
- Zhou, W.; Anastasio, M.A. Learning the ideal observer for SKE detection tasks by use of convolutional neural networks (Cum Laude Poster Award). In Medical Imaging 2018: Image Perception, Observer Performance, and Technology Assessment; SPIE: San Diego, CA, USA, 2018; Volume 10577, pp. 287–292. [Google Scholar] [CrossRef]
- Ahn, E.; Kumar, A.; Fulham, M.; Feng, D.D.F.; Kim, J. Unsupervised Domain Adaptation to Classify Medical Images Using Zero-Bias Convolutional Auto-Encoders and Context-Based Feature Augmentation. IEEE Trans. Med. Imaging 2020, 39, 2385–2394. [Google Scholar] [CrossRef]
- Ahn, E.; Kumar, A.; Feng, D.; Fulham, M.; Kim, J. Unsupervised Deep Transfer Feature Learning for Medical Image Classification. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 1915–1918. [Google Scholar] [CrossRef]
- Ahn, E.; Kim, J.; Kumar, A.; Fulham, M.; Feng, D. Convolutional Sparse Kernel Network for Unsupervised Medical Image Analysis. Med. Image Anal. 2019, 56, 140–151. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, A.; Rosenthal, J.; Waring, J.; Umeton, R. Applying Self-Supervised Learning to Medicine: Review of the State of the Art and Medical Implementations. Informatics 2021, 8, 59. [Google Scholar] [CrossRef]
- Kwak, M.G.; Su, Y.; Chen, K.; Weidman, D.; Wu, T.; Lure, F.; Li, J. Self-Supervised Contrastive Learning to Predict Alzheimer’s Disease Progression with 3D Amyloid-PET. medRxiv 2023. [Google Scholar] [CrossRef]
- Xing, X.; Liang, G.; Wang, C.; Jacobs, N.; Lin, A.L. Self-Supervised Learning Application on COVID-19 Chest X-ray Image Classification Using Masked AutoEncoder. Bioengineering 2023, 10, 901. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Wan, Y. A novel efficient method for training sparse auto-encoders. In Proceedings of the 2013 6th International Congress on Image and Signal Processing (CISP), Hangzhou, China, 16–18 December 2013; Volume 2, pp. 1019–1023. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, ICML ’08. Association for Computing Machinery, Montreal, QC, Canada, 11–15 April 2016; pp. 1096–1103. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Al-Qatf, M.; Lasheng, Y.; Al-Habib, M.; Al-Sabahi, K. Deep Learning Approach Combining Sparse Autoencoder With SVM for Network Intrusion Detection. IEEE Access 2018, 6, 52843–52856. [Google Scholar] [CrossRef]
- Binbusayyis, A.; Vaiyapuri, T. Unsupervised deep learning approach for network intrusion detection combining convolutional autoencoder and one-class SVM. Appl Intell. 2021, 51, 7094–7108. [Google Scholar] [CrossRef]
- Meng, Q.; Catchpoole, D.; Skillicom, D.; Kennedy, P.J. Relational autoencoder for feature extraction. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 364–371. [Google Scholar] [CrossRef]
- Meng, L.; Ding, S.; Xue, Y. Research on denoising sparse autoencoder. Int. J. Mach. Learn. Cyber. 2017, 8, 1719–1729. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, S.; Wu, H.; Han, W.; Li, C.; Chen, H. Joint optimization of autoencoder and Self-Supervised Classifier: Anomaly detection of strawberries using hyperspectral imaging. Comput. Electron. Agric. 2022, 198, 107007. [Google Scholar] [CrossRef]
- Riquelme, D.; Akhloufi, M.A. Deep Learning for Lung Cancer Nodules Detection and Classification in CT Scans. AI 2020, 1, 28–67. [Google Scholar] [CrossRef]
- Multipurpose Chest Phantom N1 “LUNGMAN”|KYOTO KAGAKU. Available online: https://www.kyotokagaku.com/en/products_data/ph-1_01/ (accessed on 2 August 2021).
- Pouget, E.; Dedieu, V. Comparison of supervised-learning approaches for designing a channelized observer for image quality assessment in CT. Med. Phys. 2023, 50, 4282–4295. [Google Scholar] [CrossRef]
- Brankov, J.G.; Yang, Y.; Wei, L.; El Naqa, I.; Wernick, M.N. Learning a Channelized Observer for Image Quality Assessment. IEEE Trans. Med. Imaging 2009, 28, 991–999. [Google Scholar] [CrossRef]
- Burgess, A.E.; Li, X.; Abbey, C.K. Nodule detection in two-component noise: Toward patient structure. In Medical Imaging 1997: Image Perception; SPIE: Newport Beach, CA, USA, 1997; Volume 3036, pp. 2–13. [Google Scholar] [CrossRef]
- Abbey, C.K.; Barrett, H.H. Human- and model-observer performance in ramp-spectrum noise: Effects of regularization and object variability. J. Opt. Soc. Am. A Opt. Image Sci. Vis. 2001, 18, 473–488. [Google Scholar] [CrossRef]
- Mathieu, K.B.; Ai, H.; Fox, P.S.; Godoy, M.C.B.; Munden, R.F.; de Groot, P.M.; Pan, T. Radiation dose reduction for CT lung cancer screening using ASIR and MBIR: A phantom study. J. Appl. Clin. Med. Phys. 2014, 15, 4515. [Google Scholar] [CrossRef]
- Park, S.; Witten, J.M.; Myers, K.J. Singular Vectors of a Linear Imaging System as Efficient Channels for the Bayesian Ideal Observer. IEEE Trans. Med. Imaging 2009, 28, 657–668. [Google Scholar] [CrossRef]
- Kupinski, M.A.; Edwards, D.C.; Giger, M.L.; Metz, C.E. Ideal observer approximation using Bayesian classification neural networks. IEEE Trans. Med. Imaging 2001, 20, 886–899. [Google Scholar] [CrossRef]
- Massanes, F.; Brankov, J.G. Evaluation of CNN as anthropomorphic model observer. Med. Imaging 2017, 10136, 101360Q. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. {TensorFlow}: A System for {Large-Scale} Machine Learning. In Proceedings of the 12th USENIX conference on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. Available online: https://www.usenix.org/conference/osdi16/technical-sessions/presentation/abadi (accessed on 21 December 2023).
- Nishio, M.; Nagashima, C.; Hirabayashi, S.; Ohnishi, A.; Sasaki, K.; Sagawa, T.; Hamada, M.; Yamashita, T. Convolutional auto-encoder for image denoising of ultra-low-dose CT. Heliyon 2017, 3, e00393. [Google Scholar] [CrossRef]
- Ye, Q.; Liu, C.; Alonso-Betanzos, A. An Unsupervised Deep Feature Learning Model Based on Parallel Convolutional Autoencoder for Intelligent Fault Diagnosis of Main Reducer. Intell. Neurosci. 2021, 2021, 8922656. [Google Scholar] [CrossRef] [PubMed]
- Laref, R.; Losson, E.; Sava, A.; Siadat, M. On the optimization of the support vector machine regression hyperparameters setting for gas sensors array applications. Chemom. Intell. Lab. Syst. 2019, 184, 22–27. [Google Scholar] [CrossRef]
- Wu, J.; Chen, X.Y.; Zhang, H.; Xiong, L.D.; Lei, H.; Deng, S.H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar] [CrossRef]
- Nair, A. Grid Search VS Random Search VS Bayesian Optimization. Medium. Published 2 May 2022. Available online: https://towardsdatascience.com/grid-search-vs-random-search-vs-bayesian-optimization-2e68f57c3c46 (accessed on 21 June 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Favazza, C.P.; Duan, X.; Zhang, Y.; Yu, L.; Leng, S.; Kofler, J.M.; Bruesewitz, M.R.; McCollough, C.H. A cross-platform survey of CT image quality and dose from routine abdomen protocols and a method to systematically standardize image quality. Phys. Med. Biol. 2015, 60, 8381–8397. [Google Scholar] [CrossRef]
- Chan, K.H.; Im, S.K.; Ke, W. A Multiple Classifier Approach for Concatenate-Designed Neural Networks. Neural Comput Applic. 2022, 34, 1359–1372. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CDAE | PCA | ||||
|---|---|---|---|---|---|
| λ = 0.00001 | λ = 0.0001 | λ = 0.001 | λ = 0.01 | ||
| C(SKE/BKS, SKS/BKS) | 104, 103 | 103, 102 | 101, 102 | 107, 106 | 103, 102 |
| σ(SKE/BKS, SKS/BKS) | 100, 100 | 10, 10 | 1, 1 | 0.01, 0.1 | 0.1, 0.1 |
| AUC (SKE/BKS, SKS/BKS) | 0.76, 0.74 | 0.77, 0.70 | 0.88, 0.91 | 0.63, 0.65 | 0.78, 0.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pouget, E.; Dedieu, V. Applying Self-Supervised Learning to Image Quality Assessment in Chest CT Imaging. Bioengineering 2024, 11, 335. https://doi.org/10.3390/bioengineering11040335
Pouget E, Dedieu V. Applying Self-Supervised Learning to Image Quality Assessment in Chest CT Imaging. Bioengineering. 2024; 11(4):335. https://doi.org/10.3390/bioengineering11040335
Chicago/Turabian StylePouget, Eléonore, and Véronique Dedieu. 2024. "Applying Self-Supervised Learning to Image Quality Assessment in Chest CT Imaging" Bioengineering 11, no. 4: 335. https://doi.org/10.3390/bioengineering11040335
APA StylePouget, E., & Dedieu, V. (2024). Applying Self-Supervised Learning to Image Quality Assessment in Chest CT Imaging. Bioengineering, 11(4), 335. https://doi.org/10.3390/bioengineering11040335